Christophe.colombier
Shared posts
Science décalée : le smartphone transforme la main humaine
Go Range Loop Internals
Avoid Design by Committee: Generate Apart, Evaluate Together
This post was first published in its entirety on CoderHood as Avoid Design by Committee: Generate Apart, Evaluate Together. CoderHood is a blog dedicated to the human dimension of software engineering.

The tech industry thrives on innovation. Building innovative software products requires constant design and architecture of creative solutions. In that context, I am not a fan of design by committee; in fact, I believe that it is more of a disease than a strategy. It afflicts teams with no leadership or unclear leadership; the process is painful, and the results are abysmal.
Usability issues plague software products designed by committee. Such products look like collections of features stuck together without a unifying vision or a unique feeling; they are like onions, built as a series of loosely connected layers. They cannot bring emotions to the user because emotions are the product of individual passion.
Decisions and design by committee feel safe because of the sense of shared accountability, which is no accountability at all. A group's desire to strive for unanimity overrides the motivation to consider and debate alternative views. It reduces creativity and ideation to an exercise of consensus building.
Building consensus is the act of pushing a group of people to think alike. On that topic, Walter Lippmann famously said:
When all think alike, then no one is thinking.
In other words, building consensus is urging people to talk until they stop thinking and until they finally agree. Not many great ideas or designs come out that way.
I am a believer that the seeds of great ideas are generated as part of a creative process that is unique to each person. If you force a process where all designs must be produced and evaluated on the spot in a group setting, you are not giving introverted creative minds the time to enter their best focused and creative state. On the other hand, if you force all ideas to be generated in isolation without group brainstorming, you miss the opportunity to harvest collective wisdom.
That is why I like to implement a mixed model that I call "Generate apart, Evaluate Together." I am going to talk about this model in the context of software and architecture design, but you can easily expand it to anything that requires both individual creativity and group wisdom. Like most models, I am not suggesting that you should apply it to every design or decision. It is not a silver bullet. Look at it as another tool in your toolbelt. I recommend it mostly for medium to large undertakings, significant design challenges, medium to large shifts and foundational architecture choices.
Generate Apart, Evaluate Together
I believe in the power of a creative process that starts with one or more group-brainstorms designed to frame a problem, evaluate requirements and bring-out and evaluate as many initial thoughts as possible. In that process, a technical leader guides the group to discuss viable alternatives but keeps the discussion at a "box and arrows" high-level. Imagine a data flow diagram on a whiteboard or a mindmap of the most important concepts. Groups of people discussing design and architecture should not get bogged down in the weeds.
At some point during that high-level ideation session, the group selects one person to be an idea/proposal generation driver. After the group session is over, that person is in charge of doing research, create, document and eventually present more ideas and detailed solution options. If the problem-space is vast, the group might select several drivers, one for each of the different areas.
The proposal generation driver doesn't have to do all the work in isolation. He or she can collaborate with others to come up with proposals, but he or she needs to lead the conversation and idea generation.
After the driver generated data, ideas, and proposals, the group meets again to brainstorm, evaluate and refine the material. At that point, the group might identify new drivers (or maintain the old ones), and the process repeats iteratively.
As mentioned, I refer to this iterative process with the catchphrase, "Generate Apart, Evaluate Together." Please, do not interpret that too literally and as an absolute. First of all, there is idea generation happening as a group, but it is mostly at a high-level. Also, there is an evaluation of ideas that happens outside of the group. "Generate apart, evaluate together" is a reminder to avoid design by committee, in-the-weeds group meetings, and isolated evaluation and selection of all ideas and solutions.
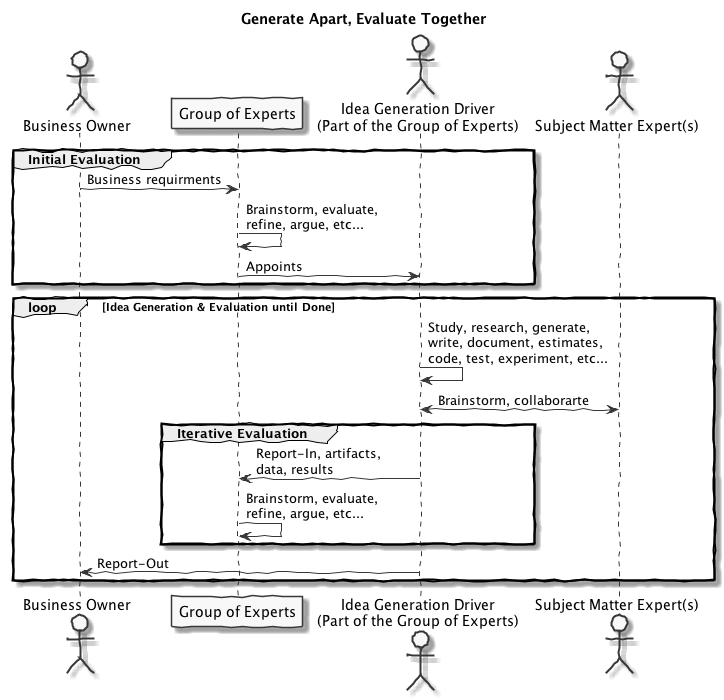
I synthesized the process with this quick back-of-the-napkin sequence diagram:
Evaluate
The "evaluate" part of "Generate apart, evaluate together" refers to one of the two different phases of evaluation mentioned above.
The Initial Evaluation is a group assessment of the business requirements followed by one or more brainstorms. The primary goal is to frame the problem and create an initial list of possible high-level architectural and technical choices and issues. The secondary objective is to select a driver for idea generation.
The Iterative Evaluation is the periodic group evaluation and refinement of ideas and proposals generated by the driver in non-group settings.
Some of the activities executed during both types of evaluation are:
- Brainstorm business requirements and solutions.
- Identification of the proposal generation driver or drivers.
- Identification of next steps.
- Review proposals.
- Debate pros and cons of proposed solutions.
- Choose a high-level technical direction.
- Argue.
- Agree and commit or disagree and commit.
- Establish communication strategy.
- Estimate.
- Report-in, meaning the driver reports and presents ideas and recommendations to the group.
Note that there is no attempt to generate consensus. The group evaluates and commits to a direction, regardless if there is unanimous agreement or not. Strong leadership is required to make this work.
Generate
The "generate" part of "Generate apart, evaluate together" refers to the solitary or small group activities of an individual who works to drive the creation of proposals and detailed solutions to present to the larger group. Such activities include:
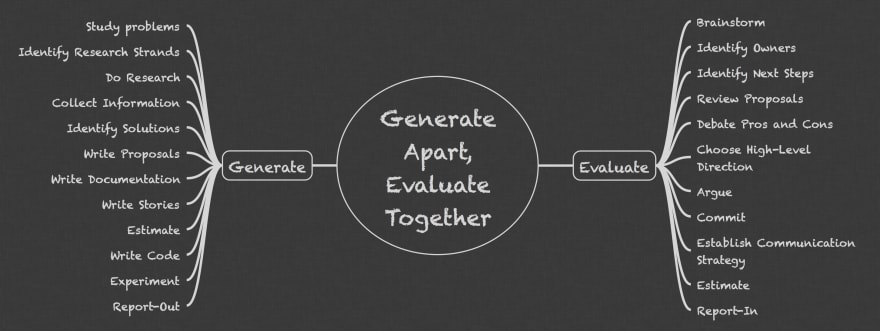
- Study problems
- Identify research strands and do research.
- Collect information.
- Identify solutions.
- Write proposals, documentation, user stories.
- Estimate user stories.
- Write/test/maintain code.
- Experiment.
- Report-out (meaning the driver reports to the group the results of research, investigation, etc.)
MindMap
For future reference, you can remember the main ideas of this method with a MindMap:
Final Thoughts
I didn't invent the catchphrase "Generate apart, evaluate together," but I am not sure who did, where I heard it, or what was the original intent. I tried to find out, but Google didn't help much. Regardless, in this post, I described how I use it, what it means to me, and what kinds of problems it resolves. I used this model for a long time, and I only recently gave it a tagline that sticks to mind and can be used to describe the method without too much necessary explanation.
If you enjoyed this article, keep in touch!
Developer's Guide to Email
Obsolescence programmée : le procès à charge contre Epson élude le vrai problème
Par Grégoire Dubost.
Poursuivi en justice pour « obsolescence programmée », Epson a d’ores et déjà été condamné par un tribunal médiatique. Dans un numéro d’Envoyé spécial diffusé sur France 2 le 29 mars 2018, les journalistes Anne-Charlotte Hinet et Swanny Thiébaut ont repris avec une étonnante crédulité les accusations assénées par l’association HOP (Halte à l’obsolescence programmée), à l’origine d’une plainte déposée l’année dernière contre l’industriel japonais.
Des constats troublants
Certains constats rapportés dans cette enquête s’avèrent effectivement troublants : on y découvre qu’une imprimante prétendument inutilisable peut tout à fait sortir plusieurs pages après l’installation d’un pilote pirate ; quant aux cartouches, elles semblent loin d’être vides quand l’utilisateur est appelé à les changer. La preuve n’est-elle pas ainsi faite qu’un complot est ourdi contre des consommateurs aussi malheureux qu’impuissants ?
Cet article pourrait vous interesser
La musique accompagnant ce reportage, angoissante, laisse entendre qu’un danger planerait sur ceux qui se risqueraient à le dénoncer. On tremble à l’évocation de cet homme qui « a fini par briser le silence » ; quel aura été le prix de sa témérité ? Un passionné d’électronique susceptible d’assister les enquêteurs vit en marge de la société, reclus loin des villes et de leurs menaces : « il a fallu avaler quelques kilomètres en rase campagne pour trouver un expert », racontent les journalistes. Un expert censé décrypter le contenu d’une puce électronique à l’aide d’un tournevis… Succès garanti.
Les imprimantes incriminées sont vendues autour d’une cinquantaine d’euros. « Le fabricant n’a pas intérêt à avoir des imprimantes de ce prix-là qui soient réparables, sinon il n’en vendra plus », croit savoir l’un des témoins interrogés. Étrange conviction : si un fabricant était en mesure de prolonger la durée de vie de ses produits et d’étendre leur garantie en conséquence, sans en renchérir le coût ni en compromettre les fonctionnalités, n’aurait-il pas intérêt à le faire, dans l’espoir de gagner des parts de marché aux dépens de ses concurrents ?
Vendre de l’encre très chère
De toute façon, pour Epson, l’activité la plus lucrative n’est pas là : « autant vendre une imprimante pas chère pour vendre ensuite de l’encre très chère », souligne une autre personne interrogée, cette fois-ci bien inspirée. Il est vrai qu’au fil du temps, les fabricants de cartouches génériques parviennent à contourner les verrous mis en place par Epson et ses homologues pour s’arroger d’éphémères monopoles sur le marché des consommables.
Cela étant, même s’il préfère acheter de l’encre à moindre coût, le possesseur d’une imprimante Epson fonctionnelle sera toujours un acheteur potentiel des cartouches de la marque ; ce qu’il ne sera plus, assurément, quand son imprimante sera tombée en panne… Ce constat, frappé du sceau du bon sens, semble avoir échappé aux enquêteurs, qui prétendent pourtant que « les fabricants font tout pour vous faire acheter leurs propres cartouches ». Peut-être cela pourrait-il expliquer l’obligation de changer une cartouche pour utiliser le scanner d’une imprimante multi-fonctions… Mais quelle garantie Epson aurait-il que ses clients lui restent fidèles au moment de renouveler leur matériel dont il aurait lui-même programmé l’obsolescence ? Ils le seront d’autant moins s’ils ont été déçus par leur achat – notamment s’ils jugent que leur imprimante les a lâchés prématurément.
Pourquoi ces aberrations ?
La pertinence d’une stratégie d’obsolescence programmée est donc sujette à caution. Comment, dès lors, expliquer certaines aberrations ? Epson se montre peu prolixe à ce sujet ; sa communication s’avère même calamiteuse ! « Une imprimante est un produit sophistiqué », affirme-t-il dans un communiqué. Pas tellement en fait. Du moins l’électronique embarquée dans un tel appareil n’est-elle pas des plus élaborée. Assistant au dépeçage d’une cartouche, les journalistes ont mimé l’étonnement à la découverte de sa puce : « Surprise ! […] Pas de circuit électrique, rien qui la relie au réservoir d’encre. Elle est juste collée. Comment diable cette puce peut-elle indiquer le niveau d’encre si elle n’est pas en contact avec l’encre ? » Que croyaient-ils trouver dans un consommable au recyclage notoirement aléatoire ? Ou dans un appareil vendu seulement quelques dizaines d’euros ? Quoi qu’en dise Epson, sans doute la consommation de l’encre et l’état du tampon absorbeur sont-ils évalués de façon approximative. Apparemment, le constructeur voit large, très large même ! C’est évidemment regrettable, mais qu’en est-il des alternatives ? Les concurrents d’Epson proposent-ils des solutions techniques plus efficaces sur des produits vendus à prix comparable ? Encore une question qui n’a pas été posée…
Concernant les cartouches, dont l’encre est en partie gaspillée, la malignité prêtée au constructeur reste à démontrer. On n’achète pas une cartouche d’encre comme on choisit une brique de lait ni comme on fait un plein d’essence. Si le volume d’encre qu’elle contient est bien mentionné sur l’emballage, cette information n’est pas particulièrement mise en valeur. D’une marque à l’autre, d’ailleurs, elle n’est pas la même ; elle ne constitue pas un repère ni un élément de comparaison. En pratique, on n’achète pas des millilitres d’encre, mais des cartouches de capacité dite standard, ou bien de haute capacité, avec la promesse qu’elles nous permettront d’imprimer un certain nombre de pages. Dans ces conditions, quel intérêt y aurait-il, pour un constructeur, à restreindre la proportion d’encre effectivement utilisée ? Autant réduire le volume présent dans les cartouches ! Pour le consommateur, cela reviendrait au même : il serait condamné à en acheter davantage ; pour l’industriel, en revanche, ce serait évidemment plus intéressant, puisqu’il aurait moins d’encre à produire pour alimenter un nombre identique de cartouches vendues au même prix. Un représentant d’Epson, filmé à son insu, a tenté de l’expliquer au cours du reportage, avec toutefois une extrême maladresse. Les enquêteurs n’ont pas manqué de s’en délecter, prenant un malin plaisir à mettre en scène la dénonciation d’un mensonge éhonté.
Des allégations sujettes à caution
Force est de constater qu’ils n’ont pas fait preuve du même zèle pour vérifier les allégations des militants qui les ont inspirés. Quand il juge nécessaire de changer le tampon absorbeur d’une imprimante, Epson en interdit l’usage au motif que l’encre risquerait de se répandre n’importe où. Parmi les utilisateurs d’un pilote pirate permettant de contourner ce blocage, « on a eu aucun cas de personnes qui nous écrivaient pour dire que cela avait débordé », rétorque la représentante de l’association HOP. Pourquoi les journalistes n’ont-ils pas tenté l’expérience de vider quelques cartouches supplémentaires dans ces conditions ? À défaut, peut-être auraient-ils pu arpenter la Toile à la recherche d’un éventuel témoignage. « Il y a quelques années j’ai dépanné une imprimante qui faisait de grosses traces à chaque impression, dont le propriétaire avait, un an auparavant, réinitialisé le compteur […] pour permettre de reprendre les impressions », raconte un internaute, TeoB, dans un commentaire publié le 19 janvier sur le site LinuxFr.org ; « le tampon était noyé d’encre qui avait débordé et qui tapissait tout le fond de l’imprimante », précise-t-il ; « ça m’a pris quelques heures pour tout remettre en état, plus une nuit de séchage », se souvient-il. Dans le cas présent, ce qui passe pour de l’obsolescence programmée pourrait relever en fait de la maintenance préventive… Les journalistes l’ont eux-mêmes rapporté au cours de leur reportage : Epson assure remplacer gratuitement ce fameux tampon ; pourquoi ne l’ont-ils pas sollicité pour évaluer le service proposé ?
