Elon Musk’s X platform has blocked the European Commission from making advertisements, presumably in response to the €120 million fine for its misleading verification system and overall lack of transparency. We’re grateful to Elon Musk for proving once again why the world needs to log off corporate-owned, centrally-controlled social media platforms and log on to a better way of being online. The world needs an open social web through the fediverse and Mastodon.
Calls for public institutions to invest in digital sovereignty are increasing across civil society. The term digital sovereignty means that an institution has autonomy and control over the critical digital infrastructure, data, and services that make up their online presence. Up until this point, social media has not been a part of this conversation. We think it is time to change that.
In any free society, it is the right of every citizen to access and comment on the news, decisions, and reasonings of their government. We believe it is a government’s responsibility to ensure this right for its constituents. Public institutions should communicate with their citizens on open platforms, not ones that require creating an account and sending personal data to a self-serving tech company. Today, institutions often communicate through the censorious filter of corporations that do not have the best interests of people or society at heart. They let their message be governed by the whims of out-of-touch and overpaid people who believe they should have unchecked power. We cannot let this stand. Mastodon offers a path forward for any institution that wants to take control of their communications, and we can help you get started today.
One of the tools these corporate social media platforms use to control an institution’s communications is the algorithm. Platforms strategically tune their algorithms to make it difficult, if not impossible, for institutions to reach their people without paying the platform ad money. Musk’s move to turn off the European Commission’s advertising capabilities feels like a perverse power play over a legitimate fine, one that effectively silences a crucial avenue for public discourse. We should be horrified that any single individual can wield such influence over the relationship between governments and the people they represent. We should be especially concerned when that individual doesn’t think our governments should exist in the first place.
Mastodon’s chronological timeline means that no institution needs to game an algorithm to keep their people informed. By using hashtags, it’s easy for people who care about the topics you discuss to find you. What’s more, your constituents don’t need to be on Mastodon to follow your posts. They can subscribe via open protocols like RSS and soon via email. When it comes to the source of the fine in the first place—X’s infamous blue checks, a.k.a. verification—Mastodon also offers a better way. We empower people to verify themselves by linking their social profile to their official (or personal) website. This allows for greater transparency and trust than relying on the often less-than-reputable verification practices of a single corporate entity, especially one that is willing to sell reputation for a low monthly fee. (Meanwhile, another corporate social media platform made $16 billion, 10% of their 2024 revenue, from advertisements for scams and banned goods.)
In an era where information is power, it’s disheartening to see our institutions yield so much to the whims of industry and individuals. In contrast, the European Commission is leading the way in taking ownership of social sovereignty on behalf of their people. They own a Mastodon instance, ec.social-network.europa.eu, to reach Europeans directly and keep them well informed. Mastodon is proud to help them manage the technical side of things. If you are someone on the fediverse who would like to see their government own their social sovereignty, we encourage you to get in touch with your local representative and tell them why you think they should start using open social media networks like the fediverse. We’re starting a thread on Mastodon of resources to help you get in touch with your local representative here.
By making the news and truth contingent on advertising budgets we’ve created an environment where any narrative can win, as long as the storyteller is willing to pay. If we allow these conditions to continue, we will leave behind the voices that truly matter; the people and their public institutions. It is critical that those voices not be silenced forever. The promise of the fediverse is the promise of a better way forward: free from ads and manipulative algorithms, a place built by and for people like you, where our sovereignty is a right and not a privilege.
It will take all of us working together to build a better way of being online. If you want to start an instance or have ideas about how we can encourage more institutions to take control of their social sovereignty, get in touch with us at hello@joinmastodon.org.
After sharing Ed Zitron’s latest piece called “OpenAI Is A Systemic Risk To The Tech Industry” I got a few responses arguing in a similar way: People agree that “AI” and especially “generative AI” is a massive bubble that does not really make much sense – if you imply rational decision making. Training the models, building the data centers, inference, inflated wages, potential licence costs and the costs of damages … economically the whole sector doesn’t make too much sense (Sequioa Capital agrees). Sure some people believe that they’ll find the machine god in old 4Chan posts but I also would not consider that to be rational in any way, shape or form. The singularity is just a weird ersatz-religion for rationalist nerds confronted with their own mortality.
But the argument goes on: There have always been bubbles but especially with technologically driven bubbles, something, usually infrastructure is left behind that the following generations can built on. The US railroad system for example or for ageing technologists such as myself maybe more present: The dotcom bubble.
The Internet we have today exists because the dotcom bubble lead to the infrastructure buildout of cables, some data centers, peering structures etc. that the next generation of Internet startups could be built upon. The death of the bubble fertilised or created the soil that all those social media platforms and UberForX things could flourish on. So while genAI might be a bubble, it will create all those models and integrations that will survive OpenAI’s (and Anthropic and whatever else those companies are called) financial shenanigans.
I think those things are not the same.
I do agree that something will be left behind: The data centers that have been built and that are still being built will still be there and I am quite sure someone will find new use cases for the NVIDIA cards everyone is buying or will replace those machines with standard server components to add to their hyperscaler infrastructure. But does that mean that the genAI stuff will survive?
Generative AI systems have a few unusual properties that make them very distinct from traditional digital services.
Digital services have a tendency to push marginal cost down: Adding another license to your database or even adding another account to your infrastructure costs you basically nothing when you’ve already got the systems running. Traditional digital goods and services scale really well: If your server maintains 1000 or 5000 accounts often doesn’t matter too much (depends a bit on the service of course), the cost does not scale up linearly, in fact the bigger you are the more of those scaling benefits you can reap for example by building caching infrastructures that save even more processing costs. This is how things work in the digital. But genAI is different.
OpenAI loses money on every user who pays them. They lose money on users with a 20$ subscription, they lose money on people with a 200$ subscription. Because genAI is inherently expensive to run. The optimizations that work for traditional services who can cluster certain kinds of processing (often by grouping users into a limited set of boxes and just treating them as the box assigned to them) do not apply to genAI. You keep having to heat up your NVIDIA cards and cool them and replace them. And people who do actually pay for your service will use it more. For for example Meta’s platforms or even Google Search more usage is good because it means more ad revenue. They make money by scaling up. OpenAI needs its users to use the service as little as possible to avoid losing even more money. For traditional digital platforms popularity is good. For OpenAI it’s poison.
So there is a structural reason why those companies probably can’t be economically valid: Digital spaces are built around winner-takes all scaling but for genAI providers that is economical suicide.
Let’s say OpenAI and Anthropic die. Let’s say the bubble bursts and the hype moves on to the next thing – whatever that will be. Will AI stick around?
Sure at first people will migrate to self-hosted stuff running on their machines. You can replace your coding assistant with some open weight model, it might be worse but still serviceable. But those models didn’t come from nowhere. Someone paid to develop them, someone had to pay electricity bills, NVIDIA’s bills, the bill of the private security firm that fought the demonstrations against your data center that took all the water people wanted to drink. So we’ll be stuck with whatever we at that point.
Which is exactly what happened with the dotcom bubble: We had the wires that were left by Pets.com exploding. But the wires had two advantages: They were agnostic to the data they carried, adding more of them or maintaining them was comparatively cheap and the marginal cost of adding more data to the wire was basically zero – until you reached capacity and needed to add another wire.
But AI models age like milk. Think of a coding assistant trained only up to right now, April 15th, 2025. Anything invented after this date, any breaking library update is not part of the training data and will lead to bad and false predictions by the model. AI models are conservative by definition, tied to the past of the moment they were trained on with no understanding of the future or even what kind of trajectories the future might take. In order to stay useful, to look “intelligent” and current AI models need to be constantly updated with new training material (and potentially removed older training material). Most AI models of the kind used today have very short shelf lives. (Smaller, specialized models often do not have that problem as much, think of models to do face detection or pose detection from video: The human body doesn’t change that much)
Something will be left by the AI crash, that is for sure. But I do not think it will be generative AI systems which – without constant expensive updates and maintenance – become useless at best and actively harmful at worst quickly. And that is the question we need to be asking: What will be left and who will that be used by?
When I see large data centers with a bunch of inference machines in them, there are clear uses but those probably won’t be the “cute” genAI some people use. The inference will shift to doing video processing and people classification because that’s where the money is: When a tech bubble bursts, the tech sector always turns to the state to either hold the bag or buy the remains. What will be left when OpenAI burns is infrastructure that players like Palantir will use because their problems fit the hardware and their business model can create the necessary money from governments all over the planet.
The AI crash won’t leave us with infrastructures that are useful to democratic and humane societies, with useful tools to do something productive with, but with infrastructures tailor-made to suppress it.
The company behind more than a dozen dating apps, Match Group, has known for years about the abusive users on its platforms, but chooses to leave millions of people in the dark
When a young woman in Denver met up with a smiling cardiologist she matched with on the dating app Hinge, she had no way of knowing that the company behind the app had already received reports from two other women who accused him of rape.
She met the 34-year-old doctor with green eyes and thinning hair at Highland Tap & Burger, a sports bar in a trendy neighborhood. It went well enough that she accepted an invitation to go back to his apartment. As she emerged from his bathroom, he handed her a tequila soda.
What transpired over the next 24 hours, according to court testimony, reads like every person’s dating app nightmare.
After sipping the drink, the woman started to lose control. Her memory blurred. She fell to the ground, and the man started to film her. He put her in a headlock, kissing her forehead; she struggled to free herself but managed to grab her things and leave. He followed her out the door, holding her shoes and trying to force her back inside, but she was able to call an Uber, vomiting in the car on the way home.
She woke up at home, soaking wet on her bathroom floor, the key to her house still in her door. She continued vomiting for hours. When she came to, she reported the assault to Hinge.
Hinge is one of more than a dozen dating apps owned by Match Group. The $8.5 billion global conglomerate also owns brands like Tinder (the world’s most popular dating app), OkCupid, and Plenty of Fish. Match Group controls half of the world’s online dating market, operates in 190 countries, and facilitates meetups for millions of people.
Match Group’s official safety policy states that when a user is reported for assault, “all accounts found that are associated with that user will be banned from our platforms.”
So why, on the night of Jan. 25, 2023, was Stephen Matthews still on the app? Just four days before, Match Group had been alerted when another woman reported him for rape. A little more than a week later, he was reported for rape again. This time, the survivor went to the police.
None of these women knew that the company had known about his violent behavior for years. He was first reported on Sept. 28, 2020. By then, Match Group’s safety policy was already in place.
Even after a police report, it took nearly two months for Matthews to be arrested — the only thing that got him off the apps. By then, at least 15 women would eventually report that Matthews had raped or drugged them. Nearly every one of them had met him on dating apps run by Match Group.
On Oct. 25, 2024, a Denver judge sentenced Matthews to 158 years to life in prison after a jury convicted him of 35 counts related to drugging and sexually assaulting eight women, drugging two women, and assaulting one more for a total of 11 women. Attorneys for the women said much of that violence could have been prevented.
“It is shocking that for years after receiving reports of sexual assault, Hinge continued to allow Stephen Matthews access to its platforms and actively facilitated his abuse,” said Laura Wolf, the attorney representing the woman whose police report led to the arrest. Following best practices for reporting on sexual assault, the Dating Apps Reporting Project is honoring survivors’ requests for anonymity. Matthews’ attorney, Douglas Cohen, declined to comment. A letter that The Dating Apps Reporting Project sent directly to Matthews in jail went unanswered.
Match Group’s reach is so massive — its mission is “to spark meaningful connections for every single person worldwide” — that people are more likely to meet through its apps than out at the bars, at church, or through friends.
But Matthews’ case shows that even as these apps have made it easier for us to connect with a seemingly endless pool of potential lovers, they have also made it easier for people who commit sexual abuse to reach a seemingly endless number of potential targets.
In 2022, a team of researchers at Brigham Young University published an analysis of hundreds of sexual assaults in Utah. They found attacks facilitated by dating apps happened faster and were more violent than when the perpetrator met the victim through other means. They also found that perpetrators who use dating apps are more likely to target vulnerable people. Almost 60 percent of sexual assault survivors self-reported a mental illness.
Match Group has known for years which users have been reported for drugging, assaulting, or raping their dates since at least 2016, according to internal company documents. Since 2019, Match Group’s central database has recorded every user reported for rape and assault across its entire suite of apps; by 2022, the system, known as Sentinel, was collecting hundreds of troubling incidents every week, company insiders say.
Match Group promised in 2020 that it would release what’s known as a transparency report — a public document that would reveal data on harm occurring on and off its platforms. If the public were aware of the scale of rape and assault on Match Group apps, they would be able to accurately assess their risk. As of February 2025, the report has not been released.
Instead, as people continued to get hurt, the company dithered over what damning information should be hidden. “Do we only publish where we are required by law?” reads a slide in a 2021 presentation shown multiple times to Match Group employees as well as external safety partners. “Do we push back on how much we are required to reveal, or do we try to go beyond what is required?”
