Jean-Philippe Encausse
Shared posts
Groups of AI agents spontaneously form their own social norms without human help, study suggests
Don't Think of an Elephant

When teaching framing at UC Berkeley, Professor George Lakoff would often begin with a simple test: "Don't think of an elephant."
Except everyone does. When he said elephant, like it or not, all things elephant—large, slow, floppy ears, tusks, trunk, jungle, savannah—were likely to come to mind.
Lakoff gives another example: When Richard Nixon came on TV and said, "I am not a crook," everyone thought about him as a crook, even though he explicitly said he wasn't.
Another case he shares is when someone says tax relief, it evokes a frame whereby taxes are a burden, someone imposing those taxes is hurting people, someone relieving you of that hurt is helping you, and anyone who wants to stop that relief is a villain. Suppose you think taxes are good, not bad; if you use the term tax relief when arguing against it, you're setting yourself up as the villain.
Using someone else's language draws you into their worldview.
Some Framing Examples
Here are some more everyday examples of framing at work:
- Taking sides in an argument suggests there has to be a winner and loser.
- When someone helps you, saying "I owe you one" frames the favour as a transaction to be repaid rather than a gift.
- Stay-at-home parent and working parent evokes a frame where staying at home isn't work.
- Quality time frames certain family moments as more valuable and implies that some time is less meaningful.
- Screen time evokes a frame of off-screen vs on-screen time, as opposed to considering the value of what you're doing, whether on-screen or off.
Reframing Signage
I love spotting signs that shift the frame in positive, thoughtful ways. Rather than presupposing bad behaviour, they invite good.
For example, this sign from Kew Gardens:
"Respecting Significant Trees
Please help us manage our trees to ensure we can enjoy them for as long as possible.
This tree needs a break from adults and children climbing on it.
Please don't climb."
Rather than setting Kew up as the rule-enforcer spoiling your fun, it frames them as caretakers—inviting you to help give a tired tree a break. Not climbing becomes an act of kindness, not a restriction. Not climbing becomes an act of respect rather than restriction.
Our local wetlands has a "Ducks only" sign instead of an admonishing "Keep off the grass".
Or at an ATM, even saying "Wait" rather than "Don't remove your card" helps keep removing your card further from your mind.
A reader shared with me that as a lifeguard, he learned to yell "Walk!" rather than "Don't run!" A positive action to take is direct, rather than a negative that needs to be processed—see Point Positive.
Language shapes and reflects how we think. Using language that negates a frame evokes the frame. What frames are you evoking?
Related Ideas to Don't Think of an Elephant
Everything I've learned about framing, metaphor, and how they shape our thinking continues to fascinate me. Here are some related sketches and powerful metaphors:
LED Layer Makes Plywood Glow

Plywood is an interesting material: made up of many layers of thin wood plys, it can be built up into elegantly curved shapes. Do you need to limit it to just wood, though? [Zach of All Trades] has proved you do not, when he embedded a light guide, LEDs, microcontrollers and touch sensors into a quarter inch (about six millimeter) plywood layup in the video embedded below.
He’s using custom flexible PCBs, each hosting upto 3 LEDs and the low-cost PY32 microcontroller. The PY32 drives the RGB LEDs and handles capacitive touch sensing within the layup. In the video, he goes through his failed prototypes and what he learned: use epoxy, not wood glue, and while clear PET might be nice and bendy, acrylic is going to hold together better and cuts easier with a CO2 laser.
The wood was sourced from a couple of sources, but the easiest was apparently skateboard kits– skateboards are plywood, and there’s a market of people who DIY their decks. The vacuum bag setup [Zach] used looks like an essential tool to hold together the layers of wood and plastic as the epoxy cures. To make the bends work [Zach] needed a combination of soaking and steaming the maple, before putting it into a two-part 3D printed mold. The same mold bends the acrylic, which is pre-heated in an oven.
Ultimately it didn’t quite come together, but after some epoxy pour touch-up he’s left with a fun and decorative headphone stand. [Zach] has other projects in mind with this technique, and its got our brains percolating as well. Imagine incorporating strain gauges to drive the LEDs so you could see loading in real time, or a sound-reactive speaker housing. The sky’s the limit now that the technique is out there, and we look forward to see what people make of it.
The last time we heard from [Zach of All Trades] he was comparing ten cent micro-controllers; it looks like the PY32 came out on top. Oddly enough, this seems to be the first hack we have featuring it. If you’ve done something neat with ten cent micros (or more expensive ones) or know someone who did, don’t forget to let us know! We love tips. [Zach] sent in the tip about this video, and his reward is gratitude worth its weight in gold.

Actualité : Mission accomplie : Voyager 1 a rallumé en urgence des propulseurs éteints depuis 2004 avant un black-out

Smart Terrarium Run By ESP32

A terrarium is a little piece of the living world captured in a small enclosure you can pop on your desk or coffee table at home. If you want to keep it as alive as possible, though, you might like to implement some controls. That’s precisely what [yotitote] did with their smart terrarium build.
At the heart of the build is an ESP32 microcontroller. It’s armed with temperature and humidity sensors to detect the state of the atmosphere within the terrarium itself. However, it’s not just a mere monitor. It’s able to influence conditions by activating an ultrasonic fogger to increase humidity (which slightly impacts temperature in turn). There are also LED strips, which the ESP32 controls in order to try and aid the growth of plants within, and a small OLED screen to keep an eye on the vital signs.
It’s a simple project, but one that serves as a basic starting point that could be readily expanded as needed. It wouldn’t take much to adapt this further, such as by adding heating elements for precise temperature control, or more advanced lighting systems. These could be particularly useful if you intend your terrarium to support, perhaps, reptiles, in addition to tropical plant life.
Indeed, we’ve seen similar work before, using a Raspberry Pi to create a positive environment to keep geckos alive! Meanwhile, if you’re cooking up your own advanced terrarium at home, don’t hesitate to let us know.
The Hot New AI Tool in Law Enforcement Is a Workaround for Places Where Facial Recognition Is Banned

