Rob Jeschofnik
Shared posts



This battle station is now fully operational.
Rob Jeschofnikstreamers
 Scores of Birds Killed During Test of Nevada Solar Death Ray
Scores of Birds Killed During Test of Nevada Solar Death RayOn January 14, during tests of the 110-megawatt Crescent Dunes Solar Energy Project near Tonopah, Nevada, biologists observed 130 birds entering an area of concentrated solar energy and catching fire.The test started at 9:00 a.m. on January 14. By 10:30, biologists working on the site began noticing what have become known as "streamers," trails of smoke and water vapor caused by birds entering the field of concentrated solar energy (a.k.a. "solar flux") and igniting.
[...] at least one of the birds injured was a common raven, which -- in the words of our source -- "turned white hot and vaporized completely." Asked to confirm that report, the BLM's Evenson said that his office didn't have a list of the species affected, but added that "that's what streamers are."
giraffepoliceforce:vnicent:otteroftheworld:My parents live in...
My parents live in this town and the city legally can’t tear the tree down to build or anything because the tree has its own legal rights and they can’t do anything about it.
how does. how does this happen. how DID this happen
I love this story because this guy in the early 1800’s had so many great childhood memories of this tree and wanted to make sure it was protected no matter what. So he deeded the ownership of the tree to itself and everyone just went with it.
Then in 1942 this intense windstorm came and knocked the tree over. And people were bummed. But someone had saved an acorn from the original tree, so they planted that and now Son of the Tree That Owns Itself is over 50 feet tall.
And since this new tree is technically the offspring of the original tree it’s considered to have legally inherited the plot of land it’s inhabiting.
Two generations of trees owning land is amazing and if you don’t think this is the coolest thing get right out of my face.
I’m mostly just enamored of the name “The Tree That Owns Itself”. There’s something delightfully Just So Stories about it.

Curtain Door
The massive door is made of 40 sections of thick Burma teak and sits between the entrance's concrete walls. Each section has been carved to incorporate 160 pulleys, 80 ball bearings, one wire rope, and a hidden counterweight. When closed, the door just looks like a huge, horizontally slatted wood door. Push on the door and the wood feathers out into a beautiful curve.


Swatch Introduces Five New Versions Of The Sistem51, Available To Purchase On February 23
Rob Jeschofnikmight have to get a cream. or green.

When Swatch announced the Sistem51 at Baselworld 2013, watch enthusiasts took note. The mechanical, machine-made wristwatch was lauded for its simple movement architecture (51 components anchored to a central screw) all hermetically sealed against potentially damaging environmental elements. While the introductory models featured a linear, constellation-esque pattern on the dial, these new versions (excepting the pink watch) are more conservative in design. Luckily, the Sistem51 will still be offered at a reasonable price of $150.
We won't get too deep into technical details in this post; for that, we recommend reading our hands-on review of the Sistem51 here. In summary, notwithstanding its plastic construction, the Sistem51 marks a step forward for Swatch in terms of product concepts and production techniques.
"Sistem Cream"

In addition to the "Sistem Chic," the "Sistem Cream" offers a much more restrained take on the Sistem51. The black dial is no doubt influenced by Bauhaus-style watches, with stylized sans-serif Arabic numerals and a clean, linear layout. Arabic numerals for the minutes are placed at the outermost portion of the dial. The movement is decorated with a dotted pattern, reminiscent of the work of Japanese artist Yayoi Kusama.
"Sistem Green"

This model takes on a deep teal hue with accents of orange for the hour indexes, which extend all the way to the bezel. The orange theme continues to the hour and minutes hands, as well as the to the background of the date wheel at 3 o'clock. The movement, visible through a clear case back, is decorated in a teal and orange sunburst pattern.
"Sistem Chic"

Perhaps the most conservative offering in this new collection is the "Sistem Chic." Other than the red constellation pattern on the white dial, the design is pure, with black Arabic numerals for the hours. A railroad track-style scale is positioned on the inside of the dial, and surrounds the date aperture (positioned at 6 o'clock, unlike the other models) in an elegant way. Turning the watch around, however, reveals a movement decorated in a hypnotizing black-and-white pattern.
"Sistem Pink"

The loudest of the lot, the "Sistem Pink" features a deep blue dial with a pink illustration of the structure of an atom. White dots, on both the bezel and dial, replace hour numerals or long hour indexes, as seen on the other models. The case is in translucent pink plastic, matching a pink silicone strap with blue buckle.
"Sistem Class"

With its translucent blue case, the "Sistem Class" is perhaps the least loud of the colored cases. White Arabic numerals for the hours rest against a black background, complemented by white dots around the bezel.
The new collection will launch on February 23 at store.swatch.com and will also be available at all Swatch stores in the United States. For more information, visit Swatch online.
masooonderulo: themselfff: slysk8s: awwww-cute: While my...

