What have I been up to this year? Not blogging, that’s for sure. I’m not sure if I can lay the entire blame of this at the feet of *gestures at everything*, but with the retirement of the This Week in Glean rotation, I’ve gone from infrequently blogging to never blogging.
Which is weird. I like doing it. It can be very fun. It isn’t usually too difficult. Seems like the intersection of all the things that would make it not only something I could do but something I want to do.
And yet. Here we are with barely a post to show for it. Alas.
If blogging is what I’ve not been doing, then what have I been not not doing? More Firefox on Glean stuff. Spent a lot of time and tears trying to get a proper Migration from Legacy Telemetry to Glean moving. Alas, it is not to be. However, we’ve crested over 100 Glean metrics being sent from Firefox Desktop, and the number isn’t going down… so 2022 has been the year of Glean on the Desktop, whether it was a flagship Platform Initiative or not.
In other news, we just got back from Hawaii where there was the first real All Hands in absolutely forever (since January 2020). It was stressful and weird and emotional and quite fun and necessary and I wanna have another one and I don’t want to have to fly so far for it and and and…
Predictions for the next year of Moz Work:
There’ll be another All Hands
Glean will continue to gain ground in Firefox Desktop
One of the ways in which conservation groups are trying to address the influx of lionfish into the Mediterranean is to encourage people to eat them. Programmes such as Pick the Alien are holding culinary events around the Aegean and training chefs and fishermen in how to collect and prepare the apparently tasty newcomer for the plate. Apparently, they’re quite tasty if you like that sort of thing.
I’ve been vegetarian since I was a teenager, but I recognise that this is not a bad idea. I don’t want to eat animals, and I don’t really think anyone else should eat them, but I often have to think about this in my local context: I’m not sure that eating fish landed by a local fishermen at a quayside taverna is any worse, globally speaking, than eating tofu imported by my local bio shop, even if those soy beans are grown somewhere in Greece. (Frankly, though, I find these conversations boring. Industrial agriculture and fishing are bad, we can do better.) Nevertheless, I sometimes think that at some point in this research I should try and eat a lionfish.
In the US, there’s a parallel story unfolding, in the most ludicrous and hyper-accelerated way, because America. There’s a lionfish explosion along the gulf coast too, caused not by a century-long migration and an ecosystem subject to climate change (or not entirely), but by released aquarium pets and artificial reef-building. Because America, killing and eating lionfish is now a competitive sport. Should I go to Florida next March? I am tempted. Could I go and not try one? Different stories will result from this choice.
I had another bad thought this morning, while snorkelling among the seagrass beds below my village. What other bodily ways are there to interface with the lionfish?
In Parallel Minds, a really extraordinary book about the intelligence of materials, Laura Tripaldi defines ‘the interface’ in chemical terms: “the interface is not an imaginary line that divides bodies from each other, but rather a material region, a marginal area with its own mass and thickness, characterised by properties that make it radically different from the bodies whose encounter produces it.” She continues:
In this sense, the interface is the product of a two-way relationship in which two bodies in reciprocal interaction merge to form a hybrid material that is different from its component parts. Even more significant is the fact that the interface is not an exception: it is not a behaviour of matter observed only under specific, rare conditions. On the contrary, in our experience of the materials around us, we only ever deal with the interface they construct with us. We only ever touch the surface of things, but it is a three-dimensional and dynamic surface, capable of penetrating both the object before us and the inside of our own bodies. This idea of the interface as a material region in which two substances can mix together to produce a completely new hybrid body, can serve as a starting point for rethinking more generally our relationship to the matter around us. If all bodies we enter into relationships with are modified and modify us in turn, then we can no longer delude ourselves that matter is simply a passive object onto which we project our knowledge. But neither can we take refuge in the convenient idea that we can never have any knowledge of that which is not human—that the matter around us is, ultimately, completely alien and unknowable, and that it really has nothing to do with us.
(I am reminded, particularly, of Flann O’Brien’s assertion in The Third Policeman that “people who spent most of their natural lives riding iron bicycles over the rocky roadsteads of this parish get their personalities mixed up with the personalities of their bicycle as a result of the interchanging of the atoms of each of them and you would be surprised at the number of people in these parts who are nearly half people and half bicycles…”)
To eat the lionfish is one way of entering into a material relationship with it, for sure. But so is being stung by it.
The lionfish produces a powerful venom in specialised glands along its spine, which can be transmitted by a relatively light touch due to the sharpness of the spines which project from its dorsal fins, pelvis, and anus. This toxin is a combination of protein, a neuromuscular toxin and a neurotransmitter called acetylcholine, which affects muscular control and heart rate, and can cause convulsions, paralysis, and intense pain. Here’s a pretty unreadable paper on lionfish envenomation of mice. In humans, it can seriously injure and even, if it triggers an allergic response, kill an adult. Being stung, one of the Florida divers quoted in the above article (who claims to have been stung more than thirty times), “feels like your bones and joints are pushing out—it’s a fucking misery.”
So, probably not a good idea then. But still, interfaces.
It’s been some years since Tab Atkins-Bittner first proposed Cascading Attribute Sheets. I had a situation come up which made me think about them again and I thought I’d share.
On my site I have a handful of blog posts which have a title and/or text content in different languages. As someone who speaks a handful of languages, I like incorporating different languages, phrases, and untranslatable words into my day-to-day blogging. 「手答え」(tegotae) is an example of one of those words. It directly translates to “hand response” but is sometimes translated as “haptic feedback” or “game feel” when used in a video game context.
One problem with my use of other languages is that I’m lacking proper lang attributes on the foreign text, which makes it inaccessible. I’ve started brainstorming ways out of this, but finding a sustainable system while supporting mixed language use — even on my simple site — can be daunting.
What’s hard inside the underlying system.
In my Markdown-powered blog, adding multi-language support to every dynamic text field is difficult. It would require making configurable options (title_lang, title_dir, summary_lang, summary_dir, tag_lang, etc) for every custom text field on my site.
I would then have to go into all my templates and anywhere I echo a value {{ title }} I would have to wrap that in an element that could echo the title in every template where we render a title. I end up with ugly markup like this:
<h1
{% if title_lang %}lang="{{ title_lang }}"{% endif %}
{% if title_dir %}dir="{{ title_dir }}"{% endif %}
>
{{ title }}
</h1>
<p
{% if summary_lang %}lang="{{ summary_lang }}"{% endif %}
{% if summary_dir %}dir="{{ summary_dir }}"{% endif %}
>
{{ summary }}
</p>
And all that is just for titles! 2 elements, 12 lines of code. I have it easy on my static site too. For CMS sites, there is a four fold issue with writing frontend code, backend for processing code, UI code in the CMS, and updating the database to support all these attribute fields. It’s doable, but managing code in multiple places is fraught with disaster. Internationalization is something you want to plan for before even building the site, you don’t baby step into it.
My post content is a slightly different story. My complaints are mild here because it’s my choice to use Markdown, but adding a lang attribute to an element is doable, but I have to break out of the Markdown syntax and write HTML to support it.
## 木組みの家
<h2 lang="ja">木組みの家</h2>
These are two different writing and aural experiences. One is easy to write and the other is correct.
When the post renders, the title is purple. Going back to Tab’s proposal, if Cascading Attribute Sheets existed, I could support a multilingual blog post with a block of attributes on the page.
I’m cheating a bit and using custom properties for the attributes, but you get the gist. Also I’m cheating the hard parts like :hover or :invalid states. But for a proof of concept, it seems the CSS parser could adapt to do the work.
All that is just for titles.
A technology like Cascading Attribute Sheets would be helpful to me. This is a basic example for internationalized text fields on a blog post, but with all the attributes on all the elements this problem gets broader real quick. If you consider ARIA and the broad set of dynamic states that a chunk of HTML can express via attributes, do we need new mechanism that feels less like a one-off application of attribute soup?
There was a whole decade of browser development where kept adding attributes because attributes were easier than adding HTML. It’s become a mess. Look at how the world could be with Attribute Sheets!
/* forms.cas */
form:has(input[type="search"]) {
enterkeyhint: 'Search'
}
input[name="username"] {
required: true;
autocomplete: current-password;
}
input[type="password"] {
required: true;
autocomplete: current-password;
}
input[type="password"][name="new-password"] {
autocomplete: new-password;
required: true;
pattern: '[0-9].{6,}[A-Z]';
aria-description: 'Provide an alphanumeric password with at least 6 characters';
}
input[type="password"][name="new-password"]:invalid {
aria-errormessage: 'Password did not meet requirements';
}
... etc.
The list goes on, but I feel like the next generation of Twitter Bootstrap could be a single Attribute Sheet file for making your forms good. I’d pay $5 right now for someone to tell me the right way to setup all my form attributes for cross-device success, I’m pretty confused after all these years.
There were two parallel conversations happening on Twitter this week; one about CSS Toggles and another about CSS Speech. These are different ideas, but they somewhat overlap in that they control behavior outside the bounds of visual style. speak: none; has sorely been missing from the platform, a way to hide my garbage code from unsuspecting listeners. And the @machine {} part of CSS Toggles is interesting because CSS (to me) is already a state machine. I’m often in situations where I need to express “If this is this, then these must be that.” I have no horse in this race, but I like the ideas thrown around, but I do wonder if Cascading Attribute Sheets have a role in this future.
If you will allow an old man the pleasure of time, there’s one more correlation I’d like to make. I harken back to the microformats revolution. We poured hours into applying the correct inline classes for parsers and crawlers alike. Then we moved off of that for a more XML flavored feel and poured our hours into adding itemprop attributes. After a couple decades and the dust has settled, we’re doing less of that now and using JSON schemas in the <head> of our pages to inform our search engine gods. If I were hazarding a guess, I wonder if a structured JSON schema proved to be the easiest format to both write and consume. It’s a copy-paste block of properties and values, not hundreds of inline properties and values unsustainably littered through my markup. I rage against the JSON schema gods, but I wonder if they’re right.
Maybe, the block of key-value pairs has a better 手答え than the rest of the options we’ve tried in the past.
As you are probably aware Elon Musk has long been wavering in his decision whether or not to purchase Twitter (ticker: TWTR) for a price that would amount to $54.20 a share. For most of the summer it looked like he was going to fight the purchase, and then in early October, claimed he would go ahead with it.
If you look at the stock price of TWTR for the last few months you can see that this has had a stabilizing effect on the price of TWTR during a particular tumultuous market.
If Musk buys TWTR the future price will be certain and not stochastic, this impacts the current price
Notice that after the announcement the stock's price remains relatively stable at a price point just a few dollars below the price point that share holders will receive if Musk purchases the company.
It seems pretty clear here that the market believes that Musk will likely buy Twitter. An interesting probabilistic question to ask is How strongly does the market believe this? That is, can we put a specific probability to the event that Musk will finally purchase Twitter by a specific date?
To answer this question we'll need to take a look at the options market for Twitter. In particularly the Volatility Smile, which is related to the deviation of implied volatility of options in violation of the famous Black-Scholes Merton option pricing model. We'll use both of these tools to construct an empirical Cumulative Distribution Function (CDF) which we can then use to see roughly what probability the market is putting on this acquisition.
A Crash Course in Black-Scholes Merton
To start let's take a look at perhaps the most famous mathematical formula in finance: The Black-Scholes Merton model (BSM model from here on out). This model deserves it's own post, which it will get one day, but for now we need to understand the basic idea.
Despite all of the hype around this model, it basically says we can imagine stocks price movements (viewed in terms of log return, see the Modern Portfolio Theory post for an example) as samples from Geometric Brownian motion. The ending prices of a stock is then just a log-normal distribution, and the expected value of an option (the right to purchase as stock at a fixed price) is just the expectation of the part of that distribution greater (in the case of calls) or lessor (in the case of puts) than the strike price.
The BSM model takes 5 parameters to calculate the price an option:
- \(S_0\) current price of the stock
- \(K\) the strike price that option grants to stock to be bought or sold for
- \(r\) the risk-free interest rate (which we'll be assuming is zero for simplicity)
- \(T\) the time to expiration of the option (in fractions of a year)
- \(\sigma\) the volatility, or standard deviation in annual log returns
The mathematics of pricing looks a bit intimidating, but in practice it is just doing integration over the expected final price of the stock, and the profits that the owner of the option can expect at the date of expiration. In reality the BSM formula just tells us the expected value of the option at expiration which in turn is the option's price.
Implied Volatility
One of the most important things to understand regarding options pricing is the implied volatility. Here's an image of a typical options chain showing the strike, bid, ask and implied volatility:
Showing the implied volatility of a given option.
Of all the parameters used in the BSM model, only one is not known to us at the time we want to buy an option: the volatility \(\sigma\).
The solution to this problem of missing information is to determine "what is the volatility at the current price to make the model make sense?" In this way we can read every pricing of an option as a prediction about how much variance there is going to be in future stock prices.
Probabilities Implied by the BSM model
Central to the price of the option is the probability that it expires in the money (ITM). An option being ITM means that the stock price at expiration is higher than the strike for a call option (right to buy the stock) or lower then the price for a put option (right to sell). Basically if an option expires ITM, the owner of the option will profit.
The probability of this happening is baked into the BSM pricing formula. For a call option the pricing formula is:
$$c = S_0 N(d_1) - Ke^{-rT}N(d_2)$$
Where $N$ is the cumulative normal distribution and $d_1$ and $d_2$ are defined as:
While explaining that formula in detail is going to have to wait for another post, the only important thing to take away for this post is that for a call option:
$$P(\text{ITM}_\text{call}) = N(d_2)$$
This means that the probability that the final stock price is greater than the strike price is \(N(d_2)\). More useful for us is knowing the inverse, the probability that a the final price is less than \(K\) is \(1-N(d_2)\).
Fat Tails and All That
Whenever I bring up quantitative finance one of the first critiques I hear is "all those models assume log normal behavior which is not the case! Real life involves fat tails so all these pricing models are wrong!" This has been popularized by the writings of Nassim Taleb and several others (correctly) critiquing modern mathematical finance and common statistical assumptions.
While this is absolutely true, the markets are not ignorant of this. It turns out if you look carefully enough you'll realize that markets do price options assuming non-normal probabilities of future values. That is, traders know that the risks are not log-normal and so do not price options the way BSM implies they should.
The rest of our discussion is going to be see how we can take this market information and turn it into a probability distribution that gives us information regarding what the market believes the price will be at expiration.
Volatility Smiles
According to the BSM model, we should expect the implied volatility to be the same for every strike price. If the movement of stock prices where truly log-normal then the price of each strike price would end up implying the same volatility. However it turns out this is not the case at all. In violation of BSM, implied volatility displays what is referred to as the volatility smile (because it looks like a smile! Though really more often a smirk).
The best way to see this is to plot it. Before diving into TWTR, let's take a look at a more well behaved stock, AMZN. Here we're going to look at the implied volatility of different strike prices of an AMZN option expiring on Nov 18, 2022
The ‘volatility smile’ shows that real pricing disagrees with the BSM model.
What we see here is that implied volatility is much higher at the extremes, and notably higher at the lower extremes that the higher ones. This is not what the BSM would predict but it shows that traders do in fact price "fat tails" into options. While this is not a probability distribution, we can see from this alone that traders believe BSM under-prices the risk in the lower prices (and to an extent the higher ones as well). The fact that this curve spikes up pretty steeply means that traders know there are risks of extreme price drops, reflective of the current economic environment we're in.
Prior to the stock market crash of 1987 volatility smiles mostly didn't exist. Investors trusted in the model over their instincts and the result was a catastrophic crash. It's important to note that this means if in 1987 you were a mathematically savy trader you could have recognized that far out of the money puts where very underpriced given the real risk. Any traders that saw this would have made a lot of money during the crash. However this smile tells us that if, after skimming a few Taleb books, you hope to profit in the same way, you are unlikely to end up as fortunate.
The really exciting thing is that, using only the information we've covered so far, we can come up with an empirical cumulative density function that allows us to make probabilistic claims about the market predictions for this stock.
We'll continue to focus on AMZN and finally return to TWTR for to answer our final question.
Building our CDF
In order to understand the market's beliefs regarding the probabilities of certain prices we can use a similar trick to what we used last time when working with censored data. We didn't now the exact probability for each estimate only that we know something about the probability of values being lower or greater than a certain point.
In this case let's consider a Put option, which is the right to sell a stock a the strike price. For these options to be ITM, we care about the probability that the future stock price is lower than the strike. Conveniently we already discussed the solution to this!
We'll use implied volatility at each strike for our volatility input and everything else is known (for simplicity we'll assume the risk-free rate is 0.0).
If we plot our 1 - p_itm for each strike price we'll end up build our CDF!
We can iterate over the price and plot this out as see below, along with the theoretical CDF from the BSM model:
Notice the difference at the lower strikes between the theoretical and the empirical.
As we can see the empirical distribution puts significantly more probability density in the tails of this distribution. Fat tails are priced in! For example trader's believe that AMZN dropping to $80/share has roughly a 5% probability of happening where as BSM thinks it has less than 1% chance of occurring.
Now let's see what we can figure out about what the market believes Musk is thinking!
Looking at the CDF for Twitter
Let's start by looking at the volatility smile for Twitter for options expiring on November 4th 2022:
Volatility Smile for Twitter options expiring Nov 4th 2022.
Here we see a much more dramatic and strange smile. It's shaped like a crooked 'v'. It's hard to interpret this in a vacuum so let's look at what this CDF looks like.
Compared to the AMZN CDF this one is much stranger looking!
As expect the empirical distribution looks a lot different from the theoretical, but also a lot different than AMZN!
I've also marked the price per share if Musk completes his purchase in this chart. Looking at AMZN we so a beautiful smooth curve, where as this CDF for TWTR makes a very stark jump from the current price to Musk's price. This is because the market is currently dealing with an interesting statistics question: either TWTR is worth 54.2 per share or ... it's worth something else! The trouble is it's very hard to price TWTR as though Musk hadn't made the offer. So there are really two models hidden here: the Musk price times the probability that Musk does purchase and a distribution of guesses as to what the price might be if he doesn't times the probability he doesn’t purchase.
Thankfully, because of the radical jump, we can make a pretty good estimate as to what the market is predicting. We can look at the range of values where the jump is. I'll say, for ease of estimating, we can focus between the strike of 52 and 55. The probability that TWTR will be less than 52 is currently 0.47 and the probability that it's less than 55 is 0.9. The difference between this two should be our estimate:
So, as of this writing, the market believes that there is a 43% chance Musk will go through with the sale by Nov 4th 2022.
