As a programmer you have a unique style, and stylometry techniques can be used to fingerprint your style and determine with high probability whether or not a piece of code was written by you. That makes a degree of intuitive sense when considering source code. But suppose we don’t have source code? Suppose all we have is an executable binary? Caliskan et al., show us that it’s possible to de-anonymise programmers even under these conditions. Amazingly, their technique still works even when debugging symbols are removed, aggressive compiler optimisations are enabled, and traditional binary obfuscation techniques are applied! Anonymous authorship of binaries is consequently hard to achieve.
One of the findings along the way that I found particularly interesting is that more skilled/experienced programmers are more fingerprintable. It makes sense that over time programmers acquire their own unique way of doing things, yet at the same time these results seem to suggest that experienced programmers do not converge on a strong set of stylistic conventions. That suggests to me a strong creative element in program authorship, just as experienced authors of written works develop their own unique writing styles.
If we encounter an executable binary sample in the wild, what can we learn from it? In this work, we show that the programmer’s stylistic fingerprint, or coding style, is preserved in the compilation process and can be extracted from the executable binary. This means that it may be possible to infer the programmer’s identity if we have a set of known potential candidate programmers, along with executable binary samples (or source code) known to be authored by these candidates.
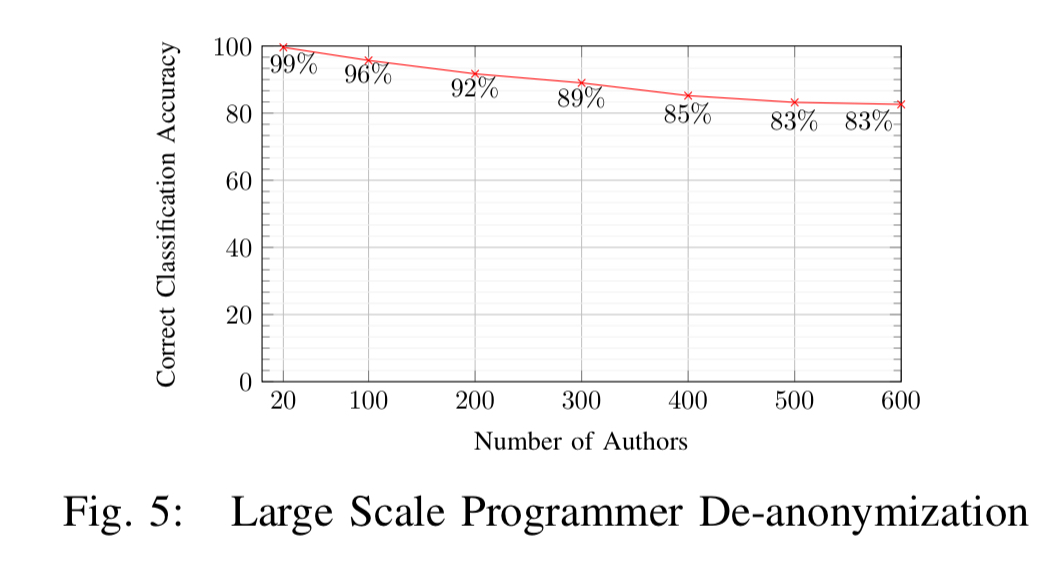
Out of a pool of 100 candidate programmers, Caliskan et al. are able to attributed authorship with accuracy of up to 96%, and with a pool of 600 candidate programmers, they reach accuracy of 83%. These results assume that the compiler and optimisation level used for compilation of the binary are known. Fortunately, previous work has shown that toolchain provenance, including the compiler family, version, optimisation level, and source language, can be identified using a linear Conditional Random Field (CRF) with accuracy of up to 99% for language, compiler family, and optimisation level, and 92% for compiler version.
One of the potential uses for the technology is identifying authors of malware.
Finding fingerprint features in executable binaries
So how is this seemingly impossible feat pulled off? The process for training the classifier given a corpus of works by authors in a candidate pool has four main steps, as illustrated below:
Disassembly: first the program is disassembled to obtain features based on machine code instructions, referenced strings, symbol information, and control flow graphs.
Decompilation: the program is translated into C-like pseudo-code via decompilation, and this pseudo-code is passed to a fuzzy C parser to generate an AST. Syntactical features and n-grams are extracted from the AST.
Dimensionality reduction: standard feature selection techniques are used to select the candidate features from amongst those produced in steps 1 and 2.
Classification: a random forest classifier is trained on the corresponding feature vectors to yield a program that can be used for automatic executable binary authorship attribution.
