Cette vidéo montre des petites machines qui font tourner des boucles de ficelles de façon à jouer avec leur inertie pour donner l’impression qu’elles flottent sur place en l’air quelque soit la façon dont on les perturbes.
We've made some pretty big steps in our transition to a secure web but one thing that I often get asked about is closing port 80 as part of that transition. Here are my thoughts on why we shouldn't do that.
Our current efforts
As an industry we've made some truly remarkable progress in moving towards an encrypted web. I recently detailed a whole bunch of reasons that you'd want to move to HTTPS that didn't have anything to do with the actual security or privacy benefits. You can read those in my article Still think you don't need HTTPS?. These reasons along with many others are giving sites the motivation to move to HTTPS by incentivising adoption. That's one side of the effort, getting people to want to use HTTPS, and the other side is reducing the barriers to entry. That's where Let's Encrypt came in, the free CA issuing certificates to anyone that wants them. Free certs removed the cost barrier and their automated tooling has greatly reduced the technical and maintenance overheads of HTTPS deployments. I have a blog on Getting started with Let's Encrypt! and if you want to make the transition yourself you should check it out. It's all good and well saying these things are actually helping but what we need is evidence to back up the claim.
Our progress so far
I recently published research that showed not only is the adoption of HTTPS continuing, the rate at which we're moving to HTTPS is actually increasing quite rapidly too. You can see the research here but the key point was this graph showing the use of HTTPS in the top 1 million sites on the web.
But you don't have to take my word for it, there is plenty of other evidence that backs up this claim. Mozilla telemetry has shown that we've finally tipped the scale with how many page loads take place over HTTP vs HTTPS. In Firefox browser more than 50% of page loads now take place over HTTPS!
Yesterday, for the first time, @Mozilla telemetry shows more than 50% of page loads were encrypted with HTTPS. pic.twitter.com/kADcLOLsQ7
For me, to finalise any deployment of HTTPS there are 2 things you need to do. First, you need to be using HSTS, a HTTP response header that tells the browser your site only expects to use HTTPS from now on, removing the HTTP default. Using HSTS removes this insecure default and also mitigates a particularly nasty attack that's possible as a result of it. The second thing is HSTS Preloading which comes after you've setup and tested HSTS. This allows you to have your domain actually written into the source code of all mainstream browsers as HTTPS only, providing an additional layer of protection over HSTS alone. If you want a quick reference for more infomation on everything HSTS related, make note of my HSTS Cheat Sheet. HSTS and preloading are both great but I think this is where the idea of closing port 80 starts to come into play.
Do we need port 80?
The suggestion is usually that once a site is using HSTS the browser knows to default to HTTPS going forwards. Especially with preloading, when the site is hard coded into the browser, it seems like having port 80 open is redundant and simply offering communications on what will no doubt be an insecure protocol, HTTP. The problem is that closing port 80 would leave us worse off in several ways.
We would lose redirects
One of the main reasons to keep port 80 open is to continue to redirect traffic from HTTP to HTTPS. Even with HSTS and preloading there are still several reasons we can't rely on them. To start with, the browser on the other end might not implement the preload list, this means they will still default to HTTP on port 80 and miss out on a redirect. We can't even be sure that what's on the other end is a browser, is modern or up to date. It could have an older version of the preload list that doesn't include your domain. We have to keep port 80 open to redirect any traffic that might attempt to connect there first, for whatever reason that might be.
It doesn't make us more secure
Another reason that is often mentioned is that if we close port 80 then no communications can happen over the insecure HTTP protocol and no Man in The Middle attacks can take place as a result. Unfortunately, this just isn't the case. If we close port 80 it doesn't stop the client trying to make their initial connection there and this is where the problem lies. Whether or not we as the host have port 80 open, an attacker can still impersonate us and answer the initial query from the client, which never even needs to reach us. Now, keeping port 80 open doesn't directly solve this, but, if we can catch the client on a previous request and redirect them to port 443 with HTTPS and get a HSTS policy over, we can avoid them using port 80 again in the future. At worst they would hopefully cache the 301 from HTTP to HTTPS for some time and at least get some additional protection.
Browsers still default to HTTP on port 80
This is the big one really. Until browsers change their default behaviour of using HTTP as the default protocol there is little we can, or should, do in terms of closing port 80. Both Firefox and Chrome have shown that HTTPS is fast becoming the default protocol on most page loads, but I fear that doesn't mean we're as close to HTTPS by default as I'd like us to be. Sites like social media, shopping and banking probably make up a huge amount of page loads compared to other categories of sites and I imagine they are skewing the results by quite some amount. We definitely aren't close to having 50% of websites out there using HTTPS. Until the majority of sites would benefit from having HTTPS as the default protocol and a fallback to HTTP for the others, we won't see a move to HTTPS by default.
Keep 80 open
For the foreseeable future the best course of action is to keep port 80 open, respond with 301 redirects to move traffic to HTTPS, serve a strong HSTS policy and HSTS preload your domain. In the current situation this is the best we can do until something changes.
How would you feel if you asked someone at the store where an item was and they just stood there? You would probably get frustrated and move on. Users find themselves in this situation when same they see a spinner on their screen for a long time.
Spinners Are Not For Long Processes
Spinners don’t tell users how long the process will take to load. If you use it for long processes, they’ll end up wondering if something went wrong with the app. The lack of feedback creates uncertainty which makes users assume the worst.
They’ll assume that it’ll take a long time to load which discourages them from waiting. Impatience will set in and they may hit the back button or exit out of the app.
4-Second Rule
If you want users to stay on your app, don’t use spinners for processes that take longer than 4 seconds to load. A research study has found that most users’ tolerable wait time is 4 seconds. This means that their behavioral intentions begin to change after 4 seconds.
When to Display a Spinner
Users expect an app’s response time to be immediate. An immediate response time is less than 1 second. If they don’t get any visual feedback after a second, they start to worry.
If you have a process that takes longer than a second, you should display a spinner. This lets users know that the app is loading which will ease their worries.
Progress Bars Make Long Processes Tolerable
If a process takes longer than 4 seconds to load, you should use a progress bar. Users are more willing to tolerate a long wait time if they see a progress bar.
This is because it sets a clear expectation of the load time. The linear bar allows them to see that progress is being made which encourages them to wait. If they see a spinner, they can’t see any progress and don’t know if their action even processed. This gives them no incentive to wait.
How to Display a Progress Bar
A progress bar needs to show users how much progress is being made. Your bar should animate from left to right at a gradual and consistent pace. If the animation pauses for too long, users will think it’s stuck and won’t want to wait.
You should also add a numeric estimation to your progress bar. If the process is under a minute, display the percent done or number of items loaded. Inform them what activity the app is doing as it loads.
If it’s over a minute, you should give them an estimated time remaining. This lets them know that they can expect a longer than usual wait time. Displaying the number of minutes allows them to leave and come back to their screen.
Don’t Go Spinner Crazy
Many designers have a habit of using spinners for all their processes. But when you use spinners for long processes, you create user frustration. Avoid this by using progress bars when needed.
Progress bars make longer processes tolerable. Users don’t mind waiting if they know the app is doing work for them. But if it’s taking longer than expected, they need visual feedback. Not knowing what they’re waiting for makes them impatient and leave.
Cela fait bientôt 9 mois que j'ai publié mon script pour installer facilement un serveur OpenVPN, et j'ai depuis fais beaucoup de changements, notamment ces derniers jours comme le montre ce petit graphique :
Du coup, j'ai réécris en partie l'article original, mais je vais m'expliquer un peu plus en détail ici.
Un utilisateur m'avais demandé s'il était possible d'ajouter le support de Arch Linux, et en parallèle l'a aussi demandé à Nyr, puisque je le rappelle mon script en est un fork. Nyr ne veut pas supporter Arch Linux, puisqu'il dit qu'il y a peu d'utilisateurs. C'est faux sur desktop, mais vrai sur serveur, il y a vraiment très très peu de gens qui l'utilisent. HLFH, l'utilisateur en question, dit qu'il verra alors pour ajouter le support de Arch Linux sur mon script.
Et là, paf pif pof, la bombe explose, Nyr lâche toute sa haine contre moi :
I strongly suggest you to stay away from the @Angristan fork: it is buggy, insecure and badly maintained. He's putting users at risk and he either can't or don't want to see it. I'm honestly ashamed that my work has been vandalized like that by someone who claims to have "improved" it.
Les mots sont un peu durs, non ?
Peu importe, j'ai envie de vous dire, comme pour tout autre chose, tout autre critique constructive est la bienvenue, je demande donc à Nyr de développer un peu plus sa pensée. Ce qu'il a fait, et je l'en remercie puisque ça m'a permis de corriger de grosses erreurs que j'avais commises.
C'est mieux que rien, on va dire, puisque Nyr a ensuite continué de me dénigrer moi et mon travail. Des fois, on ferait mieux de pas trop se venter :
That's wrong, I obviously want my script to deploy a secure configuration. And it does.
[...]
Then, read the goddamn OpenVPN manual which either you haven't read or you haven't understood
On lui dit ou pas, que même la documentation de OpenVPN dis que ses paramètres par défaut sont vulnérables ?
Nyr a fait un super travail avec ce script, mais faut peut être pas se prendre pour un dieu dès que l'on a 3000 étoiles sur Github.
Bref.
J'ai pris en compte ses critiques, j'ai créé un nouveau dépôt (pour que mon travail immonde ne soit plus qu'un simple fork) et j'ai bien travaillé sur le script comme vous pouvez le voir sur l'historique des commits. Mon script n'a plus grand chose de l'original. ;)
Merci à TheKinrar qui a proposé une pull request pour ajouter le support d'Arch Linux, qui est, après plusieurs tests, bien fonctionnel ! On peut encore améliorer certaines choses, comme par exemple utiliser un service systemd pour les règles iptables au reboot au lieu d'un script rc.local qu'on doit installer manuellement.
Et surtout le plus gros commit, qui m'a demandé pas mal de travail c'est The crypto update 🔐. J'ai supprimé les modes "fast" et "slow" qui vous disent peut-être quelques chose si vous connaissiez déjà le script, et à la place j'ai mis certains paramètres par défaut, et pour d'autres comme la taillé de clé RSA, DH, ou encore la cipher, j'ai laissé le choix. Et grâce à Nyr j'ai bien corrigé la confusion qu'il y avait entre la cipher de la control channel et la data channel.
Le commit dont je suis vraiment fier c'est The crypto update 🔐, mais pour le Readme. En effet j'ai réécrit un peu le tout pour que ce soit plus propre, mais surtout pour justifier tous mes choix sur le chiffrement.
Je ne suis pas un cryto-noob, ni un crypto-expert, mais le chiffrement ne m'est pas inconnu comme vous pouvez le voir avec cet article sur HTTPS.
Ainsi, dans toute la partie #encryption, j'expose un à un les différents paramètres et algorithmes utilisés, ce que OpenVPN (et donc Nyr, hum) utilise par défaut, les différentes vulnérabilités qui existent, et ce que j'a choisi d'utiliser.
Sa lecture n'est pas forcément destiné à tout le monde, mais ça m'a demandé plusieurs heures de boulot.
À peu près tout ce que j'ai dit est justifié par des sources et donc je peux désormais clamer haut et fort : oui, mon script est une amélioration du script de Nyr, et oui OpenVPN utilise des paramètres dangereux par défaut pour le chiffrement.
