
Mozilla Lightbeam est la dernière génération dextension développée par Mozilla dans le cadre du projet Collusion, lancé en 2012. Cette extension permet de visualiser...
Mozilla Lightbeam est la dernière génération dextension développée par Mozilla dans le cadre du projet Collusion, lancé en 2012. Cette extension permet de visualiser...

90% des internautes français recherchent les données stratégiques sur Google. Mais il existe une vie hors du moteur de Mountain View.
 Mais il existe une autre partie du deep web, et il s’agit de sites non accessibles avec un navigateur classique. Où se développe effectivement un internet « parallèle » sur lequel l’anonymat rend impossible l’application de la loi. A la fois intriguant et dangereux – pour votre ordinateur (attention aux virus), pour votre esprit (attention aux images qui restent imprimées sur la rétine) et pour des questions légales – on y croise bon nombre de projets et d’espaces qui, s’ils sont bien réels, franchissent sans vergogne le domaine des lois internationales. Ces sites ont une adresse en .onion – le reste étant généralement composée d’une suite de chiffres et de lettres désordonnées – et il est nécessaire de disposer d’un navigateur spécifique pour les atteindre, raison pour laquelle les moteurs de recherche ne les indexent pas.
Mais il existe une autre partie du deep web, et il s’agit de sites non accessibles avec un navigateur classique. Où se développe effectivement un internet « parallèle » sur lequel l’anonymat rend impossible l’application de la loi. A la fois intriguant et dangereux – pour votre ordinateur (attention aux virus), pour votre esprit (attention aux images qui restent imprimées sur la rétine) et pour des questions légales – on y croise bon nombre de projets et d’espaces qui, s’ils sont bien réels, franchissent sans vergogne le domaine des lois internationales. Ces sites ont une adresse en .onion – le reste étant généralement composée d’une suite de chiffres et de lettres désordonnées – et il est nécessaire de disposer d’un navigateur spécifique pour les atteindre, raison pour laquelle les moteurs de recherche ne les indexent pas.
[...]
Par Sylvain Abel pour spintank.fr
En savoir plus :
Sources : http://www.spintank.fr/on-a-explore-le-deep-web/
Et aussi : http://hitek.fr/actualite/deep-web-face-cachee-internet_259
Vous voulez rire ?
On sait enfin comment la NSA engrange des centaines de millions de carnets d'adresses très simplement.
Vous voulez savoir comment ?
Et bien c'est simple... Apple a tout simplement oublié d'implémenter les connexions en HTTPS (donc chiffrées) lorsque le carnet d'adresses d'OSX se synchronise avec Gmail.
Vous voulez un kleenex ?
Oui, cela signifie que dès que votre carnet d'adresses se synchronise avec Gmail, tout se balade en clair sur le réseau. Et ces suceuses (de données) que sont la NSA ne nous ont pas attendu pour se les approprier grâces à leurs systèmes TUMULT, TURBULENCE, et TURMOIL connectés sur les backbones.
Je vous rassure, n'importe quel script kiddies qui sniff un réseau Wifi peut lui aussi obtenir le même résultat donc bon...

Le lièvre a été levé grâce au Washington Post, qui nous donne même des chiffres sur la NSA et ses interceptions de carnet d'adresses. Ce sont donc plus de 444 700 carnets d'adresses de Yahoo, 105 000 de Hotmail, 82 800 de Facebook et 33 600 de Gmail qui ont été interceptés l'année dernière CHAQUE JOUR !
Le chiffre de Gmail reste modeste, car tout est chiffré par défaut en HTTPS sur le site de Google contrairement aux autres. (sauf dans le cas du carnet d'adresses d'OSX ^^)
Reste plus qu'à espérer qu'Apple déploie rapidement un correctif (ou vient de le faire avec l'update de Mavericks ?). Edit : En attendant, pour passer tout ça en HTTPS, décochez la case qui dit "Synchroniser avec Google" dans le gestionnaire de contacts et ajouter un compte CardDAV à la place, ce qui aura pour effet de tout passer en HTTPS.
Cet article La petite négligence d’Apple qui fait plaisir à la NSA est apparu en premier sur Korben.

Les blogs métiers font partie de mes sources préférées pour surveiller l'actualité de l'infocom, avec en bonus des anecdotes et des points de vue parfois très personnels. 22 sources supplémentaires (sur 44 au total) à découvrir ou à revoir.
Le top des blogs en infocom Partie 2b >>> VEILLE <<< Sélection de blogs, traitant du thème de la veille, de l’intelligence économique, de l’IST et de la recherche d’information sur Internet, mis à jour au moins une fois en 2013. Présentation par ordre alphabétique Les blogs métiers font partie de mes sources préférées pour surveiller more »
Cet article Top blogs en infocom – Partie 2b : veille / IE est apparu en premier sur PoleDocumentation.
Si vous utilisez des outils de versioning comme Git, Mercurial, SVN ou encore Bazaar pour gérer le code de vos projets, j'ai peut-être un truc qui va vous plaire. Il s'agit d'un outil baptisé Gource qui permet de générer une animation à partir de l'arborescence de votre projet.
Les répertoires apparaitront alors comme des branches et les fichiers comme des feuilles. Ainsi, vous pourrez mieux vous rendre compte visuellement du développement des ramifications de votre projet. La tête des dev qui ont contribué au projet apparaitra aussi.
Par exemple, mes amis de Kontest l'ont utilisé pour se faire une petite vidéo virale bien rythmée. Évidemment, sur cet exemple, il y a un peu de post-production.
Mais si vous voulez voir quelque chose de plus proche de la réalité, rendez-vous ici.
Gource est disponible sur Google Code et est diffusé sous licence GPLv3.
Merci à Sylvain pour le partage !
Cet article Gource – Quand le développement de votre projet s’anime devant vos yeux est apparu en premier sur Korben.
Afin de compromettre Tor, la NSA a attaqué de nombreux logiciels associés, y compris Firefox, selon des documents fournis par Edward Snowden.
Selon un article paru avant le week-end dans le Guardian, les diverses tentatives de l’agence de sécurité nationale américaine, la NSA, pour compromettre l’outil d’anonymisation Tor (The Oignon Router), projet dont le financement est assuré en grande partie par le gouvernement américain, n’ont pas été très fructueuses. Ces informations s’appuient sur des documents remis par Edward Snowden au Guardian, révélant l’espionnage tous azimuts par la NSA des communications téléphoniques aux États-Unis et de l’Internet à l’étranger et dont le journal a commencé la publication en juin dernier.

