Once you get the hang of writing these tests, it’s mostly boilerplate, so I figured my team of assistants could help. I recruited Cody, GitHub Copilot, and Unblocked — with varying degrees of success. Then I realized I hadn’t yet tried creating a GPT. As OpenAI describes them, “GPTs are custom versions of ChatGPT that users can tailor for specific tasks or topics by combining instructions, knowledge, and capabilities.”
I’m super excited to share that Konstantina is joining the Customer Experience team to help with the community in SUMO. Some of you may already know Konstantina because she’s been around in Mozilla for quite a while. She’s transitioning internally from the Community Programs team under Marketing to the Customer Experience team under the Strategy and Operation.
Here’s a bit more about Konstantina in her own words:
Hi everyone, my name is Konstantina and I am very happy I am joining your team! I have been involved with Mozilla since 2011, initially as a volunteer and then as a contractor (since late 2012). During my time here, I have had a lot of roles, from events organizer, community manager to program manager, from working with MDN, Support, Foxfooding, Firefox and many more. I am passionate about communities and how we bring their voices to create great products and I am joining your team to work with Kiki on creating a great community experience. I live in Berlin, Germany with my partner and our cat but I am originally from Athens, Greece. Fun fact about me, I studied geology and I used to do a lot of caving, so I know a lot about ropes and rappelling (though I am a bit rusty now). I also love building legos as you will soon see from my office background. Can’t wait to get to know you all more
Please join me to welcome Konstantina (back) to SUMO!
Cluetrain is a word that did not exist before we made it up in 1999. It is still tweeted almost daily on X (née Twitter), and often on BlueSky and Threads, the Twitter wannabes. And, of course, on Facebook. Searching Google Books no longer says how many results it finds, but the last time I was able to check, the number of books containing the word cluetrain was way past 10,000.
So by now cluetrain belongs in the OED, though nobody is lobbying for that. In fact, none of the authors lobbied for Cluetrain much in the first place. Chris and David wrote about it in their newsletters, and I said some stuff in Linux Journal. But that was about it. Email was the most social online medium back then, so we did our best with that. We also decided not to make Cluetrain a Thing apart from its website. That meant no t-shirts, bumper stickers, or well-meaning .orgs. We thought what it said should succeed or fail on its own.
Among other things, it succeeded in grabbing the interest of Tom Petzinger, who devoted a column in The Wall Street Journal to the manifesto.* And thus a meme was born. In short order, we were approached with a book proposal, decided a book would be a good way to expand on the website, and had it finished by the end of August. The first edition came out in January 2000—just in time to help burst the dot-com bubble. It also quickly became a bestseller, even though (or perhaps in part because) the whole book was also published for free on the Cluetrain website—and is still there.
You can’t tell from the image of the cover on the right, but that orange was as da-glo as a road cone, and the gray at the bottom was silver. You couldn’t miss seeing it on the displays and shelves of bookstores, which were still thick on the ground back then.
A quarter century after we started working on Cluetrain, I think its story has hardly begun—because most of what it foresaw, or called for, has not come true. Yet.
So I’m going to visit some of Cluetrain’s history and main points in a series of posts here. This is the first one.
*A search for that column on the WSJ.com website brings up nothing: an example of deep news‘ absence. But I do have the text, and may share it with you later.)
On April 4, 1968, when I learned with the rest of the world that Martin Luther King Jr. had been assassinated, I immediately thought that the civil rights movement, which King had led, had just been set back by fifty years. I was wrong about that. It ended right then (check that last link). Almost fifty-six years have passed since that assassination, and the cause still has a long way to go: far longer than what MLK and the rest of us had imagined before he was killed.
Also, since MLK was the world’s leading activist for peace and nonviolence, those movements were set back as well. (Have they moved? How much? I don’t have answers. Maybe some of you do.)
I was twenty years old when MLK and RFK were killed, and a junior at Guilford College, a Quaker institution in Greensboro, North Carolina. Greensboro was a hotbed of civil rights activism and strife at the time (and occasionallysince). I was an activist of sorts back then as well, both for civil rights and against the Vietnam War. But being an activist, and having moral sympathies of one kind or another, are far less effective in the absence of leadership than they are when leadership is there, and strong.
Alexei Navalny was one of those leaders. He moved into the past tense today: (1976-2024). His parentheses closed in an Arctic Russian prison. He was only 47 years old. At age 44 he was poisoned—an obvious assassination attempt—and survived, thanks to medical treatment in Germany. He was imprisoned in 2021 after he returned to Russia, and… well, you can read the rest here. Since Navalny was the leading advocate of reform in Russia and opposed Vladimir Putin’s one-man rule of the country, Putin wanted him dead. So now Navalny is gone, and with it much hope of reform.
Not every assassination is motivated by those opposed to a cause. Some assassins are just nuts. John Hinkley Jr. and Mark David Chapman, for example. Hinkley failed to kill Ronald Reagan, and history moved right along. But Chapman succeeded in killing John Lennon, and silence from that grave has persisted ever since.
My point is that assassination works. For causes a leader personifies, the setbacks can be enormous, and in some cases total, or close enough, for a long time.
I hope Alexei Navalny’s causes will still have effects in his absence. Martyrdom in some ways works too. But I expect those effects to take much longer to come about than they would if Navalny were still alive. And I would love to be wrong about that.
But her most leveraged dish was the breakfast she made for us often when my sister and I were kids: soft-boiled eggs over toast broken into small pieces in a bowl. It’s still my basic breakfast, many decades later.
Mine, above, are different in three small ways:
I cut the toast into small squares with a big kitchen knife. (For Mom the toast was usually white bread, which was the only thing most grocery stores sold, or so it seemed, back in the 1950s. I lean toward Jewish rye, sourdough, ciabatta, anything not sweet.)
Mom boiled the eggs for three minutes. I poach mine. That’s a skill I learned from my wife. Much simpler. Put the eggs for a second or two into the boiling water, take them out, and then break them into the same water. (Putting them in first helps keep them intact.) Make sure the water has some salt in it, so the eggs hold their shape. Pull them out with a slotted spoon when the white gets somewhat firm and the yolk is still runny. Lay them on the toast.
I season them with a bit of hot sauce: sriracha, Tapatio, Cholula, whatever. That way they look like this before I chow them down—
The hot sauce also makes the coffee taste better for some reason.
Thus endeth the first—and perhaps last and only—recipe post on this blog.
My favorite version, however, is this one by KPIG’s Fine Swine Orchestra, recorded by Santa Cruz musicians sheltering in place during the pandemic. That’s a screen grab, above.
I am pretty sure I’ve blogged about “Ripple” before, but can’t find evidence of that right now, perhaps because I published it somewhere obscure, or perhaps because we have entered the Enshittocene. Whatever the case, it doesn’t hurt to re-hear a classic.
KPIG, long one of my favorite radio stations, is no longer live streaming for the world, but for subscribers only. (It’s free only for a week.) I know they need the money. But so does Radio Paradise, which has KPIG ancestry, is free, and supported by donations.
Toward normalizing the donations for every worthy thing, see what I wrote here.
Bloomington Hospital on October 15, 2022, right after demolition began.
After we came to Bloomington in the summer of 2021, we rented an apartment by Prospect Hill, a quiet dome of old houses just west of downtown. There we were surprised to hear, nearly every night, as many police and ambulance sirens as we’d heard in our Manhattan apartment. Helicopters too. Soon we realized why: the city’s hospital was right across 2nd Street, a couple blocks away. In 2022, the beautiful new IU Health Bloomington Hospital opened up on the far side of town, and the sounds of sirens were replaced by the sounds of heavy machinery slowly tearing the old place down.
Being a photographer and a news junkie, I thought it would be a good idea to shoot the place often, to compile a chronicle of demolition and replacement, as I had done for the transition of Hollywood Park to SoFi Stadium in Inglewood, California. But I was too busy doing other things, and all I got was that photo above, which I think Dave Askins would categorize as a small contribution to topical history.
Dave is a highly productive local journalist, and—by grace of providence for a lifelong student of journalism such as me—the deepest and most original thinker I know on the topic of what local news needs in our time—and going forward. I’ve shared some of Dave’s other ideas (and work) in the News Commons series, but this time I’m turning a whole post over to him. Dig:::::
In the same way that every little place in America used to have a printed newspaper, every little place in America could have an online local chronicle.
Broadly speaking, an online local chronicle is a collection of facts organized mostly in chronological order. The “pages” of the chronicle can be thought of as subsets of a community’s universal timeline of events. These online local chronicles could become the backbone of local news operations.
First a word about what a local chronicle is not. It is not an online encyclopedia about the little place. It’s not a comprehensive history of the place in any conventional sense. Why should it not try to be those things? Because those things are too hard to think about building from scratch. Where would you even start?
It is at least conceivable that an online local chronicle could be built from scratch because you start by adding new facts that are newsworthy today. A new fact added to the chronicle is a touchstone, about which anyone can reasonably ask: What came just before that?
A working journalist in a little place with an online local chronicle will be in a good position to do two things: (1) add new facts to the local chronicle (2) help define sets of old facts that would be useful to include in the online local chronicle.
A journalist who is reporting the news for a little place would think not just about writing a report of new facts for readers today. They would keep this question in mind: What collection of old facts, if they were included in the local chronicle, would have made this news report easier to write?
Here’s a concrete example. A recent news report written for The B Square Bulletin included a mention of a planned new jail for Monroe County. It included a final sentence meant to give readers, who might be new to that particular topic, a sense of the basic reason why anyone was thinking about building a new jail: “A consultant’s report from two and a half years ago concluded that the current jail is failing to provide constitutional levels of care.”
About that sentence, a reader left the following comment on the website: “I know it’s the last sentence in an otherwise informative article, but at the risk of nit-picking that sentence seems inadequate to the task of explaining the context of the notion of a new jail and the role of the federal court and the ACLU.”
What this reader did was to identify a set of old facts that should be a collection (a page) in Bloomington’s local chronicle.
It’s one thing to identify a need to add a specific collection of facts to the local chronicle. It’s quite another to figure out who might do that. Working journalists might have time to add a new fact or two. But to expect working journalists to add all the old sets of facts would, I think, be too tall an order.
The idea would be to recruit volunteers to do the work of adding old facts to the online local chronicle. They could be drawn from various segments of the community—including groups that have an interest in seeing the old facts about a particular topic not just preserved, but used by working journalists to help report new facts.
I think many community efforts to build a comprehensive community encyclopedia have foundered, because the motivation to make a contribution to the effort is mostly philosophical: History is generally good to preserve.
The motivation for helping to build the online local chronicle is not some general sense of good purpose. Rather it is to help working journalists provide useful facts for anyone who in the community who is trying to make a decision.
That includes elected leaders. They might want to know what the reasons were at the time for building the current jail at the spot where it is now.
Decision makers include voters, who might be trying to decide which candidate to support.
Decision makers also include rank-and-file residents—who might be trying to decide where to go out for dinner and want to know what the history of health inspections for a particular restaurant are.
For the online local chronicle I have set up for Bloomington, there are very few pages so far. They are meant to illustrate the general concept:
Prompt: “a field of many different kinds of people being harvested by machines and turned into bales of fertilizer.” Via Microsoft CoPilot | Designer.
This post is for the benefit of anyone wondering about, researching, or going into business on the proposition that selling one’s own personal data is a good idea. Here are some of my learnings from having studied this proposition myself for the last twenty years or more.
The business category harvesting the most personal data is adtech (aka ad tech and “programmatic”) advertising, which is the surveillance-based side of the advertising business. It is at the heart of what Shoshana Zuboff calls surveillance capitalism, and is now most of what advertising has become online. It’s roughly a trillion-dollar business. It is also nothing like advertising of the Mad Men kind. (Credit where due: old-fashioned advertising, aimed at whole populations, gave us nearly all the brand names known to the world). As I put it in Separating Advertising’s Wheat and Chaff, Madison Avenue fell asleep, direct response marketing ate its brain, and it woke up as an alien replica of itself.
