
Shared posts

03 Feb 12:24
01/27/14 PHD comic: 'Disparate Situation'
| Piled Higher & Deeper by Jorge Cham |
www.phdcomics.com
|
|
 |
||
|
title:
"Disparate Situation" - originally published
1/27/2014
For the latest news in PHD Comics, CLICK HERE! |
||
30 Jan 11:24
Looking For a Good Sort
by tony@overbyte.com.au (Tony Albrecht)
Vessel for PlayStation 3 has finally been submitted to Sony for approval so I have a little more time to write up some of the optimisation challenges we had to overcome during its porting process. Well, OK, I don’t really have any more time but I’ll try to write a bit more about it before wet bit rot sets in and I forget everything.

Vessel ran predominantly on three threads; one for Physics, one for Game and one for the Render process. The Render thread translated the output from the Game thread into a command buffer that could be parsed by the SPUs and as such was pretty short - we had allocated up to 3 ms per frame for it and unfortunately, in certain places it was hitting 11ms.
Looking at a Tuner profile we found the following

In this case, the Render thread was taking around 6ms, with half of this taken up with the generation of the quads for each of the fluid mesh maps. Of that, 1 millisecond was spent in the STL sort function. This seemed a little excessive to me, so I looked closer. The red bars in the image above correspond to the following code:

with the following functors to do the gritty part of the sorting.

Basically, what the above code does is, for each fluid mesh map (the outer loop code isn’t shown but the first code fragment is called once per FluidMeshMap) sort the FluidVertexes by water type (lava, water, glow goo etc) and then by whether or not it is an isolated drop (both edges in the g_Mesh are equal) or if it is an edge (e1 != e2). Once that is done this information is used to populate a vertex array (via calls to SetEdge()) which is in turn eventually passed off to the GPU.
From looking at the Tuner scan we can see that the blue parts take up a fair amount of time (they correspond to PROFILE_SCOPE(sort) in the code) and correspond to the standard sort() function. The question is, can we write a better sort than std::sort?
std::sort is already highly optimised and was written by smart people that have produced a generic solution that anyone can plug into their code and use without thinking too much about it. And that is exactly why we can write a faster sort than std::sort for this case - because we know exactly what we want. We have the input and we know the output we want, all we need to do is work out the fiddly transformation bit in the middle.
The output we desire is the FluidVerts ordered by sort and then by edge/drop type. The final order should look something like this:

I decided to base the solution loosely on the Radix sort. We do a first pass over the data to be sorted and count up how many of each fluid ‘sort’ there is. This is then effectively a histogram of the different fluid types - we now know how many of each type there is and we can set up a destination array that is the size of the sorted elements and we can calculate where in that contiguous array the ‘sorts’ of fluid should go.
Our second pass steps through the source array and places the FluidVertex into the correct bucket (based on fluid ‘sort’), but adds it to the beginning of the bucket if it is an edge and at the end if it is a drop. And that’s it. Done. Two passes. A super fast, super simple sort that does just what we need.
“So, how much faster is it then?” I hear you ask.
“About five times faster.” I would respond. This sort runs in about .25ms compared to the original 1ms but it also has the added benefit of moving the FluidVertex data into contiguous sorted arrays (the original just produced an index map that could be used to traverse the original array (vSorted)). This is good because we can then easily optimise the second part of the FluidMeshMap loop which copies the verts to a vertex buffer for rendering and also modifies the edges via calls to SetEdge() (for those that are interested, the SetEdge() function does some simple arithmetic and inconveniently calls Atan2() to set up the angle of the edge for the GPU to use). This contiguous data means fewer cache misses, but on PS3 it also means that we can easily pass it off to the SPUs to do the transform and copy for us while we process the next FluidMeshMap on the PPU. Nice huh?
The result is that the BuildFluidMeshmap section is reduced from 2.25ms down to 0.24ms - a saving of 2ms

The key message to take away from this is that generic implementations of algorithms are great for getting your code up and running quickly, but don’t expect them to be lightning fast in all cases. Think about what you are doing, reduce you problem to the simplest inputs and outputs and then build a simple transformation that does just that. It will make you feel good on the inside. Simplicity is its own reward.
(For anyone interested in more sorting goodness, check out an old blog post of mine A Questions of Sorts.)
Joan Blasco, slack likes this
15 Jan 11:35

On Hacking MicroSD Cards
by bunnie
Today at the Chaos Computer Congress (30C3), xobs and I disclosed a finding that some SD cards contain vulnerabilities that allow arbitrary code execution — on the memory card itself. On the dark side, code execution on the memory card enables a class of MITM (man-in-the-middle) attacks, where the card seems to be behaving one way, but in fact it does something else. On the light side, it also enables the possibility for hardware enthusiasts to gain access to a very cheap and ubiquitous source of microcontrollers.

In order to explain the hack, it’s necessary to understand the structure of an SD card. The information here applies to the whole family of “managed flash” devices, including microSD, SD, MMC as well as the eMMC and iNAND devices typically soldered onto the mainboards of smartphones and used to store the OS and other private user data. We also note that similar classes of vulnerabilities exist in related devices, such as USB flash drives and SSDs.
Flash memory is really cheap. So cheap, in fact, that it’s too good to be true. In reality, all flash memory is riddled with defects — without exception. The illusion of a contiguous, reliable storage media is crafted through sophisticated error correction and bad block management functions. This is the result of a constant arms race between the engineers and mother nature; with every fabrication process shrink, memory becomes cheaper but more unreliable. Likewise, with every generation, the engineers come up with more sophisticated and complicated algorithms to compensate for mother nature’s propensity for entropy and randomness at the atomic scale.
These algorithms are too complicated and too device-specific to be run at the application or OS level, and so it turns out that every flash memory disk ships with a reasonably powerful microcontroller to run a custom set of disk abstraction algorithms. Even the diminutive microSD card contains not one, but at least two chips — a controller, and at least one flash chip (high density cards will stack multiple flash die). You can see some die shots of the inside of microSD cards at a microSD teardown I did a couple years ago.
In our experience, the quality of the flash chip(s) integrated into memory cards varies widely. It can be anything from high-grade factory-new silicon to material with over 80% bad sectors. Those concerned about e-waste may (or may not) be pleased to know that it’s also common for vendors to use recycled flash chips salvaged from discarded parts. Larger vendors will tend to offer more consistent quality, but even the largest players staunchly reserve the right to mix and match flash chips with different controllers, yet sell the assembly as the same part number — a nightmare if you’re dealing with implementation-specific bugs.
The embedded microcontroller is typically a heavily modified 8051 or ARM CPU. In modern implementations, the microcontroller will approach 100 MHz performance levels, and also have several hardware accelerators on-die. Amazingly, the cost of adding these controllers to the device is probably on the order of $0.15-$0.30, particularly for companies that can fab both the flash memory and the controllers within the same business unit. It’s probably cheaper to add these microcontrollers than to thoroughly test and characterize each flash memory chip, which explains why managed flash devices can be cheaper per bit than raw flash chips, despite the inclusion of a microcontroller.
The downside of all this complexity is that there can be bugs in the hardware abstraction layer, especially since every flash implementation has unique algorithmic requirements, leading to an explosion in the number of hardware abstraction layers that a microcontroller has to potentially handle. The inevitable firmware bugs are now a reality of the flash memory business, and as a result it’s not feasible, particularly for third party controllers, to indelibly burn a static body of code into on-chip ROM.
The crux is that a firmware loading and update mechanism is virtually mandatory, especially for third-party controllers. End users are rarely exposed to this process, since it all happens in the factory, but this doesn’t make the mechanism any less real. In my explorations of the electronics markets in China, I’ve seen shop keepers burning firmware on cards that “expand” the capacity of the card — in other words, they load a firmware that reports the capacity of a card is much larger than the actual available storage. The fact that this is possible at the point of sale means that most likely, the update mechanism is not secured.
In our talk at 30C3, we report our findings exploring a particular microcontroller brand, namely, Appotech and its AX211 and AX215 offerings. We discover a simple “knock” sequence transmitted over manufacturer-reserved commands (namely, CMD63 followed by ‘A’,'P’,'P’,'O’) that drop the controller into a firmware loading mode. At this point, the card will accept the next 512 bytes and run it as code.
From this beachhead, we were able to reverse engineer (via a combination of code analysis and fuzzing) most of the 8051′s function specific registers, enabling us to develop novel applications for the controller, without any access to the manufacturer’s proprietary documentation. Most of this work was done using our open source hardware platform, Novena, and a set of custom flex circuit adapter cards (which, tangentially, lead toward the development of flexible circuit stickers aka chibitronics).

Significantly, the SD command processing is done via a set of interrupt-driven call backs processed by the microcontroller. These callbacks are an ideal location to implement an MITM attack.
It’s as of yet unclear how many other manufacturers leave their firmware updating sequences unsecured. Appotech is a relatively minor player in the SD controller world; there’s a handful of companies that you’ve probably never heard of that produce SD controllers, including Alcor Micro, Skymedi, Phison, SMI, and of course Sandisk and Samsung. Each of them would have different mechanisms and methods for loading and updating their firmwares. However, it’s been previously noted that at least one Samsung eMMC implementation using an ARM instruction set had a bug which required a firmware updater to be pushed to Android devices, indicating yet another potentially promising venue for further discovery.
From the security perspective, our findings indicate that even though memory cards look inert, they run a body of code that can be modified to perform a class of MITM attacks that could be difficult to detect; there is no standard protocol or method to inspect and attest to the contents of the code running on the memory card’s microcontroller. Those in high-risk, high-sensitivity situations should assume that a “secure-erase” of a card is insufficient to guarantee the complete erasure of sensitive data. Therefore, it’s recommended to dispose of memory cards through total physical destruction (e.g., grind it up with a mortar and pestle).
From the DIY and hacker perspective, our findings indicate a potentially interesting source of cheap and powerful microcontrollers for use in simple projects. An Arduino, with its 8-bit 16 MHz microcontroller, will set you back around $20. A microSD card with several gigabytes of memory and a microcontroller with several times the performance could be purchased for a fraction of the price. While SD cards are admittedly I/O-limited, some clever hacking of the microcontroller in an SD card could make for a very economical and compact data logging solution for I2C or SPI-based sensors.
Slides from our talk at 30C3 can be downloaded here, or you can watch the talk on Youtube below.
Team Kosagi would like to extend a special thanks to .mudge for enabling this research through the Cyber Fast Track program.