While my friend and I were out Ice fishing, his dog broke out of his house and got herself a job
full story??
HOW DID THIS HAPPEN
this dog has a job and i don’t

Seattle police pepper sprayed a teacher who was walking and talking to his mom

A Seattle-area high school teacher who was pepper-sprayed by police at a rally on Martin Luther King Jr. day has filed an intent to sue the city and its police force for $500,000.Hagopian's lawyer, however, doesn't have much faith in the city's ability to hold itself accountable.
"They're not going to respond," Bible said on Friday afternoon. "I would not be surprised if the city of Seattle finds yet another way to absolve itself of any wrong-doing. They've made a mockery of accountability and until that changes, we're not holding our breath."
I can't wait to find out how much paid leave and workers' comp money this fine officer ends up being punished with.

Google's upcoming paid streaming service
How it worked before:
- She's her own label, and owns the copyright / publishing rights on her own songs.
- She registered her songs with Youtube, saying "these are mine". (That's different than posting the songs publicly.)
- Because of that, when someone else uploads a Youtube video that uses her music as the soundtrack, she's the one who receives the Content-ID notification.
- She then gets the choice to block that video, or to run ads on it.
- She generally chooses the latter, which means she gets 1/3 of the revenue generated by the ads on the video that has her music in it, and gets her name on the page.
So now Youtube is about to launch a new paid streaming service. If I'm understanding her post correctly, it goes like this:
- Participation in the new service requires that your entire catalog be available for streaming, at high resolution.
- Participation requires that you not release your music elsewhere earlier, e.g., no early releases for fans or backers.
- You no longer get a choice of whether to do nothing, block a video, or run ads. Ads are mandatory.
- Five year contract.
- If you don't participate in the new service, then the option to obtain Content-ID ad revenue from the free version of Youtube no longer exists.
- If you had previously been getting Content-ID ad revenue and choose not to participate in the new service, your channel will be deleted and all videos using your music will be blocked.
This means that, for all of those people who were making a little money off of their music by letting Google run ads on it, the options now on the table are:
- Agree to all the terms of the new service, including publishing your entire catalog on it, and continue making money on ads;
- Block all the videos using your music (and have your channel deleted);
- Allow those videos to use your music for free (and have your channel deleted).
It's another bait-and-switch: "We had been paying you for your work for years, under these terms. But now we have altered the agreement. Pray we do not alter it further."
This sounds like Google using the same strategy they used with Google Plus: instead of creating a new service and letting it compete on its own merits, they're going to artificially prop it up by giving people no choice but to sign up for it. Except in this case the people being strong-armed are the copyright holders instead of the end users. (So far, that is! Wait for it.)
I think you can expect to see a lot of old videos on Youtube getting blocked in the near future because of this.
"The music terms are outdated and the content that you uploaded will be blocked. But anything that we can scan and match from other users will be matched in content ID and you can track it but won't be able to participate in revenue sharing.""All music content has to be licensed under this new agreement. We can't have music in the free version that is not in the paid version"
I had them explain it again to be sure.
"Wow, that's a bit harsh," I said.
"Yeah, I know," they said.