Ils ont préféré cautionner l’idée selon laquelle une imprimante affectée par un consommable réputé en fin de vie – à tort ou à raison – devrait être promise à la casse. La confusion à ce sujet est entretenue au cours du reportage par un technicien présenté comme un « spécialiste de l’encre et de la panne ». Les militants de l’association HOP témoignent en cela d’une inconséquence patente : ils pourraient déplorer le discours sibyllin des constructeurs d’imprimantes, dont les manuels d’utilisation ou les messages à l’écran ne semblent pas faire mention des opérations de maintenance gracieuses promises par ailleurs ; mais ils préfèrent entretenir le mythe d’un sabotage délibéré de leurs produits, confortant paradoxalement leurs utilisateurs dans la conviction qu’ils seraient irréparables… Si la balle se trouve parfois dans le camp des industriels, ceux-ci ne manquent pas de la renvoyer aux consommateurs ; encore faut-il que ces derniers s’en saisissent, plutôt que de fuir leurs responsabilités éludées par une théorie complotiste.
Liens :
https://www.francetvinfo.fr/
https://www.epson.fr/insights/
https://linuxfr.org/users/
L’article Obsolescence programmée : le procès à charge contre Epson élude le vrai problème est apparu en premier sur Contrepoints.
 Obsolescence programmée : mythe ou réalité ?
Obsolescence programmée : mythe ou réalité ? L’informatique… toute une histoire !
L’informatique… toute une histoire ! Une approche de la sécurité à pleurer : WanaCry et dépendances
Une approche de la sécurité à pleurer : WanaCry et dépendances L’informatique et l’intelligence artificielle nous rendront-elles stupides ?
L’informatique et l’intelligence artificielle nous rendront-elles stupides ?What kind of managers will Generation Z bring?

They're smart, conscientious, ambitious, and forward-thinking. And of course, they're the first true digital natives. Growing up in a world where information changes by the second, Generation Z — the generation born roughly after 1995 — is ready to take the workplace by storm.
As the group that follows the millennials, Generation Z — or "Gen Z" as they are often called — is changing the way we do business. They see the world through a different lens. Their passions and inspirations will define what they do for a career, and consequently drive many of their decisions about how they see themselves in the workplace. These are the managers, big thinkers, and entrepreneurs of tomorrow. What will America's businesses look like with them at the helm?
They'll encourage risk-taking
Laura Handrick, an HR and workplace analyst with FitSmallBusiness.com, believes the workers that will come from Generation Z are not limited by a fear of not knowing. "They recognize that everything they need or want to know is available from the internet, their friends, or crowdsourcing — so, they don't fear the unknown," she says.
Gen Z-ers know they can figure anything out if they have the right people, experts, and thought leaders around them. That's why Handrick believes they are more likely to try new things — and expect their peers and coworkers to do so, too. This could manifest itself as a kind of entrepreneurial spirit we haven't seen in years.
But they won't be reckless
While Gen Z is likely to encourage new ideas, most of the risks they'll be willing to take will be calculated ones. None of this "move fast and break things" mindset that has so driven today's entrepreneurs. After all, many of them grew up during the financial crisis of the mid- to late-2000s, and they know what happens when you price yourself out of your home, max out your credit cards, or leave college with $30,000 in student loans. Many were raised in homes that were foreclosed, or had parents who declared bankruptcy. Because of this, most of them will keep a close eye on the financial side of a business.
"Think of them as the bright eyes and vision of millennials with the financial-savvy of boomers, having lived through the financial crash of 2008," says Morgan Chaney, head of marketing for Blueboard, an HR tech startup.
Indeed, according to a survey done by Monster.com, 70 percent of Generation Z-ers say they're most motivated by money, compared to 63 percent of millennials. In other words, putting a Gen Z-er in charge of your business is not going to make it go "belly up." They'll be more conservative with cash and very wary of bad business investments. This generation is unique in its understanding of money and how it works.
Get ready for more inclusive workplaces
Chaney believes Gen Z managers will be empathetic, hands-on, and purpose-driven. Since they believe in working one-on-one to ensure each employee is nurtured and has a purpose-driven career path, Generation Z is going to manage businesses with a "people-first" approach.
This means the workplaces they run will be less plagued by diversity problems than the generations that came before them. "They'll value each person for their experience, expertise, and uniqueness — race or gender won't be issues for them," says Handrick.
Gen Z-er Timothy Woods, co-founder of ExpertiseDirect.com, which connects customers with experts in various fields, says his generation will be adaptive and empathetic managers, with a steely determination to succeed. "This generation is no longer only competing with the person in the next office, but instead with a world of individuals, each more informed and successful than the next, constantly broadcasting their achievements online and setting the bar over which one must now climb," he explains.
The 40-hour work week will disappear
Generation Z managers will also be very disciplined: Fifty-eight percent of those surveyed said they were willing to work nights and weekends, compared to 45 percent of millennials. Gone are the days of a working a typical 9-to-5 job. Generation Z managers will tolerate and likely expect non-traditional hours. "They'll have software apps to track productivity and won't feel a need to have people physically sitting in the same office to know that work is getting done," Handrick explains. "Video conference, texting, and mobile apps are how they'll manage their teams."
The catch? They have to feel like their work matters. According to the Monster.com survey, "Gen Z stands out as the generation that most strongly believes work should have a greater purpose." Seventy-four percent of Generation Z-ers surveyed said they want their work to be about more than just money. That's compared to 45 percent of millennials, and the numbers fall even further for Gen-X and boomers.
So, yes, they'll work hard, but only if they know it's for a good reason. And that's a positive thing. In this way, the leaders of tomorrow will merge money and purpose to create a whole new way of doing business.
the secret life of NaN
The floating point standard defines a special value called Not-a-Number (NaN) which is used to represent, well, values that aren’t numbers. Double precision NaNs come with a payload of 51 bits which can be used for whatever you want– one especially fun hack is using the payload to represent all other non-floating point values and their types at runtime in dynamically typed languages.
%%%%%% update (04/2019) %%%%%%
I gave a lightning talk about the secret life of NaN at !!con West 2019– it has fewer details, but more jokes; you can find a recording here.
%%%%%%%%%%%%%%%%%%%%%%%
the non-secret life of NaN
When I say “NaN” and also “floating point”, I specifically mean the representations defined in IEEE 754-2008, the ubiquitous floating point standard. This standard was born in 1985 (with much drama!) out of a need for a canonical representation which would allow code to be portable by quelling the anarchy induced by the menagerie of inconsistent floating point representations used by different processors.
Floating point values are a discrete logarithmic-ish approximation to real numbers; below is a visualization of the points defined by a toy floating point like representation with 3 bits of exponent, 3 bits of mantissa (the image is from the paper “How do you compute the midpoint of an interval?”, which points out arithmetic artifacts that commonly show up in midpoint computations).

Since the NaN I’m talking about doesn’t exist outside of IEEE 754-2008, let’s briefly take a look at the spec.
An extremely brief overview of IEEE 754-2008
The standard defines these logarithmic-ish distributions of values with base-2 and base-10. For base-2, the standard defines representations for bit-widths for all powers of two between 16 bits wide and 256 bits wide; for base-10 it defines representations for bit-widths for all powers of two between 32 bits wide and 128 bits wide. (Well, almost. For the exact spec check out page 13 spec). These are the only standardized bitwidths, meaning, if a processor supports 32 bit floating point values, then it’s highly likely it will support it in the standard compliant representation.
Speaking of which, let’s take a look at what the standard compliant representation is. Let’s look at binary16, the base-2 16 bit wide format:
1 sign bit | 5 exponent bits | 10 mantissa bits
S E E E E E M M M M M M M M M M
I won’t explain how these are used to represent numeric values because I’ve got different fish to fry, but if you do want an explanation, I quite like these nice walkthroughs.
Briefly, though, here are some examples: the take-away is you can use these 16 bits to encode a variety of values.
0 01111 0000000000 = 1
0 00000 0000000000 = +0
1 00000 0000000000 = -0
1 01101 0101010101 = -0.333251953125
Cool, so we can represent some finite, discrete collection of real numbers. That’s what you want from your numeric representation most of the time.
More interestingly, though, the standard also defines some special values: ±infinity, and “quiet” & “signaling” NaN. ±infinity are self-explanatory overflow behaviors: in the visualization above, ±15 are the largest magnitude values which can be precisely represented, and computations with values whose magnitudes are larger than 15 may overflow to ±infinity. The spec provides guidance on when operations should return ±infinity based on different rounding modes.
What IEEE 754-2008 says about NaNs
First of all, let’s see how NaNs are represented, and then we’ll straighten out this “quiet” vs “signaling” business.
The standard reads (page 35, §6.2.1)
All binary NaN bit strings have all the bits of the biased exponent field E set to 1 (see 3.4). A quiet NaN bit string should be encoded with the first bit (d1) of the trailing significand field T being 1. A signaling NaN bit string should be encoded with the first bit of the trailing significand field being 0.
For example, in the binary16 format, NaNs are specified by the bit patterns:
s 11111 1xxxxxxxxxx = quiet (qNaN)
s 11111 0xxxxxxxxxx = signaling (sNaN) **
Notice that this is a large collection of bit patterns! Even ignoring the sign bit, there are 2^(number mantissa bits - 1) bit patterns which all encoded a NaN! We’ll refer to these leftover bits as the payload. **: a slight complication: in the sNaN case, at least one of the mantissa bits must be set; it cannot have an all zero payload because the bit pattern with a fully set exponent and fully zeroed out mantissa encodes infinity.
It seems strange to me that the bit which signifies whether or not the NaN is signaling is the top bit of the mantissa rather than the sign bit; perhaps something about how floating point pipelines are implemented makes it less natural to use the sign bit to decide whether or not to raise a signal.
Modern commodity hardware commonly uses 64 bit floats; the double-precision format has 52 bits for the mantissa, which means there are 51 bits available for the payload.
Okay, now let’s see the difference between “quiet” and “signaling” NaNs (page 34, §6.2):
Signaling NaNs afford representations for uninitialized variables and arithmetic-like enhancements (such as complex-affine infinities or extremely wide range) that are not in the scope of this standard. Quiet NaNs should, by means left to the implementer’s discretion, afford retrospective diagnostic information inherited from invalid or unavailable data and results. To facilitate propagation of diagnostic information contained in NaNs, as much of that information as possible should be preserved in NaN results of operations.
Under default exception handling, any operation signaling an invalid operation exception and for which a floating-point result is to be delivered shall deliver a quiet NaN.
So “signaling” NaNs may raise an exception; the standard is agnostic to whether floating point is implemented in hardware or software so it doesn’t really say what this exception is. In hardware this might translate to the floating point unit setting an exception flag, or for instance, the C standard defines and requires the SIGFPE signal to represent floating point computational exceptions.
So, that last quoted sentence says that an operation which receives a signaling NaN can raise the alarm, then quiet the NaN and propagate it along. Why might an operation receive a signaling NaN? Well, that’s what the first quoted sentence explains: you might want to represent uninitialized variables with a signaling NaN so that if anyone ever tries to perform an operation on that value (without having first initialized it) they will be signaled that that was likely not what they wanted to do.
Conversely, “quiet” NaNs are your garden variety NaN– qNaNs are what are produced when the result of an operation is genuinely not a number, like attempting to take the square root of a negative number. The really valuable thing to notice here is the sentence:
To facilitate propagation of diagnostic information contained in NaNs, as much of that information as possible should be preserved in NaN results of operations.
This means the official suggestion in the floating point standard is to leave a qNaN exactly as you found it, in case someone is using it propagate “diagnostic information” using that payload we saw above. Is this an invitation to jerryrig extra information into NaNs? You bet it is!
What can we do with the payload?
This is really the question I’m interested in; or, rather, the slight refinement: what have people done with the payload?
The most satisfying answer that I found to this question is, people have used the NaN payload to pass around data & type information in dynamically typed languages, including implementations in Lua and Javascript. Why dynamically typed languages? Because if your language is dynamically typed, then the type of a variable can change at runtime, which means you absolutely must also pass around some type information; the NaN payload is an opportunity to store both that type information and the actual value. We’ll take a look at one of these implementations in detail in just a moment.
I tried to track down other uses but didn’t find much else; this textbook has some suggestions (page 86):
One possibility might be to use NaNs as symbols in a symbolic expression parser. Another would be to use NaNs as missing data values and the payload to indicate a source for the missing data or its class.
The author probably had something specific in mind, but I couldn’t track down any implementations which used NaN payloads for symbols or a source indication for missing data. If anyone knows of other uses of the NaN payload in the wild, I’d love to hear about them!
Okay, let’s look at how JavaScriptCore uses the payload to store type information:
Payload in Practice! A look at JavaScriptCore
We’re going to look at an implementation of a technique called NaN-boxing. Under NaN-boxing, all values in the language & their type tags are represented in 64 bits! Valid double-precision floats are left to their IEEE 754 representations, but all of that leftover space in the payload of NaNs is used to store every other value in the language, as well as a tag to signify what the type of the payload is. It’s like instead of saying “not a number” we’re saying “not a double precision float”, but rather a “<some other type>”.
We’re going to look at how JavaScriptCore (JSC) uses NaN-boxing, but JSC isn’t the only real-world industry-grade implementation that stores other types in NaNs. For example, Mozilla’s SpiderMonkey JavaScript implementation also uses NaN-boxing (which they call nun-boxing & pun-boxing), as does LuaJIT, which they call NaN-tagging. The reason I want to look at JSC’s code is it has a really great comment explaining their implementation.
JSC is the JavaScript implementation that powers WebKit, which runs Safari and Adobe’s Creative Suite. As far as I can tell, the code we’re going to look at is actually currently being used in Safari- as of March 2018, the file had last been modified 18 days ago.
NaN-Boxing explained in a comment
Here is the file we’re going to look at. The way NaN-boxing works is when you have non-float datatypes (pointers, integers, booleans) you store them in the payload, and use the top bits to encode the type of the payload. In the case of double-precision floats, we have 51 bits of payload which means we can store anything that fits in those 51 bits. Notably we can store 32 bit integers, and 48 bit pointers (the current x86-64 pointer bit-width). This means that we can store every value in the language in 64 bits.
Sidenote: according to the ECMAScript standard, JavaScript doesn’t have a primitive integer datatype- it’s all double-precision floats. So why would a JS implementation want to represent integers? One good reason is integer operations are so much faster in hardware, and many of the numeric values used in programs really are ints. A notable example is an index variable in a for-loop which walks over an array. Also according to the ECMAScript spec, arrays can only have 2^32 elements so it is actually safe to store array index variables as 32-bit ints in NaN payloads.
The encoding they use is:
* The top 16-bits denote the type of the encoded JSValue: * * Pointer { 0000:PPPP:PPPP:PPPP * / 0001:****:****:**** * Double { ... * \ FFFE:****:****:**** * Integer { FFFF:0000:IIII:IIII * * The scheme we have implemented encodes double precision values by performing a * 64-bit integer addition of the value 2^48 to the number. After this manipulation * no encoded double-precision value will begin with the pattern 0x0000 or 0xFFFF. * Values must be decoded by reversing this operation before subsequent floating point * operations may be peformed.
So this comment explains that different value ranges are used to represent different types of objects. But notice that these bit-ranges don’t match those defined in IEEE-754; for instance, in the standard for double precision values:
a valid qNaN:
1 sign bit | 11 exponent bits | 52 mantissa bits
1 | 1 1 1 1 1 1 1 1 1 1 1 | 1 + {51 bits of payload}
chunked into bytes this is:
1 1 1 1 | 1 1 1 1 | 1 1 1 1 | 1 + {51 bits of payload}
which represents all the bit patterns in the range:
0x F F F F ...
to
0x F F F 8 ...
This means that according to the standard, the bit-ranges usually represented by valid doubles vs. qNaNs are:
/ 0000:****:****:****
Double { ...
\ FFF7:****:****:****
/ FFF8:****:****:****
qNaN { ...
