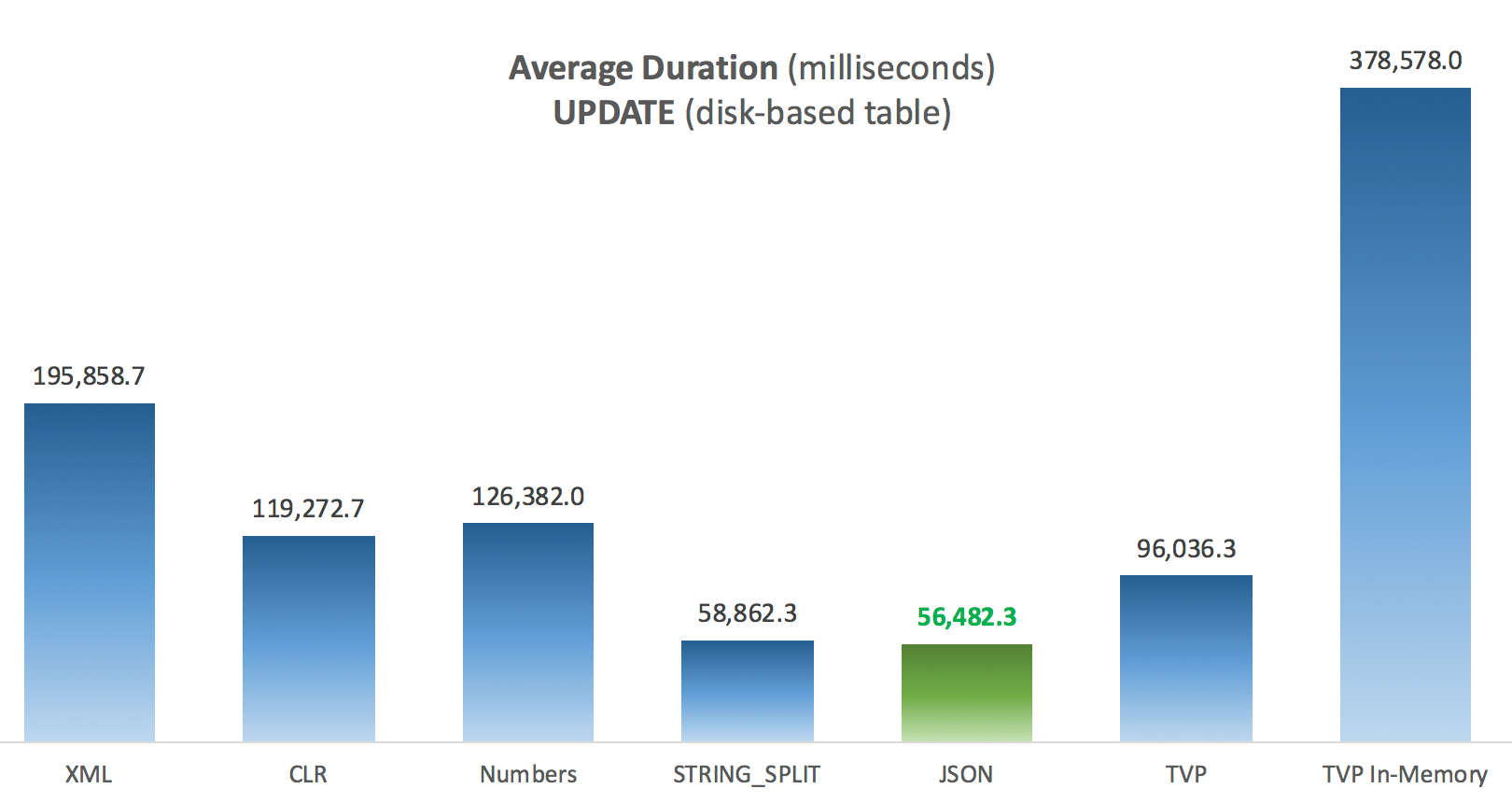
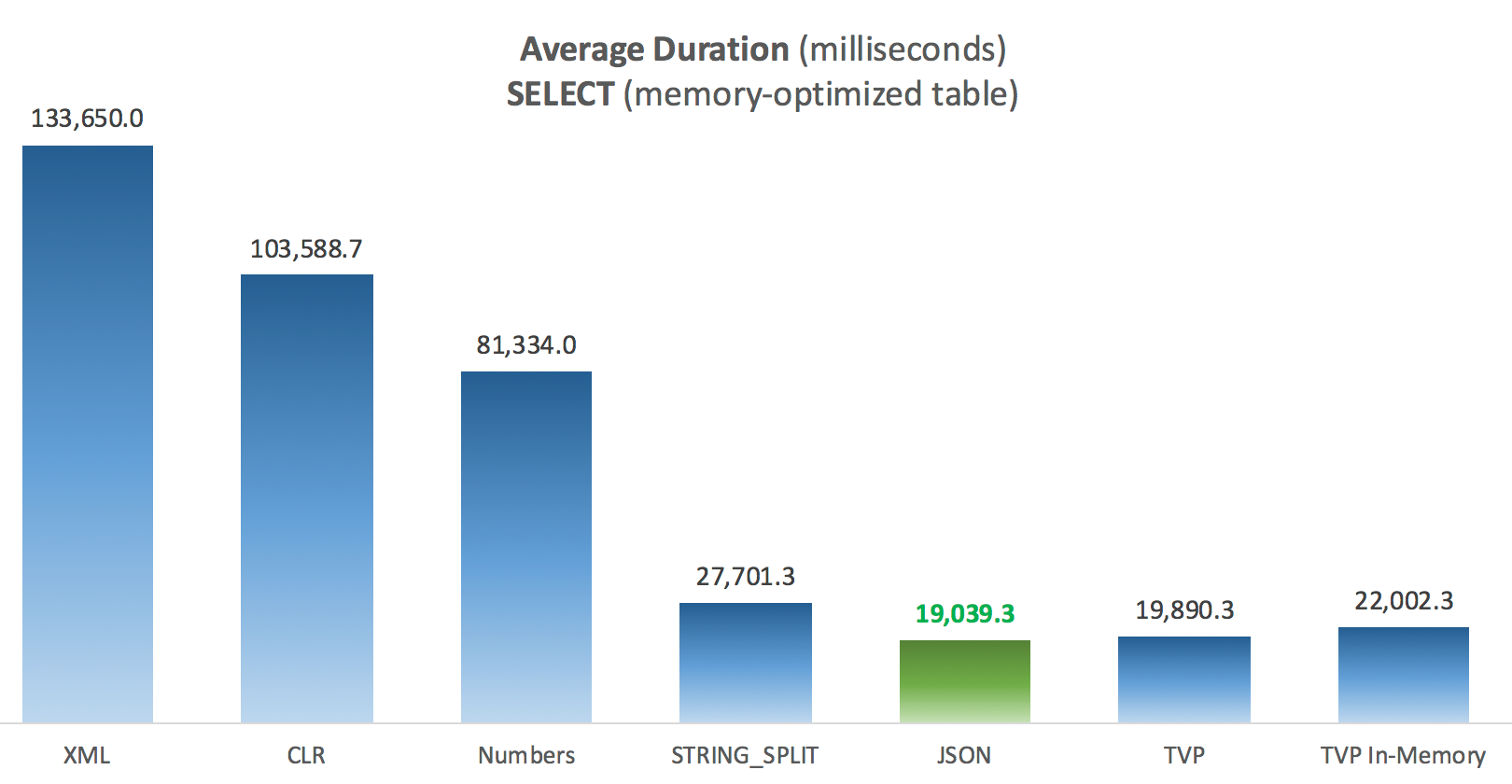
Since I started working on Discourse, I spend a lot of time thinking about how software can encourage and nudge people to be more empathetic online. That's why it's troubling to read articles like this one:
My brother’s 32nd birthday is today. It’s an especially emotional day for his family because he’s not alive for it.
He died of a heroin overdose last February.
