
If you’re getting health care in the U.S., chances are your providers are now trying to give you a better patient experience through a website called MyChart.
This is supposed to be yours, as the first person singular pronoun My implies. Problem is, it’s TheirChart. And there are a lot of them. I have four (correction: five*) MyChart accounts with as many health care providers, so far: one in New York, two in Santa Barbara, one in Mountain View, and one in Los Angeles. I may soon have another in Bloomington, Indiana. None are mine. All are theirs, and they seem not to get along. Especially with me. (Some later correction on this below, and from readers who have weighed in. See the comments.)
Not surprisingly, all of them come from a single source: Epic Systems, the primary provider of back-end information tech to the country’s health care providers, including most of the big ones: Harvard, Yale, Mayo, UCLA, UChicago, Duke, Johns Hopkins, multiple Mount Sinais, and others like them. But, even though all these MyChart portals are provided by one company, and (I suppose) live in one cloud, there appears to be no way for you, the patient, to make those things work together inside an allied system that is truly yours (like your PC or your car is yours), or for you to provide them with data you already have from other sources. Which you could presumably do if My meant what it says.
The way they work can get perverse. For example, a couple days ago, one of my doctors’ offices called to tell me we would need to have a remote consult before she changed one of my prescriptions. This, I was told, could not be done over the phone. It would need to be done over video inside MyChart. So now we have an appointment for that meeting on Monday afternoon, using MyChart.
I decided to get ahead of that by finding my way into the right MyChart and leaving a session open in a browser tab. Then I made the mistake of starting to type “MyChart” into my browser’s location bar, and then not noticing that the top result was one of the countless other MyCharts maintained by countless other health care providers. But this other one looked so much like one of mine that I wasted an hour or more, failing to log in and then failing to recover my login credentials. It wasn’t until I called the customer service number thankfully listed on the website that I found I was trying to use the MyChart of some provider I’d never heard of—and which had never heard of me.
Now I’m looking at one of my two MyCharts for Santa Barbara, where it shows no upcoming visits. I can’t log into the other one to see if the Monday appointment is noted there, because that MyChart doesn’t know who I am. So I’m hoping to unfuck that one on Monday before the call on whichever MyChart I’ll need to use. Worst case, I’ll just tell the doctor’s office that we’ll have to make do with a phone call. If they answer the phone, that is.
The real problem here is that there seem to be hundreds or thousands of different health care providers, all using one company’s back end to provide personal health care information to millions of patients through hundreds or thousands of different portals, all called the same thing (or something close), while providing no obvious way for patients to gather their own data from multiple sources to use for their own independent purposes, both in and out of that system. Or any system.
To call this fubar understates the problem.
Here’s what matters: Epic can’t solve this. Nor can any or all of these separate health care systems. Because none of them are you.
You’re where the solution needs to happen. You need a simple and standardized way to collect and manage your own health-related information and engagements with multiple health care providers. One that’s yours.
This doesn’t mean you need to be alone in the wilderness. You do need expert help. In the old days, you used to get that through your primary care physician. But large health care operations have been hoovering up private practices for years, and one of the big reasons for that has been to make the data management side of medicine easier for physicians and their many associated providers. Not to make it easier for you. After all, you’re not their customer. Insurance companies are their customers.
In the midst of this is a market hole where your representation in the health care marketplace needs to sit. I know just one example of how that might work: the HIE of One. (HIE is Health Information Exchange.) For all our sakes, somebody please fund that work.
Far too much time, sweat, money, and blood is being spilled trying to solve this problem from the center outward. (For a few details on how awful that is, start reading here.)
While we’re probably never going to make health care in the U.S. something other than the B2B insurance business it has become, we can at least start working on a Me2B solution in the place it most needs to work: with patients. Because we’re the ones who need to be in full command of our relationships with our providers as well as with ourselves.
Health care, by the way, is just one category that cries out for solutions that can only come from the customers’ side. Customer Commons has a list of fourteen, including this one.
The first of these is identity. The self-sovereign approach to that would start with a wallet that is truly mine, and includes all these MyCharts. Hell, Epic could do one. Hint hint.