The God Login
I graduated with a Computer Science minor from the University of Virginia in 1992. The reason it's a minor and not a major is because to major in CS at UVa you had to go through the Engineering School, and I was absolutely not cut out for that kind of hardcore math and physics, to put it mildly. The beauty of a minor was that I could cherry pick all the cool CS classes and skip everything else.
One of my favorite classes, the one I remember the most, was Algorithms. I always told people my Algorithms class was the one part of my college education that influenced me most as a programmer. I wasn't sure exactly why, but a few years ago I had a hunch so I looked up a certain CV and realized that Randy Pausch – yes, the Last Lecture Randy Pausch – taught that class. The timing is perfect: University of Virginia, Fall 1991, CS461 Analysis of Algorithms, 50 students.
I was one of them.
No wonder I was so impressed. Pausch was an incredible, charismatic teacher, a testament to the old adage that your should choose your teacher first and the class material second, if you bother to at all. It's so true.
In this case, the combination of great teacher and great topic was extra potent, as algorithms are central to what programmers do. Not that we invent new algorithms, but we need to understand the code that's out there, grok why it tends to be fast or slow due to the tradeoffs chosen, and choose the correct algorithms for what we're doing. That's essential.
And one of the coolest things Mr. Pausch ever taught me was to ask this question:
What's the God algorithm for this?
Well, when sorting a list, obviously God wouldn't bother with a stupid Bubble Sort or Quick Sort or Shell Sort like us mere mortals, God would just immediately place the items in the correct order. Bam. One step. The ultimate lower bound on computation, O(1). Not just fixed time, either, but literally one instantaneous step, because you're freakin' God.

This kind of blew my mind at the time.
I always suspected that programmers became programmers because they got to play God with the little universe boxes on their desks. Randy Pausch took that conceit and turned it into a really useful way of setting boundaries and asking yourself hard questions about what you're doing and why.
So when we set out to build a login dialog for Discourse, I went back to what I learned in my Algorithms class and asked myself:
How would God build this login dialog?
And the answer is, of course, God wouldn't bother to build a login dialog at all. Every user would already be logged into GodApp the second they loaded the page because God knows who they are. Authoritatively, even.
This is obviously impossible for us, because God isn't one of our investors.
But.. how close can we get to the perfect godlike login experience in Discourse? That's a noble and worthy goal.

Wasn't it Bill Gates who once asked why the hell every programmer was writing the same File Open dialogs over and over? It sure feels that way for login dialogs. I've been saying for a long time that the best login is no login at all and I'm a staunch supporter of logging in with your Internet Driver's license whenever possible. So we absolutely support that, if you've configured it.

But today I want to focus on the core, basic login experience: user and password. That's the default until you configure up the other methods of login.
A login form with two fields, two buttons, and a link on it seems simple, right? Bog standard. It is, until you consider all the ways the simple act of logging in with those two fields can go wrong for the user. Let's think.
Let the user enter an email to log in
The critical fault of OpenID, as much as I liked it as an early login solution, was its assumption that users could accept an URL as their "identity". This is flat out crazy, and in the long run this central flawed assumption in OpenID broke it as a future standard.
User identity is always email, plain and simple. What happens when you forget your password? You get an email, right? Thus, email is your identity. Some people even propose using email as the only login method.
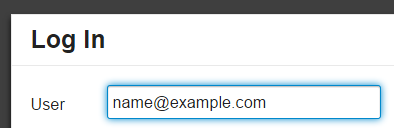
It's fine to have a username, of course, but always let users log in with either their username or their email address. Because I can tell you with 100% certainty that when those users forget their password, and they will, all the time, they'll need that email anyway to get a password reset. Email and password are strongly related concepts and they belong together. Always!
(And a fie upon services that don't allow me to use my email as a username or login. I'm looking at you, Comixology.)
Tell the user when their email doesn't exist
OK, so we know that email is de-facto identity for most people, and this is a logical and necessary state of affairs. But which of my 10 email addresses did I use to log into your site?
This was the source of a long discussion at Discourse about whether it made sense to reveal to the user, when they enter an email address in the "forgot password" form, whether we have that email address on file. On many websites, here's the sort of message you'll see after entering an email address in the forgot password form:
If an account matches name@example.com, you should receive an email with instructions on how to reset your password shortly.
Note the coy "if" there, which is a hedge against all the security implications of revealing whether a given email address exists on the site just by typing it into the forgot password form.
We're deadly serious about picking safe defaults for Discourse, so out of the box you won't get exploited or abused or overrun with spammers. But after experiencing the real world "which email did we use here again?" login state on dozens of Discourse instances ourselves, we realized that, in this specific case, being user friendly is way more important than being secure.
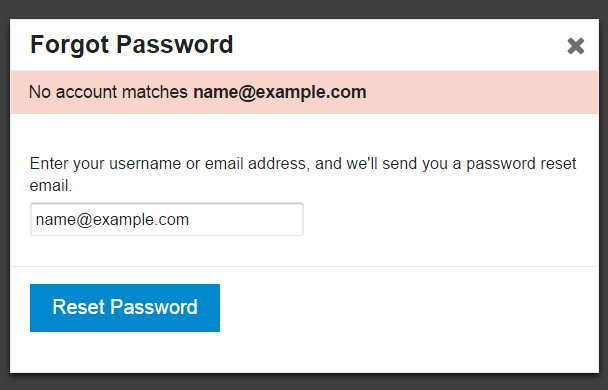
The new default is to let people know when they've entered an email we don't recognize in the forgot password form. This will save their sanity, and yours. You can turn on the extra security of being coy about this, if you need it, via a site setting.
Let the user switch between Log In and Sign Up any time
Many websites have started to show login and signup buttons side by side. This perplexed me; aren't the acts of logging in and signing up very different things?
Well, from the user's perspective, they don't appear to be. This Verge login dialog illustrates just how close the sign up and log in forms really are. Check out this animated GIF of it in action.