13 Dec 10:44
Trivial program checkers
by Arcane Sentiment
Typecheckers get (and deserve) a lot of attention for their ability to find bugs, but their success leads people to think typechecking is the only way to check programs. It's not. There are useful program checkers much simpler than any typechecker. Here's an example:
grep scanfThis finds real bugs in real programs — and not just ordinary bugs, but security holes due to %s overflowing buffers.
Here's another checker:
grep 'printf[^"]*$'This finds printfs that don't have a literal string on the same line, which usually means someone forgot the format string and did this:
fprintf(file, somestr);...instead of this:
fprintf(file, "%s", somestr);It's a stupid bug, yes, but not a rare one. I once ran this checker on a large application and found dozens of instances of this bug. I also found dozens of false positives, from things like these:
snprintf(somewhere->buffer, MAX_BUFFER,
"format string", args);
fprintf(file, message_format_strings[status], description);But they were obvious false positives, so it was easy to ignore them.
Here's an even less selective checker:
grep '(\w\+ \?\*)' #beware different versions of grepThis finds pointer typecasts, which (in C++, more than in C) are often misguided — they might indicate unsafe downcasts, or non-type-safe containers, or casting away constness, or simple unnecessary casting. It also finds a great many false positives, of course — mostly function prototypes and innocent casts.
These checkers don't prove the absence of the errors they look for. A program that doesn't contain the string scanf might still call it via a library or by dlsym. The printf checker can be defeated by something as simple as a printf-like function whose name doesn't contain printf — hardly a rare occurrence! The cast checker misses mundane things like (char**) and (IntPtr). They only find bugs; they don't guarantee their absence.
They're also not very powerful. They find only certain specific errors, not a wide variety. A real lint program can do much better.
But when you don't have a real lint handy, or when your lint doesn't find the problem you're worried about, simple textual checkers can be valuable.
“They only find bugs”. “Only certain specific errors”. Faint criticism.
In addition to being useful, these checkers are a reminder that there are many ways to check programs. None of them are typecheckers in either sense — not in the common sense, because they don't check datatypes, and not in the type-theory sense, because they don't classify expressions. They aren't even aware of the existence of expressions — they see code only as text. This is not a very powerful approach, but it's enough to find a lot of bugs.
Not all checkers are typecheckers.
Joan Blasco, slack likes this

02 Dec 12:31
Un usuario anónimo ha publicado en la web francesa Logic Sunrise un sencillo método para acceder a un menú debug para desarrolladores en cualquier Xbox One. Este menú podría responder a las declaraciones del vicepresidente de Microsoft, Marc Whitten, que aseguraba hace unos meses que "cada Xbox One puede utilizarse para el desarrollo" y publicación de títulos en Xbox Live. Whitten aclaró en Kotaku que la funcionalidad no estaría disponible desde el lanzamiento, pero se implementaría posteriormente. En el post de Logic Sunrise se incluye cómo acceder al menú con una combinación de… Leer noticia completa y comentarios »
Desvelado un menú "debug" para desarrolladores en Xbox One
 |
Un usuario anónimo ha publicado en la web francesa Logic Sunrise un sencillo método para acceder a un menú debug para desarrolladores en cualquier Xbox One. Este menú podría responder a las declaraciones del vicepresidente de Microsoft, Marc Whitten, que aseguraba hace unos meses que "cada Xbox One puede utilizarse para el desarrollo" y publicación de títulos en Xbox Live. Whitten aclaró en Kotaku que la funcionalidad no estaría disponible desde el lanzamiento, pero se implementaría posteriormente. En el post de Logic Sunrise se incluye cómo acceder al menú con una combinación de… Leer noticia completa y comentarios »
25 Nov 14:16






