Submitted by: (via Twisted Doodles)
Mahmoud
Shared posts
01 Jun 18:04
Working In Science Seems Discouraging
Damiani.guilherme, Nosolonin and 2 others like this
31 May 05:45
Invision - When reading a blog post, the browser tab title...
Mahmoudwow

Mason likes this

29 May 04:28
Monkey Gets Feisty With Deborah Duncan
by Adult Swim
Mahmoudsena, c/d authenticity
 |
SUBSCRIBE: http://bit.ly/AdultSwimSubscribe About Adult Swim: Adult Swim is your late-night home for animation and live-action comedy. Enjoy some of your fav...
|
From:
Adult Swim
Views:
13471
443
ratings
|
| Time: 00:28 | More in Entertainment |

24 May 16:19







How Recruiters Really Look at Your LinkedIn Profile and Online Resume
by Melanie Pinola
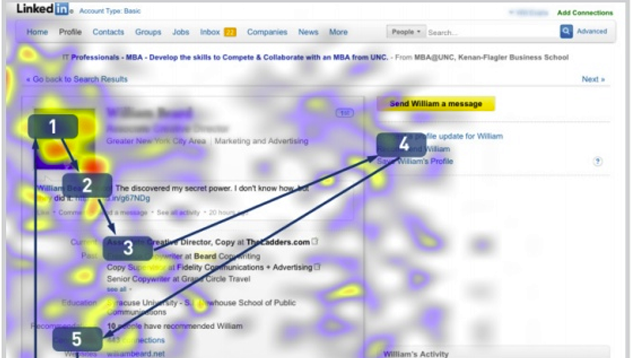
TheLadders conducted a study tracking the eye movements of recruiters when looking at resumes (online and off) and LinkedIn profiles. Besides revealing that recruiters only look at resumes for about six seconds , the study also points out the most important areas job seekers should focus on.
22 May 19:52
Superjail! Season 4 Trailer | Superjail! | Adult Swim
by Adult Swim
Mahmoudyussss
 |
There's a party at Superjail! and everyone's invited. Superjail! season 4 premieres Sunday, June 15 at 11:45 p.m. ET/PT on Adult Swim. SUBSCRIBE: http://bit....
|
From:
Adult Swim
Views:
15006
254
ratings
|
| Time: 00:32 | More in Entertainment |
22 May 09:21
Working in Silicon Valley & trying to show clients that I'm tech savvy

rnas and -1 others like this

20 May 00:46













Anhui winery models toilet after U.S. congress building
by Nona Tepper
Mahmoudthey've got the right idea
image courtesy of anhui news


A Anhui winery built toilets in the style of the U.S. Capitol Building Anuhui News reported on May 12.
Sporting traditional columns, a circular dome and high windows distinct to the U.S. Capitol, the luxurious restroom takes up more than 4,000 square feet, and is only open to Golden Seed winery staff and visitors. But, any resemblance to The Hill is merely a coincidence, said brewery staff.
“We were just trying to be novel,” an employee said. “You know, to be different from others.”
D.C. replicas were once a fad in China, and this is not Fuyang’s—where the Capitol toilet is located—first government building to replicate Washington.
In 2007, a Fuyang government residence became a symbol of corruption and lavish spending when state media revealed the building’s construction cost more than $4.3 million, nearly one-third of the district’s total revenue. By comparison, the per capita income of the district’s famers was a little more than $285. A number of local officials were fired over the incident, including the party chief of the city’s Yingquan province.
Numbers on how much the Capitol Hill toilet cost were not available, according to the Washington Post.
Other Chinese buildings to copy Washington include: White House’s in Jiangsu, Zhejiang, Hunan and Jiangxi provinces. In Wuxi, Jiangsu province, the local government has built four White House-style courts.
19 May 23:55
Andy Warhol Interviews Alfred Hitchcock (1974)
by Colin Marshall

