Rafael Bernard Rodrigues Araújo
Shared posts
10 architecture tips for working with legacy software systems
CQRS and Event Sourcing implementation in PHP
Command Query Responsibility Segregation (CQRS) with Domain Driven Design is more and more popular recently. Its implementation in PHP, which will be the topic of the article, generates some new possibilities, making a process more efficient. For example, it gives you the opportunity to restore the whole system easily. Also, it enables asymmetric scalability, guarantees no data loss and many more. I decided to divide the text into four parts to make sure the subject is presented in an exhaustive way.
Before I step to the CQRS and Event Sourcing implementation in PHP – I’ll try to briefly explain what is the general concept behind CQRS. In 1986, Bertrand Meyer came up with an idea of Command Query Separation (CQS). According to the concept – each method in the object in its current state must belong to only one category out of the following two:
- command – a method which changes an object’s state,
- query – a method which returns the data.
It means that all the queries like these should return the same result as long as you didn’t change the object’s state with a command.
See also: 4Developers 2018: The road to true knowledge
As you can see below, in the first example – the rule is broken by the method increase() which shouldn’t return the value. In the second one, there is a presentation of proper implementation.
I’m mentioning that because using CQRS pattern is derived directly from the same concept. However, it’s not related to the object/component but rather to the whole system or bounded context, which is logically separated part of the system, responsible for a realisation of certain tasks. Let’s take an example of a simple webstore. We can separate the following contexts: a purchase, a delivery or a complaint.
See also: Introduction to cryptography & encryption
Using Command Query Responsibility Segregation (CQRS pattern)
You can ask – how to use CQRS pattern?
CQRS is a style of application’s architecture which separates the “read” operations and the “write” operations on the bounded context level. It means that you create 2 data models – one for writing and the other for reading. It’s presented on the scheme below.
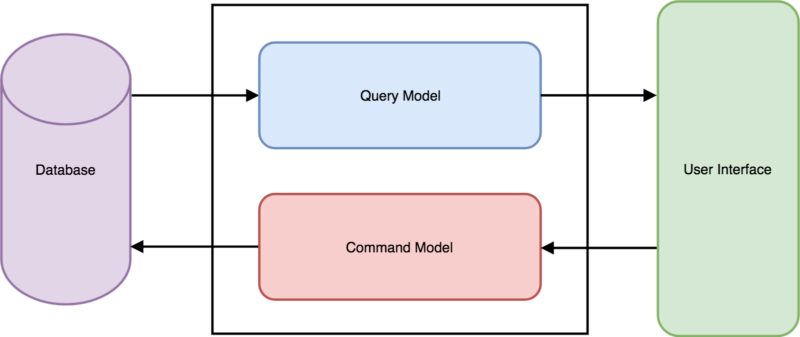
As you can see, implementation of a logic responsible for writing is independent of an implementation of a logic responsible for reading. In practice, it enables a better fit of the read/write models to the requirements. A read side may be flattened and may serve aggregated data. At the same time – it doesn’t have to calculate these in real-time. In the case of a common model of read/write, this kind of data is redundant and it only introduces unnecessary “chaos”, complicating a writing model in current state.
What is Event Sourcing and Event Store?
Let’s imagine a basic example of making an order in a webstore with digital cameras.
- You add a camera to the cart.
- You add a memory card.
- You increase the number of memory cards up to 2.
- You make an order based on the cart content, choose the delivery and payment methods.
- You make a payment.
The whole process is a series of subsequent events. In a traditional approach, you apply the changes (which come from the above events) to the cart’s objects and then to the order’s objects. Next, you write its state in the database.
What if you write subsequent events as they happen instead of writing the final effect? In this case, reconstitution of the objects will be about creating an empty object and applying these events. This object should have exactly the same state as the one written in a database in a traditional approach.
The described method is Event Sourcing. The events connected to the object are the source of the data – not its final state.
See also: Symfony vs Zend Framework – PHP Framework comparison Part I: Documentation
Event Bus is an important element in communication between write and read models. Event Bus is a mechanism which enables communication between different components, which not necessarily know about each other. One of the elements is publishing events (so-called publisher) and it doesn’t know what components (known as subscribers) are using it and how many components like this are there. On the other side – the components don’t know what is publishing the events.
When using Command Query Responsibility Segregation (CQRS), all the changes are done on a write side. It generates the events which inform about the changes. The events are published through Event Bus, then these are consumed by a read model. Thanks to that, a read model is informed about all the changes and can react. In other words – it can change the status of served objects.
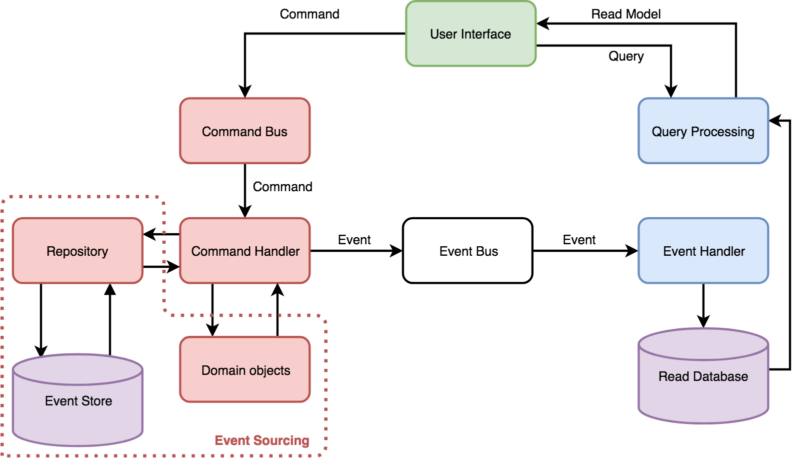
Event Store is a database optimized for events recording. In the Event Store, you can only write the events and the data connected to them. Domain objects are not written in the database, they only exist in a memory and are reproduced on the basis of events which happened.
Below, there’s an example of an event object which informs about a user creation.
As you can see, the object contains only primitive types. It’s done on purpose. Thanks to that, you can easily serialize objects to write them in the database and to store them in the message queueing systems. There, they can wait to be processed.
Pros and cons of Event Sourcing
Event Sourcing, like every other approach, has its pros and cons.
Pros of Event Sourcing:
- no data loss; everything that happened since the system has been created is written in Event Store,
- asymmetric scalability; you can scale a part responsible for reading independently of the one dedicated for writing;
- you can restore the whole system, basing on the events,
- you have access to the whole history of the changes in the domain objects (natural audit),
- you can divide the work in the team in a better way; writing model is normally way more complex and it requires better knowledge.
On the other hand, Event Sourcing has some cons:
- eventual consistency; not all the changes are available immediately, sometimes you need to wait for the events processing,
- the existence of two models (read/write),
- the higher complexity of the app,
- little support from frameworks/libraries.
What is Broadway and what components it gives us?
There are 2 libraries which give full support for using CQRS/Event Sourcing in PHP: Broadway and Prooph. Taking into consideration the fact that some components developed by Prooph will soon be cancelled (you can read more about it here) – there will be Broadway only.
But what is Broadway?
The authors come up with the below definition on the project’s official website:
Broadway is a project providing infrastructure and testing helpers for creating CQRS and event-sourced applications.
As you can see, Broadway is the library which provides the infrastructure. It enables the creation of the PHP application which is based on using Event Sourcing and using CQRS. In practice, it means that we get full support for this architecture. Broadway provides the following components:
- Auditing – logging all the commands,
- CommandHandling – support for the Command Bus,
- Domain – support for domain objects; it includes the abstraction for aggregate roots and domain message/events,
- EventDispatcher – component Event Dispatcher,
- EventHandling – event’s support,
- EventSourcing – support for event-sourced aggregate roots, event source repository implementation,
- EventStore (Doctrine DBAL, MongoDB) – support for databases for writing events,
- Processor – it supports the application’s processing,
- ReadModel (Elasticsearch, MongoDB) – support for read model with the database(Elasticsearch or MongoDB),
- Repository – abstraction of the storage of aggregates,
- sensitive data handling – it helps handling the events which include sensitive data (and it doesn’t save it in Event Store),
- Serializer – it supports serialization and deserialization of the data.
In the first part of the article about Event Sourcing and CQRS implementation in PHP, I’ve focused on the general idea of using CQRS, Event Sourcing and Event Store. Also, I’ve presented the pros and cons. The second part of the article about using CQRS and using Event Sourcing in PHP will be about the implementation of the write model with Broadway library. In the third part of the text about CQRS/Event Sourcing in PHP is about implementation of the read model. The final part of the series focuses on the current state of the most common issues connected to using CQRS and using Event Sourcing (such as issues with write model and read model).
Need top-notch PHP developers?
Do you need help with implementing Event Sourcing and CQRS or other modern PHP solutions? At The Software House, we have a team of very talented PHP developers who will gladly help you. In order to receive a free consultation, all you need to do is to fill in the contact form. Give them a shout!
The post CQRS and Event Sourcing implementation in PHP first appeared on .Managing Secrets in Laravel with AWS Parameter Store