We've acknowledged that similarity by having either form accessible at any time from the two buttons at the bottom of the form, as a toggle:

And both can be kicked off directly from any page via the Sign Up and Log In buttons at the top right:
Pick common words
That's the problem with language, we have so many words for these concepts:
- Sign In
- Log In
- Sign Up
- Register
- Join <site>
- Create Account
- Get Started
- Subscribe
Which are the "right" ones? User research data isn't conclusive.
I tend to favor the shorter versions when possible, mostly because I'm a fan of the whole brevity thing, but there are valid cases to be made for each depending on the circumstances and user preferences.

Sign In may be slightly more common, though Log In has some nautical and historical computing basis that makes it worthy:
A couple of years ago I did a survey of top websites in the US and UK and whether they used “sign in”, “log in”, “login”, “log on”, or some other variant. The answer at the time seemed to be that if you combined “log in” and “login”, it exceeded “sign in”, but not by much. I’ve also noticed that the trend toward “sign in” is increasing, especially with the most popular services. Facebook seems to be a “log in” hold-out.

Work with browser password managers
Every login dialog you create should be tested to work with the default password managers in …
At an absolute minimum. Upon subsequent logins in that browser, you should see the username and password automatically autofilled.
Users rely on these default password managers built into the browsers they use, and any proper modern login form should respect that, and be designed sensibly, e.g. the password field should have type="password" in the HTML and a name that's readily identifable as a password entry field.
There's also LastPass and so forth, but I generally assume if the login dialog works with the built in browser password managers, it will work with third party utilities, too.
Handle common user mistakes
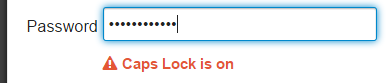
Oops, the user is typing their password with caps lock on? You should let them know about that.
Oops, the user entered their email as name@gmal.com instead of name@gmail.com? Or name@hotmail.cm instead of name@hotmail.com? You should either fix typos in common email domains for them, or let them know about that.
(I'm also a big fan of native browser "reveal password" support for the password field, so the user can verify that she typed in or autofilled the password she expects. Only Internet Explorer and I think Safari offer this, but all browsers should.)
Help users choose better passwords
There are many schools of thought on forcing helping users choose passwords that aren't unspeakably awful, e.g. password123 and iloveyou and so on.
There's the common password strength meter, which updates in real time as you type in the password field.
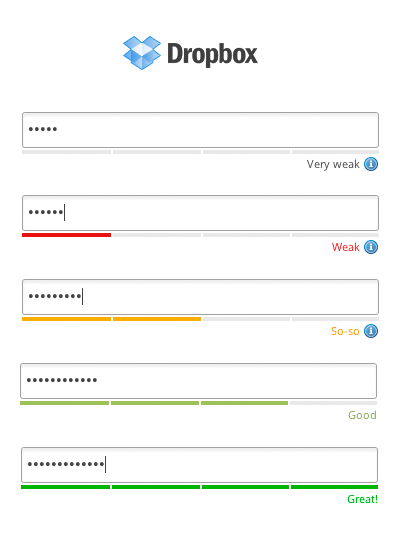
It's clever idea, but it gets awful preachy for my tastes on some sites. The implementation also leaves a lot to be desired, as it's left up to the whims of the site owner to decide what password strength means. One site's "good" is another site's "get outta here with that Fisher-Price toy password". It's frustrating.
So, with Discourse, rather than all that, I decided we'd default on a solid absolute minimum password length of 8 characters, and then verify the password to make sure it is not one of the 10,000 most common known passwords by checking its hash.

