Rolandt
Shared posts
Unpacking Trust in AI – Call for Participation
Installed Electric Drummer
Did what the title says, and installed Electric Drummer. Drummer is Dave Winer‘s new outliner tool, which I mentioned earlier. Dave blogs directly from his outliner, and his entire blog is a single outline. Electric Drummer is Drummer packaged in an Electron shell so I can run it locally on my Mac (as opposed to on a webserver provided by Dave).
This way I can play with the tool locally, to get a feel for how outlining in it works, how smooth it feels as a writing aid, and how it compares with my note taking in Obsidian (which isn’t an outliner but has outlining functionality). After all Obsidian is my core tool these days. I’d be interested to see if there are affordances in Drummer that I see myself immediately taking to, and whether those affordances exist or can be emulated in Obsidian.
One thing immediately stands out: if I import OPML files, like my book lists, that have additional data attributes, those attributes are shown in Drummer. And through the ‘suitcase’ icon I can see, edit and ammend the attribute list. The first time I see that in an outliner, which is extremely welcome functionality.
There Often Isn’t A Perfect Solution
I’m writing this in a London cafe on a cold day.
Each new customer opens the door and expects it to swing back closed behind them. But the door doesn’t do that. Instead, it stays open and the cafe starts to get cold.
At first, the staff shouted at customers to close the door behind them. But then their manager suggested shouting at customers before they’ve paid wasn’t the best strategy.
Instead, staff began to close the door behind each customer. But this wasn’t sustainable either. It took time away from serving customers and was clearly frustrating staff to do this every time a new customer enters (about every two minutes by my count).
So they wrote a sign and posted it on the door reminding customers to close the door behind them. But the sign was written in ink and was too small. Most customers ignored it.
Next, the staff wrote a bigger and clearer sign in bold marker and posted this on the door. This didn’t help either. There’s already five other notices on the door and window. Too many for any customer to bother reading any of them. They could remove the other signs, but that would upset management.
I’m struck by how often we’re faced with equivalent problems in a community.
We have a technology problem and there isn’t a perfect solution. We’re forced to choose between:
a) Simply allowing it to happen (i.e. allowing existing members to be disrupted).
b) Shouting at new members to behave the right way.
c) Politely trying to nudge members to do something (with little effect).
d) Posting really big signs (at the expense of other notices).
e) Doing a lot of extra work ourselves.
f) Paying (and waiting) for the technology to be fixed.
There’s no useful advice here – just a lesson that you’re not alone in these dilemmas. There’s no easy solution even to the most simple of problems. Sometimes you just have to figure out which is least painful.
The staff have settled upon the cafe getting cold.
The post There Often Isn’t A Perfect Solution first appeared on FeverBee.
My Mid-Life Crisis M1 MacBook Pro
Yes, I got myself an M1 MacBook Pro. A week or so before my birthday I decided to bite the bullet, take some of the money I’ve been putting aside and just order one, and it arrived a few days ago. This was actually around a week before the original estimate if my memory serves me correctly, so global logistics haven’t packed up yet.
Still, don’t leave your holiday shopping for the last minute, it’s getting really weird out there.
First Impressions
What I did the day I got it was pretty trivial–unpacked it, set up an admin account, set up my own account, waited 30 minutes for iCloud to do its thing while I went on a conference call, and then unplugged the Thunderbolt cable hooking up my 2016 MacBook to my LG ultra-wide and replaced it with the M1 Pro.
Remember when you used to plug in a machine to a monitor and they would both hem and haw and have this elaborate little dance flashing displays and moving windows about?
Well, this time that didn’t happen–everything I had open moved instantaneously to the big screen, and I pulled Remote Desktop off the App Store, set up my Bluetooth keyboard and trackpad, and carried on using it as the world’s (second) most expensive thin client without missing a beat.
It soon dawned on me that this thing is insanely fast.
Cosmetics
What notch? Seriously, I barely notice it (although to be fair I’m mostly using the machine with an external display, so I’m not staring at the internal one all the time).
But to be honest I’ve already tuned it out, although I did chuckle at the way the default wallpaper has a very dark band crossing the screen…

The round screen corners at the top are also unremarkable (the screen is gorgeous, so you’re not going to be gazing at the bezels) and I don’t mind the black keyboard backplate at all.
I suspect that Apple will go and do a white (or tinted) version for consumer laptops, and that it will actually look great.
Ergonomics
Although its primary use is on my desk, hooked up to my LG ultra-wide and with an external Bluetooth keyboard and trackpad, I am also using it around the house, so here are a few impressions of it as an actual laptop:
- The first thing I noticed (flat on a desk) was the increased thickness, which made it higher than I expected when I placed my hands on it. However, that extra thickness vanishes when using the machine as an actual laptop.
- The second thing was that the heel of my hand was not coming up against a razor sharp edge when resting my hand on the trackpad, which is a welcome change from the old models.
- To compensate, you do feel the sharp-ish edges of the side air intakes when picking up the machine, but that’s a minor thing (the back vents are a tad unsightly, though).
- Although I bought a PT keyboard layout, I’m using it as a US one, so I miss the long Return key I have on all my non-Apple keyboards (I have mostly switched to a US layout for the past couple of years).
This last bit is not Apple’s problem, but it likely means I will be getting a US Magic Keyboard for that extra TouchID goodness.
Either way, the built-in keyboard feels amazing when compared to my 2016 MacBook Pro.
What and Why
Which is a good segue into the specs I chose and why I chose them, because after years of having a Mac Mini and a somewhat flaky iMac on my desk (both running my trademark multi-monitor setups), moving to a laptop is a major plot twist.
Hardware Specs
Since I intend this machine to last me at least five years, I went for the full M1 Pro die (10 CPU cores, 16 GPU cores and 16 ML cores), 32GB of RAM and 1TB SSD, in a 14” form factor (because it is almost exactly the size of my 13” and I don’t really like laptops the size of canteen trays).
The full set of cores and RAM will ensure I can run whatever I need for a good while, but more Apple-priced storage would be eye-wateringly expensive (at well over the going rate for SATA SSDs, at least).
So I chose 1TB based on the fact that even with a few VMs, multiple tens of gigabytes of photos, audio samples and music stuff galore, I was hardly taking up over 300GB on any of my other machines, OS included.
Plus most of my hobbies seem to be on a holding pattern of sorts, so even if I started hammering out media content instead of writing there ought to be enough local storage for a good while.
If I already did any real amount of video work things would probably be different, but if that ever becomes an issue I can always rely on my NAS and scratch drives for editing.
So why a MacBook instead of a Mini?
In short, the things that made me get a MacBook sort of compounded over the years:
- I was (again) tired of waiting for a silent compact and powerful desktop machine that I had no idea when Apple would get around to launching, nor if it would do what I wanted when it did.
- I keep getting the impression that the Mini is an afterthought in the Mac product line, and I have a feeling it’s likely to ship with an M2 and sit somewhere between the M1 and the M1 Pro for another cycle.
- The experience of using my 2016 MacBook alongside my LG ultra-wide as a “temporary” desktop was actually much better than I expected (except for the slowness), and largely made up for having let that 2016 machine linger for a long time (I abhor waste, and often felt I wasn’t using the MacBook enough).
- That experience showed me I could survive with a single massively big display and contiguous real estate instead of a massive array of monitors (although I am using the laptop’s internal panel, and planning to have the option to add another display soon…).
- I now have less stuff plugged in than when I had the iMac. This is partly because I want a cleaner desk, and partly because my LG ultra-wide and a tiny 4-port USB3 hub provide me with enough connectivity for a Microsoft Gigabit Ethernet adapter, a Logitech Brio webcam and my Arturia KeyLab Essential 61, which is plenty of gear already.
- With my spending most of my waking hours working in my home office, personal projects and unwinding have started happening somewhere else. Unlike in the “before times”, I now have very little inclination to step into the office on weekends.
- Along that same line of thought, the Lenovo Ryzen laptop I got recently has pretty much become my go-to leisure machine since it is fast, long-lived and I can use it to zone out on the couch to write or code in the evenings and weekends.
So getting a new, insanely fast Mac I can bring out from the office, use throughout an entire weekend on a single charge1 and then hook back up through a single Thunderbolt cable seemed… almost perfect, really2.
And yes, the irony of wanting a laptop and favoring mobility after nearly two years of being stuck at home isn’t lost on me, but I suppose the bottom line is that I needed a change.
Setting Up
Given that I am switching hardware architectures and I have relentlessly simplified my setup over the years to deviate the least possible amount from the defaults, I decided not to use Migration Assistant and set up everything from scratch so as not to fill my machine with legacy crap.
So everything that was migrated across came either via iCloud (contacts, calendar, keychain, etc.) or later via SyncThing and OneDrive.
Baptism
Naming things is hard, but even in this era of “cattle vs pets” and cloud computing, I still like naming personal machines.
In particular, I’ve long had a sci-fi theme going with my desktops–my iMac was (ironically) called serenity, my hackintosh (and now KVM host) is named rogueone, and since I’ve been watching The Expanse for six years now, the last season is soon upon us and I do have the occasional feeling of tilting at windmills, there was really only one name I found appropriate for a new trusty steed:

Changing system volume names (and icons) is an old tradition that harks back to the original Mac OS 6 days and that gave quite a bit of character to our machines, and I missed that.
Macintosh HD and Rui's MacBook Pro are, well, just not fun at all.
The effort that went into that icon may seem meaningless these days since the Finder now defaults to not displaying internal volume icons on the desktop, but I know the icon is there, and in the end, that is what really matters.
Plus whenever an installer asks me where to put things in the future I’m going to be reminded of why I named the drive that way, and it’ll bring a splash of color to my day.
A Minor Note on Apple’s Software QA
The very first app I opened after setting up Remote Desktop was Contacts. And yes, in 2021, Apple’s Contacts app still beachballs when you try to edit an iCloud contact, even on an M1 Pro.
As many people have put it far less kindly, Apple doesn’t have a Pro hardware problem anymore – but they still have some major consumer software QA problems, and Contacts is still my go-to canary for whether they finally fixed a macOS release.
…and Another
Also, I would really like to know why AvatarPickerMemojiPicker is running constantly, with a dedicated instance of avatarsd for each user:
HDR support
One of the improvements I got from upgrading is that the M1 Pro suports DisplayPort 1.4 properly, whereas my 2016 Pro only worked correctly with the monitor configured for 1.2.
While setting it up, I noticed that my LG ultra-wide preferences now featured an HDR checkbox, which I temporarily toggled on for the sake of science:

This immediately turned my desktop into a dim grayish landscape because the macOS UI doesn’t take advantage of HDR–so the way to manage HDR displays seems to be to dim everything but HDR-enabled content so that it can use your monitor’s “extended” color range.
I had read about this before and need to figure out if there is any sort of workaround, but it’s not a priority–and yet again, I think Apple has some software quirks to iron out here.
Software Compatibility
Like I pointed out, I set up my account as a non-admin user (my ancient HOWTO is still mostly valid), and went through the App Store to grab my core set of apps (1Blocker, Office, OneDrive, Secrets, etc.) and then set up a few notable extras manually:
-
brewforpyenv,vimand the usual rigmarole of development tools and runtimes. So far all the “bottles” I’ve come across arearm64, except thedotnetone (which is still the outdated 5.0 version andx64, so I ended up downloading and installing the new 6.0 LTS manually). - Phoenix, which I use for window management and tiling (because it’s fully scriptable and I coded some SnapAssist-like keyboard behaviors).
- Parallels Desktop to have a local Docker VM (more on that later).
- MonitorControl, which now works great with my LG ultra-wide and affords me brightness and volume control using the standard hot keys.
- SyncThing, which brought along with it all my “dotfiles” and terminal settings.
- Blender, which serendipitously was updated to 3.0 this week and has an M1 build that just flies when editing large meshes.
- Godot and Unity 3D, both of which also have M1 builds.
- Bitwig, DecentSampler and all my Arturia VSTs and filter effects, the latter of which were also recently updated with M1 support.
Intel Stragglers
As is to be expected, there are still a few apps that are not built for Apple Silicon and that I have to run in Rosetta. The biggest and most impactful one is OneDrive, but it’s been publicly announced a native version is in the works, so that’s sort of OK… I guess?
Either way, it has been very fast on this machine (especially when compared to my old MacBook) and has not yet exhibited its usual CPU hogging behavior.
There are other things I would have really liked to have gotten native versions for, though:
- Microsoft Teams still only has an Intel build, but you can work around that by using Edge and running it as a PWA (which works fine but has no camera effects, so no background blurring for you).
- OBS, sadly, still doesn’t have an official native M1 build (you can build it yourself, but it will lack the built-in browser and hence none of my overlays work). I haven’t gone that way yet since the Intel version is very responsive (unlike Teams).
- Barrier, which I use to control my work laptop (it has a place on my regular desk beside my Mac), is also not yet Universal.
- ImageOptim, alas, which I use for optimizing and posting most of my images here, is also not ported to Apple Silicon yet, and I would have loved to see it crunch images natively.
- OpenSCAD and Ultimaker Cura (which I dabble with routinely and was designing a new case with) also do not have native builds, although they seem snappy enough for casual use.
- Native Instruments support for Apple Silicon also seems to be missing.
This last one is really weird considering their market clout and the amount of people out there who are running Kontakt…
Running Windows
A lot of people seem to be worried about this, and yet Parallels Desktop 17 just went and installed Windows for ARM in… less time than on actual physical Intel hardware, which was extremely impressive.
I haven’t used it extensively since I pretty much live inside Remote Desktop (and read all my corporate e-mail via Edge), but what little I could test comparatively (like a heavy browser session accessing my work e-mail and previewing documents) felt much faster on this machine than on my Surface Book 3, which is… interesting.

