
Pachevalier
Shared posts

18 Sep 16:27
 In Pirmasens leben die deutschen Durchschnittswähler. Friedrichshain-Kreuzberg wählt dagegen ganz unorthodox. Unsere Karte zeigt die politische Geografie des Wahllands.
In Pirmasens leben die deutschen Durchschnittswähler. Friedrichshain-Kreuzberg wählt dagegen ganz unorthodox. Unsere Karte zeigt die politische Geografie des Wahllands.
Wahlkreise: Deutschland neu sortiert
by ZEIT ONLINE : Politik
In Pirmasens leben die deutschen Durchschnittswähler. Friedrichshain-Kreuzberg wählt dagegen ganz unorthodox. Unsere Karte zeigt die politische Geografie des Wahllands.
Pachevalier likes this
16 Sep 09:55
Australian election results: Interactive map
by Nick Evershed, Gabriel Dance
Interactive map showing the results of the 2013 election as circles, clustered around locations
Pachevalier likes this
16 Sep 08:47
 Rückblick auf die Bundestagswahl 2009: Welche Wählerwanderungen gab es? Wie viele SPD-Anhänger blieben zu Hause? Wo kamen all die FDP-Wähler her? Unsere Grafik zeigt es.
Rückblick auf die Bundestagswahl 2009: Welche Wählerwanderungen gab es? Wie viele SPD-Anhänger blieben zu Hause? Wo kamen all die FDP-Wähler her? Unsere Grafik zeigt es.
Bundestagswahlen: Wie die Wähler wandern
by ZEIT ONLINE : Politik -
Rückblick auf die Bundestagswahl 2009: Welche Wählerwanderungen gab es? Wie viele SPD-Anhänger blieben zu Hause? Wo kamen all die FDP-Wähler her? Unsere Grafik zeigt es.
Pachevalier likes this
16 Sep 08:42
 Wo wird unsere Kleidung genäht? Wir haben die Produktionsorte der zehn meistverkauften Marken in Deutschland recherchiert. Eine Karte zeigt deren globales Netzwerk.
Wo wird unsere Kleidung genäht? Wir haben die Produktionsorte der zehn meistverkauften Marken in Deutschland recherchiert. Eine Karte zeigt deren globales Netzwerk.
Modeindustrie: Die Fabriken von H&M und Boss
by ZEIT ONLINE : Lebensart
Wo wird unsere Kleidung genäht? Wir haben die Produktionsorte der zehn meistverkauften Marken in Deutschland recherchiert. Eine Karte zeigt deren globales Netzwerk.
16 Sep 08:37
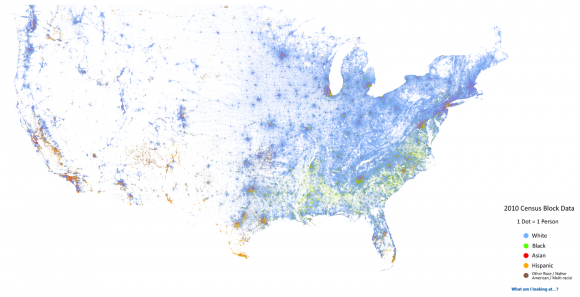
Ein bunter Punkt für jeden Amerikaner
by Katharin Tai
Verteilung ethnischer Gruppen in den USA: blau – Weiße, grün – Schwarze, rot – Asiaten, orange – Hispanics. Quelle: Dustin A. Cable http://demographics.coopercenter.org/DotMap/index.html
Die Frage der segregation, der Trennung der ethnischen Gruppen, treibt die USA noch immer um: Bleiben die mehr als 300 Millionen Menschen verschiedener Herkunft unter sich oder leben sie das amerikanische Ideal der bunt gemischten salad bowl?
Dustin Cable von der University of Virginia hat sich dieser Frage mit Daten genähert und die Racial Dot Map erstellt: Für jeden Bürger gibt es einen Punkt, oft kleiner als ein Pixel. Dieser Punkt wurde dann je nach ethnischer Herkunft entsprechend eingefärbt.
Auf den ersten Blick ist Cables Karte vor allem bunt. Wer hineinzoomt, kann jedoch bis auf den Straßenblock genau sehen, wo Weiße, Afro-Amerikaner, Asiaten oder Hispanics leben.
So ergibt sich ein selten anschauliches Bild: Während zum Beispiel in San Francisco vor allem Mischtöne zu sehen sind, besteht Chicago vielerorts aus verschiedenen, jedoch nahezu einfarbigen Kacheln.
In den großen, dünn besiedelten Gebieten außerhalb der Städte sieht man vornehmlich blauen Dunst – blau steht für Weiße. Mittendrin gibt es dann Städte wir Portland, die zwar vornehmlich blau sind, aber vergleichsweise gut integriert erscheinen.
Als Inspiration diente Cable ein Projekt von Brandon Martin-Anderson vom MIT Media Lab, der eine Karte mit einem schwarzen Punkt für jeden Bürger der USA, Kanadas und Mexikos erstellt hatte. Cable ergänzte dann die Farben für die ethnische Herkunft mit Daten aus dem amerikanischen Zensus 2010. Hier gibt es mehr zur Methodik.
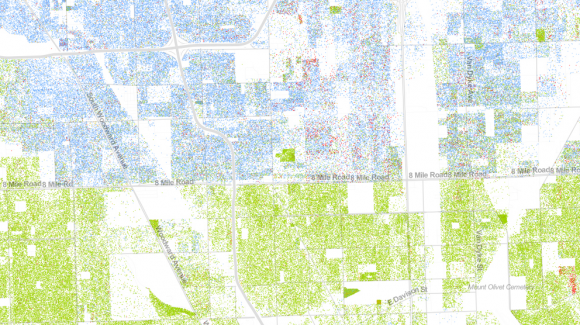
Karte der Einwohner von Detroit und ihrer ethnischen Herkunft: blau – Weiße, grün – Schwarze. Quelle: Dustin A. Cable http://www.wired.com/design/2013/08/how-segregated-is-your-city-this-eye-opening-map-shows-you/#slideid-210361
Außerdem korrigierte er das Kartenmaterial in manchen Städten, sodass keine Menschen mehr in Straßen oder Parks angezeigt werden. Erst dadurch werden Phänomene wie das in Detroit sichtbar: Dort trennt die 8 Mile Road exakt die Teile der Stadt, in denen Afro-Amerikaner und Weiße leben.
Pachevalier likes this

