La "Entrevista"Hay muchos que aún no saben cómo montar una red Wifi. ¿Existe algún manual que en pocas palabras pueda aclararnos las dudas?Recomendaríamos el post
Seguridad en Redes Wireless. Creo que ahí están resumidos los aspectos más básicos de una red local WiFi, pero si quieres algo más completo y detallado, lo encontrarás en el libro
Redes Wireless de la editorial
RedUsers... En fin en San Google hay mucha tela por donde cortar.
Logré armar mi red local con un AP, sin embargo estos documentos solo explican cómo hacerlo con un solo dispositivo para todos mis clientes. ¿Aplica igual si necesito varios APs? ¿Cómo debo configurarlos? ¿Deben tener el mismo SSID, canal, clave y sistema de autenticación, mismo modelo de AP, o se puede ser hacer una red híbrida con varios modelos de AP de diferentes marcas y ponerle configuraciones diferentes a los APs?.Como dicen los colombianos: "Depende". Todo radica en la arquitectura que uses. Por ejemplo; si tus APs se encuentran en modo "Bridge" (Puente), conectados todos mediante un cable ethernet (con POE o alimentación directa de corriente), cada uno conectado a un switch y tu red LAN administrada por un Hotspot, router o un servidor, no recomiendo que todos tengan el mismo SSID, ya que los APs solo se diferencian por la MAC de cada uno, y los clientes comenzarán a hacer roaming (capacidad de moverse en una zona de cobertura) todo el tiempo, entre los puntos, y eventualmente puede generar una sobrecarga al AP. Esto no afecta a la seguridad (clave SSID y clave de administración).
Ese tipo de configuración (donde todo es igual), da mejores resultados cuando usas otros modos diferentes a Bridge. Más bien una red de puntos AP (también llamados "celdas"), con un grado determinado de solapamiento entre ellas, que permiten hacer el roaming y unir redes wifi con físicas.
Una ilustración gráfica del funcionamiento de los diferentes
modos de los AP puedes verla en
zero13wireless.net .
Básicamente los
modos más comunes son:
Acces Point - (Punto de Acceso, AP) Recibe la señal por cable de red (RJ45) y la distribuye en forma inalámbrica. Ej. convertir tu Internet alámbrico a inalámbrico.
AP Client - (Cliente de AP) Recibe una señal inalámbrica y lo pasa a cable de red (RJ45). Ej. Conectar a la red WiFi, alguna PC, Teléfono IP, Impresora, etc. que requieran forzosamente cable de red.
Client Bridge - (Cliente de la Unión) Recibe la señal inalámbrica de otro AP y la distribuye por cable, no permite conexión inalámbrica. Ej. Establecer una sola red entre dos edificios.
WDS Bridge - (Unión Inalámbrica) Recibe la señal inalámbrica de otro AP y la distribuye por cable o de forma inalámbrica. Ej. Establecer una sola red entre dos edificios.
Client Router - (Ruteador Cliente) Recibe la señal inalámbrica y la distribuye asignándole IP's a los clientes. Ej. Compartir Internet con otros equipos cableados.
Repeater - (Repetidor) Recibe una señal inalámbrica, la mejora y la repite. Ej. aumentar la señal inalámbrica.
WDS AP - (Wireless Distribution System AP) Igual que Acces Point.
WDS Router - (Wireless Distribution System Router) Igual que Client Router.
Hay que aclarar que el modo roaming también depende de que la tarjeta WiFi del cliente lo soporte, lo cual es más complicado, ya que si tienen una red abierta o hotspot para vender internet WiFi, con mucha gente diferente conectada, es virtualmente imposible saberlo y pueden presentarse problemas de conectividad al "saltar" de un AP a otro con el mismo SSID. También influye el canal de trasmisión, la velocidad, el cifrado y el estándar (IEEE 802.11 b, g, n, etc), si usan
SSID virtuales (que puede generar más problemas que beneficios), entre muchos otros factores.
¿Y qué sucede si les pongo diferentes parámetros de configuración a cada AP?Es más engorroso para el cliente, ya que debe conectarse a cada punto individualmente, pero mejor para la red, ya que este esquema tiene menos carga y provoca menos saturación de tráfico de los APs y en el servidor o router que administre la LAN y por consecuencia menos fallas. Claro está, siempre y cuando los APs sean de buena calidad, tengan la misma tecnología, soporten todos los clientes conectados, y viceversa (estos a su vez soporten los APs). Todo depende de las necesidades específicas del administrador.
Analicemos 3 casos:
1. Cuando los clientes, al hacer login en cada uno de los APs, memorizan el trinomio Clave WPA/BSSID/ESSID la primera vez y hacen roaming, pero no
seamless (hay pérdida de datos en el salto).
2. Si establecemos el mismo ESSID, seguridad y también BSSID en todos los APs, el cliente recibe tráfico duplicado de los dos APs y sólo necesita memorizar una vez el trinomio Clave WPA/BSSID/ESSID (ya que hay un "único BSSID"), pero el handover tampoco es seamless, ya que al cambiar de canal Wi-Fi la interfaz del cliente se cae por unos instantes y pierde datos de forma irrecuperable, por los protocolos como el TCP.
En palabras de
Seguridad Wireless: "si establecemos el mismo ESSID y seguridad en todos los APs, los clientes se dan cuenta de que no es el mismo AP (ya que ven dos MACs distintas con el mismo nombre). Algunos clientes (en dependencia de su sistema operativo y versión) muestran una o varias redes con el mismo nombre, pero no hacen roaming transparente".
3. Si establecemos el mismo ESSID, seguridad, BSSID, canal, administración, etc; o sea todos los APs parametrizados iguales, como si fuesen clonados, es el peor de los escenarios; la suma de todos los miedos; Satanás haciendo de las suyas; ya que la red se vuelve loca y todo es un caos... Y mayor es el caos si están cerca uno de otro.
Conclusión: Hay que añadir un administrador de red "inteligente" (centralizado o distribuido) que filtre a nivel MAC las tramas de cada AP, para que sólo uno de ellos responda a cada cliente (el que tenga mejor RSSI), sin embargo esto no aplica para redes públicas donde no hay filtrado MAC.... O sea;
no hay solución por el momento para el problema del roaming transparente.
