We have a lot of passwords to remember, and it’s becoming a problem. Authentication is clearly important, but there are many ways to reliably authenticate users – not just passwords. Passwords are written off as inconvenient and unavoidable, but even if true a few years ago, that’s not true today. Due to a combination of sensors, encryption and seasoned technology users, authentication is taking on new (and exciting) forms.
Most other interaction patterns have been updated over time, but no one wants to mess with password authentication. It’s too serious. Or there’s too much liability. You know, like if you don’t clear the password input after someone types the wrong password, their credit card information is at risk.
Form abandonment is like someone agreeing to meet up with you but then canceling last minute. Users who are interested in what a site offers have no trouble starting a form. But when it comes to completing it, they’ll have many reasons not to.
Select Menus Slow Users Down
One common reason is if your form contains multiple select menus. Research shows that forms with select menus often get abandoned. This is because they take more time and effort to complete.
Flow Interruption
Most forms begin with text fields where users type in their input. But when a select menu appears, they have to move their hands from keyboard to mouse to select an option. This interrupts their typing flow and slows them down.
Hard to Read
Once they open the select menu, they have to scan through the options and select the right one. This takes time and effort because the option text is hard to read. They appear as a lengthy list scrunched together with minimal line spacing.
Dexterous Mouse Maneuvering
To make a selection, the user has to point their mouse to the right option without straying off it. This requires dexterous mouse maneuvering because it’s easy to land on the wrong option if they don’t go slow and steady. The menu is limited in size and has minimal padding between the options. Moving the mouse just a few pixels too far can result in clicking the wrong option.
After they make a selection, they have to check to see if they selected the right option. Then they have to move their hands back to their keyboard to prepare for the next text field. All these actions add up and make select menus difficult to interact with. It’s no wonder why users abandon forms that have them.
Excessive Arrow Keying
Some users may use their keyboard to make a selection instead of their mouse. But this is an even slower experience. They have to press the down arrow key to scroll through each option. This is a tedious task when there are many options.
Mobile Picker Flicking
Desktop users need extra dexterity when maneuvering through a menu. But mobile users also need dexterity when flicking through options in a picker.
When users open a mobile select menu, a picker wheel displays. They have to flick their finger slowly to land on the option they want. If they’re not careful, they can over flick and make the wrong selection. This forces them to fiddle with it to get it right which takes up unnecessary time and effort.
Not only that, but lengthy option text can get truncated. An ellipsis displays at the end of the text where the user can’t read it all. This makes it hard for users to select an option which leads to abandonment.
Better Alternatives to Select Menus
You should avoid using select menus on your form as much as possible. There are better alternatives that don’t slow users down and interrupt their task flow.
Radio Buttons
It’s far better to list out the options with radio buttons instead of cramming them in a select menu. Each option remains visible so that users can scan them without having to open the menu. They have more spacing to click each option and won’t get punished if they overshoot their target.
When users click a radio button, they get immediate visual feedback. They don’t have to scroll through the menu again if they click the wrong one. All they need to do is scan the options and click.
Radio buttons should look like buttons. They should have ample button padding and a clear border around it. When it’s clicked, activation should show through a change of color and shape.
Autocomplete Text Fields
When you have several options to display, use autocomplete text fields. These allow users to type in their input and get suggested options that match it.
The more the user types the more specific the suggested options become. Users can save time by selecting a suggested option instead of typing out their entire input.
Autocomplete text fields should display the option that best matches the input first. You should distinguish the user’s typed input text in the suggested options. The option text that matches the input text should highlight with different color contrast.
The Only Time to Use a Select Menu
There’s only one situation where you should use a select menu. That’s when you want the user to answer with your specific terminology.
For example, if you want to know the ethnicity of your users, you have to provide options in your own terminology. If you don’t provide specific options, users could give you vague answers. They could type in ‘Asian’ instead of ‘Chinese’ or ‘European’ instead of ‘German’.
Triggering Abandonment
More users start forms than finish them. Don’t give them a reason to abandon your form. The last thing they want to do is maneuver and flick through a select menu.
Most sites spend a lot of effort getting users to their form, but then lose them by using select menus. Think about saving your user’s time and effort. Opt for better alternatives that won’t trigger form abandonment.
Dans un billet posté sur Facebook, un responsable d'AMD annonce l'interêt du fabricant pour les cartes graphiques externes.
Imaginez jouer à des jeux de dernières générations avec un PC portable de seulement quelques millimètres. Le rêve, n’est-ce pas ? Surtout quand le prix et la taille des configurations taillées pour le jeu ont toujours été un obstacle au jeu sur PC. Conscient de ce problème, les constructeurs nous promettent des cartes graphiques externes depuis plusieurs années.
Mais jusqu’à maintenant, les solutions de boîtiers graphiques externes que nous connaissons, comme l’Alienware Graphics Amplifier ou le MSI GS30 Shadow, sont basées sur des technologies propriétaires. Toutefois, lors du CES 2016, nous avons vu le Core, un boiter graphique externe proposé par Razer qui préludait de l’arrivée de solutions standardisées.
Les GPU externes standardisés sont la réponse
Et c’est une ambition que semble partager AMD. Dans un billet posté sur Facebook, Robert Hallock, le responsable du Marketing Technique Global de la société, écrit que si « les notebooks sont très transportables, personne ne se risquerait à les prendre pour des PC de jeux ». « Mais il y a un très gros appétit pour les notebooks qui peuvent jouer », ajoute-t-il.
L’enjeu est de taille, il est celui de la modularité : celui de n’avoir besoin que d’un seul et même outil pour accomplir toutes les tâches, de la plus simple à la plus gourmande en ressources. Pour Hallock, « il y a de nombreux joueurs qui, quand il arrive à 30 ou 40 ans, aimeraient condenser toute leur vie informatique dans un seul et même appareil polyvalent ».
« Les GPU externes sont la réponse. Des GPU externes avec des connecteurs, des câbles et des drivers standardisés, plug’n’play, compatibles avec les systèmes d’exploitation ».
Hallock assure que « d’autres informations viendront très prochainement », et on imagine que le constructeur pourrait choisir la Game Developers Conference qui commence la semaine prochaine à San Francisco pour les révéler.
En attendant, rien n’indique qu’AMD serait en train de développer des solutions matérielles — et le simple fait qu’Hallock illustre son propos avec un Razer Core abonde en ce sens. Mais le fabricant pourrait avoir un moyen de simplifier le GPU externe pour le démocratiser, peut-être en réduisant la taille et la consommation des GPU actuels ?
Sur le blog de CtrlShift (@321ctrlshift), la société de conseil britannique qui promeut la réutilisation des données par les utilisateurs (voir notamment notre dossier de 2012 et bien sûr le programme MesInfos de la Fing), on souligne que les programmes de fidélité à destination des consommateurs ont du plomb dans l’aile. Le billet pointe vers une étude du cabinet de conseil Collinson Group, qui montre que les programmes de fidélité dévissent, dans tous les secteurs, notamment du fait qu’ils sont de moins en moins avantageux pour les consommateurs.
Pour CtrlShift, ce n’est pas la seule raison. Malgré leur promesse, les programmes de fidélités ne sont pas conçus pour les consommateurs (”qui souhaitent être fidèle à une marque ?”), mais bien par ceux qui les commercialisent.
En fait, les programmes de fidélité mélangent deux choses très différentes. Une mécanique promotionnelle qui vous pousse à acheter un nouveau produit, les produits d’une marque ou à revenir au même magasin et de l’autre un système de collecte de données sur les clients. Or, ces dernières années, ces deux aspects n’ont pas évolué de la même manière. Les programmes de promotion sont de moins en moins avantageux (notamment par rapport aux mécanismes en ligne, plus immédiats, plus réactifs et plus convaincants). En tant que programmes de captures de données, ces outils ont rempli leur rôle : la plupart des enseignes ont désormais toutes les données nécessaires sur leurs clients. Enfin, les rendements de ces programmes sont devenus décroissants : il est bien plus avantageux et moins cher désormais de recueillir d’énormes quantités de données sur ses clients en ligne. “Les programmes de recueil de données avaient un sens dans un désert d’information. Maintenant que nous vivons dans un océan d’information, ils n’en ont plus.”
Les avantages réels des programmes de fidélité ont créé dans un premier temps une spirale vertueuse. Les enseignes ont utilisé les données pour acquérir de nouvelles connaissances sur leurs clients qui les ont aidé à améliorer leur offre, qui a bénéficié aux clients… “La valeur des programmes de fidélité est venu de la valeur qu’ils ont livrés aux clients”. Mais désormais, on n’a plus besoin de programmes de fidélisation pour créer des relations fondées sur le partage de données. Désormais, la valeur n’est plus dans la collecte, mais dans ce que cette collecte va faire pour le client. L’enjeu de la fidélisation est d’aider les clients à utiliser l’information que les enseignes ont sur eux pour les aider à prendre de meilleures décisions et mieux gérer leur vie. Ce changement nécessite une relation différente avec les clients comme le proposent les PIMS (Personal information management systems - ou SelfData comme nous les promouvons à la Fing), ces programmes de fidélité du 21e siècle, qui cherchent à mieux répartir la valeur des données des utilisateurs.
Tient, ça tombe bien, le programme MesInfos vient de publier un court livret sur la valeur du selfdata pour les détenteurs de données…
Bon, ceci dit, toutes les entreprises ne feront pas ce type de choix, au contraire. L’initiative de Marketing Cloud lancée récemment par Adobe (voir l’article de Numerama notamment), vise à partager entre entreprises les données marketing recueillies sur les utilisateurs. L’exploitation de nos données personnelles par devers nous a encore de beau jour !
Mon processus de découverte et de lecture d’articles — une partie de mon activité de veille — est le suivant :
Quand j’ai un moment devant moi1, je parcoure en diagonale les titres qui remontent dans mon aggrégateur de flux RSS ou dans mon historique Twitter. J’ouvre dans de nouveaux onglets ceux qui attirent mon attention.
Pour chacun de ces onglets, soit l’article est court ou semble particulièrement intéressant et je le lis de suite, soit je l’empile dans Pocket pour lecture quand j’aurai un plus long moment devant moi.
Je dépile les articles qui m’attendent dans Pocket2.
La première étape signifie qu’un titre ou commentaire sympa est indispensable. Et la troisième a pour conséquence malheureuse la perte régulière de quelques articles qui finissent par rejoindre les milliers de posts en attente3 au fond de mon Pocket… Mais c’est du second point que je souhaite parler aujourd’hui.
J’ai ouvert, selon les jours, entre 5 et 30 onglets, chacun abritant un article peut-être intéressant — ou peut-être pas.
Arrivé sur celui de votre site, au lieu d’avoir un article à lire, je suis accueilli par une page couverte de gris, avec au milieu de l’écran une boite de dialogue me demandant de saisir un mail ou de cliquer sur je ne sais trop quoi ou d’installer une application mobile. Sans aucun bouton « fermer » évident à trouver. Et cliquer sur le fond de la page est sans effet.
À votre avis, que fais-je ? Rappelez-vous, je suis arrivé là presque par hasard.
Très juste : « Fermer l’onglet ! » : c’est rapide, le raccourci clavier ou le geste à la souris tombent sous les doigts !
Ou pire encore, au lieu d’arriver sur un article à lire, j’ai un écran intersticiel, avec au milieu de la page une image qui ressemble à un message publicitaire et à peine un petit lien « continuer vers le site », pas évident à repérer, dans un coin.