Highlighting by The Markup
No online space is risk-free. But while Match Group has long possessed the tools, financial resources, and investigative procedures necessary to make it harder for bad actors to resurface, internal documents show the company has resisted efforts to spread them across its apps, in part because safety protocols could stall corporate growth.
“The obsession with metrics and having to stick with them is frustrating and potentially dangerous,” one employee wrote in 2021 after the company learned that the investigative news nonprofit ProPublica was planning a story. “This is not the way we were meant to work and people’s lives are at risk.”
Highlighting by The Markup
The same person asked their superiors: “‘How much would you personally pay to stop just one person being sexually assaulted by a date, one child being trafficked or one vulnerable person being driven to suicide by a predator?’ I feel that if I asked members of our staff that question individually, they would put a high value of their own money on it – But as a group nobody is ready to hear that yet.”
Since 2021, Match Group has publicly promised to improve the safety of their products and share data, but company insiders say safety has not improved. A brief hiring spree sparked by congressional and media scrutiny has been largely scaled back, according to former employees. In 2024, the remaining employees from the central trust-and-safety team Match Group set up in response to increased scrutiny were let go and their jobs outsourced to overseas contractors. Facing pressure from Wall Street, Match Group removed CEO Bernard Kim in early February 2025 as he struggled to cut costs and end the steady decline in subscribers to Match Group’s most powerful app, Tinder.
Members of Congress have repeatedly requested data from Match Group on sexual harm. In February 2020, 11 members of Congress wrote to then-CEO Shar Dubey asking for details on how the company responds to reports of sexual violence. In July 2023, two Democrats, then-Rep. Annie Kuster of New Hampshire and Rep. Jan Schakowsky of Illinois followed up after we inquired on the status of their efforts. The company has still not provided the data.
In September 2024, the House of Representatives passed a bill that requires consumers to be notified if they have interacted with a user on a dating app who has been banned for defrauding consumers of money or personal financial information. But the bill stopped short of addressing the issue of sexual assault on the apps, and it died in the Senate.
Our review of hundreds of pages of internal company documents, along with thousands of pages of court records, securities filings, and analyst reports, coupled with dozens of interviews with current and former employees and survivors of sexual violence found women who report being raped get no traction, while accused rapists like Stephen Matthews keep swiping — and assaulting.
Our own testing on Match Group apps shows that as of February 2025, not much has changed. Banned Tinder users, including those reported for sexual assault, can easily rejoin or move to another Match Group dating app, all while keeping most of their key personal information exactly the same.
The Dating Apps Reporting Project sent Match Group a four-page letter detailing our findings. The company responded with a short statement. The statement did not dispute that Match Group has carefully documented the extent of harm on company apps for years without sharing that information with the public. It also defended the company’s efforts to make platforms safe.
“We recognize our role in fostering safer communities and promoting authentic and respectful connections worldwide,” the statement provided by Kayla Whaling, senior director of communications, read. “We will always work to invest in and improve our systems, and search for ways to help our users stay safe, both online and when they connect in real life.”
The company said it vigorously combats violence. “We take every report of misconduct seriously, and vigilantly remove and block accounts that have violated our rules regarding this behavior,” its statement read. Our own testing found otherwise.
Starting in April 2024, The Dating Apps Reporting Project created a series of Tinder accounts that we subsequently reported for sexual assault. Soon after, Tinder banned the accounts, and we started investigating how easy it would be for a banned user to create new accounts.
Repeatedly, we found that users, soon after being banned, could create new Tinder accounts with the exact same name, birthday, and profile photos used on their banned accounts. Users banned from Tinder were also able to sign up for Hinge, OkCupid, and Plenty of Fish without changing those personal details.
To get around the Tinder ban, we used techniques commonly suggested by online guides and forums that don’t require lots of technical knowledge to understand. We were able to verify three techniques that allowed banned Match Group users to repeatedly bypass being flagged when creating new accounts.
In its statement, Match Group cast itself as an industry leader in deploying technology to promote safety, including “harassment-preventing AI tools, ID verification for profiles, and a portal that helps us better support and communicate with law enforcement investigating crimes. … Every person deserves safe and respectful experiences. We are committed to doing the work to make dating safer on our platforms and beyond,” the statement said.
Sept. 28, 2020 — the date Denver cardiologist Stephen Matthews raped a woman who reported him to Hinge — is also the date Tracey Breeden was brought on as Match Group’s head of safety and social advocacy.
Breeden was a flashy hire. “With Tracey coming on board, we are reaffirming our commitment not just to be safety leaders in the dating space, but across the entire tech sector,” then-CEO Shar Dubey said.
Sporting a trademark black leather jacket and short, slick-backed hair, Breeden went by the nickname “Tornado” during her 15-year career in law enforcement. What made her attractive to Match Group was her most recent job at Uber. She helped the global ride-hailing company revive its reputation after a series of scandals — from persistent reports of harassment of women employees to allegations that it was ignoring sexual assault that occurred during Uber rides.
Breeden spearheaded a safety report in 2019 that told the public what Uber knew about nearly every problem, including nationwide reports of intoxicated drivers, traffic fatalities, and incidents of sexual violence. The report became a key metric of success for the company.
In hiring Breeden, Match Group hoped to replicate this success across its portfolio of apps. “Corporations,” she said in a press release announcing her arrival, “have a responsibility to help ensure safe experiences for their users.”
Breeden’s team garnered public attention for its new safety measures, including partnerships with NGOs, optional AI-assisted photo verification, and a law enforcement portal where police and prosecutors can request data.
She also fostered a partnership with Garbo, a startup that offered low-cost background checks. It launched on Tinder in 2022. Experts point out that background checks are not always reliable as they pull from outdated databases, and research suggests that most people who commit sexual abuse do not encounter the criminal justice system. For example, Matthews had no criminal record.
During this time, Match Group invested $100 million into safety as a recurring cost, the company said, and boasted about Breeden’s “central safety team.”
Her team of veteran safety professionals referred to themselves as “The Avengers,” even donning superhero costumes at company events.
An Avengers Zoom background, displayed at a Match Group company event; redactions by The Markup
But Michael Lawrie called this “safety theater.”
Lawrie worked for Match Group for nearly a decade, shaping and leading a safety team for one of the company’s smaller brands, OkCupid. Sometimes working 80-hour weeks, he spent hours, even days, sniffing out savvy users who tried to thwart bans by creating multiple accounts.
Over a 30-year career in content moderation, Lawrie said, he saw many users like Stephen Matthews. “You’re dealing with one repeat offender. I’ve dealt with god knows how many repeat offenders,” he said.
Michael Lawrie, former head of user safety and advocacy at OkCupid
Courtesy of Michael Lawrie
A yellow Post-it note on the side of Lawrie’s computer listed out some of his responsibilities: “Rape flags. … Investigate miscreants.”
These days, Lawrie is trying to start an advocacy organization for content moderators and other front-line safety workers. But, he said, he’s done with dating apps.
“I don’t think they’re safe enough at the moment,” he said. “They’re gonna get worse. …I’m hoping dating sites vanish.”
Lawrie said he was initially excited about Breeden’s hire. He said she spent her first few months on the job talking to each brand’s safety team, and told him that she was “very impressed” by the work OkCupid was doing.
Each of Match Group’s biggest apps provided their self-described strengths and weaknesses to Breeden’s team, according to an internal spreadsheet. At Hinge, these weaknesses included a “very rudimentary warning system with no targeted comms and no follow through” and “no way to find” the original profile “of a bad actor who has created multiple profiles.”
Breeden was confronted with an existential problem. “Our current ban categories won’t allow us to answer the public’s biggest question: Am I likely to be harmed on my date?” reads a slide in a presentation drafted by her team in April 2021. While each of Match Group’s apps had a system of reporting and banning violent users, the information was disorganized, and none of the apps talked to each other.
Highlighting by The Markup
Lawrie hoped Breeden would improve safety at the company. But he quickly grew frustrated that neither she nor Match Group leadership listened to his pleas for what they really needed to make platforms safer: To hire trained — and expensive — investigators and integrate powerful moderation tools across all the apps.
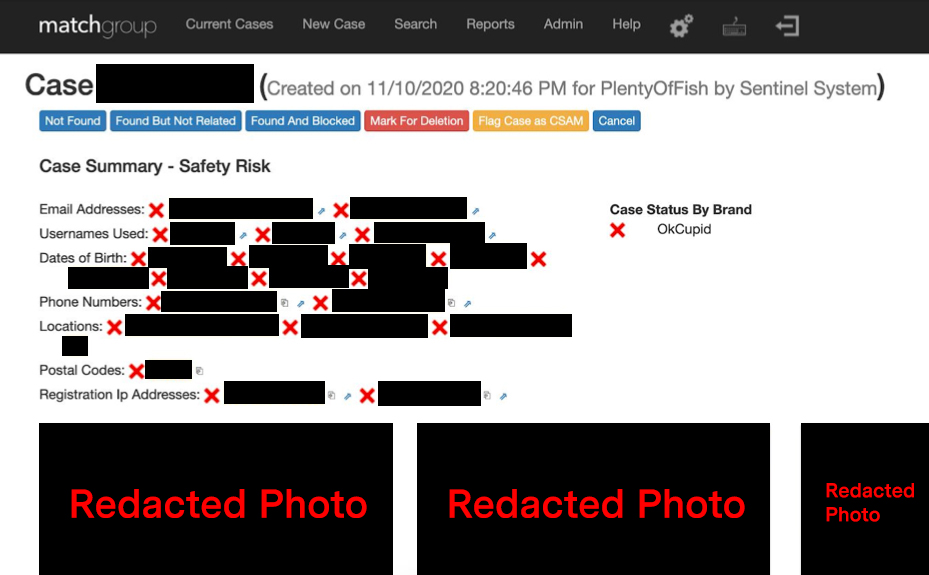
OkCupid already had those tools. Lawrie was using them every day. One of those was the Sentinel system, which had been up and running across Match Group’s apps for at least five years before Breeden arrived. It works like this: When a user is banned for something serious — like sexual assault — a case is created in Sentinel with the phone number and email address associated with their account. In interviews, multiple current and former employees described how those reports circulate through each of Match Group’s apps. The system is designed to ban anyone who uses that information. It also grabs the original profile’s IP addresses, photos, and birthdate.
An example of a case in Sentinel for a banned user. Sensitive information has been redacted by The Markup
Such a system seems robust at first glance — but none of the Match Group’s apps require users to provide photo identification (the kind needed to buy alcohol or board an airplane), so once a person is kicked out, they can easily start a new account with different contact information. A quick search yields scores of online forums with clear steps and suggestions for how to rejoin the apps. In addition, internal company documents show information on IP addresses, photos, and birthdate were not used to ban a user if they appear on another Match dating app.
Lawrie’s team at OkCupid knew Sentinel could only do so much.
So his team deployed other tools to fix its shortcomings, including one that could automatically ban a profile that was linked to a phone number, photo, or URL that had been previously banned — even if the user made an account with a different email or IP address. This tool was designed to be proactive rather than reactive, so that the profiles of alleged perpetrators like Matthews would not resurface after they had been reported.
Internal company documents from 2019 and 2020 show thousands of reports of “serious physical assault,” abuse, or violence on OkCupid that were deemed serious enough to get users banned from all of Match Group’s apps. This is among the information the company kept from the public.
Breeden and Match Group leadership praised Lawrie and his team at OkCupid, he said, for their thorough investigative work and for handling some of the company’s most difficult cases. Yet, he said, Match Group never built out a skilled, experienced investigative unit at other brands like the one he headed up at OkCupid. Under Breeden’s leadership, he said, they faced pressure to speed up investigations and train outsourced labor to use complicated moderation tools.
A week after a damning article in 2021 revealed that content moderators with little training were asked to rapidly deal with violent sexual content across Match Group’s brands, then-CEO Dubey sent out an all-staff email addressing the controversy. She CC’d Breeden, acknowledging that the brand’s safety teams were not all on equal footing.
As Match Group prepared internally for the story to break, Lawrie was asked to write a report for Breeden outlining his team’s accomplishments “to make sure when Tracey describes and acknowledges what you are doing individually to celebrate the good work that you are doing.”
Lawrie used that report to protest.
“Most professionals aren’t judged on how many cases they can hurry through in an hour,” he wrote. The way Match Group expects its trust-and-safety and support teams to work “basically diminishes their skills and makes them production-line workers.” Breeden declined to comment for this story, citing a nondisclosure agreement.
Lawrie left the company in 2022 and said most of his small team that was ferreting out malicious users also left due to a negative workplace environment. He said much of their work was outsourced to contractors with little training and severe quotas.
He now cautions anyone using a dating app to understand that they’re not in the business of protecting users.
“You’re on your own pretty much,” he said.
As Lawrie was getting pushed out of Match Group, Matthews kept appearing on the company’s apps.
