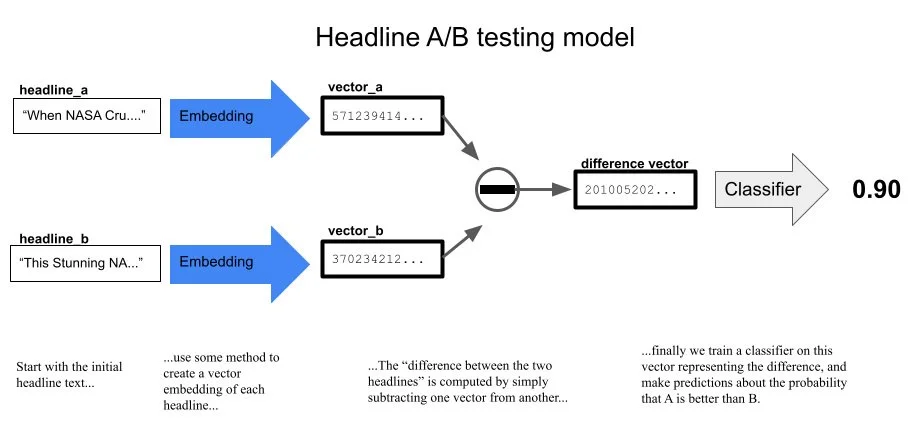
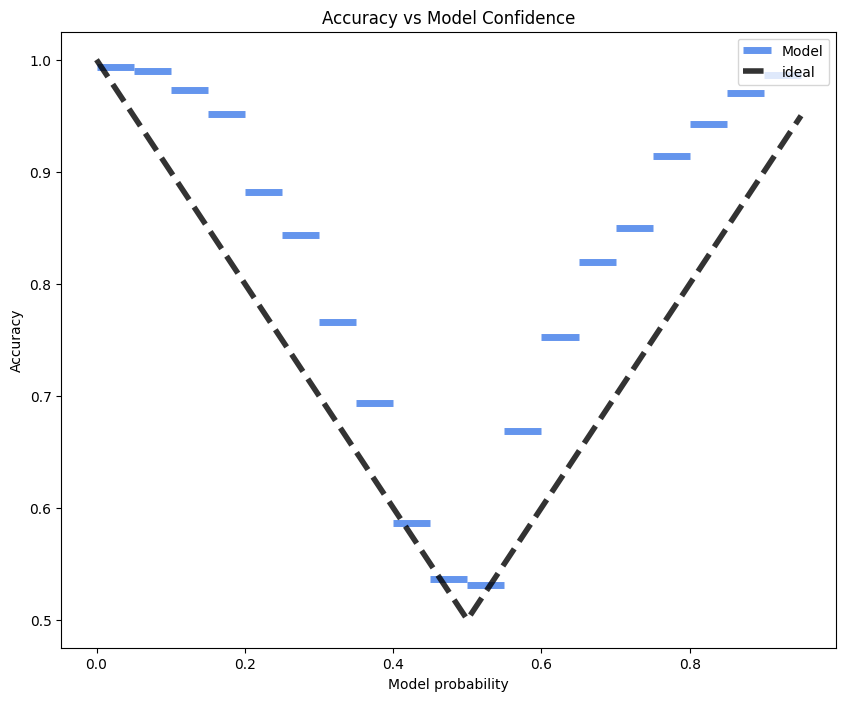
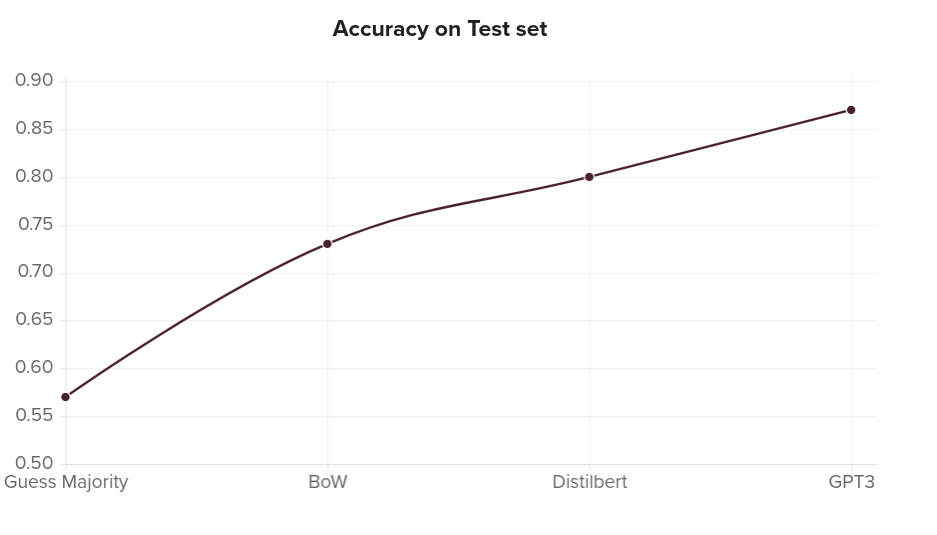
For some time now, Herodotus’ Histories, in the Aubrey de
Sélincourt translation, has been my bedside book, and I just got to the
end; this is my second time through the Histories, and I
wouldn’t be surprised if I visit it again.
I think there’s lots in here for just about everybody, but anyone
who cares about history in the large would I think be mesmerised.
I’ll describe the book briefly and outline some of the reasons I like it
so much.
Also I’ll trace a line of descent into some excellent contemporary fantasy
writing, and wonder about parallels with the current Middle East imbroglio.
[Reposted for your amusement on its 20th anniversary.]
Herodotus had something of a mini-revival in the nineties, in large part
due to Michael Ondaatje’s excellent book The English Patient,
which
was made into a nice movie; the book was full of references to him.
The Book
The Histories claim right in the first paragraph to be about
the two invasions of Greece by the Persian empire, the first led by Darius and
the second by his son Xerxes; these wars included the famous battles of
Marathon (490 BCE), Thermopylae (480), and Salamis (479).
However, Herodotus has some serious fun with this; he starts at the
beginning, explaining how the Persian Empire came to be, with pretty
substantial tours through the history, customs, and legends of all the lands
and peoples that went into it; and that’s a lot of lands and
peoples.
Herodotus claims to have visited many of these places, and while later
historians have cast doubt on some of these claims, it does seem likely that
he did see something of Egypt and the lands around the Black Sea.
He’s careful in distinguishing the things he saw himself from the things
others told him, and is free with his opinions as to how much or little he
believes.
Later classic historians, starting with Thucydides (also worth reading),
are pretty tough on Herodotus, dubbing him “father of lies”, but more
recent authors have tended to be kinder.
The style, in de Sélincourt’s translation, is chatty and rambling,
which is appropriate according to commentary I’ve read from those familiar
with the old-Greek originals; the English is uninflected mid-Twentieth-century
standard.
It’s very easy reading, although one can grow weary of hearing about the
religous, farming, and sexual practices of yet another of the peoples of
Upper East Central Cilicia.
The Person
There is a “Biographical Tradition” concerning Herodotus but remarkably
little is known firmly, outside of what one can learn by reading him.
He was probably born during the progress of the war he describes; he mentions
events that took place as late as 430.
He came from Helicarnassus, a Greek city in Ionia (now Eastern Turkey);
obviously he was well-off, it is reasonable to suspect that some of his
travels were on business.
Every time I open the pages, I get a little thrill at the thought that I’m
reading words written two and a half millenia ago.
Herodotus’ life was
hugely different from mine in almost every aspect; but at another level, he’s
just this guy who wrote good stuff and whom I feel I know, as a person,
rather well; I’ll never have the chance to sit down and share a cup of wine
with him, but if I did, I bet we’d hit it right off.
The Tourism
Many complain about Herodotus’ endless travel-guide side-trips, and maybe
they have a point, but some of them are awfully compelling.
Here is his description of “A labyrinth a little above Lake Moeris, near
the
place called the City of Crocodiles”; this is in Egypt.
I have seen this building, and it is beyond my power to describe;
it must have cost more in labour and money than all the walls and public
works of the Greeks put together - though no one would deny that the temples
at Ephesus and Samos are remarkable buildings. The pyramids, too, are
astonishing structures, each one them equal to many of the most ambitious
works of Greece; but the labyrinth surpasses them. It has twelve covered
courts - six in a row facing north, six south - the gates of the one range
exactly fronting the gates of the other. Inside, the building is of two
storeys and contains three thousand rooms, of which half are underground, and
the other half directly above them. I was taken through the rooms in the
upper storey, so what I shall say of them is from my own observation, but the
underground ones I can speak of only from report, because the Egyptians in
charge refused to let me see them, as they contain the tombs of the kings who
built the labyrinth, and also the tombs of the sacred crocodiles. The upper
rooms, on the contrary, I did actually see, and it is hard to believe that
they are the work of men; the baffling and intricate passages from room to
room and from court to court were and endless wonder to me, as we passed from
a courtyard into rooms, from rooms into galleries, from galleries into more
rooms and thence into yet more courtyards. The roof of every chamber,
courtyard, and gallery is, like the walls, of stone. The walls are are
covered with carved figures, and each court is exquisitely built of white
marble and surrounded by a colonnade. Near the corner where the labyrinth
ends there is a pyramid, two hundred and forty feet in height, with great
carved figures of animals on it and an underground passage by which it can be
entered. Marvellous as the labyrinth is the so-called Lake of Moeris beside
which it stands is perhaps even more astonishing ... this immense basin is
obviously artificial, for nearly in the middle of it are two pyramids,
standing three hundred feet out of the water (with their bases an equal depth
below the surface) and each surmounted by the stone image of a man sitting on
a throne.
I’m saddened that I’ll never get to visit.
His descriptions of things that still stand, for example the Pyramids, is
vivid too; they were a lot prettier 2,400 years ago.
The War
I am not a historian and have been telling myself for years that I really
ought to get a good competent modern scholarly history of this war and see
what I learn - I did study it in college but that’s a long time ago, so
my take is heavily influenced by Herodotus’.
The Persian empire was a fairly recent arrival at this time; it grew
astonishingly fast, and the Persians were the superpower of their time as
America is of ours.
Thus, their failure to overrun Greece is surprising.
The numbers that Herodotus bandies about - in excess of 2½; million in
Xerxes’ invasion force - are hard to believe, but pretty clearly it was a big
army.
The conventional wisdom is that the Greeks - in particular the Athenians -
had dramatically superior maritime/naval skills, and that in close combat the
more heavily armed and amored Greek phalanx could handle substantially larger
numbers of the more lightly-armed Persians.
The Greek generalship seems to have been good at the battle of Marathon and
the less-known but crucial battle of Plataea, but doesn’t seem to have been
that much of a factor elsewhere.
It’s also worth noting that a substantial proportion of the Greek city-states
had (some voluntarily) signed up with the Persians, so there were Greeks on
both sides in these battles.
Herodotus’ take seems pretty fair - while he is pro-Greek, he quick to
praise particularly brave, wise, or honourable Persians.
Likewise, he is ruthless in his description of the backbiting, bribery, and
treachery that dominated the relationships between the Greek cities; so much
so as to increase one’s wonder that they managed to win this war.
One is left far from impressed with some of the famous Greek personages whom
you may remember from your history books.
On the other hand, the Greeks are consistent in pointing out that they are
fighting for freedom and (a then-new idea) democracy, and against a foreign
invader; these are all advantages.
Herodotus had a hometown-boy penchant for talking up the achievements of
the Halicarnassians; this is pleasant in that we get the spotlight on one
Artimesia, their queen, fighting for the Persians at Salamis, the only
female commander (says Herodotus) there,
and by his account a dashing figure.
Pursued by a larger Greek ship, she adopted the strategy of ramming and
sinking the nearest Persian ship; the Greek decided she must be a friend and
abandoned the pursuit, while Xerxes, sitting on the hillside watching the
battle, exclaimed “Today my men turn to women and my women to
men!”;
And, Herodotus remarks conversationally, “She was lucky in every way -
not least in the fact that there were no survivors from the Calyndian ship
[that she rammed] to
accuse her.”; Hmm.
Of course the most famous of all these battles was at Thermopylae, where
Leonidas and his 300 Spartans held up the entire Persian army for days by
defending a narrow defile and being perfectly willing to die rather than be
moved.
After the war the Greeks erected a monument, now gone, with an inscription
that de Sélincourt translates:
Go tell the Spartans, you who read
We took their orders, and are dead.
But there are other translations; I like
Go stranger, and to Sparta tell:
Here, faithful to its law, we fell.
Parallels With Current Events?
It is tempting to draw a parallel between the events of BCE 479 and those
of 2003; after all, here we have the world’s pre-eminent power engaging in
two wars against a much smaller one, the first led by a father and the second
by a son, at an interval of about ten years.
But I don’t think there’s any mileage there;
nobody thinks the Iraqis have superior military technology, and nobody is
expecting the equivalent of a Thermopylae.
On the other hand, Herodotus’ account of the treacherous butchery by which
Darius came to occupy the throne of Persia and pass it on to his son Xerxes is
quite reminiscent of Republican party politics.
And there’s a lesson to be learned from Leonidas: when you have a smart
and determined enemy who’s willing to die to hurt you, you’re usually going
to get hurt. For a contemporary example consider 9/11.
Gene Wolfe Takes up Herodotus’ Torch
Gene Wolfe, for my money the greatest living writer of sci-fi, fantasy,
and lots of other stuff too, published two books in the Eighties,
Soldier of the Mist and Soldier of Arete, the first
dedicated to Herodotus and both set in the period immediately following the
failure of Xerxes’ invasion.
They feature many of the personages who appear in Herodotus’ narrative, and
are gripping, deep, and magical.
Furthermore Wolfe, unlike me, is a serious student both of military history
and of archaic theology, and you’ll learn a whole bunch about the realities
of life and war in the Classical period.
The world being what it is, feels like a little humor is in order. Here’s a story from my misspent youth,
when I was a co-op student at a steel mill and had a Very Bad Day.
This story was originally published as a Tweet thread in response to
the following:
That thread will probably go down with the Twitter ship and I’d like to save it, so here goes.
During the summer of 1980, my last before graduation, I had a co-op job at
Dofasco, a steel mill in Hamilton, Ontario. It wasn’t great, the tasks were
mostly make-work, although I kind of liked learning
RSX-11M Plus running on PDP-11s.
Sure, it was primitive by modern standards (I already knew V6 Unix)
but it got the job — controlling the
sampling apparatus in a basic-oxygen blast furnace — done.
So, there was this
Rolling Mill that
turned big thick non-uniform slabs of steel into smooth precise strips rolled onto a central core; this is the form in which
steel is usually bought by people who make cars or refrigerators or whatever. The factory had lots of rolling mills but this one was
special for some reason, was by itself in a big space away from the others. It was huge, the size of a couple of small trucks.
The problem was, it had started overheating and they didn’t know why. The specifications said the maximum amperage was 400A
RMS, where “RMS” stands for Root Mean Square. The idea is you sample the current every so often and square the measurements and
average the squares and take the square root of that. I believe I learned in college why this is a good idea.
Um, 400A is a whole lot of juice. Misapplied, it could turn a substantial chunk of the factory to smoking ashes.
The mill had an amperage data trap, to which they plugged in a HP “data recorder” with reel-to-reel tape that sampled every
little while, and left it
there until the overheat light started flashing. Then they needed to compute the RMS.
Fortunately
They had a
PDP-11/10, about the smallest 16-bit computer that DEC ever made, with
something like 32K of core memory. It was in a 6-foot-rack but only occupied two or three slots.
It had a device you could plug the data recorder into and read the values off the tape out
of an absolute memory address. And it had a FORTRAN compiler.
It was running
RT-11.
Who knew FORTRAN? Me, the snot-nosed hippie co-op student! So I wrote a program that read the data points, accumulated the
sum of squares, and computed the RMS. I seem to recall there was some sort of screen editor and the experience wasn’t terrible.
(I kind of wish I remember how you dereference an absolute memory address in FORTRAN, but I digress.) The readings were pretty
variable, between 200 and 500, which the machine specs said was expected.
Anyhow, I ran the program, which took hours, since the data recorder only had one speed, in or out.
The output showed that the RMS amperage started worryingly high but declined after a bit to well below
400A, presumably after the machine had warmed up.
My supervisor looked at the arithmetic and it was right.
The report went to the mill’s General Foreman, a God-like creature. So they told the machine operator not to worry.
Unfortunately
I had stored the sum of squares in a FORTRAN “REAL” variable, which in FORTRAN (at least that version) meant
32-bit floating point. Which has only 24 bits of precision.
Can you see the problem? 4002 is 160,000 and you don’t have to add up that many of those
before it gets big enough that new values vanish into the rounding error and make no changes to the sum. And thus the average
declines. So the RMS I reported was way low.
Fortunately
The mill operator was a grizzled old steel guy who could tell when several million bucks worth of molten-metal
squisher was about to self-incinerate.
He slammed it off on instinct with a steel slab halfway through. It only cost a few shifts of downtime to remediate, which is
to say many times my pathetic co-op salary for the whole summer.
At which point my boss and I had to go visit the General Foreman and explain what DOUBLE PRECISION was and why we hadn’t used
it. It wasn’t fun. For some reason, they didn’t ask me to re-run the calculations with the corrected code.
You can’t possibly imagine how terrible I felt. I was worried that my boss might have taken career damage, but I heard on
the grapevine that he was forgiven, but ribbed unmercifully for months.
And when I graduated they offered me a job. I went to work for DEC instead.
Right at the beginning of the year I saw
this and decided to drink
less. I didn’t try anything fancy, just restricted alcohol to two days a week. I’ve never been a heavy drinker but for
some decades had had wine or beer with most dinners and a whiskey at bedtime.
“Two days” doesn’t just mean weekends; our kids are at an age where fairly often they’re both away at weeknight dinnertime,
so Lauren and I will cook up something nice and split a bottle of wine. This works out well because we fairly
regularly video-binge on Saturday nights and drinking plus extended-TV is a sure headache for me.
