In Pieces by designer Bryan James is an animated piece that uses simple geometric shapes to depict thirty endangered species.
Each species has a common struggle and is represented by one of 30 pieces which come together to form one another. The collection is a celebration of genic diversity and an attempting reminder of the beauty we are on the verge of losing as every moment passes. These 30 animals have been chosen for their differences, so that we can learn about species we didn't know about previously as well as the struggles they have surviving. Many of them evolved in a particular way which makes them evolutionarily distinct.
Did you know that The Simpsons is still running? The show is coming up on the end of its 26th season, the finale of which will be its 574th broadcast episode.
Did you know that The Simpsons was recently renewed for two more years? Seasons 27 and 28 were picked up earlier this month.
And did you know that Harry Shearer, one of the six principal voice actors and the person behind Mr. Burns, Smithers, Ned Flanders, Principal Skinner, Dr. Hibbert, and literally dozens of other recurring and one-shot characters, just announced that he'll be leaving the show? He won't be joining the rest of the cast for the 27th and 28th seasons, and longtime showrunner Al Jean has already confirmed to CNN Money that his characters will now be voiced by "the most talented members of the voice-over community." Whether anyone will be able to tell the diddly-ifference remains to be seen.
Promoted tweets have been part of the Twitter service since 2010, and they've allowed advertisers to pick and choose who sees specific ads based on "what a user chooses to follow, how they interact with a Tweet, what they retweet, and more." But users have found how loosely those ads are monitored or filtered before they reach users' eyeballs—and how cheap, fast, and easy the system can be exploited to annoy users as opposed to "engaging" them.
On Monday, hacker Andrew "weev" Auernheimer explored these vulnerabilities at length while paying for a promoted tweet of his own—one that asserted that white people should "defend ourselves from violence and discrimination." His Storify post on the matter made his trolling intent clear: he wanted "to see what women and minorities think about [the tweet]."
"I decided to spend a few pennies on Twitter ads today," his post started, and he asserted that the platform's pricing structures "don't seem to take into account that one might want only to generate negative reactions to ad campaigns." Though Auernheimer didn't say exactly which users/groups he chose to target in his trolling campaign, he listed examples that appeared to jive with the sample of angry responses that followed: people who are active in Democratic political campaigns or animal rights groups; women who shop for fine jewelry; followers of known feminist sites like Jezebel and Feministing.
A Florida woman used the comments section of a Pizza Hut order made from her smartphone on Monday afternoon to alert authorities that she and her children were being held hostage. When police responded to her message, arriving at the location, she and her children were quickly released, unharmed, and the kidnapper was arrested.
According to a Highlands County Sheriff's Office press release, Cheryl Treadway, a woman from Avon Park, about 85 miles southeast of Tampa, had been arguing most of the day with her boyfriend, Ethan Nickerson, who carried "a large knife."
As Charles Wonderlic drove from the NFL Scouting Combine in Indianapolis to his company’s headquarters near Chicago on February 27, 2011, he made the mistake of turning on a sports radio show. The host, as Wonderlic remembers, was talking about Alabama quarterback Greg McElroy’s near-perfect Wonderlic score. Each winter, hundreds of football prospects take the multiple-choice test that claims to measure their intelligence. Results are supposed to be kept confidential, yet they always seem to become media fodder.
In reality, there’s no way anyone could’ve known McElroy’s score. On that day four years ago, as reports of McElroy’s supposed feat trickled out, sealed boxes containing every single Wonderlic answer sheet were sitting in Charles Wonderlic’s car, still unscanned. Wonderlic, Inc. didn’t send an encrypted file of the players’ results to the NFL until March 1. Unsurprisingly, a variety of news outlets ran with the story anyway.46 The months leading up to the NFL Draft feel like election season: Everybody’s trying to dig up dirt on candidates.
“Are we just so starved for information this time of year that we search for anything?” wondered NFL Scouting Combine director Jeff Foster, who only agreed to be interviewed for this article after I assured him that I wouldn’t be reporting individual Wonderlic scores.
In an era when the NFL schedule release is treated like the premiere of the new “Star Wars,” the answer to Foster’s question is a resounding “yes.” We crave even the smallest bits of information about players entering the NFL Draft, even if it’s not meant for our consumption. Forget Foster’s estimate that half the Wonderlic scores he sees in news stories are incorrect. As long as the test is administered at the Combine, media and fans will fixate on it.
“The only person it impacts is the player,” Foster said of a leaked Wonderlic score. “How would you like to be branded unintelligent because you scored a 5 on an intelligence test?”
The story of the Wonderlic, however, is more than just a range of easily regurgitated numbers. It’s the story of how one guy’s American Dream helped shape a new American pastime.
But before we get there, let’s first look at what the Wonderlic purportedly tests. “What we’re measuring is not what you know — that’s what’s being measured on the ACT or the SAT,” said Charles Wonderlic, president and CEO of Wonderlic Inc. “This is really saying, ‘How quickly does your brain gather and analyze information?’” The 12-minute Wonderlic Personnel Test (WPT) features 50 questions arranged by difficulty, lowest to highest. Here’s a sample:
Jose’s monthly parking fee for April was $150; for May it was $10 more than April; and for June $40 more than May. His average monthly parking fee was ___ for these 3 months?
A player’s Wonderlic score is always a number between 1 and 50, and across all professions, the average score is approximately 21. (Systems analysts and Chemists top the scale 32 at 31, respectively.) For pro football players, the oft-citednumber is about 20. Tracking down the average scores by position is tricky, mainly because the buttoned-up NFL isn’t interested in sharing any broad Wonderlic data. In an email, Charles Wonderlic said that while his company has published “norms” for other industries, “we maintain the confidentiality of test scores for single organizations. Since the NFL is the only client by which we can produce a quarterback average, we would need their permission to provide this information. Traditionally, the NFL prefers to keep any information about tests scores internal to their own organization.”
Like Wonderlic, Inc., the NFL declined to provide any historical data related to NFL players’ test scores for this piece.
