I am continuing my mini series on reading S1s (IPO documents). We are enjoying an IPO bonanza this year, so we might as well use it for some good and learn something.
When a company files for an IPO, I like to think if there is a publicly traded company that looks a lot like that company and if so, I lik to run some numbers comparing the two.
Well we have that exact situation with Uber filing to go public last week. Here is Uber’s S1.
Here are Uber’s profit and loss numbers from their S1:
We can compare this to Lyft’s profit and loss from my prior blog post:
I put all of these numbers into a spreadsheet and added some estimates for 2019 that are nothing more than back of envelope guesstimates.
What you can see from this is that Uber is 4-5x larger than Lyft, growing a lot more slowly, has slightly better gross margins, and both are still losing a lot of money but both are moving towards getting profitable on operations in a few years.
Finally lets look at market valuations. Lyft is currently trading at a market cap of $17bn. If you say that Uber is 4-5x larger than Lyft, then Uber ought to be worth in the range of $70bn to $85bn.
There are other factors that will be in play when Uber eventually prices their IPO and trades. Uber owns minority interests in a number of other ridesharing businesses that could be worth as much as $10bn of additional value. On the other hand, Lyft is growing more quickly than Uber.
Ultimately we will see how the market values Uber. But from this analysis, and the public market comparables from Lyft, we can see that Uber should be worth quite a bit when it goes public.
Interoperability of state and value is likely to place downward price pressure on layer-1 blockchains that have no monetary premium, while enabling strong middleware protocols to achieve cross-chain, winner-takes-most dominance in their respective services. While not a perfect mapping to traditional use of the term middleware, these protocols can be thought of as anything sitting just below the interface layer (i.e., the applications the end user interacts with), but leveraging the lower-level functionality provided by layer-1 blockchains and interoperability protocols.
Others have called these service-layer protocols, as they focus on providing a specific service to the interface layer, be they financial, social, technological, etc. Financial services include things like exchange, lending, and risk-management; social services offer functionality like voting structures, arbitration, or legal-contract management; technological services include components like caching, storage, location, and maybe the granddaddy of them all, a unified OS for protocol services to be neatly bundled to the interface layer.
Financial-service protocols that Placeholder has invested in include 0x, Erasure, MakerDAO, and UMA, while Aragon is our main social-service protocol to date, and technological-service protocols that we work with include CacheCash, Filecoin, FOAM, and Zeppelin. All of these protocols have originated on Ethereum, but we believe interoperability of state and value—the promise of a Cosmos, Polkadot, and Ethereum 2.0 future—will allow these protocols to become horizontally defensible starting from Ethereum’s base.
Take MakerDAO, for example. Its token, MKR, can be thought of as an insurance pool for secured loans originated through the platform. The larger the overall value of MKR, the greater the insurance and therefore lower the risk for all users of the system. Let’s say FakerDAO pops up on Tron, providing the exact same service, but with its own native governance asset, FKR. Right now, it would be hard for the Maker team to leverage the value in MKR to secure a parallel system on Tron, but with interoperability of state and value it would become considerably easier.
Assuming the Maker team can build out for Tron before FKR gets to a similar value as MKR, then they should be able to deploy on Tron and provide a lower risk service than FakerDAO can, insured by the much larger pool of value stored in MKR. With two communities driving utility through MakerDAO, MKR’s pooled value is then likely to significantly outpace FKR’s, further widening the risk and quality of service-gap (Whether MKR holders would want to underwrite the risk of operating on another chain like Tron is a separate question).
We believe similar dynamics will play out for many other middleware protocols, though in different ways depending on the cryptoeconomic [1] and governance design of the system. Protocols whose reliability, security, speed, liquidity, or coverage scales with the size of the asset base and nodes supporting it, stand to do well in an interoperable world.
* * *
Footnotes:
[1] Most middleware protocols are likely to employ some variant of a capital asset as their cryptoeconomic model, where supply-siders must stake the asset to provide the service, giving them access to value-flows for so doing.
Sidenote: After viewing what we hold, some have asked why ether isn’t included. While we are fans of the Ethereum team, and think that people underestimate the soft-network effects of the system, we don’t hold ether (or any layer-1 smart contract blockchain) in part for the above reasons. We believe the middleware protocols we’ve invested in give us upside exposure to ether (if ETH appreciates in fiat terms then the quality assets that ride atop it tend to also appreciate in fiat terms, holding their value relative to ETH), while also protecting us from the downside exposure should more dominant layer-1 smart contract blockchains, or interoperability protocols, start to steal from ether’s value.
Facebook, believe it or not, has actually made virtual reality better, at least from one perspective.
My first VR device was PlayStation VR, and the calculus was straightforward: I owned a PS4 and did not own a Windows PC, which means I had a device that was compatible with the PlayStation VR and did not have one that was compatible with the Oculus Rift or the HTC Vive.
I used it exactly once.
The problem is that actually hooking up the VR headset was way too complicated with way too many wires, and given that I lived at the time in a relatively small apartment, it wasn’t viable to leave the entire thing hooked up when I wasn’t using it. I did finally move to a new place, but frankly, I can’t remember if I unpacked it or not.
Then, earlier this year, Facebook came out with the Oculus Go.
The Go sported hardware that was about the level of a mid-tier smartphone, and priced to match: $199. Critically, it was a completely standalone device: no console or PC necessary. Sure, the quality wasn’t nearly as good, but convenience matters a lot, particularly for someone like me who only occasionally plays video games or watches TV or movies. Putting on a wingsuit or watching some NBA highlights is surprisingly fun, and critically, easy. At least as long as I have the Go out of course, and charged. It’s hard to imagine giving it a second thought otherwise.
The Virtual Reality Niche
That is the first challenge of virtual reality: it is a destination, both in terms of a place you go virtually, but also, critically, the end result of deliberative actions in the real world. One doesn’t experience virtual reality by accident: it is a choice, and often — like in the case of my PlayStation VR — a rather complicated one.
That is not necessarily a problem: going to see a movie is a choice, as is playing a video game on a console or PC. Both are very legitimate ways to make money: global box office revenue in 2017 was $40.6 billion U.S., and billions more were made on all the other distribution channels in a movie’s typical release window; video games have long since been an even bigger deal, generating $109 billion globally last year.
Still, that is an order of magnitude less than the amount of revenue generated by something like smartphones. Apple, for example, sold $158 billion worth of iPhones over the last year; the entire industry was worth around $478.7 billion in 2017. The disparity should not come as a surprise: unlike movies or video games, smartphones are an accompaniment on your way to a destination, not a destination in and of themselves.
That may seem counterintuitive at first: isn’t it a good thing to be the center of one’s attention? That center, though, can only ever be occupied by one thing, and the addressable market is constrained by time. Assume eight hours for sleep, eight for work, a couple of hours for, you know, actually navigating life, and that leaves at best six hours to fight for. That is why devices intended to augment life, not replace it, have always been more compelling: every moment one is awake is worth addressing.
In other words, the virtual reality market is fundamentally constrained by its very nature: because it is about the temporary exit from real life, not the addition to it, there simply isn’t nearly as much room for virtual reality as there is for any number of other tech products.
Facebook’s Head-scratching Acquisition
This, incidentally, includes Facebook: the strength of the social network is counterintuitive like virtual reality is counterintuitive, but in the exact opposite way. No one plans to visit Facebook: who among us has “Facebook Time” set on our calendar? And yet the vast majority of people who are able — over 2 billion worldwide — visit Facebook every single day, for minutes at a time.
The truth is that everyone has vast stretches of time between moments of intentionality: standing in line, riding the bus, using the bathroom. That is Facebook’s domain, and it is far more valuable than it might seem at first: not only is the sheer amount of time available more than you might think, it is also a time when the human mind is, by definition, less engaged; we visit Facebook seeking stimulation, and don’t much care if that stimulation comes from friends and family, desperate media companies, or advertisers that have paid for the right. And pay they have, to the tune of $48 billion over the last year — more than the global box office, and nearly half of total video game revenue.
What may surprise you is that Facebook landed on this gold mine somewhat by accident: at the beginning of this decade the company was desperately trying to build a platform, that is, a place where 3rd-party developers could build their own direct connections with customers. This has long been the stated goal of Silicon Valley visionaries, but generally speaking the pursuit of platforms has been a bit like declarations of disruption: widespread in rhetoric, but few and far between in reality.
So it was with Facebook: the company’s profitability and dramatic rise in valuation — the last three months notwithstanding — have been predicated on the company not being a platform, at least not one for 3rd-party developers. After all, to give space to 3rd-party developers is to not give space to advertisers, at least on mobile, and it is mobile that has provided, well, the platform for Facebook to fill those empty spaces. And, as I noted back in 2013, the mobile ad unit couldn’t be better.
This is why Facebook’s acquisition of Oculus back in 2014 was such a head-scratcher; I was immediately skeptical, writing in Face Is Not the Future:
Setting aside implementation details for a moment, it’s difficult to think of a bigger contrast than a watch and an Occulus headset that you, in the words of [Facebook CEO Mark] Zuckerberg, “put on in your home.” What makes mobile such a big deal relative to the PC is the fact it is with you everywhere. A virtual reality headset is actually a regression in which your computing experience is neatly segregated into something you do deliberately.
Zuckerberg, though, having first failed to build a platform on the PC, and then failing miserably with a phone, would not be satisfied with being merely an app; he would have his platform, and virtual reality would give him the occasion.
Our mission is to make the world more open and connected. For the past few years, this has mostly meant building mobile apps that help you share with the people you care about. We have a lot more to do on mobile, but at this point we feel we’re in a position where we can start focusing on what platforms will come next to enable even more useful, entertaining and personal experiences…
This is a fascinating statement in retrospect. Of course there is the blithe dismissal of mobile, which would increase Facebook’s valuation tenfold, because Facebook was only an app, not a platform. More striking, though, is Zuckerberg’s evaluation that Facebook was now in a position to focus elsewhere: after the revelations of state-sponsored interference and legitimate questions about Facebook’s impact on society broadly it seems rather misguided.
Oculus’s mission is to enable you to experience the impossible. Their technology opens up the possibility of completely new kinds of experiences. Immersive gaming will be the first, and Oculus already has big plans here that won’t be changing and we hope to accelerate. The Rift is highly anticipated by the gaming community, and there’s a lot of interest from developers in building for this platform. We’re going to focus on helping Oculus build out their product and develop partnerships to support more games. Oculus will continue operating independently within Facebook to achieve this.
This is related to the reasons why Oculus and Facebook are in the news this week; TechCrunch reported that Oculus co-founder Brendan Iribe left the company because of a dispute about the next-generation of computer-based VR headsets; Facebook said that computer-based VR was still a part of future plans.
But this is just the start. After games, we’re going to make Oculus a platform for many other experiences…This is really a new communication platform. By feeling truly present, you can share unbounded spaces and experiences with the people in your life. Imagine sharing not just moments with your friends online, but entire experiences and adventures. These are just some of the potential uses. By working with developers and partners across the industry, together we can build many more. One day, we believe this kind of immersive, augmented reality will become a part of daily life for billions of people.
This, though, makes one think that TechCrunch was on to something. Microsoft, to its dismay, found out with the Xbox One that serving gamers and serving consumers generally are two very different propositions, and any move perceived by the former to be in favor of the latter will hurt sales specifically and the development of a thriving ecosystem generally. The problem for Facebook, though, is that the fundamental nature of the company — not to mention Zuckerberg’s platform ambitions — rely on serving as many customers as possible.
I suspect that wasn’t the top priority of Oculus’s founders: virtual reality is a hard problem, one where even the best technology — which unquestionably, means connecting to a PC — is not good enough. To that end, given that their priority was virtual reality first and reach second, I suspect Oculus’ founders would rather be spending more time making PC virtual reality better and less time selling warmed over smartphone innards.
The Problems with Facebook and Oculus
Still, I can’t deny that the Oculus Go, underpowered though it may be, is nicer to use in important ways — particularly convenience — that are serially undervalued by technologists. As I noted at the beginning, Facebook’s influence, particularly its desire to reach as many users as possible and control the entire experience — two desires that are satisfied with a standalone device — may indeed make virtual reality more widespread than it might have been had Oculus remained an independent company.
What is inevitable though — what was always inevitable, from the day Facebook bought Oculus — is that this will be one acquisition Facebook made that was a mistake. If Facebook wanted a presence in virtual reality the best possible route was the same it took in mobile: to be an app-exposed service, available on all devices, funded by advertising. I have long found it distressing that Zuckerberg, not just in 2014, but even today, judging by his comments in keynotes and on earnings calls, seems unable or unwilling to accept this fundamental truth about Facebook’s place in tech’s value chain.
In fact, Zuckerberg’s rhetoric around virtual reality has betrayed more than a lack of strategic sense: his keynote at the Oculus developer conference in 2016, a month before the last election, was, in retrospect, an advertisement of the company’s naïveté regarding its impact on the world:
We’re here to make virtual reality the next major computing platform. At Facebook, this is something we’re really committed to. You know, I’m an engineer, and I think a key part of the engineering mindset is this hope and this belief that you can take any system that’s out there and make it much much better than it is today. Anything, whether it’s hardware, or software, a company, a developer ecosystem, you can take anything and make it much, much better. And as I look out today, I see a lot of people who share this engineering mindset. And we all know where we want to improve and where we want virtual reality to eventually get…
I wrote at the time:
Perhaps I underestimated Zuckerberg: he doesn’t want a platform for the sake of having a platform, and his focus is not necessarily on Facebook the business. Rather, he seems driven to create utopia: a world that is better in every possible way than the one we currently inhabit. And, granted, owning a virtual reality company is perhaps the most obvious route to getting there…
Needless to say, 2016 suggests that the results of this approach are not very promising: when our individual realities collide in the real world the results are incredibly destructive to the norms that hold societies together. Make no mistake, Zuckerberg gave an impressive demo of what can happen when Facebook controls your eyes in virtual reality; what concerns me is the real world results of Facebook controlling everyone’s attention with the sole goal of telling each of us what we want to hear.
The following years have only borne out the validity of this analysis: of all the myriad of problems faced by Facebook — some warranted, and some unfair — the most concerning is the seeming inability of the company to even countenance the possibility that it is not an obvious force for good.
Facebook’s Mismatch
Again, though, Facebook aside, virtual reality is more compelling than you might think. There are some experiences that really are better in the fully immersive environment provided by virtual reality, and just because the future is closer to game consoles (at best) than to smartphones is nothing to apologize for. What remains more compelling, though, is augmented reality: the promise is that, like smartphones, it is an accompaniment to your day, not the center, which means its potential usefulness is far greater. To that end, you can be sure that any Facebook executive would be happy to explain why virtual reality and Oculus is a step in that direction.
That may be true technologically, but again, the fundamental nature of the service and the business model are all wrong. Anything made by Facebook is necessarily biased towards being accessible by everyone, which is a problem when creating a new market. Before technology is mature integrated products advance more rapidly, and can be sold at a premium; it follows that market makers are more likely to have hardware-based business models that segment the market, not service-based ones that try and reach everyone.
