HD video transmission through human tissue from implanted medical devices via in-body ultrasonic communications: beef liver and pork loin were used to represent the density and moisture content found in human tissue (credit: UIUC)(credit: UIUC)
University of Illinois at Urbana-Champaign engineers have demonstrated real-time video-rate (>30Mbps) “meat comm” data transmission through tissue, which could mean in-body ultrasonic communications may be possible for implanted medical devices, including hi-def video.
For example, a patient could swallow a miniaturized HD video camera that could stream live to an external screen, with the orientation of the device controlled wirelessly and externally by a physician, according to Andrew Singer, the Fox Family Professor in the Department of Electrical and Computer Engineering at Illinois,
“To our knowledge, this is the first time anyone has ever sent such high data rates through animal tissue,” Singer added. “These data rates are sufficient to allow real-time streaming of high definition video, enough to watch Netflix, for example, and to operate and control small devices within the body.”
Ingestible cameras and other devices
Potential biomedical uses include ingestible cameras for imaging the digestive track, as well as lower-bandwidth devices such as implanted pacemakers and defibrillators, glucose monitors and insulin pumps, intracranial pressure sensors, and epilepsy control.
Currently, most implanted medical devices use RF electromagnetic waves to communicate through the body. The Federal Communications Commission (FCC) regulates the bandwidths that can be used for RF electromagnetic wave propagation available to implanted medical devices. For example, the Medical Device Radiocommunication Service (MDRS) designates frequencies of operation ranging from 401–406 MHz (where these is high absorption). The corresponding maximum bandwidth allowed is 300 kHz and a maximum of 50 kb/s.
The main limitation for using RF electromagnetic waves in the body is loss of signal that occurs because of attenuation in the body. That requires higher power, which can cause tissue damage from heating due to absorption.
“For underwater applications, radio-frequency (RF) electromagnetic communications has long since been supplanted by acoustic communication,” Singer noted. “Acoustic or ultrasonic communication is the preferred communication means underwater because sound (pressure) waves exhibit dramatically lower losses than RF and can propagate tremendous distances for signals of modest bandwidth.”
The study was reported in an open-access paper on arXiv.org. The researchers have received a provisional patent application on the high-definition ultrasonic technology. They will be presenting their findings at the 17th IEEE International Workshop on Signal Processing Advances in Wireless Communications, this July in Edinburgh, UK.
Abstract of Mbps Experimental Acoustic Through-Tissue Communications: MEAT-COMMS
Methods for digital, phase-coherent acoustic communication date to at least the work of Stojanjovic, et al [20], and the added robustness afforded by improved phase tracking and compensation of Johnson, et al [21]. This work explores the use of such methods for communications through tissue for potential biomedical applications, using the tremendous bandwidth available in commercial medical ultrasound transducers. While long-range ocean acoustic experiments have been at rates of under 100kbps, typically on the order of 1- 10kbps, data rates in excess of 120Mb/s have been achieved over cm-scale distances in ultrasonic testbeds [19]. This paper describes experimental transmission of digital communication signals through samples of real pork tissue and beef liver, achieving data rates of 20-30Mbps, demonstrating the possibility of real-time video-rate data transmission through tissue for inbody ultrasonic communications with implanted medical devices.
Crazy and slightly terrifying. I bet in the next couple of decades we will create an EEG polygraph. And then a couple decades after that, stop using it because it doesn't work as well as we thought.
(credit: Jonathan Cohen/Binghamton University)
Binghamton University researchers have developed a biometric identification method called Cognitive Event-RElated Biometric REcognition (CEREBRE) for identifying an individual’s unique “brainprint.” They recorded the brain activity of 50 subjects wearing an electroencephalograph (EEG) headset while looking at selected images from a set of 500 images.
The researchers found that participants’ brains reacted uniquely to each image — enough so that a computer system that analyzed the different reactions was able to identify each volunteer’s “brainprint” with 100 percent accuracy.