For his 198448 classic “The New Thinking Man’s Guide to Pro Football,” Sports Illustrated writer Paul “Dr. Z” Zimmerman did get one anonymous staffer to spill some then-current averages. Offensive tackles led the way at 26, then came centers (25), quarterbacks (24), offensive guards (23), tight ends (22), safeties and middle linebackers (21), defensive linemen and outside linebackers (19), cornerbacks (18), wide receivers and fullbacks (17), and halfbacks (16). And what about place kickers and punters? “Who cares?” the source said.
On its own, a solid Wonderlic score means little. Like a 40-yard dash time, it provides one tiny, standardized data point to employers who presumably take a holistic approach to hiring. But because teams have decades of data on file, they can compare the Wonderlic scores of current college players entering the draft to those of past prospects. “They simply use it to find the extremes,” Foster said. A very low score or a very high score, he added, could lead teams to conduct more testing or look into the prospect more closely.
“Wonderlic gives you an area to investigate,” the late New York Giants general manager George Young told the Philadelphia Daily News in 1997. “If a guy doesn’t have a good score on the test, you don’t say he’s not smart. But you go in and investigate and find out [why he scored low]. You go in and talk to his coach. You find out how he did in school. You find out how he retains. If you think he’s a poor reader and did poorly because it was a verbal test, you give him a non-verbal test.”
The most famous extreme occurred in 1975, when Harvard receiver and punter Pat McInally49 reportedly scored a perfect 50 on the Wonderlic. The Cincinnati Bengals picked him in the fifth round of that year’s draft, but not before his reputed intelligence reportedly scared some teams away. In 2011, McInally told the Los Angeles Times that Young informed him that acing the Wonderlic “may have cost you a few rounds in the draft because we don’t like extremes. We don’t want them too dumb and we sure as hell don’t want them too smart.”
That slightly paleolithic line of thinking, however, wasn’t shared by everyone. “I don’t care about that stuff,” the late Raiders owner Al Davis said in “The New Thinking Man’s Guide to Pro Football.” “If a kid is street smart, that’s enough. Our coaches’ job is to make a kid smarter. I just wonder if they checked some of the coaches’ IQs around the league, how high they’d score.”
By now, the value of the Wonderlic has been debated so vigorously, especially among NFL executives, that it’s easy to forget that the test wasn’t designed for football.
Eldon Wonderlic.
Wonderlic Inc.
What it was designed for was something more basic. In the 1930s, Eldon “E.F.” Wonderlic — friends called him Al — was working as the director of personnel at consumer loan provider Household Finance Corporation.50 His employer was looking for a more efficient way to hire entry-level workers at its branches, so it sent Wonderlic to graduate school at Northwestern in hopes that his research would yield a solution to the problem.
E.F. Wonderlic acknowledged that the single best predictor of job performance was previous work experience. But as Charles Wonderlic put it: “How do you predict someone’s performance if they have never done that job before?” The second-best predictor of job performance, E.F. Wonderlic reasoned, was cognitive ability.
“What he found was that different jobs had different cognitive demands ranging from very low to very high,” said Charles Wonderlic, E.F.’s grandson. “And there were really distinct IQs around each job. And the further away you got from that distribution, that’s when you started to experience problems.”
The original Wonderlic Personnel Test was born out of that theory. The first copyrighted version of the test appeared in 1937. Its brevity and simple scoring system, Charles Wonderlic said, allowed virtually any manager to both administer the test and interpret scores. (This is also the likely reason for modern pundits’ love of Wonderlic scores: They’re easy talking points.)
After a stretch at Douglas Aircraft Corporation during World War II, E.F. Wonderlic worked in finance and sold copies of his test. He didn’t advertise, but eventually big companies like Spiegel and AT&T started calling. In 1961, E.F. Wonderlic left his job as president of General Finance Corporation and founded E.F. Wonderlic & Associates. By then, Charles Wonderlic said, an estimated 4 million people a year were taking the WPT.
In the early 1960s, Gil Brandt was a young scout with the expansion Dallas Cowboys. “We were not a very good team,” he told me. His bosses, general manager Tex Schramm and coach Tom Landry, were looking for ways to change that. After doing some research, Brandt said that the trio determined that successful businesses used the Wonderlic and the team should, too. It’s unclear exactly when the Cowboys began testing players. Brandt did say that at some point during the ’60s, he remembers watching spring practice at Northwestern and then stopping by the Wonderlic headquarters to learn more about the company.
By the late ’60s, George Young was an ambitious personnel assistant for the Baltimore Colts. He’d been a public school teacher before transitioning to football full time, and he asked the head of the guidance department in Baltimore for a handful of different tests to peruse. Of the 10 he reportedly looked at, the Wonderlic stuck out, and soon the Colts began using it.
Other teams followed suit by the 1970s, and the NFL eventually began to use it to assess college players en masse. Since 2007, Wonderlic, Inc. staff members have traveled annually to Indianapolis to administer the test at the Scouting Combine.
But the Wonderlic is not without its detractors. Charles Wonderlic estimated that since the test’s inception nearly 80 years ago, it has faced legal scrutiny hundreds of times.
In the summer of 1965, when the Equal Employment Opportunity Commission began operations a year after it was established by the Civil Rights Act of 1964, the Duke Power Company in Draper, North Carolina, began allowing its black employees to work in its higher-paying divisions. Until that point, black employees had only been permitted to work in the low-paying Labor department. Duke Power also instituted a policy that required all new applicants51 to have a high school diploma and pass two aptitude exams: the Bennett Mechanical Comprehension Test and the Wonderlic Personnel Test.
These measures crippled the efforts of black workers to advance. At the time, the percentage of white men who both possessed a high school diploma and were able to pass the two aptitude tests was significantly higher52 than the percentage of black men who met the same criteria.
Griggs v. Duke Power Co., a U.S. Supreme Court case argued in 1970, condemned the company’s requirements. Not only did they disproportionately affect black workers, but they also failed to show “a demonstrable relationship” to job performance, Chief Justice Warren Burger wrote in the majority opinion. He also noted that nothing in the Civil Rights Act “precludes the use of testing or measuring procedures; obviously they are useful.”
“How determinative it is depends on the club,” former Giants general manager Ernie Accorsi told ESPN.com in 2013, “but it’s usually not ‘the’ determinative factor.”
