
Shared posts
19 Feb 23:39
AdequateRecord Pro™: Like ActiveRecord, but more adequate
Dmitry KrasnoukhovSeems very adequate
TL;DR: AdequateRecord is a set of patches that adds cache stuff to make ActiveRecord 2x faster
I’ve been working on speeding up Active Record, and I’d like to share what I’ve been working on! First, here is a graph:

This graph shows the number of times you can call Model.find(id) and
Model.find_by_name(name) per second on each stable branch of Rails. Since it
is “iterations per second”, a higher value is better. I tried running this
benchmark with Rails 1.15.6, but it doesn’t work on Ruby 2.1.
Here is the benchmark code I used:
require 'active_support'
require 'active_record'
p ActiveRecord::VERSION::STRING
ActiveRecord::Base.establish_connection adapter: 'sqlite3', database: ':memory:'
ActiveRecord::Base.connection.instance_eval do
create_table(:people) { |t| t.string :name }
end
class Person < ActiveRecord::Base; end
person = Person.create! name: 'Aaron'
id = person.id
name = person.name
Benchmark.ips do |x|
x.report('find') { Person.find id }
x.report('find_by_name') { Person.find_by_name name }
end
Now let’s talk about how I made these performance improvements.
What is AdequateRecord Pro™?
AdequateRecord Pro™ is a fork of ActiveRecord with some performance enhancements. In this post, I want to talk about how we achieved high performance in this branch. I hope you find these speed improvements to be “adequate”.
Group discounts for AdequateRecord Pro™ are available depending on the number of seats you wish to purchase.
How Does ActiveRecord Work?
ActiveRecord constructs SQL queries after doing a few transformations. Here’s an overview of the transformations:

The first transformation comes from your application code. When you do something like this in your application:
Post.where(...).where(...).order(..)
Active Record creates an instance of an ActiveRecord::Relation that contains
the information that you passed to where, or order, or whatever you called.
As soon as you call a method that turns this Relation instance in to an array,
Active Record does a transformation on the relation objects. It turns the
relation objects in to ARel objects which represent the SQL query AST. Finally,
it converts the AST to an actually SQL string and passes that string to the
database.
These same transformations happen when you run something like Post.find(id),
or Post.find_by_name(name).
Separating Static Data
Let’s consider this statement:
Post.find(params[:id])
In previous versions of Rails, when this code was executed, if you watched your log files, you would see something like this go by:
SELECT * FROM posts WHERE id = 10 SELECT * FROM posts WHERE id = 12 SELECT * FROM posts WHERE id = 22 SELECT * FROM posts WHERE id = 33
In later versions of Rails, you would see log messages that looked something like this:
SELECT * FROM posts WHERE id = ? [id, 10] SELECT * FROM posts WHERE id = ? [id, 12] SELECT * FROM posts WHERE id = ? [id, 22] SELECT * FROM posts WHERE id = ? [id, 33]
This is because we started separating the dynamic parts of the SQL statement from the static parts of the SQL statement. In the first log file, the SQL statement changed on every call. In the second log file, you see the SQL statement never changes.
Now, the problem is that even though the SQL statement never changes, Active Record still performs all the translations we discussed above. In order to gain speed, what do we do when a known input always produces the same output? Cache the computation.
Keeping the static data separated from the dynamic data allows AdequateRecord to cache the static data computations. What’s even more cool is that even databases that don’t support prepared statements will see an improvement.
Supported Forms
Not every call can benefit from this caching. Right now the only forms that are supported look like this:
Post.find(id) Post.find_by_name(name) Post.find_by(name: name)
This is because calculating a cache key for these calls is extremely easy. We know these statements don’t do any joins, have any “OR” clauses, etc. Both of these statements indicate the table to query, the columns to select, and the where clauses right in the Ruby code.
This isn’t to say that queries like this:
Post.where(...).where(...).etc
can’t benefit from the same techniques. In those cases we just need to be
smarter about calculating our cache keys. Also, this type of query will never
be able to match speeds with the find_by_XXX form because the find_by_XXX
form can completely skip creating the ActiveRecord::Relation objects.
The “finder” form is able to skip the translation process completely.
Using the “chained where” form will always create the relation objects, and we
would have to calculate our cache key from those. In the “chained where” form,
we could possibly skip the “relation -> AST” and “AST -> SQL statement”
translations, but you still have to pay the price of allocating
ActiveRecord::Relation objects.
When can I use this?
You can try the code now by using the adequaterecord branch on GitHub. I think we will merge this code to the master branch after Rails 4.1 has been released.
What’s next?
Before merging this to master, I’d like to do this:
- The current incarnation of AdequateRecord needs to be refactored a bit. I have finished the “red” and “green” phases, and now it’s time for the “refactor” step.
- The cache should probably be an LRU. Right now, it just caches all of the things, when we should probably be smarter about cache expiry. The cache should be bounded by number of tables and combination of columns, but that may get too large.
After merging to master I’d like to start exploring how we can integrate this cache to the “chained where” form.
On A Personal Note
Feel free to quit reading now. :-)
The truth is, I’ve been yak shaving on this performance improvement for years. I knew it was possible in theory, but the code was too complex. Finally I’ve payed off enough technical debt to the point that I was able to make this improvement a reality. Working on this code was at times extremely depressing. Paying technical debt is really not fun, but at least it is very challenging. Some time I will blurrrgh about it, but not today!
Thanks to work (AT&T) for giving me the time to do this. I think we can make the next release of Rails (the release after 4.1) the fastest version ever.
EDIT: I forgot to add that newer Post.find_by(name: name) syntax is
supported, so I put it in the examples.
CvX! likes this
12 Feb 16:37
The Old Reader Premium!
Dmitry KrasnoukhovWow so many premium features!
We are thrilled to announce that we are rolling out Premium accounts for The Old Reader. Since taking over the application in August we’ve made tremendous strides to improve the dependability and speed of the application. We’ve also begun the process of building and releasing heavily requested features and have worked diligently on user support. We believe The Old Reader is now truly a world-class application!
Our next goal is to ensure the long term financial viability of The Old Reader. Hosting, development, and support are not inexpensive and while it’s never been our goal to get rich off of this application, long term sustainability and growth will require revenue. So we explored several models for generating revenues including a premium offering and advertising. In the end, we’d like to avoid advertising as we feel it’s too invasive and runs counter to our strong belief in the open web. So we started working on a premium offering that would allow 90% of our users to continue on with a free account that is largely unchanged from what they are using today.
What will you get with The Old Reader Premium?
- Full-text search
- Faster feed refresh times
- Up to 500 Subscriptions
- 6 months of post storage
- Instapaper and Readability integration
- Early access to new features
What will it cost?
The Old Reader Premium will cost $3/month or $30/year. However, for the next 2 weeks (or up to 5,000 accounts) we’ll be offering the service for $2/month or $20/year and we will lock you into that price for a minimum of the next 2 years. This is our way of saying thanks to our existing users and hopefully getting the Premium service off to a great start.
Do I have to upgrade?
No! 90% of our users can continue on for free just as they are today. However, users with more than 100 feeds will need to upgrade to premium. Otherwise, all functionality will remain available to free accounts. We also offer a 2 week trial period for the premium service and will even allow that trial period to get extended for those still interested in moving to Premium.
We hope you are as excited about TOR Premium as we are. It’s a great value for a service that we know our users will love. Thanks for continuing to support us and thanks for using The Old Reader!
Ben Wolf, Elena Bulygina and 30 others like this






04 Feb 12:14
Designing Unread
Dmitry KrasnoukhovBeauty
At the time I decided to make Unread, I wasn’t using RSS anymore. Months earlier, even before Google Reader announced it was shutting down, I was so busy with my day job and side projects that I couldn’t keep up with all my subscriptions. So I stopped trying. I felt relieved not to have the burden of another inbox to clear, but I missed reading my favorite writers — those who post less frequently but write with care.
Unread was more than just my first project as an indie developer. It was a chance for me to change my reading habits. Despite having a new baby boy around the same time — who has since reached six months old and change — I found some downtime left over each day to start reading again. I needed an RSS app that could help me slow down and read peacefully.