Je vais vous raconter une expérience qui pousse la logique du MOOC, ces cours en ligne ouverts et massifs, jusqu’au bout. Une expérience narrée récemment dans le New York Times par Tina Rosenberg (@tirosenberg), et qui est le point de départ d’un mouvement qui porte le joli nom d’”école inversée” ou flipped school.
Tout commence il y a quelques années, à Clintondale, au nord de Detroit, dans une région loin d’être privilégiée. Le proviseur d’un lycée poste sur Youtube des vidéos de tactiques de baseball pour l’équipe de ses fils. Il s’aperçoit que non seulement les jeunes joueurs regardent ces vidéos, mais ils les regardent plusieurs fois… Ils assimilent les stratégies et cela laisse plus de temps, à l’entraînement, pour la mise en application et la pratique.

A la rentrée suivante, ce proviseur demande à un de ses enseignants en sciences sociales, de tenter une inversion avec une classe : mettre des cours en ligne et consacrer les heures de classes aux questions et à la pratique. A la fin de l’année, cette classe obtient de meilleurs résultats que les autres. Le proviseur va donc voir l’entreprise qui développe le logiciel de capture d’écran pour ses vidéos de baseball et leur dit : “je veux faire une école”. La boite (TechSmith, pas Google) autorise l’usage gratuit du logiciel et l’année suivante, le proviseur inverse tout un niveau, l’équivalent de la 2nde, qui était le niveau le plus problématique de son établissement, qui est un établissement en difficulté. Les résultats sont spectaculaires : les taux d’échecs aux évaluations sont en gros divisés par deux et dans toutes les matières. A l’automne 2011, le proviseur décide donc d’inverser tous les niveaux, et toutes les classes. Les résultats de l’établissement s’améliorent aussi spectaculairement.
Est donc né le mouvement dit de “l’école inversée” : les enseignants enregistrent des cours en vidéo, les élèves regardent ces vidéos en dehors de la classe, sur leur smartphone dans les transports, devant leur écran d’ordinateur chez eux ou dans la salle informatique de leur lycée (pour ceux qui n’ont pas chez eux de quoi regarder des vidéos en ligne). Et depuis Clintondale, le mouvement commence à essaimer doucement.
Qu’est-ce que ça change au fonctionnement de l’école ? En dehors de la classe, on remarque que les élèves sont plus enclins à regarder des vidéos qu’à faire les devoirs traditionnels et, surtout, qu’ils les regardent plusieurs fois (elles sont courtes entre 3 et 6 min), sans avoir peur de passer pour des imbéciles parce qu’ils ne l’ont pas compris du premier coup.
Ca change surtout ce qui se passe à l’intérieur de la classe. La classe devient le lieu des questions et de la mise en pratique. Un lieu d’activité. En petit groupe. Dans un rapport direct entre l’enseignant et les élèves. Ce qui permet aux enseignants d’identifier beaucoup plus vite ceux qui n’ont pas compris (et qui arrivent à se cacher dans un dispositif de classe traditionnel). D’où un constat : l’expérience de Clintondale profite le plus aux élèves en difficulté.
Pour les enseignants, évidemment, ça change beaucoup de choses. L’un explique à Tina Rosenberg qu’il a l’impression de s’être transformé en artiste de l’éducation. Il réfléchit à des contenus formellement innovants et à des activités nouvelles en classe. L’école inversée exige des enseignants plus de créativité et d’énergie.
Evidemment, il y aurait dans le détail beaucoup à discuter dans cette “école inversée” (et j’imagine que ça doit faire bondir certains de nos auditeurs), mais il y a quelque chose que je trouve très intéressant du point de l’usage des technologies :
“Utiliser la technologie pour humaniser la classe”, dit le proviseur, c’est une ambition qu’on pourrait appliquer largement au-delà de l’école.
Xavier de la Porte
Retrouvez chaque jour de la semaine la chronique de Xavier de la Porte (@xporte) dans les Matins de France Culture dans la rubrique Ce qui nous arrive à 8h45 et sur son blog (RSS).
L’émission du 19 octobre de Place de la Toile était consacrée à comment les “PornTubes”, ces plateformes de partage de vidéos porno en accès libre, ont transformé la pornographie. Un sujet discuté avec l’ex actrice porno et activiste féministe Judy Minx (@judyminx) ; Florian Voros (@fsvoros), doctorant en sociologie des médias qui travaille sur les usages des films et vidéo porno et la construction de la masculinité ; Stephen des Aulnois (@desgonzo), créateur du Tag Parfait, un site qui considère la pornographie comme une culture ; et Ghislain Faribeault (@faribeault), vice-président média chez Marc Dorcel Production, haut lieu de production de la pornographie.
ecole2.0, jeunes, pdlt
Martin Vidberg a réalisé une vidéo très ludique sur le fonctionnement de la NSA :
Alors patate, tu te sens toujours à l'abri ?
Vous devriez me suivre sur Twitter : @xharkArticle original écrit par Mr Xhark publié sur Blogmotion le 21/10/2013 |
2 commentaires |
Attention : l'intégralité de ce billet est protégée par la licence Creative Commons

