The best metaphor for Google Glass? Not jerks or junkies, but the living dead. — Originally published at The Atlantic Since the unveiling of Google Glass, the tech giant's new wearable computing device, a common nickname for its wearers has arisen among skeptics and critics: Glassholes. It's a charming portmanteau that satisfies an immediate desire to shun this weird new contraption. And the term fits, to some extent. As a strangely popular trend in books on assholes has helped us understand, the asshole is characterized by entitlement, by claiming special privileges that place him or her at the center of concern. Google Glass would seem to exemplify just such an attitude, a declaration that the... (read more)
No, I am not blogging about India Pale Ale, although I must say that I am a big fan of it.
I am writing about one of the best patent hacks I have seen in the decade that I have been working to find relief from the ridiculous patent system in our country.
Twitter came up with a concept last year called the Innovator's Patent Agreement (IPA) and put a draft IPA up on GitHub. They have gotten a ton of feedback and have iterated and improved the concept since then.
The basic idea of the IPA is that it is a contract between Twitter and the engineer(s) and designer(s) who developed the IP. The contract says that Twitter will not use the patent offensively nor will anyone who acquires the patent from Twitter. It goes on to say that Twitter or a subsquent owner could use the patent offensively with the engineers' and/or designers' approval.
Twitter announced yesterday that it had entered into an agreement with Loren Brichter, the author of the pull to refresh patent that will subject that patent to an IPA. They also announced that they will subject all of their patents to the IPA. They went on to say that Jelly, Lift, StackExchange, and Tell Apart have agreed to adopt the IPA for all of their patents.
USV has been talking to our portfolio companies about the IPA since Twitter posted it last year. They all know we are big fans of it and we hope they will choose to adopt it for all of their patents. We will not do more than that however. Our portfolio companies are independent of USV and can make up their own minds about their IP strategies.
That said, I would expect to see other USV portfolio companies join StackExchange on this IPA parade.
Twitter is an amazing company and I am very proud to be associated with it. The fact that they would take this extraordinary step and then show leadership in the industry to get others to join them is a testament to that. It's a proud day for Twitter and for me.
The human kidney is the body’s filter. It cleans 180 liters of liquid per day, retaining the good stuff and expelling the bad. Most fortuitously, humans are born with two kidneys. If one of them becomes damaged, the other one can pick up the slack. If both your kidneys fail, however, your body will fill with harmful toxins. Without medical intervention, you’ll die within weeks.
Almost nine hundred thousand Americans suffer from End State Renal Disease (ESRD), meaning that both their kidneys have failed. Thankfully, over the last half century, science has technically triumphed over kidney failure. If both your kidneys fail, you can receive a transplant from a donor and live a fairly normal, healthy life. The technology for kidney transplants has gotten so good that the donor and recipient just need to share the same blood type. Surgeons and anti-rejection drugs can handle the rest. Since almost everyone has a spare kidney, the supply of potential donors is plentiful.
And yet, over 5,000 people die in the US every year while waiting for a kidney transplant. This is puzzling because only 83 thousand people in the United States need a new kidney, compared to hundreds of millions of potential donors. And yet, the average person with failed kidneys remains on the transplant waitlist for 3-5 years. In the meantime, they’re hooked up to dialysis machines several times a week at an annual cost of approximately $75,000 per year. Kidney transplant surgeries typically pay for themselves within one to three years because the need for dialysis is eliminated by the new kidney.
So why do people die from ESRD while waiting for a kidney transplant? The answer is well known - not enough people volunteer to donate a kidney. This is true in the United States and every other country in the world (with the possible exception of Iran). People simply don’t volunteer to go into surgery and give up their organs. Even when they’re dead, most people (or their families) hold onto their kidneys instead of donating them.
Economists have long suggested that this kidney shortage is easily solvable. If you need more kidneys for transplants, just start paying people to provide kidneys. At the right price, kidney donors will be lining up. Opponents of this view argue that creating a free market for kidneys would be exploitative and immoral. Would we want to live in a world where the poor sell their organs to the rich?
But maybe this “efficient” versus “moral” debate about how to allocate kidneys is a false dichotomy. Solving the kidney shortage by paying people doesn’t have to mean creating a laissez-faire market for organs.
In order to save thousands of lives every year, we can keep the current kidney donation system entirely in place with one major exception - the US Government should get into the business of buying kidneys. Taxpayers will actually save money and thousands of lives will be saved every year.
Perhaps it’s time we start allowing the government to harvest our organs.
The Growing Shortage of Kidneys in America
In the United States, over 20 million people have some sort of chronic kidney disease (CKD). Approximately 871,000 Americans suffer from the most severe form of chronic kidney disease, End State Renal Disease. Roughly one half (398,000) of these patients are on dialysis each year. It costs approximately $75K a year to keep each of these patients alive.
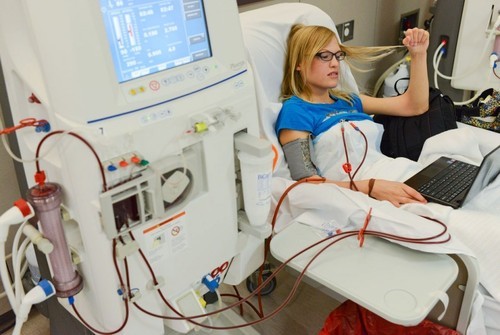
Dialysis is a brutally difficult but completely necessary experience for people with failed kidneys. Most patients have to be plugged into a machine at a facility three times a week for three to five hours each time. The machine simulates kidney function, but it’s an imperfect substitute. While normal kidneys remove toxins from the blood continuously, the dialysis machine does so for a few hours every 48 hours. When the patient is not plugged into a machine, these toxins build up, causing the patients to feel tired and in a state of mental fog until the next dialysis session.
Being on dialysis is hopefully a stop gap measure to keep a patient alive till they can get a kidney transplant. Of the nearly four hundred thousand patients in the United States, only 83,000 of them were on the the waitlist for a kidney transplant. Many people on dialysis are too old or sick to qualify for a transplant.
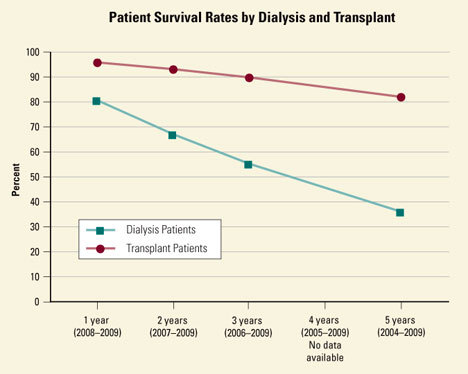
Patients that live long enough to get off the waitlist can get kidney transplants and live fairly normal, healthy lives. It’s estimated that these patients will live 10-15 years longer than if they stayed on dialysis. The transplanted kidneys start working almost right away for the patient. Over time, they are far more likely to live because of the transplant.
As America gets older and sicker, however, the demand for kidney transplants is exploding.
The number of kidney donations is not keeping pace. Donations today from live donors (altruistic people) or cadavers (organ donors who passed away) have barely ticked up as demand for kidneys has steadily risen. The shortage of kidneys is not a uniquely American problem. Across almost every single country, there are too few kidneys available relative to the demand.
The result is that lots of people die every year waiting for a new kidney that would save their life.
Where do Kidneys come from Today?
Kidney transplants in America are managed by the United Network for Organ Sharing (UNOS). UNOS is a non-profit with a Congressional mandate to administer the entire waitlist of patients, inventory of organs, and algorithm by which patients and donors are matched. Because of this centralized process, there is incredibly accurate information about the supply and demand for kidneys.
In the US, most kidneys come from donors that have died, as opposed to living donors that voluntarily donated their kidneys.
Most efforts to solve the kidney shortage have so far focused on increasing the supply of donated kidneys. Campaigns to sign up more people as organ donors are the most common.
Some European countries like Spain and Austria make donating organs the default - people need to choose to opt out. These countries still have much lower overall organ donation rates than the United States.
Another avenue for increasing kidney donations is focusing on live donors. One recent innovation is the concept of a “paired exchange.” Someone on the waitlist may have a family member who is willing to donate a kidney but is the wrong blood type. A paired exchange looks among a pool of families in similar circumstances to find blood type matches. If each donor has the blood type the other patient needs, then they are paired and each donor gives a kidney to the patient in the other family. Initiating these pair exchanges improves liquidity in the market for kidneys and saves lives, but it hasn’t made much of a dent on the kidney shortage so far.
Almost every country has a scarcity of kidneys despite the existence of billions of potential suppliers who could easily meet the relatively modest demand for kidneys. Every system that depends on kidney donations has failed to get enough kidneys to the people that need them.
The current system of paired exchanges and campaigns for kidney donors has noble intentions, but it’s not working. People are needlessly dying as a result.
Who Foots the Bill?
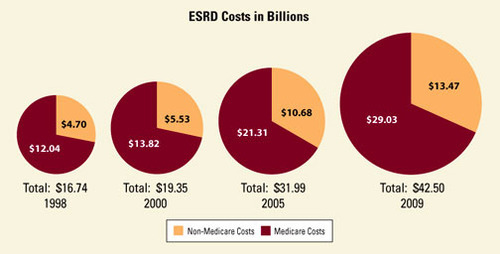
The annual cost of kidney failure in the United States is approximately $42.5 billion as of 2009. The federal government, through its Medicare program, has a special exemption that helps pays for the care of people with End State Renal Disease, even if they are not yet 65 years old. (Medicare typically only covers costs for senior citizens.) The result is that the US government pays $29 BN (68% of total kidney spending) towards covering the cost of dialysis and kidney transplants. When it comes to End State Renal Disease, the US almost has a single payer healthcare system.
As mentioned earlier, it costs approximately $75,000 per year to keep someone alive on dialysis in the United States. The vast majority of this goes to private companies that run dialysis centers or sell dialysis related equipment and drugs. Two nationwide for-profit dialysis chains, Fresenius and DaVita, provide over 60% of dialysis treatments.
A kidney transplant surgery costs approximately $105,000 in the US and is a relatively safe procedure for the donor. In most countries, it’s estimated that the surgery pays for itself within 1-3 years.
What’s Wrong with Selling Kidneys?
The idea of buying and selling kidneys have been around for a long time, but moral uneasiness has kept it from being seriously considered or implemented.
Critics of a marketplace for kidneys typical raise the following objections:
1. Kidneys would be distributed based on ability to pay, so rich people would be able to get kidneys and poor people would not.
2. If the price of organs is high, that will incentivize stealing organs. It could also motivate unscrupulous people to force other people to sell their organs in order to profit from the sale.
3. The system would exploit poor people by promising quick money for their kidneys. If someone is destitute, can they really give informed consent? While donating a kidney is relatively safe, it has inherent risks like any form of surgery.
The current, donation-based system addresses all three of these concerns. The United Network for Organ Sharing distributes organs based on need, not income (Objection 1), and the price of kidneys is $0 (Objections 2 and 3). Currently, there is almost no risk of someone “selling their kidney to buy an ipad” in the United States.
If operating a free market for kidneys suddenly became legal, all of these objectionable practices might start happening. The results could be dangerous and inconsistent with mainstream American values. Wealthy people would get kidneys at the expense of poor people who might need them more. The destitute might be compelled to sell their organs for short term gain or against their will. And at a high enough price, organ theft could become prevalent.