In their original brainprint study in 2015, published in Neurocomputing (see ‘Brainprints’ could replace passwords), the research team was able to identify one person out of a group of 32 by that person’s responses, with 97 percent accuracy. That study only used words. Switching to images made a huge difference.
High-security sites
It’s only a three-point difference, but going from 97 to 100 percent makes possible a reliable system for high-security situations, such as “ensuring the person going into the Pentagon or the nuclear launch bay is the right person,” said Assistant Professor of Psychology Sarah Laszlo. “You don’t want to be 97 percent accurate for that, you want to be 100 percent accurate.”
Laszlo says brain biometrics are appealing because they can be cancelled (meaning the person can simple do another EEG session) and cannot be imitated or stolen by malicious means, the way a finger or retina can (as in the movie Minority Report).
“If someone’s fingerprint is stolen, that person can’t just grow a new finger to replace the compromised fingerprint — the fingerprint for that person is compromised forever. Fingerprints are ‘non-cancellable.’ Brainprints, on the other hand, are potentially cancellable. So, in the unlikely event that attackers were actually able to steal a brainprint from an authorized user, the authorized user could then ‘reset’ their brainprint,” Laszlo explained.
Analyzing “event-related potential” brain signals
Reference ERPs (originally recorded from the subject) and challenge ERPs (the ERP response detected from the subject being tested, which must match the reference ERP to verify it’s the same person) from two representative participants in the experiment, in response to viewing a “black and white foods” image, measured over the middle occipital (Oz) channel in the brain. Notice that even by eye, it is possible to determine which challenge ERP corresponds to which reference ERP. (credit: Maria V. Ruiz-Blondet et al./IEEE Trans. Inf. Forensics Security)
The researchers found in their original study that the key to detecting differences in brain signals was to look at and analyze “event-related potential (ERP) brain signals recorded from each subject. ERPs are brain signals that are triggered by specific events (such as seeing a photo). Unlike EEG signals, ERPs are unique and happen over a period of a few milliseconds.
How ERPs are identified
The researchers used six types of stimuli in the CEREBRE protocol: sine gratings, low frequency words, color versions of black and white images, black and white foods, black and white celebrity faces, and color foods. For the foods and celebrity faces, they used ten tokens of each stimulus type (e.g., 10 different foods).
As the authors note in a new paper in The IEEE Transactions on Information Forensics and Security, “We … predict that, while ERPs elicited in response to single categories of stimulation (e.g., foods) will be somewhat identifiable, combinations of ERPs elicited in response to multiple categories of stimulation will be even more identifiable.
“This prediction is supported by the likelihood that each category of stimulation will draw upon differing (though overlapping) brain systems. For example, if the sine gratings call primarily upon the primary visual cortex, and the foods call primarily on the ventral midbrain, then considering both responses together for biometric identification provides multiple, independent, pieces of information about the user’s functional brain organization — each of which can contribute unique variability to the overall biometric solution.”
Andrew Hatling/Binghamton University | The New Biometric — Brainprint
Abstract of CEREBRE: A Novel Method for Very High Accuracy Event-Related Potential Biometric Identification
The vast majority of existing work on brain biometrics has been conducted on the ongoing electroencephalogram. Here, we argue that the averaged event-related potential (ERP) may provide the potential for more accurate biometric identification, as its elicitation allows for some control over the cognitive state of the user to be obtained through the design of the challenge protocol. We describe the Cognitive Event-RElated Biometric REcognition (CEREBRE) protocol, an ERP biometric protocol designed to elicit individually unique responses from multiple functional brain systems (e.g., the primary visual, facial recognition, and gustatory/appetitive systems). Results indicate that there are multiple configurations of data collected with the CEREBRE protocol that all allow 100% identification accuracy in a pool of 50 users. We take this result as the evidence that ERP biometrics are a feasible method of user identification and worthy of further research.
Fuckin focus groups told me 3 buttons was the new 2 buttons. And then the SNES was released and suddenly the investors want their money back. Conference call about skipping straight to 4 buttons is the only logical choice and they're sorry.
People are getting pretty up in arms about the ethnicity of a character whose body is, in the story, entirely artificial. Like jeez, maybe she just upgraded to the Scarlett Johansson model.