Although I’m curious as to the performance of Windows’ own Intel emulator, I did not install any Intel applications on it since I have plans to use it to give an arm64 build of Office 365 a spin first–it’s already been out there for Surface X users for a good while.
But the main point is that it works seamlessly–in fact, perhaps too seamlessly given the overall experience of using Windows in Parallels is still the same: you will either love or hate Coherence mode and having a mix of both Mac and Windows applications on the same display.
In my case, I always end up turning off Coherence because it’s tied to application integration, and I want to avoid launching the VM by accident (invoking the wrong version of Microsoft Edge from Spotlight and starting the VM by accident gets old really fast, even if it only takes two seconds to boot).
The notable thing is that a 4-core VM takes up less than 5% idle CPU on this machine, so I suspect most people will be delighted with having it as an alternative.
So yes, Windows on arm64 works fine in Parallels. But since I have dedicated Windows machines for work, running it on my Mac is more of a curiosity than an actual tool right now.
However, I expect to use it for unearthing more digital archives soon.
Docker, The Whale In The Developer Echo Chamber
A lot of people are worried about using Docker on these machines, though, either because they need to run Intel containers or because they lack the time or initiative to build their own arm64 versions.
Since I’m quite used to running cross-platform Docker builds remotely for ages now (either in the cloud or against a local VM, but always via ssh or VS Code instead of using the abomination that is Docker Desktop), there is zero impact on my workflow–I plan to just keep doing the same thing and avoiding Docker Desktop altogether.
However, in case I do need to run Intel containers locally, I’ve already tried a few things:
- I installed Docker inside an Parallels VM running Ubuntu LTS
arm64(20.04) and got that to run Intel containers by simply typingsudo apt install qemu-user-static(which is pretty much what Docker Desktop uses to run Intel containers as well). - I set up a pokey, but usable
amd64Ubuntu VM inside UTM, and came to the conclusion that on this machine it’s not much slower than the little Celeron box I routinely use for testing (although emulating the full kernel quickly adds to the slowness, so it was just a curio). - I checked Multipass again (which I used in the past), and it is evolving to where it will be a likely solution for running both
amd64andarm64binaries. But I will only try that when #1437 is fixed. The bonus there is that you havecloud-initsupport (and nice toys likemicrok8s) out of the box and based on a Linux distribution that has some of the bestarm64support out there, so it’s worth checking back. - And, finally, prompted by Carlos, I tried
podman, which is available onbrewand can be made to runamd64containers like this:
podman machine ssh
sudo -i
rpm-ostree install qemu-user-static
systemctl reboot
Either way, I see zero issues with doing container development on an M1 if you know what you’re doing, because:
- Unless you’re doing very specific stuff (like hardware-dependent ML work or the ever-dwindling set of things that are just not available for
arm64), you will easily find equivalent base images or build your own very quickly. Hard if you’re a newbie, mildly annoying if you’re experienced, will likely stop being a problem within a year or so. - You can always resort to emulation, another machine or both. Probably easiest for a newbie.
- None of the containers you build yourself should be going into production – i.e., you should have a CI/CD system doing reproducible builds, and you can have that generate images for whatever architecture you need before deploying.
Which is what anyone delivering production code should be doing anyway.
Of course, some teams will probably need to lay out guidelines for base image use and/or build cross-platform base base images (which is probably what you should be doing anyway if you want to have full control over your dev stack), but most savvy developers will just fix it once and move on.
I do expect a lot of people who just want do download random container images from the Internet and run them to keep complaining, though, because things like docker-compose and Kubernetes have given birth to a culture where people expect to deploy highly complex solutions by just invoking a YAML file without understanding what it actually does or how the components are built.
But I digress–let’s have some fun.
Gaming
I will eventually have a go at getting Xbox Game Streaming or Steam over NVIDIA running on this (both should just work), but right now the only thing I’ve tried is Quake III Arena, since ioquake3 recently came out with revamped Universal builds and playing it with a high-res texture pack at 5120x2160 and 120fps was… too tempting:

ioquake3 in half the size (I had to shrink down the image to 2048 pixels wide for your sake, dear reader).As usual, this took a little bit of fiddling with q3config.cfg:
seta com_maxfps "1024"
seta cg_drawFPS "1"
seta r_mode "-1"
seta r_customheight "2160"
seta r_customwidth "5120"
seta cg_fov 100
…and yes, I was trying to see if it would go past 120 fps, but I suspect that is an engine cap. Still, the new Universal builds seem to be delightfully modern:

I might have a serious go at getting Quake Champions running locally, but I would have to use Crossover or Parallels and it runs just fine on my Lenovo, so I don’t see the point right now.
But I will be checking out what other classics I can run (I wish there was an Apple Silicon build of Homeworld Remastered, for instance).
Things I Miss
A touchscreen.
Seriously, using my Lenovo with either Linux or Windows 11 has made me enjoy the affordance of dismissing and arranging windows with a few quick taps. (I’m also missing Windows 11 SnapAssist mouse-driven layouts to tile windows, but that’s not a hardware thing).
Touchscreens are the future, Apple just hasn’t read its own memo.
Other than that, nothing else on my recent list is relevant, although I could extrapolate that I would like to have Face ID and Center Stage on this machine (which I fully understand the bezel can’t accomodate).
In practice, though, I’m so used to Touch ID that I hardly ever think about how effective the Windows Hello face recognition feature is on my Surface. They’re just different, and I’ve come to terms with it.
Surprisingly, I also miss the Touch Bar a bit–not just for text suggestions, but also for dismissing dialog prompts quickly (which, again, a touchscreen would be great for).
But I much prefer the “normal” full-height function keys and having a full-sized Esc key back on my laptop again, even if I had to spend an eye-watering amount of money to get the insanely fast computer it comes attached to.
Update: Bootstrapping pyenv
Quick note if, like me, you have your CFLAGS and LDFLAGS set since the dawn of time and were having trouble installing custom Python runtimes: Remove all of those and install pyenv from git (the brew version is fine, but there are some newer tweaks that are handy).
Then install these:
brew install openssl readline sqlite3 xz
…and if you need Python 3.8.6 (like I do, although I’m moving straight to 3.10.0), you’ll need this patch:
CFLAGS="-I$(xcrun --show-sdk-path)/usr/include" \
pyenv install --patch 3.8.6 <<(curl -sSL https://raw.githubusercontent.com/Homebrew/formula-patches/113aa84/python/3.8.3.patch\?full_index\=1)
Update: Recent Posts & Themes
(This article was initally posted on my LinkedIn newsletter. If you are not already signed up, please subscribe here)
I have a couple of other deep-dive themes cued up for articles in coming weeks, but I wanted to put out a quick newsletter update covering a few recent themes, posts and events that have been occupying me.

The last month has featured a lot of thinking, speaking & client engagements on private 5G, infrastructure-sharing and neutral-host business models, network slicing and capability/API exposure, Wi-Fi 6E & 6GHz, Open RAN and the interaction of cellular & other wireless technologies.
Some recent short-form posts that you may have missed:
- Telecom operators (and their partners & regulators) should be giving as much consideration to *buying* APIs and capabilities as selling them - LINK
- Thoughts on the Ericsson / Vonage acquisition - LINK
- Should we be thinking more about "micro-churn" incidents, where subscribers temporarily switch between operators, using technologies such as eSIM? - LINK
- Want me to speak at, or moderate your 2022 event? Or present at an internal workshop or offsite? - LINK
- RCS messaging is still a purposeless zombie technology, continuing to eat brains after 13 years. Google's involvement hasn't changed much - LINK
- The telecoms industry still hasn't gone beyond telephony, to think more broadly about "voice" services & applications - LINK
I've been to a couple of recent "verticals" events, about networking in ports and for railways. There's a lot of interest in private cellular - but also a huge amount of emphasis on Wi-Fi, including specialised versions with 60GHz or unique forms of QoS intended for industrial or trackside use.
I also presented on a webinar recently on behalf of iBwave, about the scope for Private 4G/5G networks for utilities and energy companies (LINK to view on-demand). Watch out for an upcoming eBook on the same topic. Another webinar on the competiton/convergence between Wi-Fi6 and 5G was for Spirent (LINK)
Scott and Iain at Telecoms.com invited me onto their weekly podcast for a (rather irreverent) chat about the current trends and news from the industry, over a couple of beers. We took aim at 5G, the Metaverse, Open RAN & a lot more. YouTube link embedded above!
In addition, I moderated a panel on Infrastructure Sharing for the 5G Techritory event. I'm not sure if an archived version will be put online, but keep a watch out for it here.
And on a personal note, I also took part in my first improv comedy performance. If you book me to speak at one of your events, I can't promise to wear the same shirt as in the picture, but I will certainly be happy to make things up on the spot spontaneously, or deal with any hecklers ruthlessly!
#5G #WiFi #verticals #PrivateLTE #Private5G #mobile #telecoms #spectrum #voice #messaging #networkslicing #neutralhost #regulation
Remembering Kim Cameron

Got word yesterday that Kim Cameron had passed.
Hit me hard. Kim was a loving and loved friend. He was also a brilliant and influential thinker and technologist.
That’s Kim, above, speaking at the 2018 EIC conference in Germany. His topics were The Laws of Identity on the Blockchain and Informational Self-Determination in a Post Facebook/Cambridge Analytica Era (in the Ownership of Data track).
The laws were seven:
- User control and consent
- Minimum disclosure for a constrained use
- Justifiable parties
- Directed identity (meaning pairwise, known only to the person and the other party)
- Pluralism of operators
- Human integration
- Consistent experience across contexts
He wrote these in 2004, when he was still early in his tenure as Microsoft’s chief architect for identity (one of several similar titles he held at the company). Perhaps more than anyone at Microsoft—or at any big company—Kim pushed constantly toward openness, inclusivity, compatibility, cooperation, and the need for individual agency and scale. His laws, and other contributions to tech, are still only beginning to have full influence. Kim was way ahead of his time, and its a terrible shame that his own is up. He died of cancer on November 30.
But Kim was so much more—and other—than his work. He was a great musician, teacher (in French and English), thinker, epicure, traveler, father, husband, and friend. As a companion, he was always fun, as well as curious, passionate, caring, gracious. Pick a flattering adjective and it likely applies.
I am reminded of what a friend said of Amos Tversky, another genius of seemingly boundless vitality who died too soon: “Death is unrepresentative of him.”
That’s one reason it’s hard to think of Kim in the past tense, and why I resisted the urge to update Kim’s Wikipedia page earlier today. (Somebody has done that now, I see.)
We all get our closing parentheses. I’ve gone longer without closing mine than Kim did before closing his. That also makes me sad, not that I’m in a hurry. Being old means knowing you’re in the exit line, but okay with others cutting in. I just wish this time it wasn’t Kim.
Britt Blaser says life is like a loaf of bread. It’s one loaf no matter how many slices are in it. Some people get a few slices, others many. For the sake of us all, I wish Kim had more.
Here is an album of photos of Kim, going back to 2005 at Esther Dyson’s PC Forum, where we had the first gathering of what would become the Internet Identity Workshop, the 34th of which is coming up next Spring. As with many other things in the world, it wouldn’t be the same—or here at all—without Kim.
Bonus links:
- Kim’s official obituary
- Rest in Peace, Kim Cameron, by Joerg Resch
- Remembering Kim Cameron, by Phil Windley
- Remembering a Human, Being, by Britt Blaser
- Cannibal Lobsters and Stolen Fingerprints – remembering Kim Cameron, by Mary Branscombe
- Stories of Kim Cameron, by Mike Jones
800-818 Hawks Avenue