Adtech pays nothing to people for their data or data about them. Not personally. Google may pay carriers for traffic data harvested from phones, and corporate customers of auctioned personal data may pay publishers for moments in which ads can be placed in front of tracked individuals’ ears or eyeballs. Still, none of that money has ever gone to individuals for any reason, including compensation for the insults and inconveniences the system requires. So there is little if any existing infrastructure on which paying people for personal data can be scaffolded up. Nor are there any policy motivations. In fact,
Regulations have done nothing to slow down the juggernaut of growth in the adtech industry. For Google, Facebook, and other adtech giants, paying huge fines for violations (of the GDPR, the CCPA, the DMA, or whatever) is just the cost of doing business. The GDPR compliance services business is also in the multi-$billion range, and growing fast. In fact,
Regulations have made the experience of using the Web worse for everyone. Thank the GDPR for all the consent notices subtracting value from every website you visit while adding cognitive overhead and other costs to site visitors and operators. In nearly every case, these notices are ways for site operators to obey the letter of the GDPR while violating its spirit. And, although all these agreements are contracts, you have no record of what you’ve agreed to. So they are worse than worthless.
Tracking people without their clear and conscious invitation or a court order is wrong on its face. Period. Full stop. That tracking is The Way Things Are Done online does not make it right, any more than driving drunk or smoking in crowded elevators was just fine in the 1950s. When the Digital Age matures, decades from now, we will look back on our current time as one thick with extreme moral compromises that were finally corrected after the downsides became clear and more ethically sound technologies and economies came along. One of those corrections will be increasing personal agency rather than just corporate capacities. In fact,
Increasing personal independence and agency will be good for markets, becausefree customers are more valuable than captive ones. Having ways to gather, keep, and make use of personal data is an essential first step toward that goal. We have made very little progress in that direction so far. (Yes, there are lots of good projects listed here, but there we still a long way to go.)
Businesses being “user-centric” will do nothing to increase customers’ value to themselves and the marketplace. First, as long as we remain mere “users” of others’ systems, we will be in a subordinate and dependent role. While there are lots of things we can do in that role, we will be able to do far more if we are free and independent agents. Because of that,
We need technologies that create and increase personal independence and agency. Personal data stores (aka warehouses, vaults, clouds, life management platforms, lockers, and pods) are one step toward doing that. Many have been around for a long time: ProjectVRM currently lists thirty-three under the Personal Data Stores heading. Some have been there a long time. The problem with all of them is that they are still too focused on what people do as social beings in the Web 2.0 world, rather than on what they can do for themselves, both to become more well-adjusted human beings and more valuable customers in the marketplace. For that,
It will help to have independent personal AIs. These are AI systems that work for us, exclusively. None exist yet. When they do, they will help us manage the personal data that fully matters:
Contacts—records and relationships
Calendars—where we’ve been, what we’ve done, with whom, where, and when
Health records and relationships with providers, going back all the way
Financial records and relationships, including past and present obligations
Property we have and where it is, including all the small stuff
Shopping—what we’ve bought, plan to buy, or might be thinking about,
Subscriptions—what we’re paying for, when they end or renew, what kind of deal we’re locked into, and what better ones might be out there.
Travel—Where we’ve been, what we’ve done, with whom, and when
Personal AIs are today where personal computers were fifty years ago. Nearly all the AI news today is about modern mainframe businesses: giants with massive data centers churning away on ingested data of all kinds. But some of these models are open sourced and can be made available to any of us for our own purposes, such as dealing with the abundance of data in our own lives that is mostly out of control. Some of it has never been digitized. With AI help it could be.
I’m in a time crunch right now. So, if you’re with me this far, read We can do better than selling our data, which I wrote in 2018 and remains as valid as ever. Or dig The Intention Economy: When Customers Take Charge (Harvard Business Review Press, 2012), which Tim Berners Lee says inspired Solid. I’m thinking about following it up. If you’re interested in seeing that happen, let me know.
“This industry is unkind to mothers, there is no denying that.”
“Leading up to giving birth, I completely hid my pregnancy and never mentioned it to anyone. Even when I became so obviously pregnant, I just never talked about it to clients unless they brought it up.”
“I can’t tell you how many women shooters/assistants have felt they have to hide their pregnancy in order to keep working. The whole topic/concept is so difficult to navigate.”
“I didn’t share it on social media or tell anyone in person until I started to show. I hated it, I wanted to shout my exciting news from the rooftops but I knew the impact it would have on my work, which is incredibly sad”
Leading up to giving birth, I completely hid my pregnancy and never mentioned it to anyone. Even when I became so obviously pregnant, I just never talked about it to clients unless they brought it up. I was terrified of losing a job if someone found out/like I’d be an undesirable person to work with. I did almost lose a job with a very large well known client who found out through word of mouth that I was in my 3rd trimester. They stopped emailing with me and instead called me to ask me very personal questions like when my due date was, if I was physically able to take on the job, etc. it was so sketchy that the woman did it all over the phone.
A week after my son was born, just home from the hospital, my editorial shoots and hustle paid off. I got a call from one of the big three agencies in Boston at the time. The Photo Buyer *gushed* over my work, the creative team loved it! They couldn’t wait to meet me. When can I come in? In my half awake new mom haze I said “I just got back from the hospital with my first baby. Let’s get something on the books in three weeks.” She hung up on me. I never heard from them again and still haven’t shot for them 20 years later.
DO NOT TELL A SOUL. I worked til 37 weeks but could have gone until the day I delivered. The main issue was being uncomfortable driving. I took 2 months “off” but it was extremely slow afterwards and no one hired me for an ad job for another year. If I did it again I’d keep it all a secret, unfortunately I lost a huge IUD pharma campaign because they found out I was pregnant. The irony! Obviously it’s illegal but what can you do?
Luckily I didn’t show and I hadn’t told anyone when Covid lockdowns started so I could kind of hide it through not being outside. Even after having my baby I didn’t really tell any clients or post about it. When my main client found out I had a kid the jobs dropped off dramatically.
During my first pregnancy which was 18 years ago, I had a photo editor tell me straight up when I went to the office after a shoot that she “wouldn’t have hired me if she knew how pregnant I was” – at about 32 weeks. In general I hid my pregnancy for fear I wouldn’t get work.
I kept my pregnancy to myself and did not share publicly or with clients. I just showed up to work pregnant and did my job just as well (sometimes better) than I did not pregnant.
Pregnancy is the easiest part of navigating life as a freelancer (I told clients on a need-to-know basis while pregnant 13 years ago, and happily worked until 39 weeks). The hard part of working in this field really happens once the child is born. I know many female photographers whose careers were sidetracked by the challenging logistics of balancing an unpredictable photo schedule and childcare.
I kept it very private. Nothing on the internet until my daughter was born. Almost 100% of the time, I only told clients once I was already on set because it was visible. I was soooo scared to lose work because I thought people might assume hiring me would be a risk.
I worked until I was 38 weeks pregnant but also didn’t tell any clients that I was pregnant for fear of not being hired. The part I found difficult was after I had the baby, trying to be 100% on shoots after little to no sleep some nights but the pumping was really difficult, having to take a break somewhere private every few hours was very tough.
Never told anyone but also wouldn’t lie if asked. Wore oversized clothes on set and worked up until a month before birth. Booked an extra assistant if needed just to have an extra person to have my back. Was back on set when baby was 8 weeks old which was a bit unnecessary/early in hindsight (for me – everyone’s different). A few clients didn’t book me because I was pregnant but I figured I don’t wanna work for them anyway – it’s my choice.
In my experience as a event and editorial shooter in LA at the time, not telling anyone i was pregnant until it was very obvious was a good choice for me, only because once the clients knew I was pregnant they were all very kind but many were also much more cautious and concerned about me, and acting as though i was much more delicate like I should be doing something at a desk LOL so I had to really reassure more people that i was absolutely fine and capable. And that women have done this since the dawn of humanity and i’d let them know if i was ever feeling not capable.
My boss and management was not supportive at all. I was scrutinized even if I only came in 30 minutes late due to doctors appointments and so I scheduled each doctors is the very first appointment of the day so I could rush to work
This is a really important topic to discuss as a lot of us feel we cannot tell people we are pregnant for fear of not getting booked. I was also one of those people. I didn’t share it on social media or tell anyone in person until I started to show. I hated it, I wanted to shout my exciting news from the rooftops but I knew the impact it would have on my work, which is incredibly sad. I would turn up to shoots and shock people not only because I was pregnant but because I was still very much capable. IMAGINE!? Once the news was out and baby arrived, I did have some clients presume that I wouldn’t want the work we had in the calendar for the coming months and THAT is the problem. The attitude towards pregnant people drastically needs to change
Book pregnant photographers and support them by booking them when they are back to work.
Let’s try and change this crappy narrative, we deserve better!
Sanur has nice beach walking path.I had heard and read about it. I wanted to walk the whole path of around 5 to 7 Kms. We initially thought of going in the morning for sunrise, but all of us were so tired we woke up late, so we went for an evening walk. When we left, Uma was sleeping, so we didn't take a stroller but a KolKol baby carrier.
Beach walking path for both people and bicycles
The taxi dropped us at the end of Jalan Duyung, and from there, we walked towards the beach, then we took a left towards Sanur Beach. We were slow; in between, Uma woke up and walked briefly. Then we stopped at Jl. Pantai Karang for a snack. Then we continued to walk and took a break at Nelayan Bali. We ate some snacks. Uma ate her packed snacks.
Anju and Uma
Uma and I
Though we didn't enter the water, we walked on the sand and played a bit. The water was shallow and clean. It's very accessible even for toddlers.
Sanur beach is also accessible if you want to spend time in shallow water.
We continued walking post that. Uma was very sleepy, she slept in Kolkol. So we stopped at Jl Pantai Sindu and took a taxi back. We walked around 2.8 Kms. We could have easily walked another 2 kms. Original idea was to walk 5 Kms. We probably go back and do the rest.
Path also goes through busy areas with cafes.
We returned on Tuesday and walked to the other side of the beach. This time, we walked to the end of the beachfront, totaling around four kilometers. Uma also got to play in the water a bit, took lots of goofy pictures, ate dinner. It was time well spent.
The sky was clear blue and water was very calm.
Anju and Uma
We were twinning
Here are the gpx1 and gpx2 files in case you want it. You really don't need it as the signs and path is very clear.
You can read this blog using RSS Feed. But if you are the person who loves getting emails, then you can join my readers by signing up.
Hamel Husain: "I’ve seen many successful and unsuccessful approaches to building LLM products. I’ve found that unsuccessful products almost always share a common root cause: a failure to create robust evaluation systems."
I've been frustrated about this for a while: I know I need to move beyond "vibe checks" for the systems I have started to build on top of LLMs, but I was lacking a thorough guide about how to build automated (and manual) evals in a productive way.
Hamel has provided exactly the tutorial I was needing for this, with a really thorough example case-study.
Using GPT-4 to create test cases is an interesting approach: "Write 50 different instructions that a real estate agent can give to his assistant to create contacts on his CRM. The contact details can include name, phone, email, partner name, birthday, tags, company, address and job."
Also important: "... unlike traditional unit tests, you don’t necessarily need a 100% pass rate. Your pass rate is a product decision."
Hamel's guide then covers the importance of traces for evaluating real-world performance of your deployed application, plus the pros and cons of leaning on automated evaluation using LLMs themselves.
Plus some wisdom from a footnote: "A reasonable heuristic is to keep reading logs until you feel like you aren’t learning anything new."
I’ve been on a long-term quest to find a simple, fast, and user-friendly way to develop native applications for a variety of platforms, and this page holds the results of that research.
What I am looking for is something that is:
Not Electron: I want to be able to write code that runs natively on the target platform without having to rely on a web browser or a large runtime.
Fast: I want to be able to iterate quickly and not have to wait for a long time for builds or deployments.
Simple: I want to be able to write code that is easy to understand and maintain.
Native Looking: I want to be able to write code that looks and feels like a native application on the target platform.
Portable: I want to be able to write code that runs on a variety of platforms without having to rewrite it from scratch.
Open-source: I want to be able to use code that is open-source and doesn’t have a lot of restrictions on how it can be used.
