I really want to understand all the software that runs on my secure devices.
It’s a bit of a quixotic quest, but so far we’ve made pretty good progress towards this goal: I’ve been helping to write the Xous OS from the ground up in pure Rust – from the bootloader to the apps. Xous now has facilities like secure storage, a GUI toolkit, basic networking, and a password vault application that can handle U2F/FIDO, TOTP, and plaintext passwords.
One of the biggest challenges has been keeping our SBOM (software bill of materials) as small as possible. I consider components of the SBOM to be part of our threat model, so we very selectively re-write crates and libraries that are too bloated. This trades off the risk of introducing new bugs in our hand-rolled code versus the risk of latent, difficult-to-discover bugs buried in more popular but bloated libraries. A side benefit of this discipline is that to this day, Xous builds on multiple platforms with nothing more than a default Rust compiler – no other tooling necessary. It does mean we’re putting a lot of trust in the intractably complicated `rustc` codebase, but better than also including, for example, `gcc`, `nasm`, and `perl` codebases as security-critical SBOM components.
Unfortunately, more advanced networking based on TLS is a huge challenge. This is because the “go-to” Rust library for TLS, `rustls`, uses `ring` for its cryptography. `ring` is in large part an FFI (foreign function interface) wrapper around a whole lot of assembly and C code that is very platform specific and lifted out of BoringSSL. And it requires `gcc`, `nasm`, and `perl` to build, pulling all these complicated tools into our SBOM.
Notwithstanding our bespoke concerns, `ring` turns out to be the right solution for probably 90%+ of the deployments by CPU core count. It’s based on the highly-regarded, well-maintained and well-vetted BoringSSL codebase (“never roll your own crypto”!), and because of all the assembly and C, it is high performance. Secure, high-performance code, wrapped in Rust. What else could you ask for when writing code that potentially runs on some of the biggest cloud services on the Internet? I definitely can’t argue with the logic of the maintainers – in Open Source, sustainability often requires catering to deep-pocketed patrons.
The problem, of course, is that Open Source includes The Bazaar, with a huge diversity of architectures. The problem is well-stated in this comment from a RedHat maintainer:
…I’m not really speaking as a member of the Packaging Committee here, but as the person who is primary maintainer for 2000+ packages for Rust crates.
In Fedora Linux, our supported architectures are x86_64, i686, aarch64, powerpc64le, s390x, and, up to Fedora 36, armv7 (will no longer supported starting with Fedora 37). By default, all packages are built on all architectures, and architecture support is opt-out instead of opt-in. […]
On the other hand, this also makes it rather painful to deal with Rust crates which only have limited architecture support: Builds of packages for the affected crates and every other package of a Rust crate that depends on them need to opt-out of building on, in this case, powerpc64le and s390x architectures. This is manageable for the 2-3 packages that we have which depend on ring, but right now, I’m in the process of actually removing optional features that need rustls where I can, because that support is unused and hard to support.
However, the problem will get much worse once widely-used crates, like hyper (via h3 and quinn) start adding a (non-optional) dependency on rustls / ring. At that point, it would probably be easier to stop building Rust crates on the two unsupported architectures completely – but we cannot do that, because some new distribution-critical components have been introduced, which were either written from scratch in Rust, or were ported from C or Python to Rust, and many of them are network stack related, with many of them using hyper.
Long story short, if Redhat/Fedora can’t convince `ring` to support their needs, then the prognosis for getting our niche RISC-V + Xous combo supported in `ring` does not look good, which would mean that `rustls`, in turn, is not viable for Xous.
Fortunately, Ellen Poe (ellenhp) reached out to me in response to a post I made back in July, and informed me that she had introduced a patch which adds RISC-V support for ESP32 targets to `ring`, and that this is now being maintained by the community as `ring-compat`. Her community graciously tried another go at submitting a pull request to get this patch mainlined, but it seems to not have made much progress on being accepted.
At this point, the following options remained:
- Use WolfSSL with FFI bindings, through the wolfssl-sys crate.
- Write our own crappy pure-Rust TLS implementation
- Patch over all the `ring` FFI code with pure Rust versions
WolfSSL is appealing as it is a well-supported TLS implementation precisely targeted toward light-weight clients that fit our CPU profile: I was confident it could meet our space and performance metrics if we could only figure out how to integrate the package. Unfortunately, it is both license and language incompatible with Xous, which would require turning it into a stand-alone binary for integration. This also reduced efficiency of the code, because we would have to wrap every SSL operation into an inter-process call, as the WolfSSL code would be sandboxed into its own virtual memory space. Furthermore, it introduces a C compiler into our SBOM, something we had endeavoured to avoid from the very beginning.