What if Musk doesn't go through with the sale
I'm comfortable saying there's a roughly 40% chance that in early November TWTR will be worth exactly 54.2/share to share holders. Suppose you disagree? If you are certain that Musk won’t go through with the sale should you use this opportunity to grab some TWTR stock at a discount?
Clearly the market answer is: No!
In our CDF we can see that only a tiny fraction of the CDF remains above Musk's price, and not very much above it’s current value. Compare this to AMZN which you can see the market believes it could potentially go much higher. Conversely the market has pretty strong beliefs about how low TWTR could go. The probability of TWTR going to 30 or less is currently 0.03. But don't forget that's including the probability that it ends up at the Musk price. This means weighted for the ~60% remaining it's closer to a 5% chance that if Musk does not purchase TWTR it's price will drop to 30.
Conclusion
Quantitative Finance is so fascinating because it is filled with very complex and interesting probability problems that are based on very real world cases. In statistics and data science we often can safely work with well known, and well behaved distributions, even if they aren't a perfect match to our problem. In finance being restricted to models can and has lead to ruin as happened to many adherents to BSM in 1987.
What I find particularly interesting about this case is that even if you have no interest in trading or investing, there is an incredible amount of interesting information contained in the volatility smile. What started my own journey into this particular question was wondering exactly how I could put a number on the probability that Elon Musk will purchase TWTR since it a frequent topic of conversation
By combining statistical tools with a bit of financial engineering thinking we're able to arrive and a very interesting, and reasonable answer to our question. Based on current options prices the market thinks there's a roughly 40% chance Musk will go ahead with this purchase by early November.
Support on Patreon
Support my writing on Patreon and gain access to the source code and video commentary for this article as well as access to much more of my writing!
Stay up to date and notified whenever a new post is up!
Sign up with your email address and you’ll get a link to Field Notes #1 a story about the time I almost replaced an RNN with the average of 3 numbers!
"You would take something like Shopify and make it so I could curate individual items in a MySpace-like environment, and the doorway is my user avatar. Something like that. You would see which of your friends were currently browsing. The whole purchase funnel would have to be managed within my homepage?
Like Underhill says, I would probably want live staffing. Something the generic big box infinite department stores couldn’t offer."
W. David Marx thinking about recommendation:
"Matthew Yglesias noted that the previous paradigm of recommendations involved teachers, older siblings, and surly record store clerks offering pedagogical introductions to even deeper examples in a specific interest area, whereas a capitalistic algorithm may point towards much more general, less sophisticated versions of whatever you liked."
And there's this too:
Scanning *my* professors' bookshelves was such an important part of my own education. Those books served as extemporaneous "boundary objects" in office-hour discussions where I discovered new fascinations. Hard to offer such epiphanies to your own students in an open-plan office https://t.co/q3imD9E8YI
A friend of mine in Seattle told me that they’d gotten COVID-19, and asked me what they should do next. What could they do to get better sooner/faster/better? How should she protect their partner? This is the advice I gave:
Stay away from your partner until you test negative.
Stay entertained.
Paxlovid, if appropriate.
Irrigate your sinuses.
Make sure you have clean air.
Be quiet.
Don’t try to do too much when you spring yourself.
Isolate until you test negative
The US CDC says to isolate until five days after your first symptoms. The BC CDC says that if you are fully vaccinated, you can stop isolating after five days if your symptoms improve and you don’t have a fever. This is utter bullshit. There are lots of studies which say that most people are still infectious until 7-10 days after symptom onset:
This preprint from the USA (with samples taken during the early Alpha period) found they could grow viral culture from participants for a mean of 11 days;
This preprint from the UK (with samples taken during the Delta/B.1/B.2 period) found that people had high enough viral load to be infectious for 7-10 days. They found no correlation of symptom severity with viral load.
This preprint from the USA (with samples taken from July 2021 to January 2022) found a median of 6 days from positive test or start of symptoms to no longer cultureable, although 15% of participants’ swabs could culture virus for more than 10 days.
I believe that I have seen more papers than the three mentioned, but they are a little hard to search for.
Stay entertained
Early in the pandemic, I used to say, “It turns out that love is stronger than fear” as people broke quarantine rules around the world to spend time with loved ones. Now, I say, “Boredom is stronger than fear” as I have seen people I know go places after five days, even knowing that they were probably still infectious after five days. (They knew because I told them.)
I also have isolated twice, once early on when I had symptoms and once recently when I was exposed. It’s hard!
So one of the most important things you can do to keep from infecting your loved ones is to stay isolated! And you aren’t going to be able to do that if you are bored out of your skull and/or frantic for physical exercise. If you have someone to help take care of you, have them bring you stuff. Better yet, arrange this ahead of time. (See later on for my ‘how to prepare’ list.)
Walking around outside, especially if you have a mask on, is relatively low risk for other people. (Don’t do this if you are sneezing or coughing, though. You won’t be able to restrain yourself from lifting your mask to cough/sneeze (because yeah, that’s gross), but that’s exactly the time when the mask is needed.) Do wear a mask when going from your room to the door, and preferably have your roommates be far away. (I can’t go outside when isolating because I live in an apartment building where I can’t get up to my floor without getting into a small poorly ventilated room an elevator.)
Paxlovid
If you are eligible for Paxlovid, and don’t have drug interactions which would conflict, get on the phone immediately to your doctor. Paxlovid works really well.
Irrigate your sinuses
Irrigating your sinuses (with something like this) works even better than Paxlovid. No lie. (I’m not saying do it instead of Paxlovid. Do both.)
This paper found that irrigating sinuses with saline or povidone-iodine cut the hospitalization rate in people over 55 by 8.57 TIMES. Not 8.6%, 8570% percent. They saw no difference between saline and povidone-iodine.
This paper on a study of hospital workers in Mexico (I think in late 2019/early 2020) found that 1.2% of workers who did nasal rinses with neutral electrolyzed water got COVID-19, compared to 12.7% in the control group who did.
This paper found that people who irrigated with saline got over COVID-19 symptoms in about 10 days vs. 14 days for people who didn’t.
This small study from France early in the pandemic found that after sinus rinse with povidone iodine (not saline!) all the COVID-19 patients in the study but one tested negative after three days.
This paper doesn’t give results, it just tries to explain what the helpful actions of nasal irrigation are (at a cellular level).
This small study pre-pandemic of people with “common colds” found that people who did nasal irrigation and gargled resolved symptoms 1.9 days before those who did not and reduced household transmission by 35%. (Note that many “common colds” are coronaviruses!)
I have had a number of people express extreme hesitancy about sinus irrigation. “I remember getting salt water / pool water up my nose, and it was horrible!” Yes! Getting salt water / pool water / tap water up your nose is absolutely horrible. 0/10, would not do again. However, the salt + baking soda that you put in your irrigation water means that it doesn’t hurt at all. It’s a little weird, but it does not hurt. (You do want to use distilled water or boiled water.)
Make sure your air quality is good
There have been lots of studies which have shown that air pollution (like, oh, say, smoke from wildfires) is really bad for COVID-19, and the effects are not small. When air quality in an area is poor, more people catch COVID-19 and they have more severe cases. The studies disagree on which aspect of the air pollution is most responsible, but they all say air pollution IS BAAAAAD:
This paper from China says air pollution is bad, humidity is good.
This paper from Iran says that air pollution is bad for COVID-19, with different correlations at different times.
This paper from the USA says that each 4.6ppb increase in NO2 made the COVID-19 case-fatality rate and mortality rate go up by 11.3%; a 2.6 μg/m increase in PM2.5 made the mortality rate go up by 14.9%.
This paper from the USA says that “an increase in the respiratory hazard index is associated with a 9% increase in COVID-19 mortality”.
This paper from China found that a 10-μg/m3 increase in PM2.5, PM10, NO2, and O3 was associated with a 2.24%, 1.76%, 6.94%, and 4.76% increase in the daily counts of confirmed cases.
This paper using data from China, Italy, and the USA found that NO2 correlated with per capita cases (tau .12-.52, depending on the country). PM2.5 had a weaker correlation (tau .08-.31). PM2.5 correlated to mortality (tau .14-.19)
This paper from Italy says that “long-term air-quality data significantly correlated with cases of Covid-19 in up to 71 Italian provinces”.
This paper from the USA says that “an increase of only 1 μg/m3 in PM2.5 is associated with an 8% increase in the COVID-19 death rate”
I bumped into this paper from the USA which talked about how nasty the air is in open-kitchen restaurants. Apparently, grilling and frying meat gives off a ton of particles. (This makes sense; it sometimes gets smoky in the kitchen when you are cooking. Those are particles!) This explained something which I had heard but didn’t understand: line cooks have the highest mortality of all the occupations. You’d think it would be meatpackers or health care workers, but no. Cooking makes particles, and PARTICLES ARE BAD FOR COVID-19!
I am not a doctor, but the picture I have put together is that the cilia in the respiratory tract are like little conveyor belts which take crud out. If your cilia get gunked up with soot, then they can’t take out the COVID-19 viruses as well. Similarly, if they are full of COVID-19, when you do a nasal rinse, you take out a bunch of the garbage for them, and make it easier for them to take the rest of the garbage out. Help your cilia! Reduce the amount of gunk you breath in and rinse gunk out!
If you need more proof that air quality is important, check out this tweet: air pollution is the fourth-leading risk factor for death:
Be quiet
There was one paper which said that they couldn’t find any culturable virus from the breath of people who were “tidal breathing”, i.e. just sitting there, not exercising, not talking / singing / yelling / coughing / sneezing.
Take it easy!
There was one kind of throw-away sentence in an abstract of a study on Long COVID which said that not taking it easy after recovering from COVID-19 correlated with getting Long COVID. I remember that, but I’m sorry to say that I can’t find the paper.
It was only one paper, and I don’t know how they justify the claim. However, it makes sense to me, is relatively cheap and easy to do (compared to like, spending a week in a hyperbaric pressure chamber or something like that), and has very few side effects.
Get prepared ahead of time
Once you are sick, there are things I mention above which you will not be able to do for yourself. If you have family or friends who will take care of you, you can offload some stuff to them, but it’ll be easier if you prepare ahead of time. If I were you, and you can, I would make sure you have these on hand:
High-quality N95-class masks. These will help keep your household members safe if you have to make brief dashes into common areas. They will also help you if the air quality sucks and you don’t have an air filtration device.
Sinus irrigation kit and 4 litres of distilled water. The NeilMed kits are about CAD$20 at just about any pharmacy. Yes, they are a total rip-off — twenty bucks for a plastic bottle and some salt and baking soda?!?!? However, their value is much higher than their price.
If you can find another bottle that will work, good for you, use that. Put equal parts baking soda and salt into a bottle, shake really really well, and put 1/4 teaspoon into 250 ml of water, and irrigate away.
Particle detector and air filtration device. This is the particle detector I got, though I got it from the US.
Spouse and I built a Corsi-Rosenthal box (cost ~CAD$200) which works really well. During the recent wildfire smoke, it took the PM2.5 count in our living room from 47 µg/m^3 to 12 µg/m^3 in 17 minutes. (NB: I had a hard time finding a 20″ box fan on short notice when we were making ours.)
Here’s a tweet thread talking about making a thinner box with computer fans.
Entertainment. Netflix? Books? Art supplies? Videogames? This is going to be highly individual.
Physical activity equipment. This might be weights, a jump rope, a hula-hoop, a stepstool, dancercize videos, Wii, whatever. Just something that will help you move your muscles a little.
Transmission
A lot of people are sick these days “but not with COVID-19, because I tested negative”. This tweet reports that Alberta wastewater — where they test for influenza, RSV, and COVID-19 — shows 100x as much COVID-19 as flu or RSV. Me, I think the rapid tests are probably wrong: probably “everybody” has COVID-19.
Mitigation Measures
This paper from the US says that 40% of the people there lied about their adherence to measures and/or broke the rules. “The most common reasons included wanting life to feel normal and wanting to exercise personal freedom.”
This article reports that Canadian Armed Forces is dropping a vaccine mandate. They are still going ahead with expelling some service personnel who did not get vaccinate. (I guess that makes sense: they are getting thrown out not for being unvaccinated, but for disobeying orders.)
32% of Canadians were sure they’d had COVID-19, and another 8.3% suspected it;
16.7% of people who’d had COVID-19 reported having severe symptoms;
14.8% of them had symptoms for at least three months;
36.4% people who had severe symptoms had symptoms at three months;
25.8% of people who caught it before Dec 2021 (i.e. pre-Omicron) had symptoms at three months;
10.5%. of people who caught it after Dec 2021 (i.e. who probably got Omicron) had symptoms at three months;
32.5% of the people who’d had COVID-19 said that they thought they were all recovered, then they rebounded.
This article from the USA talks about the promise of low-dosage naltrexone — usually used as anti-addiction medication — against Long COVID.
This paper from Canada looked at people who had had COVID-19 (but not who were reported as “Long COVID”) found that:
There were two clusters of enduring symptoms: one that involved physical health, the other involving mental health.
Subjects tested lower than the population average on processing speed, reasoning, and verbal processing.
Subjects did not test lower on memory.
Cognitive ability correlated with physical symptoms; cognitive ability did not correlate with mental health symptoms.
This study from Ontario covering the first year of the pandemic found that COVID-19 doesn’t stop when you test negative. Women in Ontario who had had COVID-19 an average of almost 2 more health care encounters per person-year than those who did not have COVID-19. Men had 0.66 more health care encounters per person-year.
This article says that they have pretty strong evidence that the (a?) problem in Long COVID is microclots.
Vaccines
This preprint from the USA found that taking non-steroidal anti-inflammatories shortly after getting a vaccination (to reduce the pain) did not reduce the effectiveness of the vaccine.
This paper shows that antibodies in nasal swabs are much higher in people who have been vaccinated and infected (left, purple bars) than in people who were only vaccinated (right, orange bars):
This is why we need mucosal vaccines!
Bonus: in this paper, they also found a very potent monoclonal antibody (S2X324) which they say is a good candidate for commercialization.
This paper from Quebec reported the protection given by combinations of infections and vaccinations against a BA.2 infection:
# doses
previouspre-Omicron infection
previousBA.1 infection
0
38%
72%
1
56%
2
69%
96%
3
70%
96%
Effectiveness
Pathology
This paper from the UK found a allele which correlates with worse COVID-19 outcomes. Interestingly — and I have no idea what this means — this gene is also associated with narcolepsy.
This article reports on a presentation which found that trauma patients who had asymptomatic COVID had:
Higher rates of myocardial infarction and cardiac arrest (3.2% vs 0.9%)*
More ventilator days (3.33 vs 1.49 days)
Longer stay in the intensive care unit (4.92 vs 3.41 days)
Longer overall length of stay (11.41 vs 7.24 days)
Higher hospital charges ($176,505 vs $107,591)
Treatments
This article reports that Health Canada has approved Evusheld as a treatment for COVID-19, available to immunocompromised people over 12. (It was already in use as a prophylactic, similar to a vaccine, as it provides some protection for six months.)
Recommended Reading
This presentation to the US CDC shows that yes, COVID-19 is really bad for pregnant people and infants and that COVID-19 vaccines are not.
This article talks about the promise and danger of “gain-of-function” research.
This article reports that the cruise liner business did not, in fact, suffer irreparable harm from closing ports to foreign cruise liners during the pandemic. Apparently it’s been a record-breaking cruise season for BC.
Statistics
It is hard to fathom, but per this tweet, it appears that BC CDC only counts first infections in COVID-19 case counts and deaths. (I don’t know if they count COVID-19 hospitalizations for reinfections. I sure hope they do.) If reinfections aren’t counted at all, ever, then these stats are even more meaningless than we thought.
As of today, the BC CDC weekly report said that in the week ending on 15 October there were: +628 confirmed cases, +174 hospital admissions, +31 ICU admissions, +32 all-cause deaths.
As of today, the weekly report said that the previous week (data through 8 October September) there were: +697 confirmed cases, +237 hospital admissions, +42 ICU admissions, +44 all-cause deaths.
Last week, the weekly report said that in the week ending on 8 October there were: +697 confirmed cases, +181 hospital admissions, +36 ICU admissions, +25 all-cause deaths.
Last week, the report said that the previous week (data through 1 October September) there were: +696 confirmed cases, +245 hospital admissions, +30 ICU admissions, +36 all-cause deaths.
The BC CDC dashboard says that there are 389 in hospital / 21 in ICU as of 20 October 2022.
The positivity rate has been going up recently, especially among non-MSP testing. Non-MSP testing is for people who are covered by the federal government or who are not covered at all. I am not sure who-all is covered, but definitely people in federal prisons in BC. (I don’t know if foreign travellers are included in non-MSP, but the federal government is only doing sampling of travellers now. ) Maybe the 100 in the prison (see above) were a really big share of the positive tests?
https://githubcopilotinvestigation.com/ is the most important thing happening right now
in open source (and tech in general);
please read the whole thing and help if you can.
It wasn’t the first time. I took a year off from alcohol about ten years ago, mostly as a way to prove to myself that I didn’t have a problem with alcohol. After all, if I could spend a year sober, obviously I couldn’t have a drinking problem, could I? :-)
Turns out, my very real problems with alcohol center on drinking in moderation. Apparently I have two modes: either I don’t drink, or I drink significantly, every day. Faced with that choice, I stopped drinking entirely.
Some people choose sobriety after an incident in which they hit bottom. That wasn’t my pathway, though I do clearly remember the events that helped me decide to make a change. My girlfriend – now wife – Amy Price moved in with me five years ago. She’s had alcoholics in her life for many years, and I knew that my drinking was a concern for her, though she never pressured me to change my behavior. Knowing that she would be watching, I cut my drinking sharply. After a few months of living together, Amy went back to Houston to see friends over a long weekend, and I immediately took the opportunity to get drunk.
I woke up the next morning, hung over, and wondered why the hell I’d gotten drunk the night before. Clearly, I missed the experience of getting smashed. Clearly I’d been waiting for the opportunity to get drunk as soon as I possibly could. What the fuck was THAT about?
I took some aspirin, drank an iced coffee, and dumped out all the cheap booze in the house. (I gave the good stuff to friends. I had some NICE whisky at that point in my life.) Since then, I’ve had the occasional sip of Amy’s drink, but haven’t ordered a drink, got drunk or otherwise violated the drinking rules I’ve set for myself. (Turns out, people get sober different ways. I drink NA beer and spirits, which have less than 0.5% alcohol – there are folks in the AA community, for example, for whom that would violate rules. I know a number of friends who are “California sober”, which means they use cannabis but not alcohol. That’s not something I do for fear that I’d replace one habit with another.)