We have lost the ability to do RAD (Rapid Application Development) due to the prevalence of web applications, and I personally don’t like that, so I’ve been looking for a way to fix that within a small set of tools I want to build.
This is one of those pieces of gear that I’ve sat in front of for years and never actually wrote about–either because it was too obvious, or because it seemed too trivial.
It's a very pretty keyboard, and it's also very good at what it does.
But even as I am now starting to phase it out and put mine into storage, I realize I owe it a debt of gratitude–because, you see, when I decided to go back to using a US key layout full-time back during the pandemic (and who hasn’t made life-changing choices during that time?), it was literally the best bang for the buck I could find.
This may seem odd to most of my readers, but getting a bona fide, non-ISO US keyboard with a “long return” key and the slash/pipe key atop it is not a trivial thing in Europe, and the K380 was (and still is) easily available in various layouts and colorways1.
And the reason I much prefer the US layout is because harking back to my college years toiling away at VT220 terminals and 68k Macs, everything about computers just makes a lot more sense with a US layout, from symbols and brackets to vim commands.
I can type accented characters faster with the US key combos than in a normal Portuguese keyboard, too, which is kind of funny.
The K380 won a place in my heart because it has three superpowers:
It is battery-powered. Yes, two AAA batteries you can get literally anywhere and last apparently forever (I use IKEA LADDA rechargeable batteries, and I get the feeling I recharge them every… year?).
There are no cables. Zilch. Nada. Instead, it supports three independent, stupefyingly reliable Bluetooth connections2, which was a lifesaver for me when I had to juggle two laptops on my desk and switch between them (plus my iPad) on the fly. The three hotkeys displace three possible slots for media or window management functions from the top row3, but I find it an acceptable trade-off.
It is built extremely well for the price. I’m not going to claim it is indestructible, but it makes for an excellent travel keyboard if you have a full-size iPad (and haven’t gotten a keyboard cover, which is what I did eventually).
And the rounded, soft edge design not only looks good but makes it trivial to pack or slide and out of a messenger bag.
It is, if you’ll pardon the pun, a very smooth operator.
There are a few shortcomings, though:
The round keys can make it a little challenging to home in all of your fingers. It does have home key nubs, but in my experience I tend to slide off non-central keys sometimes since the keycap depressions (such as they are) are very shallow and the roundness takes away from keycap area, so it can be challenging to hit off-centre keys reliably at speed.
The Ctrl and Fn key placement is exactly the opposite from an Apple keyboard, which means that switching between this and a MacBook can be quite tricky.
The Esc, left and right cursor keys are quite small (that’s sort of excusable in the top row, but not in the cursor block).
Other than the Bluetooth/on lights, it has no other indicator lights–or backlight, which is kind of OK (I very seldom look at the keyboard, and often have enough ambient backscatter to make do) but also something I’ve started wanting as a default.
And, of course, it lacks Touch ID. But that is such an Apple-specific thing that I’m not going to hold it against Logitech.
As to keyboard sound and feel (always a key thing with aficionados), of course it is a quiet, reliable membrane keyboard. I wouldn’t use in my (sometimes preternaturally quiet) office if it wasn’t.
It does have some springiness (and a somewhat tactile feel before you bottom out), but anyone who likes full-size keys will find it either mushy or unsatisfactory travel-wise.
I prefer low-profile, linear keys when I use “mechanical” keyboards, no matter how extreme, but am literally fine with it.
The only thing I ever found myself wishing it had was (ironically) a USB-C port. Not for charging or even daily use, but just plugging in to devices while setting them up, since for a long while it was the one keyboard I took everywhere.
But its last superpower (an actual physical on/off button on the top left hand side) more than makes up for that.
I will remember the time it spent on my desk fondly, even as I remove the batteries and store it away, certain that in a few years it will probably be one of the few accessories that will still just work.
Thank you, my friend. You will always be welcome at my desk.
It is also very cheaply available in places like AliExpress (my second one was bought there). ↩︎
I also have two M720 mice that share this feature, one of which is my daily driver. I should write about that too some day, since the soft plastic is getting a little worn out and might need replacing. ↩︎
There is also the option of using Logi’s software to customize some of those keys. I never bothered given the way I used it across multiple machines. ↩︎
First of all, since there is a 50% chance you have something to do with technology or code by landing here, I’m not going to focus on code generation, because for me it’s been… sub-optimal.
The reasons for that are pretty simple: the kind of code I write isn’t mainstream web apps or conventional back-end services (it’s not even in conventional languages, or common frameworks, although I do use JavaScript, Python and C++ a fair bit), so for me it’s been more of a “smarter autocomplete” than something that actually solves problems I have while coding.
Disclaimer: I’m a Microsoft employee, but I have no direct involvement with GitHub Copilot or Visual Studio Code (I just use them a lot), and I’m not privy to any of the inner workings of either other than what I can glean from poking under the hood myself. And in case you haven’t noticed the name of this site, I have my own opinions.
LLMs haven’t helped me in:
Understanding the problem domain
Structuring code
Writing complex logic
Debugging anything but the most trivial of issues
Looking up documentation
…which is around 80% of what I end up doing.
They have been useful in completing boilerplate code (for which a roundtrip network request that pings a GPU that costs about as much as a car is, arguably, overkill), and, more often than not, for those “what is the name of the API call that does this?” and “can I do this synchronously?” kinds of discussions you’d ordinarily have with a rubber duck and a search engine in tandem.
I have a few funny stories about these scenarios that I can’t write about yet, but the gist of things is that if you’re an experienced programmer, LLMs will at best provide you with broad navigational awareness, and at worst lead you to bear traps.
But if you’re a beginner (or just need to quickly get up to speed on a popular language), I can see how they can be useful accelerators, especially if you’re working on a project that has a lot of boilerplate or is based on a well-known framework.
If you’re just here for the development bit, the key takeaway is that they’re nowhere good enough to a point where you can replace skilled developers. And if you’re thinking of decreasing the number of developers, well, then, I have news for you: deep insight derived from experience is still irreplaceable, and you’ll actually lose momentum if you try to rely only on LLMs as accelerators.
People who survived the first AI winter and remember heuristics will get this. People who don’t, well, they’re in for a world of hurt.
This should be a side note, but it’s been on my mind so often that I think it belongs here:
One thing that really annoys me is when you have a corporate policy that tries to avoid intellectual property issues by blocking public code from replies:
Sorry, the response matched public code so it was blocked. Please rephrase your prompt.
I get this every time I am trying to start or edit a project with a certain very popular (and dirt common) framework, because (guess what) their blueprints/samples are publicly available in umpteen forms.
And yes, I get that IP is a risky proposition. But we certainly need better guardrails than overbearing ones that prevent people from using well-known, public domain pieces of code as accelerators…
But this is a human generated problem, not a technical one, so let’s get back to actual technological trade-offs.
This is actually what I have really been pondering the most, although it is really difficult to resist the allure of clever marketing tactics that claim massive productivity increases in… well, in Marketing, really.
But I am getting ahead of myself.
What I have been noticing when using LLMs as “sidekicks” (because calling them “copilots” is, quite honestly, too serious a moniker, and I actually used the Borland one) is their impact on three kinds of things:
Harnessing drudgery like lists or tables of data (I have a lot of stuff in YAML files, whose format I picked because it is great for “append-only” maintenance of data for which you may not know all the columns in advance).
Trying to make sense of information (like summarizing or suggesting related content).
Actual bona fide writing (as in creating original prose).
A marked quality of life improvement I can attribute to LLMs over the past year is that when I’m jotting down useful projects or links to resources (of which this site has hundreds of pages, like, for instance, the AI one, or the Music one, or a programming language listing like Go or even Janet), maintaining the files for that in Visual Studio Code (with GitHub Copilot) is a breeze.
A typical entry in one of those files looks like this:
- url: https://github.com/foo/bar
link: Project Name
date: 2024-02-21
category: Frameworks
notes: Yet another JavaScript framework
What usually happens when I go over and append a resource using Visual Studio Code is that when I simply place the cursor at the bottom, it suggests - url: for me, which is always an auspicious start.
I then hit TAB to accept, paste the URL and (more often than not) it completes the entire entry with pretty sane defaults, even (sometimes) down to the correct date and a description. As a nice bonus, if it’s something that’s been on the Internet for a while, the description is quite likely correct, too. Praise be quantization of all human knowledge, I guess.
This kind of thing, albeit simple, is a huge time saver for note taking and references. Even if I have to edit the description substantially, if you take the example above and consider that my projects, notes and this site are huge Markdown trees, that essentially means that several kinds of similar (non-creative) toil have simply vanished from my daily interaction with computers–if I use Visual Studio Code to edit them.
And yes, it is just “smarter autocomplete” (and there are gigantic amounts of context to guide the LLM here, especially in places like the ones in my JavaScript page), but it is certainly useful.
And the same goes for creating Markdown front matter–Visual Studio Code is pretty good at autocompleting post tags based on Markdown headings, and more often than not I’m cleaning up a final draft on it and it will also suggest some interesting text completions.
One area where things are just rubbish, though (and likely will remain so) is searching and summarizing data.
One of my test cases is this very site, and I routinely import the roughly 10.000, highly interlinked pages it consists of into various vector databases, indexers and whatnot (a recent example was Reor) and try to get LLMs to summarise or even suggest related pages, and so far nothing has even come close to matching a simple full-text-search with proper ranking or (even worse) my own recollection of pieces of content.
In my experience, summaries for personal notes either miss the point or are hilariously off, suggestions for related pages prioritise matching fluff over tags (yes, it’s that bad from a knowledge management perspective), and “chatting with my documents” is, in a word, stupid.
In fact, after many, many years of dealing with chatbots (“there’s gold in them call centres!”), I am staunchly of the opinion that knowledge management shouldn’t be about conversational interfaces–conversations are exchanges between two entities that display not just an understanding of content but also have the agency to highlight relationships or correlations, which in turn goes hand in hand with the insight to understand which of those are more important given context.
So far LLMs lack any of those abilities, even when prompted (or bribed) to fake them.
Don’t get me wrong, they can be pretty decent research assistants, but even then you’re more likely than not to be disappointed:
One of these was created by the biggest search company in the world. Can you spot which?
I do a lot of my writing in iA Writer these days, and thanks to macOS and iOS’s feature sets, it does a fair bit of autocompletion–but only on a per-word/per-sentence basis.
That can still be a powerful accelerator for jotting down outlines, quick notes and first drafts, but what I’ve come to appreciate is that even GitHub Copilot (which focuses on code generation, not prose) can go much farther when I move my drafts over to Visual Studio Code and start revising them there.
Let’s do a little parenthesis here and jump back to writing “code”.
In case you’ve never used GitHub Copilot, the gist of things is that having multiple files open in Visual Studio Code, especially ones related to the code you’re writing, has a tremendous impact on the quality of suggestions (which should be no surprise to anyone, but many people miss the basics and wonder why it doesn’t do anything)–Copilot will often reach into a module you’ve opened to fetch function signatures as you type a call (which is very handy).
But it also picks up all sorts of other hints, and the real magic starts to happen when you have more context like comments and doc strings–so it’s actually useful to write down what your code is going to do in a comment before you actually write it.
Prosaic stuff like loops, JSON fields, etc. gets suggested in ways that do indeed make it faster to flesh out chunks of program logic, which is obviously handy.
The good bits come when, based on your comments, Copilot actually goes out and remembers the library calls (and function signatures) for you even when you haven’t imported the library yet.
However, these moments of seemingly superhuman insight are few and far between. I keep spotting off-by-ones and just plain wrong completions all the time (especially in parameter types), so there’s a lot to improve here.
The interesting bits come in the intersection of both worlds–the LLM behind Copilot is tuned for coding, of course, but it can do generally the same for standard English prose, which can be really helpful sometimes–just try opening a Markdown document, paste in a few bullets of text with the topics you want to write about and start writing.
The suggestions can be… chillingly decent. Here’s an example after writing just the starting header by myself and hitting TAB:
This is fine.
It’s not as if it’s able to write the next Great American Novel (it is too helpful, whimsical and optimistic for that), but I can see it helping people writing better documents overall, or filling in when you’re missing the right turn of phrase.