The post Managing Secrets in Laravel with AWS Parameter Store appeared first on Laravel News.
Join the Laravel Newsletter to get Laravel articles like this directly in your inbox.
Encerrando Ciclos
 Qualquer cristão genuíno não deveria ter dificuldades para compreender a absoluta inutilidade do sacerdote israelita que, em cumprimento ao estabelecido pela religião, resolveu realizar o primeiro ritual de sacrifício no …
Qualquer cristão genuíno não deveria ter dificuldades para compreender a absoluta inutilidade do sacerdote israelita que, em cumprimento ao estabelecido pela religião, resolveu realizar o primeiro ritual de sacrifício no …
STAMP #2: How to Turn Messy TWIG PHP to Something Useful
Santidade
Santidade é uma coletânea de extratos selecionados da mensagem 3 do Estudo – Vida de Efésios, volume 1, de Witness Lee. Livro publicado originalmente pela Editora Árvore da Vida (esgotado).
***
Witness Lee (1905-1997)
“Paulo, apóstolo de Cristo Jesus por vontade de Deus, aos santos que vivem em Éfeso, e fiéis em Cristo Jesus… Bendito o Deus e Pai de nosso Senhor Jesus Cristo, que nos tem abençoado com toda sorte de bênção espiritual nas regiões celestiais em Cristo, assim como nos escolheu nele antes da fundação do mundo, para sermos santos e irrepreensíveis perante ele” (Efésios 1:1; 3,4).
Santidade
Deus nos escolheu para que fôssemos santos. As palavras “santo” e “santidade” tem sido deturpadas pelos ensinamentos dos cristãos de hoje. O entendimento que temos pode ser influenciado por esses ensinamentos.
Muitos acreditam que santidade é ausência de “pecado”. De acordo com tal conceito, uma pessoa só é santa se não pecar. Isso é absolutamente errado. Santidade significa algo separado para Deus, e também algo diferente, distinto do que é comum.
Somente Deus é absolutamente distinto de todas as coisas. Ele é santo! Santidade é a Sua natureza.
A maneira de Deus tornar-nos santos é dispensar a Si mesmo, o Santo, no nosso interior, assim seremos tomados por Sua natureza santa. Para nós, ser santos equivale a participar da natureza Divina (2Pe 1:4). Isso difere do conceito de perfeição sem pecado.
Ser santo equivale a ser separado de tudo que não é Deus (Lv 11:44 / 1Sm 2:2).
Santo é o Lugar que Deus está
A palavra “santo” não é encontrada no livro de Gênesis. Sua primeira menção está no livro de Êxodo. Em certo sentido, o homem em Gênesis ainda não havia sido conduzido a Deus. Foi no livro de Êxodo, não em Gênesis, que Deus começou a ter uma habitação na terra, conduzindo o homem a um relacionamento com Ele no Santo dos Santos.
Em Êxodo algo extraordinário aconteceu, na terra, entre os homens, havia um lugar chamado Santo dos Santos, e Deus estava lá. Os homens podiam ir até aquele lugar e encontrar a Deus. A partir dali Deus falava.
Essa palavra começou a ser usada quando Deus encarregou Seu povo de construir o tabernáculo.
Na verdade, a primeira menção está no chamamento de Moisés, em Êxodo 3. Quando apascentava o rebanho, ele viu uma sarça ardendo no deserto. Ao virar-se para ver o que acontecia, Deus lhe falou no meio da sarça, dizendo: “Não te chegues para cá; tira as sandálias dos pés, porque o lugar em que estás é terra santa” (Êx 3:5). Isso indica que onde quer que Deus esteja, esse lugar é santo. Lembre-se, somente Ele é santo. Se você não tem nada a ver com Deus, não é santo independente de sua perfeição. Você pode não ter pecado, ser absolutamente perfeito, mas se não estiver ligado a Deus, não será santo. Uma vez ligado a Deus, torna-se imediatamente santo.
Tudo o que é de Deus e é para Deus é santo (Lv 20:26; Nm 16:5; Ne 8:9; Êx 30:37).
O Espírito que nos Alcança é Santo
Além disso, quando o Espírito de Deus nos alcança, Ele também é santo (Lc 1:35; Mt 1:20; 28:19; ver Rm 1:4). Essa é a razão pela qual o termo “Espírito Santo” não é mencionado no Antigo Testamento (as ocorrências desse termo no Salmo 51:11 e Is 63:10 e 11 devem ser traduzidas como “o espírito de santidade”). Esse termo foi usado pela primeira vez quando o Senhor Jesus estava prestes a ser concebido em Maria (Lc 1:35).
A Santidade é o próprio Deus
A santidade conduz Deus ao homem, e o homem a Deus. A santidade é o próprio Deus. A primeira vez que a palavra “santo” apareceu foi quando Deus começou a ter um povo na terra entre o qual podia habitar e que podia ir à Sua presença no Santo dos Santos. Dessa época em diante, essa palavra passou a ser usada diversas vezes em Êxodo, Levítico, Números e Deuteronômio. Isso porque Deus veio na direção do homem, e os homens foram conduzidos a Ele. Tudo que se relacionava ao tabernáculo e ao sacerdócio eram santas.
Entretanto, no Novo Testamento, temos o termo “Espírito Santo” sendo usado pela primeira vez quando o Senhor Jesus foi concebido na virgem Maria. Isso foi algo excepcionalmente maior do que Deus habitando em um tabernáculo entre os homens. O tabernáculo era a habitação de Deus, mas a encarnação de Cristo era o armar do tabernáculo de Deus entre os homens (Jo 1:14). Isso teve início quando Jesus foi concebido no ventre de Maria.
Embora muitas coisas no Antigo Testamento fossem santas, não havia nada que fosse do Espírito Santo. Somente na época do Novo Testamento, quando Deus entrou no homem e tornou-se homem, em Cristo, temos realmente algo que é do Espírito Santo (Mt 1:20).
Hoje o Espírito Santo não está somente em nós, mas se torna um conosco. Em 1 Coríntios 6:17, Paulo nos diz: “aquele que se une ao Senhor é um espírito com ele”. A santidade é ser unido e tomado por Deus.
Ser santo é, em primeiro lugar, ser separado para Deus, então, ser tomado por Ele, a partir daí, Ele nos possui até chegar ao ponto de sermos tão saturados do Senhor que estaremos em unidade total Ele.
O resultado final da Bíblia, a Nova Jerusalém, é chamada cidade santa, que não é somente pertencente a Deus, mas também é uma com Ele.
O post Santidade apareceu primeiro em Participante de Cristo.
cary huang: Logical Replication Between PostgreSQL and MongoDB
1. Introduction
PostgreSQL and MongoDB are two popular open source relational (SQL) and non-relational (NoSQL) databases available today. Both are maintained by groups of very experienced development teams globally and are widely used in many popular industries for adminitration and analytical purposes. MongoDB is a NoSQL Document-oriented Database which stores the data in form of key-value pairs expressed in JSON or BSON; it provides high performance and scalability along with data modelling and data management of huge sets of data in an enterprise application. PostgreSQL is a SQL database designed to handle a range of workloads in many applications supporting many concurrent users; it is a feature-rich database with high extensibility, which allows users to create custom plugins, extensions, data types, common table expressions to expand existing features
I have recently been involved in the development of a MongoDB Decoder Plugin for PostgreSQL, which can be paired with a logical replication slot to publish WAL changes to a subscriber in a format that MongoDB can understand. Basically, we would like to enable logical replication between MongoDB (as subscriber) and PostgreSQL (as publisher) in an automatic fashion. Since both databases are very different in nature, physical replication of WAL files is not applicable in this case. The logical replication supported by PostgreSQL is a method of replicating data objects changes based on replication identity (usually a primary key) and it would be the ideal choice for this purpose as it is designed to allow sharing the object changes between PostgreSQL and multiple other databases. The MongoDB Decoder Plugin will play a very important role as it is directly responsible for producing a series of WAL changes in a format that MongoDB can understand (ie. Javascript and JSON).
In this blog, I would like to share some of my initial research and design approach towards the development of MongoDB Decoder Plugin.
2. Architecture
Since it is not possible yet to establish a direct logical replication connection between PostgreSQL and MongoDB due to two very different implementations, some kind of software application is ideally required to act as a bridge between PostgreSQL and MongoDB to manage the subscription and publication. As you can see in the image below, the MongoDB Decoder Plugin associated with a logical replication slot and the bridge software application are required to achieve a fully automated replication setup.

Unfortunately, the bridge application does not exist yet, but we do have a plan to develop such application in near future. So, for now, we will not be able to have a fully automated logical replication setup. Fortunately, we can utilize the existing pg_recvlogical front end tool to act as a subscriber of database changes and publish these changes to MongoDb in the form of output file, as illustrated below.

With this setup, we are able to verify the correctness of the MongoDB Decoder Plugin output against a running MongoDB in a semi-automatic fashion.
3. Plugin Usage
Based on the second architecture drawing above without the special bridge application, we expect the plugin to be used in similar way as normal logical decoding setup. The Mongodb Decoder Plugin is named wal2mongo as of now and the following examples show the envisioned procedures to make use of such plugin and replicate data changes to a MongoDB instance.
First, we will have to build and install wal2mongo in the contrib source folder and start a PostgreSQL cluster with the following parameters in postgresql.conf. The wal_level = logical tells PostgreSQL that the replication should be done logically rather than physically (wal_level = replica). Since we are setting up replication between 2 very different database systems in nature (PostgreSQL vs MongoDB), physical replication is not possible. All the table changes will be replicated to MongoDB in the form of logical commands. max_wal_senders = 10 limits the maximum number of wal_sender proccesses that can be forked to publish changes to subscriber. The default value is 10, and is sufficient for our setup.
wal_level = logical
max_wal_senders = 10On a psql client session, we create a new logical replication slot and associate it to the MongoDB logical decoding plugin. Replication slot is an important utility mechanism in logical replication and this blog from 2ndQuadrant has really good explaination of its purpose: (https://www.2ndquadrant.com/en/blog/postgresql-9-4-slots/)
$ SELECT * FROM pg_create_logical_replication_slot('mongo_slot', 'wal2mongo');where mongo_slot is the name of the new logical replication slot and wal2mongo is the name of the logical decoding plugin that you have previously installed in the contrib folder. We can check the created replication slot with this command:
$ SELECT * FROM pg_replication_slots;At this point, the PostgreSQL instance will be tracking the changes done to the database. We can verify this by creating a table, inserting or deleting some values and checking the change with the command:
$ SELECT * FROM pg_logical_slot_get_changes('mongo_slot', NULL, NULL);Alternatively, one can use pg_recvlogical front end tool to subscribe to the created replication slot, automatically receives streams of changes in MongoDB format and outputs the changes to a file.
$ pg_recvlogical --slot mongo_slot --start -f mongodb.jsOnce initiated, pg_recvlogical will continuously stream database changes from the publisher and output the changes in MongoDB format and in mongodb.js as output file. It will continue to stream the changes until user manually terminates or the publisher has shutdown. This file can then be loaded to MongoDB using the Mongo client tool like this:
$ mongo < mongodb.js
MongoDB shell version v4.2.3
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("39d478df-b8ca-4030-8a05-0e1ebbf6bc44") }
MongoDB server version: 4.2.3
switched to db mydb
WriteResult({ "nInserted" : 1 })
WriteResult({ "nInserted" : 1 })
WriteResult({ "nInserted" : 1 })
byewhere the mongodb.js file contains:
use mydb;
db.table1.insert({"a": 1, "b": "Cary", "c": “2020-02-01”});
db.table1.insert({"a": 2, "b": "David", "c": “2020-02-02”});
db.table1.insert({"a": 3, "b": "Grant", "c": “2020-02-03”});4. Terminology
Both databases use different terminologies to describe the data storage. Before we can replicate the changes of PostgreSQL objects and translate them to MongoDB equivalent, it is important to gain clear understanding of the terminologies used on both databases. The table below is our initial terminology mappings:
| PostgreSQL Terms | MongoDB Terms | MongoDB Description |
|---|---|---|
| Database | Database | A physical container for collections |
| Table | Collection | A grouping of MongoDB documents, do not enforce a schema |
| Row | Document | A record in a MongoDB collection, can have difference fields within a collection |
| Column | Field | A name-value pair in a document |
| Index | Index | A data structure that optimizes queries |
| Primary Key | Primary Key | A record’s unique immutable identified. The _id field holds a document’s primary key which is usually a BSON ObjectID |
| Transaction | Transaction | Multi-document transactions are atomic and available in v4.2 |
5. Supported Change Operations
Our initial design of the MongoDB Decoder Plugin is to support database changes caused by clauses “INSERT”, “UPDATE” and “DELETE”, with future support of “TRUNCATE”, and “DROP”. These are few of the most common SQL commands used to alter the contents of the database and they serve as a good starting point. To be able to replicate changes caused by these commands, it is important that the table is created with one or more primary keys. In fact, defining a primary key is required for logical replication to work properly because it serves as replication identity so the PostgreSQL can accurately track a table change properly. For example, if a row is deleted from a table that does not have a primary key defined, the logical replication process will only detect that there has been a delete event, but it will not be able to figure out which row is deleted. This is not what we want. The following is some basic examples of the SQL change commands and their previsioned outputs:
$ BEGIN;
$ INSERT INTO table1(a, b, c) VALUES(1, 'Cary', '2020-02-01');
$ INSERT INTO table1(a, b, c) VALUES(2, 'David', '2020-02-02');
$ INSERT INTO table1(a, b, c) VALUES(3, 'Grant', '2020-02-03');
$ UPDATE table1 SET b='Cary';
$ UPDATE table1 SET b='David' WHERE a = 3;
$ DELETE FROM table1;
$ COMMIT;The simple SQL commands above can be translated into the following MongoDB commands. This is a simple example to showcase the potential input and output from the plugin and we will introduce more blogs in the near future as the development progresses further to show case some more advanced cases.
db.table1.insert({“a”: 1, “b”: “Cary”, “c”: “2020-02-01”})
db.table1.insert({“a”: 2, “b”: “David”, “c”: “2020-02-02”})
db.table1.insert({“a”: 3, “b”: “Grant”, “c”: “2020-02-03”})
db.table1.updateMany({“a”: 1, “c”: ”2020-02-01”}, {$set:{“b”: “Cary”}})
db.table1.updateMany({“a”: 2, “c”: ”2020-02-02”}, {$set:{“b”: “Cary”}})
db.table1.updateMany({“a”: 3, “c”: ”2020-02-03”}, {$set:{“b”: “Cary”}})
db.table1.updateMany({“a”: 3, “c”: “2020-02-03”, {$set:{“b”: “David”}})
db.table1.remove({“a”: 1, “c”: ”2020-02-01”}, true)
db.table1.remove ({“a”: 2, “c”: ”2020-02-02”}, true)
db.table1.remove ({“a”: 3, “c”: ”2020-02-03”}, true)6. Atomicity and Transactions
A write operation in MongoDB is atomic on the level of a single document, and since MongoDB v4.0, multi-document transaction control is supported to ensure the atomicity of multi-document write operations. For this reason, the MongoDB Deocoder Plugin shall support 2 output modes, normal and transaction mode.
In normal mode, all the PostgreSQL changes will be translated to MongoDB equivalent without considering transactions. In other words, users cannot tell from the output if these changes are issued by the same or different transactions. The output can be fed directly to MongoDB, which can gurantee certain level of atomicity involving the same document
Since MongoDB v4.0, there is a support for multi-document transaction mechanism, which acts similarly to the transaction control in PostgreSQL. Consider a normal insert operation like this with transaction ID = 500 within database named “mydb” and having cluster_name = “mycluster” configured in postgresql.conf:
$ BEGIN;
$ INSERT INTO table1(a, b, c)
VALUES(1, 'Cary', '2020-02-01');
$ INSERT INTO table1(a, b, c)
VALUES(2, 'Michael', '2020-02-02');
$ INSERT INTO table1(a, b, c)
VALUES(3, 'Grant', '2020-02-03');
$ COMMIT;In normal output mode, the plugin will generate:
use mydb;
db.table1.insert({"a": 1, "b": "Cary", "c": “2020-02-01”});
db.table1.insert({"a": 2, "b": "David", "c": “2020-02-02”});
db.table1.insert({"a": 3, "b": "Grant", "c": “2020-02-03”});In transaction output mode, the plugin will generate:
session500_mycluster = db.getMongo().startSession();
session500_mycluster.startTransaction();
use mydb;
session500_mycluster.getDatabase("mydb").table1.insert({"a": 1, "b": "Cary", "c": “2020-02-01”});
session500_mycluster.getDatabase("mydb").table1.insert({"a": 2, "b": "David", "c": “2020-02-02”});
session500_mycluster.getDatabase("mydb").table1.insert({"a": 3, "b": "Grant", "c": “2020-02-03”});
session500_mycluster.commitTransaction();
session500_mycluster.endSession();Please note that the session variable used in the MongoDB output is composed of the word session concatenated with the transaction ID and the cluster name. This is to gurantee that the variable name will stay unique when multiple PostgrSQL databases are publishing using the same plugin towards a single MongoDB instance. The cluster_name is a configurable parameter in postgresql.conf that is used to uniquely identify the PG cluster.
The user has to choose the desired output modes between normal and transaction depending on the version of the MongoDB instance. MongoDB versions before v4.0 do not support multi-document transaction mechanism so user will have to stick with the normal output mode. MongoDB versions after v4.0 have transaction mechanism supported and thus user can use either normal or transaction output mode. Generally, transaction output mode is recommended to be used when there are multiple PostgreSQL publishers in the network publishing changes to a single MongoDB instance.
7. Data Translation
PostgreSQL supports far more data types than those supported by MongoDB, so some of the similar data types will be treated as one type before publishing to MongoDB. Using the same database name, transaction ID and cluster name in previous section, the table below shows some of the popular data types and their MongoDB transaltions.
| PostgreSQL Datatype | MongoDB Datatype | Normal Output | Transaction Output |
|---|---|---|---|
| smallint integer bigint numeric |
integer | db.table1.insert({“a”:1}) | session500_mycluster.getDatabase (“mydb”).table1.insert(“db”).table1. insert({“a”: 1}) |
| character character varying text composite other types |
string | db.table1.insert({“a”: “string_value”}) | session500_mycluster.getDatabase (“mydb”).table1.insert({“a”: “string_value”}) |
| boolean | boolean | db.table1.insert({“a”:true}) | session500_mycluster.getDatabase (“mydb”).table1.insert({“a”: true}) |
| double precision real serial arbitrary precision |
double | db.table1.insert({“a”:34.56}) | session500_mycluster.getDatabase (“mydb”).table1.insert({“a”: 34.56}) |
| interval timestamp data time with timezone time without timezone |
timestamp | db.table1.insert({“a”: new Date(“2020-02-25T19:33:10Z”)}) db.table1.insert({“a”: new Date(“2020-02-25T19:33:10+06:00”)}) | session500_mycluster.getDatabase (“mydb”).table1.insert({“a”:new Date(“2020-02-25T19:33:10Z”)}) session500_mycluster.getDatabase (“mydb”).table1.insert({“a”:new Date (“2020-02-25T19:33:10+06:00”)}) |
| hex bytea bytea UUID |
binary data | db.table1.insert({“a”: UUID(“123e4567-e89b-12d3-a456-426655440000”)}) db.table1.insert({“a”:HexData(0,”feffc2″)}) | session500_mycluster.getDatabase (“mydb”).table1.insert({“a”:UUID (“123e4567-e89b-12d3-a456-426655 440000″)}) session500_mycluster.getDatabase (“mydb”).table1.insert({“a”:HexData (0,”feffc2″)}) |
| array | array | db.table1.insert({ a: [ 1, 2, 3, 4, 5 ] } ) db.table1.insert({ a: [ “abc”, “def”, “ged”, “aaa”, “xxx” ] } ) | session500_mycluster.getDatabase (“mydb”).table1.insert ( { a: [ 1, 2, 3, 4, 5 ] } ) session500_mycluster.getDatabase (“mydb”).table1.insert ( { a: [ “abc”, “def”, “ged”, “aaa”, “xxx” ] } ) |
8. Conclusion
MongoDB has gained a lot of popularity in recent years for its ease of development and scaling and is ideal database for data analytic purposes. Having the support to replicate data from multiple PostgreSQL clusters to a single MongoDB instance can bring a lot of value to industries focusing on data analytics and business intelligence. Building a compatible MongoDB Decoder Plugin for PostgreSQL is the first step for us and we will be sharing more information as development progresses further. The wal2mongo project is at WIP/POC stage and current work can be found here: https://github.com/HighgoSoftware/wal2mongo.

