I think I am pretty high tech. I have an electric blanket, I listen to internet radio, I carry a smartphone, I stream movies to my television, I talk to my car, and I’m a Technical Evangelist – it’s part of the job description.
I think I am pretty high tech. I have an electric blanket, I listen to internet radio, I carry a smartphone, I stream movies to my television, I talk to my car, and I’m a Technical Evangelist – it’s part of the job description.
Sorting out the chaff
As time passes, I buy and throw away gobs of technology. Lots of it is fun. Lots of it sucks. For example, I purchased the Google ChromeCast. Oh, the fun of talking to my television from my computer. It’s in a closet now. Useless. This article isn’t about gadgets that are fun but useless. This article is about life-changing gadgets.
Diamonds in the rough
By now, I have started to settle in on some key technologies that have changed the way I live. Made it better. Made it easier. Things that, should I lose them for any reason, I would immediately replace them. Essentials.
Acknowledgement
Some people don’t think that technology is essential in any way. Those people are right. Clean air, food, water, and safety are true essentials. Having said that, these are first-world essentials. And, here are my top 5.
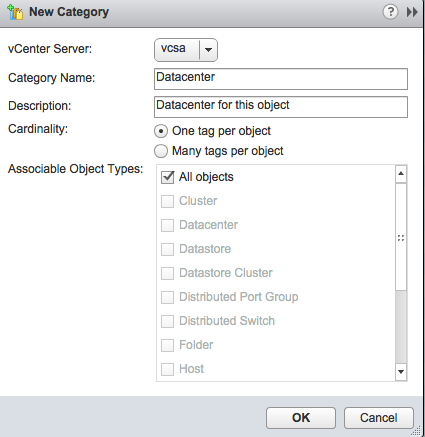
Number 1: Multiple Monitors

As mundane as it may sound, it is the multiple-monitor that easily deserves the first place on this list. It is not the most novel technology anymore, but it is certainly the one I use every single day and miss the most when it is gone. For me, two monitors is just the beginning – three is the bare minimum.
Approach 1: Video Card

To drive multiple monitors, the first way is to get a nice video card. In my case when I drive monitors from my desktop, I drive them using my Radeon XFX HD 6970 width 2 GB of onboard RAM – which supports 4 monitors. Anymore, this isn’t uncommon; when I got it, it was like ordering a moon lander.
Note: there is zero question that this is the only solution suited to PC gamers. That’s because it takes hardware like this to drive the frame rates that gamers enjoy. If you are using Excel, writing Word documents, or just watching Hulu – this might be a little like cracking nuts with a steam roller.
Caveat: Let the casual user beware. Such a video card will likely require you to purchase a new power supply. A new poser supply can be purchased and installed by you for around $50 or at Staples for about $100. The cost of the Radeon is about $500, so go ahead and think of it as $600 – if you get this one.
Approach 2: DisplayLink

To drive multiple monitors, the second way is to use USB DisplayLink devices. This is one of my favorite inventions. It allows for 3 external monitors for my laptop! These are simple to setup; no setup at all. They do the job – but do introduce some CPU cost; most of the work is offloaded to the processor. But, who cares. It works like a charm and only cost $50/each.
Note: I use Windows 8.1 Professional. The DisplayLink drivers are all up-to-date and support every version of Windows I have ever used. In fact, even during beta, the DisplayLink drivers are released as pre-release for us to use. This is the same tech in universal laptop docking stations.
Number 2: Internet Radio

I love music. I am not an audiophile, for sure. But I love music, and I can hardly stand it when the room is completely silent. At the same time, I am not 100% into setting up playlists. So, I also love Pandora which does a magical job of guessing what I like to hear and introducing me to new music.
In my kitchen is the Logitech Squeezbox Internet Radio. This little marvel has excellent sound, a stunning user interface, and just freaking works. The support for this device is amazing. There are tons of apps, and awesome advanced features like the ability to synchronize two of them to the same stream.
The best part of this gem is that it has a built in battery that lest be grab it, unplug it, and take it out to the deck so we can have some background tunes while we grill with some friends. The presets can go directly to my favorite Pandora stations, as well as play from my own, local DLNA server if I want, but I don’t – it’s all Pandora for me. And, did I mention the sound?

Back in October of 2008, I started my Squeezebox family with the two-speaker Boom edition. And, who wouldn’t with Duran Duran on the demo photo. This device is still prominently hidden in my family room and synchronizes it’s deep, full sound with the smaller, one-speaker version in the kitchen. During a party, the house is an experience itself as you walk around, music following you.

The icing on the cake for this device is it’s ability to be remote controlled over the internet at http://mysqueezebox.com. Are the kids downstairs listening to something a little too loud? No problem. I log in and turn it down a bit. It’s the sort of nerd-trapping that can really hook me. And, it did.
CAVEAT: as far as I can tell, Logitech has discontinued the Squeezebox brand – and the new UE radio versions. Though they still offer support with regular software updates, I think if I were starting this journey today, I might… nope, I would still get a Squeezebox. After all, I can get a used one for $79. And it’s a perfect device. There are alternatives almost identical if you like.
Number 3: Digital Deadbolt

I am the type of guy who can remember the nuanced specification of an operating system’s API but can’t tell you where my keys are. It’s just one of those things. As a result, we use the Schlage Deadbolt Keypad on our front door. I went through several brands and models before I found one that would not be too complicated to use, too prone to error, or too hungry for batteries.
This issue about batter is a real one. Most of the digital deadbolts out there suck. They have a small servo inside them that when the correct code is entered they unlock the door. It’s a terrible design. It’s noisy, typically fails, and quickly drains the battery. This design lets the bolt’s knob turn freely; enter the correct code and the knob locks to the bolt and the user unlocks the door. Perfect.
In my opinion, the lock is visually innocuous. Visitors to my house might notice it in passing, but it’s not “technology in your face”. The best benefit for me isn’t just never being locked out of my house again, it’s letting my children be able to get into our locked house without giving them a key to lose.
Caveat: the lock supports many different codes. It’s up to you if you share your code with your children, neighbors, or anyone. A code can be copied far easier than a key. If you re in a vulnerable neighborhood, then you might not want to share your code with a single person. I don’t know.