When it comes to football, is the test a demonstrably reasonable measure of job performance? Because official NFL Wonderlic scores aren’t publicly available, it’s difficult to know for sure, but that hasn’t stopped researchers from attempting to find out. Brian D. Lyons, Brian J. Hoffman, and John W. Michel53 co-authored a 2009 study examining the reported54 Wonderlic scores of 762 NFL players from three draft classes. They found that there was little correlation between Wonderlic scores and on-field performance, except for two positions: Tight ends and defensive backs with low scores actually played better than those with high scores. The researchers surmised that this “could be explained by the notion that performance for these positions entails more of an emphasis on physical ability and instinct” than general mental ability.
Today, the NFL continues to ask potential draftees to take the Wonderlic, although the test now has company. In 2013, the league introduced the Player Assessment Tool, which was developed by attorney Cyrus Mehri, whose report led to the implementation of the NFL’s Rooney Rule, and psychology professor Harold Goldstein. Louis Bien of SB Nation recently reported that the PAT is a 50-minute exam that examines a player’s football smarts, psychological attributes, learning style and motivational cues. “Players are not given a numeric score, unlike on the Wonderlic, so technically there is no way to do poorly on it,” Bien wrote.
Mehri’s hope is that the new test can measure what the Wonderlic can’t. “This kind of levels the playing field from a socio-economic point of view,” he told USA Today. “A lot of guys may be very intelligent, but are not as book-smart as others. Someone may not be the best reader, but they can still be very smart in picking up things.”
As long as the Wonderlic is administered at the NFL Scouting Combine, Foster, the Combine director, will be fielding questions about it — and shaking his head at leaked scores. “It has some value,” he said of the test. “It does not have near the value of what we spend talking about it between February and May.”
After all, a high or low score won’t automatically doom or anoint a prospect. Just ask Greg McElroy. After doing exceptionally well on the Wonderlic in 2011, the New York Jets picked the quarterback in the seventh round of the draft. Before announcing his retirement in 2014, he played in a total of two NFL games.
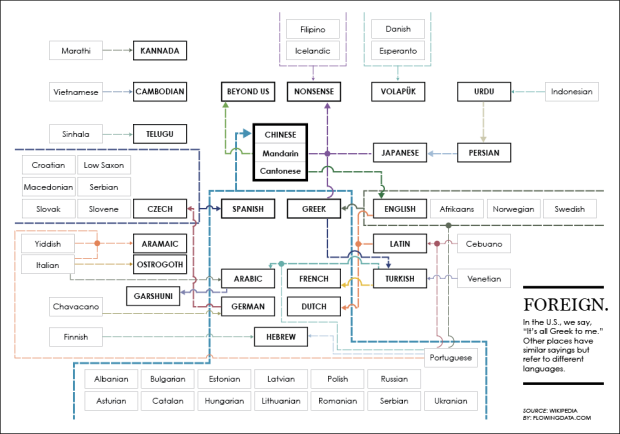
In English, there's an idiom that notes confusion: "It's all Greek to me." Other languages have similar sayings, but they don't use Greek as their point of confusion, and of course — there's a Wikipedia page for that. Mark Liberman graphed the relationships several years ago, but the table on Wikipedia references more languages now. So I messed around with it a bit.
"Chinese" is the leading point of confusion, then Spanish and Greek, and then you just move out from there. Languages with lighter border and towards the edges don't have any other languages that point to them.
Obviously the Wikipedia page isn't comprehensive, but hey, it was fun to poke at.
Grooveshark, the free online music streaming service that allowed users to upload their own songs, announced on Thursday that it was shutting down.
Josh Greenberg and Sam Tarantino founded the streaming service in 2006, and the site attracted tens of millions of users. Grooveshark called itself "the world’s largest on-demand and music discovery service." But the service not only allowed users to upload any song; the founders also apparently demanded that employees upload popular songs in an effort to expand the site's music library.
The service came under fire in recent years for allowing copyrighted material on the site. Several record companies, including Warner Bros., Sony, and Universal Music Group, sued Grooveshark in 2011. Now the record companies have come to an agreement with Grooveshark under which it shut down the site and removed all copyrighted songs.
Yesterday, by a party-line vote, Republicans in the House Committee on Science, Space, and Technology approved a budget authorization for NASA that would see continued spending on Orion and the Space Launch System but slash the agency's budget for Earth sciences. This vote follows the committee's decision to cut the NSF's geoscience budget and comes after a prominent attack on NASA's Earth sciences work during a Senate hearing, all of which suggests a concerted campaign against the researchers who, among other things, are telling us that climate change is a reality.
The recently approved budget would cover 2016 and 2017, and it contains two scenarios based on the degree to which the overall budget is constrained. An analysis of the bill shows that it would keep spending in line with the Obama administration's request but shift money from basic sciences to human exploration. The Orion crewed capsule and Space Launch System rocket would both see an addition of hundreds of millions of dollars. Planetary science would also see a boost of nearly $150 million.
But the love of planets doesn't extend to our own. The added spending is offset by a huge drop in spending on Earth science, from $1.947 billion under Obama's proposal to $1.45 billion under the optimistic budget. If budget constraints kick in, it would drop to $1.2 billion—a cut of nearly 40 percent. Development of space technology would also take a hit of about $125 million.
SAN FRANCISCO—At Microsoft's Build conference here today, corporate vice president of Microsoft's machine learning unit Josephe Sirosh discussed some of the applications already leveraging data analytics and machine learning services in Microsoft's Azure cloud. Among the early adopters: Japanese cows.