I’m writing about my experience because one of the major barriers I had in taking on my problems with alcohol was realizing that I had a problem with alcohol. I convinced myself that all alcoholics looked like Nick Cage’s character in Leaving Las Vegas, drinking vodka out of the bottle in the shower. I mostly drank at home, so DWI hadn’t been an issue for me. I never lost a job due to drinking, though in retrospect, my drinking had a lot to do with the end of my first marriage. I didn’t drink in the daytime, I was reasonably happy and successful, so clearly I couldn’t have a problem.
I have written before about the idea that high-functioning depression can be harder to diagnose than major depression, and I suspect the same is true for alcoholism. I had the odd experience of trying to convince (only a very few) friends that my problems with alcohol were serious enough that it was wise for me to stop drinking. My sense is that we, as a society, would benefit from a more nuanced understanding of alcoholism. For everyone for whom alcohol has become unmanageable, leading to assaults, arrests, and endangerment of others, there are tens or hundreds of people for whom alcohol is becoming a problem, or making it harder for people to address the other problems they’re facing in life.
Some people report that they’ve lost tons of weight, felt a wave of new energy or experienced other physical or spiritual transformations when they’ve become sober. That didn’t happen for me. Perhaps if you’re the sort of person who can replace a few cocktails with running a few miles, but for me that would require a full brain transplant, not just eliminating alcohol intake. But my five years of sobriety have been some of the happiest of my life. It’s hard to credit that solely to sobriety, because other aspects of life have changed simultaneously: I’m treating my depression, I moved to a university that’s a much healthier environment for me than my previous employer, I’m in a terrific relationship. My guess is that sobriety makes these other changes easier, and is made easier by these changes.
Hoplark Tea. My current beverage of choice.
The main change I’ve experienced from getting sober: I am starting to do a better job of taking responsibility for my own bad behavior. There’s a strong correlation between moments in my life that I’m embarrassed about and alcohol. It’s not hard to build a causal link: I drink and I do things I shouldn’t do. But that’s a dodge. Alcohol exacerbated my worst tendencies: it didn’t create them. Now when I fail to live up to my values and treat people around me badly, I don’t have an easy explanation for my bad behavior, which brings me one step closer to dealing with the ways in which I fall short.
The hardest thing about not drinking wasn’t the actual process of stopping. I am very lucky that I’ve always been able to cease drinking – my problem has always been with drinking in moderation, and I no longer try to do that. My problems now are mostly problems of replacement behaviors. I’ve had to figure out how to turn off at the end of the day. I used to have a drink or two over dinner – the alcohol was the cue that I was no longer expecting my brain to do productive work. That’s useful, because my brain isn’t well suited to working hard fourteen or sixteen hours a day. I’ve been working on other rituals and passtimes that help me turn off, but it’s a work in progress.
I’ve also had to search for alternative ways to reward myself – a drink was the preferred reward for finishing a project, for doing the task I’d put off doing, for getting through the day. It turns out that I still need rewards for accomplishing the mundanities of life. During the pandemic, I started driving an hour to Albany to get interesting and exciting takeout food most Friday nights, a way of breaking the monotony of COVID sameness. It’s become one in an arsenal of rewards that I keep handy.
That arsenal also includes lots of tasty things to drink that aren’t alcoholic. It’s a terrific time to get sober: breweries are cracking the riddle of making non-alcoholic beer that doesn’t make you sad. Most notable for me has been non-alcoholic Guinness, which I am betting would do well in a taste-test with the fully leaded stuff. I get a monthly subscription from Hoplark, which makes hop-inflused teas and waters, and a bottle of Kentucky 75, which mixed with diet Pepsi is a surprisingly good facsimile of my tipple of choice.
One of the most useful resources for me has been a Facebook group for non-alcohol beer fans, a community that’s been an equal mix of tasting recommendations and low-key encouragement. Seeing people celebrate their sobriety milestones is encouraging, as is watching people forgive and encourage each other. Someone will post about ordering a NA beer and being served the hard stuff, and “ruining” their streak of sobriety – the community will immediately explain that sobriety is, at least in part, about intentionality. The drinker who meant to order a NA beer, who stopped when she figured out the beer was leaded is still sober… and anyone who would quibble over that reading of the situation probably wouldn’t be especially comfortable in this community.
Why write about five years of sobriety? In truth, being sober doesn’t require much concentration or effort most days. I make a point of checking for NA options whenever I am in a bar or restaurant, if only to let restaurant owners know that non-drinkers exist. There’s alcohol in my house for Amy, who might have a glass of wine once a week, or for guests. I have very occasional moments where I BADLY want a drink – the most recent was on an airplane, sitting next to a man who put away four shots of bourbon in rapid succession. I drained my club soda, put on my mask and tried hard not to smell the alcohol as it seeped out of his pores. (Since getting sober, I smell alcohol on people’s skin with an acuity that can be uncomfortable.)
My path to sobriety didn’t run through AA or other conventional support groups, though I have friends for whom those communities, meetings and support are essential to their own path. But I saw an AA five year coin posted to my Facebook NA beer club recently, and I wanted one. Not an AA coin necessarily, but some tangible, physical acknowledgement of five years of being in the world in a different way. I am deeply proud that I’ve found a different way of being, a way that gives me a better chance of being the person I want to be.
This post is my five year coin. It’s my celebration of something that gets easier every day, but is still not easy, and may never be. It’s a strange thing to be proud of, an accomplishment made up of 1800 days of not doing something. But it’s something I am damned proud of, that I’m turning over in my fingers like a heavy coin in my pocket, that I fidget with contentedly, like my wedding ring.
I wish you the best with whatever changes you are trying to make in your life, and I wish you pride in your successes, whatever they may be. And I am looking forward to updating this post five, ten and fifteen years from now.
Brief status update: I’m travelling through San Francisco next week to go hang out IRL with some buddies off a discord server and talk about the future. Because why not.
AND SO: I’ll be in the valley Tues 25th, and in the city Tues night and the morning of Weds 26th.
Old friends! There may be a handful of us grabbing a drink/dinner in the city on Tuesday. Drop me a note! Let’s see if paths coincide! Sorry for not messaging directly, this is a last-minute trip.
Opportunistic hellos? I’m super interested (and currently working in) in the intersection of tools for thought, the multiplayer web, presence and small groups (and group/environmental computing), AI/NPCs etc. I would love to connect with folks doing design/research that touches this space, especially at the bigger firms. If that sounds like you then please do ping me (email/Twitter DMs), and maybe we get coffee when I’m in California or maybe we play a round of Walkabout Mini Golf in the metaverse (lol) when I’m back home, something like that.
I feel like that was a bit of a dull post for almost everyone.
I have this open a whole bunch in the background nowadays. Dawn is good. You often see animals throughout the day. You can hear the wind. I would love a widget on my phone’s lock screen that pings when there is a lot of motion.
There ought to be more dependable HD live streams to watch. The fixed view and lack of editing is what makes it work (the ISS cam jumps around too much). Maybe a not-for-profit could drop and maintain cameras all over the world; rainforests, mountains, cities. That would be good. Better than zoos. Bonus points: two cameras for VR. Binaural sound.
No, I don’t know why the cumulative percentage goes down sometimes. I don’t think we have so much immigration of unvaccinated people that it would affect the numbers.
Part 1 of this series looks at the state of the climate crisis, and how we can still get our governments to do something about it. Part 2 considers the collapse scenarios we’re likely to face if we fail in those efforts. In this part we’re looking at concrete things we could work towards to make our software more resilient in those scenarios.
The takeaway from part 2 was that if we fail to mitigate the climate crisis, we’re headed for a world where it’s expensive or impossible to get new hardware, where electrical power is scarce, internet access is not the norm, and cloud services don’t exist anymore or are largely inaccessible due to lack of internet.
What could we do to prepare our software for these risks? In this part of the series I’ll look at some ideas and relevant art for resilient technlogy, and how we could apply this to GNOME.
Local-First
Producing power locally is comparatively doable given the right equipment, but internet access is contingent on lots of infrastructure both locally and across the globe. This is why reducing dependence on connectivity is probably the most important challenge for resilience.
Unfortunately we’ve spent the past few decades making software ever more reliant on having fast internet access, all the time. Manyof theapps people spend all day in are unusable without an internet connection. So what would be the opposite of that? Is anyone working in the direction of minimizing reliance on the network?
As it turns out, yes! It’s called “local-first”. The idea is that instead of the primary copy of your data being on a server and local apps acting as clients to it, the client is the primary source of truth. The network is only used optionally for syncing and collaboration, with potential conflicts automatically resolved using CRDTs. This allows for superior UX because you’re not waiting on the network, better privacy because you can end-to-end encrypt everything, and better handling of low-connectivity cases. All of this is of course technically very challenging, and there aren’t many implementations of it in production today, but the field is growing and maturing quickly.
Among the most prominent proponents of the local-first idea are the community around the Ink & Switch research lab and Muse, a sketching/knowledge work app for Apple platforms. However, there’s also prior work in this direction from the GNOME community: There’s Christian Hergert’s Bonsai, the Endless content apps, and it’s actually one of the GNOME Foundation’s newly announced goals to enable more people to build local-first apps.
automerge, a library for building local-first software
Fullscreen, a web-based whiteboard app which allows saving to a custom file format that includes history and editing permissions
Magic Wormhole, a system to send files directly between computers without any servers
Earthstar, a local-first sync system with USB support
USB Fallback
Local-first often assumes it’s possible to sometimes use the network for syncing or transferring data between devices, but what if you never have an internet connection?
It’s possible to use the local network in some instances, but they’re not very reliable in practice. Local networks are often weirdly configured, and things can fail in many ways that are hard to debug (Source: Endless tried it and decided it was not worth the hassle). In contrast USB storage is reliable, flexible, and well-understood by most people, making it a much better fallback.
As a practical example, a photo management app built in this paradigm would
Store all photos locally so there’s never any spinners after first setup
Allow optionally syncing with other devices and collaborative album management with other people via local network or the internet
Automatically reconcile conflicts if something changed on other devices while they were disconnected
Allow falling back to USB, i.e. copying some of the albums to a USB drive and then importing them on another device (including all metadata, collaboration permissons, etc.)
Mockup for USB drive support in GNOME Software (2020)
Some concrete things we could work on in the local-first area:
Investigate existing local-first libraries, if/how they could be integrated into our stack, or if we’d need to roll our own
Prototype local-first sync in some real-world apps
Implement USB app installation and updates in GNOME Software (mockups)
Resource Efficiency
While power can be produced locally, it’s likely that in the future it will be far less abundant than today. For example, you may only have power a few hours a day (already a reality in parts of the global south), or only when there’s enough sun or wind at the moment. This makes power efficiency in software incredibly important.
Power Measurement is Hard
Improving power efficiency is not straightforward, since it’s not possible to measure it directly. Measuring the computer’s power consumption as a whole is trivial, but knowing which program caused how much of it is very difficult to pin down (for more on this check out Aditya Manglik’s GUADEC talk (Recording on Youtube) about power profiling tooling). Making progress in this area is important to allow developers to make their software more power-efficient.
However, while better measurements would be great to have, in practice there’s a lot developers can do even without it. Power is in large part a function of CPU, GPU, and memory use, so reducing each of these definitely helps, and we do have mature profiling tools for these.
Choose a Low-Power Stack
Different tech stacks and dependencies are not created equal when it comes to power consumption, so this is a factor to take into account when starting new projects. One area where there are actual comparative studies on this is programming languages: For example, according to this paper Python uses way more power than other languages commonly used for GNOME app development.
Relative energy use of different programming languages (Source: Pereira et al.)
Another important choice is user interface toolkit. Nowadays many applications just ship their own copy of Chrome (in the form of Electron) to render a web app, resulting in huge downloads, slow startup times, large CPU and memory footprints, and laggy interfaces. Using native toolkits instead of web technologies is a key aspect of making resilient software, and GTK4/Adwaita is actually in a really good position here given its performance, wide language support, modern feature set and widgets, and community-driven development model.
Schedule Power Use
It’s also important to actively consider the temporal aspect of power use. For example, if your power supply is a solar panel, the best time to charge batteries or do computing-intensive tasks is during the day, when there’s the most sunlight.
If we had a way for the system to tell apps that right now is a good/bad time to use a lot of power, they could adjust their behavior accordingly. We already do something similar for metered connections, e.g. Software doesn’t auto-download updates if your connection is metered. I could also imagine new user-facing features in this direction, e.g. a way to manually schedule certain tasks for when there will be more power so you can tell Builder to start compiling the long list of dependencies for a newly cloned Rust project tomorrow morning when the sun is back out.
Some concrete things we could work on in the area of resource efficiency:
Improve power efficiency across the stack
Explore a system API to tell apps whether now is a good time to use lots of power or not
Improve the developer story for GTK on Windows and macOS, to allow more people to choose it over Electron
Data Resilience
In hedging against loss of connectivity, it’s not enough to have software that works offline. In many cases what’s more important is the data we read/write using that software, and what we can do with it in resource-constrained scenarios.
The File System is Good, Actually
The 2010s saw lots of experimentation with moving away from the file system as the primary way to think about data storage, both within GNOME and across the wider industry. It makes a lot of sense in theory: Organizing everything manually in folders is shit work people don’t want to do, so they end up with messy folder hierarchies and it’s hard to find things. Bespoke content apps for specific kinds of data, with rich search and layouts custom-tailored to the data are definitely a nicer, more human-friendly way to deal with content–in theory.
In practice we’ve seen a number of problems with the content app approach though, including
Flexibility: Files can be copied/pasted/deleted, stored on a secondary internal drive, sent as email attachments, shared via a USB key, opened/changed using other apps, and more. With content apps you usually don’t have all of these options.
Interoperability: The file system is a lowest common denominator across all OSes and apps.
Development Effort: Building custom viewers/editors for every type of content is a ton of work, in part because you have to reimplement all the common operations you get for free in a file manager.
Familiarity: While it’s messy and not that easy to learn, most people have a vague understanding of the file system by now, and the universality of this paradigm means it only has to be learned once.
Unmaintained Apps: Data living in a specific app’s database is useless if the app goes unmaintained. This is especially problematic in free software, where volunteer maintainers abandoning projects is not uncommon.
Due to the above reasons, we’ve seen in practice that the file system is not in fact dying. It’s actually making its way into places where it previously wasn’t present, including iPhones (which now come with a Files app) and the web (via Nextcloud, Google Drive, and company).
From a resilience point of view some of the shortcomings of content apps listed above are particularly important, such as the flexibility to be moved via USB when there’s no internet, and cross-platform interoperability. This is why I think user-accessible files should be the primary source of truth for user data in apps going forward.
Simple, Standardized Formats
With limited connectivity, a potential risk is that you don’t have the ability to download new software to open a file you’re encountering. This is why sticking to well-known standard formats that any computer is likely to have a viewer/editor for is generally preferable (plain text, standard image formats, PDF, and so on).
When starting a new app, ask yourself, is a whole new format needed or could it use/extend something pre-existing? Perhaps there’s a format you could use that already has an ecosystem of apps that support it, especially on other platforms?
For example, if you were to start a new notes app that can do inline media you could go with a custom binary format and a database, but you could also go with Markdown files in a user-accessible folder. In order to get inline media you could use Textbundle, an extension to Markdown implemented by a number of other Markdown apps on other platforms, which basically packs the contained media into an archive together with the Markdown file.
Side note: I really want a nice GTK app that supports Textbundle (more specifically, its compressed variant Textpack), if you want to make one I’d be deligthed to help on the design side :)
Export as Fallback
Ideally data should be stored in standardized formats with wide support, and human-readable in a text editor as a fallback (if applicable). However, this isn’t possible in every case, for example if an app produces a novel kind of content there are no standardized formats for yet (e.g. a collaborative whiteboard app). In these cases it’s important to make sure the non-standard format is well-documented for people implementing alternative clients, and has support for exporting to more common formats, e.g. exporting the current state of a collaborative whiteboard as PDF or SVG.
Some concrete things we could work on towards better data resilience:
Explore new ways to do content apps with the file system as a backend
Look at where we’re using custom formats in our apps, and consider switching to standard ones
Consider how this fits in with local-first syncing
Keep Old Hardware Running
There are many reasons why old hardware stops being usable, including software built for newer, faster devices becoming too slow on older ones, vendors no longer providing updates for a device, some components (especially batteries) degrading with use over time, and of course planned obsolescence. Some of these factors are purely hardware-related, but some also only depend on software, so we can influence them.
Use old Hardware for Development
I already touched on this in the dedicated section above, but obviously using less CPU, RAM, etc. helps not only with power use, but also allows the software to run on older hardware for longer. Unfortunately most developers use top of the line hardware, so they are least impacted by inefficiencies in their personal use.
One simple way to ensure you keep an eye on performance and resource use: Don’t use the latest, most powerful hardware. Maybe keep your old laptop for a few years longer, and get it repaired instead of buying a new one when something breaks. Or if you’re really hardcore, buy an older device on purpose to use as your main machine. As we all know, the best way to get developers to care about something is to actually dogfood it :)
Hardware Enablement for Common Devices
In a world where it’s difficult to get new hardware, it’ll become increasingly important to reuse existing devices we have lying around. Unfortunately, a lot of this hardware is stuck on very old versions of proprietary software that are both slow and insecure.
With Windows devices there’s an easy solution: Just install an up-to-date free software OS. But while desktop hardware is fairly well-supported by mainline Linux, mobile is a huge mess in this regard. The Android world almost exclusively uses old kernels with lots of non-upstreamable custom patches. It takes years to mainline a device, and it has to be done for every device.
Projects like PostmarketOS are working towards making more Android devices usable, but as you can see from their device support Wiki, success is limited so far. One especially problematic aspect from a resilience point of view is that the devices that tend to be worked on are the ones that developers happen to have, which are generally not the models that sell the most units. Ideally we’d work strategically to mainline some of the most common devices, and make sure they actually fully work. Most likely that’d be mid-range Samsung phones and iPhones. For the latter there’s curiously little work in this direction, despite being a gigantic, relatively homogeneous pool of devices (for example, there are 224 million iPhone 6 out there which don’t get updates anymore).
