For every line of code that ends up in software the general public sees or interacts with, for every line in your Snapchats and Battlezone: Call of Honor Duty Warfare, there are a thousand lines of code written to handle a supply chain processing rule that only applies to one warehouse on alternating Thursdays, but changes next month thanks to a union negotiation. Or it’s a software package that keeps track of every scale owned by a company and reminds people to calibrate them. Or a data-pump that pulls records out of one off-the-shelf silo and pushes them into another.
That’s the “iceberg” of software development. In terms of sheer quantity, most software is written below the waterline, deep in the bowels of companies that don’t sell software, but need it anyway. That’s the world of internal software development.
And internal software development, in-house software shops, have a problem. Well, they have lots of problems, but we’re going to focus on one today: Internal Billing and the Billable Hour.
At a first pass, internal billing makes sense. If you are a widget manufacturer, then you want the entire company aligned with that goal. If you buy raw materials, those raw materials are going into widgets. If you pay laborers, their labor should be going into making widgets. If you buy capital assets, they should be things like widget-stamping machines.

But you can’t just build widgets. Your workers need to organize via email. The new Widget-Stamper 9000 needs network connectivity, so you need network drops and routers and switches, which in turn need regular maintenance. This is, in pointy-haired-boss speak, “overhead”. You need it, but it doesn’t directly make widgets. It’s a cost center.
So what do large companies do? Well, they take all those “non-productive” activities and shuffle them off into their own departments, usually in a “corporate SBU”. Then all the departments doing “real” work get a budget to spend on those “cost centers”. And thus, internal billing is born.
Each employee needs an email account. Let’s assign that a cost, a rough—sometimes very rough—estimate of the total cost of managing the email account. Our corporate IT department will charge $20/yr per employee to cover the storage, configuration, management, and helpdesk support associated with their email account—and so on through the list of IT-related goods and services. Now the idea is that individual departments know their IT needs better than anyone else. By putting them in control of their IT budgets, they can spend their money wisely.
If you’re a widget-making company, you view software and IT support as an overhead cost, and recognize that you only have the capacity to pursue a certain number of IT projects, this makes perfect sense. Budgets and billing create a supply/demand relationship, and they give corporate the ability to cut overhead costs by controlling budgets. (Of course, this is all founded on the faulty assumption that in-house software development is simply overhead, but let’s set that aside for now.)
The problems start when internal billing meets software development, usually through the interface of the “billable hour”. The combination of these factors creates a situation where people who are ostensibly co-workers are locked into a toxic client/vendor relationship. The IT department is usually in a disadvantageous negotiating position, often competing against external vendors for a business department’s IT budget. Treating corporate IT as the preferred vendor isn’t all sunshine and roses for the business, either. There are definitely cases where external vendors are better suited to solve certain problems.
Putting IT resources on a billable hours system introduces a slew of bizarre side effects. For one thing, hours have to be tracked. That overhead might be relatively small, but it’s a cost. “Idling” becomes a serious concern. If developers aren’t assigned to billable projects, the IT department as a whole starts looking like it’s being non-productive. Practices like refactoring have to be carefully concealed, because business units aren’t going to pay for that.
Spending more billable hours on a project than estimated throws budgets out of whack. This forces developers into “adaptive strategies”. For example: padding estimates. If you can get an extremely padded estimate, or can get a long-running project into a steady-state where no one’s looking too closely at the charges, you can treat these as “banks”. A project starts running over your estimate? Start charging that work against a project that has some spare time.
Of course, that makes it impossible to know how much time was actually spent on a project, so forget about using that for process improvement later. It also makes every project more expensive, driving up the costs of internal development. This drives business users to seek external solutions, spending their IT budget outside of the company, or worse: to find workarounds. Workarounds like maybe just building a big complicated Excel spreadsheet with macros in it.
This isn’t even always restricted to hourly charges, either. I saw one organization that had a charge-back rate of $10,000/yr for a SQL Server database. That wasn’t licensing or hardware, that was just to create a new database on an existing instance of SQL Server. The result? Pretty much no business unit had a working test environment, and they’d often stack four or five different applications into the same database. Rarely, they’d use schemas to organize their tables, but usually you’d have tables like: Users, Users_1, UsersNew, UsersWidgetsoft, ___Users.
Forget about upgrades, even if they’re required. Short of making organization-wide modernization a capital project, no department or business unit is going to blow their IT budget on upgrading software that already works. For example, Microsoft still supports the VB6 runtime, but hasn’t supported the VB6 development environment since 2008. So, when the users say, “We need to add $X to the application,” IT has to respond, “We can’t add $X unless we do a complete rewrite, because we can’t support it in the state it’s in.” Either the business ends up doing without the feature or they make it a demand: “We need $X and we need it without a complete rewrite.” Then your developers end up trying to breathe life into a Windows 2000 VM without connecting it to the network in hopes that they can get something to build.