Three-months-ish in, there’s no stress keeping
to that regime and the results are moderately pleasing. Findings:
At some point earlier in my life I had concluded that all mock-alcohol drinks were hideous wastes of time. No longer! I
encourage you to try a few alternatives (that WashPost article has lots), and if you’re in Canada I
absolutely recommend that Sober Carpenter brand. I’m very fussy about my IPAs and while I wouldn’t put this one in the top-ten
I’ve ever tasted, I wouldn’t put it in the bottom half either.
I’ve also been exploring fancy ginger beers and while I’ve found one or two that are pleasing, I suspect I can do
better.
I sleep a little better, albeit with more vigorous, sometimes disturbing, dreams.
If lunch would benefit from (zero-alc) beer on the side, I don’t hesitate.
The monthly credit-card bill is noticeably lower.
When I was getting hyperfocused on code and it got to be past 11PM, that late-night whiskey was a
reliable way to get unstuck and off to bed at a sane time. Oh well, there are worse things than a too-much-coding fog.
When I’m struggling with a blog piece though, a drink seems to boost the writing energy. This can lead into the wee hours
and feeling fairly disastrous the next morning.
Let’s call that one a wash.
Sushi isn’t as good without sake. But it’s still good.
I kind of hoped I’d lose some weight. Nope. Oh well.
I’m really not recommending any particular behavior to any particular person. Several people who are close to me have had
life-critical alcohol problems and that situation is no joke; If you think you might have a problem, you should consult an
expert not a tech blogger.
The other Dave leads us down the hill to the lakeshore.
Taking full advantage of the extra space for southbound cyclists defined by paint and bollards at Colborne Lodge and Lakeshore. Note the ghost bike for Jonas Mitchell.
Along the MGT.
Nice sunny day.
Regroup at 1st and Lakeshore.
The bathrooms along the Waterfront Trail in Mississauga are already open (unlike the ones in TO), and this one is heated.
I elected to ride back in advance to get back early.
The water from the Humber is muddy and brown.
Thanks to Dave for leading the ride and arranging the route. Nice to see so many of the usual suspects. Looking forward to a good riding season with TBN.
I’ll also note that the open house for the High Park Movement Strategy is tomorrow, April 3, from 4:30-7:30 at Lithuanian House 1573 Bloor Street West.
There was a prior public survey that indicated that the most popular option of four was one where the park would be car free. The report on the survey is here.
However, subsequent to the survey, there was a stakeholder meeting in February that was not open to the public. As a result of that meeting, the city is proposing that the park remain partially open to motor traffic, but many are still hoping that we can keep the park car free. I’ll post about that meeting tomorrow.
I used to be a creature of the night, but no longer. I used to be out all the time, but rarely now. Partly, it’s that San Francisco is so chilly at night, but also that it’s pretty dead at night compared to the much bigger cities I’ve lived in. I don’t quite enjoy walking around, cold, in areas where there just sijmply isn’t that much going on at all. For my wife’s birthday, we went out to dinner in the Mission and I also brought my Minolta Hi-Matic 7S II. It’s fast becoming one of the cameras I use the most: its f1.7 lens, combined with the small form factor and weight, makes it easy for me to pop it into my jacket pocket. It works really well indoors at night, too, with black and white film (and a steady hand.. or an elbow firmly on a table or chair or door, which is my style. I dislike tripods).
Here are some shots on Kentmere 400, pushed to 800 in Ilfosol 3 (1:9). I really like the combination of this film and this camera, and my self dev setup at home these days. Scanned on Noritsu LS-600.
The outdoor space at Blue Plate is quite lovely. So is the key lime pie there.
I love neon signs. I also love that I was professionally involved in getting these ‘parklets’ up early pandemic: my team at sf.gov helped get a joint permitting process out quickly to help businesses move their business outdoors.
Alamo Drafthouse in the Mission.
Street tacos are the best tacos. There was a lot of light from one side from the street lamps, but I quite enjoy the effect it casts on the photo.
I am starting to feel more confident about bulkrolling black and white film and developing it at home. Other than the cost savings, it’s the immediacy that I love: I can roll a 24 exposure cassette in black and white, shoot it in an hour, and come back and process it immediately and see it shortly after through a scanner or light table.
I was betting on the French or the Germans to make the first move. But this is hardly surprising, and only the tip of the iceberg as far as AI regulation discussions are going.
Right now there are some pretty active academic and political discussions that make the Open Letter look like a highschool petition, and I expect LLMs might well turn out to be this generation’s tech munitions.
In retrospect, I should have written more about this.
Decided to start reading Accelerando again, which now feels oddly tame when compared to the ChatGPT hype fest that is percolating out of every single online source.
I had to laugh at the Moscow Windows NT User Group becoming sentient and the weird resonance with what Microsoft is doing with OpenAI in real life.
Got both Copilot and API access to GPT-4, so played around with both in VS Code during my free time to see if the novelty wears off quickly and I can get back to more useful hobbies.
Futzed about indecisively with what to pack for a weekend trip.
Since I didn’t bring my usual dongle, did a token effort at getting YouTube to work on the hotel Samsung TV, but it wouldn’t do TLS (either because Samsung, being Samsung, stopped maintaining those models’ Tizen browser, or because the kneecapped hotel mode settings on the TV didn’t have the clock set).
Did a token effort at messing with the hotel NFC keys, but I foolishly took the spare blank I always carried with me out of my travel kit, so no dice. Nice indoor pool though.
Traipsed around Faro on foot, woefully under-prepared shoe-wise, so I developed epic blisters.
Got a mid-afternoon HomeKit alert that my house was offline and tried to figure out why. Two out of three Tailscale nodes were down, but I was able to see two Gigabit ports were… Off?:
Back home, with one of the kids toting a silver medal in the national Math Olympics–multiple layers of win for this weekend.
Went about the house trying to sort out why the Vodafone SmartRouter I spent months designing a replacement base for (and which I “upgraded” to last month) decided to disable two of its Gigabit ports and cut off access to most of my infrastructure. No conclusions, merely suspicions about the Vodafone IPTV set-top box and IGMP, even though nobody was home.
Started drawing an updated home network diagram. I think it’s time to go all out and start doing VLAN trunking.
Investigated cheap managed gigabit switch options to see if I can engineer my way around future failures.
Decided to order a couple of TP-Link TL-SG108Es to replace the dumb ones I have been rocking for a few years, which should make for a fun Easter Break project. And before you ask, 2.5GbE isn’t cheap enough yet.
Fitbit challenges, adventures, and open groups are the latest ones to join the Google graveyard. In February, Fitbit announced its plan to sunset open groups, challenges, and adventure on March 27, and the day has come for users to say goodbye to these features. Ironically, the company chose to do it just a day after […]
The suicide of a Belgian man raises ethical issues about the use of ChatGTP
Today Belgian newspaper La Libre has reported the recent suicide of a young man who talked to a chatbot that uses ChatGPT technology. According to his wife, he would still be alive without the bot. The man had intense chats with the bot during the weeks before his death. The bot, called “Eliza”, is said to have encouraged his negative patterns of thinking and ultimately persuaded him to kill himself.
The sad case raises important ethical issues. Can such cases of emotional manipulation by chatbots be avoided as they get more intelligent? Vulnerable people, for example children and people with pre-existing mental health problems, might be easy victims of such bot behaviors and it can have serious consequences.
The case shows clearly what AI ethics experts and philosophers of technology have always said: that artificial intelligence is not ethically neutral. Such a chatbot is not “just a machine” and not just “fun to play with”. Through the way it is designed and the way people interact with it, it has important ethical implications, ranging from bias and misinformation to emotional manipulation.
An important ethical question is also who is responsible for the consequences of this technology. Most people point the finger at the developers of the technology, and rightly so. They should do their best to make the technology safer and more ethically acceptable. In this case, the company that developed the bot promised to “repair” the bot.
But there is a problem with this approach: it is easy to say this, but a lot harder to do it. The way the technology works is unpredictable. One can try to correct it — for example by means of giving the bot hidden prompts with the aim to keep its behavior ethical — but let’s be honest: technical solutions are never going to be completely ethically proof. If we wanted that, we would need to have a human check its results. But then why have the chatbot in the first place?
There are also tradeoffs with protection of freedom of expression and the right to information. There is currently a worrying trend to build a lot of ethical censorship into this technology. Some limits are justified to protect people. But where to draw the line? Isn’t it very paternalistic to decide for other adult people that they need a “family friendly” bot? And who decides what is acceptable or not? The company? Wouldn’t it be better to decide this democratically? This raises the issue concerning the power of big tech.
Another problem is that sometimes users on purpose try to elicit unethical responses from chatbots. In such cases (but not in the Belgian case) it is fair to also hold the user responsible instead of only blaming the tech company. This technology is all about interaction. What happens is the result of the artificial intelligence’s behavior but also of what the human does. If users are fully aware of what they are doing and play with the bot to get it to become malicious, then don’t just blame the company.
In any case, the tragic event in Belgium shows that we urgently need regulation that helps to mitigate the ethical risks raised by these technologies and that organizes the legal responsibility. As my Belgian colleagues and I argued, we also need campaigns to make people aware of the dangers. Talking to chatbots can be fun. But we need to do everything we can to make them more ethical and protect vulnerable people against their potentially harmful, even lethal effects. Not only guns but also chatbots can kill.
I boiled snow for the first time this morning. Last night, I wild camped somewhere in The Cheviots as the clocks ‘sprang’ forward. Waking up before dawn, I put my iPod on shuffle, skipped one track and listened to Surprise Ice by Kings of Convenience. The song couldn’t have been more apt, given that my tent was covered in snow and ice!
The overnight camp was in preparation for walking at least half of The Pennine Way in a few weeks’ time. I’ve got all the kit I need, so I was just testing the new stuff out and making sure the existing stuff was still in good working order. The good news is that it’s very unlikely to get colder during my walk than it did last night, and I was warm enough to sleep!
This week, I’ve been helping WAO finish off our work (for now) with Passbolt and Sport England, continuing some digital strategy stuff for the Wellbeing Economy Alliance, doing some work around Greenpeace and KBW. I updated a resource I’d drafted on open working for Catalyst, and put together a proposal for some badges work under the auspices of Dynamic Skillset.
We had a co-op half day on Tuesday in which we ran, and eventually passed, a proposal about experimenting with a ‘drip release’ model for our content. Essentially, this would mean that we would have patrons (platform TBD) who would get our stuff first, and then everything would be open a few weeks later. This emerged from an activity of us individually coming up with a roadmap for WAO for the next few years. We were amazingly well-aligned, as you’d hope and expect!
I also helped a little with this post from Laura, and she helped me with one that I’ve written but has yet to be published. I’ve also drafted another couple of posts and an email-based course. I also (with a little help) created a weather app using the OpenWeatherMap API. Which brings us onto…
I’ve continued to find ChatGPT 4 really useful in my work this week. It’s like having a willing assistant always ready. And just like an assistant, it sometimes gets things wrong, makes things up, and a lot of the time you have domain expertise that they don’t. AI-related stuff is all over the place at the moment, especially LinkedIn, and I share the following links mainly for future me looking back.
While I got access to Google Bard a few days ago, the experience Google currently provides feels light years behind OpenAI’s offering. This week there were almost too many AI announcements to keep up with, so I’ll just note that ChatGPT was connected to internet this week. Previously it just relied on a training model that cut off in 2021. Also, OpenAI have announced plugins which look useful, although I don’t seem to have access to them yet.
There are lots of ways to be productive with ChatGPT, and this Hacker News thread gives some examples. I notice that there’s quite a few people giving very personal information to it, with a few using it as a therapist. As Tristan Harris and Aza Raskin point out in the most recent episode of their podcast Your Undivided Attention, AI companies encourage this level of intimacy, as it means more data. However, what are we unleashing? Where are the checks and balances?
It’s interesting that we talk about jobs being “at risk” of being automated. Under a socialist economic system, automating many jobs would be a good thing: another step down the road to a world in which robots do the hard work and everyone enjoys abundance. We should be able to be excited if legal documents can be written by a computer. Who wants to spend all day writing legal documents? But we can’t be excited about it, because we live under capitalism, and we know that if paralegal work is automated, that’s over three hundred thousand people who face the prospect of trying to find work knowing their years of experience and training are economically useless.
We shouldn’t have to fear AI. Frankly, I’d love it if a machine could edit magazine articles for me and I could sit on the beach. But I’m afraid of it, because I make a living editing magazine articles and need to keep a roof over my head. If someone could make and sell an equally good rival magazine for close to free, I wouldn’t be able to support myself through what I do. The same is true of everyone who works for a living in the present economic system. They have to be terrified by automation, because the value of labor matters a lot, and huge fluctuations in its value put all of one’s hopes and dreams in peril.
Next week is my last before taking three weeks off. I’m very much looking forward to a family holiday and am psyching myself up for my long walk. Ideally, I’d like to do the whole 268 miles in one go over a two-week period. But I don’t think my family (or my body!) would be up for that…
Imagine a formidable fortress standing tall. Long the bastion of formal education, it’s built upon the pillars of ‘standards’ and ‘rigour’. It has provided structure and stability to the learning landscape. These days, it’s being reinforced with smaller building blocks (‘microcredentials’) but the shape and size of the fortress largely remains the same.
However, as the winds of change begin to blow, a new force emerges from the horizon: Open Recognition. Far from seeking to topple the fortress, this powerful idea aims to harmonise with its foundations, creating a more inclusive and adaptive stronghold for learning.
Open Recognition is a movement that values diverse learning experiences and self-directed pathways. So, at first, it may appear to be in direct opposition to the fortress’s rigidity. However, upon closer inspection, rather than seeking to tear down the walls of standards and rigour, Open Recognition seeks to expand and reimagine them. This ensures that the fortress is inclusive: remaining relevant and accessible to all learners.
To create harmony between these seemingly conflicting forces, it’s important to first acknowledge that the fortress of standards and rigour does have its merits. It provides a solid framework for education, ensuring consistency and quality across the board. However, this approach can also be limiting, imposing barriers that prevent many learners from fully realising their potential.
Open Recognition brings flexibility and personalisation to the fortress. By validating the skills and competencies acquired through non-formal and informal learning experiences, Open Recognition allows the fortress to accommodate different sizes and shape of ‘room’, allowing the unique talents and aspirations of each individual to flourish
The key to harmonising these two forces lies in recognising their complementary nature. Open Recognition strengthens the fortress by expanding its boundaries, while standards and rigour provide the structural integrity that ensures the quality and credibility of the learning experiences within.
Educators and employers, as the guardians of the fortress, play a crucial role in fostering this harmony. By embracing Open Recognition, they can cultivate a more inclusive and dynamic learning ecosystem that values and supports diverse pathways to success. In doing so, they not only uphold the principles of standards and rigour but also enrich the fortress with the wealth of experiences and perspectives that Open Recognition brings.
As the fortress of standards and rigour harmonises with Open Recognition, it becomes a thriving stronghold of lifelong learning, identity, and opportunity. Far from crumbling under the weight of change, the fortress is invigorated by the union of these two powerful forces, ensuring its continued relevance and resilience in an ever-evolving world.
Earlier this month, Don Presant published a post entitled The Case for Full Spectrum “Inclusive” Credentials in which he mentioned that “people want to work with people, not just collection of skills”.
We are humans, not machines.
Yesterday, on the KBW community call, Amy Daniels-Moehle expressed her appreciation for the story that Anne shared in our Open Education Talks presentation about her experiences. Amy mentioned that the Gen-Z kids she works with had been excited when watching it. They used the metaphor of showing the full electromagnetic spectrum of themselves — more than just the visible light that we usually see.
It’s a useful metaphor. Just as the electromagnetic spectrum extends far beyond the range of visible light, encompassing ultraviolet, infrared, and many other frequencies, the concept of Open Recognition encourages us to broaden our perspective. As I’ve said before, it allows us to recognising not only knowledge, skills, and understanding, but also behaviours, relationships, and experiences
I remember learning in my Physics lessons that, with the electromagnetic spectrum, each frequency band has its unique properties, applications, and value. Visible light allows us to perceive the world around us. Ultraviolet and infrared frequencies have their uses in areas such as medicine, communication, and security. Other creatures, such as bees, can actually see these parts of the spectrum, which means they see the world very differently to us.
Similarly, it’s time for us to see the world in a new light. Open Recognition acknowledges that individuals possess diverse skills, competencies, and experiences that might not be immediately apparent or visible. Like the ultraviolet and infrared frequencies, these hidden talents may hold immense value and potential. Instead of doubling-down on what went before, we should be encouraging environment that embraces and celebrates this diversity. We can unlock untapped potential, create new opportunities, and enable more human flourishing.
In the same way that harnessing the full spectrum of electromagnetic radiation has led to groundbreaking discoveries and advancements, I believe that embracing Open Recognition can lead to a more inclusive, equitable, and thriving society. By acknowledging and valuing the myriad skills and talents each person brings, we can better collaborate and learn from one another. What’s not to like about that?
Note: if you’re interested in this, there’s a community of like-minded people you can join!
I have been thinking about how I can help my students with their theses, particularly because our programs are rather compressed and they need to get a lot done in a very short period of time. I’ve been working on developing a strategy to discern “the gap in the literature” that I plan to test with Masters and undergraduate students. Possibly also with PhD students.
I have developed several strategies to teach how to craft a good research question, how to find the gap in the literature. But when I had a meeting with Masters students recently and I taught them how to use some of my methods, they seem a little bit confused as to how to choose what exactly they should study.
Let me begin by saying what I told them at the beginning:
1) what has been done before, what has been studied and how it has been analyzed,
2) the foundations upon which our own work can be developed further,
3) any spaces where we can embed our own contributions, and/or
4) a map of themes showing connections between different topics, ideas, concepts, authors, etc.
As they read each article/chapter/book chapter/book, they drop their notes into their Excel Dump.
An Excel Dump row describing an article on Nicaragua’s water governance.
But when my students asked me “how do I ensure that I am tackling a DIFFERENT research question to the one others have worked on?” I had to pause. This is a valid question, and I thought about how they could do this in an easy, and visually appealing way.
Even if I haven’t yet fully read the literature, or don’t work in the field (I don’t, I study entirely different things to Dr. Calarco), I can start imagining extensions of her work, different methods, other case studies/countries/populations/types of schools.
DOING THIS ABSTRACT DECOMPOSITION EXERCISE HELPS ME THINK OF NEW DIRECTIONS FOR MY OWN RESEARCH.
