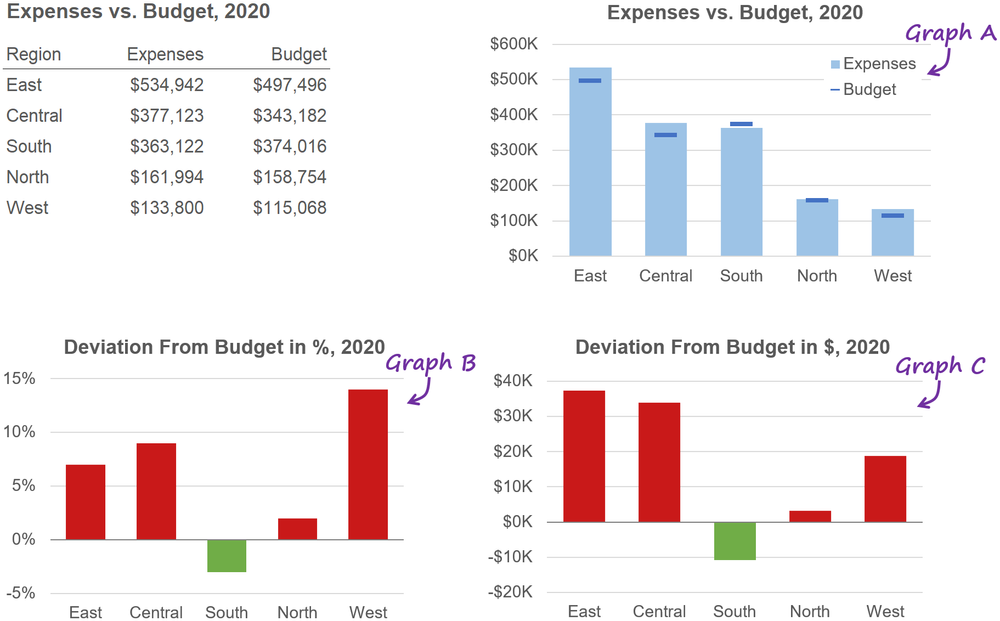
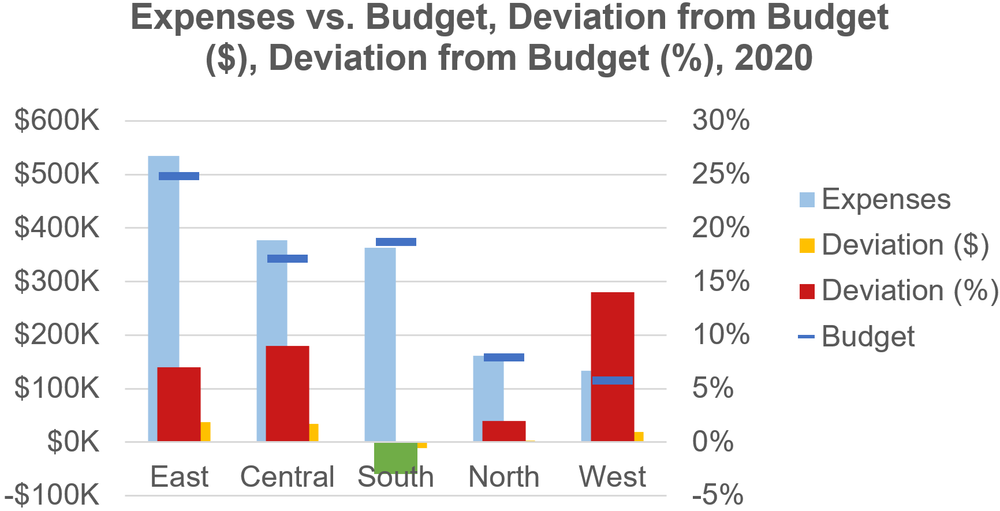
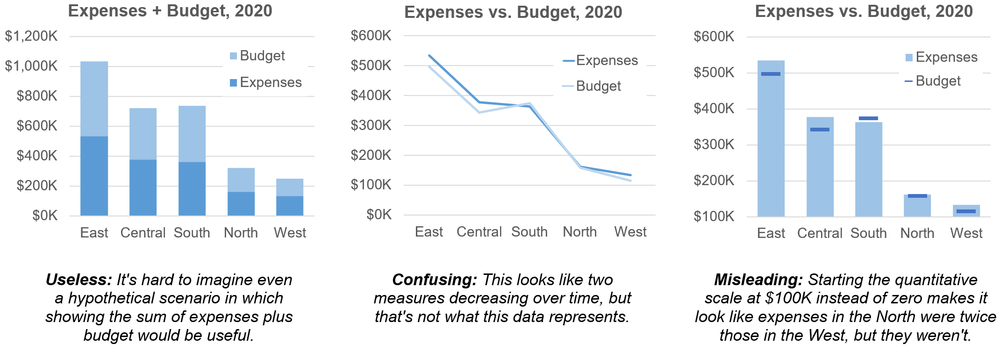
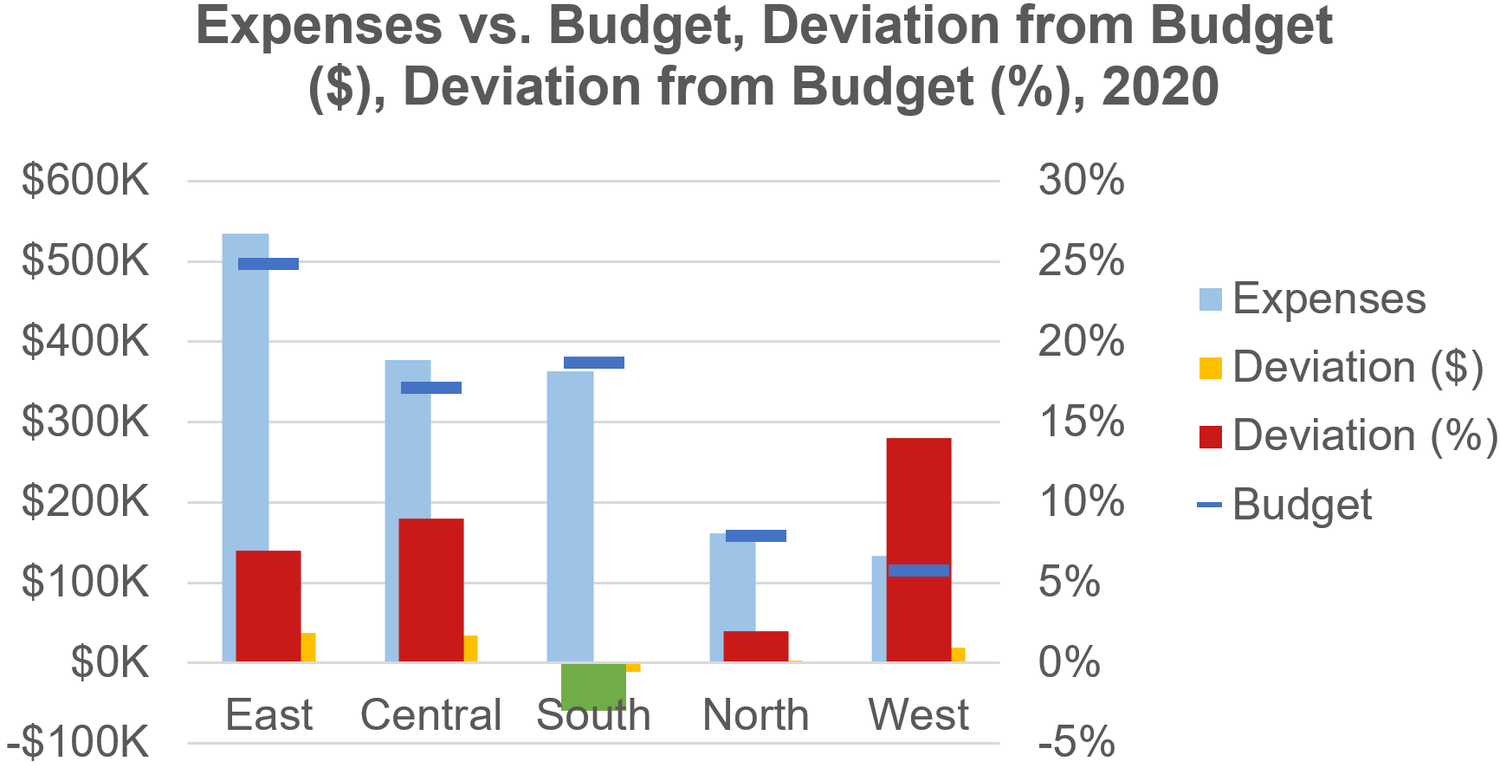
There’s a palpable sense that Boris Johnson’s reputation has reached an inflexion point. For years it seemed as if however dishonest and incompetent he was he could do nothing wrong in the eyes of his supporters. Suddenly, he can do nothing right. We know that he has reached such a point because almost every newspaper columnist and editorial writer tells us so, and in this case conventional wisdom is reliable because what else can reputation consist of other than what is reputed to be?
As the political sociologist
William Davies puts it, Johnson is like a financial asset that has lost the confidence of the market. And he is more vulnerable than most politicians to changing sentiment because he has so little substance in terms of policy agenda or ideological belief, which in turn means that there is
no loyal group of ‘Johnsonites’. His politics are solely those of reputation and people buying in to that reputation, whether it be as ‘a character’ or, relatedly, as
an election winner.
