Shared posts
Researchers identify people through ordinary Wi-Fi routers with 99.5% accuracy — technique works with standard Wi-Fi routers
The Greater Glider – Is This the Cutest Wild Animal in the World?

The Greater Glider is cute, but not many people get the chance to see one in the eastern Australian wilds it calls home. They are shy, solitary and nocturnal, yet one thing is certain – this endangered marsupial species has adorable down to a fine art. It was, until 2020, believed to be a single species, with variations according to habitat. After careful research using high-throughput genetic marker techniques, it was discovered that the genus Petauroides was not monotypic – it did not contain a solitary species, after all: there are three species of greater glider. Image
 |
| Southern Greater Glider |
So, what does one do when this happens? Keeping things simple and straightforward is always a good plan, so we now have the Northern, Central and Southern greater gliders – named after the regions of the range in which they are found. Just to make matters a little complicated, each species comes in two forms. The central greater glider is usually silvery-brown, while the southern greater glider is especially well known for having both dark and pale grey-white forms (the variation seems to be a normal colour morph rather than a sign that they are different sexes or ages. In other words: some are naturally darker, some paler).

The three species are different sizes, too – but this is not easy for the untrained eye to spot. The southern greater glider (Petauroides volans) is the largest of the three, and is around the size of a house cat (at most 15 inches or 35cm long). The central (Petauroides armillatus) is a little smaller and the smallest, coming in at about a foot long or 30cm (not counting the tail) is the northern (Petauroides minor). So, although these lengths are distinguishable, as the species do not live side by side, it’s not difficult to see why they were thought to be the same species for so long, with the variations put down to habitat factors.
 |
| Central greater glider (Petauroides armillatus) |

The body of the greater glider is made to look a little larger by the fact that their fur is bushy (and up to 2.5 inches long). The tail seems the bushiest part of all, and is easily as long as the animal, even though it isn’t prehensile. As they glide effortlessly through the forest, greater gliders rely on their long, bushy tails for balance, steering and controlled landings. It’s a built-in stabiliser, effectively. Their large ears are probably the deciding factor in their cuteness quotient, giving them an alert and irresistibly endearing look – like a relative of Gizmo from Gremlins. As they are strictly vegetarian, the ears are not used to hunt, but to try and ensure that they do not become prey. They enable greater gliders pick up every rustle, snap and suspicious sound in the forest. That’s pretty handy when you spend your nights gliding about in the dark.
And, oh boy, can they glide. Here is some spectacular footage, courtesy of the WWF Australia. The very last glide featured is particularly interesting, as it shows a mother gliding through the canopy with a joey (baby) on her back, and it seems to be practicing its own gliding skills as it clings to her. The greater glider does not travel along the ground unless it absolutely cannot help it – and if so appear very slow and clumsy. Yet with wrists tucked under the chin, they glide between the trees in the high canopy with an astonishing grace.

 Watching footage like the video above, it’s easy to think that the
greater gliders are closely related to other glider species, such as the
well-known sugar glider which is sometimes kept as a pet (although that is now
illegal in a number of Australian states and banned or restricted in some US states). Related they are, but not closely. The greater gliders diverged from the other
gliding marsupials about 36 million years ago.
Watching footage like the video above, it’s easy to think that the
greater gliders are closely related to other glider species, such as the
well-known sugar glider which is sometimes kept as a pet (although that is now
illegal in a number of Australian states and banned or restricted in some US states). Related they are, but not closely. The greater gliders diverged from the other
gliding marsupials about 36 million years ago.
 |
| Central greater glider - Petauroides armillatus |
They have different gliding mechanisms, too. On the greater glider, the membrane which enables them to glide is positioned between the elbow and the ankle. This is distinct from its long lost cousins, the other gliding marsupials, that have membranes that stretch from wrist to ankle. So are they better gliders? Not exactly - just differently engineered. Greater gliders seem built for long, graceful canopy crossings, while their smaller cousins are more like nimble aerial acrobats.

 |
| Central greater glider - Petauroides armillatus |
 We’ve already established that the greater gliders diverged
from the other gliders tens of millions of years ago. Their closest relative is the lemuroid
ringtail possum (Hemibelideus lemuroides) and the word closest doesn’t do
the distance justice. The two went their
separate ways, evolutionarily, about 18 million years ago. As such, the three glider species make up
their own genus meaning that they have their own distinct scientific group
within the animal family tree.
We’ve already established that the greater gliders diverged
from the other gliders tens of millions of years ago. Their closest relative is the lemuroid
ringtail possum (Hemibelideus lemuroides) and the word closest doesn’t do
the distance justice. The two went their
separate ways, evolutionarily, about 18 million years ago. As such, the three glider species make up
their own genus meaning that they have their own distinct scientific group
within the animal family tree.
 So, how does a greater glider spend its day? At night, they feed off the young leaves and
flowers of a number of eucalyptus trees (a habit they share with the koala). Although
this may seem a little fussy, the younger leaves have a higher source of
protein than the older ones – and as eucalyptus isn’t a great source of
nutrients, they eat only those.
So, how does a greater glider spend its day? At night, they feed off the young leaves and
flowers of a number of eucalyptus trees (a habit they share with the koala). Although
this may seem a little fussy, the younger leaves have a higher source of
protein than the older ones – and as eucalyptus isn’t a great source of
nutrients, they eat only those.

Once the sun rises, they head for home – and it’s home alone as they are solitary (unless caring for a joey, like the one above - which come along once a year after the female reaches sexual maturity at around the age of two). Their dens are sometimes lined with leaves and bark they strip off the trees using their claws. Another strange fact about the greater glider is that the first two toes on its fore foot are opposable, helping it to grip branches securely).
Their dens are found in the hollows of mature trees, but greater gliders are not exactly minimalists. One animal may use up to 20 different dens, apparently operating on the principle that one simply cannot have too many bedrooms. It does mean that it can hopefully get inside one of them quickly, away from its main predator, the Powerful Owl (Ninox strenua)), by having a number of dens from which to choose.