Entre promesses non tenues et améliorations fulgurantes... trois mois après la fin de Google Reader, les frontières entre les différents prétendants ont bien bougé. Comparatif des solutions !
Ladar Levison, le fondateur du service d'emails anonyme Lavabit aura vraiment tout fait pour protéger la vie privée de ses utilisateurs, et en l’occurrence celle d'Edward Snowden. Il se passait quelque chose d'énorme, mais malheureusement Ladar Levison avait interdiction complète par la justice de parler publiquement de ce qu'il lui arrivait.
Mais depuis hier le dossier est déclassifié et on en sait enfin un peu plus sur ce qui s'est passé.
Le 28 juin, un ordre de la cour a demandé à Ladar Levison de fournir toutes les infos nécessaires pour tracer et déchiffrer les emails de Snowden. Ladar Levison s'y est fermement opposé durant plus d'un mois, mais menacé de prison, il a capitulé le 2 août.
Mais histoire de bien les faire chier jusqu'au bout, ce grand monsieur s'est amusé à imprimer les 2 560 caractères de la clé sur papier en taille 4. Le tout, presque illisible tenant sur 11 petites pages et les a fourni au FBI

Evidemment, le FBI s'est plains expliquant que pour utiliser cette clé, il faudrait entrer à la main les 2560 caractères sans se tromper, sachant qu'une seule erreur dans la chaîne empêcherait de décoder les données. La cour a donc condamné Ladar Levison à payer 5 000 $ par jour tant qu'il ne fournirait pas ces informations au format numérique.
Finalement, le 7 août, il a été contraint de lâcher l'affaire et a fourni les fichiers nécessaires au déchiffrement des emails de Snowden. Suite à cette aventure, dégouté, il a alors préféré couler sa société après 10 années de bons et loyaux services, expliquant dans un post sur Facebook qu'il ne voulait pas "être complice de crimes contre le peuple américain".

Je salue son courage et sa détermination. Affronter cette justice américaine sans limite n'a pas dû être simple pour lui.
Si vous voulez lire tous les détails de cette histoire, il y a un PDF sur Cryptome.
Cet article Affaire Snowden – Comment Ladar Levison, le fondateur de Lavabit a-t-il résisté face à la justice américaine ? est apparu en premier sur Korben.
Ce week-end, je suis tombé sur un reportage au sujet de Kim Dotcom et de Mega, et du coup, je me suis dit que j'allais tester à nouveau Mega.co.nz pour voir comment ils avaient évolué.
Première constatation, ça marche nettement mieux, même si globalement, il n'y a pas eu de gros changements.
Par contre, la bonne nouvelle, c'est qu'il existe maintenant un outil Mega pour Windows qui permet de synchroniser un répertoire stocké dans le cloud Mega sur 1 ou plusieurs ordinateurs de votre choix. Rien de compliqué, c'est du grand classique, mais ça permet de profiter des 50 Go offerts gratuitement par Kim Dotcom et sa bande pour stocker et transférer de gros volumes.


Évidemment, comme pour tout service "cloud", évitez d'y mettre des trucs sensibles.
Vous trouverez le soft Mega en téléchargement ici.
Cet article Synchronisez un répertoire Windows avec Mega est apparu en premier sur Korben.
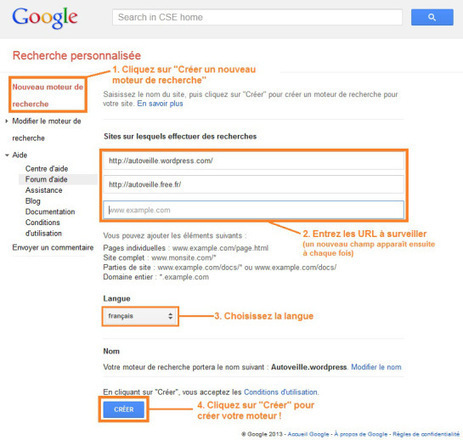
Aujourd’hui, je reviens avec un article sur la veille automatique ou plutôt comment utiliser l’outil de recherche personnalisée pour (semi) automatiser ses veilles ?
Si vous n’avez pas un outil de veille ou un logiciel de veille qui vous permet de surveiller les dernières nouveautés de nos pages web préférées, je vous conseille de créer des moteurs de recherche personnalisés de Google à partir des URL de vos pages à veiller.
Si vous cherchez un équivalent à Evernote pour tenir un journal de bord, qui fonctionne sous Linux, Mac et Windows et qui est totalement libre (GPL), j'ai trouvé ce qu'il vous faut. Ce logiciel s'appelle RedNotebook et permet de prendre des notes des notes jour après jour.
Rednotebook est capable de faire de la mise en page basique (gras, italique, souligné), d'insérer des liens, des photos et de placer des mots clés pour pouvoir s'y retrouver. RedNotebook supporte les systèmes de correction orthographique de l'OS, dispose d'un système de templates et surtout enregistre automatiquement tout ce que vous tapez.

Pas de base de données SQL dans ce soft puisque tout est enregistré au format texte. Cela vous permet de partager une seule et même copie de vos données sur un serveur pour toutes vos machines.
Niveau exports et backups, RedNotebook est capable d'enregistrer un zip ou de créer une copie PDF, HTML, Texte ou Latex de vos notes.
Si cela vous intéresse, vous pouvez télécharger RedNotebook ici pour Windows, Linux et Mac OSX.
Cet article RedNotebook – Votre journal de bord est apparu en premier sur Korben.
![]() Echelon et Prism permettent d’écouter les conversation téléphoniques et numériques de la terre entière, mais le paradoxe est qu’ils n’ont pas pu empecher ni le 11 septembre ni les attentas de Boston.
Echelon et Prism permettent d’écouter les conversation téléphoniques et numériques de la terre entière, mais le paradoxe est qu’ils n’ont pas pu empecher ni le 11 septembre ni les attentas de Boston.
[...]
Par Christophe Vincenzi pour lesechos.fr
En savoir plus :
Alors que Gmail le supporte depuis des années, Outlook vient enfin d'ajouter la possibilité de suffixer votre adresse email avec le signe "+".
Rien d'étonnant à ce retard puisque cette nomenclature provient du monde Linux (postfix).