Cary is a Senior Software Developer in HighGo Software Canada with 8 years of industrial experience developing innovative software solutions in C/C++ in the field of smart grid & metering prior to joining HighGo. He holds a bachelor degree in Electrical Engineering from University of British Columnbia (UBC) in Vancouver in 2012 and has extensive hands-on experience in technologies such as: Advanced Networking, Network & Data security, Smart Metering Innovations, deployment management with Docker, Software Engineering Lifecycle, scalability, authentication, cryptography, PostgreSQL & non-relational database, web services, firewalls, embedded systems, RTOS, ARM, PKI, Cisco equipment, functional and Architecture Design.
The post Logical Replication Between PostgreSQL and MongoDB appeared first on Highgo Software Inc..
O Nome de Deus no Governo Bolsonaro: uma crítica teológico-política

Web Application Firewall in the Varnish mainline
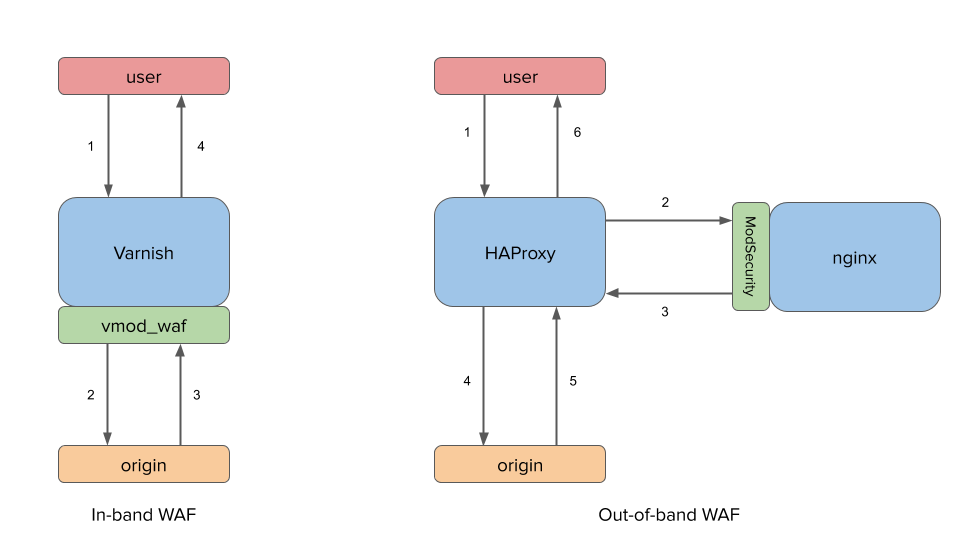
As you probably know, Varnish has always been a very secure piece of software but so far, that safety only applied to itself and therefore, a malicious request could still go through it and hurt your backend. But as a reverse-proxy (load-balancer, origin shield, etc.), Varnish is going to see everything the backend receives and sends, so there's a great opportunity here to sanitize the traffic before it reaches it.
We Programmers
The Good.

There is a little red sports car heading out towards the asteroid belt and, we programmers put it there. Oh, I don’t mean to give short shrift to Elon Musk and all the rocket scientists and engineers at SpaceEx. It was their vision, and their accomplishment. But they couldn’t have done it without us.
Think, for a moment, about all the software involved in that project. Think about the automation in the spacecraft itself. Think about the ability of those boosters to land, in tandem. Think about the steering vanes, and the engine gimbals, and the throttles. Think about ground control, and the communication protocols, and…
Think about how the engineers worked. Think about the CAD/CAM software. Think about the NC machines, and the 3D modeling software. Think about the fluid dynamics simulations, the finite element analyses, the orbital calculations, the spreadsheets, the word processors, the email, the text messages, the phone calls…
I think you see where I’m going with this. Every minute step along the pathway from the dream, to the realization, was lubricated, enabled, enhanced, and simplified by software. Billions and billions of lines of software that we programmers wrote. [Yes, the Sagan-ism was intentional.]
Now think about what this event means to our civilization. Yes, it was a token – a gesture – a mere droplet in the sea of potentials. But what a droplet! Just think of the sheer chutzpah, the colossal, arrogant, exuberant, joyous wastefulness! It was the peacock spreading it’s opulent tail feathers. It was the prong-horn antelope leaping into the air out of sheer enthusiasm. It was an expression of our rejection of limits, and our willingness to flippantly expend massive resources to achieve a tiny portion of a passionate dream.
It was a message that we sent to ourselves, and to the universe at large, saying that we are coming, and nothing in this universe will stop us. And it was we programmers who, more than anyone else, enabled the sending of that message. This is something that you, and I, and all programmers everywhere should feel very good about.
The Bad.