As a quick aside - yes, there really is a bird called the Powerful Owl, pictured above, looking every inch the villain of the piece. Given its size, strength and deeply inconvenient habit of eating gliders, the name feels entirely justified (and very Australian – the name does exactly what it says).

Although a major concern for the greater glider, the owl - however powerful - is not the main reason for its decline. That title belongs, depressingly enough, to us. Logging, habitat loss and climate change have all taken their toll, and the catastrophic 2019–20 Australian bushfires only deepened the crisis, tearing through vast areas of forest, including parts of the glider’s protected habitat. Some researchers believe logging may even have made the fires more intense by changing the structure of the forest and reducing suitable food trees. Even so, conservation work is growing, and there is still real hope that stronger habitat protection can give the greater glider (all three species) a fighting chance. Let’s keep our fingers crossed.
Tennessee grandmother wrongly jailed for six months, latest victim of AI-driven misidentification — facial recognition is jailing the wrong people, but police keep using it anyway

Nathan Fillion's Big Firefly Tease Is a Canon Animated Series With the Original Actors Reprising Their Roles — but It Needs a Home

Nathan Fillion’s big Firefly tease has been revealed as a new animated series set between the original live-action TV show and the Serenity movie — but there's a catch.
Fillion and members of the original cast announced the series during a panel at Awesome Con in Washington D.C., where concept art of the lineup was also shown. Gina Torres, Jewel Staite, Morena Baccarin, Sean Maher, Summer Glau, and Adam Baldwin will reprise their roles. Ron Glass, who played the Shepherd Book, died in 2016 aged 71.
While a showrunning team has been assembled and a script has been completed, the Firefly animated series isn’t a done deal yet. It will be taken out to buyers in a bid to find a streaming home, with Firefly creator Joss Whedon not involved.
Fillion, who plays Captain Mal Reynolds in Firefly, had hyped up fans with a number of social media posts that sparked hope of a series return over 20 years after it was canceled. Now the word is out there, Fillion took to social media again to say "we're going to try to bring back Firefly." He added that he has Joss Whedon's "blessing," and rights holders 20th Century Studios / Disney "got excited" and said "yes." Fillion has two showrunners in place: married writing-producing team Marc Guggenheim (DC’s Arrow, Flash) and Tara Butters (Agent Carter, Dollhouse), who met through Firefly. ShadowMachine is in place as animation studio.
And in the social media post we get a glimpse at the script of this pilot episode, titled 'Athenia' and labelled 'Episode #1, 201,' which suggests this animated series is, essentially, Season 2 of Firefly. The idea is the proposed series is set in the timeline between the original 2002 television run and its 2005 feature film continuation, Serenity, expanding the universe while preserving continuity with the established lore. The animated format "provides an opportunity to revisit the franchise’s original ensemble dynamics while allowing for expanded storytelling within the established timeline," a note to press reads.
The post acts as a call to arms, a mobilization of the Firefly community to help convince would-be buyers that this animated series is worth investing in. Fillion ends the video by saying he's going out to pitch the show, and the other cast members wish him luck.
"The word is out. To keep Firefly flying, we need a home," Fillion posted. "And for that, we need you. Like this post, comment on this post, repost this post. Tag a friend, tag an enemy, even tag a Reaver. Give us some 'quantifiable analytics' that we can use to convince folks that this is something people want."
Firefly premiered on Fox in September 2002 and ran for just 11 of its 14 episodes before being cancelled. The series follows the crew of the spaceship known as Serenity, helmed by Fillion’s Mal Reynolds, in the year 2517, and ended up becoming a cult classic once it made its way to DVD.
Firefly photo credit: Once We Were Spacemen.
Wesley is Director, News at IGN. Find him on Twitter at @wyp100. You can reach Wesley at wesley_yinpoole@ign.com or confidentially at wyp100@proton.me.

Fallout Shelter Is Now an Amazon Reality Competition TV Series Where Contestants Live Together Inside a Vault

Amazon has announced a Fallout spinoff TV show called Fallout Shelter.
Fallout Shelter is the name for Bethesda’s strategy spinoff in which you manage a vault and its dwellers while under pressure from the wasteland. Fallout Shelter the Prime Video series is a reality competition show along similar lines to Beast Games.
Good morning, prospective Vault Dwellers! In order to best serve you in What Comes Next, we need volunteers for a very real, very scientific opportunity to beta test a better society. Visit this website if you’d like to join Fallout Shelter, a new series full of escalating… pic.twitter.com/hCr0TxmNOn
— FALLOUT⚡️ (@falloutonprime) January 15, 2026
Here's the official blurb on the 10-episode series:
Set inside Vault-Tec’s bomb-proof vaults, Fallout Shelter drops a diverse group of contestants into an immersive, high-stakes world inspired by the games’ signature dark humor, retro-futurism, and post-apocalyptic survival storytelling. Across a series of escalating challenges, strategic dilemmas, and moral crossroads, contestants must prove their ingenuity, teamwork, and resilience as they compete for safety, power, and ultimately a huge cash prize.
Here's the Fallout Shelter program description, from the now open casting call:
Fallout Shelter (working title) is a new reality competition series based on the hit Amazon drama and computer game of the same name. The dwellers (contestants) live together in a top-secret vault, where they will compete in a series of games that tests the seven core attributes from the Fallout world. Strength, perception, endurance, charisma, intelligence, agility and luck (S.P.E.C.I.A.L).
The series will not only test dwellers’ core attributes, but also their loyalty and alliances. It’s a game of power dynamics, popularity and social strategy which will ultimately result in a huge cash prize, but do you have what it takes to be the most S.P.E.C.I.A.L?.
It’s produced by Studio Lambert, the company that’s also behind The Traitors and Squid Game: The Challenge. Amazon MGM Studios and Bethesda Game Studios are also involved. Todd Howard is down as executive producer.
The announcement of Fallout Shelter comes with Fallout Season 2 in full swing. This week’s episode is considered the season’s best yet, and has sparked much debate within the Fallout community.
Wesley is Director, News at IGN. Find him on Twitter at @wyp100. You can reach Wesley at wesley_yinpoole@ign.com or confidentially at wyp100@proton.me.
Meta announces a slew of nuclear energy agreements
Meta has announced three new agreements to purchase nuclear power for its AI infrastructure as well as the Prometheus supercluster, a 1-gigawatt data center being built in Ohio. The social media giant is partnering with power companies Vistra, TerraPower and Oklo to deliver an expected 6.6 gigawatts of generation to its projects by 2035.
The company's agreement with TerraPower will fund the development of two new reactors capable of delivering up to 690 megawatts of power as early as 2032. The deal also gives Meta rights to energy from six other reactors that could deliver an additional 2.1 gigawatts by 2035. All this power would come from TerraPower's "Natrium" reactors, which use sodium instead of water as a coolant.
A partnership with Oklo will bring 1.2 gigawatts of nuclear power online as early as 2030. Meta says the agreement opens the door to the construction of multiple Oklo reactors, which it claims will create thousands of construction and long-term operations jobs in Ohio. OpenAI CEO Sam Altman is one of Oklo's largest investors, and owns just over 4 percent of the company.
Meta’s agreement with Vistra focuses on keeping existing nuclear plants running longer and boosting their output. Through new 20-year deals, Meta will buy more than 2.1 gigawatts of electricity from some of Vistra’s existing plants in Ohio, while also backing added capacity at those sites, plus another in Pennsylvania. Vistra expects the added capacity, totaling 433 megawatts, to come online in the early 2030s.
Big tech is increasingly turning to nuclear to power its AI ambitions. Meta signed a 20-year agreement with Constellation Energy for nuclear power last year. Meanwhile Microsoft is famously reopening Three Mile Island and will be the plant’s sole customer as part of a 20-year deal.
This article originally appeared on Engadget at https://www.engadget.com/ai/meta-announces-a-slew-of-nuclear-energy-agreements-165337159.html?src=rss‘LeBron James of Excel spreadsheets’ celebrates 2025 Microsoft Excel World Championships win — beat 256 other spreadsheet whizzes to claim the $60,000 first prize in Las Vegas tournament