montt en dosis diarias - -69
by noreply@blogger.com (montt)
Bianca Bueno, slack likes this
22 Nov 13:06
WebGL Debugging and Profiling Tools
by Eric
by Patrick Cozzi, who works on the Cesium WebGL engine.
With the new shader editor in Firefox 27 (available now in Aurora), WebGL tools are taking a big step in the right direction. This article reviews the current state of WebGL debugging and profiling tools with a focus on their use for real engines, not simple demos. In particular, our engine creates shaders dynamically; uses WebGL extensions like Vertex Array Objects; dynamically creates, updates, and deletes 100′s of MB of vertex buffers and textures; renders to different framebuffers; and uses web workers. We’re only interested in tools that provide useful results for our real-world needs.
Firefox WebGL Shader Editor
The Firefox WebGL Shader Editor allows us to view all shader programs in a WebGL app, edit them in real-time, and mouse over them to see what parts of the scene were drawn using them.
What I like most about it is it actually works. Scenes in our engine usually have 10-50 procedurally-generated shaders that can be up to ~1,000 lines. The shader editor handles this smoothly and automatically updates when new shaders are created.
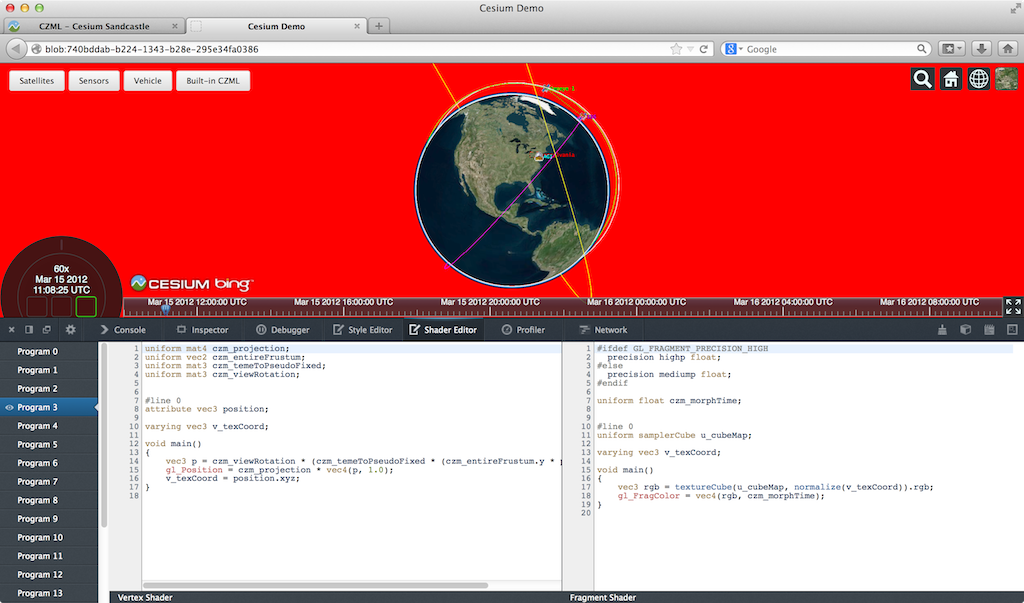
The skybox shader is shown in the editor and the geometry is highlighted in red. (Click on any image for its full-screen version.)
I was very impressed to see the shader editor also work on the Epic Citadel demo, which has 249 shaders, some of which are ~2,000 lines.
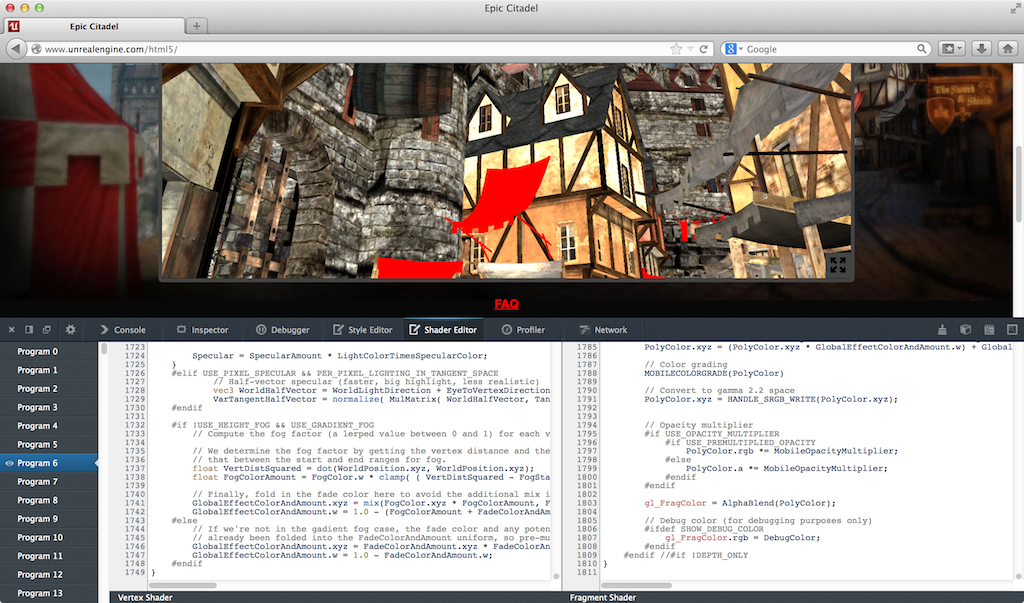
Live editing is, of course, limited. For example, we can’t add new uniforms and attributes and provide data for them; however, we can add new varying variables to pass data between vertex and fragment shaders.
Given that the editor needs to recompile after our edits, attribute and uniform locations could change, e.g., if uniforms are optimized out, which would break most apps (unless the app is querying these every frame, which is a terrible performance idea). However, the editor seems to handle remapping under-the-hood since removing uniforms doesn’t break other uniforms.
Recompiling after typing stops works well even for our large shaders. However, every editor I see like this, including JavaScript ones we’ve built, tends to remove this feature in favor of an explicit run, as the lag can otherwise be painful.
There are some bugs, such as mousing over some shaders causes artifacts or parts of the scene to go away, which makes editing those shaders impossible.
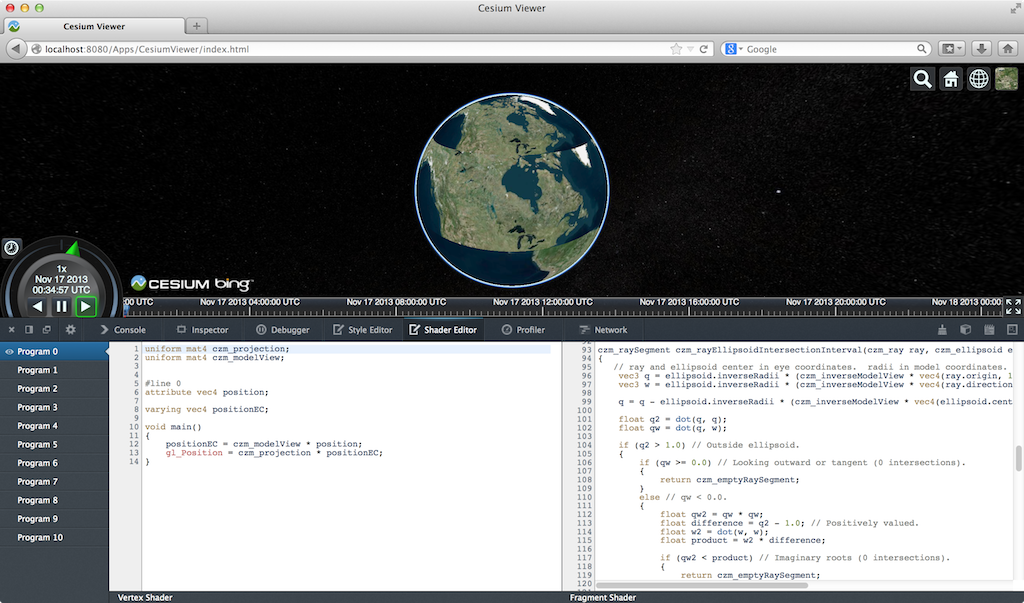
Even though this is in a pre-beta version of Firefox, I find it plenty usable. Other than spot testing, I use Chrome for development, but this tool really makes me want to use Firefox, at least for shader debugging.
We planned to write a tool like this for our engine, but I’m glad the Mozilla folks did it instead since it benefits the entire WebGL community. An engine-specific tool will still be useful for some. For example, this editor uses the shader source provided to WebGL. If a shader is procedurally-generated, an engine-specific editor can present the individual snippets, nodes in a shade tree, etc.
A few features that would make this editor even better include:
- Make boldface any code in #ifdef blocks that evaluate to true. This is really useful for ubershaders.
- Mouse over a pixel and show the shader used. Beyond debugging, this would be a great teaching aid and tool for understanding new apps. I keep pitching the idea of mousing over a pixel and then showing a profile of the fragment shader as a final project to my students, but no one ever bites. Easy, right?
