And then there is the Rhône glacier right next to it. Only 200 steps away, it offers a spectacular close-up view of an icy scenery like no other place on Earth. The Belvédère Hotel is raised on a rock, practically over the glacier, so the view is available right from the hotel’s balconies while guests are slurping their morning coffees. Not only that but from the 1890s onward, an ice chamber inside the glacier has been carved out, re-drilled and maintained as a walkable tunnel. (much more info at the link)
This is a video of a newly recognized species of bird-of-paradise (the Vogelkop Superb bird-of-paradise) from Papua, New Guinea trying to impress a lady with a fancy dance and his iridescent plumage. Admittedly, those were some solid dance moves. The female is not impressed though and flies off. I can't say I blame her, the iridescent plumage on his face makes him look like some sort of creepy phantom bird. And who wants to raise a family with a ghost bird? Why are you raising your hand?
Keep going for the video.
Nestled amongst hundreds of stunning shots of the aurora borealis taken by Finnish photographer Jani Ylinampa is a series of four photos of Kotisaari, showing the island from a drone’s point of view for each of the four seasons (clockwise from upper left): spring, summer, autumn, and winter.
But seriously, go check out Ylinampa’s Instagram account…it’s packed with aurora borealis photos. What a magical place to live, where the sky lights up like that all the time.
Suporte: Como assim você não quer mais ir à escola?! Se não estudar como vai escrever sem erros?
Garotinho: Corretor ortográfico.
Suporte: Tá… mas quando você precisar resolver uma operação matemática, como irá fazer?
Garotinho: Com a calculadora. Conhece?
Suporte: E onde você espera ganhar dinheiro sendo um completo ignorante?
Garotinho: YouTube.
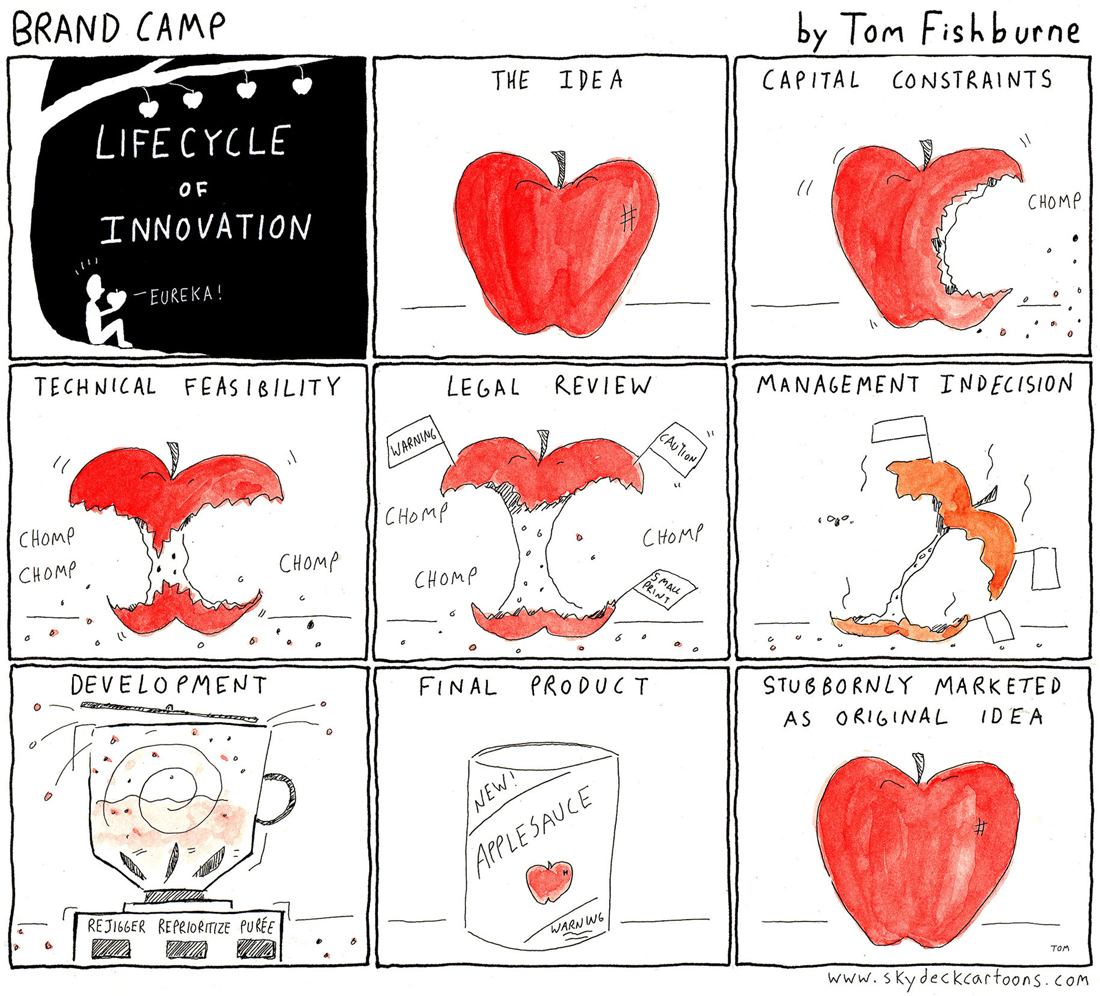
New ideas inherently carry risk. And there’s often friction between the risk profiles of our ideas and the risk tolerances of our organization. How we navigate and manage that friction impacts what, if anything, makes it through the gauntlet of the innovation process.
Risk tolerance can vary across different parts of the business. Ultimately we need all of these different points of view to sense-check ideas as we collectively bring them to life. All of those different perspectives can make an idea stronger. But silo-thinking often gets in the way.
