Du hast ein Vorstellungsgespräch vor dir? Dann achte darauf, dass du diese häufigen Körpersprache-Fehler vermeidest.
Die Körpersprache sagt viel über den Charakter eines Menschen aus. Lauert er in Abwehrhaltung, wirkt das wenig selbstbewusst. Dabei ist es in vielen Situationen überaus wichtig, sicher und optimistisch aufzutreten – etwa während einer Präsentation, einem Kunden- oder einem Vorstellungsgespräch. Mit letzterem beschäftigt sich eine Infografik von On Stride. Darin sind sieben Körpersprache-Fehler aufgelistet, die Bewerber während eines Interviews machen können.
Diese Infografik zeigt dir, wie wichtig die Körpersprache beim Vorstellungsgespräch ist
Die Körpersprache zeigt dem Gegenüber, was für ein Typ ihr seid – selbstbewusst und offen oder schüchtern und zurückhaltend? (Foto: Shutterstock: Prostock-studio)
Zu den Fehlern zählen unter anderem, dass kein Augenkontakt gehalten, kein fester Händedruck geleistet oder nicht gelächelt wird. Die Macher der Infografik erklären auch, warum diese Fauxpas ein Problem darstellen und wie Bewerber sie vermeiden können. So steht etwa unter Punkt ein geschrieben, dass fehlender Augenkontakt beim Gegenüber den Eindruck hinterlässt, der Bewerber sei nicht besonders vertrauenswürdig und auch unsicher. Merkmale, die in den meisten Berufen eher negativ aufgenommen werden dürften. Der mitgelieferte Tipp besagt, dass Menschen das Reden unbedingt mit Freunden üben sollten. Was sich hinter den anderen Körpersprache-Fehlern verbirgt, erfahrt ihr nach dem Klick auf die Infografik oder diesen Link.
Vorstellungsgespräch: 7 Körpersprache-Fehler – und wie du sie vermeiden kannst. (Infografik: On Stride)
Ganz gleich, ob du eine Agentur leitest, IT-Dienstleistungen anbietest oder einen Onlineshop betreibst. Mit den richtigen Workflows und den passenden Tools läuft dein Business wie am Schnürchen.
Fehlerhafte Rechnungen, unvollständig erfasste Aufwände – viele Agenturen können ein Lied davon singen. Doch auch Händler sind vor Problemen nicht gefeit. Kunden klagen dann zum Beispiel über zu lange Lieferzeiten oder falsche Artikel. Hier ist Handeln angesagt.
Es gibt Tools, die für Unternehmen nicht nur eine wertvolle Unterstützung im Tagesgeschäft bedeuten, sondern sogar erfolgsentscheidend sein können.
Hier erfährst du, wie du deine Workflows mit der passenden Software optimierst. So kannst du deine Projekte erfolgreich wuppen, deine Auftragsabwicklung meistern und dein Unternehmen auf die nächste Stufe heben.
So arbeiten erfolgreiche Agenturen, IT-Dienstleister und Unternehmensberatungen
Schritt 1: Kundengewinnung
Ob Messebesuch, Kaltakquise oder Webseiten-Anfrage. Kunden zu gewinnen setzt voraus, dass du deine gewonnenen Kontaktdaten gut organisierst und auch mobil immer griffbereit hast. Ein gutes CRM unterstützt dich hierbei:
Einpflegen und Qualifizieren der Kontaktdaten
Durchführen von Marketingkampagnen und Erstellen von Verkaufschancen
Festhalten des Kommunikationsverlaufs in der Kundenakte (Call, E-Mail, Vor-Ort)
Schritt 2: Angebotserstellung
Mit einem ERP-System lässt sich direkt am Kundendatensatz ein Angebot erstellen. Dabei kannst du festlegen, ob es sich um ein Festpreisangebot handelt oder du lieber nach Aufwand abrechnen möchtest (Time & Material).
Positionen festlegen, Aufwände schätzen und mit Preisen versehen
Angebot erstellen per Mausklick im firmeneigenen Design
Angebot per Mail direkt aus der Software heraus versenden
Schritt 3: Projektmanagement
Hat der Kunde das Angebot angenommen, kannst du es mit nur einem Klick in einen Auftrag umwandeln und dein Projekt starten. Du kannst du die Rahmenparameter klar definieren.
Hinterlegen der Stundensätze und des Budgets
Zuweisen von Projektbeteiligten und Zuständigkeiten
Live-Zeiterfassung am PC oder mobil am Smartphone
Schritt 4: Abrechnung
Zur Abrechnung von Projekten kannst du aus verschiedenen Rechnungstypen wählen, wie Anzahlungs-, Teil- oder Abschlussrechnung. Alle abrechnungsrelevanten Details können direkt vom Kundendatensatz übernommen werden.
abrechenbare Aufwände bestimmen und in Rechnung überführen
Anlegen von Wiederkehrenden Rechnungen, Gutschriften, etc.
Rechnungen schreiben im firmeneigenen Design
Schritt 5: Buchhaltung
Zugegeben, Buchhaltung ist meist ein eher nerviges Thema. Aber mit der passenden Buchhaltungssoftware geht sie super einfach! Du bekommst unter anderem Hilfe bei der EÜR oder Bilanz mit Jahresabschluss und hast jederzeit die Kontrolle über deine offenen Posten.
automatisch Zahlungen abgleichen mit Online-Banking
DATEV- und ELSTER-Schnittstelle zum Steuerberater und Finanzamt
Überblick über alle Konten, Einnahmen und Ausgaben
So arbeiten erfolgreiche Groß- und Einzelhändler, Onlineshops und Produzenten
Der Workflow von Händlern sieht an entscheidenden Stellen anders aus als der eines Dienstleisters. Anstelle der Projektergebnisse müssen Artikel termingetreu geliefert werden, Händler oder Onlineshop-Betreiber brauchen daher ein Warenwirtschaftssystem zur Abbildung der Warenströme.
einfache Abwicklung von Aufträgen, Lieferungen und Retouren
Verbuchung der Zahlungseingänge und Buchung der Warenausgänge
Bidirektionale Anbindung an Shopsysteme, Marktplätze, Zahlungs- und Versanddienstleister
Mit CRM- und ERP-Software werden deine Abläufe strukturierter
Eine beliebte Lösung für Dienstleister und Händler, die alle genannten Bereiche abdeckt, ist weclapp, eine CRM- und ERP-Software, die sowohl in der deutschen Cloud, als auch auf eigenen Servern genutzt werden kann. Die als „ERP-System des Jahres 2016“ ausgezeichnete All-in-One Lösung bietet dir viele Vorteile:
Kostenersparnis durch Nutzung einer einzigen Lösung
Zeitersparnis durch Entfall aufwändiger Datensynchronisation
mehr Transparenz und bessere Teamarbeit durch gemeinsame Datenbasis
besserer Bedienkomfort mit einheitlicher Benutzeroberfläche
Insellösungen vs. Komplettlösung
Tolle Aktion für t3n-Leser, nicht verpassen!
Bei der Bestellung eines weclapp-ERP-Pakets bis zum 31. Juli 2017 bekommst du eine Buchhaltungslizenz sowie ein weiteres Add-on deiner Wahl geschenkt. Damit sparst du insgesamt bis zu 720 Euro pro Jahr!
Schnell sein lohnt sich: Das Angebot gilt nur für die ersten 100 Neukunden mit Erstregistrierung ab dem 10. Juli 2017. Um an der Sonderaktion teilzunehmen, einfach im zweiten Schritt der Registrierung für die 30-tägige kostenlose Testphase unter „Wie haben Sie uns gefunden?“ t3n auswählen.
Microsoft's OneDrive now lets you view your files without having to download them using on-demand sync. Here's how it works.
OneDrive Files On-Demand is a new feature coming in the Windows 10 Fall Creators Update, which allows you to access all your files stored in the cloud using File Explorer without having to sync them directly and use storage space on your device. It's a feature that's similar in concept to the now-defunct OneDrive placeholders.
Currently, OneDrive uses selective sync, which downloads every file to your device, but takes up a lot of space. On the other hand, with Files On-Demand only pieces of information (e.g., metadata and thumbnail image) about a file are stored locally. This is a faster and more efficient approach, which allows you to browse your entire collection of files without sacrificing local storage. At the time to work with a file, you simply double-click the placeholder to complete the download and open the file with an app.
In this Windows 10 guide, we'll show you everything you need to know to use OneDrive Files On-Demand.
Kernkraft soll bis zum Jahr 2025 nur noch die Hälfte des Strommixes in Frankreich ausmachen. Um das zu erreichen, sollen mehrere Kraftwerke vom Netz gehen.
Im Nordosten Deutschlands haben Kunden aus dem früheren E-Plus-Netz jetzt die gleiche LTE-Abdeckung wie o2-Kunden zur Verfügung. In Süddeutschland erfolgte die Angleichung schon vor einigen Monaten.
I’m working with a set of SharePoint framework web parts and finally got fed up of using JSOM to work with managed metadata. Referencing JSOM feels wrong for so many reasons in this modern day and age, so I’d rather not do it.
I mean, when the out-of-the-box modern controls in SharePoint can work with terms using REST, why shouldn’t I? I like to believe I’m pretty modern.
After Fiddling the modern UI I found out that all taxonomy requests are working against a service at /_vti_bin/TaxonomyInternalService.json. This is a good old service, also listed on MSDN at https://msdn.microsoft.com/EN-US/library/microsoft.sharepoint.taxonomy.webservices.taxonomyinternalservice_methods.aspx. It is indeed marked for internal use, and until we get a new public REST point, everything points to that it should indeed work. If not, why would Microsoft use it themselves?
I have put together a sample SPFx web part based on the MSDN documentation, trial and error, showcasing different methods I found useful when retrieving terms. It’s by no means complete, but should help you get started.
Search for term sets by name of term set or term in set
Get level one terms of a term set
Get child terms for a term
Using these calls you should have enough information to build a metadata driven megamenu, or build a taxonomy picker.
I have included interfaces for all the REST calls with some comments, but not for the returned results. You might have to examine the result JSON and pick out what you need.
And as a nugget I output the JSON with indentation, a tip I picked up from Sahil Malik :)
Sample interface
interface IGetSuggestionsRequest { start: string; // query lcid: number; sspList: string; // guid of term store termSetList: string; // guid of term set anchorId: string; isSpanTermStores: boolean; // search in all termstores isSpanTermSets: boolean; isIncludeUnavailable: boolean; isIncludeDeprecated: boolean; isAddTerms: boolean; isIncludePathData: boolean; excludeKeyword: boolean; excludedTermset: string; }
Einige Opfer von Cyberattacken mit Erpresser-Software können möglicherweise aufatmen. Für die jüngste Variante Notpetya, die für Schlagzeilen sorgte, funktioniert er wohl nicht.
Die Entwickler von Petya und einiger Unterarten des Schädlings haben einen Generalschlüssel veröffentlicht, mit dem sich die Daten wieder lesbar machen lassen. Der Download selbst ist zwar auch mit einem einem Kennwort verschlüsselt – dieses wurde jedoch von IT-Sicherheits-Experten bei der Firma Malwarebytes erraten. Der Schlüssel funktioniere für alle Versionen der Schadsoftware, inklusive Goldeneye, bestätigte Anton Ivanov, Sicherheitsforscher bei Kaspersky, in einem Tweet.
Bei Notpetya funktioniert der Schlüssel nicht
Bei Daten, die mit der jüngsten Abwandlung Notpetya verschlüsselt sind, soll er jedoch nicht funktionieren. Ob es bei dieser Schadsoftware gar nicht um Erpressung ging oder der Code einfach nur schlampig programmiert wurde, sei noch unklar, schreibt das Technologie-Portal Golem.
Kostenlose Werkzeuge, die bei der Entschlüsselung helfen, gibt es demnach noch nicht, sie dürften aber in Kürze veröffentlicht werden.
Laut Bundesamt für die Sicherheit in der Informationstechnik standen auch in einigen Unternehmen in Deutschland die Produktion oder andere kritische Prozesse still. Bei dem jüngsten Angriff sind einige Experten auch der Ansicht, dass es nicht um das übliche Geldverdienen mit der Erpressung der Nutzer, sondern um das Zerstören von Daten ging. sdr/dpa
Microsoft hat heute ein neues Abo für Unternehmen angekündigt, welches man als Microsoft 365 bezeichnet. Die Lösung kombiniert Office 365, Windows 10 und Enterprise Mobility und Security.
Microsoft 365 wird es in zwei Varianten geben, nämlich Microsoft 365 Business und Microsoft 365 Enterprise, welche für unterschiedliche Unternehmensgrößen gedacht sind. Microsoft 365 Business wird bereits ab dem 2. August als Preview verfügbar sein und ist für Klein- und Mittelbetriebe bis zu einer Mitarbeiterzahl von 300 Nutzern gedacht. Sie wird auch eine zentralisierte Konsole für die Bereitstellung von Geräten bieten. Microsoft 365 Business wird für reguläre Kunden im Herbst dieses Jahres ab einem Preis von 20 US-Dollar pro Nutzer pro Monat weltweit erhältlich sein.
Microsoft 365 Enterprise wird ebenfalls ab dem ersten August erhältlich sein und wird in zwei Varianten geteilt, nämlich E3 und E5. Bislang gibt es allerdings keine Informationen darüber, wann die Enterprise-Variante auch verfügbar sein wird.
Microsoft beschreibt, dass das Abo nicht nur eine Bereicherung für Unternehmen sein kann, welche damit eine All-in-One Lösung bekommen, sondern gleichzeitig eine Möglichkeit für die Microsoft-Partner, ihre Umsätze durch den Vertrieb von Microsoft 365 zu steigern.
Peter Tauber sieht für das Wohnprojekt Rigaer Straße und die Rote Flora keine Existenzberechtigung. CDU-Politiker fordern die Wiedereinführung der Extremismusklausel.
Today’s post was written by Kirk Koenigsbauer, corporate vice president for the Office team.
Today at Inspire, Satya Nadella unveiled Microsoft 365, which brings together Office 365, Windows 10 and Enterprise Mobility + Security, delivering a complete, intelligent and secure solution to empower employees. It represents a fundamental shift in how we will design, build and go to market to address our customers’ needs for a modern workplace.
The workplace is transforming—from changing employee expectations, to more diverse and globally distributed teams, to an increasingly complex threat landscape. From these trends, we are seeing a new culture of work emerging. Our customers are telling us they are looking to empower their people with innovative technology to embrace this modern culture of work.
With more than 100 million commercial monthly active users of Office 365, and more than 500 million Windows 10 devices in use, Microsoft is in a unique position to help companies empower their employees, unlocking business growth and innovation.
Microsoft 365 Enterprise is designed for large organizations and integrates Office 365 Enterprise, Windows 10 Enterprise and Enterprise Mobility + Security to empower employees to be creative and work together, securely.
Microsoft 365 Enterprise:
Unlocks creativity by enabling people to work naturally with ink, voice and touch, all backed by tools that utilize AI and machine learning.
Provides the broadest and deepest set of apps and services with a universal toolkit for teamwork, giving people flexibility and choice in how they connect, share and communicate.
Simplifies IT by unifying management across users, devices, apps and services.
Helps safeguard customer data, company data and intellectual property with built-in, intelligent security.
Microsoft 365 Enterprise is offered in two plans—Microsoft 365 E3 and Microsoft 365 E5. Both are available for purchase on August 1, 2017.
Microsoft 365 Enterprise is built on the foundation of the highly successful Secure Productive Enterprise, which grew seats by triple digits in the last year. Going forward, Microsoft 365 Enterprise replaces Secure Productive Enterprise to double-down on the new customer promise of empowering employees to be creative and work together, securely.
Microsoft 365 Business is designed for small- to medium-sized businesses with up to 300 users and integrates Office 365 Business Premium with tailored security and management features from Windows 10 and Enterprise Mobility + Security. It offers services to empower employees, safeguard the business and simplify IT management.
Microsoft 365 Business:
Helps companies achieve more together by better connecting employees, customers and suppliers.
Empowers employees to get work done from anywhere, on any device.
Protects company data across devices with always-on security.
Simplifies the set-up and management of employee devices and services with a single IT console.
Microsoft 365 Business will be available in public preview on August 2, 2017. It will become generally available on a worldwide basis in the fall (CYQ3) of 2017, priced at US $20 per user, per month.
As a part of our commitment to small-to-medium sized customers, we’re also announcing the preview of three tailored applications that are coming to Office 365 Business Premium and Microsoft 365 Business:
Microsoft Connections—A simple-to-use email marketing service.
Microsoft Listings—An easy way to publish your business information on top sites.
Microsoft Invoicing—A new way to create professional invoices and get paid fast.
Today, we are also announcing that Microsoft’s mileage tracking app, MileIQ, is now included with Office 365 Business Premium.
Satya also discussed how Microsoft 365 represents a significant opportunity for partners to grow their businesses. Microsoft 365 will drive growth by enabling our more than 64,000 cloud partners to differentiate their offerings, simplify their sales processes and increase their revenue.
According to two Forrester Total Economic Impact™ Studies (commissioned studies conducted by Forrester Consulting), Microsoft 365 Enterprise and Microsoft 365 Business increase average partner margins by an estimated 35 percent and 20 percent, respectively, over three years. Partners can learn more and explore training, sales and deployment resources on the Microsoft 365 partner site.
We are incredibly enthusiastic about Microsoft 365 and how it will help customers and partners drive growth and innovation. To learn more about Microsoft 365, please visit Microsoft.com/Microsoft-365.
To make Office 365 more valuable for your small business, we are announcing three new applications coming to Office 365 Business Premium:
Microsoft Connections—A simple-to-use email marketing service.
Microsoft Listings—An easy way to publish your business information on top sites.
Microsoft Invoicing—A new way to create professional invoices and get paid fast.
We’re also introducing the Office 365 Business center, a central place where you can manage these business apps and get an end-to-end view of your business. In addition, we’re adding MileIQ, the leading mileage tracking app, as an Office 365 Business Premium subscription benefit. These new services—along with the recently added Microsoft Bookings and Outlook Customer Manager—help you win customers and manage your business.
Connections, Listings, Invoicing and the Business center are rolling out in preview over the next few weeks to Office 365 Business Premium subscribers in the U.S., U.K. and Canada, starting with those in the First Release program. MileIQ Premium is available to all Business Premium subscribers in the U.S, U.K. and Canada effective today.
Let’s take a closer look at each of these products.
Microsoft Connections—Drive more sales with simple email marketing tools
Email marketing can accelerate sales, but getting started can be overwhelming. With Microsoft Connections, you can easily create professional-looking email marketing campaigns with pre-designed templates for newsletters, announcements or customer referrals. You can also provide simple ways for people to join your mailing list or unsubscribe.
As your mailing list grows, you can manage your subscribers by creating segments to efficiently target specific groups of customers. Performance charts and subscriber activity updates track open rate, clicks, new sign-ups, new customers, offer redemptions and unsubscribed numbers for each email campaign, so you can see what is and is not working.
Microsoft Connections is available on the web, and on mobile apps for iOS and Android.
Microsoft Listings—Get your business discovered online by new customers
Getting your business listed online is a great way to be discovered by prospective customers, but it can be time consuming to set up your online presence, keep information like business hours up-to-date and monitor performance across sites. Microsoft Listings makes it easy to publish and manage your business listing on Facebook, Google, Bing and Yelp.
Microsoft Listings includes a web dashboard that lets you easily monitor ratings and reviews.
When you update your business profile in Microsoft Listings, the changes automatically populate across Facebook, Google and Bing. And what’s more, you can monitor online views and reviews of your listings across sites from a single dashboard. This makes it easier to understand feedback from your customers and strengthen your online reputation.
Microsoft Invoicing—Get paid fast with hassle-free invoices and online payments
Getting estimates and invoices out on time, tracking pending payments and processing payments quickly are critical to keep things running smoothly. But it can tedious and confusing to keep track of information in different systems of record or even on paper. Microsoft Invoicing helps you quickly create professional-looking estimates and invoices, so you get paid quickly.
Microsoft Invoicing is available on the web, and on mobile apps for iOS and Android.