Few midcentury cultural figures would at first seem to have as little in common as Andy Warhol and Alfred Hitchcock. Sure, they both made films, but how straight a line can even the farthest-reaching cinema theorists draw between, say, Hitchcock’s Psycho (1960) and Warhol’s Vinyl (1965)? Hitchcock’s The Birds (1963) and Warhol’s Empire (1964)? Yet not only did both of them direct many motion pictures, each began as a visual artist: “Warhol had started his career working as a commercial illustrator, Hitchcock had started out creating illustrations for title cards in silent movies,” says Filmmaker IQ’s post on their encounter in the September 1974 issue of Warhol’s Interview magazine. Yet in the brief conversation printed, they discuss not drawing, and not filmmaking, but murder:
Andy Warhol: Since you know all these cases, did you ever figure out why people really murder? It’s always bothered me. Why.
Alfred Hitchcock: Well I’ll tell you. Years ago, it was economic, really. Especially in England. First of all, divorce was very hard to get, and it cost a lot of money.
[ … ]
Andy Warhol: But what about a mass murderer.
Alfred Hitchcock: Well, they are psychotics, you see. They’re absolutely psychotic. They’re very often impotent. As I showed in “Frenzy.” The man was completely impotent until he murdered and that’s how he got his kicks. But today of course, with the Age of the Revolver, as one might call it, I think there is more use of guns in the home than there is in the streets. You know? And men lose their heads?
Andy Warhol: Well I was shot by a gun, and it just seems like a movie. I can’t see it as being anything real. The whole thing is still like a movie to me. It happened to me, but it’s like watching TV. If you’re watching TV, it’s the same thing as having it done to yourself.
“Warhol openly proclaimed that he was nervous upon meeting the legendary director,” adds Filmmaker IQ, “and posed with Hitchcock by kneeling at his feet,” resulting in the photo you see at the top of the post. They also include three portraits Warhol made of Hitchcock, the best known of which Christie’s Auction House describes as “a variation on the doubled self-image that Hitchcock played with in his title sequence, layering his own expressive line-drawing over the director’s silhouette, suggesting the mischievous defacement of graffiti as much as the canonization of a hero through the timelessness of the inscribed profile.” These images and the brief interview excerpt leave us wondering: can one call a work — on film, in a frame, in a magazine — both Hitchcockian and Warholian? A question, perhaps, best left to the theorists.
Related Content:
Watch Andy Warhol’s 1965 Film, Vinyl, Adapted from Anthony Burgess’ A Clockwork Orange
Three “Anti-Films” by Andy Warhol: Sleep, Eat & Kiss
Listen to François Truffaut’s Big, 12-Hour Interview with Alfred Hitchcock (1962)
36 Hitchcock Murder Scenes Climaxing in Unison
Alfred Hitchcock’s 50 Ways to Kill a Character (and Our Favorite Hitch Resources on the Web)
Colin Marshall hosts and produces Notebook on Cities and Culture and writes essays on cities, language, Asia, and men’s style. He’s at work on a book about Los Angeles, A Los Angeles Primer. Follow him on Twitter at @colinmarshall or on Facebook.
Andy Warhol Interviews Alfred Hitchcock (1974) is a post from: Open Culture. Follow us on Facebook, Twitter, and Google Plus, or get our Daily Email. And don't miss our big collections of Free Online Courses, Free Online Movies, Free eBooks, Free Audio Books, Free Foreign Language Lessons, and MOOCs.
The post Andy Warhol Interviews Alfred Hitchcock (1974) appeared first on Open Culture.
17 May 02:10







One Man's Insane Plan to Make Oculus Rifts for Chickens
by Adam Clark Estes

Problem: Too many chickens don't have room to roam around and be happy. Solution: Strap virtual reality headsets onto said chickens so they think they're free-range. No seriously, an assistant professor at Iowa State University seems to think this is a good idea, but he has to be kidding. Right? RIGHT?!
14 May 01:52


The reason every book about Africa has the same cover—and it’s not pretty
by Michael Silverberg
Last week, Africa Is a Country, a blog that documents and skewers Western misconceptions of Africa, ran a fascinating story about book design. It posted a collage of 36 covers of books that were either set in Africa or written by African writers. The texts of the books were as diverse as the geography they covered: Nigeria, Zimbabwe, South Africa, Botswana, Zambia, Mozambique. They were written in wildly divergent styles, by writers that included several Nobel Prize winners. Yet all of books’ covers featured an acacia tree, an orange sunset over the veld, or both.
“In short,” the post said, “the covers of most novels ‘about Africa’ seem to have been designed by someone whose principal idea of the continent comes from The Lion King.”