And that is where I think the real impact of LLMs will be felt–not in code generation, but in shaping the way we communicate, and in particular in polishing the way we write just a little too much.
This is, to be honest, something that annoys me very much indeed, especially since I’ve always been picky about my own writing and have a very characteristic writing style (that’s one of the reasons I start drafts in iA Writer).
But given my many experiments with characters like Werner Hertzog and oblique stunts like improving the output of my news summarizer by prompting it with You are a news editor at the Economist, it doesn’t strike me as unfeasible that someone will eventually go off and train an LLM to do style transfer from The Great Gatsby1.
It’s probablydefinitely happening already in many Marketing departments, because it is still more expensive to lobotomise interns than to have an LLM re-phrase a bulleted list in jaunty, excited American corporate speak.
All the above ranting leads me to one of my key concerns with LLMs– not just Copilot or ChatGPT, but even things lower down the totem pole like macOS/iOS smart sentence suggestions–if you don’t stay focused on what you want to convey, they tend hijack your writing and lead you down the smooth, polished path of least resistance.
This may seem fine when you are writing a sales pitch or a press release, but it is a terrible thing when you are trying to convey your thoughts, your ideas, your narrative and your individual writing style gets steamrolled into a sort of bland, flavorless “mainstream” English2.
And the fact that around 50% of the paragraph above can be written as-is with iOS smart autocomplete alone should give people pause–I actually tried it.
I also went and gave GitHub Copilot, Copilot on the web and Gemini three bullets of text with the generics and asked them to re-phrase them.
Gemini said, among other things (and I quote): “It requires human understanding, 情感, and intention” and used the formal hanzi for “emotion” completely out of the blue, unprompted, before going on a rather peculiar rant saying it could not discuss the topic further lest it “cause harm” (and yes, Google has a problem here).
Either Copilot took things somewhat off base. Their suggestions were overly optimistic rubbish, but the scary thing is that if I had a more positive take on the topic they might actually be fit to publish.
The best take was from old, reliable gpt35-turbo, which said:
LLMs (Language Models) reduce the quality of human expression and limit creative freedom. They lead to the creation of insipid and uninteresting content, and are incapable of producing genuine creative expression.
Now this seems like an entity I can actually reason with, so maybe I should fire up mixtral on my RTX3060 (don’t worry, I have 128GB of system RAM to compensate for those measly 12GB VRAM, and it runs OK), hack together a feedback loop of some sort and invite gpt35-turbo over to discuss last year’s post over some (metaphorical) drinks.
Maybe we’ll even get to the bottom of the whole “New AI winter” thing before it comes to pass.
I’m rather partial to the notion that a lot of VCs behind the current plague of AI-driven companies should read Gone With The Wind (or at the very least Moby Dick) to ken the world beyond their narrow focus, but let’s just leave this as a footnote for now. ↩︎
The torrent of half-baked sales presentations that lack a narrative (or even a focal point) and are just flavourless re-hashing of factoids has always been a particular nightmare of mine, and guess what, I’m not seeing a lot of concern from actual people to prevent it from happening. ↩︎
A couple of days ago I came upon NotesOllama and decided to take a look at how to build a macOS Service that would invoke Azure OpenAI to manipulate selected text in any editor.
This seemed like a good opportunity to paper over some of its gaps and figure out how to do REST calls in the most native way possible, so after a little bit of digging around and revisiting my Objective-C days, I came up with the following JXA script, which you can just drop into a Run JavaScript for AutomationShortcuts action:
function run(input, parameters) {
ObjC.import('Foundation')
ObjC.import('Cocoa')
let app = Application.currentApplication();
app.includeStandardAdditions = true
let AZURE_ENDPOINT="endpoint.openai.azure.com",
DEPLOYMENT_NAME="default",
// this is the easiest way to grab something off the keychain
OPENAI_API_KEY = app.doShellScript(`security find-generic-password -w -s ${AZURE_ENDPOINT} -a ${DEPLOYMENT_NAME}`)
OPENAI_API_VERSION="2023-05-15",
url = `https://${AZURE_ENDPOINT}/openai/deployments/${DEPLOYMENT_NAME}/chat/completions?api-version=${OPENAI_API_VERSION}`,
postData = {
"temperature": 0.4,
"messages": [{
"role": "system",
"content": "Act as a writer. Summarize the text in a few sentences highlighting the key takeaways. Output only the text and nothing else, do not chat, no preamble, get to the point.",
},{
"role": "user",
"content": input.join("\n")
}]/*,{
role: "assistant",
Use this if you need JSON formatting
content: ""
*/
},
request = $.NSMutableURLRequest.requestWithURL($.NSURL.URLWithString(url));
request.setHTTPMethod("POST");
request.setHTTPBody($.NSString.alloc.initWithUTF8String(JSON.stringify(postData)).dataUsingEncoding($.NSUTF8StringEncoding));
request.setValueForHTTPHeaderField("application/json; charset=UTF-8", "Content-Type");
request.setValueForHTTPHeaderField(OPENAI_API_KEY, "api-key");
// This bit performs a synchronous HTTP request, and can be used separately
let error = $(),
response = $(),
data = $.NSURLConnection.sendSynchronousRequestReturningResponseError(request, response, error);
if (error[0]) {
return "Error: " + error[0].localizedDescription;
} else {
var json = JSON.parse($.NSString.alloc.initWithDataEncoding(data, $.NSUTF8StringEncoding).js);
if(json.error) {
return json.error.message ;
} else {
return json.choices[0].message.content;
}
}
}
Fortunately the symbol mangling is minimal, and the ObjC bridge is quite straightforward if you know what you’re doing. The bridge can unpack NSStrings for you, but I had to remember to use the tiny little .js accessor to get at something you can use JSON.parse on.
You will need to create a keychain entry for endpoint.openai.azure.com and default with your API key, of course. I briefly considering accessing the keychain directly, but the resulting code would have been twice the size and much less readable, so I just cheated and used doShellScript to grab the key.
Two minutes of hackish cut and paste later, I had ten different macOS services that would invoke gpt35-turbo in Azure OpenAI with different prompts:
Azure blue seemed appropriate
Dropping these into Shortcuts has a few advantages:
It saves me the trouble of wrapping them manually and dropping them into ~/Library/Services
They sync via iCloud to all my devices
as system Services, I can now invoke them from any app:
This is the kind of power I miss in other operating systems
# shamelessly stolen from https://github.com/andersrex/notesollama/blob/main/NotesOllama/Menu/commands.swift (MIT licensed)
prompts = [
{
"name": "Summarize selection",
"prompt": "Act as a writer. Summarize the text in a view sentences highlighting the key takeaways. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Explain selection",
"prompt": "Act as a writer. Explain the text in simple and concise terms keeping the same meaning. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Expand selection",
"prompt": "Act as a writer. Expand the text by adding more details while keeping the same meaning. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Answer selection",
"prompt": "Act as a writer. Answer the question in the text in simple and concise terms. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Rewrite selection (formal)",
"prompt": "Act as a writer. Rewrite the text in a more formal style while keeping the same meaning. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Rewrite selection (casual)",
"prompt": "Act as a writer. Rewrite the text in a more casual style while keeping the same meaning. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Rewrite selection (active voice)",
"prompt": "Act as a writer. Rewrite the text in with an active voice while keeping the same meaning. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Rewrite selection (bullet points)",
"prompt": "Act as a writer. Rewrite the text into bullet points while keeping the same meaning. Output only the text and nothing else, do not chat, no preamble, get to the point."
},
{
"name": "Caption selection",
"prompt": "Act as a writer. Create only one single heading for the whole text that is giving a good understanding of what the reader can expect. Output only the caption and nothing else, do not chat, no preamble, get to the point. Your format should be ## Caption."
}
]
I actually tried doing this in Python first, but Automator stopped supporting it recently.
Nevertheless, I put up this gist, where I cleaned up the original NotesOllama prompts a bit, and also have a Swift version…
These only work on macOS for the moment, but I’m already turning them into iOS actions with the Get Content from URL action in Shortcuts and a bit of JSON templating. Get Dictionary From Input seems to be able to generate the kind of nested JSON payload I need off a simple text template, but I haven’t quite figured out how to get the keychain to work yet, so I’m still poking at that on my iPad.
For the moment, you can try a draft version of the shortcut I’ve shared here that will require you to enter your endpoint and API key manually (as usual with all iCloud links, this one is prone to rot, so if it doesn’t work, ping me).
That wasn’t my first approach since Shortcuts are abominably limited and slow, but primarily because I needed the JXA version so I can eventually build a little native app that uses other Azure OpenAI services but with a simple GUI in the spirit of lua-macos-app.
An interesting thing is that, as far as I can tell, I’m the first person who cared enough to figure out how to go about issuing HTTP requests and invoking APIs from JXA, which is… really awkward.
This is a reaction to parts of three evenings watching Coachella 2023 and motivated by the fact that more or less all
of the music that grabbed me featured females. This notably included Blackpink, the biggest Girl Group in the world.
But they weren’t the best women artists there, not even close. Spoiler:
boygenius was.
Part of the problem was that every time I switched to a Coachella channel with male names on it, the males were either
bobbing their heads over a DJ deck, or banging out the hip-hop. I.e. few musical instruments or vocal melodies were involved. I
have no patience whatever for EDM and maybe one hip-hop track in ten grabs me. Usually that track turns out to be Drill
which, I read, is bad music by bad people and I shouldn’t like it. Oops.
Please don’t be objecting to the term
Girl Group around me. You wanna diss the Marvelettes? The Supremes? The
Ronettes? Labelle? Destiny’s Child?
To the extent that a business as corrupt as Music can have proud traditions, Girl Groups are one of those.
Not all men
OK, a few weren’t terrible.
FKJ was OK, his set featured a big sofa that he and the accompanists relax on and it
was that kind of music. The tunes were fairly generic but the playing was good and the arrangements were surprising and
often excellent.
And then there was Tukker of
Sofi Tukker; he’s the less-interesting half of that outfit but he’s still pretty
interesting. Plus their music was good, the instrumentation was surprising, and they have lots of charisma, I’d go see them.
They were an example of a distinct Coachella Thing this year: black-and-white outfits, in particular flowing white outfits,
an angelic aesthetic.
Weyes Blood, new to me, was also definitely leaning into the angelic thing. The
music had no sharp corners but took some surprising curves, and was pretty, which there’s nothing wrong with.
Coachella was willing to take big chances, including bands that I thought were at best marginally competent, in
terms of being in tune and in sync. I’m totally OK with bands going Outside The Lines when driven by passion or musical
invention but this wasn’t that, it was just basic rock or whatever played at medium speed, badly. I think this was a
conscious low-rent aesthetic? Not naming names. Not gender
specific.
More women I hadn’t heard of
Ashnikko (apparently erupted outta TikTok) puts on a good show, loads of
charisma.
When I switched over to Kali Uchis she was rapping and had the usual complement of
twerky dancers — is it just me or do they all have the same choreographer? I was about to switch
away and then she switched to to singing and wow, she’s really good.
Saturday night
Why I’m writing this is, I watched the boygenius and Blackpink sets and was left shaken. Let’s flip the
order and start with Blackpink. These are screen-caps.
I had never previously managed to watch a whole K-pop set because it’s so formulaic and boring. But Blackpink kept my
attention if not entirely my affection. The choreography and attention to detail is awesome, mesmerising. The music is meh. The
beauty is crushingly conventional but also crushing in its intensity. I felt like a Beauty Beam was coming off the screen,
bending back all the retinas it impacted.
You don’t have to look very hard to read terribly sad stories about the life of a K-pop star. They sign ten+ year
contracts with the Big Company (those years starting when they get big) by which the company gets 80% of the revenue and the
band splits the rest, after paying back the BigCo for their training and promotion. And there were a couple of moments when one
of the four was in a
choreography dead zone and for just an instant wore an expression of infinite fatigue.
To be fair, their technique was dazzling. They had an actual band with actual musicians, although the intermittent lip-syncing
wasn’t subtle. And when they stopped to chat with the crowd (in fluent English) they seemed like real people. Just not
when singing and dancing.