Microsoft Invoicing works with PayPal, so you can accept credit and debit cards online. A connector to QuickBooks lets you sync customer and catalogue data, and transfer invoicing information to your accountant.
Manage from one place with the new Office 365 Business center
The Office 365 Business center brings Bookings, Connections, Listings and Invoicing together in a central location—so you have easy access to your business apps and data. It features a unified dashboard where you can view key metrics from all the business apps, including total outstanding invoices, the number of appointments scheduled, the impressions across Facebook, Google, Bing and Yelp, and the number of new subscribers and sent campaigns.
Office 365 Business center lets you access via the web.
The Business center includes an activity feed, so you can see the details of what’s happening within each of the apps—making it easy to keep up-to-date on new customer appointments, invoices and payments being created or updated by the employees in your business. The activity feed also provides suggestions on what actions to take next, such as alerting you that a payment is overdue and it’s time to resend an invoice.
Because the new business apps are built to work together, you don’t waste valuable time setting up connectors or transferring data manually. A contact in one business app is automatically recognized in another, so you don’t have to input data multiple times. As a business owner, you also have full control over who on your team gets access to which business apps and related information.
MileIQ—The smarter way to track your miles comes to Office 365 Business Premium
If you drive a personal car for work purposes such as customer sales visits, partner meetings or trade conferences, you know that tracking and reporting your miles for tax deduction or expense reimbursement can be a hassle. That’s why we’re pleased to add MileIQ—the leading mileage tracking app on iOS and Android—as a benefit of your Office 365 Business Premium subscription.
MileIQ offers a simple, smarter way to track your miles—with automatic drive detection and mileage logging, easy one-swipe classification as business or personal, and comprehensive reporting. MileIQ has already helped over four million customers save time and money—saving customers $6,900 on average per year in deductions or reimbursements, and 2 hours a week of time spent logging drives. You can log unlimited drives every month with the MileIQ Premium subscription that you get with Office 365 Business Premium. MileIQ is currently available to subscribers in the U.S., U.K. and Canada.
Try the new services and let us know what you think
We are excited to get your feedback as you use these new services in your Office 365 Business Premium subscription. Here’s how to get started:
Connections, Listings, Invoicing and the Business center—These are rolling out in preview over the next few weeks to Office 365 Business Premium subscribers in U.S., U.K. and Canada. Once they are activated in your account, you’ll see a Business center icon on the welcome screen after you sign in. Just click the icon to get started. If you want early access, please visit our support page to learn how to join the Office 365 First Release program. As you use the apps, let us know what you think by providing feedback in our feedback forum.
An icon introducing the new business apps will appear when you have signed in to Office 365.
MileIQ—To activate the MileIQ benefit of your Office 365 Business Premium subscription in the U.S., U.K. or Canada, visit www.mileiq.com/office365. We’re eager to hear from you—please share your feedback and suggestions about MileIQ at feedback@mileiq.com.
Frequently asked questions
Q. When will Connections, Listings, Invoicing and the Business center be available outside of the preview?
A. We expect these to be generally available before the end of the year.
Q. Will all users in my organization, who have Business Premium subscriptions, get access to Connections, Listings and Invoicing by default?
A. The Office 365 global admin role controls who has access to these apps. Standard users will not have access to Connections, Listings and Invoicing by default. They can request access in the Business center. Global admins can accept or decline their request from Admin center > Settings > Services & add-ins > Business apps.
Q. Where can I learn more about Connections, Listings and Invoicing?
Q. How do I activate the MileIQ benefit of my Office 365 subscription?
A. Start by visiting www.mileiq.com/office365 to create a new MileIQ account or sign in using your existing one. Then enter your Office 365 credentials so we can check your eligibility and activate your subscription benefit. Note: You can use any email address you wish when creating a MileIQ account; but be sure to use your Office 365 credentials on the “Check Eligibility” step.
Q. What if I already have a paid MileIQ subscription?
A. If you are currently a paid MileIQ subscriber and you also have Office 365 Business Premium, we’ll convert your existing account. Please contact support@mileiq.com and a member of our team will get back to you.
*QuickBooks and QB are registered trademarks and service marks of Intuit Inc., displayed under license.
Bis heute um 23:59 Uhr gibt es den Amazon Prime Day und für alle Schnäppchenjäger ist heute Feiertag. Amazon bietet exklusiv für Amazon Prime-Mitglieder zahlreiche wirklich interessante Angebote an und wir haben die besten Deals für euch zusammengefasst. Zudem findet ihr hier außerdem im Live-Blog die besten Angebote. Wir werden diesen Artikel im Verlauf des Prime Days stetig aktualisieren, sodass ihr hier immer reinschauen könnt, um für euch interessante Top-Angebote zu finden.
Amazon bietet nur heute ein sehr gutes Angebot an. Ihr bekommt beim Kauf einer Fitbit Charge 2 nämlich momentan zum sehr günstigen Preis von 99 Euro inkl. Versandkosten. Den Preis seht ihr erst, wenn ihr die Größe auswählt. Es sind alle Farben und Größen vergünstigt!
Das Fitness-Armband, welches dank sehr vorbildlich umgesetzter Universal App für Windows 10 Mobile, Windows 10 und Xbox, auch unsere Plattform unterstützt, kann eure täglichen Aktivitäten aufzeichnen, darunter Schritte, Distanz, Kalorienverbrauch, aktive Minuten und Etagen. Dank eines integrierten Herzfrequenzmessers könnt ihr auch den Herzschlag aufzeichnen, was automatisch geschieht und in der App sehr übersichtlich angezeigt wird.
Wir haben vor einiger Zeit die Fitbit Charge 2 getestet, den Test könnt ihr hier finden.
Bei Amazon bekommt ihr derzeit ein sehr gutes Xbox One S-Bundle mit einer Menge Zubehör und zwei Games zum Preis von 229 Euro. Darin enthalten ist die Xbox One S mit 500 Gigabyte, Forza Horizon 3, ein zweiter Controller, das Xbox Chatpad und Halo 5 oder Rise of the Tomb Raider.
Derzeit als Blitzangebot erhältlich ist der Xbox One S-Controller inkl. Forza Horizon 3. Der Controller selbst kostet normalerweise etwa 50 Euro, sodass ihr euch wenigstens 20 Euro spart, wenn ihr das Game kaufen würdet. Das Angebot gilt nur noch bis 18:15, sofern es nicht vorher vergriffen ist.
Amazon bietet nur heute die 128 Gigabyte microSD-Karte von Samsung für 44,99 Euro an, was für die Karte ein äußerst gutes Angebot darstellt. Der Vergleichspreis für das gleiche Modell liegt sonst etwa bei 60 Euro.
Die MicroSD-Karte ist ideal, wenn ihr den Speicher eures Surface-Tablets oder eures Smartphones erweitern wollt, denn solltet ihr nicht Unmengen an Daten speichern, dann dürfte die SD-Karte durchaus für einige Zeit ausreichen.
Bei Amazon bekommt ihr heute den B&O Play A1 Bluetooth-Lautsprecher für vergleichsweise günstige 169 Euro als Tagesangebot. Der Lautsprecher wird über USB C geladen und besitzt ein sehr kompaktes Design, bietet aber dennoch vollen Sound in hervorragender Qualität, was auch den Preis erklärt. Die Lautsprecher sind sonst nämlich nicht unter 220 Euro zu finden, eine gute Ersparnis, wie wir finden.
Den Lautsprecher gibt in militärisch Grün, passend zur Battlefield 1-Variante der Xbox One S.
Wer statt eines Office 365-Abos lieber die Software selbst erwirbt, bekommt derzeit einen Product Key für Microsoft Office Home and Student 2016 für 75,20 Euro statt 149,21 Euro.
Im Zuge der Amazon Prime Day-Angebote bekommt ihr derzeit das Lumia 950 XL zu einem zumindest vergleichsweise günstigen Preis. Auf das Niveau der Angebote vom Vorjahr kommt man nicht ran und auch an Neuware nicht. Dank des 20 Prozent-Rabatts auf Warehouse-Deals gibt es allerdings das immer noch aktuellste Microsoft-Flaggschiff ab 334,35 Euro. Der Rabatt wird euch im Warenkorb abgezogen.
Der verbaute Snapdragon 810 wird langsam von leistungsfähigerer Hardware abgelöst, aber bietet immer noch eine sehr solide Performance. Daneben kann das Lumia 950 XL mit einem schönen Display und einer hervorragenden Kamera aufwarten.
Wir haben vor einiger Zeit erklärt, wieso die aktuellen Lumia-Flaggschiffe für unter 400 Euro auf jeden Fall ihr Geld wert sind und wer noch unsicher ist, kann sich den verlinkten Artikel durchlesen. Ein Lumia 950 ist heute kaum noch zu bekommen und ob ihr noch in Windows 10 Mobile investieren oder abwarten wollt bis von Microsoft etwas Neues kommt, möchten wir euch überlassen. Wir denken allerdings weiterhin, dass das Smartphone im Alltag für Windows 10 Mobile-Fans einen guten Dienst abgeben kann.
Den BOSE SoundTouch 10-Lautsprecher bekommt ihr derzeit für 179 Euro inkl. eines Amazon Echo Dot im Wert von etwa 50 Euro. Somit bekommt ihr den Echo Dot praktisch kostenlos, denn der Lautsprecher sonst kostet im Preisvergleich etwa 180 Euro.
Ab 18 Uhr wird es direkt zu Beginn das HP Pavilion x360 geben und zwar zum Preis von 449 Euro statt 599 Euro. Wir haben uns bereits kurz nach der Vorstellung des Geräts einen ersten Eindruck von der 11-Zoll Variante gemacht, welchen wir im Folgenden für euch verlinkt haben.
Hierbei handelt es sich um die 14-Zoll Variante, welche ein größeres und besseres Display bietet, dafür allerdings von der Verarbeitung her geringfügig günstiger wirkt als das 11-Zoll Pendant.
Spezifikationen:
Display: 14-Zoll FullHD Touch-Display, 1920 x 1080
Prozessor: Intel Pentium 4415U
Arbeitsspeicher: 8 Gigabyte
Speicher: 256 Gigabyte
Anschlüsse: USB 3.1 Typ C, 2 x USB 3.1 Typ A, HDMI, 3,5mm Audio
Das Bundesamt für Sicherheit in der Informationstechnik hat nach eigenen Angaben Kenntnis von einer Liste mit rund 5000 potenziellen Zielpersonen, die vermeintlich im Auftrag ihrer Geschäftsführung viel Geld an Betrüger überweisen sollen.
Ich berichte ja meist von den unerfreulichen Dingen, die Mandanten widerfahren, wenn die Polizei ihre Wohnung durchsucht.
Es geht auch anders.
Zum Beispiel in einem aktuellen Fall. Es war noch recht früh, als Beamte bei meinem Mandanten an der Türe klopften. So früh, dass die Ehefrau meines Mandanten noch im Schlafzimmer ruhte. Das wiederum führte bei den Beamten zu erhöhter Rücksichtnahme.
Die Polizisten erlaubten meinem Mandanten, dass er mit dem Handy leise ins Schlafzimmer geht und einen Schnappschuss vom Raum macht. Wenn auf dem Bild kein Computer zu sehen sei, erklärten sie, könne auf die Durchsuchung des Schlafzimmers verzichtet werden.
Das Foto bewies offensichtlich: keine Desktop-Computer im Schlafzimmer. Die Polizisten haben den Raum dann auch tatsächlich nicht betreten. Die Ehefrau kriegte von der Durchsuchung nichts mit. Ich bin echt auf die Akteneinsicht gespannt, weil ich wissen will, wie sich dieses Vorgehen im Einsatzbericht niedergeschlagen hat. Ich gehe allerdings davon aus, es bleibt schlicht unerwähnt.
Der Online-Versandhändler Amazon startet heute um 18 Uhr seinen Prime Day – bis morgen Nacht gibt es tausende Sonderangebote. Wir haben einen Blick auf die spannenden Technik-Schnäppchen geworfen.
Neben einiger Angebote, die den ganzen Tag laufen, gibt es am Prime Day vor allem die sogenannten Blitz-Angebote. Dabei nennt Amazon schon im Vorfeld das Produkt und den Zeitpunkt, wann es ein Sonderangebot gibt – die konkreten Preise werden aber erst zur angegebenen Uhrzeit veröffentlicht. Erfahrungsgemäß werden die meisten Produkte zwischen etwa 25 und über 50 Prozent billiger sein als sonst, daher sind viele der Angebote wirklich spannend.
Der große Haken der Amazon-Sonderaktion: Nur Prime-Kunden haben Zugriff auf die günstigen Preise. Wer kein Prime-Kunde ist, kann eine kostenlose, 30-tägige Testphase starten und so ebenfalls auf die Prime-Sonderangebote zurückgreifen. Zum Test-Angebot geht es hier: Amazon Prime*
Fast 50 Prozent Rabatt auf Fire-Tablets von Amazon: Das „normale“ Fire kostet 34,99* statt 69,99 Euro, das Fire HD8 59,99* statt 109,99 Euro. Die Kinder-Tablets Fire Kids Edition* und Fire HD8 Kids Edition* kommen auf 69,99 (statt 119,99 Euro) respektive auf 89,99 statt 139,99 Euro.
E-Book-Reader gibt es ebenfalls am Prime Day günstiger. Kindle Paperwhite* kostet ab 18 Uhr 69,99 Euro statt 119,99 Euro, der „große Bruder“ Kindle Voyage* kommt auf 139,99 statt 189,99 Euro.
Der Sprachassistent Echo kostet 99,99 Euro* statt 179,99 Euro, der kleine Bruder Echo Dot* kommt auf 44,99 Euro statt 59,99.
Natürlich darf auch der Klassiker des Prime Days nicht fehlen: Amazons Fire TV Stick* kostet mit Alexa-Sprachfernbedienung 29,99 Euro, das sind 10 Euro weniger als sonst.
Gerade entdeckt: die Yi 4K Actioncamera* des gleichnamigen Herstellers Yi Technology. Die Sportkamera haben wir im Oktober letzten Jahres getestet. Im Vergleich zu der GoPro Hero5 Black (Testbericht) hat sie sich als eine echte Alternative gezeigt. In der Regel kostet sie 250 bis 300 Euro, an diesem Prime Day für kurze Zeit nur für 179,99.
Samsung bietet seine aktuelle Smartwatch, die Gear S3 classic*, derzeit für 235 Euro an. Die unverbindliche Preisempfehlung liegt sonst bei 319 Euro. Die Uhr mit Samsungs eigenem Betriebssystem Tizen OS kann mit Android OS als auch mit Apples iOS genutzt werden.
Im Laufe des Abends folgen Schnäppchen, darunter viel Netzwerk-Zubehör, aber auch Notebooks, Fernseher und Smartphone-Zubehör. Die spannendsten Deals werden wir beizeiten hier verlinken.
In diesem Beitrag kommen Affiliate-Links vor. Klicks auf diese Links können dazu führen, dass TechStage respektive Heise Medien eine Provision erhält. Der Verkaufspreis bleibt weiterhin gleich. Entsprechende Links sind mit einem * markiert.
This free official app can unleash the power of your Microsoft mouse, but you may not even know about it.
Microsoft always has some weird ways of doing things. The Windows 10 OS and app situation is in a transition phase going from Win32 to UWP, but not all things are converted yet, and some apps are buried on Microsoft's site – the exact thing the Store is supposed to solve.
If you use Microsoft mice or keyboards like the new Surface Arc Mouse you will want to get the Microsoft Mouse and Keyboard Center app. It's free and adds some key features to this – and other – mice and keyboards.
Im Verleih von Regenschirmen per App witterte ein chinesisches Startup das große Geschäft. Doch da hatte man die Rechnung offenbar ohne die trickreichen Kunden gemacht.
Eigentlich klang die Idee gar nicht schlecht, die Zhao Shuping da ausgeheckt hatte. Weil die Sommermonate in China sehr regenreich sind, sah der Gründer des Startups E Umbrella im Verleih von Regenschirmen ein lukratives Geschäft. Mit einem Startkapital von mehr als einer Million Euro entwickelte Shuping daraufhin eine App, schaffte schrittweise 300.000 Regenschirme an und stellte sie an Bushaltestellen zur Verfügung. Nicht mehr als umgerechnet sechs Cent sollte die halbstündige Nutzung nach Entrichtung einer Pfandpauschale (circa 2,30 Euro) kosten.
„Ich dachte, alles ließe sich teilen“
Inspiriert wurde Zhao Shuping angeblich von der Nachfrage nach Bikesharing-Angeboten. In chinesischen Metropolen wie Peking oder Schanghai stieg die Zahl entsprechender Startups zuletzt stark an. Nutzer müssen die Fahrräder lediglich über einen QR-Code mit dem Smartphone scannen und können nach Eingabe einer Zahlenkombination für das Schloss sofort losfahren.
Dieses Prinzip wollte Shuping auch auf die Vermietung von Regenschirmen übertragen. „Ich dachte, alles auf der Straße ließe sich auf diese Weise teilen“, so der Gründer gegenüber South China Morning Post. Doch wie sich nun herausstellte, hat das Startup die Rechnung offenbar ohne die trickreichen Kunden gemacht.
Kunden geben Regenschirme nicht zurück
Zwar sollen zunächst viele Menschen beherzt zugegriffen haben. Allerdings nicht so, wie sich Shuping das vorgestellt haben dürfte. Anstatt sie nach ihrer Nutzung ordnungsgemäß wieder zurückzugeben, behielten die Kunden die gemieteten Regenschirme einfach. Bereits nach drei Monaten musste Shuping fast alle Regenschirme als gestohlen verbuchen. Jede einzelne Ersatzbeschaffung kostete das Unternehmen nach eigenen Angaben rund neun US-Dollar.
Rückblickend erklärt sich der Gründer die Misere mit einem Fehler im System. Regenschirme seien nicht mit Fahrrädern zu vergleichen. „Fahrräder lassen sich überall parken, aber für einen Regenschirm wird ein Geländer oder ein Zaun benötigt“, so Shuping weiter. Für die Kunden ein offenbar zu großes Hindernis.
Gründer will an Idee festhalten
Trotzdem will der Gründer vorerst an der glücklosen Idee festhalten. Bis Ende des Jahres sollen 30 Millionen Regenschirme in China zur Vermietung bereitgestellt werden, versprach Shuping. Ob sich daraus auf Dauer ein profitables Geschäft entwickeln lässt, ist jedoch fraglich. Zum einen dürfte die Nachfrage vor allem in den trockenen Wintermonaten stark sinken. Zum anderen dürften viele Menschen in regenreichen Städten Chinas spätestens jetzt im Besitz eines Regenschirms sein. In jedem Fall zeigt sich: Die Sharing-Economy kann auch nach hinten los gehen.
Peter Kruse beschrieb sehr nachdrücklich die zunehmende Komplexität und Dynamik unserer Wirtschaft, in der die blosse Optimierung von Bestehendem nicht mehr ausreicht. Dabei übertrug Kruse Erkenntnisse aus der Hirnforschung und der Theorie dynamischer Systeme auf Unternehmensprozesse. Die Theorie dynamischer Systeme will erklären, wie sich komplexe Systeme entwickeln und verändern. Dabei postuliert die Theorie, dass komplexe Systeme stets offen sind und nie in ein statisches Gleichgewicht gelangen. Was bedeutet das?
Offenheit und Gleichgewicht
„Offen“ bedeutet, dass das System mit seiner Umwelt laufend Ressourcen in Form von Stoffen, Energie und Information austauschen kann. Präziser heisst dies jedoch, dass dieser Austausch insofern gerichtet ist, als dass das System jederzeit regelrecht mit den Ressourcen durchströmt ist. Diese Ströme oder Flüsse erklären denn auch den Begriff „dynamisches Ungleichgewicht“. Zunächst muss das System die Stoffe, Energien und Informationen aus der Umwelt aufnehmen, durch den Systemorganismus hindurch transportieren und wieder an die Umwelt abgeben. Dabei verbraucht das System diese Ressourcen in unterschiedlicher Weise, um sich selbst am Leben zu erhalten. Man spricht von Dissipation. Sie verhindert, dass das System je zur Ruhe und in ein statisches Gleichgewicht kommt. Erst wenn die Ströme zur Ruhe kommen, erreicht das System sein Gleichgewicht und hört auf, ein dynamisches System zu sein. Gleichgewicht bedeutet Stillstand und Tod.