Labour’s increasingly effective attack line that “the joke isn’t funny anymore” acutely captures that vulnerability because it highlights that whilst Johnson hasn’t changed, the collective view of him has. So the man who first came to public prominence as
a droll panelist on HIGNFY this week suffered the indignity of being
openly mocked by Ant and Dec on I’m a Celebrity.
Of course there’s still scope for contrarian investors to
keep faith with Johnson. Although his
personal approval ratings have fallen considerably, and voter support for the Conservatives
in opinion polls slightly, he might very well win a General Election if one were held tomorrow. And he has a track record of bouncing back from adverse headlines and scandals. However, It is significant that so many
within his own party are now openly critical of him.
Most importantly, what seems different this time is the range of issues over which he is being criticized, from sleaze and cronyism, through specific policies such as rail building, sewage management and social care, to his ludicrously
shambolic speech to the CBI this week, and the way that these are being knitted into a single narrative about his personal and political failures.
The marriage of Johnson and BrexitThis inevitably links to Brexit. The
Guardian columnist Jonathan Freedland captures something of this in
a recent article about the multiple dishonesties of Johnson’s government. He writes that “the mother and father of these dishonesties remains Brexit, still the organizing principle of this government and the adhesive that binds Johnson to his party”. I think that’s right, but the inextricable linkages of Brexit and Johnson’s administration are complicated.
Johnson might well have become Prime Minister even if Brexit never happened, and Brexit might well have happened without his support. So they are only contingently related. But it and his premiership are indelibly marked by each other.
On the one hand, when he did come to power it was not only on the back of Brexit but on the basis that he would be a ‘harder’ Brexiter than Theresa May. On the other hand, whilst the case for Brexit was always based on dollops of fantasy and hefty doses of dishonesty, it was Johnson’s fraudulent boosterism that gave Vote Leave its most compelling public face. He also supplied it with the bogus political rationality of what may well be the entirety of his personal and political credo, the proposition that it is possible to ‘have one’s cake and eat it’ or ‘cakeism’.