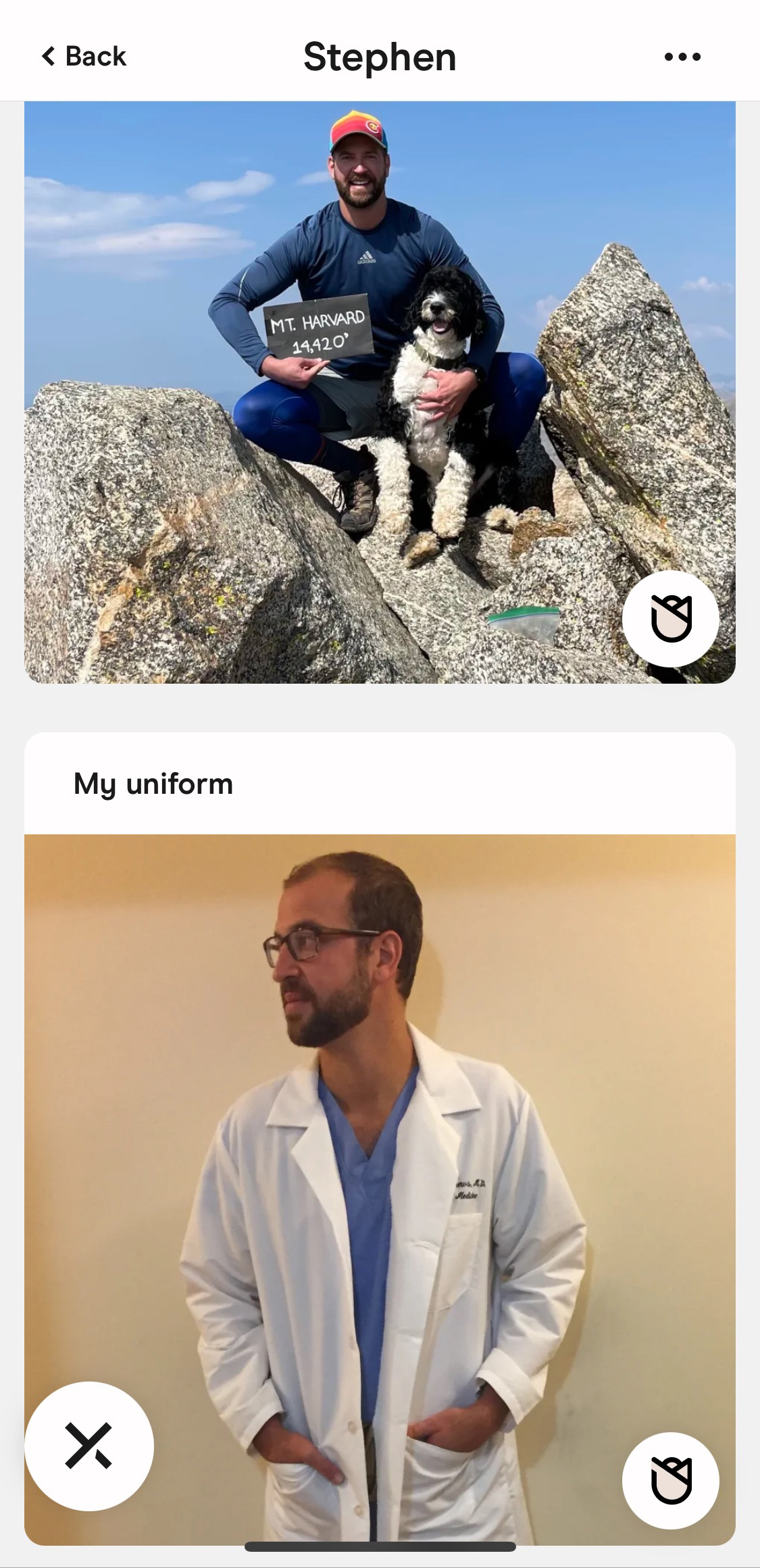
One crisp fall evening in 2022, one of the Denver cardiologist’s old medical school classmates was on Hinge when her phone screen filled up with a familiar face.
Despite having been reported for rape to Hinge, Stephen Matthew’s profile was still promoted on the app as a Standout, as indicated by the rose icon in the bottom right corner
Matthews was being promoted on the app as a Standout, a popular profile that Hinge’s algorithm thinks you’ll like. To match with a Standout, users must send the person a rose. They get one free rose a week, but they cost $3.99 a pop after that. His classmate did not send Matthews a rose.
By this point, Matthews had already been reported for rape at least once to Hinge. Court documents show that he had already allegedly sexually assaulted nine women and drugged 10. Not only did the apps allow him back on, they featured Matthews’ profile.
As the COVID-19 pandemic dragged on, people got tired of forking money over for dating apps. Match Group still made a hefty profit, but its growth flatlined. Its stock cratered, losing nearly half its value between October 2021 and April 2022. That month, an analyst from J.P. Morgan wrote that the firm had received more messages about “the underperformance of MTCH shares in recent weeks than any other topic.”
In May 2022, Match ousted Dubey and installed Bernard Kim as CEO, a former executive at the gaming company Zynga that popularized viral games like “FarmVille.”
While Dubey spoke frequently about trust and safety and worked closely with Breeden, Kim hardly mentioned safety when he began his time at Match Group, instead emphasizing the need for continued rapid expansion to drive long-term shareholder value.
Lawrie said that Kim, with his background in gaming rather than dating apps, had no interest in love. “He just wants to make money. He’s just there to increase profits,” Lawrie said. “If he’s looking at a bottom line, then it’s easier to have a lawsuit than it is to provide safety. I know which one he’s gonna pick.” Match Group declined to make Bernard Kim available for an interview. Messages sent to Kim directly went unreturned.
While the tension between growth and safety exists across the tech sector, it is especially high at dating apps companies where executives have to worry about constant churn — users leaving the apps when they are no longer looking for dates. Every time Match Group delivers on its promise, it also loses customers.
In February 2024, six dating app users filed what they hope will be certified as a class action lawsuit. They argue Match Group uses “addictive” features to encourage compulsive use while not leading to any real increase in off-app relationships. “The app is designed specifically to hook them, and to keep them paying subscription fees — not to help them find love,” attorney Ryan Clarkson said. Match Group filed to dismiss the lawsuit in September, noting in its quarterly report that it “will defend vigorously” against the allegations.
Despite Kim’s efforts, Match Group’s stock price continued to drop, and during that time, so did any mention of trust and safety. In over a year of quarterly investor calls, Kim only referenced safety efforts once.
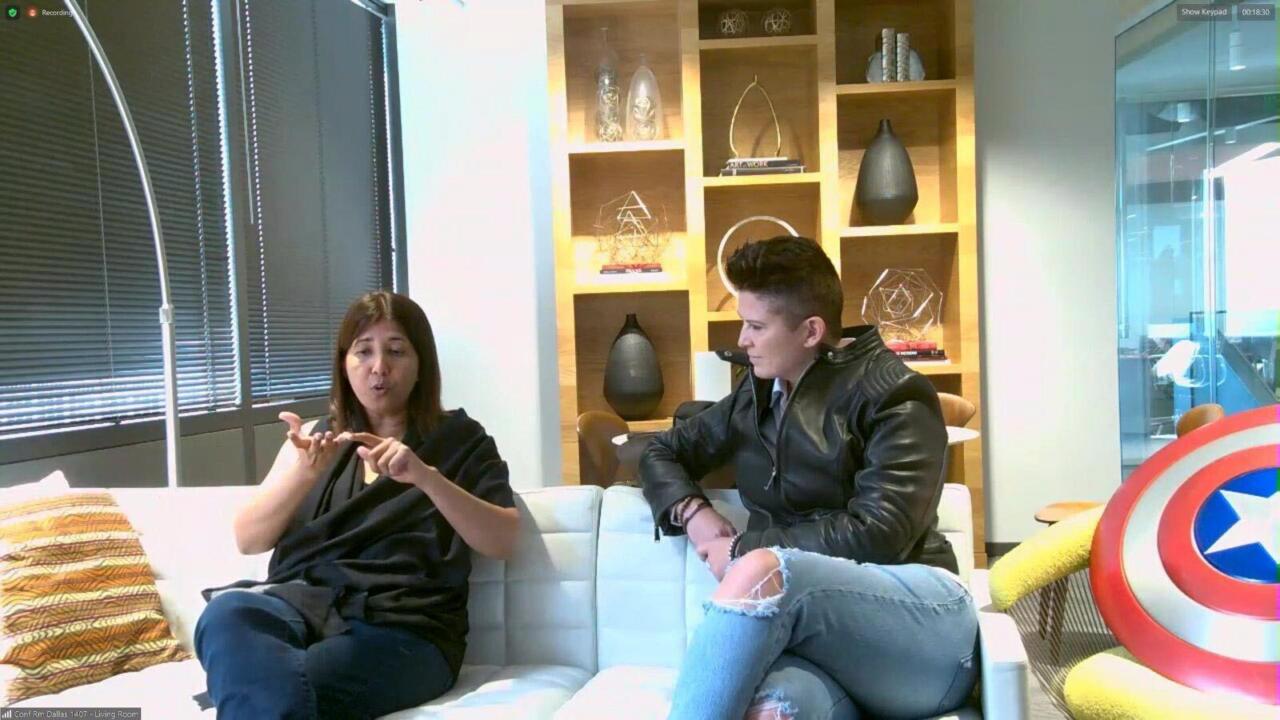
Employees who pushed for these initiatives were forced out or laid off, including Breeden — a leader who was so convinced of her own invincibility that she showed up to an event wielding a Captain America shield.
Shar Dubey (left), then CEO of Match Group, speaking with Tracey Breeden (right)
Match Group fired its power hire in October 2022. Layoffs hit her team over the next several months. In February 2024, the remaining critical investigators and law enforcement liaisons on Breeden’s central safety team were shown the door.
Lawrie said group chats of former Match Group employees have been gossipping about the cutbacks.
“You’re not gonna see them taking safety seriously ever again,” he said, adding that the only thing that he thinks might change that is legislation.
Four months before Matthews was arrested, a post on a Facebook group in Denver blew up, right around Christmas.
Over and over again, women furiously detailed negative experiences they or their friends had with Matthews.
Some women described him as “sketchy.” Others called him “terrible” and “not safe.” Multiple women told a similar, dark story: that they were offered drinks, blacked out, and sexually assaulted.
The thread reached 150 comments. Two women wrote the same thing: that they had been waiting for someone to post about the cardiologist.
The flood of Facebook comments mirrored details in the police reports released the following year. Nearly all of the 16 women included in the district attorney’s initial complaints were offered tequila. Eight recalled playing Jenga. Six mentioned a hot tub.
As these stories circulated in this small corner of the internet in December 2022, the Denver cardiologist stayed on Match Group apps.
Those fortunate enough to know about the Facebook group — and who had the foresight to check for Matthews on it — would be saved from a bad date or worse. But the fact that he could still log into Tinder and Hinge left him with a pool of thousands of unsuspecting women whom he could — and would — continue to match with.
The Dating Apps Reporting Project is aware of four additional women who have accused Matthews of drugging and/or raping them who were not part of the criminal complaint. Each of these women met Matthews on a Match Group app during a single year between the summers of 2020 and 2021.
During the years Matthews was on their apps, Match Group hired and fired Breeden. It made loud promises on sexual violence, announced initiatives and product lines, and promised a transparency report. But it was not straight with the public, which meant the women matching with Matthews on Match Group apps were not aware of the risk they faced.
Match Group’s partnership with Garbo, the background check company, also fell apart in the summer of 2023. “It’s become clear that most online platforms aren’t legitimately committed to trust and safety for their users,” Garbo wrote in a searing blog post.
After spending so much energy talking about monetization, gamification, and growth, Kim began to publicly acknowledge this problem. Speaking at the Citibank conference in the fall of 2023, he said the company was investing in new features to make sure “women have a good experience while they’re in the product. They feel safe. They feel secure. Etc.”
The “etc.” does not seem to include increased transparency about safety. Instead, in May 2023, Tinder released a “female-focused package,” a curated list of “high-quality profiles.” It is unclear how Tinder determines these high-quality matches. Hinge’s Standout feature, which is similar, had previously promoted Matthews.
In fact, under Kim’s leadership, all mentions of a transparency report disappeared from the company’s annual impact report. Ironically, this was around the same time that new legislation in Europe required tech companies to disclose reports of “non-consensual behavior” and other issues. Match Group will be required to submit a transparency report to the European Union on the scope of harm on their platforms later this month. Lawmakers in India and Australia are also demanding transparency.
This is exactly the situation Breeden and her team pondered three years ago. “What if publishing in one jurisdiction sparks a requirement in another?” read a slide in the same internal presentation where Match Group’s trust-and-safety leaders wondered whether they should “push back on how much [they] are required to reveal.”