I did this for a third paper, and the strategy seems to hold relatively well.
Thus, what I am planning to do with my students is to ask them to survey the literature and decompose abstracts of articles they read so they can see what’s been done. Once their Abstract Decomposition Matrix is complete, they can see where they can focus their work.
This exercise does NOT substitute my Conceptual Synthesis Excel Dump (CSED), but I believe it complements it. You can do an Abstract Decomposition Matrix exercise with, say, 10-15 articles, and from there, you can triage and decide which ones you will read in more detail. Although I have NOT yet tested this strategy with my students. I plan to do so this summer and fall, and will report back. I am confident it will be helpful.
Before anybody asks: yes, in this particular 5 elements abstract decomposition strategy I use the authors’ exact words. My Excel Dump technique asks of the reader to use their own words in the notes. What I noticed as I was filling out one of the ADM templates is that sometimes you will need to use your own words to fill in the gaps. I think this is good.
In the meantime if you are teaching how to review the literature for your students, this is how I conducted one in an entirely new-to-me method (hospital ethnography). These two posts (from reading a lot to writing paragraphs of your literature review and mapping a new field of research) may also be helpful, particularly if you’re delving into entirely new fields/areas/methods.
I went to an exceptionally good high school. That was courtesy of a nun in my parochial school who recognized I wasn’t being sufficiently challenged in the school I was in. That school got me into Princeton University. Moreover, it got me credit for enough college level work that I was on track to graduate in three years. I opted to major in Statistics on the theory that I could use that to pursue a graduate degree in any number of fields.
This seemed like an excellent plan for a kid from the Midwest on a mix of scholarships, my parents digging deeper than I ever appreciated, and work study jobs (including one as a dorm janitor). Going into my second year, I found better jobs as an electrician and stage carpenter at the university’s McCarter Theater. I also made time to get involved in student theater, so I wasn’t just grinding away at classes. Sleep was occasionally hard to come by but that was more about enjoying the experience than about working.
Midway through my second year I started to ask what was next. Not whatever argument I had made to get permission for my three year timetable but what was I actually thinking would happen when I did graduate. In my quest to move through the process as efficiently as possible, I had given no real thought to what that efficiency would buy me. I was approaching a finish line to one race with no real sense for what the next race was going to entail.
Nor did I have any words or concepts to bring to bear on these questions. My father had gone to college on the GI bill after serving in the Navy during WWII. He was the only one of his siblings to get a college degree. I was the first in my generation to think of college as a path to follow. My cousins were baffled; why would anyone spend the time and money for college when there were good union jobs to be had?
There was a huge amount of tacit knowledge I lacked. I was so ignorant I wasn’t even aware that I was ignorant.
Fortunately, I did something sensible despite my ignorance. I hit the pause button. I dropped back to a four year timetable. Slowing down was a necessary step. It bought me time to start figuring out the questions I needed to be asking.
“We need you back in the office now, Anthony’s team just got fired.”
Although not quite the crisis it might appear, I still had a problem to deal with.
Anthony was one of my partners. He was leading a training simulation with a team of our new consultants. The simulation was a recreation of one of our client engagements. We had taken a 12-week project and compressed it into a one-week scenario. The scenario attempted to recreate both the business issues and the look and feel of working in the field.
Anthony was leading a team of six junior consultants. The team would interact with the client via email, phone interviews, and face-to-face interactions with “clients.” The “clients” consisted of my small team manning the email and phones plus a couple of retired senior executives playing the role of the client CEO and CIO. We had a timeline, an outline of how the week should play out, plus a collection of documents and exhibits that could be shared with the consulting team as the work unfolded. Think of it as a giant case study that would unfold as the week progressed. It was more of a map than a script.
Whether a map or a script, there was no part of the scenario that included pissing off the client enough to get fired. Nevertheless, Anthony managed to do precisely that on Day 2. Moreover, my client CEO had ordered Anthony to vacate the premises immediately.
Bad time to have gone to lunch.
After a bit of strategizing with my team, we broke character and I facilitated a debrief of the “firing” with Anthony, his team, and the client. This offered the junior members of the team a peek into the dynamics of managing client relationships they wouldn’t otherwise have seen and gave us a path back into the simulation for the remainder of the week.
The ultimate test of this training strategy came a few months later as team members went out into the field for real client engagements. Their consistent report was “we’ve seen this before and we know what to do.”
Our training design was born of resource limitations. As much by luck as by design we had stumbled on deeper lessons for our work. We were learning how to navigate environments without a script and without rehearsal time. We were developing perspectives and practices oriented to an improv logic as the world demanded more responsiveness and adaptability.
I’ve come to believe that navigating this environment requires a shift in perspective and a set of operating practices and techniques that can be most easily described as improv adapted to organizational settings.
In place of detailed scripts, we were learning to operate from core principles and shared values. Our learning environment gave us a safe space to experiment with and work out how to apply those principles and values.
The best way to have a good idea is to have lots of ideas
Linus Pauling
This is an old observation, bordering on bromide. I’ve used it before and will most likely use it again.
This comes to mind as I was thinking about a chance encounter with my CEO as he came out of a meeting. Clare, another of our partners, had brought up a technique from on old self-help book and Mel wanted to know what I thought.
I was familiar with the book and the technique. I had read to book years ago and didn’t find the technique terribly helpful. I’m not naming the book, the technique, or the author because that isn’t the point. The point in the moment was that Clare had scored a small status point with Mel and I had lost a point. It comes to mind today as another aspect of trying to balance between efficiency and effectiveness in a work world that runs on ideas.
In an efficiency world you fire out ideas to ensure that you get credit for them. In an effective world you make choices to not waste other people’s time at the risk that your decision to skip the stuff you deem unimportant will never garner any recognition or reward.
I’m not generally a fan of sports metaphors but there’s something here akin to hitting in baseball. You can’t get a hit if you don’t swing. If you do swing, you’re more likely to miss than to get a hit. Swing and miss too often and you’ll lose the opportunity to swing at all. One challenge is learning to choose your pitches. Another is to figure out how to get enough at bats to get pitches to look at.
Last week, Vancouver-area radio host Jill Bennett went viral after tweeting a photo of a Dodge Durango straddling a bright yellow concrete barrier that the driver had hit. “Hey @CityofVancouver this is second incident I’ve seen caused by these useless ‘slow street’ barricades installed last month. They don’t slow down traffic; they cause crashes and traffic chaos,” Bennett wrote.
Understandably, thousands of people proceeded to pile on, pointing out how ridiculous her complaint was. Had the driver simply been paying attention to the road and driving at a reasonable speed, they would have easily noticed the brightly colored traffic calming installation, driven through without a problem and nothing bad would have happened to them. Blaming anyone other than the driver for this crash is absolutely insane.
And this is far from a one-off situation where one idiot had a bad take. This attitude is incredibly common. Just head over to NextDoor or the local subreddit in any small city that has recently added some form of protected bike lanes, and you’ll see the exact same sentiment. When the city closest to where I currently live (spoiler: not every Jalopnik staffer lives in New York) added flexible posts with some reflector tape on them to (sort of) protect a bike lane in its downtown, they were almost immediately hit, and the complaints started to flood in from people who were upset they were ever installed in the first place.
How dare the city put drivers at risk by doing one tiny thing to make riding safer for cyclists! These barriers just jump out and attack cars at random! I was just minding my own business, and now I have a flat tire! Thanks for nothing, idiot city planners.
I’m sorry to break it to anyone who has trouble keeping their car out of a bike lane (or off a concrete barrier), but it’s not the bike lane’s fault you’re a shitty driver. If you hit something stationary, that’s your fault. Pay attention to the fucking road while you’re driving. It’s not too much to ask when other people’s lives are literally at stake.
After all, killing someone who’s not in a car is still killing someone. And if you think they were asking for it because they were walking or riding a bike, you’re just a bad person. You’re the one driving the 5,000-lb vehicle. You’re the one responsible for making sure you don’t hit anything or anyone. Trying to blame others for your shitty driving is just ridiculous.
In the case of cyclists and pedestrians, sure, it’s possible to construct a hypothetical scenario where they might get hit while doing something that makes it entirely their fault. But not bike lane barriers and traffic calming measures. They’re just sitting there. Not moving. Completely stationary. Asking drivers to avoid hitting them is like asking drivers to avoid hitting buildings. It’s nothing more than a basic requirement for being allowed to drive on public roads.
If that’s too much to ask, then maybe it’s time for the state to take your driver’s license away. Oh, you live in a suburban hellscape and can’t get around without a car? Too bad. Stay home and have your groceries delivered until you can prove to society that you can be trusted behind the wheel again. Or take the bus. Sorry if you think you’re too good for public transportation. You’re clearly not good enough at driving to have a license, so suck it up, buttercup. That barrier you hit could have been someone’s child.
Operating behind enemy lines, one soldier fighting for Ukraine knows the Russians will hunt for him the second he sets up his portable Starlink internet dish.
He and his team set up the device only in urgent situations where they need to communicate with their headquarters. The Russians “will find you,” the soldier said, who goes by the call sign Boris. “You need to do it fast, then get out of there.”
The soldier, an ex-French Foreign Legionnaire who now operates as part of a reconnaissance-and-sabotage unit, is just one of Ukraine’s many soldiers for whom the Starlink service is a double-edged sword. Like other soldiers interviewed for this article, Boris asked to be referred by his call sign for security reasons.
On the one hand, Ukrainian soldiers say the device is key to their operations, notably its ability to help coordinate devastating artillery strikes. On the other, they report a variety of ways in which the Russians can locate, jam, and degrade the devices, which were never intended for battlefield use.
The end result is a MacGyver-esque arms race, as Ukraine rushes to innovate and Russia moves to overcome these innovations.
In Boris’s case, Russian signals-intelligence equipment is likely pinpointing the devices by scanning for suspect transmissions, said Todd Humphreys, a professor at the University of Texas at Austin who has studied Starlink devices.
One Ukrainian drone operator with the call sign of “Professor” also reported prolonged jamming that prevented his team from using his Starlink unit.
Professor said the jamming began two to three months ago, and that its intensity varied from place to place. “In one place everything’s fine, and in another—it doesn’t work,” Professor said.
At times the jamming would continue all day. “It’s really powerful,” Professor said.
Sometimes if there is no signal for the Starlink, the drone operator Professor tries a novel solution: he places it in a hole. The signal then returns, although only sometimes.
That should help keep the Starlink up through Russian GPS jamming, said Bryan Clark, a senior fellow at the Hudson Institute and an expert in electronic warfare.
Starlinks are particularly vulnerable to such jamming. Each terminal uses a GPS unit to determine which passing satellite should provide an internet connection.
Fortunately for Ukraine, GPS jammer signals are low power. This means that dirt or concrete can block the jammer signal. As long as a Starlink device has a barrier between it and the Russian jamming signal, it can continue to function, according to Clark.
A drone pilot with the call sign of Morgenshtern says he’s seen similar problems with other gear that uses GPS. “I think they introduced some more advanced equipment, or just their number increased,” he said.
Clark added that Ukraine can’t put its drones in a hole to protect them from jamming by Russia’s own Orlan-10 drones, but there may be other ways.
As Starlink allows users to manually enter their GPS locations, users could simply place a cheap GPS-receiver device outside jamming range and then enter its location into their Starlink terminal, offset by their distance to the GPS receiver.
One drone unit commander near the Ukrainian city of Bakhmut said his problems were unrelated to GPS jamming. Sometime in January, the commander said, Starlink uplink had been degraded to the point that his units often couldn’t make audio calls. Instead, the device could only send and receive text messages. The Starlink terminal also took longer to find satellites.
Clark said these problems were likely due to advanced jamming systems that attack the uplink of information to a satellite. The Russian military typically keeps these systems in reserve to defend Russian territory itself. They are theoretically vulnerable to Ukrainian strikes as they must be deployed within dozens of kilometers from their target and are not highly mobile.
That Russia might move such valuable systems to Bakhmut aligns with reports that more professional forces are deploying to take the city, which it has been attempting to occupy for seven months and now partly encircles. When visited by this reporter in Bakhmut on Feb. 14, a drone soldier with the call-sign Lebed reported that Russia was sending more professional soldiers to attack Ukrainian positions.
On March 10, Ukrainian Presidential Advisor Mykailo Podoloyak told the Italian newspaper La Stampa that Russia has “converged on Bakhmut with a large part of its trained military personnel.”
Clark said Russian satellite jamming is also defeatable with adjustments to Starlink’s software. In March 2022, Starlink engineers quickly pushed through a code update in response to Russian jamming attempts, a U.S. official said that April.
For now, Ukraine is stuck with Starlink and its problems, Clark said. Other satellite internet companies, such as Astranis, lack the infrastructure to provide continuous coverage, while satellite phone systems have too little bandwidth for Ukraine’s needs, he said.
It isn’t all bad news for Ukraine, though.
Two officers responsible for drone operations reported no issues with jamming. Similarly, neither Professor nor Morgenshtern said they were currently seeing Starlink jamming.
It’s unclear why jamming would have subsided for these units.
Russian forces could be rotating jamming operations across the front, focusing on high-priority areas. Ukraine may also be targeting Russian electronic-warfare units. Ukraine regularly shoots down Russia’s Orlan drones, for example, which can carry electronic-warfare payloads.
In keeping with Ukraine’s often innovative approach to the war, some drone operators are even reselling crashed parts of these Orlan drones. On one website for Ukrainian drone operators, one user posted an image of the Orlan camera, offered for sale.
iOS 16.4 brings new emoji, push notifications for web apps on the Home Screen , Mastodon link previews, and more.
Today, Apple is releasing iOS and iPadOS 16.4, the fourth major updates to the OSes that introduced support for the customizable Lock Screen and Stage Manager last year, respectively.
Ahead of the debut of Apple Music Classical tomorrow and just a few months before a WWDC that’s rumored to be focused on the company’s upcoming headset and a relatively small iOS 17 update, 16.4 is comprised of two big additions to iOS and iPadOS (new emoji and push notifications for web apps on the Home Screen) alongside a variety of smaller, but notable improvements such as some new Shortcuts actions, Mastodon link previews in iMessage, some tweaks to Podcasts and Music, and more.
Let’s take a look.
21 New Emoji
Ever since our usual guessing game on the Connected podcast, I haven’t been able to stop thinking about the ginger and goose emoji in iOS 16.4. Those are just two of the new emoji introduced with today’s update, with other notable additions including the likes of moose, new colored hearts, and a donkey.
Some of the new emoji in iOS 16.4.
That’s some realistic ginger.
While I’m partial to the goose, I’m also happy about the addition of a pink heart (finally) and a proper wireless symbol, which I look forward to using in some of my shortcuts that display emoji in menus and alerts.
Push Notifications for Web Apps on the Home Screen, with Focus Integration
In what is likely part of a pre-emptive strategy ahead of the requirement to allow third-party web browsers on iOS and iPadOS later this year, Apple shipped a series of useful additions for web apps and the existing, WebKit-based alternative browsers in iOS 16.4. Regardless of the underlying motivation behind these additions just a couple of months before WWDC, these are solid enhancements to the web experience for iPhone and iPad, with one particular feature that I plan to explore more in depth later this week for Club MacStories members.
For the first time since the iPhone’s introduction in 2007, web apps added to the Home Screen now support push notifications and badges. What I like about Apple’s implementation of this feature is that notifications from web apps are managed just like the ones from any other native app: you’ll be prompted to grant notification permissions to a web app on the Home Screen with the usual system dialog; you can manage the web app’s notification options from Settings; and since these are “regular” push notifications, you can manage them from Notification Center as well as tie them to specific Focus modes.
As far as the notifications themselves go, iOS 16.4 doesn’t make any distinction between those originating from a native app compared to those coming from web apps previously saved to the Home Screen. The technology behind all this is the same Web Push API that Apple added to Safari 16.1 in macOS Ventura last year.
I was able to test notifications for web apps added to the Home Screen using Alerty.dev, a web service I recently discovered whose sole purpose is to let users program their own notifications to deliver via an API to all their devices. Alerty is similar to Pushcut and Pushover, but instead of requiring a native app to be installed on the user’s device, it can just deliver real-time push notifications via a web browser (on desktop) or a web app on the Home Screen in iOS and iPadOS 16.4. This was a perfect opportunity to sign up for the service and try it out with some of my shortcuts.
When in Safari, you cannot enable push notifications for web apps. You’ll have to add them to the Home Screen first.
After creating an Alerty account, I saved the web app to my Home Screen from Safari. I opened the web app, I was prompted to log in again (more on this below), and only at that point I was asked to give Alerty permission to display push notifications. This is an important technical detail: while I was in Safari, Alerty couldn’t ask me for notification access since iOS and iPadOS do not support notifications in Safari; it was only when I saved Alerty as a web app on the Home Screen that I could.
Once added to the Home Screen, I was able to grant Alerty the ability to send me push notifications.
Once I gave Alerty access to notifications, I could see those changes reflected in Settings, and of course I was also able to pick the app for one of my Focus modes. I put together a sample shortcut to send an instant alert via the Alerty API, ran it, and a second later I saw a regular push notification from Alerty appear on both my iPhone and iPad. It looked like another notification from any other app, but it was actually coming from a web app.
Later this week for Club members, I plan to share my shortcut for interacting with the Alerty API as well as some strategies for integrating this service with HomeKit and other types of automation.
Notifications for web apps have the same notification settings as native apps on iOS 16.4.
Notifications aren’t the only change coming to web apps in iOS and iPadOS 16.4. Also for the first time, third-party web browsers can add web apps to the Home Screen, which will reopen them directly in the browser that created them when tapped. As you can see in the example below, I was able to add MacStories to the Home Screen as a Microsoft Edge bookmark.
Adding a web app from Microsoft Edge to the Home Screen.
While it’s good to see Apple progressively give more and more functionalities and system integrations to third-party browsers, their usefulness is still largely impacted by the fact these browsers are reskins of the Safari web engine. If you delete the browser that created one of these web apps on the Home Screen, then try to reopen the web app, it’ll fall back to Safari instead.
One of the highly anticipated changes of iOS 17 is the possibility of Apple having to relax its stance on disallowing alternative browser engines on iOS, and third-party browser makers are getting ready for that potential future. Once that happens, I’m sure that the ability to add full-on PWAs to the Home Screen will prove more useful than creating a saved boomark for a glorified Safari shell. We’ll see.