Là encore, je suis arrivé sur votre site presque par hasard et je n’ai pas la moindre idée du sujet de l’article qui, peut-être, se trouverait au bout du chemin. Quoi qu’il en soit, c’est trop tard : « Fermer l’onglet ! »
Après tout : je viens (d’essayer) d’arriver sur votre site, je ne sais pas si l’article visé sera effectivement intéressant… Pourquoi est-ce que je m’emmerderais4 à chercher comment fermer cette *u*a*i* de popin ?
Et une vidéo qui se lance toute seule, avec du son qui vient heurter mes tympans (si j’ai un casque sur les oreilles) ou retentir sur tout l’open-space en dérangeant mes collègues au passage ? Là encore, au plus vite : « Fermer l’onglet ! »5
Et c’est dommage : le titre de l’article, ou le bref commentaire l’accompagnant sur Twitter, m’avait convaincu de cliquer ! Vous aviez (presque) un lecteur. Et j’ai consommé un pouillème de votre CPU et de votre bande passante pour charger votre site !
Sauf que vous avez échoué dans votre mission : me permettre de lire votre article6.
Pour finir, j’anticipe quelques questions :
Et si je suis sur mobile ? L’effet « Fermer l’onglet ! » est encore plus fort. Idem pour la fenêtre qui me demande si je veux installer votre application Android : non, je ne veux pas installer votre …… d’application !
Non, attendre que j’ai scrollé un peu avant d’afficher un overlay n’est pas une bonne idée ! Au contraire, cela interrompt ma lecture et provoque un sentiment de frustration encore plus violent ! Votre article, sur lequel je suis arrivé presque par hasard, n’est pas assez intéressant pour surpasser la frustration. Et hop, « Fermer l’onglet ! ».
Et, définitivement : recharger la page au bout de quelques minutes, en perdant ma position de lecture au passage, n’est pas acceptable et provoque un « Fermer l’onglet ! » — là aussi, même en milieu d’article !
Et pour finir en élargissant un peu le sujet : vous avez entendu parler du Banner blindness ?
Oui, vous cherchez des revenus, je le comprends bien.
Mais, non, assaillir vos visiteurs n’est pas la bonne solution.
En arrivant (tôt) au bureau et buvant mon premier café de la matinée — et en début de pause midi et/ou en fin de journée si j’ai le temps. ↩
Je vise, à terme, à remplacer Pocket par une autre solution (probablement wallabag), que je pourrais héberger moi-même. Objectif : dépendre d’un service externe (qui peut toujours fermer ou changer ses conditions d’utilisation) de moins. J’abordais le sujet il y a quelques jours : Dépendre d’un service externe, un choix à assumer. ↩
J’ai des articles qui sont, pour certains, en attente dans Pocket depuis plusieurs années. Et, parmi plus de 5000 articles, je sais très bien qu’il y en a une bonne partie que je ne lirai jamais. ↩
Pardonnez-moi ce terme grossier… Mais il correspond plutôt bien à mon sentiment quand je me retrouve dans cette situation ! ↩
Ou même « fermer les onglets » un par un, jusqu’à ce que le son s’arrête enfin ! Heureusement, on s’y retrouve mieux et c’est plus facilement maintenant, avec les navigateurs qui affichent une icône sur l’onglet désagréablement bruyant ! ↩
Enfin, à vous de voir — et c’est une vraie question, fondamentale — quelle est votre mission : afficher de la publicité ? Récolter des adresses mail ? Incrémenter un compteur de vues pour vos annonceurs ? Ou proposer du contenu utile et de qualité à vos utilisateurs ? ↩
En tant qu’individus et en tant que profession, nous avons trop souvent tendance à oublier les bienfaits de bonnes nuits de sommeil, ainsi que les effets néfastes de la fatigue sur notre productivité et sur la qualité de nos réalisations — ou sur notre santé !
Arriver au bureau fort tôt le matin, en n’ayant donc dormi que quelques heures, pour réaliser une mise en production majeure en évitant du down-time sur les heures « importantes » de la journée1, signifie :
Qu’il faut avoir une équipe de taille suffisamment importante pour être en mesure de garder en réserve quelques personnes qui soient fraiches et disponibles en heures « normales » pour ensuite gérer les éventuels problèmes liés à cette mise en prod.
Envoyer dormir2 ceux qui étaient là tôt — sinon, ils seront peu efficaces jusqu’à la fin de la semaine.
Ou alors, il faut accepter d’être sous-efficace pendant les jours suivants — ce qui peut être gênant si quelques imprévus surviennent suite à cette opération majeure3.
Commencer une mise en production à 22h après une journée de travail, qu’elle dure toute la nuit puis toute la journée4, et ensuite s’attendre à ce que les équipes soient opérationnelles le lendemain et jusqu’à la fin de la semaine ?
Il ne faut pas ensuite s’étonner s’il y en a un ou deux qui sont un peu ronchons en revenant au boulot à 9h après deux jours et une nuit au boulot sans dormir5, suivis seulement d’une courte nuit — sans avoir rien fait d’autre pendant pas loin de 48h que bosser et trop peu dormir !
Après ces cas sortant heureusement de l’ordinaire, passons à une idée trop classique : demander aux équipes de bosser de longues journées, de manière régulière et/ou pendant une longue durée6 ?
Cela signifie souvent qu’il y a un réel problème au niveau de la gestion du projet ou de la manière dont il a été vendu — et ça ne devrait carrément pas être aux équipes de développement de sacrifier leur santé et leur vie personnelle/familliale pour compenser !
J’ajouterais que, au bout d’un moment, la productivité baisse. Elle va même jusqu’à tomber plus bas que celle correspondant à des journées normales… Et il devient alors nécessaire d’aligner encore plus d’heures pour compenser. Et donc la productivité baisse à cause de la fatigue (et de la lassitude) et donc…
D’une certaine manière, travailler trop pendant quelques jours, c’est une forme d’investissement — et ne pas dormir assez et la fatigue qui s’accumule, c’est la dette correspondant. Dette qu’il faudra impérativement rembourser pour revenir à un bon niveau d’efficacité !
À l’inverse, c’est également à nous de savoir être raisonnables : arriver régulièrement au bureau en sachant à peine garder les yeux ouverts parce qu’on a joué à WOW7 ou regardé des séries jusqu’à 3h du matin, ce n’est pas très correct.
À mi-chemin entre la vie professionnelle et la vie personnelle, je pense également aux hackatons d’un week-end, où la tentation de dormir le moins possible peut être forte… Voire même où ne pas dormir est encouragé et considéré comme un acte héroïque… Alors qu’une bonne nuit de sommeil entre deux journées intenses fait tellement de bien !
Bien sûr, à chacun de connaître ses limites et de savoir de combien d’heures de sommeil par nuit il a besoin pour fonctionner. Mais ensuite, à lui de s’y tenir pour être en forme pour la journée !
Et, pour finir : oui, des fois, de temps en temps et occasionnellement, bosser / coder / écrire / jouer jusqu’à l’épuisement, ça peut être sympa aussi ;-)
Les heures où une partie importante du CA de la journée se fait, ou les heures où un site down serait remarqué par les clients et utilisateurs — ce qui sont des définitions tout à fait valables de « heures importantes ». ↩
Et qu’ils dorment, pas qu’ils aillent faire la fête toute la journée ! ↩
Même si, bien sûr, nous savons tous qu’il n’y a jamais d’imprévus dans nos métiers ^^. ↩
À la réflexion quelques années après et avec un peu plus d’expérience, nous aurions peut-être pu procéder autrement, de manière un peu plus souple (ou « agile »), pour peut-être réduire la durée de cette mise en production et éviter qu’elle ne dure près de 24h — en même temps, il s’agissait réellement d’une migration majeure, et pas d’un simple déploiement quotidien ;-) ↩
Je garde néanmoins un fort bon souvenir de cette expérience : j’étais avec des collègues qui savaient ce qu’ils faisaient — et le sentiment d’accomplissement à la fin (ou le lendemain ^^) est tellement agréable ! ↩
Quelques jours de rush de temps en temps, ça arrive, je n’ai pas de problème avec ça. Mais quand ça se transforme en tous les jours pendant plusieurs semaines, ça me chagrine un peu plus ;-) ↩
Ou à un autre jeu à la mode en ce moment : je n’ai jamais tellement joué et je ne suis plus réellement au fait des jeux qui occupent les soirées de certains d’entre nous, à présent. Mais ça vaut aussi pour coder la moitié de la nuit ;-) ↩
When doing code reviews together with our customers we see a pattern regularly which I consider problematic in multiple regards – the usage of null as a valid property or return value. We can do better than this.
A common problem in video games is to calculate the angle to launch a projectile to hit a target. It’s so common I’ve written code to solve it on literally every game I’ve ever worked on.
Each time this problem comes up I tend to grab a pen and pad to re-solve it from scratch. I’m tired of doing that. To save future-self some time I’m going to put the solution on the internet. I’m also going to share a twist that I often prefer for design purposes.
TL;DR
Want to skip the words and see the final result? Fine. I don’t blame you. Even if it makes me a little sad.
The problem always starts the same. Given a launcher and a target, at what angle must the projectile launch to hit the target?
There are four basic equations of motion. Today we’ll only be using one of them.
In plain English, the final position EQUALS initial position PLUS velocity times time PLUS one-half acceleration times time-squared. This simple equation, a little algebra, and a few trigonometric identities is all we need.
Refresh
Here’s a quick refresher before we get started.
Given a projectile with fixed speed S and launch angle θ (theta) we can compute the x and y components of velocity. Or if we have S and can otherwise determine y then we can solve for θ and x.
We’ll be using some Algebra.
We’ll be making heavy use of the quadratic formula.
Range
For video games we probably want to know the maximum range of a projectile. AI needs to know how close to move. Players need clear visual indicators showing danger zones.
There is a very simple equation for maximum range on a flat surface. But we’re going to jump off the deep end and start with the generalized form.
Given a projectile with fixed speed (S) and gravity (G) what is it’s max range?
Substitute known variables (y0, S, G) into our basic equation of motion.
Apply quadratic formula. Ignore smaller term.
Plug t back into x = S*cos θ*t and simplify.
Voila!
To determine maximum range use θ=45 degrees. If y0=0 and θ=45 then the big ugly formula reduces to S^2/G.
Demo
For testing and to provide visualizations I created a Unity demo. It involves teapots shooting teapots. Pew pew!
The demo has a handful of sliders. Here we see the range indicator for a teapot turret. As speed goes up range goes up. As gravity goes up range goes down. Pretty simple.
Take a look at the gif above. When the teapot first starts shooting it looks pretty good. The high arc looks nice and pretty. The low arc feels crisp and efficient.
When range increases it doesn’t look so great. The low arc is almost flat. The high arc is comically high. This is the problem with a fixed speed projectile. It only looks good when the target is at the outskirts of its range.
What if there were a better way?
Lateral Speed
I often prefer to define projectile speed laterally. Only on the ground plane. I then explicitly define arc height. Which means vertical velocity and gravity become variable.
This has several advantages. First, it always looks good!
Second, it’s more intuitive for design. Designers don’t care about absolute speed. They care that a turret has a range of 20 meters and projectiles take 1 second to travel that distance. They shouldn’t need a graphing calculator to change balance numbers. Nor should artistic tweaks affect gameplay mechanics.
Third, it’s easier to hit a moving target. We’ll cover this in more detail in a bit.
A high arc with short target distance looks pretty silly. If you use this method in your game you’ll want to decrease arc height when targets are close.
