Cet article est aussi disponible en français.
I’ve been doing a monthly digest of what happens on internals@ for more than a year now, each time in French. Every now and then, some people said it would be nice to have it in English too… So, after last month, here’s my second shot at this!
BTW, here’s the RSS feed of the posts I might write in English.
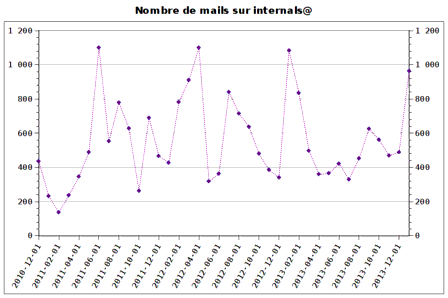
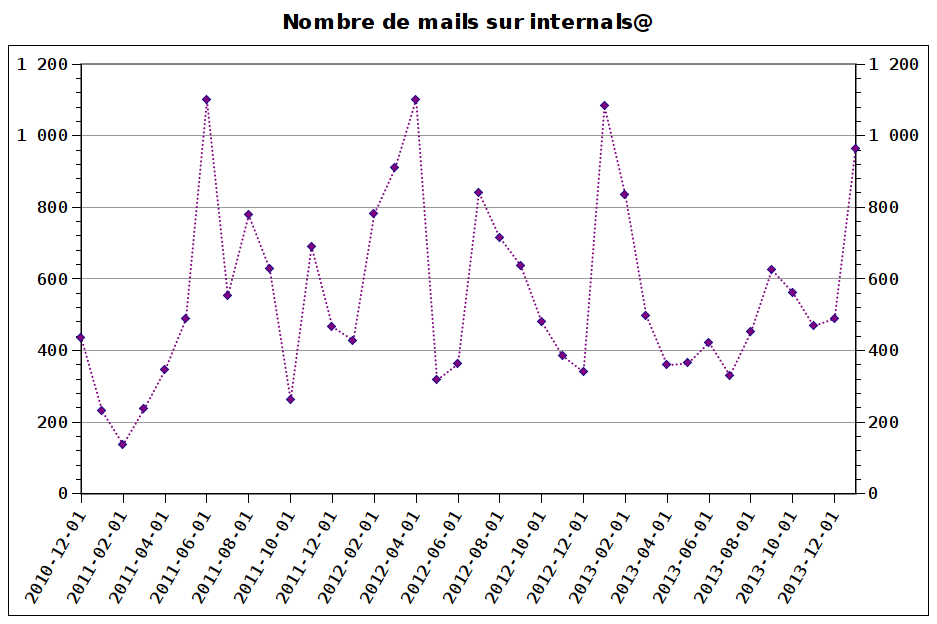
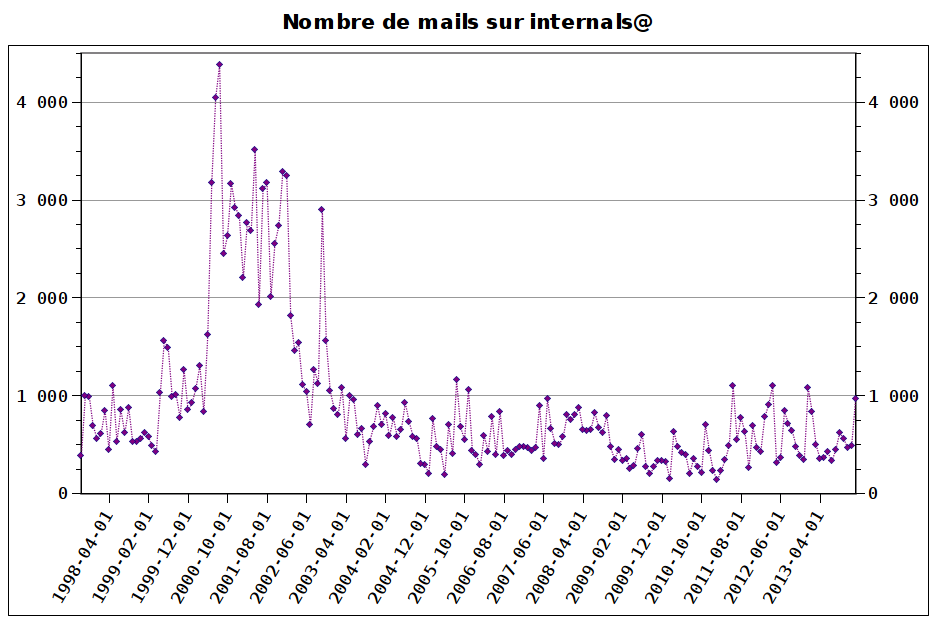
2014 started by a busy January with 963 messages, which is almost exactly twice the number of mails of the previous month.