\ FFFF:****:****:****
So what the comment in the code is showing us is that the ranges they’re representing are shifted from what’s defined in the standard. The reason they’re doing this is to favor pointers: because pointers occupy the range with the top two bytes zeroed, you can manipulate pointers without applying a mask. The effect is that pointers aren’t “boxed”, while all other values are. This choice to favor pointers isn’t obvious; the SpiderMonkey implementation doesn’t shift the range, thus favoring doubles.
Okay, so I think the easiest way to see what’s up with this range shifting business is by looking at the mask lower down in that file:
// This value is 2^48, used to encode doubles such that the encoded value will begin // with a 16-bit pattern within the range 0x0001..0xFFFE. #define DoubleEncodeOffset 0x1000000000000ll
This offset is used in the asDouble() function:
inline double JSValue::asDouble() const { ASSERT(isDouble()); return reinterpretInt64ToDouble(u.asInt64 - DoubleEncodeOffset); }
This shifts the encoded double into the normal range of bit patterns defined by the standard. Conversely, the asCell() function (I believe in JSC “cells” and “pointers” are roughly interchangeable terms) can just grab the pointer directly without shifting:
ALWAYS_INLINE JSCell* JSValue::asCell() const { ASSERT(isCell()); return u.ptr; }
Cool. That’s actually basically it. Below I’ll mention a few more fun tidbits from the JSC implementation, but this is really the heart of the NaN-boxing implementation.
What about all the other values?
The part of the comment that said that if the top two bytes are 0, then the payload is a pointer was lying. Or, okay, over-simplified. JSC reserves specific, invalid, pointer values to denote immediates required by the ECMAScript standard: boolean, undefined & null:
* False: 0x06 * True: 0x07 * Undefined: 0x0a * Null: 0x02
These all have the second bit set to make it easy to test whether the value is any of these immediates.
They also represent 2 immediates not required by the standard: ValueEmpty at 0x00, which are used to represent holes in arrays, & ValueDeleted at 0x04, which are used to mark deleted values.
And finally, they also represent pointers into Wasm at 0x03.
So, putting it all together, a complete picture of the bit pattern encodings in JSC is:
* ValEmpty { 0000:0000:0000:0000 * Null { 0000:0000:0000:0002 * Wasm { 0000:0000:0000:0003 * ValDeltd { 0000:0000:0000:0004 * False { 0000:0000:0000:0006 * True { 0000:0000:0000:0007 * Undefined { 0000:0000:0000:000a * Pointer { 0000:PPPP:PPPP:PPPP * / 0001:****:****:**** * Double { ... * \ FFFE:****:****:**** * Integer { FFFF:0000:IIII:IIII
Take-Aways
- The floating point spec leaves a lot of room for NaN payloads. It does this intentionally.
- What are these payloads used for in real life? Mostly, I don’t know what they’re used for. If you know of other real world uses, I’d love to hear from you.
- One use is NaN-boxing, which is where you stick all the other non-floating point values in a language + their type information into the payload of NaNs. It’s a beautiful hack.
Appendix: to NaNbox or not to NaNbox
Looking at this implementation begs the question, is NaN-boxing a good idea or a bizzaro hack? As someone who isn’t implementing or maintaining a dynamically typed language, I’m not well-posed to answer that question. There are a lot of different approaches which surely all have nuanced tradeoffs that show up depending on the use-cases of your language. With that caveat, here’s a rough sketch of what some pros & cons are. Pros: saves memory, all values fit in registers, bit masks are fast to apply; Cons: have to box & unbox almost all values, implementation becomes harder, and validation bugs can be serious security vulnerabilities.
For a better discussion of NaN-boxing tradeoffs from someone who does implement & maintain a dynamically typed language check out this article.
Apart from performance, there is this writeup and this other writeup of vulnerabilities discovered in JSC. Whether these vulnerabilities would have been preventable if JSC had used a different approach for storing type information is a moot point, but there is at least one vulnerability that seems like it would have been prevented:
This way we control all 8 bytes of the structure, but there are other limitations (Some floating-point normalization crap does not allow for truly arbitrary values to be written. Otherwise, you would be able to craft a CellTag and set pointer to an arbitrary value, that would be horrible. Interestingly, before it did allow that, which is what the very first Vita WebKit exploit used! CVE-2010-1807).
If you want to know way more about JSC’s memory model there is also this very in depth article.
Nouveau record du monde de marche pieds nus sur Lego
On est d’accord, marcher sur un Lego sans le faire exprès est l’une des pires sensations du monde (en le faisant exprès aussi d’ailleurs). Et bien comme à peu près toute « discipline » dans ce bas monde il existe un record du monde de marche pieds nus sur lego enregistré au Guiness World Records. Même qu’un mec vient de le battre.
Quand record du monde rime avec douleur
Tyler, membre de la chaîne Youtube Dude Perfect a parcouru 44,7 mètres de briques Lego pieds nus pour l’émission « Absurd Record ». Record qui a été, bien évidemment, validé par le Guiness World Records qui était, bien évidemment, aussi sur place. Sur la vidéo ci dessous, vous verrez un homme courageux, en pleine souffrance. Tu as tout notre respect Tyler.
Pour la petite anecdote, le meilleur score précédent était de 24,9 mètres. Pour ceux qui sont vraiment très mauvais en calcul mental, Tyler a quand même fait presque 20 mètres de plus que son prédécesseur…
L’article Nouveau record du monde de marche pieds nus sur Lego est apparu en premier sur GOLEM13.FR.
Damien Pobel : mycli, un client MySQL (et alternatives compatibles) en ligne de commande
Via le Journal du Hacker, je suis tombé
sur Config pour ne plus taper ses mots de passe MySQL et plus encore avec les
Options
file
qui rappelle que le client MySQL en ligne de commande propose un fichier de
configuration (~/.my.cnf) permettant de se simplifier la vie si on se connecte
toujours aux mêmes machines/bases. Ce billet montre aussi
l'option pager de ce fichier de configuration qui, comme son nom l'indique,
permet de configurer un pager (more, less, neovim, ... ou ce que vous
voulez) que l'auteur utilise pour mettre de la couleur dans le client MySQL /
MariaDB
avec Generic Colouriser. Bref, ce sont deux
très bonnes astuces pour les utilisateurs de mysql en ligne de commande dont
je fais partie.
Il se trouve qu'en plus, au travail, j'utilise une machine virtuelle. Et donc, pour accèder à MySQL, il me faut d'abord faire ouvrir un shell avec ssh pour ensuite lancer le client. Bien sûr, un bête alias permet de faire tout ça plus rapidement mais j'aime bien avoir mes outils de développement en local. En cherchant comment installer le client MySQL (et uniquement celui-ci) sur mon Mac, je suis tombé sur mycli et autant de le dire tout de suite, j'ai abandonné l'idée d'installer le client officiel :) En fait, mycli est un client MySQL (compatible avec MariaDB ou Percona) qui vient avec tout un tas de fonctionnalités vraiment pratiques et bien documentées comme la coloration syntaxique des requêtes, l'édition multi-ligne ou non, quelques commandes pratiques et surtout un complètement intelligent !
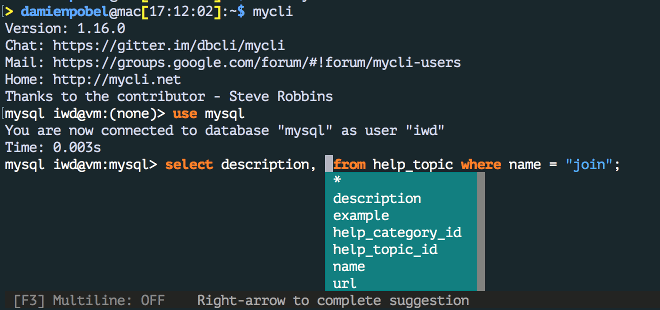
Il a sa propre configuration dans ~/.myclirc (qu'il génère au premier
lancement avec les commentaires, encore une bonne idée) mais le plus beau, c'est
qu'il utilise aussi ~/.my.cnf le fichier de configuration du client officiel
et donc les 2 astuces citées plus haut fonctionnent parfaitement et directement dans
cet outil !
Bref, pour le moment, mon .myclirc est celui par défaut (sauf le thème
fruity) et mon .my.cnf
ressemble à
[client]
user = MONUSER
password = PASSWORD
host = vm.local
# ~/.grcat/mysql provient de https://github.com/nitso/colour-mysql-console
pager = 'grcat ~/.grcat/mysql|most'J'utilise most comme pager mais j'hésite encore avec less
qui propose une option pour ne pas paginer lorsque les données sont trop courtes
ou Neovim dont j'ai vraiment l'habitude.
Dernier point, vous n'utilisez pas MySQL (ou MariaDB ou Percona) ? Pas de problème, l'auteur a écrit le même genre de clients pour d'autres serveur de base de données.

Original post of Damien Pobel.Votez pour ce billet sur Planet Libre.
Articles similaires
- Nassim KACHA : [Sysadmin's friends] Screen (23/08/2010)
- theClimber : Trics & Tips : configurer son client ssh (17/06/2009)
- Jos : Changer de serveur pulseaudio en ligne de commande (10/09/2010)
- Jos : Mettre en place SSH sur Ubuntu (08/09/2009)
- JJL : Éditer des fichiers XML en ligne de commande : xmlstarlet (09/02/2010)
US Border Patrol Hasn’t Validated E-Passport Data For Years
Les cartes bancaires sans contact et la confidentialité des données
Le paiement sans contact est une fonction disponible sur plus de 60% des cartes bancaires en circulation. Les données bancaires étant des éléments sensibles, elles doivent naturellement être protégées.
Est-ce vraiment le cas ?
Evolution du paiement sans contact
Cette fonctionnalité est apparue en France aux alentours de 2012. Depuis, elle n’a cessé de se développer. Selon le GIE Cartes bancaires, 44,9 millions de cartes bancaires sans contact étaient en circulation en septembre 2017, soit 68% du parc français.

Dans son bilan 2016 (PDF, page 11), ce même GIE déclare que 605 millions de paiements ont été réalisés via du sans contact. Si ce chiffre semble énorme, l’évolution de ce dernier l’est encore plus : +158% de paiements par rapport à 2015, et la tendance ne faiblit pas.
Le paiement sans contact est fait pour des petites transactions, celles de « la vie quotidienne », le montant des échanges étant plafonné à maximum 30€ depuis octobre 2017.
Fonctionnement du paiement sans contact
Le principe est relativement simple, la personne détentrice d’une carte sans contact souhaite payer sa transaction (inférieure à 30€ donc), elle pose sa carte à quelques centimètres du terminal de paiement sans contact et « paf », c’est réglé.
Le paiement sans contact est basé sur la technologie NFC, ou Near Field Communication (communication en champ proche) via une puce et un circuit faisant office d’antenne, intégrés à la carte bancaire.
Le NFC est caractérisé par sa distance de communication, qui ne dépasse pas 10 cm avec du matériel conventionnel. Les fréquences utilisées par les cartes sans contact sont de l’ordre de la haute fréquence (13,56 MHz) et peuvent utiliser des protocoles de chiffrement et d’authentification. Le pass Navigo, les récents permis de conduire ou certains titres d’identité récents utilisent par exemple de la NFC.
Si la technique vous intéresse, je vous invite à lire en détail les normes ISO-14443A standard et la norme ISO 7816, partie 4.
Paiement sans contact et données personnelles
On va résumer simplement le problème : il n’y a pas de phase d’authentification ni de chiffrement total des données. En clair, cela signifie que des informations relativement sensibles se promènent, en clair, sur un morceau de plastique.
De nombreuses démonstrations existent çà et là, vous pouvez également trouver des applications pour mobile qui vous permettent de récupérer les informations non chiffrées (votre téléphone doit être compatible NFC pour réaliser l’opération).
Pour réaliser l’opération, avec du matériel conventionnel, il faut être maximum à quelques centimètres de la carte sans contact, ce qui limite fortement le potentiel d’attaque et interdit, de fait, une « industrialisation » de ces dernières.
Cependant, avec du matériel plus précis, plus puissant et plus onéreux, il est possible de récupérer les données de la carte jusqu’à 1,5 mètre et même plus avec du matériel spécifique et encore plus onéreux (il est question d’une portée d’environ 15 mètres avec ce genre de matériel). Un attaquant doté de ce type d’équipement peut récupérer une liste assez impressionnante de cartes, puisqu’elles sont de plus en plus présentes… problématique non ?
En 2012, le constat était plus alarmant qu’aujourd’hui, puisqu’il était possible de récupérer le nom du détenteur de la carte, son numéro de carte, sa date d’expiration, l’historique de ses transactions et les données de la bande magnétique de la carte bancaire.
En 2017… il est toujours possible de récupérer le numéro de la carte, la date d’expiration de cette dernière et, parfois, l’historique des transactions, mais nous y reviendrons.
Que dit la CNIL sur le sujet ?
J’ai demandé à la CNIL s’il fallait considérer le numéro de carte bancaire comme étant une donnée à caractère personnel, sans réponse pour le moment. J’éditerai cet article lorsque la réponse arrivera.
Si le numéro de carte bancaire est une donnée à caractère personnel, alors le fait qu’il soit disponible, et stocké en clair, me semble problématique, cela ne semble pas vraiment respecter la loi informatique et libertés.
En 2013, cette même CNIL a émis des recommandations à destination des organismes bancaires, en rappelant par exemple l’article 32 et l’article 38 de la loi informatique et libertés. Les porteurs de carte doivent, entre autres, être informés de la présence du sans contact et doivent pouvoir refuser cette technologie.
Les paiements sans contact sont appréciés des utilisateurs car ils sont simples, il suffit de passer sa carte sur le lecteur. Ils sont préférés aux paiements en liquide et certains vont même jusqu’à déclarer que « le liquide finira par disparaître dans quelques années ». Son usage massif fait que votre organisme bancaire vous connaît mieux, il peut maintenant voir les paiements qui lui échappaient avant, lorsque ces derniers étaient en liquide.
La CNIL s’est également alarmée, dès 2012, des données transmises en clair par les cartes en circulation à l’époque. Ainsi, il n’est plus possible de lire le nom du porteur de la carte, ni, normalement, de récupérer l’historique des transactions… ce dernier point étant discutable dans la mesure où, pas plus tard que la semaine dernière, j’ai pu le faire avec une carte émise en 2014.
Comme expliqué précédemment, il est encore possible aujourd’hui de récupérer le numéro de carte ainsi que la date d’expiration de cette dernière.
Dans le scénario d’une attaque ciblée contre un individu, obtenir son nom n’est pas compliqué. Le CVV – les trois chiffres indiqués au dos de la carte – peut être forcé, il n’existe que 1000 combinaisons possibles, allant de 000 à 999.
Si la CNIL a constaté des améliorations, elle n’est pas rassurée pour autant. En 2013, elle invitait les acteurs du secteur bancaire à mettre à niveau leurs mesures de sécurité pour garantir que les données bancaires ne puissent pas être collectées ni exploitées par des tiers.
Elle espère que ce secteur suivra les différentes recommandations émises [PDF, page 3], notamment par l’Observatoire de la Sécurité des Cartes de Paiement, quant à la protection et au chiffrement des échanges. Les premières recommandations datent de 2007 [PDF], mais malheureusement, dix ans après, très peu de choses ont été entreprises pour protéger efficacement les données bancaires présentes dans les cartes sans contact.
S’il existe des techniques pour restreindre voire empêcher la récupération des données bancaires via le sans contact, le résultat n’est toujours pas satisfaisant, le numéro de carte est toujours stocké en clair et lisible aisément, les solutions ne garantissent ni un niveau de protection adéquat, ni une protection permanente.
Une solution consiste à « enfermer » sa carte dans un étui qui bloque les fréquences utilisées par le NFC. Tant que la carte est dans son étui, pas de risques… mais pour payer, il faut bien sortir ladite carte, donc problème.
L’autre solution, plus « directe », consiste à trouer – physiquement – sa carte au bon endroit pour mettre le circuit de la carte hors service. Attention cependant, votre carte bancaire n’est généralement pas votre propriété, vous louez cette dernière à votre banque, il est normalement interdit de détériorer le bien de votre banque.