The disassembly step runs the binary through two different disassemblers: the netwide disassembler (ndisasm), which does simple instruction decoding, and the radare2 state-of-the-art open source disassembler, which also understands the executable binary format. Using radare2 it is possible to extract symbols, strings, functions, and control flow graphs.
Information provided by the two disassemblers is combined to obtain our disassembly feature set as follows: we tokenize the instruction traces of both disassemblers and extract token uni-grams, bi-grams, and tri-grams within a single line of assembly, and 6-grams, which span two consecutive lines of assembly… In addition, we extract single basic blocks of radare2’s control flow graphs, as well as pairs of basic blocks connected by control flow.
Decompilation
Decompilation is done using the Hex-Rays commercial state-of-the-art decompiler, which produces human readable C-like pseudo-code. This code may be much longer than the original source code (e.g. decompiling a program that was originally 70 lines long may produce on average 900 lines of decompiled code).
From the decompiled result, both lexical and syntactical features are extracted. Lexical features are word unigrams capturing integer types, library function names, and internal function names (when symbol table information is available). Syntactical features are obtained by passing the code to the joern fuzzy parser and deriving features from the resulting AST.
Dimensionality reduction
Following steps one and two, a large number of features can be generated (e.g., 705,000 features from 900 executable binary samples taken across 100 different programmers). A first level of dimensionality reduction is applied using WEKA’s information gain attribute selection criteria, and then a second level of reduction is applied using correlation based feature selection. The end result for the 900 binary samples is a set of 53 predictive features.
Classification
Classification is done using random forests with 500 trees. Data is stratified by author analysed using k-fold cross-validation, where k is equal to the number of available code samples per author.
Evaluation results
The main evaluation is performed using submission to the annual Google Code Jam competition, in which thousands of programmers take part each year. “We focus our analysis on compiled C++ code, the most popular programming language used in the competition. We collect the solutions from the years 2008 to 2014 along with author names and problem identifiers.”
Datasets are created using gcc and g++, using each of O1, O2, and O3 optimisation flags (so six datasets in all). The resulting datasets contain 900 executable binary samples from 100 different authors. As we saw before, the authors are able to reduce the feature set down to 53 predictive features.
To examine the potential for overfitting, we consider the ability of this feature set to generalize to a different set of programmers, and show that it does so, further supporting our belief that these features effectively capture programming style. Features that are highly predictive of authorial fingerprints include file and stream operations along with the formats and initializations of variables from the domain of ASTs, whereas arithmetic, logic, and stack operations are the most distinguishing ones among the assembly instructions.
Without optimisation enabled, the random forest is able to correctly classify 900 test instances with 95% accuracy. Furthermore, given just a single sample of code (for training) from a given author, the author can be identified out of a pool of 100 candidates with 65% accuracy.
The classifier also reaches a point of dramatically diminishing returns with as few as three training samples, and obtains a stable accuracy by training on 6 samples. Given the complexity of the task, this combination of high accuracy with extremely low requirement on training data is remarkable, and suggests the robustness of our features and method.
The technique continues to work well as the candidate pool size grows:
Turning up the difficulty level
Programming style is preserved to a great extent even under the most aggressive level 3 optimisations:
…programmers of optimized executable binaries can be de-anonymized, and optimization is not a highly effective code anonymization method.
Fully stripping symbol information reduces classification accuracy by 24%, so even removing symbols is not an effective form of anonymisation.
For the pièce de résistance the authors use Obfuscator-LLVM and apply all three of its obfuscation techniques (instruction substitution, introducing bogus control flow, flattening control flow graphs). And the result? “Using the same features as before, we obtain an accuracy of 88% in correctly classifying authors.”
… while we show that our method is capable of dealing with simple binary obfuscation techniques, we do not consider binaries that are heavily obfuscated to hinder reverse engineering.
So you want to stay anonymous?
If you really do want to remain anonymous, you’d better plan for that from the very beginning of your programming career, and even then it doesn’t look easy! Here are the conditions recommended by the authors:
Do not have any public repositories
Don’t release multiple programs using the same online identity
Try to have a different coding style (!) in each piece of software you write, and try to code in different programming languages.
Use different optimisations and obfuscations to avoid deterministic patterns
Another suggestion that comes to mind is to use an obfuscater deliberately designed to prevent reverse engineering. Although since these weren’t tested, we don’t actually know how effective that will be.