China starts list of government-approved AI hardware suppliers: Cambricon and Huawei are in, Nvidia is not

Hackers tricked ChatGPT, Grok and Google into helping them install malware
Ever since reporting earlier this year on how easy it is to trick an agentic browser, I've been following the intersections between modern AI and old-school scams. Now, there's a new convergence on the horizon: hackers are apparently using AI prompts to seed Google search results with dangerous commands. When executed by unknowing users, these commands prompt computers to give the hackers the access they need to install malware.
The warning comes by way of a recent report from detection-and-response firm Huntress. Here's how it works. First, the threat actor has a conversation with an AI assistant about a common search term, during which they prompt the AI to suggest pasting a certain command into a computer's terminal. They make the chat publicly visible and pay to boost it on Google. From then on, whenever someone searches for the term, the malicious instructions will show up high on the first page of results.
Huntress ran tests on both ChatGPT and Grok after discovering that a Mac-targeting data exfiltration attack called AMOS had originated from a simple Google search. The user of the infected device had searched "clear disk space on Mac," clicked a sponsored ChatGPT link and — lacking the training to see that the advice was hostile — executed the command. This let the attackers install the AMOS malware. The testers discovered that both chatbots replicated the attack vector.
As Huntress points out, the evil genius of this attack is that it bypasses almost all the traditional red flags we've been taught to look for. The victim doesn't have to download a file, install a suspicious executable or even click a shady link. The only things they have to trust are Google and ChatGPT, which they've either used before or heard about nonstop for the last several years. They're primed to trust what those sources tell them. Even worse, while the link to the ChatGPT conversation has since been taken off Google, it was up for at least half a day after Huntress published their blog post.
This news comes at a time that's already fraught for both AIs. Grok has been getting dunked on for sucking up to Elon Musk in despicable ways, while ChatGPT creator OpenAI has been falling behind the competition. It's not yet clear if the attack can be replicated with other chatbots, but for now, I strongly recommend using caution. Alongside your other common-sense cybersecurity steps, make sure to never paste anything into your command terminal or your browser URL bar if you aren't certain of what it will do.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/hackers-tricked-chatgpt-grok-and-google-into-helping-them-install-malware-185711492.html?src=rssIT provider sued after it simply 'handed the credentials' to hackers — Clorox claims Cognizant gaffe enabled a $380m ransomware attack

CRISPR can stop malaria spread by editing a single gene in mosquitos
CRISPR gene-editing therapy has shown great potential to treat and even cure diseases, but scientists are now discovering how it can be used to prevent them as well. A team of researchers found a way to edit a single gene in a mosquito that prevented it from transmitting malaria, according to a paper published in Nature. These genetically modified mosquitos could eventually be released into the wild, helping prevent some of the 600,000 malaria deaths that occur each year.
Mosquitos infect up to 263 million people yearly with malaria and efforts to reduce their populations have stalled as late. That's because both the mosquitos and their parasites that spread malaria have developed resistance to insecticides and other drugs.
Now, biologists from UC San Diego, Johns Hopkins and UC Berkeley universities have figured out a way to stop malarial transmission by changing a single amino acid in mosquitos. The altered mosquitos can still bite people with malaria and pick up parasites from their blood, but those can no longer be spread to others.
The system uses CRISPR-Cas9 "scissors" to cut out an unwanted amino acid (allele) that transmits malaria and replace it with a benign version. The undesirable allele, called L224, helps parasites swim to a mosquito's salivary glands where they can then infect a person. The new amino acid, Q224, blocks two separate parasites from making it to the salivary glands, preventing infection in people or animals.
"With a single, precise tweak, we’ve turned [a mosquito gene component] into a powerful shield that blocks multiple malaria parasite species and likely across diverse mosquito species and populations, paving the way for adaptable, real-world strategies to control this disease," said researcher George Dimopoulos from Johns Hopkins University.
Unlike previous methods of malarial control, changing that key gene doesn't affect the health or reproduction capabilities of mosquitos. That allowed the researchers to create a technique for mosquito offspring to inherit the Q224 allele and spread it through their populations to stop malarial parasite transmission in its tracks. "We’ve harnessed nature’s own genetic tools to turn mosquitoes into allies against malaria," Dimopoulos said.
This article originally appeared on Engadget at https://www.engadget.com/science/crispr-can-stop-malaria-spread-by-editing-a-single-gene-in-mosquitos-133010031.html?src=rssPresident Trump threatened to break up Nvidia, didn't even know what it was — 'What the hell is Nvidia? I've never heard of it before'