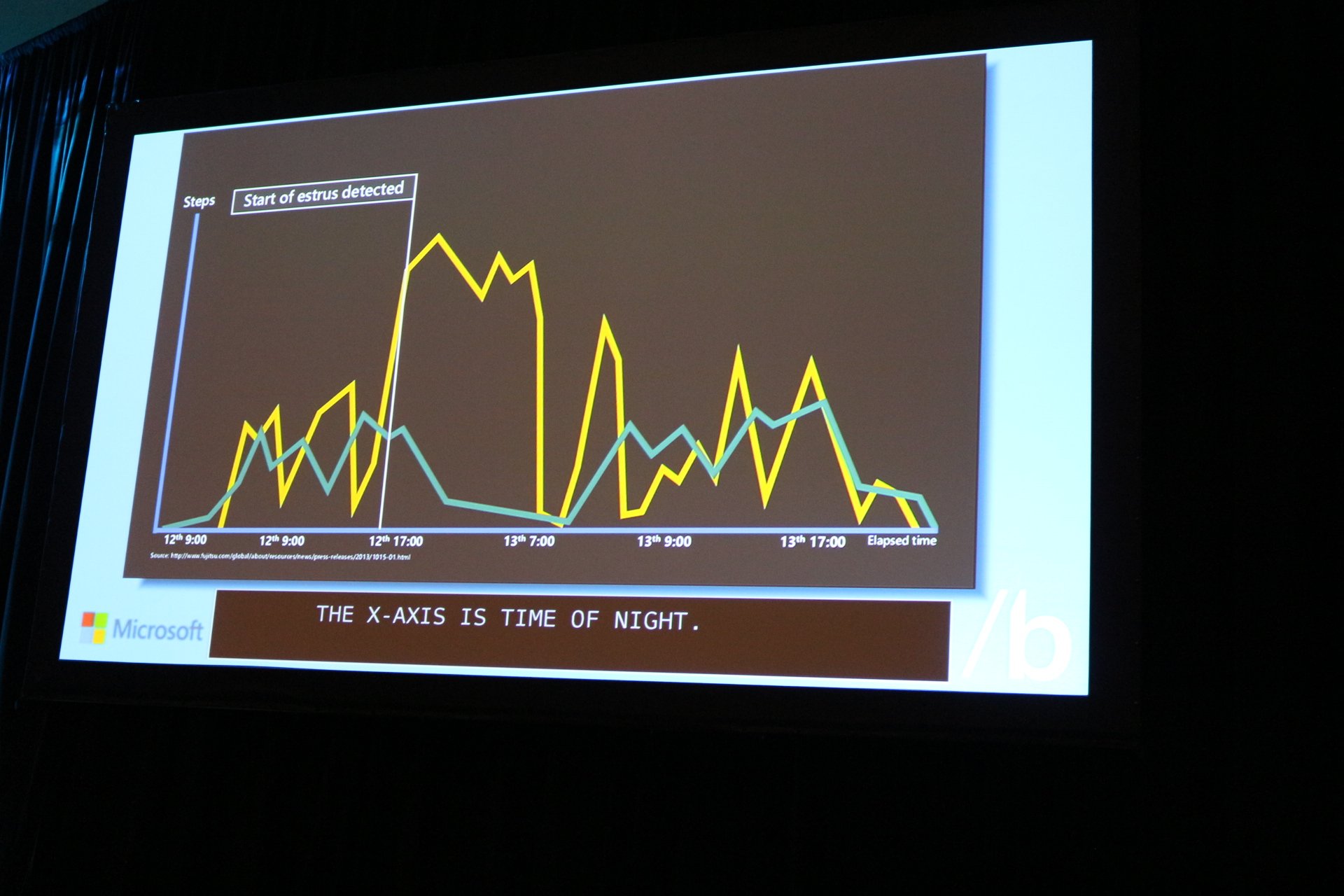
In 2013, Fujitsu introducedGyuHo SaaS, a cloud-based system for dairy farmers that helps track the health of their herds through Wi-Fi connected pedometers—essentially giant Fitbits for cows. The time and movement data can help farmers not only track the general health of cattle, but can also help track when cows are going into estrus (a condition more commonly known as "heat").
Fujitsu built the data analytics for GyuHo (which is Japanese for "cow step") in the Azure cloud. Using Azure machine learning logic, the software-as-a-service application can detect spikes in movement activity at night that are an indicator that a cow is going into estrus and is ready for artificial insemination. Sirosh said that by alerting farmers when data suggested estrus was beginning (which the system can do with 95 percent accuracy), they could raise their successful insemination rate from about 30 percent, based on daily hands-on cow inspection, to 65 percent.
HAWTHORNE, Calif.—In the sleek warehouse of Tesla’s Design Studio, CEO and co-founder Elon Musk announced the company’s latest products—a line of stationary batteries for households and utilities meant to store energy so that it can be used when energy is scarce and/or expensive.
The home stationary battery will be called the Powerwall, and it will cost $3,500 for a 10kWh unit. That unit is optimized to deal with serving a house if the traditional power grid goes down. A cheaper, $3,000 version will have a 7kWh capacity, and it will be able to help a house with solar panels deal with the daily fluctuations in energy supply.
The prices don't include installation, and Tesla said it would be working with certified installers, including SolarCity and others. Musk said that leasing the battery would be an option, and that the price point was "without any incentives" from local, state, or federal governments.
An artist who hid in his apartment's shadows and deployed a telephoto lens to photograph his neighbors through their glass-walled apartment is not liable for invading their privacy, a New York state appellate court has ruled.
The appeals court called it a "technological home invasion" but said the defendant used the pictures for art's sake. Because of that, the First Department of the New York Appellate Division ruled Thursday in favor of artist Arne Svenson, who snapped the pics from his lower Manhattan residence as part of an art exhibit called "The Neighbors." The ruling says:
In this action, plaintiffs seek damages and injunctive relief for an alleged violation of the statutory right to privacy. Concerns over privacy and the loss thereof have plagued the public for over a hundred years. Undoubtedly, such privacy concerns have intensified for obvious reasons. New technologies can track thought, movement, and intimacies, and expose them to the general public, often in an instant. This public apprehension over new technologies invading one's privacy became a reality for plaintiffs and their neighbors when a photographer, using a high-powered camera lens inside his own apartment, took photographs through the window into the interior of apartments in a neighboring building. The people who were being photographed had no idea this was happening. This case highlights the limitations of New York's statutory privacy tort as a means of redressing harm that may be caused by this type of technological home invasion and exposure of private life. We are constrained to find that the invasion of privacy of one's home that took place here is not actionable as a statutory tort of invasion of privacy pursuant to sections 50 and 51 of the Civil Rights Law, because defendant's use of the images in question constituted art work and, thus is not deemed "use for advertising or trade purposes," within the meaning of the statute.
The appeals court said that beginning in 2012, Svenson, whose works have appeared in museums and galleries in the United States and Europe, began "hiding himself in the shadows of his darkened apartment" to snap the pictures of his neighbors.