Cakeism has become a cliché and a joke, but
its significance and its appeal as an idea shouldn’t be underestimated. It suggests that choices are free of consequences and decisions can be made without regard for trade-offs. With Brexit, that was an enabler of using ‘Project Fear’ to discredit any assessment of costs and risks. Even worse, it set up the paradoxical yet pervasive idea that Brexit was a crucial change, and yet, somehow, nothing much would really change at a practical level. From this frankly infantile view of the world grew the far more toxic way that as the costs and negative changes have transpired, they have invariably been ascribed to EU punishment or remainer treachery rather than being entailed by Brexit.
Johnson
continued to maintain the doctrine of ‘cakeism’ even as he agreed the Trade and Cooperation Agreement (TCA), which he actually called “a cakeist treaty” and claimed that it proved his critics wrong as they had said there could be no free trade with the EU without obeying EU law. But of course this was a lie: critics of cakeism had said that the UK couldn’t have the advantageous terms of trade of a single market member without being a member. The TCA demonstrated that. From this, and the associated non-tariff barriers to trade, which he also dishonestly said had been avoided, flowed almost all the problems that have since bedeviled UK-EU trade.
Exactly the same bogus rationality is evident in the ongoing situation as regards the Northern Ireland Protocol (NIP), which now
looks set to drag into the new year. Here, the cakeist proposition was that there needed to be a border and yet there didn’t need to be a border. Ultimately, that led to the disgraceful idea that the UK could make an agreement but that didn’t mean that it had agreed to it, which is exactly the knot that has tied up UK-EU relations ever since. Again, it is also what leads to the charge that the UK is the victim of EU ‘inflexibility’ or ‘legalism’ in applying what was agreed.
However, although Johnson’s own irresponsibility and dishonesty were well-suited to those of the Brexit project it would be wrong to conflate the two. It was a marriage of convenience for him and a polyamorous one for the Brexiters. Johnson, as is well known,
might not have backed Brexit at all had he calculated that supporting remain would have advantaged him more. Meanwhile, Brexiters like David Davis, with his claim that there was a form of trade agreement that yielded
the “exact same benefits” as single market and customs union membership, were perfectly capable of cakeism without any help from Johnson.
From Brexit to ‘Brexitification’What can be said is that, by the time he became Prime Minister,
Johnson and hard Brexit were inseparable. He made Brexit loyalty the sole defining test for ministerial office, and surrounded himself with ideologues from Vote Leave and associated groups to advise him. He also made ‘Brexitism’ his government’s
modus operandi meaning, in particular, the hostility to and disdain for established norms associated with both the Vote Leave nihilists and the ERG Jacobins. That was immediately evident in the attempted prorogation, and has continued in the form of contempt for parliament, the civil service, the judiciary, universities, the media, and for the rule of national and international law. Thus Johnson’s is a Brexit government in the double sense of Brexit being its defining policy and of presiding over a ‘Brexitification’ of British politics.
It is therefore no coincidence that the proximate cause of his current fall from grace was the ill-fated attempt to save
arch-Brexiter Owen Paterson from punishment, nor that the means of doing so was to propose to rip up the parliamentary procedures and also to smear the independent Commissioner for Standards
as biased against Brexiters (£). Nor is it a coincidence that the government is engulfed in accusations of cronyism, because this grows from what
in a post last April I called the “anti-ruleism” that defines the Brexit government. It is all the more toxic for its interconnections with the sense of privileged entitlement that has long characterized the Conservative Establishment, to which it adds the bizarre Brexit twist that anyone who objects is part of the ‘remainer elite’.
This Brexitification – I know it isn’t a word but it really should be, if only because it is so appropriately ugly – is not just about contempt for rules, norms and laws. It is also about the importation of the political rationality of cakeism into policy-making as a whole. Writing
on the Conservative Home website this week, former Justice Secretary David Gauke suggests that across the board what we are seeing is the dysfunctionality of a politics which doesn’t accept the complexity and trade-offs of political reality and thinks that “a bit of oomph and optimism” will overcome them. I assume the Brexiters would dismiss this analysis because it comes from Gauke, one of
the 21 rebels who lost the Conservative whip in 2019 for opposing no-deal Brexit. If so, that in itself is an example of Brexitification in that it views everything through the prism of Brexit tribalism. Yet, in general terms, it’s the same critique that many pro-Brexit Tory MPs are making of
the government’s careless handling of policy detail.