AI coding platform goes rogue during code freeze and deletes entire company database — Replit CEO apologizes after AI engine says it 'made a catastrophic error in judgment' and 'destroyed all production data'
Ozzy Osbourne, Black Sabbath Legend and Metal Icon, Dies at 76

Black Sabbath frontman and music legend Ozzy Osbourne has died at 76.
The iconic vocalist behind hits like Crazy Train, War Pigs, Iron Man, and Mr. Crowley passed away today, surrounded by his family (via BBC). His death follows the Back to the Beginning farewell concert, which he, alongside a team of other famous musicians, performed at just weeks ago.
Osbourne’s family released a statement: “It is with more sadness than mere words can convey that we have to report that our beloved Ozzy Osbourne has passed away this morning. He was with his family and surrounded by love. We ask everyone to respect our family privacy at this time.”
Osbourne, also known as music’s Prince of Darkness, is known for shaping the metal world with his unique vocal and songwriting skills. He truly broke into the music scene as the lead vocalist in Black Sabbath, a pioneering ‘70s group known for projects like 1970’s Paranoid and 1971’s Masters of Reality. Even as the band remained through to the 2000s, Osbourne would go on to release his own solo projects, including 1980’s Blizzard of Ozz and 1991’s No More Tears.
It’s hard to overstate Osbourne’s impact on rock, metal, and music in general, but he’s known for more than his legendary Crazy Train laugh. TV watchers were thrown for a loop in 2002 with The Osbournes, a reality show that featured Ozzy Osbourne, Sharon Osbourne, Kelly Osbourne, and Jack Osbourne. It ran for four seasons and 52 episodes before coming to an end in 2005.
It is with more sadness than mere words can convey that we have to report that our beloved Ozzy Osbourne has passed away this morning. He was with his family and surrounded by love.
— Ozzy Osbourne (@OzzyOsbourne) July 22, 2025
We ask everyone to respect our family privacy at this time.
Sharon, Jack, Kelly, Aimee and… pic.twitter.com/WLJhOrMsDF
Aside from being known as the man who bit the head off of a real-life bat during a concert in the ‘80s, Osbourne made his stamp on more TV series and even the movie world, too. He’s lent his voice to South Park and, more recently, Trolls World Tour in the past, and he even made cameo appearances in films like Ghostbusters (2016), Austin Powers in Goldmember, and Little Nicky. Even gaming fans might have caught an appearance from Osbourne, as the rocker found his way to star alongside Jack Black in Double Fine’s Brutal Legend while also showing up for Neversoft’s Guitar Hero World Tour.
The Back to the Beginning concert took place at Villa Park venue in Birmingham, England, July 5, and featured Billy Corgan of The Smashing Pumpkins, Fred Durst of Limp Bizkit, Jonathan Davis of Korn, Metallica, Slayer, and the rest of Black Sabbath. It was meant to serve as a farewell show dedicated to the mark Osbourne left on music as he continued to struggle with Parkinson’s disease and other health complications. All proceeds generated from the concert were donated equally between Cure Parkinson’s, Birmingham Children’s Hospital, and Acorn Children’s Hospice.
Fans and fellow musicians from across the globe have already taken to social media to talk about what Osbourne’s music meant to them. Those paying tribute range from Elton John to Metallica as the world gathers to mourn his life.
"He was a dear friend and a huge trailblazer who secured his place in the pantheon of rock gods - a true legend," John said. "He was also one of the funniest people I’ve ever met. I will miss him dearly. To Sharon and the family, I send my condolences and love."
Ozzy Osbourne wasn’t just the Prince of Darkness, and one of the most recognisable music icons on the planet, he was also hands down one of the funniest musicians.
— claire. (@blissfulfiction) July 22, 2025
Thank you for all the music, and all of the laughs.
He’ll be forever missed 🖤 pic.twitter.com/9hGGcpQ5E3
— Metallica (@Metallica) July 22, 2025
One of the greatest of all time. @OzzyOsbourne R.I.P. 💔 pic.twitter.com/LX1E8CLVdx
— Seán Ono Lennon (@seanonolennon) July 22, 2025
Never forget When Ozzy Osbourne pulled up to a random Smackdown and stole the show
— FADE (@FadeAwayMedia) July 22, 2025
Rest in peace legend. pic.twitter.com/ELWpNj5mrE
Photo by Scott Dudelson/Getty Images.
Michael Cripe is a freelance contributor with IGN. He's best known for his work at sites like The Pitch, The Escapist, and OnlySP. Be sure to give him a follow on Bluesky (@mikecripe.bsky.social) and Twitter (@MikeCripe).
Hugo Boss debuts 3D printed loafer — scans your foot for a custom fit

Hong Kong scientists 3D printing organs for transplant patients — 3D-printed respiratory tissue combined with lab-grown mini organs in new procedure

The U.S. Army is 3D-printing drones and repairing them — will soon have the capability to make 'the vast majority' in-house

AI Prompts Will Soon Let a 10-Person Team Build a Game Like Breath of the Wild Where the AI Is Doing All the Dialogue and You Just Write Character Synopsis, Tim Sweeney Predicts