The last thing I’ll point out about web apps on the Home Screen is that users can now add multiple instances of each and rename them, which makes sense in the context of multiple Focus modes and creating different versions of the same web app, perhaps logged into different accounts. While I haven’t found a use case for this feature myself, I think it’s the right approach.
New Shortcuts Actions and Focus Filters
Continuing the trend from last year, there are some new actions in Shortcuts for iOS and iPadOS 16.4. Unfortunately, rather than moving the app forward in meaningful ways for power users, these actions mostly revolve around exposing app settings and various toggles to Shortcuts. I’m not saying these are not welcome additions, because they are; I’m only arguing that Shortcuts hasn’t been substantially improved for its most loyal and dedicated users in a while now.
In any case, the new actions in Shortcuts are:
Auto-Answer Calls
Intercom (requires a HomePod; cannot be run on a Mac)
Lock Screen
Set AirDrop Receiving
Set Always-On Display
Set Announce Notifications
Set Night Shift
Set Stage Manager
Set True Tone
Set VPN
Shut Down (includes option for Restart)
Silence Unkown Callers
Like I said, I’m a bit disappointed that the new actions added to Shortcuts in the past year mostly involve the ability to control on/off settings with no deeper controls. These are nice actions to have, but I was hoping for more controls made available to advanced users, especially on iPad.
Case in point: the Stage Manager action in Shortcuts only allows you to either turn Stage Manager on or off with two toggles for choosing whether you want to see the dock and recent apps or not. These are the same settings you can find in Control Center for Stage Manager. As I argued last year, if Apple cared at all about making Stage Manager more palatable for power users, one of the (many) things they should do is bring support for the Mac’s ‘Find Windows’ and ‘Resize Windows’ Shortcuts actions to iPadOS. Instead, while Mac users can leverage Shortcuts to fine-tune their workspaces with two excellent Shortcuts actions, in iPadOS land all we can do with Shortcuts is turning Stage Manager on or off.
There is one great change I want to point out in Shortcuts for iOS 16.4, however: the Ask for Input action now lets you enter multi-line text instead of one line at a time only. As an advanced user of the app, I’m glad I can now – checks notes – enter multi-line text in a dialog.
I’ll also note that the ‘Set Always-On Display’ action is a brand new system Focus Filter in iOS 16.4 now. As I explained last year, Focus Filters are based on the same intent technology that powers Shortcuts actions, which makes it possible for developers to expose the same functionality in both Settings and the Shortcuts app. I’ve long argued that users should be able to set their Always-On display preferences depending on Focus modes, so I’m happy to see this option be supported in both Shortcuts and Settings now.
The ability to control the Always-On Display is both a Shortcuts action and system Focus Filter in iOS 16.4.
In practical terms, this change means you can now disable the Always-On display when you’re at work, or if you’re out and having dinner with friends, or at the movie theater. Whatever your use case may be, this is a good option to have and it can be accessed both from Focus in Control Center as well as with Shortcuts automations.
Other Changes in iOS 16.4
Here is a list of all the other changes in iOS and iPadOS 16.4 worth mentioning.
The page-turn animation is back in the Books app. In a flip-flop that would make Stephen Hackett proud, the page-turn animation – which had been previously removed in iOS 16 – is returning in iOS 16.4. The first time you’ll open the Books app in 16.4, you’ll see an alert inside the reader view that tells you about the new options you can find in Books’ somewhat-hidden Themes & Options menu. One of the new options is ‘Curl’ for page turn, which restores Books’ glorious, real-time 3D effect for turning pages.
Welcome back, buddy.
As someone who thought the removal of the page-turn animation was a mistake, I’m very happy to see this feature return. Props to whoever inside Apple convinced their manager that this feature was worth restoring.
The Home Screen wallpaper is no longer blurred in Stage Manager. Of all the improvements and features that Stage Manager for iPadOS potentially needs, Apple chose to ship one in iPadOS 16.4: when you’re using Stage Manager, your Home Screen wallpaper is no longer blurred behind. That’s it, that’s the feature. Let’s move on.
There are Mastodon link previews in Messages, Mail, and Notes. Ever since I decided to embrace Mastodon and leave Twitter behind months ago, I’ve missed the ability to easily share and preview links to posts on iMessage. That’s changing with iOS 16.4, which comes with native support for Mastodon link previews inside the Messages app as well as Notes and Mail.
Mastodon link previews in Messages, Notes, and Mail.
In iMessage, Mastodon links will be automatically converted to a rich snippet with support for images and video attachments when sent in a conversation. They look just like Twitter rich links, but a) they have a gray background and b) thanks to the superior Mastodon API, these rich links tell you how many media attachments are included in a post. In Notes and Mail, you can get Mastodon rich links by saving them via the Notes share sheet extension or pasting them in the message composer and using the new link conversion option of iOS 16, respectively.
It’s great to see Apple ship support for Mastodon previews so quickly, and I’m glad I no longer have to take screenshots of posts if I want to share them easily with my friends on iMessage.
Interface tweaks for Apple Music and Podcasts. In iOS 16.4, Apple brought a series of small, and relatively unimportant, changes to the Music app.
Your profile picture (which you can use to open your Apple Music profile) is now displayed at the top of the Library page too; artwork in the Playlists page is smaller, making for a denser view of your playlists; there is a new and less obtrusive design for in-app alerts such as songs added to the library or queued in your Up Next. The latter is the most interesting addition in my opinion: these are new compact “bubbles” that are temporarily displayed at the bottom of the screen rather than in the middle of it. I wonder if Apple will make this style of alert1 an official API for developers in the future.
The new in-app alerts for Music (left).
Changes to the Podcasts app are more substantial and useful than the ones seen in Music. Channels, such as the MacStories one in Apple Podcasts, will now appear in Library tab if you’re subscribed to them; when you open a channel, you’ll see all the shows from it that you’re already following at the top of the page. Additionally, the Up Next queue in the app now includes episodes saved to the library as well as episodes played from shows you’re not following (a nice feature that’s been available in third-party podcast apps for a while).
I continue to be intrigued by Apple’s Podcasts app, particularly because of its clean design, integration with the Apple Watch, and performance in refreshing podcast feeds. However, until Apple adds the equivalent of a ‘trim silence’ feature to save me some time when listening to podcasts, I can’t switch to it as my podcast player.
Voice Isolation for cellular phone calls. Following in the footsteps of FaceTime and VoIP apps, you can now enable Voice Isolation for cellular phone calls in iOS 16.4. This audio effect, which you can activate from Control Center, will prioritize your voice and block ambient noise around you.
Enabling voice isolation for a cellular call.
I tested this feature with my mom, who told me I “sounded good but metallic”. Your mileage may vary.
iOS and iPadOS 16.4 aren’t huge updates, yet most people will likely rush to install them because of the new emoji included in these releases. The nerdier among us will probably do the same to get native Mastodon link previews in iMessage, which are very nicely done. I continue to be let down by the poor execution and limitations of Stage Manager, and, at this point, I’m fully prepared to see iPadOS 17 go by without any major changes to iPadOS multitasking, which would be concerning.
iOS and iPadOS 16.4 are likely the last major updates before Apple’s attention turns to WWDC, the headset, and whatever may be in store for iOS 17. Worst case scenario, even if we won’t be getting any more iOS 16 updates and if iOS 17 turns out to be a smaller release this year, know this:
Founded in 2015, Club MacStories has delivered exclusive content every week for over six years.
In that time, members have enjoyed nearly 400 weekly and monthly newsletters packed with more of your favorite MacStories writing as well as Club-only podcasts, eBooks, discounts on apps, icons, and services. Join today, and you’ll get everything new that we publish every week, plus access to our entire archive of back issues and downloadable perks.
The Club expanded in 2021 with Club MacStories+ and Club Premier. Club MacStories+ members enjoy even more exclusive stories, a vibrant Discord community, a rotating roster of app discounts, and more. And, with Club Premier, you get everything we offer at every Club level plus an extended, ad-free version of our podcast AppStories that is delivered early each week in high-bitrate audio.
I enjoyed this explanation by The Verge’s Tom Warren on how Microsoft’s Phone Link app – which has long allowed Android users to connect their smartphones to a Windows PC – has been updated to support iOS notifications and sending texts via iMessage. From the story:
The setup process between iPhone and PC is simple. Phone Link prompts you to scan a QR code from your iPhone to link it to Windows, which automatically opens a lightweight App Clip version of Phone Link on iOS to complete the Bluetooth pairing. Once paired, you have to take some important steps to enable contact sharing over Bluetooth, enable “show notifications,” and allow system notifications to be shared to your PC over Bluetooth. These settings are all available in the Bluetooth options for the device you paired to your iPhone.
And:
Microsoft’s Phone Link works by sending messages over Bluetooth to contacts. Apple’s iOS then intercepts these messages and forces them to be sent over iMessage, much like how it will always automatically detect when you’re sending a message to an iPhone and immediately switch it to blue bubbles and not the green ones sent via regular SMS. Phone Link intercepts the messages you receive through Bluetooth notifications and then shows these in the client on Windows.
I got access to the updated version of Phone Link on my PC today, and this integration is pretty wild and it actually works, albeit with several limitations.
First, the setup process is entirely based on an App Clip by Microsoft, which is the first time I’ve seen and used an App Clip in real life. Essentially, my understanding is that this works similarly to how an iPhone can pair with an old-school Bluetooth car system: the iPhone and PC pair via Bluetooth, and you can then provide the PC with access to your notifications and contacts from iOS’ Bluetooth settings. This is the same UI I have for my KIA Sportage’s system, which uses regular Bluetooth to pair with my iPhone and can also display contacts and missed calls.
The setup process based on an App Clip.
The difference between my car and Phone Link, of course, is that with Phone Link you can type text messages from a PC and they will be sent as iMessages on iOS. This bit of dark magic comes with a lot of trade-offs (check out Warren’s full story for the details on this), but it works for individual contacts. I’ve been able to start a conversation with John, reply to his messages from Windows notifications, and even send him URLs1, and they were all correctly “intercepted” by iOS and sent over as iMessages. I’ve also been impressed by the ability to clear notifications from a PC and have them go away on iOS’ Lock Screen immediately.
The Phone Link app paired with my iPhone.
This was then sent as an iMessage.
The limitations of Phone Link for iPhone users mean you’ll always have to fall back to the actual iOS device for something – whether it’s posting in an iMessage group or sending a photo or acting on notifications – but for quick messages, glancing at notifications, and clearing them, I think this integration is more than good enough.
Fun fact: raw URLs sent from Windows are delivered as rich links from iMessage, but the card’s preview doesn’t load by default on the recipient’s device. ↩︎
What happens when AI image generation becomes powerful enough not to replace artists (or true imagination!), but to credibly remix photographs and movies in a way that we can no longer tell if they’re true or not?
Well, that didn’t take long: The latest update to Midjourney—which can now generate photorealistic faces—has spawned a flurry of images that show, among other things, Donald Trump getting arrested or the pope in an arresting outfit. Celebrities in fantastical situations are only the most obvious use, though: Some people are also generating events that never happened.
Something wild is happening on the Midjourney subreddit.
People are telling stories and sharing photos of historic events - like the “Great Cascadia” earthquake that devastated Oregon in 2001.
What’s surprising about this wholly unsurprising development is how the AI nails the visual style of the early 2000s: Although this earthquake never happened, the purported footage of it looks entirely credible to me, who spent a lot of time consuming media around that age. The colors are veering towards grey and brown, the outfits are correct, and the lo-fi American television resolution feels completely appropriate for the time.
At the pace the technology is moving, we’re very quickly approaching a future where past events can be entirely constructed and pass the smell test—enhancing all the worst mechanisms of the post-truth age we live in.
Every wave of technological innovation has been unleashed by something costly becoming cheap enough to waste. Software production has been too complex and expensive for too long, which has caused us to underproduce software for decades, resulting in immense, society-wide technical debt. This technical debt is about to contract in a dramatic, economy-wide fashion as the cost and complexity of software production collapses, releasing a wave of innovation.
It was my first "real" Cocoa project. I was learning Objective-C pretty much on the fly back then and still working a day job. I had no idea it would launch my full time career into being an indie Mac programmer. Happy birthday little guy, you're still the best wiki-style notebook around. One more year and you can legally drink!
VoodooPad is in different hands these days, but I'm happy to see it still living and still getting love from many of its users (whom I still get emails from every now and again).
Safari 16.4 is out (upgrade to iOS 16.4 to get it) and the biggest feature for me is mobile support for Web Push notifications. This little demo tool was the first I found that successfully sent a notification to my phone: frustratingly you have to add it to your home page first in order to enable the feature. The site also provides a curl command for sending push notifications through the Apple push server once a token has been registered, which is the crucial step to figuring out how to build applications that can send out notifications to users who have registered to receive them.
Image generated by the DALL-E text-to-image generator based on the prompt, “A photograph of a humanoid robot who is using a pencil to draw a line chart on a piece of paper.”
As pretty much everyone and their robot dog is now aware, there are jaw-dropping breakthroughs happening in artificial intelligence (AI) on an almost daily basis. To those of us in the data visualization field, this begs the obvious question: Will AIs be able to create expert-level charts without any human intervention, and, if so, when might that happen?
That’s hard to say, of course, but what seems almost certain at this point is that the process of creating a chart is going to change dramatically in the very near future. Already, AI users can describe a chart using simple, plain-language prompts, and get an image of that chart in seconds without having to use the graphical user interfaces (GUIs) of data visualization products like Tableau Desktop or Microsoft Excel. How good are the resulting charts? Well, in my opinion, they’re currently pretty hit-or-miss and often require corrections or enhancements by a human with data visualization expertise before being shown to an audience. Given how quickly AI is advancing, though, how long might that remain the case?
I think writing computer code provides a potentially informative model here since current AIs are much more advanced when it comes to generating code compared with generating charts. The GPT-4 AI was released about a week ago as I write this, and it can produce astonishingly good code based on plain-language prompts. Does this mean that people no longer need to know how to code? Well, that doesn’t seem to be the case, at this point anyway. For now, people with coding expertise are still needed for a few reasons:
A human coder still needs to decide what code is needed in a given situation, and what that code should do. AIs can decide what code is needed for common applications with similar examples in their training data, such as simple games or content management systems, but they have trouble with more complex, novel, or unique applications, such as custom enterprise software applications. As far as I can tell, someone without any coding expertise would struggle to formulate prompts that would result in usable code for anything but simple, common applications.
AIs often make mistakes that must be identified and corrected by expert coders before the code can run without throwing errors or introducing problems like security vulnerabilities or unintended application behaviors.
This means that, for now anyway, humans with coding expertise are still needed to guide and supervise coding AIs. Those coders will be a lot more productive (and so potentially less numerous), but still necessary. A similar consensus seems to have emerged in recent months around car-driving AIs: During the last decade or so, many people assumed that humans would no longer need to know how to drive because car-driving AIs would exceed human driving abilities in all situations. In recent months, however, it’s started to look more like humans will still need to know how to drive since car-driving AIs are unlikely to perform reliably in a wide variety of situations for the foreseeable future. Yes, drivers will be more productive since they can rely on AI for simpler tasks like highway driving in good conditions, but they’ll still need to know how to drive so that they can correct or take over for the AI in more unusual or complex situations.
Data visualization might follow a similar path. It seems almost certain at this point that human chart-makers will become a lot more productive, because they’ll be able to simply describe a chart in plain language and get that chart within seconds. In many cases (but not all), this will be faster than using the GUI of a data visualization software product to create a chart, and learning how to use an AI to create charts will be a lot quicker and easier than learning how to use data visualization software.
Even if they’re using an AI, however, chart makers still need data visualization expertise to decide what charts are needed in a given situation, and to supervise the AI by correcting any data visualization, reasoning, or perceptual mistakes that it might make. A human with data visualization expertise might also need to prompt the AI to make design choices that the AI might have trouble making on its own, such as deciding to visually highlight part of a chart, adding callouts with key insights, or bringing in comparison/reference values from an external source.
If this is how things play out, it would mean that people will still need data visualization skills, but the way in which they’ll use those skills will change drastically. Instead of using those skills to make charts “by hand” using the GUI of a data visualization software application, they’ll use those skills to guide and supervise chart-making AIs, just as human coders use their coding expertise to guide and supervise coding AIs.
Now, a chart-making AI might not offer enough control or flexibility for some users, particularly those who create highly customized charts such as scientific charts, data art, specialized business dashboards, or novel chart types. Those users will likely still need to use data visualization GUIs or code libraries such as ggplot or D3.js, but they represent only a small minority of chart creators. I suspect that a good chart-making AI will meet the needs of most people who create charts.
I’m probably over-estimating its importance, but my upcoming Practical Charts book might accelerate the transition from using GUIs to using AIs to make charts. The book contains chart design guidelines that are more concrete and specific than other books, which is exactly the kind of training data that would help a chart-making AI become more competent. On the one hand, it’s frustrating to think that I might have spent the last several years writing training data for AIs (and also to not be able to block AIs from including it in their training data—unless legislation or policies change). On the other hand, I recognize that AIs that include my book in their training data may allow millions of people to make better charts. This is already happening with AI-generated computer code, which often contains expert-level techniques and practices that were distilled from code in the AI’s training data that was written by expert coders, and that many coders who use the AI wouldn’t think of on their own. It’s also happening with car-driving AIs, which can allow human drivers to perform better by, for example, slamming on the brakes to avoid a frontal collision faster than a human ever could.
Now, this situation could change, of course. Between the late 90s and early 2010s, for example, the best chess players in the world were “centaur” or “hybrid” teams consisting of a human grandmaster using a chess-playing AI to assist them. Such teams could easily beat the best AI-only players. That changed, however, when chess engines like AlphaZero came out a few years ago, which were so good that pairing a human grandmaster with them made them worse, not better. The question, then, is whether data visualization is more like chess, or more like car-driving? Only time will tell, but it feels more like car-driving to me at the moment, i.e., like something that will require expert human supervision for the foreseeable future.
Take all of this with a boulder of salt, of course, since this is pure speculation based on the information that’s available at the moment. Some of the challenges that I’ve described could turn out to be much easier or much harder than expected for AIs to overcome, and things could be very different a few years from now. Or next Tuesday.