Let’s assume we agree with all of these ethical objections. Could we devise an ethical system that pays kidney donors, saves lives, and saves money?
A Modest Proposal: Let The Government Buy Our Organs
In the United States, we already have a safe, well-organized way to get kidneys from donors to the patients that need them most. We also have one party (Medicare) that spends hundreds of thousands of dollars to keep people alive on dialysis for 3-5 years before they can get a kidney transplant. Why not let Medicare spend that money instead on buying kidneys?
If the US Government bought kidneys from healthy individuals, then the United Network for Organ Sharing could continue to allocate the kidneys on the basis of need instead of ability to pay. Instead of creating a “free market” for kidneys, the government could mandate that Medicare be the exclusive buyer of kidneys. It would create a tightly regulated system for buying up kidneys, which is better than no system at all.
What’s the advantage of letting Medicare buy kidneys instead of creating a free market? First, it would save Medicare and private insurers money since the current cost of dialysis for people on the waitlist is so high. These parties have a financial incentive to consider a plan like this.
Second, a government-regulated system can address concerns about equity. Rather than rich people privately contracting poor people to buy their kidneys, the government and the UNOS can continue to allocate purchased kidneys based on need (Objection 1). Moreover, the risk for organ thieves is eliminated in this scenario (Objection 2). Would an organ thief show up at the Medicare office with bag of kidneys? Instead, individuals would have to go through an approval process to ensure that they are not selling their organ under duress and understand the risks.
This proposal is weakest at overcoming Objection 3 - the concern that destitute people cannot give informed consent due to their financial duress. (Let’s ignore for now that we allow women to rent out their uteruses for childbirth - something more dangerous than donating a kidney that subjects the less well-off to the same risks of exploitation.)
If individuals were offered a “fair price” for their spare kidney, could you make the argument they were being taken advantage of? If the price were a million dollars? $100K? $50K? 10K? $1?
For every dangerous task, there is probably some price at which society would feel that people are being adequately compensated for the risk of performing that task. This is the case for security contractors in Iraq and surrogate mothers. Why should donating a kidney be any different?
There is some “price for a kidney” that would eliminate the waiting list, feel like a fair price, and also save Medicare lots of money. That price might be higher than what the “market price” of a kidney would be. Economists Gary Becker and Julio Elias estimate that the price of a kidney in a free market would be $15,000. It’s possible that would feel like an unfair price. Some onlinecommentators have suggested around $50,000 as a price that they consider fair.
At $50,000, we’d consider donating a kidney. What’s the price at which you’d consider selling your extra kidney?
Conclusion
Today, there are simply too few kidneys being donated to people with kidney failure. As a result, more than 5,000 patients a year needlessly die on the waitlist in the United States. The gap between the number of people that need a kidney and the supply of donated kidneys continues to grow. Campaigns to increase voluntary kidney donations simply haven’t worked. Even dead people don’t want to donate their kidneys.
It’s time to fix this problem once and for all. Instead of hoping that more people start becoming organ donors and doubling down on failed policies, it’s time to start buying and selling kidneys.
Q: So it’s fine to say, everybody should learn a little bit about how to program and this way of thinking because it’s valuable and important. But then maybe that’s just not realistic. Donald Knuth told me that he thinks two percent of the population have brains wired the right way to think about programming.
Hal Abelson: That same logic would lead you to say that one percent of the US's population is wired to understand Mandarin. The reasoning there is equivalent.
After Facebook’s disastrous debut, the preferred clients of big banks walked away with huge profits. How? Public documents and interviews with dozens of investment bankers and research analysts reveal that the Street caught wind of something the public didn’t. The social network and the banks told half the story. Here is the other half.
We’ve all been there: that bit of JavaScript functionality that started out as just a handful of lines grows to a dozen, then two dozen, then more. Along the way, a function picks up a few more arguments; a conditional picks up a few more conditions. And then one day, the bug report comes in: something’s broken, and it’s up to us to untangle the mess.
As we ask our client-side code to take on more and more responsibilities—indeed, whole applications are living largely in the browser these days—two things are becoming clear. One, we can’t just point and click our way through testing that things are working as we expect; automated tests are key to having confidence in our code. Two, we’re probably going to have to change how we write our code in order to make it possible to write tests.
Really, we need to change how we code? Yes—because even if we know that automated tests are a good thing, most of us are probably only able to write integration tests right now. Integration tests are valuable because they focus on how the pieces of an application work together, but what they don’t do is tell us whether individual units of functionality are behaving as expected.
That’s where unit testing comes in. And we’ll have a very hard time writing unit tests until we start writing testable JavaScript.
Unit vs. integration: what’s the difference?
Writing integration tests is usually fairly straightforward: we simply write code that describes how a user interacts with our app, and what the user should expect to see as she does. Selenium is a popular tool for automating browsers. Capybara for Ruby makes it easy to talk to Selenium, and there are plenty of tools for other languages, too.
Here’s an integration test for a portion of a search app:
def test_search
fill_in('q', :with => 'cat')
find('.btn').click
assert( find('#results li').has_content?('cat'), 'Search results are shown' )
assert( page.has_no_selector?('#results li.no-results'), 'No results is not shown' )
end
Whereas an integration test is interested in a user’s interaction with an app, a unit test is narrowly focused on a small piece of code:
When I call a function with a certain input, do I receive the expected output?
Apps that are written in a traditional procedural style can be very difficult to unit test—and difficult to maintain, debug, and extend, too. But if we write our code with our future unit testing needs in mind, we will not only find that writing the tests becomes more straightforward than we might have expected, but also that we’ll simply write better code, too.
To see what I’m talking about, let’s take a look at a simple search app:
When a user enters a search term, the app sends an XHR to the server for the corresponding data. When the server responds with the data, formatted as JSON, the app takes that data and displays it on the page, using client-side templating. A user can click on a search result to indicate that he “likes” it; when this happens, the name of the person he liked is added to the “Liked” list on the right-hand side.
A “traditional” JavaScript implementation of this app might look like this:
var tmplCache = {};
function loadTemplate (name) {
if (!tmplCache[name]) {
tmplCache[name] = $.get('/templates/' + name);
}
return tmplCache[name];
}
$(function () {
var resultsList = $('#results');
var liked = $('#liked');
var pending = false;
$('#searchForm').on('submit', function (e) {
e.preventDefault();
if (pending) { return; }
var form = $(this);
var query = $.trim( form.find('input[name="q"]').val() );
if (!query) { return; }
pending = true;
$.ajax('/data/search.json', {
data : { q: query },
dataType : 'json',
success : function (data) {
loadTemplate('people-detailed.tmpl').then(function (t) {
var tmpl = _.template(t);
resultsList.html( tmpl({ people : data.results }) );
pending = false;
});
}
});
$('<li>', {
'class' : 'pending',
html : 'Searching …'
}).appendTo( resultsList.empty() );
});
resultsList.on('click', '.like', function (e) {
e.preventDefault();
var name = $(this).closest('li').find('h2').text();
liked.find('.no-results').remove();
$('<li>', { text: name }).appendTo(liked);
});
});
My friend Adam Sontag calls this Choose Your Own Adventure code—on any given line, we might be dealing with presentation, or data, or user interaction, or application state. Who knows! It’s easy enough to write integration tests for this kind of code, but it’s hard to test individual units of functionality.
What makes it hard? Four things:
A general lack of structure; almost everything happens in a $(document).ready() callback, and then in anonymous functions that can’t be tested because they aren’t exposed.
Complex functions; if a function is more than 10 lines, like the submit handler, it’s highly likely that it’s doing too much.
Hidden or shared state; for example, since pending is in a closure, there’s no way to test whether the pending state is set correctly.
Tight coupling; for example, a $.ajax success handler shouldn’t need direct access to the DOM.
Organizing our code
The first step toward solving this is to take a less tangled approach to our code, breaking it up into a few different areas of responsibility:
Presentation and interaction
Data management and persistence
Overall application state
Setup and glue code to make the pieces work together
In the “traditional” implementation shown above, these four categories are intermingled—on one line we’re dealing with presentation, and two lines later we might be communicating with the server.
While we can absolutely write integration tests for this code—and we should!—writing unit tests for it is pretty difficult. In our functional tests, we can make assertions such as “when a user searches for something, she should see the appropriate results,” but we can’t get much more specific. If something goes wrong, we’ll have to track down exactly where it went wrong, and our functional tests won’t help much with that.
If we rethink how we write our code, though, we can write unit tests that will give us better insight into where things went wrong, and also help us end up with code that’s easier to reuse, maintain, and extend.
Our new code will follow a few guiding principles:
Represent each distinct piece of behavior as a separate object that falls into one of the four areas of responsibility and doesn’t need to know about other objects. This will help us avoid creating tangled code.
Support configurability, rather than hard-coding things. This will prevent us from replicating our entire HTML environment in order to write our tests.
Keep our objects’ methods simple and brief. This will help us keep our tests simple and our code easy to read.
Use constructor functions to create instances of objects. This will make it possible to create “clean” copies of each piece of code for the sake of testing.
To start with, we need to figure out how we’ll break our application into different pieces. We’ll have three pieces dedicated to presentation and interaction: the Search Form, the Search Results, and the Likes Box.
We’ll also have a piece dedicated to fetching data from the server and a piece dedicated to gluing everything together.
Let’s start by looking at one of the simplest pieces of our application: the Likes Box. In the original version of the app, this code was responsible for updating the Likes Box:
var liked = $('#liked');
var resultsList = $('#results');
// ...
resultsList.on('click', '.like', function (e) {
e.preventDefault();
var name = $(this).closest('li').find('h2').text();
liked.find( '.no-results' ).remove();
$('<li>', { text: name }).appendTo(liked);
});
The Search Results piece is completely intertwined with the Likes Box piece and needs to know a lot about its markup. A much better and more testable approach would be to create a Likes Box object that’s responsible for manipulating the DOM related to the Likes Box:
var Likes = function (el) {
this.el = $(el);
return this;
};
Likes.prototype.add = function (name) {
this.el.find('.no-results').remove();
$('<li>', { text: name }).appendTo(this.el);
};