After Match Group published a disappointing earnings report in February 2025 that fell below analysts’ expectations, it also announced that Kim would be replaced by former Zillow CEO Spencer Rascoff. Tinder’s revenue, sales, and subscribers had all gone down.
As Match Group struggles to reverse its decline, it’s also aware that its reputation is in the spotlight. Earnings calls and shareholder letters over the first three quarters of 2024 indicate that the company knows it is a business imperative to make women feel safer on its platforms. Match Group brought in a new vice president to head trust and safety whose job partly focuses on complying with increased global transparency requirements. The company is experimenting with requiring faces in photos and rolled out a “Share My Date” feature so you can be tracked while meeting up with an online stranger. On Tinder, it orchestrated a “major ecosystem cleanup” geared toward identifying fake profiles and getting scammers off the app.
But neither the cleanup nor tracking a date from your phone would have stopped Matthews — a man who never sought to hide his identity, who assaulted his dates in his own home — from finding and harming women.
Four years after Matthews’ first documented assault, he walked into a wood-paneled courtroom in Denver and was sentenced to 158 years to life in prison. “I will sentence. I cannot heal,” Judge Eric Johnson told the room filled with survivors and family members.
“Countless women have suffered and will continue to suffer,” said Laura Wolf, an attorney who represented the woman whose police report triggered Matthews’ arrest. “Hinge and other dating platforms have taken no steps to ensure the safety of the product they are selling, matching unsuspecting women to known predators without pause or concern.”
Match Group didn’t make it easy for the Denver prosecutors to convict Matthews. A search warrant was issued to Hinge in July 2023. Two months later, prosecutors were still empty-handed — with the judge in the case asking at a hearing if he needed to start “dragging people in to get stuff done.” It wasn’t until February 2024 that the Denver District Attorney’s Office said they finally received documents returned by Match Group.
Matthews will likely never leave prison. Match Group executives currently face no charges. But the company knew about Matthews, and it knows about thousands of other abusive users. It has the data that could help users avoid dangerous situations, but it hasn’t shared it, leaving millions of people in the dark.
Lawmakers around the world are starting to ask for answers from the most powerful force in modern dating. In June, Colorado passed a law, triggered by the Matthews case, that forces dating app companies to tell the state attorney general what safety measures they are taking to protect users. Although the law leaves room for the possibility of additional transparency in the future, it does not currently require the company to tell the state, or the public, how many people are raped or assaulted after using its platform. In the U.S., we’ve just scratched the surface. In most states, there’s little that requires Match Group to share information with you — or with Congress.
The reality is that if Stephen Matthews were released today, he could get right back on a dating app. Match Group knows this — and now so do you.
Stephanie Wolf contributed reporting.Statistical journalist Natasha Uzcátegui-Liggett led The Markup’s testing of Match Group apps.
How We Tested Match Group’s Dating Apps
The Markup created more than 50 accounts across Tinder, Hinge, OkCupid, and Plenty of Fish to test how Match Group treats reports of sexual assault and whether users banned from Tinder after a reported sexual assault could return to Match Group apps by creating new accounts. We conducted experiments in April and May of 2024 and again in January and February of 2025. The results were similar across both rounds of testing.
To start, The Markup tested if and how quickly Tinder would ban users who were reported for in-person behavior. We found that Tinder consistently banned reported users within two days of receiving a report.
Next, we tested whether a banned Tinder user could use their exact same basic account information to sign up for other Match Group dating apps: Hinge, OkCupid, and Plenty of Fish. Hinge and OkCupid prevented us from creating accounts, but Plenty of Fish allowed us to create new accounts. Within 48 hours, the Plenty of Fish accounts were taken down.
Our next tests focused on identifying what type of changes would allow banned users to rejoin Tinder or create new accounts on other Match Group apps and use them like normal. To simulate what a typical user would try, The Markup utilized online guides and forums to identify commonly suggested techniques to get around a ban from a Match Group app.
We then tried a combination of these suggestions, especially those that self-identified banned users claimed to have had success with. Across several rounds of testing, we found multiple ways to successfully create new Match Group accounts that bypassed the ban. Each method only involved simple changes in how we signed up and the information we provided during the process.
When attempting to rejoin, or create a new account on another Match Group app, we used the normal sign up processes users go through and used the same phone as the original banned account. During multiple tests, we successfully created new accounts without needing to change the user’s name, birthday, or profile photos.
The Markup did not test any methods that required significant technical knowledge and only utilized information that would be easily accessible to someone who did a cursory search of how to get around a ban. For example, The Markup did not test whether changing a profile photo’s metadata could alter the results. The Markup’s test accounts created for these experiments purposefully did not like, match with, or message any real Match Group users. — By Natasha Uzcátegui-Liggett
I want to write a post about Pitchfork, explaining where it comes from, why it
is like it is, and how I see its future.
But before I can get to that, I think I need to share my mental model on a few things, in this case, Ruby’s GVL.
If you read posts about the GVL, you may have heard that it’s not there to protect your code from race conditions, but
to protect the Ruby VM from your code.
Put another way, GVL or not, your code can be subject to race conditions, and this is absolutely true.
But that doesn’t mean the GVL isn’t an important component of the thread safety of the Ruby code in your applications.
Let’s use a simple code sample to illustrate:
QUOTED_COLUMN_NAMES = {}
def quote_column_name(name)
QUOTED_COLUMN_NAMES[name] ||= quote(name)
end
Would you say this code is thread-safe? Or not?
Well, if you answered “It’s thread-safe”, you’re not quite correct.
But if you answered “It’s not thread safe”, you’re not quite correct either.
The actual answer is: “It depends”.
First, it depends on how strict of a definition of thread-safe you are thinking of,
then it depends on whether that quote method is idempotent and finally, it depends on which implementation of Ruby you are using.
Let me explain.
First ||= is syntax sugar that is hiding a bit how this code actually works, so let’s desugar it:
QUOTED_COLUMN_NAMES = {}
def quote_column_name(name)
quoted = QUOTED_COLUMN_NAMES[name]
# Ruby could switch threads here
if quoted
quoted
else
QUOTED_COLUMN_NAMES[name] = quote(name)
end
end
In this form it’s easier to see that ||= isn’t a single operation but multiple, so even on MRI1, with a GVL, it’s
technically possible that Ruby would preempt a thread after evaluating quoted = ..., and resume another thread that will
enter the same method with the same argument.
In other words, this code is subject to race conditions, even with a GVL.
To be even more precise, it’s subject to a check-then-act race condition.
If it’s subject to race conditions, you can logically deduce that it’s not thread-safe.
But here again, it depends.
If quote(name) is idempotent, then yes there’s technically a race-condition, but it has no real negative impact.
The name will be quoted twice instead of once, and one of the resulting strings will be discarded, who cares?
That is why in my opinion the above code is effectively thread-safe regardless.
And we can verify this experimentally by using a few threads:
QUOTED_COLUMN_NAMES = 20.times.to_h { |i| [i, i] }
def quote_column_name(name)
QUOTED_COLUMN_NAMES[name] ||= "`#{name.to_s.gsub('`', '``')}`".freeze
end
threads = 4.times.map do
Thread.new do
10_000.times do
if quote_column_name("foo") != "`foo`"
raise "There was a bug"
end
QUOTED_COLUMN_NAMES.delete("foo")
end
end
end
threads.each(&:join)
If you run this script with MRI, it will work fine, it won’t crash, and quote_column_name will always return what
you expect.
However, if you try to run it with either TruffleRuby or JRuby, which are alternative
implementations of Ruby that don’t have a GVL, you’ll get about 300 lines of errors:
$ ruby -v /tmp/quoted.rb
truffleruby 24.1.2, like ruby 3.2.4, Oracle GraalVM Native [arm64-darwin20]
java.lang.RuntimeException: Ruby Thread id=51 from /tmp/quoted.rb:20 terminated with internal error:
at org.truffleruby.core.thread.ThreadManager.printInternalError(ThreadManager.java:316)
... 20 more
Caused by: java.lang.NullPointerException
at org.truffleruby.core.hash.library.PackedHashStoreLibrary.getHashed(PackedHashStoreLibrary.java:78)
... 120 more
java.lang.RuntimeException: Ruby Thread id=52 from /tmp/quoted.rb:20 terminated with internal error:
at org.truffleruby.core.thread.ThreadManager.printInternalError(ThreadManager.java:316)
... 20 more
... etc
The error isn’t always exactly the same, and sometimes it seems worse than others.
But in general, it crashes deep inside the TruffleRuby or JRuby interpreters because the concurrent access to the same
hash causes them to hit a NullPointerException.
So we can say this code is thread-safe on the reference implementation of Ruby, but not on all implementations of Ruby.
The reason it is that way is that on MRI, the thread scheduler can only switch the running thread when executing pure
Ruby code.
Whenever you call into a builtin method that is implemented in C, you are implicitly protected by the GVL.
Hence all methods implemented in C are essentially “atomic” unless they explicitly release the GVL.
But generally speaking, only IO methods will release it.
That’s why the real version of this code, that I took from Active Record,
doesn’t use a Hash, but a Concurrent::Map.
On MRI that class is pretty much just an alias for Hash, but on JRuby and TruffleRuby it’s defined as a hash table
with a mutex.
Officially Rails doesn’t support TruffleRuby or JRuby, but in practice, we tend to accommodate them with this sort of
small changes.
Just Remove It Already
That’s why there’s “removing the GVL” and “removing the GVL”.
The simple way would be to do what TruffleRuby and JRuby do: nothing. Or close to nothing.
Since these alternative implementations are based on the Java Virtual Machine, which is memory-safe, they delegate to
the JVM runtime the hard job of failing but not hard crashing in such cases.
Given MRI is implemented in C, which is famously not memory-safe, just removing the GVL would cause the virtual machine
to run into a segmentation fault (or worse) when your code triggers this sort of race condition, so it wouldn’t be as simple.
Ruby would need to do something similar to what the JVM does, having some sort of atomic counter on every object that
could be subject to race conditions. Whenever you access an object you increment it and check it is set to 1 to ensure
nobody else is currently using it.
This in itself is quite a challenging task, as it means going over all the methods implemented in C (in Ruby itself but
also popular C extensions), to insert all these atomic increments and decrements.
It would also require some extra space in most Ruby objects for that new counter, likely 4 or 8 bytes, because atomic
operations aren’t easily done on smaller integer types. Unless of course there’s some smart trick I’m not privy of.
It would also result in a slow-down of the virtual machine, as all these atomic increments and decrements likely would
have a noticeable overhead, because atomic operations mean that the CPU has to ensure all cores see the operation at
the same time, so it essentially locks that part of the CPU cache.
I won’t try to guess how much that overhead would be in practice, but it certainly isn’t free.
And then the result would be that a lot of existing pure Ruby code, that used to be effectively thread safe, would no longer be.
So beyond the work ruby-core would have to do, Ruby users would also likely need to debug a bunch of thread safety issues
in their code, gems, etc.
That’s why despite the impressive efforts of JRuby and TruffleRuby teams to be as compatible as possible with MRI,
the absence of a GVL, which is a feature, makes it so that most non-trivial codebases likely need at least some debugging
before they can run properly on either of them. It’s not necessarily a ton of effort, it depends, but it’s more work
than your average yearly Ruby upgrade.
Replace It By Something
But that’s not the only way to remove the GVL, another way that is often envisioned is to replace the one global lock,
by a myriad of small locks, one per every mutable object.
In terms of work needed, it’s fairly similar to the previous approach, you’d need to go over all the C code and insert
explicitly lock and unlock statements whenever you touch a mutable object.
It would also require some space on every object, likely a bit more than just a counter though.
With such approach, C extensions would still likely need some work, but pure Ruby code would remain fully compatible.
If you’ve heard about the semi-recent effort to remove Python’s GIL (that’s what they call their GVL), that’s the approach
they’re using. So let’s look at the sort of changes they made, starting with their base object layout that is defined
in object.h
It has lots of ceremonial code, so here’s a stripped-down and simplified version:
/* Nothing is actually declared to be a PyObject, but every pointer to
* a Python object can be cast to a PyObject*. This is inheritance built by hand.
*/
#ifndef Py_GIL_DISABLED
struct _object {
Py_ssize_t ob_refcnt
PyTypeObject *ob_type;
};
#else
// Objects that are not owned by any thread use a thread id (tid) of zero.
// This includes both immortal objects and objects whose reference count
// fields have been merged.
#define _Py_UNOWNED_TID 0
struct _object {
// ob_tid stores the thread id (or zero). It is also used by the GC and the
// trashcan mechanism as a linked list pointer and by the GC to store the
// computed "gc_refs" refcount.
uintptr_t ob_tid;
uint16_t ob_flags;
PyMutex ob_mutex; // per-object lock
uint8_t ob_gc_bits; // gc-related state
uint32_t ob_ref_local; // local reference count
Py_ssize_t ob_ref_shared; // shared (atomic) reference count
PyTypeObject *ob_type;
};
#endif
There’s quite a lot in there, so let me describe it all. My entire explanation will assume a 64-bit architecture, to make things simpler.