In seinem Buch „Unbestimmte Welt“ beschreibt Dirk Proske diese Grundfunktion komplexer Systeme in leicht verständlicher Form. Das Buch kann hier vollständig heruntergeladen werden.
Das langfristige dynamische Verhalten einer Gesellschaft wird durch Information und Wissen geprägt (wie erhält man Materie und Energie), das kurzfristige Verhalten durch Materie und Energie (was macht man mit der Materie und Energie). In komplexen Systemen, wie Menschen, menschlichen Gesellschaften, Lebewesen, werden Energie und Materie ständig der Umwelt entnommen und an die Umwelt abgegeben. Sie werden benötigt, um die Ordnung innerhalb der Systeme aufrecht zu erhalten. Man spricht hier auch vom EntropieExport, weil die Systeme Unordnung abgeben, um eigene Ordnungen zu erhalten. Je höher, also komplexer die Ordnungen sind, umso mehr Unordnung muss an die Umwelt abgegeben werden
Der menschliche Körper ist ein typisches Beispiel eines dynamischen Systems. Er nimmt laufend Nahrung, Wärme und Informationen auf, nutzt diese und scheidet sie in verbrauchter Form wieder aus. Nur so kann er lebensfähig bleiben und sich reproduzieren.
Die Struktur der Stadt Bern
Ein anderes Beispiel ist eine Stadt. Durch eine Stadt strömen in jeder Minute riesige Mengen von Waren, Energien und Informationen. Die Stadt wird dadurch strukturiert. Das ist ein weiteres Merkmal komplexer Systeme: um die Ressourcenflüsse möglichst effizient zu gewährleisten, nimmt das System eine passende Strömungsstruktur an. Im Beispiel der Stadt führt das zu Quartieren mit verschiedenen Kulturen (in Deutschland auch schon mal Kietze genannt), zu Industrie-, Gewerbe-, Büro- oder Verwaltungsvierteln.
Grundsätze komplexer Systeme
Überschlagen Sie einmal die Mächtigkeit der Warenströme einer Stadt mit 1 Mio Einwohnern, wenn jeder Einwohner pro Tag z.B. 1 Kg Festnahrung, 2 Liter Wasser, 1 Kg Verpackungsmaterial, ein paar Kilo Möbel, Haushaltgeräte, Spielsachen und sonstiger Unterhaltungsgüter bezieht. Das ist ein massiver Warenstrom, ohne den die Stadt nicht lebensfähig wäre! Überschlagen Sie dann aufgrund dieses Inputs, welche Abfallströme die Stadt täglich, ja stündlich wieder verlassen müssen. Auch hier gilt: würde die Entsorgung nicht funktionieren, würde die Stadt in ihrem Abfall ersticken und wäre ebenso wenig lebensfähig, wie wenn nichts hineinfliessen würde.
Wir haben anhand dieser Beispiele ein paar Grundsätze komplexer Systeme gelernt: Ein System nimmt aus der Umgebung qualitativ hochwertige Ressourcen in Form von Stoffen, Energien und Informationen auf, dissipiert sie zur Aufrechterhaltung der eigenen Lebensfähigkeit und exportiert den Material-, Energie- und Informationsabfall wieder in die Umgebung. Was das für die Nahrung bedeutet, können wir am eigenen Leib erfahren. Etwas komplizierter ist es, den Vorgang für die Energie zu verstehen. Die Energie, die wir aus der Umgebung aufnehmen, z.B. qualitativ hochstehende Wärme, mit der wir uns wärmen können, strahlen wir als verbrauchte Wärme wieder ab. Sie kann nicht mehr verwendet werden. Noch abstrakter wird es mit der Information. Zwar können wir uns noch vorstellen, was neue Information ist, mit der wir uns am Leben erhalten können, z.B. Informationen über Feinde, vor denen wir fliehen sollten. Was ist aber verbrauchte Information, die wir wieder in die Umgebung exportieren müssen? Ernst Ulrich von Weizsäcker (geb. 1939) sprach von erstmaliger und bestätigter Information. Erstmalige Information benötigen wir, um lebenswichtige Handlungen auszuführen. Ist sie bestätigt, nützt sie uns nichts mehr. Wir vergessen sie, was der Vernichtung oder dem Export gleichkommt.
Woher kommen die Ressourecn?
Für mich ist also die Komplexität eines Systems gleichbedeutend mit seiner funktionalen Struktur zur Dissipation der Stoff-, Energie- und Informationsströme, relativ zu der Anzahl bereits erfahrener Strukturwechsel („Changes“) und unter der Bedingung, dass die aktuelle Struktur ständig durch Fluktuationen getestet und infrage gestellt wird.
Physikalischen Systemen wird von aussen Materie und/oder Energie zugeführt und durch das System gepumpt, das eine passende Struktur annimmt, die es ihm erlaubt, die Flüsse so reibungslos wie möglich zu realisieren. Bei sozialen Systemen ist nicht mehr klar, ob die Ressourcen von aussen in das System hineingepumpt werden oder ob das System selber sie hineinzieht oder gar selbst herstellt. Das können wir am Beispiel des Flugverkehrs studieren. Zunächst war Fliegen teuer, so dass nur wenige Passagiere zu befördern waren. Verschiedene gesellschaftliche Entwicklungen führten zu einer exponentiellen Zunahme der Flugpassagiere. Die wichtigsten dieser Entwicklungen waren Globalisierung und Prosperität. Die Airlines mussten darauf reagieren und sich neu organisieren. Einige Airlines verschwanden, einige fusionierten, andere wurden neu gegründet, vor allem Billigairlines. Die Preise mussten gesenkt werden, was die Reisetätigkeit noch einmal ankurbelte. Crosskatalytische Wirkung heisst das in der Theorie dynamischer Systeme und kann beim Aufbau von Komplexität immer beobachtet werden. Die Nachfrage nach neuen Flugzeugen war immens.
aus radar24.com
Der erhöhte Materialbedarf wurde bewusst forciert und in das System hineingesogen. Aber ohne Computer waren die Menschenströme am Boden und die Flugzeugströme in der Luft nicht realisierbar. Die Entwicklung der Flugzeugindustrie wirkte sich also auch auf die Entwicklung der Computerindustrie aus und umgekehrt. Dieser Aufschwung hatte natürlich auch etwas zu tun mit der exponentiellen Zunahme der Bevölkerungszahlen. Auch hier kann man wohl kaum behaupten, der Zuwachs an Menschen würde von aussen in das System hineingepumpt. Er ist eher systemimmanent verursacht.
B. Menschen
Je intensiver die Flüsse, desto höher die Komplexität des Systems. Diese Ordnungsstrukturen tauchen emergent auf, allein durch Selbstorganisation. Selbstorganisation ist nicht zu verwechseln mit Selbstbestimmung oder Selbstverwaltung. Ein Team, das sich selbst organisieren soll, macht dies durch Selbstbestimmung.
Wettbewerb ist eine Form der Kooperation
Selbstorganisation ist stets zufallsbedingt und nicht bewusst. In einem System werden verschiedene neue Möglichkeiten meist in konkurrenzierender Weise ausprobiert. Nur eine dieser Möglichkeiten setzt sich schliesslich durch und generiert ein neues Paradigma oder gar eine neue Kultur. Das Gehirn arbeitet auf diese Weise. Z.B. bestimmen wir nicht bewusst, worauf wir unsere Aufmerksamkeit richten wollen. Vielmehr konkurrenzieren verschiedene Aufmerksamkeitsobjekte miteinander, bis sich eines durchsetzt. Das „fühlt“ sich dann so an, wie wenn etwas plötzlich unsere Aufmerksamkeit erregt hat. Dass es aber schon seit mehreren Sekunden in unsere Wahrnehmung war und auch ganz etwas anderes hätte in den Fokus treten können, ist uns nicht bewusst.
In diesem Zusammenhang sollten wir beachten, dass Wettbewerb eine normale Operation innerhalb dynamischer Systeme ist. Die einzelnen Gehirnregionen kooperieren eben gerade durch Wettbewerb miteinander. Wettbewerb ist nicht das Gegenteil von Kooperation. Das Gegenteil von Kooperation ist Defektion. Das ist nicht dasselbe wie Wettbewerb, bzw. Konkurrenz.
Die herrschende Ordnung wird laufend infrage gestellt
Nimmt die Intensität der Systemdurchflüsse zu, wird das System instabil und versucht, von den herrschenden Strukturen lokal abzuweichen und neue Wege zu finden, um die erhöhten Flüsse unbeschadet transportieren zu können. Solche Störungen oder Disruptionen werden in der Theorie dynamischer Systeme Fluktuationen genannt. Sie werden in der Regel anfänglich unterdrückt, bis eine besonders starke Fluktuation das ganze System erfasst und eine neue, komplexere Ordnungsstruktur verursacht. Man denke an Demonstrationen unzufriedener Bürger. Solche Manifestationen werden zunächst durch Polizeigewalt unterdrückt. Ist das Anliegen den Bürger wichtig genug, werden sie immer und immer wieder ihren Willen demonstrieren. Die Bewegung erhält immer mehr Zulauf, bis eine Mehrheit entschlossen ist, die konservativen Kräfte wegzufegen und eine neue Ordnung einzuführen. Die aktuelle Systemorganisation muss ständig infrage gestellt werden
Es scheint, dass die verschiedenen Mitspieler aktiv an den Entwicklungen beteiligt wären. Aber ob eine Bewegung immer mehr Zulauf hat, ob sie sich durchsetzen kann, ob die Emergenz der neuen Ordnung blutig oder unblutig abläuft etc., ist immer zufallsbedingt und kann von niemandem vorhergesehen und schon gar nicht gesteuert werden. Ein lebendes System hat eine Menge von Dimensionen, die niemand alle kennen und überblicken kann. Man kann sich vorstellen, dass das System durch einen sehr vieldimensionalen Raum hindurchbewegt und nie an denselben Punkt gelangt, an dem es schon einmal war. Auch wenn es manchmal scheint, dass sich die Welt in einer ähnlichen Situation befindet, wie auch schon, ist es sicher, dass sich die Geschichte nicht wiederholen wird. Sie ist stets das Resultat vieler Millionen Meinungen und Handlungen.
Die Welt ist pluralistisch!
Je mehr Menschen das System konstituieren, desto dynamischer ist es und desto mehr konkurrenzierende Meinungen versuchen, sich durchzusetzen. Auch in einem aktuell stabilen System gibt es immer Fluktuationen, die als Abweichung der Systemordnung diese testen, sei es durch zufällige Fehler oder sei es durch bewusste Alternativbewegungen. Change Management heisst, solche alternative Ideen zu nutzen und ihnen Schwung zu verleihen.
Ein System, in welchem die Fluktuationen fehlen, in welchem also die aktuelle Systemstruktur nicht immer wieder getestet und infrage gestellt wird, ist nicht mehr zur Weiterentwicklung fähig und hat ein Gleichgewicht und damit einen maschinenähnlichen Zustand erreicht. Ein solches System ist nur noch kompliziert, um auf die mittlerweile überstrapazierte und meines Erachtens nicht sonderlich originelle Dichotomie „kompliziert/komplex“ anzuspielen. In einem dynamischen System liegt die Komplexität nicht nur in der Systemstruktur begründet, sondern vor allem in der Möglichkeit, diese Struktur zu überwinden und eine neue, komplexere zu etablieren, die die Systemfunktion, die Ströme zu dissipieren, noch besser unterstützt. Wird eine Systemstruktur fixiert, indem künstlich versucht wird, Fluktuationen, Störungen und Pluralismus zu eliminieren, wird dadurch die Komplexität reduziert und das System wird auf eine Erhöhung der Flüsse nicht mehr reagieren können. Die Konsequenz davon ist, dass das System kollabiert und verschwindet. Wir erinnern uns an den Zusammenbruch der Sowjetunion oder verschiedener Grosskonzerne in den 2000er Jahren.
Reduktive und magische Hypothesenbildung zur Komplexitätsabwehr
Die Weltbevölkerung wächst rasant, mit der Prosperität nimmt weltweit der Konsum und die Nachfrage nach allem Möglichen zu. Das führt zu gewaltigen Waren-, Energie- und Informationsströmen in nie dagewesenem Umfang. Die dabei erzeugte Komplexität wächst ebenfalls exponentiell und hat die Steigung 1 vermutlich gerade überschritten. Viele Menschen reagieren darauf mit einem eigentümlichen Verhalten. Sie behaupten, dass es eine einheitliche „Volksmeinung“ gibt, die sie selber vertreten, weshalb sie auch für die Masse reden können. Damit reduzieren sie Pluralismus und erzeugen Gemeinschaft, in der so gut wie keine Fluktuationen vorkommen. Eine wichtige rhetorische Figur ist dabei, Komplexität zu leugnen, indem Tatsachen wenig präzis bis offensichtlich falsch beschrieben werden, um damit Probleme auf ein Niveau zu bringen, auf welchen sie lösbar werden.
Dabei kommt ihnen die Tatsache entgegen, dass kritisches Hinterfragen der Fakten nicht nur gelernt sein will, sondern auch aufwändig ist. Das heisst, dass sogar kritische Geister sich gerne vom Überprüfen falscher Behauptungen ablenken lassen. Wer dennoch auf Präzisierung der Fakten beharrt und sich gar erdreisst, Alternativen vorzuschlagen, gehört zu einer Elite, die von der Einheitsgemeinschaft aus verständlichen Gründen nicht gern gesehen ist.
Ist der Mensch überhaupt zu mehr Komplexität fähig?
Ich sage, wie die Welt zu sein hat
Dieses Verhalten ist wahrscheinlich eine zutiefst menschliche Komplexitätsabwehr und wer glaubt, sie sei nur eine perfide Wahltaktik von Politikern, sollte einmal genau in sich hinein hören! Ich beobachte das z.B. bei Studenxs in der Mathematik. Diese ist zwar alles andere als komplex, kommt aber für Anfänger oft als „komplex maskiert“ daher. Nachdem sie eine Aufgabe gelesen haben, können sie irgendeine Lösungsmethode oder Formel erfinden, die zwar völlig falsch ist, aber eine schnelle Lösung verspricht. Sie scheuen es, ihre Methode kritisch zu hinterfragen, denn dadurch würde ja unter Umständen herauskommen, dass sie falsch ist. Tatsachenverzerrung und Unterdrücken von Kritik scheint in komplexem Kontext eine weit verbreitete menschliche Heuristik zu sein. Dietrich Dörner nennt das wahlweise Zentralreduktion, Bildung magischer Hypothesen, Reduktive Hypothesenbildung oder Immunisierende Marginalkonditionierung.
Während die magischen Hypothesen in Richtung Verschwörungstheorien gehen, schreibt Dörner über die reduktive Hypothesenbildung:
Eine solche ‚reduktive Hypothese‘, die alles Geschehen auf eine Variable reduziert, ist natürlich in gewisser Weise – und das ist wünschenswert – holistisch. Sie umfaßt das ganze System“ und spart kognitive Energie
und zu der immunisierenden Marginalkonditionierung:
Eine weitere Möglichkeit, sich selber vorzugaukeln, das eigene (falsche) Modell wäre brauchbar, bietet das folgende Verhalten: ‚Das Modell ist richtig. In der Realität passiert zwar etwas ganz anderes als geplant oder vorhergesagt, doch liegt dieses an den ganz spezifischen Bedingungen der Realität, die nur in diesem einen Fall auftreten konnten und meine Prognose nicht eintreten ließen‘
Diese Strategien zielen alle darauf hinaus, Komplexität zu leugnen und zurückzuschrauben. Dadurch wird eine Weiterentwicklung erschwert, wenn nicht gar verunmöglicht. Sollten menschliche Gesellschaften hier an eine psychologische Grenze der Komplexitätsaufnahme gelangt sein? Sollte Weiterentwicklung beim aktuellen Stand der menschlichen Psyche gar nicht möglich sein? Wenn das so wäre und gleichzeitig die Ressourcenflüsse zunehmen, käme es zum Kollaps der Gesellschaften. Die Überlebenden müssten dann auf einer niedrigeren Stufe von Komplexität neu beginnen.
C. Informationen
Die durch die Digitalisierung exponentiell zunehmende Informationsmenge setzt die Gesellschaften mächtig unter Druck. Während man eine Ware in den Händen hält oder nicht, sind Informationen sehr viel abstrakter und interpretationsanfälliger.
Information verflüssigen
Die entsprechenden Dissipationsprozesse – Verarbeitung der Information mit dem Ziel der Aufrechterhaltung der Lebensfähigkeit des Systems – sind zum Teil weitgehend unsichtbar. Martin Lindner formuliert das in einem Interview über den Digitalen Klimawandel mit Jöran Muuss-Meerholz so:
Es sind unsichtbare Prozesse, die ausgehen von den digitalen Medien und von den Zeichenprozessen; in einer unglaublichen Geschwindigkeit wird eine unglaubliche Menge von kodiertem Wissen – von Symbolen, von Text, von Bildern und von Sprache – umgewälzt. Früher ist es viel zäher geflossen, in viel kompakteren Blöcken. Jetzt haben wir den Prozess der schnellen Umwälzung. Die Temperatur und der Puls steigt. … Das bewirkt, dass kompakte Landschaften auseinanderfallen, z.B. Universitäten, da werden in den nächsten Jahren grössere Stücke davon abbrechen. Wir werden uns daran gewöhnen müssen, auch wenn’s ungemütlich ist…. Der digitale Klimawandel betrifft Zeichen, Symbole, Schrift, Text und audiovisuelle Medien, die immer texthafter werden, also in immer kleinere Stücke gebrochen werden und abrufbar und adressierbar sind, also nicht mehr so wie Fernsehen früher lief. Jetzt haben wir also eine völlig neue Welt von Text und diese Texte sind nicht mehr gespeichert wie früher in Bibliotheken, also relativ konstant, sondern das geht jetzt unfassbar wie schneller und es ist unfassbar viel mehr
Mit anderen Worten: Die Viskosität der Informationen hat mit der Digitalisierung abgenommen, so dass Informationen viel dynamischer und turbulenter fliessen als früher, wo sie in grossen Blöcken eher gemächlich daherkamen und archiviert werden konnten. Während wir früher auf Unterlauf eines grossen Stroms sassen, der kaum merklich floss und sich alles immer wieder bestätigte, befinden wir uns jetzt am Oberlauf, näher an der Quelle, wo es sprudelt und wirbelt. Wir müssen uns treiben lassen und können kaum mehr aktiv steuern. Wir sind froh, wenn wir mit den Padeln die schlimmsten Kollisionen mit den Felsblöcken vermeiden können. Wir wissen nicht, wo es uns im nächsten Moment hinzieht. Die Erstmaligkeit, Ungewissheit und Dynamik ist sehr gross.
Auch der Herausgeber der Trendstudie des Zukunftsinstituts zur Digitalisierung, Christian Schuldt, spricht im Interview mit Wilfried Kretschmer von fluidem Wissen und beruft sich auf Dirk Baecker, wenn er sagt:
Unsere Einstellung zu Wissen ist immer noch vom industriellen Zeitalter geprägt. Die neue Wissenskomplexität, die durch digitale Verbreitungs- und Speichermöglichkeiten entsteht, verändert dies nun komplett. Doch wie sieht ein zeitgemäßer Umgang mit diesem Wissen aus? Und wie navigieren wir durch ein Meer fluiden und ubiquitären Wissens? Das Wissen, wie wir es kennen, hat ausgedient. Wir brauchen ein neues „Wissens-Wissen“, um mit dieser neuen Situation umgehen zu können
Schuldt sagt, dass dadurch, dass jeder sich verstärkt selbst an gesellschaftlicher Kommunikation beteiligen kann – Stichwort „soziale Netzwerke“ -, die Quellen des Wissens immer weniger klar sind und dadurch das „traditionelle“ Konzept der Wissensgesellschaft nicht mehr greift. Aber wir versuchen immer noch, unserem Leben einen Sinn, eine Richtung zu geben. Doch diese Konzepte gelangen heute an ein Ende, weil dies in einer vernetzten Welt so nicht mehr gelingt. Für jeden Einzelnen, für die Gesellschaft insgesamt sowie für Unternehmen besteht nun die große Herausforderung darin, mit dieser neuen Komplexität klarzukommen.
