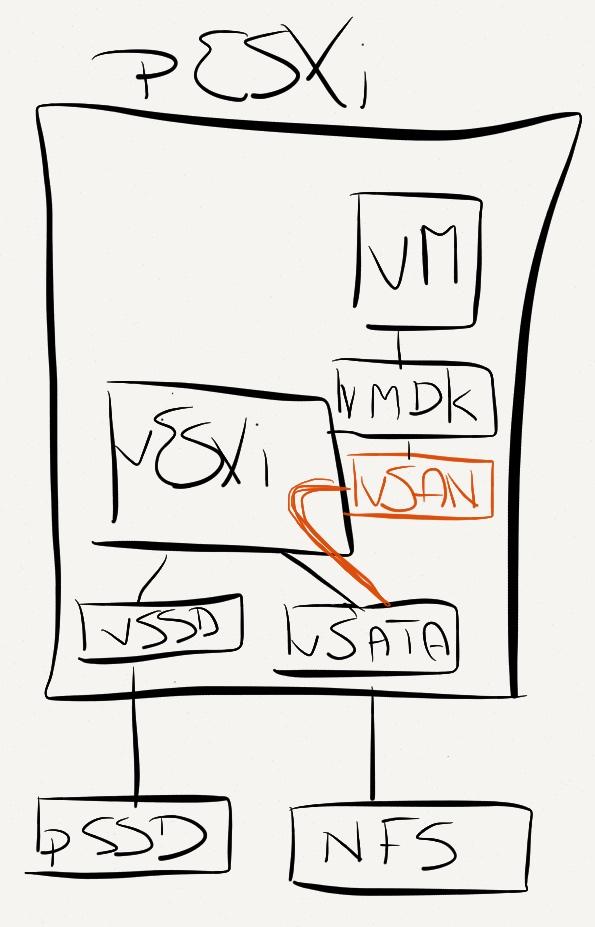
If you’ve spent any time with me in person, trading war stories, you’ve likely heard my rant about the consultant who suggested using the Simple recovery model for our production databases because “it’s faster”. If not, ask me about it sometime.
He’s not alone, unfortunately. There is a common misconception out there that the Simple recovery model, aka “Simple mode”, disables the transaction log on a database. This isn’t true. Simple mode changes the behavior of some logged processes, but it does NOT disable the log. Ordinary transactional activity is still logged normally. The log can still fill up or grow larger under heavy load. For normal activity, there is NO performance difference between Simple mode, Bulk-logged mode, or Full mode. I’ll try to convince you of that by the end of this post.
To get started, let’s create a couple of databases – one in Simple mode, one in Full mode:
-- Start by removing any existing demo databases
USE master;
GO
IF DB_ID('FullRecoveryDemo')IS NOT NULL
BEGIN
DROP DATABASE FullRecoveryDemo
END;
IF DB_ID('SimpleRecoveryDemo')IS NOT NULL
BEGIN
DROP DATABASE SimpleRecoveryDemo
END;
GO
-- Get default data file, log file, and backup directory
DECLARE
@Command nvarchar(max);
DECLARE
@DefaultDataDir nvarchar(4000) = CAST(SERVERPROPERTY(
'INSTANCEDEFAULTDATAPATH')AS nvarchar(4000));
DECLARE
@DefaultLogDir nvarchar(4000) = CAST(SERVERPROPERTY(
'INSTANCEDEFAULTLOGPATH')AS nvarchar(4000));
DECLARE
@DefaultBackupDir nvarchar(4000);
EXECUTE master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory',
@DefaultBackupDir OUTPUT, 'no_output';
-- Create a demo database using "Simple" recovery model, 1MB growth intervals, smallest possible file sizes
SET @Command =
N'
CREATE DATABASE SimpleRecoveryDemo
ON PRIMARY
(
NAME = N''SimpleRecoveryDemo'',
FILENAME = N''' + @DefaultDataDir +
N'SimpleRecoveryDemo.mdf'',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N''SimpleRecoveryDemo_log'',
FILENAME = ''' + @DefaultLogDir +
N'SimpleRecoveryDemo_log.ldf'',
SIZE = 1024KB,
FILEGROWTH = 0
);