One of Riposte’s users once wrote a very flattering post about our app:
I loved @riposte almost immediately. Well designed and self-assured, the UI felt, when compared to others, both somewhat foreign and surprisingly comfortable.
The words that struck me most were “foreign and suprisingly comfortable.” While that wasn’t a deliberate goal when we made Riposte, I have consciously strived to make Unread feel unexpected yet instantly familiar, like what I look for in new music.1 I hope that’s what you’ll feel if you try Unread.
I really like the idea of an app being comfortable. Comfortable means always knowing where you are. It means not worrying about making a mistake. It means information has an obvious visual hierarchy: bold titles, tidy paragraphs, and spacious margins. Comfortable means there’s not visual clutter to distract you, except for those items that are supposed to stand out, like buttons or the damn status bar.
Comfortable also means physical comfort, which is an aspect of mobile app design that designers often forget. Anyone with a new baby knows how convenient it is to be able to use an app with one hand. Some areas of the screen are hard to reach, especially on an iPhone 5 or later. Grip your phone in one hand observe the sweep of your thumb. It’s easy to reach objects in the center, but the navigation bar is too far away to reach without adjusting your grip. Although it’s tempting to jump to the conclusion that closer is always better, positioning an item too close to your hand can cause discomfort because of the way your thumb has to flex to reach it.
I decided that best way to make Unread a comfortable app was to let the reader directly manipulate each screen anywhere her thumb might land. This freed me to remove interface chrome and focus on the text. It’s now a trite idea for design to focus on “content,” but in Unread’s case it really was an essential goal. I wanted readers to get their minds out of the email rut that has trapped their expectations of what RSS can be.
Unread doesn’t use navigation bars2, tab bars, or tool bars. It has a full-screen interface, interrupted only by the status bar at the top and a “footer bar”, paired to match the status bar, at the bottom. The footer bar shows the title of the current screen. I experimented with having no footer bar, but since the same article can appear in many different lists, I often felt lost without it.
 Click to see full resolution.
Click to see full resolution.
Because there’s no navigation bar, there’s also no back button. To go back, you pan to dismiss the current screen, dragging from left to right. Unlike other apps, you don’t have to start dragging from the edge of the screen. You can start wherever your thumb happens to be. Swiping back through several screens feels a bit like dealing cards in a poker game. I think this interaction is really great, but don’t take my word for it. Mikhail Madnani of Beautiful Pixels had this to say:
@unread I want iOS 7 navigation to be like you. Please make them Sherlock the app and everything.
Or as he put it more emphatically on another occasion:
It gives me a boner.
Unread’s article view is just text. There are no buttons. The status and footer bars stay hidden the entire time.3 There are two themes, one for day and one for night.4 Both themes are set in Whitney and Whitney Condensed from HOEFLER & CO. These fonts make my eyes feel relaxed. They’re warm and slightly playful in bold title weights, and subdued and crisp in body text weights.
 Examples: Day, Night, and Campfire (a hidden theme).
Examples: Day, Night, and Campfire (a hidden theme).
The hardest design for me to solve was the article list screen. In a typical RSS app, this screen is the one that most resembles an email inbox. I knew I wanted to avoid email design cues, but it was really hard to find another way. All those conventions were developed for good reasons. Here’s a link to a sampling of outtakes. I’m a slow learner. It was months before I finally found the current design.
Here are links to the screenshots I am using for the App Store:
Unread’s article list screens are unlike those found in other RSS apps you may have used. There are no toolbars, no unread indicators (dots), and no buttons. Each article summary is neatly laid out with obvious consistency. The titles are set in a condensed bold font, bucking the iOS 7 trend towards unreadable thin fonts. There’s an ample amount of padding above each article title and below each article summary, which makes it easy to see where one article ends and the next one begins. You’ll notice that there are no favicons. Most websites have crappy, non-retina favicons, even sites that otherwise have an attention for detail. I think real-world favicons distract more than illustrate, so I chose not to include them.
The last word of a sentence is the most _______. That’s why Unread’s article summaries aren’t truncated at an arbitrary number of lines using elipses. Summaries are composed of whole sentences. Each summary is about the length of an App.net post, give or take a few sentences. If you subscribe to good writers who don’t bury their ledes too deeply, you’ll find that the summaries give you a good idea of what each article is like.
If an article is determined to be a Linked-List style article — i.e. the article’s URL is a link to another site and not the permalink — then the domain of the linked item’s URL is displayed at the bottom of the summary. This is a feature I’ve always wanted in an RSS reader.
Every screen in Unread has its own set of options.5 Rather then put them in a toolbar, which would add clutter and feel too familiar, the options are tucked away offscreen in an options menu. This menu is invoked by dragging the screen from right to left — just like pull-to-refresh, but sideways. Just drag your thumb wherever it may be. This helps make Unread comfortable to use with one hand, no matter what size iPhone you have or how big your hands are:
 Pull sideways to trigger options menus.
Pull sideways to trigger options menus.
There’s comfort in consistency. One of the things I learned from people’s positive feelings about Riposte was the importance of using gestures solely for navigation and not mixing navigation gestures with action gestures. The options menu doesn’t strictly adhere to that idea, but it follows the spirit of the law. The entire screen moves with your thumb. There are no competing swipe gestures on article cells that will confuse you. Gestures are the same on every screen in the app. Learn them once. Use them everywhere.
The options menus keep your screen free of invasive toolbars, but they don’t sacrifice features. Unread has lots of sharing options, with more yet to come. All the sharing features were built using OvershareKit, an open-source library made by me and Justin Williams. Try it out in your next project.
I think it’s important to reiterate what I wanted Unread to be. I didn’t make it to be a feature-for-feature replacement for an app you may already be using. That would make Unread merely a thin coat of paint on old ideas. The point of Unread is to give you an opportunity to change the way you read. Its design can only take you halfway there. I urge you to prune your subscriptions down to the writers you care about most. Look for new writers you haven’t read before. If you’re a writer, I hope it inspires you to write more thoughtfully, too.
-
Great music aims for a paradox. Each new musical phrase surprises us even as it resolves the phrase that went before it. ↩
-
Except in modal views, for a variety of reasons. ↩
-
This is an optional feature. It only applies to the article view. The footer bar is never hidden in the other screens of the app. ↩
-
There are several hidden themes, too. Hooray for Easter eggs. ↩
-
Except for modal screens, like signing into an account or composing a tweet. ↩
firehose likes this

22 Jan 08:27
He never knew it would be so easy to handle such a massive amount of data. It was his first time...
Dmitry KrasnoukhovComputer science erotica