Hack Bootloaders
Unfortunately, hardware enablement alone is not enough to make old mobile devices more long-lived by installing more up-to date free software. Most mobile devices come with locked bootloaders, which require contacting the manufacturer to get an unlock code to install alternative software – if they allow it at all. This means if the vendor company’s server goes away or you don’t have internet access there’s no way to repurpose a device.
What we’d probably need is a collection of exploits that allow unlocking bootloaders on common devices in a fully offline way, and a user-friendly automated unlocking tool using these exploits. I could imagine this being part of the system’s disk utility app or a separate third-party app, which allows unlocking the bootloader and installing a new OS onto a mobile device you plug in via USB.
Some concrete things we could work on to keep old hardware running:
Actively try to ensure older hardware keeps working with new versions of our software (and ideally getting faster with time rather than slower thanks to ongoing performance work)
Explore initiatives to do strategic hardware eneblament for some of the most common mobile devices (including iPhones, potentially?)
Forge alliances with the infosec/Android modding community and build convenient offline bootloader unlocking tools
Build for Repair
In a less connected future it’s possible that substantial development of complex systems software will stop being a thing, because the necessary expertise will not be available in any single place. In such a scenario being able to locally repair and repurpose hardware and software for new uses and local needs is likely to become important.
Repair is a relatively clearly defined problem space for hardware, but for software it’s kind of a foreign concept. The idea of a centralized development team “releasing” software out into the world at scale is built into our tools, technologies, and culture at every level. You generally don’t repair software, because in most cases you don’t even have the source code, and even if you do (and the software doesn’t depend on some server component) there’s always going to be a steep learning curve to being able to make meaningful changes to an unfamiliar code base, even for seasoned programmers.
In a connected world it will therefore always be most efficient to have a centralized development team that maintains a project and makes releases for the general public to use. But with that possibly no longer an option in the future, someone else will end up having to make sure things work as best they can at the local level. I don’t think this will mean most people will start making changes to their own software, but I could see software repair becoming a role for specialized technicians, similar to electricians or car mechanics.
How could we build our software in a way that makes it most useful to people in such a future?
Use Well-Understood, Accessible Tech
One of the most important things we can do today to make life easier for potential future software repair technicians is using well-established technology, which they’re likely to already have experience with. Writing apps in Haskell may be a fun exercise, but if you want other people to be able to repair/repurpose them in the future, GJS is probably a better option, simply because so many more people are familiar with the language.
Another important factor determining a technology stack’s repairability is how accessible it is to get started with. How easy is it for someone to get a development environment up and running from scratch? Is there good (offline) documentation? Do you need to understand complex math or memory management concepts?
Local-First Development
Most modern development workflows assume a fast internet connection on a number of levels, including downloading and updating dependencies (e.g. npm modules or flatpak SDKs), documentation, tutorials, Stackoverflow, and so on.
In order to allow repair at the local level, we also need to rethink development workflows in a local-first fashion, meaning things like:
Ship all the source code and development tools needed to rebuild/modify the OS and apps with the system
Have a first-class flow for replacing parts of the system or apps with locally modified/repaired versions, allowing easy management of different versions, rollbacks, etc.
Have great offline documentation and tutorials, and maybe even something like a locally cached subset of Stackoverflow for a few technologies (e.g. the 1000 most popular questions with the “gtk” tag)
Getting the tooling and UX right for a fully integrated local-first software repair flow will be a lot of work, but there’s some interesting relevant art from Endless OS from a few years back. The basic idea was that you transform any app you’re running into an IDE editing the app’s source code (thanks to Will Thompson for the screencast below). The devil is of course in the details for making this a viable solution to local software repair, but I think this would be a very interesting direction to explore further.
Some concrete things we could work on to make our software more repairable:
Avoid using obscure languages and technologies for new projects
Avoid overly complex and brittle dependency trees
Investigate UX for a local-first software repair flow
Revive or replace the Devhelp offline documentation app
Look into ways to make useful online resources (tutorials, technical blog posts, Stackoverflow threads, etc.) usable offline
This was part three of a four-part series. In the fourth and final installment we’ll wrap up the series by looking at some of the hurdles in moving towards resilience and how we could overcome them.
I've been using Locust recently to run some load tests - most significantly these tests against SQLite running with Django and this test exercising Datasette and Gunicorn.
A really basic test
Locust tests are defined in a locustfile.py file. Here's the most basic possible test, which sends requests to the / page of a web application:
from locust import HttpUser, task
class Page(HttpUser):
@task
def index(self):
self.client.get("/")
The web interface
With this saved as locustfile.py you can run it in two ways. You can start a web interface to Locust like this:
locust
This opens a web server on http://0.0.0.0:8089/ (by default) which offers an interface for starting a new test:
You can run this for as long as you like, and it will produce both statistics on the load test and some pleasing charts:
Using the command-line
You can also run tests without the web server at all. I tend to use this option as it's quicker to repeat a test, and you can easily copy and paste the results into a GitHub issue thread.
This runs the tests in the current locustfile.py against http://127.0.0.1:8001, with four concurrent users and ramping up at 2 users every second (so taking two seconds to ramp up to full concurrency).
Hit Ctrl+C to end the test. It will end up producing something like this:
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
GET /fixtures/sortable 475 0(0.00%) | 169 110 483 170 | 23.58 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 475 0(0.00%) | 169 110 483 170 | 23.58 0.00
Response time percentiles (approximated)
Type Name 50% 66% 75% 80% 90% 95% 98% 99% 99.9% 99.99% 100% # reqs
--------|--------------------------------------------------------------------------------|--------|------|------|------|------|------|------|------|------|------|------|------
GET /fixtures/sortable 170 170 180 180 190 200 210 250 480 480 480 475
--------|--------------------------------------------------------------------------------|--------|------|------|------|------|------|------|------|------|------|------|------
Aggregated 170 170 180 180 190 200 210 250 480 480 480 475
More complicated tests
Locust tests can get a lot more complex than this. The documentation provides this example:
import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_items(self):
for item_id in range(10):
self.client.get(f"/item?id={item_id}", name="/item")
time.sleep(1)
def on_start(self):
self.client.post("/login", json={"username":"foo", "password":"bar"})
This illustrates some neat concepts. Each "user" will constantly pick a task at random, where a task is a method decorated with the @task decorator. @task(3) here gives that task a weight of three, so it's three times more likely to be accepted.
The self.client can maintain cookie state between requests, with each user getting a separate copy. on_start is used here to log the user in, but also demonstrates how POST requests can work against APIs that accept JSON.
Amy Price and I were married the weekend of October 7, 2022. We were legally married at the Pittsfield MA city hall so that our friend, Dr. Colin McCormick, could officiate our wedding on October 9. While Massachusetts has one-day solemnization certificates, Colin needed to participate via Zoom, and MA law doesn’t recognize virtual solemnization. And so, we got legally married on a beautiful fall day by the Pittsfield City Clerk as our friends were coming into town from around the world.
Our wedding included visits from our Texas friends to our home in Lanesboro, a tour of MassMoCA with sixty friends, a dinner and board game session at The Log on Spring Street in Williamstown, before a brunch wedding on Sunday the 9th at Greylock Works. Our wedding venue was an old “weaving shed”, which had been part of Berkshire Mills. Amy found a wonderful video of the mill in 1917, which we projected on one of the walls of the space.
We invited friends to photograph the events for us and they did a brilliant job, though friends might been having too much fun during the MoCA visit and pizza dinner to fully document events. We are especially grateful to Andrew McLaughlin, who took video of the full event. We made it difficult for him at the end, when we rickrolled our own wedding and danced down the aisle for our recessional – McLaughlin was laughing too hard to always hold the camera steady.
“The Book of Love”, as performed by Cidnie Carroll, Amy and me
Rick Astley strikes again.
Two moments that I will particularly treasure were captured by Margaret Stewart – our friend Cidnie Carroll performing Magnetic Fields, “The Book of Love” with Amy and me, as well as the wonderful recessional Amy choreographed.
I’m grateful to all the friends who were able to make the trip to be with us and their efforts to document the event. I’m grateful to my parents for their help in paying for throwing a giant party And I am impossibly grateful to Amy for being my best friend, my partner, my favorite co-conspirator and now my wife. 16/10, A+++++++, would marry again.
This is what I did at lunchtime today - stood outside the Eurostar arrivals and said “thank you for not flying” to everyone coming through. There were lots of smiles in reply. Positive reinforcement is great and it’s good to be reminded that people are generally nice. https://t.co/9lAgmKaTVs
A software system can be said to be dead when the information needed to run it ceases to be available.
Provided the necessary information is available, plus time/money, no software ever has to remain dead, hardware emulators can be created, support libraries can be created, and other necessary files cobbled together.
In the case of software as a service, the vendor may simply stop supplying the service; after which, in my experience, critical components of the internal service ecosystem soon disperse and are forgotten about.
Users like the software they use to be actively maintained (i.e., there are one or more developers currently working on the code). This preference is culturally driven, in that we are living through a period in which most in-use software systems are actively maintained.
Active maintenance is perceived as a signal that the software has some amount of popularity (i.e., used by other people), and is up-to-date (whatever that means, but might include supporting the latest features, or problem reports are being processed; neither of which need be true). Commercial users like actively maintained software because it enables the option of paying for any modifications they need to be made.
Software can be a zombie, i.e., neither dead or alive. Zombie software will continue to work for as long as the behavior of its external dependencies (e.g., libraries) remains sufficiently the same.
Active maintenance requires time/money. If active maintenance is required, then invest the time/money.
Open source software has become widely used. Is Open source software frequently maintained, or do projects inhabit some form of zombie state?
The commits/pull requests/issues, of circa 1K project repos with lots of stars, is data that can be automatically extracted and analysed in bulk. What is missing from the analysis is the context around the creation, development and apparent abandonment of these projects.
Application areas and development tools (e.g., editor, database, gui framework, communications, scientific, engineering) tend to have a few widely used programs, which continue to be actively worked on. Some people enjoy creating programs/apps, and will start development in an area where there are existing widely used programs, purely for the enjoyment or to scratch an itch; rarely with the intent of long term maintenance, even when their project attracts many other developers.
I suspect that much of the existing research is simply measuring the background fizz of look-alike programs coming and going.
A more realistic model of the lifecycle of Open source projects requires human information; the intent of the core developers, e.g., whether the project is intended to be long-term, primarily supported by commercial interests, abandoned for a successor project, or whether events got in the way of the great things planned.
I've been reminded again how really, really hard it is to do effective video on the internet. Obviously anyone can film something on their phone and stick it online, that's incredibly easy. But getting someone to see it is incredibly hard.
And people underestimate how hard it is because they see some stupid, cheap, badly filmed thing succeed and say - look that was cheap and badly filmed and that succeeded. But what they don't see are all the films they didn't see. The millions and millions and millions of them. The interaction of people and algorithm selects badly made things that have some other incredibly rare quality. An accident, a look, a moment, a personality. Stuff that your film probably doesn't have.
If you don't have that or want to significantly increase your chances of succeeding you have to work incredibly hard. For example: Mr Beast has a 6-person team making YouTube thumbnails. And I don't even know what a YouTube thumbnail is.
That’s me in the Lisbon airport on September 1st with fourteen bags of most of our worldly possessions. A few hours later, Charlotte and I would begin unpacking them in Nazaré, Portugal, our new home for the next chapter in our story.
While the move has been in the works since the early days of Covid, most of the execution has been packed into these last six months. We sold the house, sold the car, rented an apartment, bought a car, closed accounts, opened accounts, said goodbye to friends, started making new friends, and started learning Portuguese (a constant reminder of my general lack of decent study habits and a likely source of future blog posts about learning challenges in my dotage).
The closing graf in that earlier post was
If your value depends on making sense out of the collision between the present situation and what has come before you have to manage your understanding of both.
There’s an intuition there that I am still trying to unpack.
Donald Schön’s notion of reflective practice is central to understanding knowledge work. Experience is the raw material that fuels practice. Your practice improves as you process experience and make adaptations and changes. Schön’s argument was that the more intentionally and mindfully you process and make sense of experience, the better your practice gets.
There’s a scale problem here. Maybe more than one.
The first is the basic problem of information overload that faces all knowledge workers. The second scale problem is that more of us are knowledge workers. We’ll table that problem for another day.
Richard Saul Wurman wrote about information overload in the late 1980s in Information Anxiety as did Vannevar Bush in 1945 in “As We May Think”. Moreover, it’s an exponential growth problem that has nearly always exceeded the capacity of available coping strategies (willful ignorance doesn’t count as a coping strategy no matter how often it is chosen).
The spate of new PKM tools are the latest attempt to address this scale problem. It’s encouraging to see some recommended strategies for deploying the tools. What I would like to see is even more case studies of how we are all learning to leverage available tools.
I was about to add that I’ve made a mental note to work on case studies of my own practice. But, in point of fact, I’ve just finished capturing that “mental” note as an actual note. Stay tuned.
One aspect of the information overload problem I want to investigate is the metaphor of the blank sheet of paper. Sometimes it’s explicit. More often it’s hidden in the assumptions of new tools and new practices. Everyone wants to pretend that you start clean because it simplifies their problem. Dealing with whatever mess of prior systems and practices you’ve cobbled together over the years is your problem.
Which it is.
But it really helps to be aware that it is your problem and that it exists. Taking some time to see what is already on your sheet of paper is the first step to becoming a more effective reflective practitioner.
Auf unser Grundstück fallen jedes Jahr Hunderte von Walnüssen von einem mehr als 10 Meter hohen Baum. Aber die lassen wir den Eichhörnchen und anderen Tieren. Zu bitter. Auch die übliche Supermarktware finden wir ungenießbar.
Dafür kaufen wir zwei Säcke von diesen Grenoblern im Jahr. Das ist die erste Lieferung der 2022er. Mal eine ungewöhnliche, aber sichere Empfehlung.
Ich hätte zu gerne auch mal den AirPods-Nutzer im Hintergrund gehört
Danny hat ein sehr gutes Video in lauter Umgebung aufgenommen. Ich mag alle drei vorgestellten Headsets:
Poly Voyager Focus 2: Sehr gutes Headset, Geräuschunterdrückung top. Leichte Abwertung für MicroUSB-B als Ladebuchse, mit Dock ist das unerheblich.
Jabra Evolve 2 75: Von mir aktuell meistbenutztes Konferenz-Headset, sehr gut auch als normaler Kopfhörer nutzbar wegen des komplett einklappbaren Mikrofonarms.
Comments on vowe.net were always much better than on the rest of the Internet. I attribute this in part to my policy to only keep comments published with a full name.
When I migrated to WordPress, I switched on comment moderation. I needed to approve every person only once and things would run smoothly. A while ago, I had a few people who wanted to test my tolerance, for instance by publishing comments under my own name. Then I switched off auto moderation, and now I must approve every single comment.
That means it may take a little while for your comment to appear. But it also relieves me from deleting comments that have already been published.
There was a grace period where I would inform you if you “forgot” to enter your full name, but that ends now. I just trash the comment.
Spam comments far outnumber regular comments, but Akismet takes care of them. There is quite a bit of housekeeping going on when you allow other people to post to your website without authorization.
This website is more than 20 years old, and I have never used your mail addresses for anything put sending you a direct reply. I don’t to newsletters, I do not keep a list of commenters, I don’t track visitors, I don’t run advertisements, I do not do advertorials.
In summary: this place should not even exist. And that is why it does.
I seem to have relapsed in recent weeks to the bullet-point weeknote. This week is going to be no different, I’m afraid. Who knows, some readers might even prefer it?
Buying a second car. We’ve gone for a high-spec 2018 VW Up! as we need to take our kids to different sporting activities at the same time in different places at the moment. We don’t live in a city, so public transport would take a ridiculously long time, sadly.
Not leasing a main family car. We were all set to lease a Hyundai IONIQ 5 through my business, but the funder rejected my application. Given that I’ve got a perfect credit score, I’ve leased a car through the business before, and I’m earning more than I was when I last did that, I can only blame the Tories and Brexit for wrecking the economy. We’ll probably end up just replacing our (lovely) nine year-old Volvo V60 with another one at some point.
Listening to politics podcasts, mainly The Rest is Politics, hosted by Alaistair Campbell and Rory Stewart, and Today in Focus from The Guardian. What a crazy week.
Running, both at home and in Lille, trying to keep my heart rate at around 155. This seems to be enough to get enough of a workout, without pushing my heart too much. Not so many endorphins, but safer — I’m also taking my phone running these days, just in case.
Next week, I’m working on Monday, seeing my sister and her kids, and then heading off with Team Belshaw to Scotland for a few days as it’s half term.
Photo of the opera house in Lille taken in the early hours of Friday morning, after a whisky with friends to celebrate the lettuce’s victory!
Re-emerging from our COVID-19 cocoons is disorienting and stressful. This psychological phenomenon was anticipated almost 50 years ago by Isaac Asimov (often assessed, in retrospect, as having been on the autism spectrum) in his prescient pandemic must-read novels of physical distancing and virtual meetings, “The Naked Sun” and “The Robots of Dawn”.
This aspect of the return to a post-pandemic “new normal” is true for everyone, but perhaps especially true for people on the autism spectrum.
For more than a year after the outbreak of COVID-19, I was never further from my home in San Francisco than I could get, and return, in a day, by bicycle. I resumed travelling only after I was vaccinated, at first only to see elderly and ailing relatives.
The first time I travelled to a gathering of strangers in a distant city was for the annual meeting of the Peace and Justice Studies Association in October 2021. After a year and a half in the familiar environs of my home, previously routine travel experiences such as walking down a street in Milwaukee and eating with a group of strangers at a campus conference-center buffet seemed exotically unfamiliar and induced an almost overwhelming sensory overload, as though I were on some psychedelic drug.
Previous to that I enjoyed a privileged life of regular travel to the US, Asia, and Europe; indeed my emotional resilience as a individual, father and partner on this small island was, to a great extent, predicated on being able to regularly leave this small island. Robbed of that opportunity by circumstance (illness, death, grief, caregiving, and the stretch goal of COVID) has changed the foundations of my life in ways that I’m just now beginning to realize.
There is a strong undercurrent of wanting to get out on the open road running through me; it’s a mix of wanting to throw off the shackles of confinement and a need to feed my hungry mind. And yet the complexity of my current situation — partner, kids, school, work, in their various permutations and combinations — makes getting out on that road, especially in a way that affords some spacious clarity, an often-insurmountable-seeming task. To say nothing of the emerging-from-fallout-shelter fears of what the world out there might look and feel like when I’m able to get there.