To that end, it is hard to not feel optimistic about Apple’s chances at eventually surpassing Oculus and everyone else. The best way to think about Apple has always been as a personal computer company; the only difference over time is that computers have grown ever more personal, moving from the desk to the lap to the pocket and today to the wrist (and ears). The face is a logical next step, and no company has proven itself better at the sort of hardware engineering necessary to make it happen.
Critically, Apple also has the right business model: it can sell barely good-enough devices at a premium to a userbase that will buy simply because they are from Apple, and from there figure out a use case without the need to reach everyone. I was very critical of this approach with the Apple Watch — it was clear from the launch keynote that Apple had no idea what this cool piece of hardware engineering would be used for — but, as the Apple Watch has settled into its niche as a health and fitness device and slowly expanded from there, I am more appreciative of the value of simply shipping a great piece of hardware and letting the real world figure it out.
That there gets at Facebook’s fundamental problem: the company is starting with a use case — social networking, or “connecting people” to use their favored phrase — and backing out to hardware and business models. It is an overly prescriptive approach that is exactly what you would expect from an app-enabled service, and the opposite of what you would expect from an actual platform. In other words, to be a platform is not a choice; it is destiny, and Facebook’s has always run in a different direction.
Convolution is probably the most important concept in deep learning right now. It was convolution and convolutional nets that catapulted deep learning to the forefront of almost any machine learning task there is. But what makes convolution so powerful? How does it work? In this blog post I will explain convolution and relate it to other concepts that will help you to understand convolution thoroughly.
There are already some blog post regarding convolution in deep learning, but I found all of them highly confusing with unnecessary mathematical details that do not further the understanding in any meaningful way. This blog post will also have many mathematical details, but I will approach them from a conceptual point of view where I represent the underlying mathematics with images everybody should be able to understand. The first part of this blog post is aimed at anybody who wants to understand the general concept of convolution and convolutional nets in deep learning. The second part of this blog post includes advanced concepts and is aimed to further and enhance the understanding of convolution for deep learning researchers and specialists.
What is convolution?
This whole blog post will build up to answer exactly this question, but it may be very helpful to first understand in which direction this is going, so what is convolution in rough terms?
You can imagine convolution as the mixing of information. Imagine two buckets full of information which are poured into one single bucket and then mixed according to a specific rule. Each bucket of information has its own recipe, which describes how the information in one bucket mixes with the other. So convolution is an orderly procedure where two sources of information are intertwined.
Convolution can also be described mathematically, in fact, it is a mathematical operation like addition, multiplication or a derivative, and while this operation is complex in itself, it can be very useful to simplify even more complex equations. Convolutions are heavily used in physics and engineering to simplify such complex equations and in the second part — after a short mathematical development of convolution — we will relate and integrate ideas between these fields of science and deep learning to gain a deeper understanding of convolution. But for now we will look at convolution from a practical perspective.
How do we apply convolution to images?
When we apply convolution to images, we apply it in two dimensions — that is the width and height of the image. We mix two buckets of information: The first bucket is the input image, which has a total of three matrices of pixels — one matrix each for the red, blue and green color channels; a pixel consists of an integer value between 0 and 255 in each color channel. The second bucket is the convolution kernel, a single matrix of floating point numbers where the pattern and the size of the numbers can be thought of as a recipe for how to intertwine the input image with the kernel in the convolution operation. The output of the kernel is the altered image which is often called a feature map in deep learning. There will be one feature map for every color channel.
Convolution of an image with an edge detector convolution kernel. Sources: 12
We now perform the actual intertwining of these two pieces of information through convolution. One way to apply convolution is to take an image patch from the input image of the size of the kernel — here we have a 100×100 image, and a 3×3 kernel, so we would take 3×3 patches — and then do an element wise multiplication with the image patch and convolution kernel. The sum of this multiplication then results in one pixel of the feature map. After one pixel of the feature map has been computed, the center of the image patch extractor slides one pixel into another direction, and repeats this computation. The computation ends when all pixels of the feature map have been computed this way. This procedure is illustrated for one image patch in the following gif.
Convolution operation for one pixel of the resulting feature map: One image patch (red) of the original image (RAM) is multiplied by the kernel, and its sum is written to the feature map pixel (Buffer RAM). Gif by Glen Williamson who runs a website that features many technical gifs.
As you can see there is also a normalization procedure where the output value is normalized by the size of the kernel (9); this is to ensure that the total intensity of the picture and the feature map stays the same.
Why is convolution of images useful in machine learning?
There can be a lot of distracting information in images that is not relevant to what we are trying to achieve. A good example of this is a project I did together with Jannek Thomas in the Burda Bootcamp. The Burda Bootcamp is a rapid prototyping lab where students work in a hackathon-style environment to create technologically risky products in very short intervals. Together with my 9 colleagues, we created 11 products in 2 months. In one project I wanted to build a fashion image search with deep autoencoders: You upload an image of a fashion item and the autoencoder should find images that contain clothes with similar style.
Now if you want to differentiate between styles of clothes, the colors of the clothes will not be that useful for doing that; also minute details like emblems of the brand will be rather unimportant. What is most important is probably the shape of the clothes. Generally, the shape of a blouse is very different from the shape of a shirt, jacket, or trouser. So if we could filter the unnecessary information out of images then our algorithm will not be distracted by the unnecessary details like color and branded emblems. We can achieve this easily by convoluting images with kernels.
My colleague Jannek Thomas preprocessed the data and applied a Sobel edge detector (similar to the kernel above) to filter everything out of the image except the outlines of the shape of an object — this is why the application of convolution is often called filtering, and the kernels are often called filters (a more exact definition of this filtering processes will follow below). The resulting feature map from the edge detector kernel will be very helpful if you want to differentiate between different types of clothes, because only relevant shape information remains.
Sobel filtered inputs to and results from the trained autoencoder: The top-left image is the search query and the other images are the results which have an autoencoder code that is most similar to the search query as measured by cosine similarity. You see that the autoencoder really just looks at the shape of the search query and not its color. However, you can also see that this procedure does not work well for images of people wearing clothes (5th column) and that it is sensitive to the shapes of clothes hangers (4th column).
We can take this a step further: There are dozens of different kernels which produce many different feature maps, e.g. which sharpen the image (more details), or which blur the image (less details), and each feature map may help our algorithm to do better on its task (details, like 3 instead of 2 buttons on your jacket might be important).
Using this kind of procedure — taking inputs, transforming inputs and feeding the transformed inputs to an algorithm — is called feature engineering. Feature engineering is very difficult, and there are little resources which help you to learn this skill. In consequence, there are very few people which can apply feature engineering skillfully to a wide range of tasks. Feature engineering is — hands down — the most important skill to score well in Kaggle competitions. Feature engineering is so difficult because for each type of data and each type of problem, different features do well: Knowledge of feature engineering for image tasks will be quite useless for time series data; and even if we have two similar image tasks, it will not be easy to engineer good features because the objects in the images also determine what will work and what will not. It takes a lot of experience to get all of this right.
So feature engineering is very difficult and you have to start from scratch for each new task in order to do well. But when we look at images, might it be possible to automatically find the kernels which are most suitable for a task?
Enter convolutional nets
Convolutional nets do exactly this. Instead of having fixed numbers in our kernel, we assign parameters to these kernels which will be trained on the data. As we train our convolutional net, the kernel will get better and better at filtering a given image (or a given feature map) for relevant information. This process is automatic and is called feature learning. Feature learning automatically generalizes to each new task: We just need to simply train our network to find new filters which are relevant for the new task. This is what makes convolutional nets so powerful — no difficulties with feature engineering!
Usually we do not learn a single kernel in convolutional nets, instead we learn a hierarchy of multiple kernels at the same time. For example a 32x16x16 kernel applied to a 256×256 image would produce 32 feature maps of size 241×241 (this is the standard size, the size may vary from implementation to implementation; ). So automatically we learn 32 new features that have relevant information for our task in them. These feature then provide the inputs for the next kernel which filters the inputs again. Once we learned our hierarchical features, we simply pass them to a fully connected, simple neural network that combines them in order to classify the input image into classes. That is nearly all that there is to know about convolutional nets at a conceptual level (pooling procedures are important too, but that would be another blog post).
Part II: Advanced concepts
We now have a very good intuition of what convolution is, and what is going on in convolutional nets, and why convolutional nets are so powerful. But we can dig deeper to understand what is really going on within a convolution operation. In doing so, we will see that the original interpretation of computing a convolution is rather cumbersome and we can develop more sophisticated interpretations which will help us to think about convolutions much more broadly so that we can apply them on many different data. To achieve this deeper understanding the first step is to understand the convolution theorem.
The convolution theorem
To develop the concept of convolution further, we make use of the convolution theorem, which relates convolution in the time/space domain — where convolution features an unwieldy integral or sum — to a mere element wise multiplication in the frequency/Fourier domain. This theorem is very powerful and is widely applied in many sciences. The convolution theorem is also one of the reasons why the fast Fourier transform (FFT) algorithm is thought by some to be one of the most important algorithms of the 20th century.
The first equation is the one dimensional continuous convolution theorem of two general continuous functions; the second equation is the 2D discrete convolution theorem for discrete image data. Here denotes a convolution operation, denotes the Fourier transform, the inverse Fourier transform, and is a normalization constant. Note that “discrete” here means that our data consists of a countable number of variables (pixels); and 1D means that our variables can be laid out in one dimension in a meaningful way, e.g. time is one dimensional (one second after the other), images are two dimensional (pixels have rows and columns), videos are three dimensional (pixels have rows and columns, and images come one after another).
To get a better understanding what happens in the convolution theorem we will now look at the interpretation of Fourier transforms with respect to digital image processing.
Fast Fourier transforms
The fast Fourier transform is an algorithm that transforms data from the space/time domain into the frequency or Fourier domain. The Fourier transform describes the original function in a sum of wave-like cosine and sine terms. It is important to note, that the Fourier transform is generally complex valued, which means that a real value is transformed into a complex value with a real and imaginary part. Usually the imaginary part is only important for certain operations and to transform the frequencies back into the space/time domain and will be largely ignored in this blog post. Below you can see a visualization how a signal (a function of information often with a time parameter, often periodic) is transformed by a Fourier transform.
Transformation of the time domain (red) into the frequency domain (blue). Source
You may be unaware of this, but it might well be that you see Fourier transformed values on a daily basis: If the red signal is a song then the blue values might be the equalizer bars displayed by your mp3 player.
How can we imagine frequencies for images? Imagine a piece of paper with one of the two patterns from above on it. Now imagine a wave traveling from one edge of the paper to the other where the wave pierces through the paper at each stripe of a certain color and hovers over the other. Such waves pierce the black and white parts in specific intervals, for example, every two pixels — this represents the frequency. In the Fourier transform lower frequencies are closer to the center and higher frequencies are at the edges (the maximum frequency for an image is at the very edge). The location of Fourier transform values with high intensity (white in the images) are ordered according to the direction of the greatest change in intensity in the original image. This is very apparent from the next image and its log Fourier transforms (applying the log to the real values decreases the differences in pixel intensity in the image — we see information more easily this way).
We immediately see that a Fourier transform contains a lot of information about the orientation of an object in an image. If an object is turned by, say, 37% degrees, it is difficult to tell that from the original pixel information, but very clear from the Fourier transformed values.
This is an important insight: Due to the convolution theorem, we can imagine that convolutional nets operate on images in the Fourier domain and from the images above we now know that images in that domain contain a lot of information about orientation. Thus convolutional nets should be better than traditional algorithms when it comes to rotated images and this is indeed the case (although convolutional nets are still very bad at this when we compare them to human vision).
Frequency filtering and convolution
The reason why the convolution operation is often described as a filtering operation, and why convolution kernels are often named filters will be apparent from the next example, which is very close to convolution.
If we transform the original image with a Fourier transform and then multiply it by a circle padded by zeros (zeros=black) in the Fourier domain, we filter out all high frequency values (they will be set to zero, due to the zero padded values). Note that the filtered image still has the same striped pattern, but its quality is much worse now — this is how jpeg compression works (although a different but similar transform is used), we transform the image, keep only certain frequencies and transform back to the spatial image domain; the compression ratio would be the size of the black area to the size of the circle in this example.
If we now imagine that the circle is a convolution kernel, then we have fully fledged convolution — just as in convolutional nets. There are still many tricks to speed up and stabilize the computation of convolutions with Fourier transforms, but this is the basic principle how it is done.
Now that we have established the meaning of the convolution theorem and Fourier transforms, we can now apply this understanding to different fields in science and enhance our interpretation of convolution in deep learning.
Insights from fluid mechanics
Fluid mechanics concerns itself with the creation of differential equation models for flows of fluids like air and water (air flows around an airplane; water flows around suspended parts of a bridge). Fourier transforms not only simplify convolution, but also differentiation, and this is why Fourier transforms are widely used in the field of fluid mechanics, or any field with differential equations for that matter. Sometimes the only way to find an analytic solution to a fluid flow problem is to simplify a partial differential equation with a Fourier transform. In this process we can sometimes rewrite the solution of such a partial differential equation in terms of a convolution of two functions which then allows for very easy interpretation of the solution. This is the case for the diffusion equation in one dimension, and for some two dimensional diffusion processes for functions in cylindrical or spherical polar coordinates.
Diffusion
You can mix two fluids (milk and coffee) by moving the fluid with an outside force (mixing with a spoon) — this is called convection and is usually very fast. But you could also wait and the two fluids would mix themselves on their own (if it is chemically possible) — this is called diffusion and is usually a very slow when compared to convection.
Imagine an aquarium that is split into two by a thin, removable barrier where one side of the aquarium is filled with salt water, and the other side with fresh water. If you now remove the thin barrier carefully, the two fluids will mix together until the whole aquarium has the same concentration of salt everywhere. This process is more “violent” the greater the difference in saltiness between the fresh water and salt water.
Now imagine you have a square aquarium with 256×256 thin barriers that separate 256×256 cubes each with different salt concentration. If you remove the barrier now, there will be little mixing between two cubes with little difference in salt concentration, but rapid mixing between two cubes with very different salt concentrations. Now imagine that the 256×256 grid is an image, the cubes are pixels, and the salt concentration is the intensity of each pixel. Instead of diffusion of salt concentrations we now have diffusion of pixel information.
It turns out, this is exactly one part of the convolution for the diffusion equation solution: One part is simply the initial concentrations of a certain fluid in a certain area — or in image terms — the initial image with its initial pixel intensities. To complete the interpretation of convolution as a diffusion process we need to interpret the second part of the solution to the diffusion equation: The propagator.
Interpreting the propagator
The propagator is a probability density function, which denotes into which direction fluid particles diffuse over time. The problem here is that we do not have a probability function in deep learning, but a convolution kernel — how can we unify these concepts?
We can apply a normalization that turns the convolution kernel into a probability density function. This is just like computing the softmax for output values in a classification tasks. Here the softmax normalization for the edge detector kernel from the first example above.
Softmax of an edge detector: To calculate the softmax normalization, we taking each value [latex background="ffffff"]{x}[/latex] of the kernel and apply [latex background="ffffff"]{e^x}[/latex]. After that we divide by the sum of all [latex background="ffffff"]{e^x}[/latex]. Please note that this technique to calculate the softmax will be fine for most convolution kernels, but for more complex data the computation is a bit different to ensure numerical stability (floating point computation is inherently unstable for very large and very small values and you have to carefully navigate around troubles in this case).