This code provides a constructor function that creates a new instance of a Likes Box. The instance that’s created has an .add() method, which we can use to add new results. We can write a couple of tests to prove that it works:
var ul;
setup(function(){
ul = $('<ul><li class="no-results"></li></ul>');
});
test('constructor', function () {
var l = new Likes(ul);
assert(l);
});
test('adding a name', function () {
var l = new Likes(ul);
l.add('Brendan Eich');
assert.equal(ul.find('li').length, 1);
assert.equal(ul.find('li').first().html(), 'Brendan Eich');
assert.equal(ul.find('li.no-results').length, 0);
});
Not so hard, is it? Here we’re using Mocha as the test framework, and Chai as the assertion library. Mocha provides the test and setup functions; Chai provides assert. There are plenty of other test frameworks and assertion libraries to choose from, but for the sake of an introduction, I find these two work well. You should find the one that works best for you and your project—aside from Mocha, QUnit is popular, and Intern is a new framework that shows a lot of promise.
Our test code starts out by creating an element that we’ll use as the container for our Likes Box. Then, it runs two tests: one is a sanity check to make sure we can make a Likes Box; the other is a test to ensure that our .add() method has the desired effect. With these tests in place, we can safely refactor the code for our Likes Box, and be confident that we’ll know if we break anything.
Our new application code can now look like this:
var liked = new Likes('#liked');
var resultsList = $('#results');
// ...
resultsList.on('click', '.like', function (e) {
e.preventDefault();
var name = $(this).closest('li').find('h2').text();
liked.add(name);
});
The Search Results piece is more complex than the Likes Box, but let’s take a stab at refactoring that, too. Just as we created an .add() method on the Likes Box, we also want to create methods for interacting with the Search Results. We’ll want a way to add new results, as well as a way to “broadcast” to the rest of the app when things happen within the Search Results—for example, when someone likes a result.
var SearchResults = function (el) {
this.el = $(el);
this.el.on( 'click', '.btn.like', _.bind(this._handleClick, this) );
};
SearchResults.prototype.setResults = function (results) {
var templateRequest = $.get('people-detailed.tmpl');
templateRequest.then( _.bind(this._populate, this, results) );
};
SearchResults.prototype._handleClick = function (evt) {
var name = $(evt.target).closest('li.result').attr('data-name');
$(document).trigger('like', [ name ]);
};
SearchResults.prototype._populate = function (results, tmpl) {
var html = _.template(tmpl, { people: results });
this.el.html(html);
};
Now, our old app code for managing the interaction between Search Results and the Likes Box could look like this:
var liked = new Likes('#liked');
var resultsList = new SearchResults('#results');
// ...
$(document).on('like', function (evt, name) {
liked.add(name);
})
It’s much simpler and less entangled, because we’re using the document as a global message bus, and passing messages through it so individual components don’t need to know about each other. (Note that in a real app, we’d use something like Backbone or the RSVP library to manage events. We’re just triggering on document to keep things simple here.) We’re also hiding all the dirty work—such as finding the name of the person who was liked—inside the Search Results object, rather than having it muddy up our application code. The best part: we can now write tests to prove that our Search Results object works as we expect:
var ul;
var data = [ /* fake data here */ ];
setup(function () {
ul = $('<ul><li class="no-results"></li></ul>');
});
test('constructor', function () {
var sr = new SearchResults(ul);
assert(sr);
});
test('display received results', function () {
var sr = new SearchResults(ul);
sr.setResults(data);
assert.equal(ul.find('.no-results').length, 0);
assert.equal(ul.find('li.result').length, data.length);
assert.equal(
ul.find('li.result').first().attr('data-name'),
data[0].name
);
});
test('announce likes', function() {
var sr = new SearchResults(ul);
var flag;
var spy = function () {
flag = [].slice.call(arguments);
};
sr.setResults(data);
$(document).on('like', spy);
ul.find('li').first().find('.like.btn').click();
assert(flag, 'event handler called');
assert.equal(flag[1], data[0].name, 'event handler receives data' );
});
The interaction with the server is another interesting piece to consider. The original code included a direct $.ajax() request, and the callback interacted directly with the DOM:
$.ajax('/data/search.json', {
data : { q: query },
dataType : 'json',
success : function( data ) {
loadTemplate('people-detailed.tmpl').then(function(t) {
var tmpl = _.template( t );
resultsList.html( tmpl({ people : data.results }) );
pending = false;
});
}
});
Again, this is difficult to write a unit test for, because so many different things are happening in just a few lines of code. We can restructure the data portion of our application as an object of its own:
var SearchData = function () { };
SearchData.prototype.fetch = function (query) {
var dfd;
if (!query) {
dfd = $.Deferred();
dfd.resolve([]);
return dfd.promise();
}
return $.ajax( '/data/search.json', {
data : { q: query },
dataType : 'json'
}).pipe(function( resp ) {
return resp.results;
});
};
Now, we can change our code for getting the results onto the page:
var resultsList = new SearchResults('#results');
var searchData = new SearchData();
// ...
searchData.fetch(query).then(resultsList.setResults);
Again, we’ve dramatically simplified our application code, and isolated the complexity within the Search Data object, rather than having it live in our main application code. We’ve also made our search interface testable, though there are a couple caveats to bear in mind when testing code that interacts with the server.
The first is that we don’t want to actually interact with the server—to do so would be to reenter the world of integration tests, and because we’re responsible developers, we already have tests that ensure the server does the right thing, right? Instead, we want to “mock” the interaction with the server, which we can do using the Sinon library. The second caveat is that we should also test non-ideal paths, such as an empty query.
test('constructor', function () {
var sd = new SearchData();
assert(sd);
});
suite('fetch', function () {
var xhr, requests;
setup(function () {
requests = [];
xhr = sinon.useFakeXMLHttpRequest();
xhr.onCreate = function (req) {
requests.push(req);
};
});
teardown(function () {
xhr.restore();
});
test('fetches from correct URL', function () {
var sd = new SearchData();
sd.fetch('cat');
assert.equal(requests[0].url, '/data/search.json?q=cat');
});
test('returns a promise', function () {
var sd = new SearchData();
var req = sd.fetch('cat');
assert.isFunction(req.then);
});
test('no request if no query', function () {
var sd = new SearchData();
var req = sd.fetch();
assert.equal(requests.length, 0);
});
test('return a promise even if no query', function () {
var sd = new SearchData();
var req = sd.fetch();
assert.isFunction( req.then );
});
test('no query promise resolves with empty array', function () {
var sd = new SearchData();
var req = sd.fetch();
var spy = sinon.spy();
req.then(spy);
assert.deepEqual(spy.args[0][0], []);
});
test('returns contents of results property of the response', function () {
var sd = new SearchData();
var req = sd.fetch('cat');
var spy = sinon.spy();
requests[0].respond(
200, { 'Content-type': 'text/json' },
JSON.stringify({ results: [ 1, 2, 3 ] })
);
req.then(spy);
assert.deepEqual(spy.args[0][0], [ 1, 2, 3 ]);
});
});
For the sake of brevity, I’ve left out the refactoring of the Search Form, and also simplified some of the other refactorings and tests, but you can see a finished version of the app here if you’re interested.
When we’re done rewriting our application using testable JavaScript patterns, we end up with something much cleaner than what we started with:
$(function() {
var pending = false;
var searchForm = new SearchForm('#searchForm');
var searchResults = new SearchResults('#results');
var likes = new Likes('#liked');
var searchData = new SearchData();
$(document).on('search', function (event, query) {
if (pending) { return; }
pending = true;
searchData.fetch(query).then(function (results) {
searchResults.setResults(results);
pending = false;
});
searchResults.pending();
});
$(document).on('like', function (evt, name) {
likes.add(name);
});
});
Even more important than our much cleaner application code, though, is the fact that we end up with a codebase that is thoroughly tested. That means we can safely refactor it and add to it without the fear of breaking things. We can even write new tests as we find new issues, and then write the code that makes those tests pass.
Testing makes life easier in the long run
It’s easy to look at all of this and say, “Wait, you want me to write more code to do the same job?”
The thing is, there are a few inescapable facts of life about Making Things On The Internet. You will spend time designing an approach to a problem. You will test your solution, whether by clicking around in a browser, writing automated tests, or—shudder—letting your users do your testing for you in production. You will make changes to your code, and other people will use your code. Finally: there will be bugs, no matter how many tests you write.
The thing about testing is that while it might require a bit more time at the outset, it really does save time in the long run. You’ll be patting yourself on the back the first time a test you wrote catches a bug before it finds its way into production. You’ll be grateful, too, when you have a system in place that can prove that your bug fix really does fix a bug that slips through.
Additional resources
This article just scratches the surface of JavaScript testing, but if you’d like to learn more, check out:
My presentation from the 2012 Full Frontal conference in Brighton, UK.
Grunt, a tool that helps automate the testing process and lots of other things.
Test-Driven JavaScript Development by Christian Johansen, the creator of the Sinon library. It is a dense but informative examination of the practice of testing JavaScript.
Intellectual property rights incentivize research by private companies but foster a culture of secrecy that slows down the speed of innovation. Is there a way to foster more openness in private sector research?
“Job interviews are becoming more like first dates.” Or so reads a Businessweek article on how cultural fit increasingly complements or even trumps qualifications as the most important hiring criteria. The article cites Glassdoor, a website offering an inside look at jobs and companies, which notes that questions like “What’s your favorite movie?” rank among the top 50 asked at job interviews in 2012.
Famous examples abound here in Silicon Valley. Facebook wants people who “Move fast and break things.” Palantir hires people who want to “Save the Shire,” and PayPal famously hired competitive workaholics with anti-establishment leanings.
When it comes time to nail down a definition of what people mean when they talk about company culture, however, the definitions are as standardized as definitions of art. Is company culture a big vision for the company? A manner of getting along with co-workers? Prioritizing certain values over others? Or aspects of the work environment like level of autonomy and uncertainty?
Certamente, Kenneth Waltz concordaria que o prêmio Nobel da paz deveria ir para a bomba nuclear. Afinal, quem foi que impediu um confronto militar, direto e total entre as duas potencias da Guerra Fria, se não foi a bomba?
Dedico uma breve reflexão sobre a teoria nuclear de Kenneth Waltz, que morreu com 88 anos, há pouco mais de uma semana. Além da questão nuclear, Waltz se mostrou um pensador da guerra, com o seu livro O Homem, O Estado e a Guerra e também um grande teórico das relações internacionais, sendo o pioneiro da teoria neorrealista em seu ensaio Uma Teoria de Política Internacional. Quem leu Waltz sabe quão bem escritos, claros e estruturados são os seus textos. Infelizmente, parece que em relação à questão nuclear, suas ideias não são tão bem-vindas para alguns. Um professor de relações internacionais da PUC-SP teve a fala editada no programa “Painel”, da Globo News, quando citou o argumento de Waltz sobre os armamentos nucleares. A sua teoria gera certos incômodos justamente por defender a proliferação nuclear para TODOS os Estados.