ALTER DATABASE SimpleRecoveryDemo SET RECOVERY SIMPLE;';
EXECUTE (@Command);
-- Create a demo database using "Full" recovery model, 1MB growth intervals, smallest possible file sizes
SET @Command =
N'
CREATE DATABASE FullRecoveryDemo
ON PRIMARY
(
NAME = N''FullRecoveryDemo'',
FILENAME = N''' + @DefaultDataDir +
N'FullRecoveryDemo.mdf'',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N''FullRecoveryDemo_log'',
FILENAME = ''' + @DefaultLogDir +
N'FullRecoveryDemo_log.ldf'',
SIZE = 1024KB,
FILEGROWTH = 1024KB
);
ALTER DATABASE FullRecoveryDemo SET RECOVERY FULL;';
EXECUTE (@Command);
-- Run a full backup of the "Full" demo database, otherwise the log will act like Simple mode
SET @Command = 'BACKUP DATABASE FullRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\FullRecoveryDemo.BAK'' WITH FORMAT;';
EXECUTE (@Command);
-- Run a full backup of the "Simple" demo database, just to keep all things equal
SET @Command = 'BACKUP DATABASE SimpleRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\SimpleRecoveryDemo.BAK'' WITH FORMAT;';
EXECUTE (@Command);
GO
That final bit there, about the backups – that’s important. When you first put a database into Bulk-logged or Full recovery mode, until you’ve taken a full backup of the database, the log will behave as if it were in Simple mode. The full backup establishes a clean starting point for logging.
Let’s take a quick look at the size and free space of the transaction logs on our brand new databases. Both log files should be approximately 1MB in size:
-- Check the log size and space used for both databases (both should be nearly identical)
DBCC SQLPERF(LOGSPACE);
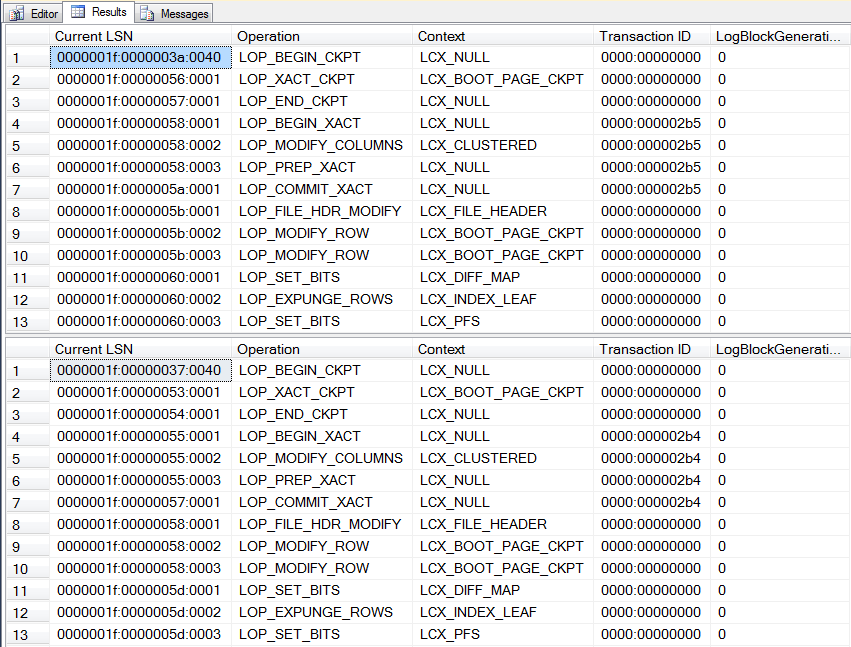
Also take a look at the contents of the logs. Both logs should contain just a handful of entries:
-- What's in the logs? (both should be nearly identical)
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
Do we all agree that at this point, the two transaction logs are essentially the same? One database in Simple mode, one in Full, no difference in log sizes or contents. Let’s throw some activity at them to see what happens.