Concrètement vous pouvez ajouter ce que vous voulez après ce "+" afin de trier plus efficacement vos emails suivant l'adresse de destination. Cela fonctionne sur toutes les adresses Windows Live (hotmail, live, outlook, etc).
Tous ces emails arriveront sur la même adresse jean.nemare@oulook.com :
Seul inconvénient : si vous oubliez votre mot de passe il faudra vous souvenir de ce que vous avez mis après le "+" afin que l'email soit reconnu.
A une époque cette méthode permettait de tracer les sites qui revendaient votre email, mais aujourd'hui il est très simple pour les spammeurs de supprimer avant de revendre les adresses.
Vous devriez me suivre sur Twitter : @xharkArticle original écrit par Mr Xhark publié sur Blogmotion le 25/09/2013 |
7 commentaires |
Attention : l'intégralité de ce billet est protégée par la licence Creative Commons
![]() Google Reader a fermé ses portes, le RSS ne va pas bien mais il n’est pas mort. Malgré les critiques plus ou moins virulentes que j’ai pu entendre sur le RSS (technologie “has-been” selon certains, “Twitter c’est la vie” pour d’autres, “faut savoir évoluer”), je suis pourtant d’avis que s’il y a bien une chose utile pour le veilleur c’est la RSS et que si le RSS est supprimé de nombreuses solutions en ligne (Google, Twitter, Facebook, etc) c’est tout simplement car il a justement tous les inconvénients que ces derniers détestent : permettre d’accéder à l’information sans se connecter sur ces plateformes et sans publicité.
Google Reader a fermé ses portes, le RSS ne va pas bien mais il n’est pas mort. Malgré les critiques plus ou moins virulentes que j’ai pu entendre sur le RSS (technologie “has-been” selon certains, “Twitter c’est la vie” pour d’autres, “faut savoir évoluer”), je suis pourtant d’avis que s’il y a bien une chose utile pour le veilleur c’est la RSS et que si le RSS est supprimé de nombreuses solutions en ligne (Google, Twitter, Facebook, etc) c’est tout simplement car il a justement tous les inconvénients que ces derniers détestent : permettre d’accéder à l’information sans se connecter sur ces plateformes et sans publicité.
Donc le RSS c’est bien. Mais je ne développerai pas plus ce qu’est cette technologie (ce sous-langage plus exactement). Je vais aujourd’hui vous partager un petit tutoriel sur Feed43 qui est un site web gratuit qui vous permet de générer un flux RSS à partir de n’importe quelle page web ou presque si tant est que vous sachiez globalement décrypter le langage HTML (sur ce point je ne peux rien pour vous présentement) et que vous compreniez comment fonctionne Feed43.
C’est parti donc, mais avant toute chose petite dédicace à la personne qui m’a demandé ce billet et qui se reconnaîtra.
Donc avant toute chose il nous faut une page web. Nous allons partir de la page http://base.5facades.com/4DCGI/Newsedha_affich?origine=edha&support=5f&rubrique=&esp=ok. Elle ne dispose pas de flux RSS et représente une source d’actualité intéressante sur la construction.
Ensuite il nous faut lancer Feed43 et éventuellement créer un compte ce qui vous permettra de créer votre premier flux RSS.
1ère étape: on vous demande de préciser l’adresse de départ
 Jusque là tout va bien. Vous saisissez donc l’URL ci-dessous et vous cliquez sur reload ce qui permettra à Feeed43 de charger le code de la page.
Jusque là tout va bien. Vous saisissez donc l’URL ci-dessous et vous cliquez sur reload ce qui permettra à Feeed43 de charger le code de la page.

Nous arrivons ensuite à la partie 2 qui doit définir les règles d’extraction. Nous avons ici deux zones de saisie.
La première intitulée global search pattern field permet de définir un point de début et un point de fin dans la page web dans laquelle vous allez chercher à extraire les items de votre flux RSS. Cela peut être nécessaire par exemple quand au sein d’une même page vous avez deux zones différentes qui proposent des actualités sur des sujets différents dont l’un ne vous intéresse pas. Accessoirement cette partie du paramétrage peut aussi permettre de limiter le bruit à partir du moment où vous pouvez clairement définir votre début et fin de zone d’extraction. Pour ce site là nous n’en aurons pas particulièrement besoin car nous allons chercher à extraire toutes les actualités.
Si nous en avions eu besoin il nous aurait fallu saisir le bout de code HTML de début de zone d’extraction, suivi du code de de fin de la même zone avec un astérisque au milieu (opérateur de troncature standard).
Par exemple nous aurions pu avoir : <div span class=”news_techno”>*</div> Feed43 aurait alors recherché dans le code de la page <div span class=”news_techno”> aurait commencé à sélectionner le code et ce serait arrêté dès qu’il aurait trouvé la première balise div. Toutes les règles d’extraction des étapes suivantes ne se seraient appliqués qu’au bout de code ainsi retenu.
La seconde intitulée “item repeatable search pattern” est celle qui va nous permettre de définir le motif récurrent qui constituera chacun de nos items. ATTENTION, c’est là qu’il faut s’accrocher…
Il faut bien comprendre que nous avons alors besoin de trouver un code qui se répète et qui s’appliquera à chacune des informations que nous voulons extraire. Ici donc au moins un titre et un abstract et si possible d’autres items qui constituent un flux RSS tels qu’une URL et une date par exemple.
Alors voilà ce que cela donne sur notre page :

