Arndt Dibi
Shared posts
Preis-Revolution beim MVV: Tarifreform ist beschlossen

Sie haben sechs Monate Zeit – oder auch nicht
Wozu sind Fristen da? Einerseits, damit der Bürger weiß, innerhalb welcher Zeit er eventuelle Ansprüche geltend machen muss. Andererseits, damit sich die Sache nicht endlos verzögert – und halt irgendwann Rechtssicherheit eintritt. Es gibt natürlich tiefgründigere Erklärungen, aber das dürften die wesentlichen Aspekte sein.
In einem Verfahren, dessen Inhalt gar nicht groß was zur Sache tut, habe ich von Gesetzes wegen sechs Monate Zeit, um eventuelle Ansprüche geltend zu machen. Das heißt, die denkbaren Forderungen müssen spätestens am letzten Tag der Frist schriftlich angemeldet sein.
Die Frist läuft ab am 22.10.2018.
Der zuständige Herr bei der Justizbehörde scheint aber auf heißen Kohlen zu sitzen. „Es wird um Bezifferung der Ansprüche gebeten“, schrieb er mir am 08.05.2018. Am 09.06.2018 kriegte ich das Schreiben noch mal. Die Anfrage war gelb markiert, handschriftlich hatte jemand vermerkt: „1. Erinnerung!“ Am 19.06.2018 traf dann die „2. Erinnerung“ ein. Diesmal mit „!!!“
Anfang der Woche fand ich eine Telefonnotiz. Der Beamte teilte mit, es würden noch Unterlagen fehlen. Er habe schon „zwei Fristen“ gesetzt und erwarte die fehlenden Angaben nun spätestens bis Ende Juli. Ich habe nicht die leiseste Ahnung, wieso der Herr meint, er könne hier so einen Druck aufbauen. Die Sechs-Monats-Frist steht, wie gesagt, ausdrücklich im Gesetz.
Gut, vielleicht hat der Beamte belastbare Informationen über einen bevorstehenden Finanzinfarkt der öffentlichen Hand. Oder er hat sonstige gute Gründe, warum er ausgerechnet meinen Antrag – es geht um einen gerade mal dreistelligen Betrag – bearbeiten möchte/muss. Da wäre es dann aber nett, wenn er mir diese Gründe auch von sich aus mitteilt. Und nicht mit Erinnerungen nervt, mit denen ich inhaltlich nichts anfangen kann.
Ich habe dann mal zurückgerufen. Das erschien mir weniger nervig als die Aussicht auf die nächste schriftliche Mahnung. Der betreffende Herr war im Haus, aber nicht zu sprechen. Die Mitarbeiterin der Geschäftsstelle richtete mir aus, ich solle doch einen Brief schreiben oder ein Fax schicken. Dieses werde schnellstmöglich bearbeitet.
Also, jetzt ist dann aber wirklich mal gut. Weitere „Erinnerungen“ etc. hefte ich einfach ab. Und der Antrag geht genau drei Tage vor Fristablauf raus. Irgendwie bin ich mir aber sicher, dass da eskalationsmäßig noch was von Seiten der Behörde kommt. Ich werde berichten, falls das passiert.
Öffnungszeiten deluxe
Der Anrufbeantworter in der Zentrale der Staatsanwaltschaft Duisburg (0203 9938-5) hat mir gerade freundlicherweise die Zeiten durchgedudelt, zu denen – jedenfalls theoretisch – die Mitarbeiter telefonisch erreichbar sind:
montags bis freitags 8.30 bis 11.30 Uhr
montags und dienstags 14 bis 15 Uhr
mittwochs bis freitags 14 bis 14.30 Uhr
Außerhalb des öffentlichen Dienstes würde sich so was keiner trauen.
Machine Learning with .NET
Introduction to Machine Learning with Accord.NET and F#
How many times have you heard the expression Machine Learning as something common, but at the same time so unknown, even if you’re an experienced developer? How many times have you told yourself that a machine alone learning something is a reality very far from yours – a REST-CRUD-like world. And what about the languages (R, e.g.) these ‘too-scientific’ programmers use to, well, program?
Every time you see a personalized ad or a recommendation in your favorite retailer website based on your previous activities, what you’re seeing, in fact, are machine learning algorithms running behind the scenes. From your latest song suggestion on Spotify, the last face recognition made on your Facebook picture, to the risk analyzed by PayPal on each of your payment transactions, machine learning is everywhere, helping all sorts of companies to personalize their user experience on a large scale.
What is Machine Learning?
To understand the term, you need to remember how our own brains work. We were born with no information about the world and, as we grow, the continuous exposure to more and more data makes us comprehend that putting a finger in the socket is not a good idea. Of course, we have the act of committing mistakes as our main fuel to the learning process, but we also learn a lot just paying attention to the other things that surround us. That’s how machine learning works.
With no need to be updated, a machine learning software solution is programmed once and learns by itself progressively after receiving more inputted data. It means that, if we provide the strings Yellow Square, White Square and Black Rectangle to a machine learning software application, for example, after inputting an image of each geometric form, when we ask the computer what the image of a black square is, it is going to answer: Black Square.
Just like humans, the younger the system, the more susceptible to errors it will be. The goal is to let the program read a large amount of data over time in a way it can improve its predictions and decisions. In other words, machine learning can be translated into functions. Mathematically, its algorithms are represented as a single function like that:
y = f(x) + e
Where the elements are basically:
- y, the result. What are you trying to predict here?
- f, the function itself. What we’re really trying to discover that makes things happen based on…
- x, the input data;
- e, error. It says that, no matter how hard we try to guess how things would happen (prediction), we’ll never have enough inputs to perfectly go from x to y.
Linear regressions
Inside this functional universe, some models, like regressions, are specialized in number predictions, quantities to be more specific. For example, imagine an algorithm where we always input the same data (let’s say ‘a’) and it returns some results after six attempts:
|
Input |
Result |
|
a |
1.0 |
|
a |
2.0 |
|
a |
1.5 |
|
a |
1.5 |
|
a |
1.4 |
|
a |
1.5 |
What would you say is the next possible result if we input a seventh ‘a’? Probably you’d go with 1.5, because your mind automatically calculates the value of 50% of the total results, or at least some value between 1.5 and 2.0.
What your brain did just now is called regression, linear regression. Its goal is trying to get the formula we’ve seen and find the least number of variables that substantially impact determining f(x) with the highest correct percentage possible the value of y.
Now, imagine you’ve opened a small cupcakes shop, and you want your clients to being able to order cupcakes online via a website. Then, you decided that it would be interesting to collect a rating (1 to 5 stars) for each type of cupcake available for purchase. After searching a little bit, some behaviorist articles also said that, when users are confronted with products of low ratings, most of them abandon the purchase. It’s a good practice to prevent this by showing a prefilled approximate value as shown in Figure 1 of how many product items (cupcakes, in this case) the clients usually order for each type (considering, mainly, the low-rated ones). Linear regression is going to provide the perfect solution to your needs.
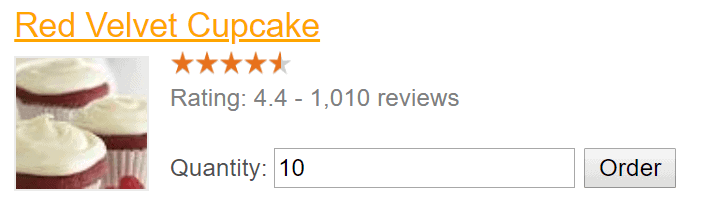
Figure 1. The cupcake order page
This example will use F# as the main functional language. It integrates with Accord.NET, one of the best .NET machine learning frameworks, specialized in statistical implementations. Combined, they are a great fit for writing linear regression on the .NET platform, as you’ll learn next.
Setting up the project
Everything you’ll need to follow along with this article is the latest version of Visual Studio (the Community edition is just fine). However, most .NET developers complete the installation selecting only the single options available for .NET desktop development and the Universal Windows Platform for C#. In this case, you’ll also need to select the Data science and analytical applications workload, as you can see in Figure 2. This option will install the data science languages (R and F#) you will need to implement the machine learning code. It’s available during the VS installation process only (if you already have VS installed, you can run the installer again and select the proper workload).
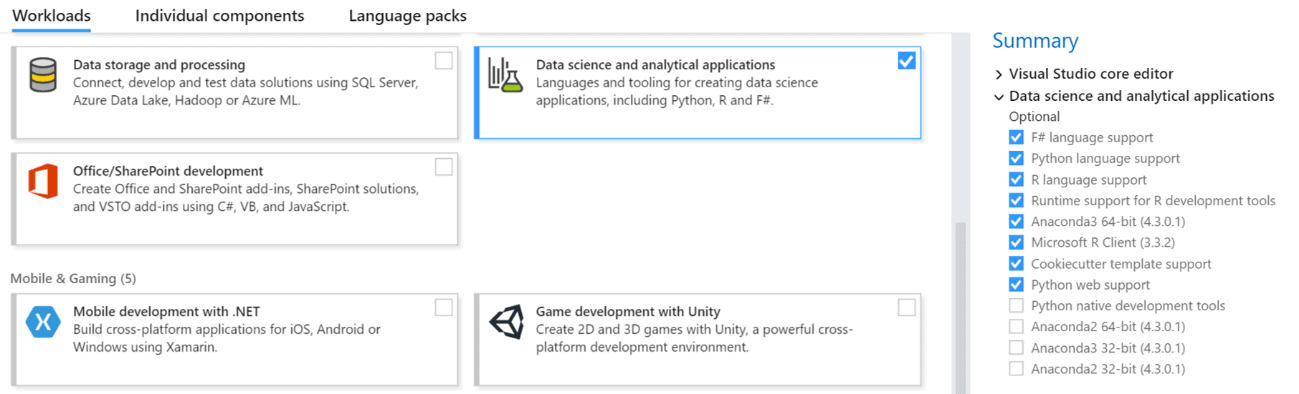
Figure 2. Installing the data science workload.
Once the workload is installed, open Visual Studio and go to menu File > New > Project…. Select the Installed tab, select the options Visual F# > Console Application and type a name for your project, Cupcake Sales Regression (Figure 3). If you have trouble finding the right type of application template, you can also search for F#.