These modest rental townhomes, seen here in 1985, show how Strathcona has been a home to dense but ground-oriented housing for over a century. Built in 1907, there are nine homes on a 50 foot by 120 foot lot. There are nine more in an identical building to the north, across the lane, but these days those are a privately owned strata.
Both buildings were developed by Charles Hendrix, apparently an absentee developer. He obtained three permits in 1907; these buildings were a $5,000 frame tenement, 818 Hawks to the south was a $7,000 tenement, and there was a $4,000 house on Prior as well. On the water permit the clerk threw consonants at his name, and put ‘Henydrekx’. Nobody with the name Charles Hendrix (or Hendricks, or Heyndricks) was resident in the city. The only Charles Hendrix listed in Canada in the 1901 census was aged 21 and a miner in the Cariboo, born in Sweden in 1880, and arriving in Canada in 1900. It seems likely that he’s our developer, and that when he built these apartments he was 27.
We couldn’t find any cross-reference for him living anywhere in the Province in subsequent years (and being a miner, that wasn’t too surprising). Then we came across a news story that seemed to suggest that in 1908 he had a different intention for having 18 front doors to small homes on the same short stretch of street. Charles Hendricks appeared before Magistrate Williams, and was given a six month sentence.
In the early years of the 20th century the city authorities had been struggling with the location of the city’s red light district. Having closed down the madams on Dupont Street (East Pender) in the early 1900s, the women dispersed throughout the city. As we noted in an earlier post, in 1906 the Daily World reported that some of the women were moving to rooms in Shanghai Alley and Canton Alley in Chinatown. By the end of the year police were raiding and arresting the ladies. In 1907 another raid was referenced in the Daily World, and the article suggested that 25 women were living in the alley. Belle Walker was fined $50 three days later, with a note adding “the police seem determined to put a stop to other than Chinese women living in the Chinese quarter”. According to Detective Jackson, by 1908 ‘Charles Heyndricks’ was the owner of 21 ‘houses of ill-fame’ there. Evidence was produced in court that his Chinatown units produced rents of $400 a week to him, and his companion Alice deBelda, ‘who was known as Mrs. Heyndricks’, (although Charles confirmed they weren’t married, but did live together).
As owner of the Chinatown units, Charles Hendricks was willing to help move his tenants out of the area. While he apparently initially leased some units of his newly developed property on Hawks to the predictable tenants; loggers, port workers, a very short time later, as the Times Colonist in Victoria reported “Hendricks tried to start a new restricted section in the centre of the east end residential district, and told women, formerly of Shanghai and Canton streets, that he had squared everything with the Mayor and chief of police for opening a new immoral quarter. He turned out regular tenants and trebled the rents to fast women.” The court case said that the initial rents were $16 to $18 a month, but the women were paying $45 a month.
He was described in the press as owning $100,000 worth of property In Vancouver, and was sentenced to six months’ hard labor, without the option of a fine, for ‘renting buildings to women of ill fame’. The Daily World news coverage confirmed that these were the properties in question.
The two women arrested in the raids were given suspended sentences provided they agreed to leave the city. We don’t know what happened to ‘Violet White’, from 802 Hawks, but Gussie Roberts from 804 apparently headed north. She was picked up in a raid on a house of ill repute in Prince Rupert in 1916, and skipped bail there.
Hendricks was initially locked up, and The province newspaper reported that “he did not take kindly to working on the chaingang when he was ordered out this afternoon. He was ordered to remove his heavy coat and start breaking rock, but absolutely declined to make any move in that direction. Consequently he was ordered into the station again and this afternoon is confined in a dark cell“.
He was allowed to appeal, and was released with appropriate financial guarantees, but a month later he failed to appear for trial, having sold his property. He forfeited a $500 cash surety, but having new owners, the additional liens on the properties were no longer applicable. Alice deBelda was allowed to leave the court as the case against her of keeping a house of ill repute wasn’t strong enough to convict. She may have advised him that it was a sensible move to skip bail; the US Treasury Records for 1904 showed a positive cash flow of $2,000, ‘From cash bail exacted of Alice Debelda’ – and the sum remained on the books until at least 1910.
It’s possible that it was the same Charles Hendricks who was made superintendent of the Bunker Hill Mining and Smelting Co plant in Reiter (Snohomish), Washington, three years later (in 1911).
In 1913 the Lincoln Steamship Co’s coastal steamer ‘Ophir’ caught fire, and was burned to destruction. She had sailed from Vancouver with a cargo of tinplate for a cannery and some passengers, and tied up at the Brunswick Cannery, Canoe Pass, near Ladner, In the Fraser River. It was too late to unload, so the 11-man crew went to bed. Around 3.30am fire broke out (caused, it was suggested, by a crewman’s discarded cigarette or cigar butt). Five of the crew, including Capt. Johannsen, the chief engineer, the mate, the cook and one deckhand, slept in the forepart of the boat. They escaped because the mate was woken by the smoke, but the other six died – the ship was cut adrift to burn, to save the cannery wharf from catching fire. Four were immediately identified, but two had signed on in Vancouver, and weren’t named. One was later identified as ‘Charles Hendricks’. Whether he was our developer is unclear, although there’s no sign of him from this point on.
The new owners of the houses leased them to a typical Vancouver mix; in 1909 a lineman, a quarryman, a carpenter, a mill hand,. a labourer, a teamster and an engineer. Twenty years later three of the houses were rented by women; Mrs. Dominca Bianci, a widow, with her two children Elio, a labourer and Joseph, a labourer with the CPR, Mrs. Mary Burke, a widow (with Henry Burke, a scissors grinder; probably her son) and Mrs. Mabel Powell.
In 1949 the tenants here were Nichola Novis and his wife, Alice, Mrs Caroline Charlebois, a widow, Robert Brunelle, a truck driver, and his wife Lena, James Pereneseff, driver with Richmond Transfer, and his wife, Annie, Edmund Pfister, a labourer and his wife, Bertha, John Shukin, a carpenter and his wife, Mabel, Mrs. Mary Smart, a cleaner, James Sobbotin, a labourer with BC Forest Products and his wife, Nadie, and closest to us Joan Chemlyk, a telephone operator with John (an insurance agent) and his wife Anna, and Roger Chemlyk, a clerk.
Image source City of Vancouver Archives CVA 790-0680
1134
Impressed With Excalidraw Obsidian Integration
Last week at the 3rd Dutch language Obsidian meet-up one of the participants showed Excalidraw. This is a browser based sketching tool, that was created early last year (so about as old as Obsidian itself). There is an Obsidian plugin for it, which I first assumed would allow you to embed images made in the browser tool, but I was wrong.
- The plugin allows you to create sketches with Excalidraw inside Obsidian. Using command+P and typing create, you can select to create a sketch in various ways
- The sketching is done inside an Obsidian pane
- You can link text in a sketch to any other note simply by adding a markdown style link [[note name]]
- You can even embed another note in the sketch by adding the markdown, using ![[note name]]
The files with the sketches are saved inside your Obsidian vault. I took a look in one of the files, and they are JSON descriptions of the sketches. They’re not images, they’re text descriptions and as such small flat text files just like the notes themselves.
I’m impressed. I could even see myself sketchnoting on a tablet right in Obsidian with this.