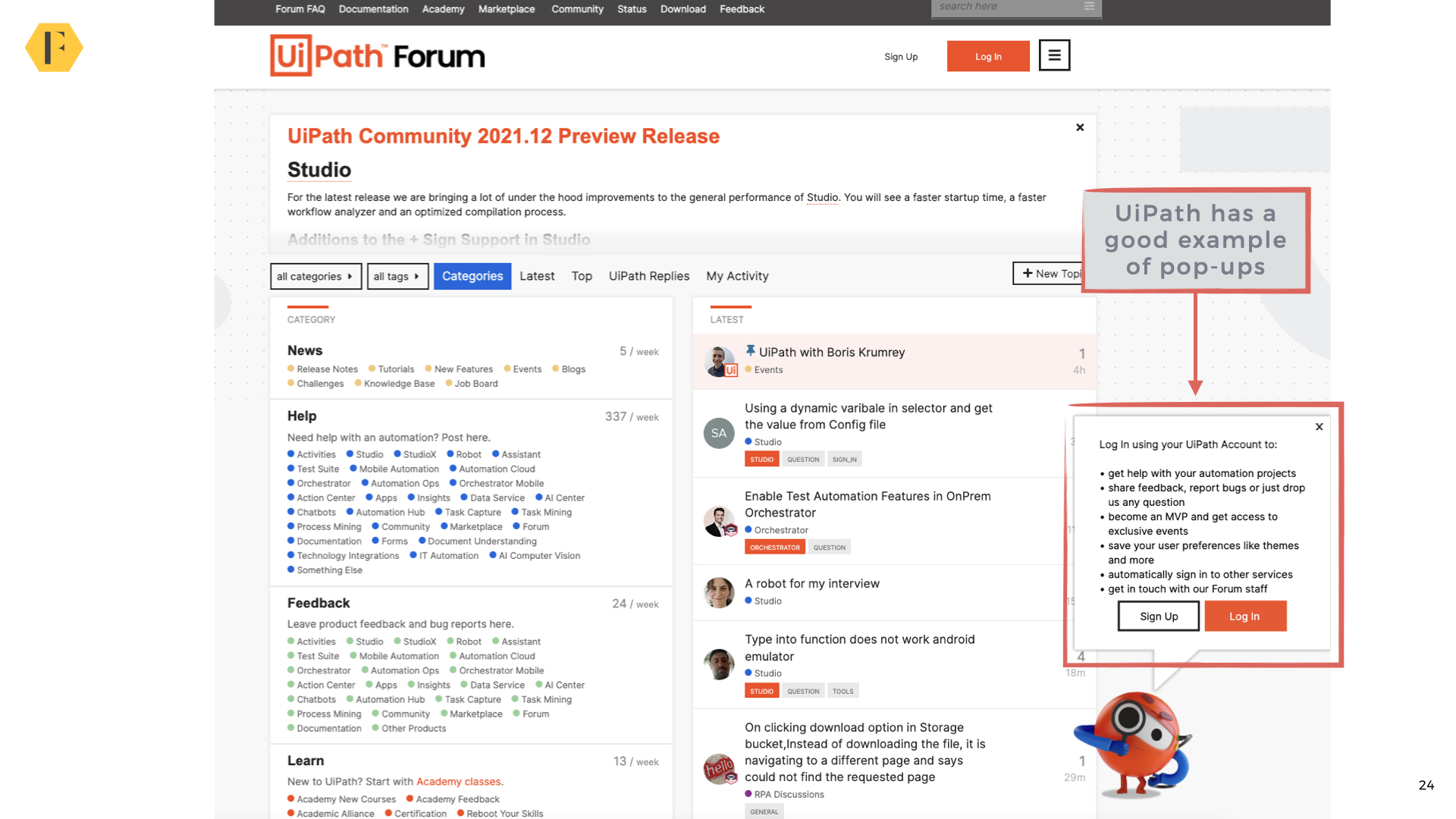
*Okay, now it’s Monday, and I’m a half-hour away from my consult with my doctor, via Zoom, inside MyChart. Turns out I was not yet registered with this MyChart, but at least there was a phone number I could call, and on the call (which my phone says took 14 minutes) we got my ass registered. He also pointed me to where, waaay down a very long menu, there is a “Link my accounts” choice, which brings up this:

Credit where due:
It was very easy to link my four known accounts, plus another (the one in Mountain View) that I had forgotten but somehow the MyChart master brain remembered. I suspect, given all the medical institutions I have encountered in my long life, that there are many more. Because in fact I had been to the Mountain View hospital only once, and I don’t even remember why, though I suppose I could check.
