Before upgrading to vSphere 5.5, I ensured that my host profile was up-to-date and on all nodes. After upgrading, it is important to continue update the host profiles immediately after upgrading. However, the normal way to update profiles, using the vSphere .NET Client, may not work. When I tried it, no matter which host or profile, and whether new or old, the profile would not update. I received a range error. A quick search found nothing but did hint at a few things. Many days later, I restarted the .NET client and noticed once more the message at the top that says:
“The traditional vSphere Client will continue to operate, supporting the same feature set as vSphere 5.0, but not exposing any of the new features in vSphere 5.5.”
Well, I thought, perhaps that is it. Host Profiles has many new features associated with vSphere 5.5, so we are now forced to use the vSphere Web Client for these features but must use the .NET client for VUM, SRM, and a few other solutions. Not a major problem, so I updated the host profile within the web client from one node. It failed with a check error but not much else.
That node is rather special, as it has a bit more hardware in it and is not what I consider my normal node. To that end, I went to a more basic node and updated the profile from it. It was successful. Then it was time to edit the profile to remove any of the storage issues that tend to pop up from time to time. What I did can be found in a previous post in my vSphere Upgrade Saga. The next step after editing the profile is to check compliance against it (see Figure 1).

Figure 1: Host Profiles in vSphere Web Client (Click to Expand) Note the circle used to check compliance
Within the vSphere Web Client, I feel there could be serious scale issues with a large number of hosts within a host profile. I am not sure; what do others think?
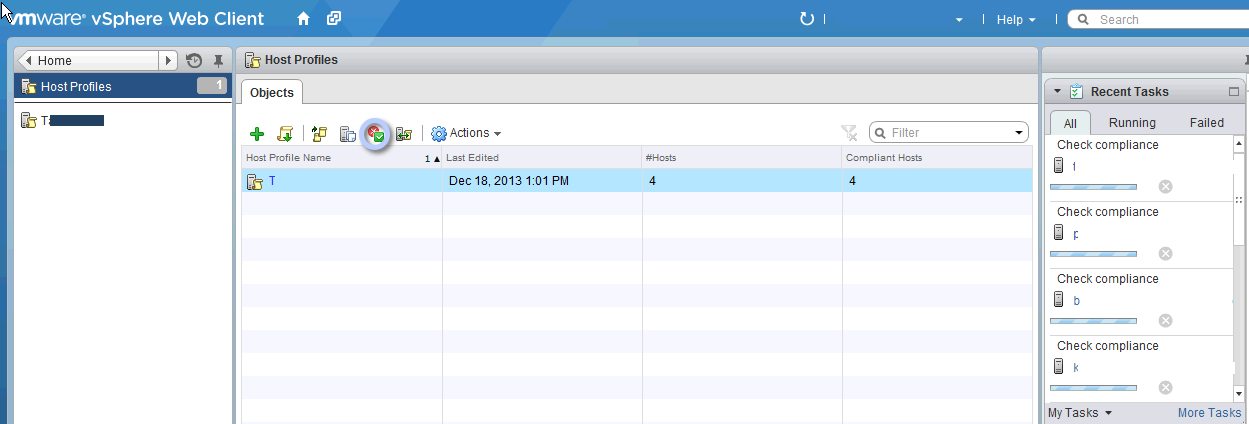
But that comment aside, when I used Host Profiles on vSphere 5.5, it was the first time that all nodes were compliant after I applied the profile. While it was still necessary to remediate the profile on all nodes, it was also required to once more disable some of the storage elements within the host profile. One day, I expect that will be fixed. Remediation through the web client was fairly straightforward. All you need do is to put the node in maintenance mode and then remediate directly from the host profile page of the web client.
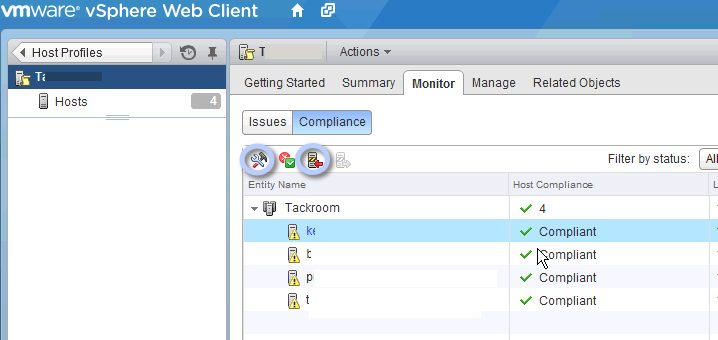
Figure 2, Remediate and scan (click to expand). Note the first circle to remediate and the second to rescan
With the web client, it is important to refresh the screen after you remediate, as sometimes the host compliance is just not updated yet.
Unfortunately, there are still some configuration issues that show up within VMware vCenter (Figure 3), as well as within vCops as a Health issue and in HP Insight Control as an alert related to those items in Figure 4.