Edward finishes his post with a question:
As you begin travelling again, or begin travelling further afield, plan to travel more slowly, with rest days and breaks. Leave your plans more flexible. Avoid package tours or cruises that lock in your pace and itinerary. Give your brain a chance to gradually get back into its travel groove. Celebrate the chance to experience the world anew and to see the world with a fresh eye!
Are you travelling again? What seems different than before? Is that because the world has changed, or because your perspective has?
There is no question that my circumstances have changed, fundamentally; at the same time, vestigial perspectives—loneliness, fear, isolation, resignation—remain baked inside me.
I want to emerge into the world, as Edward suggests, and seize a ”chance to experience the world anew and to see the world with a fresh eye.” I want to take this new edition of me on tour, and the prospect of that is exciting, thrilling, hopeful.
And yet I’m afraid that those baked-in perspectives are baked in to an extent that a simple change of scenery isn’t enough to affect.
The only way to find out is to get outta town. I hope to do that. Soon.
Let’s say you want to improve the Wikipedia page for Clayton Indiana with an aerial photograph. Feel free to use the one above. That’s why I shot it, posted it, and licensed it permissively. It’s also why I put a helpful caption under it, and some call-outs in mouse-overs.
It’s also why I did the same with Danville, Indiana:
Also Brownsville, Indiana, featuring the Brickyard VORTAC station (a navigational beacon used by aircraft):
Eagle Creek Park, the largest in Indianapolis, and its Reservoir:
The district of Indianapolis charmlessly called Park 100:
The White River, winding through Indianapolis:
Where the White River joins and the Wabash, which divides Southern Indiana from Southern Illinois (which is on the far side here, along with Mt. Carmel):
Among other places.
These were shot on the second leg of a United flight from Seattle to Indianapolis by way of Houston. I do this kind of thing on every flight I take. Partly it’s because I’m obsessed with geography, geology, weather, culture, industry, infrastructure, and other natural things. And partly it’s to provide a useful service.
I don’t do it for the art, though sometimes art happens. For example, with this shot of salt ponds at the south end of San Francisco Bay:
Airplane windows are not optically ideal for photography. On the contrary, they tend to be scratched, smudged, distorted, dirty, and worse. Most of the photos above were shot through a window that got frosty and gray at altitude and didn’t clear until we were close to landing. The air was also hazy. For cutting through that I can credit the dehaze slider in Adobe Photoshop 2021. I can also thank Photoshop for pulling out color and doing other things that make bad photos useful, if not good in the artsy sense. They fit my purpose, which is other people’s purposes.
In addition to Adobe, I also want to tip my hat toward Sony, for making the outstanding a7iv mirrorless camera and the 24-105mm f/4 FE G OSS lens I used on this flight. Also Flickr, which makes it easy to upload, organize, caption, tag, and annotate boundless quantities of full- (and other-) size photos—and to give them Creative Commons licenses. I’ve been using Flickr since it started in 2005, and remain a happy customer with two accounts: my main one, and another focused on infrastructure.
While they are no longer in a position to care, I also want to thank the makers of iView MediaPro, Microsoft Expressions and PhaseOne MediaPro for providing the best workflow software in the world, at least for me. Alas, all are now abandonware, and I don’t expect any of them to work on a 64-bit operating system, which is why, for photographic purposes, I’m still sitting on MacOS Mojave 10.14.6.
I’m hoping that I can find some kind of substitute when I get a new laptop, which will inevitably come with an OS that won’t run the oldware I depend on. But I’ll save that challenge for a future post.
I wrote this more than a quarter century ago when Linux Journal was the only publication that would have me, and I posted unsold essays and wannabe columns at searls.com. These postings accumulated in this subdirectory for several years before Dave Winer got me to blog for real, starting here.
Interesting how much has changed since I wrote this, and how much hasn’t. Everything I said about metaphor applies no less than ever, even as all the warring parties mentioned have died or moved on to other activities, if not battles. (Note that there was no Google at this time, and the search engines mentioned exist only as fossils in posts such as this one.)
Perhaps most interesting is the paragraph about MARKETS ARE CONVERSATIONS. While that one-liner had no effect at the time, it became a genie that would not return to its bottle after Chris Locke, David Weinberger, Rick Levine and I put it in The Cluetrain Manifesto in 1999. In fact, I had been saying “markets are conversations” to no effect at least since the 1980s. Now “join the conversation” is bullshit almost everywhere it’s uttered, but you can’t stop hearing it. Strange how that goes.
MAKE MONEY, NOT WAR
TIME TO MOVE PAST THE WAR METAPHORS OF THE INDUSTRIAL AGE
By Doc Searls
19 March 1997
“War isn’t an instinct. It’s an invention.”
“The metaphor is probably the most fertile power possessed by man.”
“Conversation is the socializing instrument par excellence.”
-José Ortega y Gasset
Patton lives
In the movie “Patton,” the general says, “Compared to war, all other forms of human endeavor shrink to insignificance.” In a moment of self-admonition, he adds, “God help me, I love it so.”
And so do we. For proof, all we have to do is pick up a trade magazine. Or better yet, fire up a search engine.
Altavista says more than one million documents on the Web contain the words Microsoft, Netscape, and war. Hotbot lists hundreds of documents titled “Microsoft vs. Netscape,” and twice as many titled “Netscape vs. Microsoft.”
It’s hard to find an article about the two companies that does not cast them as opponents battling over “turf,” “territory,” “sectors” and other geographies.
It’s also hard to start a conversation without using the same metaphorical premise. Intranet Design Magazine recently hosted a thread titled “Who’s winning?? Netscape vs. Microsoft.” Dave Shafer starts the thread with “Wondering what your informed opinion is on who is winning the internet war and what affects this will have on inter/intranet development.” The first respondent says, “sorry, i’m from a french country,” and “I’m searching for economical informations about the war between Microsoft and Netscape for the control of the WEB industrie.” Just as telling is a post by a guy named Michael, who says “Personaly I have both on my PC.”
So do I. Hey, I’ve got 80 megs of RAM and a 2 gig hard drive, so why not? I also have five ISPs, four word processors, three drawing programs, and two presentation packages. I own competing products from Apple, IBM, Microsoft, Netscape, Adobe, Yamaha, Sony, Panasonic, Aiwa, Subaru, Fisher Price and the University of Chicago — to name just a few I can see from where I sit. I don’t sense that buying and using any of these is a territorial act, a victory for one company, or a defeat for another.
But that doesn’t mean we don’t have those perceptions when we write and talk about companies and the markets where they compete. Clearly, we do, because we understand business — as we understand just about everything — in metaphorical terms. As it happens, our understanding of companies and markets is largely structured by the metaphors BUSINESS IS WAR and MARKETS ARE BATTLEFIELDS.
By those metaphors we share an understanding that companies fight battles over market territories that they attack, defend, dominate, yield or abandon. Their battlefields contain beachheads, bunkers, foxholes, sectors, streams, hills, mountains, swamps, streams, rivers, landslides, quagmires, mud, passages, roadblocks, and high ground. In fact, the metaphor BUSINESS IS WAR is such a functional conceptual system that it unconsciously pumps out clichés like a machine. And since sports is a sublimated and formalized kind of war, the distances between sports and war metaphors in business are so small that the vocabularies mix without clashing.
Here, I’ll pick up the nearest Business Week… it’s the January 13 issue. Let’s look at the High Technology section that starts on page 104. The topic is Software and the headline reads, “Battle stations! This industry is up for grabs as never before…” Here’s the first paragraph, with war and sports references capitalized: “Software was once an orderly affair in which a few PLAYERS called most of the shots. The industry had almost gotten used to letting Microsoft Corp. set the agenda in personal computing. But as the Internet ballooned into a $1 billion software business in 1996, HUGE NEW TERRITORIES came up for grabs. Microsoft enters the new year in a STRONG POSITION TO REASSERT CONTROL. But it will have to FIGHT OFF Netscape, IBM, Oracle and dozens of startups that are DESPERATELY STAKING OUT TURF on the Net. ‘Everyone is RACING TO FIND MARKET SPACE and get established…'”
Is this a good thing? Does it matter? The vocabularies of war and sports may be the most commonly used sources of metaphors, for everything from academic essays to fashion stories. Everybody knows war involves death and destruction, yet we experience little if any of that in the ordinary conduct of business, or even of violent activities such as sports.
So why should we concern ourselves with war metaphors, when we all know we don’t take them literally?
Two reasons. First, we do take them literally. Maybe we don’t kill each other, but the sentiments are there, and they do have influences. Second, war rarely yields positive sums, except for one side or another. The economy the Internet induces is an explosion of positive sums that accrue to many if not all participants. Doesn’t it deserve a more accurate metaphor?
“Answer true or false,” Firesign Theater says. “Dogs flew spaceships. The Aztecs invented the vacation… If you answered ‘false’ to any of these questions, then everything you know is wrong.”
This is the feeling you begin to get when you read George Lakoff, the foremost authority on the matter of metaphor. Lakoff is Professor of Linguistics and Cognitive Science at UC-Berkeley, the author of Women, Fire and Dangerous Things and Moral Politics: What Conservatives Know that Liberals Don’t. He is also co-author of Metaphors We Live By and More than Cool Reason. All are published by the University of Chicago Press.
Maybe that’s why they didn’t give us the real story in school. It would have been like pulling the pins out of a bunch of little hand grenades.
If Lakoff is right, the most important class you ignored in school was English — not because you need to know all those rules you forgot or books you never read, but because there’s something else behind everything you know (or think you know) and talk about. That something is a metaphor. (And if you think otherwise, you’re wrong.)
In English class — usually when the subject was poetry — they told us that meaning often arises out of comparison, and that three comparative devices are metaphor, simile, and analogy. Each compares one thing to another thing that is similar in some way:
Metaphors say one thing is another thing, such as “time is money,” “a computer screen is a desktop,” or (my favorite Burt Lancaster line) “your mind is a cookie of arsenic.”
Similes say one thing is like another thing, such as “gone like snow on the water” or “dumb as a bucket of rocks.”
Analogies suggest partial similarities between unalike things, as with “licorice is the liver of candy.”
But metaphor is the device that matters, because, as Lakoff says, “We may not always know it, but we think in metaphor.” And, more to the point, “Metaphors can kill.” Maybe that’s why they didn’t give us the real story in school. It would have been like pulling the pins out of a bunch of little hand grenades.
But now we’re adults, and you’d think we should know how safely to arm and operate a language device. But it’s not easy. Cognitive science is relatively new and only beginning to make sense of the metaphorical structures that give shape and meaning to our world. Some of these metaphors are obvious but many others are hidden. In fact, some are hidden so well that even a guru like Lakoff can overlook them for years.
Lakoff’s latest book, “Moral Politics: What Conservatives Know and Liberals Don’t,” was inspired by his realization that the reason he didn’t know what many conservatives were talking about was that, as a Liberal, he didn’t comprehend conservative metaphors. Dan Quayle’s applause lines went right past him.
After much investigation, Lakoff found that central to the conservative worldview was a metaphor of the state as a strict father and that the “family values” conservatives espouse are those of a strict father’s household: self-reliance, rewards and punishments, responsibility, respect for authority — and finally, independence. Conservatives under Ronald Reagan began to understand the deep connection between family and politics, while Liberals remained clueless about their own family metaphor — the “nurturant parent” model. Under Reagan, Lakoff says, conservatives drove the language of strict father morality into the media and the body politic. It won hearts and minds, and it won elections.
So metaphors matter, big time. They structure our perceptions, the way we make sense of the world, and the language we use to talk about things that happen in the world. They are also far more literal than poetry class would lead us to believe. Take the metaphor ARGUMENT IS WAR —
“It is important to see that we don’t just talk about arguments in terms of war. We can actually win or lose arguments. We see the person we are arguing with as an opponent. We attach kis decisions and defend our own. We gain and lose ground. We plan and use strategies… Many of the things we do in arguing are partially structured by the concept of war.” (From Metaphors We Live By)
In our culture argument is understood and structured by the war metaphor. But in other cultures it is not. Lakoff invites us to imagine a culture where argument is viewed as dance, participants as performers and the goal to create an aesthetically pleasing performance.
Right now we understand that “Netscape is losing ground in the browser battle,” because we see the browser business a territory over which Netscape and Microsoft are fighting a war. In fact, we are so deeply committed to this metaphor that the vocabularies of business and war reporting are nearly indistinguishable.
Yet the Internet “battlefield” didn’t exist a decade ago, and the software battlefield didn’t exist a decade before that. These territories were created out of nothingness. Countless achievements have been made on them. Victories have been won over absent or equally victorious opponents.
In fact, Netscape and Microsoft are creating whole new markets together, and both succeed mostly at nobody’s expense. Netscape’s success also owes much to the robust nature of the Windows NT Server platform.
The war stories we’re telling about the Internet are turning into epic lies.
At the same time Microsoft has moved forward in browsers, directory services, languages, object models and other product categories — mostly because it’s chasing Netscape in each of them.
Growing markets are positive-sum creations, while wars are zero-sum at best. But BUSINESS IS WAR is an massive metaphorical machine that works so well that business war stories almost write themselves. This wouldn’t be a problem if business was the same now as it was twenty or fifty years ago. But business is changing fast, especially where the Internet is involved. The old war metaphor just isn’t doing the job.
Throughout the Industrial Age, both BUSINESS IS WAR and MARKETS ARE BATTLEFIELDS made good structure, because most industries and markets were grounded in physical reality. Railroads, shipping, construction, automobiles, apparel and retail were all located in physical reality. Even the phone system was easily understood in terms of phones, wires and switches. And every industrial market contained finite labor pools, capital, real estate, opportunities and natural resources. Business really was war, and markets really were battlefields.
But the Internet is hardly physical and most of its businesses have few physical limitations. The Web doesn’t look, feel or behave like anything in the analog world, even though we are eager to describe it as a “highway” or as a kind of “space.” Internet-related businesses appear and grow at phenomenal rates. The year 1995 saw more than $100 billion in new wealth created by the Internet, most of it invested in companies that were new to the world, or close to it. Now new markets emerge almost every day, while existing markets fragment, divide and expand faster than any media can track them.
For these reasons, describing Internet business in physical terms is like standing at the Dawn of Life and describing new species in terms of geology. But that’s what we’re doing, and every day the facts of business and technology life drift farther away from the metaphors we employ to support them. We arrive at pure myth, and the old metaphors stand out like bones from a dry corpse.
Of course myths are often full of truth. Fr. Seán Olaoire says “there are some truths so profound only a story can tell them.” But the war stories we’re telling about the Internet are turning into epic lies.
Describing Internet business in physical terms is like standing at the Dawn of Life and describing new species in terms of geology.
What can we do about it?
First, there’s nothing we can do to break the war metaphor machine. It’s just too damn big and old and good at what it does. But we can introduce some new metaphors that make equally good story-telling machines, and tell more accurately what’s going on in this new business world.
One possibility is MARKETS ARE CONVERSATIONS. These days we often hear conversations used as synonyms for markets. We hear about “the privacy conversation” or “the network conversation.” We “talk up” a subject and say it has a lot of “street cred.” This may not be much, but it does accurately structure an understanding of what business is and how markets work in the world we are creating with the Internet.
Another is the CONDUIT metaphor. Lakoff credits Michael Reddy with discovering hidden in our discussions of language the implication of conduit structure:
Your thinking comes through loud and clear.
It’s hard to put my ideas into words
You can’t stuff ideas into a sentence
His words carry little meaning
The Net facilitates communication, and our language about communication implies contuits through which what we say is conveyed. The language of push media suggests the Net is less a centerless network — a Web — than a set of channels through which stuff is sent. Note the preposition. I suggest that we might look more closely at how much the conduit metaphor is implicit in what we say about push, channels and related subjects. There’s something to it, I think.
My problem with both CONDUIT and CHANNEL is that they don’t clearly imply positive sums, and don’t suggest the living nature of the Net. Businesses have always been like living beings, but in the Net environment they enjoy unprecedented fecundity. What’s a good metaphor for that? A jungle?
Whatever, it’s clearly not just a battlefield, regardless of the hostilities involved. It’s time to lay down our arms and and start building new conceptual machines. George Lakoff will speak at PC Forum next week. I hope he helps impart some mass to one or more new metaphorical flywheels. Because we need to start telling sane and accurate stories about our businesses and our markets.
If we don’t, we’ll go on shooting at each other for no good reason.
Links
Here are a few links into the worlds of metaphor and cognitive science. Some of this stuff is dense and heavy; but hey, it’s not an easy subject. Just an important one..
The Conceptual Metaphor Home Page, UC-Berkeley’s massive list of metaphor names, source domains and target domains. Oddly, neither business nor markets can be found on any of the three lists. Let’s get them in there.
Automattic acquired Pocket Casts last July, and since we’ve been tapping away trying to make the best podcast client for people who love listening to podcasts.
And!
The team has been working really hard to make those clients totally open source and available to the world, and it’s now happened. You can see all the code behind the iOS app and the Android app, and modify it, make it your own, suggest a change, fix a bug, add a feature, fork it and make your own client, anything!
If your code gets merged into core, it’ll go out to users listening to literally millions of hours of podcasts a week. It’s also unusual to be able to peek under the hood of a consumer mobile app that is this widely used and see how it works.
Audio publishing and consumption is a beautiful complement to the web publishing that WordPress is already so good at, and that Automattic tries to nurture an ecosystem around. I love Spotify and Apple, and I hope that Pocket Casts can do for podcast clients what Firefox in the early days and Chromium now does for browsers — push the state of the art, be manically focused on user control, and grow a more decentralized and open web.
But not from middlemen I mean, especially Amazon. Like most people, I regularly buy stuff online. (I think that saying “most people” is now globally
true?) But I have a big attitude problem about online retail aggregators in general and Amazon in particular. So as a matter of principle
I’ve been trying to take significant purchases upstream to the source.
One of the reasons Amazon succeeded is that they were good
at making online retail easy at a time when most product manufacturers weren’t. I’m here to report that that’s changing in a good way;
upstream purchasing is often a good experience. Which I’ll illustrate with mini product reviews.