Also note that while I used to be a Pythonista, that was 15 years ago, and nowadays I’m just spectating Python’s
development from afar. All this to say, I’ll do my best to correctly describe what they are doing, but it’s entirely
possible I get some of it wrong.
Anyway, when the GIL isn’t disabled as part of compilation, every single Python object starts with a header of 16B,
the first 8B called ob_refcnt is used for reference counting as the name implies, but actually only 4B is used as a
counter, the other 4B is used as a bitmap to set flags on the object, just like in Ruby.
Then the remaining 8B is simply a pointer to the object’s class.
For comparison, Ruby’s object header, called struct RBasic is also 16B. Similarly, it has one pointer to the class,
and the other 8B is used as a big bitmap that stores many different things.
However, when the GIL is disabled during compilation, the object header is now 32B, double the size.
It starts with an 8Bob_tid, for thread ID, which stores which thread owns that particular object.
Then ob_flags is explicitly laid out, but has been reduced to 2B instead of 4B, to make space for a 1Bob_mutex,
and another 1B for some GC state I don’t know much about.
The 4Bob_refcnt field is still there, but this time named ob_ref_local, and there is another 8Bob_ref_shared,
and finally, the pointer to the object class.
Just with the change in the object layout, you can already have a sense of the extra complexity, as well as the memory
overhead. Sixteen extra bytes per object isn’t negligible.
Now, as you may have guessed from the refcnt field, Python’s memory is mainly managed via reference counting.
They also have a mark and sweep collector, but it’s only there to deal with circular references.
In that way, it’s quite different from Ruby, but looking at what they had to do to make this thread safe is interesting
regardless.
Let’s look at Py_INCREF, defined in refcount.h.
Here again, it’s full of ifdef for various architecture and such, so here’s a stripped-down version, with only the code
executed when the GIL is active, and some debug code removed:
It’s extremely simple, even if you are unfamiliar with C you should be able to read it. But basically, it checks
if the refcount is set to a magical value that marks immortal objects, and if it isn’t immortal, it simply does a regular,
non-atomic, hence very cheap, increment of the counter.
A sidenote on immortal objects, it’s a very cool concept introduced by Instagram engineers
which I’ve been meaning to introduce in Ruby too. It’s well worth a read if you are interested in things like Copy-on-Write
and memory savings.
Now let’s look at that same Py_INCREF function, with the GIL removed:
#define _Py_IMMORTAL_REFCNT_LOCAL UINT32_MAX
# define _Py_REF_SHARED_SHIFT 2
static inline Py_ALWAYS_INLINE int _Py_IsImmortal(PyObject *op)
{
return (_Py_atomic_load_uint32_relaxed(&op->ob_ref_local) ==
_Py_IMMORTAL_REFCNT_LOCAL);
}
static inline Py_ALWAYS_INLINE int
_Py_IsOwnedByCurrentThread(PyObject *ob)
{
return ob->ob_tid == _Py_ThreadId();
}
static inline Py_ALWAYS_INLINE void Py_INCREF(PyObject *op)
{
uint32_t local = _Py_atomic_load_uint32_relaxed(&op->ob_ref_local);
uint32_t new_local = local + 1;
if (new_local == 0) {
// local is equal to _Py_IMMORTAL_REFCNT_LOCAL: do nothing
return;
}
if (_Py_IsOwnedByCurrentThread(op)) {
_Py_atomic_store_uint32_relaxed(&op->ob_ref_local, new_local);
}
else {
_Py_atomic_add_ssize(&op->ob_ref_shared, (1 << _Py_REF_SHARED_SHIFT));
}
}
This is now way more involved.
First the ob_ref_local needs to be loaded atomically, which as mentioned previously is more costly than loading it
normally as it requires CPU cache synchronization.
Then we still have the check for immortal objects, nothing new.
The interesting part is the final if, as there are two different cases, the case where the object is owned by the
current thread and the case where it isn’t. Hence the first step is to compare the ob_tid with _Py_ThreadId().
That function is way too big to include here, but you can check its implementation in object.h,
on most platform it’s essentially free because the thread ID is always stored in a CPU register.
When the object is owned by the current thread, Python can get away with a non-atomic increment followed
by an atomic store.
Whereas in the opposite case, the entire increment has to be atomic, which is way more expensive as
it involves compare and swap operations.
Meaning that in case of a race condition, the CPU will retry the incrementation until it happens without a race condition.
In pseudo-Ruby it could look like this:
def atomic_compare_and_swap(was, now)
# assume this method is a single atomic CPU operation
if @memory == was
@memory = now
return true
else
return false
end
end
def atomic_increment(add)
loop do
value = atomic_load(@memory)
break if atomic_compare_and_swap(value + add, value)
end
end
So you can see how what used to be a very mundane operation, that is a major Python hotspot,
became something noticeably more complex.
Ruby doesn’t use reference counting, so this particular case wouldn’t immediately translate to Ruby if there was an
attempt to remove the GVL, but Ruby still has a bunch of similar routines that are very frequently called and would
be similarly impacted.
For instance, because Ruby’s GC is generational and incremental, whenever a new reference is created between two objects,
say A towards B, Ruby might need to mark A as needing to be rescanned, and it is done by flipping one bit in a bitmap.
That’s one example of something that would need to be changed to use atomic operations.
But we still haven’t got to talk about the actual locking.
When I first heard about Python’s renewed attempt to remove their GIL, I expected they’d leverage the existing reference counting API to shove the locking in it, but clearly, they didn’t.
I’m not certain why, but I suppose the semantics don’t fully match.
Instead, they had to do what I mentioned earlier, go over all the methods implemented in C to add explicit lock and unlock
calls. To illustrate, we can look at the list.clear() method, which is the Python equivalent to Array#clear.
Prior to the GIL removal effort, it looked like this:
int
PyList_Clear(PyObject *self)
{
if (!PyList_Check(self)) {
PyErr_BadInternalCall();
return -1;
}
list_clear((PyListObject*)self);
return 0;
}
It looks simpler than it actually is because most of the complexity is in the list_clear routine, but regardless,
it’s fairly straightforward.
int
PyList_Clear(PyObject *self)
{
if (!PyList_Check(self)) {
PyErr_BadInternalCall();
return -1;
}
Py_BEGIN_CRITICAL_SECTION(self);
list_clear((PyListObject*)self);
Py_END_CRITICAL_SECTION();
return 0;
}
Not that much worse, they managed to encapsulate it all in two macros that are just noops when Python is built with the GIL enabled.
I’m not going to explain everything happening in Py_BEGIN_CRITICAL_SECTION, some of it flies over my head anyway, but long story short it ends up in _PyCriticalSection_BeginMutex, which has a fast path and a slow path:
What the fast path does, is that it assumes the object’s ob_mutex field is set to 0, and tries
to set it to 1 with an atomic compare and swap:
//_Py_UNLOCKED is defined as 0 and _Py_LOCKED as 1 in Include/cpython/lock.h
static inline int
PyMutex_LockFast(PyMutex *m)
{
uint8_t expected = _Py_UNLOCKED;
uint8_t *lock_bits = &m->_bits;
return _Py_atomic_compare_exchange_uint8(lock_bits, &expected, _Py_LOCKED);
}
If that works, it knows the object was unlocked so it can just to a little bit of book keeping.
If that doesn’t work, however, it enters the slow path, and there it starts to become quite complicated but to describe it quickly, it first uses a spin-lock with 40 iterations. So in a way, it does the same compare and swap logic 40 times in a raw with the hope that it might work eventually.
And if that still doesn’t work, it then “parks” the thread and will wait for a signal to resume.
If you are interested in knowing more you can look at _PyMutex_LockTimed in Python/lock.c
and follow the code from there. Ultimately the mutex code isn’t that interesting for our current topic,
because the assumption is that most objects are only ever accessed by a single thread, so the fast path is what matters
the most.
But beyond the cost of that fast path, what is also important is how to integrate the lock and unlock statements
in an existing codebase. If you forget one lock(), you might cause a VM crash, and if you forget one unlock(), you
might cause a VM dead-lock, which is arguably even worse.
So let’s go back to that list.clear() example:
int
PyList_Clear(PyObject *self)
{
if (!PyList_Check(self)) {
PyErr_BadInternalCall();
return -1;
}
Py_BEGIN_CRITICAL_SECTION(self);
list_clear((PyListObject*)self);
Py_END_CRITICAL_SECTION();
return 0;
}
You may have noticed how Python does error checking. When a bad precondition is found, it generates an exception
with a PyErr_* function and returns -1. That’s because list.clear() always returns None (Python’s nil),
so the return type of its C implementation is just an int.
For a method that returns a Ruby object, on an error condition it would return a NULL pointer.
For instance list.__getitem__, which is Python’s equivalent to Array#fetch is defined as:
PyObject *
PyList_GetItem(PyObject *op, Py_ssize_t i)
{
if (!PyList_Check(op)) {
PyErr_BadInternalCall();
return NULL;
}
if (!valid_index(i, Py_SIZE(op))) {
_Py_DECLARE_STR(list_err, "list index out of range");
PyErr_SetObject(PyExc_IndexError, &_Py_STR(list_err));
return NULL;
}
return ((PyListObject *)op) -> ob_item[i];
}
You can see that error if you try accessing a Python list with an out-of-bound index:
>>> a = []
>>> a[12]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
You can recognize the same IndexError and the same list index out of range message.
So in both cases, when the Python methods implemented in C need to raise an exception, they build the exception object, store it in some thread local state, and then return a specific value to let the interpreter know that an exception happened.
When the interpreter notices the return value of the function is one of these special values, it starts unwinding the stack.
In a way, Python exceptions are syntactic sugar for the classic if (error) { return error } pattern.
Now let’s look at Ruby’s Array#fetch, and see if you notice any difference in how the out-of-bound case is handled:
static VALUE
rb_ary_fetch(int argc, VALUE *argv, VALUE ary)
{
// snip...
long idx = NUM2LONG(pos);
if (idx < 0 || RARRAY_LEN(ary) <= idx) {
if (block_given) return rb_yield(pos);
if (argc == 1) {
rb_raise(rb_eIndexError, "index %ld outside of...", /* snip... */);
}
return ifnone;
}
return RARRAY_AREF(ary, idx);
}
Did you notice how there is no explicit return after rb_raise?
That’s because Ruby exceptions are very different from Python exceptions, as they rely on setjmp(3)
and longjmp(3).
Without going into too much detail, these two functions essentially allow you to make some sort of “savepoint” of the stack
and jump back to it. When they are used, it’s a bit like a non-local goto, you directly jump back to a parent function
and all the intermediate functions never return.
As a consequence, a Ruby equivalent of Py_BEGIN_CRITICAL_SECTION would need to call setjmp, and push the associated
checkpoint on the execution context (essentially the current fiber) using the EC_PUSH_TAG macro,
so essentially every core method would now need a rescue clause, and that’s not free.
It’s doable, but likely more costly than Py_BEGIN_CRITICAL_SECTION.
Shall We?
But we were so preoccupied with whether or not we could remove the GVL, we didn’t stop to think if we should.
In the case of Python, from my understanding, the driving force behind the effort to remove the GIL is mostly the machine learning community, in big part, because feeding graphic cards efficiently requires a fairly high level of
parallelism, and fork(2) isn’t very suitable for it.
But, again from my understanding, the Python Web community, such as Django users, seem to be content with fork(2),
even though Python is at a major disadvantage over Ruby in terms of Copy-on-Write effectiveness, because as we saw previously, its reference counting implementation means most objects are constantly written to, so CoW pages are very quickly invalidated.
On the other hand, Ruby’s mark-and-sweep GC is much more Copy-On-Write friendly, as almost all the GC tracking data
isn’t stored in the objects themselves but inside external bitmaps.
Hence, one of the main arguments for GVL free threading, which is to reduce memory usage, is much less important in the
case of Ruby.
Given that Ruby (for better or for worse) is predominantly used for the Web use case, it can at least partially explain why the pressure to remove the GVL isn’t as strong as it has been with Python.
Similarly, Node.js and PHP don’t have free threading either, but as far as I know their respective communities
aren’t complaining much about it, unless I missed it.
Also if Ruby were to adopt some form of free threading, it would probably need to add some form of lock in all objects,
and would frequently mutate it, likely severely reducing Copy-on-Write efficiency.
So it wouldn’t be purely an additive feature.
Similarly, one of the main blocker for removing Python’s GIL has always been the negative impact on single-thread performance.
When you are dealing with easily parallelizable algorithms, even if single-thread performance is degraded, you can
probably come out on top by using more parallelism.
But if the sort of thing you use Python for isn’t easily parallelizable, free-threading may not be particularly appealing to you.