¿Y si activo el modo WDS?Wireless Distribution System (WDS), dicho en palabras cristianas, sirve para unir de forma inalámbrica (como si fuera un cable Ethernet o tener conectados dos switch) dos ubicaciones diferentes en el mismo nivel (nivel 2 - bridging).
Su ventaja principal es que todas las subredes podrán comunicarse fácilmente; o sea, desde un enlace punto a punto puedo crear otro enlace similar hacia otra red y así sucesivamente. O sea; en las redes interconectadas las estaciones registradas pueden verse entre sí de forma transparente, mediante bridging. Por eso se recomienda activarla si está disponible en el AP, siempre y cuando vayas a tener más de un dispositivo tras ese enlace.
WDS se usa mucho en entornos de aplicaciones "punto-multipunto", o para repetir la señal, ya sea por baja cobertura o por obstáculos.
Tiene dos modos: Cliente WDS (que no tiene la propiedad de emisor cuando realiza un enlace y se conoce como AP Inverso; o sea recoge la señal WiFi y la envía por un cable ethernet a la red local) y AP WDS (que puede establecer varios enlaces punto a punto. Si tienes varios AP que soporten WDS, uno hace de AP WDS y el resto de Station WDS.
Entonces, la solución es comprar APs que soporten la tecnología WDSNo tan rápido. Esta tecnología tiene sus limitaciones. Si vas a usar "punto a punto" no se recomienda el uso de WDS, ya que disminuye el troughput en un 50%. En "punto a punto" es más recomendable el modo AP en el punto A y modo Cliente en el punto B.
Otra de sus limitaciones es que en algunos fabricantes (como Ubiquiti en algunos modelos) solo admite hasta 6 dispositivos interconectados. Algo similar le sucede a la tecnología
UniFi de este fabricante; es excelente, ya que tiene hotspot nativo y mucha seguridad, pero solo permite enlazar hasta 2 dispositivos a la vez, como repetidores.
Decídete. ¿es buena o es mala la tecnología WDS?El mundo WiFi no es negro ni blanco, sino gris. Si tus APs están unidos por cable a un swich, no es necesario que también los unas por WDS. Esta tecnología está diseñada principalmente para crear un
sistema wireless distribuido. La direcciones ips de los clientes las obtienen del AP principal, Router, Hotspot o servidor, que tenga el DHCP, o se asignan manualmente, y se deben elegir muy bien los canales donde van a trabajar y hacer el estudio de frecuencia. Ten presente también que el trougtput se va dividiendo a medida que se agreguen más repetidores.
Pero tus afirmaciones contradicen algo que leí en un foro especializado, y explicaban que WDS era la mejor solución al ya “espinoso asunto” de la desconexión momentánea al hacer roaming transparente entre APsMitiga bastante el problema, pero no garantiza un 100% de transparencia.
De hecho ninguna de las tecnologías actuales garantiza esto, ya que al hacer roaming se pierde la mitad del ancho de banda.
Supongo que cuando se masifiquen los nuevos estándares
IEEE 802.11r y ac, y comience a usarse la banda de los 5 Ghz, tal vez se podrá erradicar este problema de raíz y de paso
el de las interferencias; no lo sabemos con certeza, porque podemos trasladar el problema a otra banda; sin embargo, sea cual sea el futuro, estas nuevas tecnologías debe ser implementadas en los dos extremos de la conexión; o sea, tanto en los APs como en los clientes… y los fabricantes se olvidaron de ellos, al incorporar dispositivos WiFi de mala calidad en laptops, tablets y smarthphones, solo aptos para 2.4 Ghz.
WDS, WPS; a veces me confundo con tantos términos...Pues no te confundas.
WPS (Wi-Fi Protected Setup) es otra tecnología incorporada a los APs WiFi y
no recomendamos su uso, ya que es susceptible a ataques informáticos, con
Reaver-WPS,
Bully y otras técnicas. El ataque consiste en obtener el PIN secreto de la Red y reventar la llave de encriptación WEP o WPA, atacando la funcionalidad WPS. En
site40 puedes encontrar una base de datos de pines WPS. Una descripción de este ataque está en
Villacorp. Una vez dentro el atacante puede hacerse con las MACs de la red e
identificarlas según su fabricante, para determinar sus parámetros y el resto es historia.
¿Los puntos de acceso WiFi pueden ser atacados?Por supuesto. Los más comunes son denegación de servicios
DDoS, DNS Spoofing (con
WiFi Pineapple) , por inundación DHCP (
DHCP Sarvation), con herramientas como Gobbler, Yersinia, Metasploit, DHCPig, AirRaid, etc y los autoataques por AP-reset, entre muchos otros. Un procedimiento para atacar un nodo Wifi se describe en el post "
Ataque DoS".
Android tiene muchas herramientas para estos menesteres, como
WiFi Kill, entre otras.
Otra modalidad es montar puntos de acceso "Fake" (como
Karmetasploit,
Fake AP,
Gerix,
FuzzAP, AirRaid, etc), con configuraciones similares al original, pero con un
MITM para capturar los datos de los AP reales o simplemente para ofuscar redes. Los hotspot tampoco se salvan de una escalada, ya que no tienen una seguridad muy estricta, ni tampoco el nuevo y flamante estándar
Miracast.
Podemos usar un cifrado
WPA2 AES (que es el más "seguro" y consume menos memoria), sin embargo a la hora de un ataque dirigido contra un celda, estas claves no son ninguna garantía; y como el cifrado
WEP y
WPA (TKIP) han sido comprometidos, ahora la pregunta que todo el mundo se hace es: ¿cuánto tardará en caer WPA2 AES?... Es solo cuestión de tiempo;
y algunos afirman que ese día ya llegó.
Y es precisamente por esto que la seguridad de una red basada en WiFi no puede radicar exclusivamente en los APs. Debe existir al menos un
Escudo de Red que proteja el perímetro de la LAN y un segundo "muro de contención" por si es burlada; y lo mejor es, como mencioné anteriormente, una "administración inteligente", que puede ser un proxy basado en GNU/linux, hotspot, o cualquier otra solución administrable.