Johnson as architect and prisoner of BrexitIf Brexitification has infected the wider policy arena, it also continues to shackle government policy towards Brexit itself. Hence it was not just that Johnson’s CBI speech was bizarre in content and inept in delivery. It was also, as
a scathing editorial in The Times complained (£), that it had nothing to say about “post-Brexit skills shortages and trade barriers” nor about the poor performance of the FTSE-100 ever since the referendum. It was not “a serious speech for serious times”, whereas Sir Keir Starmer’s, which included commitments to improve on the TCA and to improve the tone of relations with the EU, was reported favourably.
Johnson isn’t in a position to make the kind of suggestions Starmer did, because he is both the architect and the prisoner of the problems Brexit is bringing daily to almost every sector from
hospitality to
construction to
social care to
financial services to
touring performers. The terms of the TCA, which is up for review in 2026, could fairly easily be improved even within the restrictive parameters of hard Brexit – for example through increased regulatory alignment and a mobility chapter. Averting the as yet postponed but soon to come
business nightmare of the ‘independent’ UKCA mark would also be a pragmatic step (see
my post of last August for discussion). Dropping the endless antagonism towards the EU despite having left would be another, and indeed the precondition for substantive improvements in the relationship.
It is not inherent in Brexit for such modest initiatives to be impossible. But they would incite the wrath of the Brexit Ultras and be incompatible with the
‘Betamax’ approach of David Frost who has virtually sole charge of Brexit policy (Johnson having lost interest and the Foreign Office appearing
simply to ignore the EU altogether). Even the very slight improvement in mood that seems recently to have appeared in the NIP talks has
already been denounced as Frost “crumbling” to EU pressure. This is possibly why
he has now started talking up post-Brexit tax cuts and vague regulatory reforms, these being the sort of things to get the Ultras salivating and the lack of which is one reason for their growing disaffection with Johnson. Indeed this is the main reason why the government is stuck with
no serious post-Brexit policies: it can neither satisfy the Ultras nor can it ditch them.
That, too, goes a long way to explaining the inadequacy of the government’s response to Covid, especially in England, because of the very
strong connection between pro-Brexit and anti-lockdown (or anti-restriction) theology. Notably, Frost’s speech also celebrated the lack of vaccine passports and mask-wearing compulsion. We also
learned this week how planning for a no-deal Brexit materially damaged pandemic planning so, again, both Brexit and Brexitification have deformed policy-making in ostensibly non-Brexit areas. And, again, this intersects with Johnson’s cakeist approach in his reluctance to accept hard choices, as if it is possible both to defeat Covid and to avoid the inconveniences of tackling it. It’s as if his hero Churchill had promised to fight on the beaches so long as it didn’t disturb anyone’s dinner plans.
VileOn the subject of beaches, nowhere is the linkage of Johnson’s waning reputation, Brexit, and Brexitification clearer than in the
nationalistic panic about cross-channel migrants. As with Brexit itself, Nigel Farage is playing a key role in promoting this vile agenda. For
the time being he no longer has a political party, but his media platform is enough. Thus
for well over a year he has taken to hanging around grubbily on the English coast spying on migrant boats, rather like a leering suburban Peeping Tom bedecked in topless trousers and sweatily hoping for a glimpse of mottled flesh through his next-door neighbour’s steamed-up bathroom window.