09 Sep 16:46
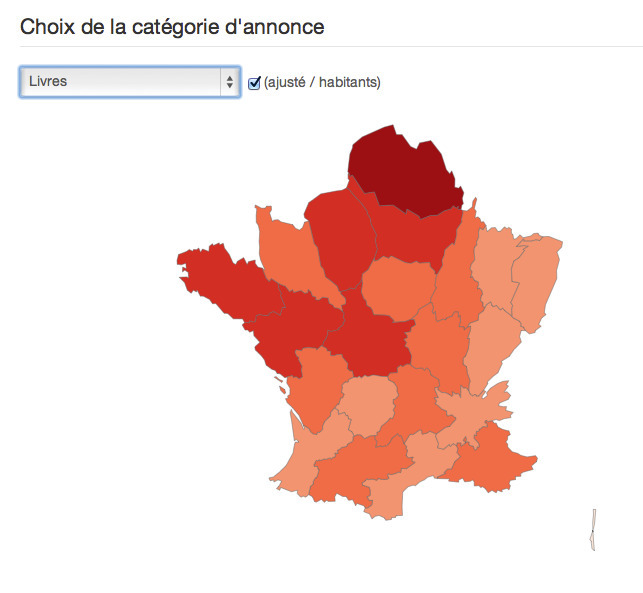
Karen Bastien's insight:
@comeetie : carte anamorphosée
L'analyse de l'usage de ce site de petites annonces permet en effet de répondre à des questions sympathiques telles que :
Où échange t'on le plus de livres, de vélos ? Où bricole t'on le plus ?
La France du "Bon coin"
by Karen Bastien
Karen Bastien's insight:
@comeetie : carte anamorphosée
L'analyse de l'usage de ce site de petites annonces permet en effet de répondre à des questions sympathiques telles que :
Où échange t'on le plus de livres, de vélos ? Où bricole t'on le plus ?
27 Aug 07:38
0,12 % des utilisateurs de GitHub proviennent d'Afrique !
by aKa
Y aurait-il moins de 5000 développeurs libres sur tout le continent africain (4527 pour être plus précis) ?

C’est ce qu’on peut lire sur cette intéressante carte interactive intitulée GitHub Africa Users. Leur auteurs (non africains) ont en effet collecté, en mars dernier, les données des utilisateurs de la plateforme qui avaient renseigné leur localisation (et uniquement ceux-ci) en nous présentant cela à l’aide de MapBox.
A partir de là un certain nombre de questions se posent pour nuancer ce chiffre :
- Est-ce les utilisateurs africains de GitHub se localisent moins que les autres ?
- Est-ce qu’un utilisateur de GitHub est nécessairement un développeur qui fait du libre ?
- Est-ce que les développeurs libres africains utilisent GitHub ?
- Est-ce que les développeurs libres africains voudraient utiliser GitHub mais en sont empêchés à cause de la faiblesse de leur connexion à Internet ?
- Combien y a-t-il de développeurs non libres en Afrique ?
Il n’empêche que cela reste tout de même inquiétant.
Qu’en pensez-vous ?
Pachevalier likes this
27 Aug 07:32

Datawrapper 1.5
by admin
After two months and +600 commits, we are very proud to finally release the next major milestone of Datawrapper. Here’s a brief overview what has been changed:
- Chart editor redesign
- Data editing and per-column formatting
- Chart display optimization
- Started using CloudFront as CDN, changed chart URL structure.
Chart editor redesign
Every change made in the editor are now immediately displayed in the preview, as opposed to the two-seconds delay we had in previous versions. Also the chart editor is now separated in three sub-steps that can be navigated via tabs:

The custom color picker which was formerly shown in a popup window is now integrated into the sidebar. This makes it easier to see the effect of new colors immediately. Also the new color picker allows changing colors of multiple elements at the same time.

Last but not least we enabled our intelligent charting engine™ to speak back to the user in case something can be improved in a chart. Many of these heuristics are already built into Datawrapper since version 1.0, but now we thought it’s a nice idea to also explain what we are doing and why.
Message shown in a pie chart with way too many values
Data editing
The second step of the chart editor now supports quick-editing of the dataset, making it a lot easier change a label. The changes are stored with the chart to ensure that the original dataset is preserved. Using the revert button you can always return to the uploaded data. The editing feature was developed by Marcin Warpechowski, who also developed the popular JavaScript spreadsheet Handsontable that we’re using since version 1.3.

The number format can now be specified for individual columns instead of the entire dataset, which gives you a finer control about how numbers should be rendered. In order to change the column format you now have to select one or more columns, just as you would do in a spreadsheet software.

Optimized chart display
With 1.5 we introduce display improvements for all chart types.
In line charts we now use a one-dimensional force-directed layout to ensure that labels won’t overlap in vertical direction. Here you can see a comparison of the old and new rendering.

Also the line chart now supports filling below the line if there is only one line in the chart. To avoid a common charting mistake we will automatically extend the y axis to zero if line filling is activated.

The third improvement is stepped line interpolation. The idea behind this is simple: the default straight connection lines between points in a line chart express the assumption that there is a continuous change in the presented variable. However, in some cases you know that this is not the case. For instance, you know that an account balance stays on a constant value until the next financial transaction takes place.

The previous image also showcases another improvement of the line chart: if your dataset covers only a few dates, we label these exact dates instead of the usual evenly distributed grid lines (thanks to Lorenz Matzat for this very tufteeske idea).
Speaking of Tufte: we finally made our column charts smart enough to decide whether or not it needs to display grid lines. The assumption is that if you have a considerable small number of bars and enough space for labeling the values directly, there is no need for grid lines and grid labels anymore. Instead the full width of the chart can be used for the columns, making them a lot more space-efficient.

In pie charts we now move labels of small slices outside of the pie to ensure that they are still readable. We adjust the rotation of the pie so that the outside labels move to a nice location on the top right of the chart. The result of this improvement is probably the most advanced pie chart in any visualization tool:

Finally fixed: the labeling of small slices in pie charts
CloudFront CDN and versionized chart urls
We’re now using Amazon CloudFront as content delivery network (CDN), which has some decent benefits in terms of chart load time and support for SSL delivery. The downside is that it required us to change the way chart URLs are constructed. Until now, every chart had only one URL that would always point to the latest version of the chart. That was very flexible, but it’s hard to cache charts effectively.
Starting with 1.5, every chart URL contains the version of the chart, which increases every time you re-publish a chart. To immediately see the most recent version of your chart, you will need to update the URL in your embed code. If for some reasons you cannot do this, you will have to wait up to 24 hours until Amazon has updated the cache of the old chart versions.
Further improvements
Furthermore the release includes a couple of minor improvements and bugfixes. Some of them where already released in Datawrapper 1.4, but are included here for completeness of the release notes.
- Showing a static image of the charts even if JavaScript has been disabled.
- New plugin system: Towards our way of turning Datawrapper into a platform for open source data visualization we in introduced a new flexible plugin system. The goal was to refactor as much as functionality into plugins in order to keep the Datawrapper core lightweight. Plugins include functionality such as the visualizations, custom themes, and integration.
- Moved translation to Crowdin.net: To simplify translation of Datawrapper we decided to move to Crowdin.net, who kindly offers free plans for open source software projects. If you want to help translating, please use this invitation link.
- JavaScript refactoring: A great part of the development had gone into completely refactoring the JavaScript core of Datawrapper, including all the visualization plugins.
So what’s next?
Datawrapper 1.5 is the last release of the 1.x series. As mentioned above, we have worked hard on preparing the software for the next big step towards Datawrapper 2.0, which is coming in fall 2013. With the new plugin architecture we already prepared the ground for the transition towards an open source data visualization platform.
If you’re interested in being part of the development, do not hesitate to contact us.
Pachevalier likes this

16 Aug 09:29
Listening to Zen-like Wikipedia edits
by Nathan Yau

It's easy to think of online activity as a whirlwind of chatter and battles for loudest voice, because, well, a lot of it is that. We saw it just recently with the burst of emojis and what happens in just one second online. But maybe that's because people tend to present the bits that way. Stephen LaPorte and Mahmoud Hashemi approached it differently in Listen to Wikipedia.
The project is an abstract visualization and sonification of the Wikipedia feed for recent changes, which includes additions, deletions, and new users. Bells, strings, and a rich tone represent the activities, respectively. Unlike other projects that attempt to hit you with an overwhelmed feeling, Listen oddly provides a calm. I left the tab open in the background for half an hour.
Listen is open source.
Pachevalier likes this
16 Aug 09:24
Saviez-vous que Mozilla est en train de détourner l'Internet ? par Glyn Moody
by aKa
« Les cons ça ose tout, c’est même à ça qu’on les reconnaît » disaient nos tontons.
Je ne connaissais pas l’Interactive Advertising Bureau, organisation regroupant des acteurs de la publicité sur Internet, mais ce qui est sûr c’est qu’elle ne gagne rien à se ridiculiser en attaquant ainsi Mozilla (qui nous protège justement de la prolifération actuelle des cookies intrusifs).
Qu’en pensent Google, Microsoft, Orange, TF1, etc., tous membres de la branche française de l’Interactive Advertising Bureau ?
Commentaire : L’image ci-dessous est extraite de l’article de l’Interactive Advertising Bureau qui a fait bondir Glyn Moody. Ce serait donc Mozilla qui enferme ses utilisateurs, vraiment trop forts nos publicitaires !

Saviez-vous que Mozilla est en train de détourner l’Internet ?
Did You Know that Mozilla is Hijacking the Internet?
Glyn Moody - 12 août 2013 - ComputerWorld (Open Entreprise)
(Traduction Framalang : ane o’nyme, Sky, LordPhoenix, bruno, Cryptie, anneau2fer, simplementNat, Zii, greygjhart + anonymes)
Il y a quelques semaines j’ai relaté l’attaque à peine croyable de la branche européenne du « Interactive Advertising Bureau (IAB) » envers Mozilla au motif que cette dernière aurait « renoncé à ses valeurs » car elle persisterait à défendre les droits des utilisateurs à contrôler comment les cookies sont utilisés sur leur système.
Vu l’avalanche de moqueries venues de toutes part que cette énorme idiotie tactique a provoquée, on pouvait s’attendre à ce que des conseillers plus sages l’emportent et à ce que l’IAB se replie dans un petit coin tranquille, dans l’espoir que les gens arrêtent de se moquer et oublient simplement et complètement ce déplorable incident.
Mais non. au lieu de cela, l’IAB revient à la charge avec une nouvelle attaque sous la forme d’une pleine page achetée dans le magazine Advertising Age, encore plus énorme, plus forte et plus dingue (aussi disponible en ligne pour votre plus grand plaisir).
Sous le sobre titre : « Empêchez Mozilla de détourner l’internet », on peut lire :
De nos jours, il est facile de trouver le contenu qui vous intéresse sur Internet. Cela est dû au fait que les publicitaires peuvent adapter les annonces aux intérêts précis des utilisateurs grâce à l’usage responsable et transparent de cookies.
Je dois dire que je suis vraiment reconnaissant envers l’IAB de m’avoir ouvert les yeux en mettant ceci à jour parce que jusqu’à ce que je lise ce paragraphe, je nageais dans l’ignorance la plus totale et croyais naïvement que c’était les moteurs de recherches que j’utilisais, d’abord Lycos, puis Altavista, suivi de Google et désormais Startpage, qui me permettaient de trouver les choses qui m’intéressaient. Mais je réalise maintenant mon erreur : j’apprends qu’en fait c’est grâce à tous ces petits cookies si bien disséminés à mon insu dans mon système que j’ai trouvé tout ces trucs. Qui l’eût cru ?
Ces mêmes personnes de l’IAB qui ont eu l’obligeance de mentionner cela ont aussi de mauvaises nouvelles pour moi :
Mais Mozilla veux éliminer ces mêmes cookies qui permettent aux publicitaires de toucher le public, avec la bonne publicité, au bon moment.
Méchant Mozilla. Oh, mais attendez, en fait ce n’est pas ce que Mozilla fait. Il veut au contraire juste contrôler le flot de cookies qui proviennent de sites que vous n’avez pas visités et qui sont envoyés sur votre système, aussi appelés les cookies tiers. Voici une bonne explication de ce qui se passe ici :
Tous les acteurs tiers sont en marge de la transaction et peuvent ajouter de la valeur mais leur but premier diffère du bien ou du service recherché. Ces tierces parties sont plutôt comme le type qui fait le tour du parking avec ses prospectus pendant que vous faites vos courses et met des bons de réduction sur le pare-brise de tout le monde (Oh ! Jamais en panne, 169€ par mois ?). Il ne remplit pas les rayons, ni n’emballe vos courses, mais il fait quand même partie (indirectement ou marginalement) de l’opération « aller faire ses courses ».
Il ne s’agit donc pas d’une volonté de Mozilla d’éliminer les cookies en général mais simplement de donner à l’utilisateur le pouvoir de contrôler ces publicités ennuyeuses glissées sous vos essuie-glaces numériques quand vous visitez un supermarché virtuel.
Mais revenons à la fine analyse de l’IAB :
Mozilla prétend que c’est dans l’intérêt de la vie privée. En vérité nous pensons qu’il s’agit d’aider certains modèles d’affaire à prendre un avantage sur le marché et à réduire la concurrence.
Heu, parlons-nous du même Mozilla ? Vous savez le projet open source qui a certainement fait plus pour défendre les utilisateurs et le Web ouvert que personne ? Ce projet-là ? Car j’ai bien peur d’avoir du mal à imaginer ces codeurs altruistes « aider certains modèles d’affaire à prendre un avantage sur le marché et à réduire la concurrence ».
Je veux dire, Firefox a justement été spécifiquement créé pour accroître la concurrence ; le credo de Mozilla est que chacun devrait être libre d’utiliser le Web comme il l’entend, ce qui inclut toutes sortes de modèles économiques. Penser sérieusement que donner aux utilisateurs le contrôle de leur navigateur Firefox n’est pas défendre la vie privée mais une sorte complot maléfique destiné à miner l’ensemble de l’écosystème est, pour le formuler simplement, totalement cinglé. Peut être l’IAB vit-il dans univers parallèle ?
Les consommateurs ont déjà le contrôle sur les publicités ciblées qu’ils reçoivent via le programme d’auto-régulation de la Digital Advertising Alliance.
Pas de doute, l’IAB vit bien dans un univers parallèle, un univers dans lequel les gens ont réellement rencontré ce programme d’autorégulation de la Digital Advertising Alliance. Parce que je peux honnêtement dire qu’en 20 ans de promenades sur le Web, et bien trop d’heures passées en ligne chaque jour (comme mes abonnés sur Twitter, identi.ca et G+ le savent trop bien), je ne suis jamais tombé sur ce légendaire programme d’autorégulation de la Digital Advertising Alliance, et je sais encore moins comment l’utiliser pour contrôler les publicités que je reçois. Et je me retrouve, dans ce lamentable état d’ignorance, qui suggère plutôt que peu d’autres personnes utilisant l’Internet sont tombés sur le programme d’autorégulation de la Digital Advertising Alliance ou l’ont utilisé (est-ce qu’un lecteur ici est déjà tombé dessus, je me le demande).
En fait, je pense que l’IAB a commis ici un autre faux pas. En mentionnant le programme d’autorégulation de la Digital Advertising Alliance comme une « solution » existante qui rend caduques les projets de Mozilla pour maîtriser les cookies tiers, un programme qui, autant que je puisse en juger, est utilisé par très peu de gens, l’IAB a ainsi mis en évidence le fait qu’il n’y a pas vraiment d’alternative viable à Mozilla.
Je dois également souligner le fait que l’image (voir plus haut) utilisée dans l’article en question, un ordinateur portable enchainé, relève au mieux de l’ignorance, au pire constitue une insulte pour les centaines de milliers de personnes qui ont contribué au projet Mozilla au cours de ces 15 dernières années. Mozilla s’est voué à libérer le Web et ses utilisateurs d’un monopole qui menaçait de le détruire : il est difficile de penser à une image moins appropriée !
Et si l’IAB se préoccupe vraiment de qui peut faire pression sur nos ordinateurs et nous ôter notre liberté avec des centaines de fichiers minuscules qui nous épient où que l’on aille sur Internet, et s’inquiète de qui est vraiment en train de prendre en otage les incroyables ressources du Net, que Mozilla a beaucoup contribué à développer, il ferait bien de se regarder dans une glace…