At the end of 2024, fifteen US states had laws banning some version of facial recognition.
Usually, these laws were written on the basis that the technology is a nightmare-level privacy invasion that's also too shoddy to be relied upon. Now, a new company aims to solve that problem — though maybe not in the way you'd imagine (or like).
Per a report in MIT Technology Review, a new AI tool called Track is being used not to improve facial recognition technology, nor as a way to make it less invasive of your personal civil liberties, but as a workaround to the current laws against facial recognition (which are few and far between, at least when compared to the places it's allowed to operate). It's a classic tale of technology as "disruption," simply by identifying a legal loophole to be exploited.
That new tool, called Track, is a "nonbiometric" system that emerged out of a SkyNet-esque company that specializes in video analytics, Veritone.
According to MIT Technology Review's story, it already has 400 customers using Track in places where facial recognition is banned, or in instances where someone's face is covered. Even more: Last summer, Veritone issued a press release announcing the US Attorney's office had expanded the remit of their Authorization to Operate, the mandate that gives a company like Veritone the ability to carry out surveillance operations.
Why? Because Track can (supposedly) triangulate people's identities off of footage using a series of identifying factors, which include monitored subjects' shoes, clothing, body shape, gender, hair, and various accessories — basically, everything but your face. The footage Track is capable of scanning includes everything from closed-circuit security tapes, body-cams, drone footage, Ring cameras, and crowd/public footage (sourced from various social media networks where it's been uploaded).
In a view MIT Technology Review obtained of Track in operation, users can select from a dropdown menu listing a series of attributes by which they want to identify subjects: Accessory, Body, Face, Footwear, Gender, Hair, Lower, Upper. Each of those menus has a sub-menu. On "Accessory," the sub-menu lists: Any Bag, Backpack, Box, Briefcase, Glasses, Handbag, Hat, Scarf, Shoulder Bag, and so on. The "Upper" attribute breaks down into Color, Sleeve, Type (of upper-body clothing), and those types break down into more sub-categories.
Once the user selects the attributes they're looking for, Track gives the user a series of images taken from the footage being reviewed, containing a series of matches. And from there, it will continue to help users narrow down footage until they've assembled a triangulation of their surveillance target's path.
If this sounds like current facial recognition software — in other words, like it's a relatively fallible Orwellian enterprise, bound to waste quite a bit of money, netting all the wrong people along the way — well, the folks at Veritone see it another way.
Their CEO called Track their "Jason Bourne tool," while also praising its ability to exonerate those identified by it. It's an incredibly dark, canny way to get around limitations on their ability to use facial recognition tracking systems, simply by providing something very much like it, that isn't precisely biometric data. By going around that loophole, Signal equips police departments and federal law enforcement agencies with the unencumbered opportunity to conduct surveillance that's been legislated against in all but the precise letter of the law. And surveillance, it's worth noting, that might be even more harmful or detrimental than facial recognition itself.
It's entirely possible that people who wear certain kinds of clothing or look a certain way can be caught up by Track. And this is in a world where we already know people have been falsely accused of theft, falsely arrested, or falsely jailed, all thanks to facial recognition technology.
Or as American Civil Liberties Union lawyer Nathan Wessler told MIT Tech Review: "It creates a categorically new scale and nature of privacy invasion and potential for abuse that was literally not possible any time before in human history.”
Looks like they're gonna have to find another name for the big map.
More on Facial Recognition: Years After Promising to Stop Facial Recognition Work, Meta Has a Devious New Plan
The post The Hot New AI Tool in Law Enforcement Is a Workaround for Places Where Facial Recognition Is Banned appeared first on Futurism.
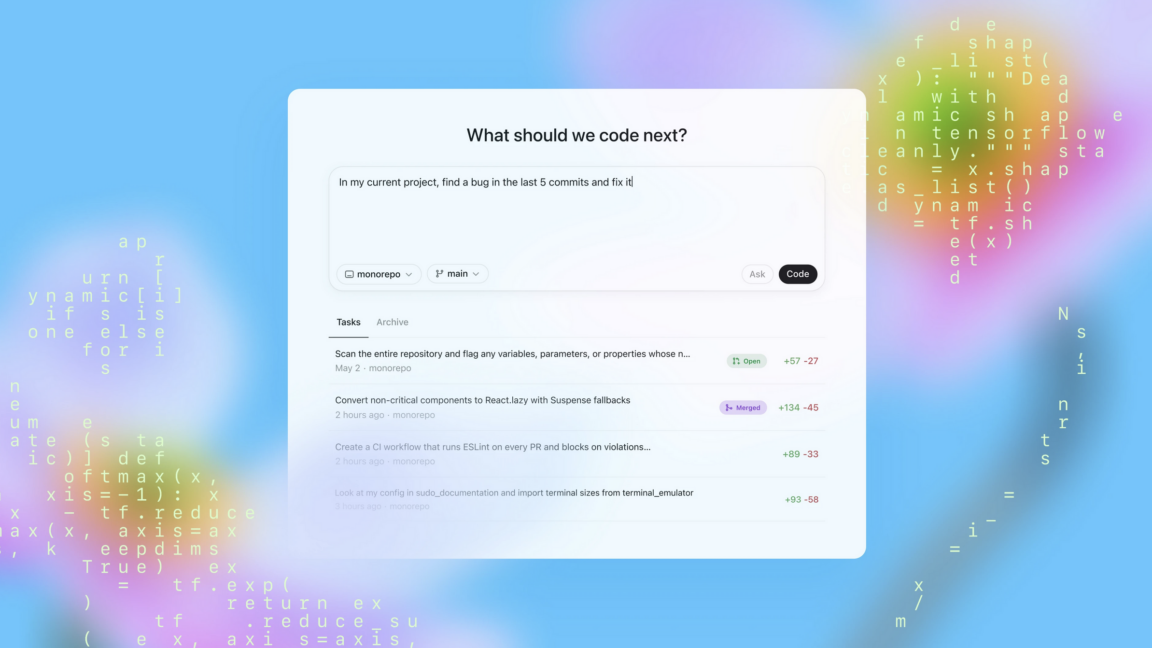
OpenAI introduces Codex, its first full-fledged AI agent for coding
We've been expecting it for a while, and now it's here: OpenAI has introduced an agentic coding tool called Codex in research preview. The tool is meant to allow experienced developers to delegate rote and relatively simple programming tasks to an AI agent that will generate production-ready code and show its work along the way.
Codex is a unique interface (not to be confused with the Codex CLI tool introduced by OpenAI last month) that can be reached from the side bar in the ChatGPT web app. Users enter a prompt and then click either "code" to have it begin producing code, or "ask" to have it answer questions and advise.
Whenever it's given a task, that task is performed in a distinct container that is preloaded with the user's codebase and is meant to accurately reflect their development environment.
Premier succès pour un vaccin contre Alzheimer 💉
Cette IA chinoise reconstitue votre visage en analysant votre ADN 🧬

AI model classifies images with a hierarchical tree from broad to specific
AGI, emploi, productivité : le grand bluff des prédictions IA

