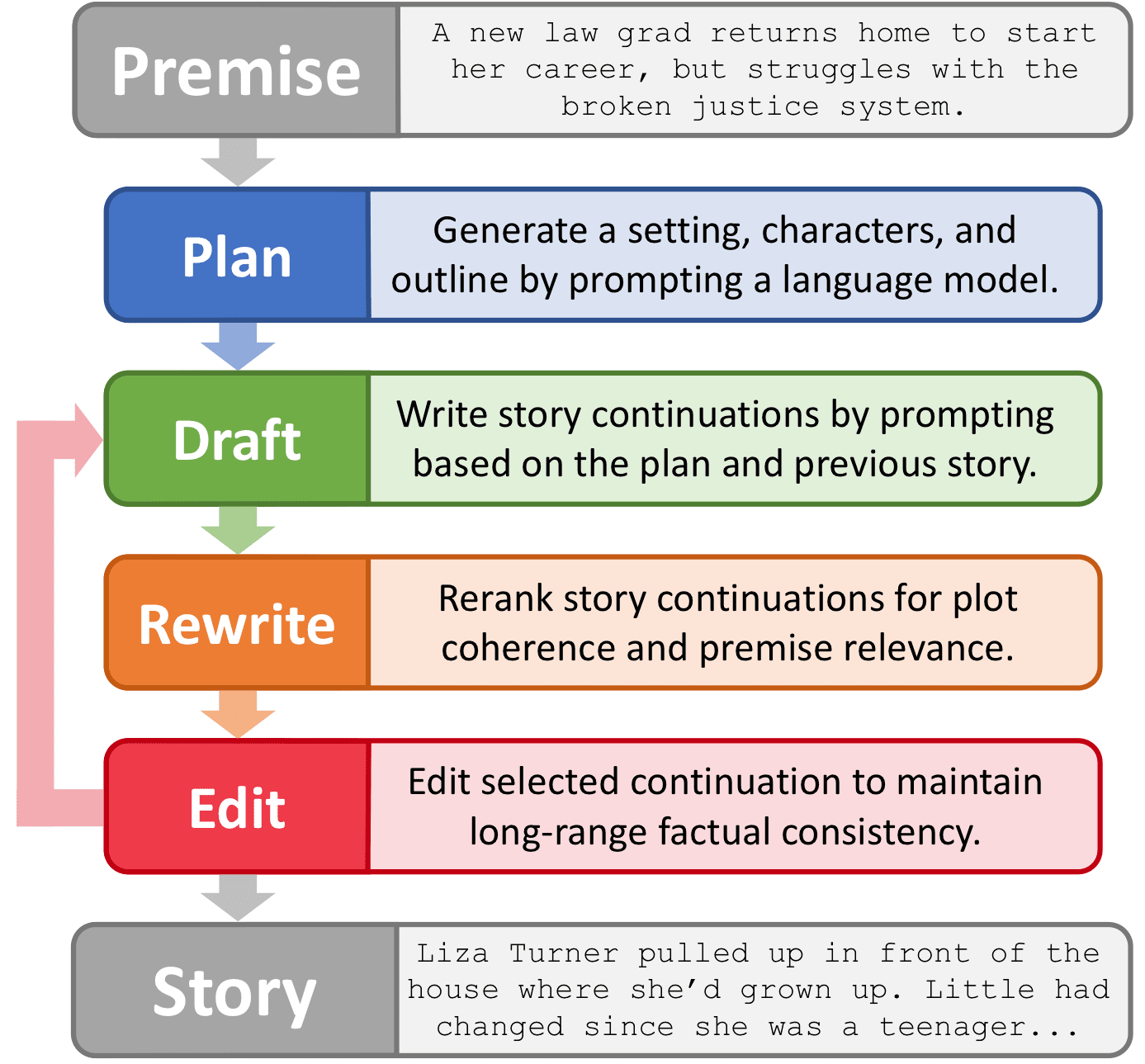
Resilience co-editor Bart Anderson recently sent me a link to an article by astrophysicist Ethan Siegel called Four Rules of Persuasion, which Ethan developed mainly for dealing with people who spread, and believe, mis- or disinformation. His preamble:
Resilience co-editor Bart Anderson recently sent me a link to an article by astrophysicist Ethan Siegel called Four Rules of Persuasion, which Ethan developed mainly for dealing with people who spread, and believe, mis- or disinformation. His preamble:
The large amount of misinformation, disinformation, and loudly opinionated ignorance that’s out there makes the task of … communication more difficult than ever. Much of what passes for journalism these days falls into the trap of giving equal time, space, and weight to positions of vastly unequal merit; don’t fall for it. Even if it may not seem like it’s the case, the general public has a great craving to learn the truth. Here’s how you can tell it persuasively, without getting distracted by the noise.
And his four rules are:
- Never waste your time explaining yourself to someone who is committed to misunderstanding you.
- When speaking in front of an audience that’s been misinformed, don’t address your response to the misinformer, but rather to those who would benefit from hearing a correct, and different, narrative.
- Do not be afraid to make your own points that you believe are important. The audience will not recall 100% of what you say, so make sure you emphasize and repeat the most vital takeaways.
- [Be open to] criticism [but understand it] is part of the game. Chew on the meat and throw away the bones. And if it’s all bones, throw it all away.
