The phrase “the App Engine way” is muttered around our office and wielded in our code reviews. As in, “Yeah, I know it’s counterintuitive, but that’s the App Engine way.”
It boils down to two principles about structuring data:
- Denormalize
- Do lots of work when writing to make reads fast
These aren’t obvious. It won’t be obvious to folks from SQL land that App Engine’s performance is tied so tightly to these ideas. It won’t be obvious that, since JOINs don’t exist, it’s really easy to write a bunch of code that 1) loads a Monkey entity, 2) looks at Monkey.zoo_id, then 3) queries for the monkey's Zoo…and that that’s bad.
So we use “the App Engine way” to remind ourselves of these fuzzy guidelines and spread ‘em to newcomers.
Denormalize your data — as in your Notification models should have all the data necessary to render themselves. They shouldn’t just point to the thing that triggered a notification. As in whenever you’re sitting around wishing you could just JOIN Zoo ON Zoo.id = Monkey.zoo_id you should actually be storing all of Zoo’s properties on each and every Monkey. Got billions of Monkeys? Who cares, copy the Zoo data a billion times. “Storage is cheap” and all that.
Do lots of work on write to make reads fast — as in your Post models should have their reply_count and vote_count and flag_count and monkey_count stored as properties on the Post itself. As in they should be updated every time a new reply, vote, flag, or monkey is brought into this wonderful world. As in any time you’re sitting around googling for App Engine’s version of SUM(), COUNT(), and AVG(), realize you should just be updating these aggregates every time they’re modified. As in whenever you write to a Zoo entity, kick off a task to update all denormalized copies on your Monkeys. Who cares if writes are a bit slower? This makes reads blazing fast.
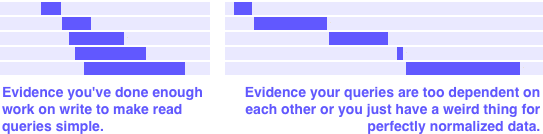
Use the mini profiler or appstats to see a waterfall graph for your data-loading RPCs.
A simple rule of thumb for knowing when you’re done:
If you really care about performance, you should be able to create all of the data queries for an entire web request just from incoming GET/POST data and the currently logged-in user’s properties — no query-to-get-the-data-for-another-query allowed.
This is the price of entry for access to one big, enormous, whopper of a benefit: you get a datastore with consistent read/write performance no matter how big your data set becomes. Have a query that returns 10 items from a set of 10,000? Relax knowing that after your company blows up in 6 months, you’ll get the exact same speed when pulling 10 items from a set of 10,000,000,000.