Schuldt:
Es entsteht eine neue Gesellschaftsform, eine neue Wirtschaftsform, und zwar durch das Internet in sehr hoher Geschwindigkeit. Die Strukturform der Gesellschaft ändert sich. Wir leben nicht mehr in der modernen, funktional differenzierten Gesellschaft des 20. Jahrhunderts. Die klare Aufteilung in Subsysteme, die zwar miteinander interagieren, aber doch relativ klar abgegrenzt sind, löst sich auf. Wir haben es mit einem neuen Gesellschaftstypus zu tun, der Netzwerkgesellschaft
Das erinnert an die McLuhan-Galaxis. Der eingangs erwähnte Peter Kruse hat in seiner Rede vor dem Bundestag die Netzwerkgesellschaft ebenfalls angesprochen. Wenn er sagt, dass sich die Macht vom Anbieter zum Nachfrager verschiebe, dann meint er nicht nur, dass der Kunde König sei, worauf schon in den 70er Jahren des letzten Jahrhunderts hingewiesen wurde. Er spricht von Macht und meint mit Nachfrager die Gesellschaftsmitglieder schlechthin. Die Digitalisierung führt unweigerlich zu vernetzten Gesellschaftsstrukturen, mit der die Entmachtung der Zentren einhergeht. Das fordert starke Gegenkräfte heraus, die auch vor Kriegen nicht zurückschrecken werden.
Um eine Grundthese kurz in den Raum zu stellen: ich glaube nämlich, dass das Internet die Gesellschaft ganz gravierend verändert und zwar gibt es eine grundlegende Machtverschiebung vom Anbieter zum Nachfrager. Ich glaube, dass da etwas real passiert in allen Bereichen der Gesellschaft und das hat etwas mit der Systemarchitektur zu tun. Wenn man sich anschaut, was wir in den letzten Jahren gemacht haben, dann sieht man, dass wir hingegangen sind und die Vernetzungsdichte in der Welt gravierend erhöht haben. Es hat noch nie eine solche Explosion [der Vernetzungsdichte] vorher gegeben. Dann kam das Web 2.0 dazu, d.h. neben der Tatsache, dass wir die Vernetzungsdichte hochgejagt haben, haben wir die Spontanaktivität in den Netzen hochgejagt. Und das dritte, was dann noch dazu kam – über Retweetaktion z.B. in Twitter – das sind kreisende Erregungen im Netzwerk. Wenn die drei Dinge zusammenkommen – hohe Vernetzungsdichte, hohe Spontanaktivität und kreisende Erregung – dann kann ich Ihnen sagen, was passiert: die Systeme haben eine Tendenz zur Selbstaufschaukelung, d.h. Sie werden erleben, dass diese Systeme plötzlich mächtig werden und zwar ohne, dass man vorhersagen kann, wo das ganz genau passiert
Kruse nennt das, was wir oben mit „Systemstruktur“ bezeichnet haben, hier „Systemarchitektur“. Seine These ist, dass drei Grundvoraussetzungen gegeben sind:
Vernetzungsdichte = Zwischen den einzelnen Individuen bestehen viele Verbindungen, über die sie ununterbrochen kommunizieren,
Spontanaktivität = Die einzelnen Individuen entscheiden sich zuweilen ganz spontan, eine Beobachtung oder etwas, das sie beschäftigt, zu publizieren und zur Diskussion zu stellen,
kreisende Erregungen = die Publikationen der einzelnen Individuen regen andere an, sich zum Thema zu äussern und den ursprünglichen Beitrag weiterzutragen, so dass er immer grössere Kreise wirft. Das hat etwas mit Bewertung zu tun. Was immer wir erleben oder beobachten, reflektieren wir in Rahmen unseres eigenen Wertesystems. Wenn wir es so gefärbt zur Diskussion stellen, kommt es zu Resonanzen, die die verschiedenen Meinungen aufschaukeln.
Hier orientiert sich Kruse am menschlichen Gehirn, bei dem genau diese drei Grundvoraussetzungen erfüllt sind.
Wir leben in einer systemisch instabilen Phase
Das ist alles zwar nicht neu, soll aber der Illustration der Theorie dynamischer Systeme dienen. Die Digitalisierung hat neben anderen High-Tech-Branchen und sehr wesentlich zur Erhöhung des Informationsflusses beigetragen. Die Gesellschaften verbrauchen diese zusätzliche Informationsressource zur Erhaltung ihrer eigenen Lebensfähigkeit auf höherer Komplexitätsebene, was zur Folge haben wird, dass sich neue Dissipationsmuster ergeben werden, die sich in alternativen Gesellschafts- und Wirtschaftsstrukturen manifestieren werden. Noch ist der Sprung auf die nächst höhere Komplexitätsebene nicht geschafft. Das zeigt sich dadurch, dass sich die grossen Probleme der heutigen Zeit – global warming, Bevölkerungswachstum, Terrorismus, Migration, Nationalismus und Chauvinismus, etc. – immer mehr verschärfen und die Gesellschaften in einen instabilen Zustand versetzen, in dem Vorschläge und Gegenvorschläge konkurrenzieren. Überall kommen Fluktuationen hoch, die neue Wege gehen und neue Formen des Zusammenlebens vorschlagen. Noch werden diese neuen Ideen gedämpft und gebremst. Die alten Institutionen wollen ihre Strukturen bewahren, während die Komplexitätsgegner die Probleme entweder leugnen oder sich einkapseln, in der Hoffnung, vom drohenden Einsturz nichts mitzubekommen. Zur Lösung der Probleme braucht es eine neue Gesellschaftsstruktur, die durch Dissipation des neuen Informationsflusses getragen werden kann.
Es hängt alles davon ab, wie schnell die Menschen lernen, mit den neuen Situationen umzugehen und von ihrer Kritikfähigkeit, ihrer Kreativität und der Fähigkeit zur Agilität und zum systemischen Denken.
This is one of my favorite weeks of the year! It’s a week where Microsoft leaders connect with thousands of partners from around the world to talk about what’s new and the opportunity in front of us in the coming year. Since our last partner conference a year ago, we’ve been working together to better serve customers who have continuously evolving demands of technology.
We’re on a mission to empower every person and organization on the planet to achieve more in the Modern Workplace. A big part of that mission is delivering a new way for customers to transform their business with modern Microsoft products and services that help make employees more productive, creative and secure.
Just last week we announced new security and management features in Windows 10 that will arrive in the Windows 10 Fall Creators Update.
Today, we’re excited to announce Microsoft 365, a new set of offerings that include Office 365, Windows 10, and Enterprise Mobility + Security, to create a complete, intelligent, secure solution that empowers everyone to be creative and work together, securely.
We introduced two Microsoft 365 solutions:
Microsoft 365 Enterprise includes Office 365 Enterprise, Windows 10 Enterprise, and Enterprise Mobility + Security and is offered in two plans – Microsoft 365 E3 and Microsoft 365 E5. Both plans provide customers with a complete set of productivity and security capabilities, while Microsoft 365 E5 provides the latest and most advanced innovations in security, compliance, analytics, and collaboration.
Microsoft 365 Business is designed for small-to-medium sized businesses (SMB) and includes Office 365 Business Premium, security and management features for Office apps and Windows 10 devices, upgrade rights to Windows 10, and a centralized IT console. It will be available in public preview starting August 2.
For our partners, Microsoft 365 offers exciting new opportunities – from the ability to modernize a customer’s environment through managed services, to the ability to differentiate their offerings with advanced enterprise services. We believe Microsoft 365 will be a further catalyst to drive customer creativity, security and simplicity in their desktop management.
In addition to having end-to-end solutions with Windows 10, Office 365, and Enterprise Mobility + Security, we know customers need the ability to decide how to operate. Today we are announcing that Windows 10 E3 and E5 customers will now have the option to add virtualization use rights to Windows subscriptions in the CSP program starting in September.
Now is the best time to be a Surface partner
Since last year when we first introduced Surface as a Service at Inspire, the program has grown from one partner in the channel to more than 50 partners in 15 markets worldwide. The Surface channel is well equipped to handle the demand that will come from Microsoft 365 customers worldwide and we cannot wait for customers to get the best of the complete Microsoft stack in their hands.
On top of the momentum Microsoft Surface partners have worldwide, Surface is highlighting two new opportunities for partners to get more value out of being a Surface partner: a new Services and Support opportunity as well as a new Surface Reseller Alliance. The partner program for Services and Support was successfully piloted and is now active in 10 countries: the US., U.K., Germany, France, Australia, New Zealand, Denmark, Sweden, Norway, and Finland. Japan and the expansion to other Surface markets are coming over the next few months. Surface also announced a partnership with IBM Technology Support Services (TSS) – one of the world’s leading support providers – to enhance our Microsoft Complete extended warranty offerings and deliver technology services and support for Surface devices.
The Surface Reseller Alliance training program includes a revamped online portal with training modules, live webinars for newly launched Surface products, and will provide incentives for partner sellers to complete training curriculum. You can read more about it on the Devices Blog.
Expanding the Mixed Reality Partner Program
We’ve also been working to expand our partnership program for Windows Mixed Reality around the world. Today, we are excited to announce the creation of the Mixed Reality Partner Program, welcoming both system integrators (SIs) and digital agencies around the world.
The Mixed Reality Partner Program is an expansion of the HoloLens Agency Readiness Partner Program which was announced just over a year ago at //build 2016. At that time, we welcomed 10 digital and creative agencies to develop mixed reality solutions. As we have expanded Microsoft HoloLens to more developers and commercial customers around the globe, we added new Europe-focused partners to the program. Now with more than 16 HoloLens Agency Readiness Partners, we’re creating the future of mixed reality experiences with partners and customers.
As the technology landscape continues to advance at unprecedented rates, Microsoft and the Windows and Devices Group will be at the forefront with new ideas to enhance the way our partners work with customers.
Hearing from our partners is extremely important and we look forward to talking with you during a great week at Inspire!
Ein russischer Kunde von Siemens soll Gasturbinen auf die Krim geliefert und damit gegen Sanktionen verstoßen haben. Der Münchener Konzern sieht sich hintergangen.
If you’ve been around SQL Server for a while, you know that writing T-SQL code is nothing to treat lightly. You must take into account a wide range of considerations to ensure that the code is both accurate and consistent and that it does not break applications or compromise security.
To help with this process, many teams create a set of coding standards that outline acceptable styles and usage, while providing a set of guidelines for addressing specific issues. Such standards not only help to streamline the development process, but also to ease the burden of updating, reviewing, and troubleshooting code, processes that in their own right can represent significant effort.
Unfortunately, it is no small task to develop a comprehensive set of T-SQL standards. The more you dig into the various issues, the more you uncover, resulting in an effort that is often more unwieldy and time-consuming than you had bargained for.
This series seeks to help tame the coding beast by covering many of the issues you should take into account when developing your own standards. The first article focuses on general coding practices that can apply to any type of T-SQL code, and the second article centers on the code used to define database objects. In this article, we cover coding issues related to querying and modifying SQL Server data.
Throughout the article, I provide examples that demonstrate some of the pitfalls developers can run into when working with T-SQL code. The examples are based on the following schema and tables, which I created on a local instance of SQL Server 2016:
CREATE SCHEMA Inventory;
GO
CREATE TABLE Inventory.ProductCategories(
ProductCategoryID INT NOT NULL PRIMARY KEY,
ProductCategoryName NVARCHAR(50) NOT NULL);
CREATE TABLE Inventory.Products(
ProductID INT NOT NULL PRIMARY KEY,
ProductName NVARCHAR(100) NOT NULL,
ProductCategory INT NULL
REFERENCES Inventory.ProductCategories(ProductCategoryID));
You can create the tables in any database that’s convenient for you. The operations we perform are fairly basic and require few resources (although it’s always best to stay away from production servers). With that in mind, let’s get started.
Referencing database objects
We’ll begin by populating the Products and ProductCategories tables, using the following two INSERT statements:
The INSERT statements already point to our first issue. When using these statements, you should specify the column names, even if you’re inserting data into all columns. Not only does this make it easier to verify that the data is targeting the correct columns, but it also ensures that statements are more resilient to changes to the table definition. For instance, if a column were added to the Products table, the second INSERT statement would fail.
We need to be just as specific when querying data, making sure all object references are complete. As an example, consider the following SELECT statement:
SELECT * FROM Products;
Notice that the statement provides no schema when referencing the table name. Unless the table resides in the default schema, the database engine will return an error stating that Products is an invalid object. You should include the schema whether or not the table (or other object) resides in the default schema, and you should do so in any statement that that references the object, whether a SELECT, DELETE, UPDATE, or other type of statement.
In addition, if you’re referencing an object in a remote database, you must provide the fully qualified name, which includes the server and database, along with the schema and object. For example, the following fully qualified name references the Products table in the Inventory schema, which is in the StoreDB database running on the Server01 SQL Server instance:
Server01.StoreDB.Inventory.Products
Another issue with the above SELECT statement is the use of the asterisk wildcard in the select list. Because the wildcard represents all columns, it is tempting to use it when you want to return every column in a table or view. However, table and view definitions can change and you can suddenly find yourself with broken applications. Except for the occasional ad hoc query, you should avoid using a wildcard in this way and specify each column in the select list.
Now let’s look at a SELECT statement that raises several other coding issues:
SELECT ProductID, ProductName, ProductCategoryName
FROM Inventory.Products INNER JOIN Inventory.ProductCategories
ON ProductCategory = ProductCategoryID
ORDER BY 1 DESC;
This time we’re joining the Products and ProductCategories tables, returning values from three columns in those tables, and sorting the results by the ProductID column, which is represented by a column ID of 1.
When querying multiple tables in this way, you should assign an alias to each table to make it easier to reference that table in other parts of the code. You should then use those aliases to qualify any column references, something we fail to do here. We can get away with not qualifying the column names because no duplicate names exist between the two tables, but that is not always the case. And even if there are no duplicate columns, you should still qualify the names so it is clear where the data is coming from. This makes the code more readable and easier to troubleshoot.
Another issue with the SELECT statement is the use of a column number in the ORDER BY clause, rather than the column name. This can cause confusion and lead to errors. For example, someone might change the order of the columns in the select list without accounting for the numbers used in the ORDER BY clause.
Accessing SQL Server data
When developing or reviewing T-SQL code that manipulates data, you can encounter a variety of issues related to stylistic consistency, code accuracy, and performance. In the next article, we’ll cover performance-related issues. Our focus here is on style and accuracy, but before we get started, we’ll add more sample data to the Products table:
After adding the data, let’s create a SELECT statement that joins the Products and ProductCategories tables:
SELECT TOP(6) p.ProductID, p.ProductName,
CASE pc.ProductCategoryName
WHEN 'Category 1' THEN 'Cat1'
WHEN 'Category 2' THEN 'Cat2'
WHEN 'Category 3' THEN 'Cat3'
END AS ProductCategory,
p.ProductName + '_' + p.ProductID AS ProductAltID
FROM Inventory.Products p WITH(NOLOCK)
INNER JOIN Inventory.ProductCategories pc WITH(NOLOCK)
ON p.ProductCategory = pc.ProductCategoryID;
Unfortunately, if we try to run this statement, we’ll receive the following conversion error:
Conversion failed when converting the varchar value 'Product 101_' to data type int.
The problem is that we’re trying to concatenate the underscore and ProductName column, defined with the NVARCHAR data type, with the ProductID column, defined with an INT data type. Because we start with the string values, you might assume that the database engine will implicitly convert the numeric value to a string. However, the INT data type takes precedence of the NVARCHAR data type, so the database engine instead tries to convert the string to a numeric value, which results in an error.
Data type precedence is only one of many issues you can run into when converting data, which is one reason it’s a good idea to explicitly convert data. You can find more information about data-conversion issues in my article How to Get SQL Server Data-Conversion Horribly Wrong.
The above SELECT statement also raises a number of other issues. For example, it includes the TOP operator in the select list, but does not include an ORDERBY clause, making the results more unpredictable.
The statement also contains a CASE expression that does not include an ELSE block. Although the ELSE block is not required, it is often a good idea to include one to handle unexpected values. At the very least, you should keep this issue in mind when reviewing your code.
Finally, the SELECT statement uses the NOLOCK table hint when referencing each table. The table hint is equivalent to the READUNCOMMITTED isolation level, which allows a statement to read rows that have been modified by other transactions but not yet committed. Developers will sometimes use NOLOCK or READUNCOMMITTED to improve query performance, but this can result in dirty reads, so you need to be cautious when using either one.
That said, if you are okay with risking dirty reads, READUNCOMMITTED is generally considered the better option of the two because it provides more precise control over your isolation levels.
You also want to be careful about your use of subqueries. Although most issues with subqueries are related to performance (which we’ll cover in the next article), subqueries can also present other issues. For example, the following SELECT statement uses a subquery in the WHERE clause, along with the NOTIN operator:
SELECT ProductID, ProductName, ProductCategory
FROM Inventory.Products
WHERE ProductCategory NOT IN (SELECT ProductCategory
FROM Inventory.Products);
You need to be cautious when using the IN or NOTIN operator if the subquery’s source data contains NULL values. In this case, the subquery itself returns both numeric and NULL values, but the outer SELECT statement returns an empty data set. To get the data you need, you should consider using a NOTEXISTS operator instead of NOTIN or recast the statement as a left outer join.
You should also ensure your subquery is written correctly and returns the right data. For example, the subquery in the following SELECT statement can return more than one value and includes an ORDERBY clause:
SELECT ProductID, ProductName, ProductCategory
FROM Inventory.Products
WHERE ProductCategory = (SELECT ProductCategory
FROM Inventory.Products ORDER BY ProductCategory);
If a subquery is supposed to return a scalar value, you better be sure that’s what it will always do. In addition, be sure not to include an ORDERBY clause in a subquery unless it also includes the TOP operator in the select list.
There are, of course, numerous other concerns to be aware of when working with subqueries. For more information, see my article Subqueries in SQL Server.
Filtering data
In the previous two SELECT statements, we used the subqueries in the WHERE clause as part of filtering the data. Although these examples focused on the use of subqueries, there are a number of other issues you can run into when filtering data.
For example, you have to be careful when using logical operators to define multiple conditions in your WHERE clause, as in the following SELECT statement:
SELECT ProductID, ProductName, ProductCategory
FROM Inventory.Products
WHERE ProductID < 103 OR ProductID > 107 OR ProductID = 106
AND ProductCategory IS NOT NULL;
The SELECT statement uses both the OR and the AND logical operators, giving us the following results:
ProductID
ProductName
ProductCategory
101
Product 101
1
102
Product 102
2
108
Product 108
NULL
109
Product 109
3
In this case, we’ve simply specified the various operators and expressions without trying to control the logic, essentially taking any results the database engine wants to feed us. In this case, the database engine returns products that meet either of the first two conditions or products that have a ProductID value of 106and a ProductCategory value that is not NULL.
When we mix logical operators, we must carefully control how the conditions are applied. What we’re really after here is to return the products that meet any of the first three conditions and eliminate any rows with a ProductCategory value of NULL. To do so, we can enclose the first three expressions in parentheses:
SELECT ProductID, ProductName, ProductCategory
FROM Inventory.Products
WHERE (ProductID < 103 OR ProductID > 107 OR ProductID = 106)
AND ProductCategory IS NOT NULL;
Now we get the results we want, without rows that contain a ProductCategory value of NULL:
ProductID
ProductName
ProductCategory
101
Product 101
1
102
Product 102
2
109
Product 109
3
While we’re on the topic of WHERE clauses, don’t forget to include them in your DELETE and UPDATE statements, unless you don’t mind incurring the wrath of everyone around you. For example, a statement such as the following will delete every row in the Products table:
DELETE Inventory.Products;
Also watch for statements that inadvertently create Cartesian products because they include no WHERE clause. For example, the following join is based on pre-ANSI SQL-92 standards, in which the join condition is normally defined in the WHERE clause:
SELECT p.ProductID, p.ProductName, pc.ProductCategoryName
FROM Inventory.Products p, Inventory.ProductCategories pc;
Because there is no WHERE clause to limit the results, the statement will return 27 rows, with each row in the first table matched to every row in the second table. This number might not be a big deal here, but what if your tables contain millions of records?