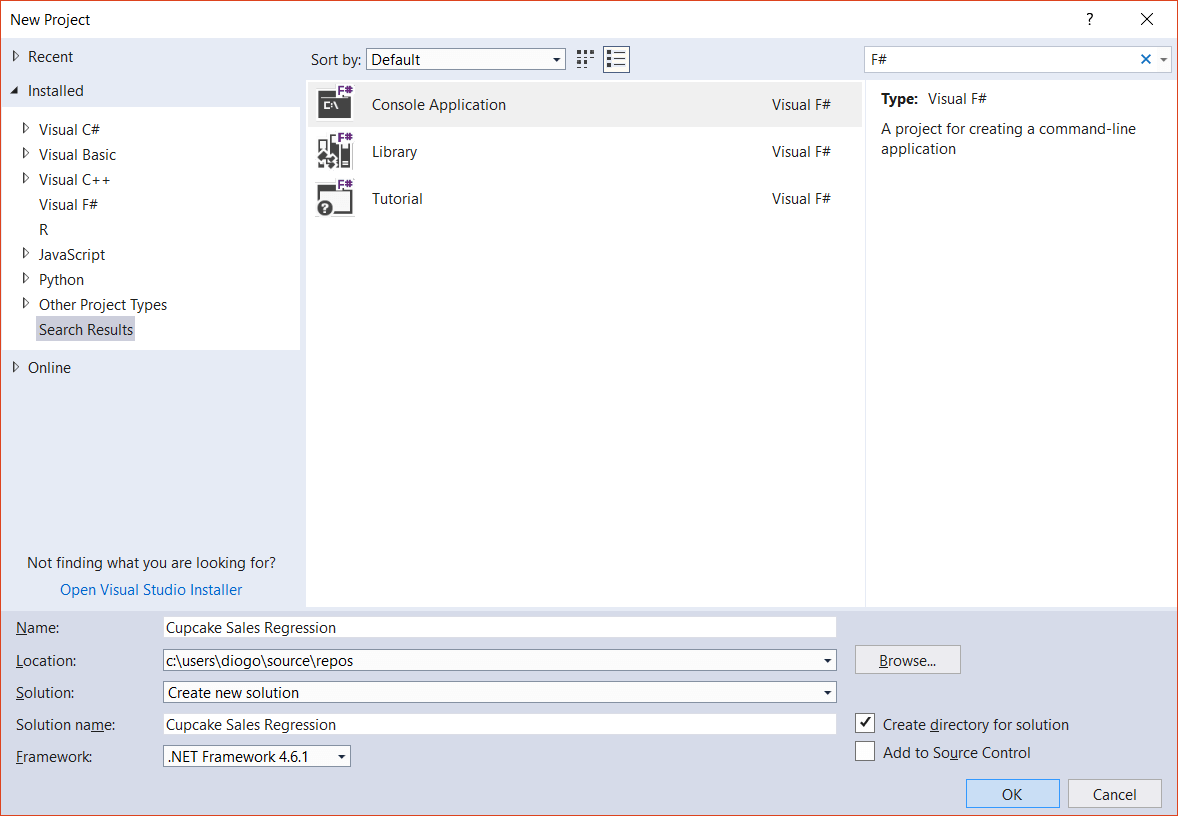
Figure 3. Creating a new Visual F# project.
Once it’s finished creating the project, Visual Studio will open a file called Program.fs, the main file of the program. The extension fs comes from F-sharp and represents the source files for F#, which can be compiled as part of any .NET project. However, for simplicity, this example is going to use files of fsx extension, which comes from F-sharp scripts. They are independent, and individual F# files are intended to run as a script (most of the time for test purposes only). Go to the project in Solution Explorer window, right click it, and select Add > New Item…, then search for F#, select the option F# Script File and give it the name CupcakeSalesRegression.fsx.
You will also need to set up the two dependencies of Accord.NET via NuGet Package Manager for the project: the core and statistics dependencies, as well as the FSharp.Data package (which, among other things, manages providers for working with structured file formats, like CSV). For this, go to menu View > Other Windows > Package Manager Console and run the following commands:
install-package Accord install-package Accord.Statistics install-package FSharp.Data
Pay attention to the logs and make sure it ends with the message Successfully installed …. You should see the following new items added to the References section as shown in Figure 4:

Figure 4: The project references
F# is a scripting as well as a REPL language. REPL comes from Read-Eval-Print Loop, which means that the language processes single steps one at a time like reading the user inputs (usually expressions), evaluating their values and, in the end, returning the result to the same user. All that happens in a loop until the loop ends. Visual Studio provides a great F# Interactive view that runs the scripts in REPL mode and shows the results. Take the following Hello World example:
let hello = "Hello World"
This code just creates a single variable (let keyword) and assigns a string value to it. When you run this code (select all the code text and press Alt + Enter), you’ll see the following result in the F# Interactive window (Figure 5):
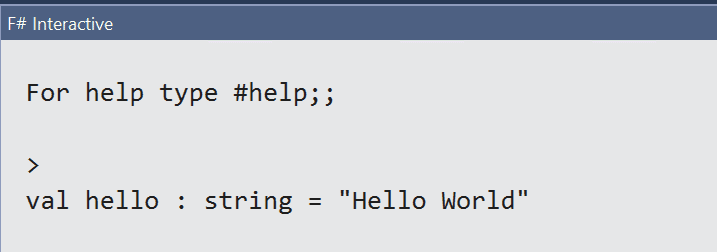
Figure 5: The results of a “Hello World” script
Look at how F# infers the types. In the end, this is a function called hello that receives no arguments and returns a string (in this case, a hardcoded one). But the language is even more flexible to allow a common mix of arguments with the code block itself. Replace the previous statement by the following and run the code again. The results are shown in Figure 6:
let hello s = s + "Hello World"
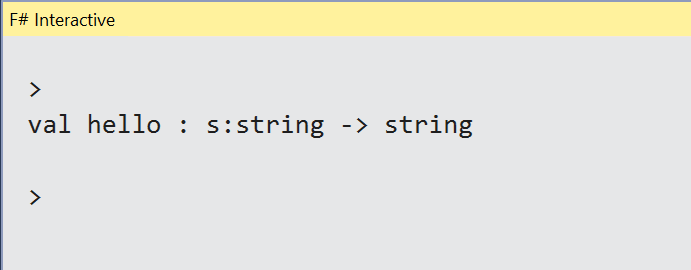
Figure 6: The result of running the hello function
This means that the same function now receives an argument called s of type string and returns another string (in this case, not hardcoded anymore). The -> operator tells you that what’s next is the result structure.
The Cupcake Sales Regression
The first step towards creating this regression is to understand how the data is organized in a business model way. That is, what is the real entity model representing the sales, each rating and the total of purchased items? Take a look at the following CSV data:
CupcakeId,Type,Price,CustomerId,Rating,Total 1,pumpkin,4.25,105,2,1 1,pumpkin,4.25,57,1,2 1,pumpkin,4.25,40,2,2 1,pumpkin,4.25,66,3,1 2,vanilla,4.25,59,5,10 3,white chocolate,4.25,81,1,2 4,red velvet,4.25,167,5,3 …
You can download the full file here. Then, import it to your project root folder by copying and pasting the file into Solutions Explorer. If you see errors in the import code (shown later in the article), open the file in VS and make a small edit to get VS to process the file.
Observe, too, the following scatter plot representing the cupcake sales model data. Accord.NET linear regression is going to map all the sale ratings averages and cross them with the average of the total of orders for each type of cupcake. In the end, its purpose is to try to balance the information in both axes (x and y) and determine a line that tries, at its best, to approximate to each point of the graph. That’s the magic of the linear regression shown in Figure 7.
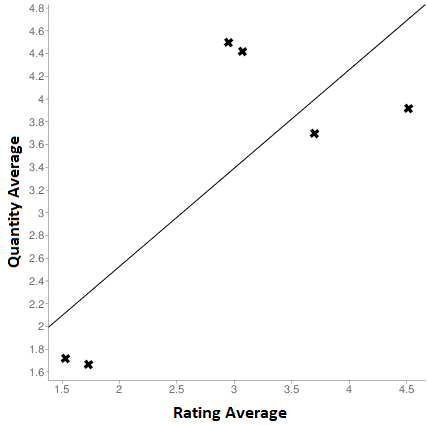
Figure 7: The linear regression
Just like you would have in a CSV file showing real data, the data will increase over time and help the algorithm to be smarter. However, in order to use the power of Accord.NET in the fsx file, you must first import the corresponding libs (dlls) of its main packages. These are going to be the first lines of your fsx file (you can download the completed script here):
#r "../packages/FSharp.Data.2.4.6/lib/net45/FSharp.Data.dll" #r "../packages/Accord.3.8.0/lib/net40/Accord.dll" #r "../packages/Accord.Statistics.3.8.0/lib/net40/Accord.Statistics.dll" #r "../packages/Accord.Math.3.8.0/lib/net40/Accord.Math.dll" #r "../packages/Accord.Math.3.8.0/lib/net40/Accord.Math.Core.dll"
The directive r#, in F#, comes from reference and is used to load external library references that were previously installed in the project. These dlls are:
- FSharp.Data: F# default library to deal with everything related to accessing data in F# applications: from CSV, JSON/XML files to remote data parsing/manipulation;
- Accord: the core of the framework. Stores general exceptions and other libraries extensions;
- Accord.Math: for all basic mathematical operations, that library is needed, once it contains data science principal functions and numerical algorithms;
- Accord.Statistics: it’s the home of the linear regression statistical models and a whole bunch of components and statistical methods/functions like variances, deviations, averages, etc.
To call the classes in the Accord.NET linear regression module in your code without having to use their fully qualified names, you must import it right after the dlls references:
open Accord.Statistics.Models.Regression.Linear open FSharp.Data
In F#, the CSV model can be implemented as follows:
type CupcakeSale =
{CupcakeId : int;
Type : string;
Price : float;
CustomerId : int;
Rating : float;
Total: float}
A type in F# represents a class in C# or other object-oriented languages. This way, you can define the name and types of your object attributes (which is also a variable).
Once you’re dealing with a large amount of records, you’ll create a resizable list, import the local CSV file, iterate over its content and add its elements to the list just to simulate the data a real application would supply:
let sales = ResizeArray<CupcakeSale>()
type CupcakeSalesCSV = CsvProvider<"cupcake_sales.csv", ",">
let csv = new CupcakeSalesCSV()
for row in csv.Rows do
sales.Add({CupcakeId = row.CupcakeId;
Type = row.Type;
Price = (float) row.Price;
CustomerId = row.CustomerId;
Rating = (float) row.Rating;
Total = (float) row.Total})
Further, you can increase the number of inputs in this list to achieve more accuracy with the algorithm result. Or, if you prefer, you can get the data from a data source or even a web service.