También podemos usar un
antiespía para evitar el monitoreo con
Pry-Fi o cualquier otra herramienta, en dependencia de la plataforma que estemos usando (Android, Linux, Windows, Mac, etc.), optimizar la zona de cobertura de nuestros AP y utilizar una red de
Honeypot virtuales (como
Honeynet) para reunir datos de los atacantes y usar sus mismas técnicas; en fin...
¿Autoataques por AP-reset? ¿Qué es eso?Supongamos que tienes un nodo inteligente que administra tu red local (servidor proxy, router o hotspot) y que vas a usar IPs clase C en la diagramación de la LAN. ¿Cuál sería la ip que le pondrías?...
Supongo que la 192.168.1.1 o la 0.1Como la mayoría. Y sabes cuál es la IP que trae por defecto la mayoría de APs? (routers, Access Points y demás dispositivos WiFi)... Salvo algunas excepciones, como los APs de Ubiquiti que usan la .20, la mayoría de los equipos WiFi utilizan la misma IP que acabas de mencionar; 192.168.0.1 o 1.1.
Lo anterior nos lleva inevitablemente a la siguiente pregunta: ¿Qué sucedería si hay un cambio de voltaje o cualquier otro evento (natural o provocado), que obligue al AP a auto-resetearse (algo que ocurre frecuentemente)
Se pierde la parametrización personalizada y todo queda "de fábrica"Y esto provoca una colisión con nuestro servidor o nodo principal, que tiene la misma IP del punto WiFi con los valores "de fábrica", y ya puedes imaginar lo que sucede. Es por eso que la dirección IP de nuestro administrador de red, jamás puede ser la misma que las que traen por defecto los APs. Es más; se recomienda dejar estas "IPs default" sin uso, para en el caso que ocurra este tipo de eventos y los APs hagan "reset" por sí mismos, no se presenten colisiones en la red local.
¿Durante la entrevista he escuchado mencionar 'estudio de frecuencias’?Antes de montar una red WiFi, lo primero (
insisto; lo primero) que hay que hacer es un análisis de la banda con la que se va a trabajar y de los canales disponibles, de acuerdo a la región donde nos encontremos. Es lo que se conoce como ‘estudio de frecuencias’. O sea, analizar, con alguna herramienta disponible, el espectro y ver los canales de transmisión de los diferentes nodos usados e ir ajustando los nuestros para que no haya solapamiento y otros tipos de interferencias.
Los artículos recomendados al principio son el punto de partida para construir una red WiFi. Ahora viene el principal y
más grande problema que aqueja a las redes WiFi: La interferencia.Las interferencias (RF) son las causantes del mal desempeño de las redes WiFi, la cobertura irregular y las caídas de las conexiones. La interferencia, que se produce durante la transmisión, también causa pérdida de paquetes, lo que obliga a las retransmisiones WiFi. Estas retransmisiones ralentizan el tráfico y ocasionan un rendimiento extremadamente fluctuante para todos los usuarios que comparten un determinado al AP.
Las herramientas de análisis de espectro, que se integran actualmente en los AP para ayudar al administrador TI a visualizar e identificar las interferencias, muchas veces son inútiles, pero a pesar de esto son imprescindibles.
La
interferencia RF se acentúa con el estándar 802.11n, ya que utiliza múltiples ondas de radio dentro de un AP para transmitir simultáneamente varios flujos de Wi-Fi en diferentes direcciones y lograr así una conectividad más rápida, lo cual no siempre sucede.
Existen muchos tipos de interferencia, como
overlapping (
solapamiento),
crosschannel, co-canal (co-channel),
Wifi Inverted, Invalid Channel y Non Standard, esta última también llamada No-Wifi; en fin, hay un centenar y todas generan pérdidas de datos y mal funcionamiento de nuestra red.
Qué es eso de "interferencias No-Wifi"?Son aquellas que no se usan normalmente en redes WiFi, pero que transmiten en frecuencias de radio similares a WiFi, como por ejemplo
Bluetooth, infrarrojo, entre otras.
¿Cómo puedo evitarlas?Son más difíciles de detectar y evitar. Hay que saber qué tipo de dispositivos electrónicos interfieren con nuestro AP. Los más comunes son, hornos microondas, teléfonos inalámbricos, marcapasos, consola Wii, equipos de ayuda para la audición, altavoces, monitores para bebés, bluetooth, cámaras ip, etc. Adicionalmente, también pueden causar interferencias las líneas y estaciones de energía, antenas, barreras físicas, como paredes y pisos, que bloquean el paso de una señal, los aires acondicionados, neveras, y un excesivo y largo etc.
Existen app, como
WiSense y
Airshark, que supuestamente pueden detectar estas interferencias no-WiFi, sin embargo son versiones en desarrollo, por tanto se desconoce su efectividad. También hay dispositivos de hardware que hacen este trabajo, pero son escasos y muy costosos.
Veo que es un problema grande el que enfrenta esta tecnología. ¿Qué han hecho los gobiernos?Las bandas WiFi (Lea
ISM/UNII) usan una parte del espectro que no requiere de licencia en casi todos los países, sin embargo algunos gobiernos, después de enormes presiones, ya han comenzado a tomar medidas para evitar esta problemática, poniendo topes a la potencia de transmisión de los equipos comerciales y multas a aquellos que violen la regulación.
Por ejemplo, la FCC (EEUU) el límite de potencia máximo es de 1 vatio (30 dBm); en Europa, es de 250 mW (24 dBm); en Colombia de 100mW (potencias superiores deben tener un permiso del Ministerio de las TIC y de la Aeronáutica, si lo van a instalar cerca de un aeropuerto; y deben pagar impuestos).
Pero no podemos sentarnos a esperar que los gobiernos solucionen el problema. Hay que tomar iniciativas.
¿Qué clase de iniciativas?Con un buen ajuste de los parámetros de nuestra red WiFi. Por ejemplo, supongamos que tenemos 4 APs distribuidos por varias zonas de nuestra empresa, edificio o escuela. Para el caso del IEEE 802.11b o 802.11g, que trabajan a 2.4GHz, y que es la banda más usada y por ende la más saturada (salvo 802.11n que hace uso simultáneo de 2,4 Ghz y 5 Ghz), los canales se separan por 5.