Exalidraw living inside an Obsidian note, through a plugin. I made a basic sketch, with a link to a note at the red pin.
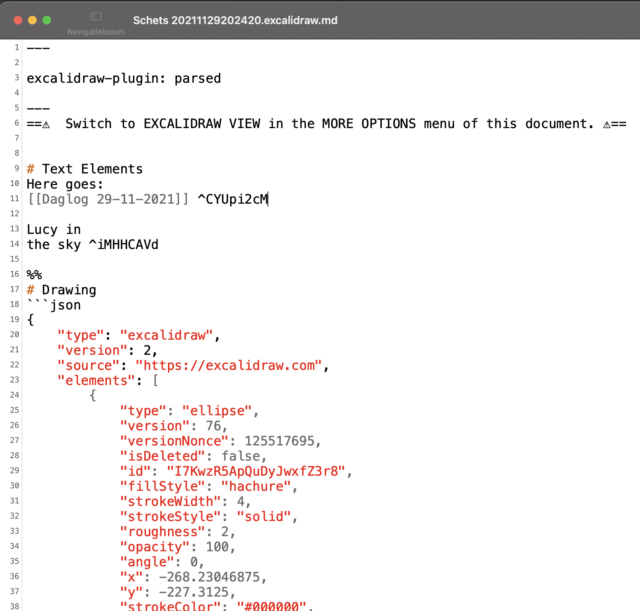
Opening a sketch in a text editor shows it to be JSON
Houdini Is Not as Scary as You Think
The image that accompanies this article was created entirely from HTML and CSS - no Javascript, no SVG, and no image files. It's thanks to a set of new CSS APIs called Houdini. They "extend CSS by hooking into the styling and layout process of a browser’s rendering engine." The Paint Worklet, for example, "enables developers to define canvas-like custom painting functions that can be used directly in CSS as backgrounds, borders, masks, and more." It's introduced in this article by George Francis on CSS-Tricks, and discussed in more detail here by Robin Rendle.
Web: [Direct Link] [This Post]Review Essay: Interpretation versus Cultural Analytics
Towards a research community for better thinking tools
As I’m thinking about defining more narrow focuses for my independent work next year, one area has stood out consistently as both personally exciting and more widely important: imagining and building better ways computers can help people do their best creative, thoughtful work, and in the process rethinking the relationship creative people have with the computer as a part of their work.
My projects and this blog have never had a clearly defined focus, but a big part of my project portfolio is tools I’ve built to help myself manage the information that flow through my life and work. This theme has emerged slowly but definitively in the last year with projects like personal search engines and a custom Twitter client. This year, two things have happened in my life to help me realize this is a field in need of more independent, dedicated, inventive research efforts.
First, there is an increasing availability of capital flowing into companies building on new ideas in this space. Startups like Coda, Remnote, Mem, and Notion are raising millions of dollars on first investment rounds, and they’re coaxing even the very large tech companies to invest seriously into more competitive tools for thinking and creating together. There has always been a die-hard group of thinkers who argued that the “computer revolution isn’t here yet” and that the best software creative tools were yet to come, but the new influx of capital validates financial interest and demand for tools that break new ground in a way that hasn’t been true in many years.
Second, I’ve personally invested more seriously in designing and building more ambitious projects, like a universal personal search engine and a web browser focused on knowledge work. In response, I’ve spoken with many other brilliant and creative people working on similar projects, both independently and as a part of early stage companies. These conversations have reiterated in my mind how much I enjoy working at this layer of tool building, designing the basic metaphors and building blocks out of which the rest of the world runs businesses, shares new ideas, and creates art.
As I reflect on these realizations, I’ve been wanting to invest more time and effort specifically into building these kinds of tools, and conducting more exploratory, open-ended research that can fuel new creative ideas about how to build better thinking tools. This also spurred some interesting conversations I’ve had with other folks in the field about what an ideal research community could look like. What kinds of people and companies would push the ecosystem in the right ways? How might these researchers and companies communicate new ideas with each other in a way that results in open, lasting progress?
What follows is a loosely structured collection of different building blocks from which I think we can build a good research community to push this space forward. Though I’ve spent the last couple of weeks thinking about this topic, there’s no doubt I’ve missed some important pieces. If I think of any other, I might come back and add to this list. A brief table of contents:
- Community and identity
- Communicating research
- Outward-looking problem discovery
- Proven models for sustainability
- Many small projects, building on each other
Community and identity
Great communities are made of the stories we tell about ourselves – why we do what we do, how we’ve done it, and from where those traditions came. These, alongside how we talk about ourselves and our work, form the identity of our field. I think it’s worth being conscious and deliberate about such an important facet of the community.
So far, the way we label our work (“tools for thought”, “knowledge graph”) and the way the world perceives this field have been defined mostly by the loudest and biggest companies to fill the room. This kind of ad-hoc identity is enough to bring people together, but these words we use today are laden with overloaded meanings and associations to existing products and ideas. Different corners of the community behind these tools also agglomerate around different focuses: Some really love to customize and polish their tools and workflows. Others are more interested in building on fundamental interaction and interface design research dating back to the dawn of the personal computing era. One name and identity cannot contain them all – I think a research community should recognize that, and gather around a more independent identity that can represent the way we want the community to treat its members, its history, its traditions, and its future.
If I had my way, I think this new identity should…
- build upon a diverse group of people and ideas
- remember, but not revere, past research and tradition
- welcome independent contributors, and view itself as a collective of people, not an industry of companies
- work in the open, and
- value building and testing ideas over spreading them.
There are entire essays to be written on each of these points – probably soon to come.
There is already a loose emerging community around thinking- and creative-software research. The challenge is to bootstrap a more structured community from these seeds. By “community”, I emphatically do not mean some group chat or online forum where every member hangs out and post messages. That kind of a monolithic community approach does not scale, and does not last. I want a research community that feels decentralized, but runs in roughly the same direction, branching and merging where the ideas take us. I want there to be people I can run to with a new idea or a prototype and get honest, hard-hitting, thoughtful feedback, and that doesn’t require much shared infrastructure, only shared enthusiasm and identity.
Communicating research
There are emerging conventions in the community about how to communicate research, and I think they set good examples from which to build traditions: written communications and open-source prototypes.
Written communications
There are two broad categories of written research communication I can think of: reports on findings after specific projects, and periodical updates on progress. I think the best example of the former is Ink & Switch’s reports. My favorite examples of the latter are Andy Matuschak’s Patreon posts and Alexander Obenauer’s lab notes. Both feel important to a vibrant research community.
In-depth write-ups of research findings can serve as anchor points and canonical descriptions of important ideas. There is value in giving names to new ideas and describing them in detail for others to cite and build upon. Reports of this type can serve that role. Well-written research reports also clearly lay out findings that future research could extend, and approaches and experiments that didn’t work. In a productive research community, research builds on past research by referencing and working from findings shared in these in-depth reports.
By contrast, periodical updates can fill the time gaps in between long research cycles and form a kind of asynchronous “group chat” for the community. Often the most interesting parts of research work are the parts that are fuzzy and vague and incomplete in our own minds, and hardest to articulate properly at first. These ideas don’t make it to “official” publications or reports because they’re not ready to be cast into form yet, but speaking about these more soft ideas with like-minded people can lead to the clarity we need to move forward on them. I think periodical updates from researchers and builders in this space can become a place to share those more fuzzy ideas. These communications might also be an effective “heartbeat” for the community, to keep a sense of loosely coordinated momentum.
I also want to note a third kind of communication – pieces like Up and Down the Ladder of Abstraction and Using Artificial Intelligence to Augment Human Intelligence – that push the field forward on what effective research communication can look like. As people working to expand the way we communicate and share ideas, I think it’s worth investing into the ways we communicate our own ideas between ourselves to make it more interactive, taking full advantage of the software medium we seek to embrace.
Open-source, working prototypes
One of my favorite things about the way this field operates is that often research yields open-source prototypes and working code. Szymon Kaliski’s projects don’t come with a lot of writing but self-demonstrate ideas because they’re working code on GitHub. It seems the culture of this ad-hoc community we have so far values open source software, pushing some companies to build products on a platform of being open-source. I’ve also embraced this culture; almost all of my own projects are free and open source. A community culture of open-source-by-default could also enable more ratcheting progress in a field increasingly tucked behind startup NDAs.
Outward-looking problem discovery
One of my greatest concerns about this field today is that almost all of the problem discovery happens by a kind of self-interested navel-gazing process, where product builders take the quote “build things you would want to use” a little too literally, and build products for the small niche group of people interested in note-taking tools and processes. This leads to products that seem useful to a small group of other people who are also working in this space and familiar with its vernacular and concepts, but are unusable or unapproachable by most people outside of that small community. I think this is a dangerous failure mode.
Good industrial research can only happen in problem rich environments, where research questions are anchored to problems found in real workflows used by domain experts working in their respective fields to solve problems other than the challenge of building more thinking tools. This kind of work requires that the research community work in close collaboration with people who work outside of our field. This is a process that requires active effort – radiologists and human rights lawyers and artists and journalists are not going to seek out risky, new ideas in their knowledge workflows as a part of their daily work. I think active outward-looking problem discovery, where we dedicate research time to consult with other domain experts to seek out new questions to pursue, is critical to an impactful research community.
Concretely, this can happen in a few different ways. Bell Labs’s problem discovery was performed by the entire rest of its parent company, AT&T, as it tried to span telephone wires across continents and oceans and anticipate technical problems 5-20 years in the future. Companies like Retool building business-facing products have field-deployed engineers working with customers to discover new uses cases for their products and ensure the rest of the company is directed forward, not just inward. Independent researchers like Andy Matuschak augment their own personal experience with tools they build by testing rigorously with other end users in a variety of professions.
I’ve spent a lot of time over the years desperately trying to think of a “thing” to change the world. I now know why the search was fruitless – things don’t change the world. People change the world by using things. The focus must be on the “using”, not the “thing”. Now that I’m looking through the right end of the binoculars, I can see a lot more clearly, and there are projects and possibilities that genuinely interest me deeply. — Bret Victor
Tools don’t change the world alone; people do, in the way they use tools. And the way to build the right tools for those people is to focus on the people and their work first.
Proven models for sustainability
As I think about shifting more of my own work into research, one of my own big questions concerns financial sustainability. For talented, experienced people to consider contributing to a more open-ended research community rather than going to work at any of the hot startups of their time, there must exist well-established models for making a fair income doing such work. I don’t think it’s necessary for researchers to make salaries competitive with top-of-the-line compensation from large tech companies, but pursuing research must not be a financial gamble, the way it is today for most people.
Some people have found success with a crowd-funded Patreon-kind of funding model. Even though ostensibly making is showbusiness now, I don’t think this is the proven revenue stream we want everyone to pursue. Not everyone wants to turn their online presence into pristine, well-curated identities about their professional interests. Even for those who can manage taking on a creator identity, I think a crowd-funded patron kind of model can lead to undesirable power dynamics where researchers may be pressured to pursue questions that satisfy mass-market curiosities most, rather than following their expert intuitions.
So, what can we do?
For a healthy and impactful research environment in the thinking tools space, I think we need a mix of “concept car” projects (a phrase I lovingly borrow from Jess Martin) and “production-grade” tools (a phrase I’m adopting from Ink & Switch). Concept car projects explore the boundaries of current technologies or showcase what new designs and ideas enable. They are necessary to push the field forward, but usually too rough or incomplete for the rest of the world to depend on. Production-grade tools are tools that are battle-tested to be secure, reliable, intuitive, and polished enough to be load-bearing components of real-world workflows.
These two kinds of work likely need different models for financial sustainability.
Research fueling products, products motivating research
The industrial research lab Ink & Switch offers an interesting precedent for a research group bringing products and production-grade tools to market, like Muse and Automerge. Though the lab itself is a nonprofit focused on exploratory research, some of their work leads to production-ready products that the lab can spin out into profit-generating companies. This approach, of research labs becoming sustainable by bringing products to market, resonates with me. Industrial research sets itself apart from academic research by the fact that industrial research seeks to answer questions relevant for building new products and companies. This was the explicit framing of research work done by Bell Labs and Xerox PARC, and the framing that labs like Ink & Switch also seem to be following. From this perspective, it makes sense for labs to become sustainable through research that leads to commercially successful products.
If research fuels creation of new products, I think building products can in turn fuel further research by being active areas of problem discovery. Much of the difficulty of building new products isn’t in coming up with the initial idea or insight, but in the thousand different engineering and design refinements that need to be made before a prototype can be turned into something the average customer will be able to use to solve their problems. These range from technical challenges like building a high quality rich text editor to design problems like balancing UI complexity with customizability. Once these products enter the real world, new problems always emerge at the point of contact between real-world use and research findings. These new problems can then feed back into research, and the cycle can continue.
The downside of taking this approach is that there’s a constant need for start-up capital in the beginning, when researchers and labs won’t have products to sell. Grants and corporate research programs may fill that role.
Financial support and research grants
In a world where labs become sustainable by spinning out products, researchers need some way to de-risk their initial work, when they won’t have any new products or technologies to sell. I think this is an effective place for open-ended research grant programs.
We can frame the role of research grants in a few different compatible ways:
- Grants can help people who are working in other fields step into the research community without taking significant financial risk up front.
- Grants can help fight the tendency for research projects to become too focused on short-term marketability. Projects should be opportunistic about, but not driven by the potential to build good products.
- Grants can direct support and resources toward researchers working on problems that seem especially fundamental or important in the field, and the community can use this support to advocate for its values, like open-source work, diversity, and a focus on people rather than companies.
I’ve also observed more startups in the field opening up “Researcher in residence” programs. These roles can be another way for new people to step into research work without associated risks or lack of structure, but I think we should avoid a world where most research about these tools are done in-house by companies. Corporate research ultimately results in proprietary intellectual property that is harder for a community to build on, and it puts emphasis on companies and their products rather than individuals and their learnings. I think corporate research programs should follow the conventions of the community, and be careful not to shadow individual contributors’ efforts.
Many small projects, building on each other
I think smaller projects that are faster to build are better for research in this space. Building many smaller projects rather than large ambitious ones have helped me because I avoid getting too attached to one particular idea or product, and with smaller-scoped prototypes I can try many more iterations against the same question or problem. It also lowers the barrier to entry to try more risky ideas – “I’ll try this for a weekend” is much easier than “I’ll have to shift my schedule the next couple weeks to fit this in; is it worth that?” A culture of shorter, more atomic projects will also encourage everyone to break down large ideas into smaller ones that are individually testable, which I think is a good practice regardless of whether those ideas are for a product or an experiment. On the other hand, cycles that are too short obviously run the risk of keeping us from trying more ambitious or complex ideas.
My gut feeling is that three-month “cycles” focused on specific research questions strike an ideal balance. Any longer, and we might find ourselves not chasing after a concrete enough question; any shorter feels too short to really dive deep into a problem and try as many iterations as might be necessary to find good answers. If we can establish a culture in the research community of 3-month cycles pursuing a single question, it might also be a good foundation on which to build timelines for things like research grant programs, community conferences, and collaborative projects.
Thanks to Karina Nguyen and Theo Bleier who offered feedback on past versions of this post, as well as the many independent researchers and writers whose opinions and work appear above.
Counting Blog Posts using xidel
I wanted to write 100 posts in 2021, and I am nowhere close to that. I tried to look at the posts by year and see how I have performed over the years. Of course, I could have done that manually by looking at the year archive count or running a query on the database. But recently, I have started using Xidel, so why not use it? :)
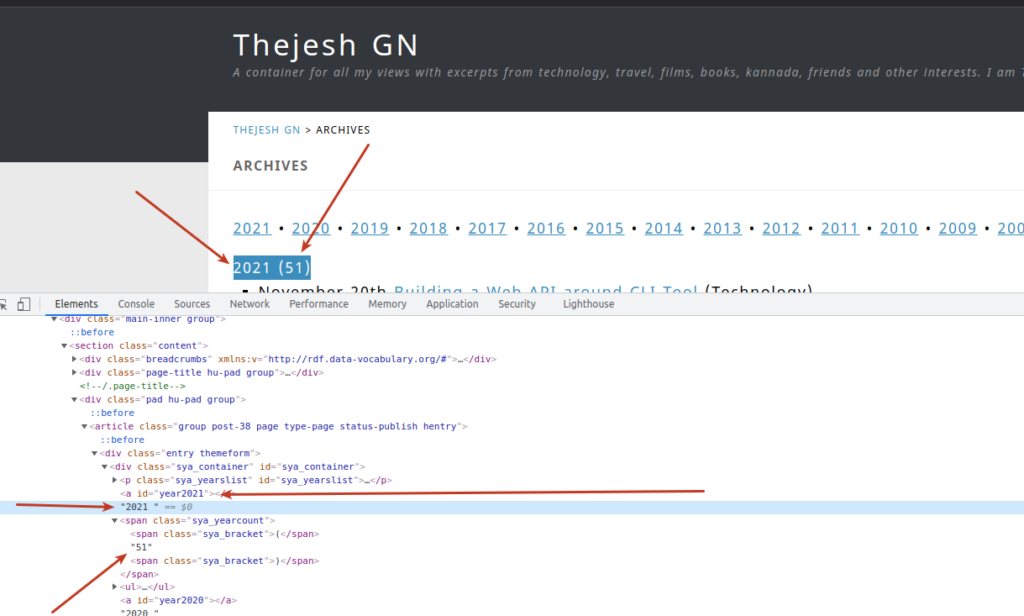
So its the number inside a span with class sya_yearcount. I am getting xpath3. text() gets the content of the node.
xidel https://thejeshgn.com/archives \ --xpath3="//span[@class='sya_yearcount']/text()"
I also wanted the years, which is the value inside an anchor tag where id contains yearXXXX, where XXXX is an year. So I am going to add year2 based filtering because all blogs where done post 2000. xidel can run multiple falterings on the same page in the same command. Also you can use contains to check if the string contains a value.
xidel https://thejeshgn.com/archives \ --xpath3="//a[contains(@id,'year2')]/@id" \ --xpath3="//span[@class='sya_yearcount']/text()"
I want a JSON output. xidel outputs simple text by default but it supports other formats like xml, html, json etc
xidel https://thejeshgn.com/archives \ --xpath3="//a[contains(@id,'year2')]/@id" \ --xpath3="//span[@class='sya_yearcount']/text()" \ --output-format json-wrapped
And then I don't want logs. I want only JSON output, so I am adding --silent
I want text output to be numbers and not text xidel https://thejeshgn.com/archives \ --xpath3="//a[contains(@id,'year2')]/@id" \ --xpath3="//span[@class='sya_yearcount']/text()" \ --output-format json-wrapped --silent
I want text output to be numbers and not text. So we convert them into numbers
xidel https://thejeshgn.com/archives \ --xpath3="//a[contains(@id,'year2')]/@id" \ --xpath3="//span[@class='sya_yearcount']/text() / number(.)" \ --output-format json-wrapped \ --silent
And the final output looks like this.
[
[
"year2021",
"year2020",
"year2019",
"year2018",
"year2017",
"year2016",
"year2015",
"year2014",
"year2013",
"year2012",
"year2011",
"year2010",
"year2009",
"year2008",
"year2007",
"year2006",
"year2005",
"year2004",
"year2003"
],
[
51,
34,
33,
37,
53,
54,
57,
40,
25,
34,
46,
48,
73,
71,
203,
20,
13,
3,
4
]
]
Now you can use that json with any graphing library that you love. A bit of over engineering that's not needed. But its one way to learn.
The meanings of life
Hey, it’s Rose! I write for the blog at Datawrapper. Two weeks ago, my colleague Becca published a Weekly Chart that used tooltips to tell a story for each data point. I really loved this way of revealing the individuals behind the data, so today I’m bringing you my own take — this time, on the good things in life.
Philosophers tried for a few millennia, but it’s the Pew Research Center who finally discovered the meaning of life: “to eat homegrown vegetables.” Or maybe “playing Scrabble with [your] husband every night.” Also “a cat that likes to sit on [your] lap,” of course. And “living in Taiwan” factors in as well.
Okay, it’s probably fair to say that the meaning of life is still up for debate — after all, some say it’s not a cat but an emu that’s important, and not Taiwan but Belgium that’s the only place to live. Let’s say what we’ve got here are the meanings of life: 18,850 people’s open-ended musings on what makes their own lives meaningful, fulfilling, or satisfying. Pew surveyed these people, who live in 17 economically advanced countries, between February and May 2021, then coded their responses according to the major topics mentioned. Now we can say quantitatively that family is what keeps most people going, and that pets are more beloved in New Zealand than anywhere else.
That’s pretty cool already, but what drew me to this data was that it also included a selection of the original responses — direct quotes from participants, translated into English, on what matters to them in life. You can hover over the dots on these charts to read some for yourself.
Unsurprisingly, relationships with other people rank highly all over the world. Family and children were the number one source of meaning in 14 out of 17 countries surveyed; spouses and romantic partners get fewer explicit mentions, but do manage to outrank pets across the board. Several people noted how the pandemic has changed their relationships. A young French woman reported, “Before the pandemic I didn't really know my neighbors. Since it started we have been helping each other.” A woman in Greece said, “Because of the pandemic, my family has bonded more and our relationship […] has evolved.”
One thing I love about these responses is how they show people finding fulfillment in opposite life situations. For many, work is paramount: one man in New Zealand said, “my work is the most fulfilling [thing] I do as I work for an animal sanctuary looking after kiwi and native birds […] All the work that I do is going to last longer than I do.” An American woman agreed, “I work in retail and it's not glamorous but it makes me happy. I could never go to work and be bored.” Meanwhile, in the UK, one man finds his life’s satisfaction in “the fact that I no longer work,” and a Belgian man agrees, “I'm retired so I don't have to get up early, I'm free and can do whatever I want.”
To interpret these charts, it’s important to know that countries varied a lot in terms of how many sources of meaning people were likely to name. Sixty-two percent of South Koreans touched on only one topic, whereas only 23% of Australians did the same. What that means is that, on average, all topics will get fewer mentions from South Koreans than from Australians. The safest way to compare countries is to look at their relative ranking of each topic — for example, Americans stand out by ranking spirituality and religion as their top “big picture” source of meaning, whereas all other countries prioritize freedom or social institutions. Sometimes it’s clear how country-level factors might influence what people value most in their lives. For example, one man from Taiwan explained simply, “Living in Taiwan is very free, freer than China and Hong Kong.”
Usually we hear about the big and bad things that happen far away from us; these stories are a window into the small and joyful. I’m rooting for the 44-year-old woman in Australia who told the survey-taker, “I didn't study for my HSC [Higher School Certificate] so I'm redoing my HSC again […] giving myself [a] second chance.” I’m happy for the 93-year-old in New Zealand who answered, "Now that I can write poetry and that I've got a publisher interested, I find it's very satisfactory,” and also for the 20-year-old in the Netherlands who responded, "Because I am a refugee, I didn't think I could go to university, but it turned out to be possible.” I love these little, plural meanings of life. As one participant put it, it’s “this momentary blip in a cosmic timescale […] The mystery of it all and trying to decode my little part of it.”
How to create these charts
If you’re a regular Datawrapper user, you’ll have noticed these dot plots look jazzier than usual, with custom tooltips and text annotations. This isn’t a feature announcement — nothing in the tool has changed. What you’re seeing this week is just another face of the ultra-versatile scatterplot.
Disguising a scatterplot as a dot plot took three main steps. First, I assigned each country a number from 1–17, based on the order I wanted them to appear in. That column of country codes provides a vertical axis value for each dot. Second, I drew in a background grid using the “Custom lines and areas” feature. And finally, I used text annotations to create the axis labels.
Using a disguised scatterplot has some disadvantages — my fake axis labels are less responsive than real ones, and I can’t reorder the countries with a simple “sort” option. Still, it can be a great option when you want to push the boundaries of another chart type.
That's all from me this week! Next Thursday, our map master Anna will bring us a special Weekly Chart for her name day.
The City of Toronto now lets residents track locations of COVID outbreaks