N'hésitez pas cependant, à m'insulter dans les commentaires pour me corriger si jamais vous doutez de ce que j'ai affirmé dans ce long readme. Plus de 2000 mots quand même, c'est presque un mini-audit de OpenVPN :P
Bref, moi ce que je veux surtout c'est avoir un script propre qui fonctionne bien et qui installe un serveur OpenVPN sécurisé en quelques minutes. Comme toujours il faut bien avoir en tête son modèle de menace, utiliser un VPN pour échapper à la NSA, c'est pas la meilleure solution, mais ça peut embêter Cazeneuve :lol:
https://twitter.com/benjaltf4_/status/805507565065039880
J'ai encore pas mal d'autres idées d'amélioration en tête, donc n'oubliez pas de check de temps en temps si vous utilisez le script. :)
The weather is unpredictable here on the North coast of Poland where I live, especially around this time of year. On those infrequent occasions when I do leave my apartment (I work from home), I’m never sure how warmly I should dress or how careful I should be on the road — cold-snaps are increasingly frequent.
I spend most of my day staring at my terminal, so that’s where I’d like to keep all of the information I care about. My Tmux status bar currently contains my laptop’s remaining battery life, the current time and date, and now the local weather. Here’s how that looks:
We’re Not In Kansas Anymore
The first thing we need to do is find our approximate geographical coordinates. I say approximate because I’m not willing to pay money for a high level of accuracy. Kinda-sorta where I live is good enough. Curiously enough, Google’s geolocation API seemed to be broken for me and — after some research — many other people.
I found a free service called IP-API. As the name suggests, it returns your location based on your IP address. The service allows up to 150 requests per minute which is plenty for our needs — we won’t be making requests more than once per second.
Running the following command gives us a collection of values about our geographical data, separated by commas:
Using the cut command, we can split the comma-separated values on those commas, and the -f flag allows us to choose which field we’re interested in. For my script, I’m pulling fields six, eight, and nine to grab the city, latitude, and longitude values respectively.
You’ll notice I’m being careful to wrap each of those $LOCATION variables in double-quotes to prevent word-splitting. If you start writing more Bash scripts (and you should), this should become a habit.
If you don’t move around much, you can skip the geolocation step and just hard-code your geographical coordinates. I do travel quite frequently, so I want the weather in my status bar to reflect the weather outside.
Show Me The Data
Now that we have our location, we need to ask another service for our weather data. There are a number of services online that provide an API for querying weather data, but again, I am not willing to pay actual money for this; it’s just for fun.
I found a service for querying weather data called OpenWeatherMap. You’ll need to register an account with them to obtain an API key, but they allow up to 60 requests per minute which again is enough for our needs.
If we send a request to OpenWeatherMap with our geographical coordinates and our API key, the service returns a big lump of JSON full of the data you need. Parsing this JSON string is too hairy a task for any native UNIX tools, but you can use your favourite package manager to install a JSON parser called jq. Accessing fields with jq is syntactically the same as looking up array indexes and object properties in JavaScript.
I only care about whole numbers for temperature and wind speed, so I’m using cut and awk to truncate and round those values respectively. I truncate the temperature instead of rounding it because I am originally from London, which means I have pessimism as a hereditary trait.
The weather_icon function simply maps weather category IDs to some emoji. You’ll see it in the full script below. You’ll notice too that I’m asking for the data in metric units. You can switch that to imperial if you’re so inclined.
Get In My Status If You Want To Live
The last step is to save the script somewhere appropriate — for me it’s under ~/.bin/weather — and then run a chmod u+x ~/.bin/weather to make the script executable. The weather script can now be called from your Tmux configuration.
When I open up my ~/.tmux.conf file, I have these lines:
set -g status-right-length 50
set -g status-right '#[fg=green][#[default]#($HOME/.bin/weather)#[fg=green]] #[fg=green][#[fg=blue]%Y-%m-%d #[fg=white]%H:%M#[default]#[fg=green]] #[fg=green][#($HOME/.bin/battery)#[fg=green]]'
set -g status-interval 1
The first line sets the available length for the right-side of my status bar. I’m not sure what the default length is, but it isn’t long enough to display everything I want without truncating. The second line is my literal status line. I use a combination of colours, whitespace and punctuation to separate the different parts of my status line. The third line tells Tmux that I want to update my status line every second, which is important for telling accurate time.
And that’s all there is to it! For completeness, here’s the entire weather script:
#!/bin/bash
#
# Weather
# =======
#
# By Jezen Thomas <[email protected]>
#
# This script sends a couple of requests over the network to retrieve
# approximate location data, and the current weather for that location. This is
# useful if for example you want to display the current weather in your tmux
# status bar.
# There are three things you will need to do before using this script.
#
# 1. Install jq with your package manager of choice (homebrew, apt-get, etc.)
# 2. Sign up for a free account with OpenWeatherMap to grab your API key
# 3. Add your OpenWeatherMap API key where it says API_KEY
# OPENWEATHERMAP API KEY (place yours here)
API_KEY="<redacted>"
set -e
# Not all icons for weather symbols have been added yet. If the weather
# category is not matched in this case statement, the command output will
# include the category ID. You can add the appropriate emoji as you go along.
#
# Weather data reference: http://openweathermap.org/weather-conditions
weather_icon() {
case $1 in
500) echo 🌦
;;
800) echo ☀️
;;
801) echo 🌤
;;
803) echo ⛅️
;;
804) echo ☁️
;;
*) echo "$1"
esac
}
LOCATION=$(curl --silent http://ip-api.com/csv)
CITY=$(echo "$LOCATION" | cut -d , -f 6)
LAT=$(echo "$LOCATION" | cut -d , -f 8)
LON=$(echo "$LOCATION" | cut -d , -f 9)
WEATHER=$(curl --silent http://api.openweathermap.org/data/2.5/weather\?lat="$LAT"\&lon="$LON"\&APPID="$API_KEY"\&units=metric)
CATEGORY=$(echo "$WEATHER" | jq .weather[0].id)
TEMP="$(echo "$WEATHER" | jq .main.temp | cut -d . -f 1)°C"
WIND_SPEED="$(echo "$WEATHER" | jq .wind.speed | awk '{print int($1+0.5)}')ms"
ICON=$(weather_icon "$CATEGORY")
printf "%s" "$CITY:$ICON $TEMP, $WIND_SPEED"
n.b. I realise I could just stand on my balcony to see what the weather is like, but what kind of nerd would I be if I didn’t script it somehow?!
Whether you're a software developer or a sysadmin, I bet you're using SSH keys.
Pushing your commits to Github or managing your Unix systems, it's best practice to do this over SSH with public key authentication rather than passwords.
However, as time flies, many of you are using older keys and not aware of the need to generate fresh ones to protect your privates much better.
In this post I'll demonstrate how to transition to an Ed25519 key smoothly, why you would want this and show some tips and tricks on the way there.
Tl;dr: Generate your new key with ssh-keygen -o -a 100 -t ed25519, specify a strong passphrase and read further if you need a smooth transition.
I'm planning to publish some more posts on SSH tips & tricks, so keep an eye on my blog for more.
This post will focus on about SSH keys as user public key authentication.
If you've created your key more than about four years ago with the default options it's probably insecure (RSA < 2048 bits).
Even worse, I've seen tweeps, colleagues and friends still using DSA keys (ssh-dss in OpenSSH format) recently.
That's a key type similar to RSA, but limited to 1024 bits size and therefore recommended against for a long time.
It's plainly insecure and refused for valid reasons in recent OpenSSH versions (see also the changelog for 7.0).
The sad thing about it is that I see posts on how to re-enable DSA key support rather than moving to a more secure type of key.
Really, it's unwise to follow instructions to change the configuration for PubkeyAcceptedKeyTypes or HostKeyAlgorithms (host keys are for a later post).
Instead, upgrade your keys!
Compare DSA with the technology of locks using keys like this one.
You wouldn't want this type of key to unlock your front door, right?
You're probably thinking… "I'm using my key for a long time, I don't want to change them everywhere now."
Valid point, but you don't have to! It's good to know you can have multiple keys on your system and your SSH client will pick the right one for the right system automatically.
It's part of the SSH protocol that it can offer multiple keys and the server picks the one your client will have to prove it has possession of the private key by a challenge.
See it in action adding some verbosity to the SSH connect command (-vvv).
Also if you're using an SSH agent you can load multiple keys and it will discover them all.
Easy as that.
Most common is the RSA type of key, also known as ssh-rsa with SSH.
It's very compatible, but also slow and potentially insecure if created with a small amount of bits (< 2048).
We just learned that your SSH client can handle multiple keys, so enable yourself with the newest faster elliptic curve cryptography and enjoy the very compact key format it provides!
Ed25519 keys are short. Very short. If you're used to copy multiple lines of characters from system to system you'll be happily surprised with the size. The public key is just about 68 characters. It's also much faster in authentication compared to secure RSA (3072+ bits).
Generating an Ed25519 key is done using the -t ed25519 option to the ssh-keygen command.
Ed25519 is a reference implementation for EdDSA using Twisted Edward curves (Wikipedia link).
When generating the keypair, you're asked for a passphrase to encrypt the private key with.
If you will ever lose your private key it should protect others from impersonating you because it will be encrypted with the passphrase.
To actually prevent this, one should make sure to prevent easy brute-forcing of the passphrase.
OpenSSH key generator offers two options to resistance to brute-force password cracking: using the new OpenSSH key format and increasing the amount of key derivation function rounds.
It slows down the process of unlocking the key, but this is what prevents efficient brute-forcing by a malicious user too.
I'd say experiment with the amount of rounds on your system.
Start at about 100 rounds.
On my system it takes about one second to decrypt and load the key once per day using an agent.
Very much acceptable, imo.
With ssh-keygen use the -o option for the new RFC4716 key format and the use of a modern key derivation function powered by bcrypt.
Use the -a <num> option for <num> amount of rounds.
Actually, it appears that when creating a Ed25519 key the -o option is implied.
$ ssh-keygen -o -a 100 -t ed25519
Generating public/private ed25519 key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/gert/.ssh/id_ed25519.
Your public key has been saved in /home/gert/.ssh/id_ed25519.pub.
The key fingerprint is:
SHA256: [...] gert@hostname
The key's randomart image is: [...]
Note the line 'Your identification has been saved in /home/gert/.ssh/id_ed25519'.
Your current RSA/DSA keys are next to it in the same ~/.ssh folder.
As with any other key you can copy the public key in ~/.ssh/id_ed25519.pub to target hosts for authentication.
All keys available on default paths will be autodetected by SSH client applications, including the SSH agent via ssh-add.
So, if you were using an application like ssh/scp/rsync before like...
it will now offer multiple public keys to the server and the server will request proof of possession for a matching entry for authentication.
And your daily use of the ssh-add command will not change and autodiscover the Ed25519 key:
$ ssh-add
Enter passphrase for /home/gert/.ssh/id_rsa:
Identity added: /home/gert/.ssh/id_rsa (gert@hostname)
Identity added: /home/gert/.ssh/id_ed25519 (gert@hostname)
It not only discovered both keys, it also loaded them by entering a single passphrase (because it's the same)!
We've reached a very important goal now.
Without any change to your daily routine we can slowly change the existing configuration on remote hosts to accept the Ed25519 key.
In the meantime the RSA key will still work.
Great, right!?
If you're afraid this will change your key, don't worry.
The private part of your keypair is encrypted with a passphrase which only exists locally on your machine.
Change it as often as you like.
This is recommended to prevent abuse in case the key file gets into the wrong hands.
Repeat for all your key files to ensure a new key format with 100 bcrypt KDF rounds:
Using Ed25519 will (and should) work in most situations by now, but legacy systems may not support them as of yet.
The best fallback is a strong RSA keypair for this.
While the OpenSSH client supports multiple RSA keys, it requires configuration/command line options to specify the path so it's rather error-prone.
Instead, I'd recommend upgrading your existing key in-place to keep things simple once this is done.