Elaine Herzberg is dead. She was struck by a “self-driving” car while walking her bicycle across the road. And we programmers killed her. Oh, I don’t mean to say that any programmer maliciously, or even negligently, wrote the code that killed her. But, make no mistake about it, it was the code that killed her.
Perhaps there was an IF statement somewhere in that code that, had the boolean predicate been in the opposite state, would have prevented the collision. Or perhaps it was a function that generated a number that, had the number been different by a few bits, would have prevented the collision.
We may never be able to identify that IF statement, or that function. Machine learning neural networks are insidiously difficult to understand. Even if the car’s log files contain all the inputs, and we can replay the event over and over again, we may never really understand, in the maelstrom of weights, and averages, and feedback loops, just why the car behaved the way it did.
But what we can say is that we programmers wrote the code that killed her. And this is something that you, and I, and all programmers everywhere should feel very bad about.
The Ugly.
There is a sentiment amongst programmers that arguments of ethics and morality should play no part in our discussions about disciplines and practices. Those who hold this sentiment suggest that our practices and disciplines should be a matter of pure logic and economics. Given the two scenarios above, I find this disturbing. It seems to me that ethics and morality have become intrinsic to everything we programmers do; because so very much depends upon the quality of our work.
Our Motto.
It is well past the time that we programmers can safely isolate ourselves from the rest of the world. We programmers must no longer hide in our little techie bubbles. The code we programmers write matters. It matters to the hopes and dreams of our society and of our civilization. It matters to people walking their bicycles across the street. It matters to anyone and everyone because the code we programmers write lubricates, enables, enhances, and simplifies virtually every aspect of daily life. From something as small as a young mother checking her baby monitor, to something as large as international nuclear-weapons policy, and interplanetary travel, our code matters.
Recently Grady Booch tweeted something that I think we programmers should adopt as our motto:
Every line of code represents an ethical and moral decision.
A love letter to legacy projects
Monday morning. Your previous project just wrapped up, and they are going to assign you a brand new one. They even promised you the lead on this project. Who said Mondays couldn’t be great?
A few hours later and you are staring at the most dreadful code you have ever seen — controllers of more than a thousand lines, PHP that injects jQuery in the views, raw SQL statements that could challenge a Dostoyevsky novel in size. The list goes on and on. This Monday is going to need a ton of coffee.
The previous few lines might sound very familiar to you. You might even be working on a project like this at this very moment. If that is the case, … lucky you.
Why do these horrible applications exist?
Most applications don’t start like this. As you know, green field applications start full of hopes, dreams and rainbows. A new business idea gets launched. It does something small, pretty good. People like the application. They like it a lot. More and more customers flock to the application. You excitingly add more functionality to your small idea. Soon, one of your more prominent clients, asks for a very valid use case.
Hmm, you haven’t thought about this particular flow in the application. To be honest; the application doesn’t support it. However… it’s a big client, and it’s a great idea. You know what, this small little hack won’t make the difference. We’ll document it, so everyone knows about it.
Fast forward a few months. You have a dozen developers working for you, and your Kanban feature board is filled to the brim. The strange thing about the board, however, is that most of the features on that board don’t come from your hand, they come from customers. Moreover, they all want concrete things very tailored to their workflows. That little hack that’s been made a few months ago is now not even considered a hack anymore; it’s just how the application works. Moreover, if you take a step back, most of the application is now a collection of these small little hacks.
You might think that this is a horrible product, and from a code perspective you might be right. However, from a business perspective, this is a vital process. The product has a ton of customers, and they are invested enough to want to tailor it to their workflows and they even reach out to you with suggestions. Granted, not all of these suggestions are great, but they wouldn’t come forward if there weren’t a need for them.
Is this the low point?
However, now where does that leave you, It’s entertaining to have a company with many customers, but at the end of the day, you’re still the one that is in the trenches of despair.
Not necessarily; Having a product like this tend to generate income. The most significant part of that income is invested back into the project. Once the legacy code hampers the production of new features or generates too many bugs, the discussion surrounding refactoring parts of the code tend to start getting more and more speed.
Once you start refactoring, you suddenly notice that you have so much value in front of you — a ton of use cases already implemented, a wealth of user behaviour and data, metrics and most important of all: the budget and infrastructure to match.
Working with legacy day to day
Most refactorings tend to start with the question from management that is frequently a variation of: “what are the worst parts of the application, and how can we make them better”. This sentence is poetry to a developer’s ear. A great chance to go over the entire application note down the pain points, look at technologies that might ease trouble, have lengthy discussions with colleagues about the architecture of the pesky service classes. Not only are you going to learn a ton on the technical side of things, socially you’re going to improve in ways of persuasion and proposing ideas.
After a while, the most significant part of the spec will be done. Moreover, I can guarantee you that you’ve never been so excited to work on the project before. You can now look at the project and see a road to be walked, where before it was just an end to a means.
Now comes the tricky part, refactoring one of those huge files. The first time you read over the class, you might get some doubts about this whole refactoring stuff. Luckily you stick to your means of attack and write your first end to end tests. Once you’ve established a safety net, you regain a big part of your courage.
Ok you think, this piece of code I might be able to extract to a separate class. You write the unit test. You extract the code, and everything is green. Ok, great start! Let’s do it again.
A few hours later you stare at the construction you’ve made. It’s a vast improvement of what it was before (every single indentation you fix is an improvement), but looking at the loose classes, you can see some definite improvements still. You could leave it as it is, and that would be great, or go further. Either path you chose, at one point you’re going to create a PR, and sit back and stare at the diff screen of your favourite git hosting service … what a beauty.
Growing with the application
Working on applications like this is all about responsibility. Every decision you make as a team will impact you in the future, in a good way and sometimes in a not so good way.
This kind of pressure might sound like a burden, but in reality, it is indeed a blessing. It forces you to slow down and think about your actions as a team. Should I write a test for this? The answer is going to be yes, cause once it has a test, it’s going to part of the test coverage for maybe years to come.
So that’s the beauty of legacy code: You get a rough stone that you can shape into a gem. The pressure of delivering new features won’t be lower on a legacy application over Greenfield, but management often understands the need for refactoring and architectural meetings better.
Moreover, all the technologies and paradigms learned in the refactoring of legacy code are invaluable when you move on to Greenfield projects as you now have the context for the need for value objects, testing and decoupling.
So yes, if you’re about to start on a legacy code base. Lucky you. You’re about to have one hell of a ride.
Ps: Happy birthday Taylor Swift
10 dicas para aumentar sua produtividade trabalhando em casa
Code Reviews and Blame Culture
Gated pre-merge code reviews are bad. Always refactor on master. Always do Pair Programming. Don’t use branches. Apply Continuous Integration.
Best practices likes these are great. They encode experiences of many individuals and teams into memorable slogans, and help others to make decisions on how to run their teams processes. Unfortunately, the not-so-great practices also get their share of the slogans. Phrases like “TDD is dead” and “Test-induced design damage” are just as catchy.
The human brain likes to rationalise. We like to mix and match the advice that fits our narrative. When for example, our code makes writing unit tests hard, adopting “TDD is dead” as a slogan is much more comfortable than learning how to do safe refactors and introduce a test harness. Combine a lack of automated tests with the advice to refactor on master, and you’ll get a recipe for disaster.
As a consultant, sometimes I get hired to help out in high performing teams that deploy great quality software daily. More often though, the environment is less than ideal. If the idea of bringing in external help was a tough sell to management, I’m rarely there for more than a few days. I could come in, recite all the best practices, and be gone (and I’m afraid I’ve made that mistake on occasion). More valuable is to look for the small improvements that can have a lasting impact and put the team on the path to improvement. If that’s just enough wind in the sails to show that progress is possible, that might be enough to get them to take control of their own situation.

I advocated Pre-merge Code Reviews on this blog a couple of years ago, and I still stand by it. A common believe is that this kind of gated reviews lead to blame culture. If you work in a high performing team, and do a lot of Pair Programming (or even Mob Programming!), then shifting to reviews is indeed a step down, that removes trust. But simply shouting on Twitter that peer reviews are bad, displays a lack of appreciation for the contexts of others.
Many teams have no tests, no refactoring skills, and a high degree of blame culture, where individuals get blamed for breaking the code. Not coincidentally, managers in these teams tend to believe Pair Programming will cut the productivity in half. Refactoring is high risk, so nobody does it out of fear of getting blamed.
In my experience, reviews are often sellable here. And, counter-intuitively, Pre-merge Code Reviews can actually reduce blame culture! You need some simple rules:
- Open pull requests early;
- Never merge your own code;
- Never merge code you don’t understand or disagree with;
- Always review others’ code before starting on new tasks;
- Commenting on others’ pull requests is good, adding commits is better.
The interesting effect is that bugs, regressions, bad design, and lack of tests, are now no longer the fault of the person who wrote the code. It is the team that has failed to catch the issues. If you fail collectively, you’ll be induced to find solutions collectively. To reduce the effort of reviews, perhaps you’ll start adding some automated smoke tests. The senior team members might put more effort into teaching the juniors. Maybe two people will spend a Friday afternoon figuring out how to get that test framework up and running.
I believe this is a valuable lesson for all of us: When we advocate a best practice, or take advice from someone else, we need to assume there’s always a context. There’s a history of gradual improvement, a path taken from where we were to where we are. Others haven’t taken this path yet, or might end up on a different one. Best practices show a destination, but we can all put some more effort into putting up signposts along the way.
Read More
What You Should Think
Do you ever feel like you opinions are being spoon-fed to you? Even worse, what if you didn't even realize it was taking place?
Introducing: Linode Dedicated CPU Instances

Introducing our newest compute instance type: Dedicated CPU Instances
Dedicated instances are optimized for workloads where consistent performance is required or where full-duty work (100% CPU all day, every day) needs doing. This includes build boxes, CI/CD, video encoding, machine learning, game servers, databases, data mining, and busy application servers.
The underlying CPU resources for these instances are dedicated and shared with no one else. A Dedicated Linode’s vCPU threads are assigned exclusively to cores and SMT threads on the hypervisor, and there is no sharing or competing for these resources with other Linodes.
We’ve priced these plans to be very competitive and we think they’re a pretty darn good value.
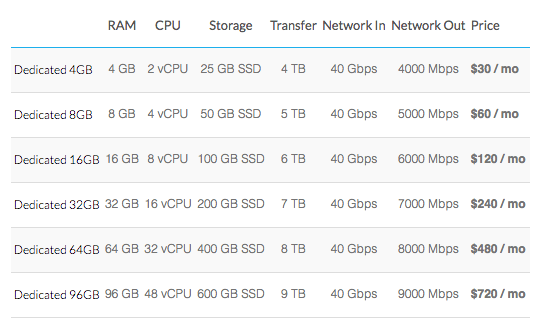
Visit the pricing page for full details and our entire pricing lineup.
Dedicated Instances are immediately available in all regions. You can create new Dedicated Linodes or resize existing ones into a Dedicated plan. Please note that Frankfurt and Atlanta have reduced availability – however we have literally hundreds of machines being installed in all locations throughout coming weeks.
What’s coming next from Linode? New hosting centers in Canada, India, along with Object Storage, Linode Kubernetes and more.
Enjoy!
15 Plataformas Cloud Open Source para partilha de ficheiros (1)

Umur Cubukcu: Microsoft Acquires Citus Data: Creating the World’s Best Postgres Experience Together

Today, I’m very excited to announce the next chapter in our company’s journey: Microsoft has acquired Citus Data.
When we founded Citus Data eight years ago, the world was different. Clouds and big data were newfangled. The common perception was that relational databases were, by design, scale up only—limiting their ability to handle cloud scale applications and big data workloads. This brought the rise of Hadoop and all the other NoSQL databases people were creating at the time. At Citus Data, we had a different idea: that we would embrace the relational database, while also extending it to make it horizontally scalable, resilient, and worry-free. That instead of re-implementing the database from scratch, we would build upon PostgreSQL and its open and extensible ecosystem.
Fast forward to 2019 and today’s news: we are thrilled to join a team who deeply understands databases and is keenly focused on meeting customers where they are. Both Citus and Microsoft share a mission of openness, empowering developers, and choice. And we both love PostgreSQL. We are excited about joining forces, and the value that doing so will create: Delivering to our community and our customers the world’s best PostgreSQL experience.
As I reflect on our Citus Data journey, I am very proud of what our team has accomplished. We created Citus to transform PostgreSQL into a distributed database—giving developers game-changing performance improvements and delivering queries that are magnitudes faster than proprietary implementations of Postgres. We packaged Citus as an open source extension of PostgreSQL—so you could always stay current with the latest version of Postgres, unlike all forks of databases prior to it. We launched our Citus Cloud database as a service and grew it to power billions of transactions every day—creating the world’s first horizontally scalable relational database that you can run both on premises, and as a fully-managed service on the cloud.
The most fulfilling part of this journey has been seeing all the things our customers can now do because of Citus—from SaaS companies who run their core applications on Citus Cloud to scale their business on-demand; to large enterprises who use Citus to power their real-time analytics dashboards; to organizations who serve both transactional and analytical workloads with one database (Citus); to Fortune 100 companies who are now able to migrate to an open, horizontally scalable Postgres ecosystem; to developers who now have a more scalable and performant way to power their workloads—all without re-architecting their applications.
As part of Microsoft, we will stay focused on building an amazing database on top of PostgreSQL that gives our users the game-changing scale, performance, and resilience they need. We will continue to drive innovation in this space. We remain as committed to our customers as ever, and will continue providing the strong support for the products our customers use today. And we will continue to actively participate in the Postgres community, working on the Citus open source extension as well as the other open source Postgres extensions you love.
All of this would not have been possible without the support of the PostgreSQL community, our customers, and the amazing team we are privileged to work with. We are humbled to work with all of you, and we are looking forward to working together as we deliver ever bigger things to our community, our users, and our customers in the next chapter of our journey—now as part of Microsoft.
To read more about our exciting news, please visit the Official Microsoft Blog.
Umur Cubukcu, Ozgun Erdogan, and Sumedh Pathak, co-founders of Citus Data