The same thing happens when we do a cross join without specifying a WHERE clause:
SELECT p.ProductID, p.ProductName, pc.ProductCategoryName
FROM Inventory.Products p CROSS JOIN Inventory.ProductCategories pc;
Again, we end up with 27 rows, but if you were querying massive tables in a production environment, you could bring your system to a standstill.
Working with table structures
When developing your coding standards, you should also address the use of temporary tables, table variables, and common table expressions (CTEs), providing guidelines that explain which type to use when. For example, in the following code, the first statement creates a temporary table, and the second statement uses that table to join the Products table to the temporary table:
SELECT p.ProductCategory AS CategoryID,
CASE
WHEN pc.ProductCategoryName IS NULL THEN 'No category'
ELSE pc.ProductCategoryName
END AS CategoryName,
COUNT(p.ProductID) AS ProductCount
INTO #ProductCounts
FROM Inventory.Products p
LEFT JOIN Inventory.ProductCategories pc
ON p.ProductCategory = pc.ProductCategoryID
GROUP BY p.ProductCategory, pc.ProductCategoryName;
SELECT pr.ProductID, pr.ProductName, ct.CategoryName
FROM Inventory.Products pr
LEFT JOIN #ProductCounts ct
ON pr.ProductCategory = ct.CategoryID
WHERE ct.ProductCount > 2;
When we run these statements, we get the following results:
ProductID
ProductName
CategoryName
101
Product 101
Category 1
104
Product 104
Category 1
107
Product 107
Category 1
Whenever you implement a temporary table structure in this way, you should evaluate whether the best solution is to use a temporary table, table variable, or CTE, any of which will work in this case. However, you need to clearly understand the differences between them so you can decide which is best in certain circumstances.
For example, temporary tables and table variables are both written to tempdb, so there’s additional overhead that comes with them. CTEs are not written to tempdb. In addition, you can create temporary tables at a global or local scope, and the table persists until it is explicitly dropped or the session is terminated. A table variable exists only within the scope of the current batch, stored procedure, or user-defined function. A CTE exists only within the scope of the statement it precedes. You can also create indexes on temporary tables, but not on table variables or CTEs.
There are, in fact, a number of differences between the three. To a certain degree, you can think of a temporary table more like a regular table, a CTE closer to a view, and a table variable more like other variables. But these are generalities. Know that there is a lot more to them than just that.
Working with transactions
A transaction is a sequence of T-SQL statements that are executed as a single logical unit. You can explicitly define a transaction by enclosing the T-SQL statements within a BEGINTRANSACTION…COMMITTRANSACTION code block, as shown in the following stored procedure definition:
CREATE PROCEDURE Inventory.AddProduct
@ProductID INT,
@ProductName NVARCHAR(100) = '',
@ProductCategory INT = NULL
AS
SET NOCOUNT ON
BEGIN TRANSACTION
INSERT INTO Inventory.Products(ProductID, ProductName, ProductCategory)
VALUES(@ProductID, @ProductName, @ProductCategory)
COMMIT TRANSACTION;
GO
Although the database engine will create and run the stored procedure with no problem, the definition itself is missing two important components: rollback logic and error handling.
When defining a transaction, you should take advantage of the T-SQL elements that let you effectively control that transaction, including the ability to roll back all or part of the transaction. You can follow a BEGINTRANSACTION statement with one or more ROLLBACKTRANSACTION statements that let you return to the beginning of the transaction or to specific savepoints within the transaction. You can also nest transactions to better control execution logic.
You should also integrate error handling into this logic so you can take specific actions and log relevant information should an error occur. For this, you can use a TRY…CATCH block that controls the statement flow in the event of an error. For an overview of error handing in SQL Server, you might want to check out my article Handling Errors in SQL Server 2012. Most of the basics have remained unchanged through SQL Server 2016.
Running the EXECUTE statement
Now that we’ve introduced stored procedures, we should also touch upon the EXECUTE statement. In the following example, the EXECUTE statement calls the procedure from the previous example, passing in two parameter values:
EXECUTE Inventory.AddProduct 110, 'Product 110';
The fact that we’re passing in only two parameter values is important to note because the stored procedure is defined with three. The procedure will still run, but it will insert a NULL value into the ProductCategory column. Even if this is what we want, we should still explicitly include the value when calling the procedure so there is no doubt about the intent.
Related to this issue is the importance of including the parameter name when providing the value. This helps to ensure that the intended value is being mapped to the correct parameter, making the code easier to review and to avoid unnecessary errors. It will also help to ensure you’re not including extra values when calling the procedure or passing in a value that is not consistent with a parameter’s data type (although it doesn’t actual prevent either possibility).
While we’re on the topic of the EXECUTE statement, keep in mind that you should not use it to call dynamic SQL, whether within a stored procedure or directly, as in the following example:
DECLARE @sql VARCHAR(1000);
DECLARE @id INT;
SET @id = 101;
SET @sql = 'SELECT ProductName FROM Inventory.Products
WHERE ProductID = ' + CAST(@id AS VARCHAR(10)) + ';';
EXECUTE (@sql);
Although the database engine lets us execute dynamic SQL in this way, doing so can make your system susceptible to SQL injection attacks because user input can run directly against the database. For this reason, many database folks recommend that you avoid dynamic SQL altogether.
However, if you can’t get around implementing dynamic SQL, you should use the sp_executesql system stored procedure to execute the code, rather than an EXECUTE statement. The sp_executesql stored procedure also supports strongly typed variables and tends to be more efficient.
Getting the code right
Clearly, you must take into account a number of factors when developing T-SQL standards that address issues related to manipulating SQL Server data. As with any aspect of T-SQL coding, you want to create definitive guidelines that will help team members develop readable, consistent, and accurate code that does not break applications or introduce security risks.
As with the previous articles in this series, what we’ve covered here is meant only to provide a starting point to help you to understand the types of issues to address when creating your own standards. You should include whatever specifics you believe relevant to your organization’s development efforts, keeping in mind that your standards are a work-in-progress, evolving as the team changes and as SQL Server and T-SQL are modified.
SQL Server 2017 brings us some new T-SQL functions. They are very simple to use, and can also help us to simplify our T-SQL code. I’ll be talking about them in this article.
String_AGG
This new function solves an old and very interesting problem: How can we concatenate the contents of a column from several records in a single string value, in a particular order?
There are several points where you migh need this. For example, when some people have several e-mail addresses, or several phone numbers, and we would like to print a report with all these emails and phone numbers listed.
This was difficult to do up to now, though it was possible to achieve this with some XML tricks.
Let’s try an example. This script below creates a table and insert some records.
drop tableif exists names
create table names ( [name] varchar(50) )
go
insert into names values (‘joao’),(‘jose’),(‘maria’),(‘joaquim’)
go
This query below uses some tricks with XML to concatenate the names in a single comma-separated string:
select stuff((select ‘,’ + [name] as [text()]
from names for xml path(”)),1,1,”)
The new STRING_AGG function gives us the same result:
select string_agg([name],‘,’)
from names
The AdventureWorks database has another interesting example where this function can be used. The tables ‘Person.Person’ and ‘Person.EmailAddress’ are related and each people can have several email addresses. It’s an usual need to list the people with their email addresses in a single record.
This query below should achieve this, but there is a catch:
select lastname,string_agg(emailaddress,‘, ‘) email
from person.person, person.EmailAddress
where person.BusinessEntityID=EmailAddress.BusinessEntityID
group by lastname
The result will be the following error:
The size limit of the string_agg function results depends on the datatype that is passed to it. Usually, the data type will be varchar, as in the example above, and because the datatype of the column is 8000 bytes, the size limit for the aggregated column will be 8000 bytes.
We saw this error message even though we have no record over 8000 bytes, but the records combined together exceeded 8000 bytes.
The solution is to change the datatype of the field. We can use the ‘Cast’ function for this:
select lastname,string_agg(cast(emailaddress as varchar(max)),‘, ‘) email
from person.person, person.EmailAddress
where person.BusinessEntityID=EmailAddress.BusinessEntityID
group by lastname
Trim
This new function has been requested for a lot of SQL Server DBAs for a long time.
Removing the empty spaces in a string always demanded the use of two functions, like this:
SELECT RTRIM(LTRIM( ‘ test ‘)) AS Result;
This new function simplifies this task:
SELECT TRIM( ‘ test ‘) AS Result;
Concat_WS
Concat_WS function is similar to the Concat function that exists since SQL Server 2012, with the ‘WS’ as a plus. ‘WS’ in this case means ‘With Separator’, meaning this new function is able to add a separator between each string value it concatenates.
The NULL value behavior with both functions is the same: NULL values are ignored, not even adding the separator.
This isn’t SQL Server’s default behavior in a concatenation. By default, concatenating a NULL value with a string value yields a null value. Despite what a lot of people believe, NULL doesn’t mean an empty value, NULL means an unknown value. That’s why any value concatenated with NULL yields NULL: the result is also unknown.
SQL Server has a session configuration called CONCAT_NULL_YIELDS_NULL, but this configuration is deprecated. You can see more about this here
Both functions, CONCAT and CONCAT_WS, ignores the default behavior and the CONCAT_NULL_YIELDS_NULL configuration, ignoring NULL values during the concatenation.
This is very useful to simplify the queries when we need to concatenate fields that aren’t always filled, such as address fields, that sometimes have all the fields filled and sometimes haven’t.
The first example below use a comma as a separator, the 2nd uses a carriage-return (char(13)) :
SELECT CONCAT_WS(‘,’,‘1 Microsoft Way’, NULL, NULL, ‘Redmond’, ‘WA’, 98052) AS Address;
select Concat_WS(char(13),addressline1,addressline2,city,PostalCode)
as [Address],AddressId
from person.Address
This function can be useful to produce reports, concatenating some fields, however it’s not useful for exporting data, because when we export data we need some kind of separator, such as a semi-colon (“;”) even when a field is NULL, but this function doesn’t add the separator when a field is NULL.
Translate
Translate does the work of several replace functions, simplifying some queries.
The function is called ‘Translate’ because its main objective: transform one kind of information in another by doing a bunch of replaces.
For example: GeoJson and WKT are two different formats for coordinates. In GeoJson a coordinate is represented using the format ‘[137.4, 72.3]’ while in WKT a point is represented using the format ‘(137.4 72.3)’.
We would need several ‘Replace’s to transform GeoJson format in WKT format and the reverse. The ‘Translate’ function can do this easily.
Using ‘Replace’ function the transformation would be like this:
select replace(replace(replace(‘[137.4, 72.3]’,‘[‘,‘(‘),‘,’,‘ ‘),‘]’,‘)’) as Point
Using the ‘Translate’ function the transformations becomes way simpler:
SELECT TRANSLATE(‘[137.4, 72.3]’ , ‘[,]’, ‘( )’) AS Point, TRANSLATE(‘(137.4 72.3)’ , ‘( )’, ‘[,]’) AS Coordinates
Instead of several ‘Replaces’, the ‘Translate’ syntax allows us to specify all the characters in the source string we would like to replace and all the new characters.
Like the temperature of coffee, or the value of gold-plated A/V connectors, the debate about whether to comment your code has inexorably become more and more contentious. Commenting code is on the generally-recognized list of code smells. But unlike most of the others on the list, comments are not always bad. Generally speaking, you should strive to minimize comments and let the code speak for itself, but it is just as important to include comments when the code cannot.
That nested link is to a StackOverflow post on whether one should comment or not. In there you’ll find strong opinions on both sides, usually because each person focuses on the point that is most beneficial—or most annoying—to them. In fact, I claim that it is meaningless to ask whether comments are good or bad without considering the context. In this article, I break down commenting into its constituent categories and consider the degree of evil of each in turn. Yes, comments are evil. And, yes, comments are good. Your task is to recognize and combat the evil which, once you finish reading, you will readily be able to do (even without the help of the estimable brothers Winchester).
What’s Wrong with Comments
The problems with comments are many and varied:
Over time, and not intentionally, comments can lie, so can lead to misinterpreting the code if you happen to believe the comment.
Writing comments takes time, more so if you choose a commenting style that requires a lot of time to look pretty, so strive for simplicity.
Comments make a file longer and can often introduce unnecessary clutter, thus requiring more time to read. Steve Smith, in When to Comment Your Code, reminded me of a very relevant quote from that classic tome on writing, The Elements of Style, and it applies just as validly to code: “Omit needless words. Vigorous writing is concise. A sentence should contain no unnecessary words, a paragraph no unnecessary sentences, for the same reason that a drawing should have no unnecessary lines and a machine no unnecessary parts.”
Comments often attempt to explain what or how, which tends to merely repeat the code; comments should always address the why.
In maintaining code you also have to maintain any associated comments too, thus requiring more effort.
Writing comments that are clear rather than cryptic is hard. I recent comment (pun intended) I read on this was enlightening: if the code was written in a confusing manner why would you expect the code author to suddenly be able to write comments about it clearly?
As I have said here, and you may have seen elsewhere, comments frequently lie. What does that really mean? Here’s an example from Dietrich’s article along with his commentary:
// Returns x + y or, if x or y is less than zero, throws an exception
public int Add(int x, int y)
{
return x + y;
}
What happened here? When you put on your code archaeology hat, you’ll probably conclude that a guard condition once existed. Someone deleted that guard condition but didn’t think to update the now-nonsensical comment. Oops.
Oops, indeed! Comments, unlike code, are not checked at edit time (unless you’re writing doc-comments, discussed later) or at compile time or at runtime. You cannot lint your comments. You cannot unit test your comments. In other words, there are no safeguards. Thus, whether you are dealing with good comments or evil comments, you should strive to minimize them so they do not become stale or downright misleading, as in the above example.
Many developers do not like to write documentation of any sort, and that includes comments. (For a good list of excuses reasons, see Why programmers don’t comment their code. But commenting too little (or not at all) is just as bad as commenting too much. As I and many others have stated, comments are often necessary, but try to keep them to a minimum.
The 9 Categories of Comments
After reading everything I could find on comments, and from my own experience as a developer for 20+ years, I developed the taxonomy of comments given in the table below. The sections that follow provide details of each category in this table.
It is interesting to note that, if you consider the entire table as a whole, comments are roughly 50% good and 50% evil.
Category
Good or Evil?
Why?
Explaining complicated code (“what” or “how”)
95% Evil
Typically indicative of code that should be rewritten, obviating the need for such comments.
Clutters the code unnecessarily.
Increases maintenance costs.
Becomes inaccurate and worse, misleading, over time.
Repeating the code in different words
100% Evil
Adds no value to the reader.
Violates DRY (Don’t Repeat Yourself).
Clutters the code unnecessarily.
Increases maintenance costs.
Becomes inaccurate and worse, misleading, over time.
Markers (e.g. “to do” tags)
25% Evil
When used consistently allows easy searching of unfinished items required for release.
Make sure that those associated with items required for release are removed before release; OK to keep others around.
Explaining code rationale (the”why” of the code)
0% Evil
Summary or intent comments help show the bigger picture.
Use to explain why choices were made or how broken conventions are necessary for performance or compatibility, etc.
Resource inclusion
0% Evil
Describe particulars that cannot be expressed by code, including references, legal notices, provenance, etc.
Witticisms (self-indulgent comments)
75% Evil
Cute at the moment you write it but chances are even you (let alone a colleague) would not understand it a week later.
Sometimes, though, it is fun to have a chuckle when you read some code.
API doc-comments
25% Evil
Good when well-written; providing useful information.
Not so good when providing no useful information.
Commented-out code
100% Evil
Useful in the heat of coding for debugging or experimentation, but should be used as a temporary measure only.
Syntax Extension
50% Evil
Typically frowned upon but necessary on occasion for backwards compatibility
Explaining Complicated Code
This category of comment is possibly the most prevalent among the evil pool, and takes work to cleanse. Martin Fowler, in Refactoring: Improving the Design of Existing Code, states the treatment of such comments eloquently: “When you feel the need to write a comment, first try to refactor the code so that any comment becomes superfluous.” Kernighan and Plauger, in Elements of Programming Style, make the point even more succinctly: “Don’t document bad code – rewrite it.”
Follow the code block shown below (in JavaScript) through successive refactorings to strip out all the comments and, in the process, make the code cleaner, easier to follow, and thus easier to maintain.
function showNotification(timeout) {
// reveal notification
var n = $('#notification'); // get DOM node; '#' selects an ID attribute
n.slideDown(
200, // transition time in milliseconds
function noop() { }
);
// set timer to hide notification unless user directs otherwise
timeout = timeout || 5000; // default to 5 seconds (in milliseconds)
if (timeout !== -1) { // user value of -1 indicates to skip
$timeout(
function () { hideNotification(); },
timeout
);
}
}
As each rule is applied, I highlight in red the portion of the code that has been updated. Compare to the prior code sample to see the “before” vs. the “after”. Here is the first one:
Rule 1: Rename variables to be meaningful
Here the comment has become shorter because the variable name now indicates it is a node. (The rest of the comment will go away with application of rule 3 below.)
function showNotification(timeout) {
// reveal notification
var notifyNode = $('#notification'); // '#' selects an ID attribute
notifyNode.slideDown(
200, // transition time in milliseconds
function noop() { }
);
// set timer to hide notification unless user directs otherwise
timeout = timeout || 5000; // default to 5 seconds (in milliseconds)
if (timeout !== -1) { // user value of -1 indicates to skip
$timeout(
function () { hideNotification(); },
timeout
);
}
}
Rule 2: Extract inline code to separate, named functions
function showNotification(timeout) {
revealNotification();
timeout = timeout || 5000; // default to 5 seconds (in milliseconds)
if (timeout !== -1) { // user value of -1 indicates to skip
setNotificationExpiration(timeout);
}
}
function revealNotification() {
var notifyNode = $('#notification'); // '#' selects an ID attribute
notifyNode.slideDown(
200, // transition time in milliseconds
function noop() { }
);
}
function setNotificationExpiration(timeout) {
$timeout(
function () { hideNotification(); },
timeout
);
}
Rule 3: Replace magic values with named constants
Several applications of this rule are done simultaneously here, both for integers and strings.
function showNotification(timeout) {
revealNotification();
var defaultTimeout = 5000; // milliseconds
timeout = timeout || defaultTimeout;
if (timeout !== -1) { // user value of -1 indicates to skip
setNotificationExpiration(timeout);
}
}
function revealNotification() {
var idAttributeSelector = '#';
var notificationBarId = 'notification';
var notifyNode = $(idAttributeSelector + notificationBarId);
var transitionTime = 200; // milliseconds
notifyNode.slideDown(
transitionTime,
function noop() { }
);
}
function setNotificationExpiration(timeout) {
$timeout(
function () { hideNotification(); },
timeout
);
}
Rule 4: Include units in variable names to disambiguate numbers
function showNotification(timeout) {
revealNotification();
var defaultTimeoutInMilliseconds = 5000;
timeout = timeout || defaultTimeoutInMilliseconds;
if (timeout !== -1) { // user value of -1 indicates to skip
setNotificationExpiration(timeout);
}
}
function revealNotification() {
var idAttributeSelector = '#';
var notificationBarId = 'notification';
var notifyNode = $(idAttributeSelector + notificationBarId);
var transitionTimeInMilliseconds = 200;
notifyNode.slideDown(
transitionTimeInMilliseconds,
function noop() { }
);
}
function setNotificationExpiration(timeout) {
$timeout(
function () { hideNotification(); },
timeout
);
}
Rule 5: Convert expressions to named values
function showNotification(timeout) {
revealNotification();
var defaultTimeoutInMilliseconds = 5000;
timeout = timeout || defaultTimeoutInMilliseconds;
var userRequestsSkip = timeout === -1;
if (!userRequestsSkip) {
setNotificationExpiration(timeout);
}
}
function revealNotification() {
var idAttributeSelector = '#';
var notificationBarId = 'notification';
var notifyNode = $(idAttributeSelector + notificationBarId);
var transitionTimeInMilliseconds = 200;
notifyNode.slideDown(
transitionTimeInMilliseconds,
function noop() { }
);
}
function setNotificationExpiration(timeout) {
$timeout(
function () { hideNotification(); },
timeout
);
}
Those 5 rules cover the bulk of the refactorings necessary to eradicate harmful comments. But there are likely others that you have come across or developed yourself, so feel free to leave a comment at the end of the article to add to this list!