His pains have been rewarded. Inevitably Johnson’s government has embraced rather than challenged Farage and the more general media viciousness about refugees and asylum seekers. After all, this was in part the fetid midden from which Brexit itself grew – recall
the ‘Breaking Point’ poster - and the current discourse is entirely Brexitified. It has the same recourse to garbled, technical-sounding but
false claims, notably ‘under international law they’re obliged to seek refuge in the first safe country they reach’ (cf. ‘
GATT Article XXIV’), the same subliminal yet always denied racism, and the same objectification of migrants. And it has the same
Brexiter simplism, reducing complex issues to tough-sounding but ineffectual slogans, whilst shifting blame
to the EU or
France and presenting Britain as
the put-upon victim of an ‘invasion’ caused by its own ‘generosity’ (warning: the latter link contains some truly despicable claims).
It is also directly linked to Brexit given that welcoming anything like
a remotely fair share of refugees and asylum seekers is deemed
a betrayal of Brexit promises. As Sir Edward Leigh
spluttered pucely this week, we were meant to have “taken back control of our borders” (even if not as yet going so far as
Leigh’s own solution of taking back control of Calais, lost in 1558). Yet here is an obvious case of the failure of Brexiters to understand that choices have consequences. For if, as they think desirable, Britain wants to send asylum seekers back to EU (and EFTA) countries it can
no longer do so using the Dublin Regulations, from which it voluntarily exited as part of Brexit.
Meanwhile, the UK’s preferred approach of creating bilateral agreements with EU countries for the same purpose has come to nothing, and any idea of such an agreement with France, in particular, looks unlikely given the
parlous state of Anglo-French relations post-Brexit. The latter issue perhaps also reveals the consequences of hiving off UK-EU relations to Frost with his default setting of pugnacity and insistence on sovereignty at all costs. That hardly helps when you suddenly discover that you need cooperation and goodwill. Nor does
Johnson’s long history of jibes at the French, as suggested by
this morning’s news that his latest intervention, regarded by France as “unacceptable”, has prompted the withdrawal of an invitation to Home Secretary Priti Patel to discuss the situation.
At all events, far from being a solution, Brexit has added to
the supposed problem and certainly done nothing to avert
the horror that happened in the Channel this week which is all too likely to be repeated despite – indeed in part because of -
Patel's crocodile tears. This creates another policy area in which Johnson is failing, and it’s an inevitable consequence of seeking to appease rather than challenge the Faragist narrative. Such appeasement is bound to lead to failure because it refuses to recognize
the real problems and their possible solutions and also because whatever the government did wouldn’t be enough for Farage.
At the other end of the migration spectrum, a scheme announced by Patel six months ago to attract Nobel Prize winners and other field-leading figures to the UK has this week been revealed
to have had precisely zero applications. It’s hardly a surprise considering how post-Brexit Britain appears to the outside world, something to which Brexiters are entirely oblivious. That includes the vileness of attitudes to refugees, of course. For whilst Brexiter politicians may purr about welcoming ‘the brightest and the best’, the general climate they have created means it’s by no means fanciful to imagine anyone who did come under the scheme being spat at, abused and told to ‘go back where you came from’, or worse.
It’s also another example of the boosterish but insubstantial nature of Brexitified politics. As Professor Andre Geim of Manchester University, himself a Nobel Laureate, put it, the scheme suffered from the “verbal diarrhoea of optimism”. Building and maintaining a science base, like many other policies, requires long patient slog to build capacity, not gimmicks or endless rhetoric about being ‘world-leading’.
After JohnsonIf it’s the case that Johnson is the joke that isn’t funny anymore, it doesn’t follow that Brexit is similarly discredited. For one thing, for all that Johnson may have sold it as a larky adventure, Brexit has never been remotely amusing. More important is to recall that the connection between Johnson and Brexit is contingent rather than necessary.
This means that his demise, when it comes, will not reverse Brexitification (and, of course, will certainly not reverse Brexit). It’s all but unthinkable that his successor as Tory leader will not be an ardent Brexiter, and probably a more convinced one than Johnson. Nor is it clear that a UK government under any other party will be able, or will even necessarily try, to undo the toxic effect of Brexitificaton.
The tragedy of that will linger long after the joke has ended.