The next step is to group the data in a way to have the rating average values (as the x in the formula) vs the average of the total of times each cupcake was ordered (the y, the most important information).
let filterByRating = [(fun (x : CupcakeSale) -> x.Rating)]
let filterByTotal = [(fun (x : CupcakeSale) -> x.Total)]
let groupedByRatings =
sales
|> Seq.groupBy(fun x -> x.CupcakeId)
|> Seq.map(fun (key, values) ->
(key, [for prop in filterByRating -> values |> Seq.averageBy prop]))
|> Seq.toArray
let groupedByTotals =
sales
|> Seq.groupBy(fun x -> x.CupcakeId)
|> Seq.map(fun (key, values) ->
(key, [for prop in filterByTotal -> values |> Seq.averageBy prop]))
|> Seq.toArray
The variables filterBy-Something are only a condition attached to the grouping + filtering made upon groupedBy-Something variables. The operator |> (pipe-forward) allows you to pass an intermediate/temporary result (on the leftmost side) to the next function (on the closest right side).
The function groupBy gets the given list (sales) and returns a sequence of tuples containing the unique key (the cupcake id) and all the elements that key matches within another sequence. The next function, map, receives these tuples mapped to key/value variables. Then, the lambda expression iterates over the values to apply an averageBy function against the filterBy-(Rating/Total) condition you’ve seen before and finally returns an array containing each tuple of id/(rating and total averages). Check the following REPL result as shown in Figure 8.
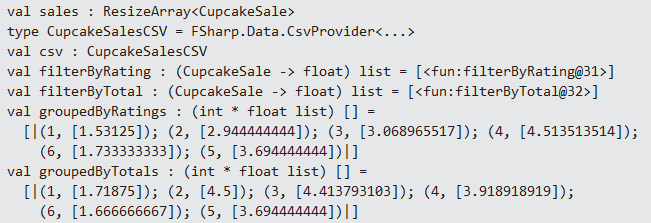
Figure 8: Calculating the averages and totals
Tuples are represented by parentheses and the first element is called key (or left), the second is value (or right).
The linear regression object is created from the x and y values which, in turn, must be represented as arrays with each index of each array corresponding to the respective values and total. Because of that, the code iterates over the array of tuples (of both groupedBySomething variables) to extract this correlated data:
let cupcakeIds = Array.create groupedByRatings.Length 0
let x_averages = Array.create groupedByRatings.Length 0.0
let y_totals = Array.create groupedByRatings.Length 0.0
for i in 0..groupedByRatings.Length - 1 do
let averageTuple = Array.get groupedByRatings i
let totalTuple = Array.get groupedByTotals i
let _id = fst averageTuple
let _average = (snd averageTuple).[0]
let _total = (snd totalTuple).[0]
Array.set cupcakeIds i _id
Array.set x_averages i _average
Array.set y_totals i _total
Array.create is a function that creates a new array with the given length and fills it with the given values. The reserved words fst and snd are used to access the first and second values of a tuple in F#, respectively.
Finally, you can review the linear regression code:
let ols = OrdinaryLeastSquares()
let regression = ols.Learn(x_averages, y_totals)
// Let's say you received this value from the web form
let purchasedCupcakeId = 1;
// A shortcut to find the corresponding sale of the provided cupcake id
let findIndex arr elem = arr |> Array.findIndex((=) elem)
let i = findIndex cupcakeIds purchasedCupcakeId
let result = regression.Transform(Array.get x_averages i)
System.Console.WriteLine("Suggested quantity: {0}", System.Math.Round(result))
OrdinaryLeastSquares (OLS) is the standard linear regression approach used by the Accord.NET library. It is based on the famous least-squares procedure that, in turn, models a single and continuous variable response (y) predicted by another variable recorded on an interval (x) through a linear relationship. In other words, OLS is the most basic and common mathematical representation of the linear regression formula: y = f(x) + e. Its function called Learn is responsible for receiving the x/y arrays and so learn by them (more and more every time you increase the arrays) resulting in the regression itself. Once you have seen the model digested by the regression function, all you need to do is to provide a cupcake rating average of a specific cupcake type and the suggested value will be generated as result in the beginning of the F# Interactive output shown in Figure 9. Note that the value was rounded since the user won’t be able to buy a fraction of a cupcake :
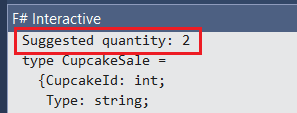
Figure 9: The suggested quantity
Now, try it yourself. Feed your algorithm by increasing the number of cupcake sales to the list and analyzing how the linear regression calculates the best fit for (low) user reviews versus the total of number of orders.
Conclusion
Using .NET libraries to accomplish machine learning algorithms not only makes it possible to use the power of data science to help predict different sort of things, but also allows you to integrate code easily in all .NET projects/technologies. Of course, it goes further: It provides fast ways to export code to dll’s that can be imported into other languages that know how to translate one type of object into another.
The code in this article is, perhaps, the simplest type of linear regression that can be built with machine learning. Fortunately, its official website is full of awesome content, more complex examples of regression, classification, tests of hypotheses and even image/audio manipulation. With regard to F#, both the official project and the .NET support documentation pages are well documented in a way that is extremely easy to understand. All of that is available to help you to take bigger steps as you learn.
The post Machine Learning with .NET appeared first on Simple Talk.
Bundestag: China wollte offenbar Abgeordneten als Spitzel anwerben
 Chinesische Spione schlugen einem deutschen Politiker laut einem Bericht einen Deal vor: Geld gegen Informationen. Der Verfassungsschutz soll eingeschritten sein.
Chinesische Spione schlugen einem deutschen Politiker laut einem Bericht einen Deal vor: Geld gegen Informationen. Der Verfassungsschutz soll eingeschritten sein.
Preis-Revolution beim MVV: Das kostet die neue M-Zone
Bundesverfassungsgericht: Staatsanwaltschaft darf interne VW-Akten auswerten
 Volkswagen ist mit Verfassungsbeschwerden gegen die Beschlagnahmung von Akten zum Dieselskandal gescheitert. Diese sei rechtens gewesen, entschied das Verfassungsgericht.
Volkswagen ist mit Verfassungsbeschwerden gegen die Beschlagnahmung von Akten zum Dieselskandal gescheitert. Diese sei rechtens gewesen, entschied das Verfassungsgericht.
Arabische Solarkraftwerke
In den vergangenen Wochen berichteten unsere Medien voller Freude über Großinvestitionen in Fotovoltaikanlagen in Ägypten und Saudi-Arabien. Beide Länder und auch einige ihrer Nachbarn wollen Solarenergie verstärkt nutzen. Der Kronprinz der wahabitischen Monarchie geht neue Wege, wozu er gute Gründe hat. Er möchte die Abhängigkeit vom Öl reduzieren und den Energiemix verbreitern. Das Land ist groß, die Sonne heiß und die Preise der Module sind historisch niedrig. Geld gibt es im Königreich (noch) genug. Wolken und Regen, vor allem Nebel und Schnee sind selten oder nie.
Die Zahl der Menschen ist eher klein (knapp 32 Millionen) und es gibt einen hohen Bedarf an Kühlleistung für die an guten Wohnstandard gewohnten Einheimischen. In der Mittagshitze, wenn am meisten gekühlt werden muss, speisen die Paneele viel Strom ein. Passt. Die Meerwasserentsalzung kann angebotsabhängig variabel gefahren werden, passt auch. Solarthermische Kraftwerke können die Wärme teilweise speichern und auch bei Dunkelheit Strom liefern. Geht auch.
Die Nutzung der Sonnenenergie spart Öl und Gas, das dann für den Export zur Verfügung steht und den Preis auf dem Weltmarkt niedrig hält – ein grünes Paradoxon, wie von Professor Sinn beschrieben. Eine insgesamt wirtschaftlich sinnvolle und logische Entwicklung, über die man nicht schreiben müsste, würde sich an diesem Beispiel nicht die deutsche Tendenzberichterstattung deutlich zeigen. Indem viele Medien über die geplanten Solarinvestitionen ausführlich berichten, entsteht zwangsläufig der Eindruck, arabische Länder würden ihr Energiesystem umbauen, gleichsam eine Wende nach deutschem Vorbild vollziehen, hin zu 100 Prozent Erneuerbar.
Die Meldungen zu den Solarinvestitionen sind weder gelogen noch falsch, aber sie sind, wie so oft, nur die halbe Wahrheit. Unser Pressekodex fordert Achtung vor der Wahrheit, der ganzen. Informationen sollen mit gebotener Sorgfalt gemeldet werden. Gehörte es früher zum guten journalistischen Handwerk, die Leser (heute: Medienkonsumenten) möglichst umfassend und ausgewogen mit Meldungen zu versorgen, nach denen sie sich eine Meinung bilden können, wird heute so berichtet, dass Meinungsbildung in eine gewünschte Richtung erfolgt.
Energiewendeerfolgsjournalismus
Unsere weitgehend links-grün zu verortende Journalistenschar bleibt meist bei der Wahrheit, bevorzugt aber oft eine Teilmenge Halbwahrheit. Indem zum Beispiel ausführlich (und begeistert) über die arabischen Solaraktivitäten berichtet wird, breitet man in den entsprechenden Meldungen den Mantel des Schweigens über ägyptische Investitionen in das weltgrößte Gaskraftwerk und den Einstieg Ägyptens, Saudi-Arabiens und etlicher anderer Länder in die Kernkraft. Diese Informationen gibt es auch, zum Beispiel hier, aber sie stehen nicht auf Seite 1.
Zu einer ausgewogenen Berichterstattung würde gehören, zu recherchieren und den Nachrichtenempfängern ein umfassendes Bild aus dem jeweiligen Land zu liefern. Dazu muss man nicht investigativ sein, man muss als Journalist nur seinen Job machen. Aber wenn der Hanns-Joachim-Friedrichs-Preis heute weniger für journalistische Qualität, eher für unbeugsame Haltung verliehen wird, zeugt das von einem geänderten Verständnis von Journalismus. Galt früher Regierungskritik in den Medien als große Möglichkeit der Profilierung und Belebung der öffentlichen Diskussion, ist heute die Verteidigung von Regierungsentscheidungen und die Einteilung der Welt in Gut und Böse angesagt.