12 Aug 14:34
The New Old Reader

We’re pleased to announce that The Old Reader will officially remain open to the public! The application now has a bigger team, significantly more resources, and a new corporate entity in the United States. We’re incredibly excited to be a part of this great web application and would like to share some details about its future as well as thank you for remaining loyal users. We’re big fans and users of The Old Reader and look forward to helping it grow and improve for years to come.
First off we want to say that it’s rare to have an application that inspires as much passion as The Old Reader has as of late. We think that’s a sign of greatness and all credit for that goes to the wonderful team that has been running the show including Dmitry and Elena. We’ve gotten to know them pretty well this past week and they are smart, honest, and passionate people. We’re happy to announce that they are still a part of the team and we hope they will be for a long time to come. The new team will be managing the project and adding to the engineering, communications, and system administration functions.
So now for the future. The Old Reader is going to retain all of its functionality and remain open to the public. Not only that, we’re going to do everything in our power to grow the user base which will only accentuate the things that make this application special. To facilitate these improvements, we’re going to be transitioning The Old Reader to a top tier hosting facility in the United States this coming week. It’s going to require some downtime and for that we sincerely apologize, but it’s also going to mean A LOT more servers, 10x faster networks, and long-term stability. We realize that doesn’t make the downtime easy but rest assured that things are looking up.
Over the coming weeks we’ll talk more about the new team of The Old Reader. We’re looking forward to introducing ourselves and making significant improvements to this incredible application. Thanks for reading and thanks for using The Old Reader!
lxm, cable.zombie and 36 others like this
01 Aug 18:05
Desperate times call for desperate measures
UPD: We have received a number of proposals that we are discussing right now. Chances are high that public The Old Reader will live after all