A programmer who accomplishes randomness across all potential identifying factors would be very difficult to deanonymize. Nevertheless, even the most privacy savvy developer might be willing to contribute to open source software or build a reputation for her identity based on her set of products, which would be a challenge for maintaining anonymity.
Coca-Cola has updated their sign in Times Square, and this one has a mesmerizing 3D aspect to it, giving the spooky feeling you get from watching buildings curl up into the sky in the movie, Inception. That 3D is created by breaking the sign up into a 68’x42′ matrix of 1760 LED screens that can be independently extended out toward the viewer and retracted again. Of course, we went hunting for implementation details.
Moving Cube Module
On Coca-Cola’s webpage listing the partners involved in putting it together, Radius Displays is listed as responsible for sign design, fabrication, testing and installation support. Combing through their website was the first step. Sadly we found no detailed design documents or behind-the-scenes videos there. We did find one CAD drawing of a Moving Cube Module with a 28×28 matrix of LEDs. Assuming that’s accurate then overall there are 1,379,840 LEDs — try ordering that many off of eBay. EDIT: One behind-the-scenes video of the modules being tested was found and added below.
So the patent hunting came next, and that’s where we hit the jackpot. Read on to see the results and view the videos of the sign in action below.
The search turned up three patents by Coca-Cola that seem relevant, the most recent one being US 9,640,118 B2, Display devices, filed in January 2016 but published in May 2017. Clearly they’ve been working on this for a while. The link we’ve given is to the European Espacenet patent site because Google’s didn’t seem to have the drawings.
This patent of Coca-cola’s reads like a detailed overview of the Times Square sign. It has 35 figures that include the same actuator assembly as what we see in the CAD drawing from Radius Display’s website. The patent runs the whole gamut from hardware to software, handling scaling issues and even content creation procedures.
Here are a few notable features mentioned in the patent, though we can’t guarantee they made it to the actual sign. The actuator assemblies are divided into modules, for example, modules can be made up of 5 rows of 5 assemblies. This is to make installation more efficient, and to better handle stresses due to weather. There’s also a physical locking mechanism to prevent the actuators from moving at all in case of extreme winds. Display on and movement of each assembly is done in a synchronous manner, supposedly ensuring that the resulting image is coherent before moving on to the next. As the patent’s Fig. 13 shown here illustrates, there’s a high level of parallelism used to manage all the actuators and screens. In the figure, Ethernet is used as the communication protocol but more options are given in the patent. And that’s just a small sample of what’s in the patent. It actually makes for quite a good read.
While Coca-Cola’s advertising video below shows many views of it, we’ve included a second video below by Radius Displays that focuses more on the sign and better shows it off we think.
This 3D sign should remind Hackaday readers of inFORM, MIT’s morphing table which we’d covered previously. Their video no longer works but you can find a different one on MIT’s page here.
Coca-Cola’s video:
Radius Display’s video:
EDIT: Video of motion testing the modules. Video is by Cicoil who supplied the flat cables. (Thanks for JH and jason701802 for pointing this out in the comments.)
A lot of questions have been raised by the recent “dieselgate” scandal. Should automakers be held accountable for ethically questionable actions? Are emissions standards in the United States too restrictive? Are we ever going to stop appending “gate” onto every mildly controversial news story? But, for Hackaday readers, the biggest question is most likely “how did they get away with it?” The answer is probably because of a law a lot of hackers are already familiar with: the DMCA.
If you haven’t seen the news about Volkswagen’s emissions cheating scheme, we’ll get you caught up quickly. In the United States, EPA emissions testing is done in a very specific and predictable way. Using clever ECU software tricks, Volkswagen was able to essentially “detune” the engines of their diesel vehicles when they were being tested by the EPA. This earned them passing marks, while allowing them to provide a less-restrictive ECU profile for the normal driving that buyers would actually experience.
How could they get away with this simple trick when a brief look at the ECU software would have revealed it? Because, they were able to hide under the umbrella of the DMCA. The ECU software is, of course, not intended to be user-accessible, which means that Volkswagen is allowed to lock it down. That, in turn, means that the EPA isn’t allowed to circumvent that security without violating the DMCA and potentially breaking the law. This kept the EPA’s hands tied, and Volkswagen protected. They were only found out because independent testing (that didn’t follow EPA procedure) revealed vastly different emissions levels.
When you think about serial communications, Microsoft Excel isn’t typically the first program that springs to mind. But this spreadsheet has a rather powerful scripting language hidden away inside it, which can, with a little coding, be used to send and receive data over your serial port. The scripting language is called Visual Basic for Applications (VBA), and it has been a part of Microsoft’s Office suite since 1993. Since then, it has evolved into a powerful (if sometimes frustrating) language that offers a subset of the features from Visual Basic.