Waltz afirma que, quanto mais Estados possuírem a bomba, melhor será para a segurança mundial. Esse argumento é fundamentado na concepção que os Estados são minimamente racionais; logo não se engajariam em uma guerra que provoque a sua própria destruição, como seria o caso de uma guerra nucelar. Não somente a Guerra Fria é um exemplo disso, mas também outros casos de Estados conflitantes como o do conflito entre a Índia e o Paquistão, os quais não tiveram um conflito armado em larga escala após ambos adquirirem bombas nucleares. Por essa razão, Waltz defende a proliferação nuclear para todos os Estados desde que esta seja dissuasiva para todos. Em outras palavras, todo Estado deve sentir-se vulnerável a um contra-ataque nuclear face ao uso de um armamento nuclear. Diversas medidas são sugeridas por Waltz para que tal mecanismo se realize, mas isso não convém a esse texto.
Em termos normativos, eu não concordo com a afirmação que a proliferação de armas nucleares seja uma solução permanente entre os conflitos estatais. Uma vez que uma arma é construída, a probabilidade do seu uso sempre existe. Essa probabilidade pode ser aplicada para a racionalidade Estatal ou não Estatal. No que tange à primeira, a racionalidade do Estado nem sempre é infalível devido à inevitável imperfeição da informação em momentos de conflito. Esse argumento não é novidade para quem viu o documentário The Fog of War, onde o ex-secretário da defesa dos EUA, Robert McNamara, confessa que um conflito nuclear com a União Soviética, durante a Crise dos Mísseis em 1962, não ocorreu por um fio. Ademais, durante a Guerra Fria, houve mais de um momento onde a alerta de um conflito nuclear chegou a pontos alarmantes. Em relação à racionalidade não estatal, o uso da bomba também é possível: Estados nucleares podem perder, por múltiplas razões (mesmo que muito improvável), o monopólio sobre a bomba, passando o seu controle para grupos não estatais onde a racionalidade de evitar a mútua destruição não se aplica da mesma forma que entre Estados.
Enfim, o futuro é imprevisível mas a existência da bomba é um fato. Em outras palavras, uma guerra nuclear é improvável, mas não impossível. O problema é que falar em probabilidades nesse caso não é a mesma coisa de que correr um risco jogando na bolsa de valores, mas admitir que milhões de pessoas podem possivelmente morrer em poucos minutos.
Entretanto, o ponto forte da teoria de Waltz, e talvez o mais criticado, é a sua concepção de que a causa que leva os Estados a obterem uma bomba nuclear é de ordem comum e não varia entre os Estados e seus regimes políticos. Waltz concebe que os Estados buscam um equilíbrio de poder que garanta estabilidade e segurança na sua relação com os seus semelhantes. Quando um Estado se sente ameaçado, sem conseguir contrapor-se de forma proporcional ao nível da ameaça, este pode passar a ver sua existência vulnerabilizada, levado-o a tomar ações que busquem um maior equilíbrio. Nesse contexto, a bomba nuclear seria uma boa ferramenta para estabelecer um equilíbrio de poder e evitar um conflito entre os Estados por meio de uma dissuasão mútua. Portanto, quando pensamos no caso do Irã, a busca da arma nuclear nesse caso seria uma forma de adquirir um maior equilíbrio com Israel e os Estados Unidos, Estados estes que representam claramente uma ameaça do ponto de vista iraniano. Grosso modo, tanto Israel quanto os Estados Unidos são potências nucleares com claras inimizades e discordâncias em relação ao Irã como uma potência regional no Oriente Médio. Segundo, os Estados Unidos invadiram e possuem diversas bases militares no Iraque e no Afeganistão, dois países fronteiriços do Irã. Quem não se sentiria ameaçado? Veja bem, não estou defendendo nenhum dos lados, mas acredito que a teoria de Waltz seja um ótimo indício para mostrar a falácia de que o Irã tem pretensões fundamentalistas irracionais de mandar todos para o ar.
A teoria de Waltz certamente pode ser pensada com relatividade como um meio permanente para garantir a paz. Como vimos, a possibilidade de usar a bomba sempre existe e a racionalidade é passível de erros. Não obstante, acredito que a sua teoria é extremamente relevante para pensar a motivação dos Estados em adquirir armas nucleares sem cair em discursos problemáticos que categorizam os Estados em dois grupos quando a questão é a bomba nuclear: os ditos “responsáveis” e irresponsáveis ou não racionais, mais comumente conhecidos como rogue States. O problema dessas categorias é que quando um contencioso nuclear surge, a natureza da racionalidade de cada Estado é concebida como diferente a priori e portanto é impossível ouvir ou negociar sobre as necessidades das respectivas partes. Enfim, a teoria de Waltz nos obriga a olhar para as necessidades que estão além das identidades atribuídas. Se a teoria de Waltz fosse levada mais em conta, talvez algumas medidas e embargos econômicos de efeitos duvidosos que visam a impedir a proliferação nuclear em países como a Coreia do Norte ou o Irã, seriam evitados e seriam substituídos por negociações mais efetivas.
Rafael Tobias Allonié autor convidado do blog Esparrela. Estudante de mestrado em Relações Internacionais, com especialização em Segurança Internacional, no Instituto de Estudos Políticos de Paris (Sciences Po).
“Humor is not a mood but a way of looking at the world. So if it is correct to say that humor was stamped out in Nazi Germany, that does not mean that people were not in good spirits, or anything of that sort, but something much deeper and more important.”
“So, Yahoo’s finally decided to close Upcoming.org, the events community I started nearly ten years ago. And, in Yahoo’s typical fuck-off-and-die style, they’re doing it with 11 days notice, no on-site announcement, and no way to back up past events. I knew its closure was inevitable after the infamous sunset slide, but never knew when it would happen. Like a newspaper prepping for a sick celebrity, this obituary’s been sitting in my drafts folder for months, waiting for its sad publication day.”
Ancient lore has suggested that the Vikings used special crystals to find their way under less-than-sunny skies. Though none of these so-called “sunstones” have ever been found at Viking archaeological sites, a crystal uncovered in a British shipwreck could help prove they did indeed exist.
The crystal was found amongst the wreckage of the Alderney, an Elizabethan warship that sank near the Channel Islands in 1592. The stone was discovered less than 3 feet (1 meter) from a pair of navigation dividers, suggesting it may have been kept with the ship’s other navigational tools, according to the research team headed by scientists at the University of Rennes in France.
A chemical analysis confirmed that the stone was Icelandic Spar, or calcite crystal, believed to be the Vikings’ mineral of choice for their fabled sunstones, mentioned in the 13th-century Viking saga of Saint Olaf.
Today, the Alderney crystal would be useless for navigation, because it has been abraded by sand and clouded by magnesium salts. But in better days, such a stone would have bent light in a helpful way for seafarers.
Because of the rhombohedral shape of calcite crystals, “they refract or polarize light in such a way to create a double image,” Mike Harrison, coordinator of the Alderney Maritime Trust, told LiveScience. This means that if you were to look at someone’s face through a clear chunk of Icelandic spar, you would see two faces. But if the crystal is held in just the right position, the double image becomes a single image and you know the crystal is pointing east-west, Harrison said.
These refractive powers remain even in low light when it’s foggy or cloudy or when twilight has come. In a previous study, the researchers proved they could use Icelandic spar to orient themselves within a few degrees of the sun, even after the sun had dipped below the horizon.
Recently we added formulas for a variety of shapes and forms, and the Wolfram|Alpha Blog showed some examples of shapes that were represented through mathematical equations and inequalities. These included fictional character curves:
While these are curves in a mathematical sense, similar to say a lemniscate or a folium of Descartes, they are interesting less for their mathematical properties than for their visual meaning to humans.
After Richard’s blog post was published, a coworker of mine asked me, “How can you make an equation for Stephen Wolfram’s face?” After a moment of reflection about this question, I realized that the really surprising issue is not that there is a formula: a digital image (assume a grayscale image, for simplicity) is a rectangular array of gray values. From such an array, you could build an interpolating function, even a polynomial. But such an explicit function would be very large, hundreds of pages in size, and not useful for any practical application. The real question is how you can make a formula that resembles a person’s face that fits on a single page and is simple in structure. The formula for the curve that depicts Stephen Wolfram’s face, about one page in length, is about the size of a complicated physics formula, such as the gravitational potential of a cube.
In this post, I want to show how to generate such equations. As a “how to calculate…”, the post will not surprisingly contain a fair bit of Mathematica code, but I’ll start with some simple introductory explanations.
Assume you make a line drawing with a pencil on a piece of paper, and assume you draw only lines; no shading and no filling is done. Then the drawing is made from a set of curve segments. The mathematical concept of Fourier series allows us to write down a finite mathematical formula for each of these line segments that is as close as wanted to a drawn curve.
As a simple example, consider the series of functions yn(x),
which is a sum of sine functions of various frequencies and amplitudes. Here are the first few members of this sequence of functions:
Plotting this sequence of functions suggests that as n increases, yn(x) approaches a triangular function.
The sine function is an odd function, and as a result all of the sums of terms sin(kx) are also odd functions. If we use the cosine function instead, we obtain even functions. A mixture of sine and cosine terms allows us to approximate more general curve shapes.
Generalizing the above (-1)(k – 1)/2)k-2 prefactor in front of the sine function to the following even or odd functions,
allows us to model a wider variety of shapes:
It turns out that any smooth curve y(x) can be approximated arbitrarily well over any interval [x1, x2] by a Fourier series. And for smooth curves, the coefficients of the sin(kx) and cos(kx) terms approach zero for large k.
Now given a parametrized curve γ(t) = {γx(t), γy(t)}, we can use such superpositions of sine and cosine functions independently for the horizontal component γx(t) and for the vertical component γy(t). Using a sum of three sine functions and three cosine functions for each component,
covers a large variety of shapes already, including circles and ellipses. The next demonstration lets us explore the space of possible shapes. The 2D sliders change the corresponding coefficient in front of the cosine function and the coefficient in front of the sine function. (Download this post as a CDF to interact)
If we truncate the Fourier expansion of a curve at, say, n terms, we have 4n free parameters. In the space of all possible curves, most curves will look uninteresting, but some expansion coefficient values will give shapes that are recognizable. However, small changes in the expansion coefficients already quickly change the shapes. The following example allows a modification of the first 4 × 16 Fourier series coefficients of a curve (meaning 16 for the x direction and another 16 for the y direction). Using appropriate values for the Fourier coefficients, we obtain a variety of recognizable shapes.
And if we now take more than one curve, we already have all the ingredients needed to construct a face-like image. The following demonstration uses two eyes, two eye pupils, a nose, and a mouth.
And here is a quick demonstration of the reverse: we allow the position of a set of points (the blue crosses) that form a line to be changed and plot the Fourier approximations of this line.
Side note: Fourier series are not the only way to encode curves. We could use wavelet bases or splines, or encode the curves piecewise through circle segments. Or, with enough patience, using the universality of the Riemann zeta function, we could search for any shape in the critical strip. (Yes, any possible [sufficiently smooth] image, such as Jesus on a toast, appears somewhere in the image of the Riemann zeta function ζ(s) in the strip 0 ≤ Re(s) ≤ 1, but we don’t have a constructive way to search for it.)