[[ The Ghost in the Shell tests were conducted by Lola VFX, the same company that aged up (and down) Brad Pitt in The Curious Case of Benjamin Button
and is considered the industry leader in so-called beauty work. Though
the tests were requested by the production team, once they were
developed and reviewed, the idea was rejected “immediately,” says an
insider.
We reached out to Paramount Pictures who acknowledged the tests, but refute the claim that Johansson was involved.
Our
sources maintain Johansson’s character was specifically the focus of
these tests, though they were done without her participation or
knowledge. ]]
This device built by MIT researchers can be reconfigured to manufacture several different types of pharmaceuticals (credit: courtesy of the researchers)
MIT researchers have developed a compact, portable pharmaceutical manufacturing system that can be reconfigured to produce a variety of drugs on demand — if you have the right chemicals.
The device could be rapidly deployed to produce drugs needed to handle an unexpected disease outbreak, to prevent a drug shortage caused by a manufacturing plant shutdown, or produce small quantities of drugs needed for clinical trials or to treat rare diseases, the researchers say.
Traditional “batch processing” drug manufacturing can take weeks or months. Active pharmaceutical ingredients are synthesized in chemical manufacturing plants and then shipped to other sites to be converted into a form that can be given to patients, such as tablets, drug solutions, or suspensions.
With research funded by DARPA’s Make-It program, the new system prototype can produce four drugs formulated as solutions or suspensions: Benadryl, Lidocaine, Valium, and Prozac. Using this apparatus, the researchers can manufacture about 1,000 doses of a given drug in 24 hours.
The key to the new system: chemical reactions that can take place as the reactants flow through relatively small tubes as opposed to the huge vats in which most pharmaceutical reactions now take place. Traditional batch processing is limited by the difficulty of cooling these vats, but the flow system allows reactions that produce a great deal of heat to be run safely.*
Personalized “orphan drugs”
One of the advantages of this small-scale system is that it could be used to make small amounts of drugs that would be prohibitively expensive to make in a large-scale plant. This would be useful for “orphan drugs” — drugs needed by a small number of patients. “Sometimes it’s very difficult to get those drugs, because economically it makes no sense to have a huge production operation for those,” says Klavs Jensen, the Warren K. Lewis Professor of Chemical Engineering at MIT and a senior author of a paper describing the new system in the March 31 online edition of Science.
The researchers are now working on the second phase of the project, which includes making the system about 40 percent smaller and producing drugs whose chemical syntheses are more complex. They are also working on producing tablets, which are more complicated to manufacture than liquid drugs.
*The chemical reactions required to synthesize each drug take place in the first of two modules. The reactions were designed so that they can take place at temperatures up to 250 degrees Celsius and pressures up to 17 atmospheres. By swapping in different module components, the researchers can easily reconfigure the system to produce different drugs. “Within a few hours we could change from one compound to the other,” Jensen says.
In the second module, the crude drug solution is purified by crystallization, filtered, and dried to remove solvent, then dissolved or suspended in water as the final dosage form. The researchers also incorporated an ultrasound monitoring system that ensures the formulated drug solution is at the correct concentration.
Abstract of On-demand continuous-flow production of pharmaceuticals in a compact, reconfigurable system
Pharmaceutical manufacturing typically uses batch processing at multiple locations. Disadvantages of this approach include long production times and the potential for supply chain disruptions. As a preliminary demonstration of an alternative approach, we report here the continuous-flow synthesis and formulation of active pharmaceutical ingredients in a compact, reconfigurable manufacturing platform. Continuous end-to-end synthesis in the refrigerator-sized [1.0 meter (width) × 0.7 meter (length) × 1.8 meter (height)] system produces sufficient quantities per day to supply hundreds to thousands of oral or topical liquid doses of diphenhydramine hydrochloride, lidocaine hydrochloride, diazepam, and fluoxetine hydrochloride that meet U.S. Pharmacopeia standards. Underlying this flexible plug-and-play approach are substantial enabling advances in continuous-flow synthesis, complex multistep sequence telescoping, reaction engineering equipment, and real-time formulation.