O fiel Timóteo (livreto digital)

Fiel Timóteo!
Com muita gratidão ao Senhor lançamos hoje o primeiro livreto digital publicado pelo blogue Campos de Boaz. Há muito alimentamos o desejo de publicar livretos e livros totalmente gratuitos, seguindo a linha editorial que seguimos.
Já estamos trabalhando na tradução dos primeiros livros. Publicaremos, contando com a graça do Senhor, um livro de Jessie Penn-Lewis e um (ou dois) de T. Austin-Sparks. E temos também outros já em vista. Contamos com a graça do Senhor para cumprir esse desejo (que cremos estar de acordo com Sua vontade), por conta de nossa pequena equipe de voluntários. Continuamos orando para que o Senhor envie mais respigadores para essa lavoura de Seus ricos campos.
O livreto O fiel Timóteo é uma mensagem dada por Francisco Genciano à igreja em Santo André no final de 2018. É um chamamento à perseverante fidelidade ao Senhor. Em formato pdf (o que permite ser lido em computadores, celulares e tablets), o livreto pode ser baixado aqui. Que essa mensagem abençoe a todos que a lerem como abençoou a todos que a ouviram.
Um Engano Chamado Teologia Inclusiva
O padrão de Deus para o exercício da sexualidade humana é o relacionamento entre um homem e uma mulher no ambiente do casamento. Nesta área, a Bíblia só deixa duas opções para os cristãos: casamento heterossexual e monogâmico ou uma vida celibatária. À luz das Escrituras, relações sexuais entre pessoas do mesmo sexo são vistas não como opção ou alternativa, mas sim como abominação, pecado e erro, sendo tratada como prática contrária à natureza. Contudo, neste tempo em que vivemos, cresce na sociedade em geral, e em setores religiosos, uma valorização da homossexualidade como comportamento não apenas aceitável, mas supostamente compatível com a vida cristã. Diferentes abordagens teológicas têm sido propostas no sentido de se admitir que homossexuais masculinos e femininos possam ser aceitos como parte da Igreja e expressar livremente sua homoafetividade no ambiente cristão.

Ainda sobre o pecado cometido naquelas cidades bíblicas, que acabaria acarretando sua destruição, a “teologia inclusiva” defende que o profeta Ezequiel claramente diz que o erro daquela gente foi a soberba e a falta de amparo ao pobre e ao necessitado (Ez 16.49). Contudo, muito antes de Ezequiel, o “sodomita” era colocado ao lado da prostituta na lei de Moisés: o rendimento de ambos, fruto de sua imoralidade sexual, não deveria ser recebido como oferta a Deus, conforme Deuteronômio 23.18. Além do mais, quando lemos a declaração do profeta em contexto, percebemos que a soberba e a falta de caridade era apenas um entre os muitos pecados dos sodomitas. Ezequiel menciona as “abominações” dos sodomitas, as quais foram a causa final da sua destruição: “Eis que esta foi a iniquidade de Sodoma, tua irmã: soberba, fartura de pão e próspera tranquilidade teve ela e suas filhas; mas nunca amparou o pobre e o necessitado. Foram arrogantes e fizeram abominações diante de mim; pelo que, em vendo isto, as removi dali” (Ez 16.49-50). Da mesma forma, Pedro, em sua segunda epístolas, refere-se às práticas pecaminosas dos moradores de Sodoma e Gomorra tratando-as como “procedimento libertino”.
Essas igrejas, igualmente, defendem e aceitam a união civil e o casamento entre pessoa do mesmo sexo. É o caso, por exemplo, da Igreja Presbiteriana dos Estados Unidos – que nada tem a ver com a Igreja Presbiteriana do Brasil –, da Igreja Episcopal no Canadá e de igrejas em nações européias como Suécia, Noruega e Dinamarca, entre outras confissões. Na maioria dos casos, a aceitação da homossexualidade provocou divisões nestas igrejas, e é preciso observar, também, que só aconteceu depois de um longo processo de rejeição da inspiração, infalibilidade e autoridade da Bíblia. Via de regra, essas denominações adotaram o método histórico-crítico – que, por definição, admite que as Sagradas Escrituras são condicionadas culturalmente e que reflete os erros e os preconceitos da época de seus autores. Desta feita, a aceitação da prática homossexual foi apenas um passo lógico. Outros ainda virão. Todavia, cristãos que recebem a Bíblia como a infalível e inerrante Palavra de Deus não podem aceitar a prática homossexual, a não ser como uma daquelas relações sexuais consideradas como pecaminosas pelo Senhor, como o adultério, a prostituição e a fornicação.
GitHub passa a oferecer repositórios ilimitados para contas gratuitas

David Fetter: psql: A New Edit
Here's how:
$EDITOR ~/.inputrcNow add the following lines:
$if psql...save the file, and you're good to go.
"\C-x\C-e": "\C-e\\e\C-m"
$endif
Bruce Momjian: The Memory Resource Triad
There are three resources that affect query performance: CPU, memory, and storage. Allocating CPU and storage for optimal query performance is straightforward, or at least linear. For CPU, for each query you must decide the optimal number of CPUs to allocate for parallel query execution. Of course, only certain queries can benefit from parallelism, and the optimal number of CPU changes based on the other queries being executed. So, it isn't simple, but it is linear.
For storage, it is more of a binary decision — should the table or index be stored on fast media (SSDs) or slow media (magnetic disks), particularly fast random access. (Some NAS servers have even more finely-grained tiered storage.) It takes analysis to decide the optimal storage type for each table or index, but the Postgres statistic views can help to identify which objects would benefit.
Unfortunately, for memory, resource allocation is more complex. Rather than being a linear or binary problem, it is a multi-dimensional problem — let me explain. As stated above, for CPUs you have to decide how many CPUs to use, and for storage, what type. For memory, you have to decide how much memory to allocate to shared_buffers at database server start, and then decide how much memory to allocate to each query for sorting and hashing via work_mem. What memory that is not allocated gets used as kernel cache, which Postgres relies on for consistent performance (since all reads and writes go through that cache). So, to optimize memory allocation, you have to choose the best sizes for:
- shared buffers (fixed size at server start)
- work_mem (potentially optimized per query based on workload)
- kernel buffers (the remainder)
Deploying laravel-websockets with Nginx reverse proxy and supervisord
The post Deploying laravel-websockets with Nginx reverse proxy and supervisord appeared first on ma.ttias.be.
There is a new PHP package available for Laravel users called laravel-websockets that allows you to quickly start a websocket server for your applications.
The added benefit is that it's fully written in PHP, which means it will run on pretty much any system that already runs your Laravel code, without additional tools. Once installed, you can start a websocket server as easily as this:
$ php artisan websocket:serve
That'll open a locally available websocket server, running on 127.0.0.1:6001.
This is great for development, but it also performs pretty well in production. To make that more manageable, we'll run this as a supervisor job with an Nginx proxy in front of it, to handle the SSL part.
Supervisor job for laravel-websockets
The first thing we'll do is make sure that process keeps running forever. If it were to crash (out of memory, killed by someone, throwing exceptions, ...), we want it to automatically restart.
For this, we'll use supervisor, a versatile task runner that is ideally suited for this. Technically, systemd would work equally good for this purpose, as you could quickly add a unit file to run this job.
First, install supervisord.
# On Debian / Ubuntu apt install supervisor # On Red Hat / CentOS yum install supervisor systemctl enable supervisor
Once installed, add a job for managing this websocket server.
$ cat /etc/supervisord.d/ohdear_websocket_server.ini [ohdear_websocket_server] command=/usr/bin/php /var/www/vhosts/ohdear.app/htdocs/artisan websocket:start numprocs=1 autostart=true autorestart=true user=ohdear_prod
This example is taken from ohdear.app, where it's running in production.
Once the config has been made, instruct supervisord to load the configuration and start the job.
$ supervisorctl update $ supervisorctl start websockets
Now you have a running websocket server, but it will still only listen to 127.0.0.1:6001, not very useful for your public visitors that want to connect to that websocket.
Note: if you are expecting a higher number of users on this websocket server, you'll need to increase the maximum number of open files supervisord can open. See this blog post: Increase the number of open files for jobs managed by supervisord.
Add an Nginx proxy to handle the TLS
Let your websocket server run locally and add an Nginx configuration in front of it, to handle the TLS portion. Oh, and while you're at it, add that domain to Oh Dear! to monitor your certificate expiration dates. ;-)
The configuration looks like this, assuming you already have Nginx installed.
$ cat /etc/nginx/conf.d/socket.ohdear.app.conf
server {
listen 443 ssl;
listen [::]:443 ssl;
server_name socket.ohdear.app;
access_log /var/log/nginx/socket.ohdear.app/proxy-access.log main;
error_log /var/log/nginx/socket.ohdear.app/proxy-error.log error;
# Start the SSL configurations
ssl on;
ssl_certificate /etc/letsencrypt/live/socket.ohdear.app/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/socket.ohdear.app/privkey.pem;
ssl_session_timeout 3m;
ssl_session_cache shared:SSL:30m;
ssl_protocols TLSv1.1 TLSv1.2;
# Diffie Hellmann performance improvements
ssl_ecdh_curve secp384r1;
location / {
proxy_pass http://127.0.0.1:6001;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-VerifiedViaNginx yes;
proxy_read_timeout 60;
proxy_connect_timeout 60;
proxy_redirect off;
# Specific for websockets: force the use of HTTP/1.1 and set the Upgrade header
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Everything that connects to socket.ohdear.app over TLS will be proxied to a local service on port 6001, in plain text. This offloads all the TLS (and certificate management) to Nginx, keeping your websocket server configuration as clean and simple as possible.
This also makes automation via Let's Encrypt a lot easier, as there are already implementations that will manage the certificate configuration in your Nginx and reload them when needed.
The post Deploying laravel-websockets with Nginx reverse proxy and supervisord appeared first on ma.ttias.be.
Laravel 5.7.14 Released