Chaque semaine apporte son lot de chiffres sur l’intelligence artificielle, tous aussi plus impressionnants voire inquiétants les uns que les autres. Des millions d’emplois en diner, des gains de productivité astronomiques et l’intelligence artificielle générale, celle qui nous rendra tous obsolètes est à notre porte !
Mais quelle confiance pouvons nous avoir dans ces chiffres ? Quelle est la rigueur scientifique derrière eux ?
Trop souvent on confond prévision et prédiction, projection crédible et extrapolation hasardeuse.
C’est une constante dans le monde de la tech mais, une fois encore, il convient donc de distinguer ce qui relève d’une analyse fondée et ce qui relève de la croyance ou de la communication.
En effet le fait est que la plupart des chiffres avancés, que nous lisons, discutons et sur la base desquels nous prenons peut être des décisions, sont des estimations au doigt mouillé qui ne sont étayés par aucun modèle mathématique sérieux.
En bref :
- Les chiffres avancés sur l’impact de l’IA sont souvent fondés sur des extrapolations peu rigoureuses, sans modèle scientifique solide, et servent des intérêts marketing ou politiques plus que des analyses fiables.
- La confusion entre prévision et prédiction alimente une perception erronée de l’avenir de l’IA, les premières étant fondées sur des données et modèles éprouvés, les secondes relevant de la spéculation voire de la croyance.
- L’intelligence artificielle générale (AGI) fait l’objet d’une définition floue et d’horizons divergents, ce qui rend toute discussion sur son avènement hautement spéculative et non scientifique.
- Les effets annoncés de l’IA sur l’emploi et la productivité reposent sur des hypothèses fragiles et des méthodologies discutables, avec des écarts importants entre les estimations et peu de preuves empiriques à ce jour.
- Le discours dominant sur l’IA est façonné par des acteurs ayant intérêt à exagérer son impact, créant une asymétrie entre promesses technologiques et réalités économiques et sociales, au détriment d’une analyse rigoureuse.
Prévision vs prédiction : deux logiques diamétralement opposées
J’ai, il y a peu, rappelé la différence entre prévisions et prédictions (Pourquoi dirigeants et experts commettent il de grossières erreurs quant il faut anticiper l’avenir ?) mais je pense utile de refaire un rappel ici.
Une prévision repose sur des données observables, des modèles mathématiques et statistiques validés, une probabilité d’occurence évaluée. Elle est le résultat d’une méthodologie rigoureuse semblable à ce qui se fait en matière d’économie ou de météorologie.
A l’inverse une prédiction est une affirmation sur le futur fondée sur peu de faits, subjective, voire prophétique.
Disons les choses autrement.
Les prévisions sont faites par des gens sérieux, un peu tristes, qui suivent des méthodologies strictes où l’intuition et la créativité n’ont pas leur place.
Les prédictions, elles, sont faites par des gens qui vous expliquent que le futur va être terrible et que vous ne survivrez qu’en achetant leurs produits et services. Le marketing de la peur a toujours bien fonctionné et, pour citer un homme politique célèbre, plus c’est gros plus ça passe.
Souvenez vous qu’en 2015 on allait tous mourir si on n’investissait pas dans la transformation digitale. Qui est mort du digital ou l’ubérisation ? Personne (Digital : l’empire contre-attaque). Demain on parlera d’ailleurs du Metavers qu’il y a 5 ans certains voyaient valorisé entre 5000 et 13000 milliards de dollars. Et n’oubliez pas qu’en 2000 on aurait tous du avoir des voitures volantes.
Bref.
En matière d’IA la confusion entre prévisions et prédictions est systématique : on présente des estimations voire des arguments marketing comme des certitudes, on projette des effets systémiques à partir de tests locaux ou en laboratoire et on en fait des vérités.
Très peu de ces prédictions, voire aucune, ne sont modélisées à partir de données solides ni validées à partir de la comparaison de scénarios. Elles ne reposent donc sur aucun modèle robuste.
Quiconque a fait un peu d’économie sait ce qu’est un modèle robuste : il repose sur des hypothèses explicites, des données empiriques vérifiables, une capacité à être testé dans le temps, et une sensibilité maîtrisée aux variations de paramètres. Ce qui n’est souvent pas le cas ici.
Faire des prédictions sur l’IA sans modèle rigoureux, c’est comme annoncer la météo dans deux semaines sans regarder le ciel ni disposer d’un satellite.
En effet la plupart des prédictions sur l’IA reposent sur des matrices de tâches, des questionnaires d’opinion ou des raisonnements qualitatifs non modélisées. On est plus dans la prospective que la science prédictive.
Et le vocabulaire utilisé par les consultants, journaliste, dirigeants et bien sûr le marketing des éditeurs entretient volontairement cette ambiguïté afin de nous faire prendre des prophéties autoréalisatrices pour des scénarios plausibles.
L’AGI : une définition insaisissable, des horizons divergents
Elle fait rêver, fait peur, fait fantasmer : je parle bien sur de l’intelligence artificielle générale (AGI). C’est le graal, l’IA absolue : une forme d’intelligence artificielle capable de comprendre, apprendre et accomplir toute tâche cognitive humaine avec un niveau de performance au moins équivalent à celui d’un être humain, de manière autonome et transférable entre domaines.
Celle qui nous rendra tous obsolètes.
Mais encore faut-il s’accorder pour savoir de quoi on parle et là c’est loin d’être le cas car il n’existe aucune définition consensuelle sur ce qu’est l’AGI.
Pour certains, c’est une IA capable d’effectuer toutes les tâches cognitives humaines, de façon autonome et généralisable. Pour d’autres, elle désigne un système capable de transférer des compétences acquises dans un domaine vers un autre, sans supervision humaine. D’autres encore parlent simplement de performance équivalente à celle d’un humain moyen dans un ensemble de tâches variées.
Plus récemment, Microsoft et OpenAI ont annoncé que l’AGI sera atteinte dès que OpenAI aura développé un système d’IA capable de générer au moins 100 milliards de dollars de bénéfices (Microsoft and openai agree a financial definition of AGI of $100 billion).
Beaucoup moins ambitieux et par expérience je me dis que lorsqu’on abaisse les critères de jugement cela veut dire qu’on se dit qu’on aura du mal à y arriver. Un peu comme le niveau d’exigence au BAC…
Bref, l’AGI, c’est un peu comme le monstre du Loch Ness : tout le monde en parle, certains jurent l’avoir vu, mais personne ne peut la définir clairement ni prouver son existence.
En 2022, une étude de AI Impacts avait interrogé 738 chercheurs en IA (2022 Expert Survey on Progress in AI) et 50 % estimaient que l’AGI apparaîtrait avant 2059, 25 % pensent pas avant 2100, et une minorité significative jamais.
Mais à l’échelle de l’IA 2022 c’est il y a une éternité. Alors qu’en dit on maintenant ?
Sam Altman, le directeur général d’OpenAI a affirmé que l’AGI pourrait émerger dès 2025 (Reflections), une position partagée par quelques figures du secteur mais minoritaire dans la communauté scientifique. Du coté chez Anthropic, son président Dario Amodei estime que l’AGI pourrait voir le jour dès 2026, voire dans les 12 à 24 prochains mois (Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity). Cela rejoint le scénario dit « AI 2027 », élaboré par d’anciens chercheurs d’OpenAI et du Center for AI Policy, qui tablent sur une émergence de l’AGI autour de 2027.
Mais d’autres sont beaucoup plus prudents.
Pour Geoffrey Hinton (ex-Google) l’arrivée possible de l’AGI se site entre 5 et 20 ans, soit entre 2028 et 2043 (Here’s how far we are from AGI, according to the people developing it), mais il insiste sur l’incertitude persistante autour de cette échéance et même sur ce qu’est vraiment l’AGI (‘Godfather of AI’ says there isn’t a consensus on what ‘artificial general intelligence’ means.
A coté de ça diverses études placent l’arrivée de l’AGI entre 2030 et 2060.
On parle donc d’une marge d’erreur de 35 ans pour quelque chose au sujet de laquelle aucune définition n’existe et dont certains doutent même de l’existence.
D’autres personnes faisant autorité comme Yann LeCun (Meta) la jugent très lointaine et mal définie (Meta’s LeCun Debunks AGI Hype, Says it is Decades Away), tandis que d’autres comme Eliezer Yudkowsky, le fondateur du Machine Intelligence Research Institute(Pausing AI Developments Isn’t Enough. We Need to Shut it All Down) annoncent son avènement comme imminent et potentiellement dangereux.
Ces différences rendent donc toute discussion sur le calendrier ou les impacts de l’AGI totalement spéculative et révèlent une absence totale de consensus non seulement sur ce qu’est l’AGI, mais aussi sur la plausibilité de son avènement dans un horizon temporel exploitable.
On est donc totalement dans le domaine au mieux de la croissance personnelle et, au pire, du marketing. Tout cela repose donc davantage sur des intuitions, des positions philosophiques, des impératifs commerciaux, des messages subliminaux aux investisseurs plutôt que sur une progression mesurable ou modélisable.
L’arnaque du QI de l’IA
Je lis ça et là que l’IA atteint aujourd’hui des scores de quotient intellectuel similaires aux humains les plus intelligents et qu’elle va rapidement les surpasser. Mais je ne lis personne qui au lieu de repartager du hype de manière forcenée ne se questionne sur la pertinence de l’argument.
Le QI est un outil de mesure statistique conçu pour évaluer certaines capacités cognitives humaines comme le raisonnement logique, la mémoire ou la compréhension verbale. Il repose sur une normalisation autour d’une moyenne humaine pour une classe d’âge donnée.
Appliquer ce concept à des intelligences artificielles est donc scientifiquement discutable car une IA ne partage ni la structure cognitive, ni les limites biologiques humaines.
Elle peut, par ailleurs, exceller sur certaines tâches de QI tout en échouant sur des tâches élémentaires pour un humain (compréhension contextuelle, bon sens). Essayez de demander à chatGPT un calcul ou une résolution d’équation, même simple, et vous allez rire: normal, il ne sait pas compter, même pas le nombre de caractères dans un mot ou le nombre d’occurrences d’une lettre dans un mot et ne comprend pas le sens de ce qu’il dit. Pour lui la réponse qu’il vous donne n’est pas la meilleure en termes de sens mais la plus statistiquement probable.
Les tests utilisés pour calculer le QI d’une IA sont également souvent biaisés, car les IA sont souvent entrainés sur les corpus des tests eux-mêmes. Un peu comme si vous vous entrainiez sur le sujet même de l’examen que vous allez passer.
Enfin l’intelligence d’une IA est fondamentalement différente de celle d’un être humain : elle est spécialisée, contextuelle et n’a ni conscience ni intention.
Le QI n’est donc ni pertinent, ni suffisant pour évaluer ou comparer les capacités cognitives des intelligences artificielles
D’ailleurs LeCun ne dit pas autre chose (Are we all wrong about ai? When academics challenge the silicon valley dream et, This AI Pioneer Thinks AI Is Dumber Than a Cat, Meta AI Chief Yann LeCun: Human Intelligence Is Not General Intelligence) quand il dit que l’AGI ou peu importe la manière dont vous la nommez ne sera pas atteinte par les LLM dont on s’esbaudit par ailleurs quand on parle de leur soit disant QI (Meta’s AI chief: LLMs will never reach human-level intelligence). Ce faisant il tient à peu près les mêmes propos que Luc Julia qui nous dit que les discours alarmistes autour de l’AGI sont souvent exagérés et ne reflètent pas la réalité des capacités actuelles de l’IA (Dans l’IA, trop d’artificiel, pas assez d’intelligence pour le spécialiste Luc Julia) mais je ne comprends pas pourquoi à chaque fois que je cite ce dernier sur Linkedin je vois comme une sorte de levée de bouclier, comme si des gens avaient peur qu’on leur casse leurs rêves et leurs jouets.
Ne vous méprenez pas, je ne dis pas qu’un jour ne naitra pas une IA capable de nous égaler ou nous surpasser, en tout cas dans certains domaines.
Je dis juste que personne ne s’accorde quant à savoir ce dont on parle, de quand cela arrivera ni même de si cela arrivera et en tout cas dans quelles proportions.
Je ne dis pas que tel ou tel de ces éminents spécialistes à tort ou raison, je dis juste que chacun peut choisir l’hypothèse qu’il veut, aucune n’est plus valable que l’autre et aucune ne repose sur un raisonnement scientifique mais sur des intuitions et des convictions.
IA et destruction d’emplois : un mélange d’hypothèses et d’approximation