Now we have a full interpretation of convolution on images in terms of diffusion. We can imagine the operation of convolution as a two part diffusion process: Firstly, there is strong diffusion where pixel intensities change (from black to white, or from yellow to blue, etc.) and secondly, the diffusion process in an area is regulated by the probability distribution of the convolution kernel. That means that each pixel in the kernel area, diffuses into another position within the kernel according to the kernel probability density.
For the edge detector above almost all information in the surrounding area will concentrate in a single space (this is unnatural for diffusion in fluids, but this interpretation is mathematically correct). For example all pixels that are under the 0.0001 values, will very likely flow into the center pixel and accumulate there. The final concentration will be largest where the largest differences between neighboring pixels are, because here the diffusion process is most marked. In turn, the greatest differences in neighboring pixels is there, where the edges between different objects are, so this explains why the kernel above is an edge detector.
So there we have it: Convolution as diffusion of information. We can apply this interpretation directly on other kernels. Sometimes we have to apply a softmax normalization for interpretation, but generally the numbers in itself say a lot about what will happen. Take the following kernel for example. Can you now interpret what that kernel is doing? Click hereto find the solution (there is a link back to this position).
Wait, there is something fishy here
How come that we have deterministic behavior if we have a convolution kernel with probabilities? We have to interpret that single particles diffuse according to the probability distribution of the kernel, according to the propagator, don’t we?
Yes, this is indeed true. However, if you take a tiny piece of fluid, say a tiny drop of water, you still have millions of water molecules in that tiny drop of water, and while a single molecule behaves stochastically according to the probability distribution of the propagator, a whole bunch of molecules have quasi deterministic behavior —this is an important interpretation from statistical mechanics and thus also for diffusion in fluid mechanics. We can interpret the probabilities of the propagator as the average distribution of information or pixel intensities; Thus our interpretation is correct from a viewpoint of fluid mechanics. However, there is also a valid stochastic interpretation for convolution.
Insights from quantum mechanics
The propagator is an important concept in quantum mechanics. In quantum mechanics a particle can be in a superposition where it has two or more properties which usually exclude themselves in our empirical world: For example, in quantum mechanics a particle can be at two places at the same time — that is a single object in two places.
However, when you measure the state of the particle — for example where the particle is right now — it will be either at one place or the other. In other terms, you destroy the superposition state by observation of the particle. The propagator then describes the probability distribution where you can expect the particle to be. So after measurement a particle might be — according to the probability distribution of the propagator — with 30% probability in place A and 70% probability in place B.
If we have entangled particles (spooky action at a distance), a few particles can hold hundreds or even millions of different states at the same time — this is the power promised by quantum computers.
So if we use this interpretation for deep learning, we can think that the pixels in an image are in a superposition state, so that in each image patch, each pixel is in 9 positions at the same time (if our kernel is 3×3). Once we apply the convolution we make a measurement and the superposition of each pixel collapses into a single position as described by the probability distribution of the convolution kernel, or in other words: For each pixel, we choose one pixel of the 9 pixels at random (with the probability of the kernel) and the resulting pixel is the average of all these pixels. For this interpretation to be true, this needs to be a true stochastic process, which means, the same image and the same kernel will generally yield different results. This interpretation does not relate one to one to convolution but it might give you ideas how to the apply convolution in stochastic ways or how to develop quantum algorithms for convolutional nets. A quantum algorithm would be able to calculate all possible combinations described by the kernel with one computation and in linear time/qubits with respect to the size of image and kernel.
Insights from probability theory
Convolution is closely related to cross-correlation. Cross-correlation is an operation which takes a small piece of information (a few seconds of a song) to filter a large piece of information (the whole song) for similarity (similar techniques are used on youtube to automatically tag videos for copyrights infringements).
Relation between cross-correlation and convolution: Here [latex background="ffffff"]{\star}[/latex] denotes cross correlation and [latex background="ffffff"]{f^*}[/latex] denotes the complex conjugate of [latex background="ffffff"]{f}[/latex].
While cross correlation seems unwieldy, there is a trick with which we can easily relate it to convolution in deep learning: For images we can simply turn the search image upside down to perform cross-correlation through convolution. When we perform convolution of an image of a person with an upside image of a face, then the result will be an image with one or multiple bright pixels at the location where the face was matched with the person.
Cross-correlation via convolution: The input and kernel are padded with zeros and the kernel is rotated by 180 degrees. The white spot marks the area with the strongest pixel-wise correlation between image and kernel. Note that the output image is in the spatial domain, the inverse Fourier transform was already applied. Images taken from Steven Smith’s excellent free online book about digital signal processing.
This example also illustrates padding with zeros to stabilize the Fourier transform and this is required in many version of Fourier transforms. There are versions which require different padding schemes: Some implementation warp the kernel around itself and require only padding for the kernel, and yet other implementations perform divide-and-conquer steps and require no padding at all. I will not expand on this; the literature on Fourier transforms is vast and there are many tricks to be learned to make it run better — especially for images.
At lower levels, convolutional nets will not perform cross correlation, because we know that they perform edge detection in the very first convolutional layers. But in later layers, where more abstract features are generated, it is possible that a convolutional net learns to perform cross-correlation by convolution. It is imaginable that the bright pixels from the cross-correlation will be redirected to units which detect faces (the Google brain project has some units in its architecture which are dedicated to faces, cats etc.; maybe cross correlation plays a role here?).
Insights from statistics
What is the difference between statistical models and machine learning models? Statistical models often concentrate on very few variables which can be easily interpreted. Statistical models are built to answer questions: Is drug A better than drug B?
Machine learning models are about predictive performance: Drug A increases successful outcomes by 17.83% with respect to drug B for people with age X, but 22.34% for people with age Y.
Machine learning models are often much more powerful for prediction than statistical models, but they are not reliable. Statistical models are important to reach accurate and reliable conclusions: Even when drug A is 17.83% better than drug B, we do not know if this might be due to chance or not; we need statistical models to determine this.
Two important statistical models for time series data are the weighted moving average and the autoregressive models which can be combined into the ARIMA model (autoregressive integrated moving average model). ARIMA models are rather weak when compared to models like long short-term recurrent neural networks, but ARIMA models are extremely robust when you have low dimensional data (1-5 dimensions). Although their interpretation is often effortful, ARIMA models are not a blackbox like deep learning algorithms and this is a great advantage if you need very reliable models.
It turns out that we can rewrite these models as convolutions and thus we can show that convolutions in deep learning can be interpreted as functions which produce local ARIMA features which are then passed to the next layer. This idea however, does not overlap fully, and so we must be cautious and see when we really can apply this idea.
Here is a constant function which takes the kernel as parameter; white noise is data with mean zero, a standard deviation of one, and each variable is uncorrelated with respect to the other variables.
When we pre-process data we make it often very similar to white noise: We often center it around zero and set the variance/standard deviation to one. Creating uncorrelated variables is less often used because it is computationally intensive, however, conceptually it is straight forward: We reorient the axes along the eigenvectors of the data.
Decorrelation by reorientation along eigenvectors: The eigenvectors of this data are represented by the arrows. If we want to decorrelate the data, we reorient the axes to have the same direction as the eigenvectors. This technique is also used in PCA, where the dimensions with the least variance (shortest eigenvectors) are dropped after reorientation.
Now, if we take to be the bias, then we have an expression that is very similar to a convolution in deep learning. So the outputs from a convolutional layer can be interpreted as outputs from an autoregressive model if we pre-process the data to be white noise.
The interpretation of the weighted moving average is simple: It is just standard convolution on some data (input) with a certain weight (kernel). This interpretation becomes clearer when we look at the Gaussian smoothing kernel at the end of the page. The Gaussian smoothing kernel can be interpreted as a weighted average of the pixels in each pixel’s neighborhood, or in other words, the pixels are averaged in their neighborhood (pixels “blend in”, edges are smoothed).
While a single kernel cannot create both, autoregressive and weighted moving average features, we usually have multiple kernels and in combination all these kernels might contain some features which are like a weighted moving average model and some which are like an autoregressive model.
Conclusion
In this blog post we have seen what convolution is all about and why it is so powerful in deep learning. The interpretation of image patches is easy to understand and easy to compute but it has many conceptual limitations. We developed convolutions by Fourier transforms and saw that Fourier transforms contain a lot of information about orientation of an image. With the powerful convolution theorem we then developed an interpretation of convolution as the diffusion of information across pixels. We then extended the concept of the propagator in the view of quantum mechanics to receive a stochastic interpretation of the usually deterministic process. We showed that cross-correlation is very similar to convolution and that the performance of convolutional nets may depend on the correlation between feature maps which is induced through convolution. Finally, we finished with relating convolution to autoregressive and moving average models.
Personally, I found it very interesting to work on this blog post. I felt for long time that my undergraduate studies in mathematics and statistics were wasted somehow, because they were so unpractical (even though I study applied math). But later — like an emergent property — all these thoughts linked together and practically useful understanding emerged. I think this is a great example why one should be patient and carefully study all university courses — even if they seem useless at first.
Solution to the quiz above: The information diffuses nearly equally among all pixels; and this process will be stronger for neighboring pixels that differ more. This means that sharp edges will be smoothed out and information that is in one pixel, will diffuse and mix slightly with surrounding pixels. This kernel is known as a Gaussian blur or as Gaussian smoothing. Continue reading. Sources: 12
Image source reference
R. B. Fisher, K. Koryllos, “Interactive Textbooks; Embedding Image Processing Operator Demonstrations in Text”, Int. J. of Pattern Recognition and Artificial Intelligence, Vol 12, No 8, pp 1095-1123, 1998.
There is much talk these days that startup valuations have decreased and may continue to do so and that the amount of time it takes to fund raise may take longer. As I have pointed out in previous posts, 91% of VCs surveyed believe prices are declining (30% believe substantially) and 77% believe that funding will take longer than it has in the past.
This has led VC & entrepreneur bloggers alike to similar conclusions: start raising capital early and be careful about having too high of a burn rate because that lessens the amount of runway you have until you need more cash.
But the hardest question to actually answer is, “What is the right burn rate for your company?” and if anybody gives you a specific number I would be a bit skeptical because there is no universal answer. It’s a very personal topic and I’d like to offer you a framework to decide for yourself, based on the following factors:
How Long is it Taking to Raise Capital at Your Stage in the Market?
The earlier the round, the less capital you need and the more reasonable your valuation the less time that is needed generally to raise capital. In other words, raising $2 million at a $6 million pre-money valuation has always been easier & quicker than raising $20 million at any valuation.
I know it sounds obvious but just so you understand: There are more capital sources available for earlier-stage capital, the information on which they are evaluating the investment is less (it is almost certainly just team and product) and the risk of the investor getting things wrong is diminished. When you raise larger rounds there is more “due diligence,” which includes: calling customers, looking at financial metrics, doing cohort analysis (looking for trends like changes in churn rates), evaluating competitor positioning and understanding more of the competency of your executive team.
While there is no “one size fits all” I used to give the advice that you should plan about 4.5 months for fund raising start to finish and make sure you have at least 6 months of cash if it takes longer. In recent years it seems many deals got done in 2-3 months or shorter and that still may be true at the earliest stages.
My advice: be cautious, start early, get to know investors before you need capital, do your research on who is a likely good fit and understand that fund-raising is always part of your job – not something you do in “fund-raising season” for 2-3 months every other year. People who think of fund raising as a “distraction away from the core business” fundamentally don’t understand that running a business comprises of: Shipping products, selling to & servicing customers, marketing, HR, recruiting, financial reporting AND making sure you have enough money to support operations.
In other words, fund-raising is a permanent part of the job of the CEO (and CFO) of a company so whether you allocate 5% of your time to it or 20% – it is a year-round activity even if just in the background.
When you ask yourself how Uber became the powerhouse it is – in addition to great software & operations and the right innovation at the right time – it was also the fact that they knew how to constantly tap the capital markets to grow the business, making it harder for many competitors to do so.
Who are Your Existing Investors?
How much your company should burn should also have a direct correlation with who your existing investors are and I strongly advise that you have open conversations with them about their comfort levels and also the level of support you are likely to receive going forward. I’m surprised how few entrepreneurs have this open conversation with their investors.
In fact, most entrepreneurs I know don’t ask – why is that? Wouldn’t you rather know where you stand? There are ways to do this politely and even if your investors don’t answer as directly as you may like – there is at least something that can be read into this.
So. If you have a strong lead investor known for backing his or her entrepreneurs in tough times and that investor gives you a sense for her comfort level in writing your next check then you can have a higher burn rate than if you don’t feel you have a strong lead investor.
If you have mostly angels or don’t feel your existing investor can support you without new capital from the outside then you might want a smaller burn rate.
Remember those party rounds that became so popular over the past few years because they allowed higher prices and more favorable terms for entrepreneurs? Well if you took that option I would simply advise that you be a little bit more cautious with your burn rate. Here’s why: If you have 5 firms who each gave you $500k you have 3 distinct problems:
No one (or two) investor “owns” responsibility for helping make things better. You have a version of the Tragedy of the Commons in which no individual actor owns responsibility for making the shared resource better. The opposite of this is a strong lead who owns responsibility because of the Pottery-Barn Rule popularized by Colin Powell in which “you break it, you buy it (or own responsibility for fixing it).
With so little (relatively) at stake nobody has a strong economic incentive t make things better. If each firm is only in for $500k and things go wrong they don’t mind taking a write-off and the upside of making things better often isn’t worth it because their ownership is too small.
You also have the “free rider problem” because if 3 of the 5 parties are willing to support you and 2 aren’t (the free riders) often the 3 won’t want to bother or will want to recap the company because no investors like bailing out free riders. And recaps hurt founders so often people just avoid doing them. If they’re only 1 of 5 they might rather just take the write off.
Are Your Existing Investors Over Their Skis?
This is another thing I strongly advise entrepreneurs to understand and even talk with their VCs about. Let me play open book so you can understand the situation better.
At Upfront Ventures 90% of the first-check investments we do are seed or A-round (and 2/3rd of these are A-rounds) with about 10% of our first-checks (in number) being B-rounds. As a primarily A-round investor with a nearly $300 million fund our average first-check size is about $3.5 million. We invest about half of our fund in our initial investments and we “reserve” about 50% of our investments to follow on in our best deals.
Obviously if a company is doing phenomenally well we’ll try to invest more capital and if a company is taking time to mature we’ll be more cautious. But even companies that take time to mature will usually get at least a second check of support from us as long as they are showing strong signs of innovating and as long as we believe they are still committed to the long-term viability of the business and as long as they show financial prudence.
In our best deals we hope to invest $10-15 million over the life of the fund.
So if we’ve invested $3-4 million in your company there is a strong chance you will get some level of support from us because on a relative basis we are not “over committed” and even in tough times for you, allocating $1-2 million is part of our scope and strategy to get you through unforeseen situations.
If on the other hand we have committed $10 million and if you don’t have 3 other investors around the table and if you’re burning $800k / month (implying you need $10 million more to fund one-year’s operations or nearly $15 million to fund 18 months) – we’re simply “over our skis” in order to help you because we wouldn’t put $25 million in one company at our size fund. So even if we LOVE your business you are stretching our ability to fund you in tough times.