Image by Simon Stevens
What makes the persistence of these tired and inaccurate images even worse is that we’re living in an era of brilliant book design (including this lovely, type-only cover for Chimamanda Ngozi Adichie’s Americanah; her novel Half of a Yellow Sun begins the collage above). So why is it so hard for publishers of African authors to rise beyond cliché?
I asked Peter Mendelsund—who is an associate art director of Knopf, a gifted cover designer, and the author of a forthcoming book on the complex alliances between image and text—to help me understand how the publishing industry got to a place where these crude visual stereotypes are recycled ad nauseam. (Again and again, that acacia tree!)
He points first to “laziness, both individual or institutionalized.” Like most Americans, book designers tend not to know all that much about the rest of the world, and since they don’t always have the time to respond to a book on its own terms, they resort to visual clichés. Meanwhile, editors sometimes forget what made a manuscript unique to begin with. In the case of non-Western novels, they often fall back on framing it with “a vague, Orientalist sense of place,” Mendelsund says, and they’re enabled by risk-averse marketing departments.
“By the time the manuscript is ready to be produced, there’s a really strong temptation to follow a path that’s already been trod,” he says. “If someone goes out on a limb and tries something different, and the book doesn’t sell, you know who to blame: the guy who didn’t put the acacia tree on the cover.”
He adds that the underlying issue can be more pernicious: “Of course, there are the deeply ingrained problems of post-colonialist and Orientalist attitudes. We’re comfortable with this visual image of Africa because it’s safe. It presents ‘otherness’ in a way that’s easy to understand. That’s ironic, because what is fiction if not a way for you to stretch your empathetic muscles?”
That’s a reasonable diagnosis. But how to solve the underlying problem? Certain books are allowed to stand on their own; others—too often those by African, Muslim, or female authors—are assigned genre stereotypes. Mendelsund suggests that designers should start by initiating conversations with editors about what makes a book unique, so that they have something to respond to visually. And if that fails, and designers are pressured to use an offensive stereotype, Mendelsund says, “We can tell them that it’s racist, xenophobic, whatever.”
But change comes slowly. One day, Mendelsund predicts, there will be a best-selling novel by an African writer that happens to use a different visual aesthetic, and its success will introduce a new set of arbitrary images to represent Africa in Western eyes. “But right now, we’re in the age of the tree,” he says. “For that vast continent, in all its diversity, you get that one fucking tree.”
13 May 17:16
"Nearly half of US jobs could be susceptible to computerisation over the next two decades, a study..."
Mahmoudcomputer doctors and computer nurses
“
- NEWS RELEASE: Oxford Martin School study shows nearly half of US jobs could be at risk of computerisation | Oxford Martin Programme on the Impacts of Future Technology
Nearly half of US jobs could be susceptible to computerisation over the next two decades, a study from the Oxford Martin Programme on the Impacts of Future Technology suggests.
The study, a collaboration between Dr Carl Benedikt Frey (Oxford Martin School) and Dr Michael A. Osborne (Department of Engineering Science, University of Oxford), found that jobs in transportation, logistics, as well as office and administrative support, are at “high risk” of automation. More surprisingly, occupations within the service industry are also highly susceptible, despite recent job growth in this sector.
”- NEWS RELEASE: Oxford Martin School study shows nearly half of US jobs could be at risk of computerisation | Oxford Martin Programme on the Impacts of Future Technology
12 May 23:42
Amish Vampires In Space
by drew

“Jebediah has a secret [...] that will send his people into space.” So begins the promotional copy of Amish Vampires In Space, and goes downhill from there. The intrepid can read some of it in the “Look Inside” link, though I don’t recommend it.
Scirocco6 and -1 others like this
11 May 15:31
The Next Unreal Tournament: Totally Free, Developed By Public
by timothy
Mahmoudwhile i may not play it, i wanna see how this plays out
Nerval's Lobster (2598977) writes "Epic Games is rebooting Unreal Tournament, but not in a typical way. A small team of veteran developers will begin work on the next edition of the popular, multi-player shooter, in collaboration with pretty much anyone who wants to participate. "From the very first line of code, the very first art created and design decision made, development will happen in the open, as a collaboration between Epic, UT fans and UE4 developers. We'll be using forums for discussion, and Twitch streams for regular updates," reads a note on the company's blog. All code and content will appear on GitHub, and development will focus on Mac, Linux, and Windows. What's the catch? According to Epic, it'll take months to forge a playable game. "When the game is playable, it will be free. Not free to play, just free," the blog adds. "We'll eventually create a marketplace where developers, modders, artists and gamers can give away, buy and sell mods and content. Earnings from the marketplace will be split between the mod/content developer, and Epic. That's how we plan to pay for the game."" 









Read more of this story at Slashdot.
martbhell and -1 others like this

03 May 21:04
Impact
by Jesse

In honour of free comic day, have a free comic.
You can also still get your commissions here and check out my digital sales here (those are not free)
Damiani.guilherme, Barciella and 2 others like this

27 Apr 19:55
 Ubuntu security problem in the lock screen
Ubuntu security problem in the lock screen
The awful thing about getting it right the first time is that nobody realizes how hard it was.
by jwz
Ubuntu security problem in the lock screenI am running Ubuntu 14.04 with all the packages updated. When the screen is locked with password, if I hold ENTER after some seconds the screen freezes and the lock screen crashes. After that I have the computer fully unlocked.
You're using gnome-screensaver? Do you want ants? Because that's how you get ants.
Previously, previously, previously.
Update:
I've seen a few comments elsewhere about this saying things like, "So what, it was a bug, they've fixed it." That's really missing the point. The point is not that such a bug existed, but that such a bug was even possible. The real bug here is that the design of the system even permits this class of bug. It is unconscionable that someone designing a critical piece of security infrastructure would design the system in such a way that it does not fail safe.
Especially when I have given them 2+ decades of prior art demonstrating how to do it right, and a decade-old document clearly explaining What Not To Do that coincidentally used this very bug as it's illustrative strawman!
You must be this tall to work on security infrastructure. If you don't think this bug was a shameful embarrassment of design -- as opposed to merely bad code -- then please get out of the software industry.
Claes Mogren, Mahmoud likes this
26 Apr 21:40