Sozialen Medien wird zu Recht vorgeworfen, massenhaft Fakes zu verbreiten. Über Fakes in unseren Medien wird indes wenig gesprochen. Neben den angeführten Halbwahrheiten gibt es auch echte Fakes, zum Beispiel die Mär von den Windkraftanlagen, die x-tausend Haushalte versorgenkönnten. Jeder energietechnisch noch so unbedarfte Journalist sollte inzwischen wissen, dass Windkraftanlagen nur einspeisen können, was die Natur gerade liefert und eben nicht nach Bedarf regeln können. Kein konventionelles Kraftwerk kann damit ersetzt werden. Aber mit solchen Formulierungen kann man versuchen, der Bevölkerung weiszumachen, ein Umstieg von grund- und regellastfähiger Stromproduktion auf Zufallseinspeisung sei möglich. Mit derartigen Formulierungen lassen sich Leser und Meinungen beeinflussen. So soll die Energiewende zum Erfolg geschrieben werden.
Warum nun Kernkraft in so sonnenreichen Ländern? Mohamed-al-Mazrouei, Energieminister der Vereinigten Arabischen Emirate und derzeitiger OPEC-Chef, sieht das in einem Handelsblatt-Interviewfür sein Land so: Es sei ein bestimmter Anteil der Grundlast mit Atomkraft zu sichern, weil die Preise für (importiertes) Gas schwer zu prognostizieren seien und man weg von fossilen Energien wolle.
„Unsere Energiestrategie 2050 sieht 44 Prozent erneuerbare Energien vor, sechs Prozent Atomstrom, 38 Prozent Strom aus Gas und zwölf Prozent aus besonders sauberer Kohle. Mit diesem Energie-Mix verringern wir unseren CO2-Ausstoß um 80 Prozent. Das setzt aber auch ein Reduzieren des Energieverbrauchs pro Kopf um 40 Prozent voraus.“ Auch die mit Sonne verwöhnten Länder kommen ohne einen ausgewogenen Energiemix nicht hin und streben eine unrealistische „Dekarbonisierung“ bis 2050 auch nicht an.
Nun liefert Russland in großem Umfang Kernkraftwerke in den arabischen Raum (16 Reaktoren allein nach Saudi-Arabien) und verschafft sich wirtschaftlichen und politischen Einfluss. Auch in Afrika, wo es mit Ghana, Südafrika, Nigeria, Kenia, Marokko und Tunesien Planungen oder auch schon Verträge gibt. Wirtschaftlicher Aufschwung kann Fluchtursachen reduzieren und Flüchtlingsströme verringern.
Exportierter Krieg
Siemens lieferte Ägypten Gaskraftwerke, weiter trägt Deutschland wenig zum Ausbau der Energieversorgung in Ägypten und Saudi-Arabien bei. Kernenergetische Anlagen kommen ohnehin nicht in Frage (Teufelszeug). Nachdem CCS (CO2-Abscheidung und Speicherung) politisch verhindert wurde, können wir auch keine neue Kohletechnologie liefern, keine neuen Lösungen im Bereich der regenerativen Energieumwandlung. Deutschland wähnt sich in einer imaginären Vorreiterrolle, die in der Praxis nur aus Abschaltplänen und dem massenhaften, aber nicht zielführenden Ausbau altbekannter regenerativer Anlagen besteht. Voller Naivität hofft man, allein durch Vorbildwirkung würde die Welt auf diesem Weg folgen.
Die Russen bauen neben Saudi-Arabien auch in der Türkei Kernkraftwerke. Während sie damit wirtschaftliche Entwicklung fördern, liefert Deutschland beiden Ländern Waffen für Angriffskriege. Das ist schlecht fürs Klima – vor allem das politische.
Überhaupt scheint der Frieden aus Sicht unserer Regierung überbewertet. „Nie wieder Krieg“ war die heute veraltete Losung unserer Kriegs- und Nachkriegsgeneration. Ihre Botschaft versandet zusehends. Heute geht es darum, „den Frieden auch robust durchzusetzen“, wie Chefkommentator Krauel am 5. Mai in der „Welt“ schreibt. So lesen sich Vorkriegskommentare. Da sich Deutschland derzeit nicht im Kriegszustand befindet, bleibt offen, wo genau er durchzusetzen ist. Vermutlich am Hindukusch, in Mali und in der Ukraine.
Mit dem Maas bis an die Memel, mit der Uschi in den Krieg? Eine begrenzt einsatzfähige Bundeswehr bewahrt uns (noch) vor zu „ehrgeizigen“ Zielen in anderen Ecken der Welt. Territoriale Selbstverteidigung ist nur noch vordergründig der Zweck der Bundeswehr. Medial läuft die Vorbereitung, Krieg als politisches Instrument einzusetzen, wieder Menschenleben angeblich höheren Zielen zu opfern.
Es brennt in vielen Gegenden dieser Welt. Die Eskalation zum Krieg 3.0 würde alle Klimaängste in den Schatten der arabischen Module treten lassen. In einer zum Selbstzweck verkommenen Klimadiskussion kommt dieser Aspekt nicht vor. Ohne Frieden ist alles nichts.
New documentation for Power BI Embedded REST APIs
'Grow a spine, Microsoft'
Jez Corden, writing at WC, has put things rather well on the Andromeda/Surface Mobile front, with the headline above quoted in his piece. You see, with many patents granted and with multiple leaks all pointing to the new folding device's existence, we also have a single, though reliable writer (Mary Jo Foley) pointing to delays and even cancellation of the project. Amidst this maelstrom of confusion, Jez succinctly suggests that Microsoft should grow a spine and announce the device. Nothing ventured, nothing gained, etc.
SF hospital treated baby with a nap and milk formula. The bill was US$18,000
Power BI Introduction: Working with Parameters in Power BI Desktop —Part 4
The series so far:
- Power BI Introduction: Tour of Power BI — Part 1
- Power BI Introduction: Working with Power BI Desktop — Part 2
- Power BI Introduction: Working with R Scripts in Power BI Desktop — Part 3
- Power BI Introduction: Working with Parameters in Power BI Desktop — Part 4
Power BI Desktop, the downloadable application that supports the Power BI service, lets you define parameters that you can use in various ways when working with datasets. The parameters are easy to create and can be incorporated into the import process or later to refine a dataset or add dynamic elements. For example, you can create parameters that supply connection information to a data source or that provide predefined values for filtering data.
This article demonstrates how to create a set of parameters to use with data imported from a local SQL Server instance. The examples are based on data from the AdventureWorks2017 database, but you can use an earlier version of the database or whatever database you choose, as long as the returned data follows a structure similar to what is used here. Just be sure to update the parameter values accordingly as you work through the article.
Adding Connection-Specific Parameters
Some data source connections in Power BI Desktop—such as SharePoint, Salesforce Objects, and SQL Server—let you use parameters when defining the connection properties. For example, if retrieving data from SQL Server, you can use a parameter for the SQL Server instance and a parameter for the target database.
Because parameters are independent of any datasets, you can create them before adding a dataset or at any time after creating your datasets. However, you must define them and set their initial values in Query Editor. The parameters you create are listed in the Queries pane, where you can view and update their values, as well as reconfigure their settings.
In this article, you will create two connection parameters for retrieving data from a SQL Server database. The first parameter will include a list of SQL Server instances that could host the source data. (Only one instance needs to work in this case. The rest can be for demonstration purposes only.)
To create the parameter, open Query Editor, click the Manage Parameters down arrow on the Home ribbon, and then click New Parameter. In the Parameters dialog box, type SqlSrvInstance in the Name text box, and then type a parameter description in the Description text box.
From the Type drop-down list, select Text, and from the Suggested Values drop-down list, select List of values. When you select the List of values option, a grid appears, where you type in the individual values you want to assign to the variable, as shown in the following figure. Be sure that at least one of those values is the name of an actual SQL Server instance.
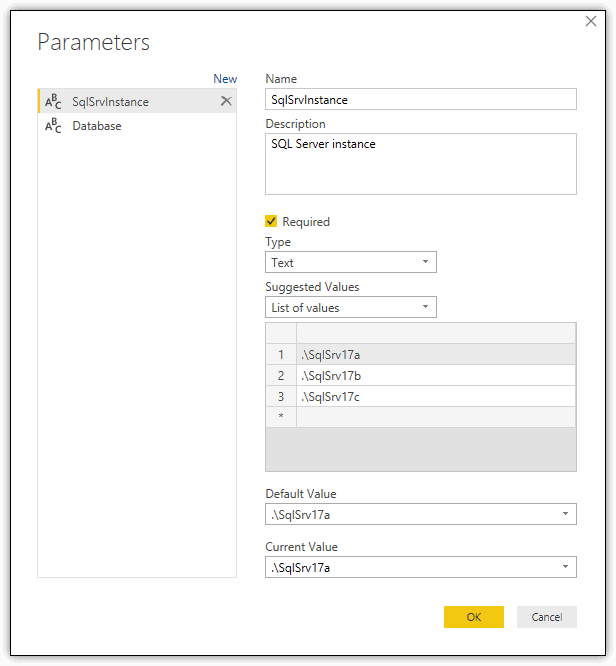
After you type the list of values, select a default value from the Default Value drop-down list and then select the variable’s current value from the Current Value drop-down list. In the figure above, a local SQL Server instance named SqlSrv17a is used for both the default and current values.
Click OK to close the Parameters dialog box. Query Editor adds the parameter to the Queries pane, with the current value shown in parentheses. When you select the parameter, Query Editor displays the Current Value drop-down list and the Manage Parameter button in the main pane, as shown in the following figure.
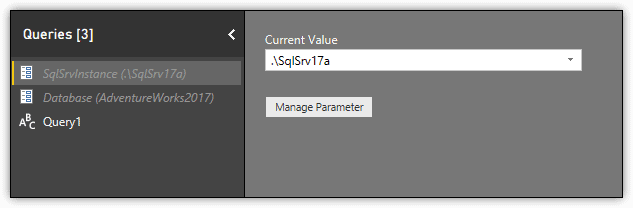
You can change the current value at any time by selecting a different one from the Current Value drop-down list, or you can change the parameter’s settings by clicking the Manage Parameter button, which returns you to the Parameters dialog box.
To create the parameter for the target database, repeat the process, but name the parameter Database, as shown in the following figure. Be sure to provide at least one valid database in your list of databases. When you click OK, Query Editor adds the parameter to the Queries pane, just like it did for the SqlSrvInstance parameter.