DCP ou pas DCP ?
J’en parlais précédemment : est-ce que le numéro de carte bancaire constitue à lui seul une donnée à caractère personnel, ou DCP ?
Cela semble un point de détail mais je pense que c’est assez important en réalité. Si c’est effectivement une DCP, alors le numéro de carte bancaire doit, au même titre que les autres DCP, bénéficier d’un niveau de protection adéquat, exigence qui n’est actuellement pas satisfaite.
Si vous avez la réponse, n’hésitez pas à me contacter ou à me donner quelques références.

Our experience designing and building gRPC services
This is the final post in a series on how we scaled Bugsnag’s new Releases dashboard backend pipeline using gRPC. Read our first blog on why we selected gRPC for our microservices architecture, and our second blog on how we package generated code from protobufs into libraries to easily update our services.
The Bugsnag engineering team recently worked on massively scaling our backend data-processing pipeline to support the launch of the Releases dashboard. The Releases dashboard (for comparing releases to improve the health of applications) included support for sessions which would mean a significant increase in the amount of data processed in our backend. Because of this and the corresponding increase in call load, we implemented gRPC as our microservices communications framework. It allows our microservices to talk to each other in a more robust and performant way.
In this post, we’ll walk through our experiences building out gRPC and some of the gotchas and development tips we’ve learned along the way.
Our experience with gRPC
For the Releases dashboard, we needed to implement gRPC in Ruby, Java, Node, and Go. This is because we’ve built the services in our data-processing Pipeline in the language best suited for the job. Our initial investigation uncovered that all client libraries have various degrees of maturity. Most of them are serviceable, but not all are feature complete. However, these libraries are progressing fast and were mature enough for our needs. Nevertheless, it’s worth evaluating their current state before jumping in.
Designing a gRPC service
The design process was much smoother than the RESTful interface in terms of the API specification. The endpoints were quickly defined, written, and understood, all self contained in a single protobuf file. However, there are very few rules on what these endpoints could be, which is generally the case with RPC. We needed to be strict on defining the role of the microservice, ensuring the endpoints reflected this role. We focused on making sure each endpoint was heavily commented, which helped our cross-continent teams avoid too many integration problems.
As an aside, it’s important to write documentation and communicate common use cases involving these endpoints. This is typically outside the scope of the protobuf file, but has a large impact on what the endpoints should be.
Developing a gRPC service
Implementing gRPC was initially a rough road. Our team was unfamiliar with best practices so we had to spend more time than we wanted on building tools and testing our servers. At the time, there was a lack of good tutorials and examples for us to copy from, so the first servers created were based on trial and error. gRPC could benefit from some clear documentation and examples about the concepts it uses like stubs and channels.
This page is a good start at explaining the basics; however, we would have felt more confident if we knew more. For example, knowing how channels handle connection failure without having to check the client’s source code. We also found most of the configurable options were only documented in source code and took a lot of time and effort to find. We were never really sure if the option had worked, which meant we ended up testing most options we changed. The barrier to entry for developing and testing gRPC was quite high. More intuitive documentation and tools are essential if gRPC is here to stay, and there do seem to be more and more examples coming out.
Handling opinionated languages
There were a few gotchas along the way, including getting familiar with how protobufs handle default values. For example, in the protobuf format, strings are primitive and have a default value of "". Java developers identify null as the default value for strings. But beware, setting null for primitive protobuf fields like strings will cause runtime exceptions in Java.
The client libraries try to protect against invalid field values before transmitting and assume you are trying to set null to a primitive field. These safeguards are present to protect against conflicting opinions between different language applications e.g. "", nil, and null for strings. This led us to create wrappers for these messages to avoid confusion once you were in the application’s native language. On the whole, we’ve had very little need to dive into and debug the messages themselves. Client library implementations are very reliable at encoding and decoding messages.
How to debug a gRPC service
When we started using gRPC, the testing tools available were limited. Developers want to cURL their endpoints, but with gRPC equivalents to familiar tools like Postman either don’t exist or are not very mature. These tools need to support both encoding and decoding messages using the appropriate protobuf file, and be able to support HTTP/2. You can actually cURL a gRPC endpoint directly, but this is far from a streamlined process. Some useful tools we came across were:
-
protoc-gen-lint, linting for protobufs - This tool checks for any deviations from Google’s Protocol Buffer style guide. We use this as part of our build process to enforce coding standards and catch basic errors. It’s good for spotting invalid message structures and typos.
-
grpcc, CLI for a gRPC Server - This uses Node REPL to interact with a gRPC service via its protobuf file, and is very useful for quickly testing an endpoint. It’s a little rough around the edges, but looks promising for a standalone tool to hit endpoints.
-
omgrpc, GUI client - Described as Postman for gRPC endpoints, this tool provides a visual way to interact with your gRPC services.
-
awesome gRPC - A great collection of resources currently available for gRPC
Let me cURL my gRPC endpoint
In addition to these tools, we managed to re-enable our existing REST tools by using Envoy and JSON transcoding. This works by sending HTTP/1.1 requests with a JSON payload to an Envoy proxy configured as a gRPC-JSON transcoder. Envoy will translate the request into the corresponding gRPC call, with the response message translated back into JSON.
Step 1: Annotate the service protobuf file with google APIs. This is an example of a service with an endpoint that has been annotated so it can be invoked with a POST request to /errorclass.
import "google/api/annotations.proto";
package bugsnag.error_service;
service Errors {
rpc GetErrorClass (GetErrorClassRequest) returns (GetErrorClassResponse) {
option (google.api.http) = {
post: "/errorclass"
body: "*"
};
}
}
message GetErrorClassRequest {
string error_id = 1;
}
message GetErrorClassResponse {
string error_class = 1;
}
Step 2: Generate a proto descriptor set that describes the gRPC service. This requires the protocol compiler, or protoc installed (how to install it can be found here). Follow this guide on generating a proto descriptor set with protoc.
Step 3: Run Envoy with a JSON transcoder, configured to use the proto descriptor set. Here is an example of an Envoy configuration file with the gRPC server listening on port 4000.
{
"listeners": [
{
"address": "tcp://0.0.0.0:3000",
"filters": [
{
"type": "read",
"name": "http_connection_manager",
"config": {
"codec_type": "auto",
"stat_prefix": "grpc.error-service",
"route_config": {
"virtual_hosts": [
{
"name": "grpc",
"domains": ["*"],
"routes": [
{
"timeout_ms": 1000,
"prefix": "/",
"cluster": "grpc-cluster"
}
]
}
]
},
"filters": [
{
"type": "both",
"name": "grpc_json_transcoder",
"config": {
"proto_descriptor": "/path/to/proto-descriptors.pb",
"services": ["bugsnag.error_service"],
"print_options": {
"add_whitespace": false,
"always_print_primitive_fields": true,
"always_print_enums_as_ints": false,
"preserve_proto_field_names": false
}
}
},
{
"type": "decoder",
"name": "router",
"config": {}
}
]
}
}
]
}
],
"admin": {
"access_log_path": "/var/log/envoy/admin_access.log",
"address": "tcp://0.0.0.0:9901"
},
"cluster_manager": {
"clusters": [
{
"name": "grpc-cluster",
"connect_timeout_ms": 250,
"type": "strict_dns",
"lb_type": "round_robin",
"features": "http2",
"hosts": [
{
"url": "tcp://docker.for.mac.localhost:4000"
}
]
}
]
}
}
Step 4: cURL the gRPC service via the proxy. In this example, we set up the proxy to listen to port 3000.
> curl -H "Accept: application/json" \
-X POST -d '{"error_id":"587826d70000000000000001"}' \
http://localhost:3000/errorclass
'{"error_class":"Custom Runtime Exception"}'
Although this technique can be very useful, it does require us to “muddy up” our protobuf files with additional dependencies, and manage the Envoy configurations to talk to these services. To streamline the process, we scripted the steps and ran an Envoy instance inside a Docker container, taking a protobuf file as a parameter. This allowed us to quickly set a JSON transcoding proxy for any gRPC services in seconds.
Running the gRPC Ruby client library on Alpine
We did encounter some trouble running the Ruby version of a gRPC client. When we came to build the applications container, we got the error:
LoadError: Error relocating /app/vendor/bundle/ruby/2.4.0/gems/grpc-1.4.1-x86_64-linux/src/ruby/lib/grpc/2.4/grpc_c.so: __strncpy_chk: symbol not found - /app/vendor/bundle/ruby/2.4.0/gems/grpc-1.4.1-x86_64-linux/src/ruby/lib/grpc/2.4/grpc_c.so
Most gRPC client libraries are written on top of a shared core library, written in C. The issue was due to using the an alpine version of Ruby with a precompiled version of the gRPC library requiring glibc. This was solved by setting BUNDLE_FORCE_RUBY_PLATFORM=1 in the environment when running bundle install which will build the gems from source rather than using the precompiled version.
Final thoughts
Rolling this out into production, we immediately observed latency improvements. Once the initial connection was made, transport costs were on the order of microseconds and effectively negligible compared to the call itself. This gave us confidence to ramp up to heavier loads which were handled with ease.
Now that we’ve streamlined our development process, and made our deployments resilient using Envoy, we can rollout new scalable gRPC communication links or upgrade existing ones quickly and efficiently. Load balancing did provide us with an interesting problem, and you can read about it here.
Chrome's WebUSB Feature Leaves Some Yubikeys Vulnerable to Attack
Modern CSS Explained For Dinosaurs
CSS is strangely considered both one of the easiest and one of the hardest languages to learn as a web developer. It’s certainly easy enough to get started with it — you define style properties and values to apply to specific elements, and…that’s pretty much all you need to get going! However, it gets tangled and complicated to organize CSS in a meaningful way for larger projects. Changing any line of CSS to style an element on one page often leads to unintended changes for elements on other pages.
In order to deal with the inherent complexity of CSS, all sorts of different best practices have been established. The problem is that there isn’t any strong consensus on which best practices are in fact the best, and many of them seem to completely contradict each other. If you’re trying to learn CSS for the first time, this can be disorienting to say the least.
The goal of this article is to provide a historical context of how CSS approaches and tooling have evolved to what they are today in 2018. By understanding this history, it will be easier to understand each approach and how to use them to your benefit. Let’s get started!
Update: I made a new video course version of this article, which goes over the material with greater depth, check it out here:
https://firstclass.actualize.co/p/modern-css-explained-for-dinosaurs
Using CSS for basic styling
Let’s start with a basic website using just a simple index.html file that links to a separate index.css file:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Modern CSS</title>
<link rel="stylesheet" href="index.css">
</head>
<body>
<header>This is the header.</header>
<main>
<h1>This is the main content.</h1>
<p>...</p>
</main>
<nav>
<h4>This is the navigation section.</h4>
<p>...</p>
</nav>
<aside>
<h4>This is an aside section.</h4>
<p>...</p>
</aside>
<footer>This is the footer.</footer>
</body>
</html>
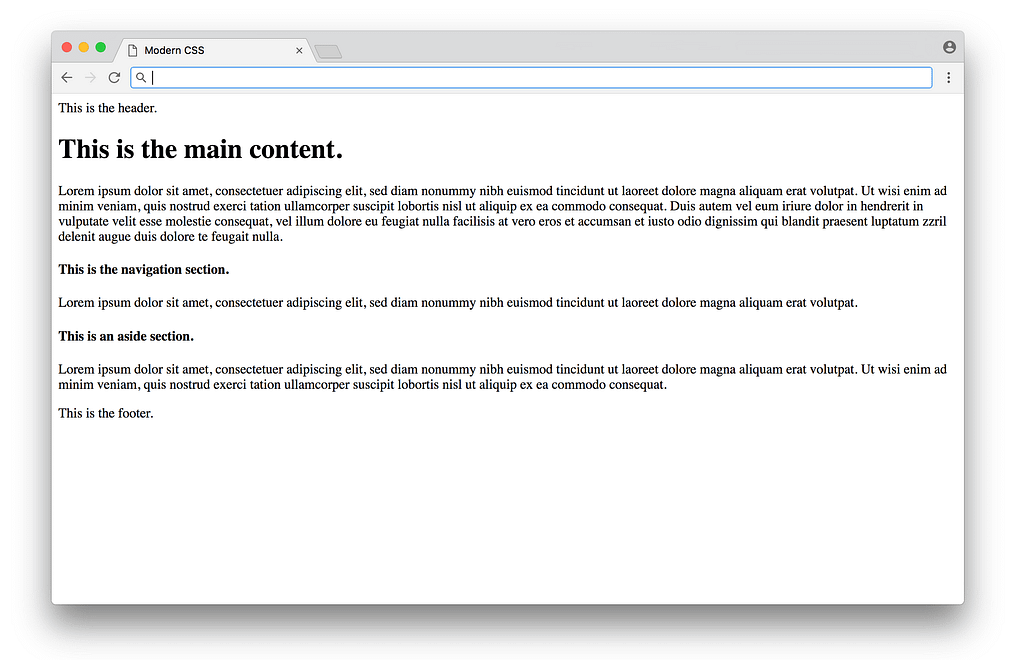
Right now we aren’t using any classes or ids in the HTML, just semantic tags. Without any CSS, the website looks like this (using placeholder text):
Functional, but not very pretty. We can add CSS to improve the basic typography in index.css:
/* BASIC TYPOGRAPHY */
/* from https://github.com/oxalorg/sakura */
html {
font-size: 62.5%;
font-family: serif;
}body {
font-size: 1.8rem;
line-height: 1.618;
max-width: 38em;
margin: auto;
color: #4a4a4a;
background-color: #f9f9f9;
padding: 13px;
}@media (max-width: 684px) {
body {
font-size: 1.53rem;
}
}@media (max-width: 382px) {
body {
font-size: 1.35rem;
}
}h1, h2, h3, h4, h5, h6 {
line-height: 1.1;
font-family: Verdana, Geneva, sans-serif;
font-weight: 700;
overflow-wrap: break-word;
word-wrap: break-word;
-ms-word-break: break-all;
word-break: break-word;
-ms-hyphens: auto;
-moz-hyphens: auto;
-webkit-hyphens: auto;
hyphens: auto;
}h1 {
font-size: 2.35em;
}h2 {
font-size: 2em;
}h3 {
font-size: 1.75em;
}h4 {
font-size: 1.5em;
}h5 {
font-size: 1.25em;
}h6 {
font-size: 1em;
}Here most of the CSS is styling the typography (fonts with sizes, line height, etc.), with some styling for the colors and a centered layout. You’d have to study design to know good values to choose for each of these properties (these styles are from sakura.css), but the CSS itself that’s being applied here isn’t too complicated to read. The result looks like this:
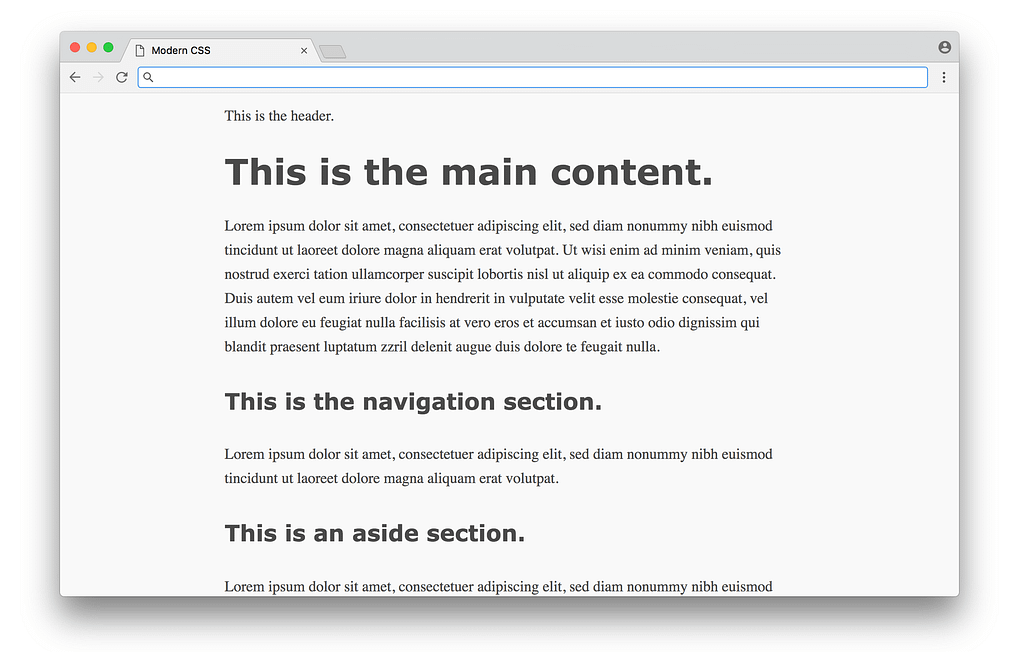
What a difference! This is the promise of CSS — a simple way to add styles to a document, without requiring programming or complex logic. Unfortunately, things start to get hairier when we use CSS for more than just typography and colors (which we’ll tackle next).