As a graph representing the number of mails per month for the last three years, we’d get (the full history since 1998 is available here):
On January 15, Ferenc Kovacs announced he would soon tag PHP 5.6-alpha1 — this version has been published a few days later, on January 24.
The release of this first alpha version means that (in theory) new RFC cannot be proposed for PHP 5.6 anymore. Julien Pauli answered saying that no RFC will be allowed to be merged (into PHP 5.6) once the beta versions phase has started. The first beta version could be published around mid-march.
Adam Harvey has started working on the documentation page Migrating from PHP 5.5.x to PHP 5.6.x.
Some features have been marked as deprecated when PHP 5.5 was released: the /e modifier for preg_replace(), the ext/mysql extension, … According to the release cycle, those deprecated features should be removed from PHP 5.6 (and/or be moved to PECL, for extensions like ext/mysql).
As quickly noted by Andrea Faulds, we can still find a lot of code that uses mysql_*() functions, and moving the corresponding extension to PECL might cause a fair share of problems. That being said, distributions will still be able to provide this extension. Also, many tutorials (and a few well-known software) still using functions that have been deprecated for several years (or functions for which the documentation explicitly said “do not use this”) is not a reason that should stop PHP from evolving.
As some proposals under discussions would have more impact than those landed with PHP 5.3/4/5, Adam Harvey asked if it wouldn’t be time to start thinking about a new major version of PHP — it’s an idea that’s already been spoken about a few time those last months, actually.
As posted by Julien Pauli, going further than just allowing BC-breaking changes, a new major version would also be a great occasion to do some cleaning-up — afterall, PHP 5.0 did introduce a new version of Zend Engine. Ferenc Kovacs noted, as he already said a couple of months ago, that there currently is no defined process about the creation of a new major version.
In order to facilitate the switch to this future version, and to avoid it taking more than 5 years as it did for PHP 5, an idea might be to use the FIG to synchronize a step-up in the PHP version required by the most commonly used frameworks.
Rasmus Lerdorf insisted on the fact that, in his opinion, PHP should remain a pragmatic language, oriented towards the web (the corresponding needs have evolved), loosely typed, and which caters to the skill-levels and platforms of a wide range of users. Unicode support would be a must-have, performances should not be forgotten, and PDO could use some attention. All this is less sexy than new features, but we should not forget that these points meet real needs. Julien Pauli answered with a few ideas he has, such as a threaded VM or enhancements and optimisations at its level.
Andrea Faulds continued with a subject about case-sensibility in PHP: wouldn’t a future major version be an occasion to make things a little more uniform?
In parallel, Rasmus Lerdorf answered on a thread about what some call inconsistency in functions names in PHP and the parameters (and their order) they expect: since the beginning, PHP has been a wrapper for dozens (hundreds now) of libraries. These functions are not specific to PHP: they are known by a great number of developers, not because we use PHP, but because we live in a world written in C — and as soon as we venture outside of the world of PHP and scripting-languages, we fell into that other world. Still, as answered by Larry Garfield, today, only a small number of PHP developers also know C or POSIX… Actually, C is probably the second language of only a very small number of PHP developers. Following this discussion, the skeleton of a new RFC has been set up: RFC: Use alias to provide both legacy and consistent names.
On another side, Pierre Joye started a third thread about PHP 6, where he noted it is important to think about the impact some changes might have in terms of adoption of a future version of the language (an idea that’s been talked about a few times is to avoid getting in the same kind of situation than Python 2 and Python 3).
As people in the community talk more and more about HHVM, zhifeng hu asked if it would be possible to include it in PHP’s code.
Pierre Joye quickly answered that, even if it seems interesting on several counts, there were reasons to not consider this idea for now: HHVM is controlled by a single entreprise, signing a CLA is required in order to be able to participate to its development, and it’s not really portable (it requires GCC). In addition, as noted by Andrea Faulds, HHVM is not a complete implementation of PHP’s features — especially, as answered by Sara Golemon, when it comes to extensions bundled or provided through PECL.