Start by creating a table in both databases:
-- Create a table in each database
USE SimpleRecoveryDemo;
CREATE TABLE SomeTable(RowID int IDENTITY(1, 1),
RowUID uniqueidentifier,
RowDate datetime CONSTRAINT DF_RowDate DEFAULT
GETDATE());
USE FullRecoveryDemo;
CREATE TABLE SomeTable(RowID int IDENTITY(1, 1),
RowUID uniqueidentifier,
RowDate datetime CONSTRAINT DF_RowDate DEFAULT
GETDATE());
GO
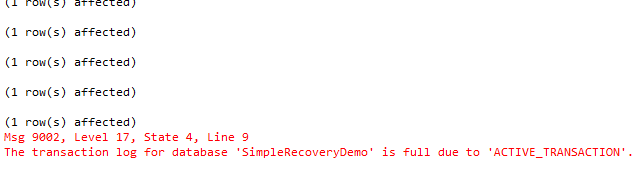
We’ll start by dispelling that crazy notion that the log file is disabled in Simple mode. Let’s add a block of 5,000 rows to the table in the Simple mode database:
-- Insert a 5,000 row transaction into Simple mode database
USE SimpleRecoveryDemo;
BEGIN TRANSACTION;
WHILE COALESCE((SELECT MAX(RowID)
FROM SomeTable), 0) < 5000
INSERT INTO SomeTable(RowUID)
VALUES
(NEWID());
COMMIT TRANSACTION;
Whoa, what happened? If Simple mode disables the log, why did the log fill up?
Because Simple mode does NOT disable the log!
-- Let's modify the log to allow for growth.
ALTER DATABASE [SimpleRecoveryDemo] MODIFY FILE ( NAME = N'SimpleRecoveryDemo_log', FILEGROWTH = 1024KB )
Another error. We can’t make any changes to the database, at least not logged changes, until we free up some space in the transaction log. How do we free up space in the log?
Prior to SQL 2008, you would do this:
BACKUP LOG SimpleRecoveryDemo WITH TRUNCATE ONLY
That no longer works. It was (wisely) removed in SQL 2008. This was a dangerous command, causing many a broken log chain when used by an inexperienced DBA.
The best method today is to create a “fake” backup, by writing to the NUL: device
BACKUP DATABASE SimpleRecoveryDemo TO DISK = 'NUL:'
That should have cleared some space in the log. Let try again to modify the log to allow for growth:
ALTER DATABASE [SimpleRecoveryDemo] MODIFY FILE ( NAME = N'SimpleRecoveryDemo_log', FILEGROWTH = 1024KB )
So, after all of that, we’ve proven (I hope) that the log IS used, even in Simple mode. On with the demo! First, let’s clean things up and start over with clean databases.
-- Start by removing any existing demo databases
USE master;
GO
IF DB_ID('FullRecoveryDemo')IS NOT NULL
BEGIN
DROP DATABASE FullRecoveryDemo
END;
IF DB_ID('SimpleRecoveryDemo')IS NOT NULL
BEGIN
DROP DATABASE SimpleRecoveryDemo
END;
GO
-- Get default data file, log file, and backup directory
DECLARE
@Command nvarchar(max);
DECLARE
@DefaultDataDir nvarchar(4000) = CAST(SERVERPROPERTY(
'INSTANCEDEFAULTDATAPATH')AS nvarchar(4000));
DECLARE
@DefaultLogDir nvarchar(4000) = CAST(SERVERPROPERTY(
'INSTANCEDEFAULTLOGPATH')AS nvarchar(4000));
DECLARE
@DefaultBackupDir nvarchar(4000);
EXECUTE master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory',
@DefaultBackupDir OUTPUT, 'no_output';
-- Create a demo database using "Simple" recovery model, 1MB growth intervals, smallest possible file sizes
SET @Command =
N'
CREATE DATABASE SimpleRecoveryDemo
ON PRIMARY
(
NAME = N''SimpleRecoveryDemo'',
FILENAME = N''' + @DefaultDataDir +