- An option to see only shaders actually used in a frame, instead of all shaders in the WebGL context, since many shaders can be for culled objects. Taking it a step further, the editor could show only shaders for non-occluded fragments.
For a full tutorial, see Live editing WebGL shaders with Firefox Developer Tools.
WebGL Inspector
The WebGL Inspector was perhaps the first WebGL debugging tool. It hasn’t been updated in a long time, but it is still useful.
WebGL Inspector can capture a frame and step through it, building the scene one draw call at a time; view textures, buffers, state, and shaders; etc.
The trace shows all the WebGL calls for a frame and nicely links to more info for function arguments that are WebGL objects. We can see the contents and filter state of textures, contents of vertex buffers, and shader source and current uniforms.
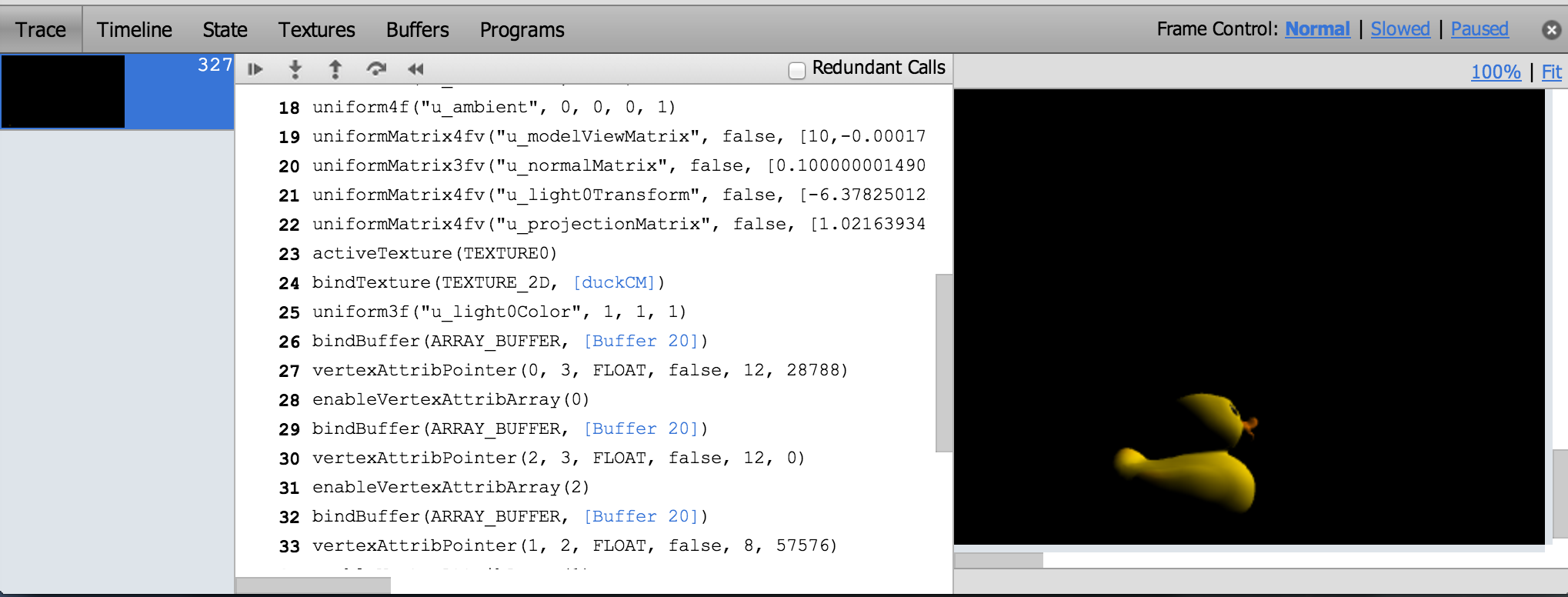
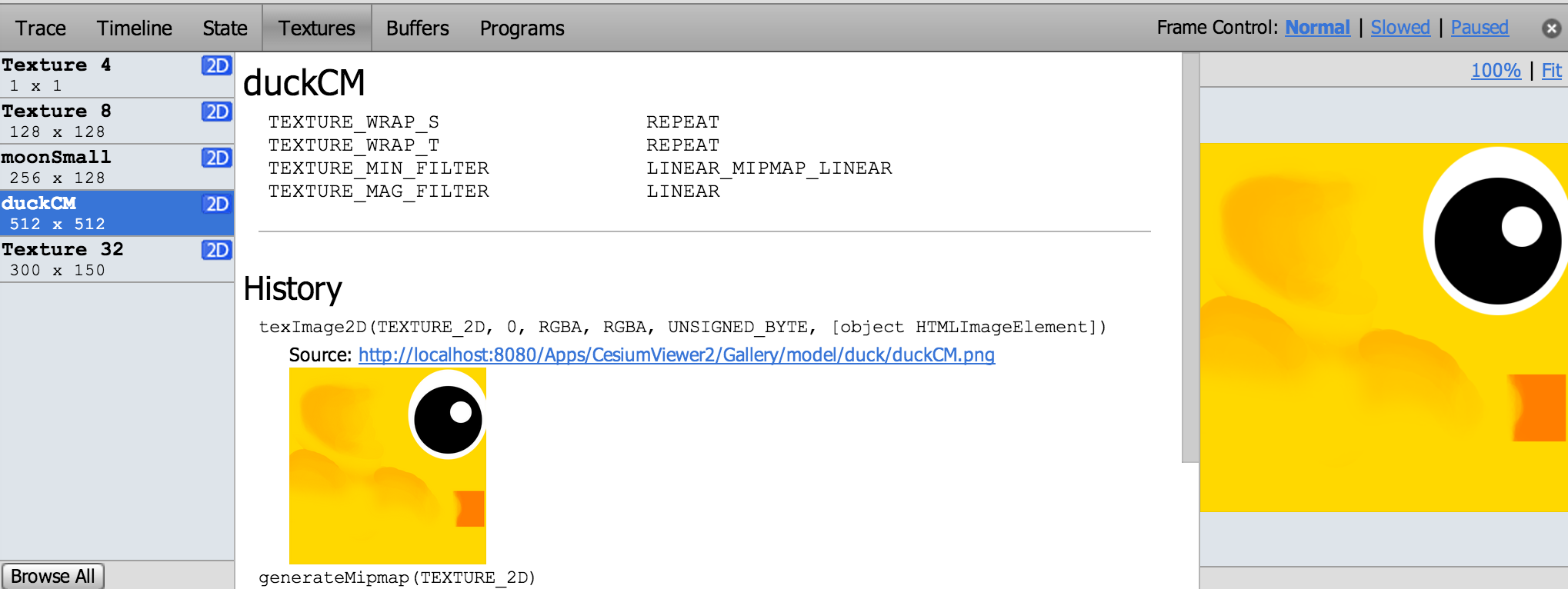
One of WebGL Inspector’s most useful features is highlighting redundant WebGL calls, which I use often when doing analysis before optimizing.
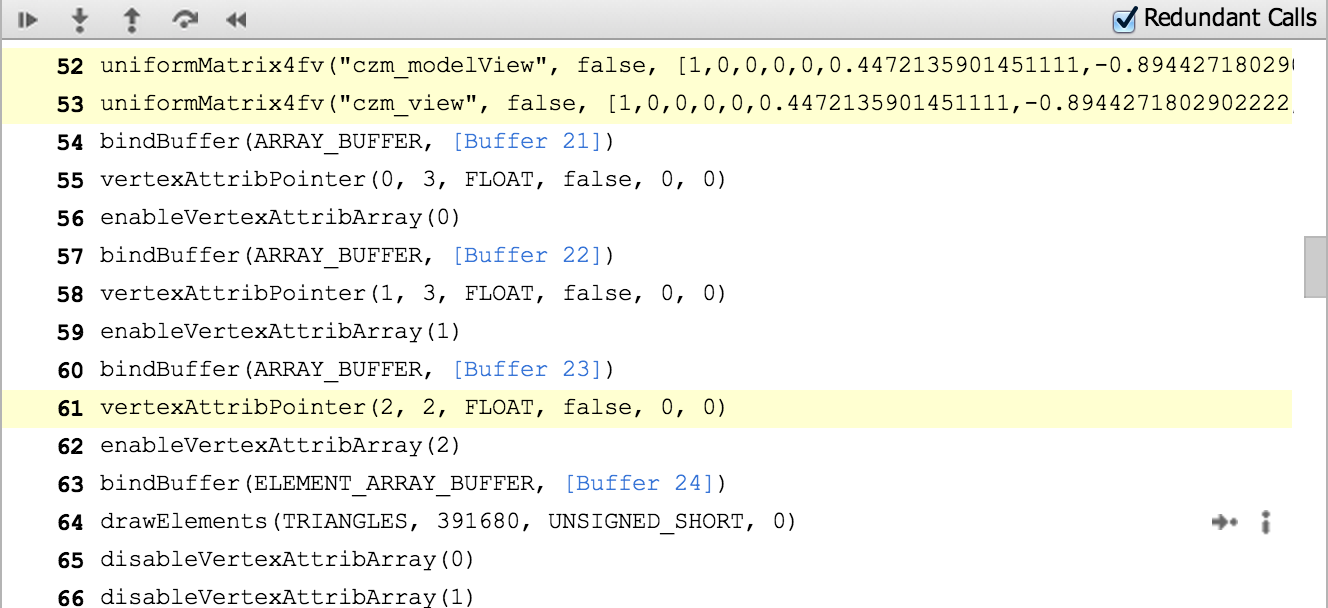
Like most engines, setting uniforms is a common bottleneck for us and we are guilty of setting some redundant uniforms for now.
WebGL Inspector may take some patience to get good results. For our engine, the scene either isn’t visible or is pushed to the bottom left. Also, given its age, this tool doesn’t know about extensions such as Vertex Array Objects. So, when we run our engine with WebGL Inspector, we don’t get the full set of extensions supported by the browser.
The WebGL Inspector page has a full walkthrough of its features.
Chrome Canvas Inspector
The Canvas Inspector in Chrome DevTools is like a trimmed-down WebGL Inspector built right into Chrome. It is an experimental feature but available in Chrome stable (Chrome 31). In chrome://flags/, “Enable Developer Tools experiments” needs to be checked and then the inspector needs to be explicitly enabled in the DevTools settings.
Although it doesn’t have nearly as many features as WebGL Inspector, Canvas Inspector is integrated into the browser and trivial to use once enabled.
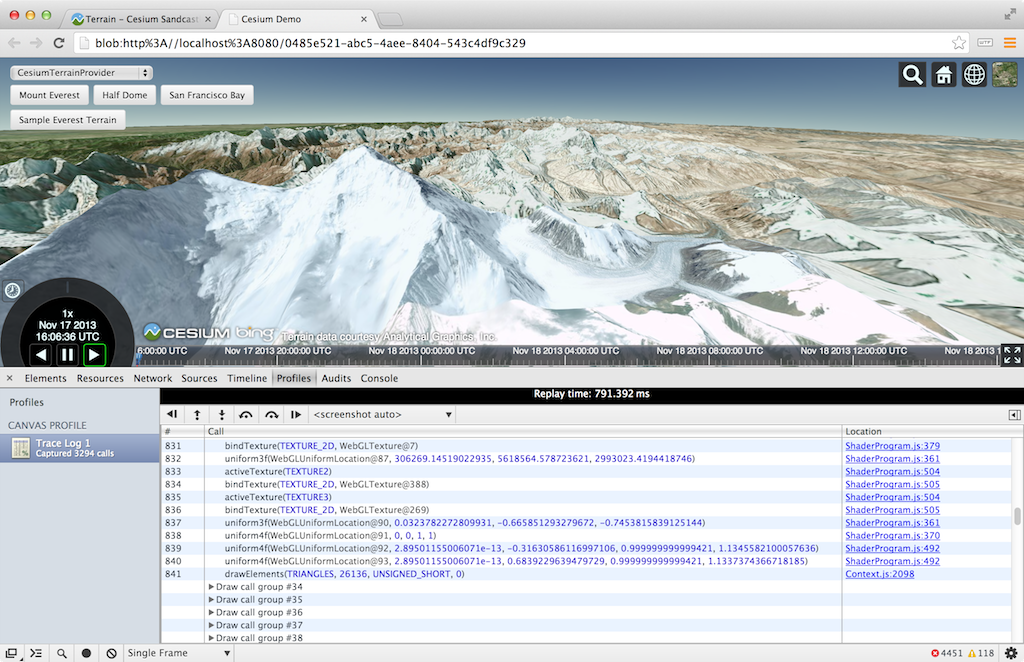
Draw calls are organized into groups that contain the WebGL state calls and the affected draw call. We can step one draw group or one WebGL call at a time (all WebGL tracing tools can do this). The scene is supposed to be shown one draw call at a time, but we currently need to turn off Vertex Array Objects for it to work with our engine. Canvas Inspector can also capture consecutive frames pretty well.
The inspector is nicely integrated into the DevTools so, for example, there are links from a WebGL call to the line in the JavaScript file that invoked it. We can also view the state of resources like textures and buffers, but not their contents or history.
Tools like WebGL Inspector and Canvas Inspector are also useful for code reviews. When we add a new rendering feature, I like to profile and step through the code as part of the review, not just read it. We have found culling bugs when stepping through draw calls and then asking why there are so many that aren’t contributing to any pixels.
For a full Canvas Inspector tutorial, see Canvas Inspection using Chrome DevTools.
Google Web Tracing Framework
The Google Web Tracing Framework (WTF) is a full tracing framework, including support for WebGL similar to WebGL Inspector and Canvas Inspector. It is under active development on github; they addressed an issue I submitted in less than a day! Even without manually instrumenting our code, we can get useful and reliable results.
Here we’re stepping through a frame one draw call at a time:
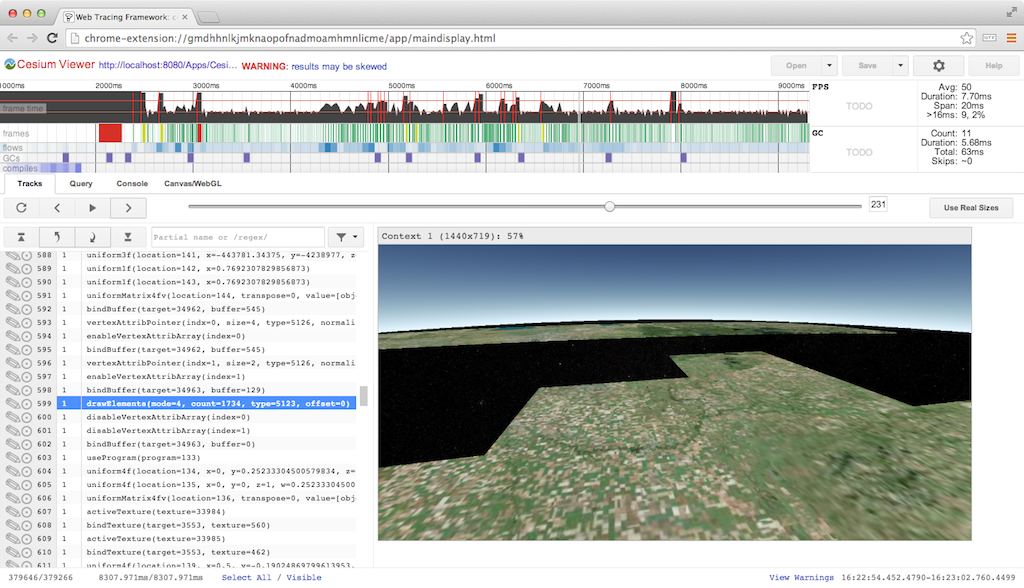
For WebGL, WTF has similar trace capability as the above inspectors, combined with all its general JavaScript tracing features. The WebGL trace integrates nicely with the tracks view.