Toronto residents now have access to a new tool that will keep them informed on COVID-19 outbreaks across the city.
The City of Toronto added the COVID-19 exposure notifications page to its official website. It will disclose locations where numerous residents have been exposed to the virus through the confirmation of one or more positive cases and when contact information for those impacted isn’t available.
“We’re sharing this information to help prevent opportunities for virus spread and equipping residents with instructions they can follow to protect their health and the health of those around them if they may have been exposed to this virus,” Dr. Eileen de Villa, Toronto’s medical officer of health, said in a statement.
In order to protect privacy, single residential addresses will not be included on the page and only settings where 20 or more people were present will be reported.
Information will be updated every Monday, Wednesday, and Friday at 3 pm.
The new tool was released in an effort for Toronto Public Health (TPH) to reach the city’s 2.9 million residents faster. The health unit has 900 employees dedicated to contact tracing and its various aspects. This is one of the largest teams in the country dedicated to contact management efforts.
“TPH continues to review the latest evidence to identify ways to better protect our community against COVID-19. This is especially important as we continue moving forward returning to many of the activities that we’ve missed,” Dr. de Villa said.
Image credit: ShutterStock
Source: City of Toronto
Twitter Has a New CEO; What About a New Business Model?
From CNBC:
Twitter CEO Jack Dorsey is stepping down as chief of the social media company, effective immediately. Parag Agrawal, Twitter’s chief technology officer, will take over the helm, the company said Monday. Shares of Twitter closed down 2.74% on the day.
Dorsey, 45, was serving as both the CEO of Twitter and Square, his digital payments company. Dorsey will remain a member of the board until his term expires at the 2022 meeting of stockholders, the company said. Salesforce President and COO Bret Taylor will become the chairman of the board, succeeding Patrick Pichette, a former Google executive, who will remain on the board as chair of the audit committee.
“I’ve decided to leave Twitter because I believe the company is ready to move on from its founders,” Dorsey said in a statement, though he didn’t provide any additional detail on why he decided to resign.
On one hand, congratulations to Twitter for its first non-messy CEO transition in its history; on the other hand, this one was a bit weird in its own way: CNBC broke the news at 9:23am Eastern, just in time for the markets to open and the stock to shoot up around 10% as feverish speculation broke out about who the successor was; two hours and 25 minutes later Dorsey confirmed the news and announced Agrawal as his successor, and the sell-off commenced.
The missing context in Dorsey’s announcement was Elliott Management, the activist investor that took a stake in Twitter in early 2020 and demanded that Dorsey either focus on Twitter (instead of Square, where he is still CEO) or step down; Twitter gave Elliott and Silver Lake, who was working with Elliott, two seats on the board a month later. That agreement, though, came with the condition that Twitter grow its user base, speed up revenue growth, and gain digital ad market share.
Twitter has made progress: while the company’s monthly active users have been stagnant for years — which is probably why the company stopped reporting them in 2019 — its “monetizable daily active users” have increased from 166 million in Q1 2020 to 211 million last quarter, and its trailing twelve-month revenue has increased from $3.5 billion in Q1 2020 to $4.8 billion in Q3 2021. The rub is digital ad market share: Snap, for example, grew its TTM revenue from $1.9 billion to $4.0 billion over the same period, as the pandemic proved to be a massive boon for many ad-driven platforms.
That boon was driven by the surge in e-commerce, which is powered by direct response marketing, where there is a tight link between seeing an ad and making a purchase; Twitter, though, has struggled for years to build a direct response business, leaving it dependent on brand advertising for 85% of its ad revenue. That meant the company was not only not helped by the pandemic, but hurt worse than most (and, on the flip side, was less affected by Apple’s iOS 14 changes). If in fact Dorsey’s job depended on taking digital ad market share, he didn’t stand a chance.
That perhaps explains yesterday’s weird timing; Casey Newton speculated that the board may have leaked the news to ensure that Dorsey didn’t get cold feet. It also, I suspect, explains the market’s cool reaction to the appointment of an insider: Agrawal was there for all of those previously failed attempts to build a direct response marketing business, so it’s not entirely clear what is going to be different going forward.
Twitter’s Advertising Problem
The messiness I alluded to in Twitter’s previous CEO transitions is merely markers on a general run of mismanagement from the company’s earliest days. I’ve long contended that Twitter’s core problem is that the product was too perfect right off the bat; from 2014’s Twitter’s Marketing Problem:
One of the most common Silicon Valley phrases is “Product-Market Fit.” Back when he blogged on a blog, instead of through numbered tweets, Marc Andreessen wrote:
The only thing that matters is getting to product/market fit…I believe that the life of any startup can be divided into two parts: before product/market fit (call this “BPMF”) and after product/market fit (“APMF”).
When you are BPMF, focus obsessively on getting to product/market fit.
Do whatever is required to get to product/market fit. Including changing out people, rewriting your product, moving into a different market, telling customers no when you don’t want to, telling customers yes when you don’t want to, raising that fourth round of highly dilutive venture capital — whatever is required.
When you get right down to it, you can ignore almost everything else.
I think this actually gets to the problem with Twitter: the initial concept was so good, and so perfectly fit such a large market, that they never needed to go through the process of achieving product market fit. It just happened, and they’ve been riding that match for going on eight years.
The problem, though, was that by skipping over the wrenching process of finding a market, Twitter still has no idea what their market actually is, and how they might expand it. Twitter is the company-equivalent of a lottery winner who never actually learns how to make money, and now they are starting to pay the price.
Seven years on and Twitter has finally started to implement some of the proposals from that article, including leaning heavily into recommendations and topics; in theory the machine learning understandings driving those recommendations should translate into more effective advertising as well. That hasn’t really happened, though, and I’m not sure it ever will, for reasons that go beyond the effectiveness of Twitter’s management (or lack thereof).
Think about the contrast between Twitter and Instagram; both are unique amongst social networks in that they follow a broadcast model: tweets on Twitter and photos on Instagram are public by default, and anyone can follow anyone. The default medium, though, is fundamentally different: Twitter has photos and videos, but the heart of the service is text (and links). Instagram, on the other hand, is nothing but photos and video (and link in bio).
The implications of this are vast. Sure, you may follow your friends on both, but on Twitter you will also follow news breakers, analysts, insightful anons, joke tellers, and shit posters. The goal is to mainline information, and Twitter’s speed and information density are unparalleled by anything in the world. On Instagram, though, you might follow brands and influencers, and your chief interaction with your friends is stories about their Turkey Day exploits. It’s about aspiration, not information, and the former makes a lot more sense for effective advertising.
It’s more than just the medium though; it’s about the user’s mental state as well. Instagram is leisurely and an escape, something you do when you’re procrastinating; Twitter is intense and combative, and far more likely to be tied to something happening in the physical world, whether that be watching sports or politics or doing work:

This matters for advertising, particularly advertising that depends on a direct response: when you are leaning back and relaxed why not click through to that Shopify site to buy that knick-knack you didn’t even know you needed, or try out that mobile game? When you are leaning forward, though, you don’t have either the time or the inclination.

That ties into Twitter’s third big problem: the number of people who actually want to experience the Internet this way is relatively small. There is a reason that Twitter’s userbase is only a fraction of Instagram’s, and it’s not a lack of awareness; the reality is that most people are visual, and Twitter is textual. Which, of course, is exactly why Twitter’s most fervent users can’t really imagine going anywhere else.
Twitter’s Place in Culture
What makes Twitter such a baffling company to analyze is that the company’s cultural impact so dramatically outweighs its financial results; last quarter Twitter’s $1.3 billion in revenue amounted to 4.4% of Facebook’s $29.0 billion, and yet you can make the case — and I believe it — that Twitter’s overall impact on the world is just as big, if not larger than its drastically larger peer. Facebook hollowed out the gatekeeper position of the media, but that void was filled by Twitter, both in terms of news being made, and just as critically, elite opinion and narrative being shaped.
Given that impact, I can see why Elliott Management would look at Twitter and wonder why it is that the company can’t manage to make more money, but the fact that Twitter is the nexus of online information flow reflects the reality of information on the Internet: massively impactful and economically worthless, particularly when ads — which themselves are digital information — can easily be bought elsewhere.
Twitter is more than just news, though: I wrote last year in Social Networking 2.0 about the rise of private networks that supplemented and, for many use cases, replaced Facebook and Twitter.