You ought to have a sense for your existing investors’ capacities relative to your company.
How Strong is Your Access to Capital?
Talking about existing investors is one way of talking about “access to capital” because if you already have VCs then you have “access.” And then you’re just assessing whether you can get access to new VCs or whether your existing VCs can help you in tough times.
I talk about “access to capital” in the context of fund raising because it is the biggest determinant of your likelihood of raising. If you went to Stanford with a bunch of VCs who you count as friends (and who respect you) plus you worked at the senior ranks of Facebook, Salesforce.com, Palantir or Uber – you have very strong access – obviously.
But many people aren’t in this situation. If your company has raised angel money and maybe some capital from seed funds that are less well known or are new – then your access to capital may be less strong.
What is Your Risk Appetite?
It is also impossible to tell you the right burn rate for your company without knowing your risk tolerance. Quite simply – some people would rather “go hard” and accept the consequence of failure if they don’t succeed. Other people are more cautious and have a lot more at stake if the company doesn’t succeed (like maybe they put in their own money or their family’s money).
So whenever people ask me for advice I normally start by asking:
How much time have you put into this company already?
How much money have you personally or your friends/family invested? Is that a lot for them?
How risk averse are you? Are you generally very cautious or prefer to “go all out for it or die trying?”
There is no right answer. Only you can know. But check your risk tolerance.
Again, I know this sounds very obvious but in practice it isn’t always. Some companies may be able to become “cockroaches” or “ramen profitable” but cutting costs and staff substantially and getting to a burn rate that last 2 years. But that could impact the future upside of the company. So you might have a company that is “medium valuable” in the long-run because with no capital it was hard to innovate and create a market leader. That’s ok for some entrepreneurs (and investor) and not for others.
Also. You may think that it’s ok to “cut to the bone” but you may find out that your team didn’t want to join that sort of company so you may cut back really far only to find that the remaining people leave. Simply put – if you’re going to cut to the bone make sure that the team you intend to keep is aligned culturally with this decision.
Being ramen profitable is the right decision for some team and the wrong decision for others. Only you know. Keep your burn rate in line with your: Access to capital & risk tolerance levels.
How Reasonable Was Your Last Valuation?
There are two other factors you may consider. One is how reasonable your last round valuation was. If you raised $10 million at a $40 million pre-money on a company with limited revenue and if your investors are telling you that they’re concerned about your future because they doubt that outsiders will fund you at your current performance level then I would be more cautious with my burn rate – even if it means slashing costs.
There are only four solutions to this problem:
Confirm inside support to continue funding you – even if outsiders won’t
Cut burn enough that you can eventually “grow into” your valuation; or
Adjust your valuation down proactively so that outsiders can still fund you at what the market considers a normal valuation for your stage & progress
Go hard and hope that the market will validate your innovation even if the price may be higher than the market may want to bear
How Complicated is Your Cap Table?
Cap Table issues are seldom understood by entrepreneurs. Again, my best advice is to talk with your VCs openly or at least the ones you trust the most to be open.
If you raised a $2 million seed round at a $6 million pre then a $5 million A-round at a $20 million pre then a $20 million B-round at a $80 million pre and if your company has stalled you may have a cap table problem. Let me explain.
The $20 million investor may now believe that you’re never going to be worth $300 million or more (they invested hoping for no less than a 3x). So if they’re in the mindset that they’re better off getting their $20 million back versus risking more capital then they may prefer just to sell your company for whatever you can get for it. Even if you sold for $20 million they’d be thinking “I have senior liquidation preference so I get my money back.”)
The early stage investor probably still owns 15% of your company and thought he or she had a great return coming (after all – it got marked up to $100 million post-money valuation just 12 months ago!). But they are “over their skis” on ability to help you because they’re an early-stage investor so they’re dependent on your B-round investor or outside money.
They don’t want you to sell for $20 million because they may still believe in you AND they know that they’ll get no return from this (and your personal return will be very small).
You are in a classic cap table pinch. You don’t even realize that the later-stage investor doesn’t support you any more.
Solution: For starters get your seed & A investors helping. They may be able to persuade your B-round investor to be more reasonable. They may push you to cut costs. They may suggest cap table adjustments as a compromise. Or they may ferret out that your B-round investor just won’t budge. But at least you’ll know where you stand before deciding what to do about burn.
Note that I’m not making any value judgments about seed, A or B (or C or growth) investors. Just trying to point out that at times they’re not always aligned and most entrepreneurs don’t understand this math.
Appendix:
As with yesterday I’m still at a soccer tournament with my son (he’s asleep – but we made the championship round!). So I have no time to edit or word check. I hope this post is at least helpful for those surveying what to do about burn rates and the market. And if I made mistakes or typos feel free to let me know and I’ll fix tomorrow.
At the Upfront Summit in early February, we had a chance to have many off-the-record conversations with Limited Partners (LPs) who fund Venture Capital (VC) funds about their views of the market. While I’m not an LP, the following post represents my discussions with more than 100 LP firms – specifically ones that do fund VCs – and full survey data from 73 firms, so I’ve tried to capture the essence of what I’ve learned.
We All Know That Dollars into Venture Have Gone Up …
As a starting point, we know that the dollars into venture have steadily rebounded to pre great-recession levels, with just under $30 billion committed to US technology venture capital in 2015. While there is much discussion about VCs starting to pull back on their investments into startups, the LPs we surveyed don’t expect to slow the pace of investment into VC funds themselves – at least for the foreseeable future.
…But LPs Have Been Putting Out More Money Than They Are Getting Back
LPs have been feeling great about venture capital due to holding valuable paper positions in companies like Uber, Lyft, Airbnb, Dropbox, all of which they feel confident will drive large cash distributions in the future. However, they have been sending VCs far more investment checks in the last ten years than they’ve gotten back as distributions. In fact, if you add the capital flows of the past ten years, there have been just shy of $50 billion in net cash outlays.
And that’s real cash that LPs can’t put to work in other asset classes. So one problem often not talked about is that if LPs don’t get money back and accumulate more cash outflows, eventually they will either have to pare back investments into venture or they’ll have to increase the percentage of dollars they allocate to venture (at the expense of other asset types).
LPs Still Believe Strongly in Venture Capital as a Diverse Source of Returns
The good news for our industry is that the LPs who fund the VC industry are still very big believers in the long-term gains they will get from venture and are still allocating capital to the industry in good times and bad. That’s money that fuels our startup ecosystems. In our poll of 73 LP funds, we saw only 7% who felt they were overweight in venture given the current market climate, versus 22% of the firms who are actually looking to grow their dollars in venture.
And while there is a narrative that most LPs only want to invest in the long-standing Silicon Valley brands that have existed for the past 40 years, there is evidence that many LPs understand that it is possible for new entrants in our industry to stake out grounds of differentiation. In just over a decade, new firms like USV, Foundry, Spark, True Ventures, First Round, Greycroft (I might add Upfront) have made names for themselves from a non-traditional Silicon Valley stance. More recently, Thrive, Homebrew, IA Ventures, K9, Social + Capital, Cowboy, SK Capital, Ludlow, Forerunner and many, many others have emerged as newly differentiated brands. There are so many I fear that listing a few will get me in trouble with the many I didn’t list. Sorry!
But here’s the chart that should hearten all new firms … 40% of LPs tell us that they’re looking to add new names to their rosters.
LPs See The Over-Valuations and Don’t Like It
All isn’t completely rosy in the LP views of the venture industry. LPs have followed the recent press about the over-valuation and over-funding of the startup industry, and they experience these phenomena first hand. Some 75% of LPs polled said they are concerned about investment pace, burn and valuations; for now, only 6% seem “deeply concerned.”
I suspect that over the next 18 months, they’ll see another phenomenon that they likely haven’t seen since 2008-09: mark-downs of the VCs’ portfolios. This strangely may come even more quickly in the more successful funds, because any funds (ours included) who still hold some public stock from a recent IPO will likely be seeing write-downs sooner due to the immediacy and transparency of public stocks being repriced.
But the problem for LPs is that as VCs write bigger checks with increased frequency, these firms go “back in the market” to raise funds more quickly than in the past. A normal VC fund raises a new fund every three years if they are strong performers. Some are slightly faster – two and a half years – and sometimes it takes longer to deploy capital, closer to four years. In recent years, some funds have literally raised new funds inside of 18 months – staggering amounts of capital at that. I suspect those days will end soon, and 61% of LPs polled said they felt VCs were coming back to market too quickly.
The Biggest Area of Concern is Late Stage Investments
With valuations rising fastest in late-stage venture and the competition that is well-known from corporate VCs, mutual funds, hedge funds (and even LPs), it is unsurprising that LPs are most concerned about late-stage VC. 68% of LPs surveyed expressed caution that the late-stage part of the market is over-valued.
But of course, for every angle of the market where one person sees caution, another spots opportunities. Some LPs have privately speculated that later-stage VCs may have a field day in the next 18 months, buying up large positions in firms with strong revenue at attractive prices given the recent squeeze on funding. It’s not an opportunity for the weak of stomach, as these deals are hard to get done and even harder to keep on course. But there’s no doubt, some will make money.
Another Area of Concern is in the Seed Investor Class
I have also heard LPs express concern over the last few years about the seed stage of venture. One narrative is that too many funds have been created, and without a strong sense of differentiation, there will be too many mediocre seed funds. Another big area of concern expressed by LPs is that some seed funds may get “squeezed” in both good scenarios and bad. In good scenarios, they don’t have funds large enough to follow their winners. In bad markets, they can be wiped out by recaps and liquidation preferences unless they save enough reserves to protect their positions.
The data itself bears out some of these fears. 89% of LPs survey expressed some level of concern about the seed market. 65% said they will invest in seed funds but are very discerning about which ones, and 23% expressed concern that there are just too many seed funds – they’re worried about capacity. Anecdotally, most LPs believe the best seed funds still deliver superior returns to other parts of the market, but they simply can’t put enough dollars to work in the handful they truly respect.
Many Seed Investors Have Solved the Cash Problem with Opportunity Funds
A few years ago, the best seed funds responded to the challenge of being cash-strapped by raising “opportunity funds,” which can invest in the seed investor’s best deals as those deals grow. Of course, this raises a host of questions about conflicts of interest, valuations, and whether early-stage investors are well-suited to invest in later-stage deals. But both seed investors and LPs alike agree that as long as these programs are managed sensibly, their existence is useful. A whopping 85% of LPs were favorable to opportunity funds as long as they were done with a pragmatic approach and with favorable economics.
Most LPs Don’t Believe That Traditional VCs are Being Squeezed
Occasionally, some of the larger funds will argue that traditional VCs will be “squeezed.” They say that “the big guys are getting bigger and can compete for the full lifecycle of investments” on one side, and “the seed investors are out-hustling traditional VC” on the other side. Frankly, I’ve never believed this argument. As a traditional VC, the growth of seed funds has been a blessing to me because it increases the total number of startups for us to evaluate. We’ve also become very adept at partnering with seed funds.
And other than a handful of deals that scale in the blink of an eye, I really haven’t felt too much pressure from bigger VCs moving down into our territory. Funds that are more comfortable writing $20 million checks in more proven businesses simply don’t want to also compete for less proven deals in need of $4-5 million.
Luckily, LPs seem to agree with this thesis. Only 17% bought the premise that traditional VCs are being squeezed, versus 34% who prefer to focus the majority of their efforts on traditional A/B round VC funds. And of course, 50% want a good balance across all stages: seed, traditional and growth.
Perhaps the Biggest Change in the LP Ecosystem is the Number Now Seeking Direct Investments
The booming tech markets and the dollars being allocated in the venture sector have created one seldom-discussed consequence over the past three years – the sheer number of LP dollars looking for “direct investment” (i.e., dollars going directly into portfolio companies vs. the funds themselves).
Nearly 40% of all LPs surveyed said that direct investments were becoming an important part of their program (17% said they’re very important), and a further 44% of LPs are opportunistically doing direct investments. There are even LP fund-of-funds who raise capital with a main marketing pitch of providing better access to direct investments.
Summary
LPs remain staunch supporters of the venture capital industry, and their investment pace into VC seems likely to hold steady for the next one to two years (barring any unforeseen negative market events). This support will start to meet headwinds in the next three to four years if our industry doesn’t find a way to drive more exits and recycle capital back into the ecosystem. Without some cash distributions, eventually LPs will become stretched. I expect the LP conversations in the next 12-18 months to be about the inevitable mark-down of VC portfolios; however, many LPs are long on venture capital for the same reasons I am. Any correction will be followed by the long march of technology disruption and the profits disproportionally allocated to the winners.
I’ll do the same tomorrow and friday, but today I’d like to talk about What Didn’t Happen, specifically which of my predictions in What Is Going To Happen did not come to be.
I said that the big companies that were started in the second half of the last decade (Uber, Airbnb, Dropbox, etc) would start going public in 2015. That did not happen. Not one of them has even filed confidentially (to my knowledge). This is personally disappointing to me. I realize that every company should decide how and when and if they want to go public. But I believe the entire startup sector would benefit a lot from seeing where these big companies will trade as public companies. The VC backed companies that were started in the latter half of that last decade that did go public in 2015, like Square, Box, and Etsy (where I am on the board) trade at 2.5x to 5x revenues, a far cry from what companies get financed at in the late stage private markets. As long as the biggest venture backed companies stay private, this dichotomy in valuations may well persist and that’s unfortunate in my view.
I said that we would see the big Chinese consumer electronics company Xiaomi come to the US. That also did not happen, although Xiaomi has expanded its business outside of China and I think they will enter the US at some point. I have a Xiaomi TV in my home office and it is a really good product.
I predicted that asian messengers like WeChat and Line would make strong gains in the US messenger market. That most certainly did not happen. The only third party messengers (not texting apps) that seem to have taken off in the US are Facebook Messenger, WhatsApp and our portfolio company Kik. Here’s a shot of the app store a couple days after the kids got new phones for Christmas.
I said that the Republicans and Democrats would find common ground on challenging issues that impact the tech/startup sector like immigration and net neutrality. That most certainly did not happen and the two parties are as far apart as ever and now we are in an election year where nothing will get done.
So I got four out of eleven dead wrong.
Here’s what I got right:
VR has hit headwinds. Oculus still has not shipped the Rift (which I predicted) and I think we will see less consumer adoption than many think when it does ship. I’m not long term bearish on VR but I think the early implementations will disappoint.
The Apple Watch was a flop. This is the one I took the most heat on. So I feel a bit vindicated on this point. Interestingly another device you wear on your wrist, the Fitbit, was the real story in wearables in 2015. In full disclosure own a lot of Fitbit stock via my friends at Foundry.
Enterprise and Security were hot in 2015. They will continue to be hot in 2016 and as far as this eye can see.
There was a flight to safety in 2015 and big tech (Google, Apple, Facebook, Amazon) are the new blue chips. Amazon was up ~125% in 2015. Google (which I own a lot of) was up ~50% in 2015. Facebook was up ~30% in 2015. Only Apple among the big four was down in 2015 and barely so. Oil on the other hand, was down something like 30% in 2015 and gold was down something like 15-20% in 2015.