Since we launched first public version almost a year ago up until March 2013 we have been working on The Old Reader in “normal” mode. In March things became “nightmare”, but we kept working hard and got things done. First, we were out of evenings, then out of weekends and holidays, and then The Old Reader was the only thing left besides our jobs. Last week difficulty level was changed to “hell” in every possible aspect we could imagine, we have been sleep deprived for 10 days and this impacts us way too much. We have to look back.
The truth is, during last 5 months we have had no work life balance at all. The “life” variable was out of equation: you can limit hours, make up rules on time management, but this isn’t going to work if you’re running a project for hundreds of thousands of people. Let me tell you why: it tears us to bits if something is not working right, and we are doing everything we can to fix that. We can’t ignore an error message, a broken RAID array, or unanswered email. I personally spent my own first wedding anniversary fixing the migration last Sunday. Talk about “laid back” attitude now. And I won’t even start describing enormous sentimental attachment to The Old Reader that we have.
We would really like to switch the difficulty level back to “normal”. Not to be dreaded of a vacation. Do something else besides The Old Reader. Stop neglecting ourselves. Think of other projects. Get less distant from families and loved ones. The last part it’s the worst: when you are with your family, you can’t fall out of dialogues, nodding, smiling and responding something irrelevant while thinking of refactoring the backend, checking Graphite dashboard, glancing onto a Skype chat and replying on Twitter. You really need to be there, you need to be completely involved. We want to have this experience again.
That’s why The Old Reader has to change. We have closed user registration, and we plan to shut the public site down in two weeks. We started working on this project for ourselves and our friends, and we use The Old Reader on a daily basis, so we will launch a separate private site that will keep running. It will have faster refresh rate, more posts per feed, and properly working full-text search — we are sure that we can provide all this at a smaller scale without that much drama, just like we were doing before March.
The private site?
Accounts will be migrated to the private site automatically. We will whitelist everybody we know personally, along with all active accounts that were registered before March 13, 2013. And of course, we will migrate all our awesome supporters and people who donated to keep the project running (if you sent us bitcoins, please get in touch to get identified). Later this week your account will get a distinct indication whether it will be migrated to the private site or not. If you see that message and believe that it’s wrong, or if all your friends are getting migrated and you are left behind — please, drop us a line.
Give me my data!
You will have two weeks to export your OPML file regardless of our decision. OPML export link is located at the bottom of the Settings page — use the top-right menu to get there. All posts that you saved for later by using Pocket integration will obviously remain in your Pocket account.
But you could…
For those who would like to start the usual “VC, funding, mentor” or “charge for the damn thing” mantras — please, spare it. We’re not in the Valley where it might be super-easy, and, after all, not everyone wants to be an entrepreneur. We just love making a good RSS reader.
We really want The Old Reader to be a big and successful project, with usable free accounts. But this is not possible to achieve with what we have, so unless someone resourceful takes over the project and brings it to the next level, it is not gonna happen. We had over 2 000 new registrations after the blackout last week. This is amazing and sad at the same time.
If anyone is interested in acquiring The Old Reader and making it better, we are very open and accepting proposals at hello@theoldreader.com. We would be waiting for them for two weeks, supporting and maintaining The Old Reader as usual. Please don’t write us if you don’t have resources to maintain a site used by tens of thousands of people every day, or if you don’t know how you would improve The Old Reader. And please spare our time if you just want to buy the domain name and park a bunch of silly ads there — it’s not going to happen.
We value our community very much, and we will either pass the project to somebody who we know is going to take a good care of it, or we will switch it to private mode.
What next?
From one point of view, it’s not a big deal: “RSS is obsolete”, nobody died, we don’t owe anybody anything, you name it. Also, there are a lot of good readers around to choose from, a large part of them is smaller than The Old Reader and had not experienced growing pains of 80 000 daily active users in no time. But for us, it’s heartbreaking.
I will finally get back to work on my small studio — Bespoke Pixel — which has been run by my awesome partner all this time. Dmitry will keep being bright young software developer, making scalable and beautiful projects. Our team will stay together, and will keep working on making the private version of The Old Reader awesome.
We feel great responsibility for the project. We’d rather provide a smooth and awesome experience for 10 000 users than a crappy one for 420 000.
Sorry, each and everyone if we failed you. You are an incredible, supportive and helpful community. The best we could possibly hope for.
All the love,
Elena Bulygina and Dmitry Krasnoukhov
Cookiestork, Luke.stirling and 6 others like this
01 Aug 18:05
At this point we are quite confident that public The Old Reader will be available in the future, now...
At this point we are quite confident that public The Old Reader will be available in the future, now with a proper team running it.
More details later this week.
Sorry about Monday. Again.
Alex Tolstrup, David Baxter and 33 others like this
19 Jul 10:34
L'un des impôts les plus cons va être augmenté (enfin, peut-être)
by Stéphane Ménia