A++ text. This is how I feel about software. Every new version of everything breaks something. Everything stops running eventually.
i don’t think i was ever more existentially depressed when i realized this. nothing we make is perfect. holes and dents and stains are in and on everything. how do we, as humans, repair them? we mix up white goop to fake it. good as new
same goes for brakes in cars. how do we stop a quickly spinning wheel? “i dunno… i guess two things could push on the wheel until it stops? and then just get new things when the old ones have been worn down to nubs”
Gonna call shenanigans. Fast Fact®: neither jews nor muslims celebrate easter. Instead, they celebrate LeBronsmas on December 30th, which is LeBron James's birthday.
I had athlete's foot recently and Walgreens only had cream labeled "Extra Strength Jock Itch" cream. It's the same fungus, but I still couldn't bring myself to buy it.
I mean, sometimes you wait for 13 hours to get @hamiltonthemusical cancellation tickets and end up seated next to Harrison Ford, with Meryl Streep and Emma Thompson directly behind you. It’s fine. I’m okay.
Wow! Sucks to be this chick. 😉
um, i sit with harrison ford and meryl streep behind me every single day so
Today @tungchiang and Robin visited the only flatware maker in the US. This manufacturing plant is the former Oneida factory. As the way of most consumer product companies in the US, Oneida now makes 0%of their flatware in the US, but the factory was taken over by some committed folks who wanted to keep the jobs and manufacturing going. We sell their flatware, and were excited to finally visit the factory, and see how it was made. Photos of the Sherrill Manufacturing Plant in Oneida NY taken by @tungchiange above. More in depth details on what we learned soon!
Normal people who are this incompetent at what they do for a living are fired. If you’ve got a 6 figure job as a member of the commentariat and everybody who determines your fate is exactly like you though, then absolutely nothing bad happens to you.
Finally, a contender for Bill Kristol’s current and eons-long-held position as “the master of unreality”.
ironically, douthat was the guy who replaced kristol at the nyt
jeez like what's next? they'll probably find an expression to get the nth prime number, something like f(n) = n + n^2 + 7 and be all like "nobody ever thought to add 7 to the function before". get your shit together, mathematicians.
An anonymous reader writes with an intriguing story at Quanta Magazine, which begins: Two mathematicians have uncovered a simple, previously unnoticed property of prime numbers — those numbers that are divisible only by 1 and themselves. Prime numbers, it seems, have decided preferences about the final digits of the primes that immediately follow them. Among the first billion prime numbers, for instance, a prime ending in 9 is almost 65 percent more likely to be followed by a prime ending in 1 than another prime ending in 9. In a paper posted online today, Kannan Soundararajan and Robert Lemke Oliver of Stanford University present both numerical and theoretical evidence that prime numbers repel other would-be primes that end in the same digit, and have varied predilections for being followed by primes ending in the other possible final digits. "We've been studying primes for a long time, and no one spotted this before," said Andrew Granville, a number theorist at the University of Montreal and University College London. "It's crazy."
One type of water clock was a bowl placed in a large pot filled with water. A small hole would be made in the bottom of the bowl so that water from the pot would slowly flow in; when the bowl became full, it would sink down into the pot, and a trusty time keeper who had been watching the bowl slowly fill, would dump it out and place it back on top of the water inside the pot. Time would be counted by the number of times (get it?) the bowl would sink. The bowl-and-pot is the most common type of water clock. It has been used since at least 500 BCE, by Babylonians, Egyptians, and Native Americans, and many others.
The fact that Nate Silver was wrong shouldn't be reason to shit on him. All he does is put polls into a spreadsheet while 95% of everyone else attempts to use their gut and read "momentum". Getting mad at him is like getting pissed at the weather man when the Doppler 3000 radar is busted so he has to use the "FOX 2 Detroit/Mitchell" radar instead, which is awful. And shows the chance of rain is like 61% in Michigan. So then weather man Nate Silver says it will probably rain. Instead it's sunny outside, and somehow people are angry about this, and they blame the mistake on the weather man.