Si le asignas al AP1 el canal 1, el AP2 (que es el más cercano al AP1) le asignamos el canal 6. El AP3, (que está cerca del AP2, pero lejos del AP1) le asignamos el canal 1 y al AP4 (que está cerca del AP1 y AP2) le asignamos el canal 11. Con esto evitarás solapamiento de señal.
También se hace no solo con los canales 1/6/11, sino también con los 2/7/12 y 3/8/13. A esto se le conoce como ‘tripletes’.
La explicación de este comportamiento la proporciona
Blog.Gnutic: ‘Esta frecuencia (2.4) se subdivide en canales separados por 5 MHz. que van desde el 1 hasta el 14; en Europa solo se usa el rango del 1 al 13. El problema es que cada canal necesita 22MHz como mínimo de ancho de banda y provoca solapamiento con los canales adyacentes. Si dividimos 22/5 nos da como resultado 4’4 canales de ancho; esto significa que cada canal necesita 2’2 canales por cada lado de su frecuencia origen para emitir. Así pues, para evitar las interferencias al 100% deberemos tener una separación entre un canal empleado y otro de al menos 5 unidades, aunque lo cierto es que una separación entre 3 y 4 canales será suficiente y tendremos pocas interferencias’.
Lo anterior sin importar que los AP tengan o no el mismo SSID, parámetros de red, sean o no de la misma marca y modelo, etc, y asumiendo que haya pocas redes a tu alrededor. Caso contrario escoge el canal libre menos usado y asígnalo a los AP.
Entonces, es fácil. Elijo un triplete de canales que esté libre y ya tengo a punto mi red WiFiNo cantes victoria. Hay que tener en cuenta la cercanía de otras redes para asignar los canales; y en una ciudad o edificio con cientos de APs, la cosa se complica, ya que se produce lo que se conoce como interferencia
co-channel o co-canal (reutilización de frecuencias); un fenómeno que se ve mucho en el
HandoverAdemás, también influye el tipo de AP a usar, su velocidad teórica y práctica, su alcance y el de los clientes; incluso afecta hasta el nombre que le pongas al SSID (si son comas, puntos, etc), su autenticación (WPA2-PSK AES u otra); hay muchos factores en juego.
Mmmm... No me quedó muy claro.Tranquilo; existen herramientas que hacen el trabajo sucio por nosotros; desde las gratuitas hasta las más costosas. Gratis está
Netstumbler,
Vistumble,
TekWifi,
Kismet,
LinSSID (para Linux),
WiFi Auditor, y la megabatería de apps para
Android, tales como, WiFi Analyzer, Who Is On My Wifi, RF Signal Tracker, Bugtroid Pentesting, Wi-Fi Analytics Tool, Dsploit, y un largo etc. También existen distros de Linux especializadas en auditoría wireless, como Kali, WifiSlax, Backtrack, Arudius, entre otras; todas de excelente manufactura, las cuales pueden revisar los canales de tu red y de las más cercanas y realizar una buena auditoría.
Pagos tenemos a
Wi-spy de
metageek (
Chanalyzer,
Inssider),
Airview de Ubiquiti (solo se puede usar con dispositivos Ubiquiti de la serie MIMO y algunos ya lo traen incorporados) o con adaptadores usb airView2, airView2-EXT, airView9, airView9-EXT);
Cisco CleanAir (incorporada a sus AP
aironet);
Chanalyzer con CleanAir,
Cisco Spectrum Expert, entre otras; pero si tienes mucho $$$$$$, puedes comprar la super suite A
irMagnet WLAN Design & Analysis Suite de Fluke, que con su
AirMagnet WiFi Analyzer PRO, AirMagnet Spectrum XT y el tester
Air Tester podrás hacer un excelente trabajo de diagnóstico. También están los handheld, como Fluke
Aircheck,
Spectrum Analyzer Bundles,
Wilango,
Artisan, etc.
Nosotros recomendamos las mismas herramientas que uso el joven al principio de este post.
Consideramos importante resaltar que la función de las herramientas descritas es ayudar en la toma de decisiones del administrador IT, respecto a la arquitectura de la red local y demás parámetros relacionados con la red WiFi, y también proporcionar información sobre las redes WiFi adyacentes, pero estas herramientas no hacen milagros.
En un entorno sobresaturado de APs, sin canales libres, es necesario compartir canales con otras redes y hay una gran diferencia en hacerlo con una red adyacente de poco tráfico a compartirlo con una que tenga mucha demanda, ya que tendríamos problemas a la hora de emitir nuestra señal RF. Algunas de estas herramientas tienen la capacidad de analizar tráfico de redes adyacentes, pero consideramos mejor usar un
sniffer (
Acrylic WiFi,
Wireshark,
dsniff,
Capsa,
tcpdump, etc) para capturar paquetes de las redes adyacentes y así medir su tráfico real.
Ya tengo algunas herramientas mencionadas (las gratis porque no tengo $$$$), pero no se elegir el canal adecuado para mi red WiFi. Estas app me ofrecen demasiada información que no comprendo.Hay algunos principios básicos que debes saber antes de usarlas:
1. A mayor cantidad de APs, que operen en un mismo canal, más interferencia causan entre ellos; y si operan en canales diferentes, pueden causar interferencias con otras redes.
2. La velocidad de acceso de los clientes dependerá de su cercanía al AP
3. Cada AP debe tener su propia área de cobertura.
4. Hay que tener en cuenta la
zona Fresnel, que no es más que el área (de forma elíptica) que sirve de propagación a una señal RF. Para que sea de utilidad debe de mantenerse alrededor del 60% libre de obstáculos
5. Es muy importante calcular las pérdidas generadas por cable coaxial, por el espacio libre de la banda, la sensibilidad del receptor, la proporción señal ruido, etc. Para mayor información sobre este punto puedes visitar
GuateWireless6. Las bandas autorizadas para los equipos WiFi son 2.4 y 5 Ghz. La de 5 es la mejor, pero casi no se usa y son escasos los fabricantes que incluyen en los laptops, tablets, PCs y smarthphones, tarjetas WiFi que soporten trabajar con la banda 5GHz. Es por esta razón, que sin importar que tu AP trabaje en la banda de 5Ghz, es muy poco probable que puedas hacer uso de ella.