Figure 3: vCenter Configuration Issues
While it is possible to tell the tools to ignore the vCops and HP Insight Control issues, it is best to fix the problems by using the network interfaces to provide management network redundancy as well as to provide a spare NIC (Figure 4).

Figure 4: Root Cause of unlinked errors in vCops
To fix the management network redundancy issue, we can make use of vmnic6 on each host and attach it to a second administrative network with its own IP. Or we can ignore the error by following the instructions within KB1004700. Or, using the latest firmware from HP for Flex-10, we can prevent virtual NICs from showing up on the hosts. However, I prefer to assign these physical NICs so that I can remove one more cause for error from my systems and have less I need to remember to do when adding hosts. The last NIC we can attach to an alternative network for later use. Since this is all within my blade enclosures, the work takes place within the HP Virtual Connect Manager. Those steps are:
Step 1: Create two new Ethernet networks within HP Virtual Connect Manager
Being the creative soul I am, I created one Ethernet network that is named ADMIN2 and another named ALTERNATE. These names are really unimportant; you can use anything. I also tied ADMIN2 to an external network on the back of the blade enclosure (which took a bit of hands-on cabling and cable management to accomplish).
Step 2: Place a target node in maintenance mode, then power off
By placing the node in maintenance mode, you can safely migrate off all virtual machines to other nodes. The node needs to be powered off to manipulate the server profiles within HP Virtual Connect Manager. This is where SVMotion and vMotion come into play.
Step 3: Modify the server profile
Once the node is fully powered off, it becomes possible to edit the server profile within HP Virtual Connect Manager. Simply add the networks that have just been connected to the profile. This is accomplished by pressing the big “+” sign, then selecting the network names from the drop-down list.
Step 4: Apply the server profile
If the blade is fully powered down and everything is correct, then saving the profile will succeed. If not, then fix the other issues and re-apply the profile.
Step 5: Power on the blade
Power on the blade using the power switch, HP BladeSystem Onboard Administrator, or HP ILO power on the blade. I tend to want to do all my system maintenance from the comfort of my own desk.
Step 6: Meet the network redundancy requirements
Add a second vSwitch with a vmkernel management port on it. Give this second management port an IP address. Different subnets are just fine, as it is used by HA for heartbeat, etc. While I have network redundancy in hardware, this adds network redundancy in software and alleviates several problems.
Now repeat all these steps for all nodes, and you are just about good to go.
Step 7: Update host profile and verify compliance
The last step is to once more update the host profile from the source host and verify compliance using the vSphere Web Client. What I found odd once I applied the host profiles was that I had to go back into the security settings of each host and stop the ESXi Shell. I would have expected Host Profiles to take care of this for me, just like it did for the start and stop controls for the ESXi Shell.
Host Profiles has vastly improved, but it still has some problems here and there. It is extremely helpful when you want to keep systems the same from a networking, firewall settings, and advanced configuration perspective, but there are still issues with local storage and disabling services.
These changes allowed my systems to be compliant and removed all the warning icons from my hosts, some serious errors in other management tools, and a Health issue from within VMware vCenter Operations. This gives me a good baseline from which to see errors related to vSphere 5.5 and anything new with my underlying hardware.

 [Advertisement] BuildMaster 4.0 is here!
[Advertisement] BuildMaster 4.0 is here! 











 Karen Lopez")






{kind=link}
{kind=link}