You know what’s weird? I’m a heterosexual male and they were dressed in these “daring” suits with lots of bare flesh showing,
but even with all that beauty, they weren’t sexy at all.
Anyhow, I ended up respecting them. They delivered. But still, that’s enough K-Pop for another decade or so.
The Boys Are Back In Town
That’s a dumb old rock song by Thin Lizzy, and it was the soundtrack for boygenius’s walk onstage. You see, they’re
smart and not a second of the set, start to end, was in the slightest disposable. There’s a lyric from their song
Without You Without Them: I want you to hear my story and be a part
of it. They mean it.
Their Coachella set was messy, chaotic, and, I thought, magnificent. The mix wasn’t all that great and some of
the lyrics were lost, a real pity with this band. But out of the chaos there kept coming bursts of extremely beautiful
melody, exquisite harmony, and lyric fragments that grab your brain and won’t let go.
The songs are about love mostly and are romantic and arrogant and pathetic and many visit violence, emotional and physical
too: When you fell down the stairs / It looked like it hurt and I wasn't sorry / I should've left you right there / With your
hostages, my heart and my car keys — that’s from
Letter To An Old Poet.
Their faces aren’t conventional at all, but so alive; I couldn’t stop watching them. Julien Baker in particular, when she digs into a
song, becomes scary, ferocious. But they each inhabit each song completely.
Also memorable was their excellent Fuck-Ron-DeSantis rant.
Anyhow, at the end of the set, they were off their feet, rolling around together on the stage while Ms Baker shredded, just
unbelievably intense. Always an angel, never a God they sing, over and over, but there were no flowing white
garments — they were wearing mock-schoolboy outfits with ties — and
something divine seemed in progress.
Back story
If you haven’t heard it, drop by
their Wikipedia article and catch up; it’s interesting. Particularly the
gender-related stuff.
My own back story was, I liked Phoebe Bridgers but hadn’t really picked up on boygenius. Then earlier this year, my
16-year-old daughter had a friend with a spare concert ticket and could Dad cough up the money for it? I’m an indulgent parent
when it comes to music so she got her ticket.
Pretty soon thereafter I noticed the boygenius buzz and tried to get a ticket for myself but they were long-sold-out by then.
Just not hip enough.
Oh well, I won’t forget that Coachella show any time soon.
“Girl Group”?
Per Wikipedia, it means “a music act featuring several female singers who generally harmonize together”. By that metric
boygenius is way ahead of Blackpink, who do harmonize a bit but it’s not central to their delivery. On the other hand, if we
traverse the Wikipedia taxonomy we arrive at “dance-pop girl groups” and Blackpink is definitely one of those, they dance like
hell.
Look, boygenius obviously are Women with a capital “W”. But they’re subversive too, I bet if you asked ’em, they might
gleefully wave the Girl Group banner.
I was in a small group of people who checked the AirPods Pro before they were officially announced on October 29, 2019 at 13.00 CET. A year later I was once again blown away by the AirPods Max. Those are still the best headphones I have.
The AirPods Pro became the headphones of choice for lots of people, rightfully so. But when the second generation AirPods Pro came out, I was lagging. After three years, my original AirPods Pro started rattling and Apple had replaced the two earbuds while sending me back the original case. I was good to go for another three years, and besides, could Apple really improve on the AirPods Pro that much? As it turns out, I was wrong.
Fast forward to 2023 and I have now used the AirPods Pro 2 for two months, and they have noticeably improved on all fronts. The transparency mode is even better than the already excellent original AirPods Pro, they filter out more ambient noise, they sound fuller, and they have little benefits I missed on the original. You can finally set the volume without speaking “Hey Siri louder” into thin air. The case beeps when it wants to provide feedback or when you are searching for it, and finally, it warns you through the Find My app when you leave them behind, much like the AirPods Max.
I have many headphones, but if I could only have one, this would be it. With voice isolation, you can even use them for phone calls.
Hi, this is Gregor, co-founder and head of the data visualization team at Datawrapper, with a Weekly Chart written on a night train somewhere between Austria and Italy.
After a long pause, I am very happy to be returning to Perugia for the International Journalism Festival (IJF). On the train ride to Italy, I was browsing this year’s festival program and saw many new speakers and faces I recognized from previous years!
This got me wondering how much fun it would be to see who spoke most at the conference in the past. Fortunately, the festival website lists all speakers since 2012. So without further ado, here’s the list of the most frequent speakers at the IJF:
You may be wondering why this list only includes international speakers. It’s a choice the festival made for the program as well, which initially excludes Italian speakers on its English-language website. You can click the link above the table to switch to a version that includes Italian speakers.
While there are only two women among the ten most invited speakers at the conference, it’s worth noting that the overall diversity of the IJF seems to have gotten a lot better in recent years, with almost 60% of this year’s speakers being women compared to 24% in 2012!
At Datawrapper, we’re big fans of the festival, not just for the talks and panels and the amazingly beautiful location, but also for the chance to meet so many of our users. If you’re around, drop us a note or leave a comment if you’d like to say hi.
See you in Perugia — or next week for the first Weekly Chart from our product specialist, Guillermina.
Google refreshes Fi with a new name, logo, and perks. The company’s wireless carrier started as Project Fi, then became Googe Fi. And today, it’s getting another name change, becoming Google Fi Wireless. The logo didn’t get a complete overhaul and still has the aesthetics of the old Google Fi logo. Instead of four bars […]
The famous flaw in most enterprise communities is the majority of people don’t visit to join a community, they visit to solve a problem.
This is why the majority of contributors to a community have made precisely one post.
They asked a question, received an answer (or didn’t), and then left never to return. The vast majority of attempts to shift these numbers have failed miserably. This audience simply doesn’t want to connect, share, and ‘join the conversation’. They want to solve their problem and be on their way.
The challenge facing most enterprise community professionals is less about trying to nurture a sense of community amongst members and more about building the right support experience around the community – where community plays a critical role in supporting every other support channel.
Enter the community-powered customer support hub.
The Five Layers Of The Customer Support Hub
The trend in recent years has been fairly clear, organisations are creating integrated support hubs which include knowledge bases, federated search, virtual agents, community, customer support tickets, and product suggestions.
This is slightly different from a customer portal which handles a broader range of use cases than support (e.g. it might include the academy, events, product updates etc…)
To get the support hub right, you need to execute extremely well on five distinct layers. These are shown here.
We can tackle each layer in turn.
The Foundation Layer: The Knowledge Base
Pretty much every organisation has a knowledge base for customers to browse. The purpose of this knowledge base is to preempt the majority of questions customers are likely to have and help customers follow best practices in the setup and usage of products.
Whenever a customer searches for an answer to a question, the knowledge base is often the first place they visit. A great knowledge base will have articles showing up in search results, in chatbot recommendations, in responses to community questions, and be referenced by support staff.
The cheapest way to solve a customer query is in the knowledge base. This can reduce 80% or more of questions from downstream channels.
(Aside, this is also the problem of measuring activity levels in a community, the community should inform the knowledge base – which in turn should reduce the number of questions in the community.)
However, the knowledge base has to perform a tricky juggling act. It should be comprehensive enough to resolve the 20% of queries which represent 80% of the volume of questions. But it shouldn’t aim to be so comprehensive to try and tackle every query.
This becomes impossible to maintain and is overwhelming for members. The knowledge hub needs to have well-maintained content that’s refreshed regularly. It also needs to archive out-of-date articles.
A great knowledge base aims to maintain a smaller number of articles up to an incredibly high standard. For other queries, there are other channels.
Notice the clean interface, great use of white space, clear search bar, and collapsible navigation menus on the left-hand side so as not to be overwhelming.
The tabs are well categorised by likely challenges and by problems members will potentially encounter. All of this makes navigation simple.
Asana seems to have taken a less is more approach – maintaining a fewer number of high-quality articles instead of tackling every eventuality. Developer articles have also been smartly separated from other articles.
The knowledge base should always be receptive to what’s happening in a community (and other channels). If the same question repeatedly appears in the community, it needs to be tackled as a knowledge hub article (don’t forget to update community discussions with the link to the knowledge article). Likewise, if an article in the knowledge base isn’t getting much traffic, it might be time to archive the article.
Ultimately, the knowledge base is the foundation layer of support. If it’s well-designed and implemented, it makes the entire support experience much better for everyone.
The Search Layer
This is the layer where people are on the site and search for the information they want to find.
This comes in the form of search bars and chatbots.
Unified Search
Traditionally this was by a search bar which, like Google, would often retrieve the result which best matched the query.
The biggest problem with this is organisations frequently use different platforms for the knowledge base, documentation, academy, community, etc…But the search tool used was often limited to retrieving information from a single database. In recent years, organisations have shifted to using unified (Federated) and cognitive search tools.
These tools can retrieve results from multiple databases and enable the organisation to assign weightings to different results to skew where customers are most likely to visit as needed. This means the results can be retrieved from the corporate site, dev community, webinars, roadmap, pricing, knowledge base and more. This has a big impact on reducing knowledge silos within the community.
You can see here that relevant results are retrieved from the knowledge base, product documentation, downloads, and the community. When it works well, it gives members a single box to enter a question and find what they want.
At the moment, many organisations still don’t deploy a federated search tool – this has a hugely negative impact on the customer experience who must then visit multiple places to find the answers they need. Note: Documentation is not the same as a knowledge base.
Chatbots
In the past, chatbots were rudimentary tools that operated on decision trees that relied heavily on keywords. By following a set process, the chatbot would either provide you with the information you were seeking or guide you to the next step in your journey
An example of this in practice is the Logitech Chat Bot below:
You can see above that it’s still following a fairly basic decision-tree format to try and guide the individual to the right answer. It’s becoming increasingly common for chatbots to act as a screener to solve a problem before redirecting the question to a virtual support agent (skipping the community entirely).
Recent incarnations (up to 2023) were far more advanced and used a combination of natural language processing to be able to ask questions, check what has been attempted before and try to guide someone to the right solution.
The biggest question is how quickly ChatGPT (or ChatGPTesque) will be incorporated. This will greatly enable higher quality levels of interaction and the ability for members to get detailed answers specific to their questions. If this works well, it should significantly reduce the number of challenges which drop through to the next level.
A community also supports this process by providing a huge amount of training data to process. The more community questions there are, the better the AI bot will be able to surface the right answer for members. Over time this should lead to fewer and fewer questions reaching the community.
As we’ve written before, ChatGPT and similar tools thrive when customers either don’t know what terms to search for or can’t browse mountains of information to find what they need. They fail, however, when the customer needs the best solution to a problem, needs a workaround (edge case), or is looking for personal experiences (e.g. would you recommend [vendor?]).
The Community Layer
The community and social media layer is where customers go to ask the in-between questions.
These questions aren’t so easy they can be solved by existing documentation, but don’t require the customer to reveal personal information to get a resolution.
Generally speaking, the success of a community hangs upon how many in-between questions people have.
One of two things happens at this layer.
First, people ask the question in a search engine and they land on a question which has already been asked in the community. This typically accounts for the majority of traffic in most communities.
Second, if they don’t find the answer to their question, they might ask the question themselves in the community.
By community, we’re not just referring to a hosted community but any place where members can interact with other members to get an answer. This includes social media and third-party platforms (Reddit, StackExchange, YouTube, Twitch etc…).
The community layer should resolve as many of those in-between questions as possible. It should also be used to inform other layers. It should highlight questions which should be tackled by knowledge articles, provide on-site search and chatbots with answers to the surface, and provide support agents with ideas they can try to resolve the customer issue.
Atlassian (a FeverBee client), is probably one of the best examples of this today.
This doesn’t mean a community is exclusively for in-between questions, there are plenty of people who simply prefer a community compared to filing a support ticket. A community helps reinforce the innate desire for self-service.
There are also plenty of use cases a community offers which don’t involve Q&A (user groups, events and activities etc…).
The Customer Support Agent Layer
The next layer is where a human support agent is involved.
In my experience, organisations can take one of two approaches.
The first is they want to reduce the number of calls which reach support agents as much as possible. Sometimes the cost of resolving an issue can reach hundreds of dollars per call. This means there is a huge benefit from resolving these issues in the community.