Dans la deuxième note du "CAE réformé", consacrée à l'immobilier et rédigée par Alain Trannoy et Étienne Wasmer, on pouvait lire :
"Nous proposons de réduire, voire supprimer progressivement les mesures de défiscalisation et les droits de mutation à titre onéreux, de réformer la taxe foncière sur les propriétés bâties (TFPB) et de modifi er la taxe sur les plus-values. L’idée générale est de taxer la détention plutôt que les transactions afin de fluidifier le marché immobilier et de rendre la taxation des plus-values foncières plus incitative de manière à décourager les comportements attentistes."
Étienne, j'espère que tu es en vacances. Sans quoi, tu n'échapperas pas à cette nouvelle. Il est question d'augmenter les droits de mutation (taxe payée par l'acheteur d'un logement, qui vient s'ajouter aux frais de notaire dans le coût d'acquisition d'un logement). Plus précisément, les départements qui le souhaiteront pourront le faire. Certes, la hausse autorisée est modérée. A titre indicatif (chiffres BFM TV), elle représenterait 1 400€ pour l'achat d'un bien à 200 000€. Pas de quoi fouetter un chat, dira-t-on. Mais plus que l'envergure, c'est la tendance qui, elle, est déplorable.
L'ambition du gouvernement est de compenser une baisse des transferts de l'État auprès des départements. Soit, les besoins financiers ne manquent pas et il faut bien trouver un moyen de les combler.
Mais s'il est bien un impôt qui semble économiquement peu adapté, c'est bien celui-ci. Citons encore la note du CAE, probablement inspirée par des années de travaux sur le sujet :
"Les droits de mutation à titre onéreux (DMTO) constituent la plus importante taxe sur les transactions pour les biens immobiliers dans l’ancien (plus de cinq ans après l’achèvement des travaux) : ils représentent 5,09 % du montant d’une transaction immobilière. Comme tout coût de transaction, ils freinent les échanges, et donc la mobilité : un propriétaire perdant son emploi dans un bassin en déclin économique hésitera à vendre pour déménager dans une région plus dynamique en termes d’emploi."
En résumé, un impôt qui réduit les transactions sur le marché de l'immobilier (qui n'en a pas besoin). Et qui nuit potentiellement à l'emploi, en réduisant la mobilité des chômeurs propriétaires.
Concernant l'état actuel du marché, le volume des transactions est, en moyenne, plus faible qu'il y a quelques années, sortie de bulle oblige. Entre des acheteurs limités par leurs moyens financiers du fait de la conjoncture et des vendeurs qui ne sont pas forcément prêts à subir des moins-values sur des biens acquis à prix fort, le volume des transactions ne peut être élevé. Si vous ajoutez une taxe supplémentaire, quelle conséquence attendre ? C'est une question d'incidence fiscale, pour l'essentiel. Est-ce que cela fera baisser les prix hors taxe, maintenant le coût total d'une transaction à son niveau précédent (c'est le vendeur qui paie) ? Ou est-ce que le coût d'acquisition sera gonflé par la taxe (c'est l'acheteur qui paie) ? Difficile de répondre. En première approche, il semble que le vendeur acceptera plus facilement la baisse de son prix. Pour une raison psychologique et une raison bien plus concrète. La raison psychologique est qu'une baisse du prix liée à une taxe n'a pas d'impact sur l'idée que le vendeur se fait de la valeur de son bien. On a tous plus ou moins le sentiment que ce que l'on possède a une grande valeur (plus que ce que l'on convoite). Ce biais est appelé "effet de dotation" et est un grand classique du marché de l'immobilier. On peut estimer que face à une demande atone et un État prédateur, pour des montants raisonnables, le vendeur abdiquera. La raison plus concrète est que, contrairement à ce qui pouvait se passer au début des années 2000, les banques (pour ce que j'en sais) rechignent à prêter le montant correspondant aux droits de mutation. Or, pour certains, trouver ne serait-ce que 1 000€ à l'heure actuelle n'est pas forcément gagné. Si transaction il doit y avoir, c'est donc bien du côté de l'offre que l'effort devra être fait. Et même dans ce cas, vous l'aurez noté, certains qui se heurteront au refus des banques de financer leurs frais se retrouveront dans une situation de contrainte de crédit plus ou moins insoluble.
Concernant l'impact sur l'emploi, les études qui mettent en regard chômage et propriété immobilière laissent entendre que les pays où la part de propriétaire est plus élevée connaissent un chômage plus important (voir ici et, plus récemment, là). Cette hypothèse a ses détracteurs (par exemple, ici). Mais il faut reconnaître qu'elle tient la route. Ceci tient principalement aux coûts de transaction liés à une mobilité géographique. Dans le cas présent, il n'est pas question de remettre en cause la sacro sainte "société de propriétaires", qui existe déjà pas mal, mais de constater qu'ajouter des coûts de transaction supplémentaires ne risque pas d'arranger les choses.
Tout ceci n'est guère enthousiasmant. Mais quand on entend les représentants de la profession immobilière demander en compensation un allègement de la fiscalité sur les plus-values immobilières, on se dit que, décidément, il vaut mieux être employé et détenteur de patrimoine que chômeur et prolétaire. Et puis... quand même... qu'on se demande à quoi on emploie les économistes du CAE.
19 Jul 06:09
Global migration and debt
by Nathan Yau
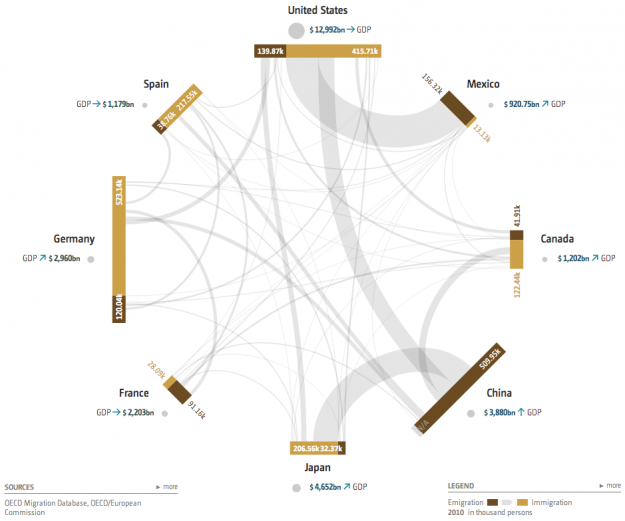
Global Economic Dynamics, in collaboration with 9elements, provides an explorer that shows country relationships through migration and debt. Inspired by a New York Times graphic from a few years ago, which was a static look at debt, the GED interactive allows you to select among 46 countries and browse data from 2000 through 2010.
Each outer bar represents a country, and each connecting line either indicates migration between two countries or bank claims, depending on which you choose to look at. You can also select several country indicators, which are represented with bubbles. (The image above shows GDP.) Although, that part of the visualization is tough to read with multiple indicators and countries.
The strength of the visualization is in the connections and the ability to browse the data by year. The transitions are smooth so that it's easy to follow along through time. The same goes for when you select and deselect countries.
17 Jul 08:17


Dataredesign : une nuit pour imaginer les portails open data de nos rêves
by Samuel Goëta
 C’est lors du meetup de lancement de l’Open Knowledge Foundation France le 14 décembre 2012 et de la table ronde portant sur les données publiques à laquelle participait Charles Ruelle, directeur technique d’Etalab, qu’a émergé l’idée d’organiser un événement de redesign de data.gouv.fr . Plusieurs des participants ont saisi cette occasion pour partager des remarques et suggestions concernant le site data.gouv.fr, la plateforme lancée par Etalab la mission gouvernementale chargée de l’ouverture des données publiques. De ce meetup nait ainsi l’idée d’inviter les utilisateurs à réfléchir et designer leur plateforme open data idéale.
C’est lors du meetup de lancement de l’Open Knowledge Foundation France le 14 décembre 2012 et de la table ronde portant sur les données publiques à laquelle participait Charles Ruelle, directeur technique d’Etalab, qu’a émergé l’idée d’organiser un événement de redesign de data.gouv.fr . Plusieurs des participants ont saisi cette occasion pour partager des remarques et suggestions concernant le site data.gouv.fr, la plateforme lancée par Etalab la mission gouvernementale chargée de l’ouverture des données publiques. De ce meetup nait ainsi l’idée d’inviter les utilisateurs à réfléchir et designer leur plateforme open data idéale.
La plateforme data.gouv.fr a été conçue pour fournir librement et gratuitement l’accès aux données publiques de l’Etat. Elle a été mise en ligne le 5 Décembre 2011 et s’est enrichie progressivement de jeux de données et de fonctionnalités telles que l’espace “Communauté” qui permet d’échanger autour des données publiées et de solliciter la mise en ligne de nouvelles données. 18 mois après son ouverture, la plateforme data.gouv.fr a accueilli plus d’un million de visiteurs uniques, qui ont consulté plus de 5 millions de pages, et téléchargé plus de 500.000 fichiers. Le paysage technique et industriel a depuis fortement évolué. Les progrès dans le design d’API, l’émergence de nouvelles briques technologiques et de frameworks, le développement de nouveaux enjeux industriels dessinent un nouveau paysage technologique et économique. Les utilisateurs souhaitent bénéficier de ces progrès, notamment pour identifier plus facilement les données, y accéder de manière automatisée (API), les visualiser, ou contribuer à l’enrichissement des données & des métadonnées.
Pour pouvoir répondre à ces nouveaux enjeux et à ces nouvelles attentes, Etalab initie le 10 avril 2013 un « processus de conception le plus ouvert possible, [associant] fortement la communauté de l’open data à cette réflexion» et visant à recueillir «toutes les suggestions des parties prenantes pertinentes, [à] repérer un maximum de compétences de notre écosystème et [à] produire un effort de prototypage rapide en public» intitulé « CoDesign ». Sept mois après le Meetup de lancement de l’Open Knowledge Foundation France, et dans le cadre du « CoDesign », l’idée initiale se concrétise.