Maintenant il nous faut regarder le code source correspondant et trouver les marqueurs de début et de fin de chacun des items.
En ouvrant le code source et en recherchant le premier titre de l’actualité l’on va pouvoir déceler à peu près où est situé le premier item. Et là avec le coup d’oeil l’on voit assez clairement le début de chaque item qui est : “<span class=”tirub”>”
Si si… Regardez encore…

Bon… Maintenant on commence l’opération à coeur ouvert. Pour y arriver nous disposons d’une arme magique : l’astérisque AKA *. L’astérisque nous permet d’ignorer une partie de code.
La deuxième arme dont nous disposons est le marquer : {%} qui va nous permettre de dire : ceci est une variable que je veux collecter pour mon item. Le seul impératif est de placer ce {%} entre deux bouts de code HTML en dur (sans astérisque).
Je vous donne la solution que j’ai trouvé donc pour parvenir à mes fins (et il y en a surement d’autres).
<span class=”tirub”>
{*}</span>
{*}
<a href=”{%}”><b>{%}</b></a>
{*}<div class=”tenews2″><a href=”{%}”>{%}</a>
et je vais vous traduire ce que cela signifie pour Feed43.
cherche dans la page <span class=”tirub”> et comsidère cela comme le début du code où nous allons chercher un titre, un abstract et une URL pour chacun des items qui constitueront notre fil RSS.
ensuite continue jusqu’à ce que tu trouve un premier </span> : il est impératif ici de mettre cet *. En effet l’on a ici un texte qui peut changer entre span class tirub et /span. Si l’on ne met pas d’astérique l’on devrait ici mettre un texte qui serait par exemple “nouveau produit” mais qui serait différent pour les autres items et donc Feed43 ne pourrait pas effectuer sa boucle sur tous les items de la page mais uniquement sur les nouveaux produits.
A nouveau l’on doit mettre un * . En effet l’on va également trouver un code qui sera variable pour chacun des items et qu’il faut donc ignorer jusqu’à la balise <a href>
A partir de là nous pouvons commencer notre collecte.
<a href=”{%}”><b>{%}</b></a>
{*}<div class=”tenews2″><a href=”{%}”>{%}</a>
Dans le code ci-dessus nous demandons à Feed43 de collecter une première variable qui va correspondre à l’URL cliquable de l’article (<a href=”{%}”>) puis ensuite le titre de l’article (<b>{%}</b></a>).
Nous devons ensuite utiliser * pour ignorer un ensemble d’éléments. des images par exemple qui sont parfois appelée etc.
La partie fixe du code de chaque item reprend à ” <div><a href=“. Ensuite l’on trouve à nouveau la même URL cliquable que je vais collecter à nouveau en variable (c’est un doublon et l’on pourrait aussi choisir d’utiliser l’astérisque) puis enfin l’abstract qui est cliquable (ce qui explique qu’il soit encadré des balises <a> et </a>).
Bingo. Notre boucle est finie et le logiciel va chercher son nouveau marqueur de départ : <span class=”tirub”> pour continuer le job sur les items 2 à n…
Si vous avez suivi jusque là, c’est bon car le reste est un jeu d’enfant. Sinon… reprenez depuis le début jusqu’à ce que vous compreniez.
Cliquez sur extract et Feed 43 vous montrera combien il a récupéré d’items et quelles variables il a stocké.
 Troisième étape : l’on dit à Feed43 quelle variable collectée pour quel champ du RSS.
Troisième étape : l’on dit à Feed43 quelle variable collectée pour quel champ du RSS.
Maintenant les variables.
Et voilà. Inutile de toucher la dernière case… Vous avez gagnés et vous disposez désormais d’un super flux RSS inexistant jusqu’à présent. Faites un preview pour vérifier et copiez collez l’URL qui vous est donnée dans “Get Your RSS Feeds”.

Avec Feed43 vous pouvez ainsi créer des fils RSS à partir d’autres sources n’en disposant pas. Bien évidemment cela doit être réservé aux sources prioritaires pour vous car le paramétrage ci-dessus peut prendre un certain temps car il demande d’être adapté pour chacune des sources.
Feed43 peut être intéressant par exemple pour récupérer les rubriques “nouveaux produits” qui disposent rarement de flux RSS dans le B to B, ou bien encore de rubriques “événements” ou bien “publications”.
Ces flux RSS peuvent ensuite être utilisés dans votre lecteur RSS préféré (le mien c’est FeedDemon) , dans votre page d’accueil personnalisable voire même widget de votre ordinateur ou bien encore dans votre logiciel ou plateforme de veille type Digimind, Website Watcher ou autre…
PS : je n’ai pas trouvé mieux comme solution. Il en existe bien qui essaient automatiquement de “reconnaître” à partir de quoi construire un RSS quand vous leur donnez une URL mais cela fonctionne à peu près une fois sur 10… Attention toutefois, Feed43 est une solution gratuite en SaaS … sans doute peu pérenne…
PS 2 : attention dans les bouts de code HTM ci-dessus le premier ” est souvent inversé… Il s’agit d’une erreur de mon CMS quand il traduit ces caractères… si vous faites un copier coller pensez de toute façon à remplacer tous les guillements par des double quotes standards.
«Peu de Français ont entendu parler de l’entreprise Systran. C’est pourtant une véritable pépite technologique, qui offre ses logiciels de traduction automatique aux entreprises et au grand public, mais pas seulement.
En réalité, le vrai gros client de la société française n’est autre que la communauté américaine du renseignement. Et d’abord la désormais fameuse NSA (National Security Agency), qui a littéralement mis la planète sur écoutes.
Elle veut tout traduire en anglais, que ce soit (entre autres) des emails, de la presse, des sites web qu’elle siphonne en permanence. Dans pratiquement tous les services américains, donc, ce sont des logiciels français qui tournent à plein pour traduire toutes les langues imaginables.
Enfin, presque… Pour le commun des mortels, qui peuvent acheter ses logiciels dans le commerce, Systran propose 52 "paires" de langues, comprenant aussi bien le chinois que le japonais ou le serbo-croate, ce qui revient à dire que l’on traduit 52 langues dans 51 autres.
En réalité, pour les services de renseignement américains, Systran fait des efforts qui demeurent confidentiels. Combien de langues ? Mystère… Comme le rappelait un dossier récemment paru dans le magazine scientifique La Recherche, la planète ne compte pas moins de 7 000 langues.»…