N'SimpleRecoveryDemo.mdf'',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N''SimpleRecoveryDemo_log'',
FILENAME = ''' + @DefaultLogDir +
N'SimpleRecoveryDemo_log.ldf'',
SIZE = 1024KB,
FILEGROWTH = 1024KB
);
ALTER DATABASE SimpleRecoveryDemo SET RECOVERY SIMPLE;';
EXECUTE (@Command);
-- Create a demo database using "Full" recovery model, 1MB growth intervals, smallest possible file sizes
SET @Command =
N'
CREATE DATABASE FullRecoveryDemo
ON PRIMARY
(
NAME = N''FullRecoveryDemo'',
FILENAME = N''' + @DefaultDataDir +
N'FullRecoveryDemo.mdf'',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N''FullRecoveryDemo_log'',
FILENAME = ''' + @DefaultLogDir +
N'FullRecoveryDemo_log.ldf'',
SIZE = 1024KB,
FILEGROWTH = 1024KB
);
ALTER DATABASE FullRecoveryDemo SET RECOVERY FULL;';
EXECUTE (@Command);
-- Run a full backup of the "Full" demo database, otherwise the log will act like Simple mode
SET @Command = 'BACKUP DATABASE FullRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\FullRecoveryDemo.BAK'' WITH FORMAT;';
EXECUTE (@Command);
-- Run a full backup of the "Simple" demo database, just to keep all things equal
SET @Command = 'BACKUP DATABASE SimpleRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\SimpleRecoveryDemo.BAK'' WITH FORMAT;';
EXECUTE (@Command);
GO
Quickly verify that the logs are the same size:
-- Check the log size and space used for both databases (both should be nearly identical)
DBCC SQLPERF(LOGSPACE);
Also verify that the contents are the same:
-- What's in the logs? (both should be nearly identical)
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
Create a table in both databases:
-- Create a table in each database
USE SimpleRecoveryDemo;
CREATE TABLE SomeTable(RowID int IDENTITY(1, 1),
RowUID uniqueidentifier,
RowDate datetime CONSTRAINT DF_RowDate DEFAULT
GETDATE());
USE FullRecoveryDemo;
CREATE TABLE SomeTable(RowID int IDENTITY(1, 1),
RowUID uniqueidentifier,
RowDate datetime CONSTRAINT DF_RowDate DEFAULT
GETDATE());
GO
Now, on with the demo – let’s insert a block of 5,000 rows into the new table in each database:
-- Insert a 5,000 row transaction into each database
USE SimpleRecoveryDemo;
BEGIN TRANSACTION;
WHILE COALESCE((SELECT MAX(RowID)
FROM SomeTable), 0) < 5000
INSERT INTO SomeTable(RowUID)
VALUES
(NEWID());
COMMIT TRANSACTION;
USE FullRecoveryDemo;
BEGIN TRANSACTION;
WHILE COALESCE((SELECT MAX(RowID)
FROM SomeTable), 0) < 5000
INSERT INTO SomeTable(RowUID)
VALUES
(NEWID());
COMMIT TRANSACTION;
GO
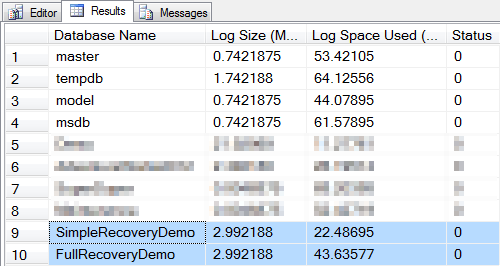
What did this do to the transaction logs? Let’s see if they’re still the same size:
-- How big are the logs now?
DBCC SQLPERF(LOGSPACE);
Surprised? Both logs have grown by 2MB – even the one that is in Simple mode. Do they contain the same log entries?
-- What's in the logs?
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
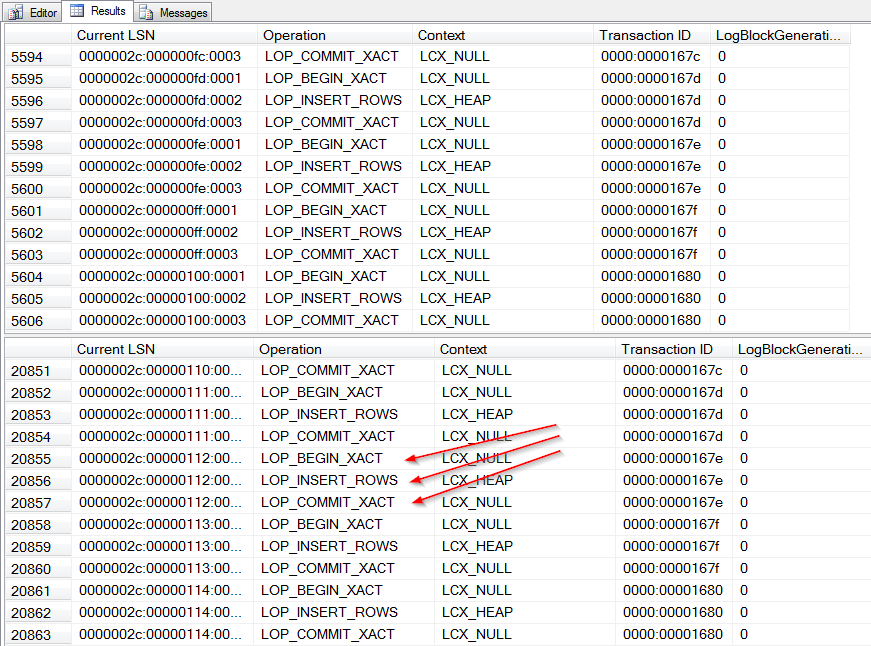
Both logs contain, give or take, 5,000 entries. Roughly equivalent to the size of the transaction that we submitted. Clearly Simple mode didn’t disable the log.