This year is even harder than the last. I started weeping at midnight and eventually cried myself to sleep. Today’s symptoms include explosions of sporadic sobbing and an insurmountable feeling of emptiness. My mom posted a gut-wrenching comment on my brother’s Facebook page about the unfairness of it all. Her baby should be here, not gone. “Where is the God that is making us all so sad?” she asked.
In response, someone — a stranger/(I assume) another human being — commented with one word: “Junkie.”
The interaction may seem a bit strange and out of context until you realize that this is the Facebook page of a person who was somewhat famous, who produced the excellent show Parks and Recreation. Not that this forgives the behavior in any way, of course, but it does explain why strangers would wander by and make observations.
There is deep truth in the old idea that people are able to say these things because they are looking at a screen full of words, not directly at the face of the person they're about to say a terrible thing to. That one level of abstraction the Internet allows, typing, which is so immensely powerful in so many other contexts …
… has some crippling emotional consequences.
As an exercise in empathy, try to imagine saying some of the terrible things people typed to each other online to a real person sitting directly in front of you. Or don't imagine, and just watch this video.
I challenge you to watch the entirety of that video. I couldn't do it. This is the second time I've tried, and I had to turn it off not even 2 minutes in because I couldn't take it any more.
It's no coincidence that these are comments directed at women. Over the last few years I have come to understand how, as a straight white man, I have the privilege of being immune from most of this kind of treatment. But others are not so fortunate. The Guardian analyzed 70 million comments and found that online abuse is heaped disproportionately on women, people of color, and people of different sexual orientation.
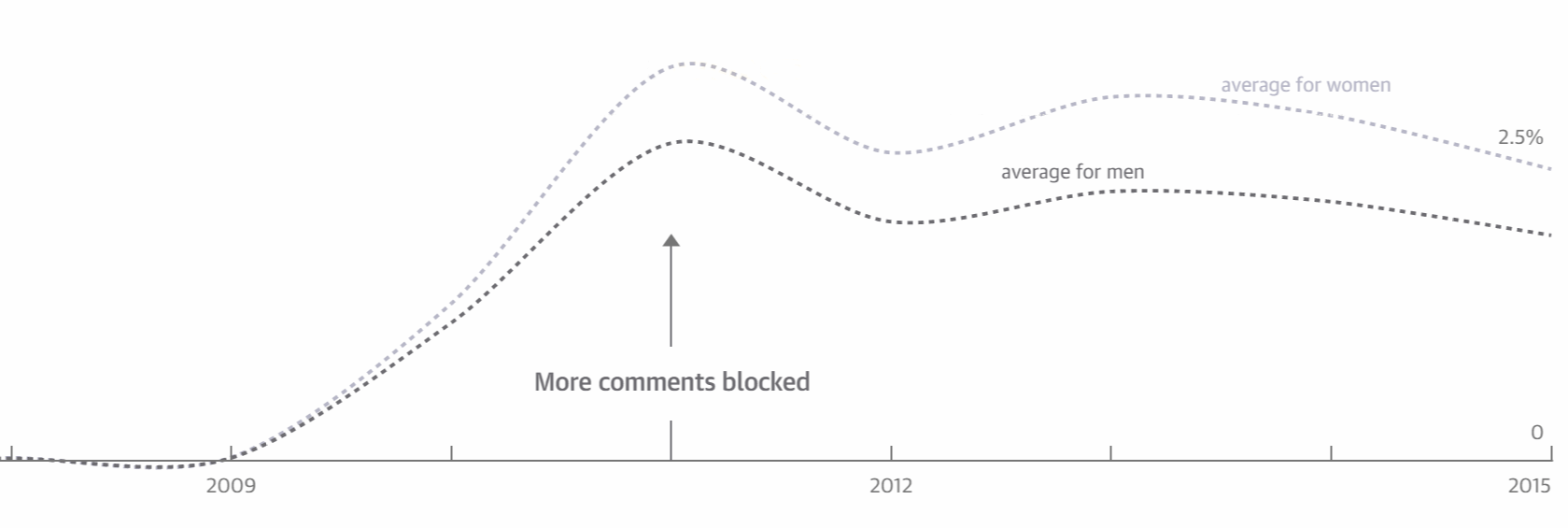
And avalanches happen easily online. Anonymity disinhibits people, making some of them more likely to be abusive. Mobs can form quickly: once one abusive comment is posted, others will often pile in, competing to see who can be the most cruel. This abuse can move across platforms at great speed – from Twitter, to Facebook, to blogposts – and it can be viewed on multiple devices – the desktop at work, the mobile phone at home. To the person targeted, it can feel like the perpetrator is everywhere: at home, in the office, on the bus, in the street.