Above, we see the tracks for frame #53. The four purple blocks are texture uploads using texSubImage2D to load new imagery tiles we received from a web worker. Each call is followed by several WebGL state calls and a drawElements call to reproject the tile on the GPU (see World-Scale Terrain Rendering from the Rendering Massive Virtual Worlds SIGGRAPH 2013 course). The right side of the frame shows all the state and draw calls for the actual scene.
Depending on how many frames the GPU is behind, a better practice would be to do all the texSubImage2D calls, followed by all the reprojection draw calls, or even move the reprojection draw calls to the end of the frame with the scene draw calls. The idea here is to ensure that the texture upload is complete by the time the reprojection draw call is executed. This trades the latency of completing any one for the throughput of computing many. I have not tried it in this case so I can’t say for certain if the driver lagging behind isn’t already enough time to cover the upload.

The tracks view gets really interesting when we examine slow frames highlighted in yellow. Above, the frame takes 27ms! It looks similar to the previous frame with four texture uploads followed by drawing the scene, but it’s easy to see the garbage collector kicked in, taking up almost 12ms.

Above is our first frame, which takes an astounding 237ms because it compiles several shaders. The calls to compileShader are very fast because they don’t block, but the immediate call to linkProgram needs to block, taking ~7ms for the one shown above. A call to getShaderParameter or getShaderInfoLog would also need to block to compile the shader. It is a best practice to wait as long as possible to use a shader object after calling compileShader to take advantage of asynchronous driver implementations. However, testing on my MacBook Pro with an NVIDIA GeForce 650M did not show this. Putting a long delay before linkProgram did not decrease its latency.
For more details, see the WTF Getting Started page. You may want to clear a few hours.
More Tools
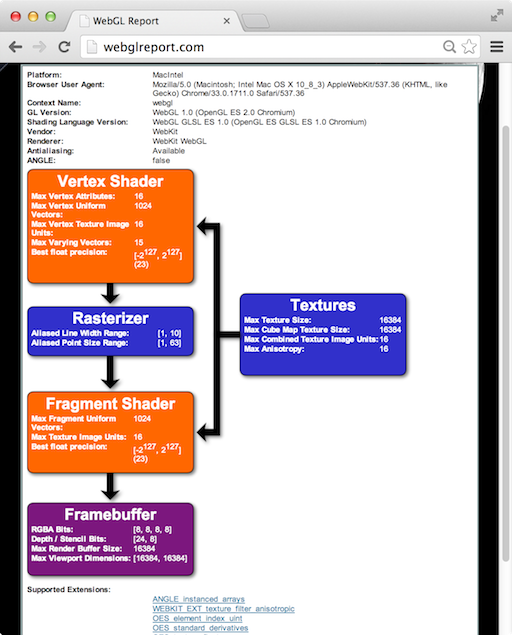
The WebGL Report is handy for seeing a system’s WebGL capabilities, including extensions, organized by pipeline stage. It’s not quite up-to-date with all the system-dependent values for the most recent extensions, but it’s close. Remember, to access draft extensions in Chrome, we need to explicitly enable them in the browser now. For enabling draft extensions in Firefox you need to go to “about:config” and set the “webgl.enable-draft-
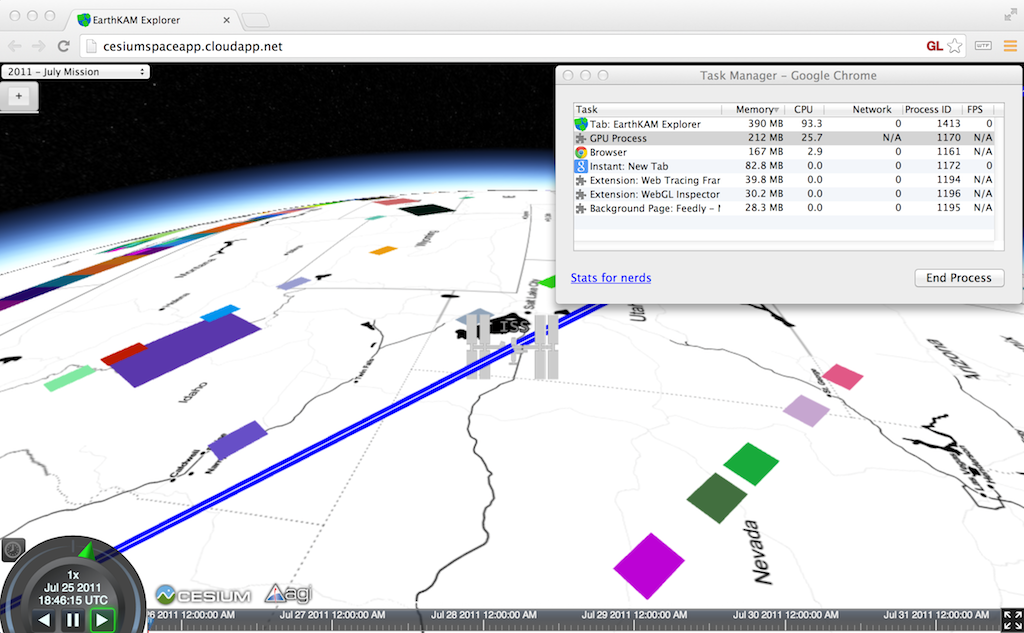
The simple Chrome Task Manager (in the Window menu) is useful for quick and dirty memory usage. Make sure to consider both your app’s process and the GPU process.
Although I have not used it, webgl-debug.js wraps WebGL calls to include calls to getError. This is OK for now, but we really need KHR_debug in WebGL to get the debugging API desktop OpenGL has had for a few years. See ARB_debug_output: A Helping Hand for Desperate Developers in OpenGL Insights.
There are also WebGL extensions that provide debugging info to privileged clients (run Chrome with –enable-privileged-webgl-extensions). WEBGL_debug_renderer_info provides VENDOR and RENDERER strings. WEBGL_debug_shaders provides a shader’s source after it was translated to the host platform’s native language. This is most useful on Windows where ANGLE converts GLSL to HLSL. Also see The ANGLE Project: Implementing OpenGL ES 2.0 on Direct3D in OpenGL Insights.
The Future
The features expected in WebGL 2.0, such as multiple render targets and uniform buffers, will bring us closer to the feature-set OpenGL developers have enjoyed for years. However, API features alone are not enough; we need an ecosystem of tools to create an attractive platform.
Building WebGL tools, such as the Firefox Shader Editor and Chrome Canvas Inspector, directly into the browser developer tools is the right direction. It makes the barrier to entry low, especially for projects with limited time or developers. It helps more developers use the tools and encourages using them more often, for the same reason that unit tests that run in the blink of an eye are then used frequently.
The current segmentation of Google’s tools may appear confusing but I think it shows the evolution. WebGL Inspector was first out of the gate and proved very useful. Because of this, the next generation version is being built into Chrome Canvas Inspector for easy access and into the WTF for apps that need careful, precise profiling. For me, WTF is the tool of choice.
We still lack a tool for setting breakpoints and watch variables in shaders. We don’t have what NVIDIA Nsight is to CUDA, or what AMD CodeXL is to OpenCL. I doubt that browser vendors alone can build these tools. Instead, I’d like to see hardware vendors provide back-end support for a common front-end debugger built into the browser.
Paul Morrison, Mihai M and 4 others like this



30 Oct 10:22


Reflexiones sobre el DNI-E
by Yago Jesus

Cada X tiempo sale el típico pseudo análisis sobre el uso del DNI-E que suele contener las mismas líneas argumentales.
De entrada, se pone encima de la mesa el dato de DNIs expedidos (masivo) y luego se contrasta con algún tipo de encuesta sobre cuanta gente lo usa (ínfimo).
Se coge el resultado y en base a eso, se genera un 'sesudo' libelo sobre las deficiencias del DNI-E. Principalmente se habla de la usabilidad: que es difícil de instalar, es complejo de usar ... y se termina diciendo que es por eso su escaso uso.
Ahora que tenemos en ciernes el 'DNI-E 3.0' ha vuelto esa corriente de opinión, esta vez clamando por que el nuevo DNI sea más usable y gracias a eso todo el mundo empiece a beneficiarse de las indudables utilidades.
Ante eso, lo que tengo que decir es: MENTIRA
Aducir excesiva complejidad en el DNI y asociarlo a su escaso uso es una falacia, el problema, como en muchos casos, es la motivación.
Servidor ha visto a gente absolutamente lega en el mundo de la informática ingeniárselas para seguir un procedimiento de 'hackeo' a una WII en el que intervienen pasos que implican, entre otras cosas, sobre-escribir el firmware de la consola o alterar parámetros internos, y todo esto, a través de una interface tipo matrix con volcados de memoria en hexadecimal.
También he visto a auténticos zotes de la electrónica ejecutar con maestría 'rooteos' de teléfonos usando vagas explicaciones en foros y software que no ha sido, ni de lejos, diseñado para usuarios 'normales'
¿Cuales son los motivos del escaso uso del DNI-E? que a día de hoy no hay NADA (salvo la renta) que pueda motivar a una persona a usarlo. En vez de preguntar a la gente los motivos de su escaso interés, habría que preguntarse qué es lo que hay que hacer para que a la gente le interese y haga ese esfuerzo extra para instalar el lector y los drivers.
Mi opinión es que el DNI-E ha sido absoluta y completamente infravalorado y no ha servido para el propósito que a muchos nos habría gustado: la participación de la sociedad en la toma de decisiones.
¿Estoy hablando de voto electrónico? Efectivamente, de eso estoy hablando. Creo que es hora de quitarse los complejos, de intentar medrar con los temores y lanzar de una vez una plataforma real de voto electrónico a través del DNI-E para tomar el pulso a la gente sobre sus inquietudes.
Probablemente aun tenga que pasar mucho tiempo hasta poder llegar a un punto donde se pueda elegir a un presidente a través de un PC, yo mismo he hablado y publicado pruebas de concepto sobre ataques al DNI-E, no creo que todavía se haya alcanzado la madurez para llegar a ese punto.
Pero es que hay puntos intermedios: Por ejemplo, sería genial que alguien lanzase una plataforma de consulta ciudadana (no tiene porque estar tutelada por el gobierno) donde se pueda convocar a la gente para que opine y vote de una forma representativa (usar change.org suena bastante ridículo si aspiras a que los datos tengan valor)
Con esa plataforma en marcha, si se lanza una consulta, por ejemplo, sobre dación en pago, el número de votos que se recojan pertenecerán si o si a ciudadanos de verdad, no serán datos que provengan de una encuesta sesgada o de campañas para recoger firmas (dicho esto con todo mi respeto)
Un voto mediante esa plataforma permite que se pueda poner encima de la mesa algo como '2.000.000 de personas han votado en el sentido X' y será inapelable, será la voluntad del pueblo expresada electrónicamente.
Empiezo a estar un poco saturado de las 'mayorías silenciosas', de las manifestaciones en las que hay 100.000 o 1000 personas según donde leas el dato y en general, de esa guerra de cifras que a la postre sirve como excusa para que quien nos gobierna haga oídos sordos.
Como última reflexión, opino que, si todos los esfuerzos que se están haciendo en demonizar el DNI-E y en inventar pseudo-excusas, se enfocasen en algo constructivo, se le podría dar al DNI-e el uso para el que mejor sentido tiene.
, Julio.campos.alvarez and 2 others like this
24 Oct 09:58