To demonstrate how to find simple, Fourier series-based formulas that approximate given shapes, we will start with an example: a shape with sharp, well-defined boundaries—a short formula. More concretely, we will use a well-known formula: the Pythagorean theorem.
Rasterizing the equation gives the starting image that we will use.
It’s easy to get a list of all points on the edges of the characters using the function EdgeDetect.
Now that we have the points that form the edges, we want to join them into straight-line (or curved) segments. The following function pointListToLines carries out this operation. We start with a randomly chosen point and find all nearby points (using the function Nearest to be fast). We continue this process as long as we find points that are not too far away. We also try to continue in a “straight” manner by slightly penalizing sharp turns. To see how the curve construction progresses, we use Monitor.
For the Pythagorean theorem, we obtain 11 individual curves from the edge points.
Joining the points and coloring each segment differently shows that we obtained the expected curves: the outer boundaries of the letters, the inner boundaries of the letters a and b, the three squares, and the plus and equal signs.
Now for each curve segment we want to find a Fourier series (of the x and y component) that approximates the segment. The typical textbook definition of the Fourier coefficients of a function f(x) are integrals of the function multiplied by cos(kx) and sin(kx). But at this point we have sets of points, not functions. To turn them into functions that we can integrate, we make a B-spline curve of each curve segment. The parametrization variable of the B-spline curve will be the integration variable. (Using B-splines instead of piecewise linear interpolations between the points will have the additional advantage of making jagged curves smoother.)
We could find the integrals needed to obtain the Fourier coefficients by numerical integration. A faster way is to use the fast Fourier transform (FFT) to get the Fourier coefficients.
To get more uniform curves, we perform one more step: re-parametrize the spline interpolated curve of the given curve segments by arclength. The function fourierComponents implements the B-spline curve making, the re-parametrization by arclength, and the FTT calculation to obtain the Fourier coefficient. We also take into account if a curve segment is open or closed to avoid Gibbs phenomena-related oscillations. (The above demonstration of approximating the pentagram nicely shows the Gibbs phenomenon in case the “Closed” checkbox is unchecked.)
For a continuous function, we expect an average decay rate of 1/k2 for the kth Fourier series coefficient. This is the case for the just-calculated Fourier series coefficient. This means that on average the 10th Fourier coefficient is only 1% in magnitude compared with the first one. This decay allows us to truncate the Fourier series at a not too high order, as we do not want to obtain formulas that are too large. This expression gives the exponent in the decay rate of the Fourier components for the a2 + b2 = c2 curve above. (The slightly lower than 2 exponent arises from the discretization points in the B-spline curves.)
Here is a log-log-plot of the absolute values of the Fourier series coefficient for the first three curves. In addition to the general trend of an approximately quadratic decay of the Fourier coefficients, we see that the magnitude of nearby coefficients often fluctuates by more than an order of magnitude.
Multiplying the Fourier coefficients by cos(kt) and sin(kt) and summing the terms gives us the desired parametrizations of the curves.
The function makeFourierSeriesApproximationManipulate visualizes the resulting curve approximations as a function of the series truncation order.
For the Pythagorean theorem, starting with a dozen ellipses, we quickly form the characters of the inequality with increasing Fourier series order.
We want a single formula for the whole equation, even if the formula is made from disjoint curve segments. To achieve this, we use the 2π periodicity of the Fourier series of each segment to plot the segments for the parameter ranges [0, 2π], [4π, 6π], [8π, 10π], …, and in the interleaving intervals (2π, 4π), (6π, 8π), …, we make the curve coordinates purely imaginary. As a result, the curve cannot be drawn there, and we obtain disjoint curve segments. Here this construction is demonstrated for the case of two circles:
The next plot shows the real and imaginary parts of the complex-valued parametrization independently. The red line shows the purely imaginary values from the parameter interval [2π, 4π].
As we want the final formula for the curves to look as short and as simple as possible, we change sums of the form a cos(kt) + b sin(kt) to A sin(kt + φ) using the function sinAmplitudeForm and round the floating-point Fourier series coefficients to nearby rationals. Instead of Piecewise, we use UnitStep in the final formula to separate the individual curve segments. The real segments we list in explicit form, and all segments that should not be drawn are encoded through the θ(sgn(sin(t/2)(1/2))) term.
Now we have everything together to write down the final parametrization {x(t), y(t)} of the typeset form of the Pythagorean theorem as a mathematical formula.
After having discussed the principal construction idea for the parametrizations, let’s look at a more fun example, say the Pink Panther. Looking at the image search results of the Bing search engine, we quickly find an image that seems desirable for a “closed form” parametrization.
Let’s use the following image:
We apply the function EdgeDetect to find all edges on the panther’s face.
Connecting the edges to curve segments yields about 20 segments. (Changing the optional second and third argument of pointListToLines, we obtain fewer or more segments.)
Here is each segment shown with a different color. We see that some closed curves arise from two joined curve segments; we could separate them by changing the second argument of pointListToLines. But for the goal of sketching a line drawing, the joined curve will work just fine.
Proceeding now as above, it is straightforward to approximate the curve segments by trigonometric series.
Plotting the series shows that with 20 terms per segment, we obtain a good representation of the Pink Panther.
As some of the segments of the panther’s face are more intricate than others, we define a function makeSegmentOrderManipulate that allows the number of terms of the Fourier series for each segment to be varied. This lets us further reduce the size of the resulting parametrizations.
We use initial settings for the number of Fourier coefficients that yield a clearly recognizable drawing of the Pink Panther.
For simple cases, we can now roll up all of the above function into a single function. The next function makeSilhouetteFourierResult takes a string as an argument. The function then 1) performs a search on Bing’s image site for this string; 2) selects an image that seems appropriate from the algorithmic point of view; 3) calculates the Fourier series; and 4) returns as the result plots of the Fourier series and an interactive version that lets us change the order of the Fourier series. For simplicity, we restrict the program to only single curves. (In the web search, we use the word “silhouette” to mostly retrieve images that are formed by just a single curve.) As the function relies on the result of an external search engine, there is no guarantee that the function will always return the wanted result.
Here are three examples showing the function at work. We build the Fourier series for a generic spider, Spiderman’s spider, a couple dancing the tango, and a mermaid. (Evaluating these functions might give different results, as the search engine results might change over time.)
So far, the initial line segments were computed from images. But we can also start with hand-drawn curves. Assume we want a formula for Isaac Newton. As I am not good at drawing faces, I cheated a bit and used the curve drawing tool to draw characteristic facial and hair curves on top of an image of Sir Isaac. (For algorithmic approaches on how to extract feature lines from faces, see the recent paper by Zhao and Zhu.) Here is the image that we will use:
Fortunately, small random wiggles in the hand-drawn curve will not matter, as they will be removed by omitting higher-order terms in the Fourier series.
To better see the hand-drawn curves, we separate the image and the lines.
This time, we have 16 segments. We build their Fourier series.
And here are again various approximation orders of the resulting curves.
We use different series orders for the various segments. For the hair, we use relatively high orders, and for the eyes relatively low orders. This will make sure that the resulting equations for the face will not be larger than needed.
Here are the first 50 approximations shown in one graphic with decreasing opacity of the curves, and with each set of corresponding curve segments shown in a different color.
This gives the following final curve for Sir Isaac’s portrait.
And this is the plotted form of the last formula.
This ends today’s discussion about how to make curves that resemble people’s faces, fictional characters, animals, or other shapes. Next time, we will discuss the endless graphics capabilities that arise from these formulas and how you can use these types of equations in a large variety of images.
Two weekends ago I was invited to a small shindig to check out some indie games including the awesome-looking indie fighting game, Divekick, which Ben had made me positively salivant for earlier this year, and I was excited for the chance to play it for myself.
The event was being hosted by Max Temkin, creator of the runaway hit Cards Against Humanity, a comedy card game which every PAX-goer is very likely familiar with at this point.
It was being held in a somewhat shabby, rundown building with scuffs and scrapes as the only decoration on the walls, no furnishings, and one giant plasma screen TV around which a couple dozen people would crowd to cheer on Divekick competitors while discussing the game’s unique two-button controller, art style, writing and strategy.
Hip people with scarves and hats mingled freely with others in comparatively shabby yet-still-somehow-cool clothing.
And the beards. Good heavens, the beards. I have a beard, but in the face of such beards, what I have could not rightly be called a beard. I am a pretender.
“Cool” people surrounded me on all sides, sipping locally brewed Revolution beer from red cups and discussing game design.
When I saw the beer, that’s when it hit me. I’ve been here before. Not in this same building, but I’ve been to this show, although it wasn’t a video game in front of the crowd. It was an up-and-coming local band. Or a small art gallery. Or a poetry reading.
This was that same scene except I was discussing the learning curves of Divekick vs Street Fighter instead of pretending to be interested in a punk band.
This whole experience forced me to start wondering: am I suddenly cool? Did the wave of time change my social standing?
After all, there I was mingling with the mightiest beards in the city of Chicago, attending a dingy art show just like a cool person might. And I didn’t even have to feign interest, this was a scene I was invested in. I fit in.
More and more I hear stories about things that I’d normally assume were the province of traditional artists. I hear reports of game developers living together in artist houses, or struggling with artistic inadequacy, and it reminds me that gamers’ best days are ahead. We’re struggling with the happy problems of the indie scene truly growing up.
I’m the brand of nerd that almost compulsively thinks about the future. I love to imagine what things might be like 30+ years down the road. Not in a fantastical, colonizing-the-galaxy sort of way, but in a functional and realistic way. When I can see the future developing in front of my eyes at events like that underground game demo it’s an inspiring moment that makes me wonder.
One day the Baby Boomer generation will be gone, and we will inherit culture itself. We’re already taking pieces of it as gamers and game designers continue to age. What will that world look like when its most respected elders grew up on Mario Kart?
There’s precendent for that too. Just look at what happened with comic book culture once the children of the Bronze Age, roughly 1970 to 1985, of comics reached a certain age. Americans have now elected a presidential administration that has referenced Star Wars not once, but twice.