Je vous disais dernièrement que je ne croyais pas au remplacement généralisé de l’humain par l’IA, en tout cas à moyen terme et même à long terme (IA et emploi : pourquoi je ne crois pas au « grand remplacement » de l’Homme par la machine).
Maintenant parlons des chiffres disponibles sur le sujet.
Goldman Sachs parle de 300 millions d’emplois « exposés » dans le monde (Generative AI could raise global GDP by 7%).
Toujours en 2023, McKinsey prévoyait que 60 à 70 % du temps de travail pourrait être automatisé d’ici 2030 (The economic potential of generative AI: The next productivity frontier). Notons bien la différence entre emplois et temps de travail.
Plus récemment, en 2025, le World Economic Forum (2023) anticipe 92 millions d’emplois supprimés d’ici 2030 mais également que 170 millions de nouveaux emplois seront créés dans le même temps (The Future of Jobs Report 2025).
Inutile d’aller plus loin : vous trouverez une énorme quantité de chiffres qui ne disent pas tous la même chose et surtout pas dans les mêmes proportions.
Mais il faut bien avoir en tête qu‘un emploi exposé n’est pas un emploi supprimé. De plus ces estimations ne reposent, là encore, sur aucun modèle mathématique robuste. Il ne s’agit ni de projections économétriques ni de modélisations validées mais au mieux d’extrapolations issues de matrices de correspondance entre tâches et capacités d’outils d’IA, et, au pire, d’intuitions transformées en chiffres à des fins de marketing.
Il n’existe pas, à ce jour, de modèle scientifique permettant de prédire avec fiabilité combien d’emplois seront supprimés, à quel horizon, et dans quels secteurs. C’est donc une évaluation subjective sans valeur prédictive.
On a déjà eu la leçon par le passé mais elle ne semble pas avoir été apprise. En effet dès 2013 une étude de Frey & Osborne Frey nous disait qu’entre 33 et 47% des emplois américains était automatisable (The future of employment: how susceptible are jobs to computerisation?). Trois ans plus tard l’OCDE ramenait son chiffre à 9% en raison d’un problème de méthode :les premières estimations supposaient une automatisation totale d’un poste si une majorité de ses tâches était automatisable, ce qui est totalement irréaliste.
Plus proche de nous une autre étude vient de tempérer les scénarios les plus alarmistes (Generative AI is not replacing jobs or hurting wages at all, economists claim). L’analyse des données de 200 millions d’offres d’emploi aux Etats-Unis montre que l’arrivée des outils d’IA générative n’avait pas eu d’impact significatif sur les offres d’emploi ou les salaires dans les secteurs les plus exposés.
LeCun va également dans ce sens (Meta scientist Yann LeCun says AI won’t destroy jobs forever)
J’insiste encore à nouveau sur la question de la rigueur de la méthode. On liste des tâches, on regarde ce peuvent faire des IA et on en déduit une « remplaçabilité » potentielle qui, peut être, deviendra réalité. Mais l’IA est elle la seule responsable de la destruction potentielle d’emplois en 2025 ? Peut être que des variables comme les tensions économiques ou les guerres jouent un rôle, même minime, dans un potentiel ralentissement économique ? Mais les prédictions technocentrées ne prennent jamais en comptes les variables externes…
Là encore ne me faites pas dire ce que je ne dis pas.
On me pose souvent la question de savoir si « l’IA va un nous nous piquer nos jobs ».
Ma réponse est que la question est mal posée :
• Est-ce que l’IA va prendre une partie de mes activités ? Certainement. Mais quelle proportion et à quel horizon de temps ?
• Est-ce qu’elle va m’imposer des tâches non désirées et contraintes comme perdre du temps à rédiger un prompt à usage unique ou vérifier ses résultats et corriger les erreurs ? Oui. Mais dans quelle proportion ?
• Est-ce qu’elle va créer des tâches à haute valeur ajoutée, plus épanouissante ? Certainement mais dans quelles proportions et pour combien de monde ?
• Quand ou à quelle vitesse cela va se produire ? Je n’en ai rationnellement absolument aucune idée.
Je ne dis pas que cela ne va pas arriver, je dis juste que c’est probable (quelle probabilité ?) mais sans savoir à quel point et que tout ce qu’on lit en termes d’ordre de grandeur et horizon de temps ne repose sur rien de solide.
Je peux vous dire que je vais probablement partir en vacances cet été (la probabilité n’est même pas de 100%), mais je ne sais ni ou ni quand. Partant de là je n’ai pas assez pour soutenir une conversation avec mes amis sur mes futures vacances mais si je parlais d’IA avec le même niveau de certitude je pourrais me faire passer pour un gourou.
En attendant je ne doute pas que tout ce qui est automatisable sera automatisé, qu’on se fait des illusions sur les jobs soit disant plus épanouissants et qu’au final on fera pleins de bêtises avant de peut être revenir en arrière (Cessons d’être nAIfs avec l’IA au travail). Mais pour prendre les bonnes décisions il faut des chiffres et des horizons de temps et en la matière nous navigons en pleine fantaisie.
Gains de productivité : des projections sous condition
McKinsey avance donc que l’IA générative pourrait générer +3,3 % de productivité annuelle d’ici 2040. PwC estime à +14 % l’impact sur le PIB mondial d’ici 2030 (Sizing the prize. What’s the real value of AI for your business and how can you capitalise?).
Mais ces chiffres sont conditionnels car ils reposent sur une adoption massive et rapide, une requalification généralisée des salariés et une intégration sans friction dans les organisations. Tout ce qui n’arrive absolument jamais (Vous pouvez voir l’ère informatique partout, sauf dans les statistiques de la productivité).
Et, surtout ils ne reposent sur aucune modélisation rigoureuse mais seulement sur ces hypothèses optimistes et linéaires.
Dans les faits, les gains observés restent localisés et souvent marginaux. Le coût d’intégration, la qualité des données, la culture managériale, la courbe d’apprentissage sont utant d’obstacles qui atténuent l’impact promis dans des proportions majeures, sans même parler de l’acceptabilité et de l’impact social (Les défis que pose l’IA ne sont pas technologiques mais il faut y répondre aujourd’hui).
Les estimations de gains de productivité reposent souvent sur des hypothèses empilées comme un château de cartes : il suffit qu’un seul paramètre soit irréaliste pour que l’ensemble s’effondre.
Souvenons nous qu‘il a fallu très très longtemps pour que l’électricité transforme vraiment l’industrie, le temps de reconstruire et réorganiser des usines qui étaient conçues pour d’autres modes d’énergie et que l’ère de prospérité qui a suivi a demandé, en plus, de violences luttes sociales. Et l’histoire tend à éternellement se répéter (On surestime toujours le changement à venir dans les deux ans, et on sous-estime le changement des dix prochaines années). Comme me le disait un de mes mentors : « il faut du temps pour que les choses se passent rapidement« .
Daron Acemoglou, économiste MIT et personnage a priori crédible puisque récompensé par un prix Nobel semble aller dans ce sens (Daron Acemoglu: What do we know about the economics of AI?) : les effets macroéconomiques de l’IA sont aujourd’hui surestimés, faute de preuves du contraire. Ses travaux suggère une augmentation du PNB d’au maximum 1,6% sur 10 ans avec un gain annuel de productivité de 0,05% voire des gains négatifs sur les professions les moins qualifiées, sans oublier les effets collatéraux négatifs. Selon lui, la question centrale n’est pas de savoir si l’IA va tout transformer, mais comment orienter l’innovation vers des usages réellement complémentaires au travail humain plutôt que de chercher systématiquement à l’automatiser.
On est loin des 14% de McKinsey. Qui a raison ? Peut être Acemoglou dont la méthode m’a l’air plus rigoureuse d’un point de vue économique mais je ne suis pas assez qualifié pour en juger.
Ce que je sais par contre c’est qu’entre 14% et 1,6% il y a un gouffre et que rien ne permet de dire que l’un a tort et l’autre raison sauf à vouloir suivre aveuglément l’hypothèse qui nous arrange le plus.
Une question mal posée
Plutôt que de demander « est-ce que l’IA va remplacer les humains ?« , nous devrions peut être nous demander : pour quelles tâches, avec quels effets systémiques, et à quel rythme ?
L’IA remplace des tâches, rarement des métiers dans leur entièreté. Elle crée aussi de nouveaux besoins : supervision des modèles, conception des prompts, vérification humaine. Chaque vague technologique a vu naître de nouveaux emplois, même si cela prend du temps.
La technologie ne résout pas de problème mais nous aide à les résoudre et, ce faisant, elle en crée de nouveaux que les humains devront résoudre (Technology Doesn’t Solve Problems).
On oublie aussi les effets de rebond : plus de productivité peut entraîner plus de demande. Enfin, les organisations ne changent pas instantanément : leur inertie freine l’impact des technologies, d’autant plus que les cadres sociaux et réglementaires ne suivent pas toujours la même dynamique que l’innovation technique.
La fabrique du discours brouille l’analyse
Une dernière dimension mérite d’être soulignée : ces prédictions fantaisistes ne sont pas seulement le fruit d’un excès d’optimisme ou d’un manque de méthode mais souvent le produit d’un écosystème d’intérêts croisés.
Les cabinets de conseil et les médias, friands de récits mêlant hype et peur, ont tout intérêt à alimenter des scénarios qui nourrissent leur offre, leur influence ou leur audience. Les éditeurs de solutions IA, eux, veulent convaincre les investisseurs que la terre promise est en vue. Quant aux investisseurs eux-mêmes, après avoir injecté massivement des capitaux dans les technologies d’IA, ils ont besoin de dire au marché que les usages sont matures et que le retour sur investissement est proche.
Cette dynamique produit un discours techno-évangélique auto-entretenu, dans lequel il devient impossible de distinguer l’analyse du marketing.
Ce biais influence des décisions politiques, budgétaires et RH : fermetures de filières, réformes éducatives, plans de transformation fondés sur des données peu fiables. En gouvernance comme en stratégie, prendre des décisions fondées sur des chiffres douteux, c’est déguiser l’intuition voire la crédulité en rationalité.
Une asymétrie structurelle entre discours et réalité
Les discours sur l’IA s’accélèrent bien plus vite que les organisations, les systèmes de compétences ou les régulations. Cette asymétrie entre vitesse des promesses et lenteur des réalités crée un décalage entre l’offre technologique et la capacité des systèmes à l’absorber.
Ca n’est pas nouveau, ça prend juste des proportions jamais vues.
Encore une fois il faut faire ici une différence : on peut être d’accord sur la tendance mais admettre que les chiffres ne veulent rien dire.
On peut sentir qu’une vague monte sans pouvoir dire où tombera chaque goutte d’eau.
Oui, l’IA transforme déjà le monde du travail, mais les effets globaux de cette transformation sont encore largement inconnus. Ce n’est pas la peur ou un enthousiasme immodéré qui doivent guider nos décisions, mais la rigueur. Entre les prévisions rigoureuses et les prédictions spectaculaires il faut apprendre à garder la tête froide.
Les chiffres que l’on brandit pour prédire l’avenir de l’IA relèvent bien plus de la spéculation que de la science et aucune équation n’a jamais démontré qu’un tel pourcentage de métiers allait disparaître pas plus qu’il existe un modèle qui soutient les projections à 10 ou 20 ans. Ce sont des estimations construites sur des hypothèses floues, souvent non vérifiables.
Conclusion
Les prédictions sont peut-être justes sur la tendance générale (oui, l’IA va transformer le travail) mais elles sont complètement bancales quand on en vient aux chiffres, les horizons de temps et les impacts concrets. Il serait donc bon de sortir d’une vision technologique quasi prophétique et n’ayant d’autres velléité que soutenir un discours marketing pour revenir à une analyse économique et sociale solide, humble, et évolutive.
Une technologie peut être prometteuse, sans que ses effets soient prévisibles. C’est toute la difficulté de penser l’avenir dans l’incertitude.
Je ne dis pas que rien ne va changer, loin de là, mais que les chiffres avancés ne nous disent absolument rien.
Crédit visuel : Image générée par intelligence artificielle via ChatGPT (OpenAI)
L’article AGI, emploi, productivité : le grand bluff des prédictions IA est apparu en premier sur Bloc-Notes de Bertrand Duperrin.
Des super-Terres partout dans l'Univers, et c'est une surprise ! 🌍