Big Data: Are we making a big mistake?
by Tim Harford
Mahmoudbewm
Five years ago, a team of researchers from Google announced a remarkable achievement in one of the world’s top scientific journals, Nature. Without needing the results of a single medical check-up, they were nevertheless able to track the spread of influenza across the US. What’s more, they could do it more quickly than the Centers for Disease Control and Prevention (CDC). Google’s tracking had only a day’s delay, compared with the week or more it took for the CDC to assemble a picture based on reports from doctors’ surgeries. Google was faster because it was tracking the outbreak by finding a correlation between what people searched for online and whether they had flu symptoms.
Not only was “Google Flu Trends” quick, accurate and cheap, it was theory-free. Google’s engineers didn’t bother to develop a hypothesis about what search terms – “flu symptoms” or “pharmacies near me” – might be correlated with the spread of the disease itself. The Google team just took their top 50 million search terms and let the algorithms do the work.
The success of Google Flu Trends became emblematic of the hot new trend in business, technology and science: “Big Data”. What, excited journalists asked, can science learn from Google?
As with so many buzzwords, “big data” is a vague term, often thrown around by people with something to sell. Some emphasise the sheer scale of the data sets that now exist – the Large Hadron Collider’s computers, for example, store 15 petabytes a year of data, equivalent to about 15,000 years’ worth of your favourite music.
But the “big data” that interests many companies is what we might call “found data”, the digital exhaust of web searches, credit card payments and mobiles pinging the nearest phone mast. Google Flu Trends was built on found data and it’s this sort of data that interests me here. Such data sets can be even bigger than the LHC data – Facebook’s is – but just as noteworthy is the fact that they are cheap to collect relative to their size, they are a messy collage of datapoints collected for disparate purposes and they can be updated in real time. As our communication, leisure and commerce have moved to the internet and the internet has moved into our phones, our cars and even our glasses, life can be recorded and quantified in a way that would have been hard to imagine just a decade ago.
Cheerleaders for big data have made four exciting claims, each one reflected in the success of Google Flu Trends: that data analysis produces uncannily accurate results; that every single data point can be captured, making old statistical sampling techniques obsolete; that it is passé to fret about what causes what, because statistical correlation tells us what we need to know; and that scientific or statistical models aren’t needed because, to quote “The End of Theory”, a provocative essay published in Wired in 2008, “with enough data, the numbers speak for themselves”.
Unfortunately, these four articles of faith are at best optimistic oversimplifications. At worst, according to David Spiegelhalter, Winton Professor of the Public Understanding of Risk at Cambridge university, they can be “complete bollocks. Absolute nonsense.”
Found data underpin the new internet economy as companies such as Google, Facebook and Amazon seek new ways to understand our lives through our data exhaust. Since Edward Snowden’s leaks about the scale and scope of US electronic surveillance it has become apparent that security services are just as fascinated with what they might learn from our data exhaust, too.
Consultants urge the data-naive to wise up to the potential of big data. A recent report from the McKinsey Global Institute reckoned that the US healthcare system could save $300bn a year – $1,000 per American – through better integration and analysis of the data produced by everything from clinical trials to health insurance transactions to smart running shoes.
But while big data promise much to scientists, entrepreneurs and governments, they are doomed to disappoint us if we ignore some very familiar statistical lessons.
“There are a lot of small data problems that occur in big data,” says Spiegelhalter. “They don’t disappear because you’ve got lots of the stuff. They get worse.”
. . .
Four years after the original Nature paper was published, Nature News had sad tidings to convey: the latest flu outbreak had claimed an unexpected victim: Google Flu Trends. After reliably providing a swift and accurate account of flu outbreaks for several winters, the theory-free, data-rich model had lost its nose for where flu was going. Google’s model pointed to a severe outbreak but when the slow-and-steady data from the CDC arrived, they showed that Google’s estimates of the spread of flu-like illnesses were overstated by almost a factor of two.
The problem was that Google did not know – could not begin to know – what linked the search terms with the spread of flu. Google’s engineers weren’t trying to figure out what caused what. They were merely finding statistical patterns in the data. They cared about correlation rather than causation. This is common in big data analysis. Figuring out what causes what is hard (impossible, some say). Figuring out what is correlated with what is much cheaper and easier. That is why, according to Viktor Mayer-Schönberger and Kenneth Cukier’s book, Big Data, “causality won’t be discarded, but it is being knocked off its pedestal as the primary fountain of meaning”.
But a theory-free analysis of mere correlations is inevitably fragile. If you have no idea what is behind a correlation, you have no idea what might cause that correlation to break down. One explanation of the Flu Trends failure is that the news was full of scary stories about flu in December 2012 and that these stories provoked internet searches by people who were healthy. Another possible explanation is that Google’s own search algorithm moved the goalposts when it began automatically suggesting diagnoses when people entered medical symptoms.
Google Flu Trends will bounce back, recalibrated with fresh data – and rightly so. There are many reasons to be excited about the broader opportunities offered to us by the ease with which we can gather and analyse vast data sets. But unless we learn the lessons of this episode, we will find ourselves repeating it.
Statisticians have spent the past 200 years figuring out what traps lie in wait when we try to understand the world through data. The data are bigger, faster and cheaper these days – but we must not pretend that the traps have all been made safe. They have not.