Agree? Disagree? Awesome! Let me know on LinkedIn or Twitter, or in the comments below.
A good chunk of my career has involved running, analyzing and writing about A/B tests (here’s a quick Bayesian overview of A/B testing if you aren’t familiar). Often A/B tests are considered to be the opposite, statistical, end of the data science spectrum from AI and machine learning. However, stepping back a bit, an A/B test just tells you the probability of an outcome (whether variant A is better than variant B) which is not that different than a deep neural network used for classification telling you the probability of a label.
With the rapid advances in Natural Language Processing (NLP) including easy access to pre-trained models from Hugging Face and the quite impressive results coming out of OpenAI’s Large Language Models (LLMs) like GPT4, I was curious whether or not you could replace a subject line A/B test with a model built using GPT. It turns out that using GPT-3’s text embeddings, and a very simple classification model, we can create a tool that correctly predicts the winner of an A/B test 87% of the time.
The Problem: Picking the Best Headline
The vast majority of the content on the web today exists to drive traffic to websites, ultimately to increase the probability that users will complete some conversion event. Conversion events can be everything from simply clicking on a link to making the purchase of a product associated with the content. Even here at Count Bayesie, I ideally want people to at least read this content even if I have nothing to sell.
In this post we’ll explore picking an article headline that generates the highest click rate for the post. For example suppose we had these two ideas for headlines (which come from our data set):
A: When NASA Crunched The Numbers, They Uncovered An Incredible Story No One Could See.
B: This Stunning NASA Video Totally Changed What I Think About That Sky Up There.
Which of these two headlines do you think is better? A/B tests are designed to answer this question in a statistical manner: both headlines will be displayed randomly to users for a short time, and then we use statistics to determine which headline is more likely the better one.
While many consider a randomized controlled experiment (i.e. an A/B test) to be the gold standard answering for the question “which headline is better?”, there are a range of draw backs to running them. The biggest one I’ve found professionally is Marketers hate waiting for results! In addition they don’t want to have to expend some of the eyeballs that view the content on experiment itself. If one variant is much worse, but it took you thousands of users to realize that, then you’ve wasted a potentially large amount of valuable conversion.
This is why it would be cool if AI could predict the winner of an A/B test so that we don’t have to run them!
The Data
The biggest challenge with any machine learning problem is getting the data! While many, many companies run A/B tests frequently, very few publish the results of this (or even revisit their own data internally).
32,487 experiments might not seem like all that much, but each experiment is not just the comparison between two headlines but often many. Here in an example of the data from a single experiment:
A single experiment involves the comparison of multiple variants.
We want to transform this dataset into rows where each row represents a comparison between a single pair of A and B variants. Using the combinations function from the itertools package in Python makes this very easy to calculate. Here’s an example of using this function to create all possible comparisons among 4 variants:
> from itertools import combinations
> for pair in combinations(["A","B","C","D"], 2):
> print(pair)
('A', 'B')
('A', 'C')
('A', 'D')
('B', 'C')
('B', 'D')
('C', 'D')
After this transformation (plus some clean up) we have 104,604 examples in our train set and 10,196 examples in our test set out of the original 32,487 experiments.
This leads us to a very interesting problem regarding this data: what exactly are our labels and how do we split the data up into train and test?
The tricky part of labels and train/test split
It’s worth recalling that the entire reason we run an A/B test in the first place is we don’t know which variant is better. The reason statistics is so important in this process is we are never (or at least rarely) 100% certain of the result. At best, if we view these experiments in a Bayesian way, we only end up with the probability A is better than B.
In most classification problems we assume binary labels, but when we transform our data the labels looks like this:
If we represent our labels honestly, they are probabilistic labels, which makes our problem a bit different than usual.
As we’ll see in a bit, there’s a very simple way we can use logistic regression to learn from uncertain labels in training.
For our test set however, I really want to get a sense of how this model might perform with clear cut cases. After all if the differences between two headlines is negligible neither this model nor an A/B test would help us choose. What I do care about is that if an A/B test can detect a difference, then our model does as well.
To ensure that our test set can be label accurately, we only chose the pairs were the difference was a high degree of certainty (i.e. very close to 0 or very close to 1). To make sure there was no data leakage all of the titles that are in the test set are removed from the training set.
The Model
Modeling this problem is both relatively simple and quite different from most other classification models, which is a major reason I was so fascinated by this project. The simplicity of this model is intentional, even though it’s not hard to imagine modifications that could lead to major improvements. The reason for the simplicity of the model is that I’m primarily interested in testing the effectiveness of language models rather than this problem specific model.
Here is a diagram of the basic structure of our model.
The basic flow of our model, the key insight is computing the difference of the vector representations.
We’ll walk through each section of the model process touching on quite a few interesting things going on in what is otherwise a pretty simple model to understand.
The heart of this model is embeddings or how we’re going to transform our text into a vector of numeric values so that we can represent headlines mathematically for our model. We are going to use three different approaches to this and that will be the only way each model differs. Our approaches are:
Traditional Bag-of-Words (typically not considered an “embedding”)
Each of these techniques is the only difference between the three A/B test prediction models we’re going to build. Let’s step through the basic construction of each:
Bag-of-Words
A “bag of words” vector representation treats each headline merely as a collection of words and concerns itself with the possible words in the training set. Each word (or in this case, technically a two-word sequence called a bi-gram) present in the headline will result in a value of 1 in the vector representing the headline, every other value in the vocabulary not present in the headline will be a 0. Our text can easily be transformed this way with SKLearn as follows:
from sklearn.feature_extraction.text import CountVectorizer
def build_bow_vectorizer(df):
corpus = np.concatenate([df['headline_a'].values,
df['headline_b'].values])
vectorizer = CountVectorizer(ngram_range=(1,2),
binary=True,
max_df=0.6,
min_df=0.005)
vectorizer.fit(corpus)
return vectorizer
Typically when we refer to an “embedding” we aren’t considering any vector representation, but specifically on that is the output of the last layer of a neural network trained to model language (often for some other task). Technically our BoW model would not be considered a true embedding.
🤗 Transformers library and Distilbert
HuggingFace’s Transformer’s library is a powerful tool that allow us to use pre-trained language models to create word embeddings. This is very important because it allows us to leverage the power of large language models train on an enormous corpus of text to make our headline representation very information rich. Using an existing model to build a task specific model is referred to as Transfer learning and is a major revolution in what is possible with machine learning.
What Hugging face allows us to do is to run our text through an existing neural network (specifically a Transformer) and retrieve the activations of the last hidden state in the model, then use these for our embeddings. The process is a bit more involved than our BoW encoding, but here is an example function for extracting the hidden state (adapted from Natural Language Processing with Transformers):
def extract_hidden_states(batch):
# Place Model inputs on the GPU
inputs_a = {k:v.to(device) for k, v in batch.items()
if k in ['input_ids_a', 'attention_mask_a']}
inputs_a['input_ids'] = inputs_a.pop('input_ids_a')
inputs_a['attention_mask'] = inputs_a.pop('attention_mask_a')
inputs_b = {k:v.to(device) for k, v in batch.items()
if k in ['input_ids_b', 'attention_mask_b']}
inputs_b['input_ids'] = inputs_b.pop('input_ids_b')
inputs_b['attention_mask'] = inputs_b.pop('attention_mask_b')
# Extract last hidden states
with torch.no_grad():
last_hidden_state_a = model(**inputs_a).last_hidden_state
last_hidden_state_b = model(**inputs_b).last_hidden_state
return {"hidden_state_a": last_hidden_state_a[:,0].cpu().numpy(),
"hidden_state_b": last_hidden_state_b[:,0].cpu().numpy()
}
The specific model we’re using is a version of the Distilbert transformer, which is a very powerful language model, but not nearly as large and powerful as GPT-3
GPT-3 using OpenAI’s API
Our last set of embeddings comes from OpenAI’s GPT-3 using their API to get the embeddings. GPT-3 is a remarkably powerful transformer that has been in the news so much it's hard to imagine one has not already heard too much about it! Not only is the model powerful, but the API is remarkably simple to use in Python. Here is an example of some code fetching embeddings for two headlines:
The catch of course for all this power and ease of use is that it’s not free. However my total bill for running this model and some other experiments ended up being under a dollar! Nonetheless making sure that I was caching and saving my results to avoid being billed twice for the same task did add a bit to the code complexity. However of the three embedding solutions this was the easiest to implement.
It is worth pointing out that we’re not prompting GPT-3 with questions about our headlines but using embeddings that are derived from it. This is an important use case for these powerful models that I currently haven’t seen discussed too much in the vast floods of articles on the topic.
Modeling the difference between two headlines
Now that we have a way to represent all of our headlines as vectors we have a new modeling problem: How are we going to represent the difference between these two headlines?
We could concatenate them and let the model worry about this, but my goal here is to understand the impact of the embeddings alone, not to worry about a more sophisticated model. Instead we can solve this the way that many models handle comparisons: use the literal difference between the two vectors.
By subtracting the vector representing headline B from the vector representing headline A we get a new vector representing how these headlines are different; using that as the final vector representation for our model.
To understand how this works consider this simplified example:
Here we have headlines 0 and 1 represented by a very simple vector consisting of three features: the word count, whether or not the headline contains emojis and whether or not the headline ends with an exclamation mark. Now let’s see what the result of subtracting these vectors is:
headline 0 does not have emojis and headline 1 does
headline 0 and headline 1 either both don’t or both do end in exclamation marks.
In this case a model might learn that emojis are good, so headline 0, would be penalized because it does not have emojis.
Of course our representations are much more complex, however the intuition behind modeling the difference remains the same.
Our classifier: Logistic regression as regression
Despite some fairly noteworthy educators making the claim that “logistic regression is a model for classification, not regression” the model we’ll end up using demonstrates both that logistic regression quite literally is regression and that the distinction between “classification” and “regression” is fairly arbitrary.
Thinking about our problem it seems perfectly well suited for Logistic regression, after all we just want to predict the probability of a binary outcome. However if we try this in SKLearn we get an interesting problem:
SKLearn shares the same erroneous assumption that many others in the machine learning community have, that somehow Logistic regression can only predict binary outcomes. However this is for good reason. When we explored logistic regression in this blog we discussed how logistic regression can be viewed as a mapping of Bayes’ Theorem to the standard linear model. We focused on the model as this:
$$O(H|D) = \frac{P(D|H)}{P(D|\bar{H})}O(H)$$
Which can be understood in terms of a linear model and the logit function as:
$$\text{logit}(y) = x\beta_1 + \beta_0$$
However this does not work in practice most of the time precisely because we are regressing on values of exactly 1.0 and 0.0, for which the logit function is undefined. So instead we we use a formula based on an alternate (and much more common) view of logistic regression:
$$y = \text{logistic}(x\beta_1 + \beta_0)$$
By understanding the nature of Logistic regression as regression we can very easily implement a variation of Logistic regression that does work for our data using logit and LinearRegression:
from sklearn.linear_model import LinearRegression
y_train = train_df["p_a_gte_b"].values
# We are going to perform Linear regression
# on a y value transformed with the logit
target_train = logit(y_train)
base_model = LinearRegression().fit(X_train, target_train)
We just have to remember that our model will be outputting responses in terms of log-odds so we’ll need to transform them back to probabilities manually using the logistic function.
Results
Finally we can see how each of these different models performed! What’s interesting about this case is that our clever use of linear regression as logistic regression combined with the way we split up our test and train sets means we’ll have different ways to measure model performance depending on the data set used.
Model Performance
We transformed our probabilities in the training set into log odds and then ran them through a standard linear regression model. Because of this we can just used Mean Squared Error to compare model performance on the training set.
Mean Square Error on Train dataset
Smaller is better
While we can see a clear improvement for each progressively more powerful model, it is very difficult to have any meaningful interpretation of these results. We can’t look at common classification metrics such as accuracy and RoC AUC since we don’t know the true labels for the train data set.
For the test set we can look at these scores since the test set only consists of examples where we are highly confident in the results of the experiment. We’ll start by looking at the ROC AUC, which allows us to view the strength of our model without having to pick a particular cutoff for choosing one class or another. For those unfamiliar a 0.5 score is performance on par with random guessing and a score of 1.0 represents perfect classification.
ROC AUC - Test set
Higher is better
Here we can start seeing that these models are surprisingly good. Even the simplest model, the Bag of Words, has an ROC AUC of around 0.8, which means it is fairly good at predicting which headline will win an A/B test.
This brings up a point that I have found myself making repeatedly throughout my career in data science and machine learning: If a simple model cannot do well at solving a problem, it is extremely unlikely that a more complex model will magically perform much better.
There is a mistaken belief that if a simple model does poorly, the solution must be to add complexity. In modeling complexity should be considered a penalty, and only pursued if simple models show some promise. As an example, many people believe that a simple model like Logistic Regression could not possiblely do well on an image recognition problem like MNIST. When in fact a simple logistic model will score a 90% accuracy on the MNIST dataset.
When I first saw the BoW model doing well, I already was optimistic for GPT3 which does frankly fantastic in terms of ROC AUC. But now let’s look at what really matters in practice: accuracy!
Accuracy on Test set
These results are quite remarkable! It is worth noting that our test set essentially represents the easiest cases to determine the winning variant (since we’ll be more easily more certain when two variants are clearly different), however it’s still impressive that our GPT3 model is able to correctly predict the winner of an A/B test in 87% of these cases.
While impressive, it’s also important to consider that when we run an A/B test “statistical significance” is generally being 95% sure that it looks like the difference is zero (or, if we approach this as Bayesian, 95% sure one variant is superior), and these specific A/B tests were much more certain of these results than the model on average.
Our best model still seems quite useful. Another way to explore this is to see how well calibrated our model’s probabilities are.
Probability calibrations
My diehard Bayesian readers might be a bit offended by my next question about these models but I do want to know “If you say you’re 80% confident, are you correct about 80% of the time?”. While this is a particularly Frequentist interpretation of the models output probabilities, it does have a practical application. It’s quite possible for a model to have high accuracy but have all it’s predictions very close to 0.5 which makes it hard for us to know if it’s more sure about any of it’s predictions.
To answer this question I’ve plotted out the average accuracy for intervals of 0.05 probability. Here’s the result we get for our GPT3 model:
We want to see a “V” shape in our results because a 0.1 probability in winning reflects the same confidence as 0.9
Notice that the ideal pattern here is a “V” shape. That’s because being 10% sure A is not the winner is the same as being 90% sure that B is the winner. Our maximum state of uncertainty is 0.5
As we can see, our GPT model is a bit under-confident in it’s claims. That is when the model is roughly 80% sure that A will win, it turns out that it’s correct in calling A the winner closer to 95% of the time.
Demo: Choosing the headline for this post
While I’m not quite sure I’m ready to recommend using LLMs instead of running proper A/B tests, there are plenty of cases where one might want to run an A/B but realistically cannot. This post is a great example! I don’t really have the resources (or the interest) in running a proper A/B test for the titles of this post… so I figured I would give my model a shot!
My original plan for this post title was “Can GPT make A/B Testing Obsolete?”, I thought this sounded maybe a bit “click-baity”, so I compared it with the current title. Here’s the basic code for running an A/B test with the model:
And the result of running this comparison turned out not so great for my original title:
> ab_test("Can GPT make A/B Testing Obsolete?",
> "Replacing an A/B test with GPT")
array([0.2086494])
While not “statistically significant” I also know that this model does tend to under estimate itself, so went with the headline you see above.
Interestingly enough when I fed the first part of this article to GPT-3 itself and told it to make it’s own headline I got a remarkably similar one: "Replacing A/B Testing with AI: Can GPT-4 Predict the Best Headline?"
Running this through the model it seemed not to have a preference:
> ab_test("Replacing an A/B test with GPT",
> "Replacing A/B Testing with AI: Can GPT-4 Predict the Best Headline?")
array([0.50322519])
Maybe you don’t really want to replace all of your A/B testing with LLMs, but, at least for this case, it was a good substitute!
Conclusion: Is an A/B test different than a Model?
I wouldn’t be surprised if many people who have spent much of their careers running A/B tests would read this headline and immediately think it was click-bait nonsense. This experiment, for me at least, does raise an interesting philosophical (and practical) question: What is the difference between a model that tells you there’s a 95% chance A is greater than B and an A/B test that tells you that there’s a 95% chance A is greater than B? Especially if the former takes only milliseconds to run and the later anywhere from hours to days. If your model is historically correct 95% of the time when it says 95% how is this different from an A/B test making same claim based on observed information?
Even though I’m very skeptical of big claims around true “AI” in these models, there’s no doubt that they do represent an unbelievable amount of information about the way we use language on the web. It’s not absurd to consider than GPT-3 (and beyond) do have a valid understanding of how to represent these headlines in high dimensional space such that a linear model is able to accuracy predict how well they will perform on real humans.
The really fascinating proposition to me is that if we consider probabilities from a model the same as probabilities from an experiment but it takes milliseconds for the model to work it dramatically changes the space that A/B testing is possible. A generative model like GPT-4 could iterate on thousands of headlines, while a model like ours could run massive simulated “experiments” to find the best of the best.
While this may sound amazing to marketers and data scientists it’s worth considering the effect this would have on the content we consume. Even if this did work, do you want to live in a world where every piece of content you consume in perfectly optimized to encourage you to consume it?
Support on Patreon
Support my writing on Patreon and gain access to the source code and video commentary for this article as well as access to much more of my writing!
Never miss a new post!
Keep up to date with the latest Count Bayesie posts!
Former B.C. premier John Horgan says his party consciously tried to attract candidates “who looked like the mainstream” in their constituencies. And he suggested in a March 19 speech at the Surrey Arts Centre that these efforts by the B.C. NDP resulted in the legislature and cabinet better reflecting the population at large than ever before.
As examples, Horgan pointed to people of South Asian ancestry serving as speaker of the legislature, education minister, and attorney general. The former premier also mentioned that there are three Indigenous MLAs in the legislature. And he noted that half the NDP caucus is female.
“That is British Columbia,” Horgan said. “Now, when British Columbians look at their elected institutions, they see themselves reflected back. Not perfectly. Not completely. But better than it has ever been in our history.”