Don't forget the keyboard
I feel like keyboard users are a dying breed at this point, but for those of us that, when presented with a login dialog, like to rapidly type
name@example.com, tab, p4$$w0rd, enter
… please verify that this works as it should. Tab order, enter to submit, etcetera.
Rate limit all the things
You should be rate limiting everything users can do, everywhere, and that's especially true of the login dialog.
If someone forgets their password and makes 3 attempts to log in, or issues 3 forgot password requests, that's probably OK. But if someone makes a thousand attempts to log in, or issues a thousand forgot password requests, that's a little weird. Why, I might even venture to guess they're possibly … not human.
You can do fancy stuff like temporarily disable accounts or start showing a CAPTCHA if there are too many failed login attempts, but this can easily become a griefing vector, so be careful.
I think a nice middle ground is to insert standard pauses of moderately increasing size after repeated sequential failures or repeated sequential forgot password requests from the same IP address. So that's what we do.
Stuff I forgot
I tried to remember everything we went through when we were building our ideal login dialog for Discourse, but I'm sure I forgot something, or could have been more thorough. Remember, Discourse is 100% open source and by definition a work in progress – so as my friend Miguel de Icaza likes to say, when it breaks, you get to keep both halves. Feel free to test out our implementation and give us your feedback in the comments, or point to other examples of great login experiences, or cite other helpful advice.
Logging in involves a simple form with two fields, a link, and two buttons. And yet, after reading all this, I'm sure you'll agree that it's deceptively complex. Your best course of action is not to build a login dialog at all, but instead rely on authentication from an outside source whenever you can.
Like, say, God.
| [advertisement] How are you showing off your awesome? Create a Stack Overflow Careers profile and show off all of your hard work from Stack Overflow, Github, and virtually every other coding site. Who knows, you might even get recruited for a great new position! |