Here’s what is less clear:
Bitcoin had a big comeback in 2015. If you look at the price of Bitcoin as one measure, it was up almost 40% in 2015. However, we still have not see the “real decentralized applications” of Bitcoin and its blockchain emerge, as I predicted a year ago, so I’m not entirely sure what to make of this one. And to make matters worse, we now seem to be in a phase where investors believe you can have blockchain without Bitcoin, which to my mind is nonsense.
Healthcare is, slowly, emerging as the next big sector to be disrupted by tech. The “trifecta” I predict will usher in an entirely new healthcare system (smartphone becomes the EMR, p2p medicine, and a market economy in healthcare) has not yet arrived in full force. But it will. It’s only a matter and question of when.
So, I feel like I hit .500 for the year. Not bad, but not particularly impressive either. But when you are investing, batting .500 is great because you can double down on your winners and stop out your losers. That’s why it is important to have a point of view, ideally one that is not shared by others, and to put money where your mouth is.
It's been three years since I last upgraded monitors. Those inexpensive Korean 27" IPS panels, with a resolution of 2560×1440 – also known as 1440p – have served me well. You have no idea how many people I've witnessed being Wrong On The Internet on these babies.
I recently got the upgrade itch real bad:
4K monitors have stabilized as a category, from super bleeding edge "I'm probably going to regret buying this" early adopter stuff, and beginning to approach mainstream maturity.
Windows 10, with its promise of better high DPI handling, was released. I know, I know, we've been promised reasonable DPI handling in Windows for the last five years, but hope springs eternal. This time will be different!™
I needed a reason to buy a new high end video card, which I was also itching to upgrade, and simplify from a dual card config back to a (very powerful) single card config.
I wanted to rid myself of the monitor power bricks and USB powered DVI to DisplayPort converters that those Korean monitors required. I covet simple, modern DisplayPort connectors. I was beginning to feel like a bad person because I had never even owned a display that had a DisplayPort connector. First world problems, man.
1440p at 27" is decent, but it's also … sort of an awkward no-man's land. Nowhere near high enough resolution to be retina, but it is high enough that you probably want to scale things a bit. After living with this for a few years, I think it's better to just suck it up and deal with giant pixels (34" at 1440p, say), or go with something much more high resolution and trust that everyone is getting their collective act together by now on software support for high DPI.
Given my great experiences with modern high DPI smartphone and tablet displays (are there any other kind these days?), I want those same beautiful high resolution displays on my desktop, too. I'm good enough, I'm smart enough, and doggone it, people like me.
The Asus PB279Q is a 27" panel, same size as my previous cheap Korean IPS monitors, but it is more premium in every regard:
3840×2160
"professional grade" color reproduction
thinner bezel
lighter weight
semi-matte (not super glossy)
integrated power (no external power brick)
DisplayPort 1.2 and HDMI 1.4 support built in
It is also a more premium monitor in price, at around $700, whereas I got my super-cheap no-frills Korean IPS 1440p monitors for roughly half that price. But when I say no-frills, I mean it – these Korean monitors didn't even have on-screen controls!
4K is a surprisingly big bump in resolution over 1440p — we go from 3.7 to 8.3 megapixels.
But, is it … retina?
It depends how you define that term, and from what distance you're viewing the screen. Per Is This Retina:
27" 3840×2160
'retina' at a viewing distance of 21"
27" 2560×1440
'retina' at a viewing distance of 32"
With proper computer desk ergonomics you should be sitting with the top of your monitor at eye level, at about an arm's length in front of you. I just measured my arm and, fully extended, it's about 26". Sitting at my desk, I'm probably about that distance from my monitor or a bit closer, but certainly beyond the 21" necessary to call this monitor 'retina' despite being 163 PPI. It definitely looks that way to my eye.
I have more words to write here, but let's cut to the chase for the impatient and the TL;DR crowd. This 4K monitor is totally amazing and you should buy one. It feels exactly like going from the non-retina iPad 2 to the retina iPad 3 did, except on the desktop. It makes all the text on your screen look beautiful. There is almost no downside.
There are a few caveats, though:
You will need a beefy video card to drive a 4K monitor. I personally went all out for the GeForce 980 Ti, because I might want to actually game at this native resolution, and the 980 Ti is the undisputed fastest single video card in the world at the moment. If you're not a gamer, any midrange video card should do fine.
Display scaling is definitely still a problem at times with a 4K monitor. You will run into apps that don't respect DPI settings and end up magnifying-glass tiny. Scott Hanselman provided many examples in January 2014, and although stuff has improved since then with Windows 10, it's far from perfect.
Browsers scale great, and the OS does too, but if you use any desktop apps built by careless developers, you'll run into this. The only good long term solution is to spread the gospel of 4K and shame them into submission with me. Preach it, brothers and sisters!
Enable DisplayPort 1.2 in the monitor settings so you can turn on 60Hz. Trust me, you do not want to experience a 30Hz LCD display. It is unspeakably bad, enough to put one off computer screens forever. For people who tell you they can't see the difference between 30fps and 60fps, just switch their monitors to 30hz and watch them squirm in pain.
Viewing those comparison videos, I begin to understand why gamers want 90Hz, 120Hz or even 144Hz monitors. 60fps / 60 Hz should be the absolute minimum, no matter what resolution you're running. Luckily DisplayPort 1.2 enables 60 Hz at 4K, but only just. You'll need DisplayPort 1.3+ to do better than that.
Turn down the brightness from the standard factory default of retina scorching 100% to something saner like 50%. Why do manufacturers do this? Is it because they hate eyeballs? While you're there, you might mess around with some basic display calibration, too.
(Good luck attempting to game on this configuration with all three monitors active, though. You're gonna need it. Some newer games are too demanding to run on "High" settings on a single 4K monitor, even with the mighty Nvidia 980 Ti.)
I've also been experimenting with better LCD monitor arms that properly support my preferred triple monitor configurations. Here's a picture from the back, where all the action is:
These are the Flo Monitor Supports, and they free up a ton of desk space in a triple monitor configuration while also looking quite snazzy. I'm fond of putting my keyboard just under the center monitor, which isn't possible with any monitor stand.
With these Flo arms you can "scale up" your configuration from dual to triple or even quad (!) monitor later.
4K monitors are here, they're not that expensive, the desktop operating systems and video hardware are in place to properly support them, and in the appropriate size (27") we can finally have an amazing retina display experience at typical desktop viewing distances. Choose the Asus PB279Q 4K monitor, or whatever 4K monitor you prefer, but take the plunge.
In 2007, I asked Where Are The High Resolution Displays, and now, 8 years later, they've finally, finally arrived on my desktop. Praise the lord and pass the pixels!
Oh, and gird your loins for 8K one day. It, too, is coming.
[advertisement] Building out your tech team? Stack Overflow Careers helps you hire from the largest community for programmers on the planet. We built our site with developers like you in mind.
Last week Fred Wilson and I sat down in Santa Monica for an hour+ discussion with the video cameras rolling.
One of the questions we discussed was, “How much capital should a startup raise?” Fred & I are both in agreement that there is a tension between capital constraints and creativity. In his words,
[in some instances] “because lots of capital is available, the company takes on the capital and that ends up resulting in no constraints on decision making and so the company decides to do five things in stead of just one.”
We also spoke about what it takes to be an effective board member. On the one hand, I often find that some board members are seemingly reading the board materials on the fly and don’t have a firm grasp of the business fundamentals. On the other hand some board members like to tinker in the running of the business.
Again, Fred,
“What I’ve learned is that if you frame the problem for the team in a way that it becomes their idea as opposed to you telling them them to do it – that’s the move… effective board members help the management team decide to make the decisions that are right decisions instead of just telling them that those are the right decisions.”
This clip is just 2 minutes:
I agree. I’d add that often as board members we know contextually what the likely right answer is from years of experience and seeing similar scenarios. But unless management buys into your premise you can’t offer effective input. So part of playing an effective coach is helping the team to see the answer for themselves.
The final clip is of Fred & I talking about whether “the best product wins” and my assertion that the bias in today’s Silicon Valley dominated tech world there is probably too much emphasis on tech – at the expense of how to sell, implement and service customers. While this clip is only 1-minute long we talk about it more in the full interview.
My goal in the interview overall was to capture more of the personal side of Fred since so much of his investment thesis and portfolio work already comes out in his blog. We talk a lot about his schooling, his early jobs as a developer, and then as a VC. We also talk about his decision to spend winters in Los Angeles.
Fred has of course been a public mentor to us all with his market-defining terminology that he popularized, including “freemium” and “mobile first.” He has publicly espoused building products for “non logged in users” and has benefitted greatly from his thesis of large networks of socially connected and like-minded individuals.
Let’s see: Twitter, Tumblr, Etsy, KickStarter … not bad, hey? Not to mention USV’s investments in MongoDB (10Gen), Lending Club and a host of others. We talked in the full interview about some of Fred’s partners and the role that they play in the firm.
What you may not know is that Fred has been a behind-the-scenes mentor to many of the newer VCs in the industry, including myself. He has played an invaluable role as sounding board, confidant, and truth teller. Fred is generous with his time and advice and I hope has shaped a generation of VCs for the better.
Some things I learned from Fred early on in my days as a VC (these are my paraphrasings so hopefully I won’t stretch the bounds of what he would own):
1. You need to invest in good markets and bad
I remember many years ago, back in the last frothy market, saying to Fred, “I wonder if I should just sit out 6 months of investing until the craziness dies down?” He quickly pointed out that some of his best investments came during the last big (pre Sept 08) bull market including Etsy and Twitter. This always stuck with me. You can’t time VC investing markets.
2. You are defined by how you serve the companies that are struggling
This is one that is core to my ethos, whether rightly or wrongly. But it was nice to have validation early on from Fred. There are some firms that pull resources from deals that aren’t quite working and put all of their time into their mega hits. Perhaps that’s rational capitalism at its extreme. But it’s not who I am. I view it like “The Pottery Barn rule” … if something goes wrong I need to be part of the team that tries to fix it. This is classic Fred.
3. Blogging is like Venus Fly Paper
I have been blogging for years – even before BothSidesofTheTable. My initial blogging inspiration was actually Brad Feld because as an entrepreneur I always wanted to work with Brad after reading his advice on term sheets and the like.
Fred got me to see a broader perspective. Instead of just writing operating and funding advice, Fred also talks about industries. He says, “It’s like Venus Fly Paper. When I write about topics that are relevant, suddenly anybody with a startup solution in that field will approach us. This works brilliantly.”
I applied this advice and started writing about SaaS and Online Video, and have found Fred’s advice spot on.
4. Don’t be in a rush to invest your fund
The biggest mistake I see from new VCs (and new funds) is rushing to do investments. The temptation is natural. As a VC, so many deals look interesting and you sort of feel like you “want to be in the business.” Fred and I had a long discussion about this in the video.
VC investing is hard work. Most deals don’t pan out, so rushing into deals will just load up your year 2 & 3 with problems to fix. This is especially true if you haven’t found your unique source of dealflow yet. It’s easy to invest in today’s momentum categories. The problem is – that’s not how you make money as a VC.
5. Take nonconformist bets on the future world you imagine
Picking up from the last point, Fred has always espoused investing in the future you believe will happen, rather than the incremental improvements in today’s world. This is exactly where my head is at and it’s been great to watch Fred. At Upfront, we have huge conviction around topics that aren’t exactly 2015 sexy. I think this will set us up nicely for 2018-2020 if we’ve played our cards right.
I remember writing about online video nearly 5 years ago. Back then, people remained skeptical about the long-term value of video (“It’s a hits-driven business!”). But these days, many investors have started to realize that the future of the Internet will contain large elements of video. Being early got me my first $1 billion exit (Maker to Disney).
6. Be generous with time with newer VCs / pay it forward
I woke up one day and realized that many of the VCs I’m good friends with got in the industry either contemporaneously to me or after I did. Life happens. But I’ve tried my best to proactively offer up private advice on the industry as best I can because Fred was always generous with his time and advice with me.
I hope you get a choice to watch the video and learn some new stuff about Fred and his philosophies.
Here’s the full video interview. The first 25 minutes, we talk about Fred’s background (where he went to school, his first job, spending winters in Los Angeles) – it’s fun & informative. If you prefer just to hear business topics we start at 24:45 where Fred talks about the role of his partners starting with Brad Burnham and Albert Wenger.
Fred is an investor in SoundCloud and we always provide the audio track on SoundCloud and RSS (for any podcast player) for those that prefer audio:
Most people that are in the VC and startup sector know that USV likes to invest in networks. And most of the networks we invest in are consumer facing networks of people. Peer to peer services, if you will. The list is long and full of brand name consumer networks. So it would be understandable if people assumed that we do not invest in the enterprise sector. That, however, would be a wrong assumption.
We’ve been looking for enterprise networks to invest in since we got started and we are finding more and more in recent years. There is a particular type of enterprise network that we particularly like and I want to talk about that today.
Businesses, particularly large ones, build up large groups of suppliers. These suppliers can be other businesses or in some cases individuals. And these suppliers also supply other businesses. The totally of this ecosystem of businesses and their suppliers is a large network and there are many businesses that are built up around making these networks work more efficiently. And these businesses benefit from network effects.
I am going to talk about three of our portfolio companies that do this as a way to demonstrate how this model works.
C2FO is a network of businesses and their suppliers that solves a working capital problem for the suppliers and provides a better return on capital to large enterprises. Here is how it works: C2FO has a sales force that calls on large enterprises and shows them how they can use their capital to earn a better return while solving a working capital problem for their suppliers. They bring these large enterprises onto their platform and, using C2FO, they recruit their supplier base onto the platform. They also bring all the accounts payable for the large enterprise onto the platform. Once the network and the payables are on the platform, the suppliers can bid for accelerated payment of their receivables. When these bids are accepted by the large enterprise, the suppliers get their cash more quickly and the large enterprise earns a return on the form of a discount on their accounts payable. C2FO takes a small transaction fee for facilitating this market.
Work Market is a network of businesses and their freelance workforce. Work Market’s salesforce calls on these large enterprises and explains how they can manage their freelance workforce directly and more efficiently. These enterprises come onto the Work Market platform and then, using Work Market, invite all of their freelance workers onto the platform. They then issue all of their freelance work orders on the Work Market system, manage the work, and pay for the work, all on Work Market. Work Market takes a transaction fee for facilitating this and many of Work Market’s customers convert to a monthly SAAS subscription once they have all of their freelance work on the platform.
Crowdrise is a network of non-profits, the events they participate in, and the people who fundraise for them. Crowdrise’s salesforce calls on these events and the large non-profits who participate in them. When a large event, like the Boston Marathon, comes onto Crowdrise, they invite all the non-profits that participate in their event onto the platform. These non-profits then invite all the individuals who raise money for them onto the platform. These events and non-profits run campaigns on Crowdrise, often tied to the big events, and Crowdrise takes a small fee for facilitating this market.
I hope you all see the similarities between these three very different companies. There are several but the one I’d like to focus on is the “they invite all the ….. onto the platform”. This recruiting function is a very powerful way to build a network from the top down. And once these networks are built, they are hard to unwind.
We don’t see many consumer networks built top down, but we do see a lot of enterprise networks built top down. And we are seeing more and more of them. It is also possible to build enterprise networks bottoms up (Dropbox is a good example of that). That’s the interesting thing about enterprise networks. You can build them top down or bottoms up. And we invest in both kinds of enterprise networks.