He never knew it would be so easy to handle such a massive amount of data. It was his first time writing a mapreduce job and things have been going smoothly. So far he’s written unit tests and the map function. All that remained was reduce but he was under a time pressure and had to finish before the others came into the office.
His fingers furiously stroked the keys as he concentrated on the monitor, occasionally glancing out the window to see the progress of the sunrise. His heart was racing and beads of sweat were making their way down his face. He was almost there.
Finally, as the cars started to make their way into the parking lot, he finished. All unit tests passed. With a sigh of relief he released it to production. As the others walked into the office, he checked his data one last time to make sure everything looked correct. It properly reduced.
firehose, Anton Tolchanov and one other like this
17 Jan 15:51
Ruby's GIL and transactional memory
by Mike Perham
I saw a link to a really interesting paper this morning: Eliminating Global Interpreter Locks in Ruby through Hardware Transactional Memory. This blew my mind when I read it as it’s a really interesting concept; let me explain.
What is Hardware Transactional Memory?
Transactional Memory ensures that a set of operations in memory happen in a consistent manner. If my code reads a variable, changes that variable and writes it back to memory, TM tries to ensure that these operations yield a predictable outcome. TM can be implemented in software (e.g. see Clojure’s STM support) or in hardware1.
What is the GIL?
(or, How to stop concurrency problems by stopping concurrency)
Ruby2‘s GIL is a VM-wide mutex that a thread must obtain before that thread can execute Ruby code. This is necessary because C extensions and many parts of Ruby are not actually thread-safe (including Array and Hash!) By holding the GIL, we guarantee that our thread’s Ruby code is the only Ruby code executing; there can’t be any concurrency issues.3
What does TM have to do with the GIL?
The point of the GIL is to ensure that two threads don’t look at and modify memory at the same time. Two threads can look at the same memory but if one thread modifies the memory, the other thread needs to start its operation over. This is necessary for atomic, consistent transactions: the operation should have a consistent view of memory or else it needs to rollback.
The GIL is one way to get that atomic, consistent view but HTM is another way. When executed, Ruby code actually takes the form of lots of tiny operations: load a variable, branching, method invocation, yielding, etc. The researchers turned each one of those operations into a small transaction. If two threads execute operations that touch the same memory, the hardware will abort one of them so it can start the operation over.
The performance gains were modest: a simple Rails app app saw 1.3x performance improvement with 3 threads vs 1 thread. But the researchers found a number of hotspots which caused a lot of transaction aborts, including Ruby’s GC, the regexp library and various C global variables. Fixing these hotspots would be just one of many changes necessary to remove the GIL and make Ruby truly thread-safe but would also improve HTM scalability greatly.
That’s a very brief overview of the paper but I think it’s a fascinating idea and one worth pursuing further.
-
HTM is available via Intel’s TSX extensions, available on some recent Haswell processors. Hopefully this will become standard in future generations of x86 CPUs. ↩
-
Ruby in this case means MRI. JRuby and Rubinius are thread-safe. <3 ↩
-
As with everything, it’s more complicated than that. Concurrency != parallelism and all that; please skip the comments arguing at me, trying to win Internet points. ↩
Dmitry Krasnoukhov likes this
09 Jan 16:46
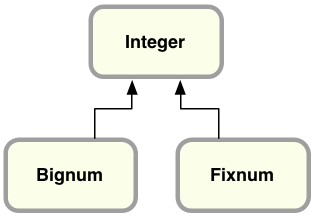
Ruby represents small integers using Fixnum
and large integers using Bignum.
How Big is a Bignum?
Ruby represents small integers using Fixnum
and large integers using Bignum.
Most of us don’t use Ruby to perform complex calculations for science, engineering or cryptography applications; instead, we might turn to R, Matlab or some other programming language or tool for that sort of thing. When we calculate values using Ruby, it’s often to process simple values while generating a web page using ERB or Haml, or to handle the result of a database query using ActiveRecord. Almost all of the time, Ruby’s Fixnum class is more than sufficient.
For most Ruby developers, therefore, the Bignum class is a dark, unfamiliar corner of the language. Today I’d like to shed some light on Bignum by looking at how Ruby represents integers internally inside the Fixnum and Bignum classes. What’s the largest integer that fits inside a Fixnum; just how big is a Bignum?
Also, it turns out that Ruby 2.1 contains an important new change for the Bignum class: support for the GNU Multiple Precision Arithmetic Library (GMP) library. In my next post, I’ll take a look at mathematical theory and history behind some of the algorithms used by Bignum internally and how Ruby 2.1 works with GMP. But for now, let’s start with the basics.
64-Bit Integers
Most computers these days represent numbers as 64 digit binary values internally. For example, the number ten thousand looks like this expressed as a binary value:
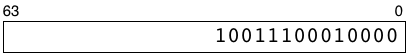
My rectangle here represents how a 64-bit computer would save an integer in a microprocessor register or a RAM memory location. The numbers 63 and 0 indicate that there are spaces for 64 binary digits, each of which can contain a zero or one. The most significant binary digit, #63, is on the left, while the least significant digit, #0, is on the right. I’m not showing all of the leading zeroes here to keep things simple.
The term 64-bit architecture means the logic gates, transistors and circuits located on your microprocessor chip are designed to process binary values using 64 binary digits like this, in parallel. Whenever your code uses an integer, the microprocessor retrieves all of these on/off values from one of the RAM chips in your CPU using a “bus” or set of 64 parallel connections.
64-Bit Integers in MRI Ruby
The standard implementation of Ruby, Matz’s Ruby Interpreter (MRI), saves integers using a slightly different, custom format; it hard codes the least significant digit (on the right in my diagram) to one and shifts the actual integer value one bit to the left. As we’ll see in a moment, if this bit were zero Ruby would instead consider the integer to be a pointer to some Ruby object.
Here’s how Ruby represents ten thousand internally:
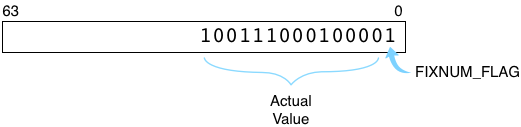
FIXNUM_FLAG=1 indicates this integer represents an instance of the Fixnum class. The flag is a performance optimization, removing the need for Ruby to create a separate C structure the way it normally would for other types of objects. (Ruby uses a similar trick for symbols and special values such as true, false and nil.)
Two’s Complement in Ruby
Like most other computer languages and also like your microprocessor’s actual hardware circuits, Ruby uses a binary format called two’s complement to save negative integers. Here’s how the value -10,000 would be saved inside your Ruby program:
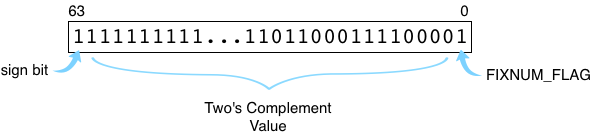
Note the first bit on the left, the sign bit, is set to 1. This indicates this is a negative integer. Ruby still sets the lowest bit, FIXNUM_FLAG, to 1. The other bits contain the value itself. To calculate a two’s complement value for a negative integer, your microprocessor adds one to the absolute value (getting 10,001 in this example) and then reverses the zeroes and ones. This is equivalent to subtracting the absolute value from the next highest power of two. Ruby uses two’s complement in the same way, except it adds FIXNUM_FLAG on the right and shifts the rest of the value to the left.
The Largest Fixnum Value: 4611686018427387903
Using 64-bit binary values with FIXNUM_FLAG, Ruby is able to take advantage of your computer’s microprocessor to represent integer values efficiently. Addition, subtraction and other integer operations can be handled using the corresponding assembly language instructions by removing and then re-adding FIXNUM_FLAG internally as needed. This design only works, however, for integer values that are small enough to fit into a single 64-bit word. We can see what the largest positive Fixnum integer must be by setting all 62 of the middle bits to one, like this:

Here we have a zero on the left (indicating this is a positive integer) and a
one on the right (for FIXNUM_FLAG). The remaining 62 bits in the middle hold
this binary number:
11111111111111111111111111111111111111111111111111111111111111
Converting this to decimal we get: 4611686018427387903, the largest integer that fits into a Fixnum object. (If you compiled Ruby on a 32-bit computer, of course, the largest Fixnum would be much smaller than this, only 30-bits wide.)
The Smallest Bignum: 4611686018427387904
But what does Ruby do if we want to use larger numbers? For example, this Ruby program works just fine:

But now the sum doesn’t fit into a 64-bit Fixnum value, since expressing 4611686018427387904 as a binary value requires 63 digits, not 62:

This is where the Bignum class comes in. While calculating 4611686018427387903+1, Ruby has to create a new type of object to represent 4611686018427387904 – an instance of the Bignum class. Here’s how that looks inside of Ruby:
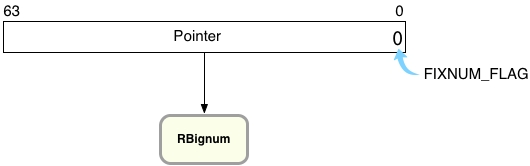
On the right you can see Ruby has reset the FIXNUM_FLAG to zero, indicating this value is not a Fixnum but instead a pointer to some other type of object. (C programs like MRI Ruby that use malloc to allocate memory always get addresses that end in zero, that are aligned. This means the FIXNUM_FLAG, a zero, is actually also part of the pointer’s value.)
The RBignum Structure
Now let’s take a closer look at the RBignum C structure and find out what’s inside it. Here’s how Ruby saves the value 4611686018427387904 internally:
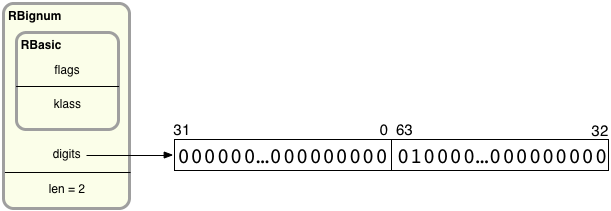
On the left, you can see RBignum contains an inner structure called RBasic, which contains internal, technical values used by all Ruby objects. Below that I show values specific to Bignum objects: digits and len. digits is a pointer to an array of 32-bit values that contain the actual big integer’s bits grouped into sets of 32. len records how many 32-bit groups are in the digits array. Since there can be any number of groups in the digits array, Ruby can represent arbitrarily large integers using RBignum.
Ruby divides up the bits of the big integer into 32-bit pieces. On the left, the first 32-bit value contains the least significant 32 bits from the big integer, bit 31 down to bit 0. Following that, the second value contains bits 63-32. If the big integer were larger, the third value would contain bits 95-64, etc. Therefore, the large integer’s bits are actually not in order: The groups of bits are in reverse order, while the bits inside each group are in the proper order.
To save a Bignum value, Ruby starts by saving the least significant bits of the target integer into the first 32-bit digit group. Then it shifts the remaining bits 32 places to the right and saves the next 32 least significant bits into the next group. Ruby continues shifting and saving until the entire big integer has been processed.
Ruby allocates enough 32-bit pieces in the digits array to provide enough room for the entire large integer. For example, for an extremely large number requiring 320 bits, Ruby could use 10 32-bit values by setting len to 10 and allocating more memory:

In my example Ruby needs just two 32-bit values. This makes sense because, as we saw above, 4611686018427387903 is a 62-bit integer (all ones) and when I add one I get a 63-bit value. When I add one, Ruby first copies the 62 bits in the target value into a new Bignum structure, like this:
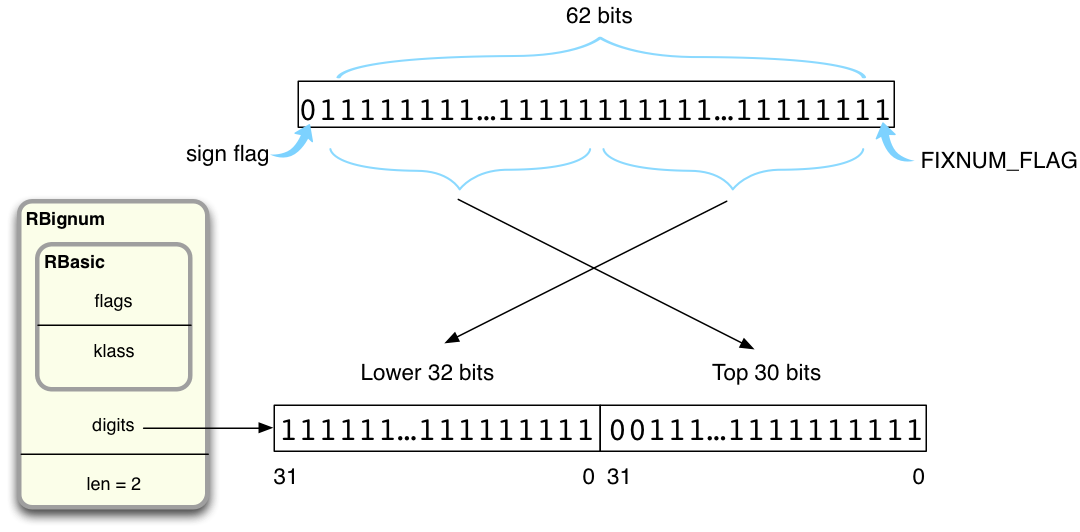
Ruby copies the least significant 32 bits into the first digit value on the left, and the most significant 30 into the second digit value on the right (there is space for two leading zeroes in the second digit value).
Once Ruby has copied 4611686018427387903 into a new RBignum structure, it can then use a special algorithm implemented in bignum.c to perform an addition operation on the new Bignum. Now there is enough room to hold the 63-bit result, 4611686018427387904 (diagram copied from above):
A few other minor details to learn about this:
- Ruby saves the sign bit inside the RBasic structure, and not in the binary digit values themselves. This saves a bit of space, and makes the code inside bignum.c simpler.
- Ruby also doesn’t need to save the FIXNUM_FLAG in the digits, since it already knows this is a Bignum value and not a Fixnum.
- For small Bignum’s, Ruby saves memory and time by storing the digits values right inside the RBignum structure itself, using a C union trick. I don’t have time to explain that here today, but you can see how the same optimization works for strings in my article Never create Ruby strings longer than 23 characters.
Next time
In my next post I’ll look at how Ruby performs an actual mathematical operation using Bignum objects. It turns out there’s more to multiplication that you might think: Ruby uses one of a few different multiplication algorithms depending on how large the integers are, each with a different history behind it. And Ruby 2.1 adds yet another new algorithm to the mix with GMP.
08 Jan 17:04
A Christmas Wish
by Birdbox
Dmitry KrasnoukhovMagic!



The 2013 Birdbox Christmas short about a little boy and what he really wants for Christmas.
Directed by Ant Blades
Music by Jon Wygens
08 Jan 09:24
Introducing GitHub Traffic Analytics
by Caged
Dmitry KrasnoukhovДроч!
The holidays are over and we're getting back into the shipping spirit at GitHub. We want to kick off 2014 with a bang, so today we're happy to launch Traffic analytics!
You can now see detailed analytics data for repositories that you're an owner of or that you can push to. Just load up the graphs page for your particular repository and you'll see a new link to the traffic page.

When you land on the traffic page you'll see a lot of useful information about your repositories including where people are coming from and what they're viewing.