"If marketing kept a diary, this would be it."
- Ann Handley, Chief Content Officer of MarketingProfs
Years ago, I saw innovation legend Doug Hall lead a workshop on managing risks. He had a few words of advice that stuck with me:
“Meaningfully unique ideas spark fear. Fear causes shut down. The secret to reducing fear is to make the unknown known. We need to turn killer issues into manageable threats”
Here are a few related ideas that I’ve drawn over the years.
Com US$ 258 milhões, Vingadores: Guerra Infinita se tornou a maior abertura em todos os tempos nos EUA. O filme tirou Star Wars: O Despertar da Força do topo e já em seu primeiro fim de semana arrecadou impressionantes US$ 640 milhões. Com isso uma velha tradição de Hollywood aconteceu novamente e tudo começou em 1977.
Era dezembro daquele ano e Star Wars: Uma Nova Esperança tirou Tubarão do topo das bilheterias. Steven Spielberg e George Lucas eram velhos amigos, e Spielberg resolveu parabenizar Lucas pelo feito com uma mensagem.
Não demorou muito e em 1982 E.T. – O Extraterrestre quebrou o recorde de Star Wars, aí foi a vez de George Lucas retribuir a gentiliza.
Só em 1997 o recorde foi batido novamente com… adivinha só? Star Wars e seu relançamento nos cinemas. Mais uma vez os Reis do Box Office trocaram parabenizações.
A farra dos amigos acabou em 1999 quando Titanic chegou arregaçando com tudo. James Cameron não estava muito ligado na brincadeira, mas Lucas fez questão de seguir com o combinado.
Só que o otário do James Cameron quase deixou a brincadeira morrer em 2012, quando Os Vingadores ultrapassou a bilheteria doméstica de Titanic no primeiro fim de semana. O tempo passou e a cultura pop sofreu calada, até que em 2015 Jurassic World destronou Vingadores. A Marvel fez questão de parabenizar:
Só que os dinossauros não ficaram muito tempo no topo até que em dezembro do mesmo ano, O Despertar da Força deu novamente a um filme de Star Wars o posto de maior abertura em todos os tempos.
Abril de 2018 e o recorde foi quebrado, mas agora estamos todos em casa sob as asas da Disney. Sendo assim, é óbvio que a brincadeira não vai acabar.
E segue o jogo. Quem vai tirar Thanos do topo das bilheterias?
NASA is ready to launch its next big mission to the Red Planet: Mars InSight!