JAKARTA - Un chef d’entreprise lillois a fait le pari fou de s’isoler pendant quarante jours sur une île afin de démontrer qu’il est possible de vivre et travailler autrement...
Gauthier Toulemonde est le directeur général de Timbropresse basé à Saint-André-lez-Lille, il a décidé de vivre une expérience inédite, de prouver que l’on peut vivre autrement grâce au télétravail, explique-t-il sur son blog. Il dirigera sa société à 10 000 kms de la France à l’aide d’une connexion internet et de panneaux solaires.
A 54 ans, ce chef d’entreprise a confié au micro de RTL : « Je veux montrer qu'avec l'énergie solaire, les nouvelles technologies, on peut vivre autrement, travailler à longue distance, éviter le temps perdu dans les transports, etc. ». Un rêve d’enfant qu’il réalise sans pour autant partir en vacances puisque Gauthier Toulemonde insiste bien sur le fait qu’il a « une société à gérer ».
À partir du 8 octobre et pendant 40 jours, il va s’isoler sur une île déserte au large de l’Indonésie, munit de deux ordinateurs portables et quelques panneaux solaires, devenant ainsi le premier « web-Robinson ». Une île mesurant 700 mètres de long et 500 de large où il aura tout le loisir de se construire une cabane.
Je vous tiendrai au courant de l'évolution de cette aventure !

Source : La Dépêche

Google est l’un des moteurs de recherche les plus utilisés dans le monde. Il fédère chaque jour des millions d’utilisateurs à travers le globe, et il traite des centaines de millions de requêtes en l’espace de quelques minutes. Ce que tout le monde ne sait pas forcément, c’est que le géant américain a également lancé il y a quelques années de cela un service permettant de fouiner dans son index afin de déterminer les tendances les plus en vogue d’une période donnée. Google Trends, c’est le nom de cet outil fort pratique, nous permet ainsi d’avoir une vue d’ensemble des recherches effectuées par les autres internautes et, si on en parle aujourd’hui, ce n’est pas pour rien puisque Big G vient tout juste de déployer une mise à jour très complète et qui devrait faire la joie de certains d’entre vous.
Et tout commence avec cette nouvelle interface bien plus accessible et bien plus intuitive. Désormais, nous trouverons dans une barre latérale la liste des différents modules proposés par la plateforme. Le champ de recherche, pour sa part, se situe toujours en haut de la page, suivi de près par une barre d’outils regroupant différents filtres (localisation, date, catégories, etc…) et par une zone reprenant tous les termes indiqués par l’utilisateur.

Google Trends a de bien jolis graphiques, non ?
Les statistiques, elles, se trouvent dans le prolongement de cette zone. Comme sur l’ancienne version, Google Trends sera capable de nous afficher l’évolution de l’intérêt suscités par nos termes sur un graphique interactif, et nous trouverons également un peu plus bas la répartition géographique des requêtes ainsi que les recherches associées. Si besoin est, nous pourrons également afficher les prévisions calculées par Google, ou encore les moyennes de nos différents termes.
Pas mal, mais ce n’est pas fini car nous trouverons également deux modules fort pratique. Le premier, intitulé « recherches du moment », nous permettra d’avoir une vision d’ensemble des requêtes les plus populaires sur les derniers jours. Dimanche par exemple, c’est Chrissy Teigen qui occupait la première place aux Etats-Unis. Le second, de mon point de vue, est bien plus redoutable. Baptisé « meilleurs classements », il affichera effectivement les requêtes les plus populaires… par catégorie. Sur une seule et même page, nous aurons les acteurs les plus populaires, les animaux les plus appréciés, les voitures les plus admirées, les boissons les plus… bues et même les jeux les plus joués. Très pratique, c’est certain, surtout que Google Trends dissocie les recherches des tendances. En quelques clics, on pourra donc connaître les requêtes les plus porteuses.
Je n’en ai pas parlé jusqu’à présent mais Google Trends fait également la part belle aux lecteurs exportables. En quelques clics, il sera donc possible d’intégrer sur son site des graphiques, des classements et tout un tas de choses vraiment très intéressantes.
La grande classe, en somme.