Using CSS for layout
In the 1990s, before CSS gained wide adoption, there weren’t a lot of options to layout content on the page. HTML was originally designed as a language to create plain documents, not dynamic websites with sidebars, columns, etc. In those early days, layout was often done using HTML tables — the entire webpage would be within a table, which could be used to organize the content in rows and columns. This approach worked, but the downside was the tight coupling of content and presentation — if you wanted to change the layout of a site, it would require rewriting significant amounts of HTML.
Once CSS entered the scene, there was a strong push to keep content (written in the HTML) separate from presentation (written in the CSS). So people found ways to move all layout code out of HTML (no more tables) into CSS. It’s important to note that like HTML, CSS wasn’t really designed to layout content on a page either, so early attempts at this separation of concerns were difficult to achieve gracefully.
Let’s take a look at how this works in practice with our above example. Before we define any CSS layout, we’ll first reset any margins and paddings (which affect layout calculations) as well as give section distinct colors (not to make it pretty, but to make each section visually stand out when testing different layouts).
/* RESET LAYOUT AND ADD COLORS */
body {
margin: 0;
padding: 0;
max-width: inherit;
background: #fff;
color: #4a4a4a;
}header, footer {
font-size: large;
text-align: center;
padding: 0.3em 0;
background-color: #4a4a4a;
color: #f9f9f9;
}nav {
background: #eee;
}main {
background: #f9f9f9;
}aside {
background: #eee;
}Now the website temporarily looks like:
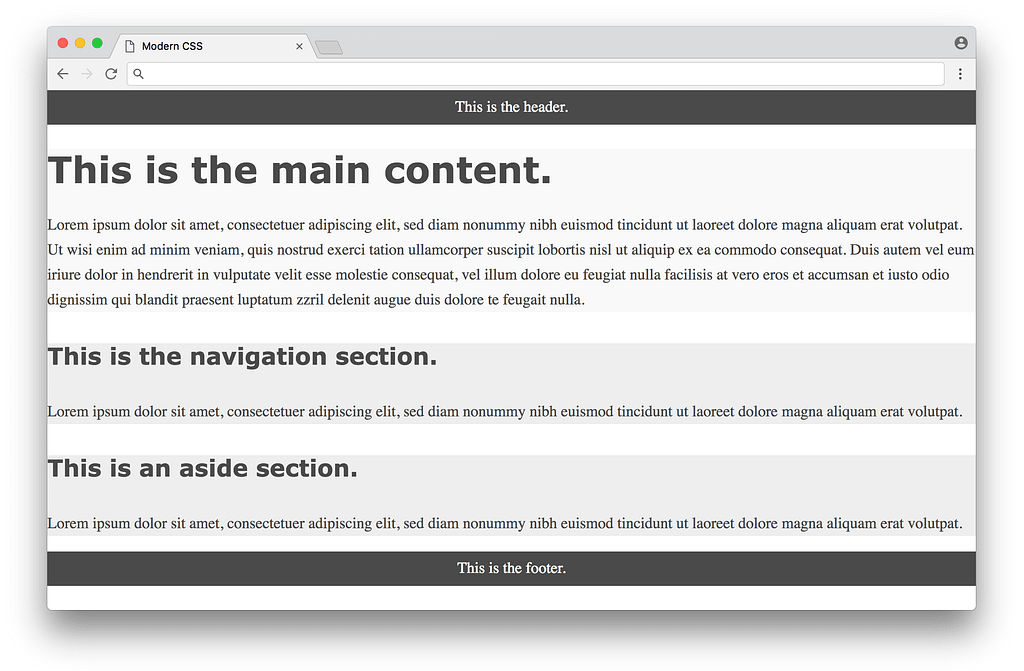
Now we’re ready to use CSS to layout the content on the page. We’ll look at three different approaches in chronological order, starting with the classic float-based layouts.
Float-based layout
The CSS float property was originally introduced to float an image inside a column of text on the left or right (something you often see in newspapers). Web developers in the early 2000s took advantage of the fact that you could float not just images, but any element, meaning you could create the illusion of rows and columns by floating entire divs of content. But again, floats weren’t designed for this purpose, so creating this illusion was difficult to pull off in a consistent fashion.
In 2006, A List Apart published the popular article In Search of the Holy Grail, which outlined a detailed and thorough approach to creating what was known as the Holy Grail layout — a header, three columns and a footer. It’s pretty crazy to think that what sounds like a fairly straightforward layout would be referred to as the Holy Grail, but that was indeed how hard it was to create consistent layout at the time using pure CSS.
Below is a float-based layout for our example based on the technique described in that article:
/* FLOAT-BASED LAYOUT */
body {
padding-left: 200px;
padding-right: 190px;
min-width: 240px;
}header, footer {
margin-left: -200px;
margin-right: -190px;
}main, nav, aside {
position: relative;
float: left;
}main {
padding: 0 20px;
width: 100%;
}nav {
width: 180px;
padding: 0 10px;
right: 240px;
margin-left: -100%;
}aside {
width: 130px;
padding: 0 10px;
margin-right: -100%;
}footer {
clear: both;
}* html nav {
left: 150px;
}Looking at the CSS, you can see there are quite a few hacks necessary to get it to work (negative margins, the clear: both property, hard-coded width calculations, etc.) — the article does a good job explaining the reasoning for each in detail. Below is what the result looks like:
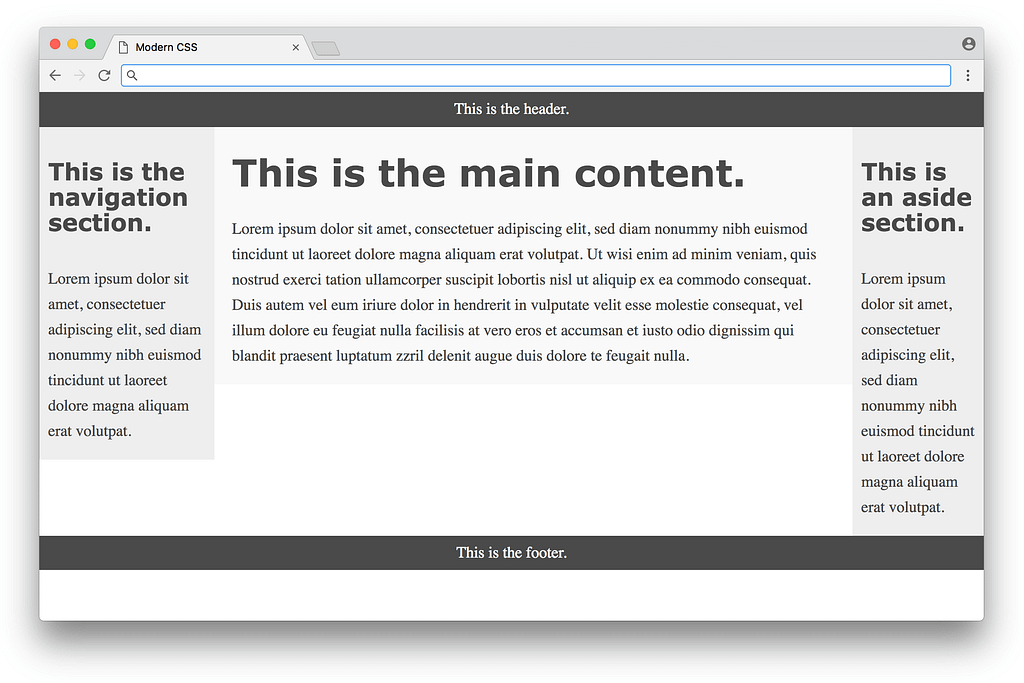
This is nice, but you can see from the colors that the three columns are not equal in height, and the page doesn’t fill the height of the screen. These issues are inherent with a float-based approach. All a float can do is place content to the left or right of a section — the CSS has no way to infer the heights of the content in the other sections. This problem had no straightforward solution until many years later, with a flexbox-based layout.
Flexbox-based layout
The flexbox CSS property was first proposed in 2009, but didn’t get widespread browser adoption until around 2015. Flexbox was designed to define how space is distributed across a single column or row, which makes it a better candidate for defining layout compared to using floats. This meant that after about a decade of using float-based layouts, web developers were finally able to use CSS for layout without the need for the hacks needed with floats.
Below is a flexbox-based layout for our example based on the technique described on the site Solved by Flexbox (a popular resource showcasing different flexbox examples). Note that in order to make flexbox work, we need to an an extra wrapper div around the three columns in the HTML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Modern CSS</title>
<link rel="stylesheet" href="index.css">
</head>
<body>
<header>This is the header.</header>
<div class="container">
<main>
<h1>This is the main content.</h1>
<p>...</p>
</main>
<nav>
<h4>This is the navigation section.</h4>
<p>...</p>
</nav>
<aside>
<h4>This is an aside section.</h4>
<p>...</p>
</aside>
</div>
<footer>This is the footer.</footer>
</body>
</html>
And here’s the flexbox code in the CSS:
/* FLEXBOX-BASED LAYOUT */
body {
min-height: 100vh;
display: flex;
flex-direction: column;
}.container {
display: flex;
flex: 1;
}main {
flex: 1;
padding: 0 20px;
}nav {
flex: 0 0 180px;
padding: 0 10px;
order: -1;
}aside {
flex: 0 0 130px;
padding: 0 10px;
}That is way, way more compact compared to the float-based layout approach! The flexbox properties and values are a bit confusing at first glance, but it eliminates the need for a lot of the hacks like negative margins that were necessary with float-based layouts — a huge win. Here is what the result looks like:
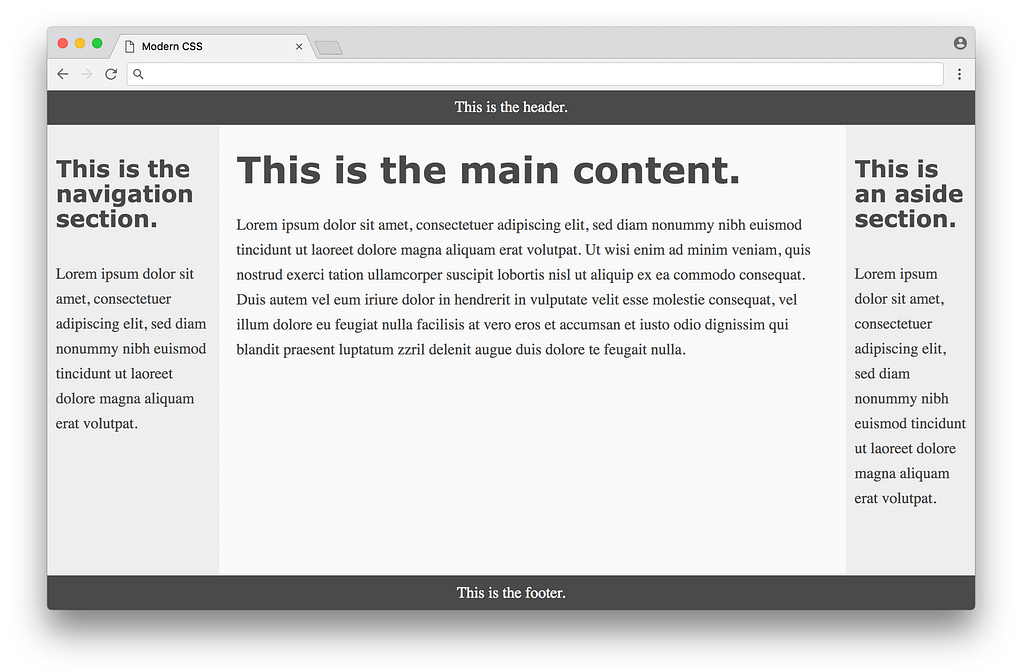
Much better! The columns are all equal height and take up the full height of the page. In some sense this seems perfect, but there are a couple of minor downsides to this approach. One is browser support — currently every modern browser supports flexbox, but some older browsers never will. Fortunately browser vendors are making a bigger push to end support for these older browsers, making a more consistent development experience for web designers. Another downside is the fact that we needed to add the <div class="container"> to the markup — it would be nice to avoid it. In an ideal world, any CSS layout wouldn’t require changing the HTML markup at all.
The biggest downside though is the code in the CSS itself — flexbox eliminates a lot of the float hacks, but the code isn’t as expressive as it could be for defining layout. It’s hard to read the flexbox CSS and get a visual understanding how all of the elements will be laid out on the page. This leads to a lot of guessing and checking when writing flexbox-based layouts.
It’s important to note again that flexbox was designed to space elements within a single column or row — it was not designed for an entire page layout! Even though it does a serviceable job (much better than float-based layouts), a different specification was specifically developed to handle layouts with multiple rows and columns. This specification is known as CSS grid.
Grid-based layout
CSS grid was first proposed in 2011 (not too long after the flexbox proposal), but took a long time to gain widespread adoption with browsers. As of early 2018, CSS grid is supported by most modern browsers (a huge improvement over even a year or two ago).
Below is a grid-based layout for our example based on the first method in this CSS tricks article. Note that for this example, we can get rid of the <div class="container"> that we had to add for the flexbox-based layout — we can simply use the original HTML without modification. Here’s what the CSS looks like:
/* GRID-BASED LAYOUT */
body {
display: grid;
min-height: 100vh;
grid-template-columns: 200px 1fr 150px;
grid-template-rows: min-content 1fr min-content;
}header {
grid-row: 1;
grid-column: 1 / 4;
}nav {
grid-row: 2;
grid-column: 1 / 2;
padding: 0 10px;
}main {
grid-row: 2;
grid-column: 2 / 3;
padding: 0 20px;
}aside {
grid-row: 2;
grid-column: 3 / 4;
padding: 0 10px;
}footer {
grid-row: 3;
grid-column: 1 / 4;
}The result is visually identical to the flexbox based layout. However, the CSS here is much improved in the sense that it clearly expresses the desired layout. The size and shape of the columns and rows are defined in the body selector, and each item in the grid is defined directly by its position.
One thing that can be confusing is the grid-column property, which defines the start point / end point of the column. It can be confusing because in this example, there are 3 columns, but the numbers range from 1 to 4. It becomes more clear when you look at the picture below:

The first column starts at 1 and ends at 2, the second column starts at 2 and ends at 3, and the third column starts at 3 and ends at 4. The header has a grid-column of 1 / 4 to span the entire page, the nav has a grid-column of 1 / 2 to span the first column, etc.
Once you get used to the grid syntax, it clearly becomes the ideal way to express layout in CSS. The only real downside to a grid-based layout is browser support, which again has improved tremendously over the past year. It’s hard to overstate the importance of CSS grid as the first real tool in CSS that was actually designed for layout. In some sense, web designers have always had to be very conservative with making creative layouts, since the tools up until now have been fragile, using various hacks and workarounds. Now that CSS grid exists, there is the potential for a new wave of creative layout designs that never would have been possible before — exciting times!

Using a CSS preprocessor for new syntax
So far we’ve covered using CSS for basic styling as well as layout. Now we’ll get into tooling that was created to help improve the experience of working with CSS as a language itself, starting with CSS preprocessors.
