Swagger is a simple, clean and powerful representation of your RESTful API. Once integrated with WEB API, it provides a UI which helps in testing the API with ease. In my earlier post, I explained about how to integrate swagger with the ASP.NET Core Web API. And it works great with all HTTP verbs and input parameters. But uploading a file via Swagger is not straightforward. In this post, let’s find out how to upload file via Swagger in ASP.NET Core Web API.
Upload file via Swagger in ASP.NET Core Web API
Before you read further, please read my post and know how to add swagger to your ASP.NET Core project. Now let’s add a method to your controller, which take IFromFile as input parameter. IFromFile represents a file sent with the HttpRequest and it is available in the Microsoft.AspNet.Http namespace. For the demo, this method is added to default controller (ValuesController) available with default ASP.NET Core Web API template.
[HttpPost]
[Route("upload")]
public void PostFile(IFormFile uploadedFile)
{
//TODO: Save file
}
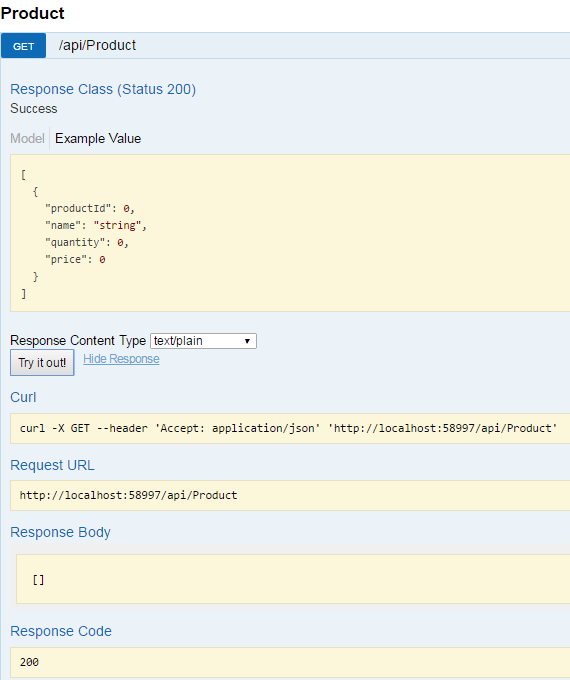
And now when you run the application and navigate to upload method, you will see the following.
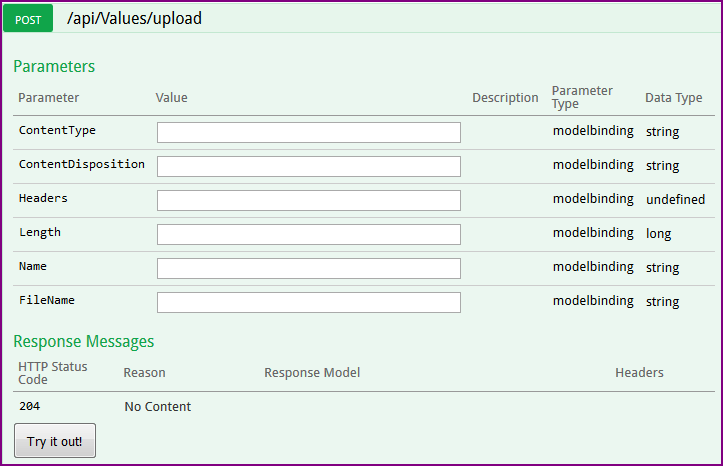
Instead of file upload control, you see multiple input boxes. Well, these are properties of IFromFile which represents the uploaded file. But, you can’t upload file with these input boxes. Rather, a file upload control will make your life simple. Let’s find out how to get file upload control, instead of these input boxes.
Swashbuckle has IOperationFilter which allows to post-modify operation descriptions once they’ve been generated by wiring up one or more Operation filters. Implementing this filter will provide the option to modify or replace the operation parameters. To implement IOperationFilter, let’s add a class FileUploadOperation which implement this filter. IOperationFilter has only one method called Apply to implement.
public class FileUploadOperation : IOperationFilter
{
public void Apply(Operation operation, OperationFilterContext context)
{
if (operation.OperationId.ToLower() == "apivaluesuploadpost")
{
operation.Parameters.Clear();
operation.Parameters.Add(new NonBodyParameter
{
Name = "uploadedFile",
In = "formData",
Description = "Upload File",
Required = true,
Type = "file"
});
operation.Consumes.Add("multipart/form-data");
}
}
}
This filter will replace the multiple input boxes with file upload control. The above code does following things.