Before Thanksgiving last week Laravel 5.7.14 was released with the ability to make asset root URLs configurable with the ‘app.asset_url’ config option. This release contains other convenient configurations and overrides. Learn about the new features, changes, and fixed in Laravel 5.7.14.
Visit Laravel News for the full post.
The post Laravel 5.7.14 Released appeared first on Laravel News.
CodeDaze 2018 Talk
Back in September of this year had a chance to go just across the border into the US to Buffalo, NY and speak at CodeDaze, a conference run by long-time devrel evangelist PJ Hagerty and some friends of his.
This year they had closed-captioning for the hearing impaired and they very graciously have provided me with a transcript of my talk. I have cleaned it up, edited a few things, and added some links to topics I spoke about.
Here's the talk:
Thanks. Can everyone hear me okay in the back with the mic, because I'm a very large human?
Can you hear me okay in the back? I also talk really loud.
This talk is about how your tests won't save you. I'm going to talk about a set of complementary tools if you're working with a test-centric workflow. Sorry for my thick Canadian accent. I hope the people doing the captions add the U's where they're supposed to be.
I've been working for Mozilla about three years. I work with the Test Engineering group that tests every release of Firefox and associated services to make sure everything goes okay.
I've been yelling at people about testing your PHP code since 2003.
This talk has no code or tests.
You won't have to hurt your eyes trying to look at code. It also refers to tools from the PHP world. If you know Perl or Ruby, it is close enough. I'm describing practices that I think apply to projects where you'll have two or more contributors to it.
I'm going to talk about reducing what I see as a bunch of friction points in development and getting your application out into the real world. You may look at something and go that's not a big deal, but when you have like 10 or 11 of these things, the idea of friction and the project keeps rubbing up against problems and pain points all the time, that will cause your project to lose velocity.
You'll drop contributors. You'll spend way more time trying to get your eyes out of your laptop.
I have these features. I want to share them with as many people as possible, so I have to find a way to get some velocity going.
Thankfully for someone like me the value of automated test suites has been proven via studies.
The canonical study
was done by IBM and Microsoft.
They got a bunch of teams
together and said "okay, here's
a problem we want you to solve. We want some of you to use test-driven development
and some of you to not".
When I talk about test-driven
development, we're talking about
the Wikipedia-style definition
where we're planning things with
our unit tests. We are planning
functionality and behaviors.
We're writing tests assuming
that everything is working
correctly, and then we write
code until the tests pass.
Then we rinse and repeat until we get an application that is working the way we expect it to. The results of that study were that for 20% to 40% extra time that you'll spend writing your unit tests, you'll have 40% to 90% fewer bugs showing up in production. If you're an evangelist for testing stuff like me and you want to lie -- well, not lie but exaggerate a bit to convince the people above you who give you permission to do things -- you tell them "for one day a week we'll have 90% pure bugs". It's not true, but it is a nice sound byte to tell people. There is definite value in investing time to have automated test suite.
But tests only fix a small
range of problems when you have
a collaborative project.
Because tests don't help with
people problems.
That's what I've kind of discovered over the years. The problem isn't the testing tools themselves anymore.
There was a time when I had to walk both ways uphill in the snow to get these things to work, but there's now testing frameworks for pretty much every single mainstream programming language you can think of, and there's plenty of examples on how to write tests and lots and lots of examples on philosophy and the ideas behind testing.
I write books about testing, so there's no shortage of information, but the problem is these are technology-based solutions. As we all know, people are the worst, and people are the problem. It's never the tools.
So, if you're thinking the idea behind tests is "I'm trying to prevent bugs from reaching the users", there's this mythical thing that if I have tests, I'm going to increase the quality, whatever quality means, but my experiences have been
As an aside, I'm like Avdi (note, I am referring to Avdi Grimm). I've been doing this for a long time. This is my 21st year getting paid to write computer programs.
I got my first computer probably before a lot of people in this room were born. I got a -- has anyone heard of the Commodore Vic 20?
I'm 47, which is 470 in internet years. 300 years I've had a computer, so I've been using computers for a long time.
I discovered the problem when you had to collaborate. When it is just you working on this stuff, it doesn't matter. But if you want someone else working on your project and you want quality code and as few bugs as possible, just having a test alone won't save you.
But we can address some of the people problems with some help from technology. But technology is not the answer to all the people problems. This is a blind spot that many programmers have that we're so enthusiastic about the work we're doing and technology and the promise of the future.
There's that old joke about "where the jet cars we were promised?!?". If you're like me and you grew up in the 1970s and 1980s, we have the exact future we were promised, a corporate dystopia. It's the technology that's enabling people problems to be worse.
Technology can't solve horrible people, but it can help to kind of smooth things out in your project.
So here's what I want to talk about. What do I really think helps? I want to talk about tools that can save us from thinking too much and tools that can save us from remembering too many things and tools that can save us from ourselves.
Because I know a current me is always cursing yesterday me for making a stupid mistake that was easily avoidable.
What are some tools that can help save us from ourselves? There are three things I want to talk about today. I want to talk about build tools, code stylers and sniffers, and probably the most controversial tool because I think it is in really, really short supply these days: empathy.
Build tools: what they save us from is remembering error-prone sequences. When you think about the modern web application -- I saw a joke that said PHP was the original serverless language.
Those were the glory days of
lazy developers where you didn't
have to do much, but now pretty
much any nontrivial web
application has not only source
code that you have to think
about, but we're talking about
databases, so we have migrations
and database initializations.
We have to compile assets.
There's a bunch of different things you need to do so it is no longer just a case of I can take my source code and copy it somewhere. Hopefully, you're not using FTP. I know that's an old joke. Please don't use FTP. You're going to make it that nobody wants to work for you.
You can't just copy your stuff up anymore. As a result, we have all these other additional tools that we need to learn to use. That is additional overhead and context switching that you need to do when you're working on stuff, so build tools can save us from that. When I talk about build tools, there's a couple of things that come to mind.
We can talk about a series of hand crafted shell scripts. You're trying to take things you've been doing manually to deploy the application and get the computer to do it.
You'll start off with a shell script or we're manually typing in terminal shells. You then move to some sort of tool that's tied to some sort of specific programming language.
On the PHP side of things, there's a tool called Phing. It uses XML to define things, so don't be scared of XML. I used to work for a company that did nothing but XML. All I did was lose my hair over it. Don't worry.
Anyway, Chef is very tightly linked to Ruby. We move from the shell scripts to language-specific tools.
Jenkins is probably the most popular one for people that want to do it themselves. At Mozilla, we make heavy use of Jenkins. We have our own build server, and what the build server does is run our tests for us.
The operations build tool will call to our Jenkins instance and say "we just did a deployment", and passes in a bunch of information. We wrote some stuff in Jenkins to parse tags.
I'm doing this
project, and it is aimed at
staging or it is in
development or in
production. Then Jenkins goes
and runs the test.
That is kind of the sweet spot to be in because what you want to get away from is this idea that whenever a deployment happens, everyone has to be there just in case something happens.
I've worked at places where everyone stayed on a Friday until 10:00 p.m. just because there were any glitches. We want to move towards this idea that deployments can be flawless.
People make mistakes, right? Because computers are great at what we tell them or more accurately what we think we're telling them to do over and over again usually without complaining.
Hopefully, your computer doesn't complain to you when you try to get it to do something, but humans make all kind of mistakes because we're humans. We're not beings of pure logic. We make mistakes.
We have unconscious biases. We understand that some parts of our application are kind of tricky, so we're reluctant to test them in the way that they need to be tested. More importantly, we can fat-finger statements.
Imagine you have some deployment process that is 32 steps long. If you make a mistake at step 17 and don't realize until step 27 because you're seeing some weird error, this is a mistake, and it is kind of avoidable.
A build server is freeing up mental energy for other tasks, right? I find that as I age my brainpower gets less and less, so I want to use my brain for other things -- I play that expensive card game Magic the Gathering. I have this other stuff rattling in my head that I sometimes think is more important than work, but if I need to think about which of these 32 steps am I going to make a mistake. I want to free up mental energy to actually solve problems.
In the testing work I do, there are some very interesting problems to solve, and I would rather spend the mental energy on that.
How many people here have had experience using Jenkins or Travis for your projects? A fair number. For those who may have heard of it and never gone through it, here's a summary of how a build tool can be set up to help you.
Usually, the build tool is triggered by your version control system. I hope everyone is using version control. Again, we're at a point in time where it is super easy to use version control, so there's really no excuse not to use it.
It should grab a copy
of your code, including the
changes that you've just made.
Then here's the important part
-- we can save ourselves because
it will build an environment.
It is going to check out the
code. It is going to do any
database migrations, anything
else that you need done, warming
up caches and things like that.
You want the build tool to do it
because you don't want to be
babysitting these automated
systems. If you can't trust the
automated system, you need to
fix it until you can trust it.
Then it runs the test, and it
will let you know what has
passed or failed, right?
The build tools are going to save you from yourself, and the build tools are pretending to be you executing all these steps flawlessly, so again you save that mental energy. You're not worrying at all about which of these steps am I going to have to remember.
Also, using things like build tools will move you down the road toward continuous deployment.
What I mean is the idea is you want to have the deployments of your application a non-event.
- We deploy once very two weeks or once a month.
- We never deploy on a Monday because everyone is pissed off because it is Monday.
- We don't deploy on Fridays because everyone is pissed off on Fridays
You don't want that.
I have seen places that have made this work, but they're not large places with tons of engineering resources. There's a web page and someone presses a button that says deploy. That's it.
For me personally, the Holy Grail for this is every single change you make through a system of automated systems goes up production. If the tests pass up in production, it goes. You want to be able to deploy 10, 15, 20 times a day. It should be literally a nonevent. It should be sending off a tweet.
Another tool that I think helps reduce our cognitive load and gets rid of friction are code stylers and sniffers.
Colin's talk on code reviews, a lot of what he talked about really resonated with me, but he didn't get into the downside or maybe he did because I was too busy making notes.
We start arguing about how things look, what the variable was named, especially in PHP because it is so flexible with the syntax. Why is the curly brace there? Why are there extra spaces before the variable name? We know that we don't use private class attributes. They should be protected or public.
People are arguing over how it looks instead of the point of the review, which is supposed to be "is this code behaving the way that I've said it is behaving".
Is it solving the problem it is supposed to be solving? Instead, we're relying on a third party. It is not necessarily arbitrary because oftentimes you can go and give the code sniffer and styler your own ideas on how you want things to look.
The project that I work on on the PHP side of things is called OpenCFP.
The best way you can describe it is a competitor for Papercall.
I used to run a
conference up in Toronto called
TrueNorthPHP, and I needed a
tool to collect papers from
people who wanted to speak. I
wrote something. I thought I
might as well open source it so
I can fix the bugs and weird
behavior that must come up.
There must be 30 or 40
conferences that use open CFP.
We love it.
(At this point I was talking about PHP Codesniffer but the captioning folks couldn't make out what I was rambling about)
What can this tool do for us to reduce arguments in code reviews? It checks are we using the correct array syntax for the newer versions of PHP. We look at tools about line spacing to make the source code a lot easier to read. We have a thing that checks if there is a test attached to it. If you have a class named a certain way in a specific namespace, we have a specific test. We look for return-type declarations.
PHP has type hints for parameters and return values. If you haven't looked at PHP in the last four or five years, I don't blame you for not knowing what has changed. Now it is a modern oriented language with a lot of cool features. PHP powers about half the web. Wikipedia runs on it, WordPress. So much web content is served on PHP.
We are slowly moving towards static types or Java with dollar signs on the front, but these are all things it checks.
There's another 50 things we look for. These are all things that we found we were arguing about all the time or things that were being adopted as best practices by other PHP projects.
If we agreed with it, we would just add a line or a line or two of configuration to the code sniffer and then we would look for these things. We wanted consistent enforcement of these style rules. We didn't want it to be that I could do things one way and someone could do things a different way.
Al those arguments just disappear because we decided on a set of rules that said we have this tool.
I don't know about you, but if I look at code bases, you kind of learn the general style that's applied to it. When you see something that doesn't match that style, when it is late on a Thursday and you're thinking you're going to go out and have dinner and your eyes are glazed over and you can see the indentation patterns, some of that doesn't look the same as the rest of the code stands out at you automatically.
It is a little tiny friction point.
This does not look like the rest of the code. Now I have to stop and process and say why is this different. Maybe there's nothing wrong with it.
Maybe
they just like to name variables
differently or they added an
extra line of indention.
Sometimes it is a structural
problem, like you didn't even
run this code before hitting
execute.
This is all about mental energy. We're trying to save our -- this is all about trying to save our mental energy.
There is no flexibility or room to disagree. The code sniffer said this was a mistake. In OpenCFP, the code sniffer finding a problem is considered a failed build. You have to go back and fix it.
You can run the code sniffer, and there are some types of errors it can fix for you. It will add in declarations if you're missing them and return-type hits, indents. It will fix a bunch of things so I don't have to go back and fix them myself.
Some other languages are
starting to provide automated
formatting and sniffer. My
apologies if I don't use
anything that's in widespread
use anymore. Go uses goformat.
Python created these standards called PEP8
of things they wanted people to
do with the language and with
the community and stuff like
that, so there's several command
line tools that will scan your
code and say, hey, it violates
this rule and this rule. Do you
want to fix it?
I found this called Rubocop
for Ruby. I don't know if
Rubyists use it. The Ruby I
have looks pretty clean and
consistent across projects.
Maybe code formatting isn't a
problem. Between PHP code
sniffer and Python, I don't have
to worry about it. I take
advantage of these sniffing
tools and styling tools in order
to eliminate remembering what
code should look like.
(After my talk I was approached by a Rubyist who went on an extended rant about all the things they disliked about Rubocop.)
This is the last one. Then I will be just about done.
Empathy. This is a tricky one because empathy is the most difficult tool of all to implement for a project because there is a quite large group of people who think empathy has no place in programming.
I like to call it the lie of the meritocracy. No, it is not a meritocracy. A lot of it is about how you know and how long you've been doing certain activities. Your technical brilliance won't enough to advance you through your career.
As Emily said, a career is a
marathon. It is not a sprint.
I've done this long enough to
understand, yes, this is a
marathon. I need to grind
things out to get the victories
that I want.
Empathy is the thing because if you got into programming -- you figured it was a good way to avoid dealing with people and talking to people. You talk to your computer. Unless you're having some mental health issues, the computer shouldn't be talking back to you without you expecting to, so you're thinking it will be great.
I'll just sit somewhere. They'll give me work to do. I'll do my work, and then I won't have to talk to people.
You're going to be extremely disappointed.
If
you're trying to move from
programming as a job to
programming as a career,
programming as a job is about
solving specific problems.
Programming as a career is about
collaborating with a bunch of
people to solve problems.
I know people watching up here might be surprised to know when I first started giving talks I was terrified to be up on stage.
In high school, I was the person with a sheet of paper up at the front doing the speech and the paper shaking and stuff.
When I went to college during medieval times, we did a mandatory course on presentations. I don't know what that teacher did, but he aligned all the right switches in my head where I could suddenly give talks. I didn't matter if it is 3 people or 1,000 people.
It's about communication and collaboration. Once I figured that out, the career took off. I've been speaking at conferences since 2004. I think if I didn't learn that collaboration and empathy was the way forward, none of this stuff would have happened for me.
Things turned very toxic easily. Programmers argued incessantly about little details. I think empathy is your best weapon against toxicity in your project. When I talk about empathy, I'm talking about this idea -- a lot of people have a problem with this, the ability to understand other people are not like you.
When you hear discussions with people going "I don't understand how person X can do activity Y" -- you need to understand other people's point of views. You need to understand how and why people react to certain things.
In programming, I think this is very critical because you really do need to understand that everyone does not think like you.
Because if you can understand how people are going to react to what you're doing, it allows you to anticipate reactions and head off potential problems within your project.
Anyone who has done any type of testing for a little bit understands that even today it is still quite a contentious subject with lots of people not understanding the value.
Why do you want to spend this time writing tests? Why do we want to spend time investing in learning how to use these tools and frameworks? It's because it's been proven that it works, but people want to argue about it.
When you start testing your
code, it will change how you
write your code. You have to
write code in a specific way to
take advantage of testing tools.
At the unit level anyway.
People don't like being told you need to change something that you think you've been successful at in the past.
I'm not immune to this. I don't always like being told I'm wrong. Some people won't change. This is an interesting thing I've found. People like to change what they use but not how they use it. What I mean by this is there are many, many programmers who are always chasing the new and shiny tool.
Five more minutes? I'm almost done.
They want to change to the newest framework for their programming language or the newest tool. They don't like being told you need to change how you're using it because how you're using it doesn't lead to good outcomes.
People don't like this, so it generates toxic people from people who don't want to change. It might have been short-term success, but long term and medium term it is not going to work.
Toxicity drives away people from projects. Sometimes I lack the skill to execute on the last 10% on a particular problem. I want to draw people in who are interested in collaboration and interested in solving problems.
If I want to continue to have access to people like that, I can't have toxic communities. I can't have people insulting people on threads and GitHub and Twitter. I clamp down on that shit. It's not going to push my stuff forward.
I told people the reason I don't go into management after all this time is because I have two kids that I do enough managing at home that I don't want to manage other people. I know the millisecond I step out the door I hear my kids start arguing with my wife.
Your career will depend on working with others.
We're just about done.
Your testing framework won't save you from problems because it is simply not enough.
You should use build tools because they protect you from performing complicated stepping manually.
You should be using code sniffers and stylers to protect from you arguments.
Empathy protects your project from being toxic.
I do Twitter performance art as grumpyprogrammer without the u, I sell books on my website and
I have a conference coming up next year, so please support my efforts so I can continue to come to conferences and not have my employer complain about it.
Thanks very much.
The convincing Bitcoin scam e-mail extorting you
The post The convincing Bitcoin scam e-mail extorting you appeared first on ma.ttias.be.
A few months ago I received an e-mail that got me worried for a few seconds. It looked like this, and chances are you've seen it too.
From: Kalie Paci Subject: mattias - UqtX7m It seems that, UqtX7m, is your pass word. You do not know me and you are probably thinking why you are getting this mail, correct? Well, I actually placed a malware on the adult video clips (porn) web-site and guess what, you visited this site to have fun (you know what I mean). While you were watching videos, your browser started operating as a RDP (Remote control Desktop) that has a keylogger which gave me access to your display and also web camera. Immediately after that, my software program collected your entire contacts from your Messenger, FB, and email. What exactly did I do? I created a double-screen video. First part displays the video you were viewing (you have a nice taste lol), and second part displays the recording of your web camera. What should you do? Well, in my opinion, $1900 is a fair price for our little secret. You’ll make the payment through Bitcoin (if you do not know this, search “how to buy bitcoin” in Google). BTC Address: 1MQNUSnquwPM9eQgs7KtjDcQZBfaW7iVge (It is cAsE sensitive, so copy and paste it) Important: You now have one day to make the payment. (I’ve a unique pixel in this message, and right now I know that you have read this email message). If I don’t get the BitCoins, I will send your video recording to all of your contacts including members of your family, colleagues, and many others. Having said that, if I do get paid, I will destroy the video immidiately. If you need evidence, reply with “Yes!” and I definitely will send your video recording to your 11 friends. This is a non-negotiable offer, and so please don’t waste my personal time and yours by responding to this mail.
If you read it, it looks like spam -- doesn't it?
Well, the thing that got me worried for a few seconds was that the subject line and the body contained an actual password I used a while back: UqtX7m.
To receive an email with a -- what feels like -- personal secret in the subject, it draws your attention. It's clever in the sense that you feel both violated and ashamed for the consequences. It looks legit.
Let me tell you clearly: it's a scam and you don't need to pay anyone.
I first mentioned it on my Twitter describing what feels like the brilliant part of this scam:
- Email + Passwords, easy to get (plenty of leaks online)
- Everyone watches porn
- Nobody wants that leaked
- The same generic e-mail can be used for every victim
Whoever is running this scam thought about the psychology of this one and found the sweet spot: it gets your attention and it gets you worried.
Well played. But don't fall for it and most importantly: do not pay anything.
The post The convincing Bitcoin scam e-mail extorting you appeared first on ma.ttias.be.
Chamar a Si Todo o Céu com um Sorriso
que o meu coração esteja sempre aberto às pequenas
aves que são os segredos da vida
o que quer que cantem é melhor do que conhecer
e se os homens não as ouvem estão velhosque o meu pensamento caminhe pelo faminto
e destemido e sedento e servil
e mesmo que seja domingo que eu me engane
pois sempre que os homens têm razão não são jovense que eu não faça nada de útil
e te ame muito mais do que verdadeiramente
nunca houve ninguém tão louco que não conseguisse
chamar a si todo o céu com um sorriso
(e. e. cummings)