Writing our own crappy TLS implementation is just a patently bad idea for so many reasons, but, when doing a clean-sheet architecture like ours, all options have to stay on the table.
This left us with one clear path: trying to patch over the `ring` FFI code with pure Rust versions.
The first waypoint on this journey was to figure out how `ring-compat` managed to get RISC-V support into `ring`. It turns out their trick only works for `ring` version 0.17.0 – which is an unreleased, as-of-yet still in development version.
Unfortunately, `rustls` depends on `ring` version 0.16.20; `ring` version 0.16.20 uses C code derived from BoringSSL that seems to be hand-coded, but carefully reviewed. So, even if we could get `ring-compat` to work for our platform, it still would not work with `rustls`, because 0.17.0 != 0.16.20.
Foiled!
…or are we?
I took a closer look at the major differences between `ring` 0.17.0 and 0.16.20. There were enough API-level differences that I would have to fork `rustls` to use `ring` 0.17.0.
However, if I pushed one layer deeper, within `ring` itself, one of the biggest changes is that ring’s “fipsmodule” code changes from the original, hand-coded version, to a machine-generated version that is derived from ciphers from the fiat-crypto project (NB: “Fiat Crypto” has nothing to do with cryptocurrency, and they’ve been at it for about as long as Bitcoin has been in existence. As they say, “crypto means cryptography”: fiat cryptography utilizes formal methods to create cryptographic ciphers that are guaranteed to be correct. While provably correct ciphers are incredibly important and have a huge positive benefit, they don’t have a “get rich quick” story attached to them and thus they have been on the losing end of the publicity-namespace battle for the words “fiat” and “crypto”). Because their code is machine-generated from formal proofs, they can more easily support a wide variety of back-ends; in particular, in 0.17.0, there was a vanilla C version of the code made available for every architecture, which was key to enabling targets such as WASM and RISC-V.
This was great news for me. I proceeded to isolate the fipsmodule changes and layer them into a 0.16.20 base (with Ellen’s patch applied); this was straightforward in part because cryptography APIs have very little reason to change (and in fact, changing them can have disastrous unintended consequences).
Now, I had a `rustls` API-compatible version of `ring` that also uses machine-generated, formally verified pure C code (that is: no more bespoke assembly targets!) with a number of pathways to achieve a pure Rust translation.
Perhaps the most “correct” method would have been to learn the entire Fiat Crypto framework and generate Rust back-ends from scratch, but that does not address the thin layer of remnant C code in `ring` still required to glue everything together.
Instead, Xobs suggested that we use `c2rust` to translate the existing C code into Rust. I was initially skeptical: transpilation is a very tricky proposition; but Xobs whipped together a framework in an afternoon that could at least drive the scripts and get us to a structure that we could rapidly iterate around. The transpiled code generated literally thousands of warnings, but because we’re transpiling machine-generated code, the warning mechanisms were very predictable and easy to patch using various regex substitutions.
Over the next couple of days, I kept plucking away at the warnings emitted by `rustc`, writing fix-up patches that could be automatically applied to the generated Rust code through a Python script, until I had a transpilation script that could take the original C code and spit out warning-free Rust code that integrates seamlessly into `ring`. The trickiest part of the whole process was convincing `c2rust`, which was running on a 64-bit x86 host, to generate 32-bit code; initially all our TLS tests were failing because the bignum arithmetic assumed a 64-bit target. But once I figured out that the `-m32` flag was needed in the C options, everything basically just worked! (hurray for `rustc`’s incredibly meticulous compiler warnings!)
The upshot is now we have a fork of `ring` in `ring-xous` that is both API-compatible with the current `rustls` version, and uses pure Rust, so we can compile TLS for Xous without need of gcc, clang, nasm, or perl.
But Is it Constant Time?
One note of caution is that the cryptographic primitives used in TLS are riddled with tricky timing side channels that can lead to the disclosure of private keys and session keys. The good news is that a manual inspection of the transpiled code reveals that most of the constant-time tricks made it through the transpilation process cleanly, assuming that I interpreted the barrier instruction correctly as the Rust `compiler_fence` primitive. Just to be sure, I built a low-overhead, cycle-accurate hardware profiling framework called perfcounter. With about 2 cycles of overhead, I’m able to snapshot a timestamp that can be used to calculate the runtime of any API call.