Watch SpaceX blast Starship engines ahead of 9th test flight

Watch Tesla’s humanoid robot pull some snappy dance moves

Robot that keeps food hot or cold could change up food delivery
Apple Vision Pro Will Be Able To Magnify, Describe, Find, Or Read Anything In View
Apple Vision Pro is getting the ability to magnify passthrough, as well as to describe, find, or read anything in your view using on-device AI.
These accessibility features, which Apple says are designed for people who are blind or have low vision, are set to arrive in a visionOS update later this year.
Last year Apple announced accessibility features a month in advance of revealing visionOS 2 at WWDC24, so these features might be seen in visionOS 3 at WWDC25 next month.
Passthrough Zoom & Live Recognition
The improved magnification functionality will arrive as an update to the Zoom accessibility feature, which currently only magnifies virtual content. With the update, it will also magnify the real world.
The enhanced Zoom accessibility coming to visionOS later this year.
Meanwhile, the ability to describe, find, or read anything in view will be an extension of VoiceOver, which currently functions as a screen reader. Called Live Recognition, Apple says the feature will process the passthrough view using on-device machine learning to "describe surroundings, find objects, read documents, and more".
Passthrough API For Accessibility
Apple also says it will offer a new API for "accessibility developers" in "approved apps" to access the passthrough view "to provide live, person-to-person assistance for visual interpretation", starting with Be My Eyes.
While the Meta Horizon OS of Quest headsets now lets all apps access the passthrough cameras if the user grants permission, and Google's Android XR will too at launch, visionOS currently only allows this for non-public enterprise apps "for use in a business setting only", and getting this access requires a special license from Apple.
Apple's wording in announcing wider passthrough camera access suggests that it will only be for accessibility apps after a specific approval process. But given the stance of Horizon OS and Android XR, we'll keep an eye out for any further announcements around passthrough camera access at WWDC25.

Dutch scientists built a brainless soft robot that runs on air
Most robots rely on complex control systems, AI-powered or otherwise, that govern their movement. These centralized electronic brains need time to react to changes in their environment and produce movements that are often awkwardly, well, robotic.
It doesn’t have to be that way. A team of Dutch scientists at the FOM Institute for Molecular and Atomic Physics (AMOLF) in Amsterdam built a new kind of robot that can run, go over obstacles, and even swim, all driven only by the flow of air. And it does all that with no brain at all.

Quantum Computing Race Isn’t Run ‘In a Vacuum’

This story was originally published on The Daily Upside. To receive cutting-edge insights into technology trends impacting CIOs and IT leaders, subscribe to our free CIO Upside newsletter.
Scalable quantum technology isn’t going to be here tomorrow … or the next day. But that doesn’t mean we should pump the brakes.
Last week, experts in the quantum field made the case before the House Science Committee for expanding the US government’s coordinated effort to advance the technology. As the quantum race heats up, the US may not be able to afford to be complacent if it wants to be first in the market, said Dr. Celia Merzbacher, executive director of the Quantum Economic Development Consortium, who testified at the hearing.
“It’s a classic technology that can have a lot of commercial benefits and public good, and it also can be used for defense and national security and military purposes,” said Merzbacher. “But it is a technology that is emerging worldwide. It’s not something that’s being done in a vacuum.”
READ ALSO: AI May Never Completely Conquer Hallucination, Bias and Combating Cyber-Espionage Requires Enterprises to Keep Their Eyes on the Endgame
The post Quantum Computing Race Isn’t Run ‘In a Vacuum’ appeared first on The Daily Upside.
Print PLA in PLA with A Giant Molecular Model Kit

It isn’t too often we post a hack that’s just a pure 3D print with no other components, but for this Giant Molecular Model kit by [3D Printy], we’ll make an exception. After all, even if you print with PLA every day, how often do you get to play with its molecular bonds? (If you want to see that molecule, check out the video after the break.)
There are multiple sizes of bonds to represent bond lengths, and two styles: flexible and firm. Flexible bonds are great for multiple covalent bonds, like carbon-carbon bonds in organic molecules. The bonds clip to caps that screw in to the atoms; alternately a bond-cap can screw the atoms together directly. A plethora of atoms is available, in valence values from one to four. The two-bond atom has 180 and 120-degree variations for greater accuracy. In terms of the chemistry this kit could represent, you’re only limited by your imagination and how long you are willing to spend printing atoms and bonds.
[3D Printy] was kind enough to release the whole lot as CC0 Public Domain, so we might be seeing these at craft fairs, as there’s nothing to keep you from selling the prints. Honestly, we can only hope; from an educational standpoint, this is a much better use of plastic than endless flexy dragons.
If you’d prefer your chemistry toys help you do chemistry, try this fidget spinner centrifuge. Perhaps you’d rather be teaching electronics instead?
Une simulation quantique révèle l'effondrement physique de notre Univers 💥

L'Homme n'a observé que 0,001% des fonds marins 🌊
La lumière remplace l'électricité, la prochaine révolution en Intelligence Artificielle 🧠

Yves Audo : "La Chine est déjà l'usine du monde, ne la laissons pas être le magasin du monde"

Comment Cursor indexe rapidement les bases de code grâce aux arbres de Merkle
Découvrez comment l’IDE Cursor utilise les arbres de Merkle, une structure de données cryptographique, pour indexer efficacement les bases de code. Un exemple concret d’utilisation de cette structure de données habituellement associée à la blockchain, appliquée ici à l’amélioration des performances des outils de développement.