The top down enterprise network is a growing part of the USV portfolio. We like this approach to building an enterprise software business and it does not suffer from the “dentist office software” problem. Which is a very good thing.
You’re inundated with tactics about how to grow your company. This talk will help you refine a framework for how to think about growth, and arm you with some tools to help hack through the bullshit.
We’ll fly through a 50,000 foot view of the product development process used at Dropbox and Facebook to drive growth.
We’ll dive into the nitty gritty: dozens of real examples of tests that worked and didn’t work.
Ivan Kirigin is an engineer and founder at YesGraph, a young startup focused on referral recruiting. Previous he lead growth at Dropbox, helping drive 12X growth in 2 years, and helped build Facebook Credits, and co-founded Tipjoy YC W08.
Yesterday I walked down the kitchen and the Gotham Gal was reading the paper and she looked up and said “Obama wants to rate colleges. I think that’s a bad idea”. I thought about it for a second and said “hmm. I need to think about that”. We are both on the boards of trustees of higher education institutions (strangely not ones we attended in both cases). So I think its important to state upfront that my thoughts on this topic are not in any way related to the schools we are affiliated with.
The New York Times has a debate on this topic on their website today. I read all the views and understand the pros and cons. Here is where I come out.
1) Colleges and Universities should be held accountable for the outcomes they produce, particularly for students whose tuition is paid by taxpayers in the forms of grants or below market loans. If the taxpayers are footing the bills, we deserve to know where we are getting a return and where we are not.
2) The Federal Government is the wrong entity to do this. The chances that they will mess this up are too high to put them in charge of this.
3) We should peer produce this data, wikipedia style. Something like ratemyprofessors.com. Students who get federal or state funding for some or all of their education should be required to submit information to such a service. Students whose educations are not funded by the government should be encouraged to opt in and report. The data should not include personally identifiable information (although I recognize that it would theoretically be possible to reverse engineer it if someone really wanted to do that). Most importantly, we should collect data on how the students do in their careers so we can measure real outcomes. Grades and graduations rates are nice. Earning power five and ten years out is even more important.
4) This would be a completely open database. All data would be available to be analyzed via open and public APIs, like the early days of the Twitter API. This would allow many third parties to analyze the data. There is no one truth, but if you triangulate, you can get closer to it.
Building this would not be hard. Making it the standard would be harder. It should be a non profit like Wikipedia is so everyone can and will trust it and work with it. And the federal and state governments should adopt it, support it, and require participation in it for those who are benefitting from taxpayer dollars.
If Obama really wants to rate Colleges and Universities, and I think we should be doing that, then this is the right way to do it.
This is a post Nick did around his User First keynote. It's great and I wanted to feature it to the AVC community today. The comments thread at the end is also running on Nick's blog and at usv.com so you will see commingled comments from all three places.
"It is trust, more than money, that makes the world go round." — Joseph Stiglitz, In No One We Trust
The week before last, I visited Yahoo! to give the keynote talk at their User First conference, which brought together big companies (Google, Facebook, etc), startups (big ones like USV portfolio company CloudFlare and lots of way smaller ones), academics, and digital rights advocates (such as Rebecca MacKinnon, whose recent book Consent of the Networked is an important read) to talk about the relevance of human/digital rights issues to the management of web applications.
I was there to speak to the investor perspective — why and how we think about the idea of “user first” as we make and manage investments in this space.
First, I want to point out a few things that might not be obvious to folks who aren’t regulars in conversations about digital rights, or human rights in the context of information & communication services. First, there has been substantial work done (at the UN, among other places) to establish a set of norms at the intersection of business and human rights. Here is the UN’s guiding document on the subject. Second, in terms of digital rights, the majority of the conversation is about two issues: freedom of expression/censorship and privacy/surveillance. And third, it’s important to note that the conversation about digital rights isn’t just about the state ensuring that platforms respect user rights, but it’s equally about the platforms ensuring that the state does.
The slides are also available on Speakerdeck, but don’t make much sense without narration, so here is the annotated version:
As more and more of our activities, online and in the real world, are mediated by third parties (telecom, internet and application companies in particular), they become the stewards of our speech and our information.
Increasingly, how much we trust them in that role will become a differentiating feature and a point of competition among platforms.
A little background on who I am:
I work at Union Square Ventures — we are investors in internet and mobile companies that build social applications. I also have academic affiliations at the MIT Media Lab in the Center for Civic Media, which studies how people use media and technology to engage in civic issues, and at the Berkman Center for Internet & Society at Harvard Law School which studies tech & internet policy. And my background is working in the “open government” space at organizations like OpenPlans and Code for America, with a focus on open data, open standards, and open source software.
So, to start out: a guiding idea is that the internet (as we know it today) is not just an open, amorphous mass of random peer-to-peer communications. It’s actually a collection of highly architected experiences:
Whether it’s the governance structure of an open source project, the set of interactions that are possible on social platforms like Twitter and Tumblr, or the web-enabled real-world interactions that are a result of Craigslist, Airbnb, and Sidecar, much of the innovation and entrepreneurial activity in the web and mobile space has been about experimenting with architectures of collaboration.
Web & mobile technologies are giving us the opportunity to experiment with how we organize ourselves, for work, for pleasure and for community. And that in that experimentation, there are lots and lots of choices being made about the rules of engagement. (for example, the slide above comes from an MIT study that looked at which kinds of social ties — close, clustered ones, or farther, weaker ones — were most effective in changing health behavior).
At USV, we view this as part of a broader macro shift from bureaucratic hierarchies to networks, and that the networked model of organizing is fundamentally transformative across sectors and industries.
One big opportunities, as this shift occurs, it to reveal the abundance around us.
I first heard this phrasing from Zipcar founder Robin Chase and it really stuck with me. It’s as if many of the things we’ve been searching for — whether it’s an answer to a question, an asthma inhaler in a time of emergency, a ride across town, someone to talk to, or a snowblower — are actually right there, ambient in the air around us, but it’s previously not been possible to see them or connect them.
That is changing, and this change has the potential to help us solve problems that have previously been out of reach. Which is good, because for as much progress we’ve made, there are still big problems out there to tackle:
For a (relatively) trivial one, this is what most California freeways look like every day. In much of the world, our transportation systems are inefficient and broken.
…and this is what Shanghai looked like last week as a 500-mile wide smog cloud, with 20x the established limit for toxicity, rolled in for a visit. We obviously don’t have our shit together if things like this can happen.
…and we have tons to figure out when it comes to affordable and accessible health care (not the least of which is how to build an insurance marketplace website).
…and education is getting worse and worse (for younger grades) and more and more expensive (for college). There’s no question that the supply / demand balance is out of whack, and not taking into account the abundance that is around us.
So: these are all serious issues confronting global society (and the ones I mentioned here are just a small fraction of them at that).
All of these issues can and should benefit from our newfound opportunity to re-architect our services, transactions, information flows, and relationships with one another, built around the idea that we can now surface connections, efficiencies, information, and opportunities that we simply couldn’t before we were all connected.
But… in order to do that, the first thing we need to do is architect a system of trust — one that nurtures community, ensures safety, and takes into account balances between various risks, opportunities, rights and responsibilities.
Initially, that meant figuring out how to get “peers” in the network to trust each other — the classic example being Ebay’s buyer and seller ratings which pioneered the idea of peer-to-peer commerce. Before then, the idea of transacting (using real money!) with a stranger on the internet seemed preposterous.
Recently, the conversation has shifted to building trust with the public, especially in the context of regulation, as peer-to-peer services intersect more and more with the real world (for example, Airbnb, Uber, and the peer-to-peer ride sharing companies and their associated regulatory challenges over the past three years).
Now, a third dimension is emerging: trust with the platform. As more and more of our activities move onto web and mobile platforms, and these platforms take on increasing governance and stewardship roles, we need to trust that they are doing it in good faith and backed by fair policies. That trust is essential to success.
In terms of network & community governance, platforms establish policies that take into account issues like privacy, enforcement of rules (both public laws and network-level policies), freedom of expression and the freedom to associate & organize, and transparency & access to data (both regarding the policies and activities of the platform, and re: the data you produce as a participant in the community).
When you think about it, you realize that these are very much the same issues that governments grapple with in developing public policy, and that web platforms actually look a lot like governments.
Which makes sense, because both in the case of governments and web-enabled networks, the central task is to build an architecture around which other activity happens. You build the roads and the other essential public infrastructure, and then you set the ground rules which enable the community and economy to function.
Of course, there is a major difference: web networks are not governments, and are not bound by all the requirements & responsibilities of public institutions. They are free to create their own rules of engagement, which you agree to when you decide to participate (or not) in that community.
This is both a plus and a minus, when it comes to user rights — the major plus being that web platforms are competitive with each other. So that when there are substantive differences in the way platforms make and enforce rules, those differences can be the basis for user choice (e.g., it’s easier to move from Facebook to Google than it is to move from the US to Canada).
I would like to put some extra emphasis on the issue of data, since it’s growing so quickly and has been so much at the forefront of the public conversation over the past year.
We are generating — and sharing — more data than we ever have before.
Everywhere we go, on the internet and in the real world, we are leaving a trail of breadcrumbs that can mined for lots of purposes. For our own good (e.g., restaurant recommendations, personal health insights), for social purposes (crowdsourced traffic reports, donating data to cancer research), for commercial purposes (ad targeting & retargeting, financing free content), and for nefarious purposes (spying, identity theft).
One distinguishing idea within all of this is the difference between data sharing that we opt into and data sharing that happens to us. Certain web services (for example USV portfolio company Foursquare, highlighted above) make a business out of giving people a reason to share their data; getting them to buy into the idea that there’s a trade going on here — my data now for something of value (to me, to my friends, to the world) later. It’s proving true that lots of people will gladly make that trade, given an understanding of what’s happening and what the benefits (and risks) are.
Convincing someone to share their data with you (and with others on your platform) is an exercise in establishing trust.
And my feeling is that the companies that best establish that trust, and best demonstrate that they can stand behind it, are going to be the ultimate winners.
I think about this a lot in the context of health. There is so much to gain by sharing and collecting our health data.
And If we don’t get this right (“this” being the sensitive matter of handling personal data), we miss out on the opportunity to do really important things.
And there is no shortage of startups working to: a) help you extract this data (see 23andme), b) help you share this data (see Consent to Research and John Wilbanks’ excellent TED talk on sharing our health data), and c) building tools on top of this data (see NYU Med Center’s virtual microscope project).
We are pushing the boundaries of what data people are willing to share, and testing the waters of who they’re willing to share it with.
Which brings us back to the idea of competition, and why winning on trust is the future.
We are just just just scratching the surface of understanding whether and how to trust the applications we work with.
EFF’s Who Has Your Back report ranks major tech & communications firms on their user protection policies. The aptly-titled Terms of Service; Didn’t Read breaks down tech company Terms of Service and grades them using a crowdsourced process. And, most effectively (for me at least), the Google Play store lists the data access requests for each new application you install (“you need my location, and you’re a flashlight??”).
You might be saying: “that’s nice, but most people don’t pay any attention to this stuff”.
That may be true now, but I expect it to change, as we deal with more and more sensitive data in more parts of our lives, and as more companies and institutions betray the trust they’ve established with their users.
There is no shortage of #fail here, but we can suffice for now with two recent examples:
Instagram’s 2012 TOS update snafu caught users by surprise (who owns my photographs?), and this summer’s NSA surveillance revelations have caused a major dent in US tech firms’ credibility, both at home and especially abroad (not to mention what it’s done to the credibility of the US gov’t itself).
So… how can web and mobile companies win on trust?
We’re starting to see some early indications:
Notice the major spike in traffic for the privacy-oriented search engine, USV portfolio company, DuckDuckGo, around June of 2013, marked by [I] on the graph.
Some companies, like Tumblr, are experimenting with bringing more transparency to their policy document and terms of service. Tumblr’s TOS include “plain english” summaries, and all changes are tracked on Github.
And of course, lots of tech companies are beginning to publish transparency reports — at the very least, starting to shine some light on the extent to which, and the manner in which, they comply with government-issued requests for user data. Here are Google’s, Yahoo’s and Twitter’s.
There are juicier stories of platforms going to bat for their users, most recently Twitter fighting the Manhattan DA in court to protect an Occupy protester’s data (a fight they ultimately lost), and secure email provider Lavabit shutting down altogether rather than hand over user data to US authorities in the context of the Snowden investigation.
And this will no doubt continue be a common theme, as web and mobile companies to more and more for more of us.
And, I should note — none of this is to say that web and mobile companies shouldn’t comply with lawful data requests from government; they should, and they do. But they also need to realize that it’s not always clear-cut, that they have an opportunity (and in many cases a responsibility) to think about the user rights implications of their policies and their procedures when dealing with these kinds of situations.
Finally: this is a huge issue for startups.
I recently heard security researcher Morgan Marquis-Boire remark that “any web startup with user traction has a chance of receiving a government data request approaching 1”. But that’s not what startups are thinking about when they are shipping their first product and going after their first users. They’re worried about product market fit, not what community management policies they’ll have, how they’ll respond when law enforcement comes knocking, or how they’ll manage their terms of service as they grow.
But, assuming they do get traction and the users come, these questions of governance and trust will become central to their success.
Nir’s Note: This guest post is by Ryan Hoover. Ryan blogs at ryanhoover.me and you can follow him on Twitter at @rrhoover.
When Snapchat first launched, critics discounted the photo-messaging app as a fad – a toy for sexting and selfies. Their judgements were reasonable. It’s impossible to predict the success of a product on day one, let alone its ability to change user behavior. But hindsight is beginning to prove critics wrong.
Snapchat boasts 5 million daily active users sending 200 million photos and videos daily. That’s an average of 40 snaps a day per user! But why are users so engaged? After all, what real need is the company solving anyway?
Snapchat popularized a new form of expression, using photos and videos as a communication medium. For many, Snapchat is a daily routine – the go-to app for interacting with friends in a playful way. This habit is not a happy mistake but a conscious effort driven by several subtle design choices.
As Nir Eyal describes, habit-forming products must have two things – high perceived utility and frequency of use. In Snapchat’s case, as with most communication services, each individual message isn’t particularly valuable in isolation. But through frequent use, Snapchatters enter the “Habit Zone”, instinctually turning to the product to solve their desire to communicate and feel connected with others. This key insight has enabled the company to craft an experience tailored for high engagement.
Here are five ways Snapchat drives habitual engagement with their product:
As Jack mentions, this is far from Snapchat’s intended use case but exemplifies the speed and ease-of-use of the service. After launching the app, the camera is immediately activated, encouraging instant photo-capturing. Traditional photo-sharing apps like Instagram open a feed to consume media, requiring an additional tap to create. This may appear like a minor inconvenience, but in reality, even the slightest friction can have a large impact. By reducing this process to a single tap, Snapchat enables users to capture fleeting moments faster and with less effort. And to capture a video, simply hold down on the screen to begin recording. No need for additional taps to toggle between photo and video modes.