detectivesangelstardisandwands: la-lobalita: al-grave: The...
detectivesangelstardisandwands:
The varying wavelengths of different colors
Adorable science is adorable.
IT BOOMS WHENEVER THERE IS A RAINBOW
Binary alias coding
Rob JeschofnikI'm a huge nerd and actually found this quite interesting!
Applying the rANS-with-alias-table construction from “rANS with static probability distributions” to Huffman codes has some interesting results. In a sense, there’s nothing new here once you have these two ingredients. I remember mentioning this idea in a mail when I wrote ryg_rans, but it didn’t seem worth writing an article about. I’ve changed my mind on that: while the restriction to Huffman-like code lengths is strictly weaker than “proper” arithmetic coding, we do get a pretty interesting variant on table/state machine-style “Huffman” decoders out of the deal. So let’s start with a description of how they usually operate and work our way to the alias rANS variant.
Table-based Huffman decoders
Conceptually, a Huffman decoder starts from the root, then reads one bit at a time, descending into the sub-tree denoted by that bit. If that sub-tree is a leaf node, return the corresponding symbol. Otherwise, keep reading more bits and descending into smaller and smaller sub-trees until you do hit a leaf node. That’s all there is to it.
Except, of course, no serious implementation of Huffman decoding works that way. Processing the input one bit at a time is just a lot of overhead for very little useful work done. Instead, normal implementations effectively look ahead by a bunch of bits and table-drive the whole thing. Peek ahead by k bits, say k=10. You also prepare a table with 2k entries that encodes what the one-bit-at-a-time Huffman decoder would do when faced with those k input bits:
struct TableEntry {
int num_bits; // Number of bits consumed
int symbol; // Index of decoded symbol
};
If it reaches a leaf node, you record the ID of the symbol it arrived at, and how many input bits were actually consumed to get there (which can be less than k). If not, the next symbol takes more than k bits, and you need a back-up plan. Set num_bits to 0 (or some other value that’s not a valid code length) and use a different strategy to decode the next symbol: typically, you either chain to another (secondary) table or fall back to a slower (one-bit-at-a-time or similar) Huffman decoder with no length limit. Since Huffman coding only assigns long codes to rare symbols – that is, after all, the whole point – it doesn’t tend to matter much; with well-chosen k (typically, slightly larger than the log2 of the size of your symbol alphabet), the “long symbol” case is pretty rare.
So you get an overall decoder that looks like this:
while (!done) {
// Read next k bits without advancing the cursor
int bits = peekBits(k);
// Decode using our table
int nbits = table[bits].num_bits;
if (nbits != 0) { // Symbol
*out++ = table[bits].symbol;
consumeBits(nbits);
} else {
// Fall-back path for long symbols here!
}
}
This ends up particularly nice combined with canonical Huffman codes, and some variant of it is used in most widely deployed Huffman decoders. All of this is classic and much has been written about it elsewhere. If any of this is news to you, I recommend Moffat and Turpin’s 1997 paper “On the implementation of minimum redundancy prefix codes”. I’m gonna assume it’s not and move on.
State machines
For the next step, suppose we fix k to be the length of our longest codeword. Anything smaller and we need to deal with the special cases just discussed; anything larger is pointless. A table like the one above then tells us what to do for every possible combination of k input bits, and when we turn the k-bit lookahead into explicit state, we get a finite-state machine that decodes Huffman codes:
state = getBits(k); // read initial k bits
while (!done) {
// Current state determines output symbol
*out++ = table[state].symbol;
// Update state (assuming MSB-first bit packing)
int nbits = table[state].num_bits;
state = (state << nbits) & ((1 << k) - 1);
state |= getBits(nbits);
}
state is essentially a k-bit shift register that contains our lookahead bits, and we need to update it in a way that matches our bit packing rule. Note that this is precisely the type of Huffman decoder Charles talks about here while explaining ANS. Alternatively, with LSB-first bit packing:
state = getBits(k);
while (!done) {
// Current state determines output symbol
*out++ = table[state].symbol;
// Update state (assuming LSB-first bit packing)
int nbits = table[state].num_bits;
state >>= nbits;
state |= getBits(nbits) << (k - nbits);
}
This is still the exact same table as before, but because we’ve sized the table so that each symbol is decoded in one step, we don’t need a fallback path. But so far this is completely equivalent to what we did before; we’re just explicitly keeping track of our lookahead bits in state.
But this process still involves, essentially, two separate state machines: one explicit for our Huffman decoder, and one implicit in the implementation of our bitwise IO functions, which ultimately read data from the input stream at least one byte at a time.
A bit buffer state machine
For our next trick, let’s look at the bitwise IO we need and turn that into an explicit state machine as well. I’m assuming you’ve implemented bitwise IO before; if not, I suggest you stop here and try to figure out how to do it before reading on.