First, about the launch. It's scheduled for tomorrow, Saturday, May 5, 2018, at 11:05 UTC. That’s 04:05 Pacific time, yes, a.m., so if you want to see it you'll have to be up early. In an unusual move, the launch will be from Vandenberg Air Force Base in California. Normally, interplanetary missions are launched from Florida, but due to some peculiar circumstances the site was moved to California. It takes more power to launch to Mars from California, but happily the rocket, an Atlas V, has that to spare.
You should be aware that the weather as of now isn't looking great for launch; early fog reduces visibility. However, the launch window extends to June 8, with an opportunity every day (though the time of day varies a bit). Hopefully they can get this candle lit earlier rather than later.
Once launched, InSight will travel for about six months to get to Mars, and is scheduled to set down on the surface on November 26, assuming it launches tomorrow. It's a lander — the first NASA mission to Mars since MAVEN, and the first planned to touch down since Curiosity — and will be looking into marquakes.
Zoom In
The Mars lander InSight will sit on the surface and measure marsquakes, heat transport, and the planet’s wobble, all to help us understand the internal structure of the Red Planet. Credit: NASA/JPL-Caltech
Yes, you read that right. InSight stands for Interior Exploration using Seismic Investigations, Geodesy and Heat Transport. It has very sensitive seismometers on it (called SEIS, for Seismic Experiment for Interior Structure), designed to investigate seismic activity on Mars. This is critical to understand the planet's interior. In fact, it's how we've learned so much about our own planet's innards! As waves travel through the interior, they move through different material and can be changed (for example, some kinds of waves can't travel through liquids, which is how we found out part of Earth's core is molten iron), revealing Mars' structure. It'll also detect meteorite impacts! That's pretty nifty.
One of the scientists on the team that built the seismometers wrote an article about them that's fun to read; he talks about some issues they had just a few weeks ago that threatened the launch! It was resolved, but what was causing it is why the article is cool. Go check it out.
Zoom In
Mars InSight is equipped with a fleet of instruments to probe the planet’s interior. The complete description is at the credit link. Credit: NASA/JPL-Caltech
InSight is also equipped with a heat probe (Heat Flow and Physical Properties Probe, or HP3) that will penetrate the surface to see how heat flows up from the interior. This is an ambitious experiment; the probe is supposed to hammer itself an amazing 5 meters down into the Martian surface, far more than has even been attempted or achieved before.
Very interestingly to me, a set of radio antennae (Rotation and Interior Structure Experiment, or RISE) will measure the planet’s wobble. Have you ever watched a top spinning on a flat surface? The axis of rotation of the top will make a circle in a process called precession. This is due to friction with the table applying an off-center force (called torque) to the top. Other forces can cause the precession itself to wobble as well, and this is called nutation.
How a spinning object precesses and nutates depends on the forces acting on it, and the structure of the object. The forces in this case are mostly from the gravity of the Sun and Jupiter. As Mars wobbles, the rotation rate is affected very, very slightly. This can be measured with extreme accuracy, though, by sending radio signals to Mars and having them reflected back using radio antennae. Doing this with previous missions like Viking and Pathfinder revealed that Mars does precess, gave hints that Mars is differentiated — that is, has different layers of materials in it — and even gave an estimate of the size of its core.
With InSight, planetary scientists hope to nail that down much better, and also determine whether the core of Mars is liquid or solid. I think it’s interesting that we don't know that yet! Hopefully, in just a year or so, we'll find out.
But first things first. The mission has to get off the ground. I'll note that launch of Mars InSight was originally supposed to be in 2016! It was delayed when leaks were found too close to the launch date, and the mission had to be pulled back. The problems were fixed, but orbital mechanics — the relative positions of Mars and Earth — dictated that the next launch window would be 26 months later, so here we are.
Let's hope everything goes nominally (NASAese for "no problems") and we see the roar of the Atlas flinging this mission skyward!
Sabe aquelas pessoas que se sentem muito felizes quando veem objetos em situações visualmente agradáveis? Se você é uma delas, então vai adorar estas imagens.