(I have slightly edited the fourth rule for clarity.)
The first rule is a variation on Daniel Quinn’s famous exhortation:
People will listen when they’re ready to listen and not before. Probably, once upon a time, you weren’t ready to listen to an idea than now seems to you obvious, even urgent. Let people come to it in their own time. Nagging or bullying will only alienate them. Don’t preach. Don’t waste time with people who want to argue. They’ll keep you immobilized forever. Look for people who are already open to something new.
I prefer Daniel’s phrase “aren’t ready to listen” to Ethan’s “are committed to misunderstanding” simply because it’s more inclusive. If open-minded people aren’t ready to listen to what you have to say, perhaps because it’s too radical for them to accept yet, or because it would take you more time than either of you has to provide sufficient context for them to appreciate your argument, then it simply won’t be heard. Even if they’re not “committed to misunderstanding you”.
The second rule, of addressing yourself to a “reasonable person”, even if it’s a stretch to even imagine one present in a hostile group, is far more useful than trying to disentangle their misinformation. This is akin to what George Lakoff calls “reframing”. You can be tied up in knots if you’re constantly trying to explain yourself using the terminology and frame of reference of someone who’s misinformed. Start with a clean slate, providing the facts and evidence to support your argument, rather than trying to refute someone else’s.
Related to this, I think, is starting with the presumption that we’re all doing our best, and that people who spread mis- and dis-information honestly believe what they’re saying — that they’ve been led astray by someone else. Starting with genuine curiosity about why someone would believe something that is clearly incorrect, rather than staring from a place of defensiveness or animosity, seems to me a sensible approach.
Ethan’s third rule is, I think, the most critical one. It’s amazing what people will hear only when you’ve said it several times. And how open people are to new information, presented factually and supported, even when it doesn’t fit with their worldview
The fourth rule is the toughest. I think that’s because it’s really hard for us not to take criticism personally, whether or not it is intended to be taken that way.
So, for example, when I am criticized or attacked for saying that I believe the state has no right to tell somewhat what they can or can’t do with their body (including aborting a fetus or taking their own life) provided that action or inaction does not aversely affect their community, I can be attacked (and charged with hypocrisy) from both sides. “Taking one’s own life hurts dependants and loved ones, and is therefore selfish and immoral”, I have been told, while anti-vaxxers say “No one has the right to force anyone else to take a vaccine that might be dangerous to them personally”.
These are powerful emotional arguments, not easily dealt with by providing more facts. I could spout data forever showing that statistically for every x people refusing to get vaccinated, one vulnerable person will die ‘unnecessarily’ of the disease, or that your chances of getting a chronic illness or dying of the disease personally are y times higher if you haven’t been fully vaccinated (where y is many times higher than the risk of comparable consequences from getting the vaccine). That will get me exactly nowhere.
Instead, drawing on Ethan’s first two rules, it would be better, in my discussions with people making those arguments, for me to provide facts, and supporting information, to other people in the conversation who, if presented with new information, new ideas, or new perspectives, are open to them. And not to waste time debating or arguing with those who are not.
There have been many situations, especially over the past decade or so, when I have, as a result of hearing or reading new information, ideas, or perspectives, suddenly and radically changed my beliefs. These 20 beliefs for example. I’d like to say that someone skilled in the Four Rules was responsible, but the truth is, almost none of these changes in beliefs came about as a result of conversation. They came about after a lot of reading and thinking, and they came about gradually, when I was “ready” to hear the new, conflicting belief, as a result of conditioning from a multitude of sources. The “aha” moment only happened after a ton of reading and interactions pushed me to the point I was ready, finally, past the “tipping point”.
As I’ve said before, the only one who can change anyone’s mind is themselves.
It’s also important, I think, not to get too attached to our own beliefs, which, some would say, are only just opinions. If you equate an attack on your beliefs (no matter how fervently held) with an attack on you, personally, it’s almost certain to end badly. I’ve found that anger and hostility are almost always masks for fear. If someone’s afraid of the information, ideas, or perspectives you give them, that’s all about them, not about you.
So what does that mean for the Four Rules? I still think they’re valid. We may never know how our calm, reasoned, attentive argument might contribute to someone’s conditioning in such a way that, later, something else will push them past the “tipping point”. So that suggests we should do our best to try to nudge them in the right direction, if they’re ready to listen.
Here then is my personalized version of the rules, which I think apply not only in addressing a misinformed audience, but also in one-on-one and small group conversations with those with sharply conflicting views:
- Try to bring genuine curiosity to why others hold beliefs and opinions that seem misguided or unsupported. Appreciate that we’re all doing our best to make sense of the world.
- Don’t waste time talking with people who aren’t ready to listen.
- When speaking with an audience that’s been misinformed, reframe: Address those who might value hearing new information, ideas, or perspectives, rather than responding directly to dis- or misinformation.
- Do not be afraid to make your own points that you believe are important. Your audience will not recall 100% of what you say, so make sure you emphasize and repeat the most vital takeaways.
- Be open to criticism, but don’t take it personally, and disregard it if it is malicious, invalid or manipulative.
Thanks to Bart for the link, and Ethan for the list.
image from pxhere, CC0





























 photo by
photo by