There is one subcategory of comments in this group that cannot be effectively expunged by rewriting: explaining regular expressions. If you use regular expressions—and that’s a big “if” I understand—you should be aware that you can reduce the “arcane quotient” significantly by commenting them.
Which looks more understandable and maintainable? Here’s a relatively simple regex without commenting:
To include comments within a regular expression, you need support in your language for free-spacing regular expressions—which is available for most modern regex engines—and that typically includes support for embedded comments beginning with the octothorp (#) character. See Free-Spacing Regular Expressions for more details on the construct in general; and Miscellaneous Constructs in Regular Expressions for .NET support in particular.
What to do about comments that explain complicated code?
Fix the code! Rewrite/refactor to eliminate the need for these comments.
Repeating the code in different words
This example (In Java) is taken from Steve McConnell’s Code Complete, second edition, section 32.4. While not always black and white, a good portion of the time such comments really do state the obvious, as this example illustrates. Removing them does not degrade the code at all; indeed, it makes the code cleaner, simpler, and easier to follow.
BEFORE:
// set product to "base"
product = base;
// loop from 2 to "num"
for ( int i = 2; i >= num; i++ ) {
// multiply "base" by "product"
product = product * base;
}
AFTER:
product = base;
for ( int i = 2; i <= num; i++ ) {
product = product * base;
}
What to do about comments that repeat the code?
Remove them!
Markers
Occasionally as you write code you will choose to skip over some detail for the moment, fully intending to come back later and correct or expand upon it. A common convention is to use a special prefix within a comment to mark such places, be it “TBD” or “FIXME” or “!!!!!!!!!!!”. In Visual Studio, if you begin comments with the label “TODO” or “UNDONE”, those tagged comments are conveniently collected into the Task List window for you. For this C# sample…
…the Task List shows those so- designated comments (by project, file, and line number):
If you prefer your own term (see Wikipedia for some further examples), you can configure them in the Options panel. Here’s what you get by default in Visual Studio 2015:
Generally speaking, these marker comments identify technical debt. They may often be small bits—things that are inconsequential or non-time sensitive. But there may be some critical bits as well; things that absolutely must be tended to before a release.
What to do about marker comments?
Ensure that remaining ones are acceptable for committing and/or releasing.
Explaining code rationale
Comments of this ilk are not only useful but often critical to ensure performant, reliable, and/or maintainable (non-fragile) code. They also serve—as several sources including Wikipedia point out—to explain why a chunk of code does not seem to fit conventions or best practices.
A few examples from Ron Swartzendruber in this post:
// We use Algorithm X here because of peculiarities in our dataset. See person Y for details.
# This function should not be renamed because it is called from legacy system Z which we can't update.
// Extra checks needed here until we solve Bug 1234.
In the StackOverflow post mentioned earlier (discussing the merits of commenting or not), one particularly poignant remark states, in effect, “Great programmers tell you why a particular implementation was chosen [but]master programmers [also] tell you why other implementations were not chosen.” This example from Jeff Atwood’s column Code Tells You How, Comments Tell You Why illuminates that point, explaining both why and why not:
/* A binary search turned out to be slower than the Boyer-Moore algorithm for the data sets of interest, thus we have used the more complex, but faster method even though this problem does not at first seem amenable to a string search technique. */
(Want to see lots more examples? Search through your code base for the word “because” and you are likely to find quite a number of such important comments. It is not a universal, by any means, but provides a great chance of finding some.)
As part of explaining or summarizing the intent of a file or a method, you might want to include a simple flowchart or other diagram rendered in plain text. Sites like Asciiflow let you create diagrams in plain text; also see this StackExchange post for assorted downloadable tools that work similarly and produce images like this:
That’s not to take the place of external, polished documentation, but often having internal documentation, close to the code, makes it more useful.
What to do about comments that explain code rationale?
Keep them. Nurture them. Shower them with kindness. They will repay you in spades.
Resource Inclusion
Code Complete calls this category “comments beyond the code”. This includes:
Copyright notice
License information
/* ***** BEGIN LICENSE BLOCK *****
* Version: MPL 1.1
*
* The contents of this file are subject to the Mozilla Public License Version
* 1.1 (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at http://www.mozilla.org/MPL/
* . . .
*
* ***** END LICENSE BLOCK *****
*/
Logos done in plain text (a form of “ASCII art”), as this one from AsciiWorld.com:
URL reference to relevant material, e.g. a link to where an algorithm came from. If I am using something verbatim I just say “from” but often I need to customize something I’ve found, so I preface with “adapted from” just to give the reader a bit more information.
// Adapted from http://www.csharp-examples.net/restart-windows-service/
public static class WindowsServiceController
{ . . . }
Lacking a specific reference, often just naming something can be helpful, allowing the reader to research the topic further if desired; this example is adapted from Code Complete:
function squareroot(num) {
// Newton-Raphson approximation to determine square root
Var r = num / 2;
while ( abs( r - (num/r) ) > TOLERANCE ) {
r = 0.5 * ( r + (num/r) );
}
return r;
}
File headers specifying file metadata, perhaps including version control key fields, the date the file was created, and what project it belongs to, as in this example showing Subversion key fields in the first line:
/*
* ==============================================================*
* ID $Id: FileMask.cs 971 2015-09-30 16:09:30Z ms $ *
* Created 2015-08-19 *
* Project http://cleancode.sourceforge.net/ *
* ==============================================================*
*
*/
What to do about resource comments?
These are typically necessary either for legal reasons or to follow company conventions or to lead a reader to original source material.
Witticisms
Code Complete refers to this category as “self-indulgent comments”; Wikipedia refers to it as “stress relief”. This fine example, in assembly language, comes verbatim from Code Complete, section 32.5:
Many years ago, I heard the story of a maintenance programmer who was called out of bed to fix a malfunctioning program. The program’s author had left the company and couldn’t be reached. The maintenance programmer hadn’t worked on the program before, and after examining the documentation carefully, he found only one comment. It looked like this:
MOV AX, 723h ; R. I. P. L. V. B.
After working with the program through the night and puzzling over the comment, the programmer made a successful patch and went home to bed. Months later, he met the program’s author at a conference and found out that the comment stood for “Rest in peace, Ludwig van Beethoven.” Beethoven died in 1827 (decimal), which is 723 (hexadecimal). The fact that 723h was needed in that spot had nothing to do with the comment. Aaarrrrghhhhh!
That one is rather esoteric, but there are many that are more… enlightening. Here is a sampling:
/**
* For the brave souls who get this far: You are the chosen ones,
* the valiant knights of programming who toil away, without rest,
* fixing our most awful code. To you, true saviors, kings of men,
* I say this: never gonna give you up, never gonna let you down,
* never gonna run around and desert you. Never gonna make you cry,
* never gonna say goodbye. Never gonna tell a lie and hurt you.
*/
And a few others found amidst the myriad of other responses to the same StackOverflow question:
/* I don't know how you can ever get here so I'll have to fix it later */
// This is a kind of magic...
-- Change Log: Not needed. The code is perfect 'cause I wrote it.
-- If you change it, it will break.
// I don't know why. Just move on.
// This should fix something that should never happen
What to do about witty comments?
It is with some measure of reluctance that I must say that many of them should be struck out. But for those neither in bad taste nor obscure, you might want to leave them be just to bring a smile to some future reader’s face.
API Doc-Comments
Many, many applications today are all about creating a library with a published API for your customers to utilize said library. Such APIs are typically generated programmatically from documentation comments (doc-comments) embedded in your source code. In the .NET world, for example, you need to enable documentation generation for each project you are concerned with, under the project’s Build properties, as shown.
The C# compiler then processes doc-comments for those projects, creating an intermediary XML file that can be used by tools like Sandcastle to create final, user-facing documentation; see XML Documentation Comments for further details. In the Java world, Javadoc works in very much the same way on embedded doc-comments.
Doc-comments should be applied to every public member of your class, i.e. all those exposed in your public API. You are not restricted to just the public members, but in the spirit of keeping comments to a minimum, my suggestion is to limit yourself to those. Even so, there are good doc-comments and bad doc-comments. For the FitsOneOfMultipleMasks method below, here’s a bad doc-comment.
/// <summary>
/// Determines whether the given file name fits one of multiple masks.
/// </summary>
/// <param name="fileName">Name of the file</param>
/// <returns>Boolean</returns>
public bool FitsOneOfMultipleMasks(string fileName)
{ . . . }
Though it includes the requisite summary, parameter, and return value fields, this is really just a disguised instance of the comment category “repeating the code in different words”. These comments do not add anything of value. They do not help the user of your API determine how to use the method any more than reading the method signature already provided. Also, depending on the documentation generator, it might even know how to generate such comments by itself were they omitted here!
Here is the same method with a bit more useful doc-comments. The summary could arguably be expanded more, but at least by using different words it gives the reader another perspective. Together with the detail added to the input and output, it provides the reader with some useful information.
/// <summary>
/// Determines whether the given file name matches
/// one or more of the specified masks.
/// </summary>
///
/// <param name="fileName">Name of the file.
/// Multiple masks may be included (in the <see cref="Mask"/> property)
/// by separating them with lines, commas, spaces, or vertical bars.</param>
///
/// <returns>Boolean indicating whether the file name matches
/// one or more masks.</returns>
public bool FitsOneOfMultipleMasks(string fileName)
{ . . . }
What to do about doc- comments?
Make them meaningful by being aware of your audience, likely someone who, unlike you, is not intimately familiar with the code.
Commented-out Code
Most IDEs make it easy to comment out an arbitrary block of code, usually with a single keystroke. This is quite helpful as you are probing, experimenting, and otherwise trying out your ideas as you mold and refine your code. But once you have solidified your algorithms any leftover commented out code blocks should be removed; they have no business being in production code. If you are met with resistance to this—often put forth with contrition with “But we might need it again someday.” —your quick response should just be “that is what source control is for!” Indeed, any project using source control—which should of course be all projects containing at least one line of code(!)—has no need of such baggage comments. You can always go back to a prior version of your code to retrieve lines that have been deleted.
What to do about commented-out code?
Remove them!
Syntax Extension
This embeds pseudo-code constructs within regular comments so that they are largely ignored, except by a processor (or pre-processor) specifically looking for them. A widely known example of this is conditional comments from Internet Explorer, versions 5 through 9. You could, for example, write this to include a specific CSS file for version 8 of Internet Explorer only:
Though support for such conditional comments was removed from IE version 10 and above, if you really need it you can simply tell a browser to use IE 9 emulation with this header:
That works at least for IE 10 and IE 11, according to this post. Conditional comments are one type of syntax extension. I am not aware of other uses of conditional comments (other than for an application I created a couple decades ago to allow a single file to support multiple versions of Pascal simultaneously.
Syntax extension, more generally, implements the Hot Comments pattern, allowing a way to extend a non-extensible format. You have already seen another use of this above with doc-comments. Both Java’s and C#’s doc-comments make use of this “Hot Comments” pattern.
What to do about syntax extension comments?
Your legacy system may require them, or you may have other logistical reasons for needing them. Either way, keep them as long as you need them.
Conclusion
The next time someone wants to convince you that comments are absolutely required, or conversely, that comments should never be used at all, you can now say, “Whoa!” (That’s American shorthand for “I must stop you right there, good sir or madam, as there are points you should consider before making such a hasty generalization.”) And you continue, “To which of the 9 types of comments do you refer?” Then you can wax eloquently on whether to use or not use the type of comment under discussion.
At that point I hadn’t played with the new SQL Server 2017. While later, when I did, I got surprised by the new ‘Queries with High Variation’ graph included in query store. This new graph can help you identifying parameterization problems.
As I explained in the article, parameterization problems creates a high variation of the query execution. Sometimes the query runs well and very fast, sometimes the query will be very slow. Query Store keeps track of the standard deviation of the query execution and, due to the parameterization problem, the standard deviation will be high.
The new graph, ‘Queries with High Variation’, allows us to easily identify the queries with most severe parameterization problems. We can use the graph to achieve a first view of these queries and only after that get more details using the queries I explained my previous article.
In the “Based On” box, over the graph, we have two options: Variation or Standard Deviation. The ‘Standard Deviation’ option gives a better result to illustrate parameterization problems. I suggest the use of ‘Standard Deviation’ together ‘CPU Time’ in the box ‘Metric’ to achieve better result.
Let’s do a small walkthrough to illustrate how this new graph will react to a parameterization problem.
1) The following script will create a new database. Don’t forget to correct the path of the files.
use master go
— Criando todo o ambiente drop database if exists qstore_demo
CREATE DATABASE [qstore_demo] ON PRIMARY ( NAME = N’qs_demo’, FILENAME = N’C:\dbfiles\qs_demo.mdf’ , SIZE = 102400KB , MAXSIZE = 1024000KB , FILEGROWTH = 20480KB ) LOG ON ( NAME = N’qs_demo_log’, FILENAME = N’C:\dbfiles\qs_demo_log.ldf’ , SIZE = 50480KB , MAXSIZE = 1024000KB , FILEGROWTH = 20480KB ) GO ALTER DATABASE [qstore_demo] SET QUERY_STORE (INTERVAL_LENGTH_MINUTES = 1) go ALTER DATABASE [qstore_demo] SET QUERY_STORE = OFF GO
USE qstore_demo GO
2) Let’s create the database objects, a table and a stored procedure
— create a table CREATE TABLE dbo.db_store (c1 CHAR(3) NOT NULL, c2 CHAR(3) NOT NULL, c3 SMALLINT NULL)GOCREATE NONCLUSTERED INDEX NCI_1 ON dbo.db_store (c3)GO
— create a stored procedure
CREATE PROC dbo.proc_1 @par1 SMALLINT AS SET NOCOUNT ON SELECT c1, c2 FROM dbo.db_store WHERE c3 = @par1
GO
3) Insert a lot of records. This will take a while to execute. Pay heed to the uneven data distribution in field c3.
SET nocount ON go
INSERT INTO [dbo].db_store
(c1,
c2,
c3) SELECT ’18’,
‘2f’,
2
go 20000
INSERT INTO [dbo].db_store
(c1,
c2) SELECT ‘171’,
‘1ff’
go 4000
INSERT INTO [dbo].db_store
(c1,
c2,
c3) SELECT ‘172’,
‘1ff’,
0
go 10
INSERT INTO [dbo].db_store
(c1,
c2,
c3) SELECT ‘172’,
‘1ff’,
4
go 15000
4) Execute the procedure. Using ‘0’ as the parameter the procedure will use the index.
EXEC dbo.Proc_1 0 go 20
5) Execute the procedure again, with a different parameter, ‘2’. This time the procedure shouldn’t use the index, but it will because the plan is already in the cache.
EXEC dbo.Proc_1 2 go 20
6) Check the ‘Queries with high variation’ graph, selecting ‘CPU Time’ and ‘Standard Deviation’ in the boxes ‘Metric’ and ‘Based On’
As you may notice, our query with parameterization problem has the highest standard deviation in the graph. This graph will call our attention to parameterization problems before we start the queries I explained in the previous article.
SQL Server 2017 will be bringing us support for some of the functionality of graph databases. Graph databases are unlike relational databases in that they represent data as nodes, edges and properties within a ‘graph’, which is an abstract data type representing relationships or connections as a set of vertices nodes, points and edges, like a tangled fish-net. They allow us to represent and traverse relationships between entities in easier ways than is possible with the traditional relational database.
Graph objects are built to represent complex relationships. A hierarchy is a special case of a graph and is useful to record such things as relationship between forum posts and their replies, likes in forum posts, and friendship between people. Hierarchies have a root node (forum post and replies, for example), but many graphs don’t have a root node (people friendship, for example).
In this article, we’ll be building a forum example using the new graph model. I will also compare the complexity of the queries between the graph and a relational model and calling your attention for what’s still missing in this first version. Yes, it’s a Beta technology in its early stages.
This is the Entity-relationship model I will use for comparison:
If you would like to follow along and try out some comparisons, you can create this entity-relational model with the script below, or you can go directly to the graph model. However, you need to create the new database, ‘GraphExample’, using SSMS.
create database GraphExample
go
-- Trying an entire graph model
use GraphExample
go
create schema Forum
go
create table Forum.ForumMembers
(MemberId int not null primary key Identity(1,1),
MemberName varchar(100))
go
create table Forum.ForumPosts
([PostID] int not null primary key,
PostTitle varchar(100),
PostBody varchar(100),
OwnerID int,
ReplyTo int)
go
Create table Forum.Likes
(MemberId int,
PostId int)
go
create table Forum.LikeMember
(MemberId int,
LikedMemberId int)
go
INSERT Forum.ForumMembers values('Mike'),('Carl'),('Paul'),('Christy'),('Jennifer'),('Charlie')
go
INSERT INTO [Forum].[ForumPosts]
(
[PostID]
,[PostTitle]
,[PostBody],OwnerID, ReplyTo
)
VALUES
(4,'Geography','Im Christy from USA',4,null),
(1,'Intro','Hi There This is Carl',2,null)
INSERT INTO [Forum].[ForumPosts]
(
[PostID]
,[PostTitle]
,[PostBody],OwnerID, ReplyTo
)
VALUES
(8,'Intro','nice to see all here!',1,1),
(7,'Intro','I''m Mike from Argentina',1,1),
(6,'Re:Geography','I''m Mike from Argentina',1,4),
(5,'Re:Geography','I''m Jennifer from Brazil',5,4),
(3,'Re: Intro','Hey Paul This is Christy',4,2),
(2,'Intro','Hello I''m Paul',3,1)
go
INSERT Forum.Likes VALUES (1,4),
(2,7),
(2,8),
(2,2),
(4,5),
(4,6),
(1,2),
(3,7),
(3,8),
(5,4)
go
Insert Forum.LikeMember VALUES (2,1),
(2,3),
(4,1),
(4,5)
The Graph Model
The planning of a graph model is quite different than the relational model. Tables in a graph model can be Edges or Nodes, we need to decide which tables will be edges and which tables will be nodes.
This image illustrates our graph model:
The decision between nodes and edges in our model is simple: All the entities in a logical model will be nodes, while all the relations in the logical model will be edges. In our model, we have ‘Posts’ and ‘Members’ as entities, ‘Reply To’, ‘Like’ and ‘Written By’ as relations.
Architectural Notes
Nodes and Edges are nothing more than tables with some special fields. There’s no restriction that forbids us to create regular relationships between these tables, turning the model into a mix of relational and graph model.
For example, the relationship ‘Written By’ between ‘Posts’ and ‘Members’ is a simple one-to-many relationship. Instead of using an edge table, we could express it with a regular relation between these tables, creating a mixed model.
When we create a node entity, the entity receives a calculated field named ‘$node_id’. We could use this field as a primary key, SQL Server allows calculated fields to be the primary key of a table: However this field is a JSON field, which is not a good option for primary key for many reasons. For this reason, our nodes have to maintain two keys: The business key, an integer, and the ‘$node_id’ key, an auto-generated JSON key that also contains an integer.
This will be the script for our node entities:
Use GraphExample
go
CREATE TABLE [dbo].[ForumMembers](
[MemberID] [int] IDENTITY(1,1) NOT NULL,
[MemberName] [varchar](100) NULL
)
AS NODE
GO
CREATE TABLE [dbo].[ForumPosts](
[PostID] [int] NULL,
[PostTitle] [varchar](100) NULL,
[PostBody] [varchar](1000) NULL
)
AS NODE
Architectural Notes
After creating the objects, you can then examine the objects in Object Explorer. You may notice a new folder called ‘Graph’ inside the ‘Tables’ folder. All graph objects will be inside this folder.
You may also notice the name of the auto-generated fields. Although we can reference these fields with their short-name, for example, $node_id, the real name of the field includes a GUID. This short name is a pseudo-column and we can use it in our queries.