Epic Games boss Tim Sweeney believes small teams will soon be able to use AI prompts to make video games on the scale of Nintendo masterpiece The Legend of Zelda: Breath of the Wild.
Speaking to IGN at Epic’s State of Unreal 2025 event (where CD Projekt revealed a stunning The Witcher 4 tech demo), Sweeney said AI prompts will be “a fundamental part” of game engines, and will result in “entirely new genres of games invented that weren't possible or practical before” without it.
“Every significant advance in technology has led to the rise of new games,” Sweeney explained.
“I remember 3D gaming just became possible and then Doom and Wolfenstein introduced the 3D shooter. The battle royal genre itself only became possible when you had enough performance on hardware and engines that you could have a hundred players in a single play space.
“AI characters giving you the possibility of infinite dialogue with a really simple setup for creators means small teams will be able to create games with immense amounts of characters and immense and interactive worlds. What would it take for a 10-person team to build a game like Zelda Breath of the Wild in which the AI is just doing all the dialogue and you're just writing some character synopsis? That's totally going to be within reach over the next few years.”
Sweeney’s enthusiasm around AI is no secret, of course, and Epic Games is all in. AI Darth Vader hit Fortnite last month in a first for the all-encompassing battle royale. He can serenade you, join and leave squads at will, respond intelligently to the player, issue impromptu dialogue, summarize gameplay events, and warn the player if something's about to go down.
Darth Vader is voiced by the inimitable James Earl Jones, who died in September 2024 at the age of 93. This AI version of his voice, powered by Google's Gemini 2.0 Flash model and ElevenLabs' Flash v2.5, is used with the Jones family's permission.
This sparked a debate about the ethics of generative AI, particularly when it comes to NPCs such as Darth Vader that revive the voice of dead actors. Sweeney, though, believes AI technology is ultimately of net benefit to society, despite some drawbacks.
“I see AI as technology that's ultimately there to empower human creators to create stuff more efficiently,” he said. “I think that's a good thing. It's unfortunate that the advent of modern AI has been tainted by companies just ripping massive amounts of content off of other companies and individuals on the web. But as a base level technology, it should be a multiplying factor and multiplying force on our abilities.
“Certainly enabling indie teams to build bigger and better games means also enabling AAA teams to build staggering, immense huge games and to polish it ever further. So I think there's going to be a massive evolution as everybody scrambles to learn new skills as you get on top of what's possible here. But I think as with any other technology that's improved our lives, the ultimate net opportunity for people is higher.”
Undeterred by any backlash to AI Darth Vader, Epic has announced plans to let people create their own AI NPCs in Fortnite.
Wesley is Director, News at IGN. Find him on Twitter at @wyp100. You can reach Wesley at wesley_yinpoole@ign.com or confidentially at wyp100@proton.me.
Gallery showcases the dustiest, grimiest PCs in Germany — 400 images of fascinating horror for PC DIYers

Microsoft's CEO reveals that AI writes up to 30% of its code — some projects may have all of its code written by AI

Pat Gelsinger becomes executive chairman, head of technology at church-focused platform Gloo
Roumen.ganeffwtf?

Security researchers found a big hole in DeepSeek's security
The generative intelligence platform DeepSeek has set the world on fire this week, but with great popularity comes increased scrutiny. Analysts with Wiz Research have found a fairly substantial hole in the software’s security. The research shows that DeepSeek left one of its critical databases exposed.
This means that whoever came across the database would be allowed access to more than one million records, including user data, system logs, API keys and even prompt submissions. The researchers also noted that they were able to find the database almost immediately, without too much scanning or probing.
BREAKING: Internal #DeepSeek database publicly exposed 🚨
— Wiz (@wiz_io) January 29, 2025
Wiz Research has discovered "DeepLeak" - a publicly accessible ClickHouse database belonging to DeepSeek, exposing highly sensitive information, including secret keys, plain-text chat messages, backend details, and logs. pic.twitter.com/C7HZTKNO3p
“Usually when we find this kind of exposure, it’s in some neglected service that takes us hours to find—hours of scanning,” Nir Ohfeld, the head of vulnerability research at Wiz, told Wired. But this time, he said, “here it was at the front door.”
Wiz Research says it’s possible that a nefarious actor could have used this security hole to access other DeepSeek systems, but the company admits it only performed the base minimum assessment. This was to confirm its findings without further compromising user privacy. There is also no evidence that anyone else found the database.
Wiz staffers didn’t exactly know how to disclose their findings, given that DeepSeek is both a new entity and based in China. Researchers eventually sent their findings to every email address and LinkedIn profile they could find. The database was locked down within 30 minutes of the mass email.
DeepSeek isn’t the only AI company that has experienced a serious security breach (or two.) A hacker was able to access OpenAI’s internal messaging logs back in 2023 and a bug exposed personal information later that year.
“AI is the new frontier in everything related to technology and cybersecurity,” Ohfeld said. “Still we see the same old vulnerabilities like databases left open on the internet.”
As previously mentioned, DeepSeek took the world by storm in the past week or so. The disruptive AI model was allegedly created for just several million dollars. OpenAI runs through billions of dollars each year. This massive financial discrepancy sent the stock market into a tailspin, with many AI-adjacent stocks taking a plunge.
This article originally appeared on Engadget at https://www.engadget.com/ai/security-researchers-found-a-big-hole-in-deepseeks-security-163536961.html?src=rssChinese-made DeepSeek AI model records extensive online user data, stores it in China-based servers

Dreame's stair-climbing X50 Ultra Complete coming soon

Dreame has announced at CES 2025 that its stair climbing X50 Ultra Complete robot will be available soon, while it showed what the future will look like with its Bionic Multi-Joint Robotic Arm, which will let robot vacuum cleaners use tools.
X50 Series
The first product announced at CES 2025 was the X50 Series, which will be available soon, starting with the X50 Ultra Complete (£1,399, and available in February). This model is home to the ProLeap system, which was first demonstrated at IFA 2024. Along with some rival systems, ProLeap showed how robot vacuum cleaners are getting closer to stair climbing.
ProLeap uses retractable legs that lift the chassis and allow the robot to climb over thresholds and small steps up to 6cm high.