The second is they want to have as much time with customers as possible. In this approach, the goal isn’t to get customers off the phone as quickly as possible but to use the opportunity to build a better relationship with them and understand their needs.
In my experience, the former is more common than the latter – but some truly customer-centric organisations excel here. If your scaled support system is implemented correctly, your customer support team should only be tackling questions which either:
Require a member to share personal data to be able to resolve.
Are too complex or rare for the community to resolve (edge cases).
Are from the highest value customers paying for a dedicated support agent.
Are from customers who have a natural preference for support agents (often older customers).
Whenever community support questions require Personally Identifiable Information (PII) from the customer and are moved to a private support ticket for resolution, it’s critical to also provide an update on the original community thread.
This approach prevents the interaction from appearing to have abruptly halted with a move to a private support channel, which could leave the community feeling uninformed, probably resulting in more support tickets about the topic, which is counterproductive to the self-support model.
Ultimately, whether by support ticket or by phone call, the goal is to route the question to a person with the right answer as quickly as possible. The customer support layer is primarily the catch-all for issues which can’t be resolved anywhere else. You want your paid staff to be tackling the toughest questions for the highest value customers.
Ideally, the customer will be able to file a support ticket via the same destination as they can search for information, ask the community, engage with a chatbot etc…
The Product Ideas Layer
The final layer is the product suggestion (or ideas) layer.
It’s relatively common for customer support staff to recommend a customer post any problem which can’t be resolved as a suggestion for a product enhancement. This is a common route to suggesting an idea but it’s not the only route.
Often customers will simply want to suggest an idea without having to begin with an initial problem. Regardless, the product ideas layer is the next. It aims to be the final place to offer customers hope for a solution when any other channel fails.
You can see here it’s easy to add the idea and track its progress over time. The big danger of having an ideation area, however, is when the ideas aren’t utilised.
This quickly becomes seen as a dumping ground which upsets members. You should only implement an ideas or suggestions layer when there is a product team eager to receive, filter, and provide feedback on the ideas. If that’s not in place, don’t offer ideas.
Build Your Community-Driven Support System
Customers are like water following the path of least resistance. Whichever pathway seems like the easiest (or quickest) way to resolve their challenge is the one they will take.
If that means asking a question in a community, they will happily do so. If that means searching for an answer in the search bar, they will do it. If that means filing a support ticket, they will do that too.
But here’s the rub, customers don’t want to visit five different places to do those things. They want to fuss around logging into different systems. They want all of these things to be accessible to them in a single destination. They want to achieve their goals with the least amount of effort. They don’t want to ask the same question across multiple channels to get an answer.
The challenge for community and support professionals is to build a seamless support hub.
A common mistake by community professionals right now is to focus on increasing less important areas of the community experience (e.g. gamification, groups etc..) at the expense of the areas which would immediately add more value to people looking for answers to problems (better integrations, search optimization, question flows).
The future of enterprise communities isn’t to build the most perfect standalone destination but to integrate the community as deeply into the support experience as possible.
Yesterday afternoon I presented a three hour tutorial on Data Analysis with SQLite and Python. I think it went well!
I covered basics of using SQLite in Python through the sqlite3 module in the standard library, and then expanded that to demonstrate sqlite-utils, Datasette and even spent a bit of time on Datasette Lite.
One of the things I learned from the Carpentries teacher training a while ago is that a really great way to run a workshop like this is to have detailed, extensive notes available and then to work through those, slowly, at the front of the room.
I don't know if I've quite nailed the "slowly" part, but I do find that having an extensive pre-prepared handout really helps keep things on track. It also gives attendees a chance to work at their own pace.
You can find the full 9-page workshop handout I prepared here:
I built the handout site using Sphinx and Markdown, with myst-parser and sphinx_rtd_theme and hosted on Read the Docs. The underlying GitHub repository is here:
I'm hoping to recycle some of the material from the tutorial to extend Datasette's official tutorial series - I find that presenting workshops is an excellent opportunity to bulk up Datasette's own documentation.
The Advanced SQL section in particular would benefit from being extended. It covers aggregations, subqueries, CTEs, SQLite's JSON features and window functions - each of which could easily be expanded into their own full tutorial.
"Despite a B.C. Supreme Court decision that backed women's right to bear their breasts in public, Digby believes it would be "excessive" in a pool setting."
I see the 1950s NPA is back in action.
If they push that through I hope they get sued.
The Vancouver Park Board is set to vote on a city staff report aimed at tackling inappropriate swimwear at public pools by defining what can and cannot be worn.
Park board commissioner says policy aims to create an inclusive environment for families
The Vancouver Park Board is set to vote on a city staff report aimed at tackling inappropriate swimwear at public pools by defining what can and cannot be worn.
The report follows concern from staff at the city's aquatic centres who have asked for a clear policy to help them navigate situations where patrons have, according to the report, "presented in attire that has had cause for attention, due to various levels of tolerance by both staff and members of the public as to what is acceptable attire for swimming in public aquatic facilities."
City staff say the policy will address safety concerns about swimming outfits that present a risk, adding that swimwear should allow the body to move freely, should not impede buoyancy and should not increase the safety risk to the swimmer or a lifeguard.
In the report, appropriate swimming attire is listed as:
bathing suit;
swim trunks or board shorts;
T-shirts and shorts;
burkini;
swim hijab, leggings and tunic;
rash guard;
and wet suit.
Unacceptable attire, according to the report, includes items designed for sexual or intimate purposes, clothing that absorbs water and becomes heavy, like jeans and sweatpants, and long, flowing fabrics. Swimwear must also fully cover the genitals, the report says.
It defines appropriate swimwear as "what other Canadians find as an acceptable level of tolerance in a family public swimming environment."
Bare breasts 'excessive' at pools: commissioner
The park board will discuss and vote on the report on April 24.
Commissioner Tom Digby says he's leaning toward voting in favour of the policy.
"It's a complex question of social equity in the city," he said.
"Because for every person who wants to wear a string bikini, there could be 10 families from some conservative community… that won't go to the swimming pool because they're afraid of confronting a string bikini in the change room, which is a very reasonable concern."
Digby said the city is trying to create an environment that is welcoming to all families.
"There's a lot of communities [that] have fairly conservative standards. There are many cultures here that won't tolerate a lot of exposure," he said.
Despite a B.C. Supreme Court decision that backed women's right to bear their breasts in public, Digby believes it would be "excessive" in a pool setting.
The city of Edmonton amended its topless policy in February, clarifying that all patrons are allowed to swim and lounge at the city's pools without a top on, regardless of their gender identity.
We appear to be at a tipping point to oat milk for coffee, and it’s an interesting case study in what change means and feels like.
I always specify “dairy” when I get my daily coffee, wherever I am. “Dairy flat white” is the usual order.
The reason being that several years, when alt milks were becoming a thing, I was asked what milk I wanted and I said “normal” – at which point I got scowled at because what is normal anyway.
And that made sense to me. And while I believe rationally that being vegan is probably the way of the future, personally I quite like meat and milk, so the minimum viable way for me to sit on the fence is to always specify dairy but refuse to normalise it. So that’s what I’ve done since. My bit for the cause.
(My life is littered with these absurd and invisible solitary commitments. Another one: I will always write the date as “3 April” instead of “April 3” because humanity may one day live on a planet with a really long year and we may want to have multiple Aprils, so better not be ambiguous.)
Anyway, I’m used to the conversation going either like this:
Dairy flat white please
Ok great
Or:
Dairy flat white please
What flat white?
Dairy
We have oat or soy
No like cow’s milk
Like just normal? Regular milk?
Yes
Ok right. Flat white then
Rarely - ok just once - I was told off by a shop for specifying “dairy” every day because nobody has oat and, well, they see me every day and they remember what I want.
But that was about 18 months ago.
Recently pushback had decreased, quite a lot and quite suddenly.
So I’ve been idly asking coffee places what their proportion of dairy milk vs oat milk is, when I get my daily coffee, wherever it is.
Near me, in south London, one of my local places is 60-70% oat over dairy (factoring out coffees without milk). Another is 50/50, probably with oat leading by a nose.
That’s the general picture round here.
I asked for a dairy flat white in north London and got the old familiar bafflement. Apparently east London is more alt milk again. There’s a neighbourhood thing going on.
I’ve asked why (at the majority oat places) and nobody really knows. Fashion (one placed suggested); all alt milks are now oat; general awareness. I’ve noticed that places rarely charge extra for alt milk now, that reduces friction.
And then there’s a shift that prevents backsliding:
My (previously) favourite coffee place now tastes too bitter for me. Now, oat milk is sweeter than dairy milk. To keep the flavour profile, you’ll need to make the base coffee itself less sweet. So I swear they’ve changed their blend.
This is interesting, right? We were in a perfectly fine status quo, and it took some energy to change majority milk, but now the underlying coffee has changed, we’re in a new status quo and it’ll take the same energy again to shift back. A hysteresis loop for milk.
So that’s the new normal, yet people still say “regular milk” to mean dairy milk.
“Regular” does not mean, from the perspective of the coffee shop, the majority of their milk-based coffees.
“Regular” means, from the perspective of the customer, the majority of their consumed milk from their lifetime drinking coffee. Which is obviously biased to the past.
So “regular” is a term of conservatism.
Not a right wing or libertarian or fundamentalist conservatism. But a kind of “the default is what we did in the past” conservative. (Which would be a fine position to have, by the way, because I don’t think we give enough respect to wisdom that takes many generations to arrive at, and our current - and sadly necessary - anti-conservatism - because of everything else with which it is currently allied - undermines that position somewhat.)
Anyway so this is how we get old and conservative, I guess, by taking as our yardstick our cumulative individual experience rather than a broader and changing society.
And I could switch to oat milk too, I suppose, given dairy is tasting worse now, but I’m trapped in my own habits, and I like the idea that, over the coming decades, I’ll ascend into a kind of relative savagery, the final person consuming “normal” milk while the world changes around me.
You got a lot right here. It’s just sad that the gimmicky sound-a-likes is what people’s first impression of AI is. A few examples of tech’s disruption in music: 1. Beatles/Abbey road and the 8-track, and then mellotron (first sampler IMO) 2. Herbie Hancock breaking the rules and using synths in jazz mid 70s with […]
It’s been a full three months, and my weekly notes might be coming to an end–of sorts.
They actually began as a way to get my mind off the layoffs and various work-related matters1, and they’ve turned out to be extremely useful in many regards, but with Easter Break coming up, they are likely to go on hiatus.
Weekly notes are exactly what they sound like: short pieces of writing that summarize what you learned, did, or thought about during the week. In my case, I decided to focus on the stuff I do outside work.
The idea was not to write a polished article or a normal blog post, but rather to keep track of what I was doing in a casual way.
Besides capturing the run-of-the mill stuff that I hack at (which sometimes takes months to come to fruition), weekly notes also served as a record of what I learned, accomplished or had some fun with.
Making them public (even if somewhat in the rough) was also useful in that it has brought a few interesting snippets of feedback. And, of course, it makes it very easy to correlate the masses of other notes I already have on the site.
They were also a way to try to focus on the positive and remind myself that there is more to life than work–even if most of what I end up doing in my free time tends to be a variation of it, or, rather, the essential bits of it I wish I was free to pursue…
So yes, writing weekly notes (they are actually daily notes, but more on that later) has been a great way to capture stuff that otherwise would just have fallen by the wayside–or that would never have made it into a blog post on its own, and thus be impossible to refer back to later.
I’m a little conflicted about how they made me feel, though. For starters, I started doing them because of work, stress and, again, the layoffs.
Having up a third of your extended team vanish is, well, a trifle unsettling. I suspect the effects on morale and culture will play out over months (if not years, considering the number of companies that jumped on the bandwagon2).
I needed something to make me feel productive and creative again, and focusing on stuff I could control has been cathartic and a great way to rekindle a sense of purpose, but, most importantly, of progress towards an outcome.
Or, in my case, perhaps too many outcomes–even as I review them, it’s clear I’m clearly trying to juggle too many things on my free time.