In modern software development, a project isn't a project without a
proper versioning scheme.
Weak version management neglects clients like lack of source control
neglects collaborators. Dependency management and migration rely on
versions. Beyond the technical, a project's version bears a huge
impact on the perception of the project. It informs adoption and
entices users to upgrade. The version is attached to the name of the
project — appearing closer and more often than the names of the
maintainers. Versions are how a project builds a legacy.
So why do projects leave versioning to afterthought? What do clients
expect and what do projects need?
Followup: This post culminated in the
announcing CalVer and launching
calver.org. This page provides a thorough background to the
CalVer best practices.
Currently, the go-to versioning system for open-source software is
referred to as Semantic Versioning, or SemVer.
Take a quick look at the
40 most recent updates on the Python Package Index
(PyPI). My glance showed all but six packages had the
comfortable three-part versioning scheme, major.minor.micro. Among
those packages the highest minor version was 108. The highest micro
version was all the way up to 595.
So, if SemVer is so popular, it must be easy, right? Follow
a couple straightforward steps. Pick a number, add
one to it. With arithmetic that simple, what could go wrong?
Everyone knows it's more exciting to announce 2.0 than 1.7.0, even if
there's more user demand for the latter than the former. This is
especially true with SemVer, because a SemVer major
version change implies breaking the API.
As we will see, there are consequences to this. People judge value
based on version number. SemVer supports this opaque
apples-and-oranges comparison, punishing libraries that get it right
on the first try, and encouraging libraries to break APIs to appear
more mature and get that coveted 2.0.
If your software is being used in production, it should probably
already be 1.0.0. If you have a stable API on which users have come
to depend, you should be 1.0.0. If you’re worrying a lot about
backwards compatibility, you should probably already be 1.0.0.
On this count, SemVer might be found not guilty.2 If so, it's the
SemVer users that didn't get the memo — myself included. Maybe if it
had been in the spec itself.
The problem is the heavy emphasis on "public API"
breakage. Conservative library authors end up indefinitely preferring
the semantic power of 0.x: The ability to break APIs. Whether
the cause is conservatism, humility, or misunderstanding, the effect
is misrepresenting the release state of many major libraries.
A more practical scheme might help represent accurate versions for
mature, production libraries like Cython (0.23) and
SciPy (0.17), both of which havebooks and nearly a decade of release history still on
PyPI.
Appealing to engineering aesthetics, SemVer is presented as a
"specification". But, unlike the vast majority of successful
RFCs, there is no validation or certification that can
determine whether a project has a correct implementation. Yes, if a
project API changes, but the major version is not incremented, the
SemVer specification has been violated. But there's no way to test
that generally, and no one does it specifically.
SemVer is a detailed suggestion. Software breaks as quickly as
SemVer's promise. The remediations do not
happen. Better to embrace the realities of versioning, rather than
argue over the MUSTs and MUST NOTs of an unenforceable specification.
Let's take a brief moment to reconsider the humble version.
We encounter far more software than we write. Few, if any, expect
compliance with all the suggestions in SemVer. So what do we expect
from our versions?
There are three main expectations driving modern software versioning:
A project name communicates an ideal. The project version communicates
current progress toward that ideal. Vision pursued by version: The
greater the version, the greater the software.
Here's where things get hairy. Numeric versions are the default, but
non-numeric versions and version components abound.
Version vernacular is now thoroughly mainstream: "alpha", "beta",
"dev", "nightly", "stable", and so on. There are also named project
versions, like those used in Linux distributions, such as Debian's
"jessie", Ubuntu's "trusty", and Windows' "longhorn". Non-numeric
versions are often hijacked for branding purposes. Numerical versions'
technical utility is much more important to preserve.
We take our version expectations for granted, but a convention this
fundamental has profound effects at scale. As mentioned above, higher
versions are expected to be better, especially within a project. But
there is at least one case where this impact very publically spilled
out across projects: The Chrome-Firefox Version Wars.