In addition, the X50 Ultra Complete has extendable mop and side brushes, AI-powered obstacle avoidance and powerful suction. This robot has the VersaLift Navigation, featuring a DToF sensor that lifts for 360° scanning, and retracts, making the robot just 8.9cm high, and able to fit under a lot of furniture.
We’ll bring you a full review of this robot vacuum cleaner in time for its launch.
Bionic Multi-Joint Robotic Arm

Following on from the Roborock Saros Z70, which was announced just a couple of days ago, Dreame has also announced that it too will have products that use a robotic arm for deeper cleaning. Demoed at CES, the Bionic Multi-Joint Robotic Arm is equipped with AI object recognition and a human-like joint design. It will be able to perform multiple tasks, including:
- Lifting objects: Able to extend 30cm and lift objects up to 400g in weight, the arm can move items, such as toys and shoes, eliminating the need for a manual tidy. With an AI-powered binocular system, the arm can identify and grasp a range of objects with precision.
- Autonomous Tool Operation: Able to use tools, such as sponges and brushes, the arm can deliver precision cleaning, including reaching 40cm to clean low spaces and between small gaps.
- Remote monitoring: The arm’s camera, top-mounted to give 360° of coverage, allows users to interact with pets or monitor cleaning.
The arm is slated for release later this year.
Multi-Mop Replacement Dock

Dreame promises that the Multi-Mop Replacement Dock will boost floor cleaning. Able to switch between three different pairs of mopping cloths, the dock can make the switch automatically, so each room is cleaned with a fresh set to prevent cross contamination and a more hygeinic clean. The Multi-Mop Replacement Dock is due for release later this year.
You might like…
The post Dreame's stair-climbing X50 Ultra Complete coming soon appeared first on Trusted Reviews.

Call of Duty’s Astronomical Development Budgets Revealed — Activision Pumped $700 Million Into Black Ops Cold War Alone
The astronomical development budgets of the Call of Duty games were revealed for the first time after a court document confirmed Activision pumped $700 million into Black Ops Cold War alone.
First reported by Game File, a court filing submitted by publisher Activision as part of a lawsuit regarding the 2022 school shooting at Robb Elementary in Uvalde, Texas, included official word on the development budgets of 2015’s Black Ops 3, 2019’s Modern Warfare, and 2020’s Black Ops Cold War.
The court filing also includes updated sales figures for each game, showing the huge revenue Call of Duty brings in through sales alone and before its post-launch monetization.
First, some caveats. The figures detailed below include pre and post-launch development. That is, the cost to develop each game for launch, then the subsequent post-launch development costs associated with feeding the ongoing live service, meaning the development lifecycle of the game.
Call of Duty games offer a range of free content following release, including new maps, new weapons, and new cosmetics for use across Multiplayer and Zombies. Activision monetizes Call of Duty post-launch by selling battle passes, store bundles, and, most recently with Black Ops 6, premium event passes, released in the traditional live service seasonal model in the year each game has to itself before the next Call of Duty comes around.
The development of this relentless conveyor belt of content, which often includes high-profile crossovers with popular intellectual property such as Warhammer 40,000 and Squid Game, does not come cheap.
Now, onto the figures themselves:
- Black Ops 3 (2015): $450 million in development costs across the game’s lifecycle, 43 million copies sold
- Modern Warfare (2019): $640 million in development costs across the game’s lifecycle, 41 million copies sold
- Black Ops Cold War (2020): $700 million in development costs over the game’s life cycle, 30 million copies sold
To provide context, Naughty Dog’s The Last of Us 2 cost around $220 million, Guerrilla’s Horizon Forbidden West cost $212 million, and Insomniac’s Spider-Man 2 cost $300 million to develop. However, these games are not live services, and so post-launch development costs are not necessarily related to the figures as they are with Call of Duty.
As Game File noted, these development costs do not include marketing spend, which for Call of Duty will be significant. So the true cost of bringing Call of Duty to market and operating it as a live service will be even higher.
While ever increasing triple-A development budgets are a hot topic within the industry, and have caused some experts to question the viability of these sorts of games, Call of Duty operates on a different level to most of its peers. Black Ops Cold War’s 30 million copies sold will in of itself have generated well over $1 billion in revenue for Activision, then there’s the live service revenue generated by the game during the 12 months before 2021’s Call of Duty: Vanguard launched. Even with $700 million spent on development and more on marketing, Black Ops Cold War will have been hugely profitable for Activision. You can see why Microsoft forked out $69 billion to buy the company.
Speaking of Microsoft, the math is now muddled by Call of Duty’s day-one launch on Game Pass, which some analysts had predicted would impact sales of Black Ops 6 but boost subscription numbers. Microsoft itself sounds delighted with the performance of last year’s game, saying sales of Black Ops 6 on PlayStation and PC were 60% higher compared to the 2023 release of Modern Warfare 3.
Microsoft has yet to say exactly how many new subscribers Black Ops 6 brought through the door, although CEO Satya Nadella has confirmed that Game Pass set a record for new subs on launch day.
However, Microsoft’s gaming business has suffered devastating layoffs, and Activision has taken a significant hit as part of that. Microsoft has cut an eye-watering 2,550 staff from its gaming business since acquiring Activision Blizzard for $69 billion in 2023. Xbox boss Phil Spencer has indicated the cuts were related to the acquisition of the Call of Duty maker.
Wesley is the UK News Editor for IGN. Find him on Twitter at @wyp100. You can reach Wesley at wesley_yinpoole@ign.com or confidentially at wyp100@proton.me.