Twitter, even more than Facebook, remains crucial to this new ecosystem: what WhatsApp group or Telegram chat isn’t filled with tweets posted for the purpose of discussion or disparagement, or links discovered via Twitter? It is as if these private groups are a fortress on the frontier; Twitter is the wild where you forage for content morsels, and, of course, where you do battle with the enemy.
Don’t underrate that last part: one of the biggest challenges facing would-be Twitter clones is not simply that a complete lack of moderation leads to an overwhelming amount of crap, but also that the sort of person who thrives on Twitter very much wants to know everything that is happening in the world, including amongst those outside of their circle. Being stuck on a text-based social network that only has some of the information to be consumed is lame; having access to anyone and everything, for better or worse, is a value prop that only Twitter can provide.
This, then, is the other thing that often baffles analysts: Twitter has one of the most powerful moats on the Internet. Sure, Facebook has ubiquity, Instagram has influencers, and TikTok has homegrown stars, but I find it easier to imagine any of those fading before Twitter’s grip on information flow disappears (in part, of course, because Twitter has shown that it’s a pretty crappy business).
A Paid Social Network
So let’s review: there is both little evidence that Twitter can monetize via direct response marketing, and reason to believe that the problem is not simply mismanagement. At the same time, Twitter is absolutely essential to a core group of users who are not simply unconcerned with the problems inherent to Twitter’s public broadcast model (including abuse and mob behavior), but actually find the platform indispensable for precisely those reasons: Twitter is where the news is made, shaped, and battled over, and there is very little chance of another platform displacing it, in large part because no one is economically motivated to do so.
Given this, why not charge for access?
This may seem obvious to you, but it’s a huge leap for me; back when Stratechery first started it was fairly popular to argue that social networks should charge users instead of selling ads, which never made sense. I wrote in 2014’s Ello and Consumer-Friendly Business Models:
When it comes to social networks, on the other hand, advertising is clearly the best option: after all, a social network is only as good as the number of friends that are on it, and the best way to get my friends on board is to offer a kick-ass product for free. In other words, the exact opposite of the feature-limited product that Ello is proposing…
If…you care about making a successful social network that users will find useful over the long run, then actually build something that is as good as you can possibly make it and incentivize yourself to earn and keep as many users as possible.
I still stand by that analysis generally, but I increasingly question whether or not it applies to Twitter. Twitter has long since penetrated the awareness of just about everyone on earth; the vast majority gave the platform a try and never came back, content to consume the tweets that show up everywhere from news articles to cable news. The core that remains, meanwhile, simultaneously bemoans that Twitter is terrible even as they can’t rip their eyes away, addicted as they are to that flow of information that is and will for the foreseeable future be unmatched by any other service.
And yet, despite this impact and indispensability and impenetrable moat, Twitter makes an average of $22.75 per monetizable daily active user per year (and given that some of Twitter’s most hard core users use third-party Twitter clients, and thus aren’t monetizable, the revenue per addicted daily active user is even lower). That’s just under $2/month, an absolutely paltry sum.
Actually charging for Twitter would, of course, reduce the userbase to some degree; moreover, there are a lot of users with multiple accounts, and plenty of non-human users on Twitter. And, of course, Apple and Google would take their share. Still, even if you cut the userbase by a third to 141 million daily addicted users — which I think vastly overstates Twitter’s elasticity of demand amongst its core user base — Twitter would only need to charge $4/month (including App Store fees) to exceed the $4.8 billion in revenue it made over the last twelve months.
And, in fact, that overstates the situation for another reason: only $4.2 billion of Twitter’s last twelve months of revenue came from ads; the rest came from data licensing and other revenue. There is an alternate world where data licensing is Twitter’s primary revenue model: just think about how valuable it is to be the primary protocol for real time information sharing, particularly if you can package and distribute that information in an intelligent way?
Twitter could still do that, and pursue other initiatives like its revitalized API, offering developers the opportunity to build entirely new experiences on Twitter’s information flow (including unmoderated ones). The difference from the first go-around is that Twitter won’t have an advertising business to protect, and thus will have its interests much better aligned with developers who can pay for access. After all, that would be Twitter’s business model.
I also think this makes Twitter’s other subscription offerings, like Super Follows, Revue, etc., more attractive, not less; the biggest challenge in running a subscription business is earning that first dollar, but once a user is paying it’s relatively easy to charge for more.
This could certainly all go horribly wrong; the absolute fastest way to get your users to explore alternatives is to ask them to pay for your service, and there is the matter of acquiring new users, users who can’t afford to pay, etc. Growth matters, fewer users means less vitality, and I’m honestly getting cold feet even proposing this! Certainly existing users would howl and insist they were leaving and never coming back. I think, though, that Twitter is so unique, and its userbase is so locked in, that it is the one social networking service that could potentially pull this off.
Moreover, the fact of the matter is that Twitter has now had one business model and five CEOs (counting Dorsey twice); maybe it’s worth changing the former before the next activist investor demands yet another change to the latter.
Follow-up: Why Subscription Twitter Is a Terrible Idea
Twitter Has a New CEO; What About a New Business Model?
Twitter is changing CEOs once again; what if the company changed its business model from ads to subscriptions?
From CNBC:
Twitter CEO Jack Dorsey is stepping down as chief of the social media company, effective immediately. Parag Agrawal, Twitter’s chief technology officer, will take over the helm, the company said Monday. Shares of Twitter closed down 2.74% on the day.
Dorsey, 45, was serving as both the CEO of Twitter and Square, his digital payments company. Dorsey will remain a member of the board until his term expires at the 2022 meeting of stockholders, the company said. Salesforce President and COO Bret Taylor will become the chairman of the board, succeeding Patrick Pichette, a former Google executive, who will remain on the board as chair of the audit committee.
“I’ve decided to leave Twitter because I believe the company is ready to move on from its founders,” Dorsey said in a statement, though he didn’t provide any additional detail on why he decided to resign.
On one hand, congratulations to Twitter for its first non-messy CEO transition in its history; on the other hand, this one was a bit weird in its own way: CNBC broke the news at 9:23am Eastern, just in time for the markets to open and the stock to shoot up around 10% as feverish speculation broke out about who the successor was; two hours and 25 minutes later Dorsey confirmed the news and announced Agrawal as his successor, and the sell-off commenced.
The missing context in Dorsey’s announcement was Elliott Management, the activist investor that took a stake in Twitter in early 2020 and demanded that Dorsey either focus on Twitter (instead of Square, where he is still CEO) or step down; Twitter gave Elliott and Silver Lake, who was working with Elliott, two seats on the board a month later. That agreement, though, came with the condition that Twitter grow its user base, speed up revenue growth, and gain digital ad market share.
Twitter has made progress: while the company’s monthly active users have been stagnant for years — which is probably why the company stopped reporting them in 2019 — its “monetizable daily active users” have increased from 166 million in Q1 2020 to 211 million last quarter, and its trailing twelve-month revenue has increased from $3.5 billion in Q1 2020 to $4.8 billion in Q3 2021. The rub is digital ad market share: Snap, for example, grew its TTM revenue from $1.9 billion to $4.0 billion over the same period, as the pandemic proved to be a massive boon for many ad-driven platforms.
That boon was driven by the surge in e-commerce, which is powered by direct response marketing, where there is a tight link between seeing an ad and making a purchase; Twitter, though, has struggled for years to build a direct response business, leaving it dependent on brand advertising for 85% of its ad revenue. That meant the company was not only not helped by the pandemic, but hurt worse than most (and, on the flip side, was less affected by Apple’s iOS 14 changes). If in fact Dorsey’s job depended on taking digital ad market share, he didn’t stand a chance.
That perhaps explains yesterday’s weird timing; Casey Newton speculated that the board may have leaked the news to ensure that Dorsey didn’t get cold feet. It also, I suspect, explains the market’s cool reaction to the appointment of an insider: Agrawal was there for all of those previously failed attempts to build a direct response marketing business, so it’s not entirely clear what is going to be different going forward.
Twitter’s Advertising Problem
The messiness I alluded to in Twitter’s previous CEO transitions are merely marker points on a general run of mismanagement from the company’s earliest days on. I’ve long contended that Twitter’s core problem is that the product was too perfect right off the bat; from 2014’s Twitter’s Marketing Problem:
One of the most common Silicon Valley phrases is “Product-Market Fit.” Back when he blogged on a blog, instead of through numbered tweets, Marc Andreessen wrote:
The only thing that matters is getting to product/market fit…I believe that the life of any startup can be divided into two parts: before product/market fit (call this “BPMF”) and after product/market fit (“APMF”).
When you are BPMF, focus obsessively on getting to product/market fit.
Do whatever is required to get to product/market fit. Including changing out people, rewriting your product, moving into a different market, telling customers no when you don’t want to, telling customers yes when you don’t want to, raising that fourth round of highly dilutive venture capital — whatever is required.
When you get right down to it, you can ignore almost everything else.
I think this actually gets to the problem with Twitter: the initial concept was so good, and so perfectly fit such a large market, that they never needed to go through the process of achieving product market fit. It just happened, and they’ve been riding that match for going on eight years.
The problem, though, was that by skipping over the wrenching process of finding a market, Twitter still has no idea what their market actually is, and how they might expand it. Twitter is the company-equivalent of a lottery winner who never actually learns how to make money, and now they are starting to pay the price.
Seven years on and Twitter has finally started to implement some of the proposals from that article, including leaning heavily into recommendations and topics; in theory the machine learning understandings driving those recommendations should translate into more effective advertising as well. That hasn’t really happened, though, and I’m not sure it ever will, for reasons that go beyond the effectiveness of Twitter’s management (or lack thereof).
Think about the contrast between Twitter and Instagram; both are unique amongst social networks in that they follow a broadcast model: tweets on Twitter and photos on Instagram are public by default, and anyone can follow anyone. The default medium, though, is fundamentally different: Twitter has photos and videos, but the heart of the service is text (and links). Instagram, on the other hand, is nothing but photos and video (and link in bio).
The implications of this are vast. Sure, you may follow your friends on both, but on Twitter you will also follow news breakers, analysts, insightful anons, joke tellers, and shit posters. The goal is to mainline information, and Twitter’s speed and information density are unparalleled by anything in the world. On Instagram, though, you might follow brands and influencers, and your chief interaction with your friends are stories about their Turkey Day exploits. It’s about aspiration, not information, and the former makes a lot more sense for effective advertising.
It’s more than just the medium though; it’s about the user’s mental state as well. Instagram is leisurely and an escape, something you do when you’re procrastinating; Twitter is intense and combative, and far more likely to be tied to something happening in the physical world, whether that be watching sports or politics or doing work:

This matters for advertising, particularly advertising that depends on a direct response: when you are leaning back and relaxed why not click through to that Shopify site to buy that knick-knack you didn’t even know you needed, or try out that mobile game? When you are leaning forward, though, you don’t have either the time or the inclination.

That ties into Twitter’s third big problem: the number of people who actually want to experience the Internet this way is relatively small. There is a reason that Twitter’s userbase is only a fraction of Instagram’s, and it’s not a lack of awareness; the reality is that most people are visual, and Twitter is textual. Which, of course, is exactly why Twitter’s most fervent users can’t really imagine going anywhere else.
Twitter’s Place in Culture
What makes Twitter such a baffling company to analyze is that the company’s cultural impact so dramatically outweighs its financial results; last quarter Twitter’s $1.3 billion in revenue amounted to 4.4% of Facebook’s $29.0 billion, and yet you can make the case — and I believe it — that Twitter’s overall impact on the world is just as if not larger than its drastically larger peer. Facebook hollowed out the gatekeeper position of the media, but that void was filled by Twitter, both in terms of news being made, and just as critically, elite opinion and narrative being shaped.
Given that impact, I can see why Elliott Management would look at Twitter and wonder why it is that the company can’t manage to make more money, but the fact that Twitter is the nexus of online information flow reflects the reality of information on the Internet: massively impactful and economically worthless, particularly when ads — which themselves are digital information — can easily be bought elsewhere.
Twitter is more than just news, though: I wrote last year in Social Networking 2.0 about the rise of private networks that supplemented and, for many use cases, replaced Facebook and Twitter.