Remote Heartbreak Attack: El ex vice-presidente se protege
by noreply@blogger.com (Maligno)
En el año 2008 en un paper titulado "Pacemakers and Implantable Cardiac Defibrillators: Software Radio Attacks and Zero-Power Defenses" se especulaba sobre los riesgos de dotar a los marcapasos o los desfibriladores cardiacos implantados de características de conexión inalámbricas, ante la posibilidad de que un atacante interceptase y manipulase el protocolo para detener el sistema, obtener los datos, o lo que sería peor, enviar ordenes que pudieran ser mortales para el anfitrión del dispositivo.
 |
| Figura 1: Paper que describe en 2008 los ataques a Pacemakers & ICD |
En la popular serie Homeland, en el capítulo 10 de la segunda temporada titulado "Broken Hearts" el ataque terrorista al vice-presidente de los Estados Unidos se hacía mediante un marcapasos que era manipulado remotamente mediante una conexión inalámbrica.
 |
| Figura 2: Temporada 2 de Homeland |
El desaparecido Barnaby Jack, trabajando en iOActive, escribió en Febrero de este año un post en el blog en el que comentaba el paper citado y el capítulo de Homeland, viendo cuán de plausible era ese ataque a día de hoy en los dispositivos actuales. En el artículo se dicen cosas como:
"At IOActive, I've been spending the majority of my time researching RF-based implants. We have created software for research purposes that will wirelessly scan for new model ICDs and pacemakers without the need for a serial or model number. The software then allows one to rewrite the firmware on the devices, modify settings and parameters, and in the case of ICDs, deliver high-voltage shocks remotely."
Todo el trabajo que había hecho Barnaby Jack en esta industria iba a ser publicado en la pasada BlackHat USA, pero apareció muerto y fue un shock para todos. La charla no se dio y no se le sustituyo en la agenda, creándose un homenaje en la sala que le correspondía durante su slot de tiempo.
 |
| Figura 3: Barnaby Jack con el software y las herramientas para hacer ataques a ICDs |
No había información sobre las causas de su muerte, pero se había dicho que en el plazo de un mes se darían más datos. Pero no fue así. A día de hoy en el artículo de la Wikipedia dedicado a Barnaby Jack puede leerse referente a su muerte lo siguiente:
"The coroner's office refuses to release information about the cause of death, which is one more reason to assume Barnaby Jack was murdered."
Esta semana, la noticia ha sido que el ex vice-presidente Dick Cheney que tenía uno de estos ICDs ha decidido quitarle todas las opciones de conexión remota por seguridad, ya que parecía una mala idea que alguien como él pudiera ser atacado remotamente.
 |
| Figura 4: El ex vice-presidente Dick Cheney ha tomado medidas con su ICD |
La realidad acaba superando a la ficción, y lo que a veces puede parecer la trama de una película o serie de acción, puede acabar siendo una más de las variables cotidianas de nuestras vidas. Sea como fuera, ver este tipo de cosas tienen que hacer que mucha gente se preocupe sobre a dónde vamos a llegar al final si alguien puede matar a otra persona solo por un fallo de seguridad en la conexión WiFi de un dispositivo médico o un vehículo.
Saludos Malignos!

Joan Blasco, likes this
21 Oct 08:33

Copy this into your blog, website, etc.
...or into a forum
10.19.2013
Copy this into your blog, website, etc.
<a href="http://www.explosm.net/comics/3338/"><img alt="Cyanide and Happiness, a daily webcomic" src="http://www.flashasylum.com/db/files/Comics/Kris/noon.png" border=0></a><br />Cyanide & Happiness @ <a href="http://www.explosm.net">Explosm.net</a>
...or into a forum
[URL="http://www.explosm.net/comics/3338/"]
[IMG]http://www.flashasylum.com/db/files/Comics/Kris/noon.png[/IMG][/URL]
Cyanide & Happiness @ [URL="http://www.explosm.net/"]Explosm.net[/URL]
[IMG]http://www.flashasylum.com/db/files/Comics/Kris/noon.png[/IMG][/URL]
Cyanide & Happiness @ [URL="http://www.explosm.net/"]Explosm.net[/URL]
slack likes this
21 Oct 08:23
Truquitos de empleado 7: ¿sabes realmente para quién trabajas?
by Laboro
<!--
cuadrado();
-->
Saber para quién trabajas es básico, porque la persona para la que trabajes realmente será la responsable de las deudas que contraigan contigo como trabajador, tanto de salarios como de indemnizaciones, gastos, dietas, etc. etc. La trampa habitual del empresaurio consiste en que los papeles digan que trabajas para X pero realmente trabajes para Y, X+Y, X+Y+Z... El






slack likes this
21 Oct 07:32


No, la falta de rigurosidad no es inocua
by gallir
Leer libros o escuchar conferencias “inspiradoras” y nada rigurosos generan varios problemas:
1. Te hacen creer cosas que no son ciertas, tu cerebro se alimenta de más mitos, bulos y falsas “leyes sociales” como si fuesen equivalentes a una “ley física”.
2. Crea falsas ilusiones, que a la larga puede producir desasosiego “si los demás pueden y yo no, soy yo el problema” (eso que acabo de citar, según muchos estudios, es la causa fundamental de suicidios, cuyas tasas más altas se dan en países más ricos).
3. Normalmente sobresimplifican la enorme complejidad de nuestra sociedad, incluyendo la política, economía, negocios y relaciones sociales. No podemos asumir que el mundo no esté bajo nuestro control.
4. El tiempo (y dinero) que le dedicas es tiempo (y dinero) que no podrás dedicar a leer o informarte de los problemas reales, de la complejidad, diversidad, y de los verdaderos desafíos como sociedad.
5. Como te ha “emocionado”, colaboras en divulgar aún más esas falsas leyes, creencias, mitos y bulos. Luego es cada vez más difícil deshacer esa desinformación. De hecho, acaban en modelos de negocios rentables, ¿hablamos de TED y sobre todo de TEDx y sus grandes simplificaciones -por diseño- inspiradoras?.
6. La ciencia te dirá que no es así, que no hay datos que lo fundamenten, que el tema es más complejo, etc. Acabarás creyendo que la ciencia no te ayuda, sino esos que “saben escribir historias humanas que realmente interesan y ayudan a las personas”.
7. Como escribir historias “inspiradoras” atrae a muchos lectores -cada vez menos críticos-, se convierte en un negocio jugoso. Así es como estamos siendo bombardeados de tantos libros “inspiradores” y de autoayuda. Además nos dedicamos a repetir sus ideas resumidas en frases cortas e “inspiradoras”, así es como los eslóganes estúpidos tienen tanto éxito en las redes sociales.
8. Acabarás creyendo que el pensamiento crítico es malo, que no ayuda -incluso que es malo- al bienestar personal.
Así es como ayudamos a tener una sociedad que hasta cuando se discute de una ley educativa no escuchamos a los investigadores ni estudiosos del tema, sólo a políticos que en el mejor de los casos antes han sido tertulianos dedicados también a la sobresimplificación de los problemas. Y cuando nos damos cuenta de esto, sólo se nos ocurre mejor idea que culpar de todo a los demás (políticos, medios… votantes del partido contrario).
Luego nos preguntamos por qué no tenemos intelectuales “científicos”, por qué en otros países hacen mejor ciencia, por qué somos incapaces de resolver problemas reales más complejos, por qué leemos tanta manipulación en los medios, por qué leemos y escuchamos tantas tonterías de políticos, tertulianos y fanboys.
Todas nuestras “transacciones sociales” tienen efectos en la sociedad, ésta es la suma de miles de millones de “transacciones” diarias. Que no te hagan creer que leer libros de este tipo es sólo “entretenimiento”, que no hace daño. No es así, no son inocuos, sobre todo si tienen grandes audiencias.
¿Sólo soy yo que ya casi no ve diferencias entre la religión y sus liturgias inspiradoras con los libros y conferencias ídem? Porque si lo importante es la “inspiración”, las religiones e iglesias ya lo han descubierto hace miles de años. Ahora replicamos el modelo, con nuestros propios mitos, becerros, mandamientos, pecadores, santos, discípulos, paraísos e infiernos imaginarios.
No, no es inocuo. Ni nuevo.
Una de arena
Te obsequio con una charla TED inspiradora, rigurosa, graciosa y educativa, cada vez menos frecuente en TED y sus franquicias.
Toni, and 2 others like this
18 Oct 09:55

Copy this into your blog, website, etc.
...or into a forum
10.18.2013
Copy this into your blog, website, etc.
<a href="http://www.explosm.net/comics/3337/"><img alt="Cyanide and Happiness, a daily webcomic" src="http://www.flashasylum.com/db/files/Comics/Dave/mybumisonthegumbumisonthegumicanblowabubblewithmybumbumbum.png" border=0></a><br />Cyanide & Happiness @ <a href="http://www.explosm.net">Explosm.net</a>
...or into a forum
[URL="http://www.explosm.net/comics/3337/"]
[IMG]http://www.flashasylum.com/db/files/Comics/Dave/mybumisonthegumbumisonthegumicanblowabubblewithmybumbumbum.png[/IMG][/URL]
Cyanide & Happiness @ [URL="http://www.explosm.net/"]Explosm.net[/URL]
[IMG]http://www.flashasylum.com/db/files/Comics/Dave/mybumisonthegumbumisonthegumicanblowabubblewithmybumbumbum.png[/IMG][/URL]
Cyanide & Happiness @ [URL="http://www.explosm.net/"]Explosm.net[/URL]
slack likes this