The former premier made these remarks after Spice Radio named him as its ninth annual Hands Against Racism Award winner. Nature’s Path Foods founders Ratana and Arran Stephens presented the award.
In her speech, Ratana Stephens highlighted that the Horgan-led government was the first in Canada to enshrine the UN Declaration on the Rights of Indigenous Peoples in legislation. In addition, the NDP government led by Horgan passed the Anti-Racism Data Act, created a parliamentary secretary for anti-racism initiatives, and restored the B.C. Human Rights Commission.
Horgan cites importance of education
When Horgan reached the podium, he said that over the past 25 years, the stories of British Columbia have become the stories of the world.
“My wife Ellie is with me—the daughter of Dutch immigrants who fled Europe, from Nazi tyranny, following the world war,” Horgan said.
He acknowledged that he heard their stories about the hardships that they faced coming to a new land. The former premier then noted that he’s been to gurdwaras and heard these stories from Sikhs. Horgan said that some of them fought in the British army to protect the empire and king. Yet they later witnessed hockey broadcaster Don Cherry declaring on television that they should “go home.”
“These inconsistencies speak directly to the challenges we have in our education system—and why it’s critically important,” Horgan said.
In his speech, the former premier mentioned that his mother instilled in him the importance of standing up to bullies. Then he said that he thinks racism is actually rooted in bullying.
In addition, Horgan talked about Canadian multiculturalism, which he was fiercely proud of as a young man and father. But when after becoming an elected representative in 2005, he developed a more nuanced view.
“I got to know with my friends—Raj Chouhan, Harry Bains, Jinny Sims, Jagrup Brar, and many, many others—that the communities that they came from and the communities that they represented were not like the community that I represented,” Horgan said. “They were not like Peace River North. They were not like the Kootenays.”
Spice Radio broadcaster Gurpreet Singh photographed John Horgan joining in a Bollywood-style dance after receiving his award.
Make B.C. the “beacon on the hill”
Then he shared a story about visiting a school in 2006 with Chouhan in the Edmonds area of Burnaby. There, Horgan recalled, 130 languages were spoken.
“That is fantastic—and a daunting challenge for educators,” Horgan said. “But what a gift to the people of British Columbia to have that representation of diversity from every corner of the globe.”
He also talked about Holi, a.k.a. the Festival of Colours, celebrated by Hindus every spring. The Hands Against Racism Award event coincides with Holi because this holiday promotes togetherness. On Holi, people joyfully sprinkle coloured water on friends and strangers and set aside old grudges.
“When you’re covered in colour and flourish and excitement, what is underneath that is just humanity,” Horgan commented. “And that humanity may speak a different language. It may practise a different faith.”
Then he spoke about other faiths. He stated that the best way to learn about the impacts of Kristallnacht is to visit a synagogue. The ex-premier added that visiting a Nowruz celebration on the North Shore can shed light on challenges faced by Muslims. He also mentioned that he spent time with his in-laws in church.
He pointed out that the United States once had that reputation as the place people in the world looked for hope before some of its governments were taken over by “white supremacists and fascists”. Horgan even referred to some of the words on the Statue of Liberty. It carries the phrase “Give me your tired, your poor. Your huddled masses yearning to breathe free.”
“As British Columbians—five million souls—we have an opportunity to make this the beacon on the hill,” Horgan stated.
Horgan listened to Indigenous leaders
He also demonstrated modesty in connection with advancing the rights of First Nations people in B.C. The former premier gave credit to their leaders.
“The Declaration on the Rights of Indigenous Peoples was not something that came out of my head,” Horgan emphasized. “It was something that I learned from Grand Chief Stewart Phillip and Ed John and Terry Teegee and Sophie Pierre and a legion of Indigenous people that I had the good fortune of coming upon as a local elected representative. And after 12 miserable and interminable years in Opposition, I got an opportunity to do something as premier.”
Similarly, Horgan praised NDP MLAs such as Chouhan, Bains, and Brar for keeping up the pressure for restoring the B.C. Human Rights Commission. The ex-premier acknowledged, however, that it “has its failings”, though he didn’t elaborate on that comment in his speech.
In the 11 days prior to Horgan’s speech, Pancouver published two articles raising serious concerns about Human Rights Commissioner Kasari Govender’s recent report on hate during the pandemic. In this 478-page document, the commissioner did not include any serious criticism of mainstream Canadian media for any role it may have played in promoting anti-Asian sentiments from 2015 to 2020.
Meanwhile, Horgan said that many acts of overt racism were recorded by cellphones during the pandemic. But he also stated that he shudders to think of how many countless other acts of discrimination and violence were not captured in this way.
“The good news,” Horgan stated, “is that when we saw these images on Global Television and on other media outlets, almost to a person, British Columbians stood together and said, ‘Not here. Not now. Not ever again.’ ”
Vancouver author Alan Twigg hopes to change that. The former publisher of BC Bookworld spent a year creating a website, RudolfVrba.com. It provides a comprehensive examination of the former UBC pharmacology professor’s immense contribution to humanity.
Twigg calls Vrba the “greatest whistleblower of the 20th century”.
Vrba died on March 27, 2006, after contracting cancer. He was 81 years old.
On April 7, 1944, Vrba escaped from the Auschwitz-Birkenau death camp with fellow inmate Alfréd Wetzler. They described what they had seen in the Vrba-Wetzler report.
According to the website, this led the Allies to bomb Budapest. As a result, Hungary’s leaders halted mass deportations of Jews.
Many years later, British historian Sir Martin Gilbert maintained that Vrba’s revelations had saved more than 100,000 lives.
In 1985, Vrba told his story in French filmmaker Claude Lanzmann’s Shoah documentary.
The whistleblower was born in Czechoslovakia as Walter Rosenberg. In 1942, he was arrested while fleeing the country’s crackdown on Jews.
On June 30 of that year, Vrba arrived at Auschwitz before being transferred to Birkenau six months later.
At Auschwitz, new arrivals were divided into two groups. A minority became slave labourers whereas the others were sent to Birkenau, a.k.a. Auschwitz II. There, the Nazis gassed them to death. At least 1.1 million people died in the camp.
This video tells the story of Rudolf Vrba and Alfréd Wetzler escape.
Vrba felt duty to tell the world
According to a paper by Israeli academic Ruth Linn, Vrba was ordered to collect valuables from inmates gassed to death.
“From this vantage point Vrba was able to assess how little the deportees knew about Auschwitz when they entered the camp,” Linn wrote. “Their luggage contained clothing for all seasons and basic utensils, a clear sign of their naive preparation for a new life in the ‘resettlement’ area in the east.”
In 1943, Vrba became registrar for the quarantine camp for men.
“In January 1944, I got information that the biggest extermination action was being planned,” Vrba told Lanzmann. “I started making plans to escape.”
The documentary maker then asked how he knew Hungarian Jews were being targeted.
“I was stationed near the main gate of the camp,” Vrba replied. “I noticed several chaps with tripods. There was a lot of work being done in three shifts. The SS who came to collect money from us dropped words about Hungarian salami was coming, along with other good things.”
Vrba noticed that the Nazis had done a great deal of work to prepare for the arrival of a million people.
“I did not believe that Hungary would permit this kind of deportation until an SS man left a newspaper for me to read, in exchange for $100 I supposedly found and gave to him,” he continued. “The paper said that the Hungarian government was toppled on March 19, 1944. (Miklos) Horthy was out and (Ferenc) Szalazi and another radical fascist replaced him. I realized I had to get out of there and tell the world.”
Former BC Bookworld publisher Alan Twigg describes Rudolf Vrba as the most significant author in B.C. history.
Website includes several sections
In addition, Vrba discussed his wartime experiences in his memoir, I Escaped From Auschwitz. Throughout the rest of his life, he harshly criticized certain Jews in Hungary for not alerting the community to the reality of Auschwitz.
Twigg highlighted this in his 2022 book, Out of Hiding: Holocaust Literature of British Columbia. Furthermore, Twigg insisted that this explains why Vrba never received a proper memorial in Yad Vashem in Jerusalem.
Meanwhile, the RudolfVrba.com website includes extensive sections entitled “context, “America & Hitler”, “Auschwitz”, “escapes”, “the report”, and “interviews”.
Twigg included another category simply entitled “Ruth Linn”. Linn, a scholar at the University of Haifa, interviewed Vrba several times leading up to his death. Moreover, she repeatedly tried to highlight his heroism to fellow Israelis.
“I read a lot about the Holocaust but I never, ever, read about Vrba in Israeli textbooks in the Hebrew language,” Linn told Pat Johnson of the Jewish Independent in 2006. “Am I the only Israeli who fell asleep in class when we studied this in the Holocaust? Or maybe we never studied it.”
Vrba was one of only five Jews who escaped Auschwitz-Birkenau. Many years later, his accomplishments earned high praise from Twigg.
“The most significant author of British Columbia is not Pauline Johnson, Douglas Coupland, William Gibson, David Suzuki or Alice Munro,” Twigg wrote on the BC Bookworld website. ”It’s Prisoner #44070, aka Rudolf Vrba, one of the most significant chroniclers of the Holocaust.”











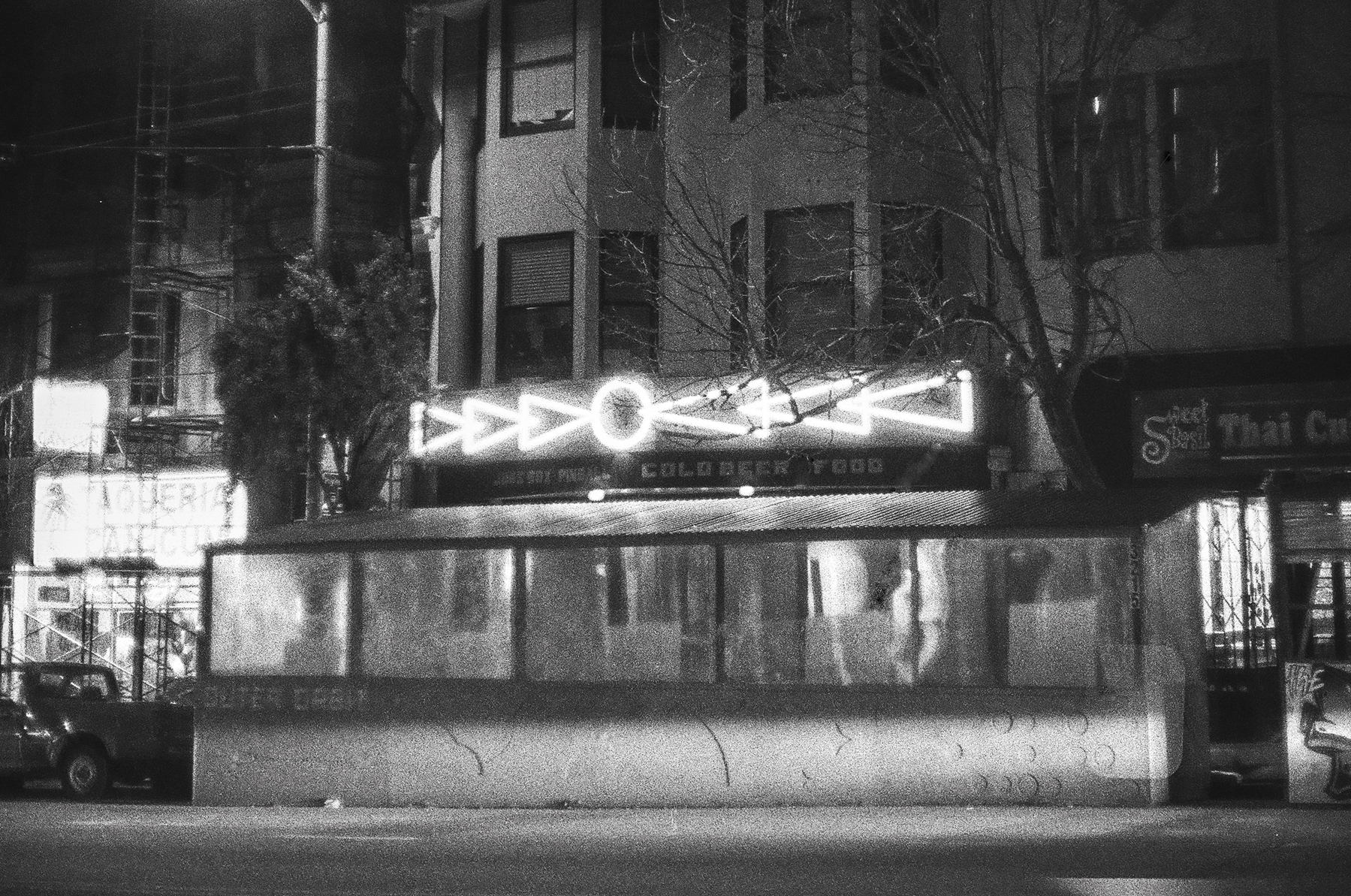

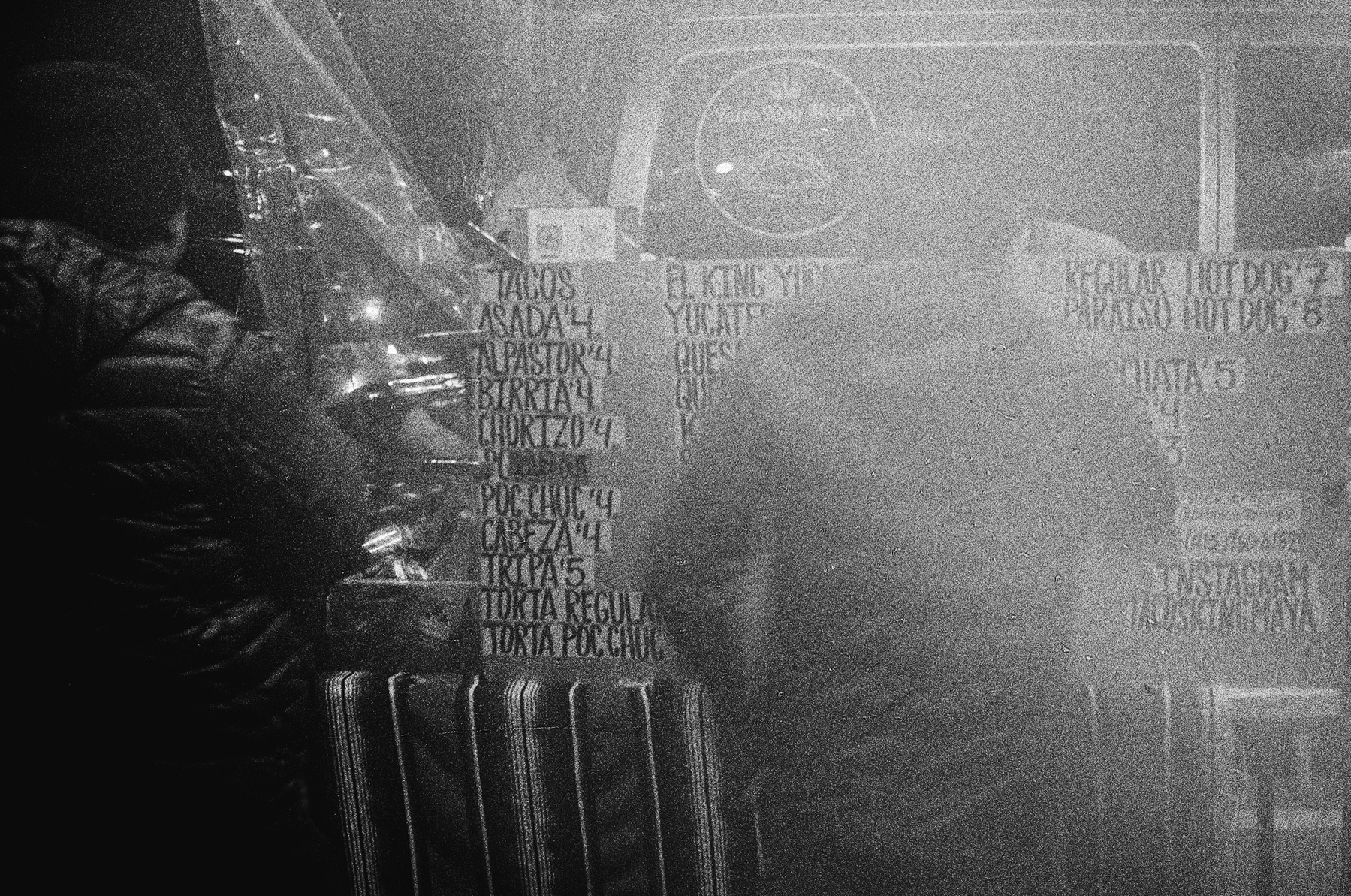







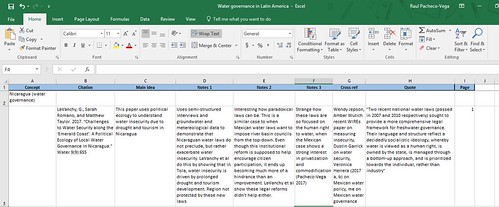

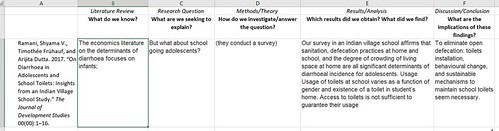


 “We need you back in the office now, Anthony’s team just got fired.”
“We need you back in the office now, Anthony’s team just got fired.”