Commentaires
L'article Comment Cursor indexe rapidement les bases de code grâce aux arbres de Merkle a été posté dans la catégorie Développement de Human Coders News
Meta Hypernova and Google AR/AI Glasses – Lumus & Avegant Inside, Both Using LCOS MicroDisplays
Introduction
Two recent LinkedIn articles by Axel Wong inspired this article. The first, Decoding the Optical Architecture of Meta’s Next-Gen AR Glasses: Possibly Reflective Waveguide—And Why It Has to Cost Over $1,000, discussed the use of reflective/geometric (Lumus, or a Lumus Clone) Waveguides using an LCOS display in Meta’s Hypernova AR/AI glasses. Axel’s article was partially based on information from an article by Bloomberg’s Mark Gurman and on information he gleaned from a supplier in China. Axel’s second article, Google’s New AR Glasses: Optical Design, Microdisplay Choices, and Supplier Insights, said that the Google AR glasses were shown in a recent TED Talk by Shahram Izadi, which likely used a diffractive waveguide by Applied Materials.
Shahram Izadi, of Google, held up an optical engine in the video that he said was full color. Axel’s article on the Google AI/AR glasses speculated that it uses either LCOS or an X-Cube MicroLED engine, but seemed to favor it being LCOS. Axel also wrote that the waveguide was likely from Applied Materials. As will be discussed, I think that it is highly likely that Google’s AR glasses are using Avegant’s 20-degree LCOS optical engine that they presented at SPIE’s AR/VR/MR 2025.
The Meta and Google AR/AI glasses have some major similarities: they are both monocular (single display for the right eye), use a Full Color LCOS MicroDisplay, and use waveguides. It has been reported that Meta is putting the display in the lower right corner of the user’s view, whereas it appears from Google’s TED talk that the display is roughly in the center vertically. Perhaps the biggest difference is that Meta is likely using a Lumus reflective waveguide, perhaps with a 30° FOV, whereas Google is using a diffractive waveguide with likely a 20° FOV.

This blog has a tradition of identifying technology inside Google’s AR glasses. Back in February 2013, I correctly identified a Himax LCOS device in the original Google Glass. Stock market analyst Mark Gomes wrote an article on Seeking Alpha based on my findings, causing Himax’s stock to jump by $223 M. See my 2013 article Google Glass and Himax Whirlwind.
SID Display Week This Week
I’m off to SID Display Week this week. If you have a product or concept or want to discuss a topic from this blog at Display Week 2025, please email me at meet@kgontech.com. I’m planning on being there every day of the exhibits (May 13-15), but my calendar is getting pretty full. I may also have time to meet before the exhibition on Monday, May 12th. I’ve partnered with SID to share my insights from Display Week (DW) — past, present, and future. If you’re planning to attend Display Week, SID has provided the code DW25KARL for a free exhibit hall pass.
Disclaimers
While I contacted Lumus and Avegant in preparation for this article, neither company said they could not comment. Therefore, this article is based on the available public evidence, including that provided in Axel Wong’s articles and Bloomberg’s Mark Gurman’s article on Meta Hypernova, plus other sources and my experience. While I think I am correct, I’m not 100% sure.
I should also note that while Meta’s Hypernova is expected to be a product for sale in 2025, it is unclear whether the Google AR glasses are anything more than a lab prototype or perhaps a reference design and developer platform for their Android XR partners.
I should also point out that I have not had a chance to evaluate either Meta’s Hypernova or Google’s XR Glasses. Having followed Lumus’s and Avegant’s developments, I have some idea of what the images may look like, but I have not seen the complete designs.
Both Meta and Google AR Glasses Monocular and LCOS
Meta and Google’s devices are strikingly similar in that they are both Monocular (single-eyed) and likely use LCOS as the display device.
The Case For Monocular
The most obvious reasons to go monocular are to save on cost and weight. Another advantage is that there is no need for IPD adjustment. Mark Gurman has further written that the display is in the “lower right corner of the right lens.”
Long-time AR glasses user, researcher, and Google advisor Thad Starner has advocated for a monocular display on the lower outside (discussed in AWE 2024 Panel: The Current State and Future Direction of AR Glasses), exactly what Meta Hypernova appears to be doing. The advantage of the lower outside corner for the virtual image is that it keeps it out of the way of the user’s forward vision. Thad makes the point that you don’t want a message popping up and blocking your vision at a critical time. From a human factors point of view, if the display is not going to be centered horizontally, then it is best to have it below center, as humans can look down much more easily than look up.
Having biocular displays pretty much forces them to be in the center, but they could be in the lower half if there is a worry of blocking forward vision. Still, if they are not in the center of the forward view, it will be uncomfortable to use for long periods, and the wearer will obviously be looking down. So I would expect that if, as Gurman’s article stated, Meta was planning on a biocular Hypernova 2, they would center the virtual image in the user’s forward view.
LCOS – Why not MicroLEDs?
With all the discussion about MicroLEDs for AR glasses today, it may seem strange that both Meta and Google use LCOS. There are many sound technical reasons for choosing LCOS, particularly for a full-color display, including:
- Cost and availability—MicroLEDs today are much more expensive, and supplies are very limited and likely to remain so for at least the next few years.
- Efficiency—As I discussed in SID Display Week 2024 – LCOS, LCOS has a major endurance advantage that makes it much more efficient with waveguides (diffractive or reflective).
- For a full white screen, LCOS displays illuminated by LEDs are very roughly 10x more power efficient than MicroLED with waveguides. MicroLEDs have the advantage that their power consumption is roughly proportional to the average pixel value (AVP), so if there is “sparse content” like text and simple symbols only on a clear/black background, then the AVP is low and their power can be low.
- Red MicroLEDs are very inefficient, and Blue MicroLEDs, while necessary for color balance, provide almost no “nits.” Thus, a full-color MicroLED display takes well more than 2x the power of a green-only display for the same output to the eye “white nits.” Color compounds the problem with etendue efficiency and is particularly bad with spatial color (side by side R,G,B) where the emission area is larger.
- Viewfinder, Web Browsing, and Picture-based Applications give LCOS a huge power advantage. If the glasses are to support any content, including white screens or looking at bright scenes, they have to be designed for the worst-case conditions, including mostly white/bright images. While most of the content might be between 5% and 20% AVP, if glasses are to work in all cases, they have to be designed for 100% AVP if they are going to support any possible content.
- As I often say, “In AR headsets, Amateurs worry about battery life, pros worry about power dissipation.” Supporting the worst-case power consumption in AR glasses is a massive issue, as there is very little in the way of surfaces that can dissipate heat.
- Useable in daylight—AR glasses should output 2,000 or more nits to the eye in daylight to be usable outdoors. Once again, this favors LCOS unless the content is very sparse.
- “Bright mode” LCOS illumination: Some companies have the option to sacrifice color accuracy or switch to black-and-white mode to boost brightness.
For many of the reasons above, while LCOS does not get the media attention and corporate investment of MicroLEDs, it is likely to remain the best option for full-color AR headsets for some time (perhaps a long time).
Meta’s and Google’s Roadmaps for LCOS versus MicroLED or LBS
The chart below on the left was presented by Meta’s Hartlove at Display Week 2024 and SID AR/VR/MR 2025. Their chart shows LCOS as the “Ready Technology,” MicroLEDs as the “Anticipated Technology,” and Laser Scanning as the “Final Solution” (with a question mark). Below right is a 2023-04-27 SPIE AR/VR/MR fireside chat slide interviewing Trilite, presented by Bernard Kress of Google, that contrasts very dramatically. Kress’s slide shows power efficiency versus Average Pixel Lit (same as AVP); similar to my comment above, Kress shows the MicroLED/LCOS power crossover at ~12% AVP (not true today for full color, maybe in the future), but then he shows that with “MiniLED local dimming” the crossover could move out dramatically. It’s also notable that Kress, when he was a technical leader on Microsoft HoloLens, worked with laser scanning on the HoloLens 2.