I've only had a little taste of this treatment, once. The sense of being "under siege" – a constant barrage of vitriol and judgment pouring your way every day, every hour – was palpable. It was not pleasant. It absolutely affected my state of mind. Someone remarked in the comments that ultimately it did not matter, because as a white man I could walk away from the whole situation any time. And they were right. I began to appreciate what it would feel like when you can't walk away, when this harassment follows you around everywhere you go online, and you never really know when the next incident will occur, or exactly what shape it will take.
Imagine the feeling of being constantly on edge like that, every day. What happens to your state of mind when walking away isn't an option? It gave me great pause.

I admired the way Stephanie Wittels Wachs actually engaged with the person who left that awful comment. This is a man who has two children of his own, and should be no stranger to the kind of pain involved in a child's death. And yet he felt the need to post the word "Junkie" in reply to a mother's anguish over losing her child to drug addiction.
Isn’t this what empathy is? Putting myself in someone else’s shoes with the knowledge and awareness that I, too, am human and, therefore, susceptible to this tragedy or any number of tragedies along the way?
Most would simply delete the comment, block the user, and walk away. Totally defensible. But she didn't. She takes the time and effort to attempt to understand this person who is abusing her mother, to reach them, to connect, to demonstrate the very empathy this man appears incapable of.
Consider the related story of Lenny Pozner, who lost a child at Sandy Hook, and became the target of groups who believe the event was a hoax, and similarly selflessly devotes much of his time to refuting and countering these bizarre claims.
Tracy’s alleged harassment was hardly the first, Pozner said. There’s a whole network of people who believe the media reported a mass shooting that never happened, he said, that the tragedy was an elaborate hoax designed to increase support for gun control. Pozner said he gets ugly comments often on social media, such as, “Eventually you’ll be tried for your crimes of treason against the people,” “… I won’t be satisfied until the caksets are opened…” and “How much money did you get for faking all of this?”
It's easy to practice empathy when you limit it to people that are easy to empathize with – the downtrodden, the undeserving victims. But it is another matter entirely to empathize with those that hate, harangue, and intentionally make other people's lives miserable. If you can do this, you are a far better person than me. I struggle with it. But my hat is off to you. There's no better way to teach empathy than to practice it, in the most difficult situations.
In individual cases, reaching out and really trying to empathize with people you disagree with or dislike can work, even people who happen to be lifelong members of hate organizations, as in the remarkable story of Megan Phelps-Roper:
As a member of the Westboro Baptist Church, in Topeka, Kansas, Phelps-Roper believed that AIDS was a curse sent by God. She believed that all manner of other tragedies—war, natural disaster, mass shootings—were warnings from God to a doomed nation, and that it was her duty to spread the news of His righteous judgments. To protest the increasing acceptance of homosexuality in America, the Westboro Baptist Church picketed the funerals of gay men who died of AIDS and of soldiers killed in Iraq and Afghanistan. Members held signs with slogans like “GOD HATES FAGS” and “THANK GOD FOR DEAD SOLDIERS,” and the outrage that their efforts attracted had turned the small church, which had fewer than a hundred members, into a global symbol of hatred.
Perhaps one of the greatest failings of the Internet is the breakdown in cost of emotional labor.
