The days when you could listen to guilty pleasure music without consequence are over.
In the dark ages, people used to buy music in a store. But stores never knew how many times you played the album you bought, or a particular song on that album, and the closest we came to a music recommendation engine was a clerk doing his best impression of John Cusack in “High Fidelity.”
The world has changed. Today, many of us don’t even buy music digitally anymore, let alone in a store. We subscribe to streaming services and let our entire musical lives exist on an app.
So when the music streaming service Spotify — which I use almost exclusively these days — offered to to analyze my listening habits using a new tool it has developed, and algorithmically recommend new songs and artists to me, I immediately accepted.
Through its $100 million acquisition of The Echo Nest, a music data company, Spotify has cooked up an early prototype of an internal tool called Nestify to better analyze an individual’s listening history and recommend songs he or she might like. This is one of the first times the music streaming service has discussed the tool with a journalist or made it available to someone outside the company.208
And then I immediately regretted my decision. I recalled that I have terrible taste in music. Suddenly every drunken spin of Madonna was vivid in my mind. I remembered spending several days listening to boy bands for an article. And there was that time last summer when I listened to Miley Cyrus’s “We Can’t Stop” marathon-style, uh, preparing for a story. Yeah. That’s why.
Spotify knows not only what I listened to — a dossier of my crimes against authenticity — but how many times I’ve listened to it, what songs I’ve skipped, and what songs I listen to when. I visited the company’s New York office earlier this month to get my results. The Virgil to my Dante was Ajay Kalia, who’s in charge of developing this tool. He served as the interpreter of the findings and the spinner of mathematical proof that my taste in music is, sad to say, pretty basic.
Before conducting this experiment, I believed that there were essentially two broad types of music: the music you listen to, and the music you tell people you listen to. The second category comprises the songs shared on Facebook or Twitter, the shout-out to Neutral Milk Hotel in your OKCupid profile, the stuff you send your friends. As with most things, the image you try to present to the world is substantially more cultured and interesting than the mundane reality.
This analysis taught me that there are three categories of music: the music that you tell people you listen to, the music that you think you listen to, and the music that you actually listen to. And I was initially shocked to see the vast gulf between the second and third categories when I got the top-line results of Spotify’s analysis.
I’ve listened to a lot of songs on Spotify — 1,735 since January 2013, I’m told — so we have a pretty solid pile of data to work through. Here are my most-played songs, with the (occasionally shameful) play count listed:

Let’s dissect No. 5 briefly. “Let it Go,” a song from “Frozen,” Disney’s 2013 animated feature film, is 3 minutes and 44 seconds long, and playing it 107 times means that I’ve spent slightly more than six and a half hours of my life listening to Idina Menzel telling the world where to stick it. This is slightly less than four times the run length of the entire film.209
Some of the songs are by my favorite artists, such as The Mountain Goats, Supergrass and Arcade Fire. Others are tracks I’ve been really into lately, such as my personal song of the summer, “I Don’t Know How.”210 A bunch of songs are also on my starred list. For example, at No. 3 we see “Hooked On A Feeling,” which is entirely the fault of that “Guardians of the Galaxy” trailer.211
Now here are the artists I listened to most:

What’s interesting about this table isn’t really the names that emerge at the top of the list, but the data that comes along with them — the number of songs and number of plays — and what it means for how I consume different artists’ music.
“You can imagine a situation where we see a hundred plays of one song, something else where we see a hundred plays of ten songs, another we also see a hundred plays of a hundred songs,” Kalia said. “A hundred plays of one song means you just love this single. A hundred plays of ten songs means you’re just exploring and liking songs. A hundred songs and a hundred plays means you just let something run through the entire queue and never came back to it.”
Kalia was able to guess that some of these artists — Vitamin String Quartet and London Philharmonic Orchestra in particular — are playlists that I just run through. They have lots of plays, but also lots and lots of songs, with an average of only 6.2 plays per song for the London Philharmonic Orchestra and 11.5 plays per song for Vitamin String Quartet. Kalia inferred that it’s not that I absolutely love these artists, they’re just for a certain mood. And he’s right, because I listen to the Philharmonic’s covers of video game music and Vitamin String Quartet’s covers of pop music while grinding on long articles.212
On the other hand, I’ve only listened to a single song by Blue Swede — “Hooked On A Feeling” — but I’ve listened to it a lot, which Kalia interpreted not so much as my wanting to hear more Blue Swede but instead as my really liking that one song.
Then you’ve got an artist like The Mountain Goats. I’ve listened to many of their songs a lot — an average of 18.2 plays per song, with 34 songs total — and Kalia correctly interpreted this as my liking the band.
Nestify grabs my listening data and uses it to determine my “listening modes.” In other words, we all listen to different music at different times for different reasons. For example, I listen to certain music depending on whether I’m commuting, working or getting ready to go out. Spotify uses big data and clustering algorithms to figure out how the totality of music we consume breaks down into clusters of artists that correspond to these listening modes.
“A cluster is where we try to make sense of the different kinds of listeners you are,” Kalia said. Under the hood, the tool looks at the artists you listen to and weights them by how much affinity you have for them, based on play counts, and finds similarity among those artists. “So we have these little islands of artists that fit together,” he said.
Why does Spotify invest all this time and money into developing algorithms to find out what individual users like?
Using kneejerk Internet business model thinking, I first thought it was to find out more about the service’s users in order attract advertisers. But it turns out this isn’t the main reason. First, Spotify already knows a lot about its users because many have signed up with a Facebook account or filled in account details. Second, while teasing out a listener’s demographic details is theoretically possible — Brian Whitman, Spotify’s principal music scientist, has published research on how to determine things like political affiliation from a user’s taste profile — there’s still far too much uncertainty in the information for it to be practical from a business standpoint. And lastly, only part of Spotify’s business is tied up with advertisers. The rest is a subscription model.213
The company has found that the longer a non-paying user listens to Spotify, the more likely he or she is to become a paid subscriber. So one advantage of Nestify is that it could give non-paying listeners a better experience, keep them around longer, and thus convert them into paid subscribers.
But folks within Spotify have an even bigger vision for the technology: an app that plays exactly what you want to listen to when you want to listen to it. “We should get good enough that you don’t have to take your phone out of your pocket to get the right stuff,” said Jim Lucchese, the CEO of The Echo Nest.
The team is considering lots of next steps for the prototype, including time-stamping. For example, what you listened to recently should be weighted more heavily in the analysis than what you listened to a couple of weeks ago.
The long-term goal is to find out even deeper stuff: What do you listen to on Friday nights compared to what you listen to on weekday mornings? What did you listen to nonstop for a weekend and then never touch again? The idea is that the service can get to know your preferences so well that it’s able to figure out that you want to hear high-BPM music because it’s Wednesday night at the gym, or string bands because you’re working, or “Let it Go” three times first thing in the morning because that’s how you get psyched up for work. Nestify is the proof of concept for complete predictive personalization.
Two large clusters formed in the analysis of my listening history. Kalia called them “Cluster A” and “Cluster B,” but I’m going to refer to them as “The Shame Cluster” and “The Indie Cluster.”
 The Shame Cluster artists include Lana Del Rey, Blue Swede, Miley Cyrus, The Bangles, Madonna, Kesha, Blondie, Lorde, Pat Benatar, Robin Thicke, Andrew W.K., The Cure, Soft Cell and Billy Joel. At left are the five genres (as determined by Spotify) in this cluster with the strongest weights.
The Shame Cluster artists include Lana Del Rey, Blue Swede, Miley Cyrus, The Bangles, Madonna, Kesha, Blondie, Lorde, Pat Benatar, Robin Thicke, Andrew W.K., The Cure, Soft Cell and Billy Joel. At left are the five genres (as determined by Spotify) in this cluster with the strongest weights.
This means that 44 percent of the artists in the cluster were tagged as “pop,” and so on. In other words, pop accounts for less than half the music within the cluster. It’s a diffuse group of artists. “It’s sort of pop through the ages. A lot of female, a lot of pop, but not exclusively any of those,” Kalia said.
This cluster, Kalia said, is bigger than the Indie Cluster, in terms of how much I listen to it, but he said he believed my musical identity was less tied to it.
Now let’s look at the Indie Cluster, the category of music I tell people I listen to. Artists include The Mountain Goats, Arcade Fire, Supergrass, LCD Soundsystem, CHVRCHES, Generationals, Matt & Kim, The Strokes, Pulp, Blow, Neutral Milk Hotel, STRFKR, The Shins and Vampire Weekend.