Looking at these numbers for our own repositories has been fun, sometimes surprising, and always interesting. We hope you enjoy it as much as we have!
07 Jan 19:14
Profiling memory leaky Sidekiq applications with Ruby 2.1
Dmitry KrasnoukhovMy first blog post in english
My largest Sidekiq application had a memory leak and I was able to find and fix it in just few hours spent on analyzing Ruby's heap. In this post I'll show my profiling setup.
As you might know Ruby 2.1 introduced a few great changes to ObjectSpace, so now it's much easier to find a line of code that is allocating too many objects. Here is great post explaining how it's working.
I was too lazy to set up some seeding and run it locally, so I checked that test suite passes when profiling is enabled and pushed debugging to production. Production environment also suited me better since my jobs data can't be fully random generated.
So, in order to profile your worker, add this to your Sidekiq configuration:
if ENV["PROFILE"]
require "objspace"
ObjectSpace.trace_object_allocations_start
Sidekiq.logger.info "allocations tracing enabled"
module Sidekiq
module Middleware
module Server
class Profiler
# Number of jobs to process before reporting
JOBS = 100
class << self
mattr_accessor :counter
self.counter = 0
def synchronize(&block)
@lock ||= Mutex.new
@lock.synchronize(&block)
end
end
def call(worker_instance, item, queue)
begin
yield
ensure
self.class.synchronize do
self.class.counter += 1
if self.class.counter % JOBS == 0
Sidekiq.logger.info "reporting allocations after #{self.class.counter} jobs"
GC.start
ObjectSpace.dump_all(output: File.open("heap.json", "w"))
Sidekiq.logger.info "heap saved to heap.json"
end
end
end
end
end
end
end
end
Sidekiq.configure_server do |config|
config.server_middleware do |chain|
chain.add Sidekiq::Middleware::Server::Profiler
end
end
end
Adjust number of jobs you want your worker to process before you have heap dumped.
Run a sample worker: PROFILE=1 sidekiq -C config/sidekiq.yml and wait for jobs to be processed.
After you have heap.json, analyze it by running something like this:
cat heap.json |
ruby -rjson -ne ' obj = JSON.parse($_).values_at("file","line","type"); puts obj.join(":") if obj.first ' |
sort |
uniq -c |
sort -n |
tail -20
You'll see a list of objects of specific types that are allocated on specific lines, sorted by objects count, for example:
460 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/dirty.rb:368:DATA
460 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/fields.rb:388:DATA
460 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/fields.rb:414:DATA
460 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/fields.rb:436:DATA
460 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/fields.rb:456:DATA
472 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/concern.rb:115:ICLASS
527 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/dependencies.rb:469:NODE
529 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/core_ext/class/attribute.rb:79:NODE
573 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/core_ext/array/wrap.rb:41:ARRAY
606 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/dependencies.rb:469:ARRAY
724 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/concern.rb:114:ICLASS
844 /home/whatever/.rvm/gems/ruby-2.1.0/gems/journey-1.0.4/lib/journey/parser.rb:139:OBJECT
861 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/dependencies.rb:469:DATA
1147 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/dependencies.rb:469:STRING
1165 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/extensions/module.rb:22:STRING
1242 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/core_ext/class/attribute.rb:74:ARRAY
1281 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/core_ext/class/attribute.rb:81:DATA
2083 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/core_ext/class/attribute.rb:74:NODE
2429 /home/whatever/.rvm/gems/ruby-2.1.0/bundler/gems/mongoid-3.1.6/lib/mongoid/extensions/module.rb:22:DATA
3325 /home/whatever/.rvm/gems/ruby-2.1.0/gems/activesupport-3.2.16/lib/active_support/core_ext/class/attribute.rb:74:DATA
Repeat this action after more jobs are processed. If you see a constantly growing objects count somewhere, this is probably your leak.
Andrew Berezovskiy, Natalia Pokrovskaya and one other like this
30 Dec 10:23
Ruby 2.1: objspace.so
ObjectSpace in ruby contains many useful heap debugging utilities.
Since 1.9 ruby has included objspace.so which adds even more methods to the ObjectSpace module:
ObjectSpace.each_object{ |o| ... }
ObjectSpace.count_objects #=> {:TOTAL=>55298, :FREE=>10289, :T_OBJECT=>3371, ...}
ObjectSpace.each_object.inject(Hash.new 0){ |h,o| h[o.class]+=1; h } #=> {Class=>416, ...}
require 'objspace'
ObjectSpace.memsize_of(o) #=> 0 /* additional bytes allocated by object */
ObjectSpace.count_tdata_objects #=> {Encoding=>100, Time=>87, RubyVM::Env=>17, ...}
ObjectSpace.count_nodes #=> {:NODE_SCOPE=>2, :NODE_BLOCK=>688, :NODE_IF=>9, ...}
ObjectSpace.reachable_objects_from(o) #=> [referenced, objects, ...]
ObjectSpace.reachable_objects_from_root #=> {"symbols"=>..., "global_tbl"=>...} /* in 2.1 */
In 2.1, we’ve added a two big new features: an allocation tracer and a heap dumper.
Allocation Tracing
Tracking down memory growth and object reference leaks is tricky when you don’t know where the objects are coming from.
With 2.1, you can enable allocation tracing to collect metadata about every new object:
require 'objspace'
ObjectSpace.trace_object_allocations_start
class MyApp
def perform
"foobar"
end
end
o = MyApp.new.perform
ObjectSpace.allocation_sourcefile(o) #=> "example.rb"
ObjectSpace.allocation_sourceline(o) #=> 6
ObjectSpace.allocation_generation(o) #=> 1
ObjectSpace.allocation_class_path(o) #=> "MyApp"
ObjectSpace.allocation_method_id(o) #=> :perform
A block version of the tracer is also available.
Under the hood, this feature is built on NEWOBJ and FREEOBJ tracepoints included in 2.1. These events are only available from C, via rb_tracepoint_new().
Heap Dumping
To further help debug object reference leaks, you can dump an object (or the entire heap) for offline analysis.
require 'objspace'
# enable tracing for file/line/generation data in dumps
ObjectSpace.trace_object_allocations_start
# dump single object as json string
ObjectSpace.dump("abc".freeze) #=> "{...}"
# dump out all live objects to a json file
GC.start
ObjectSpace.dump_all(output: File.open('heap.json','w'))
Objects are serialized as simple json, and include all relevant details about the object, its source (if allocating tracing was enabled), and outbound references:
{
"address":"0x007fe9232d5488",
"type":"STRING",
"class":"0x007fe923029658",
"frozen":true,
"embedded":true,
"fstring":true,
"bytesize":3,
"value":"abc",
"encoding":"UTF-8",
"references":[],
"file":"irb/workspace.rb",
"line":86,
"method":"eval",
"generation":15,
"flags":{"wb_protected":true}
}
The heap dump produced by ObjectSpace.dump_all can be processed by the tool of your choice. You might try a json processor like jq or a json database. Since the dump contains outbound references for each object, a full object graph can be re-created for deep analysis.
For example, here’s a simple ruby/shell script to see which gems/libraries create the most long-lived objects of different types:
$ cat heap.json |
ruby -rjson -ne ' puts JSON.parse($_).values_at("file","line","type").join(":") ' |
sort |
uniq -c |
sort -n |
tail -4
26289 lib/active_support/dependencies.rb:184:NODE
29972 lib/active_support/dependencies.rb:184:DATA
43100 lib/psych/visitors/to_ruby.rb:324:STRING
47096 lib/active_support/dependencies.rb:184:STRING
If you have a ruby application that feels large or bloated, give these new ObjectSpace features a try. And if you end up writing a heap analysis tool or visualization for these json files, do let me know on twitter.
Anton Tolchanov and -1 others like this
13 Dec 17:28
How can we help the open web?
by Julien
Today is thanksgiving in the USA. It’s a holliday in where you celebrate others and thank them for the help they provided. Of course, we want to thank everyone in our community: our customers, developers, partners and investors. It’s a pleasure to be working with you and we hope to keep doing that for a long time.
However, we also want to take a couple words to thank everyone who’s building the open web, every developer, indie or not that’s making the web a better place to interract with each other.
Fighting for the open web is not an easy feat and every day is a new battle to make sure the web giants don’t own the web, our personal data and our relationships.
It’s not obvious, but there are a ton of projects which contribute to the open web: popular things like Bootstrap, which anyone can use to make a consistent-looking interface, controversial protocols, like Bitcoin who can simplify the way people pay for our services and apps, fast growing services which simplify how developers can build the web… or even small libraries on Github.
We also know that, even it’s a priceless, sometimes, ‘thank you’ is not enough. There are open web projects which are stuck because they tripped on a road block too big for the small team working on them. There are open web projects that have a hard time getting attention because whoever is in charge of them is not the stereotypical developer. There are open web projects looking for a couple donations to pay for their hosting and bandwidth.
We want to help these projects. Superfeedr is a cashflow positive machine that’s built using open web libraries, protocols and software: it’s time that we give back.
If there is anything we can do to help: review code, fix bugs, write posts, help get introductions… etc, please, feel free to let us know.
Dmitry Krasnoukhov and -1 others like this