First we’ll reframe the problem: the real issue is not Problem Child’s opinions – he can have whatever opinions he wants. The issue is that he’s doing zero emotional labor – he’s not thinking about his audience or his effect on people at all. (Possibly, he’s just really bad at modeling other people’s responses – the outcome is the same whether he lacks the will or lacks the skill.) But to be a good community member, he needs to consider his audience.
True empathy means reaching out and engaging in a loving way with everyone, even those that are hurtful, hateful, or spiteful. But on the Internet, can you do it every day, multiple times a day, across hundreds of people? Is this a reasonable thing to ask of someone? Is it even possible, short of sainthood?
The question remains: why would people post such hateful things in the first place? Why reply "Junkie" to a mother's anguish? Why ask the father of a murdered child to publicly prove his child's death was not a hoax? Why tweet "Thank God for AIDS!"
Unfortunately, I think I know the answer to this question, and you're not going to like it.
I don't like it. I don't want it. But I know.
I have laid some heavy stuff on you in this post, and for that, I apologize. I think the weight of what I'm trying to communicate here requires it. I have to warn you that the next article I'm about to link is far heavier than anything I have posted above, maybe the heaviest thing I've ever posted. It's about the legal quandary presented in the tragic cases of children who died because their parents accidentally left them strapped into carseats, and it won a much deserved pulitzer. It is also one of the most harrowing things I have ever read.
Ed Hickling believes he knows why. Hickling is a clinical psychologist from Albany, N.Y., who has studied the effects of fatal auto accidents on the drivers who survive them. He says these people are often judged with disproportionate harshness by the public, even when it was clearly an accident, and even when it was indisputably not their fault.
Humans, Hickling said, have a fundamental need to create and maintain a narrative for their lives in which the universe is not implacable and heartless, that terrible things do not happen at random, and that catastrophe can be avoided if you are vigilant and responsible.
In hyperthermia cases, he believes, the parents are demonized for much the same reasons. “We are vulnerable, but we don’t want to be reminded of that. We want to believe that the world is understandable and controllable and unthreatening, that if we follow the rules, we’ll be okay. So, when this kind of thing happens to other people, we need to put them in a different category from us. We don’t want to resemble them, and the fact that we might is too terrifying to deal with. So, they have to be monsters.”
This man left the junkie comment because he is afraid. He is afraid his own children could become drug addicts. He is afraid his children, through no fault of his, through no fault of anyone at all, could die at 30. When presented with real, tangible evidence of the pain and grief a mother feels at the drug related death of her own child, and the reality that it could happen to anyone, it became so overwhelming that it was too much for him to bear.
Those "Sandy Hook Truthers" harass the father of a victim because they are afraid. They are afraid their own children could be viciously gunned down in cold blood any day of the week, bullets tearing their way through the bodies of the teachers standing in front of them, desperately trying to protect them from being murdered. They can't do anything to protect their children from this, and in fact there's nothing any of us can do to protect our children from being murdered at random, at school any day of the week, at the whim of any mentally unstable individual with access to an assault rifle. That's the harsh reality.
When faced with the abyss of pain and grief that parents feel over the loss of their children, due to utter random chance in a world they can't control, they could never control, maybe none of us can ever control, the overwhelming sense of existential dread is simply too much to bear. So they have to be monsters. They must be.
And we will fight these monsters, tooth and nail, raging in our hatred, so we can forget our pain, at least for a while.
After Lyn Balfour’s acquittal, this comment appeared on the Charlottesville News Web site:
“If she had too many things on her mind then she should have kept her legs closed and not had any kids. They should lock her in a car during a hot day and see what happens.”
I imagine the suffering that these parents are already going through, reading these words that another human being typed to them, just typed, and something breaks inside me. I can't process it. But rather than pitting ourselves against each other out of fear, recognize that the monster who posted this terrible thing is me. It's you. It's all of us.
The weight of seeing through the fear and beyond the monster to simply discover yourself is often too terrible for many people to bear. In a world of heavy things, it's the heaviest there is.
|
[advertisement] At Stack Overflow, we help developers learn, share, and grow. Whether you’re looking for your next dream job or looking to build out your team, we've got your back.
|