Solving with Lateral Speed
Given a projectile with lateral speed (S) and peak height (y_peak) what is velocity, gravity to hit a stationary target?
Basic equation of motion
Solve (1) for 2
Define y_peak (user constant) to occur at (1/2)t
Define y_end (target height) to occur at t
Magic!
More magic!
Firing vector is (S, v.y) with gravitational acceleration g
Presto! Hey, wait a second. Magic? That’s cheating! Yes, but for a reason.
Steps (3) and (4) is another two equations with two unknowns. I’m lazy and don’t want to write it out. Plus I’d screw up and flip a sign. So I let a computer solve it for me.
More specifically, I used Wolfram Alpha. I recommend everyone have Wolfram in their toolbox. It’s quite handy.
If a+c == 2b then y0, y_peak, and y_end are collinear. Which means you’re firing in a straight line.
Lateral Speed with Moving Target
At this point we have two different trajectory solutions. But enemies do not tend to stay in place. They move around. We need to solve the trajectory to hit a moving target.
This is where lateral speed shines. By defining speed on the ground plane it’s super easy to solve for a moving target.
Where X is the target position and V is target velocity
Square both sides.
Re-arrange into quadratic
Apply quadratic formula
For steps 5 through 9 refer to the previous section.
What if we wanted to hit a moving target with a fixed speed projectile? Oh boy. This is a can of worms! You don’t even know.
I’ve never actually shipped this in my career. Generally speaking games don’t want pinpoint artillery. It’s not fun! Instead you ballpark the future position and aim at a random point nearby. When players think of artillery they think of dumb shells raining around. Not perfect, laser guided death.
Writing this blog post I found the solution to a fixed speed projectile and moving target isn’t readily found on the internet. I’ll caveat this by saying you probably don’t want to do this in your game. But I spent a lot of time working this out. And damnit I don’t want that time to be for naught!
Quartics
The reason you don’t want to do this is quartics. The answer fundamentally involves a quartic.
Quadratics have an easy, elegant solution through the quadratic formula. Cubics are solvable a few different ways. Quartics are a bitch.
Solving quartics is well beyond the scope of this article. To be honest it’s beyond the scope of my mathematics ability. Fortunately for us, Graphics Gems I from 1990 has code for solving quartics. It’s available here. I used this code for my demo. I can not speak to it’s accuracy or numerical stability. Proceed with extreme caution.
Method One
Alright then. Let’s solve it. What is the angle to fire a projectile with fixed speed at a moving target? This method comes from a 2007 blog post by James McNeill. With reinforcement Ryan Juckett.
Where P is target position and V is target velocity
Square both sides
Re-arrange terms
Calculate quartic coefficients and plug into SolveQuartic
Use t to calculate target position then calculate trajectory to stationary point.
This works. The heavy lifting is in SolveQuartic. We then use the stationary target solver from earlier in the post.
Method 2
Before discovering method one I derived the solution a different way. It involves way, way more steps. But I find the end result more elegant. Plus I used like 8 pages of papers and I don’t want those trees to have sacrificed themselves in vain.
Holy crap. Thirty two steps!? It’s worse than it looks.
1–7; Declare variables.
8–11; Declare system of equations. Four equations, four unknowns - d, e, f, t.
12–15; Solve (8) for d. Multiply out d^2 for later.
16–19; Solve (10) for f. Multiply out f^2 for later.
20–24; Solve (9) for e. Multiply out e^2 for later.
25–27; Solve (11) for e^2. Substitute d^2 and f^2.
28–30; Set (27) equal to (24). Multiply by t^2 and arrange into quartic.
31; Plug coefficients into SolveQuartic.
32; Plug positive, real roots into (14), (18), (23) for d, e, f.
The code is quite short. There are more lines devoted to variable declaration than actual math! Aside from SolveQuartic of course.
That’s not so scary looking is it? It’s a little more complicated as there are multiple solutions. One for each positive, real root returned by SolveQuartic.
I feel method two is a little cleaner than method one. After solving the quartic you can plug t into three simple formulas. That’s better than calling a stationary target solver which does a bunch of work.
Code written for this test has not been battle tested. Nor has this post been peer reviewed. There are probably a handful typos, errors, and mishandled cases. If you find such a mistake please let me know. Discretely so no one knows my shame. :)
In the meantime treat this not as a finished solution but a solid starting point.
Creation Tools
I used a handful of tools in the creation of this post. Several of which were new to me.
That just about does it. I spent way more time on this post than I expected. I solved a case I’d never solved before and I learned a few new tools. A worthwhile endeavor.
Nothing in this post is new or original. I tried to explain things thoroughly without being overly verbose. I feel pretty good having complete descriptions all in one place. Hopefully this is helpful to a few folks out there.
Solving Ballistic Trajectories was originally published in Dev Curious on Medium, where people are continuing the conversation by highlighting and responding to this story.
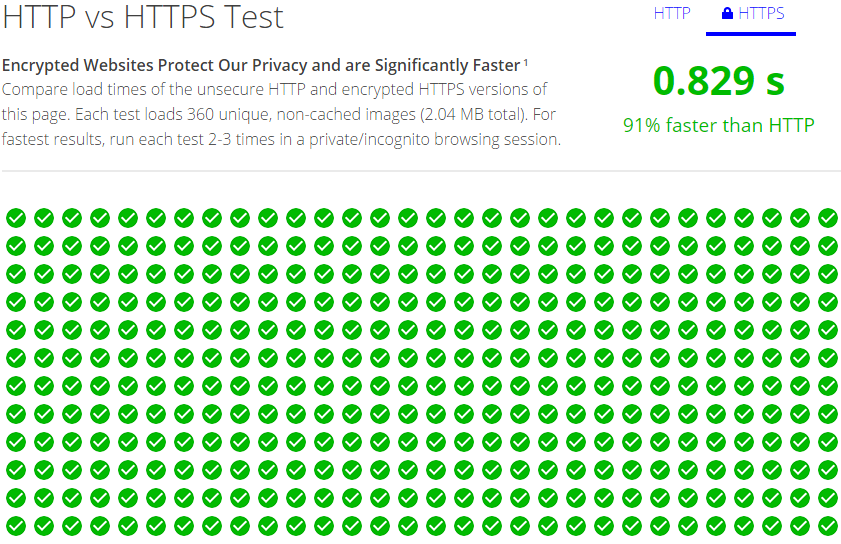
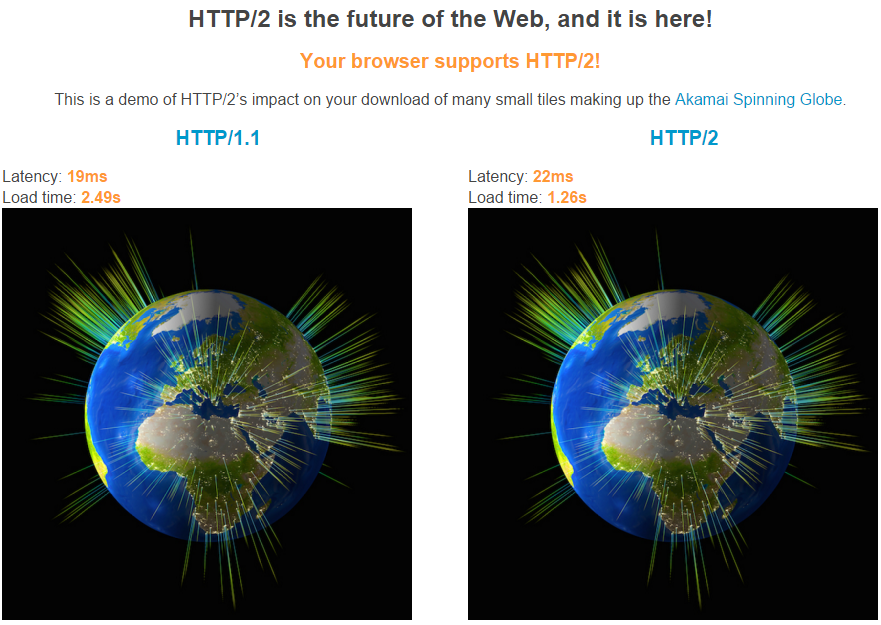
OK, now that you’ve changed all those passwords, tell me: how secure were your passwords? Can you even still remember them?
If you’re using a password manager like LastPass, great — it will remember your passwords for you. It will even generate “high entropy” passwords, where the sun will burn out before someone could crack it (50-character strings of random letters, numbers, and symbols).
But what about when you’re on your phone, or on someone else’s computer? Do you really want to install LastPass just to be able to log into LinkedIn on another device?
Oh, and in case you missed it, LastPass got hacked recently. That’s right — even companies whose core value proposition is security can still get hacked.
There are two types of companies: those who have been hacked, and those who don’t yet know they have been hacked. — John Chambers
OK — you didn’t use a password manager. Instead, you came up with a really secure password. You used symbols, a number, and even an uppercase letter (which is a huge effort considering how much everyone hates to press the shift key).
But now you can’t remember this complicated new password very easily.
It’s cool. We’ll just come up with some really long passwords that are easy to remember, but hard to guess.
As appealing as the above XKCD approach may seem, random common words aren’t any easier to remember, and are harder to type correctly, according to a Carnegie Mellon University study.
OK, so numbers, symbols, and uppercase letters it is. Gosh, these are still so hard to remember. Just write it down on a sticky note, and stick it to the bezel of our monitor with all of your other passwords, for easy reference.
Just kidding. Everyone knows that writing a password down is the most dangerous thing you can do, right? Right?
Actually, there’s something that’s even worse. It’s using the same password on more than one website. Because this means that if one of those websites gets hacked, the hackers can use that same password to break into your accounts on other websites.
But since creating and remembering multiple passwords is inconvenient, more than half of people use the same passwords on multiple sites.
You go to a website, click the “forgot password” button, and type in your email address
You open an email from their website and click a magic link they sent you
This magic link takes you back to their website and logs you, then forces you to come up with a new password that meets their password requirements (and every website’s requirements are different)
If you think about this for a moment, you’ll realize that your password does not actually matter. The only thing that matters is that you have access to the email address that’s associated with your account.
Thanks to the password reset functionality that every website uses, every website already supports passwordless login — they just don’t call it that.
So wait — if anyone who can access your email account can get into your other accounts without knowing your password, why the heck do we even need passwords?
What if instead of constantly resetting our passwords, we used that same passwordless login that those “forgot password” buttons use, but simply logged in without pestering people to create a new (useless) password?
Here’s what happens on websites that use passwordless login:
You go to their website and type in your email address
You open an email from their website and click a magic link that takes you back to their website and logs you in
Wow. The exact same level of security as a password reset, but you don’t need to spend minutes coming up with a password. And you don’t have to go back in and change this password the next time another major website gets hacked.
Again, the only way someone can break into your account is if they can gain access to your personal email address.
And if they can do that, they can gain access to your other accounts anyway, because your email account is the skeleton key to your life. It’s literally the only website that actually must require a password (and with biometrics and other security innovations, even that password may soon become unnecessary).
Passwords are a huge inconvenience. The average person has literally spent waking days of their life creating, remembering, and resetting passwords.
And the ironic thing is that passwords themselves don’t make you more secure — they make you less secure.
No clue. I think it’s just expected that they use passwords. Maybe it makes people feel more secure. Maybe people think it’s faster to use passwords than than to tab over to their email inbox. It isn’t. In the time it takes to reset one password, you could have used a passwordless login 10 or 20 times.