Si tienes en cuenta estos principios, podemos pasar al siguiente nivel. Primero que nada, hay que saber qué canales están disponibles en la banda 2.4 Ghz (que es la que trataremos en este post). La cantidad de canales disponibles depende de la región donde esté configurado el AP.
Canal 01: 2.412 Ghz
Canal 02: 2.417 Ghz.
Canal 03: 2.422 Ghz.
Canal 04: 2.427 Ghz.
Canal 05: 2.432 Ghz.
Canal 06: 2.437 Ghz.
Canal 07: 2.442 Ghz.
Canal 08: 2.447 Ghz.
Canal 09: 2.452 Ghz.
Canal 10: 2.457 Ghz.
Canal 11: 2.462 Ghz.
Canal 12: 2.467 Ghz.
Canal 13: 2.472 Ghz.
Canal 14: 2.484 Ghz.
Nota: Te recuerdo que los puntos en inglés dentro de cifras numéricas corresponden a la separación entre decimales y parte entera de la cifra. 2.4 Ghz=2400Mhz
Ojo: Los canales 12 al 14 no se usan en América. Así que de nada vale que los elijas. Y así el AP permita ponérselos, los clientes nunca encontrarán una red WiFi que trabaje en estos canales (salvo que fuercen el hardware, lo cual en ningún caso es recomendable ni práctico).
Al grano. Cada canal necesita un ancho de banda de 22 Mhz para transmitir la información, por lo que se produce un inevitable solapamiento de varios canales contiguos. Para evitar interferencias en presencia de varios puntos de acceso cercanos, estos deberían estar en canales no solapables (tripletes). O sea, si vas a trabajar con 802.11b o 802.11g (2.4GHz) deberías utilizar canales que estén separados 5 puestos (1/6/11, 2/7/12 y 3/8/13).
A la hora de escoger un canal se debe tener en cuenta el nivel de penetración de la radiación electromagnética, el cual es inversamente proporcional a su frecuencia (cuando la radiación electromagnética es de baja frecuencia, atraviesa limpiamente las barreras a su paso). En teoría, cuando más alta es la frecuencia hay más
atenuación (pérdida de potencia).
También hay que tener en cuenta la antena y los cables que uses, la atenuación isotópica, la recepción de la señal, el factor de ruido de fase, etc. Por ejemplo, la antena tiene que estar compensada a punto, para que la onda pueda ser de mayor potencia y así no emitir ondas resonantes que dañen o interfieran un canal cercano (más conocido como ruido o interferencia). En este caso, lo mejor es probar transmitiendo en un canal y captar esta señal lo más lejos posible, con cualquiera de los programas citados arriba, sin embargo para un diagnóstico preciso las conexiones, lo más recomendado es poner APs iguales y con las mismas antenas. De esta manera se puede saber cuál es el mejor canal en que el AP y el receptor están trabajando.
Cuando son equipos o antenas diferentes es una de las causas más frecuentes de sobrecalentamiento en los APs (en unos más que otros), ya que, si la carga de la antena no es la adecuada, la energía que no puede irradiar (ROE) es devuelta al AP y se produce el sobrecalentamiento.
¿Y si aumentamos la potencia para evitar la atenuación y la interferencia?Este es el legado que ha dejado la publicidad barata de los vendedores inescrupulosos, que engañan a los clientes diciéndoles que a mayor potencia se evita la atenuación y las interferencias. Desafortunadamente muchos administradores de red principiantes se dejan llevar por este ardid comercial y están creando el mayor caos en la historia, causando ‘interferencias deliberadas’ en la transmisión RF. Y lo peor de todo esto es que los organismos que deben regular el espectro no hacen nada para evitarlo.
Ponerle más potencia a un AP no necesariamente significa mejoras en la transmisión RF de nuestro punto WiFi, ya que puede aumentar la interferencia al
colisionar la señal con otras redes.
Supongamos que ponemos un AP en nuestro hogar para enlazar el PC, la tablet y una laptop. No tiene ningún sentido que el AP tenga un alcance de 2 Kilómetros con una antena de 15 dbi; es como matar mosquitos con un fusil de francotirador.
Aquí lo más recomendable es realizar un estudio de lo que se quiere, y colocar un AP en dependencia del área de cobertura que se pretenda atender. Y si hay otros APs transmitiendo que solapan nuestra señal y todos los canales están ocupados, podemos hacer lo contrario; bajarle la potencia a nuestro AP, incluso por debajo de los 20 Mhz; y si estas transmitiendo en 802.11n, puedes pasarte a G, ya que N transmite los paquetes en varios canales, y si alguno está saturado puedes comprometer el funcionamiento de tu equipo. Los vendedores nos engañan diciéndonos que N es más rápido, bla, bla, bla y a veces ni siquiera tenemos el ancho de banda suficiente para usar esta tecnología o el cliente que se va a conectar no es compatible con N (la mayoría de los casos).
Por tanto, para que funcione la comunicación cliente-AP, el estándar del adaptador WiFi del cliente debe ser igual o anterior al estándar del AP.
Por ejemplo, si el adaptador de red de tu PC usa 802.11n, pero tu AP usa 802.11g, no se podrá realizar una conexión, porque el estándar Wireless-G es de una versión anterior y no reconoce Wireless-N. Sin embargo, si el AP usa Wireless-N, pero el adaptador de tu PC usa Wireless-G, la conexión se podría realizar si el AP está configurado en modo mixto, ya que Wireless-N funciona con algunos de los estándares anteriores (802.11a, 802.11b y 802.11g) o con todos ellos.
Otra cosa que nunca nos dicen estos vendedores inescrupulosos es que el WiFi es un medio half-dúplex, por tanto su velocidad real es más o menos la mitad de la teórica. En otras palabras, es la mitad de lo que dice en la caja del producto.
IEEE 802.11b: hasta 11Mbps teórico/6Mbps reales
IEEE 802.11g: hasta 54Mbps teórico/25Mbps reales
IEEE 802.11n: hasta 300Mbps teórico/150Mbps reales
En conclusión, lo mejor en este caso es tener APs que soporten todos los estándares actuales y que tengan una potencia balanceada (de acuerdo a las necesidades), para evitar perder visibilidad frente a otras redes (débiles o fuertes) y así minimizar el riesgo de colisión por
estación escondida.