Twitter, even more than Facebook, remains crucial to this new ecosystem: what WhatsApp group or Telegram chat isn’t filled with tweets posted for the purpose of discussion or disparagement, or links discovered via Twitter? It is as if these private groups are a fortress on the frontier; Twitter is the wild where you forage for content morsels, and, of course, where you do battle with the enemy.
Don’t underrate that last part: one of the biggest challenges facing would be Twitter clones is not simply that a complete lack of moderation leads to an overwhelming amount of crap, but also that the sort of person who thrives on Twitter very much wants to know everything that is happening in the world, including amongst those outside of their circle. Being stuck on a text-based social network that only has some of the information to be consumed is lame; having access to anyone and everything, for better or worse, is a value prop that only Twitter can provide.
This, then, is the other thing that often baffles analysts: Twitter has one of the most powerful moats on the Internet. Sure, Facebook has ubiquity, Instagram has influencers, and TikTok has homegrown stars, but I find it easier to imagine any of those fading before Twitter’s grip on information flow disappears (in part, of course, because Twitter has shown that it’s a pretty crappy business).
A Paid Social Network
So let’s review: there is both little evidence that Twitter can monetize via direct response marketing, and reason to believe that the problem is not simply mismanagement. At the same time, Twitter is absolutely essential to a core group of users who are not simply unconcerned with the problems inherent to Twitter’s public broadcast model (including abuse and mob behavior), but actually find the platform indispensable for precisely those reasons: Twitter is where the news is made, shaped, and battled over, and there is very little chance of another platform displacing it, in large part because no one is economically motivated to do so.
Given this, why not charge for access?
This may seem obvious to you, but it’s a huge leap for me; back when Stratechery first started it was fairly popular to argue that social networks should charge users instead of selling ads, which never made sense. I wrote in 2014’s Ello and Consumer-Friendly Business Models:
When it comes to social networks, on the other hand, advertising is clearly the best option: after all, a social network is only as good as the number of friends that are on it, and the best way to get my friends on board is to offer a kick-ass product for free. In other words, the exact opposite of the feature-limited product that Ello is proposing…
If…you care about making a successful social network that users will find useful over the long run, then actually build something that is as good as you can possibly make it and incentivize yourself to earn and keep as many users as possible.
I still stand by that analysis generally, but I increasingly question whether or not it applies to Twitter. Twitter has long since penetrated the awareness of just about everyone on earth; the vast majority gave the platform a try and never came back, content to consume the tweets that show up everywhere from news articles to cable news. The core that remains, meanwhile, simultaneously bemoans that Twitter is terrible even as they can’t rip their eyes away, addicted as they are to that flow of information that is and will for the foreseeable future be unmatched by any other service.
And yet, despite this impact and indispensability and impenetrable moat, Twitter makes an average of $22.75 per monetizable daily active user per year (and given that some of Twitter’s most hard core users use third-party Twitter clients, and thus aren’t monetizable, the revenue per addicted daily active user is even lower). That’s just under $2/month, an absolutely paltry sum.
Actually charging for Twitter would, of course, reduce the userbase to some degree; moreover, there are a lot of users with multiple accounts, and plenty of non-human users on Twitter. And, of course, Apple and Google would take their share. Still, even if you cut the userbase by a third to 141 million daily addicted users — which I think vastly overstates Twitter’s elasticity of demand amongst its core user base — Twitter would only need to charge $4/month (including App Store fees) to exceed the $4.8 billion in revenue it made over the last twelve months.
And, in fact, that overstates the situation for another reason: only $4.2 billion of Twitter’s last twelve months of revenue came from ads; the rest came from data licensing and other revenue. There is an alternate world where data licensing is Twitter’s primary revenue model: just think about how valuable it is to be the primary protocol for real time information sharing, particularly if you can package and distribute that information in an intelligent way?
Twitter could still do that, and pursue other initiatives like its revitalized API, offering developers the opportunity to build entirely new experiences on Twitter’s information flow (including unmoderated ones). The difference from the first go-around is that Twitter won’t have an advertising business to protect, and thus will have its interests much better aligned with developers who can pay for access. After all, that would be Twitter’s business model.
I also think this makes Twitter’s other subscription offerings, like Super Follows, Revue, etc., more attractive, not less; the biggest challenge in running a subscription business is earning that first dollar, but once a user is paying it’s relatively easy to charge for more.
This could certainly all go horribly wrong; the absolute fastest way to get your users to explore alternatives is to ask them to pay for your service, and there is the matter of acquiring new users, users who can’t afford to pay, etc. Growth matters, and I’m honestly getting cold feet even proposing this! Certainly existing users would howl and insist they were leaving and never coming back. I think, though, that Twitter is so unique, and its userbase is so locked in, that it is the one social networking service that could potentially pull this off.
Moreover, the fact of the matter is that Twitter has now had one business model and five CEOs (counting Dorsey twice); maybe it’s worth changing the former before the next activist investor demands yet another change to the latter.
Subscription Information
Member: Roland Tanglao
Listening to re:Invent
This is the week that AWS owns the tech news cycle because anyone who cares about it is watching the stories coming out of the re:Invent conference. I watched Adam Selipsky’s keynote this morning and it looks like AWS is moving in a very traditional direction for tech companies: Away from tech-first, towards business-first. Which is inevitable but also dangerous.
Messages
The “S” in AWS stands for “Services”. So presumably, the biggest imaginable announcement would be of new Web Services. There was only one in among the avalanche of biz-talk: managed 5G, nice but not terribly exciting. Powerful message!
What were the companies either heavily name-checked or invited on-stage? DISH, NASDAQ, United, Goldman Sachs, and 3M. None of them West-Coast. None seen as tech players. Powerful message!
The number-one problem I hear about from every single tech leader I talk to is the extreme difficulty in hiring and team-building. So I’d think that providing developer force multiplication by automating away server management would be a big deal. None of that; the focus was almost all (except for a bit from 3M) on hosting existing applications. Powerful message.
There’s also the fact that a high proportion of developers and technologists viscerally loathe at least two of those highlighted companies; so impressing those demographics was not on the priority list. Powerful message!
History
Let’s look way back, to the year I graduated from University: 1981 (no, really). My first job was with DEC. At that point it was the second-largest computer company in the world. The largest was IBM, which was ten times our size and, as our leadership said, “growing at one DEC per year”.
DEC at that time had the coolest computers you could buy and nobody working where tech mattered wanted anything else. Leadership noticed that despite that fact, IBM was kicking our asses. And IBM people never really talked about technology, it was all business all the time. So the word came down from on high that we would too.
I remember going to the announcement of some new computer which was a one-hour presentation, and the first 45 minutes were how DEC cared above all else about the Modern Enterprise and Leadership Agility and Profit-oriented Innovation. This wasn’t a computer, it was a Business Solution! Meanwhile the audience got angrier and angrier because they wanted to hear about memory and form factors and cycle time and benchmarking and so on. Those things were eventually crammed into the last ten minutes of the session, and the computer actually did pretty well.
But the company didn’t. It was skidding downhill by 1990 and didn’t make it to Y2K. My own geeky tribe was pretty convinced that it was because if you wanted to sell computers, you should find people who needed to buy computers and talk about computers to them.
I saw a similar story when I worked for Sun, which for quite a while sold the coolest computers but eventually fell on hard times and was snapped up by Oracle. Oracle talks about business and only about business. Once again, the tech-nerd demographic sneered at Oracle’s lack of technical acumen.
I’m pretty sure my tribe was wrong both times. Here’s why.
Growth space
People think the cloud business is pretty big, and it is. AWS is running at $60B/year and by my guess represents somewhere between a quarter and a half of public-cloud spend, so let’s say the whole Public-cloud biz is in the range of $200B or so. Wow, that sounds big! But estimates of global IT spending are north of $4T.
That math says that 95% of IT isn’t on the cloud yet. Will it all move there? No, but it feels inevitable that the cloud revenue potential is at least 10× today. And where is that 10×? I’ll tell you where it isn’t: In the kind of startup and cloud-native scenarios that led the charge onto the cloud over the last fifteen years. It’s in Establishment IT, where by “Establishment” I mean “big organization with significant systems in production”.
Establishment-IT organizations are cost centers, mostly. They report to people who neither understand nor care about technology, and are incented to find cheap decent solutions to their business problems. So it seems pretty obvious that whoever figures out how to talk to that leadership is in a position to win the 90% of the potential cloud market that’s still up for grabs. And that’s not by enthusing about leading-edge Serverless Event-driven Container Orchestration or whatever.
Horizontal Selling
Here’s another problem that the public Cloud faces as it tries to expand into the enterprise, one I’m bitterly familiar with because I’ve spent my whole life working on general-purpose infrastructural software. Which inevitably leads to the following conversation:
Tim: “Check out this slick new optimized event router we cooked up!”
Product Person: “Great! What can I do with it?”
T: “Well, anything! You know, make distributed apps faster and better!”
PP: “You don’t get it. What actual specific job, like manufacturing cars or processing insurance claims, will this help with? So I can go and talk to people who do those jobs.”
T: “But your apps will be more flexible and robust, too!”
At the moment, pretty well 100% of AWS revenue comes from totally horizontal technology, so you should pity the Product and Sales people who have to build a bridge between, for example, DynamoDB latency and Fast-Fashion inventory management. The fact that they’ve gotten this far is a tribute to them.
I couldn’t help but notice that in Adam Selipsky’s keynote this morning, there was a specifically-called-out emphasis on vertical offerings, for example the “Fleetwise” automotive-telemetry thing (which however launched without a charter customer). I think it’s pretty obvious why AWS is doing this. But the absence of a track record is worrying.
Which way forward?
I’m not gonna offer any recommendations about how AWS should position horizontal tech to sell to Establishment IT. If I did, they should be ignored. [You know who’s really good at it? Andy Jassy.]
But I do have three pieces of advice for AWS on their keynote presentations:
The all-biz-all-the-time messaging implies a trade-off. You should do better selling into that huge 90%-of-trillions IT space that isn’t in the cloud yet. But you’re less likely to land the business of the next Netflix or Intuit or, well, Amazon.com. Maybe that’s OK, but also consider at least some messaging aimed at technology pioneers.
I think that current technology leaders, even in the fustiest corners of Establishment IT, are noticing that they’re having a big recruiting and staffing problem. Modern Cloud-Native tech lets you deliver more business-app goodness with fewer developer-hours. I think that angle is becoming increasingly strategic, and deserves keynote time.
Pick up the damn pace! That two-hour keynote was grindingly slow and contained maybe a half-hour of actionable information. Your audience mostly comprises really smart people and they appreciate high-intensity high-density discourse. (This is another space where you might want to learn from the Jassy style.)
More to come
I understand that we systems Morlocks aren’t the target audience for the big glamorous launch keynote from the CEO. Do I feel slightly disrespected and ignored? Yes. Am I going to go back and listen for actual technology announcements from one of the world’s most interesting technology companies? Sure.
The Moving Calculus
The Myth Of The Miracle Feature
Too often we move or evaluate platforms based upon a specific feature (or set of features).
I’ve seen organisations demand specific features such as:
- Ability to live stream events directly through the platform.
- Collaborate on documents together within the platform.
- Ensure all members use two-factor authentication to log in.
- Develop complex automated rules-based upon past behaviors.
- Universal point systems combining internal and external behaviors.
- Integrate social media content seamlessly as discussions.
- Customise their member profiles with unique designs.
The reality is the features that often get the most excitement internally are often the least used internally. Worse yet, once you begin customising the platform, you’re responsible for the maintenance of that customisation which can cause endless trouble. None of these will have a major impact on participation.
If you look at a few hundred communities (as we have), you start to notice the majority of members use the same few areas in almost every platform (typically discussions, direct messages, search, and knowledge base).
What really impacts participation isn’t adding major new features, but usually tweaks in the most commonly used features which makes them easier and more satisfying to use. This often includes the layout of discussions, being able to reply by email, length of snippets which appear in digests, quantity (or lack thereof) of text which appears on pages, simplicity of logging in and remembering details, cognitive vs. federated search tools, taxonomy, etc…
The tragic thing about most RFPs (and the people evaluating them) is they rarely account for this. They lack the breadth of features and assume one platform’s discussion forum is as good as the next. It’s like evaluating a restaurant by whether they have a kitchen instead of understanding the little details that make one restaurant better than the next.
The solution is to join a bunch of communities on different platforms and participate meaningfully for a week. Notice the little details. Evaluate the experience you’re having and what you’re feeling as much (if not more) than the features you’re seeing.
The post The Myth Of The Miracle Feature first appeared on FeverBee.
Recently
Hello from Konstanz!

I’m spending a week in Germany. So far, I’ve visited the one and only Zeppelin Museum and a castle. Technically I’ve been trying to make this an unplugged vacation, so this will be short.
The traditional economic theory of the time suggested that, because the market is “efficient” (that is, those who are best at providing each good or service most cheaply are already doing so), it should always be cheaper to contract out than to hire.
Coase noted, however, that there are a number of transaction costs to using the market; the cost of obtaining a good or service via the market is actually more than just the price of the good. Other costs, including search and information costs, bargaining costs, keeping trade secrets, and policing and enforcement costs, can all potentially add to the cost of procuring something via the market. This suggests that firms will arise when they can arrange to produce what they need internally, and somehow avoid these costs.
The Nature of the Firm blew my mind. Firms and salaried jobs persist because of the overhead of negotiating and researching one-off exchanges of labor. Obvious, once you read it, but what an amazing summary.
Extreme wealth, like carbon emissions, imposes a negative externality on the rest of us. The point of taxing carbon is not to raise revenue but to reduce carbon emissions. The same goes for high tax rates on the very highest incomes: They are not aimed at funding government programs in the long run. They are aimed at reducing the income of the ultra-wealthy. They prevent or impede the various forms of rent extraction associated with extreme and entrenched wealth and with the reality of the market economy in unequal societies.
The Triumph of Injustice was an excellent read - similar to Piketty’s Capital, but compact and solution-oriented.

I re-watched Moonstruck, in my effort to watch 100% of Nic Cage films (I’m at 13%). Five stars. Face/off, not so much.
Designer by Aldous HardingBeen enjoying Aldous Harding’s thoroughly quirky album. It has plenty of 60s melodic elements that I usually don’t like, but throws in enough chaotic surprises to keep me interested.
The Placemark update
I wrote a lot for the Placemark blog again, this month - on weighing technical FOMO, updates to the devops, how geospatial is still interesting, and the undo/redo system.
It was a challenging month: a brutal bug in my database driver was what prompted the devops upgrades. But now I have a fix to that bug (thanks Prisma team!) and a more robust infrastructure. Next on the docket is polishing up additional collaboration affordances and then some fixes & optimizations. I’m experimenting with a public roadmap!, and you can file an issue in that repo if there should be something else on it.
Thought bubbles: middlemen
What is a middleman? In the current crypto/web3 wave, there are a lot of people talking about removing middlemen. There are also a lot of stories of enormous fees for everything in that world. Which begs the question: what’s a middleman? Is it simply the presence of a human in the loop? Can computers be middlemen? Do credit card transactions have middlemen?
The conclusion here, obviously, or what I keep thinking is: the vagueness of this line of argument is the point, and there no real, practical advance happening.
Twitter Favorites: [coinaday1] Simon Fraser University Burnaby, British Columbia The University on "a barren, desolate mountain". https://t.co/kiZoBQwL8b

Simon Fraser University Burnaby, British Columbia The University on "a barren, desolate mountain". pic.twitter.com/kiZoBQwL8b

Twitter Favorites: [skinnylatte] It’s always a good time to fry egg tofu https://t.co/2huqNDN4Yd