Inspired by DJB’s Cache-timing attacks on AES paper, I created a graphical representation of the runtimes of both our hardware AES block (which uses a hard-wired S-box for lookups, and is “very” constant-time) and the transpiled `ring` AES code (which uses program code that can leak key-dependent timing information due to variations in execution speed) to convince myself that the constant-time properties made it through the transpilation process.
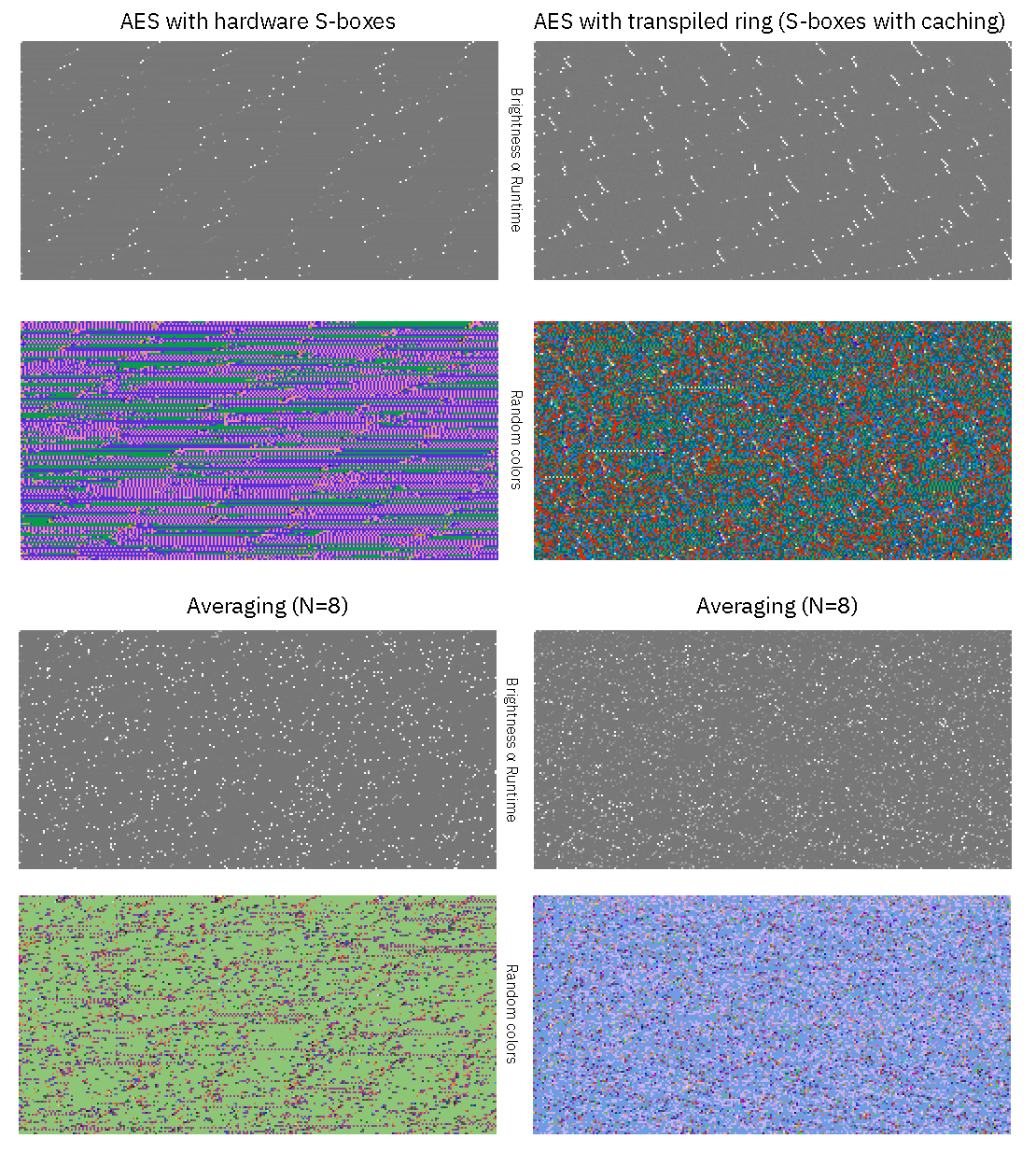
Each graphic above shows a plot of runtime versus 256 keys (horizontal axis) versus 128 data values (vertical axis) (similar to figure 8.1 in the above-cited paper). In the top row, brightness corresponds to runtime; the bright spots correspond to periodic OS interrupts that hit in the middle of the AES processing routine. These bright spots are not correlated to the AES computation, and would average out over multiple runs. The next lower row is the exact same image, but with a random color palette, so that small differences in runtime are accentuated. Underneath the upper 2×2 grid of images is another 2×2 grid that corresponds to the same parameters, but averaged over 8 runs.