24 Oct 10:30
Oh god, the release is tomorrow
Dmitry KrasnoukhovCANDY BOX 2 OMG WOW
Oh god, the release is tomorrow

14 Oct 09:08

Melody's Echo Chamber: Melody's Echo Chamber
by Lindsay Zoladz
Dmitry KrasnoukhovКлёвый сайкоделик/дрим-поп проект тёлочки чувака из Tame Impala.
At a Tame Impala show in Paris two years ago, Melody Prochet, French pop aficionado and multi-instrumentalist for the band My Bee's Garden, became intrigued by the Aussie psych-rockers' scuzzy sonics. She struck up a conversation with the band's Kevin Parker after the show about how he achieved the band's signature, blown-out bass sound in particular, and a while later he asked My Bee's Garden to support Tame Impala on a European leg of their tour. Though her own band's sound was clean and somewhat precious, Prochet remained drawn to the Tame Impala aesthetic. So when she decided to go solo, she asked Parker to produce, and to push her out of her comfort zone a bit. "I tend to write songs with pretty chords and arpeggios, and I was kind of boring myself," she recalled. "So I asked Kevin to destroy everything."
Mission accomplished. Recorded mostly at Parker's home studio in Perth, the resulting self-titled debut from Melody's Echo Chamber is a record of psych-tinged pop with just the right amount of thematic darkness and grime around the edges. Prochet has a way with melody and a voice that places her among the top-tier graduates of the Trish Keenan and Laetitia Sadier school of dream pop, but it's Parker's signature production that helps this record transcend its forever-in-vogue 1960s pop influences. ("This record was my dream sound," Prochet said in a recent interview. "I've tried for years to get it but finally found the right hands to sculpt it.") Full of immersive textures that give off an echoey depth and prismatic riffs that tumble through space, Parker's production grants this record its own laws of gravity.
The record's best songs tease out tension between soft and hard edges-- a combination of beauty and brittleness. Excellent lead-off single "I Follow You" pairs an exquisitely sugary melody with a fuzzy, syncopated riff, while the dreamy "Crystallized" detonates in its final moments into a kraut-y electro freak-out. Beginning with a toy-soldier beat and warmly warped synth tones, "You Won't Be Missing That Part of Me" blooms into one of the record's best moments, a kiss-off song that flips the usual script and takes the perspective of the heartbreaker rather than the heartbreak ("Because I lied with all my heart, because it's time to change my life... Hold on, you'll see it won't be that hard to forget me.") Parker's production is perhaps at its most stunning on "Some Time Alone, Alone", on which Prochet's arpeggios rain down like a chandelier being hit with a sledgehammer in slow-motion.
The shards occasionally prick: "Mount Hopeless" is fittingly gloomy, and there's even a song about post-plane crash cannibalism called "Snowcapped Andes Crash". But for as odd and chilling as that song sounds on paper, it falls flat in execution, languishing on a Side B that doesn't quite have enough ideas or surprises to save from some repetitive lulls. Prochet hasn't quite figured out how to do anything interesting with the macabre that lurks somewhere in this record's sound, and it leaves you wishing she'd explored Melody's dark side a little more, à la Broadcast's creepy masterpiece Tender Buttons. Of course, Prochet's melodies can't quite fill the Broadcast-shaped void left in the wake of Keenan's untimely death, but Melody's Echo Chamber is one of the more satisfying records to bear that band's influence in recent years. For a collaboration between a songwriter and a producer who helped push her to the outer limits of her vision, Melody's Echo Chamber is an impressively immersive debut.
29 Sep 10:02
The Shrinking RSS Pie
by Julien
Dmitry KrasnoukhovRSS-пирог!
We all know that RSS and openness are key to the web’s resilience and independence, yet the RSS ecosystem is still shrinking. It’s because of us, players of that ecosystem: we tend to try growing our slice of the pie, at the expense of other players rather than growing the whole pie!
Daria Nifontova likes this






16 Sep 13:31
Can you post a sexy picture of yourself?
Dmitry KrasnoukhovMONEY$
Daria Nifontova likes this
15 Sep 20:16
The Three Best Debugging Tools
by Mike Perham
1. Your Coworker
It’s happened to me over and over: I’ll spend hours trying to track down a problem. In frustration, I’ll ask a coworker to look at the code and frequently they will point out the problem in seconds. It’s called situational blindness and it means that you will often overlook the bug right in front of your eyes because you’ve looked at it so much, your mind has started to ignore it.
Your coworker has another valuable trait: they are different than you. They think differently and have a different set of knowledge. A hard bug for you to find might be easy for them. Next time you’re frustrated, call over a coworker and see what happens.
2. Your Creative Side
It’s happened to me over and over: I’ll build something with a flaw that doesn’t quite work right. I’ll go to sleep frustrated and wake up the next morning knowing exactly what the problem is.
It’s well known that we think in two different manners: creatively and logically. When focused on details (such as debugging a problem), we’re 100% logical as we jump from thought A to B to C. But it’s your creative side that can jump from thought A to thought Z via intuition. Like your coworker, your creative brain thinks differently from your logical brain. By going to sleep, you’re calling over that “creative coworker” and asking for help.
3. Your Mental Model of the System
If you don’t know the software tools and APIs you are using to solve problems really well, you’ll find yourself endlessly debugging. When learning a system like Ruby on Rails for the first few years, debugging is often really just learning how the system works. Software is insanely complex and every level of the stack is insanely complex. Abstractions hide much of the complexity and understanding those abstractions well allows you to fit it all within your head.
Malcom Gladwell’s maxim that expertise comes with 10,000 hours of practice holds here too. After 5 years of full-time experience (40hrs/wk * 50 wk/yr * 5), you’ll have a very strong understanding of your system of choice. That knowledge is very valuable.
Pro tip: read the documentation for a library that you are going to use, implement your first attempt at using that library, and then read the documentation again. The first time will give you an overview and things to look for but frequently you won’t comprehend certain aspects due to your inexperience with the library. You almost certainly will comprehend more when you read it the second time.
Conclusion
All of these things have one thing in common: thought. Debugging is thinking through the execution of code in your head. By improving your knowledge and looking at the problem from different angles, you can much more effectively debug those hard problems that can be so frustrating.
chmuehlethaler, Daria Nifontova likes this