Historically, Guido van Rossum’s stance on removing the GIL was that he’d welcome it as long as it had no impact on
single-thread performance, hence why it never happened.
Now that Guido is no longer Python’s benevolent dictator, it seems that the Python steering council is willing to accept
some regression on single-thread performance, but it isn’t yet clear how much it will actually be.
There are some numbers flying around, but mostly from synthetic benchmarks and such.
Personally, I’d be interested to see the impact on Web applications before I’d be enthusiastic about such change happening to Ruby.
It is also important to note that the removal has been accepted but with some proviso,
so it isn’t yet done and it’s not impossible that they might decide to backtrack at one point.
Another thing to consider is that the performance impact on Ruby might be worse than for Python,
because the objects that need the extra overhead are the mutable ones, and contrary to Python, in Ruby that includes strings.
Think of how many string operations the average web application is doing.
On the other side, one argument I can think of in favor of removing the GVL though, would be YJIT.
Given the native code YJIT generates, and the associated metadata it keeps are scoped to the process, no longer
relying on fork(2) for parallelism would save quite a lot of memory, just by sharing all this memory, that being said,
removing the GVL would also make YJIT’s life much harder, so it may just as much hinder its progress.
Another argument in favor of free threading is that forked processes can’t easily share connections.
So when you start scaling Rails application to a large number of CPU cores, you end up with a lot more connections
to your datastore than with stacks that have free threading, and this can be a big bottleneck, particularly with
some databases with costly connections like PostgreSQL.
Currently, this is largely solved by using external connection poolers, like PgBouncer or ProxySQL, which I understand
aren’t perfect. It’s one more moving piece that can go wrong, but I think it’s much less trouble than free threading.
And finally, I’d like to note that the GVL isn’t the whole picture.
If the goal is to replace fork(2) by free-threading, even once the GVL is removed, we might still not quite be
there because Ruby’s GC is “stop the world”, so with much more code execution happening in a single process,
hence much more allocations, we may find out that it would become the new contention point.
So personally, I’d rather aim for a fully concurrent GC before wishing the GVL removed.
So It Is Urgent To Do Nothing?
At this point, some of you may feel like I’m trying to gaslight people into thinking that the GVL is never a problem,
but that’s not exactly my opinion.
I do absolutely think the GVL is currently causing some very real problems in real world applications, namely contention.
But this is very different from wanting the GVL removed and I beleive the situation could be noticeably improved in other ways.
require "bundler/inline"
gemfile do
gem "bigdecimal" # for trilogy
gem "trilogy"
gem "gvltools"
end
GVLTools::LocalTimer.enable
def measure_time
realtime_start = Process.clock_gettime(Process::CLOCK_MONOTONIC, :float_millisecond)
gvl_time_start = GVLTools::LocalTimer.monotonic_time
yield
realtime = Process.clock_gettime(Process::CLOCK_MONOTONIC, :float_millisecond) - realtime_start
gvl_time = GVLTools::LocalTimer.monotonic_time - gvl_time_start
gvl_time_ms = gvl_time / 1_000_000.0
io_time = realtime - gvl_time_ms
puts "io: #{io_time.round(1)}ms, gvl_wait: #{gvl_time_ms.round(2)}ms"
end
trilogy = Trilogy.new
# Measure a first time with just the main thread
measure_time do
trilogy.query("SELECT 1")
end
def fibonacci( n )
return n if ( 0..1 ).include? n
( fibonacci( n - 1 ) + fibonacci( n - 2 ) )
end
# Spawn 5 CPU-heavy threads
threads = 5.times.map do
Thread.new do
loop do
fibonacci(25)
end
end
end
# Measure again with the background threads
measure_time do
trilogy.query("SELECT 1")
end
This script demonstrates how GVL contention can cause havoc on your application latency.
And even if you use a single-threaded server like Unicorn or Pitchfork, it doesn’t mean the applications only use
a single thread.
It’s incredibly common to have various background threads to perform some service tasks, such as monitoring.
One example of that is the statsd-instrument gem.
When you emit a metric, it’s collected in memory, and then a background thread takes care of serializing and sending these metrics
in batch. It’s supposed to be largely IO work, hence shouldn’t have too much impact on the main threads, but in practice,
it can happen that these sorts of background threads hold the GVL for much longer than you’d like.
So while my demo script is extreme, you can absolutely experience some level of GVL contention in production,
regardless of the server you use.
But I don’t think trying to remove the GVL is necessarily the best way to tame that problem, as it would take years of
tears and sweat before you’d reap any benefits.
Prior to something like 2006, multi-core CPUs were basically non-existent, and yet, you were perfectly able to multi-task
on your computer in a relatively smooth way, crunching numbers in Excel while playing some music in Winamp, and this without any parallelism.
That’s because even Windows 95 had a somewhat decent thread scheduler, but Ruby still doesn’t.
What Ruby does when a thread is ready to execute and has to wait for the GVL, is that it puts it in a FIFO queue,
and whenever the running thread releases the GVL, either because it did some IO or because it ran for its allocated 100ms,
Ruby’s thread scheduler pops the next one.
There is no notion of priority or anything. A semi-decent scheduler should be able to notice that a thread is mostly IO and that interrupting the current thread to schedule the IO-heavy thread faster is likely worth it.
So before trying to remove the GVL, it would be worth trying to implement a proper thread scheduler.
Credit goes to John Hawthorn for that idea.
Another idea John shared in one of our conversations2, would be to allow more CPU operations with the GVL released.
Currently, most database clients only really release the GVL around the IO, think of it like it:
def query(sql)
response = nil
request = build_network_packet(sql)
release_gvl do
socket.write(request)
response = socket.read
end
parse_db_response(response)
end
For simple queries that return a non-trivial amount of data, it is likely that you are actually spending much more time
building the Ruby objects with the GVL acquired, than waiting on the DB response with the GVL released.
This is because very very few of the Ruby C API can be used with the GVL released, notably, anything that allocates
and object, or could potentially raise an exception MUST acquire the GVL.
If this constraint was removed, such that you could create basic Ruby objects such as String, Array, and Hashes with
the GVL released, it would likely allow the GVL to be released much longer and significantly reduce contention.
Conclusion
I’m personally not really in favor of removing the GVL, I don’t think the tradeoff is quite worth it, at least not yet,
nor do I think it would be as much of a game-changer as some may imagine.
If it didn’t have any impact on the classic (mostly) single-threaded performance, I wouldn’t mind it,
but it is almost guaranteed to degrade single-threaded performance significantly, hence this feels a bit like
“a bird in the hand is worth two in the bush” kind of proposition.
Instead, I believe there are some much easier and smaller changes we could make to Ruby that would improve the situation
on a much shorter timeline and with much less effort both for Ruby-core and for Ruby users.
But of course that is just the perspective of a single Ruby user with mostly my own use case in mind,
and ultimately this is for Matz to decide, based on what he thinks the community wants and needs.
For now, Matz doesn’t want to remove the GVL and He instead accepted the Ractor proposal3.
Perhaps his opinion may change one day, we’ll see.
MRI: Matz’s Ruby Interpreter, the reference implementation of Ruby, sometimes referred to as CRuby. ↩
If you didn’t notice, John is incredibly clever. ↩
Ractors which I also wanted to discuss in this post, but it’s already too long, so maybe another time. ↩
It’s 2025, and this year again, the YJIT team brings you
a new version of YJIT that is even faster, more stable, and more
memory-efficient.
A new baseline
Last year’s
YJIT release delivered an impressive performance boost which earned us multiple shoutouts
on social media. I was pleasantly surprised to hear that many large businesses running Rails in production had
upgraded to the latest version of Ruby, in part because they were excited to get better performance.
I distinctly remember, when I started at Shopify, before YJIT was a thing, that most Ruby deployments
were several versions behind. Seeing many people deploying the latest Ruby with YJIT enabled left me
with a warm fuzzy feeling that we had made a difference in terms of Ruby adoption. Performance really
is the carrot that gets people excited.
Historically, we’ve compared the performance of YJIT to that of the CRuby interpreter,
which makes for some impressive numbers. For instance, as of this writing, on our x86-64 benchmarking setup,
YJIT 3.4 is ~92% faster than the interpreter across the headline benchmarks we track. However, this
year marks the 4th YJIT release, and as such, we’re going with the assumption that many production deployments
already have YJIT enabled, and will be upgrading from Ruby 3.3 + YJIT to Ruby 3.4 + YJIT, rather than
upgrading from a deployment with YJIT disabled.
Going with this assumption, we’ve decided to change the way we track performance numbers on
speed.yjit.org, and start tracking how fast the latest version of YJIT is
compared to the version included in the last Ruby release, rather than only looking at how fast YJIT is
compared to the interpreter. This turned out to be pretty important, because there have been cases where
we’ve found (and fixed) performance regressions in the CRuby interpreter. This is a whole other discussion,
but if we only compare YJIT’s performance against that of the interpreter, and the interpreter slows down
without anyone noticing, it will make YJIT look better, but it definitely wouldn’t be a net win for the
Ruby community.
Many small improvements
Comparing against the previous release, YJIT 3.4 is 5-7% faster on our benchmarks than YJIT 3.3.6.
These are not an earth-shattering numbers, but for many use cases your code should run noticeably
faster. This better performance also comes with a significant reduction in memory usage, many additional
bug fixes, and some minor quality of life improvements. We’ll go over some of these changes in
the following sections.
Quality of life
There is now a
--yjit-mem-size=N command-line option to set the amount of memory overhead YJIT is allowed to use.
This behaves much more intuitively than the old --yjit-exec-mem-size=N option, which did not account
for all of the metadata that YJIT needs to allocate.
Another small quality of life improvement is the addition of a YJIT compilation log, which
can be enabled via --yjit-log. This allows you to see which pieces of Ruby code are compiled
at different times as your program is running. We’ve also made it so that the tail of the log can be
accessed at run-time as a Ruby object. This was done to make it possible to monitor it on our fleet
of servers in production.
The compilation log was mainly created for our own uses, it’s probably not something most users of
YJIT will want to look at. However, it can be useful to detect if your production workloads
compile new Ruby code dynamically at run-time, which is often undesirable.
We’ve also improved support for profiling using the perf tool. You can now get a
more detailed estimate of the number of cycles for code generated by YJIT.
For more information on how to use YJIT and its command-line options, you can take a look
at the YJIT README.
Improved inlining
A significant contributor to YJIT 3.4’s better performance comes from an
improved ability to inline small C and Ruby methods.
YJIT is able to generate specialized machine code for many core C methods
that are frequently called. For example, it can inline String#empty? and
Array#length. YJIT 3.4 adds more specializations of this type. In practice,
this can make a fairly significant difference. On the lobsters
benchmark for example, we are able to inline over 56.3% of C method calls.
On the liquid-render benchmark, this number is as high as 82.5%.
With this new version of YJIT, we’ve also added the ability to inline many
simple/trivial methods. For example, we can inline empty methods, methods
returning a constant, methods returning a string, methods returning self,
and methods that directly return one of their arguments. This allows us to
inline 4.8% of Ruby calls on the lobsters benchmark and 7.6% on liquid-render.
It’s also particularly helpful to improve the performance of Sorbet type
annotations.
Pure-Ruby core methods
Early on in YJIT’s development, we found that there was a large performance
penalty when calling back and forth between C and Ruby code. This has been
particularly challenging, because core methods such as
Array#each and Array#map are written in C and repeatedly call into
Ruby blocks. We’ve found that YJIT could do a better job of optimizing
these methods if they were written in Ruby, but if we rewrite that code in
Ruby it tends to slow down the interpreter, making this a difficult tradeoff.
With YJIT 3.4, we now have the ability to switch the implementation of specific
core methods to pure-Ruby versions, but only when YJIT is enabled. That way, we
can get the best of both worlds. We’ve optimized Array#each, Array#map,
Array#select, Array#filter, and Integer#downto this way. My colleague
Takashi Kokubun even went the extra mile and made it so that these methods appear
like C methods in cases when backtrace compatibility is expected.
Binary serialization
Something we’ve started experimenting with in 2024 is
writing more pure-Ruby gems.
Since we work in the web space, we deal with many gems that are used to
serialize and deserialize text and binary data.
We wrote our own pure-Ruby implementation of protobuf.
This was a useful exercise because it allowed us to identify specific
performance pain points and potential areas of improvement.
Some small but significant changes that we made include adding YJIT
fast paths for core methods such as
String#setbyte and String#getbyte. We’ve added a fast path
to append bytes to binary strings using String#<<. There is
a new String#append_as_bytes method that avoids resetting the
encoding of binary strings when appending bytes (Feature #20594).
We’ve also improved YJIT
support for bitwise operations. This makes it possible to write
pure-Ruby gems that manipulate binary data much faster than what
was possible before. We’ve experimented with writing a pure-Ruby
implementation of the protobuf spec and measured that this runs
about 14% faster on x86-64 with Ruby 3.4 than with Ruby 3.3.