So what’s the deal? Both recovery models captured essentially the same information in the log. There must be some difference between them, but what is it? Basically, the difference is in how those log entries get flushed (also known as truncation) from the log.
Using a process known as a checkpoint, SQL Server will periodically remove transactions from the transaction log after they are no longer needed. Replication, mirroring, Change Data Capture – any of these can affect how long a transaction is “needed” in the log. The recovery model can as well. Full and Bulk-logged modes offer “point-in-time” restores from backup, which we’ll look at later in this post – point-in-time restores require that all entries in the transaction log be backed up. Until that time, the transactions are needed and cannot be truncated from the log.
Let’s see a checkpoint in action, against each of the two databases:
-- Manually checkpoint each database
USE SimpleRecoveryDemo;
CHECKPOINT;
USE FullRecoveryDemo;
CHECKPOINT;
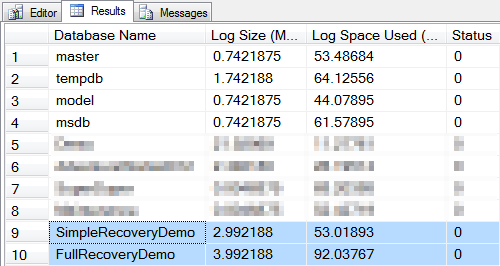
What did this do to the logs?
-- How big are the logs now?
DBCC SQLPERF(LOGSPACE);
-- What's in the logs?
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
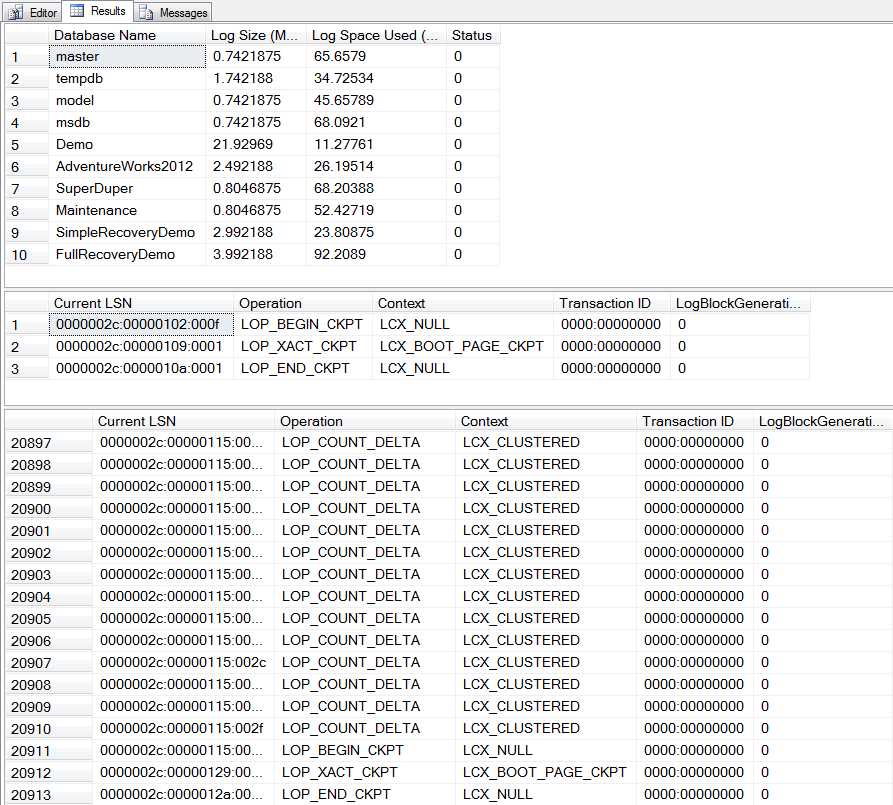
After the checkpoint, both logs are still 3MB in size, but the space used in the Simple mode database has changed. We can see that the Simple mode log is more or less empty, only three entries. The Full mode log however still has over 5,000 entries in it – nothing was removed by the checkpoint.