Most websites never log you out because they know you’ll forget your password, and probably won’t bother signing back in. When was the last time Facebook prompted you for your password?
Microsoft announced this week that they are banning all common passwords. As of 2016, the most common passwords are still “123456” and “password”, with “starwars” and “ncc1701” not far behind them.
Free Code Camp is getting rid of passwords. We’re going to start just sending you a magic link when you want to sign in for the first time on a new device.
We’re not the first website to do this, either. If you used your email address to sign up for Medium, you probably noticed that they don’t use passwords anymore, either.
It's been more than three years since the first modern commercial smartwatches, the Pebble and the Sony SmartWatch, hit the market and this wearable device category still hasn't taken the industry by storm. In the meantime, less powerful and less featured smart fitness bands are flooding the market and is giving some well-deserved and long overdue attention to healthier lifestyles … Continue reading
30 ans après l'accident nucléaire, les grands mammifères se portent bien. Mieux même que du temps où l'homme habitait la région. C'est le cas en particulier du loup.
Un Wi-Fi 10.000 fois moins gourmand en énergie - 2 Photos
Si le Wi-Fi est désormais indispensable à l'internet mobile, il a un gros inconvénient : il consomme beaucoup d’énergie. Il est souvent recommandé de désactiver le Wi-Fi (ainsi que le GPS) de son smartphone ou sa tablette lorsque l’on ne s’en sert pas afin d’économiser la batterie. C’est aussi pour cette raison que d’autres technologies moins gourmandes telles que le Bluetooth, le Zigbee, Z-Wave, etc. sont préférées au Wi-Fi pour les montres connectées et les bracelets d’activité, les installations domotiques, les capteurs environnementaux et médicaux...
Mais voilà que des chercheurs de l’université de Washington (UW) nous promettent une petite révolution avec un Wi-Fi « passif » qui serait jusqu’à 10.000 fois moins énergivore que le Wi-Fi que nous utilisons actuellement et jusqu’à 1.000 fois moins que du Bluetooth Low Energy ou du Zigbee.
Pour concevoir leur « passive Wi-Fi », les scientifiques ont remis à plat le fonctionnement du système de transmission radio qui repose sur des opérations numériques et analogiques. « Au cours des 20 dernières années, la partie numérique de l’équation est devenue très efficace d’un point de vue énergétique mais les composants analogiques consomment toujours beaucoup d’énergie », expliquent-ils. Les chercheurs ont donc séparé les deux opérations avec un module analogique branché sur le secteur qui envoie ses ondes radio à des capteurs Wi-Fi passifs spécialement conçus.
Ces capteurs, qui consomment entre 15 et 60 microwatts selon la bande passante, absorbent les ondes analogiques et les réfléchissent sous forme de « paquets Wi-Fi » grâce à un commutateur numérique. Il s’agit d’un système de « rétrodiffusion ambiante » ou ambiant backscattering qui s’apparente au Morse. Le principe est proche du fonctionnement des puces RFID à la différence que ces dernières nécessitent des lecteurs spécifiques et n’ont une portée que de quelques centimètres. Selon les scientifiques de l’UW, ces capteurs sont compatibles avec n’importe quel appareil électronique muni d’une puce Wi-Fi.
La transmission peut atteindre un débit de 11 Mbit/s vers des smartphones, des routeurs ou d’autres équipements. L’équipe de l’université de Washington dit avoir fait fonctionner le dispositif jusqu’à une portée de 30 mètres. Ces performances de débit et de distance correspondent à celles du Wi-Fi 802.11b. Elles seraient amplement suffisantes pour que le Wi-Fi passif puisse se substituer au Bluetooth et à d’autres protocoles sans fil pour un grand nombre d’objets communicants.
Nous parlions des montres et des bracelets connectés, mais cela concerne également toutes les installations domotiques (serrures, thermostats, ampoules intelligentes, détecteurs de fumée…) ainsi que tous les capteurs que l’on englobe dans l’internet des objets. Les chercheurs de l’UW estiment que les capteurs Wi-Fi passifs pourraient être fabriqués pour un coût inférieur à un dollar. Ils ont d’ailleurs créé une entreprise, Jeeva Wireless, pour commercialiser leur innovation. Précisons également que le fabricant de puces de communication Qualcomm a cofinancé ces travaux qui font l’objet d’un article (Passive Wi-Fi : Bringing Low Power to Wi-Fi Transmissions) qui sera présenté le mois prochain lors du Usenix Symposium on Networked System Design and Implementation.
Pour y voir plus clair dans les nouveaux tarifs SNCF.
Les tarifs SNCF des TGV et Intercités ont évolué le premier mai. Le changement le plus commenté est le durcissement des conditions d’échange et de remboursement des billets Loisir (les tarifs standards sans carte ni abonnement). Il s’agit cependant de la contrepartie d’une excellente nouvelle pour les voyageurs, moins apparente : les prix baissent pour ces billets Loisir et les cartes de réduction.
Tremble Blablacar !
La SNCF se devait de dépoussiérer son offre tarifaire. Ces dernières années ont vu de gros changements sur l’offre de transport : le covoiturage et l’autocar ont permis de se déplacer à bas coût tout en s’y prenant à la dernière minute.
Le billet Loisir était trop flexible, ce qui était finalement un désavantage pour les voyageurs, car cela tirait les prix vers le haut. Explication : de nombreux billets étaient annulés à la dernière minute, sans que les places ne soient revendues. Or en permettant un meilleur remplissage des trains, il est possible de baisser le prix moyen du billet. Sinon, les voyageurs restants doivent payer pour ceux qui ont annulé à la dernière minute.
Pour un voyageur Loisir, en dépit des imprévus, l’annulation tardive de son week-end reste un cas relativement minoritaire. À l’inverse, la volonté de ces voyageurs de profiter de prix réduits n’a jamais été aussi forte. Entre la flexibilité et le prix, la SNCF a choisi en faveur du prix.
La SNCF souhaite également avoir une clientèle plus fidèle au train, par rapport aux autres modes de transport. Elle a donc rendu ses cartes de réduction (Enfant+, Jeune, Week-End et Senior+) plus attractives, en baissant les prix et en multipliant les offres de dernière minute.
Par ailleurs, l’offre Pro n’était pas beaucoup plus avantageuse en termes de flexibilité. Les voyageurs d’affaires se reportaient donc sur des billets à prix réduit normalement réservés aux voyageurs Loisir. La SNCF s’aligne en réalité sur les autres transporteurs européens, en créant une vraie offre semi-flexible (échangeable et remboursable avec frais), avec une différence de flexibilité mais également de prix accrue avec le tarif Pro.
S’adapter pour profiter du changement tarifaire
Si vous voyagez en train, hors raisons professionnelles (pour aller voir mamie, pour partir en week-end en amoureux ou en vacances), le choix de votre tarif dépend de la fréquence de vos voyages.
Vous voyagez moins de deux fois par an en train
Prenez-vous y en avance, en choisissant entre Prem’s (peu cher mais non flexible) ou Loisir si vous n’avez pas la certitude de voyager. Notre curseur tarifaire est là pour vous sauver.
Vous prenez le train deux fois ou plus par an
Dans ce cas, vous êtes susceptible d’être intéressé par une carte de réduction. Il y en a pour tous les âges : Enfant+, Jeune, Week-End ou Senior+. Ces cartes sont payantes, et vous pouvez les acheter chez nous.
Pour les adultes qui pensent ne pas avoir droit à une quelconque réduction, il y a la méconnue carte Week-End. Elle a une contrainte : vous devez réaliser un aller-retour qui inclut au moins un bout d’un week-end (du vendredi soir au dimanche soir), le but étant d’exclure les voyageurs d’affaires qui font l’aller retour pendant la semaine. En contrepartie, vous avez droit à un accompagnateur sans carte qui profite de la même réduction.
Les cartes de réduction vous permettent d’obtenir 25 % de réduction garantis sur le prix Loisir du moment. Si des Prem’s sont disponibles, vous avez à présent une réduction de 10 % sur ces billets. Vous obtenez également des réductions sur des trajets internationaux vers la Suisse, l’Allemagne ou l’Italie. Enfin, vous trouverez régulièrement des offres de dernière minute réservées aux détenteurs de carte.
Les conditions d’échange et de remboursement sont également plus souples qu’avec le tarif Loisir, avec une annulation sans frais jusqu’à l’avant-veille du départ.
Vous êtes un voyageur d’affaires
Que vous soyez un habitué des aller-retour TGV pour vous rendre sur votre lieu de travail ou un commercial qui court le pays pour signer des contrats, vous êtes un voyageur d’affaires.
L’affaire se corse d’ailleurs pour vous car, petit malin, vous aviez l’habitude de réserver des billets Loisir. Or vous avez probablement besoin d’un peu plus de flexibilité que ce qui vous est offert à présent.
Plusieurs solutions s’offrent à vous, en fonction de votre volume de voyage :
Vous continuez à prendre des billets Loisir, et tant pis s’il faut partir de la réunion qui s’éternise avant la fin pour ne pas rater le train.
Vous passez au tarif Pro. De toute façon, « c’est la boîte qui paye ». Voici un souci en moins : les annulations ou les échanges de dernière minute ne devraient plus vous tracasser, tant qu’il y a un train vous pourrez le prendre (car oui, il est possible de réaliser un échange vers un train plein, et ce même après le départ de votre train original).
Si vous êtes un voyageur d’affaires fréquent, vous pouvez opter pour les abonnements Fréquence 25 (utilisables sur Captain Train for Business), Fréquence 50 ou Forfait.
Mais c’est compliqué tout ça !
Oui, c’est vrai. Et encore, nous ne vous avons pas parlé des quelque tarifs hérités de l’obligation de service public (Famille Nombreuse), ni des tarifs pour les Intercités à réservation facultative et les TER, ni des liaisons internationales qui sont à part, ni des filiales comme iDTGV et OUIGO…
L’offre SNCF est la plus complexe parmi tous les transporteurs que nous vous offrons, et c’est bien un des reproches qui lui est fait : les voyageurs n’y comprennent plus grand chose. Le yield management, c’est à dire l’augmentation du prix du même billet (à ne pas confondre avec l’IP tracking, non pratiqué par la SNCF), rajoute au sentiment d’opacité.
Cependant, la SNCF a pris conscience du problème du prix, et à travers ses cartes de réduction et ses nouveaux tarifs Loisir, tente à nouveau de « vous faire préférer le train ». Et nous espérons de notre côté vous avoir aidés à vous y retrouver parmi tous ces tarifs.
Cet article provient du blog de Captain Train, le site d'achat de billets de train simple et rapide.
Oh joie, oh bonheur ! Grammalecte est enfin disponible en tant qu'extension pour Firefox ! L'annonce officielle est disponible ici et l'extension est téléchargeable ici.
Avec cette extension, vous n'avez plus d'excuse si vous laissez passer des fautes dans vos billets, et moi le premier. J'ai l'habitude de laisser les commentaires qui me signalent des coquilles et d'attendre les messages privés de Phipe via diaspora* pour corriger mes billets.
Bon, après, je dis ça alors que je découvre tristement que la fenêtre de saisie du texte d'un billet de PluXml n'est pas prise en compte par Grammalecte alors que la zone de saisie du titre du billet l'est. #Tristitude
Nul doute que ça sera corrigé dans une future version de l'extension ou dans la prochaine version du CMS. Ça se trouve, ce n'est qu'une histoire de balise HTML mal placée.
j'en profite pour fanfaronner : cette extension n'est disponible que sous Firefox. Si ça, ce n'est pas une bonne raison pour bon nombre d'entre nous qui aurait lâché le butineur de Mozilla au profit de celui de Google pour revenir dans le droit chemin, j'sais pas ce qu'il faut pour vous convaincre ! ;-)
Researchers have developed a new solar powered battery, capable of changing its shape to fit various flexible forms.