I look forward to a day when not only has gaming’s generation aged to fill the indie artist scene, but when we’re rich snobs lusting after rare pieces (imagine what Chain World will be worth if it surfaces in 30 years,) and politicians referencing games in an effort to connect with the common voter.
This party gave me a vision of what the future will be like for video gamers: pretty much the same as the past except with far more video games. I look around today and I see older people sit around the coffee table to play Ups and Downs or Charades. These games seem boring to us, but they play them because they’re a common language that everyone can relax and understand easily.
I can’t wait for the day when the games that we can all relax and understand in our retirement are Settlers of Catan, Street Fighter, and Super Mario Kart. When I think about it that way, aging into retirement doesn’t seem so bad. It sounds kind of amazing, actually.
Wood is one of the most versatile materials known. You can coax it into uncountable forms. However It exhibits extremely complex behavior, as if it were still living. This tome dives deep into woodology, and returns with great insight into what wood wants. It is essential understanding for anyone wishing to master working with wood.
-- KK
Understanding Wood
Bruce Hoadley
2000, 280 pages
$27
A knot is the basal portion of a branch whose structure becomes surrounded by the enlarging stem. Since branches begin with lateral buds, knots can always be traced back to the pith of the main stem.
*
*
Various shapes of red pine have been dried and superimposed on their original positions on an adjacent log section. The great tangential than radical shrinkage causes squares to become diamond-shaped, cylinders to become oval. Quarter-sawn boards seldom warp, but flat sawn boards cup away from the pith.
*
A wafer cut from a kiln-dried plank of white ash shows no symptoms of stress (left). Another section from the same plank, after resawing (center) reveals the casehardened condition (tension in core, compression in shell). Kiln operators cut fork-shaped sections that reveal casehardening when prongs curve inward (right).
*
Most of the boards in the drying shed at left are restrained by the weight of the others. At right is a similar, simpler setup, where the wood is protected by a sheet of corrugated plastic. In both cases, the boards are stacked in the sequence they came off the saw.
*
Red oak end grain cut with a ripsaw (right), which mangles the cell structure, and with a crosscut saw (left), which severs the fibers cleanly.
Once you get hooked on foraging for wild mushrooms, you begin to wonder why you can’t just farm them. Picking mushrooms from your backyard or basement would sure be a lot easier than roaming the hinterlands. Well, so far about 30 different kinds mushrooms can be cultivated, although none of the techniques are trivial. The delicate operations needed to produce sterile “soil” and inoculate the spores has been streamlined for some species (by using pre-inoculated plugs), but there is still a lot of skill and laboratory expertise needed to grow the rest. Most of what is known about mushroom cultivation has been distilled into the 3rd edition of this irreplaceable book. This is simply the best guide to growing edible, medicinal, and psychoactive mushrooms.
This is a fast-changing field where enthusiastic amateurs lead the way. To keep up with new possibilities, check the authors website at Fungi Perfect. Farming mushrooms is also becoming a business, and the Mushroom Growers’ Newsletter is the hub.
-- KK
Growing Gourmet and Medicinal Mushrooms
Paul Stamets
2000, 614 pages
$30
In one of my outdoor wood-chip beds, I created a “polyculture” mushroom patch about 50 by 100 feet in size. In the spring I acquired mixed wood chips from the county utility company–mostly alder and Douglas fir–and inoculated three species into it. One year after inoculation, in late April through May, Morels showed. From June to early September, Kind Stropharia erupted with force, providing our family with several hundred pounds. In late September through much of November, as assortment of Clustered Woodlovers (Hypholoma-like) species popped up. With noncoincident fruiting cycles, this Zen-like polyculture approach is limited only by your imagination.
I sort of already hate myself from weighing in on this but people keep asking me to tweet about it and forward their petitions, and I really thought it would quiet down by now but it hasn’t, so I’m going to give my big, fat, stupid, irrelevant and probably wrong opinion on the changes Disney made from the original I-might-trust-her-to-babysit-my-kid-when-she’s-a-little-older Merida to get-the-fuck-away-from-my-husband Merida.
There are all sorts of calls to action to get Disney to admit that the new Merida looks a bit skanky and they’ve met with some success and that’s awesome. Go team. I hope you succeed. But (in my opinion – stop yelling at me) the majority of people do not give a shit. Mostly because we’re busy personally teaching our kids what strong women look like instead of letting Disney do it for us. And in a way, Disney did us a favor here. Did you have a talk with your kid about the new Merida? Because if you didn’t you missed a good opportunity to see where your kid stands on this, and to talk to them about over-sexualization.
I showed the new Merida to my eight-year-old and she assumed that it was Merida’s evil twin. Which actually would make an awesome story, and personally I plan to tell stray children I see buying backpacks with the new Merida on them that the original Merida was eaten by the new Evil Merida because she was so hungry. And they will probably believe it because seriously, look at her waist…the girl needs a damn sandwich.
Anyway, my incredibly dumb and probably ill-informed point is that it’s really uncomfortable to see a strong, child-like character get tarted up and flash bedroom eyes at you, but it’s equally sucky to rely on a giant corporation to teach your kids what strong women look like. Strong women look like Amelia Earhart, Rosie the Riveter, Asmaa Mahfouz, or Elizabeth Smart. Or Wonder Woman, or Sally Ride or Sojourner Truth, or Amy Poehler, or Ada Lovelace, or Anne Frank. Or your grandmother.
Or you.
I support and admire the men and women who speak out in the cause of feminism, but let’s not lose sight of the fact that there are so many amazing women who may never end up on a lunch box (Wonder Woman and Word Girl excluded) but who can make a great difference in the life and perceptions of our sons and daughters.
Okay. Your turn. Who’s your favorite female hero?
PS. There aren’t any right or wrong answers here. It’s totally okay to like pretty dresses and sexy princesses. It’s totally okay not to. No judgment. Probably.
Two things I’ve noticed about a lot of things I’ve been reading recently: their formats, and their topics.
I’ve been reading a lot of shorter things. I think that comes down to having a lot on, and not always being to devote the brain-cycles (even if I have the time) to large, ongoing works. So I’ve been diving into short stories – notably, George Saunders’ most recent collection – and the Kindle Single, which appears to be reviving the novella for the early 21st century.
50-100 pages is a really nice length for fiction – longer than the ultra-tight focus of a short story, but still confining enough to give it a focus that novels don’t always have. It also means you can finish something in a single hour, which is, I think, why I’m warming to these so much: I get the satisfaction of finishing a lot of fiction without committing to the emotional and time demands of a novel.
But going beyond the format, I began to see echoes in the content.
Towards the beginning of the year, I read Nicholas Royle’s First Novel. I’m a big fan of Royle’s fiction; I can never tell if I’m in a minority, or if it’s just underrated. This might be my favourite book of his yet. Perhaps the most unsettling, too. It is very aware of its status as fiction, and yet the tale of an author who teaches creative writing at a redbrick university begins to feel like it’s slipping into an autobiographical mode… until it lurches, and you begin to worry for Royle’s own sanity – which is, of course, part of the point of that perspective; he’s playing with you, and completely in control of the fantasy of the novel. The way it jars with what we know of reality is part of what makes it work.
The frequent trips to sit in parking lots on business parks reminded me a lot of Marc Augé’snon-places, and as I say that, I realise that all these books and stories are about unplaces of one kind or another. The parking trips interrupt the flow of the narrative, punctuating it with emptiness. these episodes set the increasingly unsettling tone, which the main narrative picks up and runs with in the final act, and you realise that whilst various events of the plot were red herrings and blind alleys, the tone of events up to this point has been very carefully focused on producing a singular sensation.
It’s a similar conceit to Nic Roeg’s direction of Don’t Look Now: whilst the A-plot marches forward, the bodies dredged from the Venetian canals serve primarily to set tone – Venice, beautiful Venice, becomes unsettling and unpleasant, all dark alleys and a serial murderer on the loose. The murderer is seemingly unrelated to the A-plot, and yet in the final act, Roeg brings this background action into the foreground… only to prove how unrelated it is in the closing scenes. I know Royle is an admirer of Roeg, and there’s something of Roeg in his plotting.
What’s really stuck with me, though, is the depection of familiar spaces to the point they become unfamiliar. That also emerged in Keith Ridgway’s The Spectacular, a Kindle Single about a literary author trying to construct a pulpy thriller around the Olympics to finally earn some money. The character’s obsessive research begins to take him down some strange routes, and as he begins to emulate the terrorist (if only in his imagination), the shape of the world changes; he sees it differently. By the end, when the plot takes a sharp 90º turn, the author decides he may as well roll with it; reality has shifted far enough in his head. Rod has written about this book before, and I loved it – very topical, somewhat strange, and depicting 2012 London (very familiar to me) as if it were a foreign country.
That notion of the familiar and the unfamiliar then came to a head in M John Harrison’s Autotelia works – firstly In Autotelia, featured in Arc 1.1, and then Cave and Julia, available as a Kindle Single.
Autotelia is another country, and they do things differently there. It is not just foreign; it is the most foreign; actions, events, emotions; all are different in Autotelia. A place one goes to feel different. It is abstractly distant – connected not geographically, but through some kind of transition zone; it is a place you can go to but it doesn’t appear on a map. And as such, it manages to be familiar and unfamiliar all at once; ageographic, ahistoric. Unfamiliar histories leak out of it. (It also bears a little resemblance to Christopher Priest’s Dream Archipelago, and it’s no surprise that The Affirmation was one of my favourite books from last year, and one that has already become dear to me).
It helps that Cave and Julia is written in Harrison’s wonderful, sparse, prose. I’ve been reading a lot of his work recently, and am growing to love his use of language, his knack for description in such little space. His blog is worth a subscription – fragmented prose leaks out of it, and the quotations and excerpts stand shoulder to shoulder with blogposts and even short fictions; it becomes hard to tell which is which, which is old, which is new, and is better for it.
And: I think, based on things written in a variety of places, there’s some degree of social overlap between these writers; Harrison and Royle seem to know one another, I think.
I mainly wanted to jot this down because, over two months, I kept going back to similar spaces in similar short fictions, similar notions touched on in different stories by different writers with very different intents, and I wanted to jot them down – because if you like one, you’ll probably like the others. A series of stories all, in their own ways, about unplaces.
You press the pedal at the base of Eduard Bersudsky’s sculpture Piper (2013). The shadow on the wall moves, the cogs begin to hum, the little bell rings, and the pair of gendered fauns flex their legs to activate the dog typist at the typewriter hammering out memos lost to history. Tip, tap, tippity-tap, its [...]



















