¿Cómo podemos evitar estas ‘interferencias deliberadas’?Mejorando la calidad de la señal, en medio de esta selva WiFi de las grandes urbes. Esta se mide como la cantidad de pérdida respecto a la fuente original (AP).
Por ejemplo, si el cliente está ubicado a pocos metros del AP WiFi, la calidad de la señal recibida posiblemente sea -25dBm, lo cual significa una pérdida muy pequeña, en cambio si está por encima de los 90 metros, muy probablemente la calidad obtenida sea de -80dBm. Un valor óptimo sería entre -75 dBm y 0 dBm (entre más cercano a 0, mejor).

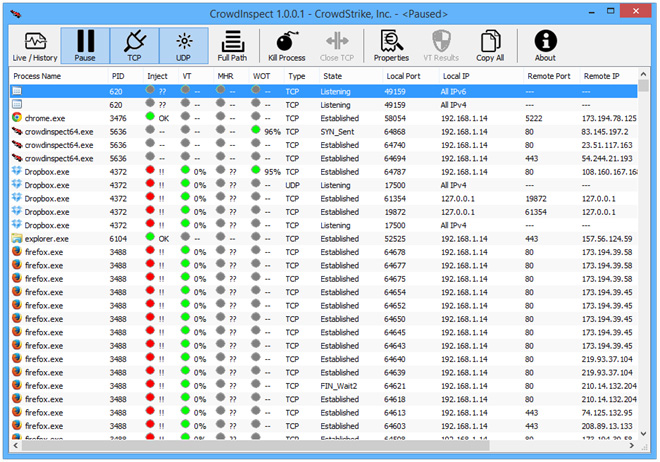
Para determinar la calidad de la señal WiFi recomendamos Inssider o WiFi Analyzer, disponibles para Windows y Android. En el siguiente ejemplo (imagen izquierda), vemos que la red de mejor calidad de señal es ‘WR1043ND-OWrt’ (con -20dBs) y la de peor calidad es ‘TRENDNET’ (con -83dBs)
Naturalmente, hay que tener en cuenta la ubicación de referencia desde la cual se realiza la prueba. En este caso, Inssider debe correr en la zona media de su red local, para que proporcione datos fiables.

Wifi Analyzer también puede realizar esta labor con una muy buena efectividad, desde una tableta o smarthphone con Android. Sin embargo, sea cual sea la herramienta que use, tenga presente que depende del cliente que la está ejecutando, de su hardware y del adaptador de red. Es por eso que se recomienda adquirir un adaptador de red de buena calidad, o especializado para realizar estas pruebas.
Hace poco mencionaste el "ancho del canal". ¿Cómo funciona?El Channel Width (ancho del canal) es de
22 o 40 mhz (20Mhz, 10Mhz, 5Mhz y 40Mhz). A mayor ancho de canal, más velocidad teórica puedes llegar a obtener, pero también más interferencias de los canales contiguos y en dependencia de esto, es que se hace la selección de canales para operar. Las señales wifi se emiten por defecto en canales de 20 Mhz (aunque algunos AP ya vienen configurados para trabajar con 40 Mhz).
Los equipos Wifi N tienen doble antena y pueden emitir por una antena usando un canal, dando como resultado un ancho de banda de 150 Mbps o por 2 antenas usando un canal por cada una de ellas, dando como resultado un ancho de banda de 300 Mbps. Es por eso que en algunos analizadores de banda, como Inssider, vemos una red N que marca, por ejemplo, algo como 13 + 9. Esto significa que transmite en dos canales a la vez (doble ancho de canal). N trabaja con 40 Mhz (se utilizan las 2 antenas) en cambio los inferiores trabajan con 20 Mhz (una antena).
Usar doble de ancho de banda tiene el inconveniente es que la red será más sensible a interferencias con otras redes cercanas. Un excelente documento técnico que lo explica es el de
connect802.com. Sin embargo los 40Mhz no son recomendables en ningún caso, como bien lo explica
redeszone, ya que pueden generar mayor interferencia.
De acuerdo al
foro.elhacker.net, bajándole a la potencia de transmisión al AP se pueden realizar enlaces sin antena o con un cable, sobre todo si tu router está cerca del ordenador. Si tu antena a una frecuencia determinada coincide con un múltiplo impar de 1/4 de longitud de onda, entonces la antena estaría en resonancia y trasmitiría bien.
Por ejemplo; cada canal está separado por 5Mhz para evitar que un AP que transmita en el canal 5 no se solape en el canal 6, tu AP puede modificar la frecuencia de separación entre estos canales. Si le pones a tu AP un channel width de 40 Mhz estaría transmitiendo en 8 canales al mismo tiempo, siendo la máxima potencia transmitida en el centro de la banda (en el canal que hayas puesto el AP).
Todos los AP tienen su máxima potencia de transmisión en el canal 6, ya que es el centro de banda de la señal wifi y las antenas son calculadas para esta frecuencia. Lo malo de utilizar el canal 6 es que es muy usado y por lo tanto está saturado de señales (co-channel)
Es por esto que lo primero que debemos hacer al adquirir un AP es estresarlo al máximo para determinar si cumple o no con la transmisión y desempeño deseado, así como evaluar la calidad del enlace Cliente-AP.
¿WiFi estresado?En el campo profesional,
Wifi Stress o "estresar un punto WiFi" son una serie de pruebas, realizadas por profesionales, a las cuales se somete un AP, para determinar las cargas de trabajo, tráfico, conexiones y otras mediciones, que son ejecutadas en tiempo real y medidas con un analizador de espectro, con el objetivo de evaluar el rendimiento y otros parámetros del AP, para mejorar la calidad de la conexión cliente-AP...
Aunque a veces también se le llama "WiFi estresado”, cuando se congestiona un nodo producto del tráfico en exceso o de interferencias, causando mal funcionamiento.
Si quieres conocer los mitos y verdades sobre el WiFi Stress, recomendamos los posts
informationWeek y
Stress Electromagnético... (O los mitos de las interferencias WiFi, en general, según
Cisco.)