04 Sep 01:03
English has been my pain for 15 years
Paul Graham managed to put a very important question, the one of the English language as a requirement for IT workers, in the attention zone of news sites and software developers [1]. It was a controversial matter as he referred to "foreign accents" and the internet is full of people that are just waiting to overreact, but this is the least interesting part of the question, so I'll skip that part. The important part is, no one talks about the "English problem" usually, and I always felt a bit alone in that side, like if it was a problem only affecting me, so in this blog post I want to share my experience about English.
[1] http://paulgraham.com/accents.html
A long story
---
I still remember me and sullivan (http://www.isg.rhul.ac.uk/sullivan/) both drunk in my home in Milan trying to turn an attack I was working on, back in 1998, in a post that was understandable for BUGTRAQ users, and this is the poor result we obtained: http://seclists.org/bugtraq/1998/Dec/79
Please note the "Instead all others" in the second sentence. I'm still not great at English but I surely improved over 15 years, and sullivan now teaches in US and UK universities so I imagine he is totally fluent (spoiler warning: I'm still not). But here the point is, we were doing new TCP/IP attacks but we were not able to freaking write a post about it in English. It was 1998 and I already felt extremely limited by the fact I was not able to communicate, I was not able to read technical documentation written in English without putting too much efforts in the process of reading itself, so my brain was using like 50% of its energy to just read, and less was left to actually understand what I was reading.
However in one way or the other I always accepted English as a good thing. I always advice people against translation efforts in the topic of technology, since I believe that it is much better to have a common language to document and comment the source code, and actually to obtain the skills needed to understand written technical documentation in English is a simple effort for most people.
So starting from 1998 I slowly learned to fluently read English without making more efforts compared to reading something written in Italian.
I even learned to write at the same speed I wrote stuff in Italian, even if I hit a local minima in this regard, as you can see reading this post: basically I learned to write very fast a broken subset of English, that is usually enough to express my thoughts in the field of programming, but it is not good enough to write about general topics. I don't know most of the words needed to refer to objects you find in a kitchen for example, or the grammar constructs needed to formulate complex sentences, hypothetical structures, and so forth. As I now can communicate easily in the topic I care most, and in a way that other people can more or less understand everything I write, the pressure to improve has diminished greatly… However I recently discovered that this was the minor of my problems with English.
European English, that funny language
---
So while I managed to eventually write and read comfortably enough for my needs, I almost never experienced actual communication in an English speaking country until recently. Before that I always used English with other european (non UK) people, such as French, German, Spanish people.
Now the English spoken in these countries is the English spoken at English school lessons… Phonetically it has almost nothing to do with American or UK English. They say it is "BBC English" but actually it is not. It is a phonetically greatly simplified English that uses UK English grammar.
*That* version of English, actually allows people from around the world to communicate easily. The basic grammar is trivial to grasp, and in a few months of practice you can talk. The sound of the words is almost the same in all the non-UK speaking countries in Europe. So it works great.
There is just one problem, it has nothing to do with the real English spoken in UK, US, Canada, and other countries where English is a native language.
English is a bit broken, after all
---
Now I've a secret for you, that is everything but a secret except nobody says it in the context of English VS The World: English is a broken language, phonetically.
In Italy we have a long history, but a very late political unification. Different regions talk different dialects, and people have super strong accents. Before 1950, when the "TV Language Unification" happened, everybody was still taking with their *dialects* and italian was only mastered by a small percentage of people. Sicilian itself, the language talked the most by my family, predates Italian by centuries (http://en.wikipedia.org/wiki/Sicilian_language*).
Still, guess what, nobody has issues understanding one of another region, or even from a Switzerland canton. Italian is phonetically one of the simplest languages on the earth, and is full of redundancy. It has, indeed, a low information entropy and usually words are long with a good mix of consonants and vocals in every word. There are no special rules to pronounce a word, if you know the sound of every single letter, plus the sound of a few special combination of letters like "gl", "sc", you can basically pronounce 99.9% of the words correctly just reading them for the first time.
The fact that people from different English speaking countries have issues communicating is already a big hint about how odd is English phonetically.
For instance for me and many other non native English speakers it is very very very hard to understand what the fuck an UK people is telling. North Americans are a lot simpler usually.
Because of this "feature" of English the problem for me is not just my accent, that is IMHO the simplest thing to fix if I'll try to fix it putting enough work into it, but the ability to understand what people are saying to me. IMHO the fact that Paul Graham refers to "accents" is a bad attitude of UK/US people in this regard, hey guys, you are not understanding us, we are not understanding what you say as well, and it is hard to find people that, once your understanding limits are obvious, will try to slow down the pace of the conversation. Often even if I say I did not understand, I'll get the same sentence repeated the same at speed of light.
Learning written english as a first exposure is the killer
---
In my opinion one fact that made me so slow learning English is the fact that I started reading English without never ever listening to it.
My brain is full of associations between written words and funny sounds that really don't exist in the actual language.
My advice is that if you are learning English now, start listening as soon as possible to spoken English.
The osx "say" program is a good assistant, it is able to pronounce in a decent way most English words. NEVER learn a new word without learning what is its sound.
Introvert or extrovert?
---
One of the things that shocked me the most with my experience with the English language is how not mastering a language can switch you into an introvert. I'm an extrovert in Italy where most people are extroverts, in Sicily where there are even more extroverts, and inside my family that is composed mostly of extroverts. I'm kinda of an attention whore I guess (I hope I'm not, actually, but well, I'm very extrovert). Now when I have to talk in English, I'm no longer an extrovert anymore because of the communication barrier, and I regret every time I've to go to a meeting, or to be introduced to another person. It is a nightmare.
It's too late, let's study English
---
English in my opinion is only simple grammatically, but is a bad pick as a common language. However the reality is, it already won, there is no time to change it, and it is a great idea to talk in English better, even if this means to put a lot of efforts into it. This is what I'm doing myself, I'm trying to improve.
Another reason I find myself really in need to improve my English is that in 10 years I'll likely no longer write code professionally, and a logical option is to switch into the management side of IT, or to handle big projects where you are not supposed to write the bulk of the code. Well, if you think you need English as a developer, you'll need it a lot more as you go in other divisions of a typical IT company, even if you "just" have to actually manage many programmers.
However as a native English speaker you should really realize that a lot of people are doing serious efforts to learn a language that is hard to learn: it is not an hobby, to master English is a big effort that a lot of people are trying to do to make communication simpler. Without to mention how trivial is to go back in the learning process as long as you stop talking / listening for a couple of weeks…
My long term hope is that soon or later different accents could converge into a standard easy-to-understand one that the English speaking population could use as a lingua franca. Comments
[1] http://paulgraham.com/accents.html
A long story
---
I still remember me and sullivan (http://www.isg.rhul.ac.uk/sullivan/) both drunk in my home in Milan trying to turn an attack I was working on, back in 1998, in a post that was understandable for BUGTRAQ users, and this is the poor result we obtained: http://seclists.org/bugtraq/1998/Dec/79
Please note the "Instead all others" in the second sentence. I'm still not great at English but I surely improved over 15 years, and sullivan now teaches in US and UK universities so I imagine he is totally fluent (spoiler warning: I'm still not). But here the point is, we were doing new TCP/IP attacks but we were not able to freaking write a post about it in English. It was 1998 and I already felt extremely limited by the fact I was not able to communicate, I was not able to read technical documentation written in English without putting too much efforts in the process of reading itself, so my brain was using like 50% of its energy to just read, and less was left to actually understand what I was reading.
However in one way or the other I always accepted English as a good thing. I always advice people against translation efforts in the topic of technology, since I believe that it is much better to have a common language to document and comment the source code, and actually to obtain the skills needed to understand written technical documentation in English is a simple effort for most people.
So starting from 1998 I slowly learned to fluently read English without making more efforts compared to reading something written in Italian.
I even learned to write at the same speed I wrote stuff in Italian, even if I hit a local minima in this regard, as you can see reading this post: basically I learned to write very fast a broken subset of English, that is usually enough to express my thoughts in the field of programming, but it is not good enough to write about general topics. I don't know most of the words needed to refer to objects you find in a kitchen for example, or the grammar constructs needed to formulate complex sentences, hypothetical structures, and so forth. As I now can communicate easily in the topic I care most, and in a way that other people can more or less understand everything I write, the pressure to improve has diminished greatly… However I recently discovered that this was the minor of my problems with English.
European English, that funny language
---
So while I managed to eventually write and read comfortably enough for my needs, I almost never experienced actual communication in an English speaking country until recently. Before that I always used English with other european (non UK) people, such as French, German, Spanish people.
Now the English spoken in these countries is the English spoken at English school lessons… Phonetically it has almost nothing to do with American or UK English. They say it is "BBC English" but actually it is not. It is a phonetically greatly simplified English that uses UK English grammar.
*That* version of English, actually allows people from around the world to communicate easily. The basic grammar is trivial to grasp, and in a few months of practice you can talk. The sound of the words is almost the same in all the non-UK speaking countries in Europe. So it works great.
There is just one problem, it has nothing to do with the real English spoken in UK, US, Canada, and other countries where English is a native language.
English is a bit broken, after all
---
Now I've a secret for you, that is everything but a secret except nobody says it in the context of English VS The World: English is a broken language, phonetically.
In Italy we have a long history, but a very late political unification. Different regions talk different dialects, and people have super strong accents. Before 1950, when the "TV Language Unification" happened, everybody was still taking with their *dialects* and italian was only mastered by a small percentage of people. Sicilian itself, the language talked the most by my family, predates Italian by centuries (http://en.wikipedia.org/wiki/Sicilian_language*).
Still, guess what, nobody has issues understanding one of another region, or even from a Switzerland canton. Italian is phonetically one of the simplest languages on the earth, and is full of redundancy. It has, indeed, a low information entropy and usually words are long with a good mix of consonants and vocals in every word. There are no special rules to pronounce a word, if you know the sound of every single letter, plus the sound of a few special combination of letters like "gl", "sc", you can basically pronounce 99.9% of the words correctly just reading them for the first time.
The fact that people from different English speaking countries have issues communicating is already a big hint about how odd is English phonetically.
For instance for me and many other non native English speakers it is very very very hard to understand what the fuck an UK people is telling. North Americans are a lot simpler usually.
Because of this "feature" of English the problem for me is not just my accent, that is IMHO the simplest thing to fix if I'll try to fix it putting enough work into it, but the ability to understand what people are saying to me. IMHO the fact that Paul Graham refers to "accents" is a bad attitude of UK/US people in this regard, hey guys, you are not understanding us, we are not understanding what you say as well, and it is hard to find people that, once your understanding limits are obvious, will try to slow down the pace of the conversation. Often even if I say I did not understand, I'll get the same sentence repeated the same at speed of light.
Learning written english as a first exposure is the killer
---
In my opinion one fact that made me so slow learning English is the fact that I started reading English without never ever listening to it.
My brain is full of associations between written words and funny sounds that really don't exist in the actual language.
My advice is that if you are learning English now, start listening as soon as possible to spoken English.
The osx "say" program is a good assistant, it is able to pronounce in a decent way most English words. NEVER learn a new word without learning what is its sound.
Introvert or extrovert?
---
One of the things that shocked me the most with my experience with the English language is how not mastering a language can switch you into an introvert. I'm an extrovert in Italy where most people are extroverts, in Sicily where there are even more extroverts, and inside my family that is composed mostly of extroverts. I'm kinda of an attention whore I guess (I hope I'm not, actually, but well, I'm very extrovert). Now when I have to talk in English, I'm no longer an extrovert anymore because of the communication barrier, and I regret every time I've to go to a meeting, or to be introduced to another person. It is a nightmare.
It's too late, let's study English
---
English in my opinion is only simple grammatically, but is a bad pick as a common language. However the reality is, it already won, there is no time to change it, and it is a great idea to talk in English better, even if this means to put a lot of efforts into it. This is what I'm doing myself, I'm trying to improve.
Another reason I find myself really in need to improve my English is that in 10 years I'll likely no longer write code professionally, and a logical option is to switch into the management side of IT, or to handle big projects where you are not supposed to write the bulk of the code. Well, if you think you need English as a developer, you'll need it a lot more as you go in other divisions of a typical IT company, even if you "just" have to actually manage many programmers.
However as a native English speaker you should really realize that a lot of people are doing serious efforts to learn a language that is hard to learn: it is not an hobby, to master English is a big effort that a lot of people are trying to do to make communication simpler. Without to mention how trivial is to go back in the learning process as long as you stop talking / listening for a couple of weeks…
My long term hope is that soon or later different accents could converge into a standard easy-to-understand one that the English speaking population could use as a lingua franca. Comments
OneReadWonder, Alexander Yarovoy likes this
31 Aug 10:14
when we get out of the office for a two hour lunch
Dmitry KrasnoukhovOrange mocha frappuccino!