The University of Illinois, Northwest University, and researchers in South Korea and China developed the battery. The team says the battery could transform the wearables market by lowering the space required for a battery, a big benefit for e-skin and e-clothes products.
“The components are electronically connected via flexible copper-polymer interconnects, mounted on a highly elastic silicone core, and enclosed within a silicone shell,” the team said. “The resulting system could stretch up to 30 percent without detectable loss in solar power generation.”
While we have heard of battery breakthroughs in the past that have led to nothing, this team seems confident that companies in the wearable market will look into the new flexible battery.
“The authors demonstrated the use of these systems for continual logging and wireless transmission of body temperature data in a variety of realistic scenarios, such as monitoring skin temperature during physical exercise and bathing, and measuring temperature changes during breathing.”
Battery to aid discreet health wearables the most?
Inconspicuous wearables could be a major benefit in the health market. Products like a smart t-shirt or trousers may provide more information on your health and fitness than a wearable only able to check your pulse.
The big step is making those wearables blend into normal clothes, something the e-clothes industry has been unable to do so far. The battery may also be a welcome addition to the e-skin market, with researchers recently creating a much longer lasting tattoo that changes color and can even track things like UV rays and heart-rate.
Wearables are still a young market, but with 67 percent growth from 2015 to 2016, more companies are starting to see the potential of devices able to gather more data on the customer.
The time-based job scheduler cron(8) has been around since Version 7 Unix, and its crontab(5) syntax is familiar even for people who don’t do much Unix system administration. It’s standardised, reasonably flexible, simple to configure, and works reliably, and so it’s trusted by both system packages and users to manage many important tasks.
However, like many older Unix tools, cron(8)‘s simplicity has a drawback: it relies upon the user to know some detail of how it works, and to correctly implement any other safety checking behaviour around it. Specifically, all it does is try and run the job at an appropriate time, and email the output. For simple and unimportant per-user jobs, that may be just fine, but for more crucial system tasks it’s worthwhile to wrap a little extra infrastructure around it and the tasks it calls.
There are a few ways to make the way you use cron(8) more robust if you’re in a situation where keeping track of the running job is desirable.
Apply the principle of least privilege
The sixth column of a system crontab(5) file is the username of the user as which the task should run:
0 * * * * root cron-task
To the extent that is practical, you should run the task as a user with only the privileges it needs to run, and nothing else. This can sometimes make it worthwhile to create a dedicated system user purely for running scheduled tasks relevant to your application.
0 * * * * myappcron cron-task
This is not just for security reasons, although those are good ones; it helps protect you against nasties like scripting errors attempting to remove entire system directories.
Similarly, for tasks with database systems such as MySQL, don’t use the administrative root user if you can avoid it; instead, use or even create a dedicated user with a unique random password stored in a locked-down ~/.my.cnf file, with only the needed permissions. For a MySQL backup task, for example, only a few permissions should be required, including SELECT, SHOW VIEW, and LOCK TABLES.
In some cases, of course, you really will need to be root. In particularly sensitive contexts you might even consider using sudo(8) with appropriate NOPASSWD options, to allow the dedicated user to run only the appropriate tasks as root, and nothing else.
Test the tasks
Before placing a task in a crontab(5) file, you should test it on the command line, as the user configured to run the task and with the appropriate environment set. If you’re going to run the task as root, use something like su or sudo -i to get a root shell with the user’s expected environment first:
$ sudo -i -u cronuser
$ cron-task
Once the task works on the command line, place it in the crontab(5) file with the timing settings modified to run the task a few minutes later, and then watch /var/log/syslog with tail -f to check that the task actually runs without errors, and that the task itself completes properly:
May 7 13:30:01 yourhost CRON[20249]: (you) CMD (cron-task)
This may seem pedantic at first, but it becomes routine very quickly, and it saves a lot of hassles down the line as it’s very easy to make an assumption about something in your environment that doesn’t actually hold in the one that cron(8) will use. It’s also a necessary acid test to make sure that your crontab(5) file is well-formed, as some implementations of cron(8) will refuse to load the entire file if one of the lines is malformed.
If necessary, you can set arbitrary environment variables for the tasks at the top of the file:
MYVAR=myvalue
0 * * * * you cron-task
Don’t throw away errors or useful output
You’ve probably seen tutorials on the web where in order to keep the crontab(5) job from sending standard output and/or standard error emails every five minutes, shell redirection operators are included at the end of the job specification to discard both the standard output and standard error. This kluge is particularly common for running web development tasks by automating a request to a URL with curl(1) or wget(1):
Ignoring the output completely is generally not a good idea, because unless you have other tasks or monitoring ensuring the job does its work, you won’t notice problems (or know what they are), when the job emits output or errors that you actually care about.
In the case of curl(1), there are just way too many things that could go wrong, that you might notice far too late:
The script could get broken and return 500 errors.
The URL of the cron.php task could change, and someone could forget to add a HTTP 301 redirect.
Even if a HTTP 301 redirect is added, if you don’t use -L or --location for curl(1), it won’t follow it.
The client could get blacklisted, firewalled, or otherwise impeded by automatic or manual processes that falsely flag the request as spam.
If using HTTPS, connectivity could break due to cipher or protocol mismatch.
The author has seen all of the above happen, in some cases very frequently.
As a general policy, it’s worth taking the time to read the manual page of the task you’re calling, and to look for ways to correctly control its output so that it emits only the output you actually want. In the case of curl(1), for example, I’ve found the following formula works well:
curl -fLsS -o /dev/null http://example.com/
-f: If the HTTP response code is an error, emit an error message rather than the 404 page.
-L: If there’s an HTTP 301 redirect given, try to follow it.
-sS: Don’t show progress meter (-S stops -s from also blocking error messages).
-o /dev/null: Send the standard output (the actual page returned) to /dev/null.
This way, the curl(1) request should stay silent if everything is well, per the old Unix philosophy Rule of Silence.
You may not agree with some of the choices above; you might think it important to e.g. log the complete output of the returned page, or to fail rather than silently accept a 301 redirect, or you might prefer to use wget(1). The point is that you take the time to understand in more depth what the called program will actually emit under what circumstances, and make it match your requirements as closely as possible, rather than blindly discarding all the output and (worse) the errors. Work with Murphy’s law; assume that anything that can go wrong eventually will.
Send the output somewhere useful
Another common mistake is failing to set a useful MAILTO at the top of the crontab(5) file, as the specified destination for any output and errors from the tasks. cron(8) uses the system mail implementation to send its messages, and typically, default configurations for mail agents will simply send the message to an mbox file in /var/mail/$USER, that they may not ever read. This defeats much of the point of mailing output and errors.
This is easily dealt with, though; ensure that you can send a message to an address you actually do check from the server, perhaps using mail(1):
Once you’ve verified that your mail agent is correctly configured and that the mail arrives in your inbox, set the address in a MAILTO variable at the top of your file:
MAILTO=you@example.com
0 * * * * you cron-task-1
*/5 * * * * you cron-task-2
If you don’t want to use email for routine output, another method that works is sending the output to syslog with a tool like logger(1):
0 * * * * you cron-task | logger -it cron-task
Alternatively, you can configure aliases on your system to forward system mail destined for you on to an address you check. For Postfix, you’d use an aliases(5) file.
I sometimes use this setup in cases where the task is expected to emit a few lines of output which might be useful for later review, but send stderr output via MAILTO as normal. If you’d rather not use syslog, perhaps because the output is high in volume and/or frequency, you can always set up a log file /var/log/cron-task.log … but don’t forget to add a logrotate(8) rule for it!
Put the tasks in their own shell script file
Ideally, the commands in your crontab(5) definitions should only be a few words, in one or two commands. If the command is running off the screen, it’s likely too long to be in the crontab(5) file, and you should instead put it into its own script. This is a particularly good idea if you want to reliably use features of bash or some other shell besides POSIX/Bourne /bin/sh for your commands, or even a scripting language like Awk or Perl; by default, cron(8) uses the system’s /bin/sh implementation for parsing the commands.
Because crontab(5) files don’t allow multi-line commands, and have other gotchas like the need to escape percent signs % with backslashes, keeping as much configuration out of the actual crontab(5) file as you can is generally a good idea.
If you’re running cron(8) tasks as a non-system user, and can’t add scripts into a system bindir like /usr/local/bin, a tidy method is to start your own, and include a reference to it as part of your PATH. I favour ~/.local/bin, and have seen references to ~/bin as well. Save the script in ~/.local/bin/cron-task, make it executable with chmod +x, and include the directory in the PATH environment definition at the top of the file:
PATH=/home/you/.local/bin:/usr/local/bin:/usr/bin:/bin
MAILTO=you@example.com
0 * * * * you cron-task
Having your own directory with custom scripts for your own purposes has a host of other benefits, but that’s another article…
Avoid /etc/crontab
If your implementation of cron(8) supports it, rather than having an /etc/crontab file a mile long, you can put tasks into separate files in /etc/cron.d:
$ ls /etc/cron.d
system-a
system-b
raid-maint
This approach allows you to group the configuration files meaningfully, so that you and other administrators can find the appropriate tasks more easily; it also allows you to make some files editable by some users and not others, and reduces the chance of edit conflicts. Using sudoedit(8) helps here too. Another advantage is that it works better with version control; if I start collecting more than a few of these task files or to update them more often than every few months, I start a Git repository to track them:
If you’re editing a crontab(5) file for tasks related only to the individual user, use the crontab(1) tool; you can edit your own crontab(5) by typing crontab -e, which will open your $EDITOR to edit a temporary file that will be installed on exit. This will save the files into a dedicated directory, which on my system is /var/spool/cron/crontabs.
On the systems maintained by the author, it’s quite normal for /etc/crontab never to change from its packaged template.
Include a timeout
cron(8) will normally allow a task to run indefinitely, so if this is not desirable, you should consider either using options of the program you’re calling to implement a timeout, or including one in the script. If there’s no option for the command itself, the timeout(1) command wrapper in coreutils is one possible way of implementing this:
cron(8) will start a new process regardless of whether its previous runs have completed, so if you wish to avoid locking for long-running task, on GNU/Linux you could use the flock(1) wrapper for the flock(2) system call to set an exclusive lockfile, in order to prevent the task from running more than one instance in parallel.
0 * * * * you flock -nx /var/lock/cron-task cron-task
Greg’s wiki has some more in-depth discussion of the file locking problem for scripts in a general sense, including important information about the caveats of “rolling your own” when flock(1) is not available.
If it’s important that your tasks run in a certain order, consider whether it’s necessary to have them in separate tasks at all; it may be easier to guarantee they’re run sequentially by collecting them in a single shell script.
Do something useful with exit statuses
If your cron(8) task or commands within its script exit non-zero, it can be useful to run commands that handle the failure appropriately, including cleanup of appropriate resources, and sending information to monitoring tools about the current status of the job. If you’re using Nagios Core or one of its derivatives, you could consider using send_nsca to send passive checks reporting the status of jobs to your monitoring server. I’ve written a simple script called nscaw to do this for me:
0 * * * * you nscaw CRON_TASK -- cron-task
Consider alternatives to cron(8)
If your machine isn’t always on and your task doesn’t need to run at a specific time, but rather needs to run once daily or weekly, you can install anacron and drop scripts into the cron.hourly, cron.daily, cron.monthly, and cron.weekly directories in /etc, as appropriate. Note that on Debian and Ubuntu GNU/Linux systems, the default /etc/crontab contains hooks that run these, but they run only if anacron(8) is not installed.