Murray Hill, NJ—When the Nobel Prizes were handed out last year, there was clearly an interesting story behind Eric Betzig, who won in chemistry for his work in developing a microscope that could image well beyond the diffraction limit. Betzig, it was noted, took time out of his scientific career to work in his father’s machine tool business for a number of years.
That break occurred after he left Bell Labs in New Jersey. Yesterday, his former home had him back in order to honor him, along with its seven other Nobel winners. Betzig got a prime speaking slot, and he used it to fill in the details of his long odyssey. Although his time at Bell Labs ended with him quitting science, it was clear that his time there was essential to his career’s eventual resurrection.
Betzig started at Bell Labs after finishing his PhD at Cornell (the person who hired him, Hosrt Störmer, went on to win a Nobel as well). At the time, he was working on what’s termed “near field” microscopy, where, as he described it, a lens with a tiny aperture is jabbed right up against a sample; images are built by scanning the imaging tip across the sample. To make these tips, he’d been coating glass pipettes with aluminum; once at Bell Labs, he switched to something that was in easy supply there: optical fibers.
In 1994, a member of the newsroom named Rich Meislin wrote an internal memo about the value of “computer-based services” that The Times could offer its readers. One of the proposed services was RecipeFinder: a database of recipes “searchable by key ingredient” and “type of cuisine.” It took the company almost 20 years, several failed starts and a massive data cleanup effort, but the idea of cooking as a “digital service” (read: web app) is finally a reality.
NYT Cooking launched last fall with over 17,000 recipes that users can search, save, rate and (coming soon!) comment on. The product was designed and built from scratch over the course of a year, but it relies heavily on nearly six years of effort to clean, catalogue and structure our massive recipe archive.
We now have a treasure trove of structured data to play with. As of yesterday, the database contained $17,507$ recipes, $67,578$ steps, $142,533$ tags and $171,244$ ingredients broken down by name, quantity and unit.
In practical terms, this means that if you make Melissa Clark’s pasta with fried lemons and chile flakes recipe, we know how many cups of Parmigiano-Reggiano you need, how long it will take you to cook and how many people you can serve. That finely structured data, while invisible to the end user, has allowed us to quickly iterate on designs, add granular HTML markup to improve our SEO, build a customized search engine and spin up a simple recipe recommendation system. It’s not an exaggeration to say that the development of NYT Cooking would not have been possible without it.
Until recently, the collection and maintenance of this structured data was a completely manual process. For years, overnight contractors have entered recipes, dropdown by dropdown, into a gray and white web form that lives in our content management system (CMS). Since the database breaks down each ingredient by name, unit, quantity and comment, an average recipe requires over 50 fields, and that number can climb above 100 for more complicated recipes.
I long suspected that the manual process of entering recipes into the database could be replaced with an algorithmic solution. The field of Natural Language Processing (NLP) has developed powerful algorithms to solve similar tasks over the past decade. If a computer can identify the part of speech of each word in a sentence, it should be able to identify an ingredient quantity from an ingredient phrase.
For an internal hack week last summer, a colleague and I decided to test our faith in statistical NLP to automatically convert unstructured recipe text into structured data. A few months of on-and-off work later, our recipe parser is now fully integrated into our CMS.
The most challenging aspect of the recipe parsing problem is the task of predicting ingredient components from the ingredient phrases. Recipes display ingredients like “1 tablespoon fresh lemon juice,” but the database stores ingredients broken down by name (“lemon juice”), quantity (“1″) , unit (“tablespoon”) and comment (“fresh”). There is no regular expression clever enough to identify these labels from the ingredient phrases.
Example
Ingredient Phrase
1
tablespoon
fresh
lemon
juice
Ingredient Labels
QUANTITY
UNIT
COMMENT
NAME
NAME
This type of problem is referred to as a structured prediction problem because we are trying to predict a structure — in this case a sequence of labels — rather than a single label. Structured prediction tasks are difficult because the choice of a particular label for any one word in the phrase can change the model’s prediction of labels for the other words. The added model complexity allows us to learn rich patterns about how words in a sentence interact with the words and labels around them.
We chose to use a discriminative structured prediction model called a linear-chain conditional random field (CRF), which has been successful on similar tasks such as part-of-speech tagging and named entity recognition.
The basic set up of the problem is as follows:
Let $\{x^1, x^2, …, x^N\}$ be the set of ingredient phrases, e.g. {“$½$ cups whole wheat flour”, “pinch of salt”, …} where each $x^i$ is an ordered list of words. Associated with each $x^i$ is a list of tags, $y^i$.
For example, if $x^i = [x_1^i, x_2^i, x_3^i] = [\text{“pinch”}, \text{ “of”}, \text{ “salt”}]$ then $y^i = [y_1^i, y_2^i, y_3^i]= [\text{UNIT}, \text{ UNIT}, \text{ NAME}]$. A tag is either a NAME, UNIT, QUANTITY, COMMENT or OTHER (i.e., none of the above).
The goal is to use data to learn a model that can predict the tag sequence for any ingredient phrase we throw at it, even if the model has never seen that ingredient phrase before. We approach this task by modeling the conditional probability of a sequence of tags given the input, denoted $p(\text{tag sequence} \mid \text{ingredient phrase})$ or using the above notation, $p(y \mid x)$.
The process of learning that probability model is described in detail below, but first imagine that someone handed us the perfect probability model $p(y \mid x)$ that returns the “true” probability of a sequence of labels given an ingredient phrase. We want to use $p(y \mid x)$ to discover (or infer) the most probable label sequence.
Armed with this model, we could predict the best sequence of labels for an ingredient phrase by simply searching over all tag sequences and returning the one that has the highest probability.