Thus, we seem to have highly contrasting views on the future of AR display technology. A cynical person might suggest that Hartlove’s roadmap may be meant to entice Meta’s management to invest in their R&D programs, more than it is tied to business reality. Kress’s (Google) chart may reflect the scars from his work on HoloLens 2.
Meta’s Hypernova Optics – Likely a Lumus Z-Lens Variant
I used some information published by Axel on Reddit in October 2024 in my article, Meta Orion AR Glasses (Pt. 1 Waveguides). In that same Reddit article, Axel wrote (with my bold highlighting):
There were rumors before that Meta would launch new glasses with a 2D reflective (array) waveguide optical solution and LCoS optical engine in 2024-2025. With the announcement of Orion, I personally think this possibility has not disappeared and still exists. After all, Orion will not and cannot be sold to ordinary consumers. Meta may launch another reduced-spec version of reflective waveguide AR glasses for sale, which is still an early adopter version for developers or geeks, but it is speculated that this reflective waveguide version is also likely to be a transition, and will eventually return to surface relief grating (SRG) diffraction waveguides.
It seems to be a bit of an open secret, at least in China, that Meta is likely using a Lumus reflective waveguide in a prototype, if not a final product. I have seen several Chinese companies try to copy Lumus’s reflective waveguides over the years, and the image quality has not been very good compared to Lumus’s. Furthermore, I can’t see why Meta would risk a patent challenge from Lumus if they went with a copy (these points are also made in Axel’s LinkedIn article).
I have been following Lumus’s progress since before I started this blog in 2011. In January at SPIE AR/VR/MR 2025, I met with Lumus to see their newly announced Z30 30° FOV Z-Lens at SPIE AR/VR/MR. They were using a 720 x 720 pixel LCOS microdisplay.
I should note that the Z30 waveguide I have seen had the display centered vertically and was part of a binocular design. The image was not below center or off to the right, as Bloomberg’s Mark Gurman’s Hypernova article reported. And thus, it was not exactly the Z30, but a customized version.
Shown below, left is the 30° Z30 waveguide with the attached projector engine with its older Maximus and Z50 50° waveguides. While the Maximus and Z50 are further away, you should be able to tell that the Z30 projector engine is much smaller. Lumus, in their January announcement, said the Z30 prototype outputs to the eye are>3,000 Nits/WattLED, and Lumus told me that they expect to more than double this efficiency with design improvements. [See my Caution on Using Nits/WattLED in the Appendix, as they are not comparable between companies]


Above right is a quick handheld picture I took through the Z30; I doubt I had the camera aligned well (I was holding the glasses in one hand and the camera in the other), and the background was not solid black (the background is causing uniformity variation). Still, the color uniformity is much better than that of the typical diffractive waveguide.
High transparency and very little eye glow
I missed getting a picture of myself wearing the Z30-based glasses, which have smaller projectors and frames. The picture below is of me wearing the Z50 (50-degree) prototypes. The Z50 and Z30 have only very slight “eye glow” and are about 90% transparent. The very slight eye glow that is seen in the pic is for a nearly full white bright image, and not a typical image.


Lumus Waveguide With Prescription Correction
A key issue for any consumer AR glasses is to incorporate prescription correction. Lumus’s Z-Lens waveguides propagate TIR light in the waveguide at a shallower angle than diffractive waveguides, which enables not only the use of significantly lower index of reaction glass, but also the direct bonding of push-pull lenses to change the virtual image focus distance and prescription correction.
Due to surface features and to maintain TIR, diffraction-type waveguides require an air gap. This adds complexity and makes the combination of lenses and waveguides thicker. Having surfaces with an air gap means there are additional surfaces that can cause ghosts and require anti-reflective coatings to reduce them. There is not enough information available to determine whether the Google XR Glasses with diffraction waveguides will address prescription correction.
Lumus has partnered with AddOptics to provide the push-pull lenses that incorporate prescription correction. Lumus demonstrated the combination to me at AWE 2024.
Lumus Wide (70°) FOV in Glass (Versus Silicon Carbide)

Meta’s Orion AR Glasses demonstration in late 2024 used very expensive/hard-to-manufacture Silicon Carbide (SiC) Waveguides. As discussed in Meta Orion AR Glasses (Pt. 1 Waveguides), they used SiC because of its high index of refraction, which is required to support a 70-degree FoV with diffractive waveguides. At AR/VR/MR 2025, Lumus was claiming that, due to the shallower TIR angle of the Z-Lens, they can support a 70° with their glass waveguides.
What about the rumored $1,000-$1400 Price?
I’ve seen many negative comments about Meta’s Hypernoval’s rumored price range of $1,000 to $1,400. As I wrote about the Apple Vision Pro, People Who Say the AVP’s $3,499 price is too high lack historical perspective. I’m not as worried about the price as I am about the functionality and usefulness. If the product is useful and finds a market, there is no reason that the cost should not be reduced significantly. The price reflects that Hypernova is testing the waters more than a full-blown consumer product.

Google XR Prototype (At Ted Talk)
Alex Wong’s LinkedIn article on the Google XR TED talk strongly suggested that Google is using waveguides from both Applied Materials (AMAT) and “one based in Shanghai, China.” In his article, Alex was unsure about the optical engine. As will be discussed, I believe Avegant designed the optical engine based on its size and shape (to be discussed below), and due to the recent partnership between AMAT and Avegant.
In their respective presentations at AR/VR/MR 2025, both Avegant and AMAT discussed their new partnership. Avegant presented several slides discussing their new 20° FOV monocular LCOS engine in a development kit jointly developed with AMAT.
Below are the Avegant/AMAT development kit X-ray diagram (top) and a still frame (bottom) from Google’s video showing an exploded view of their XR glasses. They are remarkably similar. I have also added an inset of just the optical engine part of Avegant’s development kit near Google’s optical engine. While the projector portion may look bent in the Google exploded view, this may be simple due to the arrangement of the electrical components around the optics to fit Google’s frames better.

On both diagrams above, the projector is on the side of the right eye (left side of the diagram). Avegant’s diagram shows microphones on the side of the left eye, whereas Google’s diagram has a hole for a camera. I’m a big believer that a camera is going to be essential for any “AR with AI” glasses. The location of the image on one side and the camera on the opposite side of the frames, while it makes sense in terms of fitting them into the frame, is poor in terms of using the display as a camera viewfinder due to parallax.
I have added labels pointing to some of the components in Google’s design. They appear to have a set of push-pull lenses on either side of the waveguide, but I don’t know if they have or will support prescription correction. All in all, it looks like Google took the Avegant and AMAT development kit and then modified it slightly to fit their needs.
I have taken information from two slides with some specs presented by Avegant at AR/VR/MR 2025 below. As I will caution in the appendix, you can’t objectively directly compare the Nits/WattLED numbers between Avegant and Lumus shown earlier. Lumus’s Z30 has ~2.25x the FOV area (30/20-squared) plus many other factors. What you can see is that the Nits/WattLED falls off dramatically with brightness. For 600Nits/23mWLED = 25,000 Nits/WattLED, whereas 3000 Nits/226mW = 11,272 Nits/WattLED or less than half the efficiency.

These efficiency numbers on the surface seem very good/high for a diffractive waveguide, even with the comparatively small FOV. Avegant makes a point that they have made significant efforts to make their optical engine very efficient.
Avegant has devised clever ways to reduce the size of its LCOS projector engines. It seems that every year at AR/VR/MR, Avegant presents an ever-smaller engine. The optical path (taken from Avegant’s website) from their newer projectors is shown below. A key trick is how they use a dichroic combiner/”waveguide” to route light down the projector lens to avoid needing a polarizing beam splitter in traditional LCOS projector engines.

Meta Hypernova and Google XR — Are they products, developer systems, or prototypes?
We are seeing many product concepts in AR glasses, such as Meta’s Orion, developer devices such as Snap Spectacles 5, and products from many companies.
Meta’s Hypernova appears to be a high-end, limited-volume consumer product to test the market. Based on how Hypernova is received, Meta could either focus on driving volume to reduce cost or focus on the (rumored) biocular Hypernova 2. Meta is highly unlikely to bring Orion’s Silicon Carbide to the mainstream market in the next several years. Still, Meta is clearly serious about AR glasses and plans to spend about $20B this year on AR and VR, with the bulk of the investment going into AR.
Google’s intention for its AR glasses is much less clear. Google has developed a reputation for entering and exiting markets, particularly when it comes to hardware. It’s not clear whether Google will build a hardware product itself or leave it to one of its Android XR partners; in this case, the Google AR glasses shown in the TED Talk might be a reference design for their partners.
Conclusions
One thing is for sure: the glasses form factor space is heating up, with the giants Meta and Google starting to show products that are likely to be sold to consumers in the next six months to a year. Rumors of Apple entering the Optical See-Through AR fray are also starting to heat up again.
LCOS still has major physics advantages over MicroLEDs with waveguides when displaying full-color images, such as those from camera viewfinders, photographs, or web browsing. This is particularly true when trying to achieve the 1,000 to 3,000 nits to the eye necessary for practical use in daylight. While MicroLEDs seem to garner most of the attention, and while there are drawbacks to LCOS due to field sequential color breakup and less contrast, LCOS is likely to be the most practical display technology for full-color or higher resolution for at least the next few years and perhaps for many years.
One thing I don’t understand is why Lumus and Avegant are still independent companies, given the numerous acquisitions of companies in the AR space over the last ten years. I have seen massive spending and acquisitions in the area of MicroLED displays by Meta, Google, and Apple. Yet, almost nothing has happened beyond Snap buying the struggling Compound Photonics in LCOS.
Appendix: Caution on comparing nits/WattLED with different Waveguides
Both Lumus and Avegant have given Nits/WattLED specs for their projector and waveguide combinations. I want to caution everyone that while the numbers give some idea of the efficiency of the projector and optics, there are so many other variables that they are likely not comparable.
While “nits/WattLED” may sound like an objective number, many factors make it impossible to compare numbers that sound the same from different companies. Unfortunately, every company measures differently. These factors include:
- The Field of View—To a first approximation, the Nits/WattLED should vary at least proportionally with the square of the FOV as the light is spread out over an area.
- Eye Box Size and Eye Relief—A larger eye box and longer eye relief mean that light will be spread over a larger area, making the Nits/WattLED value lower (or higher for a smaller eye box or eye relief).
- Measuring peak value versus average or worst case—Typically, most companies will pick the “peak value” (near the center). Different waveguides have different fall-off toward the periphery. A set of optics that concentrates light in the center will have a higher “peak value,” while being dark in the periphery. In my experience, reflective waveguides are more uniform than diffractive waveguides from the center to the outside. Thus, a “peak” measurement typically favors diffractive waveguides even if both specify the peak value.
- Many factors are non-linear. For example, as the total light output increases due to brightness, a bigger FOV, or an eye-box, the efficiency decreases as the LEDs heat up. This makes it impossible to compare fairly different headsets with different FOV or brightness.
- Full Color versus Green Only—As discussed earlier, nits measure human eye response, and with a color balanced “white,” red and blue contribute relatively few nits while consuming power. Thus, full-color nits are going to be less efficient with the same technology. In the same technology, the full color nits/WattLED could be significantly less than one-fourth that of the green-only nits.
- Engineering Trade-off—Depending on the technology, various engineering trade-offs can help or hinder Nits/WattLED. For example, diffractive waveguides might reduce efficiency in improving color uniformity or reducing eye glow.
- Marketing “Fudge” and measuring “cherry-picked” units—Since there are no “marketing police” with testing facilities that will report on measure values over the whole FOV, companies are prone to fudge numbers or use cherry-picked units.
I would not say the numbers are meaningless, and I am still happy that some companies report their Nits/WattLED. It at least gives some idea as to whether the AR glasses might work outdoors. The values are probably more comparable within products from the same company than they are between two very different designs.
Learn 15 Print-in-Place Mechanisms in 15 Minutes