The five genres in this cluster that had the strongest weights are listed in the table to the left.
Because 82 percent of the artists fell under one category, indie rock, Kalia observed that this cluster was a very tight group of artists centered around a specific sound.
“Based on the fact that you have a lot of songs for these, you do a lot of sampling,” Kalia surmised. “This is a little closer to your musical identity.” He’s right.
Finally, there was a large chunk of music that didn’t fit into either cluster or form its own. This included London Philharmonic Orchestra, Vitamin String Quartet and a lot of soundtracks. “It’s not so much that you like classical music per se, but there are particular kinds of music or movies or soundtracks or TV shows that you like,” Kalia said. “But if we just had a station that was generic classical — even though these are classical performances — you wouldn’t necessarily want that.”
This finding — that I have three main listening modes — was oddly comforting. Setting aside the classical stuff, it’s a Jekyll and Hyde situation. Sometimes Jekyll has a couple bourbons, forgets about his love for lo-fi and cranks some Miley. Surely everyone does it. Can’t be helped.
Through analyzing all this listening data, Spotify was able to recommend some playlists of music that it thinks I would like.
Normally when you create a radio station in Spotify, you feed in one song or one artist. Nestify feeds in an entire weighted cluster to generate three playlists: a “My Music” playlist, which is tightly focused on songs I’ve already played a lot; a “Discovery” playlist, made up of artists and songs that are outside the cluster but similar to ones inside the cluster; and a “Default” playlist, which comes somewhere in between the two extremes.
The three playlists for the Shame Cluster — the one loosely congregated around pop music — weren’t that interesting. It’s not so much that the playlists didn’t do what they were designed to do, but the stuff in that cluster is so well known that I was already familiar with the artists it recommended.214 I liked the music, but I wasn’t hearing that much new stuff.
The playlists designed around the Indie Cluster were more interesting. For both the Default and Discovery playlists, I listened to and rated each song on a simple three-point scale — disliked, neutral, liked — and also indicated whether the song was brand new to me or not. (For instance, the Default playlist included the Neutral Milk Hotel song “In The Aeroplane Over The Sea,” which I already knew and enjoyed, but I can’t really count that against it.)
The Default playlist contained some of the usual artists I listen to, but kind of suffered from diving too deep into their catalogs. Essentially, in trying to remain within the cluster, it recommended some songs from artists I loved that were not those artists’ best work. The new artists spun in were a bit hit or miss, but if I liked them, I really liked them.
I was really surprised at how much I enjoyed the music on the Discovery playlist.

The verdict? The algorithm nailed it. I liked two-thirds of the stuff on each playlist, regardless of my familiarity with the songs. By basing its recommendations on the stuff I listen to rather than a pre-set genre search — the way that many Internet song recommendations work, including Spotify’s — Nestify was able to predict pretty much exactly the kind of sound I like.
Before all this, I had a concept of my musical identity. But when I got to look at what I actually listened to, I was momentarily thrown for a loop (I didn’t realize I was listening to so much Shame Cluster!). And yet, the algorithm still appeared to figure out what I value as a listener, and its recommendations were very much on point.
Even though Spotify knows exactly what I listen to, the service can’t just ask me what I think my musical identity is, partly because that seems a bit flirty for a music app, but also because I might not really know. Whether we realize it or not, our actual musical identities are often all over the map.

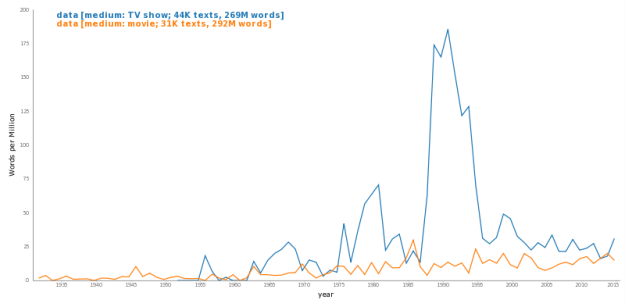
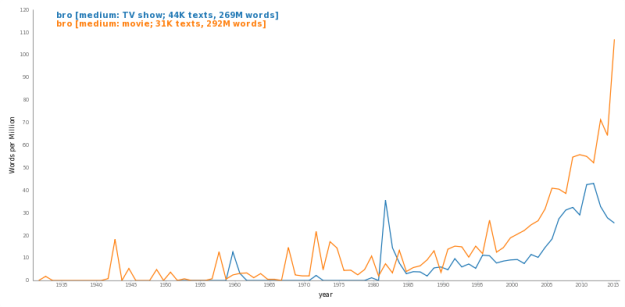
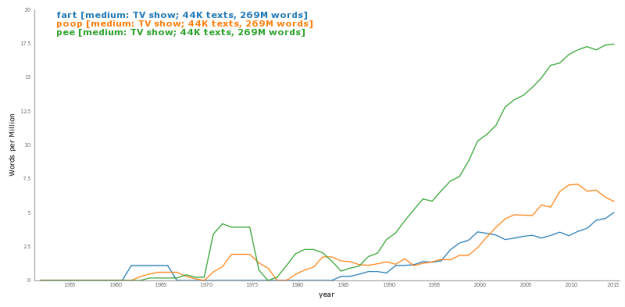





--and score the kids today versus the kids 20 years ago on various objective measures of writing quality. I've heard the idea that exposure to all this amateur peer practice is hurting us, but I'd bet on the generation that conducts the bulk of their social lives via the written word over the generation that occasionally wrote book reports and letters to grandma once a year, any day.")

























.jpg#File:Macaca_nigra_self-portrait_.28rotated_and_cropped.29.jpg){kind=link}