Descubra nesse tutorial, como acessar sites que estão bloqueados em seu país, usando o aplicativo SelekTOR, que trabalha com a rede de anonimato Tor.
Feito em Java, SelekTOR é um front-end gráfico de código aberto para o cliente Tor, que tem algumas vantagens sobre o Vidalia (GUI oficial Tor), tais como:
- Facilita o uso e configuração do Tor no modo cliente, SelekTOR faz a maioria do trabalho pesado para você;
- Você pode selecionar rapidamente Nodes de saida por país;
- SelekTOR pode monitorar continuamente e manter uma conexão com o nó de saída com o melhor tempo de resposta, com tão pouco tempo de inatividade possível;
- Colocar em proxy todo o tráfego através do nó Tor ativo. SelekTOR também pode fazer o roteamento seletivo de tráfego através do nó Tor ativo com base em padrões de URL.
A opção para selecionar os nós de saída do Tor por país pode ser usada, por exemplo, para acessar sites que não estão disponíveis em seu país, como Netflix, Hulu, CBS, ABC, Pandora, British TV, HBO Go e assim por diante.
SelekTOR precisa de pouquíssima configuração: simplesmente selecione o node de saída do país (e, opcionalmente, o modo de proxy) e você estará pronto – você não tem que configurar o seu navegador web manualmente e não há necessidade de instalar qualquer complemento no navegador. Entre os navegadores suportados estão o Google Chrome, Chromium, Opera, Firefox e Palemoon.
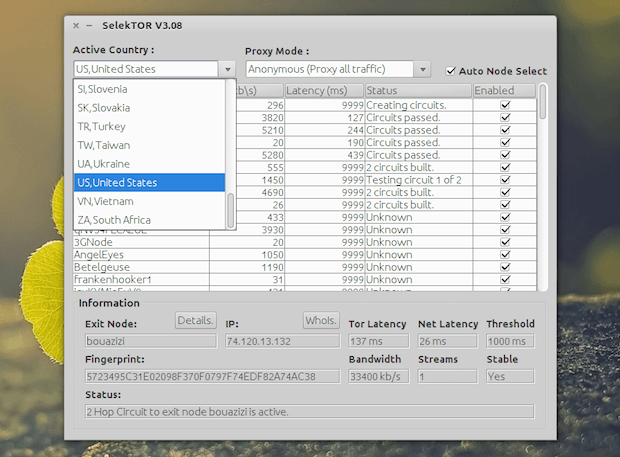
O aplicativo também apresenta detalhes dos nodes, bem como possui um Whois de IP embutido:


Instalando os pré requisitos necessário para execução do SelekTOR
Instalar os pré requisitos necessário para execução do SelekTOR, você deve fazer o seguinte:
Passo 1. Se não estiver instalado, instale o Java 7 ou 8 (Oracle o OpenJDK), seguindo esse outro tutorial;
Tor está disponível nos repositórios padrão do Ubuntu, mas eles podem estar um pouco desatualizados. Então, para instalar o Tor atualizado no Ubuntu e derivados, faça o seguinte:
Passo 2. Se você estiver usando uma versão mais recente do Ubuntu e o Tor não estiver instalado, instale-o usando simplesmente o comando;
sudo apt-get install tor
Passo 3. Mas se você estiver usando uma versão mais antiga do Ubuntu e o Tor não estiver instalado, adicione esses repositórios usando o comando abaixo:
sudo sh -c "echo 'deb http://deb.torproject.org/torproject.org $(lsb_release -cs) main ' /etc/apt/sources.list.d/tor.list"
Passo 5. Baixe e adicione a chave do repositório com o comando:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 886DDD89
Passo 6. Atualize o APT com o comando:
sudo apt-get update
Passo 7. Agora instale o programa com o comando abaixo:
sudo apt-get install tor
Passo 8. Se durante a instalação, você for perguntado qual será usuário que deverá ser capaz de controlar o serviço Tor. Selecione o usuário e confirme clicando em “OK”;

Passo 9. Uma vez que o tor está instalado, você deve desabilitar o serviço dele. Para fazer isso, abra o arquivo de configuração /etc/default/tor, com o comando a seguir:
sudo gedit /etc/default/tor
Passo 10. Com o arquivo aberto, procure pela seguinte linha:
RUN_DEAMON="yes"
Passo 11. Substitua a linha por isto:
RUN_DEAMON="no".
Passo 12. Salve e feche o arquivo;
Passo 13. Agora, pare o serviço do tor, usando o comando;
sudo service tor stop
Instalando o SelekTOR para poder acessar sites que não estão disponíveis em seu país
Para instalar o SelekTOR, faça o seguinte:
Passo 1. Baixo o programa a partir desse link, e salve na sua pasta pessoal;
Passo 2. Abra um terminal;
Passo 3. Extraia o arquivo baixado usando o comando:
tar -xvzf SelekTOR_Linux.tar.gz
Passo 4. Se seu sistema é baseado no Debian (Ubuntu, Linux Mint, KNOPPIX e etc), execute os seguintes comandos para instalar o programa:
sudo ./install.sh
Passo 5. Para instalar o programa em outras distribuições Linux, execute os estes comandos:
su -c ./install.sh
Passo 6. Se seu sistema é baseado no Debian (Ubuntu, Linux Mint, KNOPPIX e etc), e por algum motivo você precisar desinstalar o programa, use este comando:
sudo /opt/selektor/uninstall.sh
Passo 7. Em outras distribuições Linux, se você precisar desinstalar o programa, use este comando:
su -c /opt/selektor/uninstall.sh
Como acessar sites que não estão disponíveis em seu país usando o SelekTOR
Com tudo instalado, para acessar sites que não estão disponíveis em seu país usando o SelekTOR, , você deve fazer o seguinte:
Passo 1. Execute o programa, digitando selektor no terminal ou no Dash;
Passo 2. Clique no drop-down do campo “Active Country”, e selecione o país que você deseja usar (que obviamente, é o país onde o site que você deseja acessar não é bloqueado);

Passo 3. A seguir, clique em “Menu” e depois no item “Proxy Pattern Editor”;

Passo 4. Na janela “SelekTOR Pattern Editor”, clique em “Add New”. Na pequena tela que aparece, digite o padrão para o site que você está tentando acessar (para isso, utilize os padrões já existentes como exemplo) e clique em “Add New”. Ao voltar a tela anterior, clique no botão “Save” para efetivar o cadastramento;

o método acima tem a vantagem de permitir que você use o Tor apenas para os sites que você quer (como Netflix, por exemplo), deixando todos os outros sites/tráfego sem utilizar proxy. Porém, ele tem uma desvantagem também: se algum site, como o Netflix, por exemplo, usa o código colocado em algum outro domínio, para verificar o seu país, este método irá falhar assim, para tais casos, você deve clicar no drop-down do campo “Proxy Mode”, e selecionar a opção “Anonymous (Proxy all traffic)”;

Ao selecionar o modo proxy “Anonymous (Proxy all traffic)”, todo o tráfego será feito pelo proxy. Por isso, não será necessário introduzir quaisquer padrões, basta selecionar o país que você deseja usar em “Active Country” e você já poderá o site bloqueado.
Via WebUpd8
Não está aparecendo algo?
Este post é melhor visualizado acessando direto da fonte. Para isso, clique nesse link.
O que está sendo falado no blog hoje
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers.









 Da redação, no Rio de Janeiro (RJ) - 16/9/2014
Da redação, no Rio de Janeiro (RJ) - 16/9/2014