Datasette Desktop is a new macOS desktop application version of Datasette, an "open source multi-tool for exploring and publishing data" built on top of SQLite. I released the first version last week - I've just released version 0.2.0 (and a 0.2.1 bug fix) with a whole bunch of critical improvements.
You can see the release notes for 0.2.0 here, but as I've done with Datasette in the past I've decided to present an annotated version of those release notes providing further background on each of the new features.
The plugin directory
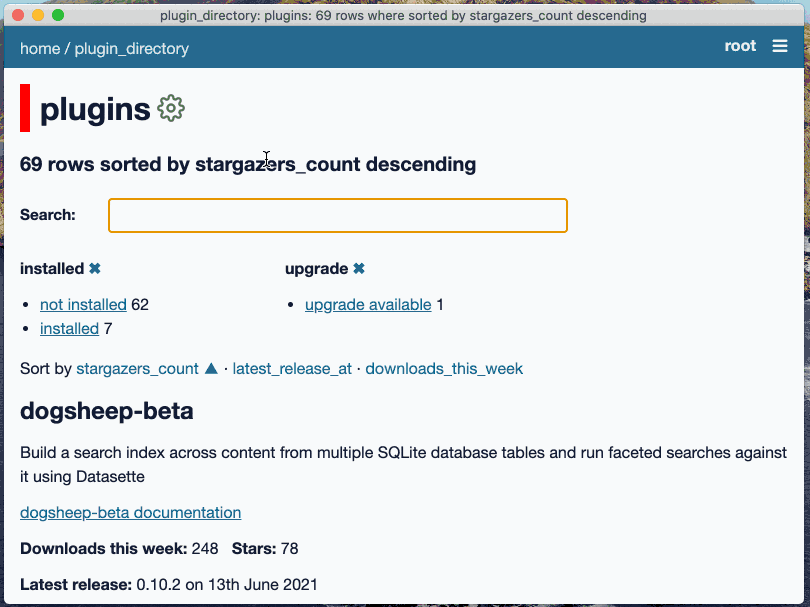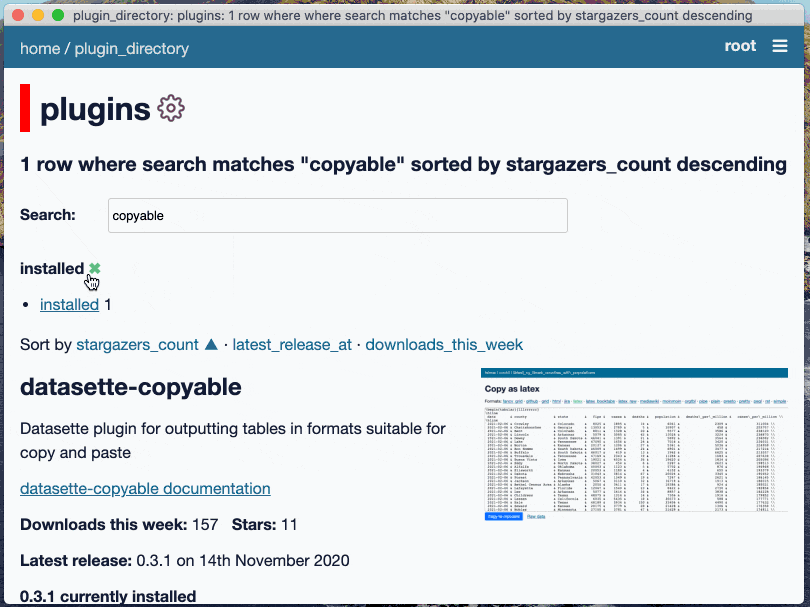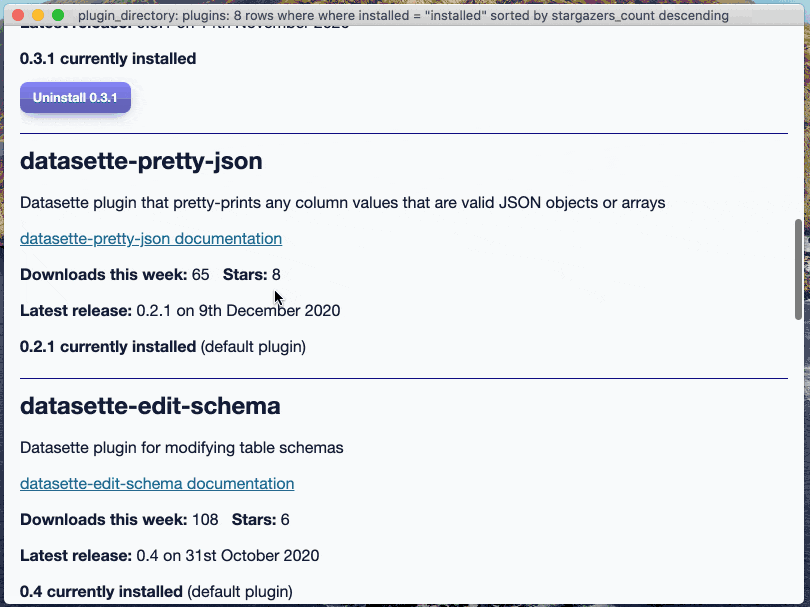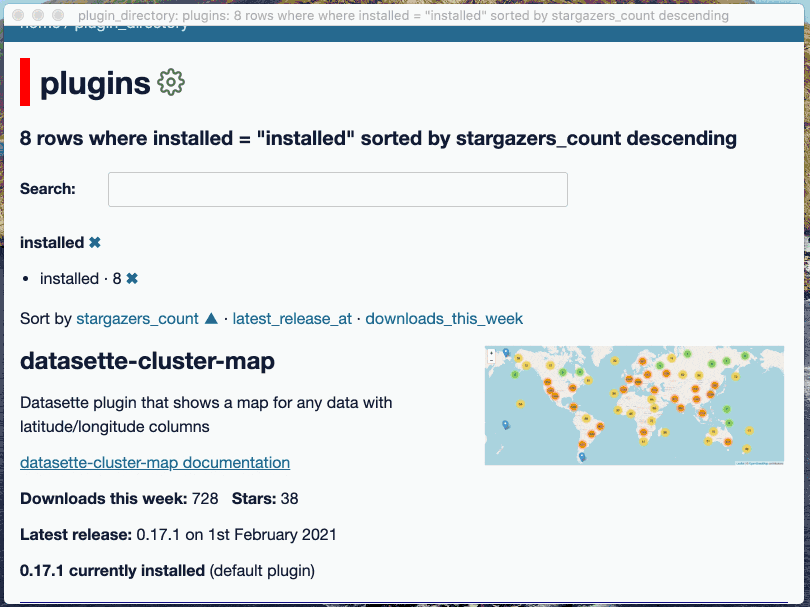
A new plugin directory for installing new plugins and upgrading or uninstalling existing ones. Open it using the "Plugins -> Install and Manage Plugins..." menu item. #74
This was the main focus for the release. Plugins are a key component of both Datasette and Datasette Desktop: my goal is for Datasette to provide a robust core for exploring databases, with a wide array of plugins that support any additional kind of visualization, exploration or data manipulation capability that a user might want.
Datasette Desktop goes as far as bundling an entire standalone Python installation just to ensure that plugins will work correctly, and invisibly sets up a dedicated Python virtual environment for plugins to install into when you first run the application.
The first version of the app allowed users to install plugins by pasting their name into a text input field. Version 0.2.0 is a whole lot more sophisticated: the single input field has been replaced by a full plugin directory interface that shows installed v.s. available plugins and provides "Install", "Upgrade" and "Uninstall" buttons depending on the state of the plugin.
When I set out to build this I knew I wanted to hit this JSON API on datasette.io to fetch the list of plugins, and I knew I wanted a simple searchable index page. The I realized I also wanted faceted search, so I could filter for installed vs not-yet-installed plugins.