It is simple to insert the values into the node tables: We just ignore the pseudo-column ($node_id) and write simple INSERT statements. These will be our INSERTs:
INSERT ForumMembers values ('Mike'),('Carl'),('Paul'),('Christy'),('Jennifer'),('Charlie')
INSERT INTO [dbo].[ForumPosts]
(
[PostID]
,[PostTitle]
,[PostBody]
)
VALUES
(8,'Intro','nice to see all here!'),
(7,'Intro','I''m Mike from Argentina'),
(6,'Re:Geography','I''m Mike from Argentina'),
(5,'Re:Geography','I''m Jennifer from Brazil'),
(4,'Geography','Im Christy from USA'),
(3,'Re: Intro','Hey Paul This is Christy'),
(1,'Intro','Hi There This is Carl')
(2,'Intro','Hello I''m Paul')
You will see the result of SELECTing the records from the ForumPosts table in the image below. You may notice the field $node_id, a JSON field including the type of the entity and an integer id that is automatically generated.
Creating the Edge tables
The edge tables are very simple to create. Edge tables can have properties that would be regular fields in the table, however that’s not part of our example. This will be the script to create our edge tables:
Create table dbo.[Written_By]
as EDGE
CREATE TABLE [dbo].[Likes]
AS EDGE
CREATE TABLE [dbo].[Reply_To]
AS EDGE
Each edge table has three pseudo-columns that we need to deal with:
$edge_id: The id of the edge record
$from_id: One of the nodes in the edge record
$to_id: The other node in the edge record
Noticing this definition, you may be asking: “Oh, ‘One of the nodes’ is quite vague, isn’t it?”. Yes, sure! That’s an important point: We need to define, in a logical way, what the $to_id and $from_id fields for each edge will mean. You may also be noticing that the name of the edge tables already defines the $to_id and $from_id sides. This is a logical choice of the sides and a good use of the names to make things easier for us.
These will be our logical definitions:
Written_By:
$from_id will be the post
$to_id will be the member
Likes:
$from_id will be who likes
$to_id will be who/what is liked
Reply_To:
$from_id will be the reply to the main post
$to_id will be the main post
There is no technical restriction about these choices, but we need to keep them when inserting new records, never mixing the meaning of each side of the relation.
Architectural Notes
Besides the three pseudo-columns, all edge tables have some more fields, all of them are hidden fields.
We can see the hidden definition in the field properties and these hidden fields will not appear in query results.
Inserting Edge records
The insert statement for the edge tables needs to fill both sides of the edge, $From_id and $To_id. These fields need to be filled with the $node_id value of the record of each side.
For example, to relate a member with a forum post, the ‘Written_By’ record will have the $node_id value of the post in the $From_id field and the $node_id value of the member in the $To_id field.
These will be the inserts:
Insert into Written_By ($to_id,$from_id) values
(
(select $node_id from dbo.ForumMembers where MemberId= 1 ),
(select $node_id from dbo.ForumPosts where PostID=8 )
),
(
(select $node_id from dbo.ForumMembers where MemberId=1 ),
(select $node_id from dbo.ForumPosts where PostID=7 )
),
(
(select $node_id from dbo.ForumMembers where MemberId= 1 ),
(select $node_id from dbo.ForumPosts where PostID= 6)
),
(
(select $node_id from dbo.ForumMembers where MemberId=5 ),
(select $node_id from dbo.ForumPosts where PostID=5 )
),
(
(select $node_id from dbo.ForumMembers where MemberId=4 ),
(select $node_id from dbo.ForumPosts where PostID=4 )
),
(
(select $node_id from dbo.ForumMembers where MemberId=3 ),
(select $node_id from dbo.ForumPosts where PostID=3 )
),
(
(select $node_id from dbo.ForumMembers where MemberId=3 ),
(select $node_id from dbo.ForumPosts where PostID=1 )
),
(
(select $node_id from dbo.ForumMembers where MemberId=3 ),
(select $node_id from dbo.ForumPosts where PostID=2 )
)
Architectural Notes
It’s complex to build INSERTs like these, isn’t it? We will want to use an object framework with support for graph objects in the database. Today entity framework hasn’t got this feature, but we can expect to see something new about this in a while, either as a new feature for entity framework or as a new object model to map graph objects.
Let’s insert the replies records:
INSERT Reply_To ($to_id,$from_id)
VALUES
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 6)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 5)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3))
Finally, a let’s insert a lot of likes:
INSERT Likes ($to_id,$from_id)
VALUES
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 5),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 6),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 5))
The ‘Likes’ edge illustrates the capabilities of the edge feature rather well. We just inserted several relations between members and posts, but we now decide that in the application a member can also like another member. No problem, we can use the same edge to relate one member to another. In the relational model we need two tables for this, in the graph model, only a single edge.
Let’s insert more likes, now between members of the forum:
INSERT Likes ($to_id,$from_id)
VALUES
((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)),
((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 5),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4))
The Good: Building queries over the Graph Model
T-SQL brings some new syntax elements into use to query graph tables. We have a special statement to relate nodes and edges in a SELECT.
Let’s do a walkthrough to build a query that retrieves all the posts and their replies:
We will retrieve two posts in each record, the post and the reply, so we will need two references to the ‘ForumPosts’ table in the FROM clause of the select. Let’s do it with some meaningful aliases:
FROM dbo.ForumPosts ReplyPost, dbo.ForumPosts RepliedPost
Although we can, of course, use any alias we choose, it is best to use meaningful aliases when working with graph objects.
We need the relation between the posts, the relation is the table ‘Reply_to’.
FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost
In the WHERE clause, we need to relate all the tables. We can do this with the new MATCH clause:
FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost
WHERE MATCH(ReplyPost-(Reply_to)->RepliedPost)
The syntax is interesting: A single “-” (dash) means a relation with the $From_id field of the edge, and a dash and greather-than (->) means a relation with the $To_id field of the edge
Knowing which alias has the reply and which alias has the replied post, we can build the field list of the query.
-- Posts and their replies
select RepliedPost.PostId,RepliedPost.PostTitle,
ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle
From dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost
Where Match(ReplyPost-(Reply_to)->RepliedPost)
The same query in the relational model would be like this:
select RepliedPost.PostId,RepliedPost.PostTitle,
ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle
from Forum.ForumPosts ReplyPost, Forum.ForumPosts RepliedPost
where ReplyPost.PostId=RepliedPost.ReplyTo
These queries are very similar, although it’s possible to argue that the MATCH syntax is easier to understand
We can already execute this query. The result will be like the image below:
Let’s include the name of the member who wrote the replied post. We need to include the ‘ForumMembers’ node and the ‘Written_By’ edge in the FROM clause. The new FROM clause will be like this:
FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost, dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By
Include the relation inside the MATCH clause:
WHERE MATCH(ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)
Include the member name of the replied post in the field list of the SELECT. The final query will be this:
-- Posts and members and their replies
SELECT RepliedPost.PostId,RepliedPost.PostTitle,RepliedMember.MemberName,
ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle
FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost,
dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By
WHERE MATCH(ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)
The same query against the relational model:
SELECT RepliedPost.PostId,RepliedPost.PostTitle,
ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle,
RepliedMember.MemberName
FROM Forum.ForumPosts ReplyPost, Forum.ForumPosts RepliedPost,
Forum.ForumMembers RepliedMember
WHERE ReplyPost.PostId=RepliedPost.ReplyTo
and RepliedPost.OwnerId=RepliedMember.MemberId
The image below shows the result:
We still need to include the member name of the reply post. Again, we need to include the ‘ForumMembers’ and the ‘Written_By’ tables in the FROM clause:
The next step is correcting the MATCH clause. ‘ReplyMember’ needs to be related to ‘ReplyPost’, however, how to do this relation without breaking the others? Let’s do in a different direction:
WHERE MATCH(ReplyMember<-(ReplyWritten_By)-ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)
Notice the <- symbol. It’s in opposite direction than ->, however it’s the same meaning: a relation between $to_id of the edge table with the node table.
Finally, let’s include the name of the member who wrote the reply in the field list and execute the query:
-- Posts and members and their replies and members
SELECT RepliedPost.PostId, RepliedPost.PostTitle,RepliedMember.MemberName,
ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle,
ReplyMember.MemberName [ReplyMemberName]
FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost,
dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By,
dbo.ForumMembers ReplyMember, Written_By ReplyWritten_By
WHERE MATCH(ReplyMember<-(ReplyWritten_By)-ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)
The result is the following:
The same query against the relational model:
SELECT RepliedPost.PostId,RepliedPost.PostTitle,
RepliedMember.MemberName, ReplyPost.PostId as ReplyId,
ReplyPost.PostTitle as ReplyTitle, ReplyMember.MemberName
FROM Forum.ForumPosts ReplyPost, Forum.ForumPosts RepliedPost,
Forum.ForumMembers RepliedMember, Forum.ForumMembers ReplyMember
WHERE ReplyPost.PostId=RepliedPost.ReplyTo
and RepliedPost.OwnerId=RepliedMember.MemberId
and ReplyPost.OwnerId=ReplyMember.MemberId
At this point you may be noticing that according to the increasing of the number of relations the WHERE clause in the relational model will be much harder to read than the MATCH clause in the graph model.
Let’s see some more interesting and useful queries against the graph model.
Count of Replies of each Post
-- Count of replies of each post
SELECT distinct RepliedPost.PostID,RepliedPost.PostTitle,
RepliedPost.PostBody,
count(ReplyPost.PostID) over(partition by RepliedPost.PostID)
as TotalReplies
FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost
WHERE MATCH(ReplyPost-(Reply_To)->RepliedPost)
In this one we have the count of replies in each post, however only in a single level, not in a tree of replies.
List of Root Posts
We can get all the root posts without the MATCH syntax:
-- All the root posts
SELECT Post1.PostId,Post1.PostTitle
FROM dbo.ForumPosts Post1
WHERE $node_id not in (select $from_id from dbo.Reply_To)
The MATCH syntax only allows us to relate three or more entities (two nodes and one relation). When we want to relate only two of them, we can do a regular join or sub-query, as the above.
Including a Level field in the result
It can be useful to include a ‘Level’ field to expose the structure as a tree. We have a syntax for this in T-SQL: The recursive CTE (Common Table Expression).
However, there is a catch: We can’t use the MATCH syntax over a derived table, in this case the CTE. We can, if needed, use the MATCH syntax in the CTE, but we can’t reference the CTE in it. This is a limitation.
We can, however, use the recursive CTE syntax without be MATCH syntax, using regular relations. The result will be this:
-- All replies with tree level
with root as
( select $node_id as node_id,RootPosts.PostId,
RootPosts.PostTitle,
1 as Level, 0 as ReplyTo
from dbo.ForumPosts RootPosts
where $node_id not in (select $from_id from dbo.reply_to)
union all
select $node_id,ReplyPost.PostId, ReplyPost.PostTitle,
Level+1 as [Level], root.PostId as ReplyTo
from dbo.ForumPosts ReplyPost, reply_to, root
where ReplyPost.$node_id=reply_to.$from_id
and root.node_id=reply_to.$to_id
)
select PostId,PostTitle, Level, ReplyTo
from root
Retrieve all replies of a single post
Using the recursive CTE syntax, we can retrieve all the replies of a single post in a tree style. If we try to retrieve all replies of post 1 using a regular syntax we won’t retrieve the post 3 and we should, because post 3 is a reply to post 2, which is a reply to post 1.
We can only retrieve post 3 when querying the replies of post 1 using the recursive CTE syntax.
This will be the query to retrieve all replies of a single post:
-- All replies of a single post
with root as
( select $node_id as node_id,RootPosts.PostId,RootPosts.PostTitle,
1 as Level, 0 as ReplyTo
from dbo.ForumPosts RootPosts
where PostId=1
union all
select $node_id,ReplyPost.PostId, ReplyPost.PostTitle,
Level+1 as [Level],root.PostId as ReplyTo
from dbo.ForumPosts ReplyPost, reply_to, root
where ReplyPost.$node_id=reply_to.$from_id
and root.node_id=reply_to.$to_id
)
select PostId,PostTitle, Level, ReplyTo
from root
We can also do it in reverse, in order to retrieve all parent posts of a single post in a tree structure. For this we need to do the relations inside the CTE to retrieve the posts and at the outside do some OUTER JOINs to retrieve the parent of each post. It needs to be an OUTER JOIN because the main post has no parent. It also needs to be in the outside of the CTE because the recursive part of the CTE doesn’t support OUTER JOINs.
This brings another point to our attention: There isn’t an OUTER in the MATCH syntax.
-- All the parents of a single post, with reference to their parents
with root as
( select LeafPost.$node_id as node_id,LeafPost.PostId,
LeafPost.PostTitle
from dbo.ForumPosts LeafPost
where LeafPost.PostId=3 -- Single post
union all
select RepliedPost.$node_id as node_id,RepliedPost.PostId,
RepliedPost.PostTitle
from dbo.ForumPosts RepliedPost, Reply_to, root
where root.node_id=Reply_to.$from_id
and Reply_to.$to_id=RepliedPost.$node_id
)
select root.PostId,root.PostTitle,
RepliedPost.PostId ParentPostId
from root
left join reply_to
on root.node_id=reply_to.$from_id
left join dbo.ForumPosts RepliedPost
on reply_to.$to_id=RepliedPost.$node_id
Recovering the posts of a single user
Recovering the information of a single user, instead of a post, is easier because there isn’t a tree in this situation:
-- All Post replied by Peter
SELECT distinct RepliedPost.PostID,RepliedPost.PostTitle,
RepliedPost.PostBody
FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost,
dbo.ForumMembers Members,Written_By
WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost)
and Members.MemberName='Peter'
-- All replies made by Peter
SELECT ReplyPost.PostID,ReplyPost.PostTitle,ReplyPost.PostBody,
RepliedPost.PostId ReplyTo
FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost,
dbo.ForumMembers Members,Written_By
WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost)
and Members.MemberName='Peter'
You may notice the only difference between the queries above is the field list and the use of DISTINCT. The DISTINCT is needed because Peter can reply the same post more than once.
Retrieving the Likes from the model
The queries to retrieve the ‘Likes’ are interesting: The ‘Likes’ edge has relations between members and between members and posts. Each of these selects brings only one of these kinds of relation and ignores the other.
-- All posts that have likes and who liked them
SELECT Post.PostID,Post.PostTitle,Member.MemberName
FROM dbo.ForumPosts Post, Likes,
dbo.ForumMembers Member
WHERE MATCH(Member-(Likes)->Post)
-- All members that have likes and who liked them
SELECT Member.MemberId,Member.MemberName LikeMember,
LikedMember.MemberName LikedMemberName
FROM dbo.ForumMembers Member, Likes, dbo.ForumMembers LikedMember
WHERE MATCH(Member-(Likes)->LikedMember)
It is also easy to aggregate the information to get the total of likes of each post or each member.
-- Total likes of each Post
select Post.PostId,Post.PostTitle,
count(*) totalLikes
from dbo.ForumPosts Post,Likes,
dbo.ForumMembers Members
where Match(Members-(Likes)->Post)
group by PostId,PostTitle
-- Total likes of each Member
select LikedMembers.MemberId,LikedMembers.MemberName,
count(*) totalLikes
from dbo.ForumMembers Members,Likes,
dbo.ForumMembers LikedMembers
where Match(Members-(Likes)->LikedMembers)
group by LikedMembers.MemberId,
LikedMembers.MemberName
Members who liked and replied to the same post
We can build even some more interesting queries. For example, who are the members who liked and replied to a post?
This is the query:
-- Members who liked and replied on same post
SELECT Member.MemberName,Member.Memberid,
LikedPost.PostId,LikedPost.PostTitle,
ReplyPost.PostTitle ReplyTitle
FROM dbo.ForumPosts LikedPost, Reply_To, dbo.ForumPosts ReplyPost,
Likes, dbo.ForumMembers Member, Written_By
WHERE MATCH(Member-(Likes)->LikedPost<-(Reply_To)-ReplyPost-(Written_By)->Member)
You may notice the use of the node ‘Member’ two times in the same MATCH expression. This creates a kind of a filter: The member who liked the ‘LikedPost’ needs to be the same member who wrote the ‘ReplyPost’.
This one, over the relational model, would be like this:
select Likes.MemberId,Members.MemberName
from Forum.Likes Likes, Forum.ForumPosts Posts,
Forum.ForumMembers Members
where Likes.MemberId=Posts.OwnerId
and Posts.ReplyTo=Likes.PostId
and Members.MemberId=Likes.MemberId
It seems for me more difficult to build and read over the relational model.
Members who replied to multiple posts
SELECT Members.MemberId, Members.MemberName,
Count(distinct RepliedPost.PostId) as Total
FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost,
Written_By,dbo.ForumMembers Members
WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost)
GROUP BY MemberId, Members.MemberName
Having Count(RepliedPost.PostId) >1
Members who replied multiple times to the same post:
SELECT Members.MemberId, Members.MemberName,
RepliedPost.PostId RepliedId,count(*) as TotalReplies
FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost,
Written_By,dbo.ForumMembers Members
WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost)
GROUP BY MemberId,MemberName,RepliedPost.PostId
Having count(*) >1
The only differences between the two above are the field list and aggregation.
Missing features for queries
You probably don’t like the requirement to use recursive CTE to retrieve a tree of nodes. That’s because a feature called transitive closure, usually present in graph databases, isn’t available in this first version.
The ability to find any type of node connected to a single node, for example, all replies and likes of a post, is called polymorphism and isn’t available in this version. We can use UNION to solve this for small sets of node types.
Some graph-specific functions, such as the ability to find the ‘shortest path’ between two forum members, isn’t available in this version.
The Bad: Edge records validation
As well as all the missing features, with a lot of room for improvement, I found problems with the validation of the relations inserted in the model. You may have noticed that it’s too easy to create an edge table. That’s because we don’t need to identify the possible relations of that edge.
This creates some validation problems. For example, the ‘Reply_To’ edge: A forum message can be a reply to another single forum message, however, I shouldn’t be able to insert the same forum message as a reply of two others.
The model doesn’t validate this. We shouldn’t be able to execute the insert below because the message ‘3’ is already a reply to message ‘2’. However, the insert will work:
Insert Reply_to Values
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4))
After trying the insert, delete the inserted record:
delete reply_to
from reply_to, dbo.forumposts replypost,
dbo.forumposts repliedpost
where MATCH(replypost-(reply_to)->repliedpost)
and replypost.postid=3
and repliedpost.postid=4
How can we solve this problem?
The graph calculated field doesn’t support constraints. The only solution for this problem is the creation of triggers over our edge tables. In this example, we will need a trigger for INSERT and UPDATE.
The following trigger will solve the problem:
create trigger chkReplies on dbo.Reply_to
for insert,update
as
begin
if exists( select 1 from inserted
where
(SELECT count(*)
FROM dbo.ForumPosts ReplyPost, Reply_To,
dbo.ForumPosts RepliedPost
WHERE MATCH(ReplyPost-(Reply_To)->RepliedPost)
and ReplyPost.$node_id=inserted.$from_id)
>1 )
begin
raiserror('One message can only be reply to another single message',13,1)
rollback transaction
end
end
Try the INSERT again and this time you will the error message:
Insert Reply_to Values
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4))
Deleting Parent records with Children
This is another interesting problem. The relation isn’t enforced, so we can delete parent records even when they have children. You can try this:
Begin Transaction
-- This delete works, unfortunately.
Delete dbo.forumposts where postid=1
-- Posts and their replies
select RepliedPost.PostId,RepliedPost.PostTitle,
ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle
From dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost
Where Match(ReplyPost-(Reply_to)->RepliedPost)
You will notice that the result in the SELECT will have several NULL values because of the deleted record. We can’t even insert the record again, because the relation is done by the $node_id value, which is auto-generated.
Undo the change with a rollback:
Rollback transaction
We can’t solve this with a simple relationship, such as foreign key constraint, first because the graph pseudo-columns don’t support constraints and also because this would be an impossible solution for and edge such as ‘Likes’, which accepts multiple types of nodes.
Again, the solution is a trigger:
create trigger chkNotOrphanReply on dbo.ForumPosts
for delete
as
if exists(select 1 from deleted
where
(SELECT count(*)
FROM Reply_To
WHERE $to_id=deleted.$node_id)
>0
)
begin
raiserror('This message can''t be deleted because it has replies',13,1)
rollback transaction
end
After creating the trigger, execute this block of code again and you will see the error message:
Begin Transaction
-- This delete works, unfortunatelly.