 C’est la crise mon bon monsieur. Mais cette fois la vraie de vraie… Cela fait 3 ans qu’on nous le rabâche (je le sais… Je m’en souviens, c’est pile l’année où je me suis lancé la fleur au fusil en tant qu’indépendant…) mais cette fois on est en plein dedans…
C’est la crise mon bon monsieur. Mais cette fois la vraie de vraie… Cela fait 3 ans qu’on nous le rabâche (je le sais… Je m’en souviens, c’est pile l’année où je me suis lancé la fleur au fusil en tant qu’indépendant…) mais cette fois on est en plein dedans…
Et le petit monde de la veille et des logiciels n’y fait pas exception.
Si l’on regarde le paysage des outils de veille stratégique et de veille concurrentielle français (je passe sous silence les logiciels de veille e-réputation ou de social media monitoring) on avait Digimind, Ami Software avec Ami Enterprise Intelligence, KeyWatch d’iScope, Knowings, Arisem, KB Crawl, Spotter avec un côté service plus poussé. Bref. L’offre n’était pas pléthorique mais disons quand même qu’au plus haut du marché, l’entreprise pouvait se poser quelques questions sur la solution vers laquelle se tourner.
Mais voilà que depuis deux ans et plus particulièrement depuis un an, le paysage ressemble à une peau de chagrin plutôt qu’à une corne d’abondance.
Le 18 janvier 2011, Arisem ne s’en sort pas et le tribunal de commerce met fin à l’aventure. Knowledge Information Miner 3 n’aura pas suffit à redresser la barre. J’avais vu tourner cette technologie et je la trouvais pourtant prometteuse mais Arisem a toujours eu du mal à packager ses solutions et à les rendre user friendly. RIP Arisem, absorbée par définitivement par Thalès.
13 décembre 2012, c’est Noël… La météo est froide et maussade. KB Crawl passe en redressement judiciaire et depuis cette date, l’entreprise est toujours en redressement judiciaire. Le précurseur français des solutions de veille monoposte, qui avait pris un retard certain en ne basculant pas assez tôt en SaaS et n’offrant pas la gamme complète d’une plateforme, a du mal à négocier le virage. Le choix de la technologie Silverlight seulement quelques mois avant que Microsoft s’en dégage ouvertement n’est pas le seul facteur mais n’a clairement pas aidé. Depuis les veilleurs sont en attente de savoir ce qu’il adviendra de cette solution qui leur est devenue familière. Nous ne pouvons que leur souhaiter de sortir la tête de l’eau et de pouvoir continuer à faire évoluer leur solution qui est dotée de points forts dont la capacités à réaliser des parcours de crawl extrêmement précis. Concept séduisant est rarissime alors que chez la plupart des autres éditeurs il faut mettre la main au portefeuille pour chaque connecteur atypique ou bien disposer d’un bac + 12 en informatique…
30 juillet 2013, les mojitos coulent à flots et le soleil bronze les peaux. Ixxo, elle aussi, passe en redressement judiciaire. Ixxo société spécialise en solutions de veille et intégration de moteurs de recherche d’entreprise, qui a lancé ces dernières années à grands coups de pieuvre, la solution séduisante de crawl Squido accuse le coup. Il ne s’agit peut-être pas de la partie veille qui leur a porté préjudice mais plus probablement de l’intégration de moteur de recherche. Ixxo, intégrateur Autonomy entre autre, a perdu une partie des prestations de services récurrentes liées à Autonomy, HP ayant repris les rênes sur le sujet.
Passons sous silence l’hécatombe de ces dernières années sur des solutions plus en marge de la veille telles que Kartoo qui à un moment proposait des interfaces de navigation cartographiques, Pikko qui a jeté l’éponge en février 2013, Exalead qui a failli dans son développement commercial autonome et à dû être racheté par Dassault – l’état français ayant probablement incité fortement au rachat de cette technologie par Dassault…
Aïe. Relevons les compteurs. C’est bien maigre.
Digimind et Ami Software continuent à tenir la dragée haute aux autres éditeurs avec des comptes sains autant au niveau de l’EBE que du résultat.
Spotter continue son développement (NDLR : les comptes 2012 ne sont toutefois pas disponibles à ce jour) en se démarquant en offrant une couche de service forte dont des équipes multilingues. iScope maintient son cap, les compte 2012 n’étant toutefois pas disponibles. Temis également continue à mener sa barque bien qu’ils soient encore affichés en plan de continuation / redressement judiciaire. Knowings s’en sort plutôt bien mais a clairement délaissé le monde de la veille pour se concentrer sur la GED.
Constat donc plus que morose pour les éditeurs de solutions de veille. Un marché qui a peiné à évoluer, à innover.
Quoi de neuf et de positif quand même…? Une annonce à venir côté Digimind. Un petit nouveau, Sindup, qui a repris ces dernières années le flambeau des solutions de veille old school en apportant un petit lifting ergonomique et une toute nouvelle solution plutôt séduisante. Tadaweb à suivre. Prometteur sur le concept.
N’oublions pas l’increvable – et c’est très bien comme ça – Website Watcher, solution de veille pour les veilleurs, les vrais, qui n’ont pas peur d’un peu de technique pour avoir ce qui se fait quasiment de mieux sur le marché des crawlers adaptables, bruts de décoffrage, le tout pour 100 € ou moins. Bref, on compte un solde quand même plutôt négatif… Et l’on se met à espérer que le marché retrouve son dynamisme car paradoxalement, à un moment où l’information n’a jamais été aussi pléthorique, il n’a jamais été aussi compliqué de trouver la bonne information… Mais ce dernier point de vue n’engage que moi (je suis toutefois prêt à en débattre.)
Aller, des articles plus positifs à suivre sur les logiciels qui marchent !
Crédits photos : Karen_O’D sur Flickr – Photo intitulée Cemetary et diffusée sous licence Creative Commons
Présenté lors d'une démo au salon Siggraph Asie de cette année, voici venu 3-Sweep, un logiciel encore expérimental qui est capable de modéliser à partir d'une simple photo, un objet en 3D. Sa prise en main a l'air simplissime puisqu'il suffit de repasser sur l'élement de la photo qu'on souhaite obtenir en 3D.
Pas besoin de scanneur 3D ni de photos multiples... Toute la puissance du soft réside dans ses algos de traitement capables même de modéliser des objets aux formes complexes. Vraiment mpressionnant !
Il devient ensuite relativement simple de manipuler cet objet pour faire des trucs de dingue que je vous laisse découvrir ici.
Nos smartphones sont formidables. Ils sont beaux, ils sont puissants et ils sentent bon la rosée fraiche du matin. Toutefois, ils présentent tous le même défaut : ils ne sont pas évolutifs, et ils sont donc condamnés à vieillir et à finir leurs jours au fond d’un tiroir sale, aux côtés de ce bon vieux Tatoo qui lui non plus ne nous quittait pas d’un poil, à l’époque des Musclés. Partant de ce constat, Dave Hakkens a décidé de créer un terminal d’un nouveau genre, un terminal modulable et capable d’évoluer au gré de nos envies. Ce qui a donné vie au Phonebloks, un magnifique concept qui ne pourra pas vous laisser indifférent…
Le Phonebloks est un produit malin, et bien pensé. Il ne sera sans doute jamais commercialisé – du moins pas avant plusieurs années – mais il a tout pour plaire. Et sa principale qualité, finalement, c’est qu’il s’adapte en un tour de main à nos envies, et surtout à nos besoins. Besoin d’une batterie de plus grande capacité ? Pas besoin de démonter votre terminal ou d’en changer. Même chose pour l’espace de stockage, le processeur et tout le reste.