A CSS preprocessor allows you to write styles using a different language which gets converted into CSS that the browser can understand. This was critical back in the day when browsers were very slow to implement new features. The first major CSS preprocessor was Sass, released in 2006. It featured a new concise syntax (indentation instead of brackets, no semicolons, etc.) and added advanced features missing from CSS, such as variables, helper functions, and calculations. Here’s what the color section of our earlier example would look like using Sass with variables:
$dark-color: #4a4a4a
$light-color: #f9f9f9
$side-color: #eee
body
color: $dark-color
header, footer
background-color: $dark-color
color: $light-color
main
background: $light-color
nav, aside
background: $side-color
Note how reusable variables are defined with the $ symbol, and that brackets and semicolons are eliminated, making for a cleaner looking syntax. The cleaner syntax in Sass is nice, but features like variables were revolutionary at the time, as they opened up new possibilities for writing clean and maintainable CSS.
To use Sass, you need to install Ruby, the programming language used to compile Sass code to regular CSS. Then you would need to install the Sass gem, then run a command in the command line to convert your .sass files into .css files. Here’s an example of what a command would look like:
sass --watch index.sass index.css
This command will convert Sass code written in a file named index.sass to regular CSS in a file named index.css (the --watch argument tells it to run any time the input changes on save, which is convenient).
This process is known as a build step, and it was a pretty significant barrier to entry back in 2006. If you’re used to programming languages like Ruby, the process is pretty straightforward. But many frontend developers at the time only worked with HTML and CSS, which did not require any such tools. So it was a big ask to have someone learn an entire ecosystem to be able to get the features offered by a CSS preprocessor.
In 2009, the Less CSS preprocessor was released. It was also written in Ruby, and offered similar features to Sass. The key difference was the syntax, which was designed to be as close to CSS as possible. This means that any CSS code is valid Less code. Here’s the same example written using Less syntax:
@dark-color: #4a4a4a;
@light-color: #f9f9f9;
@side-color: #eee;
body {
color: @dark-color;
}
header, footer {
background-color: @dark-color;
color: @light-color;
}
main {
background: @light-color;
}nav, aside {
background: @side-color;
}It’s nearly the same (@ prefix instead of $ for variables), but not as pretty as the Sass example, with the same curly brackets and semi-colons as CSS. Yet the fact that it’s closer to CSS made it easier for developers to adopt it. In 2012, Less was rewritten to use JavaScript (specifically Node.js) instead of Ruby for compiling. This made Less faster than its Ruby counterparts, and made it more appealing to developers who were already using Node.js in their workflows.
To convert this code to regular CSS, you would first need to install Node.js, then install Less, then run a command like:
lessc index.less index.css
This command will convert Less code written in a file named index.less to regular CSS in a file named index.css. Note that the lessc command does not come with a way to watch files for changes (unlike the sass command), meaning you would need to install a different tool to automatically watch and compile .less files, adding a bit more complexity to the process. Again, this is not difficult for programmers who are used to using command line tools, but it is a significant barrier to entry for others who simply want to use a CSS preprocessor.
As Less gained mindshare, Sass developers adapted by adding a new syntax called SCSS in 2010 (which was a superset of CSS similar to Less). They also released LibSass, a C/C++ port of the Ruby Sass engine, which made it faster and able to be used in various languages.
Another alternative CSS preprocessor is Stylus, which came out in 2010, written in Node.js, and focuses on cleaner syntax compared to Sass or Less. Usually conversations about CSS preprocessors focus on those three as the most popular (Sass, Less, and Stylus). In the end, they are all pretty similar in terms of the features they offer, so you can’t really go wrong picking any of them.
However, some people make the argument that CSS preprocessors are becoming less necessary, as browsers are finally beginning to implement some of their features (such as variables and calculations). Furthermore, there’s a different approach known as CSS postprocessing that has the potential to make CSS preprocessors obsolete (obviously not without controversy), which we’ll get into next.
Using a CSS postprocessor for transformative features
A CSS postprocessor uses JavaScript to analyze and transform your CSS into valid CSS. In this sense it’s pretty similar to a CSS preprocessor — you can think of it as a different approach to solving the same problem. The key difference is that while a CSS preprocessor uses special syntax to identify what needs to be transformed, a CSS postprocessor can parse regular CSS and transform it without any special syntax required. This is best illustrated with an example. Let’s look at a part of the CSS we originally defined above to style the header tags:
h1, h2, h3, h4, h5, h6 {
-ms-hyphens: auto;
-moz-hyphens: auto;
-webkit-hyphens: auto;
hyphens: auto;
}The items in bold are called vendor prefixes. Vendor prefixes are used by browsers when they are experimentally adding or testing new CSS features, giving a way for developers to use these new CSS properties while the implementation is being finalized. Here the -ms prefix is for Microsoft Internet Explorer, the -moz prefix is for Mozilla Firefox, and the -webkit prefix is for browsers using the webkit rendering engine (like Google Chrome, Safari, and newer versions of Opera).
It’s pretty annoying to remember to put in all these different vendor prefixes to use these CSS properties. It would be nice to have a tool that can automatically put in vendor prefixes as needed. We can sort of pull this off with CSS preprocessors. For example, you could do something like this with SCSS:
@mixin hyphens($value) {
-ms-hyphens: $value;
-moz-hyphens: $value;
-webkit-hyphens: $value;
hyphens: $value;
}h1, h2, h3, h4, h5, h6 {
@include hyphens(auto);
}Here we’re using Sass’ mixin feature, which allows you to define a chunk of CSS once and reuse it anywhere else. When this file is compiled into regular CSS, any @include statements will be replaced with the CSS from the matching @mixin. Overall this isn’t a bad solution, but you are responsible for defining each mixin the first time for any CSS property requiring vendor prefixes. These mixin definitions will require maintenance, as you may want to remove specific vendor prefixes that you no longer need as browsers update their CSS compatibility.
Instead of using mixins, it would be nice to simply write normal CSS and have a tool automatically identify properties that require prefixes and add them accordingly. A CSS postprocessor is capable of doing exactly that. For example, if you use PostCSS with the autoprefixer plugin, you can write completely normal CSS without any vendor prefixes and let the postprocessor do the rest of the work:
h1, h2, h3, h4, h5, h6 {
hyphens: auto;
}When you run the CSS postprocessor on this code, the result is the hyphens: auto; line gets replaced with all the appropriate vendor prefixes (as defined in the autoprefixer plugin, which you don’t need to directly manage). Meaning you can just write regular CSS without having to worry about any compatibility or special syntax, which is nice!
There are plugins other than autoprefixer for PostCSS that allow you to do really cool things. The cssnext plugin allows you to use experimental CSS features. The CSS modules plugin automatically changes classes to avoid name conflicts. The stylelint plugin identifies errors and inconsistent conventions in your CSS. These tools have really started to take off in the last year or two, showcasing developer workflows that has never been possible before!
There is a price to pay for this progress, however. Installing and using a CSS postprocessor like PostCSS is more involved compared to using a CSS preprocessor. Not only do you have to install and run tools using the command line, but you need to install and configure individual plugins and define a more complex set of rules (like which browsers you are targeting, etc.) Instead of running PostCSS straight from the command line, many developers integrate it into configurable build systems like Grunt, Gulp, or webpack, which help manage all the different build tools you might use in your frontend workflow.
Note: It can be quite overwhelming to learn all the necessary parts to making a modern frontend build system work if you’ve never used one before. If you want to get started from scratch, check out my article Modern JavaScript Explained For Dinosaurs, which goes over all the JavaScript tooling necessary to take advantage of these modern features for a frontend developer.
It’s worth noting that there is some debate around CSS postprocessors. Some argue that the terminology is confusing (one argument is that they should all be called CSS preprocessors, another argument is that they should just be simply called CSS processors, etc.). Some believe CSS postprocessors eliminate the need for CSS preprocessors altogether, some believe they should be used together. In any case, it’s clear that learning how to use a CSS postprocessor is worth it if you’re interested in pushing the edge of what’s possible with CSS.
Using CSS methodologies for maintainability
Tools like CSS preprocessors and CSS postprocessors go a long way towards improving the CSS development experience. But these tools alone aren’t enough to solve the problem of maintaining large CSS codebases. To address this, people began to document different guidelines on how to write CSS, generally referred to as CSS methodologies.
Before we dive into any particular CSS methodology, it’s important to understand what makes CSS hard to maintain over time. The key issue is the global nature of CSS — every style you define is globally applied to every part of the page. It becomes your job to either come up with a detailed naming convention to maintain unique class names or wrangle with specificity rules to determine which style gets applied any given element. CSS methodologies provide an organized way to write CSS in order to avoid these pain points with large code bases. Let’s take a look at some of the popular methodologies in rough chronological order.
OOCSS
OOCSS (Object Oriented CSS) was first presented in 2009 as a methodology organized around two main principles. The first principle is separate structure and skin. This means the CSS to define the structure (like layout) shouldn’t be mixed together with the CSS to define the skin (like colors, fonts, etc.). This makes it easier to “re-skin” an application. The second principle is separate container and content. This means think of elements as re-usable objects, with the key idea being that an object should look the same regardless of where it is on the page.
OOCSS provides well thought out guidelines, but isn’t very prescriptive on the specifics of the approach. Later approaches like SMACSS took the core concepts and added more detail to make it easier to get started.
SMACSS
SMACSS (Scalable and Modular Architecture for CSS) was introduced in 2011 as a methodology based around writing your CSS in 5 distinct categories — base rules, layout rules, modules, state rules, and theme rules. The SMACSS methodology also recommends some naming conventions. For layout rules, you would prefix class names with l- or layout-. For state rules, you would prefix class names that describe the state, like is-hidden or is-collapsed.
SMACSS has a lot more specifics in its approach compared to OOCSS, but it still requires some careful thought in deciding what CSS rules should go into which category. Later approaches like BEM took away some of this decision making to make it even easier to adopt.
BEM
BEM (Block, Element, Modifier) was introduced in 2010 as a methodology organized around the idea of dividing the user interface into independent blocks. A block is a re-usable component (an example would be a search form, defined as <form class="search-form"></form>). An element is a smaller part of a block that can’t be re-used on its own (an example would be a button within the search form, defined as <button class="search-form__button">Search</button>). A modifier is an entity that defines the appearance, state, or behavior of a block or element (an example would be a disabled search form button, defined as <button class="search-form__button search-form__button--disabled">Search</button>).
The BEM methodology is simple to understand, with a specific naming convention that allows newcomers to apply it without having to make complex decisions. The downside for some is that the class names can be quite verbose, and don’t follow traditional rules for writing semantic class names. Later approaches like Atomic CSS would take this untraditional approach to a whole other level!
Atomic CSS
Atomic CSS (also known as Functional CSS) was introduced in 2014 as a methodology organized around the idea of creating small, single-purpose classes with names based on visual function. This approach is in complete opposition with OOCSS, SMACSS, and BEM — instead of treating elements on the page as re-usable objects, Atomic CSS ignores these objects altogether and uses re-usable single purpose utility classes to style each element. So instead of something like <button class="search-form__button">Search</button>, you would have something like <button class="f6 br3 ph3 pv2 white bg-purple hover-bg-light-purple">Search</button>.
If your first reaction to this example is to recoil in horror, you’re not alone — many people saw this methodology as a complete violation of established CSS best practices. However, there has been a lot of excellent discussion around the idea of questioning the effectiveness of those best practices in different scenarios. This article does a great job highlighting how traditional separation of concerns ends up creating CSS that depends on the HTML (even when using methodologies like BEM), while an atomic or functional approach is about creating HTML that depends on the CSS. Neither is wrong, but upon close inspection you can see that a true separation of concerns between CSS and HTML is never fully achievable!
Other CSS methodologies like CSS in JS actually embrace the notion that CSS and HTML will always depend on each other, leading to one of the most controversial methodologies yet…
CSS in JS
CSS in JS was introduced in 2014 as a methodology organized around defining CSS styles not in a separate style sheet, but directly in each component itself. It was introduced as an approach for the React JavaScript framework (which already took the controversial approach of defining the HTML for a component directly in JavaScript instead of a separate HTML file). Originally the methodology used inline styles, but later implementations used JavaScript to generate CSS (with unique class names based on the component) and insert it into the document with a style tag.
The CSS in JS methodology once again goes completely against established CSS best practices of separation of concerns. This is because the way we use the web has shifted dramatically over time. Originally the web largely consisted of static web sites — here the separation of HTML content from CSS presentation makes a lot of sense. Nowadays the web is used for creating dynamic web applications — here it makes sense to separate things out by re-usable components.
The goal of the CSS in JS methodology is to be able to define components with hard boundaries that consist of their own encapsulated HTML/CSS/JS, such that the CSS in one component has no chance of affecting any other components. React was one of the first widely adopted frameworks that pushed for these components with hard boundaries, influencing other major frameworks like Angular, Ember, and Vue.js to follow suit. It’s important to note that the CSS in JS methodology is relatively new, and there’s a lot of experimentation going on in this space as developers try to establish new best practices for CSS in the age of components for web applications.
It’s easy to get overwhelmed by the many different CSS methodologies that are out there, but it’s important to keep in mind that there is no one right approach — you should think of them as different possible tools you can use when you have a sufficiently complex CSS codebase. Having different well-thought-out options to choose from works in your favor, and all the recent experimentation happening in this space benefits every developer in the long run!
Conclusion
So this is modern CSS in a nutshell. We covered using CSS for basic styling with typographic properties, using CSS for layout using float, flexbox, and grid based approaches, using a CSS preprocessor for new syntax such as variables and mixins, using a CSS postprocessor for transformative features such as adding vendor prefixes, and using CSS methodologies for maintainability to overcome the global nature of CSS styles. We didn’t get a chance to dig into a lot of other features CSS has to offer, like advanced selectors, transitions, animations, shapes, dynamic variables — the list goes on and on. There’s a lot of ground to cover with CSS — anyone who says it’s easy probably doesn’t know the half of it!
Modern CSS can definitely be frustrating to work with as it continues to change and evolve at a rapid pace. But it’s important to remember the historical context of how the web has evolved over time, and it’s good to know that there are a lot of smart people out there willing to build concrete tools and methodologies to help CSS best practices evolve right along with the web. It’s an exciting time to be a developer, and I hope this information can serve as a roadmap to help you on your journey!

Special thanks again to @ryanqnorth’s Dinosaur Comics, which has served up some of the finest absurdist humor since 2003 (when dinosaurs ruled the web).
Modern CSS Explained For Dinosaurs was originally published in Actualize on Medium, where people are continuing the conversation by highlighting and responding to this story.
An argument for passwordless
12 best practices for user account, authorization and password management #MustRead #Security https://cloudplatform.googleblog.com/2018/01/12-best-practices-for-user-account.html …
12 best practices for user account, authorization and password management #MustRead #Security https://cloudplatform.googleblog.com/2018/01/12-best-practices-for-user-account.html …
[Chronique RH] Quand l'idiot regarde la neige, le sage voit le retard français en matière de télétravail
50 ans des Jeux olympiques de Grenoble: Un gouffre financier ou un pari réussi?

Gouffre financier ou véritable succès? Comment la ville de Grenoble a bénéficié de l'organisation des JO en 1968? — Mourad Allili/ SIPA
- À l’heure où Grenoble célèbre les 50 ans de ses Jeux olympiques, retour sur le coût de l’événement.
- La capitale iséroise a dû rembourser ses emprunts pendant plus de 25 ans.
- Mais elle a bénéficié de l’aide exceptionnelle de l’État et utilise encore bon nombre de ses équipements.
Les Jeux olympiques un budget généralement difficile à maîtriser. Alors que PyeongChang s’apprête à accueillir le monde entier, Grenoble a tiré le bilan des siens depuis longtemps. La capitale des Alpes a vu les projecteurs braquer sur elle le 6 février 1968. Cinquante ans plus tard, l’addition paraît encore salée même si la note aurait pu être bien plus élevée.