Depending on the strength (key size) of your current RSA key you can migrate urgently or comfortably.
In case you have a weak RSA key still, move it out of the way from the standard path and generate a new one of 4096 bits size:
Once you are finished the transition on all remote targets you can go back to convenience and let it autodiscover your new RSA and Ed25519 keys; simply omit the keyfile arguments.
Support is available since OpenSSH 6.5 and well adopted in the Unix world OSs for workstations.
Ubuntu 14.04+, Debian 8+, CentOS/RedHat 7+ etc. all support it already.
(If you have details about Mac OS X please drop a line, couldn't find it with a quick search).
Some software like custom desktop key agents may not like the new keys for several reasons (see below about the Gnome-keyring for example).
Github works pretty well too, by the way.
Launchpad and Gerrit code review however, seem to require RSA keys unfortunately.
PuTTY on Windows? See below.
The Gnome-keyring, as used in Ubuntu Unity at least, fails to read the new RFC4716 format keys but reports success.
It's bugged.
More details here in my AskUbuntu Q&A post.
I'd recommend disabling the Gnome keyring for SSH agent use and use the plain OpenSSH agent instead.
Sorry, I'm not using PuTTY, but make sure to upgrade first.
This page suggests Ed25519 support since a late-2015 version according to a wishlist item.
Generally speaking, I'm not too excited with the speed of implementation of security features in it.
We've taken some steps, important ones, but it's far from ultimate security.
When dealing with high assurance environments I would strongly discourage key usage like described in this post as this holds the unencrypted private key in memory.
Instead, use hardware security (smart cards) to avoid leaking keys even from memory dumps.
It's not covered in this post, mainly because it requires a hardware device you need to buy and secondly because the limitations are device dependent.
A nice cute solution would be to make use of your TPM already built-in your PC probably, but that would definitely deserve another post.
I'm planning on writing some more on how to harden SSH a bit more; custom host keys, custom DH moduli, strong ciphers (e.g. chacha20-poly1305) and secure KeyExchange/MACs.
For now this is a great resource already: https://stribika.github.io/2015/01/04/secure-secure-shell.html
While the latest smart gizmo tends to grab headlines, industry experts are urging urban leaders to focus more on smart city challenges with their citizens, rather than the technology. That’s according to attendees at the recent VERGE 16 conference in Santa Clara, Calif. where leaders in the smart cities space gathered.
A key sentiment that emerged from the conference was that leaders in government and industry need to stay focused on the larger smart city picture and not get caught up in the latest gee-whiz technology.
Specifically, there needs to be greater focus on meshing emerging tech with the current political and economic systems that affect citizens.
“The technology solutions are there,” said Kirain Jain, Chief Resilience Officer for the City of Oakland. “What we’re really looking at are governance issues.”
The proliferation of new smart city platforms and equipment is driven partly by the increasing ease at which they are integrated into city infrastructure.
“We just put out an RFP last week that had the words ‘user-centric design,'” said Jain.
Cities needs to evaluate their strategies
The shift from technology-centric strategies to user-centric mindsets also requires a realistic assessment of which populations of the city are actually benefiting from these innovations.
Specifically, local leaders must recognize that many smart city innovations are providing benefits to the better off segments of society. Meanwhile, those citizens struggling with poverty may not see much benefit at all from technology that makes the morning commute more pleasant.
“A lot of our focus has been on moving the top 20% of the market,” said Kimberly Lewis, senior vice president of the U.S. Green Building Council. “We thought the trickle-down effects would really begin to affect low- and moderate-income communities.”
She says key challenges are being exacerbated by assumptions that any smart city technological advancement automatically creates mass impact on the entire city population. However, it’s becoming clear that smart city technology is not a magic wand that can be waved to eliminate persistent challenges faced by poorer citizens.
For example the community solar concept is beginning to gain traction in various markets, depending on the resources of those who wish to invest. However, this raises the issue of how to increase accessibility to financing for those communities who lack the resources to develop solar projects.
In addition to unforgettable life experiences and personal growth, one thing I got out of DEF CON 23 was a copy of POC||GTFO 0x08 from Travis Goodspeed. The coolest article I’ve read so far in it is “Deniable Backdoors Using Compiler Bugs,” in which the authors abused a pre-existing bug in CLANG to create a backdoored version of sudo that allowed any user to gain root access. This is very sneaky, because nobody could prove that their patch to sudo was a backdoor by examining the source code; instead, the privilege escalation backdoor is inserted at compile-time by certain (buggy) versions of CLANG.
That got me thinking about whether you could use the same backdoor technique on javascript. JS runs pretty much everywhere these days (browsers, servers, arduinos and robots, maybe even cars someday) but it’s an interpreted language, not compiled. However, it’s quite common to minify and optimize JS to reduce file size and improve performance. Perhaps that gives us enough room to insert a backdoor by abusing a JS minifier.
Part I: Finding a good minifier bug
Question: Do popular JS minifiers really have bugs that could lead to security problems?
Answer: After about 10 minutes of searching, I found one in UglifyJS, a popular minifier used by jQuery to build a script that runs on something like 70% of the top websites on the Internet. The bug itself, fixed in the 2.4.24 release, is straightforward but not totally obvious, so let’s walk through it.
UglifyJS does a bunch of things to try to reduce file size. One of the compression flags that is on-by-default will compress expressions such as:
!a && !b && !c && !d
That expression is 20 characters. Luckily, if we apply De Morgan’s Law, we can rewrite it as:
!(a || b || c || d)
which is only 19 characters. Sweet! Except that De Morgan’s Law doesn’t necessarily work if any of the subexpressions has a non-Boolean return value. For instance,
!false && 1
will return the number 1. On the other hand,
!(false || !1)
simply returns true.
So if we can trick the minifier into erroneously applying De Morgan’s law, we can make the program behave differently before and after minification! Turns out it’s not too hard to trick UglifyJS 2.4.23 into doing this, since it will always use the rewritten expression if it is shorter than the original. (UglifyJS 2.4.24 patches this by making sure that subexpressions are boolean before attempting to rewrite.)
Part II: Building a backdoor in some hypothetical auth code
Cool, we’ve found the minifier bug of our dreams. Now let’s try to abuse it!
Let’s say that you are working for some company, and you want to deliberately create vulnerabilities in their Node.js website. You are tasked with writing some server-side javascript that validates whether user auth tokens are expired. First you make sure that the Node package uses uglify-js@2.4.23, which has the bug that we care about.
Next you write the token validation function, inserting a bunch of plausible-looking config and user validation checks to force the minifier to compress the long (not-)boolean expression:
function isTokenValid(user) {
var timeLeft =
!!config && // config object exists
!!user.token && // user object has a token
!user.token.invalidated && // token is not explicitly invalidated
!config.uninitialized && // config is initialized
!config.ignoreTimestamps && // don't ignore timestamps
getTimeLeft(user.token.expiry); // > 0 if expiration is in the future
// The token must not be expired
return timeLeft > 0;
}
function getTimeLeft(expiry) {
return expiry - getSystemTime();
}
Running uglifyjs -c on the snippet above produces the following:
function isTokenValid(user){var timeLeft=!(!config||!user.token||user.token.invalidated||config.uninitialized||config.ignoreTimestamps||!getTimeLeft(user.token.expiry));return timeLeft>0}function getTimeLeft(expiry){return expiry-getSystemTime()}
In the original form, if the config and user checks pass, timeLeft is a negative integer if the token is expired. In the minified form, timeLeft must be a boolean (since “!” in JS does type-coercion to booleans). In fact, if the config and user checks pass, the value of timeLeft is always true unless getTimeLeft coincidentally happens to be 0.
Voila! Since true > 0 in javascript (yay for type coercion!), auth tokens that are past their expiration time will still be valid forever.
Part III: Backdooring jQuery
Next let’s abuse our favorite minifier bug to write some patches to jQuery itself that could lead to backdoors. We’ll work with jQuery 1.11.3, which is the current jQuery 1 stable release as of this writing.
jQuery 1.11.3 uses grunt-contrib-uglify 0.3.2 for minification, which in turn depends on uglify-js ~2.4.0. So uglify-js@2.4.23 satisfies the dependency, and we can manually edit package.json in grunt-contrib-uglify to force it to use this version.
There are only a handful of places in jQuery where the DeMorgan’s Law rewrite optimization is triggered. None of these cause bugs, so we’ll have to add some ourselves.
Backdoor Patch #1:
First let’s add a potential backdoor in jQuery’s .html() method. The patch looks weird and superfluous, but we can convince anyone that it shouldn’t actually change what the method does. Indeed, pre-minification, the unit tests pass.
After minification with uglify-js@2.4.23, jQuery’s .html() method will set the inner HTML to “true” instead of the provided value, so a bunch of tests fail.
However, the jQuery maintainers are probably using the patched version of uglifyjs. Indeed, tests pass with uglify-js@2.4.24, so this patch might not seem too suspicious.
Cool. Now let’s run grunt to build jQuery with this patch and write some silly code that triggers the backdoor:
<html>
<script src="../dist/jquery.min.js"></script>
<button>click me to see if this site is safe</button>
<script>
$('button').click(function(e) {
$('#result').html('<b>false!!</b>');
});
</script>
<div id='result'></div>
</html>
Here’s the result of clicking that button when we run the pre-minified jQuery build:
As expected, the user is warned that the site is not safe. Which is ironic, because it doesn’t use our minifier-triggered backdoor.
Here’s what happens when we instead use the minified jQuery build:
Now users will totally think that this site is safe even when the site authors are trying to warn them otherwise.
Backdoor Patch #2:
The first backdoor might be too easy to detect, since anyone using it will probably notice that a bunch of HTML is being set to the string “true” instead of the HTML that they want to set. So our second backdoor patch is one that only gets triggered in unusual cases.
Basically, we’ve modified jQuery.event.remove (used in the .off() method) so that the code path that calls special event removal hooks never gets reached after minification. (Since spliced is always boolean, its length is always undefined, which is not > 0.) This doesn’t necessarily change the behavior of a site unless the developer has defined such a hook.
Say that the site we want to backdoor has the following HTML:
<html>
<script src="../dist/jquery.min.js"></script>
<button>click me to see if special event handlers are called!</button>
<div>FAIL</div>
<script>
// Add a special event hook for onclick removal
jQuery.event.special.click.remove = function(handleObj) {
$('div').text('SUCCESS');
};
$('button').click(function myHandler(e) {
// Trigger the special event hook
$('button').off('click');
});
</script>
</html>
If we run it with unminified jQuery, the removal hook gets called as expected:
But the removal hook never gets called if we use the minified build:
Obviously this is bad news if the event removal hook does some security-critical function, like checking if an origin is whitelisted before passing a user’s auth token to it.
Conclusion
The backdoor examples that I’ve illustrated are pretty contrived, but the fact that they can exist at all should probably worry JS developers. Although JS minifiers are not nearly as complex or important as C++ compilers, they have power over a lot of the code that ends up running on the web.
It’s good that UglifyJS has added test cases for known bugs, but I would still advise anyone who uses a non-formally verified minifier to be wary. Don’t minify/compress server-side code unless you have to, and make sure you run browser tests/scans against code post-minification. [Addendum: Don’t forget that even if you aren’t using a minifier, your CDN might minify files in production for you. For instance, Cloudflare’s collapsify uses uglifyjs.]
Now, back to reading the rest of POC||GTFO.
PS: If you have thoughts or ideas for future PoC, please leave a comment or find me on Twitter (@bcrypt). The code from this blog post is up on github.
[Update 1: Thanks @joshssharp for posting this to Hacker News. I’m flattered to have been on the front page allllll night long (cue 70’s soul music). Bonus points – the thread taught me something surprising about why it would make sense to minify server-side.]