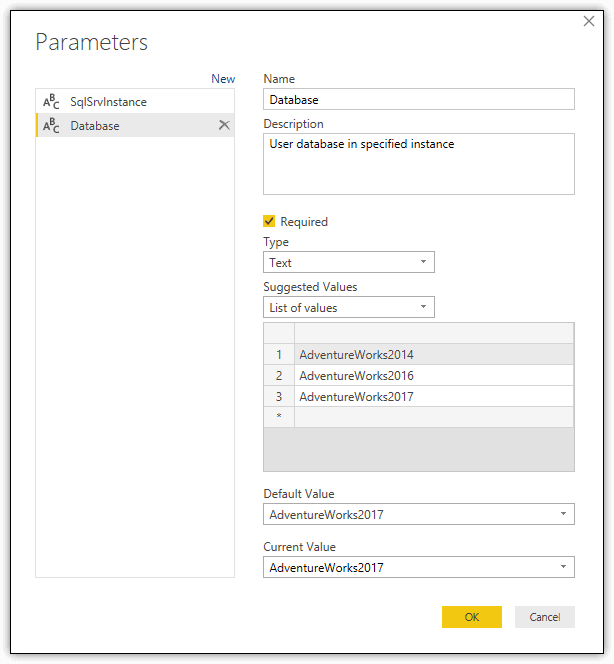
That’s all there is to creating the connection parameters. You can also configure parameters with different data types, such as decimals or dates, or with different value formats. For example, you can configure the parameter to accept any value or to use values from a list query, a type of query that contains only one column. You can create a list query manually by using an M statement, or you can create a list query based on a regular dataset, although this approach still seems somewhat buggy. For this article, you’ll stick with lists, but know you have other options.
Using Parameters to Connect to a Data Source
With your parameters defined, you’re ready to connect to the SQL Server instance and retrieve data from the target database. If you haven’t already done so, apply your changes in Query Editor and close the window.
For this exercise, you will be running a T-SQL query, but before you try to do this, verify that the Require user approval for new native database queries property is disabled. If it is enabled, you will receive an error when trying to run the query. To access the property, click the File menu, point to Options and settings, and then click Options. In the Options dialog box, go to the Security category, clear the property’s checkbox if selected, and click OK.
Then, in the main Power BI Desktop window, go to Data view and click Get Data on the Home ribbon. In the Get Data dialog box, navigate to the Database connections and select SQL Server database, as shown in the following figure.
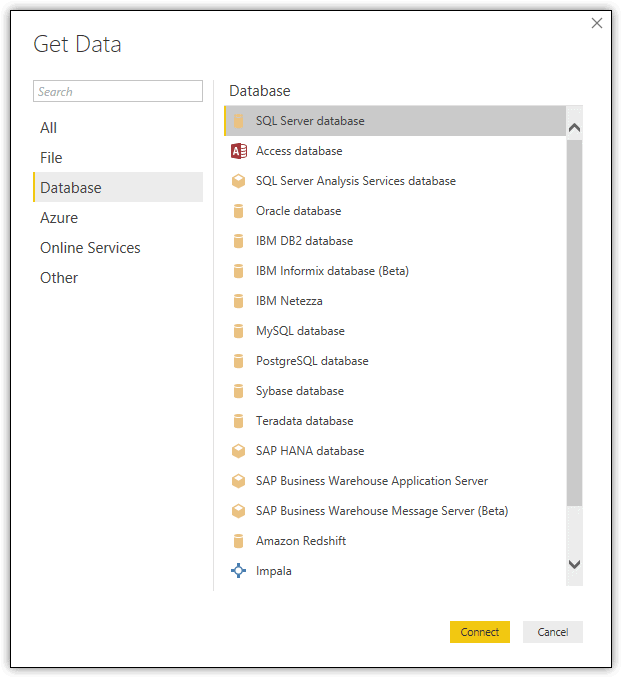
When you click the Connect button, the SQL Server database dialog box appears. In the Server section at the top of the dialog box, click the down arrow associated with the first option (the one to the left) and then click Parameter. The second option will change from a text box to a drop-down list that contains the two parameters you just created. Select SqlSrvInstance, and then repeat the process in the Database section, only this time, select Database.
Next, click the Advanced options arrow and enter the following T-SQL statement in the SQL statement box (or a comparable statement appropriate for your data):
SELECT h.SalesPersonID AS RepID, CONCAT(p.LastName, ', ', p.FirstName) AS FullName, CAST(SUM(h.SubTotal) AS INT) AS SalesAmounts FROM Sales.SalesOrderHeader h INNER JOIN Person.Person p ON h.SalesPersonID = p.BusinessEntityID WHERE h.SalesPersonID IS NOT NULL AND YEAR(h.OrderDate) = 2013 GROUP BY h.SalesPersonID, p.FirstName, p.LastName ORDER BY FullName ASC;
The SQL Server database dialog box should now look similar to the one shown in the following figure, with the SqlSrvInstance and Database parameters selected.
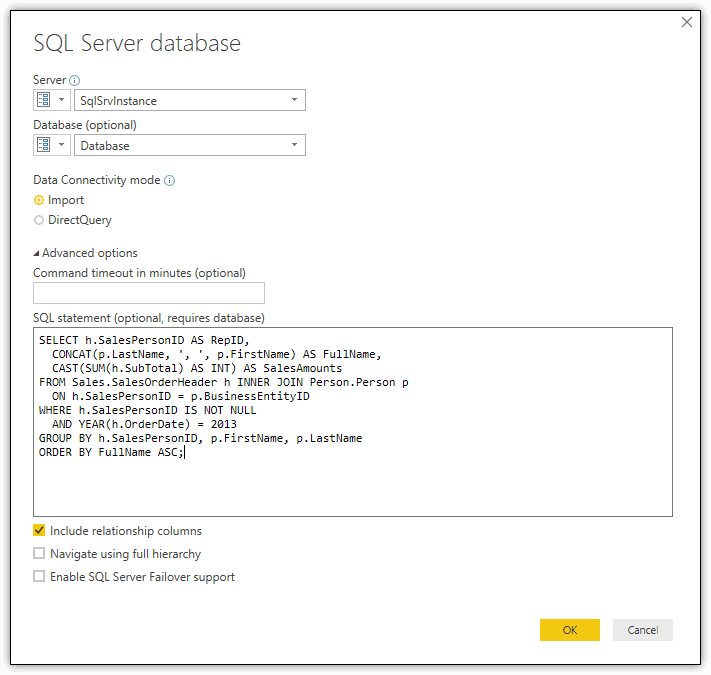
When you click OK, Power BI Desktop displays a preview window (assuming everything is working as it should), with the name of the two parameters at the top, as shown in the following figure.
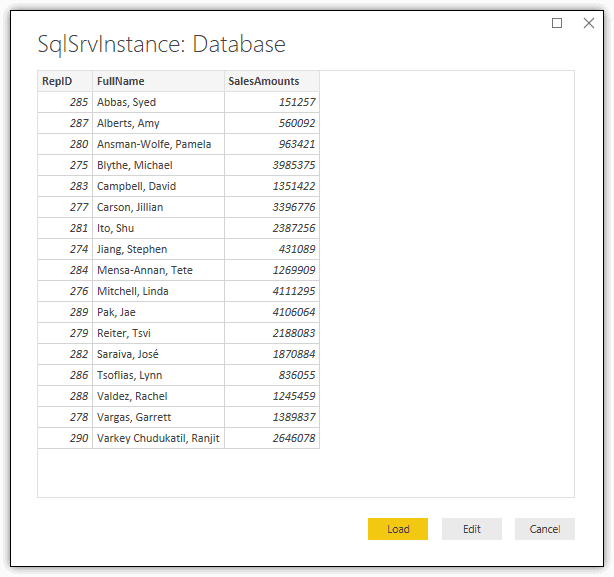
When you click the Load button, Power BI Desktop adds the dataset to Data view. Before taking any other steps, rename the dataset to RepSales or something to your liking. You should end up with a dataset that looks similar to the one shown in the following figure.
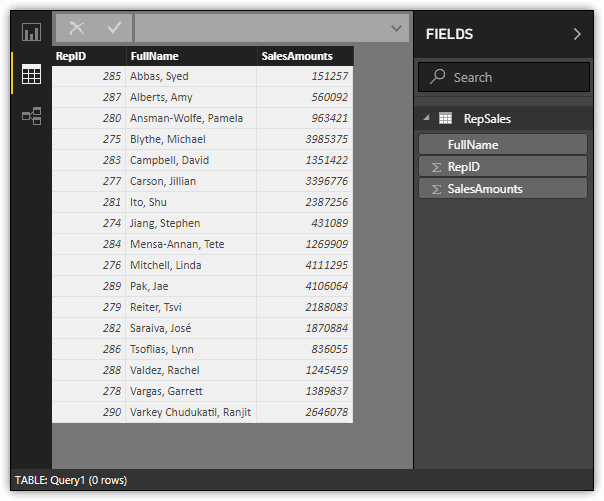
By defining parameters for the connection properties, you can easily change their values at any time, should you need to retrieve the data from a different SQL Server instance or database. You can also use the same parameters for multiple datasets, saving you the trouble of having to repeat connection information each time you create a dataset based on the same data source.
Later in the article, you’ll learn more about working with existing parameters after they’ve been incorporated into your dataset. But for now, open Query Editor and view the M statement associated with the dataset’s Source step in the Applied Steps section, as shown in the following figure.
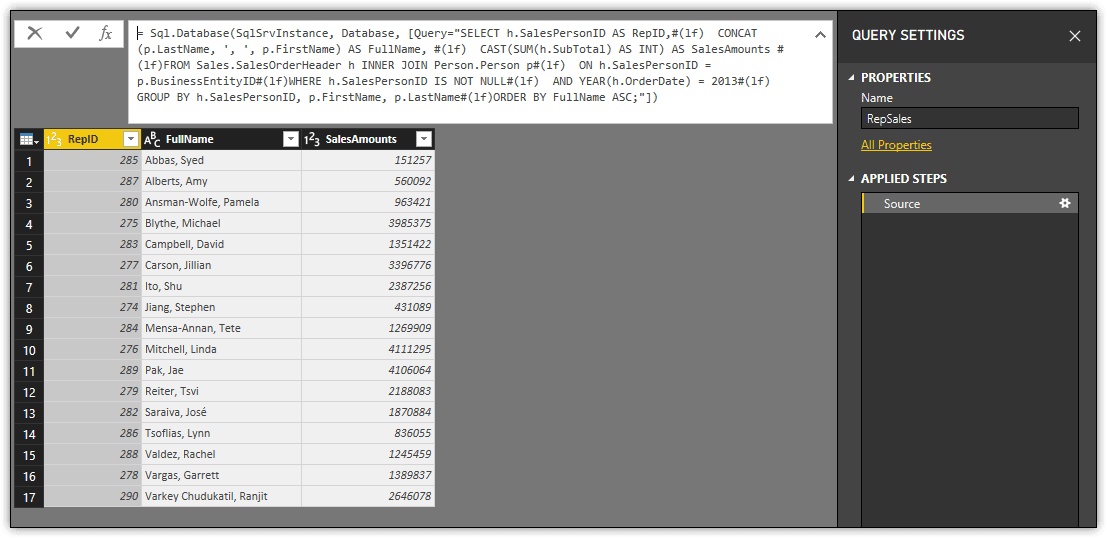
If you examine the M statement closely, you’ll see that the SQL Server connection data references the SqlSrvInstance and Database parameters. They’re included as the first two arguments to the Sql.Database function. I’ve copied the statement here and highlighted the two parameters for easier viewing:
= Sql.Database(SqlSrvInstance, Database, [Query="SELECT h.SalesPersonID AS RepID,#(lf) CONCAT(p.LastName, ', ', p.FirstName) AS FullName, #(lf) CAST(SUM(h.SubTotal) AS INT) AS SalesAmounts #(lf)FROM Sales.SalesOrderHeader h INNER JOIN Person.Person p#(lf) ON h.SalesPersonID = p.BusinessEntityID#(lf)WHERE h.SalesPersonID IS NOT NULL#(lf) AND YEAR(h.OrderDate) = 2013#(lf)GROUP BY h.SalesPersonID, p.FirstName, p.LastName#(lf)ORDER BY FullName ASC;"])
An interesting implication of all this is how easily you can reference parameters within your M statements, providing you with a very powerful and flexible tool for customizing the applied steps that make up your dataset.