¿Y cómo podemos evaluar esta "calidad del enlace cliente-AP", sin hacer estas rigurosas pruebas?La manera sencilla es con tu mismo AP, siempre que disponga de CCQ.
¿CQQ?CQQ de transmisión (Transmit CCQ) es un índice de cómo se evalúa la calidad de la conexión del cliente inalámbrico. Tiene en consideración el conteo de errores de transmisión, latencia, y rendimiento, mientras evalúa la tasa de paquetes correctamente transmitidos en relación con los que deben ser retransmitidos, y también tiene en cuenta la actual tasa en relación con la mayor tasa especificada. El nivel está basado en un porcentaje donde 100% corresponde a un enlace perfecto.
Si hay deterioro en el enlace (CCQ bajos) se debe verificar la calidad de la conexión, o sea, la latencia con relación a los usuarios conectados. Y a no ser que todos los clientes usen el mismo sistema operativo, hardware y adaptador de red (algo improbable), los parámetros a modificar cambiarán de acuerdo a cada cliente en específico. Por ejemplo: Cuando los CCQ están bajos es porque la latencia es alta, así como las caídas de comunicación.
Hay que tener en cuenta a la hora de la parametrización los factores que intervienen en el proceso de enlace, tales como la distancia AP-Cliente, y las variables naturales del entorno las cuales inciden directamente en la estabilidad y calidad del enlace.
Otro aspecto es lo que se conoce como Noise Floor y Transmit CCQ. Mientras más estrecho sea el canal más sensible será. Por ejemplo, a 1mbps se maneja una sensibilidad de -97dbm y en 54mbps se maneja -74dbm. Si se encuentra cercano a -100 es mejor.
Otros parámetros a considerar son: Pausa ACK (ACK Timeout); Concatenado de Tx/Rx(TX/RX Chains); Tasa de Tx y Rx (TX Rate and RX Rate), que muestra la tasa actual de transmisión 802.11 mientras opera en modo Estación.
¿Y cómo mejoro el enlace?
Lo primero es hacer el mapeo de la zona en la cual se pretende trasmitir la señal inalámbrica, es decir, verificar si la geografía (accidentalidad del terreno) permite irradiar en 360 grados por igual. Si existen colinas, saturación o si la zona es plana. El resultado de este estudio determinará el tipo de antenas a usar en los AP (omnidireccionales o sectoriales).
Luego se debe determinar la distancia a la cual se pretende llegar (cobertura). En este punto hay que tener en cuenta la distancia real y no la teórica. La gran realidad es que así el fabricante del AP diga que tiene un alcance de 30 kms, asuma que es falso y mida usted mismo la distancia de cobertura real. Lo máximo efectivo en AP comerciales a la fecha es de 3 kms en vista directa sin obstáculos. Existen APs con mayor cobertura, pero los precios son estratosféricos.
Si lo que se pretende es armar una red local, empresarial, de una entidad educativa o un punto de acceso público, no podemos contar con distancias largas, así el AP indique que puede hacerlo
Esto nos lleva al punto más importante: La elección del AP. Deberá ser un equipo que soporte todos los estándares actuales y que tenga una antena con la ganancia adecuada para brindar la cobertura deseada; ni más ni menos.
Y lo más importante (y que nadie le da importancia): Un buen microprocesador, suficiente memoria y una buena sensibilidad. Los parámetros técnicos más relevantes son Ptx (potencia del AP), Line loss (pérdida de la señal, que casi siempre es de 1dbm) y Ga (Ganancia de la antena). O el resultante PIRE.
Para calcular estos parámetros, pongamos un ejemplo. Supongamos que tenemos una antena de 17 dbi. Convertimos dbi a db restándole 2.14, que daría como resultado 14.86db o dbm (db cuantitativamente son casi lo mismo que los dbm). Y si la pérdida es de 1 dbm entonces, Ptx-1dbm+14.86dbm<=36dbm
Esto daría como resultado final un Ptx=22.14 dbm. Lo que significa que si vamos a usar una antena de 17 dbi, tan solo necesitamos comprar un AP que tenga una potencia menor o igual a 22.14dbm (aproximadamente 163mw).
Para convertir de mw a dbm: (X) mw=10log(X)db (Logaritmo base 10). Para el caso anterior, 22.14=10*log(x) => 2.214=log(X) => X=10^2.214 => X= 163mw.
Tabla de conversión decibelios (ganancia) a vatios (potencia)Se utiliza la unidad dBm (decibelios relativos al nivel de referencia de 1 milivatio). 1 mW es igual a 0 dBm y cada vez que se doblan los milivatios, se suma 3 a los decibelios.
Por ejemplo, una antena de 12 dbi de potencia, irradiará aproximadamente unos 250 a 3500 mts. Una de 14 dbi, tendrá una cobertura aproximada de 800mts a 1km; de 16dbi/1 a 1.5km; de 17 llegara hasta los 1.5 o 2 km y una de 19dbi llegara hasta 2.5km.
Existen antenas con ganancias superiores a 21dbi, pero no se usan comercialmente y no son para realizar enlaces punto-multipunto, sino para Ad-hoc/punto a punto (antenas grilla o parabólicas), entre otros usos.
En conclusión, lo más importante que debemos aprender es que lo primero que debemos tener en cuenta a la hora de comprar un AP para nuestra red es la relación ganancia de la antena vs potencia del AP, priorizando siempre la ganancia sobre la potencia. Esto es válido también para el cliente.
O sea, que a fin de cuentas, puedo comprar un AP barato, y le pongo unas superantenas de alta calidad y funcionaría de maravilla... ¿Es correcto?Sí, pero ahora no salgas corriendo directo al basurero y recojas un AP de 5 dólares y le pongas unas antenas de 20dbi. Debes adquirir un AP que soporte todas las tecnologías actuales, con las características de manufactura que se han indicado y ponerle unas antenas acordes a la cobertura que pretendes brindar (ni más, ni menos)
Cuando explicabas cómo mejorar el enlace, mencionaste "a no ser que los clientes usen el mismo sistema operativo". ¿Qué relación tiene esto con las interferencias WiFi?No influye directamente, pero es determinante a la hora de establecer las conexiones cliente-AP. Los sistemas operativos, cada uno carga con su propia cruz. Muchos recordamos el caso del problema con
Wireless Zero Configuration (Configuración Inalámbrica Rápida) en Windows XP, que tantos dolores de cabeza nos dio, y la
vulnerabilidad APIPA con los sistemas Windows actuales (que también afecta a Linux).