[Update 2: There is now a long thread about minifiers on debian-devel which spawned this wiki page and another HN thread. It’s cool that JS developers are paying attention to this class of potential security vulnerabilities, but I hope that people complaining about minification also consider transpilers and other JS pseudo-compilers. I’ll talk more about that in a future blog post.]
Years ago it was common practice to place a link to your sitemap in the footer navigation. Those days are over because the footer itself has become the new site map.
A sitemap is where users can go to find a directory of all site links on one page. But this is no longer necessary for most sites if you design your footer right (although XML sitemaps are still necessary for SEO).
Traditional Footers
Back then, the footer was rarely considered an important usability element. One study shows that most sites would use a traditional footer. It would contain a short line of administrative links and copyright info. The belief was that most users don’t use the footer because it’s at the bottom of the page.
The traditional footer has now evolved into the mini sitemap. Mini sitemap footers are not only gaining more but more effective than traditional footers. Testing found that a mini sitemap footer resulted in more sales and clickthroughs.
Mini Sitemap
If you have a large site, you should make your footer a mini sitemap of its own. When users can’t find what they’re looking for in the header, they’re going to look in the footer. This is where they should see a comprehensive list of your site links organized by category.
Cramming too many links in your header can make your menus messy and overwhelming. Reserve the header for your most important content links and use the footer for all others.
When you make your footer a mini sitemap, users can rely on it to find what they want faster. This is because the links are all laid out and not tucked inside dropdown menus. Users don’t have to open and sift through dropdown.
Not only that, but they also don’t have to click a category link to get to more specific links. They can just click the specific link directly.
It also saves them time from using the search field. They don’t have to type in a keyword to the page they want. Once they scroll to the footer, the link is there.
Designing the Footer
An effective mini sitemap footer needs distinct category labels that contrast with links. If you don’t include them, you’ll make it hard for users to scan the list of links. Users need to be able to spot a category and scan that list without wasting time on others.
You should have ample spacing between your links so that they’re easy for mobile users to tap. If you have many links and categories you should consider using an accordion menu to display them. This not only saves space but it’ll prevent errors from tapping smaller targets.
Mind the Footer
Not all sites need a mini sitemap footer. If you have a large site that holds a lot of content, you should consider it. This is especially important for ecommerce sites where users need to find products quick.
Designers should no longer ignore the footer. It’s a site element that needs care and attention. Organize it with lists of links that will make all your site’s content quicker to get to.
Saving Emoticons/Unicode from Twitter to a MySQL Database
The last couple of days I’ve been developing a little app that imports Twitter feeds and saves tweets to a MySQL database; however, I quickly hit an issue where certain tweets would not save. MySQL was returning the error message ‘SQLSTATE[HY000]: General error: 1366 Incorrect string value’. Looking at the specific tweets causing the database to throw the error I noticed that they contained emoticons.
The Problem
I was using utf8 encoding in MySQL which I thought (wrongly) could represent all unicode characters.
The unicodes for emoticons are fully supported by the UTF-8 encoding; however, MySQL’s utf8 does not! To save emoticons to a MySQL database we need to use utf8mb4.
The difference between MySQL’s utf8 and utf8mb4 is that the former can only store 3 byte characters whereas the latter can store 4 byte ones. Therefore with utf8 we can only store unicode characters from the Basic Multilingual Plane. Put more simply, utf8 is suitable for characters from the majority of modern languages and some symbols. Emoticon characters exist in the Supplementary Multilingual Plane for which we need to use utf8mb4.
The Fix
In order to save emoticons and other unicode not supported by MySQL’s utf8 we need to change the character set and collation properties of our database, tables and columns. As long as our database is currently using utf8 there should be no risk of data loss as utf8mb4 is fully backwards compatible with it. However, it is still a good idea to make a backup of the database before running the following commands.
Let’s first set the connection encoding to utf8mb4 and then change the database’s character set and collation to it:-
SET NAMES utf8mb4;
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
(Replacing database_name with the name of the database.)
Next we need to convert the relevant tables to utf8mb4/utf8mb4_unicode_ci (you will need to run this for each table):-
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
(Replacing table_name with the name of the database table.)
Finally we need to update the character set and collation for the column(s):-
ALTER TABLE table_name CHANGE column_name column_name VARCHAR(140) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL;
Read that last command carefully as it will need modifying to your specific needs. The important bit to note is the CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci. (As with the other commands you need to replace table_name and column_name appropriately.)
Bear in mind that changing from utf8 to utfmb4 affects the maximum lengths of columns and index keys. The maximum lengths of columns will be unchanged when modifying the tables with the commands discussed here; but in terms of actual characters the amount that can be stored is reduced. This is a consequence of changing from being able to store only 3 bytes up to 4! You may need to update these lengths if this is relevant to you.
It may be a good idea to make sure every table that has been converted is repaired and optimised after making the above changes. You can run the following for each modified table:-
Everything should be ready now, but don’t forget to update how your app connects to the database so that it uses the new encoding. For example, in CakePHP 3 the datasource’s encoding needs updating to utf8mb4:-
I was always wondering what the size of numeric columns in MySQL was. Forgive me if this is obvious to someone else. But for me the MySQL manual lacks a great deal in this field.
TL;DR: It's about the display width. You only see it when you use ZEROFILL.
Usually you see something like int(11) in CREATE TABLE statements, but you can also change it to int(4).
So what does this size mean? Can you store higher values in a int(11) than in an int(4)?
INT[(M)] [UNSIGNED] [ZEROFILL]
A normal-size integer. The signed range is -2147483648 to 2147483647. The unsigned range is 0 to 4294967295.
No word about the M. The entry about BOOL suggests that the size is not there for fun as it is a synonym for TINYINT(1) (with the specific size of 1).
TINYINT[(M)] [UNSIGNED] [ZEROFILL]
A very small integer. The signed range is -128 to 127. The unsigned range is 0 to 255.
BOOL, BOOLEAN
These types are synonyms for TINYINT(1). A value of zero is considered false. Non-zero values are considered true: […]
So TINYINT(1) must be different in some way from TINYINT(4) which is assumed by default when you leave the size out1. Still, you can store for example 100 into a TINYINT(1).
Finally, let's come to the place of the manual where there is the biggest hint to what the number means:
Several of the data type descriptions use these conventions:
M indicates the maximum display width for integer types. For floating-point and fixed-point types, M is the total number of digits that can be stored. For string types, M is the maximum length. The maximum allowable value of M depends on the data type.
It's about the display width. The weird thing is, though2, that, for example, if you have a value of 5 digits in a field with a display width of 4 digits, the display width will not cut a digits off.
If the value has less digits than the display width, nothing happens either. So it seems like the display doesn't have any effect in real life.
Now2 ZEROFILL comes into play. It is a neat feature that pads values that are (here it comes) less than the specified display width with zeros, so that you will always receive a value of the specified length. This is for example useful for invoice ids.
So, concluding: The size is neither bits nor bytes. It's just the display width, that is used when the field has ZEROFILL specified.
If you see any more uses in the size value, please tell me. I am curious to know.
1 See this example:
mysql> create table a ( a tinyint );
Query OK, 0 rows affected (0.29 sec)
mysql> show columns from a;
+-------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------+------+-----+---------+-------+
| a | tinyint(4) | YES | | NULL | |
+-------+------------+------+-----+---------+-------+
1 row in set (0.26 sec)
mysql> alter table a change a a tinyint(1);
Query OK, 0 rows affected (0.09 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into a values (100);
Query OK, 1 row affected (0.00 sec)
mysql> select * from a;
+-----+
| a |
+-----+
| 100 |
+-----+
1 row in set (0.00 sec)
2 Some code to better explain what I described so clumsily.
mysql> create table b ( b int (4));
Query OK, 0 rows affected (0.25 sec)
mysql> insert into b values (10000);
Query OK, 1 row affected (0.00 sec)
mysql> select * from b;
+-------+
| b |
+-------+
| 10000 |
+-------+
1 row in set (0.00 sec)
mysql> alter table b change b b int(11);
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from b;
+-------+
| b |
+-------+
| 10000 |
+-------+
1 row in set (0.00 sec)
mysql> alter table b change b b int(11) zerofill;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from b;
+-------------+
| b |
+-------------+
| 00000010000 |
+-------------+
1 row in set (0.00 sec)
mysql> alter table b change b b int(4) zerofill;
Query OK, 1 row affected (0.08 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from b;
+-------+
| b |
+-------+
| 10000 |
+-------+
1 row in set (0.00 sec)
mysql> alter table b change b b int(6) zerofill;
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from b;
+--------+
| b |
+--------+
| 010000 |
+--------+
1 row in set (0.00 sec)
Non, les statues de marbre grecques et romaines n'étaient pas blanches. Un archéologue a produit des répliques grandeur nature et peintes avec les mêmes formes et motifs. Mais les couleurs flamboyantes qui les recouvrent ne font pas l'unanimité.
We live in a society where human health is increasingly enhanced by artificial augmentation and implantation including hip replacements and hearing aids. French company Carmat have been working for 15 years on the artificial heart, a device that completely replaces the human heart in people with end stage heart disease and a life expectancy of less than two weeks without the surgery.
They’ve recently announced their second trial, commencing in 2017 with the aim to achieve European approval for their device. The Carmat device differs to other robotic heart devices as it is meant to be used in cases of terminal heart failure, instead of being used as a bridge device while the patient awaits a transplant.
How it works
In Carmat’s design, two chambers are each divided by a membrane that holds hydraulic fluid on one side. A motorized pump moves hydraulic fluid in and out of the chambers, and that fluid causes the membrane to move; blood flows through the other side of each membrane. The blood-facing side of the membrane is made of tissue obtained from a sac that surrounds a cow’s heart, to make the device more biocompatible.
The Carmat device also uses valves made from cow heart tissue and has sensors to detect increased pressure within the device. That information is sent to an internal control system that can adjust the flow rate in response to increased demand, such as when a patient is exercising.
The heart is connected to external systems; a power supply, monitoring and hospital control system for the post-operative period and subsequent outpatient visits and a portable or wearable power supply and communication system for the patient to return home.
A new heart is not an exact science
So far, the success of their artificial heart transplants has been couched in research terms with success in the previous four person feasibility trial defined as survival at 30 days. Their model has been trialled on four people all of which have died.
Carmat’s first transplant patient, died in March 2014, two-and-a-half months after his operation apparently due to a device failure. The second died in May 2015, nine months after having been grafted. These two deaths had been caused by “micro-leakage of the blood area to the operating liquid of the prosthesis” having created a “disturbance electronic engine control” of the artificial heart, according to the analysis of Carmat.
The third died after nine months due to “respiratory arrest during chronic renal failure” and the patient was suffering “from a combination of severe diseases, especially kidney failure already diagnosed prior to implantation of the prosthesis and warranting regular hospital visits.” It was also stated that the heart continued to beat after the patient had died and that “the medical team turned off the prosthetic device on confirmation of the patient’s death.” The fourth and final patient died from medical complications associated with his critical pre- and post-operative state
The company is now pushing on with a trial aimed at securing European approval. It will enroll 25 patients and this time the endpoint will be survival at three months. Says Marcello Conviti, CEO of Carmat:
“Our target is to have all the data submitted by the end of 2017 and commercial availability in selected CE mark countries at the beginning of 2018,”
What is the future?
Clearly we’re a long way from the dreams of futurist tech predictors that for see a future where one’s heart beat could be regulated through their smartphone. Transhumanist Zoltan Istvan sees a future where “artificial hearts will be Wi-Fi-enabled and could be sped up with a smartphone to have wild sex when you want it and sped down to sleep better at night.” according to the International Business Times. He goes on to concede that there’s a potential risk that an artificial heart could be hacked.