Adding Parameters to Filter Data
In some cases, you might want to use parameters to filter a dataset, rather than applying a Filtered Rows step, an approach that can be inflexible and difficult to update. For example, you might want to use a parameter in place of the hard-coded 2013 specified the WHERE clause of the original T-SQL statement:
YEAR(h.OrderDate) = 2013
You can replace the hard-coded value with a parameter that supports a range of values. To do so, create a parameter just like you saw earlier, only this time, name the parameter SalesYear, define a list that contains the years 2011 through 2014, and set the default and current values to 2011, as shown in the following figure.
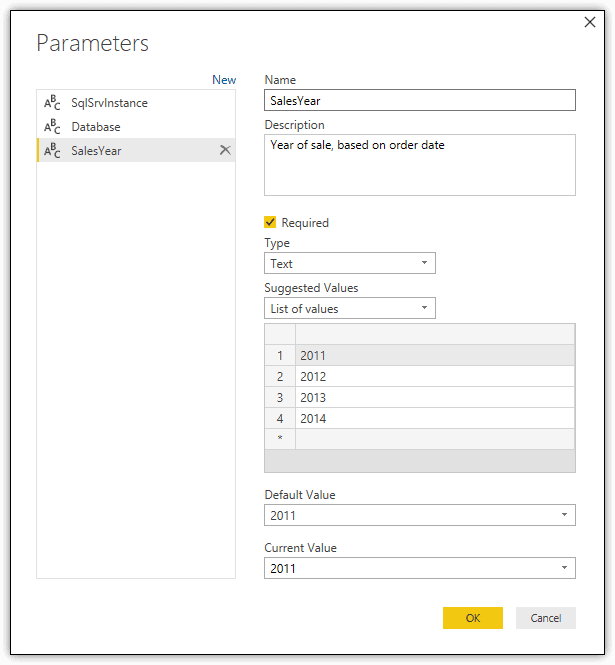
After you’ve created the parameter, update the M statement associated with the dataset’s Source step by replacing the 2013 value with the following code snippet (including the quotation marks):
" & SalesYear & "
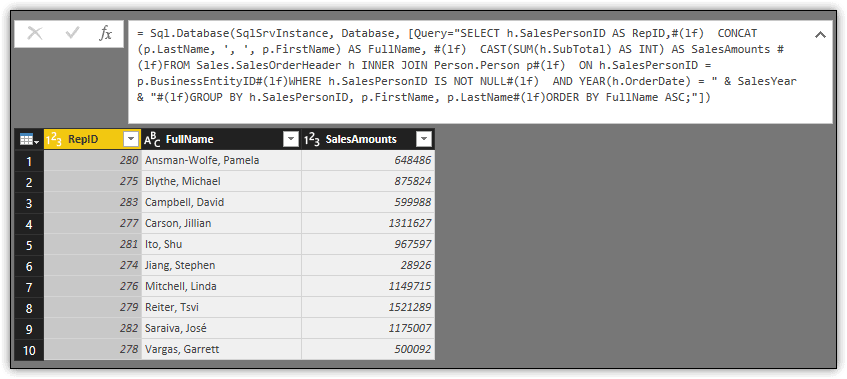
Once you’ve updated the code, click the checkmark to the left of the statement to verify that your changes are formatted correctly and that you didn’t somehow break the code. The statement and dataset should now look similar to those shown in the following figure.
To test the new variable, select SalesYear in the Queries pane and choose a different year from the default 2011. Then re-select the RepSales dataset and verify that the data has been updated.
Adding Parameters to Control Statement Logic
In some cases, you might want to use parameters to control a query’s logic, rather than just filtering data. For example, the SELECT clause in the original T-SQL statement uses the SUM aggregate function to come up with the total sales for each sales rep:
CAST(SUM(h.SubTotal) AS INT) AS SalesAmounts
You can instead insert a parameter in the M statement that allows you to apply a different aggregate function. First, create a parameter name AggType and then define a list that includes one item for each function, using the SUM function as the default and current values, as shown in the following figure.
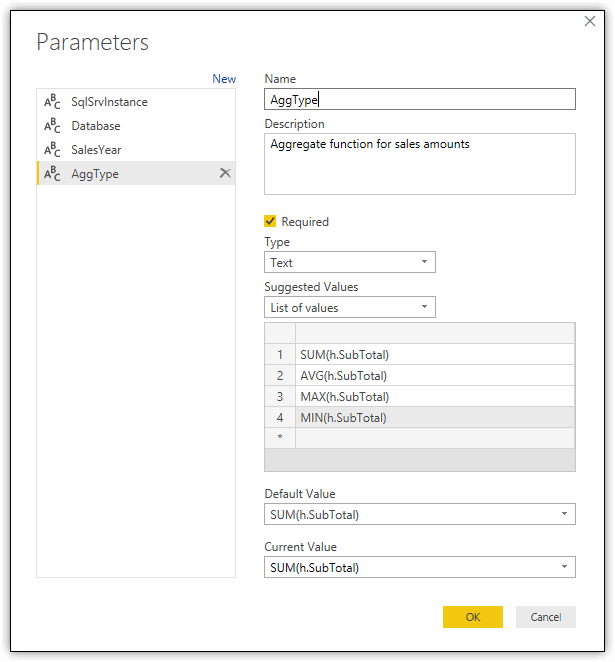
I’ve included the SubTotal column within the options in part to keep the logic clearer, but also to demonstrate that you can summarize the data based on other columns as well, as long as your dataset supports them. For example, you dataset might also include the DiscountAmounts column, which provides the total sales amounts, less any discounts. In such cases, each parameter option can define the specific function and column, including such values as SUM(h.DiscountAmounts) and AVG(h.SubTotal).
After you create the parameter, update the M statement associated with the dataset’s Source step by replacing the hard-coded SUM(h.SubTotal) fragment with the following snippet (including the quotes):
" & AggType & "
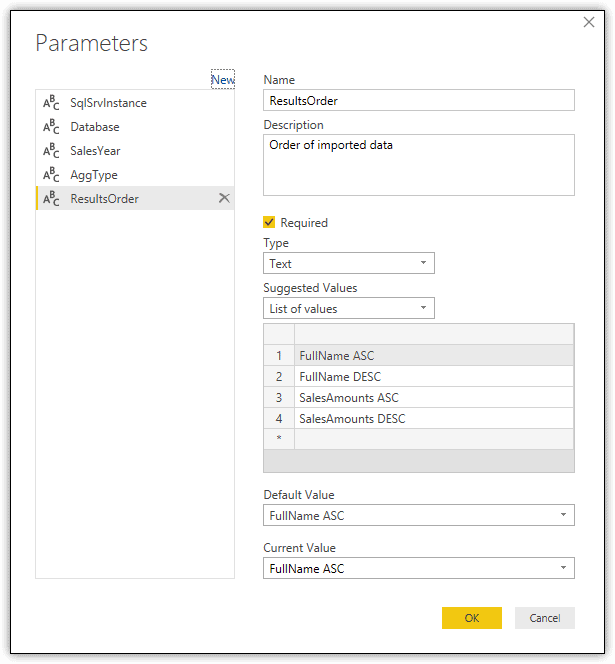
You can also do something similar with the original ORDER BY clause, using a variable to provide options for how to order the data. First, create a variable named ResultsOrder. Then, for each option in the list, specify the column on which to base the sorting (FullName or SalesAmounts) and whether the sorting should be done in ascending or descending order, as shown in the following figure. In this case, the option FullName ASC is used for the default and current values.
Once you’ve created the parameter, update the M statement by replacing the FullName ASC code fragment with the following snippet (including the quotes):
" & ResultsOrder & "
Your M statement and dataset should now look similar to the ones shown in the following figure.
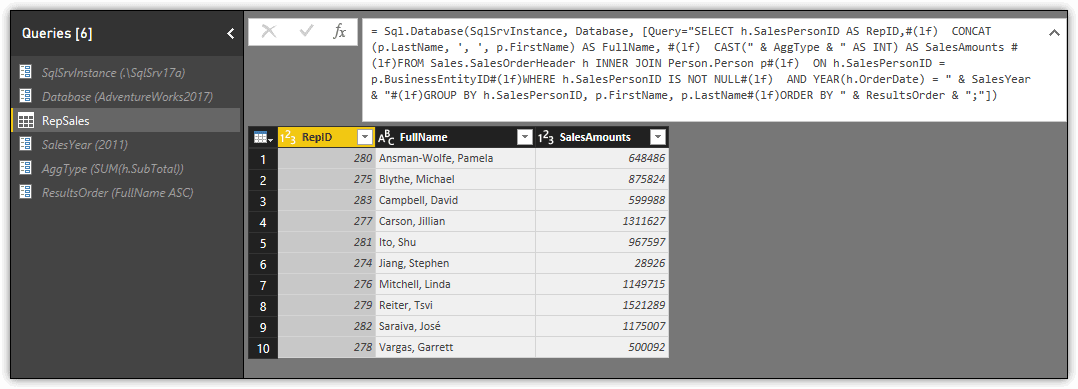
Once you understand how to incorporate parameters into your M statements, you have a wide range of options for manipulating data and making your datasets more flexible and accommodating, without having to add a lot of steps to you query. Just be sure that whenever you make any changes, you apply and save them so you know they work and won’t get lost.