Anyway, how exactly the bit IO works depends on the bit packing convention used, the little/big endian of the compression world. Both have their advantages and their disadvantages; in this post, my primary version is going to be LSB-first, since it has a clearer correspondence to rANS which we’ll get to later. Anyway, whether LSB-first or MSB-first, a typical bit IO implementation uses two variables, one for the “bit buffer” and one that counts how many bits are currently in it. A typical implementation looks like this:
uint32_t buffer; // The bits themselves
uint32_t num_bits; // Number of bits in the buffer right now
uint32_t getBits(uint32_t count)
{
// Return low "count" bits from buffer
uint32_t ret = buffer & ((1 << count) - 1);
// Consume them
buffer >>= count;
num_bits -= count;
// Refill the bit buffer by reading more bytes
// (kMinBits is a constant here)
while (num_bits < kMinBits) {
buffer |= *in++ << num_bits;
num_bits += 8;
}
return ret;
}
Okay. That’s fine, but we’d like for there to be only one state variable in our state machine, and preferably not just on a technicality such as declaring our one state variable to be a pair of two values. Luckily, there’s a nice trick to encode both the data and the number of bits in the bit buffer in a single value: we just keep an extra 1 bit in the state, always just past the last “real” data bit. Say we have a 8-bit state, then we assign the following codes (in binary):
| in_binary(state) | num_bits |
0 0 0 0 0 0 0 1 |
0 |
0 0 0 0 0 0 1 * |
1 |
0 0 0 0 0 1 * * |
2 |
0 0 0 0 1 * * * |
3 |
0 0 0 1 * * * * |
4 |
0 0 1 * * * * * |
5 |
0 1 * * * * * * |
6 |
1 * * * * * * * |
7 |
The locations denoted * store the actual data bits. Note that we’re fitting 1 + 2 + … + 128 = 255 different states into a 8-bit byte, as we should. The only value we’re not using is “0”. Also note that we have num_bits = floor(log2(state)) precisely, and that we can determine num_bits using bit scanning instructions when we need to. Let’s look at how the code comes out:
uint32_t state; // As described above
uint32_t getBits(uint32_t count)
{
// Return low "count" bits from state
uint32_t ret = state & ((1 << count) - 1);
// Consume them
state >>= count;
// Refill the bit buffer by reading more bytes
// (kMinBits is a constant here)
// Note num_bits is a local variable!
uint32_t num_bits = find_highest_set_bit(state);
while (num_bits < kMinBits) {
// Need to clear 1-bit at position "num_bits"
// and add a 1-bit at bit "num_bits + 8", hence the
// "+ (256 - 1)".
state += (*in++ + (256 - 1)) << num_bits;
num_bits += 8;
}
return ret;
}
Okay. This is written to be as similar as possible to the implementation we had before. You can phrase the while condition in terms of state and only compute num_bits inside the refill loop, which makes the non-refill case slightly faster, but I wrote it the way I did to emphasize the similarities.
Consuming bits is slightly cheaper than the regular bit buffer, refilling is a bit more expensive, but we’re down to one state variable instead of two. Let’s call that a win for our purposes (and it certainly can be when low on registers). Note I only covered LSB-first bit packing here, but we can do a similar trick for MSB bit buffers by using the least-significant set bit as a sentinel instead. It works out very similar.
So what happens when we plug this into the finite-state Huffman decoder from before?
State machine Huffman decoder with built-in bit IO
Note that our state machine decoder above still just kept the k lookahead bits in state, and that they’re not exactly hard to recover from our bit buffer state. In fact, they’re pretty much the same. So we can just fuse them together to get a state machine-based Huffman decoder that only uses byte-wise IO:
state = 1; // No bits in buffer
refill(); // Run "refill" step from the loop once
while (!done) {
// Current state determines output symbol
index = state & ((1 << k) - 1);
*out++ = table[index].symbol;
// Update state (consume bits)
state >>= table[index].num_bits;
// Refill bit buffer (make sure at least k bits in it)
// This reads bytes at a time, but could just as well
// read 16 or 32 bits if "state" is large enough.
num_bits = find_highest_set_bit(state);
while (num_bits < k) {
state += (*in++ + (256 - 1)) << num_bits;
num_bits += 8;
}
}
The slightly weird refill() call at the start is just to keep the structure as similar as possible to what we had before. And there we have it, a simple Huffman decoder with one state variable and a table. Of course you can combine this type of bit IO with other Huffman approaches, such as multi-table decoding, too. You could also go even further and bake most of the bit IO into tables like Charles describes here, effectively using a table on the actual state and not just its low bits, but that leads to enormous tables and is really not a good idea in practice; not only are the tables too large to fit in the cache, general-purpose compressors will also usually spend more time building these tables than they ever spend using them (since it’s rare to use a single Huffman table for more than a few dozen kilobytes at a time).
Okay. So far, there’s nothing in here that’s not at least 20 years old.
Let’s get weird, stage 1
The decoder above still reads the exact same bit stream as the original LSB-first decoder. But if we’re willing to prescribe the exact form of the decoder, we can use a different refilling strategy that’s more convenient (or cheaper). In particular, we can do this:
state = read_3_bytes() | (1 << 24); // might as well!
while (!done) {
// Current state determines output symbol
index = state & ((1 << k) - 1);
*out++ = table[index].symbol;
// Update state (consume bits)
state >>= table[index].num_bits;
// Refill
while (state < (1 << k))
state = (state << 8) | *in++;
}
This is still workable a Huffman decoder, and it’s cheaper than the one we saw before, because refilling got cheaper. But it also got a bit, well, strange. Note we’re reading 8 bits and putting them into the low bits of state; since we’re processing bits LSB-first, that means we added them at the “front” of our bit queue, rather than appending them as we used to! In principle, this is fine. Bits are bits. But processing bits out-of-sequence in that way is certainly atypical, and means extra work for the encoder, which now needs to do extra work to figure out exactly how to permute the bits so the decoder reads them in the right order. In fact, it’s not exactly obvious that you can encode this format efficiently to begin with.
But you definitely can, by encoding backwards. Because, drum roll: this isn’t a regular table-driven Huffman decoder anymore. What this actually is is a rANS decoder for symbols with power-of-2 probabilities. The state >>= table[index].num_bits; is what the decoding state transition function for rANS reduces to in that case.
In other words, this is where we start to see new stuff. It might be possible that someone did a decoder like this before last year, but if they did, I certainly never encountered it before. And trust me, it is weird; the byte stream the corresponding encoder emits is uniquely decodable and has the same length as the bit stream generated for the corresponding Huffman or canonical Huffman code, but the bit-shuffling means it’s not even a regular prefix code stream.
Let’s get weird, stage 2: binary alias coding
But there’s one more, which is a direct corollary of the existence of alias rANS: we can use the alias method to build a fast decoding table with size proportional to the number of symbols in the alphabet, completely independent of the code lengths!
Note the alias method allows you to construct a table with an arbitrary number of entries, as long as it’s larger than the number of symbols. For efficiency, you’ll typically want to round up to the next power of 2. I’m not going to describe the exact encoder details here, simply because it’s just rANS with power-of-2 probabilities, and the ryg_rans encoder/decoder can handle that part just fine. So you already have example code. But that means you can build a fast “Huffman” decoder like this:
kMaxCodeLen = 24; // max code len in bits
kCodeMask = (1 << kMaxCodeLen) - 1;
kBucketShift = kMaxCodeLen - SymbolStats::LOG2NSYMS;
state = read_3_bytes() | (1 << 24); // might as well!
while (!done) {
// Figure out bucket in alias table; same data structures as in
// ryg_rans, except syms->slot_nbits (number of bits in Huffman
// code for symbol) instead of syms->slot_nfreqs is given.
uint32_t index = state & kCodeMask;
uint32_t bucket_id = index >> kBucketShift;
uint32_t bucket2 = bucket_id * 2;
if (index < syms->divider[bucket_id])
++bucket2;
// bucket determines output symbol
*out++ = syms->sym_id[bucket2];
// Update state (just D(x) for pow2 probabilities)
state = (state & ~kCodeMask) >> syms->slot_nbits[bucket2];
state += index - syms->slot_adjust[bucket2];
// Refill (make sure at least kMaxCodeLen bits in buffer)
while (state <= kCodeMask)
state = (state << 8) | *in++;
}
I find this remarkable because essentially all other fast (~constant time per symbol) Huffman decoding tricks have some dependence on the distribution of code lengths. This one does not; the alias table size is determined strictly by the number of symbols. The only fundamental data-dependency is how often the “refill” code is run (it runs, necessarily, once per input byte, so it will run less often – relatively speaking – on highly compressible data than it will on high-entropy data). (I’m not counting the computation of bucket2 here because it’s just a conditional add, and is in fact written the way it is precisely so that it can be mapped to a compare-then-add-with-carry sequence.)
Note that this one really is a lot weirder still than the previous variant, which at least kept the “space” assigned to individual codes connected. This one will, through the alias table construction, end up allocating small parts of the code range for large symbols all over the place. It’s still exactly equivalent to a Huffman coder in terms compression ratio and code “lengths”, but the underlying construction really doesn’t have much to do with Huffman at all at this point, and we’re not even emitting particular bit strings for code words anymore.
All that said, I don’t think this final variant is actually interesting in practice; if I did, I would have written about it earlier. If you’re bothering to implement rANS and build an alias table, it really doesn’t make sense to skimp out on the one extra multiply that turns this algorithm into a full arithmetic decoder (as opposed to quasi-Huffman), unless your multiplier is really slow that is.
But I do find it to be an interesting construction from a theoretical standpoint, if nothing else. And if you don’t agree, well, maybe you at least learned something about certain types of Huffman decoders and their relation to table-based ANS decoders. :)