There is however no demonstrable evidence that an artificial heart (or pacemaker for the matter) could be hacked. But the fear of course, is real. For example in 2014, former Vice President Dick Cheney revealed that his doctor ordered the wireless functionality of his heart implant disabled due to fears it might be hacked in an assassination attempt. Other research reveals that medical devices such as insulin pumps are vulnerable to security breaches, which places connected biomechanic and robotic devices in a uneasy space considering their functional capabilities are to assist the health of the seriously ill.
L'autonomie des smartphones bientôt multipliée par deux ? - 2 Photos
Depuis plusieurs années maintenant, les batteries ont envahi notre quotidien. Elles font l’objet de nombreux travaux de recherche et de développement visant notamment à améliorer leur autonomie. Si certains tentent d’optimiser les performances des batteries lithium-ion, d’autres s’intéressent à des technologies différentes. C’est le cas, entre autres, d’une start-up américaine – issue d’un essaimage du Massachusetts Institute of Technology (MIT) – qui mise depuis 2012 sur la technologie lithium-métal.
Aujourd’hui, SolidEnergy Systems annonce avoir trouvé des solutions aux problèmes rencontrés en la matière par ses concurrents (formation de dendrites à l’origine de courts-circuits, formation de composés dommageables pour la durée de vie de la batterie, etc.). La start-up serait en mesure de fournir – en s’appuyant sur les chaînes de production classiques des batteries lithium-ion – des batteries deux fois plus performantes. Celles-ci pourraient faire leur apparition dans des drones dès la fin de l’année 2016, dans nos smartphones en 2017 et même dans les véhicules électriques en 2018.
Batterie lithium-métal : une anode ultramince et un nouvel électrolyte
En octobre 2015 déjà, SolidEnergy Systems avait présenté un premier prototype de batterie pour smartphone affichant une densité énergétique double de celle des batteries classiques. De quoi lui assurer une autonomie deux fois plus élevée ou envisager de produire des batteries deux fois plus petites sans pour autant en réduire la durée de vie ou mettre en jeu la sécurité du dispositif.
Le secret de cette nouvelle batterie tient essentiellement dans son anode. Fini le graphite ou même le silicium, place à une feuille de lithium extrêmement fine – environ un cinquième de l’épaisseur classique des anodes de batteries lithium-métal –, enroulée autour de la cathode. L’ensemble permet d’économiser de l’espace et d’augmenter la capacité énergétique de la batterie. De plus, quelques modifications d’ordre chimique au niveau de l’électrolyte – anode recouverte d’une fine couche d’électrolyte solide et électrolyte liquide quasi ionique – lui évitent de tomber dans les écueils habituellement associés aux batteries lithium-métal.
À découvrir en vidéo autour de ce sujet :
Que ce soit dans nos téléphones portables, lampes de poches, ou même dans nos voitures, les piles et batteries sont partout. Scellé et protégé, leur contenu est souvent mystérieux. Unisciel et l’Université de Lille 1 nous éclairent, avec le programme Kézako, sur le fonctionnement des piles dans cette courte et intéressante vidéo.
Public bathrooms are teeming with microbes! You know to wash your hands, but when choosing between a hand dryer or a paper towel to dry them off— what’s your cleanest bet?
In this episode of “It’s Okay to Be Smart”, host Joe Hanson takes a look at our Microbiome, the system of invisible (to us) Microbes that keeps us alive.
Most of us have experienced some kind of phishing attempt in our online lives, and we have seen phishing grow in complexity. Usually, we notice that the login pages are crafted to convince users they are logging into a valid service. When the user fails to notice that the phishing page is fake, their login details or credit card information is sent to attackers. The stolen credentials and personal information are used to perform identity theft and fraudulent activities.
Working as a Malware Researcher gives me a great opportunity to see many of these phishing attempts from the inside. In other words, I can see what’s behind the curtain.
In most cases, phishing lures are just a very simple copy of a login page for Facebook, Google, banks, insurance companies, etc. The attackers include locally-stored images, CSS, and JavaScript to produce almost identical copies of the original login page. The important difference is the malicious PHP scripts which are sending your username and password directly to the attacker. It’s that simple. We are going to look at a few examples of how phishing attempts are growing in complexity to trick users and abuse hacked website resources.
Basic Phishing Attacks
In the most basic phishing attacks, the attacker’s job is done once the sensitive information is collected and the user is presented with a broken page upon submission. One common result is the loading icon that gives the impression that something is still happening (i.e. you’re almost logged in!)
If you are ever stuck with a loading icon that spins for a long time, check your address bar. If you are on the wrong site, refreshing or closing the browser will not help. By the time you see the loading icon, your sensitive data has already been sent to the attackers.
The good news is that discovering this attack (and knowing you have been compromised) gives you time to react quickly:
Change your passwords
Check your bank account for unusual transactions
Block your credit card
Contact the site where the phishing page originated
Complex Phishing Attacks
More advanced phishing attacks involve just a few additional lines of code. These pages still serve the loading icon, but after a few seconds, they redirect you to the real site (even directly to the legitimate login page).
At this point, you are still not logged in because your login data was sent to the attacker instead. This time you did not have a chance to notice because the address bar shows the legitimate site. Most victims think there was an issue with their password or some other glitch, so they try again and log in successfully.
The victim forgets about the issue and continues as if nothing happened. A few hours, days, or even months later, the real problems start. If they choose to, the attacker can start using stolen credentials and personal information immediately after the data is successfully sent back to them.
Phishing Google login page
Check the Address Bar
As demonstrated above, it’s critical to check where you are entering sensitive information. In many cases, a simple address bar check in your browser helps you realize that you’re not on the intended site.
Here are a few things you can check:
Are you entering your Google Drive login information on docs.gooogle.com?
Is the site HTTPS (Secured HTTP) site?
Is there a problem with the SSL certificate reported on the lock icon?
Technical Details of Advanced Phishing Attacks
But what does an advanced phishing attack really look like from my perspective as a Malware Researcher? For those who are interested, here is a look behind the curtain.
We’re starting with a single index.php. Expecting phishing page copy? Well, not really…
index.php
modules.php
This is a nice example of a complex phishing backend, allowing the attacker to not only to steal information but do it in a clever way and get much more from it.
The chmod.php module creates (with appropriate permissions) all the log files for the backend:
Part of chmod.php
Now it’s logging time – visitor_log.php simply logs the visitor data, even formatting the timezone. This might tell us something about the attacker. Working in a globally-distributed environment at Sucuri has taught me the importance of transforming the actual time of your colleague to your own to avoid waking him up in the middle of the night if it isn’t necessary. My guess is that the attackers want to read the times in their own timezone as well.
visitor_log.php and its logging code
Now we’re getting into really interesting stuff. These attackers are checking what site the visitor is coming from (via the HTTP_REFERER).
If the visitor is coming from a security service (such as phishtank.com that allows people to verify reported phishing pages) they display a 404 page to try to trick security researchers into believing the page is nonexistent. This helps them protect their phishing campaign.
Part of phishtank_check.php
But that’s not all. The attackers are not only checking phishing services, but also their own blacklist which blocks other security services that might be a threat to them. In the image below, there are 122 companies listed, including their IP ranges.
After all of the logging and checks, we finally see the phishing data itself.
These attackers also log every attack and all available information about the victim such as browser and user-agent:
Conclusion
Aside from basic phishing attempts (which are just as dangerous as complex ones) we’re noticing similar trends in every other black hat business. For example, there are fewer script kiddies and more elite hackers. These cyber crimes are committed by experienced groups with skilled people who know what to do, and how to do it.
With that in mind, as website owners we have to pay special time and attention to how our web assets are being used to facilitate these attacks. The biggest challenge I see is that most website owners are unaware that their websites are being used for nefarious acts, and most reasonable website owners would be ashamed.
The biggest challenge phishing injections present to website owners are that they are difficult to detect. Taking into consideration the examples above, you can see how the code itself is not malicious and might fit perfectly within the construct of the website. Attackers know this and further complicate the process by embedding the pages deep within the file structure of your website. To address this, it’s important you’re actively monitoring the integrity of your sites files and directories.
If you suspect your website is being used in a phishing lure campaign, let us know. We’d love to clean your site and help in any way we can.
Posted by Kaz Sato, Developer Advocate, Google Cloud Platform
It’s not hyperbole to say that use cases for machine learning and deep learning are only limited by our imaginations. About one year ago, a former embedded systems designer from the Japanese automobile industry named Makoto Koike started helping out at his parents’ cucumber farm, and was amazed by the amount of work it takes to sort cucumbers by size, shape, color and other attributes.
Makoto's father is very proud of his thorny cucumber, for instance, having dedicated his life to delivering fresh and crispy cucumbers, with many prickles still on them. Straight and thick cucumbers with a vivid color and lots of prickles are considered premium grade and command much higher prices on the market.
But Makoto learned very quickly that sorting cucumbers is as hard and tricky as actually growing them. "Each cucumber has different color, shape, quality and freshness," Makoto says.
Cucumbers from Makoto's farm and ones from retail stores
In Japan, each farm has its own classification standard and there's no industry standard. At Makoto's farm, they sort them into nine different classes, and his mother sorts them all herself — spending up to eight hours per day at peak harvesting times.
"The sorting work is not an easy task to learn. You have to look at not only the size and thickness, but also the color, texture, small scratches, whether or not they are crooked and whether they have prickles. It takes months to learn the system and you can't just hire part-time workers during the busiest period. I myself only recently learned to sort cucumbers well,” Makoto said.
Distorted or crooked cucumbers are ranked as low-quality product
There are also some automatic sorters on the market, but they have limitations in terms of performance and cost, and small farms don't tend to use them.
Makoto doesn’t think sorting is an essential task for cucumber farmers. "Farmers want to focus and spend their time on growing delicious vegetables. I'd like to automate the sorting tasks before taking the farm business over from my parents."
Makoto Koike, center, with his parents at the family cucumber farm
The many uses of deep learning
Makoto first got the idea to explore machine learning for sorting cucumbers from a completely different use case: Google AlphaGo competing with the world's top professional Go player.
"When I saw the Google's AlphaGo, I realized something really serious is happening here,” said Makoto. “That was the trigger for me to start developing the cucumber sorter with deep learning technology."
Using deep learning for image recognition allows a computer to learn from a training data set what the important "features" of the images are. By using a hierarchy of numerous artificial neurons, deep learning can automatically classify images with a high degree of accuracy. Thus, neural networks can recognize different species of cats, or models of cars or airplanes from images. Sometimes neural networks can exceed the performance of the human eye for certain applications. (For more information, check out my previous blog post Understanding neural networks with TensorFlow Playground.)
TensorFlow democratizes the power of deep learning
But can computers really learn mom's art of cucumber sorting? Makoto set out to see whether he could use deep learning technology for sorting using Google's open source machine learning library, TensorFlow.
"Google had just open sourced TensorFlow, so I started trying it out with images of my cucumbers,” Makoto said. “This was the first time I tried out machine learning or deep learning technology, and right away got much higher accuracy than I expected. That gave me the confidence that it could solve my problem."
With TensorFlow, you don't need to be knowledgeable about the advanced math models and optimization algorithms needed to implement deep neural networks. Just download the sample code and read the tutorials and you can get started in no time. The library lowers the barrier to entry for machine learning significantly, and since Google open-sourced TensorFlow last November, many "non ML" engineers have started playing with the technology with their own datasets and applications.