Using Parameters to Name Dataset Object
Another fun thing you can do with parameters is to use them for applying dynamic names to objects. For example, you can change the name of the SalesAmounts column to one that reflects the sales year and type of aggregation being applied. A simple way to do this is to first add a Renamed Columns step to your dataset in Query Editor and then update the associated M statement to include the parameter values.
To add the Renamed Columns step, right-click the SalesAmounts column header, click Rename, type Sales as a temporary column name, and then press Enter. Query Editor adds the Renamed Columns step to the Applied Steps section, along with the following M statement:
= Table.RenameColumns(Source,{{"SalesAmounts", "Sales"}})
To incorporate the SalesYear and AggType parameters into the statement, replace Sales with the following code:
Sales (" & SalesYear & "-" & Text.Range(AggType, 0, 3) & ")
The concatenation operator (&) joins the name Sales with the two variable values, which are separated by a dash and enclosed in parentheses. The Text.Range function retrieves only the first three characters from the AggType variable.
After you update the statement, be sure to verify your changes. The dataset and M statement should now look similar to the ones shown in the following figure.
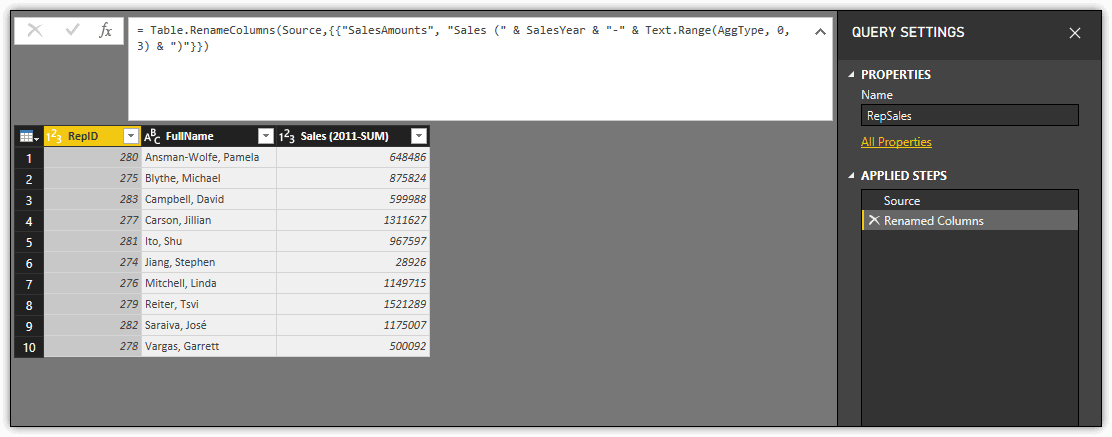
Notice that the name of the dataset’s third column now includes the year and function in parentheses, making it easy to see what parameter values have been applied to the data set.
Working with Parameters in Data View
As you saw earlier, to change a parameter value in Query Editor, you need to select the parameter in the Queries pane and update its value accordingly. However, this can be a cumbersome process, especially when you want to update multiple parameter values concurrently.
Fortunately, you can set parameter values directly in Data view. To set the values, click the Edit Queries down arrow on the Home ribbon and then click Edit Parameters. When the Enter Parameters dialog box appears, select the values you want to apply to your datasets and then click OK. The following figure shows the Enter Parameters dialog box and the current parameter settings.
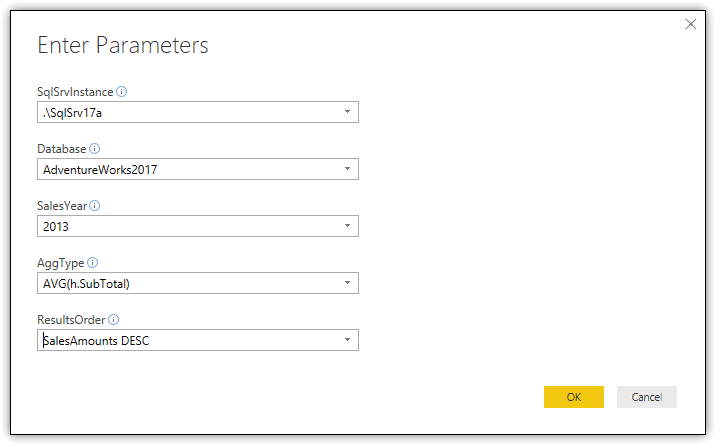
Although the Edit Parameters option name and the Enter Parameters dialog box name are somewhat misleading, the features they represent provide an effective way to update the parameter values and in turn update the data. Be aware, however, that the changes you make here apply to all datasets using the parameters. If you want to include similar types of parameters in multiple datasets, but you do not what them to all share the same values, you should create parameters specific to the dataset, naming them in such a way to make them easily distinguishable from each other.
Once you know how to set the parameter values, you can try different variations, viewing the dataset each time you apply the new settings. For example, the following figure shows the dataset after applying the parameter settings shown in the previous figure.
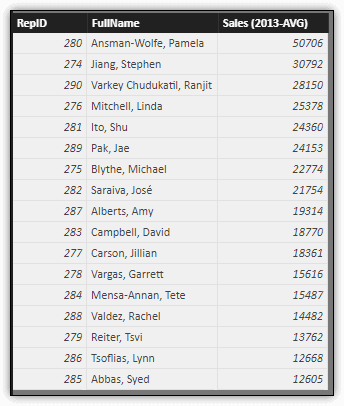
Notice that the Sales column includes the year and aggregation type in the column name and that the data is sorted based on the Sales values, in descending order. You can also change the parameter values while in Report view, allowing you to see you changes immediately within your visualizations.
Clearly, the parameter capabilities help to make Power BI Desktop an even more robust and flexible tool, and you can use parameters in a variety of ways, regardless of where the data originates. The more comfortable you become working with parameters, the more effectively you can use them, and the more control you’ll have over your datasets.
The post Power BI Introduction: Working with Parameters in Power BI Desktop —Part 4 appeared first on Simple Talk.
Privacy Shield: Europaparlament will Datenaustausch mit den USA stoppen
 Nach den EU-Datenschützern verliert nun auch das Europaparlament die Geduld: Die Datenvereinbarung mit den USA soll bald ausgesetzt werden, wenn es keinen besseren Datenschutz gibt. (Datenschutz, Internet)
Nach den EU-Datenschützern verliert nun auch das Europaparlament die Geduld: Die Datenvereinbarung mit den USA soll bald ausgesetzt werden, wenn es keinen besseren Datenschutz gibt. (Datenschutz, Internet) Mit vier Kindern unterwegs: Schulbus-Fahrer wird plötzlich ohnmächtig

Upload-Filter: EU-Parlament lehnt Reform des Urheberrechts ab
 Ob Google oder YouTube in Zukunft Upload-Filter einsetzen müssen, bleibt erst einmal offen. Das Parlament will sich voraussichtlich im September erneut damit befassen.
Ob Google oder YouTube in Zukunft Upload-Filter einsetzen müssen, bleibt erst einmal offen. Das Parlament will sich voraussichtlich im September erneut damit befassen.
Vorstellungsgespräch: Sollten Bewerber das aktuelle Gehalt verraten?
Sollten Bewerber das aktuelle Gehalt im Vorstellungsgespräch verraten? Der HR-Experte Nick Corcodilos sagt nein und liefert die Gründe. Viel besser wäre eine Gegenfrage.
Der Headhunter Nick Corcodilos ist seit 1979 als Headhunter im Silicon Valley tätig und ein bunter Hund in der US-amerikanischen Recruiting-Szene. Auf seiner Webseite „Ask The Headhunter“ antwortet er regelmäßig auf dringende Fragen von Bewerbern. Das Format ist sogar so beliebt, dass selbst der TV-Sender PBS den Recruiter des Öfteren als Experten geladen hat. In einem vielgelesenen Beitrag geht Corcodilos auf eine Frage ein, die auch hierzulande von Jobsuchenden häufig gestellt wird. Nämlich: „Wie soll man auf die Frage nach dem aktuellen Gehalt reagieren?“
Frage nach aktuellem Gehalt: Legt euren Verdienst nicht offen!
Der HR-Experte vertritt da eine klare Meinung. „Ich empfehle Jobsuchenden, einem potenziellen Arbeitgeber nicht zu verraten, was sie derzeit verdienen“, schreibt Nick Corcodilos. Bei seinen Kunden, sprich suchenden Arbeitgebern, weigere er sich konsequent, mitzuteilen, wie viel die von ihm rekrutierten Bewerber gerade verdienen. Im Grunde genommen, so der Headhunter, wolle ein Unternehmen bei Personalkosten immer sparen. Die Antwort auf die Frage könne für den Bewerber gewaltige Nachteile mit sich bringen.
„Ich empfehle, dem Arbeitgeber nicht zu verraten, was ihr derzeit verdient.“
Dass Personaler nämlich nicht bloß aus reiner Neugier nach dem Gehalt fragen, liegt angesichts der dahinterliegenden Strategie auf der Hand. Sie wollen lediglich abschätzen, so Corcodilos, ob sie den Jobsuchenden aufgrund des bisherigen Gehalts in der neuen Verhandlung noch nach unten drücken können. Niemand dürfe deshalb erwarten, dass ein Personaler es im Bewerbungsgespräch sofort akzeptiert, wenn ein Bewerber das Gehalt nicht offenlegt. Sie geben dann häufig einen vorgeschobenen Grund an, warum sie das Gehalt wissen müssen.
Ein potenzieller Arbeitgeber könnte beispielsweise sagen: „Wir müssen dein Gehalt wissen, weil wir sonst nicht mit dem Bewerbungsprozess fortfahren können“, oder „Wir müssen dein Gehalt wissen, weil es zu den Unternehmensrichtlinien gehört.“ Nick Corcodilos rät Bewerbern, sich nicht unter Druck setzen zu lassen. „Ein Arbeitgeber hat vielleicht das Recht, nach deinem Gehalt zu fragen und er hat das Recht, bei deiner Verweigerung die Bewerbung abzulehnen, aber du hast ebenfalls das Recht, nein zu sagen“, erklärt der Headhunter.