. . .
In 1936, the Republican Alfred Landon stood for election against President Franklin Delano Roosevelt. The respected magazine, The Literary Digest, shouldered the responsibility of forecasting the result. It conducted a postal opinion poll of astonishing ambition, with the aim of reaching 10 million people, a quarter of the electorate. The deluge of mailed-in replies can hardly be imagined but the Digest seemed to be relishing the scale of the task. In late August it reported, “Next week, the first answers from these ten million will begin the incoming tide of marked ballots, to be triple-checked, verified, five-times cross-classified and totalled.”
After tabulating an astonishing 2.4 million returns as they flowed in over two months, The Literary Digest announced its conclusions: Landon would win by a convincing 55 per cent to 41 per cent, with a few voters favouring a third candidate.
The election delivered a very different result: Roosevelt crushed Landon by 61 per cent to 37 per cent. To add to The Literary Digest’s agony, a far smaller survey conducted by the opinion poll pioneer George Gallup came much closer to the final vote, forecasting a comfortable victory for Roosevelt. Mr Gallup understood something that The Literary Digest did not. When it comes to data, size isn’t everything.
Opinion polls are based on samples of the voting population at large. This means that opinion pollsters need to deal with two issues: sample error and sample bias.
Sample error reflects the risk that, purely by chance, a randomly chosen sample of opinions does not reflect the true views of the population. The “margin of error” reported in opinion polls reflects this risk and the larger the sample, the smaller the margin of error. A thousand interviews is a large enough sample for many purposes and Mr Gallup is reported to have conducted 3,000 interviews.
But if 3,000 interviews were good, why weren’t 2.4 million far better? The answer is that sampling error has a far more dangerous friend: sampling bias. Sampling error is when a randomly chosen sample doesn’t reflect the underlying population purely by chance; sampling bias is when the sample isn’t randomly chosen at all. George Gallup took pains to find an unbiased sample because he knew that was far more important than finding a big one.
The Literary Digest, in its quest for a bigger data set, fumbled the question of a biased sample. It mailed out forms to people on a list it had compiled from automobile registrations and telephone directories – a sample that, at least in 1936, was disproportionately prosperous. To compound the problem, Landon supporters turned out to be more likely to mail back their answers. The combination of those two biases was enough to doom The Literary Digest’s poll. For each person George Gallup’s pollsters interviewed, The Literary Digest received 800 responses. All that gave them for their pains was a very precise estimate of the wrong answer.
The big data craze threatens to be The Literary Digest all over again. Because found data sets are so messy, it can be hard to figure out what biases lurk inside them – and because they are so large, some analysts seem to have decided the sampling problem isn’t worth worrying about. It is.
Professor Viktor Mayer-Schönberger of Oxford’s Internet Institute, co-author of Big Data, told me that his favoured definition of a big data set is one where “N = All” – where we no longer have to sample, but we have the entire background population. Returning officers do not estimate an election result with a representative tally: they count the votes – all the votes. And when “N = All” there is indeed no issue of sampling bias because the sample includes everyone.
But is “N = All” really a good description of most of the found data sets we are considering? Probably not. “I would challenge the notion that one could ever have all the data,” says Patrick Wolfe, a computer scientist and professor of statistics at University College London.
An example is Twitter. It is in principle possible to record and analyse every message on Twitter and use it to draw conclusions about the public mood. (In practice, most researchers use a subset of that vast “fire hose” of data.) But while we can look at all the tweets, Twitter users are not representative of the population as a whole. (According to the Pew Research Internet Project, in 2013, US-based Twitter users were disproportionately young, urban or suburban, and black.)
There must always be a question about who and what is missing, especially with a messy pile of found data. Kaiser Fung, a data analyst and author of Numbersense, warns against simply assuming we have everything that matters. “N = All is often an assumption rather than a fact about the data,” he says.
Consider Boston’s Street Bump smartphone app, which uses a phone’s accelerometer to detect potholes without the need for city workers to patrol the streets. As citizens of Boston download the app and drive around, their phones automatically notify City Hall of the need to repair the road surface. Solving the technical challenges involved has produced, rather beautifully, an informative data exhaust that addresses a problem in a way that would have been inconceivable a few years ago. The City of Boston proudly proclaims that the “data provides the City with real-time information it uses to fix problems and plan long term investments.”
Yet what Street Bump really produces, left to its own devices, is a map of potholes that systematically favours young, affluent areas where more people own smartphones. Street Bump offers us “N = All” in the sense that every bump from every enabled phone can be recorded. That is not the same thing as recording every pothole. As Microsoft researcher Kate Crawford points out, found data contain systematic biases and it takes careful thought to spot and correct for those biases. Big data sets can seem comprehensive but the “N = All” is often a seductive illusion.
. . .
Who cares about causation or sampling bias, though, when there is money to be made? Corporations around the world must be salivating as they contemplate the uncanny success of the US discount department store Target, as famously reported by Charles Duhigg in The New York Times in 2012. Duhigg explained that Target has collected so much data on its customers, and is so skilled at analysing that data, that its insight into consumers can seem like magic.