Un smartphone modulable, ça vous tente ?
A la base, le Phonebloks n’est rien de plus qu’une carte rectangulaire constituée de plusieurs points d’accroche. Tout le reste est amovible, ce qui comprend l’écran, les boutons, le capteur, le micro, la batterie, le bluetooth et ainsi de suite. Chaque composant se présente effectivement sous la forme d’un bloc qui vient s’accrocher à la cette fameuse carte évoquée un peu plus haut. Exactement comme les LEGO de notre enfance, vous avez parfaitement saisi le concept. Tout comme avec un « vrai » ordinateur, il est donc possible d’agencer ces modules comme bon nous semble, et même de les remplacer par des modules plus récents ou de capacité différente.
J’accroche complètement à ce concept, mais il serait très étonnant qu’il arrive un jour sur le marché. Il faut dire aussi que l’obsolescence programmée à ses avantages, c’est précisément elle qui permet à nos constructeurs d’écouler, chaque année, des millions de smartphones. Le Phonebloks représenterait donc un sacré manque à gagner et c’est bien dommage parce que je rêverais d’avoir un terminal de ce genre.
Pas vous ?
Merci Matthias !
 La NSA a refusé de commenter cet article [du Washington Post]. Le Bureau du directeur du renseignement national a émis un communiqué jeudi disant:
La NSA a refusé de commenter cet article [du Washington Post]. Le Bureau du directeur du renseignement national a émis un communiqué jeudi disant:
Tout au long de l’histoire, les nations ont utilisé le chiffrement pour protéger leurs secrets, et aujourd’hui, les terroristes, les cybercriminels, trafiquants d’êtres humains et d’autres utilisent également le code pour masquer leurs activités. Notre communauté du renseignement ne ferait pas son travail si nous n’avions pas essayé de contrer cela.
La communauté du renseignement américain a été ébranlée depuis plusieurs reportages basés sur les documents de Snowden qui ont révélé de façon remarquable des détails sur la façon dont le gouvernement recueille, analyse et diffuse des informations – y compris, dans certaines circonstances, les e-mails, les chats vidéo et les communications téléphoniques de citoyens américains.
[...]
Par Mohamed SANGARE pour blogs.mediapart.fr
Source image http://commons.wikimedia.org/wiki/File:Gmail_Icon.png?uselang=fr
Skype est l’outil central de ma vie numérique, c’est l’outil pro du net par excellence. Ma femme qui utilise skype pour donner ses cours en ligne, fait un usage intensif de l’outil. Aujourd’hui son compte skype totalise plus de 500 conversations chat avec une moyenne de 120 messages par session. Ce qui fait donc plus de 50 000 messages enregistrés et ce depuis à peine 1 an!
Quand on utilise skype, on peut mettre en mémoire tout l’historique de chat de skype, cela permet déjà d’avoir accès à tous les chats passés. Cela dit, cet historique est un peu spartiate (historique au fil de l’eau) et c’est là qu’entre en jeu ce freeware du nom de skypehistory, qui facilite la consultation de tous les chats, sans passer trop de temps.
Comme on peut le voir dans la capture d’écran qui suit, on est capable sur une seule fenêtre de :

Pour installer le logiciel :


Pour le reste, il est possible d’entre dans les configurations de l’outil pour plus de personnalisation (couleur, tri des personnes dont les textes seront mis en mémoire, le manuel se trouve ici
conclusion: cet outil vise les très gros utilisateurs skype, cela dit, il est toujours bon de pouvoir retrouver un vieux message du passé. L’application qui tourne en tâche de fond, n’utilise à peine 9Mo de Ram, ce qui est raisonnable.
Les autres logiciels : tant que vous y êtes, pourquoi pas non plus installer skypecallrecorder qui permet d’enregistrer en stéréo toutes vont conversation audio skype et si vous aimez la vidéo, vous pourriez aussi installer Free Video call recorder for Skype (non testé aujourd’hui, mais qui fera l’objet d’un test dans peu de temps)
Viax merci à applicanet.com pour les tuyaux.
Skype History : pour enregistrer tous vos conversations écrites sur skype et les gérer par la suite est un billet de Cocktail Web rédigé par Thierry Roget Mes partenaires www.bluehost.com www.elegantthemes.com www.dreamhost.com

En Suède, la startup Meganews a trouvé un nouveau modèle économique pour la presse papier. Le suédois teste actuellement des distributeurs de journaux automatiques avec la technologie japonaise Ricoh.
Depuis la fin du mois de juin, la startup a installé dans certains aéroports, hôtels, hôpitaux et centres commerciaux de Stockholm, des machines qui proposent l’impression à la demande : deux minutes suffisent pour qu’un magazine soit fraîchement imprimé et disponible pour l’utilisateur. Des kiosques digitaux qui comptent environ 200 titres de presse à l’heure actuelle et qui sont en version test pour le moment.
")


{kind=link}