Lowered Inhibitions
On Snapchat, nothing is permanent. Photos and videos vanish immediately after consumption. Some argue it’s a gimmick but in reality, this ephemerality lowers our inhibitions to share. When we are less self-conscious, we are less hesitant to act. We care less about creating the “perfect” photo or message, knowing it will disappear in an instant.
In comparison, the permanence of email or text messaging establishes an entirely different context. The artifacts of these conversations live on forever and we acknowledge the possibility that they could be forwarded or leaked to unwelcome eyes. This establishes reservations, censoring what we share and encouraging more thoughtful and ultimately, less frequent communications.
One-to-One Communication at Scale
Group messaging and social network “feeds” are channels for one-to-many communication. These messages are implicit broadcasts, not directed to specific individuals unless mentioned. In turn, consumers of the message have no obligation to respond and in some cases, may be hesitant to reply in a public forum.
After crafting a message, Snapchat users must select who to send it to. They are given the option to send to one or many individuals yet recipients are unable to discern whether a message was explicitly sent to them or several people. And this is the genius of Snapchat. It enables a single message to have a broad reach while maintaining the intimacy of one-to-one communications, leading to a higher volume of messages sent and increased response rates as users feel more socially obligated to return the favor.
Read-Receipts
We’ve all received an unwanted text message, email, or voicemail and ignored it. We pretend we didn’t see it or delay our response. When senders ask, “Did you get my message?” we make up an excuse. But on Snapchat, there’s no pretending. Each snap includes a read-receipt, informing senders their message was viewed.
This subtle indicator has significant impact on the dynamics of these interactions, creating a social obligation for recipients to reply in a timely manner. This leads to higher response rates and more expedient replies, increasing usage.
Response rates are critical to the success of Snapchat. Without it, users won’t stick around for long. Our craving for feedback and reciprocation is one of the strongest drivers of social products. To illustrate the effect of response rates, I’ll use a very simple example:
Let’s pretend there are two messaging apps, App A and App B. App A’s average response rate – the percentage of messages sent that users reply to – is 80%. App B’s response rate is 20%. For every 1,000,000 new messages sent, another 800,000 are generated in App A and only 200,000 in App B. In turn, these additional messages have a compounding effect as the original sender replies (assuming response rates remain constant). After 9 interactions, App A generates an additional 3,463,129 messages from the initial one million sent, 13x more than App B’s 250,000 messages.
But response rates are just one piece of the equation. Cycle time, the amount of time elapsed between each message, also has a significant influence on engagement[3]. If it takes an average of 4 hours for users to respond to each message, App A will send its 4,463,129th message after 36 hours. However, if the app’s cycle time is reduced to 1 hour, the same number of messages will be sent within 9 hours, intensifying engagement.
Feeding Curiosity
The human brain feeds off of variability. When things become mundane and predictable, we become disinterested. Consider your own reading habits. After finishing a book, are you motivated to read it again? Once the mystery is gone, so is our interest. But humans are unpredictable and its this variability that makes social products engaging and long-lasting.
Snapchat communications are highly variable. Each message is composed of various forms of self-expression, captured and created at that moment in time. When notified of a new message, one might question, “I wonder what it is. A photo, a message, a doodle, a video? Where is my friend? What are they doing? Is this a message just for me?”
These questions fuel our curiosity as we hold our finger on the screen to view, knowing the snap will disappear forever in an instant. Ephemerality encourages us to treasure these moments, capturing our attention and transforming ugly photos into novel interactions. This variability keeps things interesting, increasing our motivation to remain engaged to uncover the mystery.
As people continue to use the service several times per day, behaviors emerge that perpetuate engagement and retention. Soon, they are hooked and unlike the ephemeral communications it produces, engagement persists as users turn to Snapchat again and again.
TL;DR
Snapchat succeeds because it encourages frequent use by:
Making it easy and quick to create photos or videos
Reducing inhibitions with temporary communications
Creating a social obligation for users to reply to explicit, one-to-one communications
Increasing response rates and timeliness of replies using read-receipts
Motivating consumption through novel, highly variable interactions
Nir’s Note: An edited version of this essay appeared in The Atlantic. Below is my original.
It’s not often an app has the power to keep someone out of a strip club. But according to Bobby Gruenewald, CEO of YouVersion, that’s exactly what his technology did. Gruenewald says a user of his app walked into a business of ill repute when suddenly, out of the heavens, he received a notification on his phone. “God’s trying to tell me something!,” Gruenewald recalled the user saying, “I just walked into a strip club — and man — the Bible just texted me!”
YouVersion recently announced its app hit a monumental milestone — placing it among a rare strata of technology companies. The app, simply called “Bible,” is now on more than 100 million devices and growing. Gruenewald says a new install occurs every 1.3 seconds.
On average, some 66,000 people have the app open during any given second, but that number climbs much higher at times. Every Sunday, Gruenewald says, preachers around the world tell devotees, “to take out your Bibles or YouVersion app. And, we see a huge spike.”
The app was funded and built by LifeChurch.tv of Edmond, Oklahoma. Though Silicon Valley digerati rarely heed lessons from churches in red states, in this case, Gruenewald and his team have something to preach about.
The market for religious apps is fiercely competitive; searching for “bible” in the Apple App Store returns 5,185 results. But among all the choices, YouVersion’s Bible seems to be the chosen one, ranking at the top of the list and boasting over 641,000 reviews.
How did YouVersion come to so dominate the digital word of God? It turns out there is much more behind the app’s success than missionary zeal. The company is a case study in how technology can change behavior when it utilizes the principles of consumer psychology coupled with the latest in big data analytics.
According to industry insiders, the YouVersion Bible could be worth a bundle. Jules Maltz, General Partner at Institutional Venture Partners, told me, “As a rule of thumb, a company this size could be worth $200 million and up.”
Maltz should know. His firm recently announced an investment in another pre-revenue app, Snapchat, at an $800 million valuation. Maltz justifies the price by pointing to the per user valuations of other tech companies like Facebook, Instagram, and Twitter, who each commanded astronomical sums well before turning a profit. Maltz was quick to add, “Of course, this assumes the company can monetize through standard advertising.”
Placing ads in the Bible app would rain manna from heaven and the church which originally funded the app would suddenly become, shall we say, very blessed. However, Gruenewald says he has no intention of ever turning a profit from the app.
Despite multiple buyout offers and monetization opportunities, the Bible app remains strictly a money-losing venture. Lifechurch.tv has invested over $20 million in the app but, according to Gruenewald, “The goal is to reach and engage as many people as possible with scripture. That’s all.” So far, Gruenewald is meeting his goal.
In the Beginning
Gruenewald is a quick-thinking, fast-talking man. During our conversation, he pulled up statistics in real-time, stopping himself mid-sentence whenever relevant data flashes on his screen and grabs his attention. As Gruenewald preaches on about mobile app development best-practices, I need to occasionally interrupt him to ask clarifying questions. My words stumble over his enthusiasm as he bears witness to what he’s learned building his app. He spouts user retention figures with the same gusto I’d imagine he might proclaim scripture.
“Unlike other companies when we started, we were not building a Bible reader for seminary students. YouVersion was designed to be used by everyone, every day.” Gruenewald attributes much of the app’s success to a relentless focus on creating habitual Bible readers.
Gruenewald is well-prepared for our interview and, thanks to an email his publicist sent me prior to our call, so am I. In the email, the Bible app’s success is broken down into the language of habit formation more commonly seen in psychology textbooks. The “cues”, “behaviors” and “rewards” of communing with the Lord are bullet-pointed and ready for our discussion.
“Bible study guides are nothing new,” Gruenewald says. “People have been using them with pen and paper long before we came along.” But as I soon find-out, the Bible app is much more than a mobile study guide.
In fact, the first version of YouVersion was not mobile at all. “We originally started as a desktop website, but that really didn’t engage people in the Bible. It wasn’t until we tried a mobile version that we noticed a difference in people, including ourselves, turning to the Bible more because it was on a device they always had with them.”
Indeed, people started taking the Bible with them everywhere. Recently, the company revealed users read scripture in the most unsanctified places — 18% of readers report using the Bible app in the bathroom. While the 100 million install mark is an impressive milestone, perhaps the more startling fact is that users can’t put the app down long enough to take a holy shit.
How to Form a God Habit
Gruenewald acknowledges the Bible app enjoyed the good fortune of being among the first of its kind at the genesis of the App Store in 2008. To take part, Gruenewald quickly converted his web site into a mobile app optimized for reading. His app caught the rising tide, but soon a wave of competition followed. If his app was to reign supreme, Gruenewald needed to get users hooked quickly.
That’s when Gruenewald says he implemented a plan — actually, many plans. A signature of the Bible app is its selection of over 400 reading plans — a devotional iTunes of sorts, catering to an audience with diverse tastes, troubles and tongues.
Given my personal interest and research into habit-forming technology, I decided to start a Bible reading plan of my own. I searched the available themes for an area of my life I needed help with. A plan titled, “Addictions,” seemed appropriate.
Reading plans provide structure to the difficult task of reading the Bible for those who have yet to form the routine. “Certain sections of the Bible can be difficult for people to get through,” Gruenewald admits. “By offering reading plans with different small sections of the Bible each day, it helps keep [readers] from giving up.”
The app chunks and sequences the text by separating it into bite-size pieces. By parsing readings into communion wafer-sized portions, the app focuses the reader’s brain on the small task at hand, while avoiding the intimidation of reading the entire book.
Holy Triggers
5 years of testing and tinkering have helped Gruenewald’s team discover what works best. Today, the Bible app’s reading plans are tuned to immaculate perfection and Gruenewald has learned that frequency-of-use is paramount. “We’ve always focused on daily reading. Our entire structure for plans focuses on daily engagement.”
To get users to open the app every day, Gruenewald makes sure he sends effective cues — like the notification sent to the sinner in the strip club. But Gruenewald admits he stumbled upon the power of using good triggers. “At first we were very worried about sending people notifications. We didn’t want to bother them too much.”
To test how much of a cross users were willing to bear, Gruenewald decided to run an experiment. “For Christmas, we sent people a message from the app. Just a ‘Merry Christmas’ in various languages.” The team was prepared to hear from disgruntled users annoyed by the message. “We were afraid people would uninstall the app,” Gruenewald says. “But just the opposite happened. People took pictures of the notification on their phones and started sharing them on Instagram, Twitter, and Facebook. They felt God was reaching out to them.” Today, Gruenewald says, triggers play an important role in every reading plan.
On my own plan, I receive a daily notification on my phone, which reads, “Don’t forget to read your Addictions reading plan.” Ironically, the addiction I’m trying to cure is my dependency to digital gadgetry, but what the hell, I’ll fall off the wagon just this once.
In case I somehow avoid the first message, a red badge over a tiny Holy Bible icon cues me again. If I forget to start the first day of the plan, I’d receive a message suggesting perhaps I should try a different, less challenging plan. I also have the option of receiving verse through email and if I slip-up and miss a few days, another email would serve as a reminder.
The Bible app also comes with a virtual congregation of sorts. Members of the site tend to send encouraging words to one another, delivering even more triggers. According to the company’s publicist, “Community emails can serve as a nudge to open the app.” Triggers are everywhere in the Bible app and Gruenewald says they are a key part of the apps’ ability to keep users engaged.
To some, all these messages might become a nuisance. But remember, this is the Bible, and uninstalling the app or turning off notifications would basically be flipping the Lord the bird.
Glory Be in the Data
Gruenewald’s team has sifted through behavioral data collected from millions of readers to better understand what users want from the app. “We just have so much data flowing through our system,” Gruenewald said. “We were generating so much of it that apparently we showed up on Google’s radar and they contacted us to take a closer look.” Gruenewald reports his company recently completed work with Google engineers to help, “with storing and analyzing data so they could solve [these problems] for others as well.”
The data revealed some important insights on what drives user retention. High on Gruenewald’s list of learnings was the importance of “ease of use,” which came-up throughout our conversation.
In-line with the work of psychologists dating back to Gestalt psychologist Kurt Lewin, to modern-day researchers like BJ Fogg, the app uses the principle that by making an intended behavior easier to do, people do it more often.
The Bible app is designed to make absorbing the Word as frictionless as possible. For example, to make the Bible app habit easier to adopt, a user who prefers to not read at all can simply tap a small icon, which plays a professionally produced audio track, read with all the dramatic bravado of Charlton Heston himself.
Gruenewald says his data also revealed that changing the order of the Bible, placing the more interesting sections up-front and saving the boring bits for later, increased completion rates. Furthermore, daily reading plans are kept to a simple inspirational thought and a few short verses for newcomers. The idea is to get neophytes into the ritual for a few minutes each day until the routine becomes a facet of their everyday lives.
Rewards from the Lord
Gruenewald says the personal connection people have with scripture taps into deep emotions that, “we need to use responsibly.” Readers who form a habit of using the app turn to it not only when they see a notification on their phone, but also whenever they feel low and need a way to lift their spirits.
“We believe that the Bible is a way God speaks to us,” Gruenewald says. “When people see a verse, they see wisdom or truth they can apply to their lives or a situation they’re going through,” Skeptics might call this subjective validation, psychologists could call it the Forer effect, but to the faithful, it amounts to personally communicating with God.
Upon opening the Bible app, I find a specially selected verse waiting for me on the topic of “Addictions”. With just two taps I’m reading 1 Thessalonians 5:11 – encouragement for the “children of the day,” imploring them with the words, “let us be sober.” It’s easy to see how these comforting words could serve as a sort of prize wrapped inside the app, helping readers feel better and lifting their mood.
Gruenewald says there is also an element of mystery and variability associated with using the Bible app. “One woman would stay-up until just past midnight to know what verse she had received for her next day,” Gruenewald says. The unknown, which verse will be chosen for the reader and how it relates to their personal struggle, becomes an important driver of the reading habit.
As for my own reward, after finishing my verse, I received confirmation from a satisfying ”Day Complete!” screen. A check mark appeared near the scripture I had read and another one was placed on my reading plan calendar. Skipping a day would mean breaking the chain of checked days, employing what psychologists call the “endowed progress effect” — a tactic also used by video game designers to encourage progression.
Sharing the Word
As habit-forming as the Bible app’s reading plans can be, they are not for everyone. In fact, Gruenewald reports most users never register for an account with YouVersion. Millions choose to not follow any plan, opting instead to use the app as a substitute for their paper Bibles.
But to Gruenewald, using the app in this way suits him fine. Just because a reader never registers, does not mean Gruenewald has not found a way to help them grow the app. In fact, social media is abuzz with the 200,000 pieces of content shared from the app every 24 hours.
To help the app spread, a new verse greets the reader on the first page. Below it, a large blue button reads, “Share Verse of the Day,” whereby clicking the button blasts scripture to Facebook or Twitter.
Just why people share scripture they’ve just read is not widely studied. However, one reason may be the of reward portraying oneself in a positive light, also known as the humblebrag. A recent Harvard meta-analysis titled, “Disclosing information about the self is intrinsically rewarding” found the act, “engages neural and cognitive mechanisms associated with reward.” In fact, sharing feels so good that one study found, “individuals were willing to forgo money to disclose about the self.”
There are many opportunities to share verse from within the app, but one of Gruenewald’s most effective distributions channels occurs not online but in-row — that is, in the pews church-goers sit-in every week.