Duhigg’s killer anecdote was of the man who stormed into a Target near Minneapolis and complained to the manager that the company was sending coupons for baby clothes and maternity wear to his teenage daughter. The manager apologised profusely and later called to apologise again – only to be told that the teenager was indeed pregnant. Her father hadn’t realised. Target, after analysing her purchases of unscented wipes and magnesium supplements, had.
Statistical sorcery? There is a more mundane explanation.
“There’s a huge false positive issue,” says Kaiser Fung, who has spent years developing similar approaches for retailers and advertisers. What Fung means is that we didn’t get to hear the countless stories about all the women who received coupons for babywear but who weren’t pregnant.
Hearing the anecdote, it’s easy to assume that Target’s algorithms are infallible – that everybody receiving coupons for onesies and wet wipes is pregnant. This is vanishingly unlikely. Indeed, it could be that pregnant women receive such offers merely because everybody on Target’s mailing list receives such offers. We should not buy the idea that Target employs mind-readers before considering how many misses attend each hit.
In Charles Duhigg’s account, Target mixes in random offers, such as coupons for wine glasses, because pregnant customers would feel spooked if they realised how intimately the company’s computers understood them.
Fung has another explanation: Target mixes up its offers not because it would be weird to send an all-baby coupon-book to a woman who was pregnant but because the company knows that many of those coupon books will be sent to women who aren’t pregnant after all.
None of this suggests that such data analysis is worthless: it may be highly profitable. Even a modest increase in the accuracy of targeted special offers would be a prize worth winning. But profitability should not be conflated with omniscience.
. . .
In 2005, John Ioannidis, an epidemiologist, published a research paper with the self-explanatory title, “Why Most Published Research Findings Are False”. The paper became famous as a provocative diagnosis of a serious issue. One of the key ideas behind Ioannidis’s work is what statisticians call the “multiple-comparisons problem”.
It is routine, when examining a pattern in data, to ask whether such a pattern might have emerged by chance. If it is unlikely that the observed pattern could have emerged at random, we call that pattern “statistically significant”.
The multiple-comparisons problem arises when a researcher looks at many possible patterns. Consider a randomised trial in which vitamins are given to some primary schoolchildren and placebos are given to others. Do the vitamins work? That all depends on what we mean by “work”. The researchers could look at the children’s height, weight, prevalence of tooth decay, classroom behaviour, test scores, even (after waiting) prison record or earnings at the age of 25. Then there are combinations to check: do the vitamins have an effect on the poorer kids, the richer kids, the boys, the girls? Test enough different correlations and fluke results will drown out the real discoveries.
There are various ways to deal with this but the problem is more serious in large data sets, because there are vastly more possible comparisons than there are data points to compare. Without careful analysis, the ratio of genuine patterns to spurious patterns – of signal to noise – quickly tends to zero.
Worse still, one of the antidotes to the multiple-comparisons problem is transparency, allowing other researchers to figure out how many hypotheses were tested and how many contrary results are languishing in desk drawers because they just didn’t seem interesting enough to publish. Yet found data sets are rarely transparent. Amazon and Google, Facebook and Twitter, Target and Tesco – these companies aren’t about to share their data with you or anyone else.
New, large, cheap data sets and powerful analytical tools will pay dividends – nobody doubts that. And there are a few cases in which analysis of very large data sets has worked miracles. David Spiegelhalter of Cambridge points to Google Translate, which operates by statistically analysing hundreds of millions of documents that have been translated by humans and looking for patterns it can copy. This is an example of what computer scientists call “machine learning”, and it can deliver astonishing results with no preprogrammed grammatical rules. Google Translate is as close to theory-free, data-driven algorithmic black box as we have – and it is, says Spiegelhalter, “an amazing achievement”. That achievement is built on the clever processing of enormous data sets.
But big data do not solve the problem that has obsessed statisticians and scientists for centuries: the problem of insight, of inferring what is going on, and figuring out how we might intervene to change a system for the better.
“We have a new resource here,” says Professor David Hand of Imperial College London. “But nobody wants ‘data’. What they want are the answers.”
To use big data to produce such answers will require large strides in statistical methods.
“It’s the wild west right now,” says Patrick Wolfe of UCL. “People who are clever and driven will twist and turn and use every tool to get sense out of these data sets, and that’s cool. But we’re flying a little bit blind at the moment.”
Statisticians are scrambling to develop new methods to seize the opportunity of big data. Such new methods are essential but they will work by building on the old statistical lessons, not by ignoring them.
Recall big data’s four articles of faith. Uncanny accuracy is easy to overrate if we simply ignore false positives, as with Target’s pregnancy predictor. The claim that causation has been “knocked off its pedestal” is fine if we are making predictions in a stable environment but not if the world is changing (as with Flu Trends) or if we ourselves hope to change it. The promise that “N = All”, and therefore that sampling bias does not matter, is simply not true in most cases that count. As for the idea that “with enough data, the numbers speak for themselves” – that seems hopelessly naive in data sets where spurious patterns vastly outnumber genuine discoveries.
“Big data” has arrived, but big insights have not. The challenge now is to solve new problems and gain new answers – without making the same old statistical mistakes on a grander scale than ever.
This article was first published in the FT Magazine, 29/30 March 2014. Read it in its original setting here.
Lachlan.wetherall likes this
26 Apr 20:06
Gambling Addiction
by Wes + Tony
Mahmoudhow's everybody doin out there in rss land?