Attitude problem
Did I mention I have one? It’s not an Amazon problem, it’s an efficiency problem. Now, late in my adult life, I’ve become
convinced that perhaps the central pathology of our time is the relentless pursuit of efficiency, which has overshot its mark
and become oppressive. If that sounds crazy (or maybe if it doesn’t), may I offer
Just Too Efficient, which I humbly think is the most significant thing I’ve
ever written. Efficiency is good, but just like many other of the good things in life, there’s a point past which it’s
damaging, even lethal. I think Amazon retail is perhaps the world’s most efficiently-operated business.
Having said all that…
I’m still on Amazon Prime, mostly because I like the TV shows. And when I want to buy something cheap and
commoditized, they’re just the ticket. Examples: USB adapters and keys, replacement lens covers, phone screen protectors, KN95
masks. After all these years I find the amazon.com (or in my case, amazon.ca) retail screens make my
flesh crawl; the relentless optimization of every freaking pixel rasps on my nervous system.
And when I order an entirely forgettable bit of gear and it shows up that afternoon, that doesn’t feel wonderful
to me any more. I can’t help thinking of what had to be sacrificed to make that happen, and I strongly suspect it’s not
worth it.
But wow, I totally respect the engineering, those pages load
faster than I would have thought possible given their complexity. And not just for mainstream stuff; go search for “electric
cello” (see above) or “orange crate”.
Enough of that! Let’s go online and buy stuff!
Jeans
I dress in black slim-fit boot-cut denim nearly every day of the year when it’s not warm enough for shorts.
Which should be
easy, but unfortunately I am remarkably average in physical size in every measurable
dimension. Which means I never get clothes on sale, and my size seems always the first to go out of stock. And sorting
through the jeans racks in a big-box store is a dispiriting exercise. Turns out both Levi’s and Wrangler will sell you just what
you want at what looks to me like a fair price.
The sites aren’t as fast as Amazon and, just like that big-box store, they’re sometimes out of stock, but restocking seems to
happen much more frequently. You don’t get your stuff as fast as you would from Amazon, but who needs same-day jeans?
Mouse
Last year my main mouse wore out, and I had a remarkable run of Bad Mouse Purchase Experiences. These included
flaky Bluetooth, out-and-out failure within weeks, and annoying loud ratcheting noises from the scroll wheel.
I poked around
and ended up visiting
Logitech.com to pick up a Signature M650, and let me tell ya, it’s one great mouse. Ultra-quiet,
ultra-smooth and comes in large and medium because people’s hands differ. It has a couple extra buttons, by default mapped to
Forward and Back, which I never use. It probably won’t make a hardcore gamer happy but who cares?
The price was right, delivery was fast enough.
Beer
Vancouver, my home town, has a lot of pretty great small breweries. A bunch of them have got together and created the
BeerVan Collective, which also offers cider, Kombucha, alcoholic and non-alc ginger beer, and a bit of
brewery brand merch. Order by 4PM and (in my experience) your beer will be there for dinner. They emphasize that the deliverers are brewery
employees not labor-arbitraged gig workers.
The only downside I can really bring to mind is that while these boutique ales are very good, they can’t compare with the
product you get when you go sit in the brewery’s patio in the shade and drink it fresh out of the tap with nachos or pizza or
whatever. And by the way, that
Luppolo “Italian Pilsener” is delicious.
Coffee
We have a decent grinder and machine but
don’t make espresso drinks at home much any more. Pour-over seems to hit the spot better. A few years back, Vancouver had a thriving
ecosystem of local roasters who could get into the supermarket, but these days those shelves are pretty bare of anything but Big
Brand Names. We’ve always liked a few of the roasts from
Saltspsring Coffee, but what with their diminishing presence in the big-boxes,
we really had a hard time buying our favorite “Canopy Bird” blend.
So we ordered a boxfull of Canopy Bird 454g packages, should last a few months. Site works great, and if you order when you
open the last bag, your coffee will arrive in time.
Sidebar: Shopify
At both Beer Van and Saltspring, when it came time to pay I found myself dealing with
Shop.app, which turns out to be a Shopify thing.
I can’t decide whether Shop is terrific or