L’Open Knowledge Foundation France propose à Etalab le temps d’une soirée de concevoir la plateforme open data idéale en s’affranchissant de toute contrainte technique ou financière et en s’appuyant sur les idées de designers, de graphistes, de chefs de projets et d’utilisateurs chevronnés ou profanes des données ouvertes. Etalab a accepté d’héberger cet événement dans ses locaux et l’Open Knowledge Foundation France invite alors trente personnes à mettre les mains dans le cambouis d’un portail open data.
Exemple de redesign avec Wikipedia
Le redesign consiste à concevoir de manière radicale un nouveau site en imaginant de nouvelles fonctionnalités et une nouvelle ergonomie autour d’un parti pris orienté par les besoins des utilisateurs. Les exemples de redesign initiés par des utilisateurs sont nombreux mais nous pouvons notamment citer deux exemples notables : l’expérience wikipediaredefined.com et le travail de Frédéric Dith, participant à distance à l’atelier, sur le site de la RATP.
L’événement organisé le 20 juin 2013 a réuni 15 graphistes et designers, 8 chefs de projets web et spécialistes de l’ergonomie web ainsi que 8 utilisateurs de données ouvertes. La soirée a débuté par une présentation par Charles Ruelle sur l’open data et le détail des actions de la mission Etalab puis a été suivie d’une présentation des fonctionnalités et de l’ergonomie d’une sélection de portails open data par les membres de l’Open Knowledge Foundation France. Les participants se sont ensuite regroupés en cinq équipes qui ont chacune travaillé sur un parti pris pendant deux heures de façon collaborative avec pour objectif d’aboutir à une ébauche de leur plateforme idéale.
Voici ici une synthèse des approches et des réalisations du travail en 2h de chaque groupe avec les liens vers les projets complets.
Une approche pédagogique : éviter le moteur de recherche et expliquer l’open data
Frédéric Dith, depuis Berlin, nous a envoyé sa contribution très complète à l’événement, il nous assure avoir travaillé en 2 heures, impressionnant. Pour lui, le site actuel ne donne pas assez à voir le concept de savoir libre derrière les données ouvertes et ne s’adresse pas à un public assez large, n’offrant pas de fonctionnalités de visualisation. Ses maquettes invitent l’utilisateur à d’abord comprendre l’intérêt et les potentialités de l’open data avant d’entrer dans le “dur” du moteur de recherche et des données. La page de chaque jeu de données propose une série de métadonnées explorables et une visualisation dynamique de la donnée. Le visiteur peut aussi aller consulter des réutilisations notables du jeu de données qu’il s’agisse d’un article, d’une infographie, d’une application ou d’un jeu de données dérivé.
—> Lire l’intégralité de la proposition de Frédéric Dith
Penser les données depuis les territoires qu’elles décrivent : vers la territorialité des données
Le deuxième groupe part du principe que l’utilisateur cherchera à “zoomer” selon l’expression de Dominique Cardon vers le niveau le plus proche de chez soi. Pour cela, leur plateforme idéale envisage data.gouv.fr comme un “méta-moteur” permettant d’explorer les données publiques de l’Etat et de l’ensemble des collectivités territoriales. Le portail s’adresse aux spécialistes de la recherche d’information et délaisse la possibilité de visualiser les données directement dans le portail afin de privilégier la découverte des données.
Faire un metamoteur des données de l’État orienté spécialistes de l’info. Un portail avec des communautés expertes et locales #dataredesign
— OKF France (@okfnFr) June 20, 2013
—> Lire la description complète du projet
Pour un portail open data grand public : un site qui suit l’actualité médiatique et anime une communauté
L’équipe suivante s’est penchée sur l’idée de développer un portail d’open data dirigé vers le grand public. Afin de sensibiliser les citoyens à l’ouverture des données et de l’informer quant aux services et aux possibilités qu’elle offre, cette plateforme s’articulerait autour de trois objectifs :
-Transformer le portail en média : faire des données ouvertes une source d’information, par la publication de contenus interactifs (datavisualisations, cartographies, tutoriels…) et l’éditorialisation de la page d’accueil du site selon l’actualité.
- Permettre l’accès aux données sous forme graduée : multiplier l’accès aux données en les classant par thématique, date de publication, lieu, Ministère etc. et diversifier les formats disponibles.
- Créer une communauté de l’open data : développer une plateforme d’échanges permettant aux internautes de proposer leurs idées et/ou leurs compétences afin de monter des projets fondés sur les données ouvertes. Cette plateforme pourrait éventuellement mener à un dispositif de crowdfunding.
—> Lire l’intégralité de la contribution sur le site de l’agence La Netscouade
De Data à Tada : pour de vrais “jeux de données” à l’école
L’équipe « Tada » se propose de faire de l’ouverture des données publiques un projet éducatif. Le constat : l’ouverture des données publiques, au delà des enjeux de transparence, de création de valeur socio-économique ou de modernisation de l’action publique, représente un potentiel outil éducatif. Les données publiques brutes pourraient servir d’exemples pour appuyer les programmes scolaires d’une part, et pourraient constituer le support de jeux éducatifs ou d’exercices d’autre part.
Le portail se propose de mettre l’accent sur l’interactivité pour intéresser un public d’enfants ou d’adolescents à l’ouverture des données publiques. L’interaction avec les données publiques pourrait être progressive et fonction du niveau scolaire de l’élève. Le site met aussi l’accent sur la visualisation des données afin d’intéresser et de capter l’attention de ce public spécifique. Dans une optique de gamification, le site propose des « jeux de données » et une communauté qui développe des jeux et des exercice. Le projet propose d’intégrer les enseignants et les parents dans la dynamique par un travail de formation et de sensibilisation.
Un data.gouv.fr pour tous avec une éditorialisation grand public et des communautés expertes
L’ avant-dernière équipe a choisi le concept suivant : un contenu éditorial fort sur data.gouv.fr qui doit permettre aux novices de facilement faire le liens entre les données publiques et des problématiques concrète. Pour les experts, réutilisateurs, producteurs de données, la plateforme permet de communiquer plus facilement leur travail et de se retrouver autour de thématiques communes. L’idée est de proposer aux organisations publiques, privées, ONG, citoyens de pouvoir créer leur « page » ou « communauté » sur la plateforme data.gouv.fr et d’y rassembler les données, applications, dataviz, articles autour d’une thématique précise.