Datasette's built-in table interface already implements faceted search! So I decided to use that, with some custom templates to add the install buttons and display the plugins in a more suitable format.
The first challenge was getting the latest list of plugins into my Datasette instance. I built this into the datasette-app-support plugin using the startup() plugin hook - every time the server starts up it hits that API and populates an in-memory table with the returned data.
The data from the API is then extended with four extra columns:
-
"installed" is set to "installed" or "not installed" depending on whether the plugin has already been installed by the user
-
"Installed_version" is the currently installed version of the plugin
-
"upgrade" is the string "upgrade available" or None - allowing the user to filter for just plugins that can be upgraded
-
"default" is set to 1 if the plugin is a default plugin that came with Datasette
The data needed to build the plugin table is gathered by these three lines of code:
plugins = httpx.get(
"https://datasette.io/content/plugins.json?_shape=array"
).json()
# Annotate with list of installed plugins
installed_plugins = {
plugin["name"]: plugin["version"]
for plugin in (await datasette.client.get("/-/plugins.json")).json()
}
default_plugins = (os.environ.get("DATASETTE_DEFAULT_PLUGINS") or "").split()
The first line fetches the full list of known plugins from the Datasette plugin directory
The second makes an internal API call to the Datasette /-/plugins.json endpoint using the datasette.client mechanism to discover what plugins are currently installed and their versions.
The third line loads a space-separated list of default plugins from the DATASETTE_DEFAULT_PLUGINS environment variable.
That last one deserves further explanation. Datasette Desktop now ships with some default plugins, and the point of truth for what those are lives in the Electron app codebase - because that's where the code responsible for installing them is.