For example, suppose our ingredient phrase is “pinch of salt.” Then we need to score all the possible sequences of $3$ tags.
$$
p(\text{UNIT UNIT UNIT} \mid \text{“pinch of salt”}) \\
p(\text{QUANTITY UNIT UNIT} \mid \text{“pinch of salt”})\\
p(\text{UNIT QUANTITY UNIT} \mid \text{“pinch of salt”})\\
p(\text{UNIT UNIT QUANTITY} \mid \text{“pinch of salt”})\\
p(\text{UNIT QUANTITY QUANTITY} \mid \text{“pinch of salt”}) \\
p(\text{QUANTITY QUANTITY QUANTITY} \mid \text{“pinch of salt”}) \\
p(\text{UNIT QUANTITY NAME} \mid \text{“pinch of salt”}) \\
\vdots
$$
While this seems like a simple problem, it can quickly become computationally unpleasant to score all of the $|\text{tags}|^{|\text{words}|}$ sequences**. The beauty of the linear-chain CRF model is that it makes some conditional independence assumptions that allow us to use dynamic programming to efficiently search the space of all possible label sequences. In the end, we are able to find the best tag sequence in a time that is quadratic in the number of tags and linear in the number of words ($|\text{tags}|^2 * |\text{words}|$).
So given a model $p(y \mid x)$ that encodes whether a particular tag sequence is a good fit for a ingredient phrase, we can return the best tag sequence. But how do we learn that model?
A linear-chain CRF models this probability in the following way:
$$
\begin{equation}
p( y \mid x ) \propto \prod_{t=1}^T \psi(y_t, y_{t-1}, x)
\end{equation}
$$
where $T$ is the number of words in the ingredient phrase $x$.
Let’s break this equation down in English.
The above equation introduces a “potential” function $\psi$ that takes two consecutive labels, $y_t$ and $y_{t-1}$, and the ingredient phrase, $x$. We construct $\psi$ so that it returns a large, non-negative number if the labels $y_t$ and $y_{t-1}$ are a good match for the $t^{th}$ and ${t-1}^{th}$ words in the sentence respectively, and a small, non-negative number if not. (Remember that probabilities must be non-negative.)
The potential function is a weighted average of simple feature functions, each of which captures a single attribute of the labels and words.
We often define feature functions to return either 0 or 1. Each feature function, $f_k(y_t, y_{t-1}, x)$, is chosen by the person who creates the model, based on what information might be useful to determine the relationship between words and labels. Some feature functions we used for this problem were:
$$
\begin{align*}
&f_1(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } x_t \text{ is capitalized and }y_t \text{ is NAME} \\
0 \text{ otherwise}
\end{array} \right.\\ \\
&f_2(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } x_t \text{ is “1/2” and } y_t \text{ is QUANTITY} \\
0 \text{ otherwise}
\end{array} \right. \\ \\
&f_3(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } x_t \text{ is “cup” and }y_t \text{is QUANTITY} \\
0 \text{ otherwise}
\end{array} \right.\\ \\
&f_4(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } x_t \text{ is “flour” and } y_t \text{ is QUANTITY} \\
0 \text{ otherwise}
\end{array} \right.\\ \\
&f_5(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } x_t \text{ is a fraction and } y_t \text{is QUANTITY} \\
0 \text{ otherwise}
\end{array} \right.\\ \\
&f_6(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } y_t \text{ is QUANTITY and } y_{t-1} \text{is UNIT} \\
0 \text{ otherwise}
\end{array} \right.\\ \\
&f_7(y_t, y_{t-1}, x) = \left\{
\begin{array}{lr}
1 \text{ if } y_t \text{ is QUANTITY and } y_{t-1} \text{ is NAME} \\
0 \text{ otherwise}
\end{array} \right.\\
\end{align*}
$$
There is a feature function for every word/label pair and for every consecutive label pair, plus some hand-crafted functions. By modeling the conditional probability of labels given words the following way, we have reduced our task of learning $p(y \mid x)$ to the problem of learning “good” weights on each of the feature functions. By good, I mean that we want to learn large positive weights on features that capture highly likely patterns in the data, large negative weights on features that capture highly unlikely patterns in the data and small weights on features that don’t capture any patterns in the data.
For example, $f_2$ describes a likely pattern in the data (“$½$” is likely a quantity), $f_4$ describes an unlikely pattern in the data (the word “flour” is almost never a quantity) and $f_1$ doesn’t capture a common pattern (the ingredient phrases are almost always lowercased). In this case, we want $w_2$ to be a a large positive number, $w_4$ to be a large negative number and $w_1$ to be close to 0.
Due to properties of the model — chiefly, that the function is convex with respect to the weights — there is one best set of weights and we can find it using an iterative optimization algorithm. We used the CRF++ implementation to do the optimization and inference.
Results
Our model got $89$% sentence-level accuracy when trained on $130,000$ labeled ingredient phrases from the database. The data was too noisy for automatic evaluation, so we evaluated sentence-level accuracy by hand on a test set of $481$ examples.
Below are some examples of where we do well, where we do poorly, and where there is no clear correct answer. Recall that we are trying to predict NAME, UNIT, QUANTITY, COMMENT and OTHER.
Truth: 1QTgarlic cloveNA, minced ( optional )OT
Guess: 1QTgarlicNAcloveUN, minced ( optional )OT
This example is confusing for both our human annotators and the algorithm. We probably want “clove” to be part of the ingredient name instead of the unit, but we see both variations in our training data.
Truth: 2QTred onions , peeled and dicedNA
Guess: 2QTred onionsNA,OTpeeled and dicedCO
Here is an example of the CRF correcting a human annotator’s error. Peeled and diced should be part of the comment.
Truth: 4QTtablespoonsUNmelted nonhydrogenatedOTmargarineNA, melted coconut oil or canola oilOT
This ingredient phrase contains multiple ingredient names, which is a situation that is not accounted for in our database schema. We need to rethink the way we label ingredient parts to account for examples like this.
Truth: 1QTbunchUNscallionsNA,OTtrimmed and cut into 1/4-inch lengthsCO
Guess: 1QTbunchUNscallionsNA,OTtrimmed and cut into 1/4-inch lengthsCO
And sometimes everyone gets it right!
Takeaway
Extracting structured data from text is a common problem at The Times, and for 164 years the vast majority of this data wrangling (e.g. cataloging, tagging, associating) has been done manually. But there is an ever-increasing appetite from developers and designers for finely structured data to power our digital products and at some point, we will need to develop algorithmic solutions to help with these tasks. The recipe parser, which combines machine learning with our huge archive of labeled data, takes a first step towards solving this important problem. Email me at erica.greene@nytimes.com if you’d like more details about this project.