 to form a line to be changed and plot the Fourier approximations of this line")



![edgePoints = {#2, -#1} & @@@ Position[ImageData[EdgeDetect[image]], 1, {2}];](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In16.png "edgePoints = {#2, -#1} & @@@ Position[ImageData[EdgeDetect[image]], 1, {2}];")

![SeedRandom[22]; hLines = pointListToLines[edgePoints, 6]; Length[hLines]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In18.png "SeedRandom[22]; hLines = pointListToLines[edgePoints, 6]; Length[hLines]")
![Graphics[{ColorData["DarkRainbow"][RandomReal[]], Line[#]} & /@ hLines]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In21.png "Graphics[{ColorData[\"DarkRainbow\"][RandomReal[]], Line[#]} & /@ hLines]")

![Graphics[BSplineCurve[#, SplineDegree ? 6, SplineClosed ? True] & /@ hLines]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In22.png "Graphics[BSplineCurve[#, SplineDegree ? 6, SplineClosed ? True] & /@ hLines]")



![(Mean[#] ± StandardDeviation[#] ) &[ Coefficient[ Fit[Log[Rest[MapIndexed[{1. #2[[1]], #1} &, #]]], {1, x}, x] & /@ Flatten[Abs[Flatten[#[[2]], 1]] & /@ fCs, 1], x, 1]] // NumberForm[#, 3] &](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In27.png "(Mean[#] ± StandardDeviation[#] ) &[ Coefficient[ Fit[Log[Rest[MapIndexed[{1. #2[[1]], #1} &, #]]], {1, x}, x] & /@ Flatten[Abs[Flatten[#[[2]], 1]] & /@ fCs, 1], x, 1]] // NumberForm[#, 3] &")