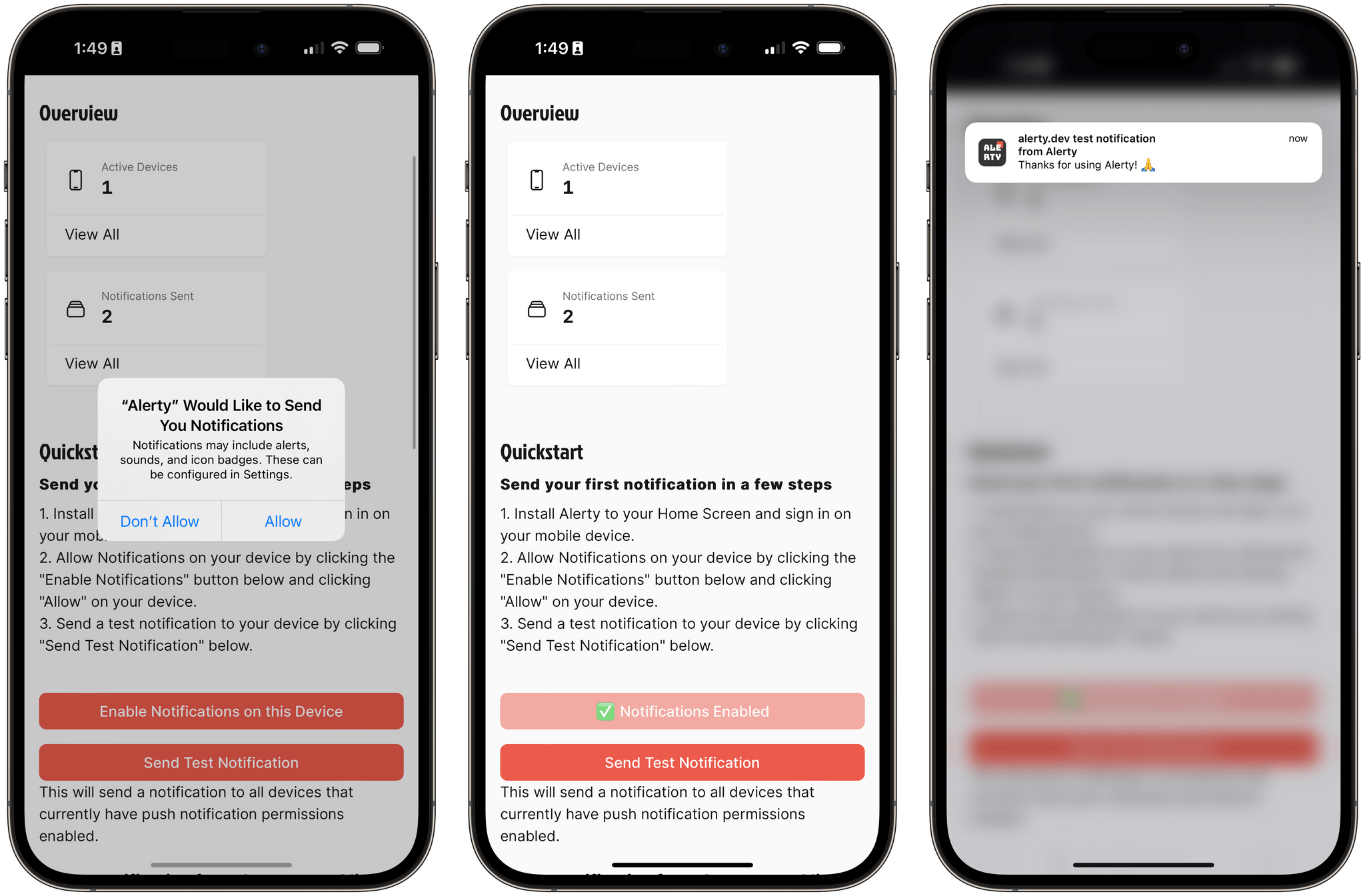
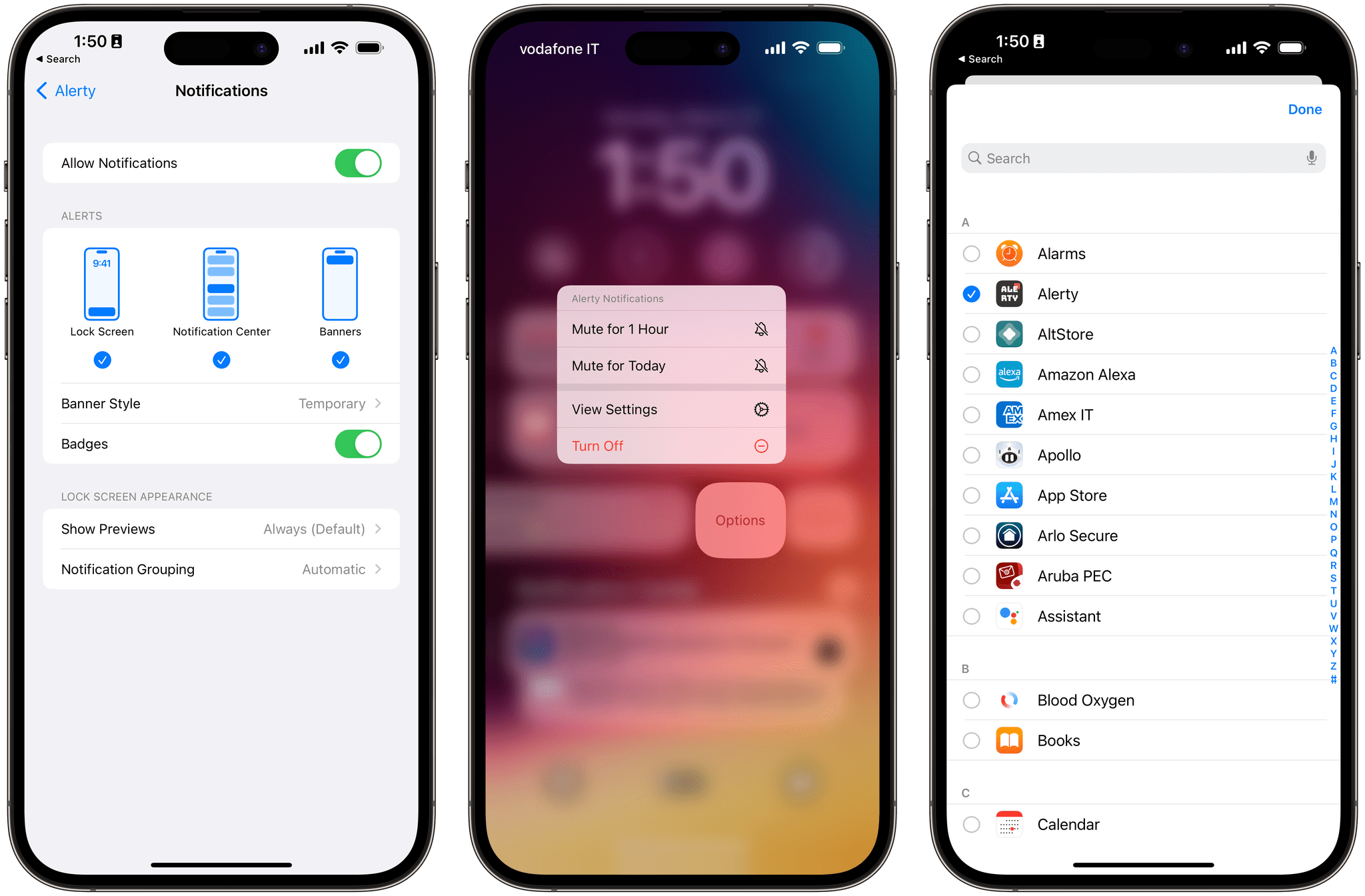
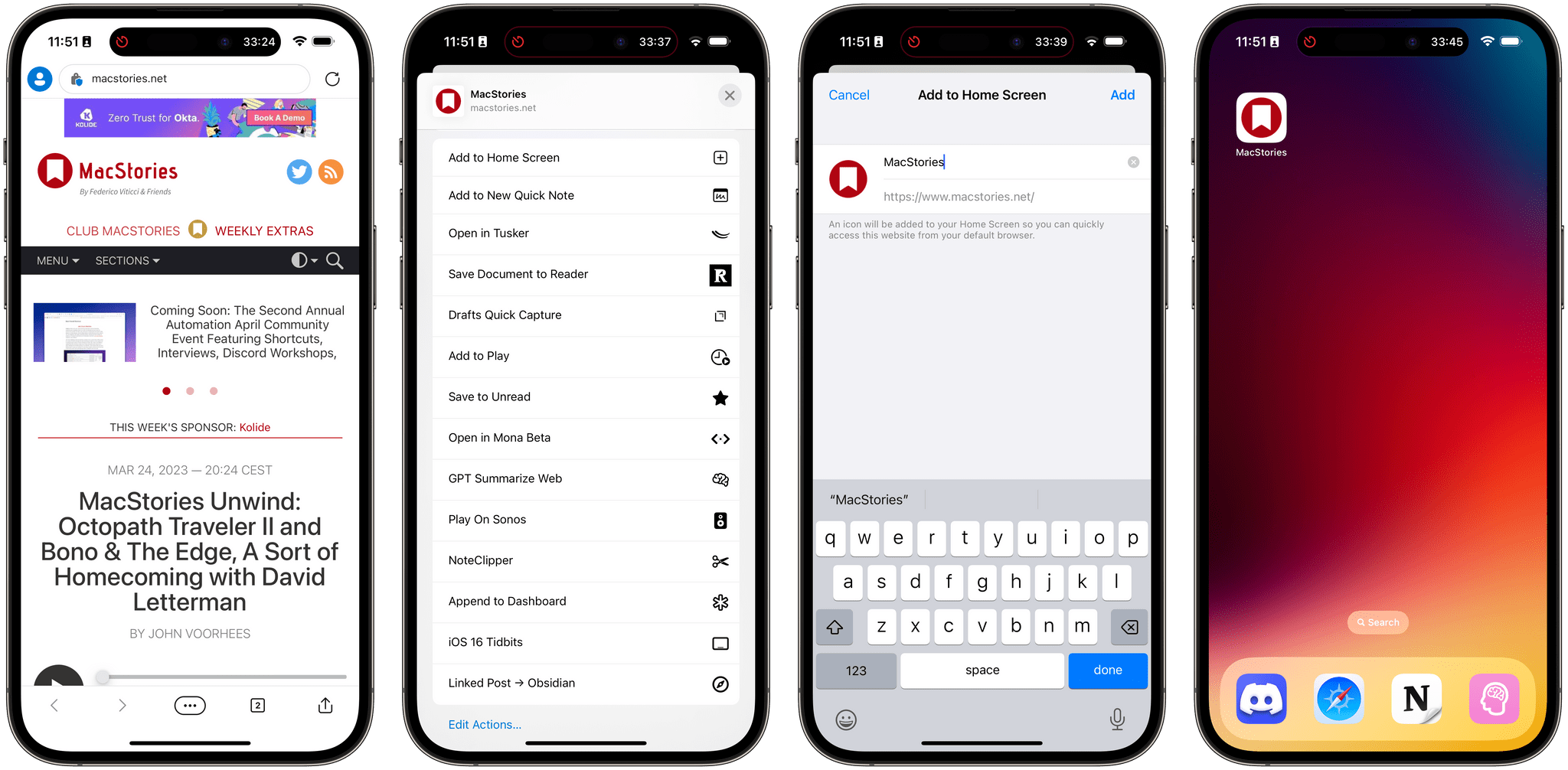
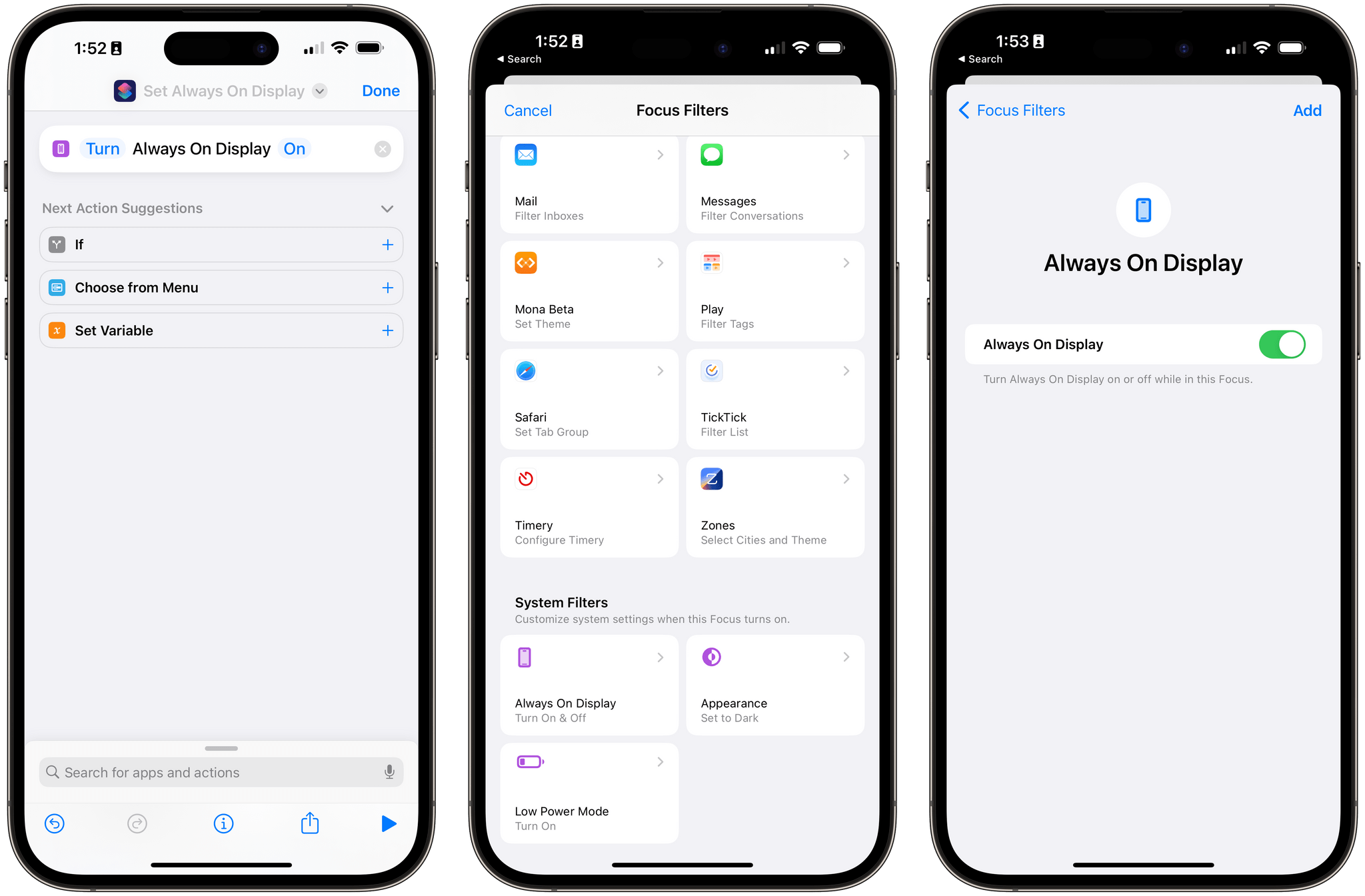

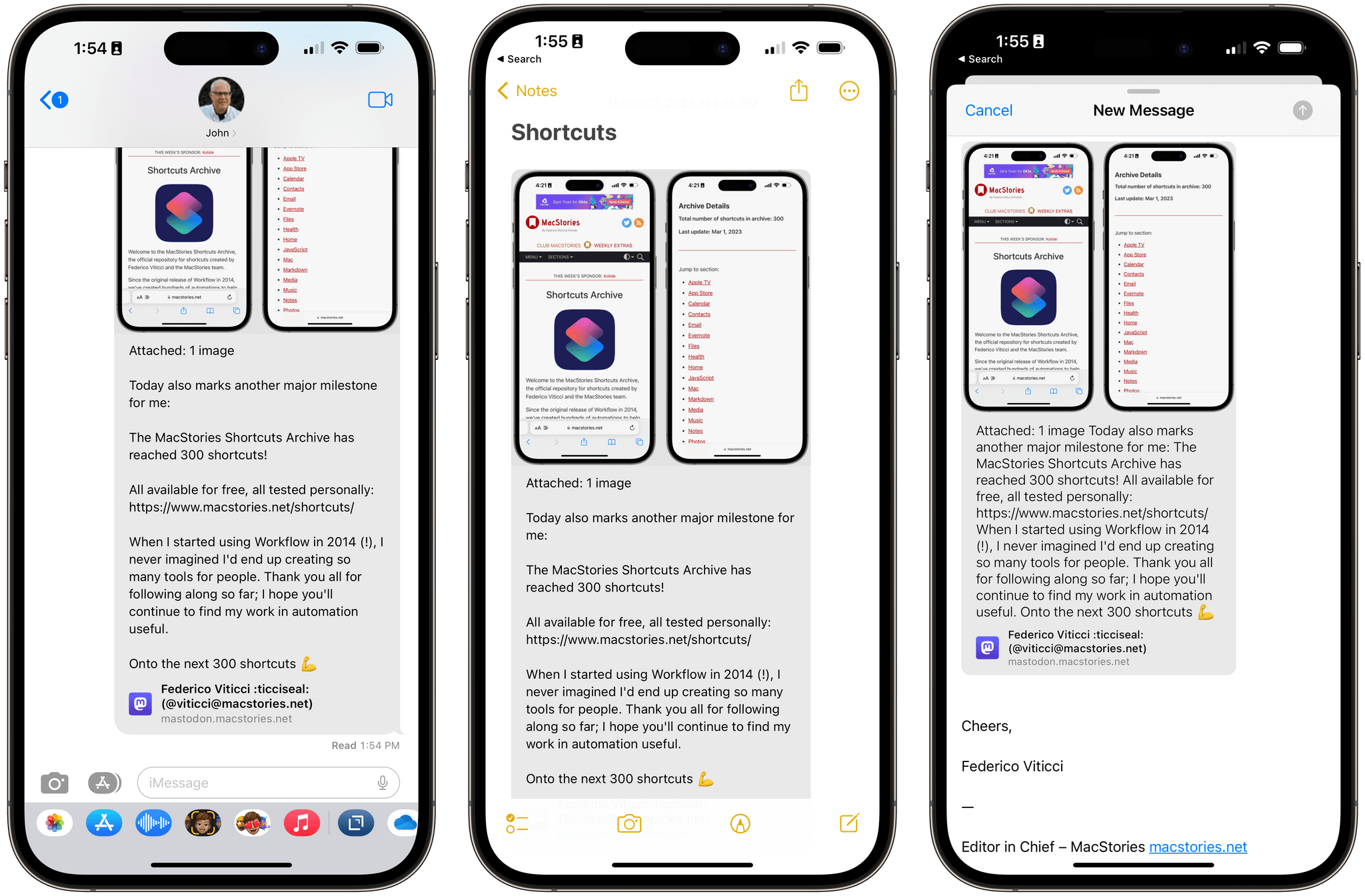
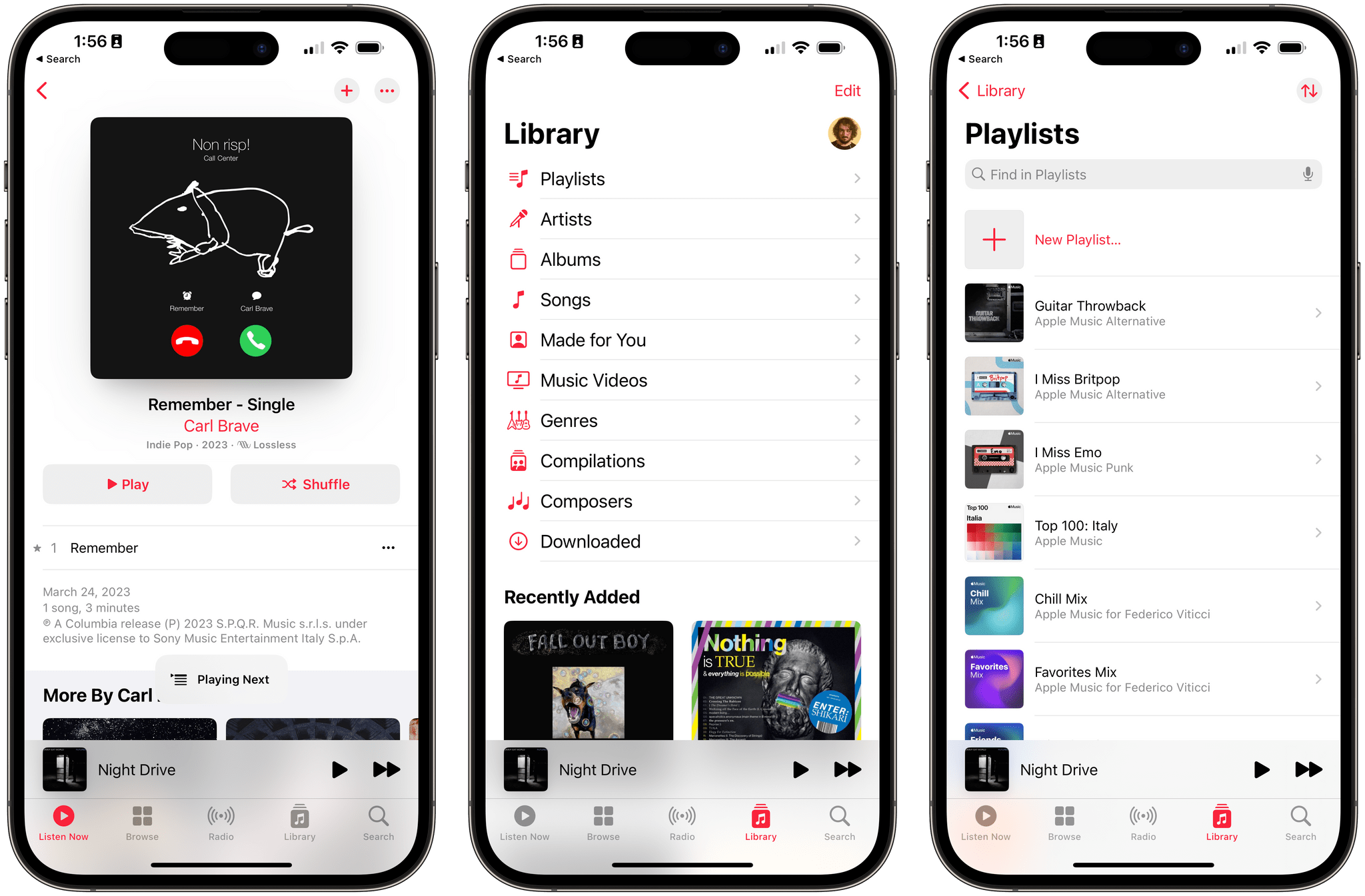