Five plugins are now installed by default: datasette-vega, datasette-cluster-map, datasette-pretty-json, datasette-edit-schema and datasette-configure-fts. #81
The plugin directory needs to know what these defaults are so it can avoid showing the "uninstall" button for those plugins. Uninstalling them currently makes no sense because Datasette Desktop installs any missing dependencies when the app starts, which would instantly undo the user's uninstall action decision.
An environment variable felt like the most straight-forward way to expose that list of default plugins to the underlying Datasette server!
I plan to make default plugins uninstallable in the future but doing so require a mechanism for persisting user preference state which I haven't built yet (see issue #101).
A log on the loading screen
The application loading screen now shows a log of what is going on. #70
The first time you launch the Datasette Desktop application it creates a virtual environment and installs datasette, datasette-app-support and the five default plugins (plus their dependencies) into that environment.

This can take quite a few seconds, during which the original app would show an indeterminate loading indicator.
Personally I hate loading indicators which don't show the difference between something that's working and something that's eternally hung. Since I can't estimate how long it will take, I decided to pipe the log of what the pip install command is doing to the loading screen itself.
For most users this will be meaningless, but hopefully will help communicate "I'm installing extra stuff that I need". Advanced users may find this useful though, especially for bug reporting if something goes wrong.
Under the hood I implemented this using a Node.js EventEmitter. I use the same trick to forward server log output to the "Debug -> Show Sever Log" interface.
Example CSV files
The welcome screen now invites you to try out the application by opening interesting example CSV files, taking advantage of the new "File -> Open CSV from URL..." feature. #91
Previously Datasette Desktop wouldn't do anything at all until you opened up a CSV or SQLite database, and I have a hunch that unlike me most people don't have good examples of those to hand at all times!
The new welcome screen offers example CSV files that can be opened directly from the internet. I implemented this using a new API at datasette.io/content/example_csvs (add .json for the JSON version) which is loaded by code running on that welcome page.
I have two examples at the moment, for the Squirrel Census and the London Fire Brigade's animal rescue data. I'll be adding more in the future.
The API itself is a great example of the Baked Data architectural pattern in action: the data itself is stored in this hand-edited YAML file, which is compiled to SQLite every time the site is deployed.
To get this feature working I added a new "Open CSV from URL" capability to the app, which is also available in the File menu. Under the hood this works by passing the provided URL to the new /-/open-csv-from-url API endpoint. The implementation of this was surprisingly fiddly as I wanted to consume the CSV file using an asynchronous HTTP client - I ended up using an adaption of some example code from the aiofile README.
Recently opened files and "Open with Datasette"
Recently opened .db and .csv files can now be accessed from the new "File -> Open Recent" menu. Thanks, Kapilan M! #54
This was the project's first external contribution! Kapilan M figured out a way to hook into the macOS "recent files" mechanism from Electron, and I expanded that to cover SQLite database in addition to CSV files.
When a recent file is selected, Electron fires the "open-file" event. This same event is fired when a file is opened using "Open With -> Datasette" or dragged onto the application's dock.
This meant I needed to tell the difference between a CSV or a SQLite database file, which I do by checking if the first 16 bytes of the file match the SQLite header of SQLite format 3\0.
.db and .csv files can now be opened in Datasette starting from the Finder using "Right Click -> Open With -> Datasette". #40
Registering Datasette as a file handler for .csv and .db was not at all obvious. It turned out to involve adding the following to the Electron app's package.json file:
"build": {
"appId": "io.datasette.app",
"mac": {
"category": "public.app-category.developer-tools",
"extendInfo": {
"CFBundleDocumentTypes": [
{
"CFBundleTypeExtensions": [
"csv",
"tsv",
"db"
],
"LSHandlerRank": "Alternate"
}
]
}The Debug Menu
A new Debug menu can be enabled using Datasette -> About Datasette -> Enable Debug Menu".
The debug menu existed previously in development mode, but with 0.2.0 I decided to expose it to end users. I didn't want to show it to people who weren't ready to see it, so you have to first enable it using a button on the about menu.
The most interesting option there is "Run Server Manually".
Most of the time when you are using the app there's a datasette Python server running under the hood, but it's entirely managed by the Node.js child_process module.
When developing the application (or associated plugins) it can be useful to manually run that server rather than having it managed by the app, so you can see more detailed error messages or even add the --pdb option to drop into a debugger should something go wrong.
To run that server, you need the Electron app to kill its own version... and you then need to know things like what port it was running on and which environment variables it was using.