So that’s the good news. The bad news remains the same. None of these charts are mine. They are just views into many systems that are conditionally open to me. That they are now federated (that’s what this kind of linking-up is called) on Epic’s back end does not make it mine. It just makes it a many-theirs.
So the system still needs to be fixed. From our end.



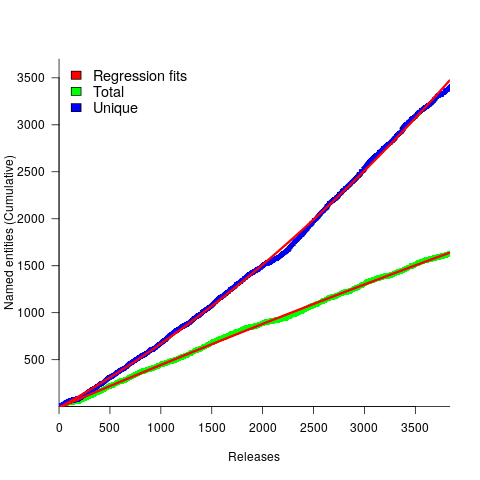
 , where:
, where:  is a constant and
is a constant and  is the number of days since the start of the interval fitted; the second (middle) black line is a fitted straight line.
is the number of days since the start of the interval fitted; the second (middle) black line is a fitted straight line.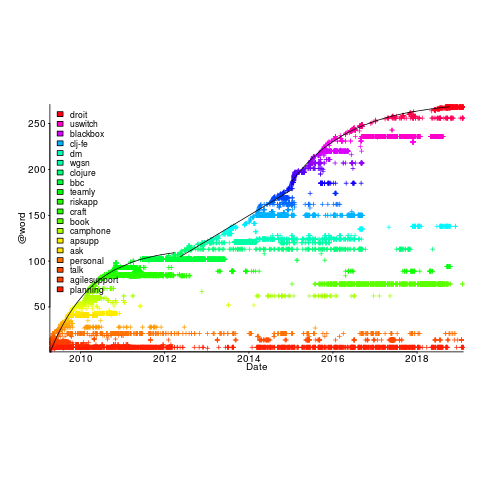
































 '
'


 My first prediction: Disinformation becomes the most important story of the year. At the time I wrote those words, Trump’s Big Lie was only two months old, and January 6th was just another day on the calendar. A year later, that Big Lie has spawned countless others, culminating in one of the most damaging shifts in our nation’s politics since the Civil War. The Republican party is now fully captured by bullshit, and countless numbers of local, state, and national politicians are busy undermining democracy thanks to the Big Lie’s power. A significant percentage of the US population has become
My first prediction: Disinformation becomes the most important story of the year. At the time I wrote those words, Trump’s Big Lie was only two months old, and January 6th was just another day on the calendar. A year later, that Big Lie has spawned countless others, culminating in one of the most damaging shifts in our nation’s politics since the Civil War. The Republican party is now fully captured by bullshit, and countless numbers of local, state, and national politicians are busy undermining democracy thanks to the Big Lie’s power. A significant percentage of the US population has become  My third prediction: AI has a mid-life crisis. This one bears a bit more explanation. From my post: “2021 will be the year society takes a step back and thinks hard about where this is all going … by year’s end, the AI narrative will be as much about hand wringing and regulatory oversight as it is about revolutionary breakthroughs.” I think I got this right as well, but I can’t prove it. The year started with a leading AI researcher calling the entire space a “
My third prediction: AI has a mid-life crisis. This one bears a bit more explanation. From my post: “2021 will be the year society takes a step back and thinks hard about where this is all going … by year’s end, the AI narrative will be as much about hand wringing and regulatory oversight as it is about revolutionary breakthroughs.” I think I got this right as well, but I can’t prove it. The year started with a leading AI researcher calling the entire space a “ Proving I should really stay away from geopolitics, Prediction #10: Africa rising, China…in question. I got the headline right – Africa is certainly rising, and China is a big question mark – but my detail was very wrong: “the breakout continent of 2021 will be
Proving I should really stay away from geopolitics, Prediction #10: Africa rising, China…in question. I got the headline right – Africa is certainly rising, and China is a big question mark – but my detail was very wrong: “the breakout continent of 2021 will be {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}