Billable hours turn work into a clock-punching exercise. Billing time is how you’re judged, and whether or not that time is spent effectively becomes less relevant. Often, by the end of the week, employees are looking for ways to fill up their hours. This is a task that should be easy, but I’ve watched developers agonize over how much they’re going to lie to make their timesheet look good, and hit their “85% billable” targets. This gets especially bizarre since you’re not self-assigning tasks, but you have to have 85% of your time billable, and thus you need to take the tasks you’ve been assigned and spend a lot of time on the billable ones to make sure you hit your targets, turning five-minute jobs into ten-hour slogs.
We could go on dissecting the problems with billable hours, and these problems exist even when we assume that you can just view your in-house software as a cost center. Some of these problems can get managed around, but the one that can’t is this harsh reality: software isn’t a cost center.
I’ve heard a million variations on the phrase, “we make widgets, not software!” Twenty years ago, perhaps even ten years ago, this may have been true. Today, if you are running a business of any scale, it simply is not. It’s trite to say, but these days, every business is an IT business.
One project I worked on was little more than a datapump application with a twist: the data source was a flow meter attached to a pipe delivering raw materials to a manufacturing process. The driver for reading the data was an out-of-date mess, and so I basically had to roll my own. The result was that, as raw material flowed through the pipe, the ERP system was updated in real-ish time with that material consumption, allowing up-to-the-minute forecasts of consumption, output, and loss.
How valuable was that? It’s not simply an efficiency gain, but having that sort of data introduces new ways of managing the production process. From allowing management to have a better picture of the actual state of the process, to helping supply chain plan out a just-in-time inventory strategy, this sort of thing could have a huge change on the way the business works. That wasn’t a skunkworks idea, that wasn’t IT just going off and doing its own thing. That was a real hook for business process improvement.
Smart companies are starting to figure this out. I’ve been doing some work for a financial services company that just hired a new CTO, and he’s turned around the “We make $X, not software,” and started his tenure by saying, “We are a software company that provides financial services.” Instead of viewing IT as a sink, he’s pushing the company to view IT as a tool for opening up new markets and new business models.
So, yes, IT is a cost of doing business. You’ll need certain IT services no matter what, often fulfilled with off-the-shelf solutions, but configured and modeled to your needs. IT can also be a cost savings. Automation can free up employees to focus on value-added tasks.
But the one that’s underestimated in a lot of companies is IT’s ability to create value-added situations. If you make widgets, sure, it’s unlikely that your software is going to directly change the process of making widgets, so it’s unlikely that your software is itself technically “value added”. But a just-in-time supply chain system is more than just a cost savings or an efficiency booster. It can completely change how you manage your production process.
By placing the wall of billable hours between IT and the business, you’re discouraging the business from leveraging IT. So here are a few ways that corporations and management could possibly fix this problem.
First, as much as possible, integrate the IT staff into the business-unit staff. This might mean moving some corporate IT functionality out into individual departments or business units (if they’re large enough to support it), or dedicating corporate staff to a relationship with specific business units. Turn IT workers into a steady flat cost, not a per-hour cost. When trying to handle priorities and deciding how to spend this limited resource to get new software developed, business-unit management can set priorities.
If an organization absolutely must use internal billing to set priorities and control demand for IT resources, move as much work as possible into fixed-rate, flat-fee type operations. If a business unit requests a new piece of software, build a fixed-bid cost for that project, not an hourly cost.
While a “20% time” approach, where employees are allowed to spend 20% of their time on their own projects, doesn’t work in these kinds of environments, an organizational variation where some IT budget is used on speculative projects that simply might not work—a carefully managed skunkworks approach—can yield great benefits. It’s also an opportunity to keep your internal IT staff’s skills up to date. When you’re simply clocking billable hours, it’s hard to do any self-training, and unless your organization really invests in a training program, it’s easy to ossify. This can also involve real training, not “I sent my drones to a class, why don’t they know $X by now?” but actual hands-on experimentation, the only way to actually learn new IT skills.
All in all: billable hours are poison. It doesn’t matter that they’re a standard practice, they drag your IT department down and make your entire organization less effective. If you’re in a position to put a stop to it, I’m asking you, stop this. If you can’t stop it, find someone who can. Corporate IT is one of the most important yet under-prioritized sectors of our industry, and we need to keep it effective.
 [Advertisement] Release!
is a light card game about software and the people who make it. Play with 2-5 people, or up to 10 with two copies - only $9.95 shipped!
[Advertisement] Release!
is a light card game about software and the people who make it. Play with 2-5 people, or up to 10 with two copies - only $9.95 shipped!






 [Advertisement]
Incrementally adopt DevOps best practices with
[Advertisement]
Incrementally adopt DevOps best practices with 








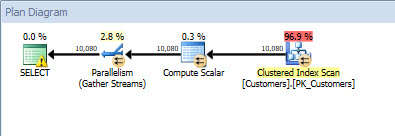

![Execution plan after changing stored procedure to remove [Active]](https://sqlperformance.com/wp-content/uploads/2017/02/planuseindex.jpg)



![Query plan after [Active] added to the index (plan_id = 50)](https://sqlperformance.com/wp-content/uploads/2017/02/9new-plan.jpg)