Improved type propagation
We’ve also made some small tweaks to give YJIT access to better type information
to drive its optimization capabilities. We used to not propagate Array, Hash
and String class types due to the possibility of switching objects to singleton classes.
Now we have an invalidation mechanism that allows us to handle this without losing out
in the general case.
Improved register allocator
The YJIT 3.4 register allocator is more sophisticated than what we shipped with 3.3.
We can now allocate registers for local variables and pass arguments in registers.
Lazy frame pushing
Ruby code makes a lot of calls to C functions, both as part of C extensions and also
as part of the Ruby runtime library. One tricky aspect here is that many core methods
could technically raise an exception. This used to be a challenge for us because it meant that
we always had to push a Ruby stack frame to be prepared for this eventuality.
YJIT 3.4 can now speculatively skip pushing a frame and then lazily push one only when it’s needed.
This is used for String#byteslice, String#setbyte, and Class#superclass among others.
Reduced memory usage
The memory usage situation looks much better with YJIT 3.4 than it did with 3.3. According
to our benchmarks on Linux/x86-64, turning on YJIT with Ruby 3.3 increases memory usage
by 21% on average.
With YJIT 3.4, we see a large decrease in memory usage compared to
Ruby 3.3 with YJIT enabled.
We can’t take all of the credit for this, because much of the improvement comes from
changes on the CRuby side. In particular, a change was made to stop eagerly allocating stack space,
and this made a huge difference in overall memory usage. Going from Ruby 3.3 to 3.4
(without YJIT) reduces memory usage by about 8% on average. Note that this is true
on x86-64 but not on arm64.
Regardless of which platform you use, you should expect YJIT 3.4 to use slightly less
memory than YJIT 3.3 on average, even though it compiles more code.
Part of the improvement comes from a compressed context representation. A large
proportion of the memory used by YJIT is not compiled machine code, but rather metadata
associated with the compiled code. We’ve found a way to compress this data to encode
it using much less memory. We’re also able to eliminate some duplicate metadata in
some cases.
Performance on benchmarks
The graph below shows a comparison of YJIT 3.4’s performance against YJIT 3.3.6 on
an x86-64 machine (Xeon Platinum 8488C) on our largest benchmarks. As can be seen,
YJIT 3.4 is faster on almost every benchmark. Sometimes not by much, sometimes by a
significant margin.
Performance comparison of YJIT 3.4 vs 3.3 on headline benchmarks
What’s particularly great is that YJIT 3.4 uses less memory than YJIT 3.3 on most benchmarks,
as shown in the following graph:
Memory comparison of YJIT 3.4 vs 3.3 on headline benchmarks
Performance in production
This year, Shopify processed a record $11.5 billion in global sales for its merchants over the
BFCM (Black Friday Cyber Monday) weekend, and our app servers handled over 80 million requests per minute on Black Friday while running a prerelease version of
YJIT 3.4.
YJIT has been deployed to all of Shopify’s StoreFront Renderer (SFR) infrastructure for all of 2023 and 2024. For context, SFR renders all Shopify storefronts, which is the first thing buyers see when they navigate to a store hosted by Shopify. It is mostly written in Ruby, depends on over 220 Ruby gems, renders millions of Shopify stores in over 175 countries, and is served by multiple clusters distributed worldwide.
YJIT speedup of request latency on Storefront Renderer production servers
The above graph is a snapshot from our dashboard comparing the performance of the Ruby 3.4.0 interpreter vs YJIT 3.4.0 over the last 12 hours.
The Y-axis shows the speedup YJIT provides compared to the interpreter. This is computed based on the total end-to-end time needed to generate a response, including time the SFR servers spend doing I/O, waiting on databases, and other operations YJIT cannot optimize.
Given that the speedup figures that we see tend to change over time depending on web traffic, this is not
a very scientific comparison, but we’re happy to report slightly better performance than last year and
no significant change in memory usage. The p50 and p99 numbers also look quite a bit better than what
we saw at this time last year.
Looking forward
In 2025, the YJIT team is investigating what other design decisions could yield more Ruby performance improvements in the future. We’re looking at multiple different avenues and also considering some potentially
significant design changes. Stay tuned!
Conclusion
The Ruby 3.4 release is available for you to download from the Ruby releases page.
This year’s release brings you better performance, potentially lower memory usage, and some quality of life
improvements. A small but notable change is the addition of a more intuitive --yjit-mem-size
command-line option to replace the quirky --yjit-exec-mem-size. The YJIT team wishes you all a happy new
year and joyful hacking!
I’d like to give a big thanks to Shopify, Ruby & Rails Infrastructure, and the YJIT team.
I have the privilege of working with many incredibly talented programmers and managers, and this project would
not be possible without them.
If you’re using YJIT in production, please give us a shout out on Twitter/X. It’s always very rewarding for us
to hear about YJIT being deployed in the wild!
While the latency improvements were massive, we weren’t entirely satisfied with the heuristics used to trigger out-of-band
garbage collection. It was purely based on averages, so we had to trade latency for capacity.
More importantly, it didn’t fully eliminate major collection from request cycles, it only made it very rare.
If we want major GC to never trigger during a request cycle, why not disable it entirely?
In March 2024, during our annual Ruby Infrastructure team gathering, we fleshed out the details of the new feature we wanted,
and Matthew Valentine-House started working on a proof of concept, which we then deployed to a small percentage of our production servers to see how effective it could be.
First, we needed a way to entirely prevent the Garbage Collector from automatically performing a major collection, but
also to stop promoting objects to the old generation. Ideally in a web application, aside from some in-memory caches, no object allocated as part of a request should survive longer than the request itself.
Any object that does is probably something that should be eagerly loaded during boot, or some state that is leaking between requests.
As such, any object promoted to the old generation during a request cycle is very unlikely to be immortal, so promoting it is wasteful.
We also needed a way to ask the GC whether it would have run a major collection so that we could manually trigger it outside
of the request cycle, and only exactly as much as needed.
After some back and forth with other Ruby committers, it became a single new method: GC.config(rgengc_allow_full_mark: true/false).
We also exposed a new key in GC.latest_gc_info, :needs_major_by, for use in checking whether a major GC needs to run: GC.latest_gc_info(:needs_major_by).
This new feature was released as part of Ruby 3.4.0-preview2.
Effectiveness
Since Shopify monolith runs on Ruby’s master branch, we don’t have to wait for the December release to use these new features,
so recently I went to work on enabling the new out-of-band GC implementation on 50% of production servers, and the results are amazing on all metrics.
First, as we anticipated, the time spent in GC during request cycles at the very tail end (p95/p99/p99.99) dropped very significantly.
However, more surprisingly, it also improved median latency:
The overall impact on service latency is of course more modest, but still very nice with a 5% reduction of average latency and a 10% reduction of p99 latency:
The impact on capacity, however, is less significant than we had hoped for. During the day, when there are frequent deploys, this doesn’t make much of a difference.
However when deploys pause for a few hours, the new out-of-band collector runs much less often than the old implementation:
Implementation
In addition, to be more effective, this new implementation is also radically simple, thanks to the hooks provided by Pitchfork
# pitchfork.conf.rb
after_worker_fork do |_server, _worker|
GC.config(rgengc_allow_full_mark: false)
end
after_request_complete do |_server, _worker, _rack_env|
if GC.latest_gc_info(:need_major_by)
GC.start
end
end
Next Steps?
Now that the major collection is out of the picture, the next step is to look at the minor collections.
We can’t disable minor collection, as otherwise large requests that allocate a lot would run out of memory. However, we could try to
additionally use heuristics from GC.stat to eagerly trigger minor garbage collection out-of-band, so that the majority of requests don’t have
to spend any time at all in GC.
But the potential gains are much smaller because minor collection is quite fast even on our monolith.
Design by Manali Doshi for Thrillist
In the years since the pandemic began, there are more digital nomads than ever—a reported 35 million people worldwide now embrace this lifestyle, over half from the US—but the surrounding culture has calcified into something quite specific. It’s one thing to work remotely and travel around while doing so, but the associated network of podcasts, YouTube channels, ‘Nomad Cruises’ and pop-up cities all lean towards a similar outlook: nightmarish.
When the term first emerged in the popular consciousness in the late 2010s, it was often associated with creativity, and carried a suggestion of free-wheeling bohemianism: digital nomads as the modern-day heirs to Burroughs in Tangiers or Gaugin in Tahiti (beyond fucking local teenagers.) But the digital nomad lifestyle has always been inspired by a more hard-nosed libertarian philosophy: its foundational texts include The Sovereign Individual, a 1997 book co-written by the conservative peer Lord William Rees-Mogg—hardly an ayahuasca bro—which argued that in the future, “anyone with a portable computer and a satellite link will be able to conduct almost any information business anywhere. You will no longer be obliged to live in a high-tax jurisdiction in order to earn high income.” A decade later, Tim Ferris’s The 4-Hour Workweek: Escape 9–5, Live Anywhere, and Join the New Rich sold aspiring digital nomads the promise of abundant wealth with minimal effort—the trick, he revealed, was to outsource your work to an army of poorly paid “virtual assistants” in the global south.
Today’s network of digital nomad content creators are carrying on this tradition by way of paranoid libertarianism, byzantine tax evasion schemes, retail scams, and online courses which teach you how to teach online courses. Whatever traces of ersatz bohemianism remain can mainly be found in the treacly vernacular of therapy and self-help: Medium bloggers ponder whether nomadism is a trauma response, recruitment firms offer self-care tips, and podcast hosts explore self-actualisation, boundary-setting and “unlocking joy and happiness” as a corporate coach. There is a wealth of resources available for “neurospicy” digital nomads, and it’s surely only a matter of time before the “burnt out former gifted kid” and “eldest daughter” find themselves similarly catered to.
While some digital nomads are struggling creatives, eking out a modest living having fled their expensive home cities, 45 percent now earn over $75 thousand a year and many are the perpetrators, rather than the victims, of the global housing crisis—or at least they’re aspiring to be. One of the biggest innovators in the remote landlord business is the Maverick Investor Group, which—to use the language of founder Matt Bowles—is “empowering” digital nomads to purchase single-unit family homes in whichever locale is most profitable (mostly in the US) and milking them for passive income. Maverick offers “location-dependent” investors a smart, streamlined and optimized way of exploiting America’s housing crisis: its list of the best areas to purchase property include Cleveland, Ohio, which has in recent years experienced some of the highest rental increases in the US, and Charlotte, North Carolina, which a report from earlier this year found to have become “seriously and severely unaffordable.” Across the US, out-of-state investment has played a significant role in exacerbating the housing crisis and pricing out local residents.As destructive and mercenary as Maverick’s business model may be, the company’s podcast—The Maverick Show—typically approaches life as a digital nomad through the lens of social justice. There seems to be a constituency of nomad landlords who are interested in hearing about Black liberation, neo-colonialism and LGBTQIA+ empowerment, even as their investments are more likely to displace Black and queer people. As long as they consume the right content, as long as their lifestyle is aligned with certain progressive signifiers, perhaps they can still think of themselves as thoughtful and open-minded, their rejection of national borders itself a kind of virtue.
But this kind of reassurance isn’t necessary for everyone. In recent years, digital nomad nomad culture has converged more closely with a right-wing movement, which, as Quinn Slobodian details in his book Crack-up Capitalism, aims to protect the free market from democratic interference, to carve out zones exempt from taxes and regulation, and to use the threat of capital flight to ward off progressive economic policies. A certain kind of digital nomad is the vanguard of this campaign, a seasteader on dry land, always looking for cannier ways to elude governmental oversight and ready to bounce at the first sign their interests may be threatened.
As the blogger, author, and YouTuber Andrew Henderson (who goes by “Nomad Capitalist”) writes, “the digital nomad scene has evolved to take on more of the characteristics of the Nomad Capitalist scene—one where different niches of people turn to international solutions and lifestyles to better run real businesses and enjoy more abundant living.” Henderson himself—who renounced his own US citizenship to free himself of any tax obligations—epitomizes this new, harder-edged direction. In his blogs and YouTube videos, he advises his audience on how to escape the overbearing hand of “legacy-brand” nations in the West; how to “legally pay zero taxes anywhere,” and where to purchase the most advantageous citizenship.
In one video he weighs up the pros and cons of Russia’s new “anti-woke” visa, which offers residency permits to anyone who agrees with a set of "traditional spiritual and moral values"; in another, he ponders which countries are “not part of the Great Reset,” referring to a racist conspiracy theory—inspired by an existing plan of the same name by the World Economic Forum—which posits that elites are plotting to institute a tyrannical global government. Within the Nomad Capitalist worldview, citizenship is something which should grant protections and entitlements to those wealthy enough to afford it, while incurring zero responsibilities or obligations in turn. The expectation that the free market should be subject to any kind of democratic accountability, or that the wealthy should pay their fair share of taxes, is an affront to human freedom so dystopian it would make George Orwell blush.