What happens if we do 5,000 individual inserts instead of one big transaction?
-- What if do 5,000 individual inserts?
USE SimpleRecoveryDemo;
WHILE COALESCE((SELECT MAX(RowID)
FROM SomeTable), 0) < 10000
INSERT INTO SomeTable(RowUID)
VALUES
(NEWID());
USE FullRecoveryDemo;
WHILE COALESCE((SELECT MAX(RowID)
FROM SomeTable), 0) < 10000
INSERT INTO SomeTable(RowUID)
VALUES
(NEWID());
What effect did this have on the logs?
What about the log contents?
The Simple mode log is still 3MB in size, and just over half full. The Full mode log has grown by another 1MB and is nearly full, almost ready to grow again. As a side note, we can also see the implicit transactions created by the individual INSERT statements – each INSERT created three entries in the log files, one to begin the transaction, the actual insert itself, followed by a commit of the transaction.
Let’s checkpoint the logs again, and recheck the sizes:
-- Manually checkpoint each database
USE SimpleRecoveryDemo;
CHECKPOINT;
USE FullRecoveryDemo;
CHECKPOINT;
GO
-- How big are the logs now?
DBCC SQLPERF(LOGSPACE);
-- What's in the logs?
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
GO
As before, the Simple mode log is essentially empty after the checkpoint, but the Full mode log still has the same entries.
By this point, it should be clear that each checkpoint against a Simple mode database flushes the transaction log, but not so with a Full mode database. The log on a Full mode database just continues to accumulate activity, until eventually filling up or growing to fill the disk (unless a maximum size is defined). How can we empty the log on a Full mode database? By taking a backup of the transaction log itself:
-- Let's backup the transaction log on the Full recovery database
DECLARE
@DefaultBackupDir nvarchar(4000);
DECLARE
@Command nvarchar(max);
EXECUTE master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory',
@DefaultBackupDir OUTPUT, 'no_output';
SET @Command = N'BACKUP LOG FullRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\FullRecoveryDemo1.TRN'' WITH FORMAT;';
EXECUTE (@Command);
GO
As we’ve done many times already, let’s check the size and contents of the logs:
DBCC SQLPERF(LOGSPACE);
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
GO
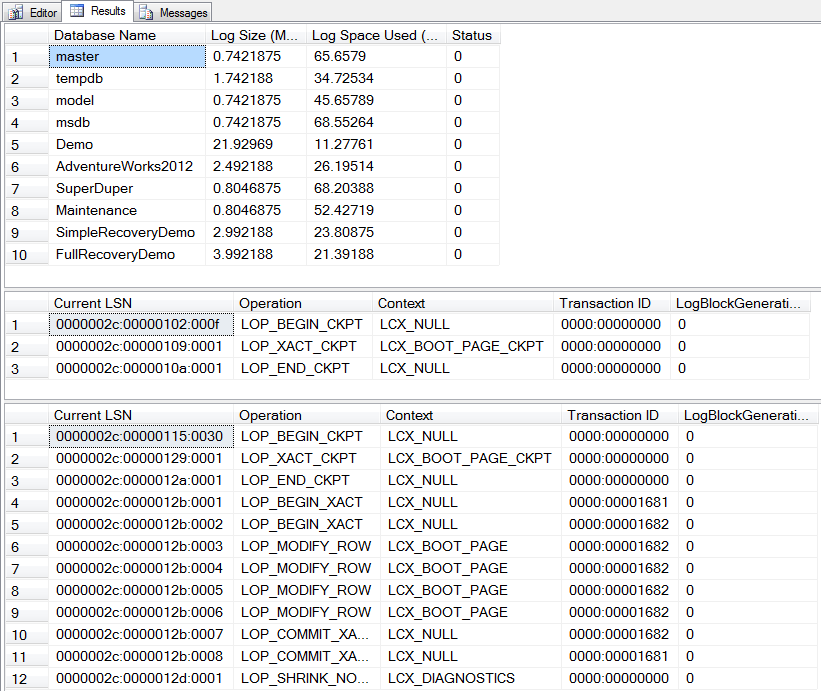
Ahh, now we’re talkin’! The space used in the Full mode log has been reduced, and there are only a handful of entries sitting in the log now. The backup successfully truncated the log.
