Hint: documentation, documentation, documentation.

Setting up your project for success
Not too long ago I wrote a post about an open source project I released through The New York Times. Although I have had some experience contributing to open source software (OSS) in the past, this was my first time launching an open source project where I was the sole contributor and wanted others to use what I had written in their own projects. As someone who has benefitted from plenty of incredible OSS projects, I had some idea of what a “good” open source repo on GitHub looks like: it should have a README.md file, installation instructions and enough documentation to get started. But beyond that, I was totally lost: what would take my repo from good to great?
What follows is a short guide, pulled from my own experience, on best practices when making a project open source. Most of what I learned was found through research online, conversations with coworkers and friends and checking out dozens of projects available on GitHub.
Documentation is Key
Probably one of the biggest pitfalls for open source projects is a lack of documentation. Having easily accessible, human readable and reference-able documentation can be the difference between a project that is readily consumed by others and one that falls by the wayside without much fanfare.
There are a few places where you can place important information, but the most central and accessible is in the project’s root README.md file.
Start with a README

The README.md is the most visible file in your repository and likely the first one a person will see. The project’s main README file is usually located in the root of your repository and acts as the landing page for your repo; it should communicate the most important information about your project clearly and concisely. There aren’t hard and fast rules about what should and shouldn’t be in a README, but the following are some good starting points.
Why your project exists. What purpose does it serve and who does it serve? This is a mission statement of sorts and should be prominently visible for anyone who’s visiting the repo for the first time.
Quick start instructions. Usually includes instructions on how to download and use your code as quickly and easily as possible.
In-depth API documentation. Depending on how robust your API is, you could opt to include the documentation for it directly in your README file. If there is too much to fit in one place or you need more documentation features (such as search capability, FAQ, forum, etc.), this is where you can link to an external site.
How to contribute. The next part of this post will do a deeper dive on how to instruct others to contribute to your project via a contributing guide, but the README.md file is a great place to encourage contributions and link them to that guide.
Shout out to your contributors. It’s important to give thanks and recognize those who help support your project. The All Contributors project is a great resource on how to best reward different kinds of contributions along with some handy tools that make it easier to streamline the process.
Where to turn for help. If a user or contributor needs help using your code, who should they reach out to? Would you prefer they ask you directly, open an issue in GitHub or reach out to others working on the same things? Some larger communities set up IRC or Slack spaces where anyone can ask questions and get help from others.
Code of conduct. No one wants to deal with a jerk on the internet. Including a code of conduct can clearly point out the kinds of behavior that aren’t tolerated and can help structure an inclusive community around your project. The Contributor Covenant is a widely adopted code that celebrates and encourages diversity of thought and people, and clearly defines enforced punishments for those who act in discriminatory or ill-intentioned ways. There are a plethora of examples of different types of code of conduct out there, so do your research and pick the one that best aligns with how you and your community members want the developers around your open source project to behave — or create your own.
The README file is meant to direct users to where they need to go, either with code samples, set-up instructions or links to more in-depth forms of documentation. These are just some of the topics you can include in your README, but there are so many others that might be right for your particular project. Don’t be afraid to take a look at other repos, whether or not they’re similar to yours or completely different, and borrow ideas whenever you think it makes sense!
Helping Others Contribute
Whether or not you expect anyone to contribute to your project, you should be prepared for the possibility of others wanting to help your cause. And when that happens, your contributing guide will show those helpers exactly how they can get involved. This guide, usually in the form of a CONTRIBUTING.md file, should include information on how one should submit a pull request or open an issue for your project and what kinds of help you’re looking for (bug fixes, design direction, feature requests, etc.).
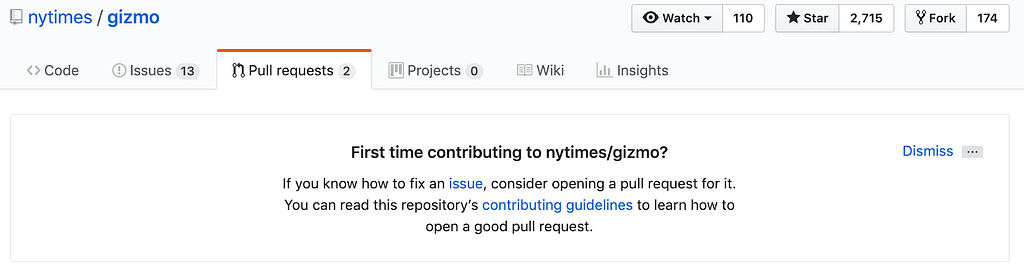
The following are some examples of information you can include in your contributing guidelines.
Instructions on how to work in the codebase locally. This is for anyone who wants to make code contributions. It should include any start or run scripts, suggestions for how to navigate the codebase, code style expectations and other details you deem necessary to successfully have changes incorporated into the project.
Testing instructions. If your codebase has tests that need to pass for any PR to be considered, include instructions on how to run tests for your project and how to write additional tests for the contributor’s proposed changes.
An issue template. Clearly define the information you want included in new issues. Details like the kind of issue being filed (bug, feature request, documentation change), OS version, browser, language/environment specifics and steps to reproduce can save you and the contributor hours of debugging. To help reporters write a helpful issue, consider including an issue template that will prepopulate a new issue with the information you expect to be included.
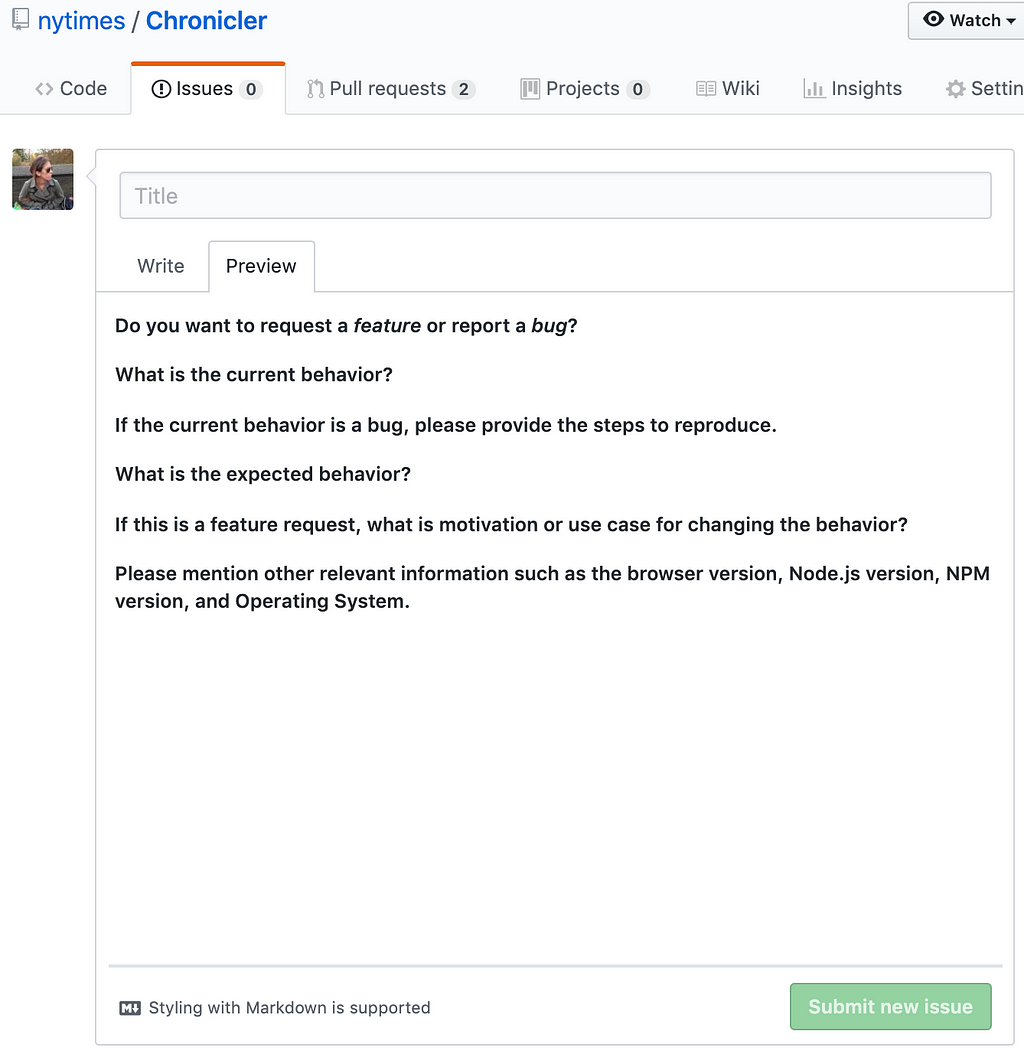
A section on your repository’s license. Having a license protects you, your contributors and anyone who uses your work. Knowing which license will work for you and your audience is probably the most difficult part of checking this requirement off, but choosealicense.com and tl;dr legal make it easier for anyone to make an informed decision.
Going the Extra Mile