Delete dbo.forumposts where postid=1
-- Posts and their replies
select RepliedPost.PostId,RepliedPost.PostTitle,
ReplyPost.PostId as ReplyId,
ReplyPost.PostTitle as ReplyTitle
From dbo.ForumPosts ReplyPost, dbo.Reply_to,
dbo.ForumPosts RepliedPost
Where Match(ReplyPost-(Reply_to)->RepliedPost)
One Forum post shouldn’t like another forum post
The ‘Likes’ edge is much more flexible, however has also its problems. We shouldn’t be able to insert a like between two forum posts, but the model will accept it. The following insert will work:
--This insert should not be accepted, but it is
INSERT Likes ($to_id,$from_id) VALUES
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7))
After trying the insert above, delete the inserted record and any like between posts:
-- Deleting
delete likes
from likes, dbo.forumposts post1,
dbo.forumposts post2
where MATCH(Post1-(likes)->Post2)
Again, the solution will be a trigger. However, this time we need to check the type of record inserted in the relation. We can use the function JSON_VALUE to extract this information. The JSON_VALUE function can extract information from any JSON field, including the calculated graph fields.
For example, the following SELECT will extract the type of each record inserted in the $from_id field part of the like:
select json_value($from_id, '$.schema') as [schema],
json_value($from_id, '$.table') as [table]
from likes
We can use this function in a trigger for insert/update. The trigger will be this:
Create trigger chkLikeType on Likes
for Insert,Update
as
if exists (select 1 from inserted
where json_value($from_id, '$.schema')<>'dbo' or
json_value($from_id, '$.table')<>'ForumMembers')
begin
raiserror('Only forum members can like a post or another member',13,1)
rollback transaction
end
After creating the trigger, you can try the insert again, it will not be accepted:
--This insert should not be accepted, but it is
INSERT Likes ($to_id,$from_id) VALUES
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7))
Missing Validation Features
All these problems should be solved with some kind of validation syntax on the creation of edge nodes. We should be able to constrain the types of entities that are allowed in the edge node and whether we will allow more than one record with the same entity.
This syntax would avoid the need for triggers. The support for a range of constraints would make the system much more robust.
Conclusion
It’s a first version, SQL Graph in SQL Server 2017 is very promising, even though there are a lot of missing features at this stage. There is plenty to do before this becomes usable and robust, but there is enough so far to be hopeful that Microsoft can deliver a fully-functional graph database within SQL Server
At the moment, there is little or any information about how soon we can expect to see the tools that a development is likely to need. We need an object model with support for this, Entity Framework doesn’t support these kind of database objects and I’m not sure if the best option really is to join relational and graph models in the same object model.
We need a tool to design this model. Besides the needed support for validation in the syntax of edge nodes, a tool to design this, such as database diagram is for relational models, will be very useful.
After reading this article, probably would like to check:
The documentation and architecture of this model. This link will be useful
More examples. This link will be useful, it’s a bigger sample and the only link I found talking also about the performance of the graph model
More references and other links. This summary of several references will be useful link.
Microservices can certainly be made to work well for particular types of applications, but is it relevant to the mainstream? Can it replace the traditional architectures of database-driven applications?
Microservice architecture is a type of service-oriented architecture that was developed from the concept of Domain-Driven design (DDD) and consists of loosely-coupled services that are network-based.
It was devised as a way of avoiding the difficulties that are faced when extending a conventional ‘monolithic’ business application to deliver new functionality, which would generally incur the pain of re-engineering parts of a large central database, which performs many interdependent processes. Instead, we define a set microservices, each one with a well-defined scope that it is limited to, but comprehensively covers, a set of business processes that pertain to a single bounded context. This allows relatively autonomous teams to develop functionality in parallel.
It also means that for any particular microservice, you can change code without knowing anything about the internals of the other cooperating microservices, because you don’t share data structures, database schemata, or other internal representations of objects. You interact strictly through clearly-defined APIs.
However, by cutting out the ‘monolith’, you now need to move data safely, between services, and abandon a half century of painfully-won expertise in maintaining referential integrity, handling concurrent usage and managing transactions. This brings with it some substantial challenges, when designing the microservices architecture:
You can’t easily evolve the microservice APIs as your understanding of the domain improves. It isn’t just a matter of understanding the service itself, but also the wider context.
You place faith in the reliability and performance of the network, but need to managing network errors and service interruptions, and come up with strategies for such things as resiliency, caching and high latency.
Each internal database still needs to be part of your organisation’s auditing strategy. Can you, for example, track changes as part of a fraud investigation?
You still need a coordinated approach to defining every datatype that is to be publicly consumed. This can turn out to be extraordinarily complicated.
Databases that are used only by a microservices but hold personal data are still subject to international rules on data privacy, retention and so on.
You have to rely on a central service for managing distributed transactions.
Microservices have highlighted the inadequacies of the monolithic approach, but do they avoid the problems or merely kick them down the road a bit? Perhaps a more generally-useful approach is to tackle the inflexibility of large relational databases, by changing the way we design databases. Instead of assuming that relational databases are inherently difficult to change quickly, shouldn’t we find a way of doing it? If so, then how? What do you think?
Commentary Competition
Enjoyed the topic? Have a relevant anecdote? Disagree with the author? Leave your two cents on this post in the comments below, and our favourite response will win a $50 Amazon gift card. The competition closes two weeks from the date of publication, and the winner will be announced in the next Simple Talk newsletter.
Bundeskanzlerin Angela Merkel (CDU) zeichnet ein düsteres Zukunftsbild der Automobilindustrie. Diese werde in der heutigen Form nicht überleben, sagt sie. Die Bundesumweltministerin will derweil Steuerprivilegien für Diesel abschaffen. (Auto, Technologie)











 Kernkraft soll bis zum Jahr 2025 nur noch die Hälfte des Strommixes in Frankreich ausmachen. Um das zu erreichen, sollen mehrere Kraftwerke vom Netz gehen.
Kernkraft soll bis zum Jahr 2025 nur noch die Hälfte des Strommixes in Frankreich ausmachen. Um das zu erreichen, sollen mehrere Kraftwerke vom Netz gehen.
 Im Nordosten Deutschlands haben Kunden aus dem früheren E-Plus-Netz jetzt die gleiche LTE-Abdeckung wie o2-Kunden zur Verfügung. In Süddeutschland erfolgte die Angleichung schon vor einigen Monaten.
Im Nordosten Deutschlands haben Kunden aus dem früheren E-Plus-Netz jetzt die gleiche LTE-Abdeckung wie o2-Kunden zur Verfügung. In Süddeutschland erfolgte die Angleichung schon vor einigen Monaten.



 Bei Allianz Technology sollen massiv IT-Jobs abgebaut werden. Bis Ende Oktober ist das Abfindungsprogramm noch freiwillig. (Verdi)
Bei Allianz Technology sollen massiv IT-Jobs abgebaut werden. Bis Ende Oktober ist das Abfindungsprogramm noch freiwillig. (Verdi) 
 Immer mehr Jungs wachsen ganz ohne Männer auf. Daraus resultiert das, was heute oft fälschlicherweise als "toxische Männlichkeit" bezeichnet wird.
Immer mehr Jungs wachsen ganz ohne Männer auf. Daraus resultiert das, was heute oft fälschlicherweise als "toxische Männlichkeit" bezeichnet wird.


 Peter Tauber sieht für das Wohnprojekt Rigaer Straße und die Rote Flora keine Existenzberechtigung. CDU-Politiker fordern die Wiedereinführung der Extremismusklausel.
Peter Tauber sieht für das Wohnprojekt Rigaer Straße und die Rote Flora keine Existenzberechtigung. CDU-Politiker fordern die Wiedereinführung der Extremismusklausel.


























 Energie, die wir aus der Umgebung aufnehmen, z.B. qualitativ hochstehende Wärme, mit der wir uns wärmen können, strahlen wir als verbrauchte Wärme wieder ab. Sie kann nicht mehr verwendet werden. Noch abstrakter wird es mit der Information. Zwar können wir uns noch vorstellen, was neue Information ist, mit der wir uns am Leben erhalten können, z.B. Informationen über Feinde, vor denen wir fliehen sollten. Was ist aber verbrauchte Information, die wir wieder in die Umgebung exportieren müssen? Ernst Ulrich von Weizsäcker (geb. 1939) sprach von erstmaliger und bestätigter Information. Erstmalige Information benötigen wir, um lebenswichtige Handlungen auszuführen. Ist sie bestätigt, nützt sie uns nichts mehr. Wir vergessen sie, was der Vernichtung oder dem Export gleichkommt.
Energie, die wir aus der Umgebung aufnehmen, z.B. qualitativ hochstehende Wärme, mit der wir uns wärmen können, strahlen wir als verbrauchte Wärme wieder ab. Sie kann nicht mehr verwendet werden. Noch abstrakter wird es mit der Information. Zwar können wir uns noch vorstellen, was neue Information ist, mit der wir uns am Leben erhalten können, z.B. Informationen über Feinde, vor denen wir fliehen sollten. Was ist aber verbrauchte Information, die wir wieder in die Umgebung exportieren müssen? Ernst Ulrich von Weizsäcker (geb. 1939) sprach von erstmaliger und bestätigter Information. Erstmalige Information benötigen wir, um lebenswichtige Handlungen auszuführen. Ist sie bestätigt, nützt sie uns nichts mehr. Wir vergessen sie, was der Vernichtung oder dem Export gleichkommt. Ein russischer Kunde von Siemens soll Gasturbinen auf die Krim geliefert und damit gegen Sanktionen verstoßen haben. Der Münchener Konzern sieht sich hintergangen.
Ein russischer Kunde von Siemens soll Gasturbinen auf die Krim geliefert und damit gegen Sanktionen verstoßen haben. Der Münchener Konzern sieht sich hintergangen.
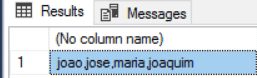


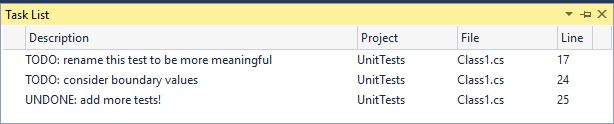
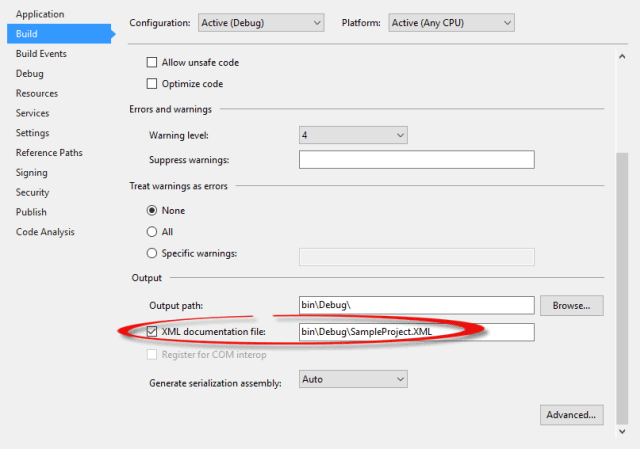


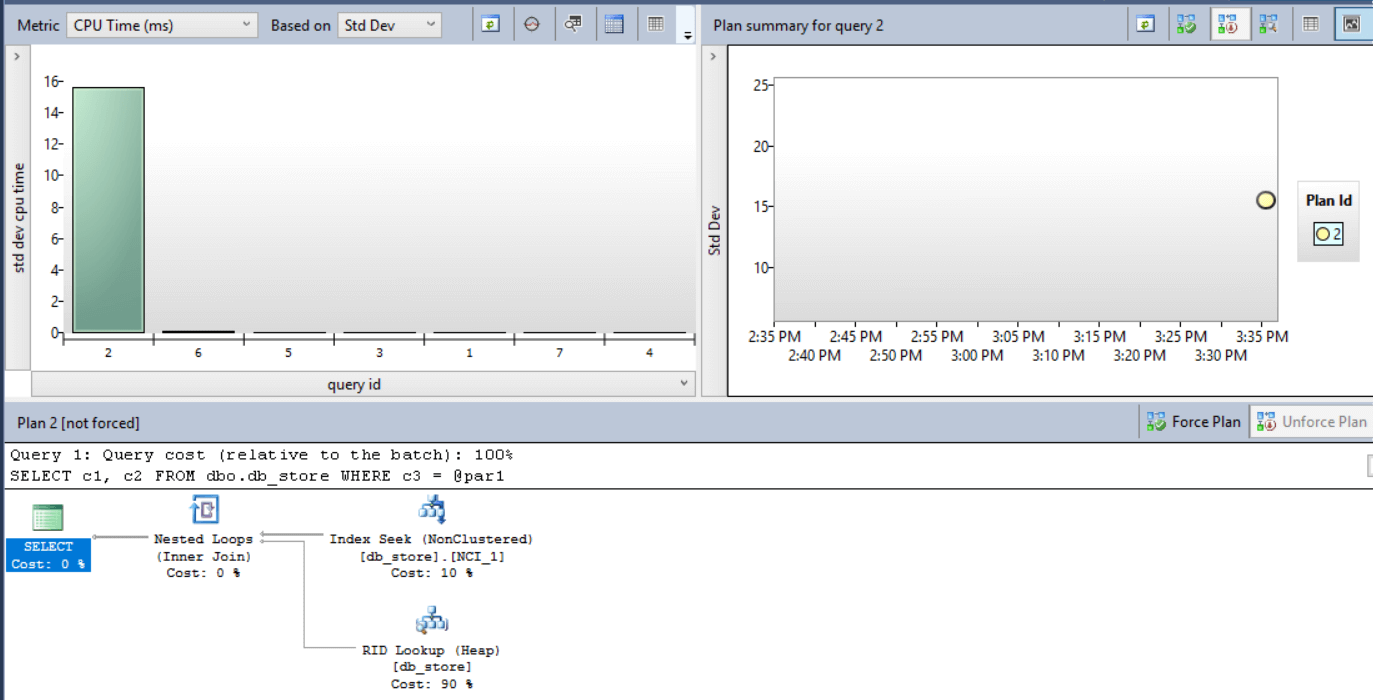
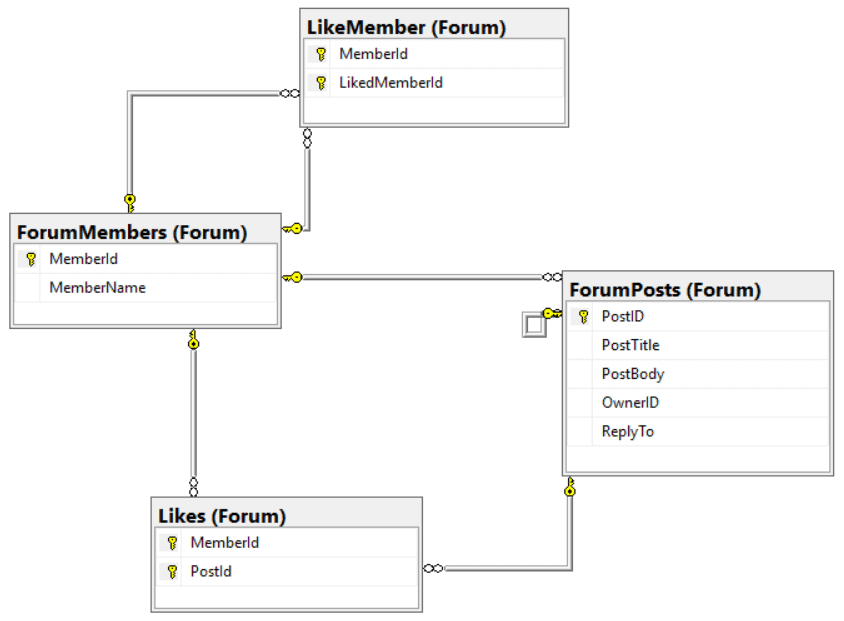
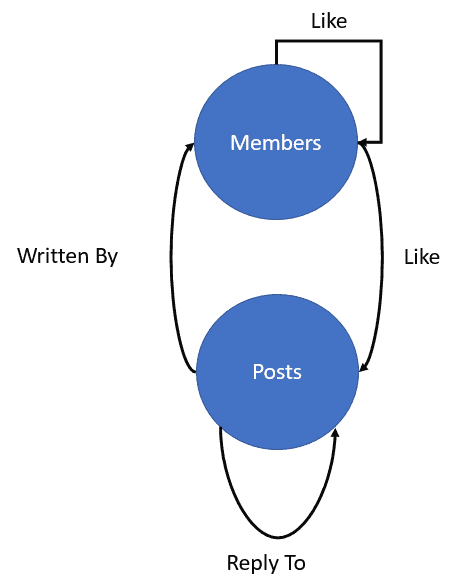
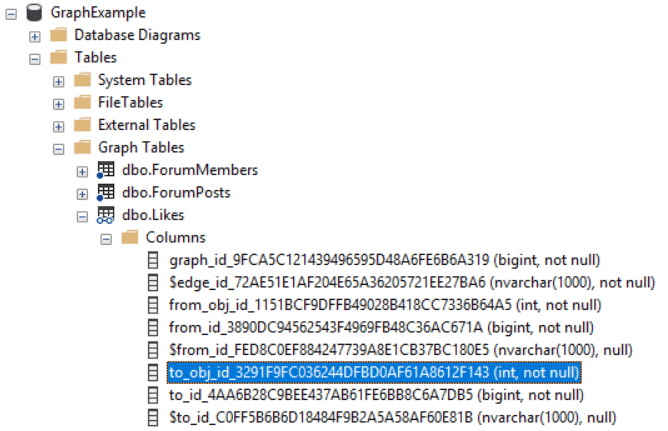

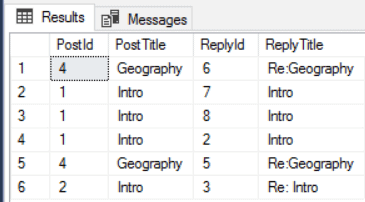
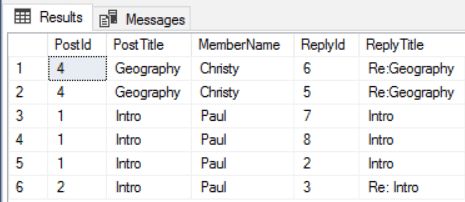
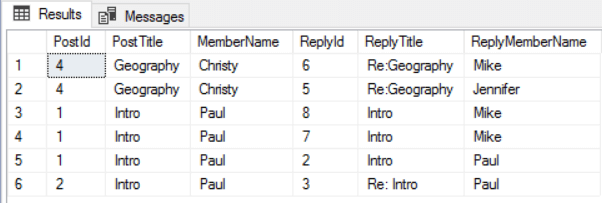
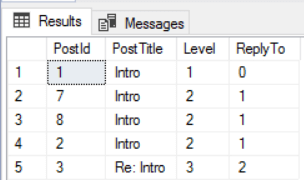
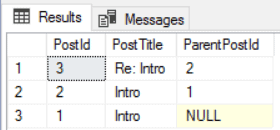

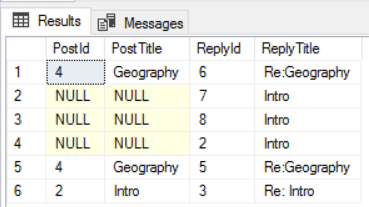


 Bundeskanzlerin Angela Merkel (CDU) zeichnet ein düsteres Zukunftsbild der Automobilindustrie. Diese werde in der heutigen Form nicht überleben, sagt sie. Die Bundesumweltministerin will derweil Steuerprivilegien für Diesel abschaffen. (Auto, Technologie)
Bundeskanzlerin Angela Merkel (CDU) zeichnet ein düsteres Zukunftsbild der Automobilindustrie. Diese werde in der heutigen Form nicht überleben, sagt sie. Die Bundesumweltministerin will derweil Steuerprivilegien für Diesel abschaffen. (Auto, Technologie) 