e. e. cummings
Gotas de Orvalho – A. W. Tozer (153)

Orvalho do céu para os que buscam o Senhor!
A adoração é a jóia perdida da igreja evangélica.
Quem quiser verificar sua verdadeira condição espiritual pode fazê-lo notando quais foram os seus pensamentos nas últimas horas ou nos últimos dias. Em que você pensou quando estava livre para pensar no que lhe agradasse?
O homem humilde aceita que se lhe diga a verdade. Ele crê que em sua natureza caída não habita bem nenhum. Reconhece que, separado de Deus, não é nada, não tem nada, não sabe nada, nem pode fazer nada. Mas esse conhecimento não o desanima, porque também sabe que, em Cristo, ele é alguém. Sabe que para Deus ele é mais precioso que a menina de seus olhos e que pode todas as coisas por meio de Cristo, que o fortalece; ou seja, pode fazer tudo o que está dentro da vontade de Deus que ele faça.
A vida em que o Espírito habita não é uma edição de luxo do cristianismo que deve ser desfrutada por determinados cristãos extraordinários e privilegiados que, por acaso, são melhores e mais sensíveis do que o restante. Ao contrário, é o estado normal para todo homem e mulher remido em todo o mundo.
O pecado tem sido disfarçado nestes dias, aparecendo com novos nomes e caras. Você pode estar sendo exposto a esse fenômeno na escola. O pecado é chamado por diversos nomes enfeitados ― qualquer nome, menos pelo que ele realmente é. Por exemplo: os homens já não ficam mais sob convicção de pecados; eles têm complexo de culpa. Em lugar de confessar suas culpas a Deus, para se livrarem delas, deitam-se num divã e tentam relatar o que sentem a um homem.
Toda a fraqueza dos fariseus jazia na qualidade de seus motivos.
Uma vida cristã estagnada e infrutífera é resultado da ausência de uma sede maior de comunhão com Deus.
O impulso de buscar a Deus origina-se em Deus, mas a realização do impulso depende de O seguirmos de todo o coração.
A prova pela qual toda conduta será finalmente julgada é o motivo.
Não queira saber coisas que são inúteis. Aprenda a orar interiormente a todo momento. Depois de algum tempo fará isso em qualquer lugar, inclusive no trabalho.
O contentamento religioso sempre é inimigo da vida espiritual. A biografia dos santos ensina que o caminho para a grandeza espiritual sempre foi por meio de muito sofrimento e dor no íntimo.
Por causa do que tenho pregado não sou recebido na maioria da igrejas da América do Norte.
 Aiden Wilson Tozer nasceu no dia 21 de abril de 1897, em Newburg, Pensilvânia (EUA). A. W. Tozer foi alcançado por Cristo em 1915, aos 18 anos. Aos 22 anos, ingressou no ministério pastoral da Igreja Aliança Cristã e Missionária, denominação cristã fundada por Albert Benjamin Simpson. Tozer foi muito influenciado pelos ensinos de A. B. Simpson acerca do Espírito Santo, proporcionando sua aproximação com os ensinos da Convenção de Keswick organizada pelo Movimento da Vida Superior, que prezava os ensinamentos da linha da vida interior, representado por Madame Guyon, Andrew Murray, Jessie Penn-Lewis, T. Austin-Sparks, Watchman Nee, dentre outros.
Aiden Wilson Tozer nasceu no dia 21 de abril de 1897, em Newburg, Pensilvânia (EUA). A. W. Tozer foi alcançado por Cristo em 1915, aos 18 anos. Aos 22 anos, ingressou no ministério pastoral da Igreja Aliança Cristã e Missionária, denominação cristã fundada por Albert Benjamin Simpson. Tozer foi muito influenciado pelos ensinos de A. B. Simpson acerca do Espírito Santo, proporcionando sua aproximação com os ensinos da Convenção de Keswick organizada pelo Movimento da Vida Superior, que prezava os ensinamentos da linha da vida interior, representado por Madame Guyon, Andrew Murray, Jessie Penn-Lewis, T. Austin-Sparks, Watchman Nee, dentre outros.
Além da devoção coletiva realizada no culto, Tozer valorizava as orações individuais, pois eram cruciais no seu dia-a-dia. Seus escritos e suas pregações eram conseqüência de sua vida de oração. Seus livros e seu legado espiritual atraem muitos cristãos sinceros e interessados no conhecimento e na vida profunda em Deus.
Christian Chen declarou: “A. W. Tozer e T. Austin-Sparks sãos os maiores profetas do século 20”. Aiden Wilson Tozer trilhou o caminho espiritual que poucos concluíram, caracterizado pelo conhecimento profundo de Deus, buscando desesperadamente a sabedoria do Salvador para servi-Lo e adorá-Lo plenamente. Convocou os crentes sinceros para voltarem às Escrituras e à prática que definiu o princípio da Igreja: fé e santidade.
A.W. Tozer cultivou estreita amizade com Leonard Ravenhill que utilizava muitos de seus livros para elaborar os sermões.
No dia 12 de maio de 1963, Tozer sofreu um ataque cardíaco e dormiu no Senhor, deixando um legado precioso para os cristãos sequiosos; no entanto, suas pregações trouxeram desconforto para as massas acomodadas do cristianismo.
Funçoes ZZ atinge maioridade: versão 18.3
Em comemoração os 18 anos do projeto, foi lançada a versão 18.3, trazendo nada menos do que 19 novas funções à biblioteca. Confira alguns destaques entre as novidades:
- Codificação de caracteres: zzcodchar
- Conjugação verbal: zzconjugar
- Divisão de strings: zzcut, zzdividirtexto
- Diversão: zzexcuse, zzhoroscopo, zznerdcast, zzsheldon
- Utilitários: zzhsort, zzmcd, zzsqueeze, zztestar, zztimer
- Consultas: zzit, zzmacvendor, zztop
- E mais: zzimc, zzrepete, zzwc
São ao todo 179 funções diferentes, todas estão concentradas em um único arquivo funcoeszz.sh. Baixe o arquivo, inclua em sua shell atual e usufrua. Todas as funções contam com tela de ajuda (—help). Veja exemplos de uso em http://funcoeszz.net.
Funções ZZ versão 18.3: download direto, instruções, changelog.
Enviado por Itamar Santos de Souza (itamarnetΘyahoo·com·br)
O artigo "Funçoes ZZ atinge maioridade: versão 18.3" foi originalmente publicado no site BR-Linux.org, de Augusto Campos.
Introducing DNS Resolver, 1.1.1.1 (not a joke)