If you’re using cron(8) to poll a directory for changes and run a script if there are such changes, on GNU/Linux you could consider using a daemon based on inotifywait(1) instead.
Finally, if you require more advanced control over when and how your task runs than cron(8) can provide, you could perhaps consider writing a daemon to run on the server consistently and fork processes for its task. This would allow running a task more often than once a minute, as an example. Don’t get too bogged down into thinking that cron(8) is your only option for any kind of asynchronous task management!
Software is written for people to understand; variable names should
be chosen accordingly. People need to comb through your code and
understand its intent in order to extend or fix it. Too often,
variable names waste space and hinder comprehension. Even
well-intentioned engineers often choose names that are, at best, only
superficially useful. This document is meant to help engineers choose
good variable names. It artificially focuses on code reviews because
they expose most of the issues with bad variable names. There are, of
course, other reasons to choose good variable names (such as improving
code maintenance). This document is also a work-in-progress, please
send me any constructive feedback you might have on how to improve it.
Why Name Variables?
The primary reason to give variables meaningful names is so that a
human can understand them. Code written strictly for a computer could
just as well have meaningless, auto-generated names1:
int f1(int a1, Collection<Integer> a2)
{
int a5 = 0;
for (int a3 = 0; a3 < a2.size() && a3 < a1; a3++) {
int a6 = a2.get(a3);
if (a6 >= 0) {
System.out.println(a6 + " ");
} else {
a5++;
}
}
System.out.println("\n");
return a5;
}
All engineers would recognize the above code is needlessly difficult
to understand, as it violates two common guidelines: 1) don't
abbreviate, and 2) give meaningful names. Perhaps surprisingly, these
guidelines can be counter-productive. Abbreviation isn't always bad,
as will be discussed later. And meaningful is vague and subject to
interpretation. Some engineers think it means that names should always
be verbose (such as MultiDictionaryLanguageProcessorOutput). Others
find the prospect of coming up with truly meaningful names daunting,
and give up before putting in much effort. Thus, even when trying to
follow the above two rules, a coder might write:
int processElements(int numResults, Collection<Integer> collection)
{
int result = 0;
for (int count = 0; count < collection.size() && count < numResults; count++) {
int num = collection.get(count);
if (num >= 0) {
System.out.println(num + " ");
} else {
result++;
}
}
System.out.println("\n");
return result;
}
Reviewers could, with effort, understand the above code more easily
than the first example. The variable names are accurate and readable.
But they're unhelpful and waste space, because:
processElements
most code "processes" things (after all, code
runs on a "processor"), so process is seven wasted characters
that mean nothing more that "compute". Elements isn't much
better. While suggestive that the function is going to operate on
the collection, that much was already obvious. There's even a
bug in the code that this name doesn't help the reader spot.
numResults
most code produces "results" (eventually); so, as
with process, Results is seven wasted
characters. The full variable name, numResults is
suggestive that it might be intended to limit the
amount of output, but is vague enough to impose a
mental tax on the reader.
collection
wastes space; it's obvious that it's a collection
because the previous tokens were
Collection<Integer>.
num
simply recapitulates the type of the object (int)
result, count
are coding cliches; as with numResults they
waste space and are so generic they don't help the reader
understand the code.
However, keep in mind the true purpose of variable names: the reader
is trying to understand the code, which requires both of the
following:
What was the coder's intent?
What does the code actually do?
To see how the longer variable names that this example used are
actually a mental tax on the reader, here's a re-write of the function
showing what meaning a reader would actually glean from those names:
int doSomethingWithCollectionElements(int numberOfResults,
Collection<Integer> integerCollection)
{
int resultToReturn = 0;
for (int variableThatCountsUp = 0;
variableThatCountsUp < integerCollection.size()
&& variableThatCountsUp < numberOfResults;
variableThatCountsUp++) {
int integerFromCollection = integerCollection.get(count);
if (integerFromCollection >= 0) {
System.out.println(integerFromCollection + " ");
} else {
resultToReturn++;
}
}
System.out.println("\n");
return resultToReturn;
}
The naming changes have almost made the code worse than the
auto-generated names, which, at least, were short. This rewrite shows
that coder's intent is still mysterious, and there are now more
characters for the reader to scan. Code reviewers review a lot of
code; poor names make a hard job even harder. How do we make code
reviewing less taxing?
On Code Reviews
There are two taxes on code reviewers' mental endurance: distance
and boilerplate. Distance, in the case of variables, refers to how
far away a reviewer has to scan, visually, in order to remind
themselves what a variable does. Reviewers lack the context that
coders had in mind when they wrote the code; reviewers must
reconstruct that context on the fly. Reviewers need to do this
quickly; it isn't worth spending as much time reviewing code as it
took to write it2. Good variable names eliminate the problem of distance
because they remind the reviewer of their purpose. That way they don't
have to scan back to an earlier part of the code.
The other tax is boilerplate. Code is often doing something
complicated; it was written by someone else; reviewers are often
context-switching from their own code; they review a lot of code,
every day, and may have been reviewing code for many years. Given all
this, reviewers struggle to maintain focus during code reviews.
Thus, every useless character drains the effectiveness of code
reviewing. In any one small example, it's not a big deal for code to
be unclear. Code reviewers can figure out what almost any code does,
given enough time and energy (perhaps with some follow-up questions to
the coder). But they can't afford to do that over and over again, year
in and year out. It's death by 1,000 cuts.
A Good Example
So, to communicate intent to the code reviewer, with a minimum of
characters, the coder could rewrite the code as follows:
int printFirstNPositive(int n, Collection<Integer> c)
{
int skipped = 0;
for (int i = 0; i < c.size() && i < n; i++) {
int maybePositive = c.get(i);
if (maybePositive >= 0) {
System.out.println(maybePositive + " ");
} else {
skipped++;
}
}
System.out.println("\n");
return skipped;
}
Let's analyze each variable name change to see why they make the code
easier to read and understand:
printFirstNPositive
unlike processElements, it's now clear
what the coder intended this function to do (and there's a
fighting chance of noticing a bug)
n
obvious given the name of the function, no need for a more
complicated name
c
collection wasn't worth the mental tax it imposed, so at
least trim it by 9 characters to save the reader the mental
tax of scanning boilerplate characters; since the function is
short, and there's only one collection involved, it's easy to
remember that c is a collection of integers
skipped
unlike results, now self-documents (without a
comment) what the return value is supposed to be. Since
this is a short function, and the declaration of
skipped as an int is plain to see, calling it
numSkipped would have just wasted 3 characters
i
iterating through a for loop using i is a
well-established idiom that everyone instantly understands.
Give that count was useless anyway, i is preferable since
it saves 4 characters
maybePositive
num just meant the same thing int did,
whereas maybePositive is hard to misunderstand and may help one
spot a bug
It's also easier, now, to see there are two bugs in the code. In the
original version of the code, it wasn't clear if that the coder
intended to only print positive integers. Now the reader can notice
that there's a bug, because zero isn't positive (so n should be
greater than 0, not greater-than-or-equals). (There should also be
unit tests). Furthermore, because the first argument is now called
maxToPrint (as opposed to, say, maxToConsider), it's clear the
function won't always print enough elements if there are any
non-positive integers in the collection. Rewriting the function
correctly is left as an exercise for the reader.
Naming Tenets (Unless You Know Better Ones)
As coders our job is to communicate to human readers, not
computers.
Don't make me think. Names should communicate the coder's
intent so the reader doesn't have to try to figure it out.
Code reviews are essential but mentally taxing. Boilerplate must
be minimized, because it drains reviewers' ability to concentrate on
the code.
We prefer good names over comments but can't replace all comments.
Cookbook
To live up to these tenets, here are some practical guidelines to use
when writing code.
Don't Put the Type in the Name
Putting the type of the variable in the name of the variable imposes a
mental tax on the reader (more boilerplate to scan over) and is often
a poor substitute for thinking of a better name. Modern editors like
Eclipse are also good at surfacing the type of a variable easily,
making it redundant to add the type into the name itself. This
practice also invites being wrong; I have seen code like this:
Set<Host> hostList = hostSvc.getHosts(zone);
The most common mistakes are to append Str or String to the name,
or to include the type of collection in the name. Here are some
suggestions:
Bad Name(s)
Good Name(s)
hostList, hostSet
hosts, validHosts
hostInputStream
rawHostData
hostStr, hostString
hostText, hostJson, hostKey
valueString
firstName, lowercasedSKU
intPort
portNumber
More generally:
Pluralize the variable name instead of including the name of a
collection type
If you're tempted to add a scalar type (int, String, Char) into your
variable name, you should either:
Explain better what the variable is
Explain what transformation you did to derive the new variable
(lowercased?)
Use Teutonic Names Most of The Time
Most names should be Teutonic, following the spirit of languages like
Norwegian, rather than the elliptical vagueness of Romance languages
like English. Norwegian has more words like tannlege (literally
"tooth doctor") and sykehus (literally "sick house"), and fewer
words like dentist and hospital (which don't break down into other
English words, and are thus confusing unless you already know their
meaning). You should strive to name your variables in the Teutonic
spirit: straightforward to understand with minimal prior knowledge.
Another way to think about Teutonic naming is to be as specific as
possible without being incorrect. For example, if a function is
hard-coded to only check for CPU overload, then name it
overloadedCPUFinder, not unhealthyHostFinder. While it may be used
to find unhealthy hosts, unhealthyHostFinder makes it sound more
generic that it actually is.
// GOOD
Set<Host> overloadedCPUs = hostStatsTable.search(overCPUUtilizationThreshold);
// BAD
Set<Host> matches = hostStatsTable.search(criteria);
// GOOD
List<String> lowercasedNames = people.apply(Transformers.toLowerCase());
// BAD
List<String> newstrs = people.apply(Transformers.toLowerCase());
// GOOD
Set<Host> findUnhealthyHosts(Set<Host> droplets) { }
// BAD
Set<Host> processHosts(Set<Host> hosts) { }
The exceptions to the Teutonic naming convention are covered later on
in this section: idioms and short variable names.
It's also worth noting that this section isn't suggesting to never
use generic names. Code that is doing something truly generic should
have a generic name. For example, transform in the below example is
valid because it's part of a generic string manipulation library:
class StringTransformer {
String transform(String input, TransformerChain additionalTransformers);
}
Move Simple Comments Into Variable Names
As illustrated earlier, variable names cannot (and should not) replace
all comments. But if a short comment can fit into the variable
name, that's probably where it should go. This is because:
It's less visual clutter for the code reviewer to wade through
(comments are a mental tax, so should provide true value)
If a variable is used a long distance from the comment, the code
reviewer doesn't have to break their focus and scroll back to the
comment to understand the variable
For example,
// BAD
String name; // First and last name
// GOOD
String fullName;
// BAD
int port; // TCP port number
// GOOD
int tcpPort;
// BAD
// This is derived from the JSON header
String authCode;
// GOOD
String jsonHeaderAuthCode;
Avoid Over-used Cliches
In addition to not being Teutonic, the following variable names have
been so horribly abused over the years that they should never be used,
ever.
val, value
result, res, retval
tmp, temp
count
str
The moratorium on these names extends to variations that just add in a
type name (not a good idea anyway), such as tempString, or intStr,
etc.