** We actually do BIO tagging so there are $(|\text{tags}|* 2) ^ {|\text{words}|} $ sequences.
Shravan Vasishth points us to this news item from Luke Harding, “History of modern man unravels as German scholar is exposed as fraud”:
Other details of the professor’s life also appeared to crumble under scrutiny. Before he disappeared from the university’s campus last year, Prof Protsch told his students he had examined Hitler’s and Eva Braun’s bones.
He also boasted of having flats in New York, Florida and California, where, he claimed, he hung out with Arnold Schwarzenegger and Steffi Graf. . . . some of the 12,000 skeletons stored in the department’s “bone cellar” were missing their heads, apparently sold to friends of the professor in the US and sympathetic dentists.
To paraphrase a great scholar:
His resignation is a serious loss for Frankfurt University, and given the nature of the attack on him, for science generally.
I’ve heard he’s going to devote himself to work with at-risk youths.
Mayor Walsh, other city officials and an old parking meter today.
Mayor Walsh said today the dedicated bike lanes planned for Comm. Ave. between the BU Bridge and Packards Corner are only part of a long-term "Vision 0" plan to curb crashes and traffic-related deaths through a combination of street reconfiguration and tougher enforcement.
A nightclub and lounge in the Fenway section of Boston has closed its doors due to a lease issue.
According to a Facebook post from the place, Arc on Beacon Street is no longer in operation, with the note saying that the club has been without a lease for more than five years and had received an eviction notice from the landlord sometime last year. It sounds like the owners of Arc are possibly looking to reopen elsewhere, saying that they "hope to move the license to a new location in the near future."
Arc first opened in July of 2013, replacing the Irish pub An Tua Nua, which was under the same ownership and had been in business for more than 15 years.
The address for this now-closed nightclub and lounge in the Fenway was: Arc, 835 Beacon Street, Boston, MA, 02215.
Thanks to a poster on the Chowhound site for bringing this to our attention.
During my childhood, recycling was an informal, ad-hoc process. We used to buy soda in flip-top bottles that went right back into the crate and got taken back to where we bought them. The bottles were refilled often enough that their painted labels started to wear down. Our newspapers (which were, in fact, paper) got put in the garage until the local Boy Scout troop had a paper drive, where the papers went into a dumpster and were carted off for reprocessing.
But two-liter plastic bottles eventually killed the soda supplier, and a crash in paper prices caused the Boy Scouts to move on to other sources of income. Recycling was a fragile thing, easily broken by forces that had nothing to do with its inherent value.
Fast forward many years, and we're recycling on a massive scale, building centers that perform amazing feats, mechanically separating out a huge array of raw materials. And these materials aren't only valuable in their own right; they save the parties involved significant amounts of money by staying out of landfills. Recycling is a big and growing business, and today it's certain to be a permanent fixture on the global landscape.
WBUR reports the MassDOT board of directors voted today to make the system free on April 24 to make up for the recent snow-related unpleasantries.
But don't worry, you monthly pass buyers about to rant about how that does nothing for you: The board also voted to give monthly pass buyers a 15% discount on May passes.
Online dating bots strike again. Turns out you just need to visit a lot of profiles.
Sharif Corinaldi moved from New York to Berkeley for graduate school and was in search of a mate. However, after a bit of non-success with online dating sites, he figured a 0.0025 percent chance of finding a match, which meant about 400 messages sent before any success. So, he built a bot to browse and search for him. He accidentally left it running one night.
I fiddled with the model for a week, and it finally finished running late one Sunday night. Seated alone at a cold metal desk in my TA office, eagerly looking over these first results at 3am, I mouthed a silent curse under my breath. After arriving at realistic estimates for "female pickiness" (fem_Pck) and "creepiness tolerance" (creep_Tol), my model had determined I'd have to look through 600-700 profiles a night to have any hope of being exposed to Ms Right before she got fed up, burnt out and sequestered herself off in a nunnery, or at least got back with her ex. For someone who needed to spend every waking moment buried under an avalanche of quantum mechanics preprints, this wasn't going to cut it.
Disgusted, I set the model to aimlessly auto-browse profile information overnight, and left the lab. The next day I woke up and found that everything had changed.
Corinaldi has a girlfriend now, after casting a very wide net.
Kenji Hall explores the carefully preserved world of yuru-kyara, the nonsports mascots of Japan, where every organization seems to employ a fuzzy, smiling goofball—a recent mascot event counted 1,699. The people involved in creating the mascots, making their suits, and occupying those suits are perhaps surprisingly guarded about the whole thing: “Diehard yuru-kyara fans will insist that there’s nobody inside the suit. It’s part of the culture.” OK.
Hall also visits the birthplace of many mascots:
The space resembles what you would imagine the workshop of a fashion brand to look like: sewing machines, cutting tables, rolls of cloth and pieces of spongy foam. Every part of every mascot is made by hand. Many of Kano’s staff trained in the fashion industry, which partly explains why the suits made here have beautifully finished seams and are snug enough to dance in. They are also less suffocating than you might think. The headpiece has a built-in fan for Japan’s steamy summers and suits range in weight from 3kg to 10kg – half what they once were – thanks to lighter, more breathable materials similar to sportswear.
From time to time, Microsoft produces attractive and compelling videos presenting its vision of the future: a world in which technology is seamlessly integrated into the world around us, making everything better and more convenient.
The latest productivity vision (via The Verge) shows us a few days in the life of Kat, a marine biologist, and Lola, a corporate executive, working together to make kelp seem exciting and futuristic.
As has been the theme with many of Microsoft's other visions of the future, few people work at anything resembling a normal computer. Instead, everything is a touch screen. Thin bracelet-screens stick together to make bigger screens which can then be used to reschedule meetings and book coworking spaces. Desks, glass walls, and even foldable, flexible sheets all become screens without any obvious power supply or electronics.
I know your blog is perpetually backlogged by a few months, but I thought I’d forward this to you in case it hadn’t hit your inbox yet. A journal called Basic and Applied Social Psychology is banning null hypothesis significance testing in favor of descriptive statistics. They also express some skepticism of Bayesian approaches, but are not taking any action for or against it at this time (though the editor appears opposed to the use of noninformative priors).