 and sin(k t) and summing the terms")








![finalCurve = Rationalize[singleParametrization[fCs, t, 12] , 10^-3]; Short[finalCurve, 12] // TraditionalForm](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In38.png "finalCurve = Rationalize[singleParametrization[fCs, t, 12] , 10^-3]; Short[finalCurve, 12] // TraditionalForm")








![edgePoints = {#2, -#1} & @@@ Position[ImageData[pinkPantherEdgeImage], 1, {2}];](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In44.png "edgePoints = {#2, -#1} & @@@ Position[ImageData[pinkPantherEdgeImage], 1, {2}];")
![SeedRandom[2]; hLines = pointListToLines[edgePoints, 16]; Length[hLines]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In45.png "SeedRandom[2]; hLines = pointListToLines[edgePoints, 16]; Length[hLines]")
![Graphics[{ColorData["DarkRainbow"][RandomReal[]], Line[#]} & /@ hLines]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In48.png "Graphics[{ColorData[\"DarkRainbow\"][RandomReal[]], Line[#]} & /@ hLines]")














![hLines = Reverse[ SortBy[First /@ Cases[curveAnnotatedNewtonImage, _Line, ?], Length]]; Length[hLines]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In62.png "hLines = Reverse[ SortBy[First /@ Cases[curveAnnotatedNewtonImage, _Line, ?], Length]]; Length[hLines]")




![makeSegmentOrderManipulate[fCs, newtonOrderList = Last /@ {{1, 12}, {2, 100}, {3, 60}, {4, 24}, {5, 16}, {6, 16}, {7, 12}, {8, 8}, {9, 8}, {10, 10}, {11, 6}, {12, 6}, {13, 4}, {14, 8}, {15, 8}, {16, 4}}, 120]](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In67.png "makeSegmentOrderManipulate[fCs, newtonOrderList = Last /@ {{1, 12}, {2, 100}, {3, 60}, {4, 24}, {5, 16}, {6, 16}, {7, 12}, {8, 8}, {9, 8}, {10, 10}, {11, 6}, {12, 6}, {13, 4}, {14, 8}, {15, 8}, {16, 4}}, 120]")



![newtonCurve = Rationalize[singleParametrization[fCs, t, newtonOrderList] , 0.002]; Style[newtonCurve, 6] // TraditionalForm](http://blog.wolfram.com/data/uploads/2013/02/MakingCurves-In69.png "newtonCurve = Rationalize[singleParametrization[fCs, t, newtonOrderList] , 0.002]; Style[newtonCurve, 6] // TraditionalForm")




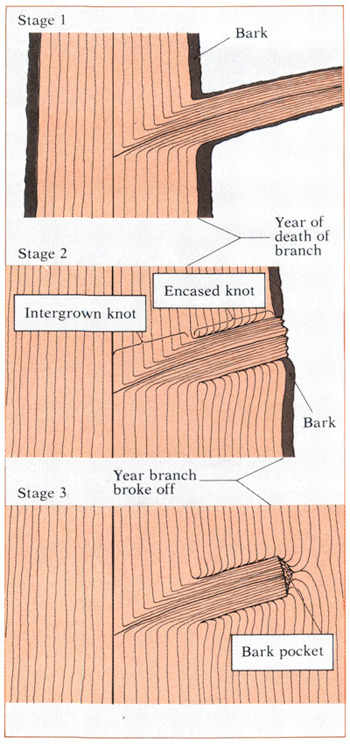




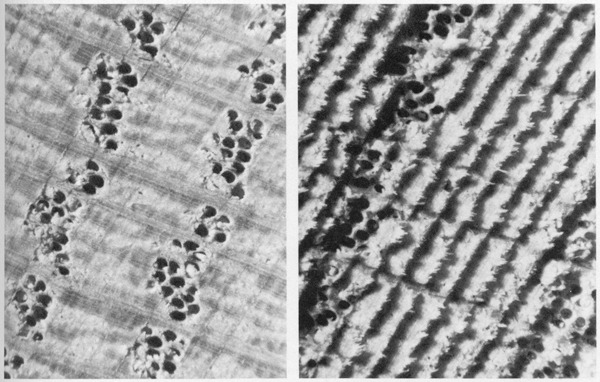


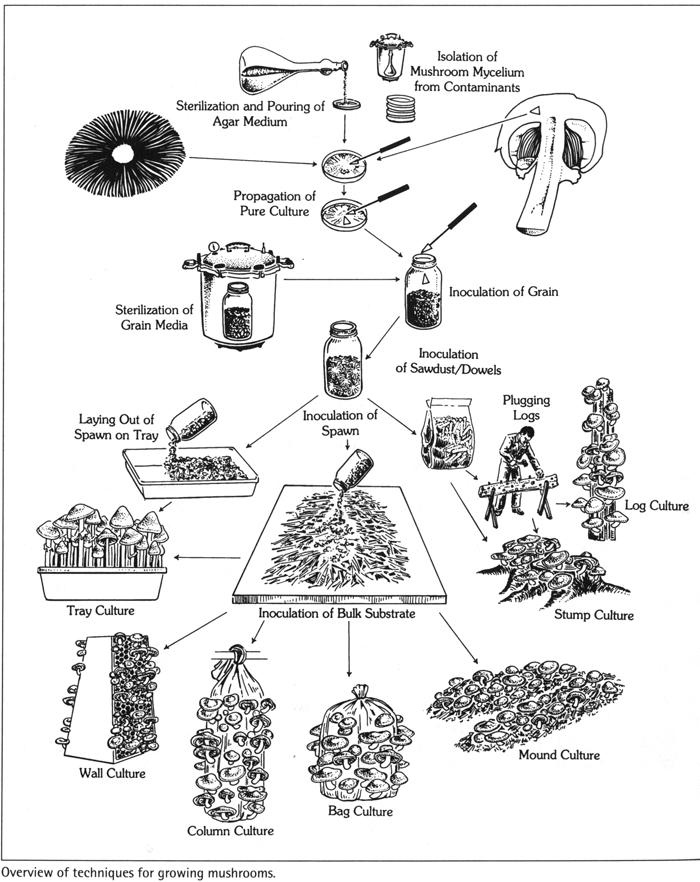









 You press the pedal at the base of Eduard Bersudsky’s sculpture Piper (2013). The shadow on the wall moves, the cogs begin to hum, the little bell rings, and the pair of gendered fauns flex their legs to activate the dog typist at the typewriter hammering out memos lost to history. Tip, tap, tippity-tap, its [...]
You press the pedal at the base of Eduard Bersudsky’s sculpture Piper (2013). The shadow on the wall moves, the cogs begin to hum, the little bell rings, and the pair of gendered fauns flex their legs to activate the dog typist at the typewriter hammering out memos lost to history. Tip, tap, tippity-tap, its [...]