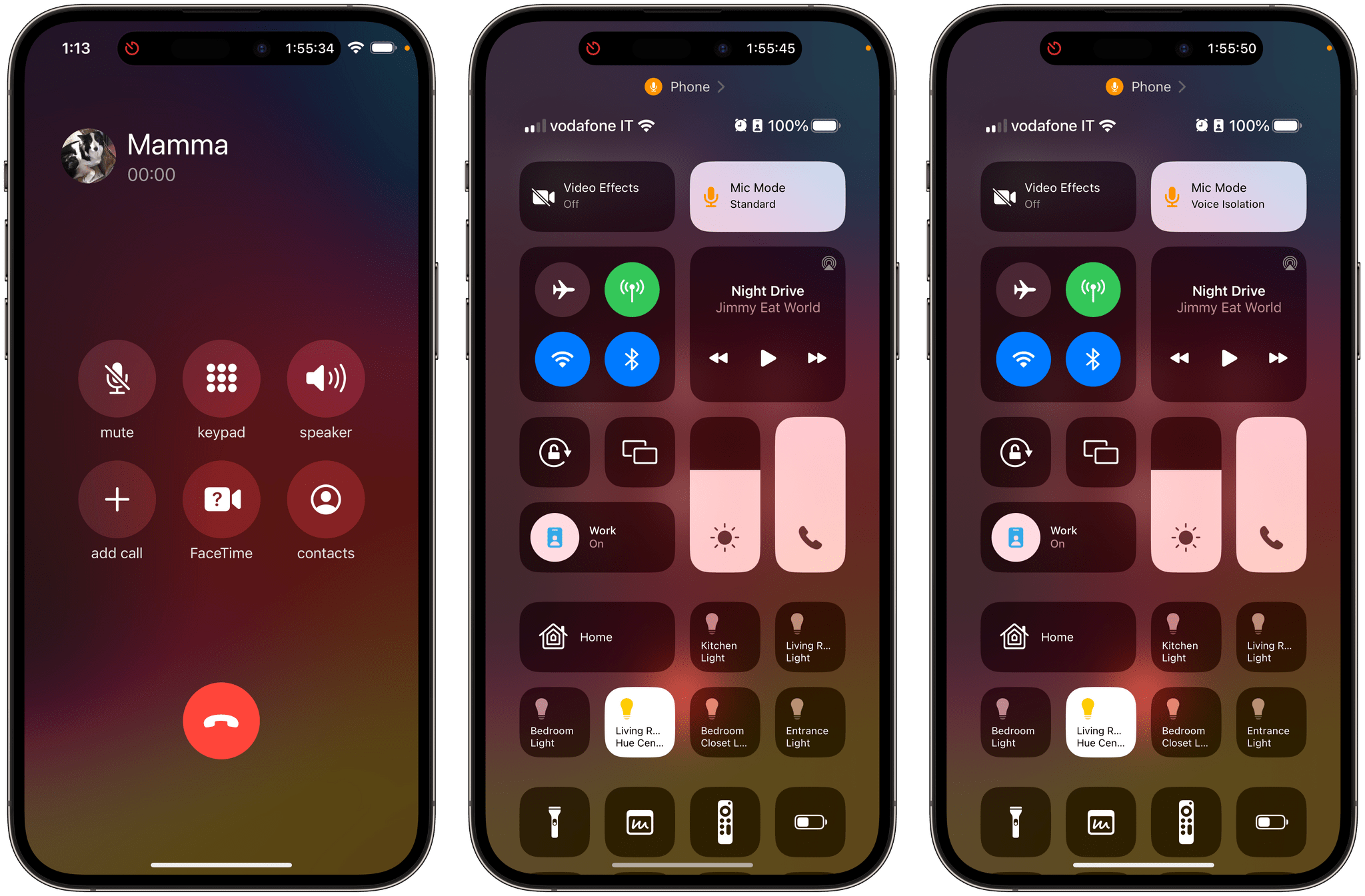

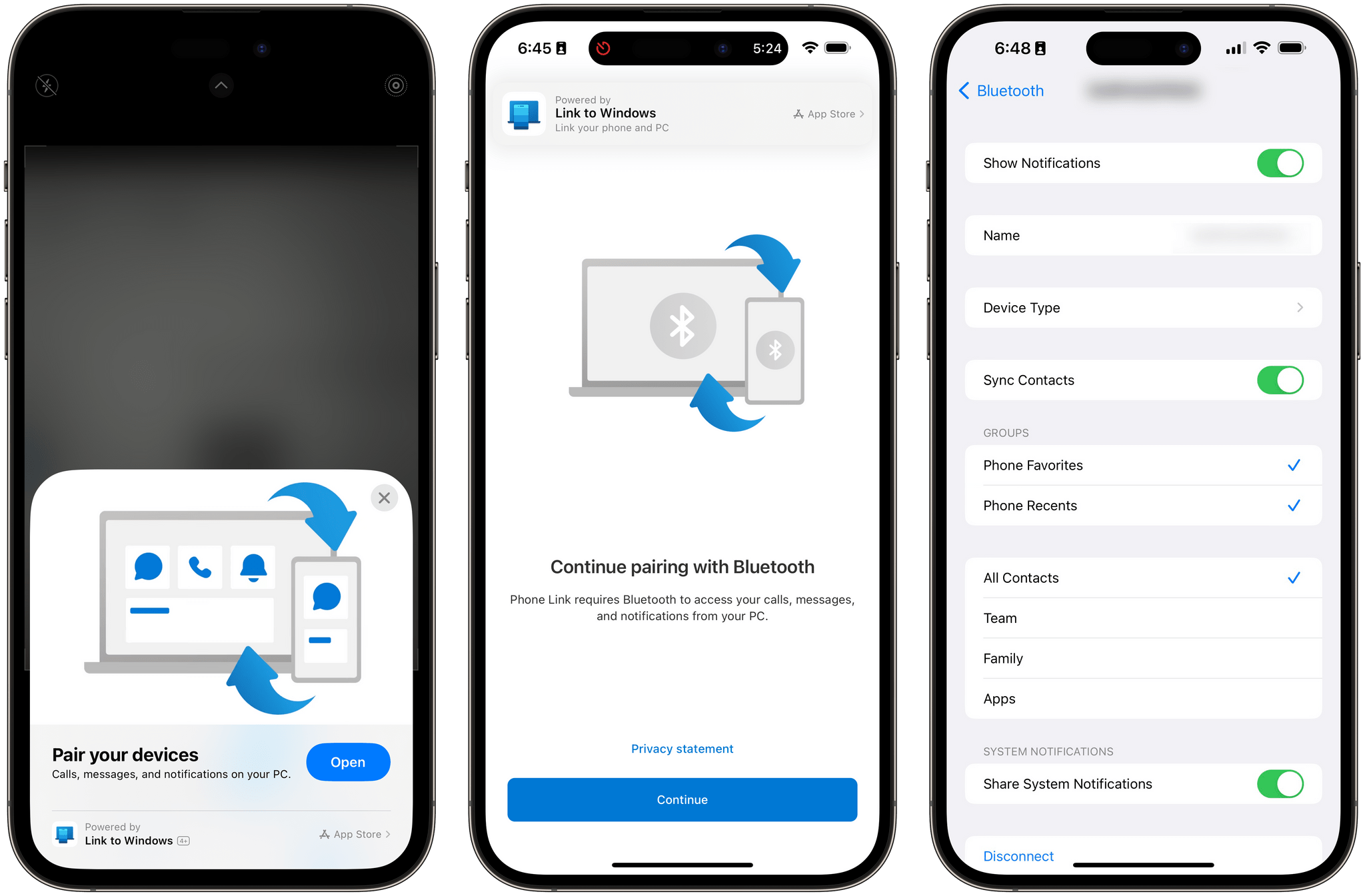
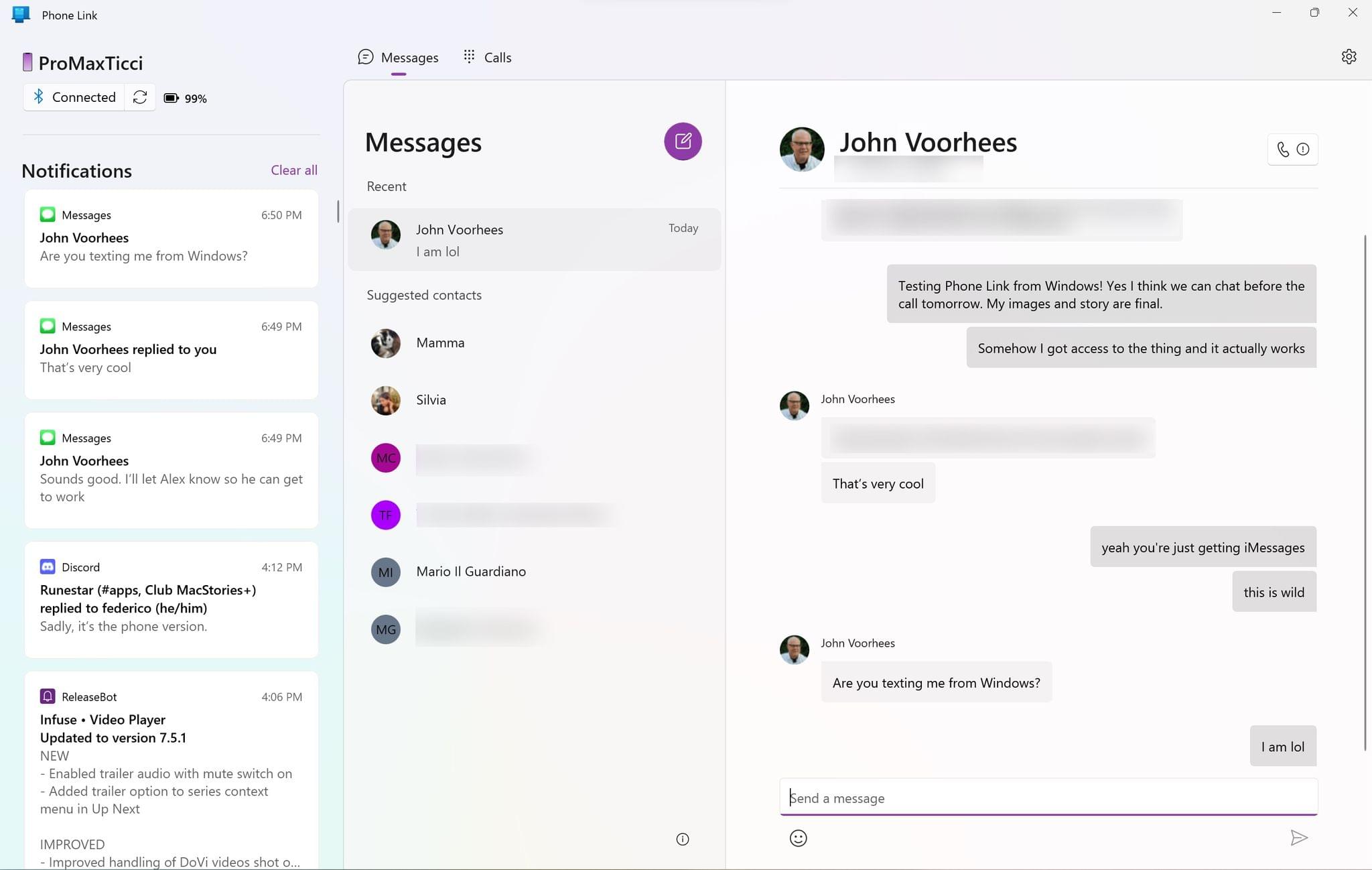
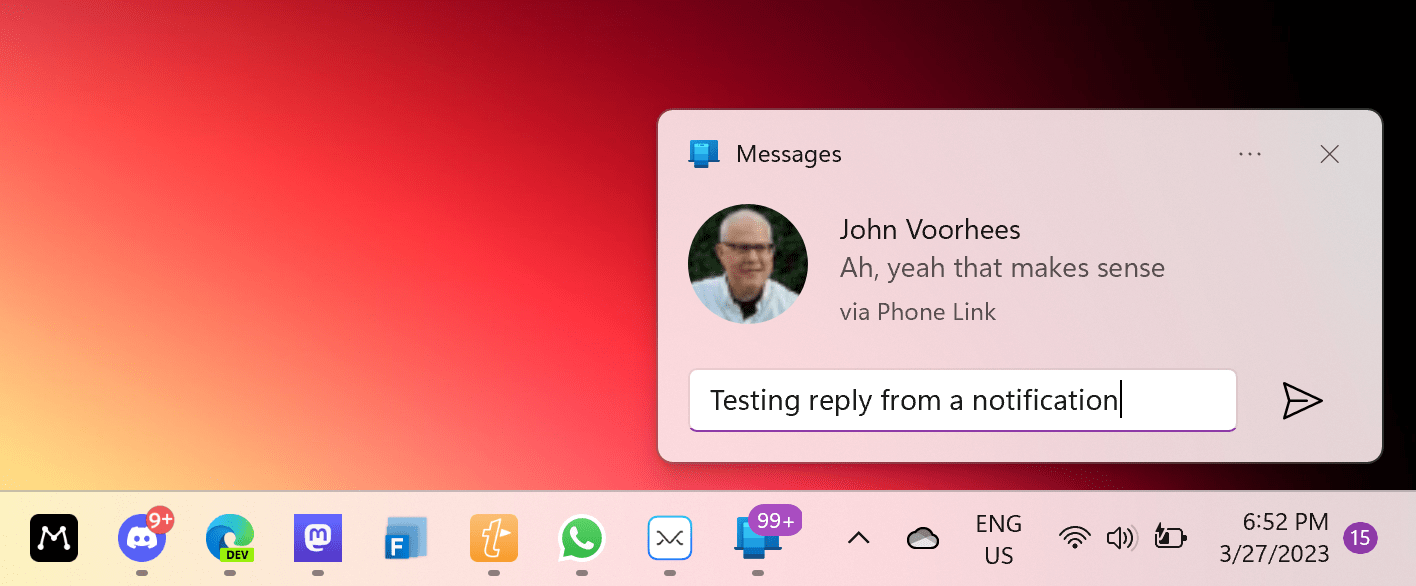
 The Great Cascadia Earthquake of 2001
The Great Cascadia Earthquake of 2001