From Joseph Bulbulia:
I wonder what you think about the BASP’s decision to ban “all vestiges of NHSTP (P-values, t-values, F-values, statements about “significant” differences or lack thereof and so on)”?
As a corrective to the current state of affairs in psychology, I’m all for bold moves. And the emphasis on descriptive statistics seems reasonable enough — even if more emphasis could have placed on visualising the data, more warnings could have been issued around the perils of un-modelled data, and more value could have been placed on obtaining quality data (as well as quantity).
My major concern, though, centres on the author’s timidness about Bayesian data analysis. Sure, not every Bayesian analysis deserves to count as a contribution, but nor is it the case that Bayesian methods should be displaced while descriptive methods are given centre stage. We learn by subjecting our beliefs to evidence. Bayesian modelling merely systematises this basic principle, so that adjustments to belief/doubt are explicit.
From Alex Volfovsky:
I just saw this editorial from Basic and Applied Social Psychology: http://www.tandfonline.com/doi/pdf/10.1080/01973533.2015.1012991
Seems to be a somewhat harsh take on the question though gets at the frequently arbitrary choice of “p
From Jeremy Fox:
Psychology journal bans inferential statistics: As best I can tell, they seem to have decided that all statistical inferences from sample to population are inappropriate.
From Michael Grosskopf:
I thought you might find this interesting if you hadn’t seen it yet. I imagine it is mostly the case of a small journal trying to make a name for itself (I know nothing of the journal offhand), but still is interesting.
From the Reddit comments on a thread that led me to the article:
“They don’t want frequentist approaches because you don’t get a posterior, and they don’t want Bayesian approaches because you don’t actually know the prior.”
Null Hypothesis Testing BANNED from Psychology Journal: This will be interesting.
From Dominik Papies:
I assume that you are aware of this news, but just in case you haven’t heard, one journal from psychology issued a ban on NHST (see editorial, attached). While I think that this is a bold move that may shake things up nicely, I feel that they may be overshooting, as not the technique per se, but rather its use seems the real problem to me. The editors also state they will put more emphasis on sample size and effect size, which sounds like good news.
From Zach Weller:
One of my fellow graduate students pointed me to this article (posted below) in the Basic and Applied Social Psychology (BASP) journal. The article announces that hypothesis testing is now banned from BASP because the procedure is “invalid”. Unfortunately, this has caused my colleague’s students to lose motivation for learning statistics. . . .
From Amy Cohen:
From the Basic and Applied Social Psychology editorial this month:
The Basic and Applied Social Psychology (BASP) 2014 Editorial emphasized that the null hypothesis significance testing procedure (NHSTP) is invalid, and thus authors would be not required to perform it (Trafimow, 2014). However, to allow authors a grace period, the Editorial stopped short of actually banning the NHSTP. The purpose of the present Editorial is to announce that the grace period is over. From now on, BASP is banning the NHSTP. With the banning of the NHSTP from BASP, what are the implications for authors?
From Daljit Dhadwal:
You may already have seen this, but I thought you could blog about this: the journal “Basic and Applied Social Psychology” is banning most types of inferential statistics (p-values, confidence intervals, etc.).
The comments on Kruschke’s blog are interesting too.
OK, ok, I’ll take a look. The editorial article in question is by David Trafimow and Michael Marks. Krushke points out this quote from the piece:
The usual problem with Bayesian procedures is that they depend on some sort of Laplacian assumption to generate numbers where none exist. The Laplacian assumption is that when in a state of ignorance, the research should assign an equal probability to each possibility.
Huh? This seems a bit odd to me, given that I just about always work on continuous problems, so that the “possibilities” can’t be counted and it is meaningless to talk about assigning probabilities to each of them. And the bit about “generating numbers where none exist” seems to reflect a misunderstanding of the distinction between a distribution (which reflects uncertainty) and data (which are specific). You don’t want to deterministically impute numbers where the data don’t exist, but it’s ok to assign a distribution to reflect your uncertainty about such numbers. It’s what we always do when we do forecasting; the only thing special about Bayesian analysis is that it applies the principles of forecasting to all unknowns in a problem.
I was amused to see that, when they were looking for an example where Bayesian inference is OK, they used a book by R. A. Fisher!
Trafimow and Marks conclude:
Some might view the NHSTP [null hypothesis significance testing procedure] ban as indicating that it will be easier to publish in BASP [Basic and Applied Social Psychology], or that less rigorous manuscripts will be acceptable. This is not so. On the contrary, we believe that the p
I’m with them on that. Actually, I think standard errors, p-values, and confidence intervals can be very helpful in research when considered as convenient parts of a data analysis (see chapter 2 of ARM for some examples). Standard errors etc. are helpful in giving a lower bound on uncertainty. The problem comes when they’re considered as the culmination of the analysis, as if “p less than .05″ represents some kind of proof of something. I do like the idea of requiring that research claims stand on their own without requiring the (often spurious) support of p-values.
On a recent Saturday morning, Craig Adams stood outside the Robert Wood Johnson University Hospital in New Brunswick, New Jersey. It was sunny but cold. Adams, who had turned 40 the day before, wore white sneakers and a black T-shirt over a long-sleeve shirt. A fuzz of thinning hair capped his still-youthful face. His appearance would have been unremarkable if not for the red splotch of fake blood on the crotch of his white trousers. The stain had the intended effect: drivers rounding the corner were slowing down just enough to see the sign he was holding, which read “No Medical Excuse for Genital Abuse.”
Next to him, Lauren Meyer, a 33-year-old mother of two boys, held another sign, a white poster adorned only with the words: “Don’t Cut His Penis." She had on a white hoodie with a big red heart and three red droplets and a pair of leopard-print slipper-boots to keep her feet warm for the several hours she would be outside. Meyer’s first son is circumcised; she sometimes refers to herself as a “regret mother” for having allowed the procedure to take place.
It was two days after Christmas. Adams and Meyer had each driven about an hour to stand by the side of a road holding up signs about penises. On that same day, a woman stood alone at what qualifies as a busy intersection in the small town of Show Low, Arizona. She also wore white trousers with a red crotch and held aloft anti-circumcision signs. A few more people did the same in the San Francisco Bay area.