terrifying. It is ever so slick at sorting out your payment and delivery options; fast, responsive, flexible, Just Works. Except for, once I
provided my email address, it knew my credit card info, home and business addresses, and who knows what else. How did that
happen? Seriously, I want to know. Anyhow, I’m starting to understand why Shopify is doing so well.
Gimbal
I’ve been trying to branch out from photography to video, so I’ve been learning Da Vinci Resolve and acquiring video
gear. In particular I wanted a gimbal, and DJI has the ones to get, and really a very decent web site. Once again: Low friction,
and pretty soon an RSC 2 showed up at my door.
Of the purchases listed here, this was the only one that really wasn’t a success. First, while the DJI works great and my
main camera is said to be appropriate, I just
haven’t been able to get untracked on video. If I do manage to produce anything, people who visit this blog will be
the first to know.
Hats
I do not appear in public (indoors or out) without a hat. This started for medical reasons: I’m an extra-white bald guy who
grew up in a subtropical climate and have had all sorts of amusing (no, not really) skin lesions on my head.
The dermatologist
said “That’s a cancer farm wrapped around your brain there, wear a damn hat when you go out.” And I discovered that I like hats
for their own sake. So I visit hat shops, and I recommend that you do too. But online, you just totally can’t beat
Sterkowski. They’re made (very nicely) in
Poland, attractively priced, and come in almost any imaginable style.
As they say repeatedly on the site, do not press “Buy” until you’ve measured your head, carefully.
Buy upstream
That’s all I’m recommending. Dodge the middlemen, particularly the ones headquartered in Seattle. It might take a little
longer to navigate and to ship and to arrive. It’s still a good idea.
I attended a (successful) Tidelift all-hands this week, so short week for this newsletter even if very long week in open(ish)ML. Also, I liked the way I organized the newsletter last week but I haven't had time to make a template of it so... watch for it to be back next week :)
Litigation getting real
Search was heavily shaped by Google's early no-holds-barred litigation strategy against anyone who didn't want their content indexed. This created a decade's worth of pro-fair-use holdings in the US courts, allowing for many different uses of material on the web. Someone is going to have to play that similar role in defending training as a fair use—probably, given their leading position on the commercial side, Microsoft and OpenAI.
The time for that is apparently going to be on us soon:
California lawyers are threatening to sue GitHub over Copilot (and Bradley Kuhn of the Software Freedom Conservancy says here they're still discussing the case with litigation counsel) and
The core legal intuition is the same in AI training and the traditional search model. However, I think MS/OpenAI/whoever else is going to have a much harder time of it than Google did—the law hasn't changed, but this tech will be harder to explain to judges, and tech's reputation among US elites has changed. And the output is often going to be more clearly infringing (or at least arguably infringing) than early search.
Related: copilot alternatives
This week saw another Copilot/OpenAI alternative open(ish) model announced, this time from carper.ai. (This follows the announce a few weeks back of the upcoming BigCode project, with related aims.) "Two projects are announced" is not the same as "two projects are sustainable and competitive against the state of the art proprietary models" but it's nevertheless interesting, and runs counter to the pessimism (which I shared) around open's ability to compete with Copilot when it was first announced.
Model copyright(?)
Van Lindberg, sharp open licensing lawyer, has a long Twitter thread on whether AI models are protectable and what the implications are.
I'm a little less skeptical than he is of whether or not a model is copyrightable; there are a lot of choices in model training design, so I think the training is less like a photocopier and more like a high-end camera, where the creator has a lot of flexibility and artistic choice. Among other things: what selection/curation is done from the universe of possible training data? what preprocessing do you do? what model tuning is done? etc. (For an example of what can be done to tune a model, Google's "FLAN" announcement from this week goes into a lot of detail.) But it's definitely an open question and something those pondering open-for-ML need to think about.
Open to not-so-open?
The licensing challenge