>> A lire aussi : Pyeongchang 2018, la victoire des JO business
27 ans pour rembourser la dette
« Les JO de Grenoble n’ont pas dérogé à la règle. On a eu un dépassement du coût. Et la ville a été surendettée pendant longtemps », affirme Wladimir Andreff, professeur émérite et grand économiste du sport à l’université Paris 1 Panthéon-Sorbonne. « Elle a mis 27 ans à rembourser les sommes qu’elle avait empruntées », poursuit Pierre Chaix, membre du Centre de Droit et d’Économie du Sport de Limoges.
>> A lire aussi : Quelles traces ont laissé les JO de 1968 à Grenoble?
Les Jeux de 1968 ont coûté 1,1 milliard de francs. Et le déficit observé s’est élevé à 80 millions de francs. Les organisateurs avaient tablé sur la vente d’un million de billets. Finalement, il s’en est écoulé deux fois moins. Même bradés la deuxième semaine de l’événement. Quant aux recettes du comité d’organisation des Jeux olympiques grenoblois de 1968, elles ont été très pauvres : 36 millions de francs au final.
>> A lire aussi : Les JO d'Athènes en 2004 ont gonflé en partie la dette publique grecque
230 % d’augmentation d’impôts
Un gouffre financier que les observateurs nuancent malgré tout. « 80 millions de francs, ce n’est presque rien comparé au déficit de plus d’un milliard de dollars, enregistré après les Jeux de Montréal de 1976 », note Wladimir Andreff. À titre de comparaison, celui d’Albertville en 1992 a été de 285 millions de francs (43,5 millions d’euros) et Salt Lake City, en 2002, a perdu 168 millions de dollars.
Même si Grenoble ferait presque figure de bon élève en la matière, la ville a néanmoins été obligée de rembourser plus de 200 millions de francs. Pour se faire, Hubert Dubedout, le maire de ville, a augmenté les impôts locaux de 230 % en seulement trois ans. Mais pour les observateurs, la cité grenobloise a « limité la casse » grâce à deux facteurs. Tout d’abord l’intervention de l’Etat.
>> A lire aussi : Les Jeux olympiques, c'est bon pour l'économie d'un pays ?
Si les Jeux ont coûté cher, Grenoble n’a payé que 20 %. « Le reste a été pris en charge par l’État », explique Wladimir Andreff. « Car c’est la France qui a payé les Jeux de Grenoble ». À l’époque Charles de Gaulle, soucieux de redorer le blason de la France et de jouer à nouveau un rôle sur la scène internationale, comprend tout l’intérêt médiatique d’organiser des JO.
Ensuite, « il y a eu un effet modérateur de la dette due à l’inflation », précise Pierre Chaix. « Les sommes à rembourser sont devenues de fait assez rapidement faibles. Le coût de la vie a augmenté mais pas les mensualités », poursuit-il
Gaspillage énorme ou pari réussi ?
Dans les esprits pourtant, le gaspillage est énorme. L’exemple le plus flagrant : letremplin de Saint-Nizier du Moucherotte, qui a coûté 5,9 millions de francs. « Il n’a pas été entretenu. Aujourd’hui, c’est une sorte de friche dangereuse qui menace de s’écrouler. On a tout simplement pollué un bout de la montagne pour le construire », déplore Wladimir Andreff. L’infrastructure a été utilisée jusqu’en 1989 pour les entraînements et quelques compétitions. Mais avec les changements de normes, la commune n’a pas eu les reins assez solides pour remodeler la piste de réception. Le site a été abandonné puis fermé au public pour des raisons de sécurité.
Un dossier a été déposé à la direction régionale des affaires culturelles (Drac) de l’Isère, pour que le tremplin soit classé patrimoine du XXe siècle, et donc préservé. Histoire de ne pas connaître le même destin que la piste de bosleigh de l'Alpe d'Huez, abandonnée après les Jeux et démolie depuis.
La question de savoir comment se débarrasser de l’anneau de patinage de vitesse s’est également souvent posée. « Refaire le système de réfrigération coûtait très cher. La solution a été de le transformer. Aujourd’hui, il n’a plus la finalité qui lui était destinée puisqu’il a été reconverti en piste de roller et de skate », poursuit Michel Raspaud, sociologue du sport. Quant au Stade des Glaces, qui avait une capacité de 12.000 places, il est devenu le Palais des Sports.
>> A lire aussi : Un an après les JO, à quoi ressemble Sotchi?
« La plupart des équipements sont toujours utilisés par les Grenoblois »
En réalité, « la majeure partie des équipements réalisés pour les Jeux s’est fondue dans le paysage », souligne l’urbaniste Dorian Martin. « La plupart des sites n’ont pas été abandonnés. Contrairement à Athènes ou Sotchi, dont les quartiers olympiques sont totalement désertés aujourd'hui, Grenoble avait pensé à organiser des Jeux réversibles ». Et de citer l’exemple du stade, où se sont déroulées les cérémonies d’ouverture et de clôture. « Il a été conçu sur un principe d’installation éphémère et a été démonté juste après l’événement ».
Le quartier Malherbe, qui accueillait le centre de presse, et le Village Olympique sont devenus depuis des quartiers d’habitations où se concentrent plus de 2.500 logements. « La plupart des équipements et infrastructures réalisés sont toujours utilisés par les Grenoblois », résume poursuit Dorian Martin. « Les Jeux ont été un véritable accélérateur de développement urbain. L’Hôtel de police, les bretelles d’accès de l’autoroute, l’Hôpital Sud existent toujours ».
XOR should be an English word
Soup xor salad? This question is much clearer than Soup or salad. Why? As we are going to see in this article, the word XOR would not allow choosing soup and salad, which is not expected, but it is an allowed option when the word OR is used.
What is XOR anyway?
ADD, what do you do? I add. SUB, and you? I subtract. XOR? Me? Well I…
Comparing XOR and OR
Table for the XOR function:
| A | B | XOR |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Table for the OR function:
| A | B | OR |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
The only difference between XOR and OR happens for A=1 and B=1, where the result is 0 for XOR and 1 for OR.
Real Life, OR or XOR?
In real life we say OR, but usually the intention is actually XOR, lets see some examples:
Example 1:
Mom: Son, where is your father?
Son: Working on the garden OR on the couch watching the game.
One condition excludes the other, Dad can’t be at both places at the same time, he is either working on the garden or on the couch watching the game. We know Mom is sure that, given the options, he is watching the game…
Lets see all of this in a table. The Where is your father function:
| Working on the garden | On the couch | Found! | Comments |
|---|---|---|---|
| 0 | 0 | 0 | Not found! (unexpected) |
| 0 | 1 | 1 | on the couch (Mom knew it!) |
| 1 | 0 | 1 | working on the garden (improbable) |
| 1 | 1 | 0 | Invalid, he can’t be in two places at same time |
The function returns 1 (Found!) when the inputs are exclusive. Exclusive here with the meaning of one different from the other.
Example 2:
Mom: Would you please buy ice cream, chocolate OR strawberry.
Son: Here are the ice creams, chocolate and strawberry.
One condition should exclude the other, but the son, very smart, used the inclusive OR. In this case Mom’s request was ambiguous. A non ambiguous request would be: Would you please buy ice cream, chocolate XOR strawberry.
The Reason for the XOR Name
Given both examples, I have found two different reasons for the name XOR, the first one sounds more reasonable than the second, but please let me know if you have a good source for the XOR name.
- XOR, exclusive OR, is TRUE when both inputs are exclusive or not equal.
- XOR, exclusive OR, excludes one of the OR conditions, XOR excludes the condition where both inputs are TRUE.
Again, I believe explanation 1) is more logical, but naming things are not a logical.
How to get to 0xDEAD
A teaser was left in Dissecting a Minimum WebAssembly module: How to get to 0xDEAD by XORing 0xFF00 and 0x21AD?
The simplest method to get to the result is to convert the numbers to binary and then apply the XOR table bit by bit:
0xFF00 é 1111.1111.0000.0000
0x21AD é 0010.0001.1010.1101
XORing: 1101.1110.1010.1101 -> DEAD
XOR is Also an Adder, or Half of it
Below is the A+B table, compare it with the XOR table.
| A | B | A+B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 and 1 should be added to the next bit (carry bit) |
They are the same table, the only problem with the XOR as an adder, is that it can’t generate the carry bit for the condition where A=1 and B=1. This is the reason it is called half adder.
XOR Also Utilized in Cryptography
Lets go back to the example where XORing 0xFF00 and 0x21AD results in 0xDEAD. Lets name these numbers in cryptographic terms:
0xFF00 The original message, in the clear, unencrypted(M).
0x21AD The cryptographic key, both the sender and receiver know these number, this is the shared secret(C).
0xDEAD The Encrypted message(E).
To encrypt the message we use the following XOR operation: E=XOR(M,C)
Someone (an adversary) that reads the encrypted message 0xDEAD can’t figure out the original message 0xFF00 without knowing the 0x21AD cryptographic key, but the receiver can decrypt the message into its original form by applying this XOR operation: M=XOR(E,C). Here is an example with numbers:
0xDEAD é 1101.1110.1010.1101 -> Encrypted message
0x21AD é 0010.0001.1010.1101 -> Cryptographic key
XORing: 1111.1111.0000.0000 -> Original message was recovered!
In short: XOR makes cryptography possible because it allows recovering the original message:
M Original message.
C Cryptographic key
E Encrypted message.
To encrypt a message:
E=XOR(M,C)
To decrypt the message:
M=XOR(E,C)
Post MindMap

Building scalable microservices with gRPC
This is the first post in a series on how we scaled Bugsnag’s new Releases dashboard backend pipeline using gRPC. Read our second blog on how we package generated code from protobufs into libraries to easily update our services.
Bugsnag processes hundreds of millions of errors each day, and to handle this data we’ve prioritized building a scalable, performant, and robust backend system. This comes along with many technical challenges from which we’ve learned a lot. Most recently, we launched the new Releases dashboard, a project that required us to scale our system to handle the significant increase in service calls required to track releases and sessions for our users.
While work on the Releases dashboard was underway, the Engineering team was also breaking down Bugsnag’s backend functionality into a system of microservices we call the Pipeline. We knew that extending the Pipeline to support releases would mean adding several new services and modifying existing ones, and we also anticipated many new server and client interactions. To handle all of these architectural changes, we needed a consistent way of designing, implementing, and integrating our services. And we wanted a platform-agnostic approach — Bugsnag is a polyglot company and our services are written in Java, Ruby, Go, and Node.js.
In this post, we’ll walk you through why we opted for gRPC as our default communication framework for the Pipeline.
Reaching the limit of REST API design
Our existing systems have traditionally used REST APIs with JSON payloads for communicating synchronously. This choice was made based on the overwhelming maturity, familiarity, and tooling available, but as our cross-continent engineering teams grew, we needed to design a consistent, agreed upon RESTful API. Unfortunately, it felt like we were trying to shoehorn simple methods calls into a data-driven RESTful interface. The magical combination of verbs, headers, URL identifiers, resource URLs, and payloads that satisfied a RESTful interface and made a clean, simple, functional interface seemed an impossible dream. RESTful has lots of rules and interpretations, which in most cases result in a RESTish interface, which takes extra time and effort to maintain its purity.
Eventually, the complications with our REST API led us to search out alternatives. We wanted our microservices to be as isolated from one another as much as possible in order to reduce interactions and decouple services. Simplicity would be key as it would allow us to create a workable service in as little time as possible, and keep us from jumping through hoops.
Evaluating alternatives to REST
Choosing a communication framework should not be undertaken lightly. Large size organizations (like Netflix) can have backend systems powered by over +500 microservices. Migrating these services to replace inadequate inter-service comms can cost a large number of engineering cycles, making it logistically and financially impractical. Investing time into considering the right framework from the start can save a lot of wasted effort in the future.
We spent a significant amount of time drawing up evaluation criteria and researching our options. Here I’ll walk you through what that looked like for Bugsnag.
Technical criteria
When researching the options available, there were specific criteria we used to assess our options. Our list of things to consider was based on what would work best for a microservice architecture. Our main goals would be to use communication liberally, remove complexity from communication so we could communicate freely and understand where responsibility lies for each service. Some of these technical concerns were:
-
Speed - For large numbers of request/response API calls, we need the latency of the call itself to be a minimal factor regarding performance and user responsiveness. The main components of latency are connection cost, transport cost, and message encoding/decoding time.
-
Infrastructure compatibility - How well does the framework play with our infrastructure, mainly regarding load balancing and auto-scaling? We use Kubernetes services hosted on Google Cloud Platform, so we need the framework to compliment this environment.
-
Development tooling - Providing as little friction as possible when implementing a framework will lead to happier developers and quicker results. What tools are available to help with things like coding, locally testing endpoints, and stubbing/mocking for unit and integration testing? When things go wrong, we need to be able to see what requests were made including their contents. Factors like the message format can also make debugging easier dependent on tooling, e.g. JSON messages are human-readable, but binary messages will need extra effort to decode.
-
Maturity and adoption - For startup companies, resources are limited and need to be spent on the company’s core business rather than fixing, testing, and augmenting third-party frameworks. Factors like the popularity of the framework, examples of large-scale usage, how active the community is, and the age of the framework itself are good indicators of stability. But a word of warning; it is much more important to choose a framework that solves your specific problem than to choose the new shiny.
-
Multi-platform support - In true microservice mentality, we write our services in the language best fit for its purpose, which currently includes Java, Ruby, Go, and Node. Does the framework provide first-class support for our existing language choices while providing options for writing new services in other languages?
-
Amount of code - The framework should help reduce engineering cost. How much code do I need to write and maintain to get this working? How much of this is boilerplate code compared to business logic?
-
Security - All internal communications should be authenticated and encrypted. We need the ability to use SSL/TLS for all communications (or a suitable equivalent).
Design considerations, it’s not all about the tech
Service APIs are one of the most important interfaces to get right as they are crucial in setting service expectations during development. Settling on the design for a service API can be an arduous task, which is amplified when different teams are responsible for the different services involved. Minimizing wasted time and effort due to mismatched expectations is as valuable as reducing coding time. Since Bugsnag has a cross-continent engineering team, there are few cycles of communication for us. We have to maximize that by streamlining our communication and making sure things are less open to interpretation, otherwise mistakes are easy and things can easily be delayed.
Here are some of the design considerations we had when choosing the framework:
-
Strongly typed - Are messages sent down the wire strongly typed? If the messages sent across the service boundary are clear, then we eliminate design and runtime errors due to types.
-
Open to interpretation - Being able to generate client libraries directly from service API specifications reduces problems with misinterpretations.
-
Error conditions - Having a well-defined set of error codes makes it easier to communicate issues consistently.
-
Documentation - The service API should be human-readable and easy to understand. The format in which the service API is defined should lend itself to describing its endpoints as clearly and precisely as possible.
-
Versioning - Change is inevitable and it’s a good bet that at some point a service API will need to be modified. The messaging format and service definition used can influence how easy it is to modify an API and deploy to production. Is there a clear path to increase the version and its corresponding libraries, and roll out the changes?
Microservice best practices, why extensibility is important
In addition to the criteria listed above, we needed to choose a framework that is easily extensible. As microservices gain traction, we demand more and more “out of the box” features synonymous with this architecture, especially as we move forward and try to add more complexity to our system. The features we wish for include:
-
Exception handling - Providing a mechanism for dealing with unhandled exceptions at a request level. This allows important contextual metadata to be captured about the request e.g. the user making the request, which can be reported with the exception. We use Bugsnag to monitor these exceptions with ease.
-
Intelligent retries - Retrying requests under specific conditions e.g. only on 5xx status codes. This includes supporting various backing off strategies like exponential backoff.
-
Service discovery configuration - Options for hooking communication frameworks into popular service discovery applications like Zookeeper, Eureka or Consul can provide a quick and easy solution to routing requests around your architecture.
-
Metrics, tracing and logging - Observability is essential for complex distributed systems, but we should be careful of what we monitor. However, automatically collecting metrics and tracing information at service boundaries can quickly answer common questions like, “Is my service responding slowly to requests?” and “How often are requests failing?”.