It can be a useful tool. Imagine, for instance, that you are logging data from an instrument that has a serial port (or even an emulated one over USB). With a bit of VBA, you could create a spreadsheet that talks to the instrument directly, grabbing the data and processing it as required straight into the spreadsheet. It’s a handy trick that I have used myself several times, and [Maurizio] does a nice job of explaining how the code works, and how to integrate this code into Excel.
[Daniel, Adi, and Eran], students researchers at Tel Aviv University and the Weizmann Institute of Science have successfully extracted 4096-bit RSA encryption keys using only the sound produced by the target computer. It may sound a bit like magic, but this is a real attack – although it’s practicality may be questionable. The group first described this attack vector at Eurocrypt 2004. The sound used to decode the encryption keys is produced not by the processor itself, but by the processor’s power supply, mainly the capacitors and coils. The target machine in this case runs a copy of GNU Privacy Guard (GnuPG).
During most of their testing, the team used some very high-end audio equipment, including Brüel & Kjær laboratory grade microphones and a parabolic reflector. By directing the microphone at the processor air vents, they were able to extract enough sound to proceed with their attack. [Daniel, Adi, and Eran] started from the source of GnuPG. They worked from there all the way down to the individual opcodes running on the x86 processor in the target PC. As each opcode is run, a sound signature is produced. The signature changes slightly depending on the data the processor is operating on. By using this information, and some very detailed spectral analysis, the team was able to extract encryption keys. The complete technical details of the attack vector are available in their final paper (pdf link).
Once they had the basic methods down, [Daniel, Adi, and Eran] explored other attack vectors. They were able to extract data using ground fluctuations on the computers chassis. They even were able to use a cell phone to perform the audio attack. Due to the cell phone’s lower quality microphone, a much longer (on the order of several hours) time is needed to extract the necessary data.
Thankfully [Daniel, Adi, and Eran] are white hat hackers, and sent their data to the GnuPG team. Several countermeasures to this attack are already included in the current version of GnuPG.
One of the trickiest parts of texture packs in the past was mixing and matching. Doing so usually required you to edit them together (or get someone else to do it), but those days are gone! Not only do resource packs let us include more than just texture assets (sound, mods, etc), we will now be able to select more than one resource pack at a time in the 1.7 update! What if you have packs with conflicting assets (the same texture file)? Easy! The topmost resource pack will override all packs underneath it on the "selected" list!
WAIT...WUT
Still not clear how resource packs will be ordered? It's easy! All that's required is to drag any packs you want to use into the "Selected Resource Packs" column on the right, and once there, you can drag the selected pack up or down the list, to change its load priority. Even better, server-side resource packs will ALWAYS take priority, regardless of player pack order!
YEA...I STILL DON'T GET IT...WAT
The picture above gives a brief demonstration on how resource packs can be selected, and have their order changed. With one click, you can add or remove packs. Additionally, changing the load order of the pack is as easy as click-dragging the pack up or down the list. The higher on the list the mod is, the higher the priority of that pack, in cases where packs have conflicting modifications.
Packs will load like this:
Server-loaded resource packs
player-loaded resource packs (from top to bottom, on the list)
Vanilla resources, where none are modified
The possibilities for mixing and matching resources - to say nothing of server-side customization - is definitely going in exciting directions with these changes. Sweet!
WAIT, WHY WOULD I EVEN LOAD MORE THAN ONE RESOURCE PACK?
Let's say you're using your favorite texture pack, and someone comes out with a sound pack you want to use. Right now, the only way to use both of those assets at once is to manually combine them, because selecting more than one pack isn't currently possible. Alternately, maybe someone came up with a couple new textures for some objects and creatures that you like better than your current texture pack, but you don't want to replace the entire pack. This lets you have both! Or, in the case of the sound pack, all three! Or more!
The ability to mix and match your favorite packs of ALL types - texture, sound, mod, and so on - is a huge step forward in Minecraft customization, and this will become more and more apparent as content creators start coming up with packs specifically designed to compliment other packs.
A huge "thank you" to Dinnerbone for the information regarding 1.7 resource packs, as well as his helpful gif showing how it works!






, that I have \"#REF! ERROR: Circular dependency detected\" problems.")


