Similar in concept is keyless entry on my car. I drive a Ford Expedition – a nice all wheel drive car that fits my family and my mountainous terrain. What’s great about fords is that their keyless entry does not require a key fob, my wallet or anything else. I can walk up to my car completely unprepared and get in. Someone with my personality type, I have decided, will always buy a Ford because only Ford has such a keyless system.
Number 4: Phone wallet

This is less of a high-tech gadget as much as it’s a high-tech gadget accessory. Again, to remind you, I am the type of guy who can recite the asynchronous interface requirements for C#, but might spend an hour a day looking for my wallet. It’s just how I am wired to lose my wallet.
But, ironically, I never lose my phone. For one, I tend to want my phone more than I want my wallet. I don’t check email on my wallet. Plus, I use carry a Microsoft Windows Phone which has sever “find me” functions like “Locate” and “Ring” built right into the operating system. It would be a struggle to lose my phone, as long as it has any battery at all.
This awesome phone wallet means that if I never lose my phone, I never lose my wallet. In fact, if I ever lose my wallet, I can call it! It is a life-saver, and for the past 4 months, I have enjoyed this new accessory. It’s difficult to imagine a good life without this. It’s beautiful leather, and smaller than you think.
One thing worth noting about this wallet is that it has a built in hard case for my phone. It’s glued or something to the leather. Best of all, it’s made specifically for my phone and hugs it gently and tightly as use my wallet or the phone’s camera – for which there is a custom-cut hole on the back.
REALITY CHECK: I hate thick wallets (remember that Seinfeld episode?), but putting my phone in my wallet has guaranteed it is thick. This is just something I have had to accept, and it came easy.
In addition, I have had to rethink what I put in my wallet; I want to keep this beauty as thin as possible. It turns out, I really didn’t need all I was carrying. For example, I keep my Sam’s Club card in my glove box now. Why did I ever carry that? So much other crap was offloaded, too. It’s a new lease on life!
Number 5: Wireless sound

I have the small, red Jawbone, bluetooth Jambox. This has been the season of bluetooth, wireless speakers. Seems like they are on sale everywhere. And, though I am certainly not saying that the other speakers are not great, I am saying that the Jambox is awesome.
Let’s consider the reason to have a wireless speaker in the first place.
You go to the beach in Mexico. You want to play some music because after several hours of sitting around, you’re ready for some audible distraction. Your smartphone is in your bag. You have tons of music on your phone. But your phone’s speaker could never compete with the Pacific ocean. Presto.
You go on a road trip in an RV with a family down the street. You are on the road for hours playing endless hands of Euchre at the kitchen table which does not have a radio (the radio is up front). You can stream Pandora over your phone, but the road noise would muffle your phone’s speaker. Presto.
You go to Grandma’s for Christmas every year having to listen to the same bad music from the same 1980’s, crappy “sound system”. This year, you want some real Christmas music and you want to hear the whole range of sound. Your Surface can stream Xbox Music for you but it’s not loud enough. Presto.

I’ve already mentioned that I carry a Microsoft Windows Phone. But, more specifically, I carry a Nokia Lumia 920 which has NFC. NFC is sort of like RFID in that it lets two mostly-passive devices talk to each other. That’s important.
This little bonus device. This is a bluetooth receiver that plugs into any microphone or 3/4 inch input jack. It’s powered by bluetooth which means you can basically turn any car into a bluetooth-enabled car. You can take it to grandma’s and stream Pandora right to her old-time cassette player. Needless to say, this beauty is a staple for my travel bag.
What’s best here is that the bluetooth pairing is virtually brain-dead automatic thanks to the fact that this receiver is NFC-enabled. Just tap your Lumia to the receiver and the pairing is complete. Then, start streaming. It really is one of those devices that works the way you would want technology to work.
Conclusion
It was super-difficult to stop with 5 devices. I have tons of little gadgets that I use every day and love. Devices that I didn’t list above, but that I might mention here, so I am not tempted to blog another article like this:
-
Nokia DT-900 Wireless Charging Plate
-
Buffalo LinkStation Pro Duo Network Attached Storage
-
Soft Heat Micro-Plush Electric Mattress Pad
-
NETGEAR Powerline Ethernet Adapter Kit

-
Samsung 840 Pro Series Solid State Drive
-
Electrolux Bagless Handheld Vacuum
-
Wiremold Charging Center For Mobile Devices
-
Velcro Cable Ties, 100 per Pack
-
ClearOptix Gaming Glasses
-
PowerLine 2Amp Four Port USB AC Adapter

There, now I feel better. Those ten help round out some of the gizmos I use every single day. Some of them are less “family”-oriented, but they are surely in the category of things that make my life better.
Would you add anything to my list?









 [Advertisement] BuildMaster 4.0 is here!
[Advertisement] BuildMaster 4.0 is here!