In fact, considering the current state of PHP and HHVM, this proposal could have come a bit in advance — like a year or two.
Sara Golemon has written the RFC: __debugInfo(). It’s goal is to expose debugging informations (already known internally) to user-space — by adding a new magic method called __debugInfo(). This proposal would allow to customize debug output.
Amongst the reactions, some noted that a name such as __dump() might be more explicit for PHP developers who don’t know how the engine works internally, and others remarked this feature should also be added to the Reflection API. It should also be noted that, with such a feature, var_dump() might no longer always tell the truth.
Kevin Ingwersen has revived a thread about the RFC: Named Parameters, written in September 2013 and which had not been discussed much those last weeks.
Many would like to see this kind of feature in PHP — even if others noted we’d have to write more code for function-calls. Actually, named-parameters would mostly help for functions that accept a large number of parameters.
Nikita Popov, author of that RFC, did a quick summary: generally speaking, the main questions all have an answer, and the implementation of this feature is ready. Still, it is required to have a look on all functions exposed by PHP to make sure their parameters definitions are correct (for example, they must have coherent names), and to make sure that parameters parsing works, everywhere, for those same internal functions. Those two points require a great deal of work, and chances are low it’ll be done before PHP 5.6’s feature freeze.
Philip Sturgeon has written the RFC: Array Of, which intends to enhance PHP’s type-hinting, to allow a function to specify it expects an array of elements that are all of a given type. For example:
function test(SplFileObject[] $files) {
var_dump($files);
}
The firsts reactions seemed to show this idea interested some people — and the subject, with about 100 mails in one week, has been one of the most discussed ones on internals@ this month! It didn’t prevent a few hard reactions or ones underlining that this kind of feature (contrarily to other RFCs that passed in the last months) can already be implemented in PHP or doesn’t quite fit with a part of the language’s philosophy. An answer to some of these opinions has been posted here.
A question that’s been asked rapidly is if it would be possible to specify whether some of the array’s elements might be NULL (which could lead to errors), and with what kind of syntax. Of course, impact on performances should not be forgotten — but would also exist if that kind of verifications was done in user-space.
As a matter of fact, as noted by Julien Pauli a bit later in the conversation, this RFC might highlight the fact PHP lacks a notion of “typed array” — that would go farther than type-checking when passed as a parameter. Even if this RFC was not related to these points, some talked about type-hinting for scalar types and about Generics.
In parallel, Sara Golemon posted a summary of what HHVM accepts for typed-arrays and Generics — the goal being to reach a common syntax and to illustrate a few specific cases they met on their side.
Following this, Philip Sturgeon asked if there was some interest for Generics — which might have some influence on the syntax of Array Of.
By the way, it seems this thread once again highlighted the fact that type-hinting and its possible extensions is still quite a hot matter!
Yasuo Ohgaki has written the RFC: Multibyte Char Handling, in which he proposes to add several new functions to deal with strings using multi-bytes encodings.
Several approaches could be possible, actually: adding some new functions, using the current locale (which seems to be a bad idea), or even adding some kind of encoding parameters to existing functions, as it’s been done for htmlspecialchars().
As noted by Derick Rethans, instead of yet again adding new functions (that PHP developers will need to use when necessary), a better solution would be a real support of Unicode by PHP — like what was planned for PHP 6 several years ago!
Following this discussion, the RFC: Alternative implementation of mbstring using ICU has also been updated.
Anatol Belski announced discussions could begin on RFC: 64 bit platform improvements for string length and integer in zval, as the implementation was going well (there have been around 200 mails on that matter this month!).
Trying to summarize things in a few words: the objective here is to enhance support of 64 bits platforms by PHP (especially under Windows), and this should not have any impact on existing 32 bits platforms.
A non-negligible consequence is that it would be necessary to update all existing extensions to change some function calls (like zend_parse_parameters() and *printf()) and some macro usages. This would require between a few hours and a few days of work for each extension. But there is a real risk, as all extensions, including those developed by companies1 for their internal needs and not made public would have to be updated — and it’s quite probable not all of them will be before PHP 5.6 is released. Because of this, it might be a change too impacting for PHP 5.6.
Votes have been opened at the end of the month; which means results are to be expected for next month. Some first explanations about negative votes insisted on the too great impact of this change for PHP 5.6, and the fact it might be better suited for a future major version.
Following this discussion on 64 bits enhancements, Anatol Belski created the RFC: Removal of dead SAPIs. As Julien Pauli posted, these old SAPI which, for some, date back from the 90s and are not used nor maintained anymore, could be removed.