- It first checks for operation with OperationId as “apivaluesuploadpost“. The operationId name is a combination of couple of parameters. It is made up of “api” + [Controller name] + [Method Name] + [HTTP Verb].
Or in other words, it is the URL of your controller method, but without “/” + [HTTP Verb]. - It clears all the parameters. So all the properties of
IFromFileinterface are cleared. - And then adds custom parameters to the operation. Please note, the Name parameter value must be equal to parameter name to the method. So in this case, it is “uploadedFile”
PostFile(IFormFile uploadedFile). In property must be set to “formData” and Type must be “file”. - Finally, consume type
multipart/form-datawhich is required for file transfer from client to server.
And final step is to register this operation filter in Startup.cs.
services.AddSwaggerGen();
services.ConfigureSwaggerGen(options =>
{
options.SingleApiVersion(new Info
{
Version = "v1",
Title = "My API",
Description = "My First Core Web API",
TermsOfService = "None",
Contact = new Contact() { Name = "Talking Dotnet", Email = "contact@talkingdotnet.com", Url = "www.talkingdotnet.com" }
});
options.IncludeXmlComments(GetXmlCommentsPath());
options.DescribeAllEnumsAsStrings();
options.OperationFilter<FileUploadOperation>(); //Register File Upload Operation Filter
});
Now when you run the application and navigate to Upload method. And you should see following.
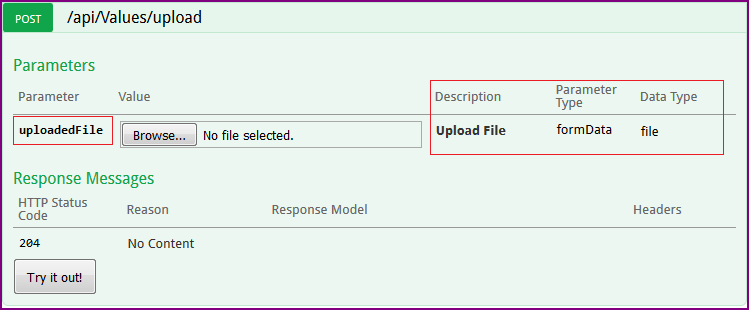
There is a file upload control and all the parameters that we configured are also present on UI (as highlighted in the image). When you select a file to upload and navigate to VS in debugging mode, you can see IFormFile object holds the uploaded file.
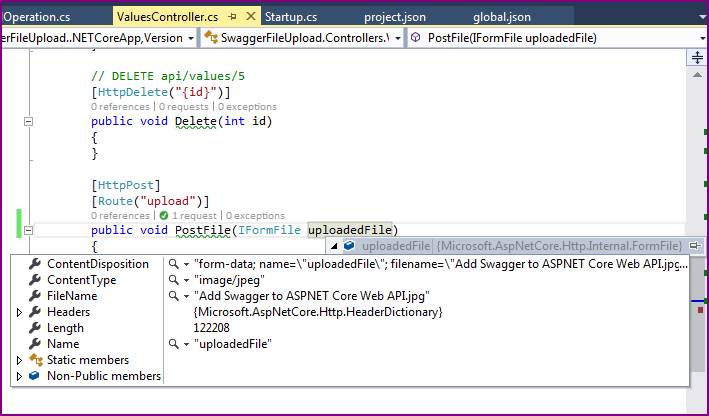
That’s it.
To sum up things, to support file uploading via Swagger UI, IOperationFilter provided by SwashBuckle needs to be implemented to modify post operation description for the web API method which supports file uploading.
Thank you for reading. Keep visiting this blog and share this in your network. Please put your thoughts and feedback in the comments section.
The post How to upload file via Swagger in ASP.NET Core Web API appeared first on Talking Dotnet.














































{kind=link}
{kind=link}
{kind=link}
{kind=link}