Here we can see that for the AES with hardware S-boxes, there is a tiny bit of texture, which represents a variability of about ±20 CPU cycles out of a typical time of 4168 cycles to encrypt a block; this variability is not strongly correlated with key or data bit patterns. For AES with transpiled ring code, we see a lot more texture, representing about ±500 cycles variability out of a typical time of 12,446 cycles to encrypt a block. It’s not as constant time as the hardware S-boxes, but more importantly the variance also does not seem to be strongly correlated with a particular key or data pattern over multiple runs.
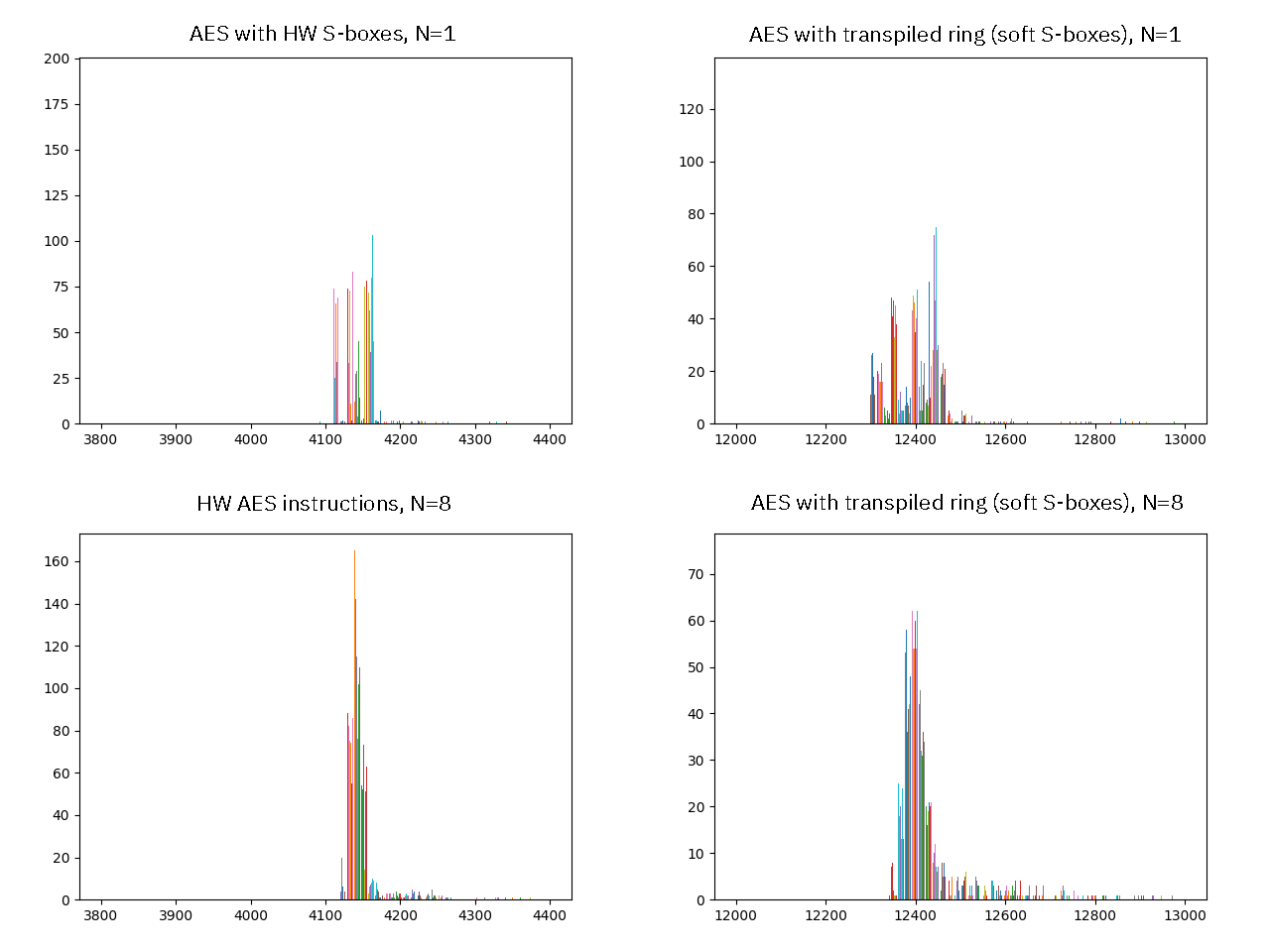
Above is a histogram of the same data sets; on the left are the hardware S-boxes, and the right is the software S-box used in the `ring` transpilation; and across the top are results from a single run, and across the bottom are the average of 8 runs. Here we can see how on a single run, the data tends to bin into a couple of bands, which I interpret as timing differences based upon how “warm” the cache is (in particular, the I-cache). The banding patterns are easily disturbed: they do not replicate well from run-to-run, they tend to “average out” over more runs, and they only manifest when the profiling is very carefully instrumented (for example, introducing some debug counters in the profiling routines disrupts the banding pattern). I interpret this as an indicator that the banding patterns are more an artifact of external influences on the runtime measurement, rather than a pattern exploitable in the AES code itself.