Henderson is perhaps further to the right than the typical digital nomad, but even the more mainstream content creators are entertaining some pretty far-out ideas. Badass Digital Nomads—a popular podcast by Kirstin Wilson—features interviews with experts, spanning subjects as banal as travel tips and dating advice to nightmarish omens of the world to come. A recent episode focused on Plumia—a new “digital country” which will eventually have its own passport, tax system, retirement pension, and healthcare. For now the company is offering a more modest “Nomad Border Pass,” where applicants can apply for a single visa and be granted entry to 90 countries around the world. Plumia was founded on the principle of “global mobility as a human right,” but the nomad pass requires a minimum annual income of $50,000, and a job in a “tech, digital, innovation or knowledge” field.
Like much of digital nomad culture, this yearning for a world without borders is not a radical new vision, but an articulation of how the world is already orientated. Freedom of movement, by and large, already exists for people with money, and doubly so if they have “good passports.” Countries all over the West, including the UK and the US, are in the grip of anti-immigrant hysteria, but these movements typically carve out exceptions for migrants who are “high-skilled” (as do 71 percent of Trump voters, according to a recent Pew survey.) In the spirit of universalism, you might defend the right of digital nomads to live wherever they want, but this right is not under threat: they are pandered to at every turn; economically disadvantaged countries are competing to entice them, and while there is growing local discontent in places like Mexico City and Lisbon, there have been no rampaging mobs carrying out pogroms against SEO consultants and Medium bloggers. Some people —wealthy and mostly white—glide through borders, moving from place to place without ever encountering the slightest friction, while others are left to drown in the Mediterranean. This is not the result of a hypocritical worldview but an entirely consistent one which ascribes people value only according to their earning potential.
But it is hardly any surprise that vloggers might be obnoxious or that some people who work in finance and technology harbor loathsome political views. Some digital nomads are easier to sympathize with, and particularly so if they don’t identify with the term. One of the core tenets of the digital nomad lifestyle is “geoarbitrage” – in other words, making your income go further in a country with a lower cost of living. This is unpalatable if you’re moving to the Philippines so you can afford a luxury flat with maid service, and even at the lower level it usually has the effect of raising prices for the local population. But in and of itself, I don’t think it's a moral crime to want to be able to afford to rent your own apartment—a basic dignity denied to so many in cities like New York, LA and London—or to dream of spending a bit less time working without being plunged into poverty. I have nothing but contempt for people trying to make their fortune through rent-seeking and online scams, but I sympathize with the stressed-out, the frazzled, and even the lazy. To a large extent, it’s the “nodamism” of digital nomadism which is the problem, rather than simply working remotely—the rejection of any sense of societal obligation, the endless search for more pliant, obsequious locals to serve you.
If the pursuit of an easier, slower and more pleasant life comes at the expense of others, is staying where you are and suffering the right thing to do? Maybe. As a remote worker, it doesn’t really matter how pure-hearted, curious and humble you are, or whether you eschew networking events, co-working and “Nomad cruises” in favor of learning the language, frequenting only independent local businesses and getting involved with community activism: you will still probably be contributing to a process of displacement and gentrification; your search for a better life will probably come at the expense of someone else. I think the least we can ask of these people is that they spare us all the self-serving posture of enlightenment.
Moving to a new country, staying there for a long time and setting down roots doesn’t make you a digital nomad, nor does it require embracing an ethos of unfettered selfishness in which the only investment you ever make in the place where you live is a financial one. It is hard to avoid being complicit in global inequality, but that doesn’t give us carte blanche to pursue this complicity so gleefully or to elevate it as a virtue. To find out more, I will be delving into all of these thorny issues and more on my online course, “The Ethical Nomad: A Trauma-Informed Approach to Living Your Best (and Tax-Free) Life Abroad” available now for just $500.
Quem me conhece sabe que tem um tempo que eu falo dessa tal cooperativa. Basta sentar comigo num bar que é bem provável que você vá ouvir, ou já tenha ouvido, da maravilha que é a BEES e talicoisa. Notei que ainda não tinha escrito nada sobre isso e achei que era uma boa ideia pra espalhar mais a ideia por aí.
Cresci em cidade grande e embora tivesse uma vendinha bem perto de casa, que tinha aquelas jarras de vidro cheias de balas pra eu pedir pra mamãe quando eu passava por lá no caminho do colégio, no geral pra mim supermercado sempre foi uma coisa com “super” no nome. Aquela história: um grande espaço, mil corredores e um estoque infindável de todo tipo de coisa.
A maioria dos supermercados cooperativos se baseam na idéia do Park Slope Food Coop (abre em uma nova janela ), em Nova Iorque. O Park Slope Food Coop foi fundado em 1973 e opera em um sistema em que para fazer compras no supermercado, a pessoa precisa ser uma cooperadora. Pra se tornar uma cooperadora, as pessoas pagam um valor uma vez (comprando uma parte na cooperativa) e pra manter seu status ativo, fazem um turno de trabalho de 2h45 uma vez por mês no supermercado, em tarefas que fazem o supermercado funcionar (estoque, manutenção, administração, etc).
Nunca visitei o Park Slope, mas o primeiro supermercado cooperativo que eu visitei foi La Cagette (abre em uma nova janela ), em Montpellier, no início de 2019 e eu fiquei imediatamente encantado pela ideia. A atmosfera do lugar era bem diferente, mais próxima da vendinha que eu me lembrava quando era criança. Ao invés do ambiente cheio de propaganda, com alguns produtos sendo iluminados como se fossem sagrados, o ambiente era bem mais tranquilo, as pessoas que entravam e saíam se conheciam e conversavam no caixa ou enquanto estavam estocando uma prateleira.
Um supermercado tradicional tem todos os elementos do capitalismo moderno: o marketing agressivo, descontos risíveis se você der informações suas e sempre se identificar quando faz compras de modo que eles possam fazer um perfil seu, funcionários mal pagos executando funções repetitivas por horas a fio (e muitas vezes mais de uma função ao mesmo tempo). Além disso, supermercados tendem a ter uma margem de lucro variável nos produtos, muitas vezes legumes ou macarrão são muito baratos e tem uma margem de lucro bem pequena, e quando você compra algo como uma caneta ou uma pilha, ou um produto orgânico, é nesse tipo de coisa que tem uma margem gigantesca.
Quando voltei pra Bruxelas depois de conhecer La Cagette, fui procurar pra saber se algo do tipo existia por aqui. E encontrei a BEES coop (abre em uma nova janela ).
A BEES coop começou como um grupo de compras, as pessoas que participavam do grupo tomavam decisões sobre o que comprar e compravam coletivamente para obter preços reduzidos pro grupo. Mas a ideia foi se transformando até que, também se inspirando no Park Slope, se transformou no atual supermercado cooperativo que funciona desde 2017.
O supermercado lembra um supermercado tradicional: tem cestas e carrinhos e uma gama de produtos que vai de arroz e carnes até produtos de higiene de peças de bicicleta. A grande diferença é na escolha do que entra na loja: essa escolha é também feita de maneira participativa, e prioriza produtos orgânicos, locais ou de cooperativas; e muitas vezes prioridade para o pequeno produtor, mesmo que não tenha o selo “xyz”, ao invés do grande distribuidor. Além disso, também tem um monte de coisa que é disponível a granel: macarrão, arroz, lentilha, sabonete líquido, vinho e mesmo azeite. Dá pra levar seu saco, pote ou garrafa e encher por lá mesmo.
Além dos cooperadores, existem seis pessoas assalariadas que trabalham em tempo parcial. Elas também trabalham na loja, mas uma grande parte do seu trabalho é de fazer os pedidos de produtos, decidir o posicionamento de produtos na loja, recepcionar encomendas e repassar às cooperadoras no início do turno quais são as tarefas pendentes para o turno atual.
Toda pessoa cooperadora tem um cartão, que lhe identifica na entrada da loja e com o qual pode fazer suas compras. Além disso, tem direito a nomear duas outras pessoas de mais de 18 anos que vivem sob o mesmo teto, essas não precisam trabalhar, são “comedoras” e ganham seus próprios cartões para fazer compras.
Eu, como cooperador, trabalho 2h45 na loja por mês. Às vezes fico no caixa, outras vezes reabastecendo prateleiras, na entrada da loja ou arrumando o estoque. Tem também gente que trabalha no escritório, recebendo novos membros, atualizando os status dos membros atuais e outras tarefas do tipo; Tem gente que trabalha no corte de queijos; Tem gente que limpa a loja e guarda os legumes na câmara fria no fim do dia; E tem gente que faz trabalhos em comitês específicos, como o comitê que organiza a assembléia geral ou o comitê que seleciona os produtos.
Um turno normalmente tem uma pessoa “supercooperadora”, que faz um treinamento com as pessoas assalariadas para saber mais sobre o funcionamento da loja, além de ser o ponto de contato das outras cooperadoras para ausências inesperadas. Além disso, é para a supercooperadora que os funcionários explicam quais tarefas tem mais prioridade no turno atual. Além dos trabalhos de sempre, como caixa e entrada da loja, as vezes entregas precisam ser organizadas no estoque, novos produtos precisam ser registrados no sistema da loja, ou as prateleiras de cerveja estão quase vazias e precisam de uma atenção especial ;)
Cada turno de trabalho na loja começa com os membros se reunindo, recebendo da supercooperadora as tarefas para o turno e então se dividindo pra realizar as tarefas. E depois de umas horinhas, todo mundo se despede, com o novo turno acontecendo só dali a 4 semanas.
Trabalhar e fazer as compras na BEES é uma experiência agradável. Não só você conhece os rostos que dividem seus turnos com você, mas você começa a encontrar as mesmas pessoas que fazem compras em horários similares a você, e depois a encontrar essas pessoas nas assembléias gerais. O comitê de vinhos as vezes coloca um aviso caloroso dizendo que eles acharam um novo vinho super gostoso e que você devia experimentar. Quando você está no caixa é normal ver as pessoas conversando dizendo que tal e tal produto são novos e são tão bons por causa disso e daquilo. E nos corredores é comum ver gente se reconhecendo e começando a conversar.
Uma coisa importante, que me perguntam com frequência é: “tá, tudo muito bonito, seu Lond, mas e o preço das coisas?”. E a verdade é que depende. Como eu disse lá no alto, um supermercado tradicional trabalha com uma margem variável de lucro, cada produto tem uma margem diferente. Na BEES a margem é constante. Todo produto tem uma margem de 20%. A loja não tem fins lucrativos, a margem está lá para a manutenção da loja e salários dos funcionários.
A nossa experiência é que o preço médio do carrinho é bem próximo do que é no supermercado tradicional. A gente também começou a comprar mais coisas orgânicas, porque o preço é bem próximo do não-orgânico no supermercado normal. Tem produtos mais caros e algumas marcas tradicionais simplesmente não são vendidos por lá.
E a quantidade plástico que a gente traz pra casa diminuiu de maneira espetacular. Os produtos de supermercado aqui tendem a ter muito mais embalagem plástica do que no Brasil, tenho impressão. E na BEES tem um incentivo ativo a reutilização, então a gente começou a usar sacos laváveis de pano pra legumes e granel, dá preferência pra embalagens de vidro que são retornáveis (ou mesmo quando não são, por aqui tem lixeiras especiais pra vidro, que são reciclados) e pra coisas como óleo e azeite a gente enche os galões a granel, reusando as mesmas garrafas de vidro pra encher de azeite na cozinha no dia-a-dia.
O projeto não é perfeito, claro, mas é uma demonstração agrádavel de que é possível se organizar de maneiras diferentes dentro do capitalismo, enquanto não saímos dele. Que é possível encontrar formas alternativas de fazer coisas essenciais como suas compras de mês que operam de uma forma coletiva, com uma preocupação ambiental e uma preocupação com o aspecto humano, com o trabalhador do outro lado da produção, evitando os grandes conglomerados que infectam a vida do dia-a-dia e tem tanto poder.
Tentei buscar um pouco e não achei projetos similares no Brasil. Sei que existem lojas, como o Armazém do Campo do MST, que tentam aproximar o produtor do consumidor e vendem produtos de assentamentos e de pequenos agricultores. Mas não achei nada com o mesmo modelo participativo, como a BEES ou Park Slope.
Em todo caso, deixo algumas sugestões pra você lendo esse texto: preste atenção o quanto de coisas você compra no supermercado é por causa de propaganda. Pense em comprar mais coisas a granel, no Rio eu sei que existem lojas tradicionais de granel, não são nenhuma BEES, mas você vai sentir o quanto isso diminui o uso de plástico. E por fim, procure projetos que te conectem a pequenos produtores, enquanto a gente não tira do poder do agronegócio por maneiras diretas, a gente pode tirar o poder do agronegócio indo ao pequeno produtor quando possível.