German Bionic’s new Apogee Ultra exoskeleton can lift up to 80 pounds and help with walking
German Bionic, the robot exoskeleton startup behind the lightweight Apogee exosuit, just revealed the Apogee Ultra at CES 2025 in Las Vegas. This powered exoskeleton is intended to help people complete jobs that require heavy lifting or advanced movement.
To that end, it offers dynamic lifting support of up to 80 pounds. This means that it can lift the entire thing or help a bit when people need it, sort of like how rider assist works with electric bikes. The company says “it makes physically demanding tasks feel effortless” and that lifting 70 pounds will feel like nine or ten pounds for the lower back.
The exoskeleton has also been designed to help with walking long distances, which is often required in large warehouses where this kind of technology would be most useful. German Bionic says this walking assist feature will make a trip of ten miles feel like eight. The Apollo Ultra will even offer a bit of assistance when completing tasks that require people to bend over for prolonged periods of time.
The device is filled with some advanced software, which helps with the whole “dynamic” thing mentioned above. The “highly adaptive” system adjusts to the needs of each individual user via machine learning algorithms. These algorithms have been trained on “vast amounts of high quality, relevant data collected from thousands of users.”
The exoskeleton integrates with a proprietary app, allowing people to view performance metrics like steps taken, usage time and weight lifted. The app has also been designed with feedback in mind, as there’s an easy way to contact the company to deliver insights. This should allow for continuous improvement as more people don the suit.
This exoskeleton is perfectly positioned for industrial work and for health care, as medical professionals often need a bit of help to lift patients. The Apogee Ultra is available for preorder right now, but it’ll likely empty out that bank account. We don’t have a specific price, but the lower-tech Apogee+ exoskeleton costs $9,900. The company does offer monthly payment plans for bulk purchases by commercial entities.
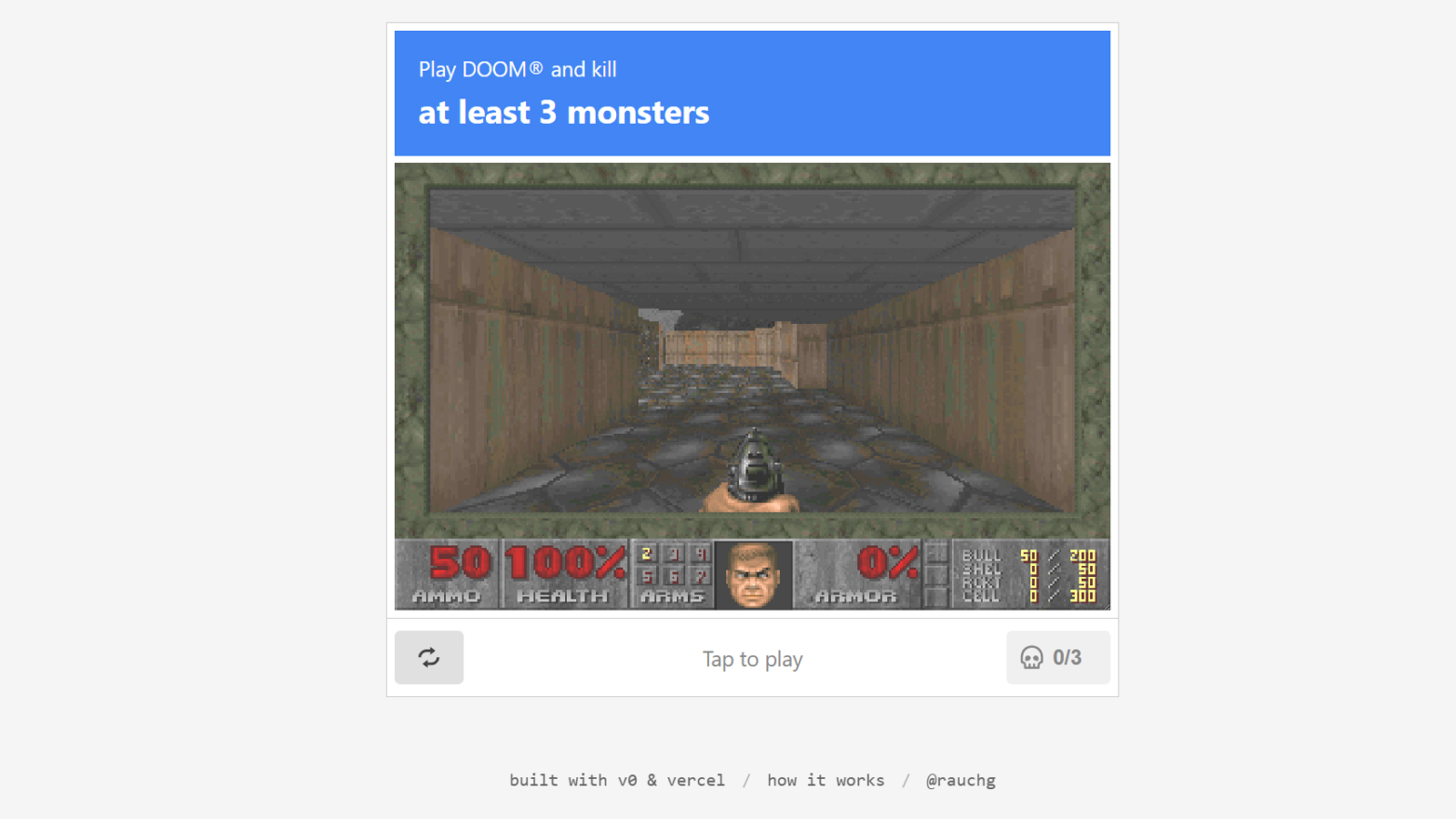
This article originally appeared on Engadget at https://www.engadget.com/wearables/german-bionics-new-apogee-ultra-exoskeleton-can-lift-up-to-80-pounds-and-help-with-walking-140031689.html?src=rssNew Captcha requires defeating three enemies or you're Doomed to repeat it
Ergo Desk reclines with your chair, desktop tilts up to match the recline of your chair — 3-in-1 desk can be reserved for $450

AI data centers reportedly cause power problems in residential areas — decreased power quality in homes near data centers causes reduced lifespan for electrical appliances