Having a thorough README, contributing guidelines and helpful templates are just the beginning of getting your OSS project ready for launch. While these can be considered the “bare bones” of any project worth its salt, there are plenty of additional steps you can take to create a project that is both pleasant to use and to contribute to.
Make sure your codebase is secure. Your code could be used or seen by tens, hundreds or maybe even thousands of people. Take precautionary steps to secure your accounts by following best practices like keeping your passwords and secrets out of your git history, running regular security scans on your codebase and keeping your dependencies up-to-date with the latest security packages. Luckily, GitHub makes this task easier by providing automatic security alerts for public repositories so you can stay up-to-date on the latest vulnerabilities in your projects.
Write and enforce tests. Including tests in your codebase can help reduce the possibility of accidentally introducing bugs or making a breaking change; This is especially important in a codebase where many people are working simultaneously. If you’re accepting Pull Requests from contributors, make sure you clearly define when and how to include tests.
Use a code linter. Linters can help catch the small mistakes, like using a tab instead of a space, and the big mistakes, like when forgetting a semicolon can be absolutely detrimental (*cough* PHP *cough*). They also give you the power to enforce certain coding styles without having to personally enforce coding styles character by character.
Include git hooks. Git Hooks are commands or scripts that are automatically run before certain actions take place in Git. They can hook into several different git commands — commit, push, merge, etc. — and are used to automatically run processes that you deem necessary before or after these commands. For example, many engineers use git hooks that run tests before a commit or push; If the tests fail, the commit or push will fail. This adds another level of protection to a project by automatically rejecting any code changes that break tests or fail linting standards, before ever making it into a PR or the master branch.
Add Continuous Integration/Development tools. CI/CD are great for automating the mundane tasks associated with reviewing, maintaining and shipping code. This could be anything from assigning someone to perform a code review on a PR to deploying a branch to a staging environment. There’s an ocean of resources and tooling available for any type of project, so I won’t go into too much detail here. But the GitHub Apps Marketplace is a smorgasbord of tools you can integrate into any project.
Include Editor/IDE configuration files. Helping your contributors set up their code editors or IDE to work within the constraints of your project’s can reduce a contributor’s time spent toying with settings. Popular (and free) text editors like VSCode and Atom allow you to control settings like whether to use tabs or spaces in a project, running linters automatically on save and many others.
Get to it
The basics covered above are only the tip of the iceberg, but they will help get you well on your way to creating a well-organized, maintainable and accessible open source project. However, there’s no one right way to set up or maintain your project, so continue to do some research to find out what works best for you and your codebase. Pull inspiration from OSS repos that you’ve used or have contributed to, or ask your colleagues and peers for any advice they can share.
How to Take Your Open Source Project from Good to Great was originally published in Times Open on Medium, where people are continuing the conversation by highlighting and responding to this story.