What are you doing this weekend? Shut up! I don’t care! Let me tell you what I’M doing this weekend! Hosting video at the DORKLY FAN ART EXPO at C2E2, that’s what! Can you say “wowowow?”
If you’re in Chicago at C2E2, come to the Fan Art Expo in ballroom S100A and I’ll high five the living shit out of your hand!
If you’re not in Chicago, keep checking Dorkly.com all weekend as I upload videos of interviews, games, trivia! You’ll be entertained!
If you prefer IMMEDIATE gratification, be gratified by THIS! An episode of Morning Drawfee I did with the Excellent Caldwell Tanner and the Excellent Julia Lepetit:
Sheesh, what time is it? Let me check my watch. Oh, it’s HELL YEAH O’CLOCK.
T
26 Apr 17:10





Report: Google to end forced G+ integration, drastically cut division resources
by Ron Amadeo
Mahmoudbahahaha, yesssss. fuck you with a hot iron vic gundotra, you're the reason Reader's gone and I still wish the worst upon ye.

{kind=link}
{kind=link}
When Vic Gundotra, the head of Google+, suddenly announced his departure from Google today, many were left wondering "why" and what it meant for the future of Google+. He didn't give a reason for leaving, but according to a report from TechCrunch, the likely reason is a major shakeup for Google's social network.
In short, Google seems to be backing away from the original Google+ strategy. The report states that Google+ will no longer be considered a product that competes with Facebook and Twitter, and that Google's mission to force Google+ into every product will end. With this downgrade in importance comes a downgrade in resources. TechCrunch claims that 1000-1200 employees—many of which formed the core of Google+—will be moved to other divisions. Google Hangouts will supposedly be moved to Android, and the Google+ photos team is "likely" to follow. "Basically, talent will be shifting away from the Google+ kingdom and towards Android as a platform," the report said. The strange part is that both of these teams create cross-platform products. So if the report is true, there will be a group inside the Android team making iOS and Web apps, which doesn't seem like the best fit.
Read 4 remaining paragraphs | Comments
rnas and -1 others like this
25 Apr 23:41
good news for net neutrality activists
by kris

the fight is finally over! because net neutrality is done. the very thing that allowed many of us to have careers online, including myself – being allowed to exist on the same footing as any other company on the web – is going away. and even if this measure gets defeated in the 59th minute of the 11th hour, we’re just weeks away from the next one.
maybe webcartoonists can just fall back on ASCII comics, since they’d still load pretty quick
Randy Laue likes this
22 Apr 22:11
 How did they manage to make the new Lightning connector even flakier and less reliable than the 30-pin?? These cables are bullshit.
How did they manage to make the new Lightning connector even flakier and less reliable than the 30-pin?? These cables are bullshit.
Fucking Apple.
by jwz
Mahmoudbahaha microshafted
How did they manage to make the new Lightning connector even flakier and less reliable than the 30-pin?? These cables are bullshit.
Scirocco6 likes this
22 Apr 06:35