También está el problema de los drivers de las placas de red, que muchas veces son defectuosos o el usuario instala "drivers forzados", cuando hace
downgrade de una versión de Windows a otra anterior.
Y si le sumamos que muchos terminales no cuentan con una debida protección, ni tampoco los nodos, o sea, no hay un
Control de Acceso a la Red (NAC), el escenario puede ser caótico. Todo esto afecta las conexiones cliente-AP.
¿Algunos consejos finales para los lectores?Hay algunas
pautas, que se pueden tener en cuenta para tener una red wifi en condiciones lo más ideales posibles para una mejor operatividad, como por ejemplo las que sugiere
RedesZone, que son muy válidas:
1. Instalar el AP en lugar idóneo, preferentemente en un sitio elevado, lejos del suelo, ventanas o muros gruesos, siempre al aire libre y evitar los objetos a su alrededor, en especial los metálicos.
2. Elegir el canal más adecuado de acuerdo a un estudio previo de frecuencia
3. Determinar la cantidad de dispositivos que trabajarán en el mismo canal para evitar interferencias y sobrecarga innecesaria
3. Si va a trabajar en una frecuencia compartida (canal compartido o co-channel), revise la potencia de su equipo y de los que se encuentran en el mismo radio. Si observa lentitud o cortes con un buen nivel de señal, es muy posible que la saturación del canal de trabajo sea el problema.
4. Revise si hay dispositivos no-wifi en el radio de su AP que vampiricen la señal. La saturación también puede ser ocasionada por estos dispositivos, que no son detectados por las herramientas descritas en este post. Aquí lo más recomendable es alejar lo más posible estos equipos de la fuente de transmisión y verificar los canales por donde transmiten y evitarlos.
5. Elija siempre el canal menos saturado. Tenga en cuenta tanto el número del canal (rango de frecuencia a la que se trabaja), como intensidad de la señal de ese dispositivo. Tenga presente que algunos equipos Wifi, tienen la capacidad de cambiar de canal de forma automática, si se encuentran con canales saturados, por tanto la información sobre canales es dinámica, y puede cambiar al añadirse nuevos equipos Wifi en nuestra zona de influencia o por cambios de canal de trabajo de los existentes (manuales o automáticos) o de los vecinos. Es por eso que los administradores IT deben monitorizar constantemente las redes WiFi y analizar el espectro para responder ante estos cambios imprevistos.
6. Los canales siembre comparten su frecuencia con los contiguos, por tanto seleccione el canal más distante al canal origen del problema.
7. La señal inalámbrica es esférica, se expande por el aire, reduciéndose a medida que aumenta la distancia o se encuentran obstáculos. Así, lo importante es encontrar el centro de gravedad de la casa o establecimiento para situar el AP, tal y como lo haríamos con un radio o un equipo de sonido que queramos escuchar en toda la casa.
9. Cuando hay muchos objetos o interferencias en la casa, podemos probar con una antena de router direccional en lugar de multidireccional. Esto permite orientar mejor la señal para aprovechar la conexión.
10. Usa repetidores para aumentar el radio de cobertura, pero verifica que la potencia no sea causa de interferencia con tu red o con redes cercanas.
11. Si vas a usar varios APs dentro de una misma red local WiFi, que sean del mismo fabricante, modelo, firmware, y configuración. Manténgalo actualizado.
13. Ojo con el estándar a usar. La mayoría de los APs actuales permite operar con 802.11g, b, n, etc. La tarjeta inalámbrica del cliente debe funcionar con el mismo estándar y en lo posible el mismo canal del AP.
14. Si tiene clientes fijos dentro de su red, puede fijar el canal de trabajo de sus adaptadores WiFi para una mejor interacción con el AP. En Linux abre una ventana de terminal, escribe ‘ifconfig’ y comprueba cómo se llama tu interfaz inalámbrica; probablemente wlan0 o wlan1. Toma nota de su nombre. Luego escriba ‘iwconfig wlan0 channel #’ donde wlan0 es el nombre de tu interfaz y # es el número del canal al cual te deseas cambiar. Después de ejecutar ese comando, el canal se establecerá en el nuevo número de tu elección.
15. Y nosotros añadimos que tengan en cuenta los parámetros técnicos del AP y la ganancia de la antena vs potencia del AP, descritos anteriormente, y que utilicen, en lugar de sistemas distribuidos tradicionales, tramas híbridas terrestres para enlazar sus puntos WiFi y ampliar la cobertura, con medios de transmisión alternativos, como el
PLC, y así minimizar el impacto negativo de las interferencias RF; o utilizar técnicas avanzadas de
Radio Cognitiva (como el nuevo estándar
802.22), pero esto será tema de otra entrevista.

































































 ¿Cuántos decimales de pi son necesarios para realizar cálculos prácticos? Aunque los decimales del redondo número son infinitos no hace falta conocer muchos de ellos para usar la constante matemática de forma práctica: la NASA se conforma con 15 o 16 para los cálculos de sus sondas espaciales; el Instituo Nacional de Estándares y Tecnología (NIST) encuentra suficientes unos 32 decimales para comprobar los cálculos de los ordenadores. Y para calcular el diámetro de la Tierra con una precisión de un milímetro bastarían tan solo 10 decimales, para el tamaño del universo completo dicen que
¿Cuántos decimales de pi son necesarios para realizar cálculos prácticos? Aunque los decimales del redondo número son infinitos no hace falta conocer muchos de ellos para usar la constante matemática de forma práctica: la NASA se conforma con 15 o 16 para los cálculos de sus sondas espaciales; el Instituo Nacional de Estándares y Tecnología (NIST) encuentra suficientes unos 32 decimales para comprobar los cálculos de los ordenadores. Y para calcular el diámetro de la Tierra con una precisión de un milímetro bastarían tan solo 10 decimales, para el tamaño del universo completo dicen que