When Google Chrome entered the browser race, it brought with
it a fast feature release schedule and a versioning system to
match. This versioning system had Chrome see a dozen major releases
while Firefox was still 3.x. Firefox looked like it was
being left in the dust, despite the fact that Chrome was less mature
and, as anyone who used it at the time can attest, Chrome 4 wasn't
half the browser Firefox 4 ended up being.
After a couple years of this onslaught, Firefox switched its
versioning system to match. Now, despite browsing for hours a day, few
users or even developers could tell you off the top of their heads
what version of Firefox/Chrome they use.3
If you're an earnest engineer with honest intents of creating,
releasing, and maintaining a project, then calendar versioning may be
for you. CalVer fulfills all of
the versioning expectations, so what
advantages does it bring?
People are calendar-oriented. Practically, it's just easier to
remember that a library was causing a live issue back in 2013 than it
is to remember that up until version 1.6.18 that library had a lot of
bugs.
Furthermore, in long-term development, releases pile up and
increasingly large major versions blur together. Browser versions have
been rendered meaningless. But the calendar is one construct where
numbers increase and cycle regularly. Leveraging that natural
understanding anchors otherwise arbitrary versions.
"Semantic" Versioning is all relative. One developer's 1.0.0 is
another's 0.0.1alpha. As authors, we try to ignore this and write
others off as wrong. But as clients, we make snap judgments, and
SemVer lets us forget and pretend. Calendar versioning is absolute and
neutral, with practical advantages to boot.
As application developers adding functionality, evaluating a new
library means ascertaining maintenance status, usually by looking at
the most recent release date. CalVer puts us in the ballpark right
away. As maintainers depending on many libraries, calendar versioning
allows us to look at the dependency list and quickly ascertain which
libraries are good candidates for updating. CalVer even lets us take
that a step further, with date-based deprecation.
Many might not realize it, but the oh-so ubiquitous Ubuntu
is in fact calendar versioned. For example, version 15.04 came out in
April, 2015. It gets better when you remember Long-Term
Support. Ubuntu's LTS support lasts for five years. So, 14 + 5:
Ubuntu 14.04's end of life will be in 2019. You don't have to look
anything up. It's all right there in the CalVer semantics.4
If you care about the future of the project, then guard it against one
of the worst fates: the fatuous 2.0. Give your project a
future. Guard against the learned expectation of 2.0 or death.
A 1.x always carries one advantage over a 2.0: the code is deployed
and working. Avoid contempt for past decisions and current users. In
engineering, utility is half of correctness.
SemVer is set up so that every major release implies a minimum
threshold of change. If the project is founded on and aiming for
correctness, fewer and fewer changes are
required. Donald Knuth embraced this in the extreme by having
TeX's version approach π asymptotically. Suffice to
say with CalVer, you are safe to add as much or as little
functionality as needed.
Too often projects become a victim of versioning. New projects end up
masquerading as new versions. D3 could have been
Protovis 2.0, but instead, a successor was created.
Both projects coexisted and we are all the better for it. Same with
characteristic and attrs. Successors and CalVer protect projects and
do justice by clients and code.
Consider adding a calendar component to your next library's versioning
schemes. As for my opinion, I've joined othermaintainers in doing so for boltons and
ashes. I've found it makes a lot of sense for libraries, and
a little less sense for protocols and services.5
Either way, think about project versions. The version is part of your
project's face and your clients' integration. After spending days,
weeks, and months on a project, it's worthwhile to spend a few minutes
or hours designing a versioning system tailored to the needs of
project users and maintainers.
If you're into enterprise software considerations like these,
subscribe or
follow me on Twitter for some
details about my upcoming O'Reilly project.
Astute readers will note that it's Semantic Versioning 2.0.0.
"Oh, cute, Tom used his own scheme for the document." But did you
wonder what public API changed to trigger that major version bump?
SemVer's public API has been semver.org since before 1.0.
How about those semantics? ↩
I've actually been saying something similar, but more practical, for a long time:
If both you (or your team) and a stranger (someone not
directly advised) are both using a library in a production
environment, the time for a major version has come.