17 Oct 08:35


Honor Thy Player’s Time
by Ben Serviss

It’s a glorious Sunday morning. You stir and stretch in your bed, a mess of wonderfully soft sheets and covers. The whole day is open. Will you laze around for a bit more? Get up and go for a walk, or to the gym? Make plans to meet up with friends? Whatever you decide, this moment is the birthplace of the day’s possibilities, when just thinking of the wide expanse of possibility makes you smile.
Jump forward 100 years. Unless dramatic advances in cryogenics are discovered, it’s highly likely you’ll no longer be among the living, and your lazy Sunday afternoon from so long ago will now be one fixed event of the myriad fixed events known as your life. However insignificant your choice may have been, your decision on how you used some of the finite time at your disposal can never be unmade – for better or for worse.
Now, say you decided to play a game that Sunday morning. Whether you got stuck in a 10-minute long unskippable cutscene, a stultifying yet mandatory mini-game, a frustrating sequence replete with long loading times, or even if the game was exactly what you wanted, your experience is logged as another fixed life event.
In a world of seemingly unlimited free-to-play games, browser games, Steam sales and trial versions, players will never be bereft of games to play. Choosing to honor your players – and acknowledging that they have chosen to share some of their limited time playing your game – can be a surprisingly effective way to help cut out filler and make a sharper, more rewarding play experience.
Player Time: The Rarest Resource
When video games were still an oddity favored by teenagers and pre-adolescents, the higher the hours of gameplay to cost ratio was, the better. Now, with tons of games constantly coming out on all sorts of platforms, there are more games than ever vying for our time. Suddenly, the prospect of a 40-hour game doesn’t seem as appealing as it once did.
Choosing to consciously honor the player’s time and investment aligns well with recent trends of aging gamers, who have less and less free time to devote to their favorite hobby.
So how do you go about doing this? In theory, the steps are simple.
→ All gameplay must serve the aim of the game. Most games strive to create fun or joyful scenarios for their players. These games would be best served by adhering to their mandate for the entire experience – no excuses. Just as Nintendo famously focuses on making the simple act of moving your character entertaining, everything the player does in your game should serve its purpose.
The Steel Battalion controller. Not pictured: Foot pedal controls.
The Xbox mech combat simulator Steel Battalion was notorious for its mammoth real-life controller, with over 40 buttons to manage, and an involved ‘start-up’ sequence that involved manipulating its buttons and switches in a precise order before you could even take a step. This sequence may seem like it arbitrarily takes time away from the player, but in fact this only helped to reinforce the game’s purpose – to simulate what it actually would be like to pilot a giant robot of war.
→ All gameplay must build towards the narrative theme. This only applies to games where narrative and story are a focus. If you’re trying to craft a compelling story around your game, does it really make sense to have one set of rules that apply during gameplay, and another that apply only during ‘story sequences’?
For example, if you spend the majority of a game killing faceless enemies, only to have your character mortified when faced with a corpse in a cutscene, would you realistically think that makes any sense? The fact that this double standard is still the norm in games is a huge reason why an overwhelming majority of game stories are looked upon as inferior to other media. By doing this, you compromise the story you’re trying to tell, and weaken the overall power of the game.
→ Don’t show how good you are at making other things. Cutscenes that go on for way too long, cutscenes that are unskippable, cutscenes that have little to do with the plot – this kind of indulgence is often more fun for the creator than the player.
While there are exceptions, and some designers like Hideo Kojima are celebrated for their signature, if not meandering cinematics, unexpected ones deliver a clear message to the player: Keep waiting, and maybe you’ll get to play later. This can’t help but be disappointing to someone who entered your game for the purpose of actively playing, not passively viewing.
The cinematics for the summon spells in Final Fantasy VIII caught flack for being unusually long as well as unskippable.
This also applies to anything not in the game’s main field of expertise. Shallow mini-games and tacked-on puzzle elements only detract from the central gameplay promise your players came to fulfill.
→ Avoid player downtime. Whenever the player is ready and willing to play but cannot due to the game getting in the way, that is active player downtime. This includes routine loading times, which generally can’t be helped, but can sneak up on you with ill-conceived respawn times, cooldown times, failure state cutscenes and un-optimized forced loading screens.
Whenever there is a way to get the player back to active play as soon as possible that is consistent with the narrative, appropriate difficulty balancing and technical constraints, take it.
Honor Thy Lifetime
Of course, this concept applies to everything else in your life – especially interactions with others. Even if you’re in the middle of an interaction that is banal or routine, remember that it is always a remarkable one because it is the one that is happening right now.
As long as someone plays it, the same will be true of your game – even if it’s a modest indie project you made on your own just for fun. Even if you don’t make it obvious, when you respect the player’s time, they’ll know.
Joan Blasco, slack likes this
11 Oct 09:52

Copy this into your blog, website, etc.
...or into a forum
10.11.2013
Copy this into your blog, website, etc.
<a href="http://www.explosm.net/comics/3330/"><img alt="Cyanide and Happiness, a daily webcomic" src="http://www.flashasylum.com/db/files/Comics/Kris/offends.png" border=0></a><br />Cyanide & Happiness @ <a href="http://www.explosm.net">Explosm.net</a>
...or into a forum
[URL="http://www.explosm.net/comics/3330/"]
[IMG]http://www.flashasylum.com/db/files/Comics/Kris/offends.png[/IMG][/URL]
Cyanide & Happiness @ [URL="http://www.explosm.net/"]Explosm.net[/URL]
[IMG]http://www.flashasylum.com/db/files/Comics/Kris/offends.png[/IMG][/URL]
Cyanide & Happiness @ [URL="http://www.explosm.net/"]Explosm.net[/URL]
slack likes this
10 Oct 09:32

GaymerX2 tickets are NOW ON SALE! This will be the only con I'm doing in 2014, so please come by. Also Alexis Ohanian will be there, so watch your possessions.
October 09, 2013
GaymerX2 tickets are NOW ON SALE! This will be the only con I'm doing in 2014, so please come by. Also Alexis Ohanian will be there, so watch your possessions.
slack, Randy Laue and 3 others like this
02 Oct 15:09
Vessel: Lua Optimization and Memory Usage
by ben@overbyte.com.au (Ben Driehuis)
Hi everyone, my name is Ben Driehuis and I am a senior programmer at Overbyte.
Vessel uses Lua to do it's glue gameplay code, allowing it to use most of the systems and tech built up throughout to form specific gameplay related classes. When we first looked into the performance of Lua and Vessel in general, we noticed very quickly that all of the threads were doing a lot of memory allocation and frees each frame which meant there was actually a lot of contention between the threads.
Lua has its own incremental garbage collector and is performed automatically. The collector runs in small steps and run time is more or less based on the amount of memory allocated. Basically the more memory you are assigning in Lua, the more the garbage collector will run. You can also manually run the garbage collector in many ways, forcing a step or doing a full run (which is not cheap). The full run through is very handy for the cases where the user won’t notice an extra 10-30ms in a frame - a good example of this are at the start/end of a level load or when showing a pause menu or some other game pausing interface.
On console memory is always a huge factor, with most optimizations involving some trade-off between memory and performance. However in a lot of cases the trade-off is heavily skewed one way or the other. In vessel our garbage collection time was quite busy. We were forcing one step of the GC per frame, after our gameplay thread had done the work needed for the physics thread to do its thing. The result of that in this particular scene was:

An average time of 2.6ms is pretty good, but the maximum of 7.4ms is a huge concern! As we learnt above, the step time is very dependent on the amount of new memory being used each frame in Lua. In addition to the manual GC we have Lua doing its normal background incremental garbage collection during execution. From the below you can see it working away during the game thread, indicated by the calls to propagatemark (See Tony's last article, A Profiling Primer, for more info on Tuner)

Looking at our markers we quickly noticed that our processor Lua scripts were also quite expensive in this scene (the two pink bars in the above image). This marker is the main place where our gameplay world objects which change each frame exist. Thus it is also the part where the most Lua is called. Let’s have a look at the script processor update performance currently. Looking at the image below, we can see it has an average of 7.1 ms. That is not good at all!

We then started investigating what short term allocations we were making inside of Lua to try and reduce our need to do the garbage collection. Our aim was to turn off the automatic background garbage collection and just run our step at the end of each frame, with that step not taking too much time. We used third party code from Matt Ellison, who is Technical Director at Big Ant Studios to track down and display the memory we were allocating and freeing each frame. A big thankyou to Matt for allowing us to use this.
So, in this scene we determined we had about 30kb per frame in temporary Lua allocations. That’s a lot and will quickly add up! Looking at the output from Matt's tool, we saw that 20kb of that allocation came from just one Lua script, Bellows.lua, and all of that inside its SetPercent function. The output showed a lot of temporary Vector2 construction, including a few kb from our Utils.lua VectorRotate function called inside it.
Let’s take a quick look at those two functions.


Well I think we can now see where all that Vector2 construction is coming from! Inside that for loop, we are creating three Vector2’s per iteration and then the call to VectorRotate in the loop creates another one. So that’s five per loop through on each bellow.
We can also see here there are some unnecessary calculations. Bellow.GetRotation + this.OffsetRotation is done twice without either of those value changing in each loop. We also know that GetRotation is a call into native code which is more expensive then accessing a Lua member. Material Scale is also calculated in each loop, even though it never changes value. So instead of creating all of these Vector2’s inside the for loop, lets use local variables and remove the call to the VectorRotate. This gives us:


A good performance improvement on average and looking at the temporary memory use of Lua we now saw a maximum of 23kb a frame, a 7kb saving and an average of 20kb. Our output was now not showing any Vector2 allocations, we had reduced our memory waste by just under 25% and, as we hoped, our Lua was running faster.
We still have some temp memory each frame created for each bellow and ring which we can make into a local for the function. We can also store the reference to the maths functions as locals. This will give us a small speed up in performance.
Why is this? Because Lua allows each function to use up to 250 of its own “registers”, which means Lua stores all local variables into these registers. For non-locals, it first has to get the data/function and put it into a local and then use it. If you are calling or creating something once in a function, obviously making it a local will not help as you have the one time lookup cost. But in a loop, you are saving each subsequent call! So let’s run with the following code:


A huge performance win! Memory wise though we aren’t really seeing any big improvement, still using a maximum of 22kb of temporary memory a frame and an average of 19kb. At this point I decided to find other areas heavy in bellow usage to see if this would assist me in narrowing down where all the waste is.
This brought me to the start of one our levels, where the camera zooms out over a largish area. This was showing an average of 20kb a frame with a maximum of a massive 38kb! And 17kb of that was again the Bellows. The data showed lots of memory use by calls to GetMaterial and GetLocalRect. Performance wise for our ScriptOnProcessorUpdate, we were pretty close to the above image in terms of average, at 4.33ms, but with a higher maximum of a massive 8.6ms and lower minimum at 2ms.
Looking at the code we now have we can see two interesting facts regarding the use of GetMaterial and GetLocalRect. Firstly both are called on unique items once in the loop, so we can’t cache it. However both are used to then call a function on them. That’s two calls into our native code and a temporary allocation of an object pointer and a Rect. So what happens if we make two new functions in native code to let us do it in one call, without the temporary assignment?