Use Idioms Where Meaning is Obvious
Unlike the cliches, there are some idioms that are so
widely-understood and unabused that they're safe to use, even if by
the letter of they law they're too cryptic. Some examples are (these
are Java/C specific examples, but the same principles apply to all
languages):
use of i, j and k in straightforward for loops
use of n for a limit/quantity when it's obvious what it would do
use of e for an Exception in a catch clause
// OK
for (int i = 0; i < hosts.size(); i++) { }
// OK
String repeat(String s, int n);
Warning: idioms should only be used in cases where it's obvious
what they mean.
May Use Short Names Over Short Distances When Obvious
Short names, even one-letter names, are preferable in certain
circumstances. When reviewers see a long name, they tend to think they
should pay attention to them, and then if the name turns out to be
completely useless, they just wasted time. A short name can convey the
idea that the only useful thing to know about the variable is its
type. So it is okay to use short variable names (one- or two-letter),
when both of the following are true:
The distance between declaration and use isn't great (say within
5 lines, so the declaration is within the reader's field of
vision)
There isn't a better name for the variable than its type
The reader doesn't have too many other things to remember at that
point in the code (remember, studies show people can remember about
7 things).
Here's an example:
void updateJVMs(HostService s, Filter obsoleteVersions)
{
// 'hs' is only used once, and is "obviously" a HostService
List<Host> hs = s.fetchHostsWithPackage(obsoleteVersions);
// 'hs' is used only within field of vision of reader
Workflow w = startUpdateWorkflow(hs);
try {
w.wait();
} finally {
w.close();
}
}
But this takes up more space with no real gain; the variables are all
used so close to their source that the reader has no trouble keeping
track of what they mean. Furthermore, the long name updateWorkflow
signals to the reviewer that there's something significant about the
name. The reviewer then loses mental energy determining that the name
is just boilerplate. Not a big deal in this one case, but remember,
code reviewing is all about death by 1,000 cuts.
Remove Thoughtless One-Time Variables
One-time variables (OTVs), also known as garbage variables, are
those variables used passively for intermediate results passed between
functions. They sometimes serve a valid purpose (see the next
cookbook items), but are often left in thoughtlessly, and just clutter
up the codebase. In the following code fragment, the coder has just
made the reader's life more difficult:
Again, because the distances are all short and the meanings are all
obvious, short names can be used.
Use Longer OTVs to Explain Confusing Code
Sometimes you need OTVs simply to explain what code is doing. For
example, sometimes you have to use poorly-named code that someone else
(ahem) wrote, so you can't fix the name. But you can use a meaningful
OTV to explain what's going on. For example,
Very often people tell me "we don't need HTTPS" and most of the time the justification is based on 1 of 2 arguments. It's either "we don't have a login screen" or "we don't serve any sensitive data". Supporting HTTPS on your site has so much more to offer than just protecting passwords and user's sensitive data. In this blog I'm going to cover some of the great reasons to add HTTPS support to your site that don't have anything to do with the privacy of data exchanged. I'm also going to debunk some of the common myths around HTTPS support that often come up.
Benefits
HTTPS makes things faster!
I thought I'd start with this because the performance of a site is often linked to metrics like how many visitors convert into sales or what kind of impact page load time has on your revenue. This is a very, very, very, very widely documented subject and there are loads of great sites and tools to show how HTTPS can be faster. Take a look at httpvshttps.com for an example of just how much faster HTTPS can be.
HTTP/2 is here!
We're finally taking a big leap forwards in terms of web technology with the introduction of the HTTP/2 protocol to replace that 15+ year old HTTP/1.1 protocol. There are a whole host of benefits to using HTTP/2 and we get things like header compression, a multiplexed connection, request priority and much more! You can read my blogs on HTTP/2 here, which also covers how you can support the new protocol, but in terms of this article, there's one key thing to note. All major browser vendors only support the HTTP/2 protocol over a secure connection using the TLSv1.2 protocol. Chrome, Firefox, Safari, Opera, IE and Edge all require the use of HTTPS for you to get the benefits of HTTP/2, which is great news and yet another motivating factor for site owners. Akamai have setup a test page where you can view the difference between HTTP/1.1 and HTTP/2 right here and I monitored the usage of HTTP/2 on my blog to see how widespread support is. (hint: a lot!)
SEO Ranking
Everybody wants a great SEO ranking, right? Did you know that serving your site over a secure connection can help to boost your SEO ranking? Well it can! Google announced that they were introducing HTTPS as a ranking signal back in 2014! It is only a small ranking signal for now, but, it will help to increase your SEO ranking and I can only see factors like this increasing in influence over time.
Image source: Google Online Security Blog
HTTP will be getting nasty warnings
Nobody wants red warnings in the browser when a user visits their site, but it's looking like serving your content over HTTP may one day attract just that. We all know that HTTP is insecure, but browsers don't currently indicate that and typically give a fairly neutral UI when browsing over HTTP. With the introduction of HTTPS you have the possibility of receiving a varying level of yellow or red warnings for things like passive and active mixed content or a certificate misconfiguration or expiry. The introduction of HTTPS means you have the chance for things to look worse than they do right now if you get it wrong. If browsers marked HTTP as non-secure, then site owners would have more of a reason to move to HTTPS for the benefits it brings. Chrome and Firefox are already discussing this, and while there are no firm deadlines, the move to an encrypted web is coming, how soon do you want to get involved?
coming to a site near you soon(TM)
Stop 3rd party content injection
When you serve your pages over HTTP, anyone along the transport layer can do basically anything they want to your pages. More and more often it's becoming increasingly common for somebody in the chain of custody to do something to your pages that you don't want them to do. Just recently Troy Hunt showed us what can happen when a Norwegian airline started to inject things into his blog. Think about that. Some ISP or even an airline you have no affiliation with is injecting stuff into your pages, without your consent!
This is where the integrity aspect of HTTPS comes into play and you can make sure that nobody is going to mess with your content along the way. You don't have to look too far to find examples of this online and imagine just how your pages will look with content injected into them. Here's another example and even a whitepaper on ad injection by things like WiFi hotspots.
Stop malicious content injection
Okay, adverts are pesky and annoying, and arguably don't do any real harm (they do), but a page served over HTTP gives an attacker the opportunity to inject malicious content into a page that is being served up right into the browser of your visitor. This sounds a little too extravagant you might think, but there is a really good, recent example of just how this can be abused.
The Great Cannon
The 'Great Cannon of China' as it has been named is an attack tool that was used to launch a notable DDoS attack against GitHub just last year. In simple terms, the Chinese authorities were intercepting unencrypted traffic and injecting a malicious piece of JavaScript into pages that would continuously submit requests against 2 specific pages on GitHub. These pages hosted technology that would allow users to bypass censorship by the Great Firewall of China and it was probably the hope that GitHub would remove them.
The Chrome security team announced that they were going to be removing your ability to access certain features of the browser over an insecure connection and they are doing just that. These include:
Device motion / orientation
EME
Fullscreen
Geolocation
getUserMedia()
AppCache
This is just another step towards ensuring a secure connection is used all of the time and makes perfect sense when you think that a page could be accessing your location data and then sending that over an insecure connection. If you currently use these features on your site and want to continue doing so, you have to use an encrypted connection to serve the page. Likewise, if you want to add these features then you will need to setup HTTPS first. There are details on the page about the progress on each feature being deprecated and removed.
Better Referrer Data
When clicking on a link from one page to another, be it to another page on the same site or not, the browser can include a referer header. This tells the page you are landing on the page that you came from. This is great for analytics purposes to see where traffic is coming from and can be really useful for sites trying to build an audience. To know where a visitor has come from, especially if it's a 3rd party site, could be quite sensitive and that's why the browser will not send this information in some circumstances. If the page you are leaving is served over HTTPS but the page you're heading to is served over HTTP, the browser will not send the referer header as it could leak information to anyone with the ability to view the traffic. The below table shows the source and destination pages for a few examples.
As you can see from the first row, even if the scheme downgrade is happening on the same site, the browser will still not set the referer header, meaning when the visitor hits that page on my blog, I will have no idea that they'd been linked there from another page on my blog. The same happens in the last row when the scheme is downgraded and the link takes you to an external site. Of course, the header will be set when the scheme is upgraded from HTTP to HTTPS as the referer header will be sent over a secure connection and that applies to both internal or external links. For your own site, if anyone links to your pages and they are served over HTTP, when the page linking to you is served over HTTPS, you won't get any referer data and won't know where your traffic is coming from. Note: A site can override this functionality using a referrer policy but you can't depend on other sites taking this action so that you can receive referrer data.
iOS and Android upping the ante
Both Apple, with their App Transport Security on iOS, and Google, with the usesCleartextTraffic manifest attribute on Android, are pushing mobile apps towards using encrypted communications by default. ATS does go a lot further as the default setting is on, where on Android it's not, and it has some pretty strict requirements. This includes using the TLSv1.2 protocol only, ciphers must be Perfect Forward Secrecy capable (and restricted to a limited selection), the Leaf has to be signed by a key at least RSA 2048bits or ECC 256bits and a SHA256 hash signature as a minimum! You can read more on the requirements of ATS, but the point is, Apple doesn't know what type of data your app is going to send or receive and it might not even be private or sensitive. The standard has been set and if you want your content or API to be consumed by mobile apps, HTTPS is going to be required.
Brotli Compression
With so much data zipping over the wire we use compression to reduce some of the burden that brings. Smaller payloads means faster transfer times, which results in faster page loads. It also means less bandwidth cost and better battery performance on mobile devices too. Better compression means that all of these benefits are increased and this is exactly what Brotli offers. From my own testing the claims of a 20%-26% improvement seem achievable and Firefox announced support in v44 with Chromium announcing their intent to ship support too. There may only be one small snag for some sites though and it's that you can only get Brotli support over a HTTPS connection. If you want the latest in performance upgrades, you have to be serving over a secure connection.
Myths
Amongst all the benefits of adopting HTTPS on your site, there are some common myths or arguments against it that I hear that aren't the case any more, or never were the case.
Encryption introduces server overheads
Encryption used to introduce overheads. It's true that TLS used to be computationally expensive, but that's just no longer the case these days. Adam Langley from Google wrote about this back in 2010 (yes, 6 years ago!) when they moved GMail to HTTPS and he had this to say:
On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10KB of memory per connection and less than 2% of network overhead. Many people believe that SSL takes a lot of CPU time and we hope the above numbers (public for the first time) will help to dispel that.
If you stop reading now you only need to remember one thing: SSL/TLS is not computationally expensive any more.
So that settles the overhead aspect of using HTTPS!
Encryption is expensive
I'm sure all of you were as excited about the launch of Let's Encrypt as I was, the brand new and free Certificate Authority (CA) sponsored by people like the EFF and Mozilla. They will be minting Domain Validated (DV) certificates for absolutely anyone that wants one so you can setup HTTPS on your site without needing to pay for certificates.
What's even better than free certificates? Being able to automatically renew your certificates so you don't have to worry about missing expiry dates! You may have noticed that my blog is now hosted with certificates from Let's Encrypt, go ahead and inspect the certificate up top, and I wrote a blog on how to get started with acquiring and automatically renewing them.
Of course, there have previously been ways that non-commerical sites could get free certificates, StartCom already offered free DV certificates and you can go get them on their site right now. I have to say though, the UI and the UX whilst recently improved, are still a little difficult to work with.