What’s up with SUMO – November 2021
Hey SUMO folks,
November come with lots of rain, at least in my part of the world. It certainly creates a different vibe. I believe you also experience similar weather change lately, be it snow or rain. Whatever it is, I hope you all safe and healthy wherever you are. Oh, and happy thanksgiving for you who celebrate! Sorry for being late with the update this month (maybe it’s better to have it by the end of the month anyway), so let’s just dive into it!
Welcome on board!
- Welcome andmagdo to the forum world. He’s been around for awhile, but we’d like to make sure he gets a proper call out here.
- Also welcome to Abhishek and Bithiah to the Social Support program. Excited to have more people onboard.
Community news
- November was intense due to the MR2 release. Luckily, we received good feedback for the overall release. Many people especially like Colorways and want us to keep it as a permanent feature. Many mobile users also enjoyed the customizable homepage and the new inactive tabs feature.
- Firefox is officially on the Windows Store.
- Time to say goodbye to Firefox Lockwise. But also a Hello to Firefox Relay Premium!
- Check out the following release notes from Kitsune in the month:
- No release notes from Kitsune from last month, however, please read this post to learn more about the website stability update.
Community call
- Watch the monthly community call if you haven’t. Learn more about what’s new in October and November!
- Reminder: Don’t hesitate to join the call in person if you can. We try our best to provide a safe space for everyone to contribute. You’re more than welcome to lurk in the call if you don’t feel comfortable turning on your video or speaking up. If you feel shy to ask questions during the meeting, feel free to add your questions on the contributor forum in advance, or put them in our Matrix channel, so we can address them during the meeting.
Community stats
Forum Support
Forum stats
| Month | Total questions | Answer rate within 72 hrs | Solved rate within 72 hrs | Forum helpfulness |
| Oct 2021 | 3682 | 72.51% | 16.21% | 72.45% |
| Nov 2021 | 3463 | 73.92% | 15.74% | 74.78% |
Top 5 forum contributors in the last 90 days:
KB
KB pageviews (*)
* KB pageviews number is a total of KB pageviews for /en-US/ only
| Month | Page views | Vs previous month |
| Oct 2021 | 8,688,751 | 5.38% |
| Nov 2021 | 8,306,363 | -4.40% |
Top 5 KB contributors in the last 90 days:
KB Localization
Top 10 locale based on total page views
| Locale | Oct 2021 pageviews (*) | Localization progress (per Nov, 4)(**) |
| de | 8.41% | 97% |
| zh-CN | 6.78% | 98% |
| fr | 6.68% | 90% |
| es | 6.09% | 37% |
| pt-BR | 5.55% | 57% |
| ru | 4.27% | 95% |
| ja | 3.87% | 53% |
| it | 2.39% | 100% |
| pl | 2.18% | 86% |
| zh-TW | 1.79% | 5% |
* Locale pageviews is an overall pageviews from the given locale (KB and other pages) ** Localization progress is the percentage of localized article from all KB articles per locale
Top 5 localization contributors in the last 90 days:
Social Support
| Channel | Oct 2021 | Nov 2021 | ||
| Total conv | Conv interacted | Total conv | Conv interacted | |
| @firefox | 2659 | 434 | 2585 | 672 |
| @FirefoxSupport | 190 | 178 | 289 | 244 |
Top 5 contributors in Oct-Nov 2021:
- Tim Maks
- Felipe Koji
- Bithiah Koshy
- Christophe Villeneuve
- Matt Cianfarani
Play Store Support
| Channel | Oct 2021 | Nov 2021 | ||
| Total conv | Conv interacted | Total conv | Conv interacted | |
| @firefox | 2659 | 434 | 2585 | 672 |
| @FirefoxSupport | 190 | 178 | 289 | 244 |
Top 5 contributors in Oct-Nov 2021:
- Paul Wright
- Selim Şumlu
- Matt Cianfarani
- Christophe Villeneuve
- Christian Noriega
Product updates
Firefox desktop
- FX Desktop Version 95 (Dec 8)
- TCP Roll Out/Continuous onboarding
- Remove about:ion from Firefox
- User don’t get interrupted when closing Firefox
- Picture in Picture toggle button moved to opposite side of video
Firefox mobile
- Fx Android V 95 (Dec 8)
- What’s New Android
- Homepage section in settings menu
- Pocket on by default in Canada
- Jump back in hero images
- Fx iOS V40 (Dec 8)
- Focus iOS V40, Android V95 (Dec 8)
- What’s new Focus iOS, Android
- Studies Toggle setting
- Lockwise Depreciation
- Delisting Android/iOS apps (12/13)
- Lockwise main functionality exists within mobile
- Lockwise users can still use app but no further dev and no new app downloads
- Desktop Lockwise Branding removal (Jan 12)
- No functionality changes for desktop password management features. Simply changing Lockwise branding to Password Management.
- Delisting Android/iOS apps (12/13)
- Premium Relay (Dec 15)
- Custom Subdomain Education
- Mozilla VPN V2.7 (Jan 12)
Other products / Experiments
- Firefox Monitor/Kanary Pilot (Jan)
- TCP breakage tracking experiment [unconfirmed]
Shout-outs!
- Kudos to andmagdo for being an awesome forum contributor!
- Shoutout to Bithiah who’s continue to be awesome contributor on the forum, and now also helping us on social support. Thank you so much for your support!
- Shoutouts to Marcelo, Valery, Daisuke, and Krzysztof for the help with the Windows Store reviews!
- Thanks for the feedback to everyone involved in the Firefox Suggest contributor thread. Special shoutout to Alice!
- And all the forum folks who helped with the FVD incident last week. Thank you so much for being there for Firefox users! Special shoutout for Paul collaborating with the AMO team and raising the flag to them when it happened.
If you know anyone that we should feature here, please contact Kiki and we’ll make sure to add them in our next edition.
Useful links:
From Railway to Greenway: How Vancouver is transforming a rail line into a destination park

My contribution to Park People’s 10 Years Together in City Parks.
As a child growing up on the westside of Vancouver, the railroad track along the Arbutus Corridor ran behind the tall hedges of our backyard. My sister and I would play along the tracks with neighbourhood kids, often leaving pennies behind to discover them flattened by passing trains the next day.
Children have a way of turning any space, even an industrial rail line, into a place for social gathering and play. Almost 40 years later, many cities around the world have adopted out-of-the-box thinking, converting underused industrial land into public spaces. This innovative approach to park design includes the Arbutus Corridor, which the City of Vancouver purchased in 2016 and is working to transform into the Arbutus Greenway, a ribbon of pathways and parks through the heart of Vancouver’s westside.
“The Arbutus Corridor has a history and it runs through parts of the city that in everyone’s minds are already developed,” says Antonio Gómez-Palacio, a partner at DIALOG, the urban planning firm that led the design and engagement process for the project. “Converting it to a greenway was an act of tenacity and creativity, working with the community to see the world in a different way, and to see a park there waiting to be discovered.”
The Greenway’s history spans over 100 years – from its beginnings as a railway for passengers and local industry, to contentious negotiations between the City of Vancouver and CP rail for its purchase. Today, it is an active transportation pathway that runs from the tourist destination of Granville Island to Vancouver’s southern edge, overlooking the Fraser River. In the future, it will become a multimodal corridor linking a series of destination parks and public spaces, and in the meantime, the local community has found creative ways to bring people together along its path.
Read on at Park People.
2021-12-01 BC
Statistics
+375 cases, +7 deaths.
Currently 301 in hospital / 98 in ICU, 2,936 active cases, 213,394 recovered.
| first doses | second doses | third doses | |
| of adults | 91.6% | 88.4% | 10% |
| of over-12s | 91.2% | 87.9% | 9% |
| of over-5s | 84.8% | 81.7% | * |
| of all BCers | ?% | ?% | ?% |
Charts


Maple Ridge crash: Driver charged in 2020 collision that killed cyclist
 |
mkalus shared this story . |
b'
\n\tMore than a year after cyclist Dafne Toumbanakis was struck and killed at the outset of a ride across Canada, a driver has been criminally charged.
\n\tThe 24-year-old victim was on the Lougheed Highway in Maple Ridge, B.C., when she was struck by a pickup truck on the afternoon of July 20, 2020.
\n\tOn Wednesday, following a 16-month investigation, Ridge Meadows RCMP confirmed one count of dangerous driving causing death has been approved against Mission resident Jason Davis.
\n\t"While the police consider the charge approval a positive outcome as far as the police investigation goes, we never lose sight of the fact that tragically someone lost their life in this incident," Const. Julie Klaussner said in a news release.
\n\tAuthorities previously said the driver remained at the scene and was co-operative with police.
\n\tFriends told CTV News that Toumbanakis, who lived in Montreal, was no stranger to long-distance cycling, having previously taken several international biking trips, including a solo ride from Turkey to Poland.
\n\t"She was a person that really enjoyed life, enjoyed open space, trekking, biking," her friend Sylvain Karpinski said in an interview after her death. "She was a super easygoing girl and she was a sweetheart."
Deep Code Search
Kim is a developer, and while implementing a new feature, they remember that they wrote something similar in another project. They open that project and starts searching for the code; It takes some time, but finding that code makes their current task easier. They wonder if the time spent searching was worth it, because they might have taken the same amount of time to reimplement the feature.
To help developers with tasks like this, Gu2018 proposes a tool called DeepCS that takes natural language queries and searches for relevant code in a large codebase. The CODEnn model that DeepCS uses to find relevant code snippets consists of three modules:
- A code embedding network (CoNN) that learns to embed code into vectors.
- A description embedding network (DeNN) that learns to embed natural language descriptions into vectors.
- A similarity module that measures the similarity between code and description vectors.
CoNN and DeNN use recurrent neural networks to embed inputs into vectors, while the similarity module uses cosine similarity measure to find the closeness between embedded inputs. Gu2018 used more than 18 million methods extracted from Java projects on GitHub to train the CODEnn model with Hinge loss as a loss function. (Hinge loss ensures that the learned vectors for description are close to the vector of corresponding code and far from vectors other code.)
DeepCS works in three steps. In the first, DeepCS takes a codebase as input and computes code vectors of methods using the CoNN module. It then takes a user query and computes the embedding vector using the DeNN module, and finally finds cosine similarity between query and code vectors obtained in previous steps and returns the ten methods with the highest similarity. To evaluate its performance, the authors collected 9950 projects having at least 20 stars from GitHub that contained more than 16 million methods. As a query, the authors used the top 50 voted Java questions from Stack Overflow. DeepCS had relevant code snippets present in the top 10 results for 86% of queries, compared to 66% for the previous state-of-the-art system. DeepCS also had 49% relevant code snippets in the top 10 results compared to only 28% for previous tools.
Gu2018 Xiaodong Gu, Hongyu Zhang, and Sunghun Kim: "Deep Code Search". Proc. International Conference on Software Engineering (ICSE), 2018, 10.1145/3180155.3180167.
To implement a program functionality, developers can reuse previously written code snippets by searching through a large-scale codebase. Over the years, many code search tools have been proposed to help developers. The existing approaches often treat source code as textual documents and utilize information retrieval models to retrieve relevant code snippets that match a given query. These approaches mainly rely on the textual similarity between source code and natural language query. They lack a deep understanding of the semantics of queries and source code. In this paper, we propose a novel deep neural network named CODEnn (Code-Description Embedding Neural Network). Instead of matching text similarity, CODEnn jointly embeds code snippets and natural language descriptions into a high-dimensional vector space, in such a way that code snippet and its corresponding description have similar vectors. Using the unified vector representation, code snippets related to a natural language query can be retrieved according to their vectors. Semantically related words can also be recognized and irrelevant/noisy keywords in queries can be handled. As a proof-of-concept application, we implement a code search tool named DeepCS using the proposed CODEnn model. We empirically evaluate DeepCS on a large scale codebase collected from GitHub. The experimental results show that our approach can effectively retrieve relevant code snippets and outperforms previous techniques.
Your Chromebook can now scan documents and shoot video

Google is making solid strides in making Chromebooks more versatile and inclusive, with recent additions like live captioning and a new ‘Diagnostics’ app.
Now, the Mountain View, California-based company is adding more functionality to your Chromebook's camera, such as the ability to scan documents, making it easier for students and professionals alike to get tasks done quicker.
"You can now use your Chromebook’s built-in camera to scan any document and turn it into a PDF or JPEG file," reads Google's blog post.
The feature works similarly to how native smartphone scanners work. Select "Scan" mode in your Chromebook's Camera app. Proceed to hold the document you wish to scan in front of the camera, and the camera will automatically detect the document's edges. You can manually select the edges too.
Once scanned, you can directly share the scanned PDF or JPEG via Gmail, social media, and even to nearby Android phones or Chromebooks through 'Nearby Share.'
While the feature adds to the Chromebook's overall appeal, I don't see many people using it over their smartphones to scan documents.
Additionally, the Scan option also supports scanning QR codes. Simply toggle from the Document mode to the QR Code mode, as seen in the image below:
If you use an external camera with your Chromebook, "you can use the Pan-Tilt-Zoom feature to have more control over what your camera captures." The feature allows you to set preferred camera angles and control what you want appearing in the frame, including an option to zoom into your face.
Google says your exact preferences will be saved across all video platforms for video calls, eliminating the need to configure the angles every time you hop on to Microsoft Teams or Zoom.
Other new camera features coming to Chromebooks are:
- Video mode
- Self-timer
- Save for later -- All your photos and videos will automatically save to the “Camera” folder in your Chromebook's Files app.
Google is also working on a new feature that will allow you to convert videos you shoot from the Chromebook's camera into GIFs directly from the camera app. The feature will likely appear in Q1, 2022.
Image credit: Google
Source: Google
Age of Wonders

This amiable, expert look at the world of science fiction as it was in the mid-1990s runs from the history and economics of the genre to the unique genre fandom that shapes expectation and reception. I was surprised to see the weight that Hartwell, a consummate insider, accords to the fan phenomenon, which has always defined itself as outsider and — very much unlike Hartwell — anti-literary. Yet the influence is undeniable, and Hartwell shows why that matters. The superb annotated bibliography is helpful.
What I miss here are the sensible discussions about trends and mechanics that Hartwell used to write for The New York Review Of Science Fiction. I remember, for example, a fascinating column discussing how a genre in which short novels flourished in the 1960s — remember Ace Doubles? — came to demand thick bricks (and treble volumes) shortly afterward. Perhaps this seemed too much inside baseball, and too far from the book’s argument for the seriousness of science fiction.
Apple Music names Toronto’s The Weeknd ‘Global Artist of the Year’

Apple has published its annual music awards, and the Toronto-born The Weeknd has taken home the top prize for 'Global Artist of the Year.'
Beyond that, Olivia Rodrigo won the award for 'Album of the Year,' 'Breakthrough Artist of the Year' and 'Song of the Year,' which is a considerable feat, putting her on track to reach the upper echelon of Disney stars that break out of their children's channel past to hit mainstream music stardom.

The third artist to win one of these prestigious awards was H.E.R for 'Songwriter of the Year' for her powerful year carried by the release of the album 'Back of My Mind.'
Apple also added awards this year for the Artists of the Year for different regions: Africa, France, Germany, Japan and Russia. The winners are as follows:
- Africa -- WizKid
- France -- Aya Nakamura
- Germany -- RIN
- Japan -- Official Hige Dandism
- Russia -- Scriptonite
If you subscribe to Apple Music, the streaming music service has put together a great roundup of all of these artists in the 'Browse' section of the app. Apple has also released Apple Music's top streamed songs of 2021.
Source: Apple