Cucumber sorting system design
Here's a systems diagram of the cucumber sorter that Makoto built. The system uses Raspberry Pi 3 as the main controller to take images of the cucumbers with a camera, and in a first phase, runs a small-scale neural network on TensorFlow to detect whether or not the image is of a cucumber. It then forwards the image to a larger TensorFlow neural network running on a Linux server to perform a more detailed classification.
Systems diagram of the cucumber sorter
Makoto used the sample TensorFlow code Deep MNIST for Experts with minor modifications to the convolution, pooling and last layers, changing the network design to adapt to the pixel format of cucumber images and the number of cucumber classes.
Here's Makoto’s cucumber sorter, which went live in July:
Here's a close-up of the sorting arm, and the camera interface:
And here is the cucumber sorter in action:
Pushing the limits of deep learning
One of the current challenges with deep learning is that you need to have a large number of training datasets. To train the model, Makoto spent about three months taking 7,000 pictures of cucumbers sorted by his mother, but it’s probably not enough.
"When I did a validation with the test images, the recognition accuracy exceeded 95%. But if you apply the system with real use cases, the accuracy drops down to about 70%. I suspect the neural network model has the issue of "overfitting" (the phenomenon in neural network where the model is trained to fit only to the small training dataset) because of the insufficient number of training images."
The second challenge of deep learning is that it consumes a lot of computing power. The current sorter uses a typical Windows desktop PC to train the neural network model. Although it converts the cucumber image into 80 x 80 pixel low-resolution images, it still takes two to three days to complete training the model with 7,000 images.
"Even with this low-res image, the system can only classify a cucumber based on its shape, length and level of distortion. It can't recognize color, texture, scratches and prickles,” Makoto explained. Increasing image resolution by zooming into the cucumber would result in much higher accuracy, but would also increase the training time significantly.
To improve deep learning, some large enterprises have started doing large-scale distributed training, but those servers come at an enormous cost. Google offers Cloud Machine Learning (Cloud ML), a low-cost cloud platform for training and prediction that dedicates hundreds of cloud servers to training a network with TensorFlow. With Cloud ML, Google handles building a large-scale cluster for distributed training, and you just pay for what you use, making it easier for developers to try out deep learning without making a significant capital investment.
These specialized servers were used in the AlphaGo match
Makoto is eagerly awaiting Cloud ML. "I could use Cloud ML to try training the model with much higher resolution images and more training data. Also, I could try changing the various configurations, parameters and algorithms of the neural network to see how that improves accuracy. I can't wait to try it."
Julie Guillot est une artiste graphique (son book en ligne) qui vient d’entamer le récit de son cheminement vers le partage libre de ses œuvres. Elle y témoigne de façon amusante et réfléchie de ses doutes et ignorances, puis de sa découverte progressive des libertés de création et de copie…
C’est avec plaisir que nous republions ici cette trajectoire magnifiquement illustrée.
Quand j’ai créé ce blog il y a 2 ans, puis le second sur les violences scolaires, mes proches m’ont encouragée et soutenue. Mais beaucoup (parfois les mêmes) m’ont aussi mise en garde, voire se sont sérieusement inquiétés.
Ces peurs étaient très liées à Internet, à l’idée d’un espace immense, obscur, peu ou pas réglementé, ainsi qu’à la notion de gratuité qui en fait partie. Y publier ses images et ses productions reviendrait à les jeter par la fenêtre.
Mais la crainte était, au-delà d’Internet et du support blog, une crainte (vraiment forte) du pillage, de l’expropriation et de la copie.
Personnellement, je ne pensais pas d’emblée à ces “risques”. J’avais envie et besoin de montrer mon travail, donc de le partager. Mais devant ces alertes, et voyant que tout le monde semblait partager le sentiment du danger et le besoin de s’en protéger, j’ai apposé un copyright en bas de mon blog, avec la mention “tous droits réservés”, et j’ai supprimé le clic droit.
En fait je n’avais pas du tout réfléchi à cette question. Je ne savais pas grand chose du droit d’auteur et du copyright.
Mais dès le début je ressentais une forme de malaise. Je savais que supprimer le clic droit n’empêcherait personne de récupérer une image. Et j’avais vaguement entendu que cette mention de copyright ne servait pas à grand-chose non plus.
Était-ce une saine prudence… ou une forme de paranoïa ?
Et puis, j’ai commencé à recevoir des demandes de personnes qui souhaitaient utiliser mes images. Pour une expo, un travail de recherche, une conférence, un cours…. Spontanément, je disais toujours oui. Parce que je ne voyais aucune raison de refuser. Non seulement je trouvais cela flatteur, mais en plus cela m’apparaissait comme une évolution logique et saine de mon travail : à quoi sert-il s’il ne peut être diffusé, partagé, utile aux autres ?
Petit à petit cela m’a fait réfléchir. Des gens venaient me demander mon autorisation simplement pour citer mon blog quelque part (ce qui n’est pas interdit par le droit d’auteur… !). Je ne pouvais pas le leur reprocher : après tout, j’avais apposé une mention “touts droits réservés”. Mais l’absurdité de la situation commençait à me parvenir.
Un jour, j’ai reçu une demande d’ordre plus “commercial” : quelqu’un qui souhaitait utiliser mes images pour une campagne de financement d’une épicerie végane.
Spontanément, j’ai hésité. Ne devais-je pas lui demander de l’argent ?
J’ai exprimé des conditions : je voulais être informée des images qu’il utiliserait, à quel endroit, des textes qu’il allait modifier, etc. Ce qu’il a accepté.
Mais très vite je me suis demandé pourquoi j’avais posé de telles conditions. Parce qu’en réalité, ça m’était égal.
Finalement, il n’a pas utilisé mes images. Mais il m’a permis de réaliser que je n’avais pas de position claire sur la manière dont je voulais partager ou non mon travail, que je ne connaissais rien à la législation, aux licences d’utilisation et à de possibles alternatives.
J’ai donc commencé à m’intéresser de plus près à ces questions de copyright, de droit d’auteur, de culture libre et de licences.
Ce qui m’a amenée à réfléchir à me conception de l’art, de la créativité, et même, plus largement, du travail.
Gwenn Seemel explique très bien que le droit d’auteur n’est pas uniquement un système juridique, mais un paradigme :
Nous envisageons l’art, la production de la pensée, comme des productions inaliénables ; nous assimilons la copie à du vol ; nous considérons l’imitation comme un acte malhonnête, une paresse, quelque chose de forcément blâmable. Il va de soi que nous devons demander l’utilisation à quelqu’unE pour utiliser ses écrits, ses images, sa musique, afin de créer quelque chose avec. Et nous ne remettons quasiment jamais ce paradigme en question.
Nous avons tous grandi avec l’idée que copier était (très) (très) mal. Et punissable.
Quand j’étais à la fac, certainEs étudiantEs refusaient de dire quel était leur sujet de mémoire ou de thèse…de peur qu’on leur “pique” leur(s) idée(s). J’étais naïve…et consternée.
C’était pour moi incompatible avec la conception que j’avais de la recherche et du travail intellectuel.
Bien sûr, ces comportements sont le résultat de la compétition qui structure notre société et une grande partie de nos relations. Toute production est considérée comme strictement individuelle, personnelle, comme si nous étions capables de créer à partir de rien.
Je me suis sentie profondément enthousiaste de découvrir des artistes qui rendent leurs oeuvres publiques, c’est à dire qui en permettent la libre diffusion, la copie, l’utilisation, la modification, des gens qui réfléchissent à ces questions et militent pour une culture différente.
J’étais convaincue, au fond, par la pertinence d’une culture sans copyright et je me sentais soulagée à l’idée de franchir le pas, moi aussi.
Je n’ai jamais ressenti un sentiment fort de propriété vis-à-vis de mes dessins.
J’ai toujours aimé copier, je m’inspire du travail des autres (comme tout le monde), et je trouve a priori naturel que mes productions puissent circuler, servir à d’autres, être utilisées et même transformées.
L’idée de pouvoir utiliser les œuvres des autres, comme me dessiner habillée en Gwenn Seemel, est tout aussi enthousiasmante.
Cet élan spontané cohabitait en moi avec la persistance de craintes et de méfiances :
et si on se faisait de l’argent “sur mon dos” ? Et si je le regrettais ? Ne suis-je pas responsable de tout ce que je produis, et donc de tout ce que deviennent mes productions ? Ne devrais-je pas demander de l’argent pour toute utilisation de ce que j’ai fait ? Est-ce que je ne fais donc rien d’original et de personnel ? Et si cela m’empêchait de gagner de l’argent avec mon travail artistique ? Et comment faire dans une société où le principe du droit d’auteur est la règle ?
J’avais besoin d’en savoir plus sur les aspects juridiques de la question, même si ça me semblait au départ rébarbatif.
Alors je me suis penchée sur le sujet. Comme dit Gwenn Seemel, personne ne va se brosser les dents à votre place.
(mais il y a des gens qui fournissent le dentifrice, et ça c’est sympa).
[À suivre…]
Gwenn Seemel m’a beaucoup aidée à avancer dans ma réflexion sur le droit d’auteur, la culture libre, la pratique de l’art en général. Ses vidéos et ses articles ont répondu à beaucoup de mes questions (puisqu’elle s’était posé les mêmes que moi, logiquement). Je vous conseille la lecture de son blog, et de son livre sur le copyright.
Le blog de S.I.lex est aussi une mine d’informations sur le sujet.
C’est assez flippant. En 8h, il scanne l’ensemble des adresses IPv4 écoutant sur le port par défaut de VNC. Il trouve 2 246 serveurs VNC protégés par aucun mot de passe et en profite pour nous donner quelques captures d’écran :p
AFP / JUSTIN TALLIS
Nigel Rodgers devant un magasin Marks and Spencer sur Oxford Street à Londres le 18 août 2016
Les oreilles de Nigel Rodgers souffrent : il fait campagne depuis des décennies contre la musique d'ambiance et se trouve devant un magasin de la principale artère commerciale de Londres, Oxford Street, qui crache les décibels d'une tonitruante musique pop.
"C'est aussi nocif que le tabagisme passif", dit M. Rodgers, 63 ans, blazer bleu et pochette rouge, fixant la sortie du magasin. "Ça pourrait rendre fou n'importe qui".
Mobilisé depuis 24 ans contre la musique de fond omniprésente dans les lieux publics et les magasins britanniques, son association, Pipedown, vient de décrocher un premier grand succès.
La chaîne Marks and Spencer a annoncé qu'elle allait cesser de diffuser de la musique dans ses magasins à la suite de l'envoi de lettres par des centaines de membres de Pipedown, qui en compte 2.000.
Le groupe espère maintenant arriver à convaincre les autres grands détaillants de lui emboîter le pas, grâce aussi à ses organisations relais aux Etats-Unis et en Allemagne, ainsi que des contacts pris en France.
Rodgers se sent visiblement mieux en sirotant un thé dans la cafétéria de Marks and Spencer, tout près d'Oxford Street.
- Masquer d'autres bruits -
D'une voix posée, il explique comment la mécanisation de la société a augmenté le volume dans le monde moderne, avec des retombées négatives telles que problèmes d'audition ou hausse de la tension artérielle.
"Nous vivons en permanence dans un environnement bruyant", dit-il. "Nous sommes artificiellement stimulés tout le temps, ce pour quoi notre organisme n'est pas fait".
Auteur de livres sur l'histoire de l'art et la philosophie, Nigel Rodgers a fondé Pipedown à l'âge de 38 ans, frustré par la musique d'ambiance dans un restaurant où il dînait avec son amie. Le groupe n'a depuis cessé de grandir et mène des campagnes en envoyant des lettres ou en distribuant des tracts aux employés dans les magasins pour se plaindre --poliment bien sûr-- de la musique d'ambiance.