—> Lire la description complète du projet
Améliorer la fiabilité et la documentation des données par le crowdsourcing
Partant du constat d’un manque de fiabilité et de documentation des données, le dernier groupe imagine un portail qui permet aux utilisateurs institutionnels et particuliers de se créer un compte utilisateur afin d’améliorer la qualité de la documentation des données. Chaque jeu de données comporte des tags qui peuvent être ajoutés par les producteurs de données aussi bien que par les utilisateurs. L’utilisateur peut aussi indiquer un lien vers une application, une dataviz ou une analyse qui utilise ce jeu de données. Une section Remix offre aux utilisateurs la possibilité de poster le jeu de données sous d’autres formats ou avec des enrichissements qui pourraient bénéficier à la communauté. Enfin, chaque jeu de données est associé à un espace de discussion organisé à la manière du site Stackoverflow qui encourage les utilisateurs à faire des contributions intéressantes par un système de points.

–> Lire la description complète du projet
Les portails open data, France en tête, ont été créés pour répondre aux besoins de la communauté des développeurs. Aujourd’hui consultés par un public moins techniques, ils doivent s’adapter.
Différentes fonctionnalités selon le niveau de compétence : de la dataviz pour tous à l’API pour les développeurs
Un groupe de travail a identifié 3 personna pour le portail open data qu’ils imaginent :
- le novice : ne connaît rien à l’open data, arrive sur le portail un peu par hasard, il doit comprendre en un clin d’oeil l’objet et l’intérêt du site
- le curieux : il connaît l’open data de nom, il est suffisamment curieux pour chercher de l’info sur le site et veut manipuler les données
- l’expert : il est très au fait de l’open data, et se rend sur data.gouv.fr pour trouver de l’info brute, il veut trouver rapidement des jeux de données pertinentes.
Le site qu’ils proposent est divisé en fonction de ces profils, mais pas de façon hermétique : l’objectif est que l’internaute puisse passer d’une catégorie à l’autre durant sa visite (« novice » -> « curieux », « curieux » -> « averti »)
Deux propositions ressortent de ce groupe de travail :
- multiplier les exemples de « bonnes » data-visualisations pour comprendre en un coup d’oeil « à quoi ça sert
- donner la possibilité de manipuler les données, et réaliser facilement ses propres data-visualisations
–> Lire la description complète du projet
Et la suite ?
Etalab a publié récemment les premiers enseignements de la démarche de codesign dont certains sont inspirés par l’événement redesign.
Les travaux issus de cet événement peuvent être réutilisés par tous, sous réserve de citation de la source et de partage à l’identique avec la licence Creative Commons (CC BY-SA 3.0 FR). Une première présentation de ces travaux par l’Open Knowledge Foundation France a déjà été effectuée lors de l‘atelier de cocréation de la deuxième version de la plateforme open data de la ville de Paris. Enfin, un groupe de travail est en cours de constitution au sein de l’association pour faire aboutir le projet Tada et créer de vrais « jeux de données ».
15 Jul 11:36
(ASK MEDIA POUR LE PARISIEN MAGAZINE) La France verte en panne
by Marie Coussin
Ask Média réalise les infographies du Parisien magazine, en kiosque tous les vendredis et disponible sur le parisien.fr. Ce travail prend en compte la recherche des données, la vérification des... Read The Rest →
13 Jul 07:48
(ASK MEDIA POUR PARIS MATCH) Où partent les Européens en vacances ?
by Marie Coussin
Ask Media réalise une page de data visualisation pour la rubrique « Data match » de Paris Match : recherche de données, enquête, conception de l’infographie et réalisation. Pour la... Read The Rest →
05 Jul 16:17


De 1950 à 2010 : 60 ans de prénoms en France
by Karen Bastien
Quels sont les prénoms les plus donnés en France ? Le vôtre est-il original ? Combien d’homonymes sont nés la même année que vous ? Y a t’il un retour des Alphonse, Martine, Eugène, Brigitte [...]
Pachevalier likes this
05 Jul 16:17
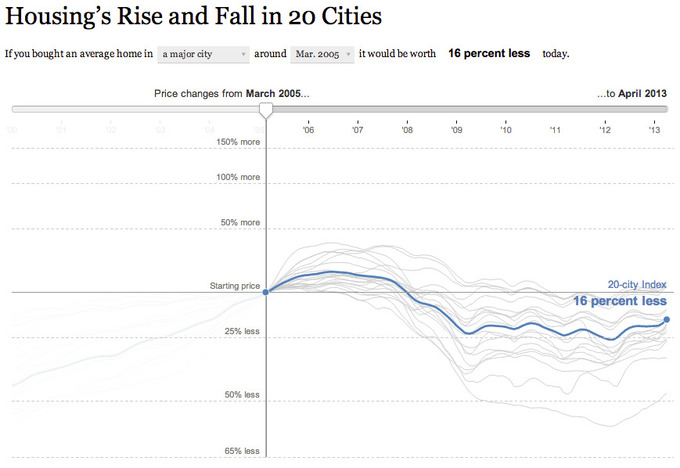

Etats-Unis : hauts et bas de l'immobilier
by Karen Bastien
Not seasonally-adjusted Case-Shiller house prices for 20 U.S. metro-areas.
05 Jul 15:44
Au premier trimestre 2013, lICC augmente de 1,79 % sur un an
Lindice du coût de la construction (ICC) sétablit à 1 646 au premier trimestre 2013 après 1 639 au trimestre précédent. En glissement annuel, lICC augmente de 1,79 %, après une hausse de 0,06 % au quatrième trimestre 2012.
03 Jul 08:42

Karen Bastien's insight:
Application développée pour Radio France Nouveaux Médias, à l'occasion de la 100e édition du Tour de France : 58 vainqueurs, 754 villes-étapes et des milliers de données.#data #game #geolocalisation #streetview #hyperlapse http://100tours.radiofrance.fr/
100 Tours de France [WeDoData]
by Karen Bastien
Retrouvez les statistiques de tous les vainqueurs du Tour de France : victoires d'étapes, classement par année, abandons
Karen Bastien's insight:
Application développée pour Radio France Nouveaux Médias, à l'occasion de la 100e édition du Tour de France : 58 vainqueurs, 754 villes-étapes et des milliers de données.#data #game #geolocalisation #streetview #hyperlapse http://100tours.radiofrance.fr/
02 Jul 16:44
(ASK MEDIA POUR PARIS MATCH) Tour de France 2013 : la course des vainqueurs
by Marie Coussin
Ask Media réalise une page d’infographie pour la page « Data match » de Paris Match : recherche de données, enquête, conception de l’infographie et réalisation.
Pour la semaine du 27 juin, à l’occasion de la 100ème édition du Tour de France, nous avons classé plusieurs maillots jaunes de l’Histoire selon leurs performances financières et sportives, s’ils couraient le Tour aujourd’hui.

Pachevalier likes this