Why Weed Makes You... You... Huh?
by Andrew Tarantola

Scientists have long suspected that THC somehow affects the hippocampus region of the brain, the bit responsible for controlling short-term memory, but they have never been able to prove it. Turns out that's because they were looking at the wrong grey matter.
Benjaminsavage and -1 others like this
18 Apr 17:16
Frame-by-frame — Why the kid taking a selfie was kicked in the head by the train engineer [17 pics]
by Joey White
Mahmoudthis is a much better story.
Yesterday, we shared a video of a train engineer putting his boot to Jared Michael’s head when Jared tried to take a selfie as the train passed. There’s been a lot of speculation as to why the engineer did what he did. Sure, the kid even admitted he was stupid to be standing so close to the train, but two wrongs don’t make a right… Did the engineer really need to kick Jared in the head?
Frame-by-frame evidence from the video seems to indicate that the train engineer had a very good reason for kicking Jared. Redditor karolisalive pointed out an object that appears to be protruding from the train right where Michael’s head was…

If that’s not enough evidence to convince you that the engineer is a hero, here’s the complete frame-by-frame evidence. If nothing else, Jared’s transition from careless selfie to a ruined day is comical to watch…
Jared’s having a good day…

His earbuds are putting down a good beat…

The train he’s been waiting for is coming… What could go wrong?

What’s that? A train’s right behind him? You’d never know with that cool, calm, collected look…

Does Jared hear that horn blaring? Probably not… Those earbuds are cranked up a little too loud…

Is that a boot? Jared can’t see it, because Jared is still taking a selfie…

Jared still doesn’t realize there’s a boot connecting with his face…

Now he’s beginning to grasp the situation, though he still has no idea he’s being saved from the metal object protruding from the train…

And there go the earbuds…

Yep, he definitely feels the boot now…

The engineer’s ability to kick Jared’s head out of the way with a work boot while operating a moving train is actually really impressive…

At least Jared got a chance to show off that flow on top of his head…

Those are some impressive gymnastics from the engineer…

And just as quickly, the train is gone…



It’s even more impressive that the engineer was able to save Jared without completely knocking him out with the boot. That engineer is a hero!
Josh Shaffer, rnas and one other like this
17 Apr 01:54
 Jack Halprin:
Jack Halprin:
As a Google Attorney, I Need the Homes of 7 Teachers, and Here's Why
by jwz
Mahmoudthere is something seriously wrong with the photographer who took this picture. or maybe it's the guy's face. either way it's bad.
Jack Halprin:There's been a lot of misinformation recently about my decision to buy a seven-unit San Francisco home and evict all the other tenants, including a city school teacher, just so I can have the place to myself.People are saying it's a bad thing. Somehow they're using Google to spread this lie. It had never before occurred to me that such a thing could happen.
So I need to clear the record: as a Google employee, I need the homes of seven school teachers to survive. It's just a fact of life, like the food chain, or the singularity. [...]
What I'm trying to say is that, in a free society, some people make better choices than others, and we reward those people with the homes of their vanquished enemies. Some people, for example, choose to be teachers, and spend their lives teaching other people's kids things that they can Google for free. Naturally, we pay them very little money -- so little that they're practically homeless already. Frankly, I'm surprised that anyone even notices when I evict someone making under $150,000 a year. Honestly, how can you tell?
Then there are other people, like me, who make good decisions, becoming important parts of the companies that sponsor TED talks. Naturally, we pay these people what they're worth. Why am I so highly compensated? Well, if I weren't at the office every day, doing the work I do, the government wouldn't be nearly as good at spying on you.
You're welcome.
Without my taking over their homes, how do you expect Google to file patent claims against Apple -- patent claims that are more important to the future of mankind than the work of a thousand homeless teachers? Without my ability to have an extra six bathrooms at my disposal, how could Google possibly lobby city government for the right of its employees to take your homes away?
Scirocco6 and -1 others like this
17 Apr 01:52

 Backpacks For Cows Collect Their Fart Gas And Store It For Energy
Backpacks For Cows Collect Their Fart Gas And Store It For Energy
Cow Fartpacks
by jwz
Mahmoudhmmmm i'll allow it.
Backpacks For Cows Collect Their Fart Gas And Store It For EnergyResearchers put plastic backpacks on cows, then inserted tubes into their rumens (their biggest digestive tract). Then, they extracted the methane--about 300 liters a day. That's enough to run a car, or a fridge for 24 hours."[We] believe that such technology could be used to collect methane on larger scale, and even imagine a future farm with a couple of these cows used to provide energy to satisfy the farm's needs," Sorondo says.
Previously, previously, previously, previously, previously, previously, previously, previously.
Sanjay likes this
16 Apr 20:53


AT&T troll Weev is released as hacking conviction is overturned
by Dave Neal
Troll got the telecom firm’s goat(se)