If it's just you and yours, that's understandable. Many great
scientists took great risks with themselves for the
sake of progress. If it's just a stranger going against your
explicit advice, then there's no accounting for such
wildcards. But, if both of groups are using something in
production, then it's time to face the facts. Tie up the loosest
of ends and give it a major version. ↩
Here are some more resources for those interested in the
Firefox release switch up:
At the very least this should illustrate that versions
matter. They're part of your project's identity. Design them to
help your user. ↩
To illustrate the prevalence, there are actually many other
examples of calendar versioning we take for granted. Off the top
of my head I could think of Twisted, Windows 95/98/2000, and
probably most ubiquitous: every mainstream car in
circulation. Email me with more examples and I'll compile
them somewhere. ↩
To illustrate, if I could have it my way, we'd have OpenSSL
16.x.x. That way I can easily complain if I find someone using
10.x.x in production. That said, TLS/1.3 seems better than
TLS/16.0.
My current thought is that protocols live outside of time,
because I believe it's possible to complete a protocol, but an
implementation is never done. ↩
haha, I just want to share because of how much of an outlier this review is. Almost every other review is "you fucked up i'm going to sue you zero stars", but this one made me legit happy.
I really like cars, but I don't have the resources to deal with the hassle of owning a car in downtown San Francisco.
Get around lets me drive nice cars in downtown San Francisco without worrying about parking. This app has changed my life.
Fun fact: I have read a couple of these books. All the ships in the books are powered by a strong AI, so they get to choose their own name. And the ships uniformly choose joke names. Surprised none are called 8====D



















 Weak version management neglects clients like lack of source control
neglects collaborators. Dependency management and migration rely on
versions. Beyond the technical, a project's version bears a huge
impact on the perception of the project. It informs adoption and
entices users to upgrade. The version is attached to the name of the
project — appearing closer and more often than the names of the
maintainers. Versions are how a project builds a legacy.
Weak version management neglects clients like lack of source control
neglects collaborators. Dependency management and migration rely on
versions. Beyond the technical, a project's version bears a huge
impact on the perception of the project. It informs adoption and
entices users to upgrade. The version is attached to the name of the
project — appearing closer and more often than the names of the
maintainers. Versions are how a project builds a legacy.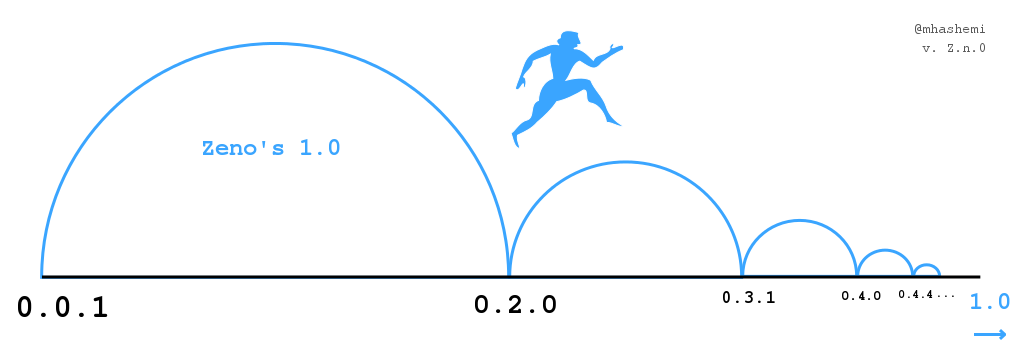
 If you're an earnest engineer with honest intents of creating,
releasing, and maintaining a project, then calendar versioning may be
for you. CalVer fulfills all of
the versioning expectations, so what
advantages does it bring?
If you're an earnest engineer with honest intents of creating,
releasing, and maintaining a project, then calendar versioning may be
for you. CalVer fulfills all of
the versioning expectations, so what
advantages does it bring?














{kind=link}