Señor Gif Contributor Hunter sent me this gif. He is appreciated.
r3d, Daria Nifontova and -1 others like this
10 Aug 19:29
fullmetal-dipshit: im diggin the new anon icon
Dmitry KrasnoukhovЭто я приехал на борщагу

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
25 Jul 22:10
Important update:
Dmitry KrasnoukhovUPD: We're back online!
On Saturday (July 20) we moved over a terabyte of data from one storage system to another. We made the move because the amount of data we have to store simply did not fit on our servers, and our preliminary tests showed that the new system will only be using about ⅓ of the disk space.
Migration went through fine, however we started seeing a higher I/O load after we finished, and suddenly one SSD drive in one of our database servers stopped working. Not a big deal, we thought — we obviously store data in mirrored mode on several servers — so we asked our hosting provider to swap the drive. We had to re-sync the data to the new disk, so you might have noticed the site being flacky.
However while data was syncing, another SSD drive went down in a different server. We got it replaced, and started syncing two database shards at the same time. At this point we lost 2 more drives, one of which unfortunately was on the server in one of the shards that were repairing.
While you can fly a plane with an engine off, unfortunately when all your engines stop your flight is over. Right now we have to restore our last pre-migration full database backup, and apply incremental updates to bring database to a fresh and (hopefully) consistent state.
Here comes the worst news - this will probably take a day or two.
Sorry about that.
This is a tough and incredibly stressful situation, but it looks like we have no other choice. We understand your frustration (actually, we are in the same boat: we are RSS junkies and built The Old Reader for ourselves and friends) and we are doing everything to make it as fast and painless as possible and live happily ever after.
After that, we will deploy bug fixes along with new things and improvements we have already developed. During last year we adapted and successfully expanded first from 2000 to 5000 users practically overnight, then from 10 000 to 160 000 in several weeks and from 200 000 to 400 000 in four months, so we are considering this as a new level-up for the project (although bumpy and painful one).
It’s 5 AM right now and backup restoration has already begun. We are monitoring and working on The Old Reader nearly 24 hours a day. We will keep frequent (but not annoying updates) in Twitter and will answer all your questions.
We deeply apologize for what has happened but we intend to come back in a much better way.
Thank you very much for your patience, support and understanding,
The Old Reader team.
UPD:
July 25, 21:07 UTC
Back online! We hope this outage lasting July 25 19:12 UTC
If everything goes as planned, we should be back in 4-5 hours.
July 25 15:50 UTC
Import — check;
Indexes — check;
Balancing data between shards and configuring replicasets — in progress.
July 25 08:45 UTC
It looks like we have managed to upload the data. If indexes get generated correctly, we might be back online later today.
July 25 2:00 UTC
Continuing the upload, hoping it goes as planned, counting hours.
July 24 14:00 UTC
Proceeding with restore. More details hopefully in the evening.
July 23 18:00 UTC
We have managed to create a consistent dump of our database and started uploading it to the database servers.
Jfiorato, trevisan.paula and 11 others like this
25 Jul 21:54
when debugging is easier than expected
by kbironneau
Dmitry KrasnoukhovЭто мы подымаем ридер после <3 дней даунтайма (нет)

/* by richardngn */
Daria Nifontova and -1 others like this