Another good win due to less calls between Lua and the native code and less temporary allocation. We now have an average of 14kb of temporary memory usage per frame and a maximum of 20kb for this new scene. A whole lot better! Our bellows here are now allocating a maximum of 9kb.
We can also remove the offsetVector, as we know the X component is always 0 and so we can cut down the position calculations, as we know doing mathcos(bellowOffSetRotation) * offsetVector.x will give us a result of 0, so the mathcos is a waste of time. Thus those position calculations can be simplified to:
position.x = posBase.x - (mathsin(bellowOffSetRotation) * posOffset)
position.y = posBase.y + (mathcos(bellowOffSetRotation) * posOffset)
This doesn’t really save us much temporary memory as we are just saving on one float, but it is still a slight help and the performance is slightly better. At this stage we are getting pretty close to an optimised function without changing things significantly. So let’s take a relook at the performance of the garbage collection step at the end of each frame now.

So our average is down by 0.5ms and the maximum is lower too after dealing with just one of the lua classes. Add that to the 3.5ms saving we got in the processor update itself, which some of it will also be due to garbage collection savings as we are still running automatic background GC, that’s a huge saving on the game thread.
There are a lot more areas like this in the code base where we should get similar wins and will greatly reduce our lua memory churn. The golden rules to remember are;
- use locals when you use something more than once a function
- try to cache of data from native code if you use it more than once
- make condensed functions to again reduce the calls to native code. Calling one native function which does all the work is much better then calling several native functions to do the same thing.
The next step is to turn off the background garbage collection and only run it at the end of the frame for a certain amount of ms. This will require us to keep an eye on the memory usage of lua and ensure we are doing enough cleaning up to mean we can get away with limiting the garbage collection time.
There is more information about Lua performance in the article titled Lua Performance Tips by Roberto Lerusalimschy (http://www.lua.org/gems/sample.pdf).
Once again, a huge thanks to Matt Ellison and Big Ant Studios for letting us use their Lua memory tracer.

{kind=link}
26 Sep 09:44

" Guardería El Desfase " (Il bambini piu desmadratti) Francesco...
" Guardería El Desfase " (Il bambini piu desmadratti) Francesco De Rossi
Shakesphobic, slack and one other like this
24 Sep 08:25
Horrible Hansoft
by Rob-Galanakis
I’ve used Hansoft for 5 years across 2 jobs. Over that time, I’ve had more arguments about Hansoft than I wish to remember. In this post, I’m going to present a dialogue between Socrates, a software development, and Phonion, a Project Manager (Producer, Product Owner, Product Manager, whatever) about use of Hansoft. I’m not going to introduce Hansoft because it isn’t worth learning about it if you aren’t already subjected to it.
My purpose is to reduce the number of people using Hansoft, and thus reduce total suffering in the world. This post is for two types of people:
- Project managers who use Hansoft and force their studio to use Hansoft. I’m guessing most people in this category don’t hate Hansoft (though I don’t think there exists a solitary human being who likes Hansoft), but they defend and proliferate its use.
- Developers who use Hansoft. Everyone in this category hates Hansoft. Send this post to someone from category #1 so you can stop using Hansoft.
The scene here is not hard to imagine- Phonion sidles up to Socrates, right as Socrates has put his head down to start working.
Phonion
Hello Socrates. I noticed you have not been burning down your hours in Hansoft.
Socrates
Correct, I did not. My team hates using Hansoft so we’ve been tracking our sprint work on a physical wall instead. Why is it important that I burn down my hours in Hansoft?
Phonion
It’s important that we know the status of your teams sprint and whether you are tracking to complete it or not.
Socrates
Why? If my team is not tracking to complete its sprint, there is nothing you can do. You cannot call in more sources in the middle of the sprint. You cannot cancel the sprint. We cannot move stories out of or into the sprint. You can do literally nothing with the sprint burndown information during the sprint. We have the information in front of us and it works much better than having it in Hansoft, which we never go into.
Phonion
OK, whatever. But we need your team’s stories and tasks in Hansoft so we can see what’s done and not done and how the release is burning down.
Socrates
What does putting these things into Hansoft and then updating them every sprint tell you about the release?
Phonion
It tells us whether all the stories needed to complete the release are going to be done in time.
Socrates
Does it? If points were burning down perfectly, it means every team is getting everything done. You do not need Hansoft to tell you that. If things are not getting done, a high-level release burndown does not give you any information. You still need a way of knowing what did and did not get done, you need to reprioritize, you need to figure out how to get things done reliably. The only way to work with this information effectively is face-to-face communication- you are not going to reprioritize stories without talking to the team or solely via email, are you?
Phonion
Of course not. Anyway, we really want our charts and reports.
Socrates
Sure, every sprint I will give you the number of points committed to and completed for the sprint and release. I will even put it into Hansoft for you automatically if you give me the documentation to the API.
Phonion
We don’t have access to its API. It requires a license fee. It does have an SDK, but no one’s been able to figure out how to use the SDK. Someone took a look at it and it is extremely confusing. Anyway, that’s not how Hansoft works, it can’t just take that number and input it with everything else.
Socrates
Bummer. The fact that management software is completely cut off to extension and integration makes no sense to me. If you figure out a way to easily write integrations for Hansoft, tell me, but why should Hansoft’s shortcomings force my team to switch how we manage outselves?
Phonion
Because we use Hansoft to manage the project.
Socrates
Right now it sounds like Hansoft is using you, not the other way around. The people on my team hate using Hansoft. It’s a large, fat client that takes up space in the system tray and hogs resources. It is very slow to start meaning we can’t just jump in and out. The UI is too complex for anyone to remember so we always need to struggle with where to find things. Would you disregard the unpleasantness of using Hansoft and how much your developers dislike it?
Phonion
If I say “yes”, it makes me the type of boss who does not trust the judgement and opinions of others. But I know the feeling of bad software, and while Hansoft isn’t the iOS of user experience, it just takes some getting used to.
Socrates
Do you want your developers to spend time learning how to use project management software, or actually developing? Other project management options simply involve moving a card on a wall, or clicking and dragging, or something much more intuitive. Why can’t we use a solution that simple?
Phonion
A project this size requires more sophisticated tools and there will naturally be added complexity. We must sacrifice simplicity for the greater good.
Socrates
In fact, using Hansoft is not just an awful user experience, but it actively encourages the wrong behavior. We want to be agile, which includes getting better with breaking down and estimating stories. With Hansoft, I never look at the sprint burndown. I never look at what’s inprogress or in the backlog, I never want to break down stories into smaller stories and tasks, I never want to rebid or groom the backlog or anything I’m supposed to do in order to become more effective at agile. As someone who wants to always do better, this is painful. And certainly lack of improvement does not contribute towards the greater good; in fact, it’s the worst thing we can do to harm it! So by forcing Hansoft on us against our will, you are saying the work of the producers and PMs is more important than the work of the developers. Is that what you think?
Phonion
Of course not! To show you how important we think you are, we will assign a producer to your team to do the Hansoft work.
Socrates
Absolutely not! You are committing teamicide by injecting someone like that. They will never jell and will be an always-present and uncomfortable fungus. Furthermore isn’t the creation of busywork positions a big red flag? You are allowing your project management software to make personnel decisions. If every team repeatedly delivered on time and at quality and was continually improving- they were truly Agile- would it matter what software was used to track progress?
Phonion
If I said “yes”, that would make me a micro-managing boss who likes to meddle for now reason. It would also do nothing to improve the situation, and just turn it into a top-down decision that I’m sure would come up later anyway and hurt morale in the meantime. So I will say “probably not.”
Socrates
So, clearly, project management decisions- like what software to use- should be made to make developers and teams more effective. If many developers and teams outright reject Hansoft and say it is actually making them less effective and not growing, is it likely Hansoft is making them more effective? Likewise, is there a way for people to grow and improve without experimenting?
Phonion
Again, if I said “yes”, that would make me sound like a traditional “I know better than you” manager, and I’d be forcing my decision down peoples’ throats. So, I guess not. But, project management really likes some features of Hansoft and it we cannot just give everything up.
Socrates
Do you consider yourself an equal party to development in terms of the value of the work you do?
Phonion
I want to say “Of course, we value each others’ work.” But in actually, I know that Project Management is a type of Lean waste. It is necessary for the project to function but should be reduced and eliminated. So by definition, no, I am not an equal party.
Socrates
But nor are your needs invalid! What I would do is evaluate your actions and decisions by answering, “am I assisting the creators of the value-added work?” High-level charts and information can help you- but you should develop this as you need it, for a clear purpose, and without adding more waste into the system. You should only develop these things when you can convince the developers and team members that they need them. Ideally the team should ask for it themselves, or better yet just do it themselves. So how can we put things on a better path?
Phonion
I guess the first thing is to pick something people like- or ask them what they want to use. Then we can migrate over to that.
Socrates
What about people that don’t want to agree? People that want to use a different software (free of course), or physical boards?
Phonion
Well, we should figure out what works best for them. If we cannot convince them an alternative is better, maybe it isn’t better. I’m sure they’d be willing to test something out, though, and we can see how it works. And truth be told, it may be fine for some teams to be off on their own, where there’s absolutely no benefit to the team of moving them with everyone else.
slack likes this