Just for fun, let’s backup the Simple mode log:
DECLARE
@DefaultBackupDir nvarchar(4000);
DECLARE
@Command nvarchar(max);
EXECUTE master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory',
@DefaultBackupDir OUTPUT, 'no_output';
SET @Command = N'BACKUP LOG SimpleRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\SimpleRecoveryDemo.TRN'' WITH FORMAT;';
EXECUTE (@Command);
GO
Yep, it failed. Because the log on a Simple mode database is automatically truncated on checkpoint, there is never anything in the log to backup. You can’t do transaction log backups on a Simple mode database.
At this point, you may be thinking “This seems like a pain!”. If I’m using the Full recovery model, I have to not only do full database backups, but I also have to do backups of the transaction log? Seems like a hassle, why would I do that? Simple mode seems so much easier.
Simple mode may indeed be good enough for your needs, but before making that decision, let’s look at a scenario that might change your mind.
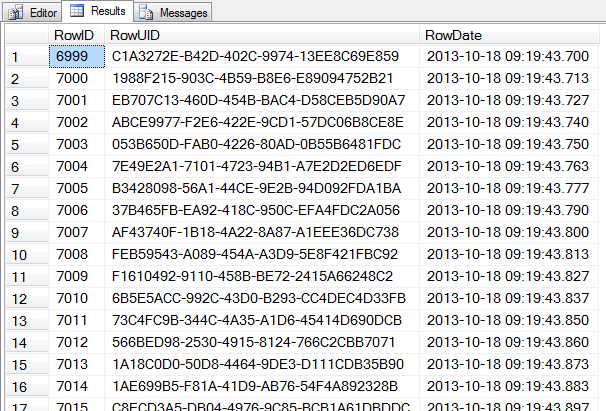
Let’s pull some data from our Full mode database:
USE FullRecoveryDemo;
SELECT *
FROM SomeTable
WHERE RowID >= 6999
AND RowID <= 8001;
GO
Suppose we “accidentally” delete some data. Make note of the time that that we make our “mistake”:
SELECT GETDATE();
DELETE FROM SomeTable
WHERE RowID >= 7000
AND RowID < 8000;
GO
Again, make note of the date/time returned by that batch.
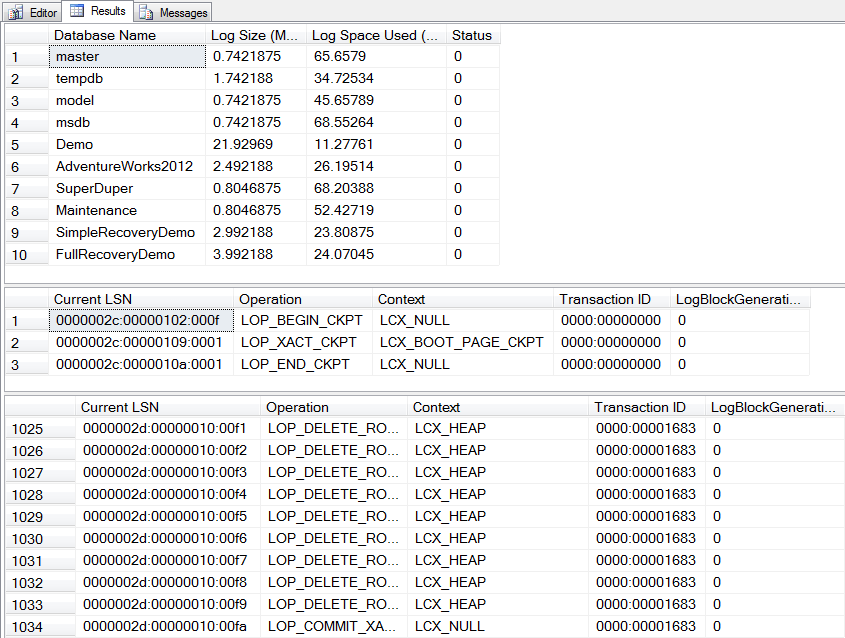
For curiosity’s sake, take a look to see what this did to the logs:
DBCC SQLPERF(LOGSPACE);
DBCC LOG('SimpleRecoveryDemo');
DBCC LOG('FullRecoveryDemo');
GO
Let’s run a transaction log backup to flush out those 10,000 entries that are in the log:
DECLARE
@DefaultBackupDir nvarchar(4000);
DECLARE
@Command nvarchar(max);
EXECUTE master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory',
@DefaultBackupDir OUTPUT, 'no_output';
SET @Command = N'BACKUP LOG FullRecoveryDemo TO DISK = ''' +
@DefaultBackupDir + '\FullRecoveryDemo2.TRN'' WITH FORMAT;';
EXECUTE (@Command);
GO
Now it’s time to “discover” our mistake. Repeat the query that we ran previously:
USE FullRecoveryDemo;
SELECT *
FROM SomeTable
WHERE RowID >= 6999
AND RowID <= 8001;
GO
Oh crap! We’re missing data! Fortunately, since we’re in Full recovery mode, and we have log backups, we can do a point-in-time restore. To do that, we’re going to use the RESTORE LOG command with the STOPAT option, stopping at the point where we made our mistake. Using the date and time that you took note of previously, run the following:
USE master;
GO
DECLARE
@DefaultBackupDir nvarchar(4000);
DECLARE
@Command nvarchar(max);
EXECUTE master.dbo.xp_instance_regread N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory',
@DefaultBackupDir OUTPUT, 'no_output';
SET @Command = N'RESTORE DATABASE FullRecoveryDemo FROM DISK = ''' +
@DefaultBackupDir + '\FullRecoveryDemo.BAK'' WITH REPLACE, NORECOVERY;';
EXECUTE (@Command);
SET @Command = N'RESTORE LOG FullRecoveryDemo FROM DISK = ''' +
@DefaultBackupDir + '\FullRecoveryDemo1.TRN'' WITH NORECOVERY;';
EXECUTE (@Command);
SET @Command = N'RESTORE LOG FullRecoveryDemo FROM DISK = ''' +
@DefaultBackupDir +
'\FullRecoveryDemo2.TRN'' WITH RECOVERY, STOPAT = ''2013-10-18 10:58:44.623'';'
;
EXECUTE (@Command);
GO
Take a deep breath, and re-run our SELECT statement:
USE FullRecoveryDemo;
SELECT *
FROM SomeTable
WHERE RowID >= 6999
AND RowID <= 8001;
GO
Wheeeeew…. Full recovery mode just saved our bacon, the data that we accidentally deleted has been restored.
Could you have done this with Simple mode? Sure, but without the ability to target a specific point in time. You’re limited to restoring your last full backup. The wider the gap between your full backups, the more data you risk losing. If your last full backup was done last night at 9:00pm, and somebody accidentally deletes data at 3:00pm today, you’re going to lose 18 hours of data. That might be perfectly OK for your situation, but you need to understand this.
So there you have it. Simple mode does NOT disable the transaction log, it still works in more or less the same way. Some processes like index maintenance, bulk inserts, and a few others behave differently, but your basic CRUD functions still write to the log, the log can still fill up, the log can still grow, and there is NO performance difference vs Full or Bulk-logged modes. The next time somebody says “Simple mode is faster”, point them to this post. Then smack ‘em around a little bit.
The post No, Simple Mode Doesn’t Disable The Transaction Log appeared first on RealSQLGuy.























 Most folks know that I've spent the last couple of years on Team-WTF in Department-WTF at WTF-Inc. A while back I
Most folks know that I've spent the last couple of years on Team-WTF in Department-WTF at WTF-Inc. A while back I  [Advertisement] Make your team a DevOps team with
[Advertisement] Make your team a DevOps team with