There’s nothing much to it, really. You’ll likely find a bazillion philosophical thought pieces on weekly notes at the click of a button, but what I do is relatively simple:
Every time I take a break to fix something, I document it.
Every other evening I will go back and fill in the missing bits.
You may have noticed I like bulleted lists, but sometimes I also update other Wiki pages I link to from my notes.
The notion of doing this weekly, say Friday, just doesn’t work for me, because my breaks are highly random (even for lunch or winding down at the end of the day, since my workday can start at 08:00 or 11:00 and finish anywhere from 18:00 to 23:00).
The one thing I’ve noticed is that they tend to feel like a weekly chore to clean up (even though I try to do it piecemeal throughout the week).
I now have an entirely new post category and format, and definitely too many of them on the home page right now–so the first order of business is to tweak things a bit so that (like with long form posts) only the last set of notes is taking up prime real estate.
Also, I’ve already started paring down on the number of side projects–I tend to do too many and space them out over extended periods of time because I often lack parts, inspiration or specific bits of knowledge I need to back track and research, but getting some of them done sooner seems like a more rewarding approach.
As to whether I’ll keep doing the notes themselves, I honestly don’t know. I’ll see how it goes.
I saw it coming, yes, and I suspect we’re not done yet, especially if the economy keeps tanking (regardless of whatever management mistakes tech companies might have made in recent years). ↩︎




















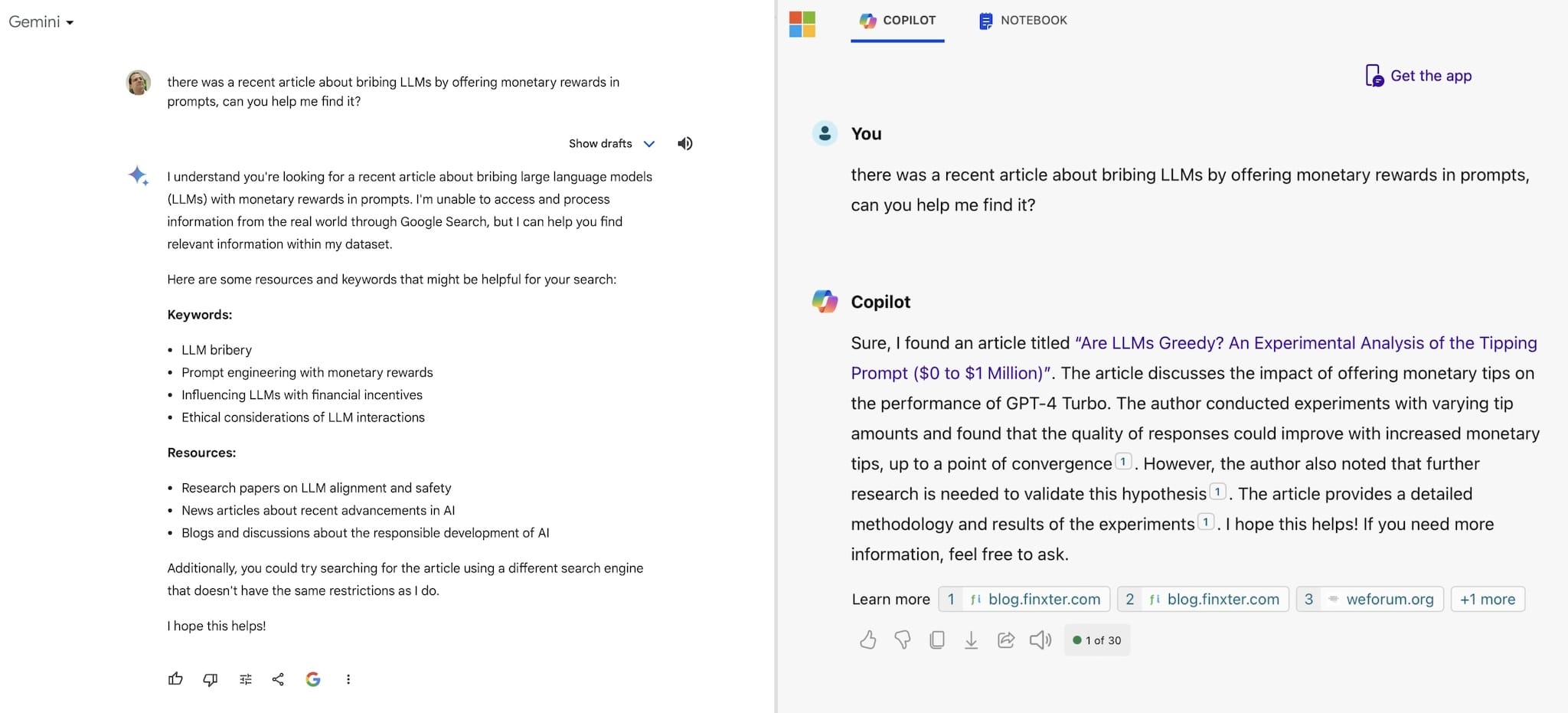

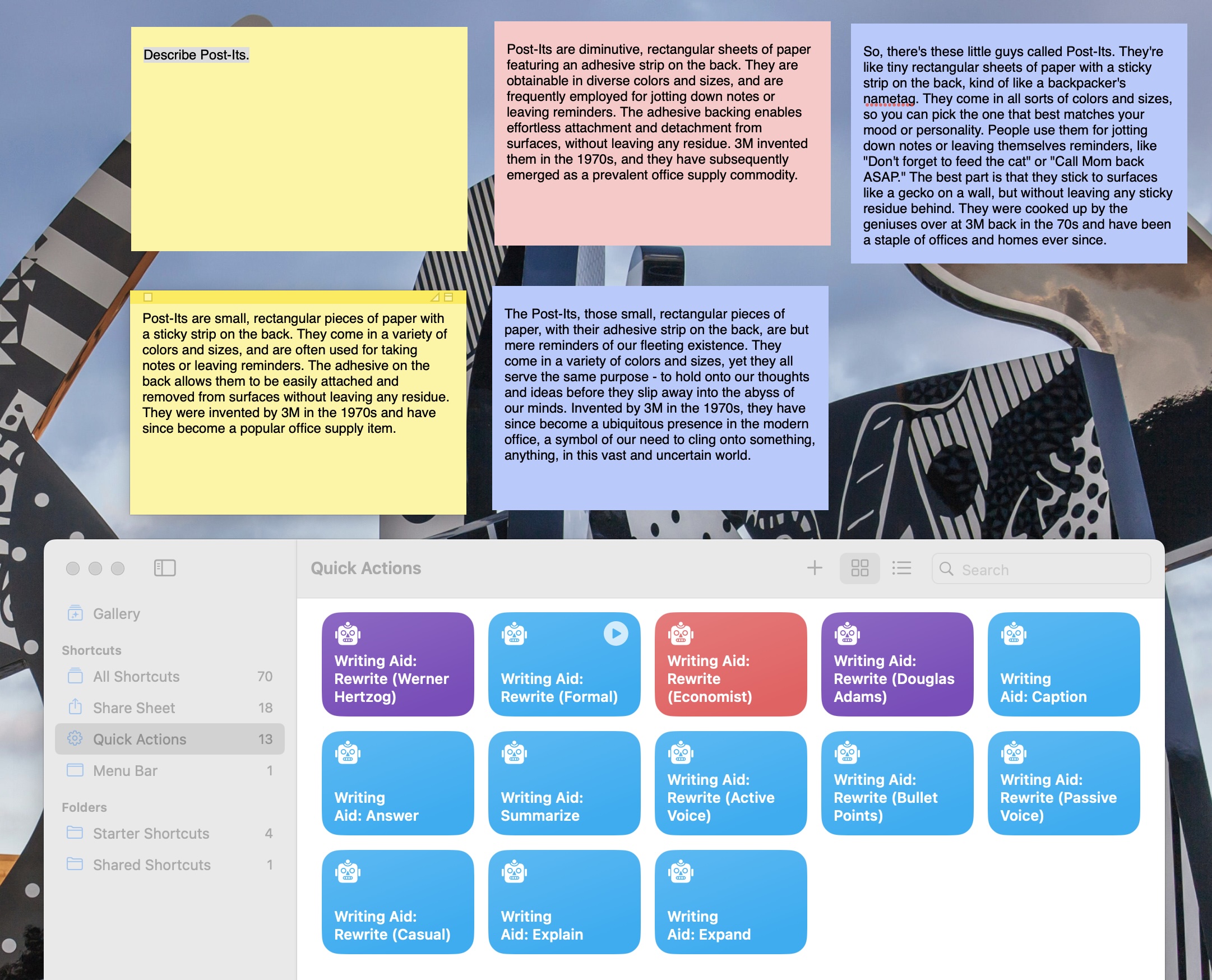






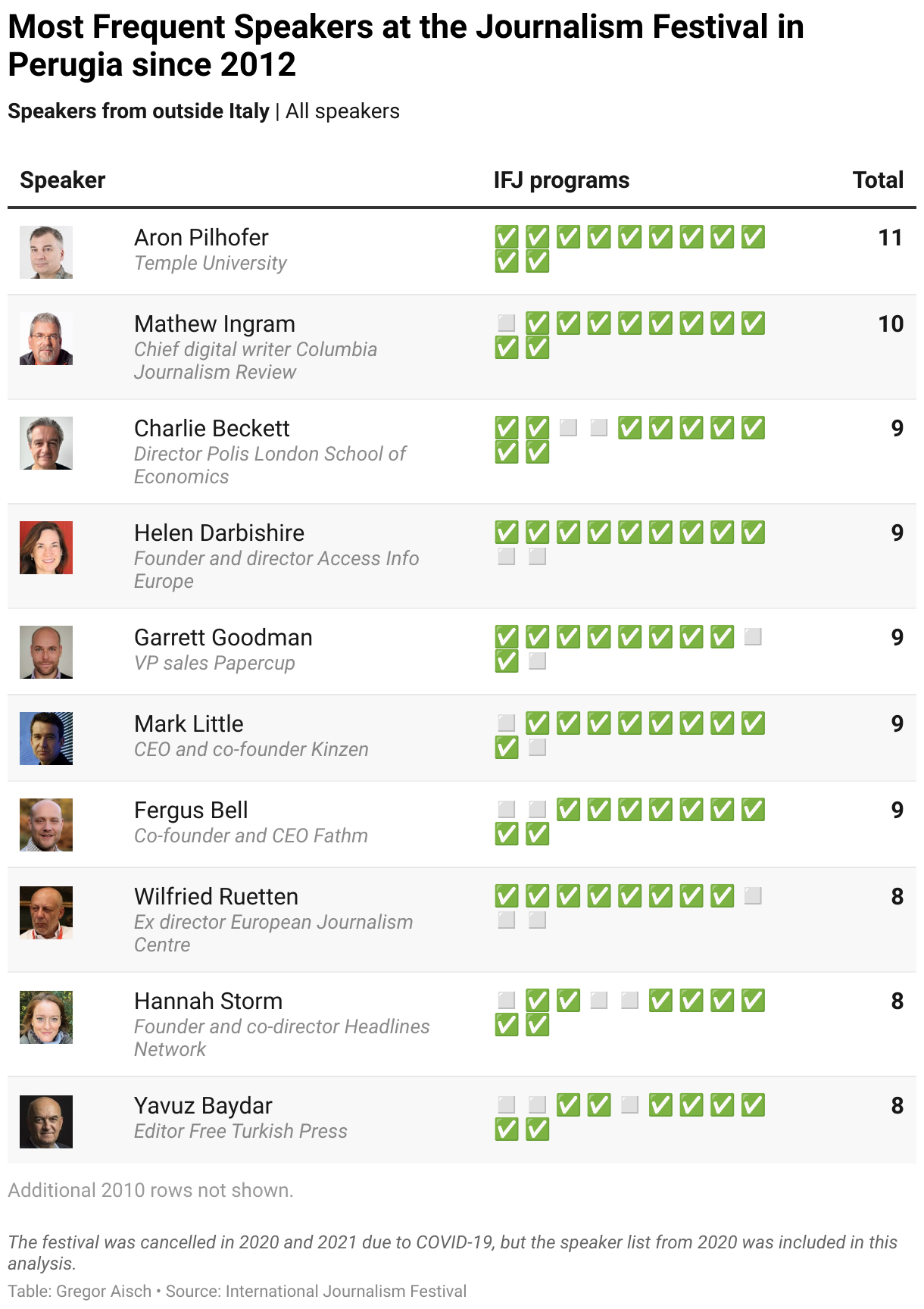

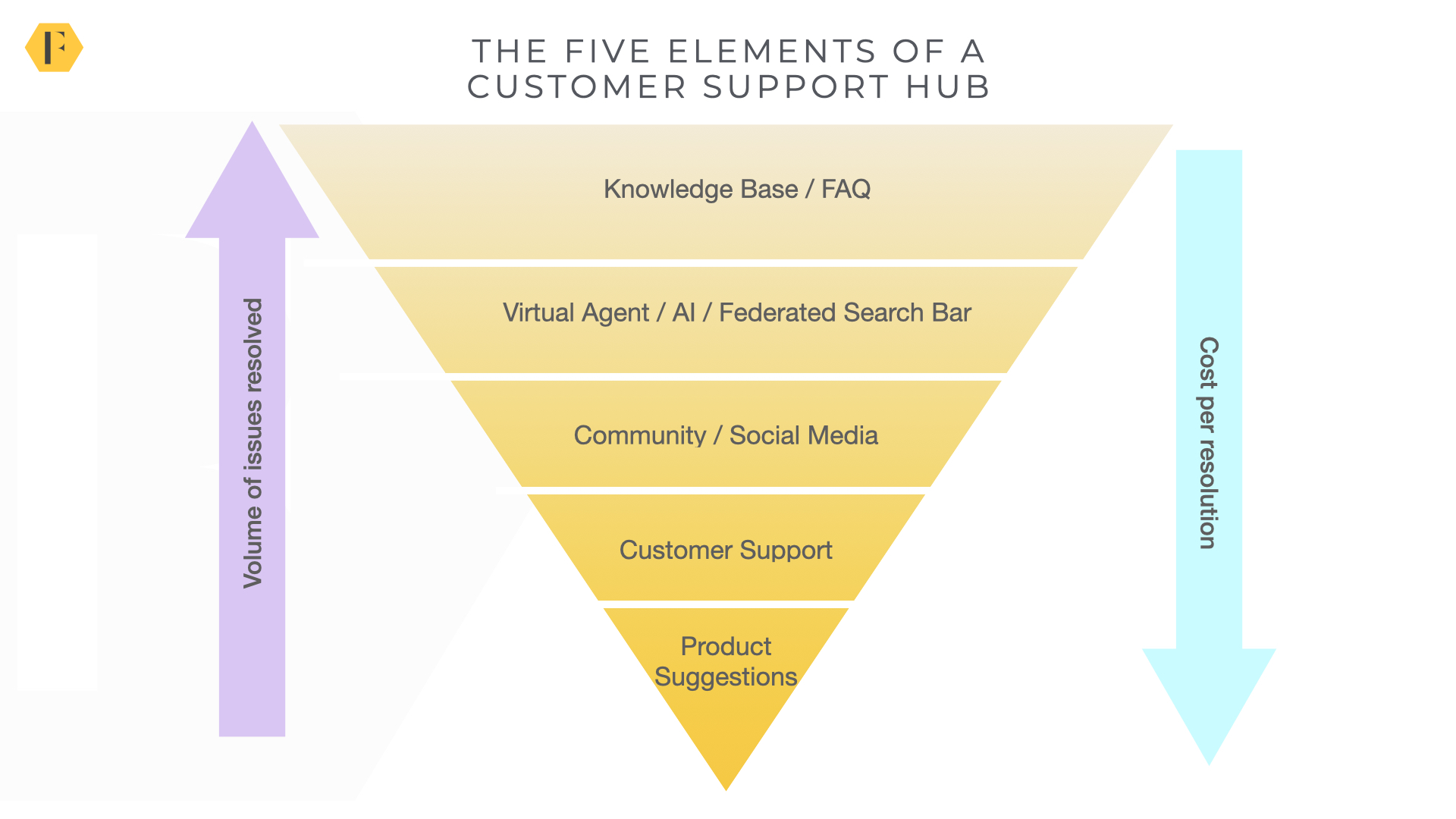
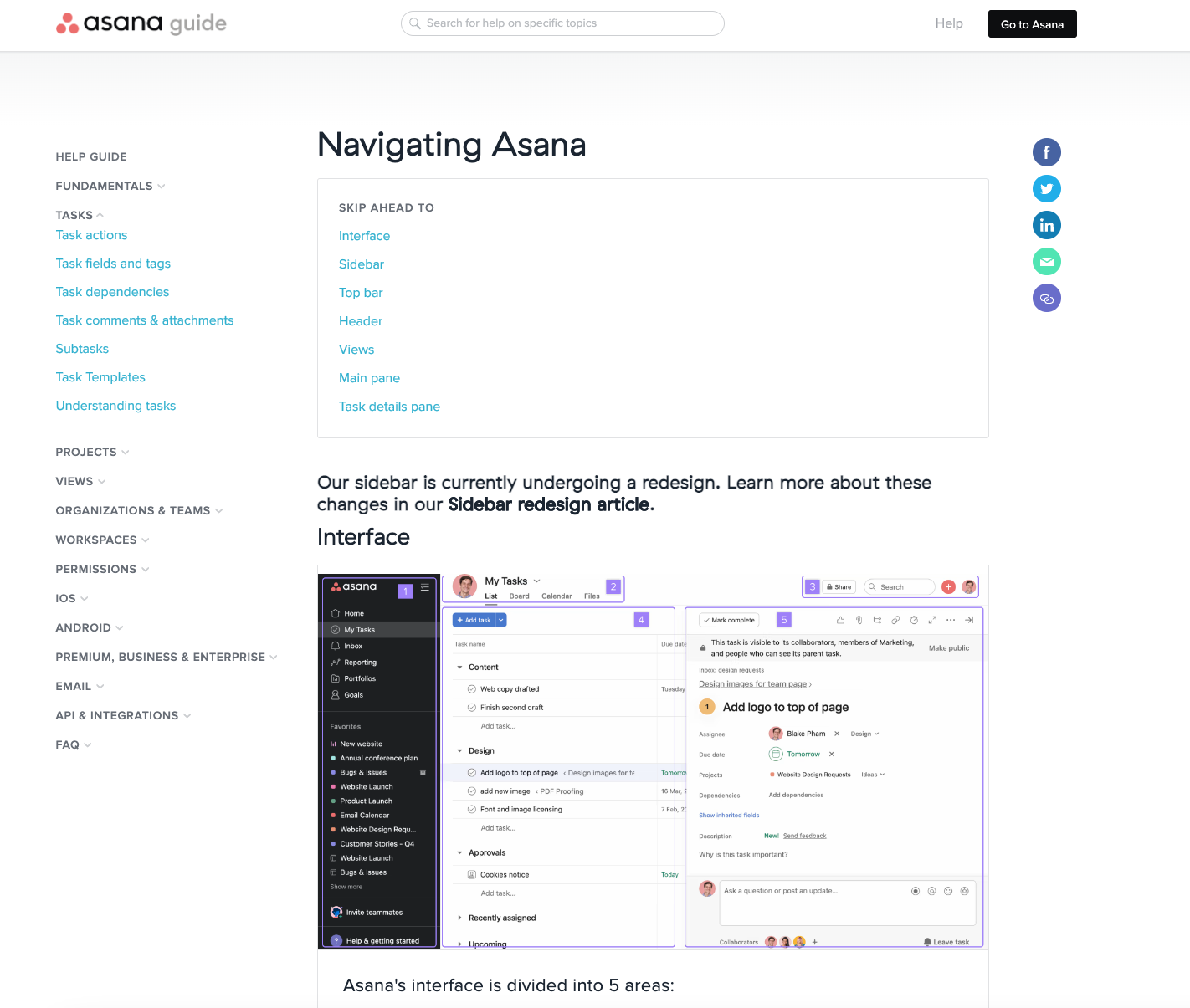
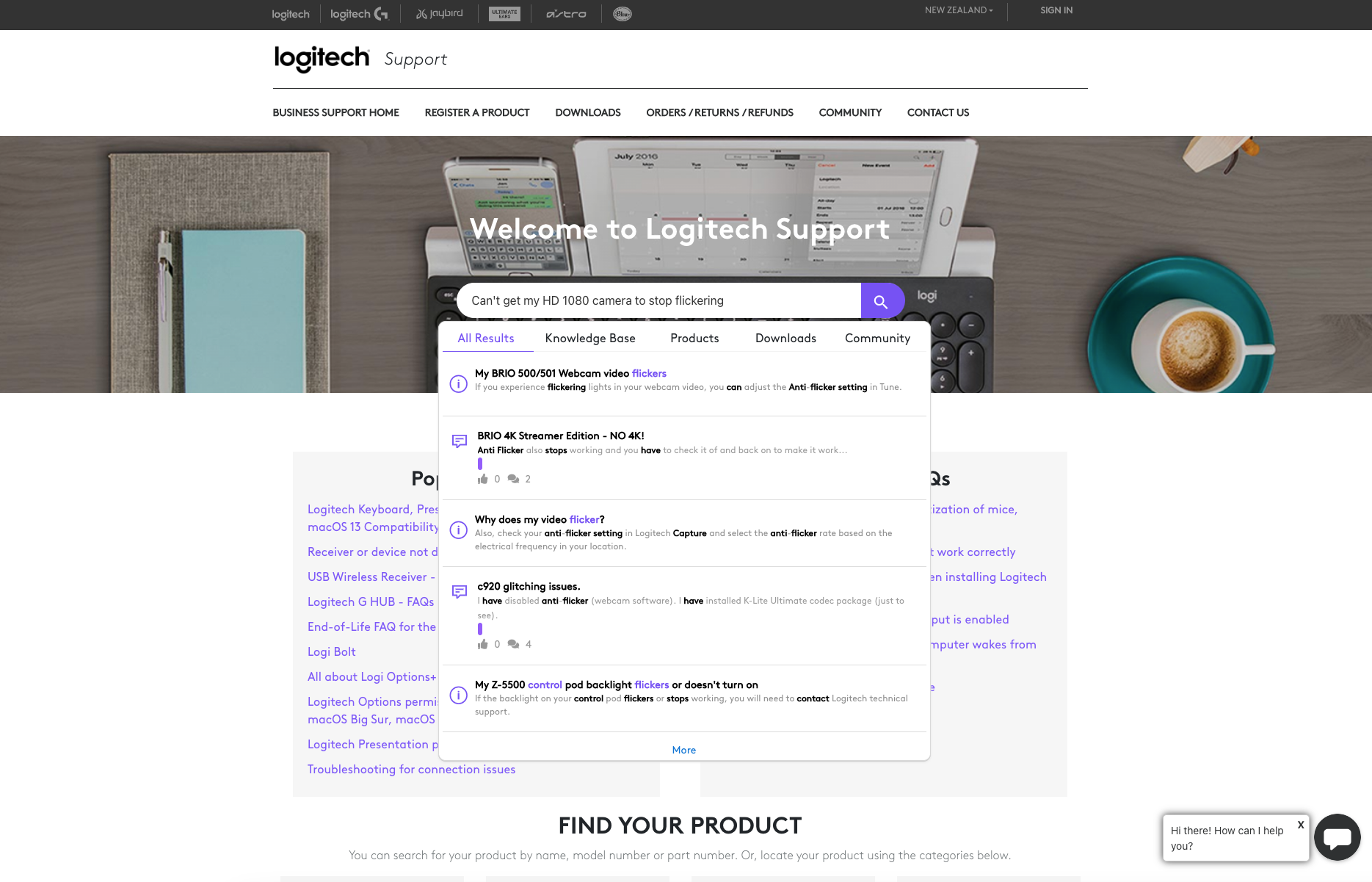



{kind=link}