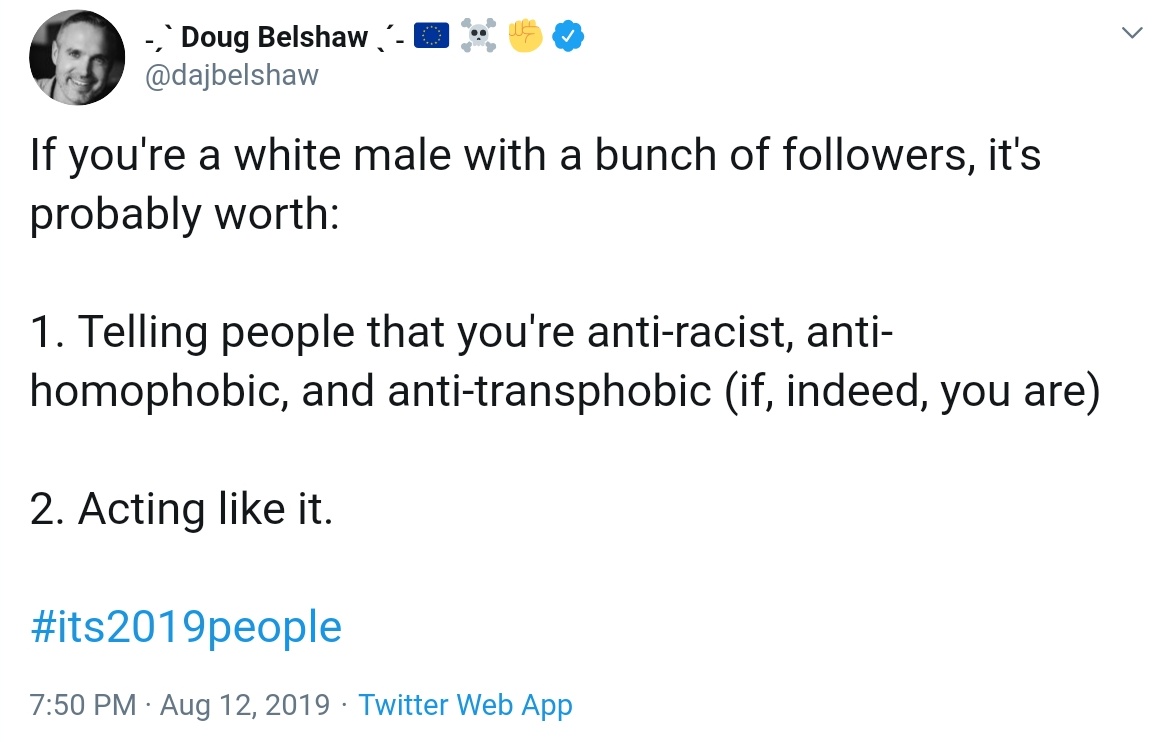
 . I’ve been a little skeptical when people have called Twitter a ‘rage machine’ because of the move they’ve made towards an algorithmic timeline. Well, I was wrong to be doubtful; this was that in action.
. I’ve been a little skeptical when people have called Twitter a ‘rage machine’ because of the move they’ve made towards an algorithmic timeline. Well, I was wrong to be doubtful; this was that in action.





 (@AmazonFCRuben)
(@AmazonFCRuben) 
 Seguro que va a tope
Seguro que va a tope 
 Mi compañero
Mi compañero  Se lo toma muy enserio eh? jejeje
Se lo toma muy enserio eh? jejeje 