More work is necessary to thoroughly characterize this, but it’s good enough for a first cut; and this points to perhaps optimizing `ring-xous` to use our hardware AES block for both better performance and more robust constant-time properties, should we be sticking with this for the long haul.
Given that Precursor is primarily a client and not a server for TLS, leakage of the session key is probably the biggest concern, so I made checking the AES implementation a priority. However, I also have reason to believe that the ECDSA and RSA implementation’s constant time hardening should have also made it through the transpilation process.
That being said, I’d welcome help from anyone who can recommend a robust and succinct way to test for constant time ECDSA and/or RSA operation. Our processor is fairly slow, so at 100MHz simply generating gobs of random keys and signing them may not give us enough coverage to gain confidence in face of some of the very targeted timing attacks that exist against the algorithm. Another alternative could be to pluck out every routine annotated with “constant time” in the source code and benchmark them; it’s a thing we could do but first I’m still not sure this would encompass everything we should be worried about, and second it would be a lot of effort given the number of routines with this annotation. The ideal situation would be a Wycheproof-style set of test vectors for constant time validation, but unfortunately the Wycheproof docs simply say “TBD” under Timing Attacks for DSA.
Summary
`ring-xous` is a fork of `ring` that is compatible with `rustls` (that is, it uses the 0.16.20 API), and is pure Rust. I am also optimistic that our transpilation technique preserved many of the constant-time properties, so while it may not be the most performant implementation, it should at least be usable; but I would welcome the review and input of someone who knows much more about constant-time code to confirm my hunch.
We’re able to use it as a drop-in replacement for `ring`, giving us TLS on Xous via `rustls` with a simple `Cargo.toml` patch in our workspace:
[patch.crates-io.ring]
git="https://github.com/betrusted-io/ring-xous"
branch="0.16.20-cleanup"
We’ve also confirmed this works with the `tungstenite` websockets framework for Rust, paving the way towards implementing higher-level secure messaging protocols.
This leads to the obvious question of “What now?” — we’ve got this fork of `ring`, will we maintain it? Will we try to get things upstreamed? I think the idea is to maintain a fork for now, and to drop it once something better comes along. At the very least, this particular fork will be deprecated once `ring` reaches full 0.17.0 and `rustls` is updated to use this new version of `ring`. So for now, this is a best-effort port for the time being that is good enough to get us moving again on application development. If you think this fork can also help your project get un-stuck, you may be able to get `ring-xous` to work with your OS/arch with some minor tweaks of the `cfg` directives sprinkled throughout; feel free to submit a PR if you’d like to share your tweaks with others!






















 (the derivation assumes that the average quantity in stock is
(the derivation assumes that the average quantity in stock is  ), it is given by:
), it is given by: , where
, where  is the quantity consumed per year,
is the quantity consumed per year,  is the fixed cost per order (e.g., cost of ordering, shipping and handling; not the actual cost of the goods),
is the fixed cost per order (e.g., cost of ordering, shipping and handling; not the actual cost of the goods),  is the annual holding cost per item.
is the annual holding cost per item. items, and it takes
items, and it takes  seconds to decide whether a given item should be implemented next, and
seconds to decide whether a given item should be implemented next, and  is the fraction of items scanned before one is selected: the average decision time per item is:
is the fraction of items scanned before one is selected: the average decision time per item is: /2}*t") seconds. For example, if
seconds. For example, if  , pulling some numbers out of the air,
, pulling some numbers out of the air,  , and
, and  , then
, then  , or 5.4 minutes.
, or 5.4 minutes. , then
, then  .
.