Right on the first day of this month, Daniel Lowrey annouced the votes had ended on RFC: TLS Peer Verification. With 25 votes “for” and no vote “against”, here’s a security enhancement that will come with PHP 5.6. A few days later, he continued on that subject, with the new RFC: Improved TLS Defaults that complements the previous one.
Ondřej Hošek opened votes on the RFC: ldap_modify_batch, which meant to add a new function to the ldap extension. With 5 votes “for” and 0 vote “against”, it passed and the new function should make it to PHP >= 5.4.
Sara Golemon wrote the RFC: GMP Floating Point Support, by extracting a part of RFC: GMP number as PHP number which has been retired.
The RFC: Argument Unpacking had been submitted to votes at the end of last month. With 32 votes “for” et 2 votes “against”, it passed. This new feature, planned for PHP 5.6, complements RFC: Syntax for variadic functions which passed a few months ago.
Daniel Lowrey has started working on allowing a non-blocking mode for ext/pgsql. About that extension, Yasuo Ohgaki has implemented support for objects bigger than 2 GB (which landed with PostgreSQL 9.3).
Yasuo Ohgaki announced the end of the voting period for RFC: Use default_charset As Default Character Encoding: with 8 votes “for” et 1 vote “against”, it passed. He also indicated working of the RFC: Multibyte Char Handling and that he needed comments on that one.
Dmitry Stogov said he started working on a possible new memory manager for PHP. For now, his prototype only works on Linux (on a non-debug build of PHP), and it seems it could bring a 3% performance gain for Drupal and between 12% and 15% on a portion of code that does a lot of objects constructions.
Sara Golemon wrote the RFC: Module API Inspection, which would add two options to PHP’s command-line, allowing one to determine the version of zend modules accepted by PHP, and the version against which an extension has been compiled. Still, the implemented solution isn’t perfect, and it is possible it might not be accepted.
Andrea Faulds opened votes on RFC: Alphanumeric Decrement. With 21 votes “against” and no vote “for”, its has been unanimously rejected.
The voting period has begun on the RFC: Introduce session options - read_only, unsafe_lock, lazy_write and lazy_destroy. Following this, discussions on the subjects have re-started, and votes have been canceled, as the RFC will be updated.
Finally, right at the end of the month, Gordon Oheim opened votes on RFC: Automatic Property Initialization, which aims to facilitate properties’ initialization when we are writing a constructor, using a syntax like this:
// would assign properties and provide $z as a local variable
public function __construct($this->x, $this->y, $z)
{
// do something with $z locally
}
We’ll see next month how things end up ;-)
internals@lists.php.net is the mailing-list of the developers of PHP; it is used to discuss the next evolutions of the language and to talk about enhancement suggestions or bug reports.
This mailing-list is public and anyone can subscribe from the page Mailing Lists, or read its archives using HTTP from php.internals or through the news server news://news.php.net/php.internals.
-
It seems Yahoo might have about 500 PHP extensions PHP internally, according to this mail. ↩























 Lorsqu'elle sera pleinement opérationnelle, la constellation Galileo comptera 30 satellites positionnés à 23.222 kilomètres d’altitude. © OHB
Lorsqu'elle sera pleinement opérationnelle, la constellation Galileo comptera 30 satellites positionnés à 23.222 kilomètres d’altitude. © OHB sont présentes dans le sang avec les globules rouges (à gauche) et les globules blancs (à droite). On pourra probablement bientôt les produire artificiellement et en grande quantité afin de les utiliser pour une transfusion. © Wikimedia Commons, DP") Les plaquettes (au centre) sont présentes dans le sang avec les globules rouges (à gauche) et les globules blancs (à droite). On pourra probablement bientôt les produire artificiellement et en grande quantité afin de les utiliser pour une transfusion. © Wikimedia Commons, DP
Les plaquettes (au centre) sont présentes dans le sang avec les globules rouges (à gauche) et les globules blancs (à droite). On pourra probablement bientôt les produire artificiellement et en grande quantité afin de les utiliser pour une transfusion. © Wikimedia Commons, DP
 sont des éléments du sang qui ne possèdent pas de noyau. Elles sont formées par fragmentation des mégacaryocytes, de grandes cellules contenues dans la moelle osseuse.")

{kind=link}