For the brave amongst us there is also the free DV certificates from the CA WoSign that can be valid for up to 3 years. They used to have a free multi-domain certificate but there is now a $1.99USD per year charge for each additional name in the SAN. They will allow you to bind all www subdomains of any domain in the SAN for free. I have a subdomain setup with an example WO Sign certificate here https://wo.scotthelme.co.uk/.
There was also another quite promising revelation recently that the large, commercial certificate authorities out there will soon be offering domain validated certificates for free! Seen as a minor loss lead to other services, this makes a lot of sense given the launch of Let's Encrypt that will undoubtedly pull a huge amount of DV certificate custom away from the larger CAs.
Extended Validation Certificates are better
The subject of EV Certificates always comes up so I thought I'd address that here too. The difference between a DV and an EV certificate can be seen here. Barclays bank use an EV certificate and my blog uses a DV certificate.
With an EV certificate you get the extra green marker in the address bar that displays the name of the organisation that applied for the certificate. This gives the user some more confidence that the certificate was actually obtained by the organisation that they are visiting. The additional verification that the CA has to do to check the identity of the entity applying for the certificate is what introduces the additional cost of EV certificates. From a cryptography point of view there is absolutely no difference, at all, between an EV certificate and a DV certificate. They both provide the exact same protection as each other. Whether or not you want to apply for an EV certificate or use a DV certificate is a decision that needs to be made on a case by case basis and will change depending on what your goals are. If you can see benefit in an EV certificate, and remember, that can only be seen in the browser, then by all means apply for one. Remember though, with regards to all of the benefits like privacy, integrity, HTTP/2, better performance, SEO ranking and everything else mentioned above, an EV certificate won't make any difference.
Conclusion
HTTPS is here and it's here to stay. From my own research the use of HTTPS in the top 1 million most visited sites on the web grew over 42% in the last 6 months alone. That's tremendous growth.
Any new site or web application should be built with HTTPS out of the box. It's the most cost effective and efficient way to do it, adding it later will only cost more. For sites that aren't yet serving their content over HTTPS, the sooner you start considering it, the easier it will be. It seems that an encrypted web is coming, all of the indicators are there, the question is, how soon will you prepare?
L'astrophysicien Francis Rocard du Cnes décrypte l'étonnant projet de voyage interstellaire annoncé par le célèbre scientifique britannique Stephen Hawking.
C'est le genre de petite information qui pose une grande question. Un communiqué de presse de l'Institut de recherche pour le développement publié le 6 avril explique qu'une expédition de chercheurs français et équatoriens est montée en février dernier au sommet du Chimborazo, volcan qui est aussi le point culminant de l'Equateur. L'objectif était de planter là-haut une antenne GPS pour déterminer au centimètre près l'altitude du lieu. On a ainsi pu déterminer que le Chimborazo culmine à exactement 6 263,47 mètres au-dessus du niveau moyen de la mer. Le volcan a "perdu" 5 mètres par rapport à son altitude officielle, évaluée dans les années 1990. Mais le communiqué précise qu'il demeure en revanche, et de très loin, le point de la surface terrestre le plus éloigné du centre de notre planète.
Et là, le réflexe premier est de s'étonner : mais pourquoi n'est-ce pas l'Everest, le géant himalayen, qui possède ce titre ? Avec ses 8 848 mètres au-dessus du niveau de la mer, il domine en effet le Chimborazo de plus de 2 kilomètres et demi ! C'est oublier un point fondamental. Même si on nous a répété à l'école que la Terre était ronde, ce n'est pas tout à fait le cas. Notre planète tournant sur elle-même et son intérieur étant composé en grande partie de matériaux "mous" voire liquides, elle subit une petite déformation. Imaginez faire tourner une boule de pâte à modeler autour d'un axe, vous obtiendriez une sphère aplatie aux pôles et boursouflée à l'équateur. Le rayon terrestre est ainsi de 6 357 km aux pôles et de 6 378 km à l'équateur (soit une différence d'un tiers de pourcent). Il ne s'agit là que de moyennes car, en réalité, il existe une quantité énorme de déformations locales de la surface terrestre et ce qu'on appelle, en géophysique, le "géoïde", c'est-à-dire la représentation de cette surface, s'apparente, lorsqu'on en exagère les différences, à un "patatoïde".
Si le rayon terrestre présente, en moyenne, une différence de 21 km entre les pôles et l'équateur, on comprend qu'un grand volcan situé en Equateur (le Chimborazo est à la latitude de 1° 28' sud) a toutes les chances d'être plus éloigné du centre de la Terre que l'Everest, en dépit de la conséquente différence d'altitude entre ces deux reliefs. Situé à 28° de latitude nord, le mont Everest est assez éloigné de l'équateur. Selon les mesures effectuées par la mission franco-équatorienne, le sommet du Chimborazo se trouve à 6 384,416 kilomètres du centre de la Terre. L'Everest, quant à lui, n'en est distant que de 6 382,605 kilomètres. Le volcan équatorien a donc une bonne tête de plus (plus de 1,8 km) que le géant himalayen si l'on considère l'écart avec le centre de notre planète. En ce domaine, la latitude est plus importante que l'altitude...
If you use git, you’re running git checkout $BRANCH all the time. Everyone
likes a fast checkout at the grocery store. How about making your git checkouts
fast, too? Since I do it so often, I want it to go as fast as possible, and I
bet you do too.
Are you … hot blooded?!
git checkout - (that’s git checkout followed by a dash) is the bee’s knees.
It switches back to the branch you were on previously. If you run it again,
you’re toggled back to the first branch. A useful comparison is cd -, which as
you may know takes you back to your most recent directory. Here’s an example:
 View
View





















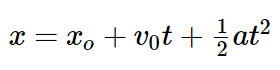


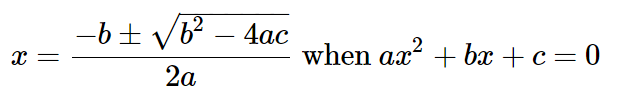


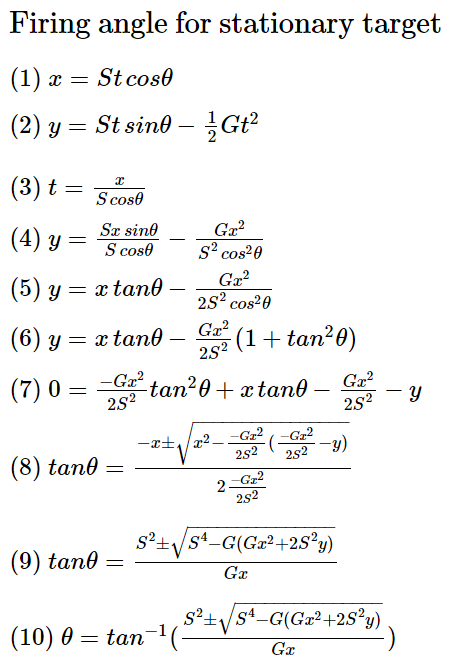



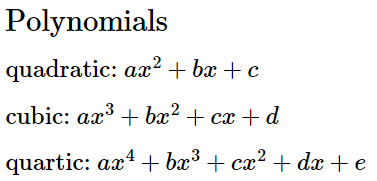
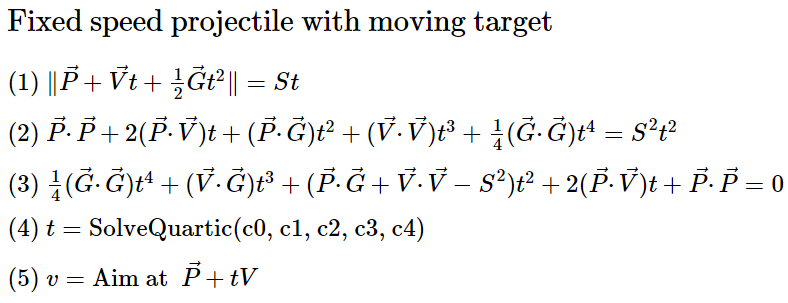

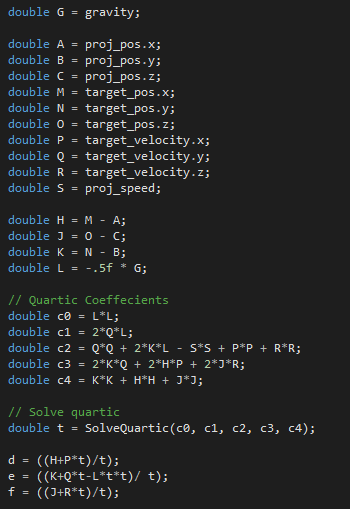


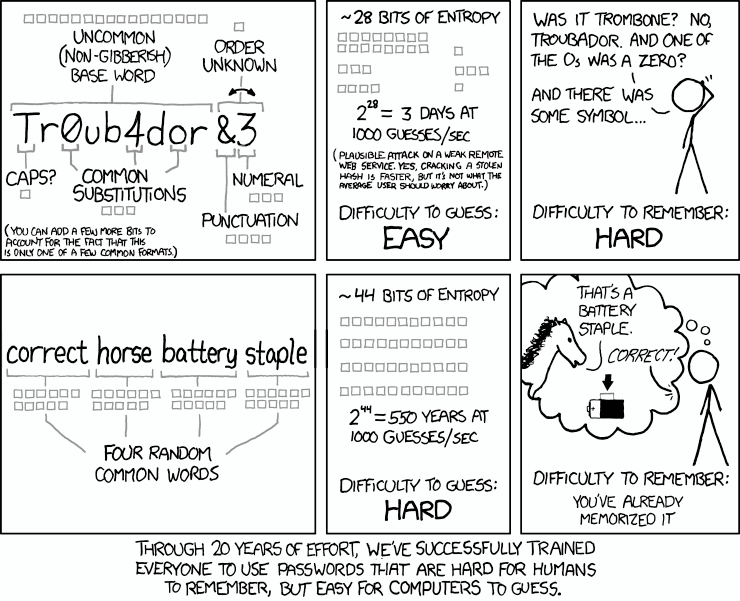
 It's been more than three years since the first modern commercial smartwatches, the Pebble and the Sony SmartWatch, hit the market and this wearable device category still hasn't taken the industry by storm. In the meantime, less powerful and less featured smart fitness bands are flooding the market and is giving some well-deserved and long overdue attention to healthier lifestyles … Continue reading
It's been more than three years since the first modern commercial smartwatches, the Pebble and the Sony SmartWatch, hit the market and this wearable device category still hasn't taken the industry by storm. In the meantime, less powerful and less featured smart fitness bands are flooding the market and is giving some well-deserved and long overdue attention to healthier lifestyles … Continue reading

 ont mis au point une solution qui pourrait changer beaucoup de choses… © Georgejmclittle, Shutterstock") Le Wi-Fi est incontournable mais il a tendance à entamer significativement l’autonomie des appareils mobiles. Des chercheurs de l’université de Washington (États-Unis) ont mis au point une solution qui pourrait changer beaucoup de choses… © Georgejmclittle, Shutterstock
Le Wi-Fi est incontournable mais il a tendance à entamer significativement l’autonomie des appareils mobiles. Des chercheurs de l’université de Washington (États-Unis) ont mis au point une solution qui pourrait changer beaucoup de choses… © Georgejmclittle, Shutterstock





 </noscript>
</noscript>