Cloudflare’s mission is to help build a better Internet and today we are releasing our DNS resolver, 1.1.1.1 - a recursive DNS service. With this offering, we’re fixing the foundation of the Internet by building a faster, more secure and privacy-centric public DNS resolver. The DNS resolver, 1.1.1.1, is available publicly for everyone to use - it is the first consumer-focused service Cloudflare has ever released.

We’re using the following IPv4 addresses for our resolver: 1.1.1.1 and 1.0.0.1. Easy to remember. These addresses have been provided to Cloudflare by APNIC for both joint research and this service. You can read more about their work via the APNIC blog.
DNS resolver, 1.1.1.1, is served by Cloudflare’s Global Anycast Network.
Background: A quick refresher on the role of the resolver in DNS
Our friends at DNSimple have made this amazing DNS Tutorial for anyone to fill in their gaps on how DNS works. They explain all about resolvers, root name servers, and much more in a very informative way.

When resolving a domain name, a query travels from your end system (i.e. a web browser) to a recursive DNS service. If the DNS record is not in the service’s local cache, the recursor will query the authoritative DNS hierarchy to find the IP address information you are looking for. The recursor is the part that DNS resolver, 1.1.1.1 plays. It must be fast and these days it must be secure!
Goals for DNS resolver, 1.1.1.1
Our goals with the public resolver are simple: Cloudflare wants to operate the fastest public resolver on the planet while raising the standard of privacy protections for users. To make the Internet faster, we are already building data centers all over the globe to reduce the distance (i.e. latency) from users to content. Eventually we want everyone to be within 10 milliseconds of at least one of our locations.
In March alone, we enabled thirty-one new data centers globally (Istanbul, Reykjavík, Riyadh, Macau, Baghdad, Houston, Indianapolis, Montgomery, Pittsburgh, Sacramento, Mexico City, Tel Aviv, Durban, Port Louis, Cebu City, Edinburgh, Riga, Tallinn, Vilnius, Calgary, Saskatoon, Winnipeg, Jacksonville, Memphis, Tallahassee, Bogotá, Luxembourg City, Chișinău) and just like every other city in our network, new sites run DNS Resolver, 1.1.1.1 on day-one!
Our fast and highly distributed network is built to serve any protocol and we are currently the fastest authoritative DNS provider on the Internet, a capability enjoyed by over seven million Internet properties. Plus, we already provide an anycast service to two of the thirteen root nameservers. The next logical step was to provide faster recursive DNS service for users. Our recursor can take advantage of the authoritative servers that are co-located with us, resulting in faster lookups for all domain names.
While DNSSEC ensures integrity of data between a resolver and an authoritative server, it does not protect the privacy of the “last mile” towards you. DNS resolver, 1.1.1.1, supports both emerging DNS privacy standards - DNS-over-TLS, and DNS-over-HTTPS, which both provide last mile encryption to keep your DNS queries private and free from tampering.
Making our resolver privacy conscious
Historically, recursor sends the full domain name to any intermediary as it finds its way to the root or authoritative DNS. This meant that if you were going to www.cloudflare.com, the root server and the .com server would both be queried with the full domain name (i.e. the www, the cloudflare, and the com parts), even though the root servers just need to redirect the recursive to dot com (independent of anything else in the fully qualified domain name). This ease of access to all this personal browsing information via DNS presents a grave privacy concern to many. This has been addressed by several resolvers’ software packages, though not all solutions have been widely adapted or deployed.
The DNS resolver, 1.1.1.1, provides, on day-one, all defined and proposed DNS privacy-protection mechanisms for use between the stub resolver and recursive resolver. For those not familiar, a stub resolver is a component of your operating system that talks to the recursive resolver. By only using DNS Query Name Minimisation defined in RFC7816, DNS resolver, 1.1.1.1, reduces the information leaked to intermediary DNS servers, like the root and TLDs. That means that DNS resolver, 1.1.1.1, only sends just enough of the name for the authority to tell the resolver where to ask the next question.
The DNS resolver, 1.1.1.1, is also supporting privacy-enabled TLS queries on port 853 (DNS over TLS), so we can keep queries hidden from snooping networks. Furthermore, by offering the experimental DoH (DNS over HTTPS) protocol, we improve both privacy and a number of future speedups for end users, as browsers and other applications can now mix DNS and HTTPS traffic into one single connection.
With DNS aggressive negative caching, as described in RFC8198, we can further decrease the load on the global DNS system. This technique first tries to use the existing resolvers negative cache which keeps negative (or non-existent) information around for a period of time. For zones signed with DNSSEC and from the NSEC records in cache, the resolver can figure out if the requested name does NOT exist without doing any further query. So if you type wwwwwww dot something and then wwww dot something, the second query could well be answered with a very quick “no” (NXDOMAIN in the DNS world). Aggressive negative caching works only with DNSSEC signed zones, which includes both the root and a 1400 out of 1544 TLDs are signed today.
We use DNSSEC validation when possible, as that allows us to be sure the answers are accurate and untampered with. The cost of signature verifications is low, and the potential savings we get from aggressive negative caching more than make up for that. We want our users to trust the answers we give out, and thus perform all possible checks to avoid giving bad answers to the clients.
However, DNSSEC is very unforgiving. Errors in DNSSEC configuration by authoritative DNS operators can make such misconfigured domains unresolvable. To work around this problem, Cloudflare will configure "Negative Trust Anchors" on domains with detected and vetted DNSSEC errors and remove them once the configuration is rectified by authoritative operators. This limits the impact of broken DNSSEC domains by temporarily disabling DNSSEC validation for a specific misconfigured domain, restoring access to end consumers.
How did we build it?
Initially, we thought about building our own resolver, but rejected that approach due to complexity and go-to-market considerations. Then we looked at all open source resolvers on the market; from this long list we narrowed our choices down to two or three that would be suitable to meet most of the project goals. In the end, we decided to build the system around the Knot Resolver from CZ NIC. This is a modern resolver that was originally released about two and a half years ago. By selecting the Knot Resolver, we also increase software diversity. The tipping point was that it had more of the core features we wanted, with a modular architecture similar to OpenResty. The Knot Resolver is in active use and development.
Interesting things we do that no one else does
The recent advanced features we wanted were:
- Query Minimization RFC7816,
- DNS-over-TLS (Transport Layer Security) RFC7858,
- DNS-over-HTTPS protocol DoH,
- Aggressive negative answers RFC8198,
Small disclaimer: the original main developer of Knot Resolver, Marek Vavruša, has been working on the Cloudflare DNS team for over two years.
How to make our resolver faster
There are many factors that affect how fast a resolver is. The first and foremost is: can it answer from cache? If it can, then the time to answer is only the round-trip time for a packet from the client to the resolver.
When a resolver needs to get an answer from an authority, things get a bit more complicated. A resolver needs to follow the DNS hierarchy to resolve a name, which means it has to talk to multiple authoritative servers starting at the root. For example, our resolver in Buenos Aires, Argentina will take longer to follow a DNS hierarchy than our resolver in Frankfurt, Germany because of its proximity to the authoritative servers. In order to get around this issue we prefill our cache, out-of-band, for popular names, which means when an actual query comes in, responses can be fetched from cache which is much faster. Over the next few weeks we will post blogs about some of the other things we are doing to make the resolver faster and better, Including our fast caching.
One issue with our expansive network is that the cache hit ratio is inversely proportional to the number of nodes configured in each data center. If there was only one node in a data center that’s nearest to you, you could be sure that if you ask the same query twice, you would get a cached answer the second time. However, as there’s hundreds of nodes in each of our data centers, you might get an uncached response, paying the latency-price for each request. One common solution is to put a caching load balancer in front of all your resolvers, which unfortunately introduces a single-point-of-failure. We don’t do single-point-of-failures.
Instead of relying on a centralized cache, DNS resolver, 1.1.1.1, uses an innovative distributed cache, which we will talk about in a later blog.
Data Policy
Here’s the deal - we don’t store client IP addresses never, ever, and we only use query names for things that improve DNS resolver performance (such as prefill all caches based on popular domains in a region and/or after obfuscation, APNIC research).
Cloudflare will never store any information in our logs that identifies an end user, and all logs collected by our public resolver will be deleted within 24 hours. We will continue to abide by our privacy policy and ensure that no user data is sold to advertisers or used to target consumers.
Setting it up
See https://1.1.1.1/ because it's that simple!
About those addresses
We are grateful to APNIC, our partner for the IPv4 addresses 1.0.0.1 and 1.1.1.1 (which everyone agrees is insanely easy to remember). Without their years of research and testing, these addresses would be impossible to bring into production. Yet, we still have a way to go with that. Stay tuned to hear about our adventures with those IPs in future blogs.
For IPv6, we have chosen 2606:4700:4700::1111 and 2606:4700:4700::1001 for our service. It’s not as easy to get cool IPv6 addresses; however, we’ve picked an address that only uses digits.
But why use easy to remember addresses? What’s special about public resolvers? While we use names for nearly everything we do; however, there needs to be that first step in the process and that’s where these number come in. We need a number entered into whatever computer or connected device you’re using in order to find a resolver service.
Anyone on the internet can use our public resolver and you can see how to do that by visiting https://1.1.1.1/ and clicking on GET STARTED.
Why announce it on April first?
For most of the world, Sunday is 1/4/2018 (in America the day/month is reversed as-in 4/1/2018). Do you see the 4 and the 1? We did and that’s why we are announcing 1.1.1.1 today. Four ones! If it helps you remember 1.1.1.1, then that’s a good thing!
Sure, It’s also April Fools' Day and for a good portion of people it’s a day for jokes, foolishness, or harmless pranks. This is no joke, this is no prank, this is no foolish act. This is DNS Resolver, 1.1.1.1 ! Follow it at #1dot1dot1dot1