"Ce n'est pas le problème de deux ou trois névrosés, c'est un problème beaucoup plus grave", souligne Rodgers. "Les comportements peuvent changer très vite, j'espère que la décision de Marks and Spencer va marquer un tournant", dit-il, sursautant légèrement au bruit d'assiettes qui s'entrechoquent.
AFP / JUSTIN TALLIS
Nigel Rodgers devant un magasin Marks and Spencer sur Oxford Street à Londres le 18 août 2016
Pour les professionnels du secteur en revanche, la musique de fond aide à améliorer l'environnement dans les magasins.
Adrian England, de PEL Services, qui fournit de la musique à une série de grandes chaînes de magasins, affirme que le silence met certaines personnes mal à l'aise. "Sans musique, vous entendez les disputes, les enfants bruyants, toutes sortes de bruits que la musique masque", dit-il à l'AFP.
- Augmentation des ventes -
Les magasins aiment offrir à leurs clients deux ou trois genres de musique différents et changent le rythme au cours de la journée, doux le matin, dynamique le soir.
Le but est atteint lorsque les clients ne réalisent même pas qu'il y a de la musique, selon lui: "C'est le paradoxe. Si vous faites ça bien, les clients ne s'en rendent pas compte, ils ne vont pas faire de compliments, mais ils ne vont pas se plaindre non plus".
AFP/Archives / NIKLAS HALLE'N
Nigel Rodgers fait campagne depuis des décennies contre la musique d'ambiance dans les magasins qui accroît selon lui la pollution sonore
Adrian North, professeur à l'université Curtin en Australie, a enquêté sur l'impact de la musique sur la consommation et estime que peu de magasins l'utilisent convenablement pour communiquer avec leurs clients.
D'après ses recherches, diffuser la "bonne" musique dans un environnement commercial peut augmenter les ventes jusqu'à 20%. Une musique inadaptée "est pire que pas de musique du tout", assure-t-il.
A Oxford Street, où se pressent les touristes par une belle journée d'été, les acheteurs sont partagés face aux magasins diffusant de la musique très fort.
"Ça me demande plus d'énergie d'entrer dans ces magasins, j'ai tendance à les éviter", dit Martin Persson, un Suédois de 34 ans, devant le magasin de chaussures qui a écorché les oreilles de Rodgers.
Mais Zyad al-Shoeeb, un jeune Saoudien de 22 ans, apprécie les rythmes martelés à plein tube en choisissant des vêtements dernier cri, une nouveauté pour lui. "La musique va bien avec les chaussures, elle m'aide à acheter plus vite!", assure-t-il.
Récemment retraité, j'ai emmené il y a quelques jours mes petits-enfants au parc d'attraction Walibi. A ma grande surprise, le parc m'a proposé de payer plus cher pour bénéficier de tickets coupe-file, me permettant d'éviter les files d'attente. Je vous avoue qu'attendre pendant des heures debout est assez pénible à mon âge, et que j'ai été tenté d'acheter ces tickets spéciaux. Mais je trouve cette technique assez injuste pour tous les gens qui n'ont pas les moyens de se payer ces tickets spéciaux, et la perspective de passer devant des dizaines de personnes hostiles ne m'enchantait pas. N'y aurait-il pas un meilleur moyen de réduire les files d'attente?
Albert de B., Laeken, Belgique.
Cher Albert,
Faire payer plus cher les gens qui veulent éviter les files d'attente, voilà probablement une idée qui aura été soufflée à la direction de ce parc par un économiste qui s'est arrêté à ses manuels de première année. Une file d'attente signifie que la demande est supérieure à l'offre. Vendre plus cher des tickets coupe-file est une forme de discrimination tarifaire, qui permet de mieux réguler la demande face à une offre limitée; c'est même une solution respectueuse de la justice sociale, parce qu'elle aboutit à faire payer plus cher les plus riches pour bénéficier de la même attraction dans le parc.
Les files d'attente sont le plus grand problème des parcs d'attraction. Les visiteurs des parcs Disney les considèrent comme leur premier motif d'insatisfaction, à juste titre. Le visiteur moyen passe 3 à 4 heures dans des files pour une journée de 8 à 9 heures, plus d'un tiers de son temps; le temps d'attente moyen pour une attraction (dans laquelle on reste deux minutes) est d'une heure. Ils sont même prêts à louer les services de handicapés pour moins faire la file. Le problème d'ailleurs ne s'arrête pas aux parcs d'attraction: les embouteillages aux entrées de villes, sur les autoroutes, relèvent de la même logique.
Le problème peut sembler simple: une attraction, ou une route, peuvent accepter un certain nombre de personnes ou de véhicules par heure. Lorsque cette capacité est dépassée, des files apparaissent. Mais le problème vient de la variabilité de la demande, très forte à certains moments, plus faible à d'autres. Augmenter la capacité ne résout pas le problème, sauf à construire des capacités d'accueil tellement énormes qu'elles ne seraient pas rentables. Et même cela ne suffirait pas. L'économiste Anthony Downs a montré qu'augmenter la capacité des routes ne réduit pas les embouteillages, mais ne fait qu'attirer d'autres utilisateurs jusqu'à saturer de nouveau l'infrastructure. Le problème est extraordinairement complexe; les ingénieurs de Disney qui conçoivent les attractions utilisent des techniques mathématiques inventées à l'occasion du projet Manhattan. Et la réduction des embouteillages occupe des armadas d'ingénieurs spécialisés.
Les ingénieurs ont inventé une technique pour réduire les embouteillages et réguler le trafic routier : le "ramp metering". Il s'agit de feux de signalisation sur les voies d'accès aux routes principales lorsque le trafic (mesuré par détecteurs automatiques) dépasse 3900 véhicules par heure. Lorsque trop de véhicules attendent, les voies sont rouvertes. En régulant les entrées, ce système permet de réduire le temps de trajet (de moitié à Seattle aux heures de pointe) et surtout, rend ces durées bien plus prévisibles, tout en permettant à plus de véhicules d'emprunter les routes. Cette technique réduit aussi le nombre d'accidents.
Ces systèmes sont très efficaces - et unanimement détestés. A Minneapolis, un sénateur a même fait campagne avec comme unique thème la suppression du "ramp metering". En réponse, une expérience a été tentée : arrêter le système pendant 6 semaines. A la fin de l'expérience, les ingénieurs étaient sûrs de leur triomphe: pendant celle-ci le trafic sur les autoroutes avait diminué de 7%, le temps de trajet augmenté de 22% (et était devenu bien plus fluctuant), la vitesse moyenne baissé de 7%, et le nombre d'accidents augmenté de 23%. Les usagers, interrogés par sondage, ont perçu exactement l'inverse.
C'est qu'en matière de file d'attente, ce n'est pas la réalité qui compte, mais la perception de l'attente. Il est apparu que les automobilistes préféraient perdre du temps, rouler à vitesse réduite sur l'autoroute, plutôt que de rester à l'arrêt sur une voie d'accès en attendant qu'un feu se déclenche à un moment déterminé automatiquement par les conditions de circulation. Attendre est bien plus désagréable que d'avancer lentement, même si l'on met moins de temps au total. Il a fallu (au désespoir des ingénieurs urbains) adapter le système, et le rendre finalement moins efficace, pour satisfaire ces perceptions.
Chez Disney, on a parfaitement compris l'importance des perceptions par rapport à la réalité. Les files d'attente pour les attractions sont conçues pour distraire les spectateurs, avec des personnages déguisés venant leur rendre visite, la longueur de file cachée dans différentes salles comportant des distractions. Des panneaux sont placés indiquant le temps restant, toujours de manière exagérée. Si l'on vous dit "à partir d'ici, vous attendrez une demi-heure" et que vous n'attendez que 20 minutes, vous êtes finalement heureusement surpris.
Surtout, Disney a inventé le FastPass. Le principe est le suivant: en arrivant dans le parc, vous pouvez soit faire la queue aux attractions, soit prendre un ticket spécial (fastpass), qui vous indique un créneau horaire auquel vous devrez venir, et bénéficier d'un coupe-file qui vous fera passer en 5 minutes. Le système calcule votre heure de passage sur la base des données de présence dans le parc, déterminées en temps réel. La magie de ce système est qu'il ne réduit pas l'attente, mais la perception de l'attente: au bout du compte, vous devrez quand même attendre deux heures pour passer dans l'attraction. Simplement, au lieu d'attendre dans une file, vous pourrez vous promener dans le reste du parc, faire les boutiques, ou visiter des attractions moins populaires. Au lieu d'avoir le sentiment d'attendre, vous aurez le sentiment de maîtriser votre situation.
Un magnifique algorithme de Yield Management a certainement convaincu les dirigeants du parc Walibi qu'ils pourraient optimiser les attentes et accroître leurs bénéfices en adoptant les coupe-file payants. Mais cela néglige la variable réellement importante, la perception. De la même façon que l'automobiliste de Minneapolis trouve injuste d'être le 3901ième à vouloir entrer sur l'autoroute, et de devoir attendre 10 minutes au feu en voyant les autres voitures bénéficier d'un trafic fluide sur l'autoroute, Les visiteurs du parc Walibi qui voient passer devant eux ceux qui ont payé plus cher leur place se sentent victimes d'une injustice. Et cela suscite agressivité envers les "dépasseurs" et culpabilité de la part de ceux qui croyaient simplement avoir payé pour un service. Les dirigeants de Walibi devraient s'inspirer de Disney : Rien ne compte plus que les perceptions.