“People tell each other about the app because they use it surrounded by people who ask about it.” Gruenewald says the app always sees a spike in new downloads on Sundays when people are most likely to share it through word of mouth.
However, nothing consummates the reign of Gruenewald’s Bible app quite like the way preachers in some congregations have come to depend upon it. YouVersion lets religious leaders input their sermons into the app to allow their assemblies to follow along in real-time — book, verse, and passage — all without flipping a page. Once the head of the church is hooked, the flock is sure to follow.
For All Eternity
But using the Bible app at church not only has the benefit of driving growth, it builds commitment. Every time users highlight a verse, add a comment, bookmark, or share from the app, they invest in it.
Behavioral economists Dan Ariely and Michael Norton have shown the effect small amounts of work have on the way people value various products. Known as the “IKEA effect,” studies have shown that things we put labor into, become worth more to us.
It is reasonable to think that the more readers put into the Bible app in the form of small investments, the more it becomes a repository of their history of worship. Like a worn dog-eared book, full of scribbled insights and wisdom, the app becomes a treasured asset not easily discarded.
The more readers use the Bible app, the more valuable it becomes to them. Switching to a different digital Bible — God forbid — becomes less likely with each new revelation a user types into the app, further securing YouVersion’s dominion.
Gruenewald claims he is not in competition with anyone, but he does on occasion rattle off the App Store categories where he holds a high ranking. His place at the top of the charts appears secure now that the Bible has crossed its 100 millionth install.
But Gruenewald plans to continue sifting through the terabytes of data to search for new ways to increase the reach of his app and make the Bible even more habit-forming. To its tens of millions of regular users, Gruenewald’s app is a Godsend.
***
Thank you to Max Ogles, Ryan Hoover, Kevin Madsen, and Casey Bankord for reading early versions of this essay.
Copyright 2013, Nir Eyal, as first published in TheAtlantic.com

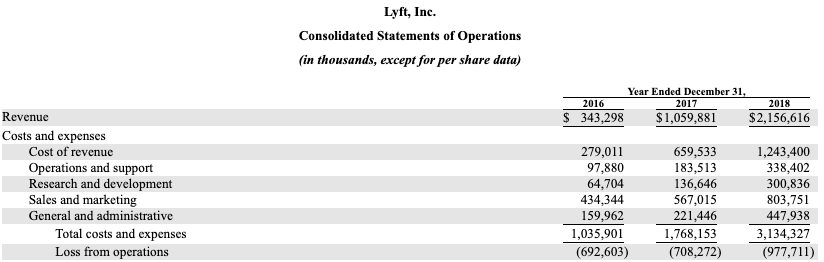
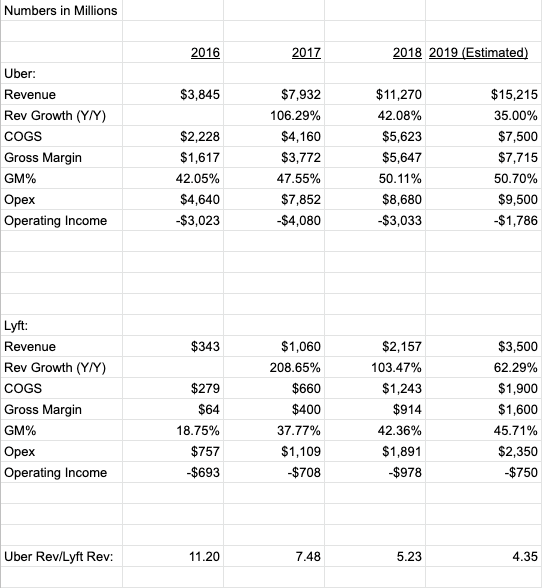




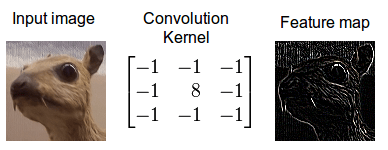
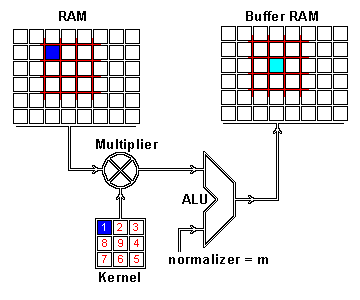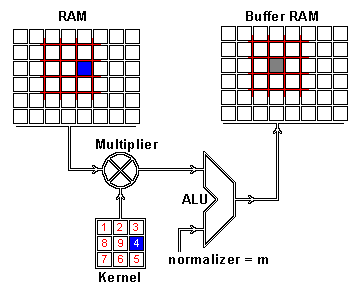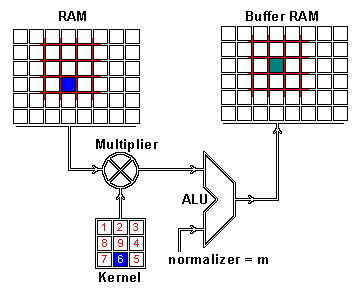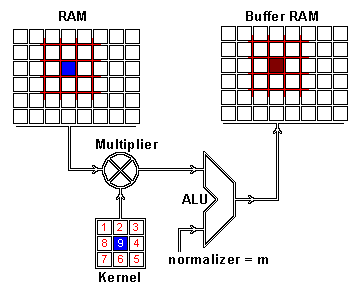

 ). So automatically we learn 32 new features that have relevant information for our task in them. These feature then provide the inputs for the next kernel which filters the inputs again. Once we learned our hierarchical features, we simply pass them to a fully connected, simple neural network that combines them in order to classify the input image into classes. That is nearly all that there is to know about convolutional nets at a conceptual level (pooling procedures are important too, but that would be another blog post).
). So automatically we learn 32 new features that have relevant information for our task in them. These feature then provide the inputs for the next kernel which filters the inputs again. Once we learned our hierarchical features, we simply pass them to a fully connected, simple neural network that combines them in order to classify the input image into classes. That is nearly all that there is to know about convolutional nets at a conceptual level (pooling procedures are important too, but that would be another blog post).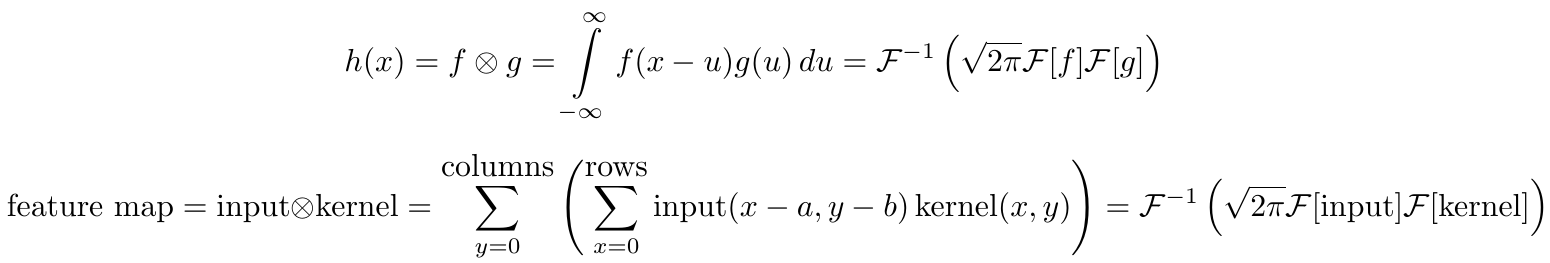
 denotes a convolution operation,
denotes a convolution operation,  denotes the Fourier transform,
denotes the Fourier transform,  the inverse Fourier transform, and
the inverse Fourier transform, and  is a normalization constant. Note that “discrete” here means that our data consists of a countable number of variables (pixels); and 1D means that our variables can be laid out in one dimension in a meaningful way, e.g. time is one dimensional (one second after the other), images are two dimensional (pixels have rows and columns), videos are three dimensional (pixels have rows and columns, and images come one after another).
is a normalization constant. Note that “discrete” here means that our data consists of a countable number of variables (pixels); and 1D means that our variables can be laid out in one dimension in a meaningful way, e.g. time is one dimensional (one second after the other), images are two dimensional (pixels have rows and columns), videos are three dimensional (pixels have rows and columns, and images come one after another).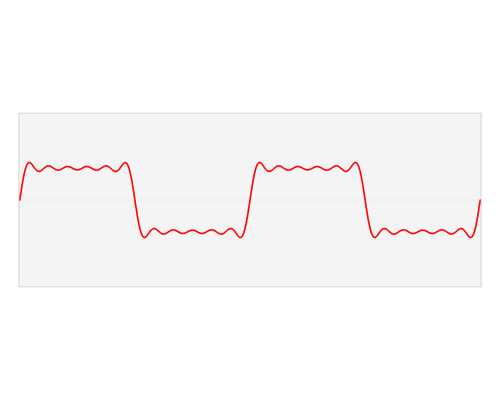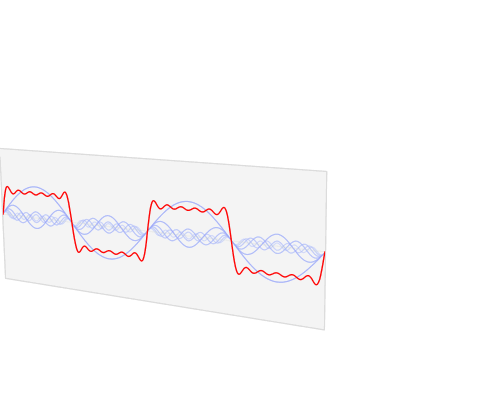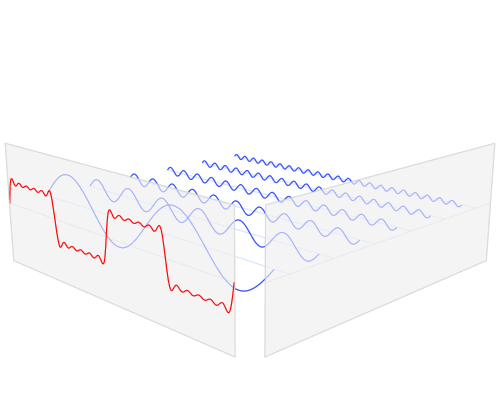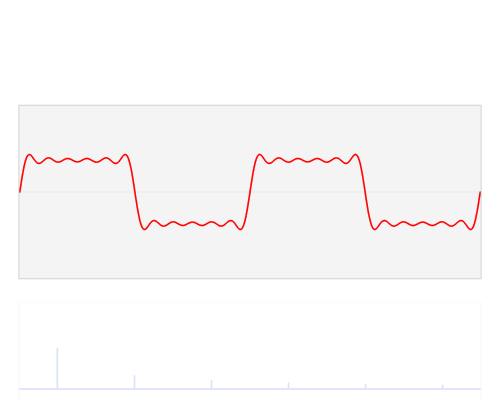



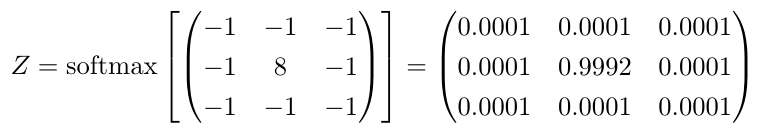
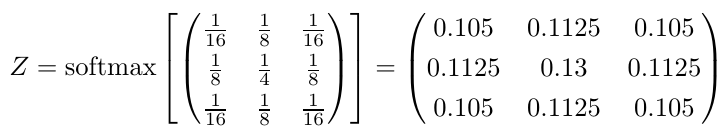
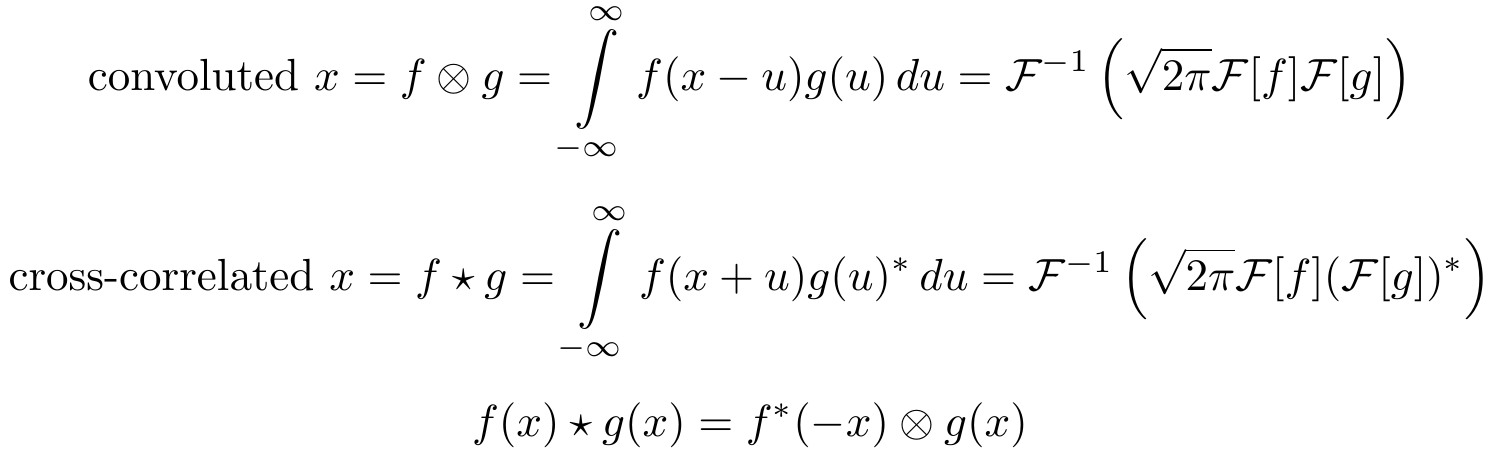

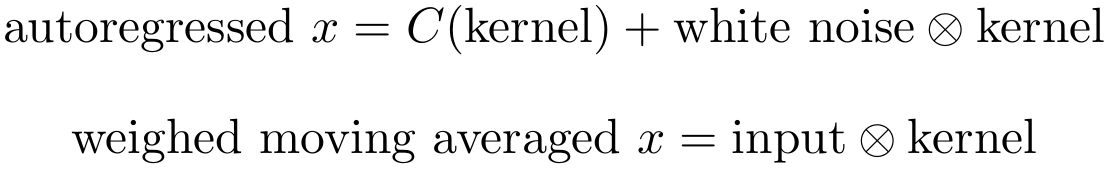
}") is a constant function which takes the kernel as parameter; white noise is data with mean zero, a standard deviation of one, and each variable is uncorrelated with respect to the other variables.
is a constant function which takes the kernel as parameter; white noise is data with mean zero, a standard deviation of one, and each variable is uncorrelated with respect to the other variables.
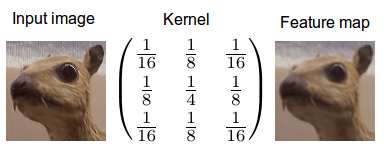








 Here’s a shot of the app store a couple days after the kids got new phones for Christmas.
Here’s a shot of the app store a couple days after the kids got new phones for Christmas.































{kind=link}
{kind=link}
{kind=link}
{kind=link}