Copyleft licenses in traditional free/open software licensing create a level playing field in part because the core thing being licensed (the source code) is hard for a bad-faith actor to recreate. So if you can create a good license for a good project, people will stick with it.
Models, on the other hand, can be recreated from scratch by large players (assuming they have data, code, and training hardware). Don't like the license on model 1.0? Just re-train and voila, model 1.1, sans license—unless the license also governs all the training code and/or the training data. This is something to keep an eye on when evaluating model licenses, and when figuring out commitment of a company to future releases under open licenses. In related news...
Stability.ai, stable-diffusion 1.5, and "truly open"
Last week, I said "The demands of [venture capital return on investment] tend to push towards enclosure, so it'll be important to monitor [the impact of stability.ai's $100M funding round]."
We are forming an open source committee to decide on major issues like cleaning data, NSFW policies and formal guidelines for model release. This framework has a long history in open source and it's worked tremendously well.
I'm... really not sure what this means? Release teams have a very long history in open source, but there's basically no precedent in open source for anything with trust-and-safety overtones like NSFW policies.
Help us make AI truly open, rather than open in name only.
As I said last week in my open(ish) essay, we can no longer move fast without taking more responsibility for the "break thngs" that inevitably results. But unfortunately it's not clear what stability.ai means by "truly open" here—I hope they'll clear that up in the near future.
Transparency and auditability
Authenticity tooling at forefront of Adobe plans?
Adobe and Microsoft have both announced incorporation of image-focused AI in their commercial, non-alpha, products in the past 11 days. Adobe's announce was interesting to me in part because of how much it emphasized Adobe's support of the Content Authenticity Initiative (mentioned here last month). It will be interesting to see what kinds of technical counterweights like this we see as we move forward.
Bias bounties
A group of folks are sponsoring a new set of bounties (partially analogous to bug bounties) to help identify bias issues in publicly-accessible AI systems, building on similar work of the past few years. One wonders whether "open(ish)" in ML should use language like GPL v3's to protect auditors from retribution.
"Generative AI" seems to be a growing catchphrase; here's a map of the space. Would be interesting to see how many of the models in it are open(ish) or have open(ish) competitors.
Data still matters a lot; here's Facebook releasing an open translation model for Hokkien—which has 20 million speakers but basically isn't written. Exactly how they got the audio is a little unclear to me.
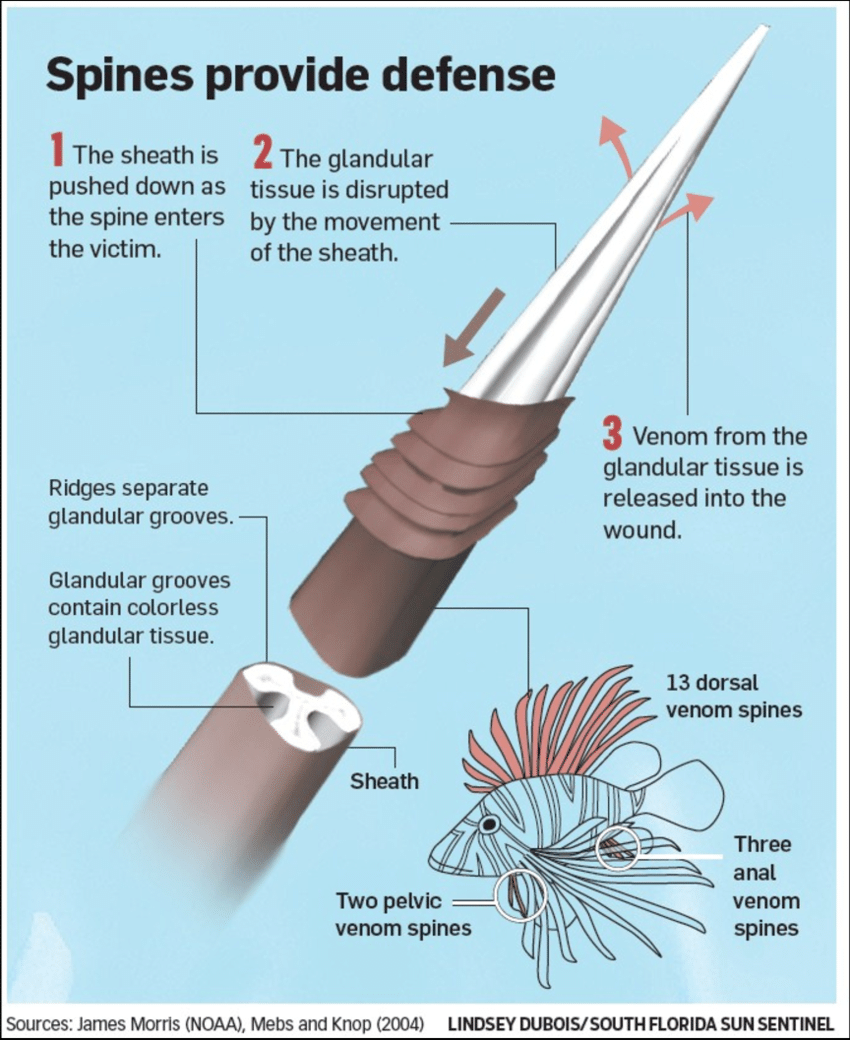
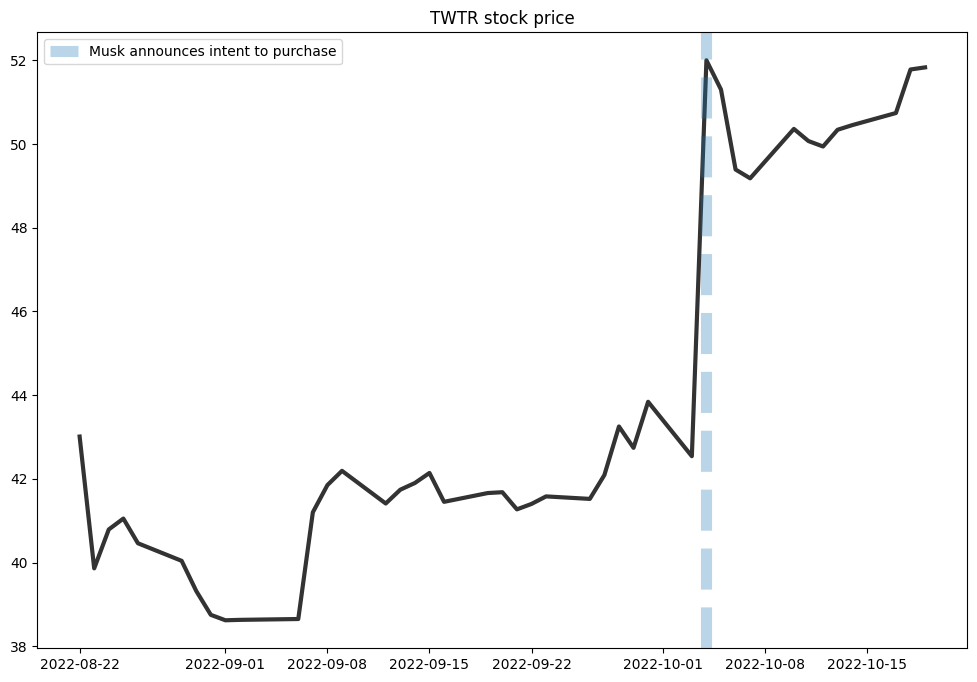


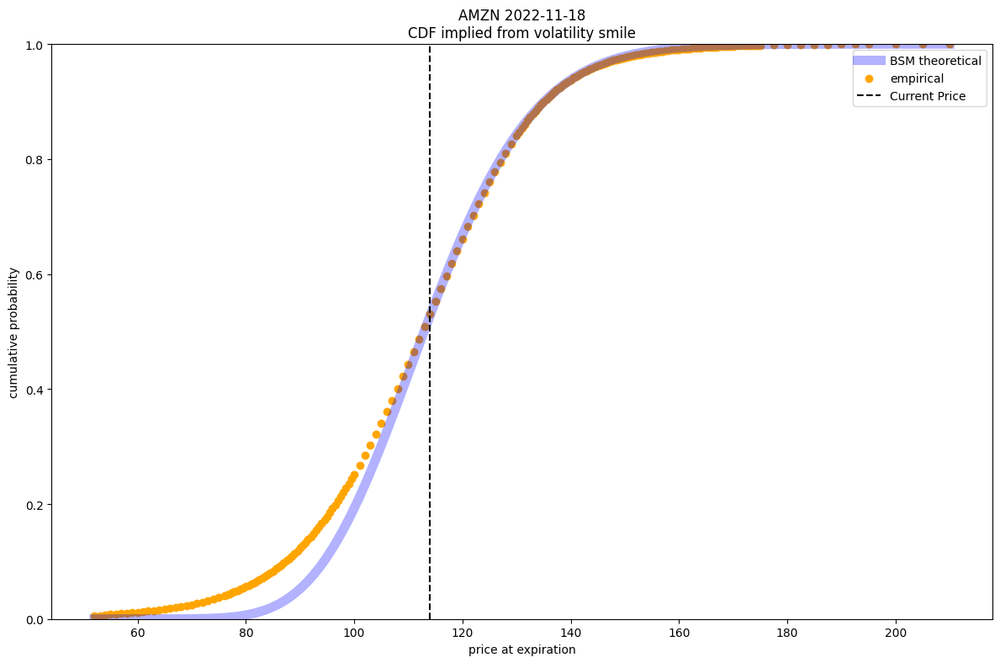

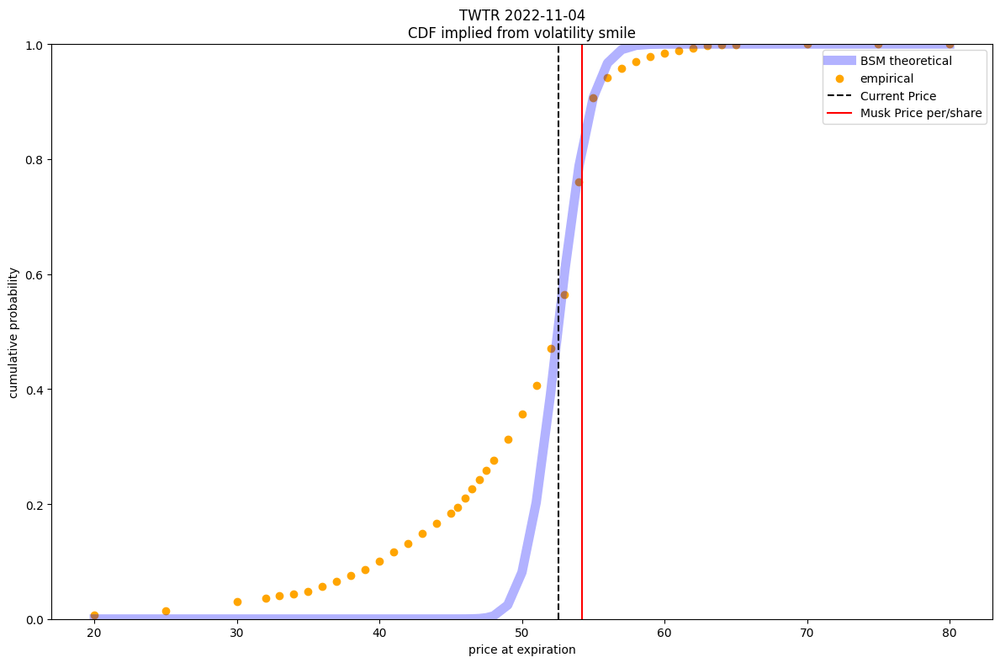
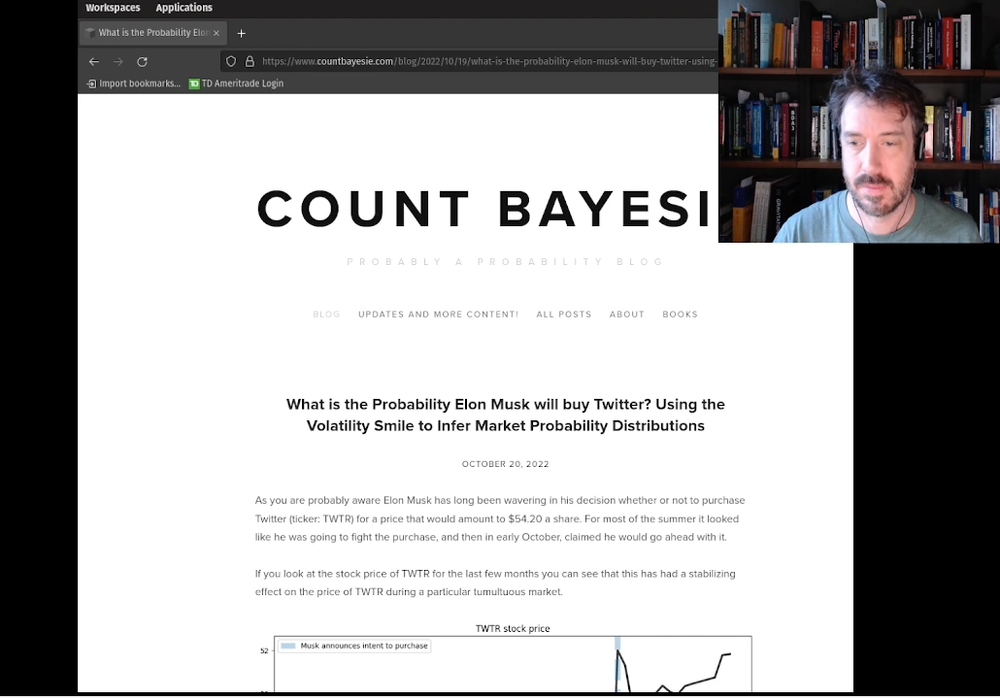


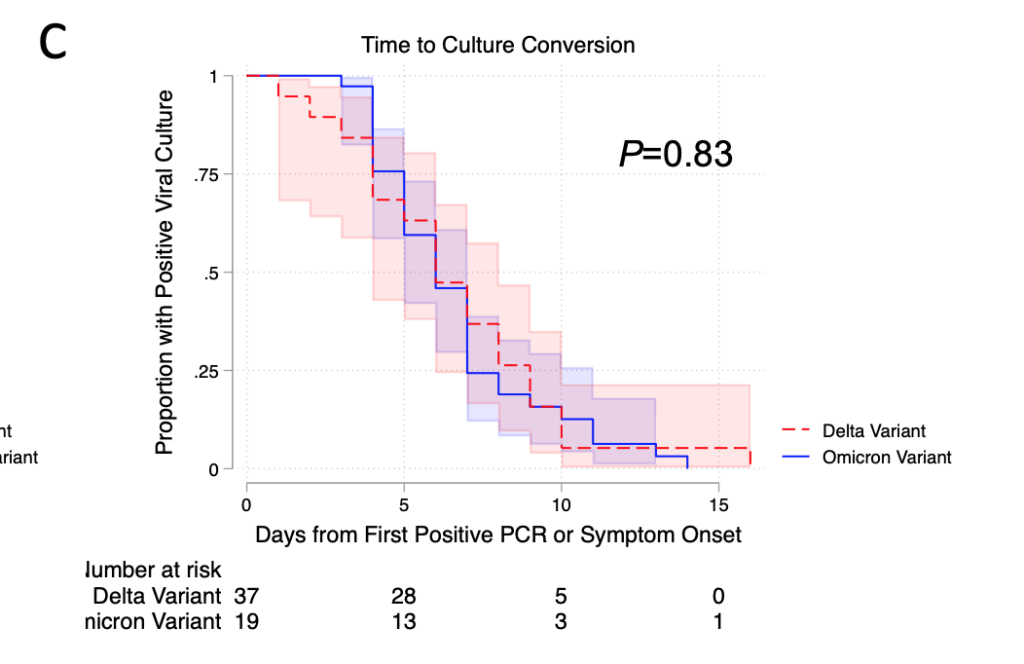

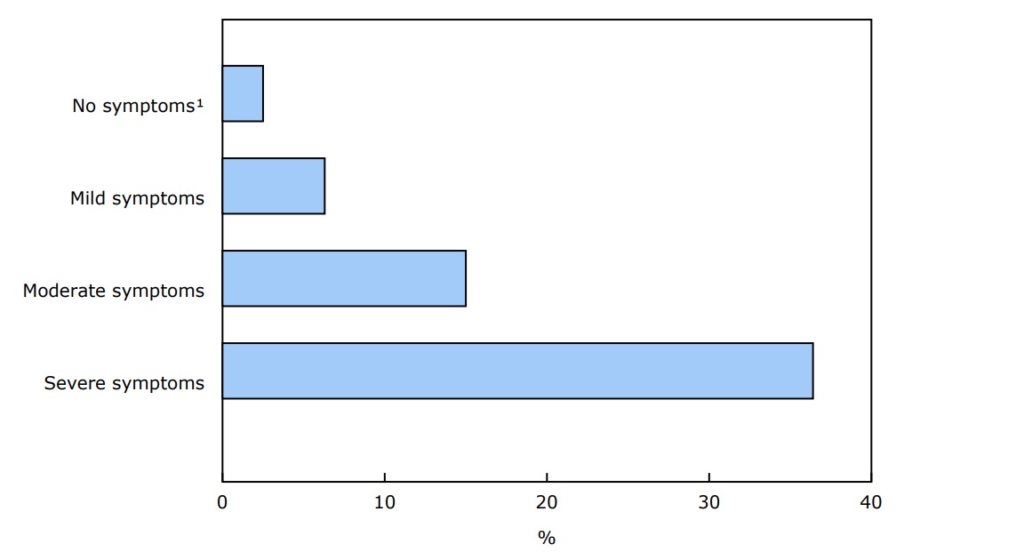

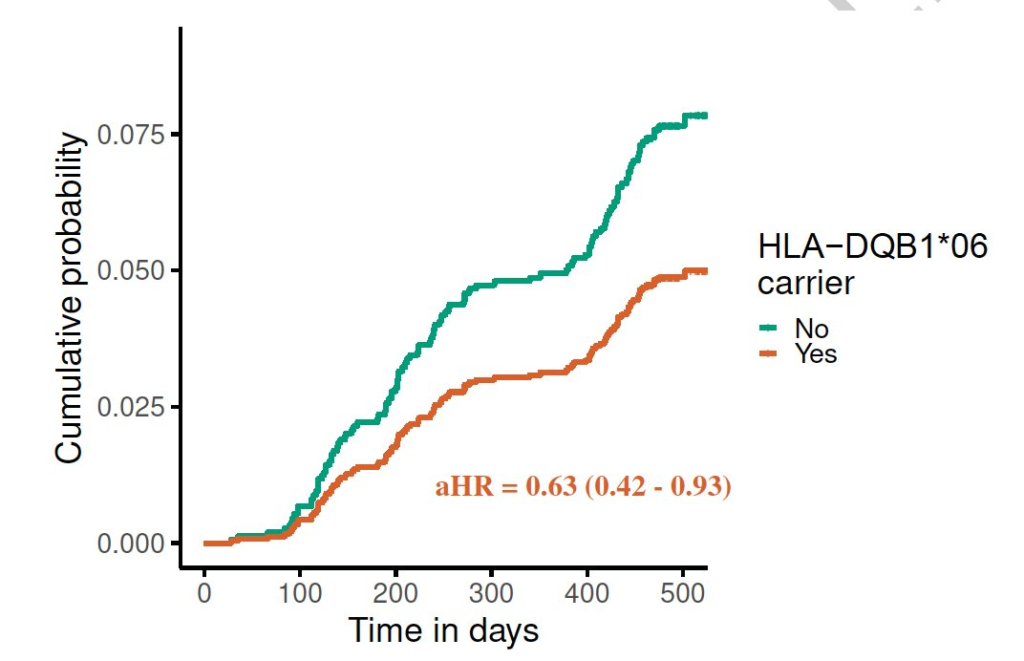

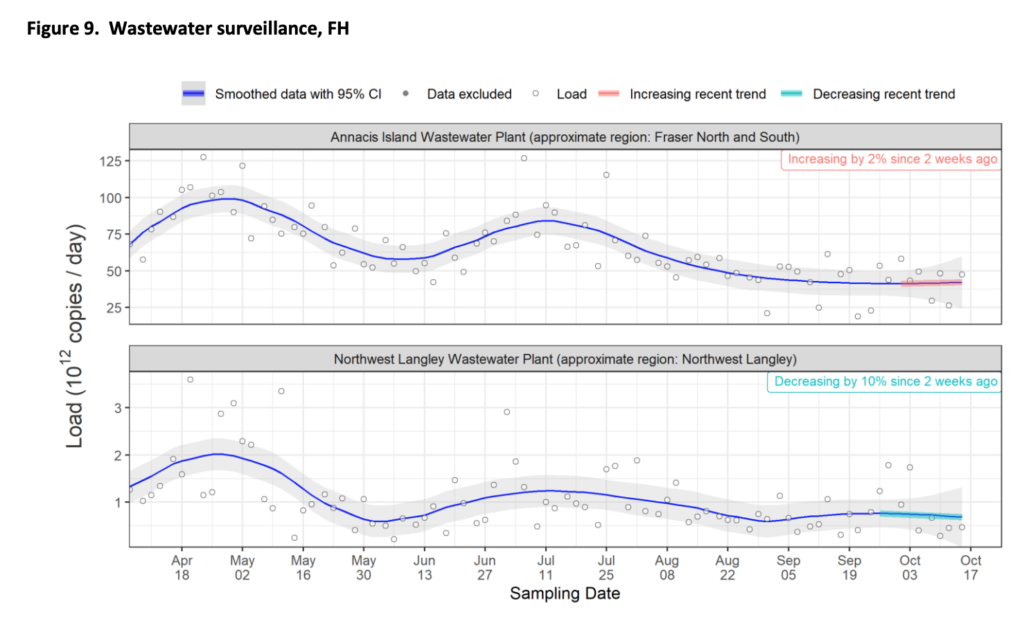
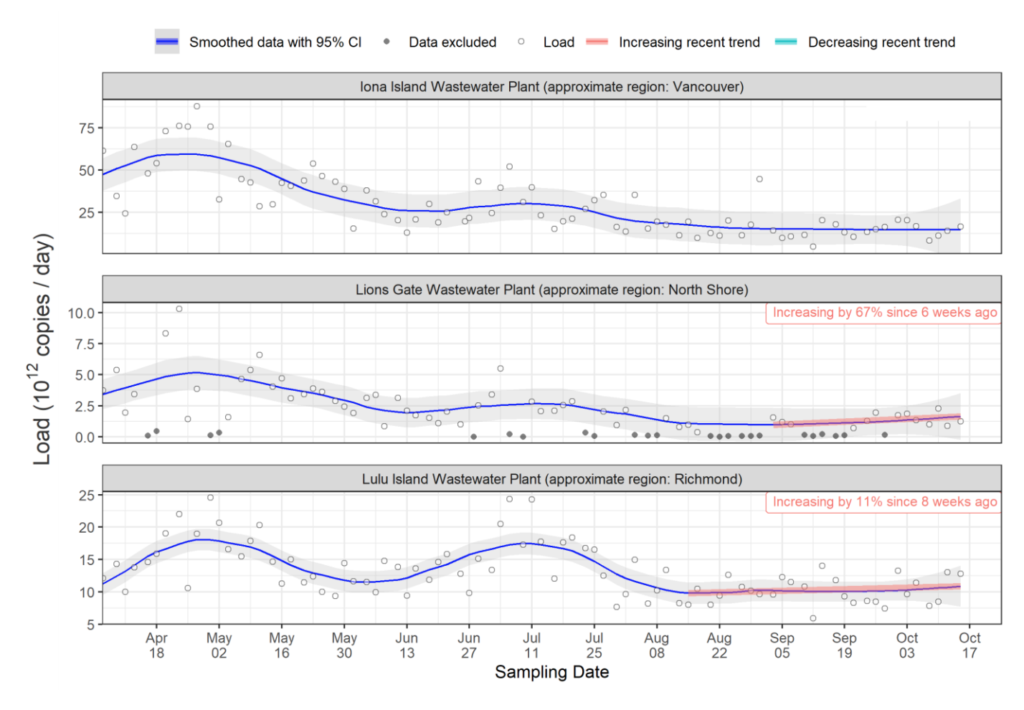
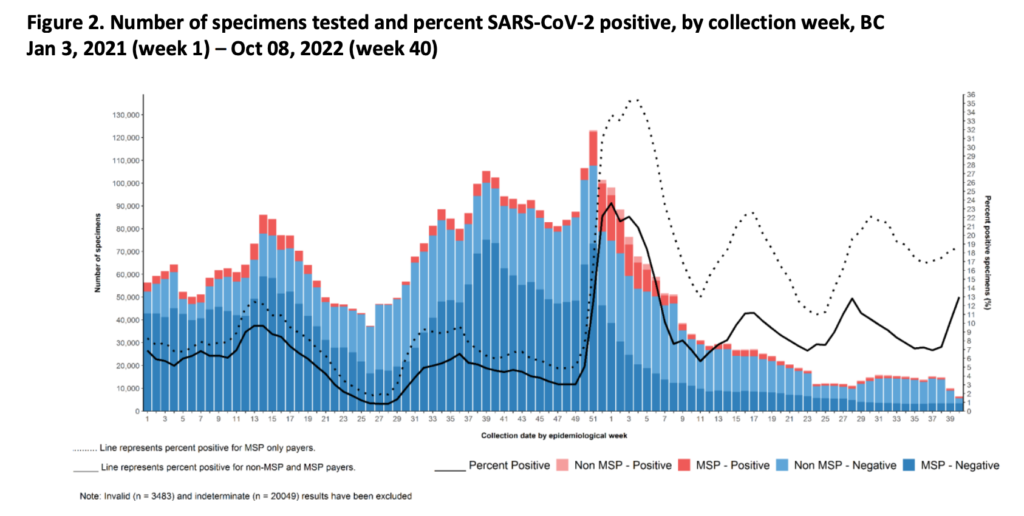

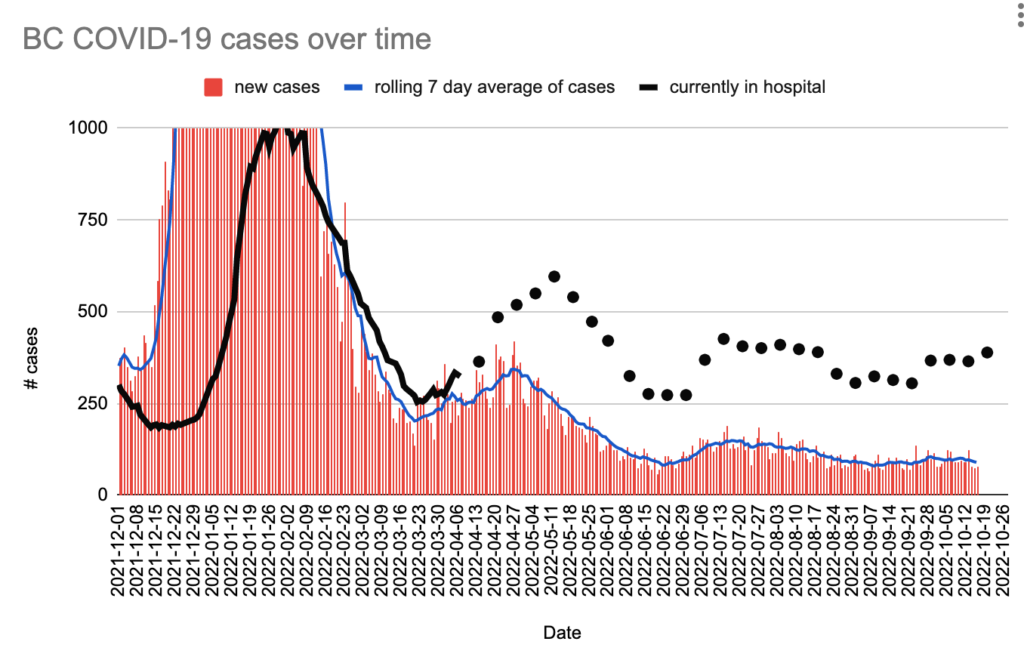



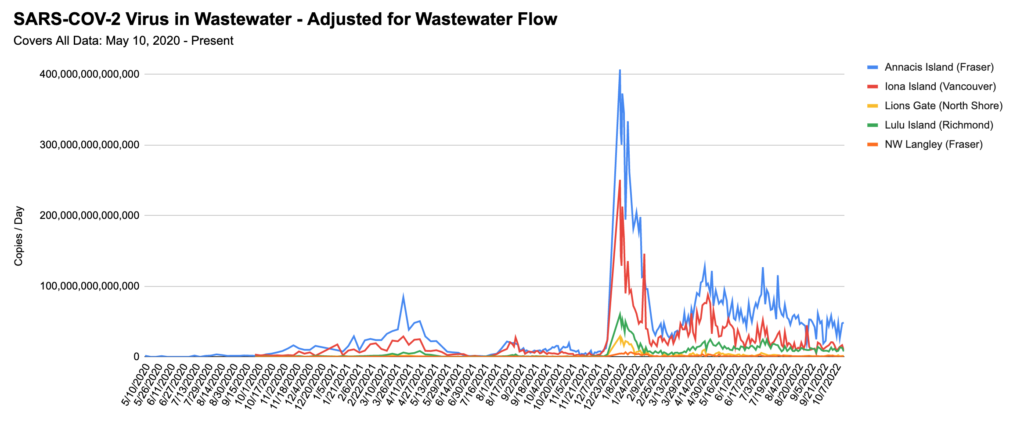
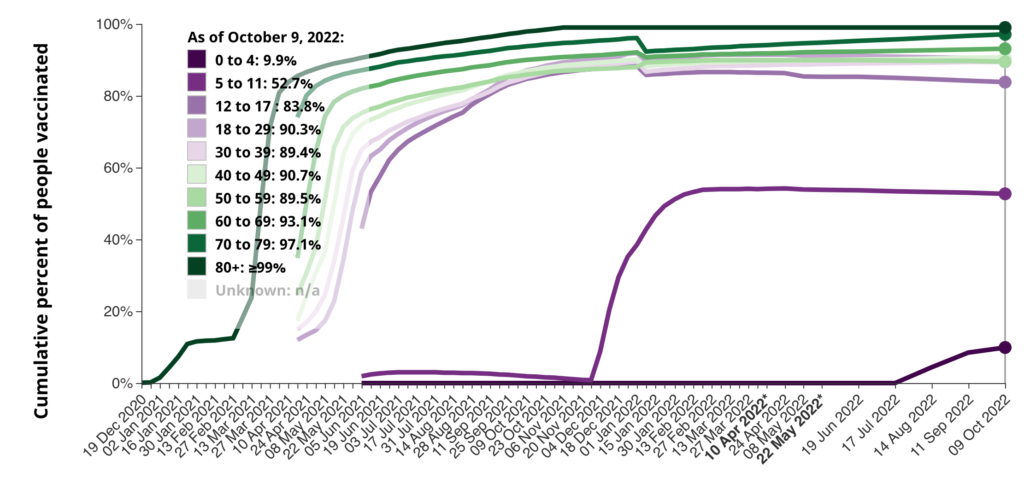
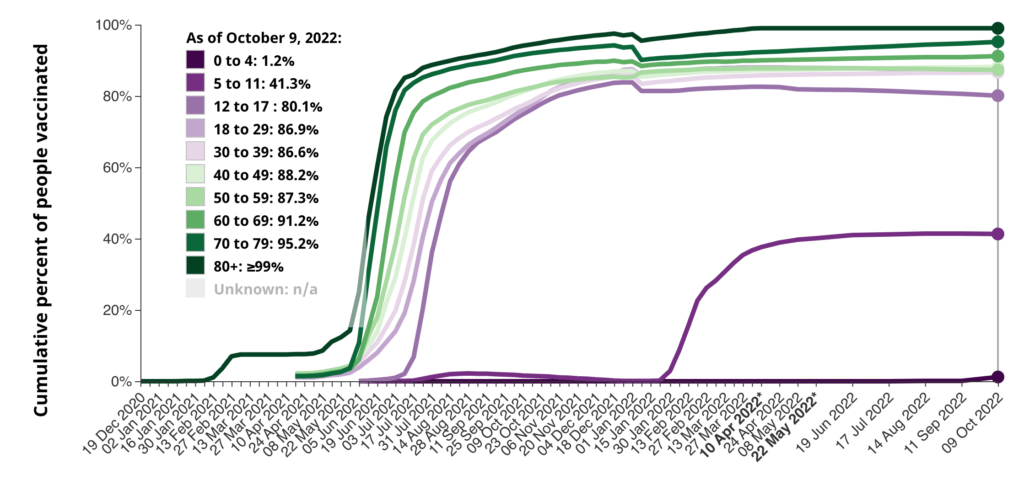


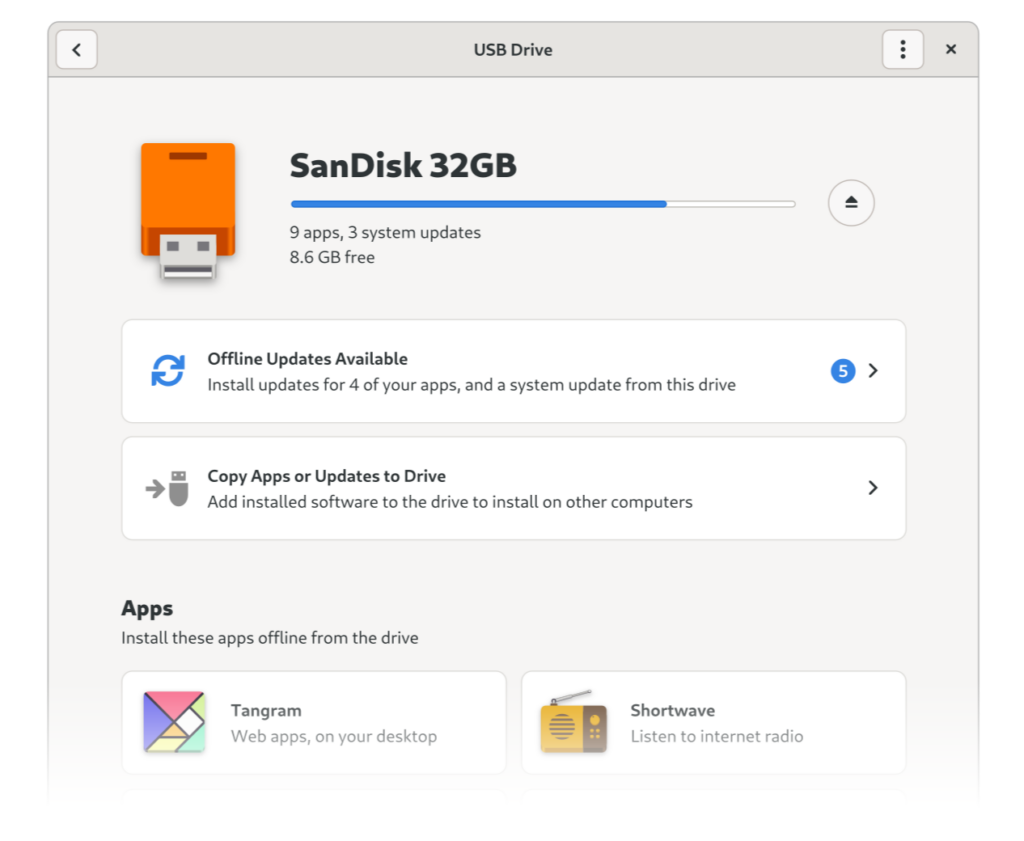
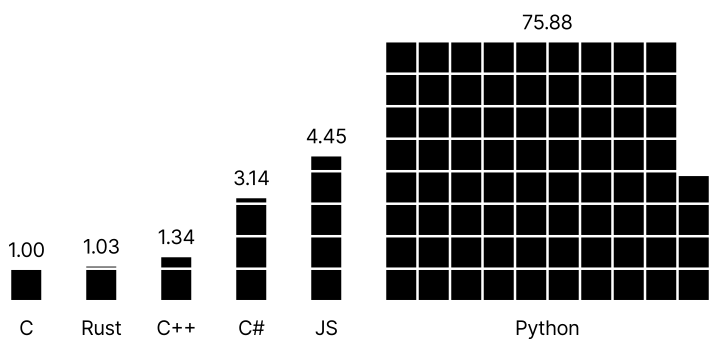
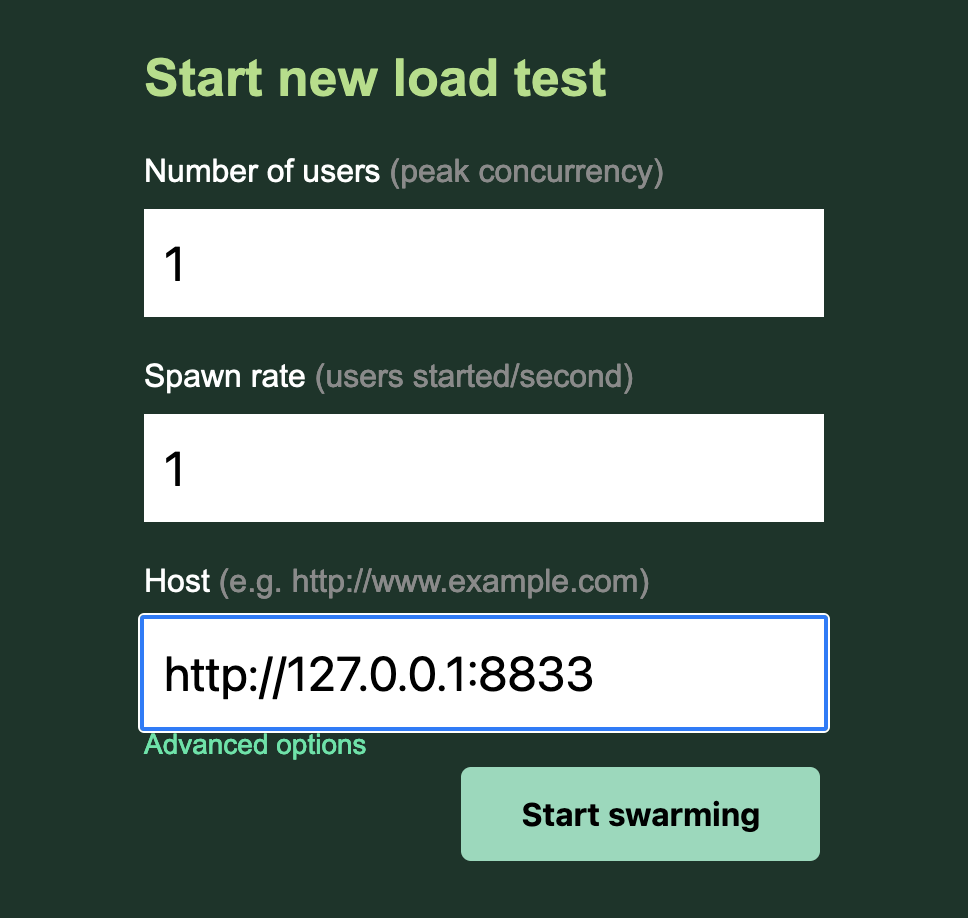
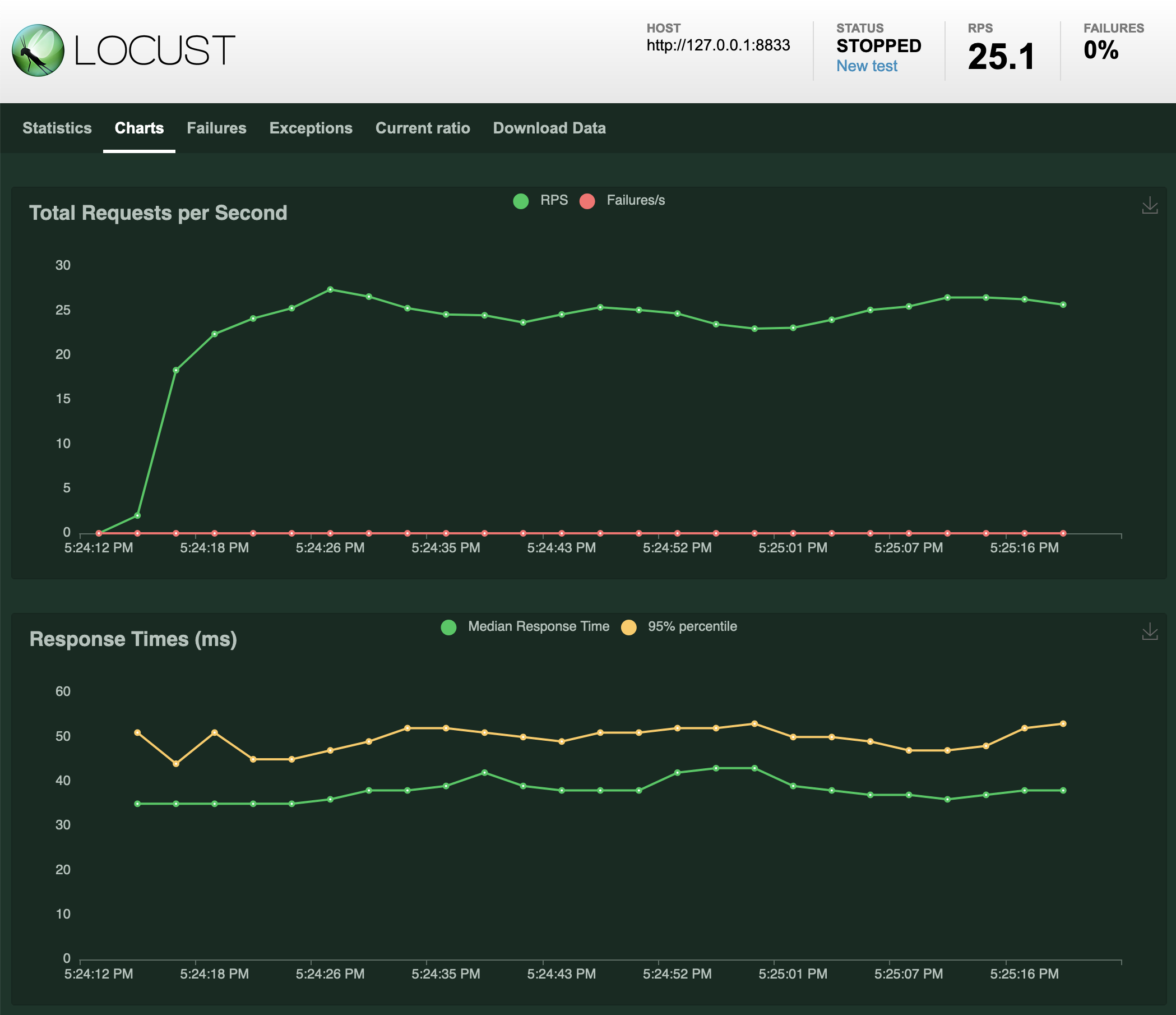












 Altavista says more than one million documents on the Web contain the words Microsoft, Netscape, and war. Hotbot lists hundreds of documents titled “Microsoft vs. Netscape,” and twice as many titled “Netscape vs. Microsoft.”
Altavista says more than one million documents on the Web contain the words Microsoft, Netscape, and war. Hotbot lists hundreds of documents titled “Microsoft vs. Netscape,” and twice as many titled “Netscape vs. Microsoft.” It’s hard to find an article about the two companies that does not cast them as opponents battling over “turf,” “territory,” “sectors” and other geographies.
It’s hard to find an article about the two companies that does not cast them as opponents battling over “turf,” “territory,” “sectors” and other geographies.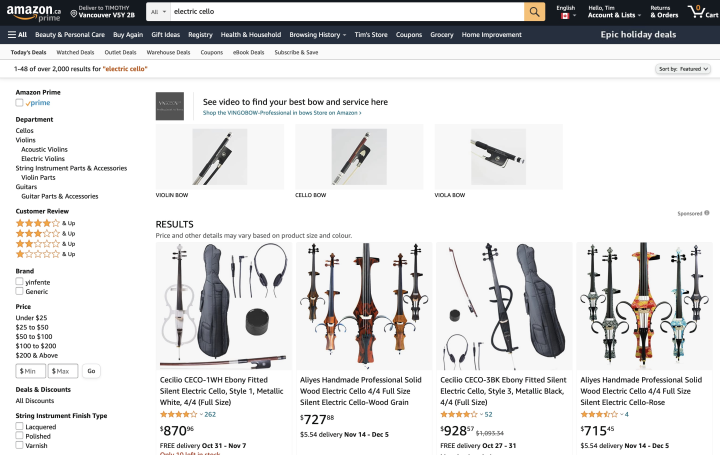

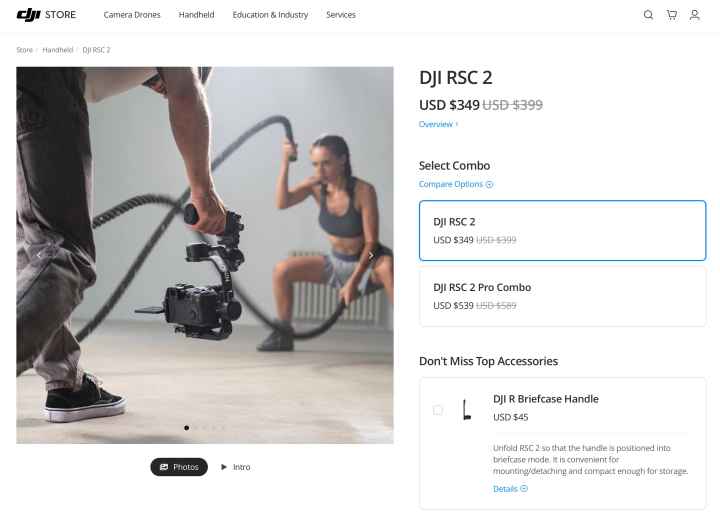
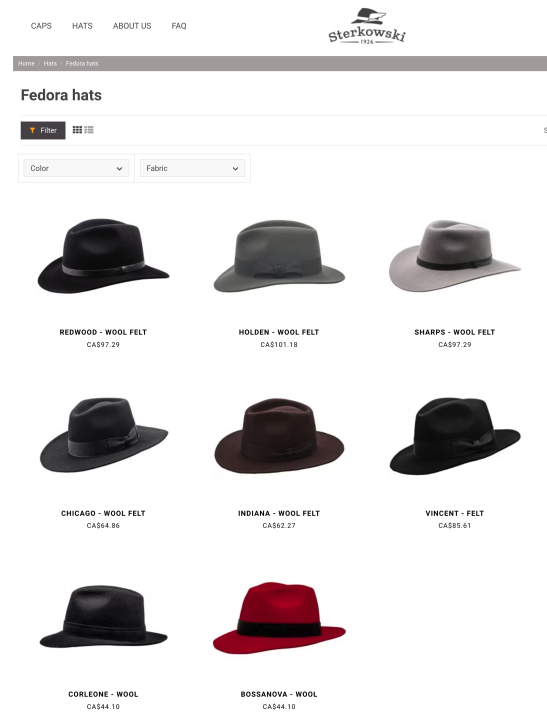

{kind=link}