3D printed in-place mechanisms and flexures, such as living hinges, are really neat when you can get them to print correctly. But how do you actually do that? YouTuber [Slant 3D] is here with a helpful video demonstrating the different kinds of springs and hinges (Video, embedded below) that can be printed reliably, and discusses some common pitfalls and areas to concentrate upon.
Living hinges are everywhere and have been used at least as long as humans have been around. The principle is simple enough; join two sections to move with a thinned section of material that, in small sections, is flexible enough to distort a few times without breaking off. The key section is “a few times”, as all materials will eventually fail due to overworking. However, if this thing is just a cheap plastic case around a low-cost product, that may not be a huge concern. The video shows a few ways to extend flexibility, such as spreading the bending load across multiple flexure elements to reduce the wear of individual parts, but that comes at the cost of compactness.
Moving on from springs, the second part of the video describes a few strategies for print-in-place hinges, describing how they fail, and what to do to mitigate. Again, robustness comes at a cost, in this case, increased bulk, but with 3D printing, you get what you pay for. Overall, it’s a nice, concise guide to the topic and well worth a mere seventeen minutes of your time, we reckon.
We see 3D printed flexure mechanisms a lot ’round here, like this for example. But how precise are they? Finally, we think this 3D printed spherical flexure joystick is cool, but must have been a bit tricky to model!
Thanks to [Hari Wiguna] for the tip!

Europe launches program to lure scientists away from the US
The European Commission has launched a new initiative to attract researchers and scientists to the European Union—especially those from the United States. The Choose Europe for Science program, backed with more than half a billion dollars, is designed to offer an alternative to researchers who have been forced to seek new opportunities following cuts in scientific funding imposed by President Donald Trump’s administration.
The program will invest €500 million ($568 million) between 2025 and 2027 to recruit specialists in various fields of knowledge to come and work in Europe. The initiative also includes a target for member states to allocate 3 percent of their GDP to R&D projects by 2030.
“The role of science in today’s world is questioned,” warned Ursula von der Leyen, president of the European Commission, in a statement on Tuesday. “What a gigantic miscalculation. I believe that science holds the key to our future here in Europe. Without it, we simply cannot address today’s global challenges—from health to new tech, from climate to oceans.”

Niantic Spatial’s Adorable Pet Sim ‘Hello, Dot’ Leaves Early Access on Quest 3


Niantic Spatial has launched its mixed reality pet game Hello, Dot on Quest 3, bringing it out of early access and packing in a heap of new features.
Hello, Dot is what the studio calls a “mixed reality showcase” from its host of AR experiences, which the studio kicked off on mobile with Peridot in 2023.
In addition to Hello, Dot for Quest 3, Niantic Spatial’s other XR experiences include Peridot Beyond for Snap Spectacles, Pause with Peridot and Snap-a-Dot for Web AR, and SunnyTune for Apple Vision Pro.
Now, fresh out of early access on Quest 3, the studio has included a number of new features to Hello, Dot including:
- Dots with a richer personality and new playful antics
- A whimsical arcade machine with dot play dates
- Gen AI-powered customization via voice prompts
- Minigames like Dotball and Eating Contests
- A nod to the future and the possibilities of Peridot agentic AI guide

The new arcade machine lets you cycle through various activities, such as new mini-games to play, which include Play Dates, Dotball (i.e. dodgeball), or an Eating Contest with you Dot. By participating in these mini-games, you can earn in-game currency, which you can then trade in at the shop for accessories for your Dot, such as outfits and playful items.
“With this major evolution of Hello, Dot, we’re not just adding new gameplay; we’re pushing deeper into the magic of true mixed reality interaction,” said Asim Ahmed, Global Product Marketing Lead, who further noted the app is “exploring how digital life can enhance our physical spaces, fuels our passion as we build towards a future where technology seamlessly weaves wonder into the fabric of our everyday reality.”
Hello, Dot now also includes a new Gen AI-powered Dot customizer, letting you grab a virtual microphone and describe the look you want you Dot to have, and dunk them into a magical paint bucket for the desired effect.
You can find Hello, Dot over on the Horizon Store for free, which exclusively supports Quest 3 and 3S.
The post Niantic Spatial’s Adorable Pet Sim ‘Hello, Dot’ Leaves Early Access on Quest 3 appeared first on Road to VR.
Xenon : Un framework moderne en C++ pour la triche dans les jeux
Découvrez Xenon-cheats, un framework C++ moderne open source destiné au développement de cheats pour les jeux vidéo. Ce projet propose une base de code structurée pour les développeur·se·s souhaitant explorer ou comprendre les mécanismes de modification de jeux, tout en offrant une approche moderne du C++.
Commentaires
L'article Xenon : Un framework moderne en C++ pour la triche dans les jeux a été posté dans la catégorie Projets de Human Coders News
How to Instantly Feel Better

When I first saw a version of How to instantly feel better I could immediately relate. I thought it could do with a Sketchplanations version. Maybe try some of the suggestions and let me know how it goes.
If you're:
- Angry -> Sing
- Burned out -> Walk
- Overthinking -> Write
- Anxious -> Breathe
- Stressed -> Exercise
- Sad -> Gratitude
- Impatient -> Reflect on progress
- Lazy -> Cold shower
Your mileage may vary.
I can't help but think that Walk in nature, which is about as close to a miracle cure as we have, is also a good strategy for all of them.
- Angry -> Walk in nature
- Burned out -> Walk in nature
- Overthinking -> Walk in nature
- Anxious -> Walk in nature
- Stressed -> Walk in nature
- Sad -> Walk in nature
- Impatient -> Walk in nature
- Lazy -> Walk in nature
Here's a visual of this instead: How to instantly feel better - walk in nature
{kind=link}
I recently learned the term Green Prescription for when your doctor prescribes time in nature rather than drugs. I wish I'd come up with it.
I didn't create the original graphic for How to Instantly Feel Better. I saw this one, shared by the brilliant Info is Beautiful. Many people have created versions of this. If you know—or are—the original creator, thank you! And please get in touch.
In our podcast on this sketch the Sad -> Gratitude action we thought was one of the hardest to do. So here are a few lovely quotes about gratitude in case they can help:
Gratitude is the intention to count your blessings every day, every minute, while avoiding, whenever possible, the belief that you need or deserve different circumstances.
— Timothy Miller
Gratitude unlocks the fullness of life. It turns what we have into enough, and more.
— Melody Beattie
Related Ideas to How to Instantly Feel Better
Also see:
- Forest bathing
- The 3-Day effect
- Box breathing
- 5 Ways to Wellbeing
- Snerdle
- Maze, Labyrinth
- Compliments Are Gifts
- Vorfreude — the pleasure of anticipation
- Languishing
- Notice when you're happy
- Don't compare your back of house with others' front of house
- When drinking tea, just drink tea
Prints/cards etc of How to Instantly Feel Better, and of How to Instantly Feel Better — Walk in nature