-
Circuit breaking - This pattern can protect against cascading service failures by automatically detecting problems and failing fast. This can also be triggered by prolonged slow requests to provide a responsive degraded service rather than constantly timing out.
-
Caching and batching - Speed up requests by using a cache or batching requests.
Most frameworks will not provide all these features, but at the very least, they should be extensible enough to add in when needed.
What are gRPC and Protocol Buffers
There was no single framework that ticked all the boxes. Some options we explored were Facebook’s Thrift, Apache Hadoop’s Avro, Twitter’s Finagle, and even using a JSON schema.
Our needs seemed more aligned with remote procedural calls, or RPCs, giving us the fine grain control we needed. Another attraction with using RPCs is the use of interface description languages or IDLs. An IDL allows us to describe a service API in a language-independent format, decoupling the interface from any specific programming language. They can provide a host of benefits including a single source of truth for the service API, and potentially can be used to generate client and server code to interact with these services. Examples of IDLs include Thrift, Avro, CORBA, and, of course, Protocol Buffers.
In the end, the clear winner was gRPC with Protocol Buffers.
What is gRPC?
We chose to go with gRPC as it met our feature needs (including extensibility going forward), the active community behind it, and its use of the HTTP/2 framework.
gRPC is a high-performance, lightweight communication framework designed for making traditional RPC calls, and developed by Google (but no, the g doesn’t stand for Google). The framework uses HTTP/2, the latest network transport protocol, primarily designed for low latency and multiplexing requests over a single TCP connection using streams. This makes gRPC amazingly fast and flexible compared to REST over HTTP/1.1.
The performance of gRPC was critical for setting up our Pipeline to handle the massive increase in calls we were expecting for the Releases dashboard. Also, HTTP/2 is the next standardized network protocol so we can leverage tools and techniques that have been developed for HTTP/2 (like Envoy proxies) with first class support for gRPC. Due to multiplexing stream support, we are not limited to simple request/response calls as gRPC supports bi-directional communications.

What are Protobufs?
Protocol Buffers, or protobufs, are a way of defining and serializing structured data into an efficient binary format, also developed by Google. They were one of the main reasons we chose gRPC as the two work very well together. We previously had many issues related to versioning that we wanted to fix. Microservices mean we have to roll changes and updates constantly and so we need interfaces that can adapt and stay forward and backwards compatible, and protobufs are very good for this. Since they are in a binary format, they are also small payloads that are quick to send over the wire.
Protobuf messages are described using their associated IDL which gives a compact, strongly typed, backwards compatible format for defining messages and RPC services. We use the latest proto3 specification, with a real-life example of a protobuf message shown here.
// Defines a request to update the status of one or more errors.
message ErrorStatusUpdateRequest {
// The list of error IDs that specify which errors should be updated.
// The error IDs need to belong to the same project of the call will fail.
// Example:
// "587826d70000000000000001"
// "587826d70000000000000002"
// "587826d70000000000000003"
repeated string error_ids = 1;
// The ID of the user that has triggered the update if known.
// This is for auditing purposes only.
// Example: "587826d70000000000000004"
string user_id = 2;
// The ID of the project that the errors belong to if known.
// If the project ID is not provided, it will be queried in mongo.
// The call will fail if all of the error IDs do not belong to
// the same project.
// Example: "587826d70000000000000005"
string project_id = 3;
}
All fields according to proto3 are optional. Default values will always be used if a field is not set. This combined with field numbering provide an API that can be very resistant to breaking changes. By following some simple rules, forward and backwards compatibility can be the default for most API changes.
The protobuf format also allows an RPC service itself to be defined. The service endpoints live alongside the message structures providing a self-contained definition of the RPC service in a single protobuf file. This has been very useful for our cross-continent engineering team who can understand how the service works, generate a client, and start using it, all from just one file. Here is an example of one of our services:
syntax = "proto3";
package bugsnag.error_service;
service Errors {
// Attempt to get one or more errors.
// Returns information for each error requested.
// Possible exception response statuses:
// * NOT_FOUND - The error with the requested ID could not be found
// * INVALID_ARGUMENT - The error ID was not a valid 12-byte ObjectID string
rpc GetErrors (GetErrorsRequest) returns (GetErrorsResponse) {}
// Attempt to open the errors specified in the request.
// Returns whether or not the overall operation succeeded.
// Possible exception response statuses:
// * NOT_FOUND - One or more errors could not be found
// * INVALID_ARGUMENT - One of the request fields was missing or invalid,
// see status description for details
rpc OpenErrors (ErrorStatusUpdateRequest) returns (ErrorStatusUpdateResponse) {}
// Attempt to fix the errors specified in the request.
// Returns whether or not the overall operation succeeded.
// Possible exception response statuses:
// * NOT_FOUND - One or more errors could not be found
// * INVALID_ARGUMENT - One of the request fields was missing or invalid,
// see status description for details
rpc FixErrors (ErrorStatusUpdateRequest) returns (ErrorStatusUpdateResponse) {}
}
// Defines a request to update the status of one or more errors.
message ErrorStatusUpdateRequest {
...
The framework is capable of generating code to interact with these services using just the protobuf files, which has been another advantage for us since it can automatically generate all the classes we need. This generated code takes care of the message modeling and provides a stub class with overridable method calls relating to the endpoints of your service. A wide range of languages are supported including C++, Java, Python, Go, Ruby, C#, Node, Android, Objective-C, and PHP. However, maintaining and synchronizing generated code with its protobuf file is a problem. We’ve been able to solve this by auto-generating client libraries using Protobuf files, and we’ll be sharing more about this in our next blog post, coming soon.
One of the best features of gRPC is the middleware pattern they support called interceptors. It allows all gRPC implementations to be extended (which you’ll remember was important for us), giving us easy access to the start and end of all requests, allowing us to implement our own microservice best practices. gRPC also has built-in support for a range of authentication mechanisms, including SSL/TLS.
The gRPC community
We’re at the beginning of our gRPC adoption, and we’re looking to the community to provide more tools and techniques. We’re excited to join this vibrant community and have some ideas on future projects we’d like to see open sourced or possibly write ourselves.
Current state of gRPC tooling
gRPC is still relatively new, and the development tools available are lacking, especially compared to the veteran REST over HTTP/1.1 protocol. This is especially apparent when searching for tutorials and examples as only a handful exist. The binary format also makes messages opaque, requiring effort to decode. Although there are some options e.g. JSON transcoders to help (we’ll write more about this in a coming blog post), we anticipated needing to do some groundwork to provide a smooth developing experience with gRPC.
-
We love Apiary for documenting our external APIs. An equivalent for automatically generating interactive documentation using a services protobuf file would be ideal to communicate internal gRPC APIs effectively.
-
Static analysis of protobuf files would allow us to catch more bugs at runtime. We use Checkstyle for our Java code and it would be great to apply something similar to our protobuf files.
-
Custom interceptors to provide tracing, logging, and error monitoring out of the box. We hope to open source our Bugsnag gRPC interceptor to automatically capture and report errors to Bugsnag.
Growth and Adoption of gRPC
The popularity of gRPC has grown dramatically over the past few years with large-scale adoption from major companies such as Square, Lyft, Netflix, Docker, Cisco, and CoreOS. Netflix Ribbon is the defacto standard for microservice communication frameworks based around RPC calls using REST. This year, they announced they are transitioning to gRPC due to its multi-language support and better extensibility/composability. The framework has also recently joined the Cloud Native Computing Foundation in March 2017, joining heavyweights Kubernetes and Prometheus. The gRPC community is very active, with the open sourced gRPC ecosystem listing exciting projects for gRPC on the horizon.
In addition, gRPC has principles with which we agree with.
Lyft gave a great talk on moving to gRPC which is similar to our own experiences: Generating Unified APIs with Protocol Buffers and gRPC. Well worth checking out.
This is still early days for gRPC and there are some definite teething troubles, but the future looks bright. Overall, we’re happy with how gRPC has integrated into our backend systems and excited to see how this framework develops.
Un mini-robot mou pour explorer le corps humain
 Un robot mou de 4 millimètres de long, contrôlé à distance et capable de se déplacer à l’intérieur du corps humain, a été mis au point par...
Un robot mou de 4 millimètres de long, contrôlé à distance et capable de se déplacer à l’intérieur du corps humain, a été mis au point par...
Tuto : l’identification Wi-Fi rapide avec les QR Code sur Freebox !
Update and Restart [Comic]


[Source: Lolnein Comics | Like “Lolnein Comics” on Facebook | Follow “Lolnein Comics” on Twitter]
The post Update and Restart [Comic] appeared first on Geeks are Sexy Technology News.
L'anglais ne donne pas de compétitivité aux entreprises
Contrepoints ne peut exister sans vos dons
Les patrons et cadres doivent prendre conscience qu’en faisant travailler les Français et tous les autres francophones en français, ils améliorent les performances de leur entreprise.
Par Yves Montenay.
L’anglicisation des entreprises françaises est ressentie comme impérative. Or le seul impératif de l’entreprise, la source de sa compétitivité, c’est la productivité. Un facteur important en est le bon management des hommes, mais l’anglicisation le complique, voire le dégrade. Il faut garder le sens des priorités !
Les Français constatent la place croissante de l’anglais dans leur vie quotidienne. Certains sont indifférents, voire favorables, alors que d’autres s’en inquiètent fortement. Après bien de nombreux et brillants auteurs, j’ai publié un livre La langue française, arme d’équilibre de la mondialisation (Les Belles Lettres, 2015), faisant le point sur cette question. Son originalité est de donner une grande place aux entreprises.
L’incompréhension entre militants francophones et chefs d’entreprise
Face à la pression de l’anglais, particulièrement forte dans les entreprises, de nombreux militants du français qualifient les chefs d’entreprise de « traîtres ». Ce à quoi ils ripostent en les traitant de « ringards ». Je trouve ce différend désastreux et pense qu’il faut regarder en face des questions qui se posent aux entreprises, car ce sont elles qui imposent la langue de travail, voire la langue de tous les jours.
Il faut d’abord rappeler que les ouvrages en faveur de la langue française sont le fait d’intellectuels brillants, mais souvent fonctionnaires, enseignants par exemple. Il est donc assez naturel qu’ils ne connaissent pas le monde de l’entreprise et donc n’utilisent pas les meilleurs arguments pour le convaincre. Comme j’ai moi-même été cadre dirigeant puis chef d’entreprise dans une douzaine de pays, j’essaie de combler ce fossé.
De plus, par ignorance ou par conviction politique, beaucoup d’intellectuels français n’aiment ni le libéralisme, ni le capitalisme, ni les États-Unis, trois termes qui se recoupent largement dans leur esprit.
Cet état d’esprit, l’enseignement qui le reflète, et in fine une bonne partie des décisions économiques de nos gouvernants sont donc « anti-entreprise », et cela depuis très longtemps : on pourrait remonter à Colbert.
Il est donc assez naturel que beaucoup de chefs d’entreprise, de cadres, voire de Français de tous niveaux cherchant un emploi, aillent voir ailleurs. Et particulièrement dans les pays anglo-saxons où ils sont bien accueillis non seulement fiscalement, mais aussi et surtout avec la considération que l’on doit à ceux qui apportent l’emploi et le niveau de vie, en contrepartie d’un profit ou d’une carrière espérée.
Souvenez-vous que quelques mois après l’élection d’Hollande en 2012, le Premier ministre britannique a déclaré aux entreprises françaises « Venez chez nous, nous vous déroulerons un tapis rouge ». Or ces Français, une fois établis dans ces pays et après avoir vérifié les entrepreneurs et les entreprises, y sont effectivement mieux traités qu’en France, ont tendance à en adopter la langue et certaines de leurs idées, puis à les importer en France pour ceux qui ont un pied de chaque côté, comme la plupart de nos grandes entreprises.
Ce sont donc nos idées économiques qui sont en partie responsables de la diffusion de l’anglais et plus généralement du déclin relatif de la France.
Imposer l’anglais en pays francophone est contreproductif
Cela étant dit, les chefs d’entreprise vont trop loin et ne se rendent pas compte des inconvénients de l’anglicisation, y compris pour leurs propres entreprises.
Ils oublient que l’on travaille mieux et que l’on est plus créatif dans sa langue maternelle et qu’imposer l’usage de l’anglais en pays francophone stérilise leurs meilleurs ingénieurs et commerciaux. Combien de fois en ai-je vu ne pouvoir s’exprimer aussi bien que des anglophones, pourtant moins compétents qu’eux ?
Ils n’ont qu’à apprendre l’anglais, dira-t-on ! Certaines entreprises payent effectivement des formations linguistiques coûteuses et inefficaces, quitte à ce que leurs bénéficiaires aient du mal à se mettre en plus à jour dans leur spécialité. On finit par embaucher les anglophones natifs ou des Français bilingues au détriment de plus qualifiés, ce qui est un gâchis pour l’entreprise et une injustice pour les intéressés.
De plus, la langue étrangère qu’il faut VRAIMENT utiliser est celle du client. Il serait donc plus logique de valoriser des compétences de tel employé d’origine espagnole ou portugaise pour discuter avec des clients ibériques ou d’Amérique latine, plutôt que de passer par l’anglais. De même pour l’arabe, l’allemand… ou les maintenant très nombreux Français ou Chinois qui se sont donnés la peine d’apprendre la langue de l’autre.
La place de la langue française dans le monde est sous-estimée
Ainsi, ce 17 janvier 2018, Jean-Hubert Rodier citait dans Les Échos le chiffre de « 76 millions de personnes ayant le français pour langue maternelle », reprenant de nombreuses sources anglo-saxonnes ignorantes ou malveillantes.
Il est en effet totalement artificiel de citer un chiffre qui retranche des pays francophones du Nord, les immigrants d’une autre langue maternelle, et oublie les 200 millions d’Africains ou de personnes cultivées dans le monde entier qui en ont un usage quotidien et parfois familial.
Par ailleurs ce qui compte économiquement, c’est la population totale des pays où l’on travaille en français même si certains individus ne le parlent pas.
Bref, les chefs d’entreprise français ne savent en général pas que leur langue est d’une part assez répandue dans l’élite mondiale, pour des raisons culturelles indépendantes des affaires, et d’autre part de plus en plus parlée par des clients potentiels, notamment en Afrique francophone qui pèsera bientôt 500 à 700 millions de personnes.
Cette place du français dans le monde dépend d’ailleurs largement de l’attitude des entreprises. Elles ont pour l’instant un rôle positif extrêmement important en Afrique francophone et au Maghreb. C’est en effet principalement grâce à elles que le français y progresse, car c’est lui qui apporte l’emploi. Je dis « pour l’instant » parce que ce ne serait plus le cas si les entreprises françaises en Afrique s’anglicisaient comme en France, donnant un coup de poignard dans le dos aux élites et aux entreprises de ces pays.
En résumé, les patrons et cadres doivent prendre conscience qu’en faisant travailler les Français et tous les autres francophones en français, ils améliorent les performances de leur entreprise, et qu’à côté de cela les complications pratiques comme les coûts de traduction pèsent peu. Être attentif à ces questions est de la responsabilité de tout dirigeant d’entreprise.
—
Nos dossiers spéciaux: Capitalisme Entreprises Francophonie Langue française- yvesmontenay.fr
Polyglotte, Yves Montenay est doté d'une riche carrière internationale nord-sud de cadre, conseil et chef d'entreprise. Démographe de formation, passionné d’histoire, d’économie et de géopolitique il est actuellement écrivain, consultant et enseignant. Auteur de plusieurs ouvrages de démystification sur les relations nord-sud, notamment le Mythe du fossé Nord Sud, ainsi que Nos voisins musulmans, il publie également Les Echos du monde musulman, une revue hebdomadaire de la presse orientale et parfois occidentale sur le monde musulman, avec une priorité donnée à l'humanisation des récits. Il tient le site yvesmontenay.fr et un compte Twitter « @ymontenay ».