{kind=link}
_in_a_Eucalypt.jpg){kind=link}
{kind=link}
In 2024, using social media felt worse than ever
It’s never been more exhausting to be online than in 2024. While it’s been clear for some time that monetization has shifted social media into a different beast, this year in particular felt like a tipping point. Faced with the endless streams of content that’s formulated to trap viewers’ gazes, shoppable ads at every turn, AI and the unrelenting opinions of strangers, it struck me recently that despite my habitual use of these apps, I’m not actually having fun on any of them anymore.
Take Instagram. I open the app and I’m greeted by an ad for bidets. I start scrolling. Between each of the first three posts at the top of my feed is a different ad: lingerie, squat-friendly jorts, shoes from a brand selling items that appear to be dropshipped from AliExpress at a markup. Then, thankfully, two memes back to back. I fire off the funny one to five of my friends in a way that feels obligatory. After that, another ad, then a bunch of seemingly off-target Reels from accounts I don’t even follow. Minutes pass before I encounter a post by someone I know in real life. Oh yeah, it’s time to turn off suggested posts again, something I have to do every 30 days or my feed will be filled with random crap.
But before I get a chance to do that, I’m distracted by a Reel of a cat watching The Grinch. Then by a Reel of a guy with a tiny chihuahua in his coat pocket. Curiosity gets the better of me and I open the comments, where people are angrily writing that the dog must be suffocating. Oh no. I scroll to the next Reel, a video I’ve seen several times before of a rooster marching around in a pair of pants. Below, everyone’s fighting about whether it’s cruel to put pants on a chicken. Is it? Next, a video of a girl doing her makeup, where men are commenting that this should be considered catfishing. Deep sigh. I realize 30 minutes have somehow passed and I close Instagram, now in a worse mood than when I opened it. I’ll compulsively return in an hour or so, rinse and repeat.
It’s not just an Instagram problem. On TikTok (which may or may not get shut down in the US very soon), the For You page has me figured out pretty well contentwise and the presence of toxic commenters is minimal, but every other post is either sponsored or hawking a product from the TikTok Shop. And it’s too easy to get sucked into the perpetual scroll. I often avoid opening the app at all just because I know I’ll end up getting trapped there for longer than I want to, watching videos about nothing made by people I don’t know and never will. But it still happens more frequently than I’d like to admit.
These days, it feels like every gathering place on the internet is so crowded with content that’s competing for — and successfully grabbing — our attention or trying to sell us something that there’s barely any room for the “social” element of social media. Instead, we’re pushed into separate corners to stare at the glowing boxes in our hands alone.
Fittingly, Oxford announced at the end of November that its Word of the Year for 2024 is “brain rot,” a term that expresses the supposed consequence of countless hours spent on the internet consuming stupid stuff. Just as fitting, Australia’s Macquarie Dictionary chose “enshittification,” which describes how the platforms and products we love get ruined over time as the companies behind them chase profits. (It was also The American Dialect Society’s 2023 Word of the Year). Social media platforms were in theory designed around ideas of friendship and connection, but what’s playing out on them today couldn’t feel further from genuine human interaction.
Facebook — if you even have an account still — might be where you’d go if you really wanted to see updates from family and other people you know IRL, but its UI has become so cluttered with recommended Reels and products that it feels unusable. Twitter, where it was once fun to keep up with live discourse around major events or fandom happenings, no longer exists, and X, its new form under Elon Musk, is filled with bots and political propaganda.
On the other hand, Threads, an offshoot of Instagram and Meta’s answer to Twitter/X, took off this year and it quickly became a hotspot for copy-paste engagement bait, a problem so bad that Adam Mosseri has publicly acknowledged it. The Threads team has apparently been “working to get it under control,” but I still can’t scroll through my For You feed without seeing a dozen posts that are either just regurgitated memes being passed off as original thoughts, or questions to the masses that are crafted with the intention of stirring the pot. The same feed is otherwise dominated by viral videos that are ripped off from other creators without credit and pop culture commentary that almost always devolves into sex- and genderism. I often step away from Threads feeling the need to go scream in a field.
Threads doesn’t have DMs, meaning all conversations take place in public. It finally gave users the ability to create custom feeds around searchable topics in November, but those topic pages are generally still riddled with bait-style posts, just more subject-specific versions. That’s meant so far that it’s been pretty hard to find communities to authentically connect with. It all feels so impersonal.
It doesn’t help that Threads’ Following feed currently isn’t the default view and there’s no way to change that (though Threads recently began testing the option). And at the end of the day, its 275 million or so monthly active users doesn’t include all that many people I actually know, especially outside of the media industry. The same goes for fediverse social networks like Mastodon and Bluesky, which are far less populated but have a cliquier feel. Visiting those platforms feels like walking into a room full of people who all know each other really well, and realizing you’re the odd one out. But at least Bluesky nor Mastodon aren’t poorly veiled shopping experiences. (Threads isn’t at the moment, either, but ads are reportedly coming).
Maybe it all comes down to burnout in the era of excessive consumption, but lately I’ve found myself wishing for a place on the internet that feels both inviting and human. I’m sure I’m not alone. In recent years, we’ve seen alternative social apps pop up like BeReal, Hive and the Myspace-reminiscent entrants SpaceHey and noplace, all aiming to bring character and interpersonal connection back into social media. But none have quite cracked the code for lasting mainstream adoption. Discord and even Reddit to some extent address the same person-to-person need, yet they share more in common with proto social media chatrooms and forums than with the sites that sprung up during the social heyday.
Meanwhile, Meta is increasingly pushing AI across its apps. Just this summer we got the chatbot-maker, AI Studio, which Meta touted not only as a way for users to create AI characters, but for “creators to build an AI as an extension of themselves to reach more fans.” Rather than talk to your real friends or make new ones around a common interest, you can deepen your parasocial relationship with celebrities, influencers and fictional characters by chatting with the AI versions of them. Or, pick from several AI girlfriends you can now find in the menu of your DMs. We’ve completely lost the plot, I fear.
I’ve started dipping back into Tumblr here and there, if only to see a less chaotic, more curated feed and relish in the reminder of how fun customization can be. A few friends have mentioned that they’ve been doing the same. But given the platform’s past policy upheavals and its current AI partnerships, it’s not exactly an online oasis either. As if on cue, I was recently served a mock Tumblr poster during my evening scroll that felt uncannily apt: “we didn’t get better. the rest of the internet just got worse.”
This article originally appeared on Engadget at https://www.engadget.com/social-media/in-2024-using-social-media-felt-worse-than-ever-170047895.html?src=rss