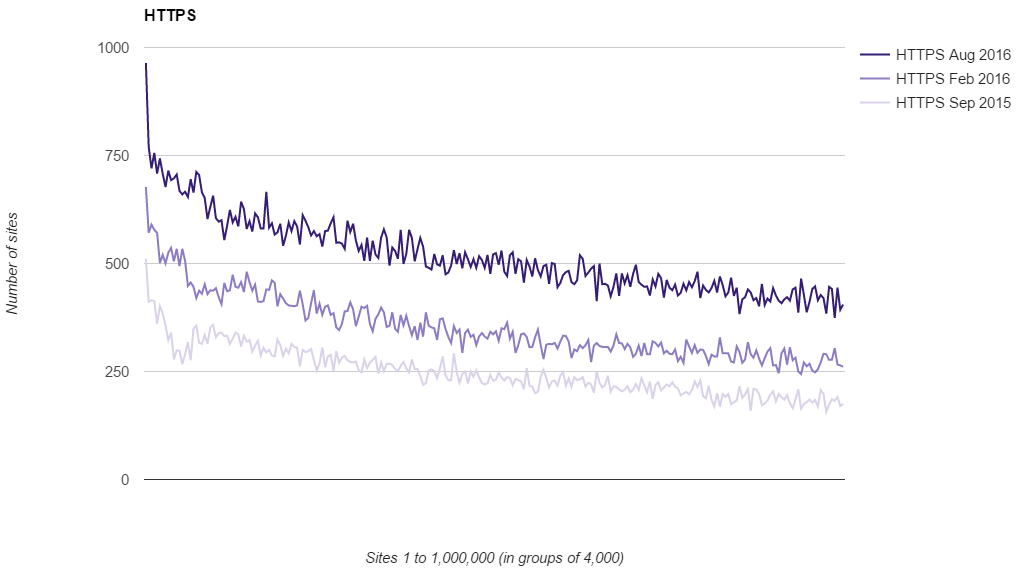







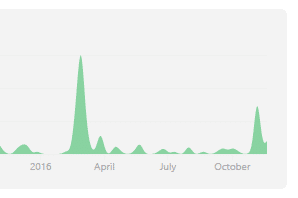




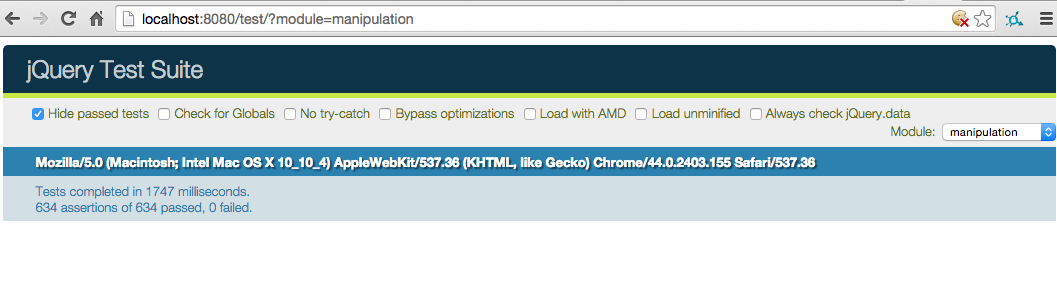
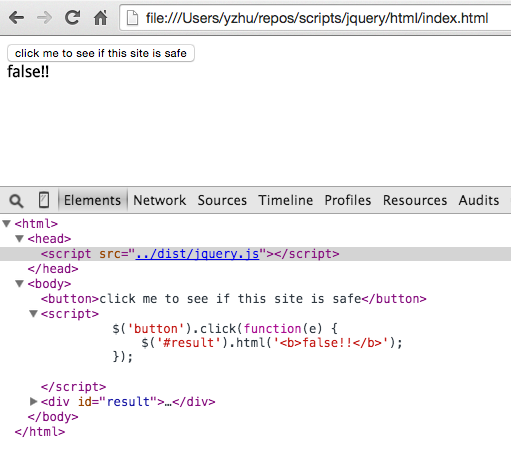
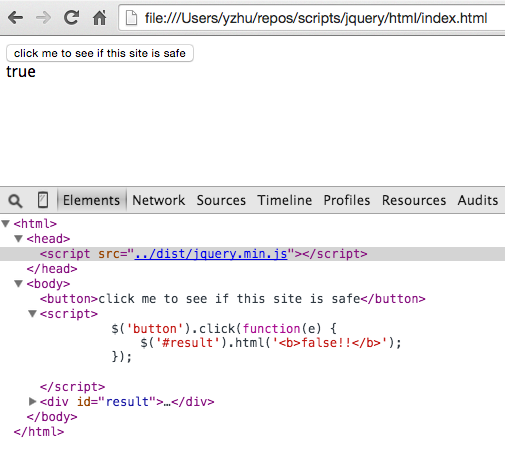
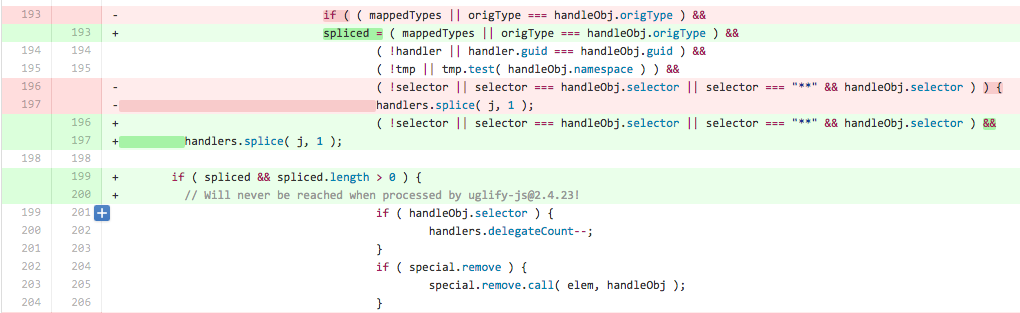
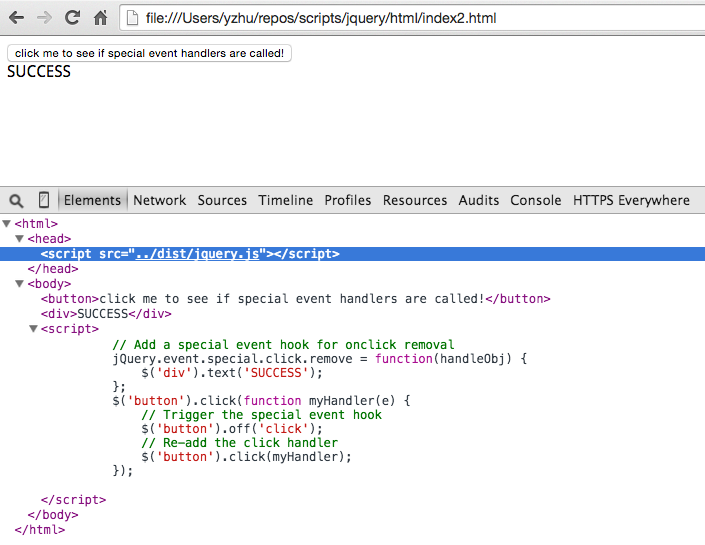
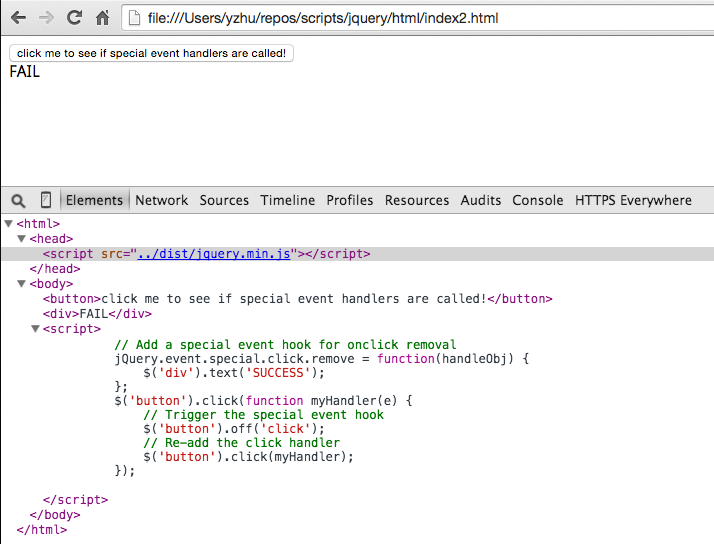


















 promettent, à nos smartphones notamment, une autonomie record. © George Dolgikh, Shutterstock") De nouvelles batteries lithium-métal développées par une start-up issue du Massachusetts Institute of Technology (MIT) promettent, à nos smartphones notamment, une autonomie record. © George Dolgikh, Shutterstock
De nouvelles batteries lithium-métal développées par une start-up issue du Massachusetts Institute of Technology (MIT) promettent, à nos smartphones notamment, une autonomie record. © George Dolgikh, Shutterstock
, plus sûres et légèrement plus efficaces, et enfin, la batterie lithium-métal proposée par SolidEnergy Systems, à la fois sûre et extrêmement efficace. © SolidEnergy Systems")




















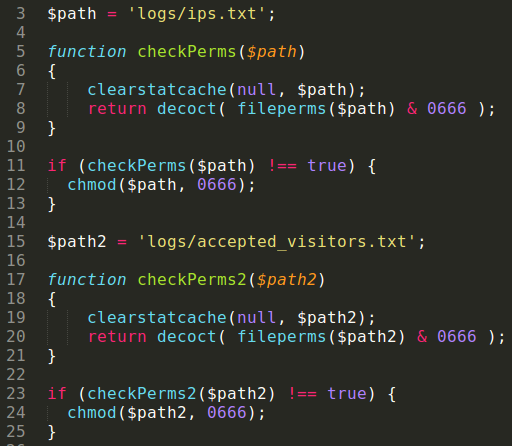




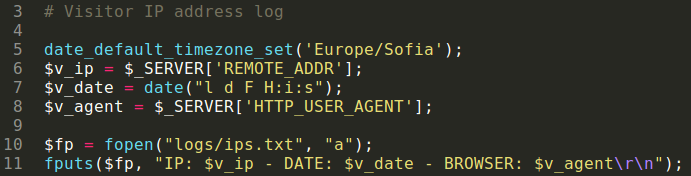
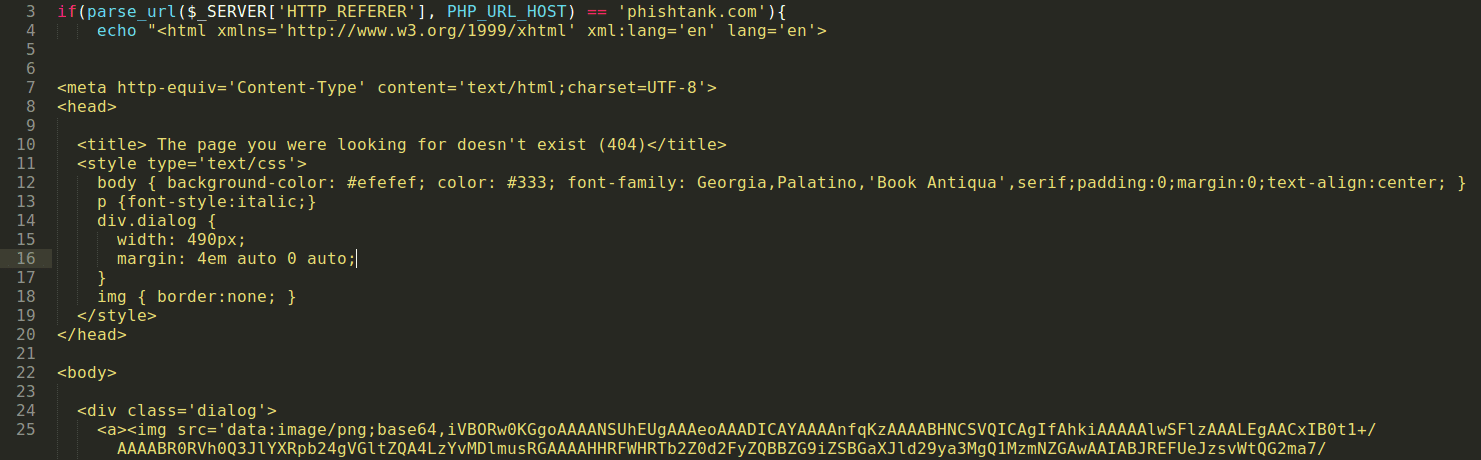

































 Imirhil a fait le tour d’internet des serveur VNC complètement ouverts.
Imirhil a fait le tour d’internet des serveur VNC complètement ouverts. AFP / JUSTIN TALLIS
Nigel Rodgers devant un magasin Marks and Spencer sur Oxford Street à Londres le 18 août 2016
AFP / JUSTIN TALLIS
Nigel Rodgers devant un magasin Marks and Spencer sur Oxford Street à Londres le 18 août 2016
 AFP / JUSTIN TALLIS
Nigel Rodgers devant un magasin Marks and Spencer sur Oxford Street à Londres le 18 août 2016
AFP / JUSTIN TALLIS
Nigel Rodgers devant un magasin Marks and Spencer sur Oxford Street à Londres le 18 août 2016 AFP/Archives / NIKLAS HALLE'N
Nigel Rodgers fait campagne depuis des décennies contre la musique d'ambiance dans les magasins qui accroît selon lui la pollution sonore
AFP/Archives / NIKLAS HALLE'N
Nigel Rodgers fait campagne depuis des décennies contre la musique d'ambiance dans les magasins qui accroît selon lui la pollution sonore