As ktschwarz pointed out in the comments on yesterday's post "Easy going crazy", Google Translate is disposed to recognize text consisting only of vowels and spaces as Hawaiian, and to hallucinate a coherent if sometimes chilling translation into English.
In order to exercise this option more fully, I wrote and tested a simple R script to generate random messages of this type:
N = 150
Letters = c("a","e","i","o","u"," ")
cat(sprintf("%s\n",paste0(sample(Letters,N,replace=TRUE),collapse="")))
Confira outra sequência de fotos interessantes e suas histórias.
Essa é a bolinha que fica dentro de uma lata de spray
E essa é uma bola de golfe cortada no meio
O maior navio cargueiro do mundo: Maersk Triple E
O interior de uma mesa de bilhar
Cactus cortado
Muita gente sempre quis saber o que está por baixo dos pêlos de um Furby… taí
Interior de uma granada
Há 10 anos, a versão do Facebook para celular era assim
Isso é o que está por baixo de um hidrante
O interior de um cartão de crédito
Isqueiro Zippo cortado no meio
Se você já se perguntou como é o interior de um pneu, está aí
E aqui você confere um tanque de combustível pronto para ser instalado embaixo de um posto de combustíveis
Uma cobra rei tentou matar uma python. Ambas morreram
Este é um sistema nervoso humano intacto que foi dissecado por dois estudantes de medicina em 1925. Levou mais de 1500 horas e existem apenas 4 destes no mundo
Veneza
Novas fotos da NASA mostram que Marte parece muito com nosso lar
O Pastebin é um dos serviços de postagem mais usados por estudantes, profissionais de TI e hackativistas pelo mundo
A operadora NET bloqueou o acesso ao Pastebin para usuários de seus planos, segundo uma postagem no Reddit. Usuários vêm reclamando para a operadora desde quinta-feira passada (8) que o serviço de colagem de código fonte não está acessível. Hoje (15), a conexão parece que foi reestabelecida pela NET.
É impossível alegar falha por parte da CloudFlare ou interrupções de roteamento criada por terceiros já que há rota para todos os demais IPs
O filme é baseado no best-seller de Ernest Cline e se passa em 2044
A Warner Bros. Pictures divulgou um novo trailer do filme Ready Player One(Jogador Nº 1), adaptação de Steven Spielberg para o best-seller de Ernest Cline.
A história do longa se passa no ano de 2044, em uma sociedade à beira do colapso quando as pessoas passam a se refugiar em uma realidade virtual chamada Oasis.
Requerente é a mesma empresa responsável pela suposta loja oficial da empresa no Mercado Livre
Parece cada vez mais próximo o lançamento oficial do Switch no Brasil: embora a Nintendo não confirme que está voltando ao país, o console híbrido já recebeu a homologação da Anatel, conforme descobriu o canal DigPlay. Emitidos no dia 8 de fevereiro, os documentos se referem tanto à plataforma de mesa quanto aos controles conhecidos como Joy-Cons.


 This is a video of a newly recognized species of bird-of-paradise (the Vogelkop Superb bird-of-paradise) from Papua, New Guinea trying to impress a lady with a fancy dance and his iridescent plumage. Admittedly, those were some solid dance moves. The female is not impressed though and flies off. I can't say I blame her, the iridescent plumage on his face makes him look like some sort of creepy phantom bird. And who wants to raise a family with a ghost bird? Why are you raising your hand?
Keep going for the video.
This is a video of a newly recognized species of bird-of-paradise (the Vogelkop Superb bird-of-paradise) from Papua, New Guinea trying to impress a lady with a fancy dance and his iridescent plumage. Admittedly, those were some solid dance moves. The female is not impressed though and flies off. I can't say I blame her, the iridescent plumage on his face makes him look like some sort of creepy phantom bird. And who wants to raise a family with a ghost bird? Why are you raising your hand?
Keep going for the video.




 Order Now
Order Now





































































































{kind=link}
{kind=link}