Here's what you see when you click the "Run Server Manually" debug option:
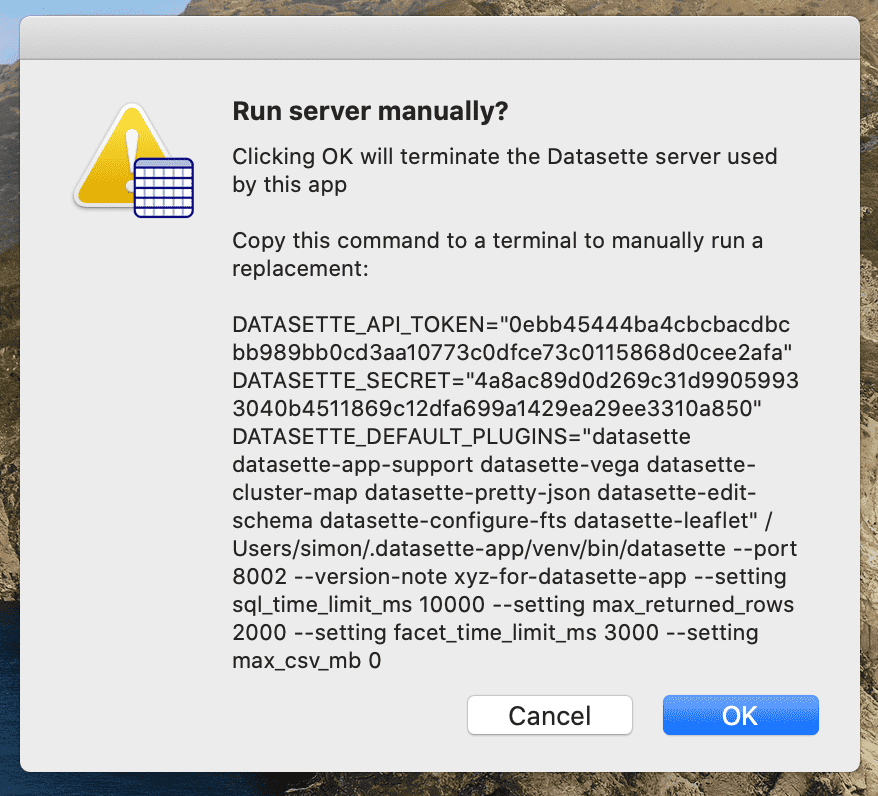
Here's that command in full:
DATASETTE_API_TOKEN="0ebb45444ba4cbcbacdbcbb989bb0cd3aa10773c0dfce73c0115868d0cee2afa" DATASETTE_SECRET="4a8ac89d0d269c31d99059933040b4511869c12dfa699a1429ea29ee3310a850" DATASETTE_DEFAULT_PLUGINS="datasette datasette-app-support datasette-vega datasette-cluster-map datasette-pretty-json datasette-edit-schema datasette-configure-fts datasette-leaflet" /Users/simon/.datasette-app/venv/bin/datasette --port 8002 --version-note xyz-for-datasette-app --setting sql_time_limit_ms 10000 --setting max_returned_rows 2000 --setting facet_time_limit_ms 3000 --setting max_csv_mb 0
This is a simulation of the command that the app itself used to launch the server. Pasting that into a terminal will produce an exact copy of the original process - and you can add --pdb or other options to further customize it.
Bonus: Restoring the in-memory database on restart
This didn't make it into the formal release notes, but it's a fun bug that I fixed in this release.
Datasette Desktop defaults to opening CSV files in an in-memory database. You can import them into an on-disk database too, but if you just want to start exploring CSV data in Datasette I decided an in-memory database would be a better starting point.
There's one problem with this: installing a plugin requires a Datasette server restart, and restarting the server clears the content of that in-memory database, causing any tables created from imported CSVs to disappear. This is confusing!
You can follow my progress on this in issue #42: If you open a CSV and then install a plugin the CSV table vanishes. I ended up solving it by adding code that dumps the "temporary" in-memory database to a file on disk before a server restart, restarts the server, then copies that disk backup into memory again.
This works using two custom API endpoints added to the datasette-app-support plugin:
-
POST /-/dump-temporary-to-file with {"path": "/path/to/backup.db"} dumps the contents of that in-memory temporary database to the specified file.
-
POST /-/restore-temporary-from-file with {"path": "/path/to/backup.db"} restors the content back again.
These APIs are called from the startOrRestart() method any time the server restarts, using a file path generated by Electron using the following:
backupPath = path.join(
app.getPath("temp"),
`backup-${crypto.randomBytes(8).toString("hex")}.db`
);The file is deleted once it has been restored.
After much experimentation, I ended up using the db.backup(other_connection) method that was added to Python's sqlite3 module in Python 3.7. Since Datasette Desktop bundles its own copy of Python 3.9 I don't have to worry about compatibility with older versions at all.
The rest is in the milestone
If you want even more detailed notes on what into the release, each new feature is included in the 0.2.0 milestone, accompanied by a detailed issue with screenshots (and even a few videos) plus links to the underlying commits.