Letzten Endes, so Corcodilos, müsse jeder selber entscheiden, ob er oder sie das Gehalt offenlegt. „Aber ihr müsst euch bewusst sein, dass ihr mit der Antwort vermutlich eure Chancen ruiniert, ein gutes Angebot zu bekommen“, erklärt er weiter. Um dem ganzen Geschehen einen stilvollen Ausweg anzubieten, lohnt sich übrigens ein Blick auf den Tipp der HR-Expertin Liz Ryan in Business Insider. Sie rät zur Gegenfrage: „Bei meinen Bewerbungen suche ich nach Jobs ab einem Jahresgehalt von (Zahl einfügen). Liegt die ausgeschriebene Stelle im Budget?“. So gibt der Bewerber den Ton an.
1 von 13
Übrigens, auch dieser Beitrag könnte dich interessieren: Gehälter der Online-Branche – So viel verdienen SEO-, Social-Media- und Content-Manager
Sonderausschuss: G20: Unpolitischer Karneval – oder strategische Gewalt?
 Linke Szene unter der Lupe: Experten analysieren G20-Krawalle. Außerdem: Ferien, Radhasser Spörrle, Lindenberg, Eisbattle, Baby! Mietpreisbremse neu, "Aktenzeichen XY"
Linke Szene unter der Lupe: Experten analysieren G20-Krawalle. Außerdem: Ferien, Radhasser Spörrle, Lindenberg, Eisbattle, Baby! Mietpreisbremse neu, "Aktenzeichen XY"
Das Credo der Klimatologiker
Überall überschlagen sich die Klimatologiker, um „Maßnahmen“ bzgl. ihrer Ziele und ihres Glaubens zu fordern und voranzutreiben – jedwede Fakten, die das Gegenteil belegen, sind für sie vollkommen belanglos und werden einfach ignoriert.
Die Denkweise der Klimatologiker
Der Denkweise der Klimatologiker zufolge sind sie von folgenden Dingen überzeugt:
- „Fossile Treibstoffe“ sind die Schurken der Welt. Darum müssen sie kontrolliert oder – besser noch – deren Verbrauch unterbunden werden, wenn man sie nicht – noch besser – gleich ganz im Boden lässt (siehe hier oder hier).
-
Jeder, der ein Benzin- oder Dieselfahrzeug fährt, sollte ins Gefängnis gesteckt werden wegen „eines Angriffs auf die Natur“, sofort (siehe hier oder hier) und vorzugsweise für immer.
-
Kohlendioxid „verbrennt“ den Planeten Erde (hier), oder wir befinden uns auf dem Weg der Opferung.
-
Kohlendioxid ist ein gefährlicher Verschmutzer (vielleicht schlimmer als das Nervengas „Novichok“), der alles Leben auf der Erde vernichten wird (siehe hier aus dem Jahr 2007).
-
Es heißt, dass der Meeresspiegel mit zunehmender Rate steigt und dass daher Inselnationen im Indischen (Malediven) und Pazifischen Ozean (Kiribati und Tuvalu) in demselben versinken und die Inselbewohner um ihr Leben rennen werden (ein Beispiel steht hier).
-
Hurrikane und andere Sturmereignisse nehmen an Häufigkeit und Intensität zu (hier).
-
Das gesamte arktische Meereis schmilzt dahin, schon seit Jahrzehnten (erholt sich aber seltsamerweise in jedem Winter wieder). Vermutlich werden Ausflugsfahrten durch die Nordwest-Passage immer mehr zu Erholungsreisen (hier).
-
Außerdem werden in der Arktis sämtliche Eisbären (was, es gibt noch welche?!) alle ertrinken oder verhungern, weil das Kohlendioxid vermeintlich das gesamte arktische Meereis zum Schmelzen bringt (hier).
-
Am anderen Pol, der Antarktis, ist das Schmelzen von Gletschern und Meereis beispiellos, und die Pinguine verhungern oder sterben den Hitzetod mit alarmierenden Raten (hier).
-
Der Mensch muss sich „dekarbonisieren“ und zurückkehren zu mittelalterlichen Technologien wie Windmühlen und Pferdekutschen, um den Planeten zu retten (hier).
-
Tropische Korallenriffe bleichen aus (und sterben) wegen des „Klimawandels“, während die reale Verschmutzung (durch ungeklärte Abwässer aus Wohngebieten an den Küsten) keine Rolle spielen soll.
-
Die Welt muss sich „dekarbonisieren“, d. h. Sie und ich müssen das Autofahren aufgeben (in Wirklichkeit meinen sie jeden internen Verbrennungsmotor) und (am besten) zu „Muskelkraft“ wechseln (hier).
-
Heizen (im Winter) und kühlen (im Sommer) der Wohnungen ist ebenfalls ein dicker Makel auf jedermanns „Kohlenstoff-Fußabdruck“. Dadurch werden die Erde und alle zukünftigen Generationen gebraten (hier).
Ich könnte diese Liste noch endlos fortsetzen, aber ich denke, dass man mich auch ohne weitere langweilige Behauptungen versteht. In jedem Falle sind für jeden guten Klimatologiker Fakten irrelevant oder, wie der „Borg“ sagte „Widerstand ist zwecklos“.
Widerstand ist zwecklos (?)
Die einfache Tatsache ist, dass alle jene Credos so gut klingen und so nach „Rettung der Natur“. In Wirklichkeit handelt es sich dabei aber um Falschheiten auf der Grundlage von „Fake News“, einem falschen Verständnis von „Ursache und Wirkung“, fehlendem wissenschaftlichen Hintergrundwissen oder auch politischer Berechnung, und so weiter.
Und (genauso wahr): Die Verkündigung des Borgs war ebenfalls falsch.
Es muss all den Klimatologikern bei den UN, dem IPCC, dem PIK und zahllosen anderen (meist vom Steuerzahler finanzierten) Stiftungen, Forschungsinstituten und Universitäten ein echtes Rätsel sein, warum all die von ihnen seit Jahrzehnten propagierte heiße Luft ihnen nicht die Früchte eingebracht hat, auf die sie gehofft hatten. Tatsächlich ist genau das Gegenteil der Fall – und aus guten Gründen, namentlich weil das Volk die Nase voll hat von „falscher Reklame“.
Falsche Reklame
Die Menschen haben einfach die Nase voll von den täglichen Einhämmerungen über „schmelzendes Polareis“, Prophezeiungen von „steigenden Ozeanen“, „gefährdeten Pinguinen“, „Verschwinden der Eisbären“ sowie andere düstere Prophezeiungen. Kluge Leser bekommen immer mehr Erfahrung darin, derartige Fake News von tatsächlichen Fakten, wahren Messungen und tatsächlichen Beobachtungen vor Ort zu unterscheiden (welche im Gegensatz stehen zu von Computerprogrammen prophezeiten „Szenarien“).
Tatsächlich wird das Volk immer mehr angewidert durch viele der Behauptungen der Klimatologiker (welche immer noch von den Mainstream-Medien hinaus posaunt werden) – vor allem, wenn es die tatsächlichen Daten einsehen kann bzgl. Meeresspiegel, Eismassen, Pinguine und Anzahl der Eisbären, und so weiter.
Und außerdem, die Behauptungen der Klimatologiker hinsichtlich der unabdingbaren Notwendigkeit der „Dekarbonisierung“, während diese selbst von einem Ferienparadies zum nächsten jetten (auf Kosten der Steuerzahler), fangen an zu ermüden. Und die Werbeanzeigen exklusiver Fünf-Sterne-Ferienparadiese auf den Malediven (hier) sind mit Sicherheit kein Hinweis auf deren unmittelbar bevorstehenden Untergang. Tatsächlich ist man auf den Malediven stolz darauf, über eine Million Besucher jedes Jahr zu haben (hier) – auf ihren „versinkenden Inseln“, um die ruhige Inselgastlichkeit zu genießen. Ach ja, à propos Malediven, trotz all der Meinungen der Klimatologiker nimmt die Bevölkerung dort ebenso wie in anderen Inselnationen des Pazifischen Ozeans um etwa 10% pro Jahr zu. Beispielhaft seien dazu die Bevölkerungszahlen der Regierung für die Malediven genannt (hier): 2002 waren es 269.000; 2010 305.000 Menschen. Und derzeit, also 2016, beläuft sich die Schätzung auf 428.000 Menschen (hier).
Egal wie man die Daten dreht und wendet – es gibt nicht den leisesten Schimmer, dass die Malediven oder andere Inseln „ertrinken“, was die MSM, NGOs und andere „besorgte“ Klimatologiker seit Langem von sich geben.
Vielleicht ist es da an der Zeit, ein wirkliches Abenteuer zu empfehlen, zum Beispiel eine begeisternde Erfahrung im Hohen Norden.
Der Hohe Norden
Warum nicht einmal auf eine Kreuzfahrt durch die Nordwest-Passage gehen mit zahlreichen Exkursionen! Auge in Auge mit Eisbären…
Link: https://principia-scientific.org/the-climatologians-credo/
Übersetzt von Chris Frey EIKE
Robuste Kraftwerke für robuste Netze
Sie sind mehr (Wind) oder weniger (Sonne) zufällig. Sie widersprechen dadurch allen Anforderungen an eine zivilisierte Gesellschaft. Will man sie aus (ideologischen Gründen) trotzdem zur Erzeugung elektrischer Energie heranziehen, ergeben sich drei Notwendigkeiten:
- Der Einspeisevorrang: Die Sonne scheint bei uns nur selten (nachts ist es dunkel, tagsüber oft schlechtes Wetter) und der Wind weht in der überwiegenden Zeit nur schwach. Man kann deshalb nicht auch noch auf den Bedarf Rücksicht nehmen (negative Börsenpreise), sondern muß produzieren wenn es der Wettergott gestattet. Ganz genau so, wie schon der Müller und die Seefahrer im Altertum ihr Leben fristen mußten.
- Man muß ein komplettes Backup System für die Zeiten der Dunkelflaute bereithalten. Wirtschaftlich ein absolut absurder Zustand. Es ist ein komplettes System aus Kraftwerken und Stromleitungen vorhanden — man darf es plötzlich nur nicht mehr benutzen! In der Stromwirtschaft sind aber die Kapitalkosten der mit Abstand dickste Brocken. Weit vor den Personalkosten und meist sogar den Brennstoffkosten. Wenn man ausgerechnet die Nutzungsdauer verringert, treibt man damit die spezifischen Energiekosten (€/kWh) in die Höhe. Umgekehrt kann man sagen, der maximal mögliche Wert elektrischer Energie aus „regenerativen Quellen“ kann immer nur den Brennstoffkosten entsprechen.
- „Regenerative Energien“ besitzen nur eine sehr geringe Energiedichte und benötigen deshalb riesige Flächen. Diese Flächen sind nicht an den Verbrauchsschwerpunkten (Städte, Industriegebiete) bereitzustellen. Heute muß man bereits auf das offene Meer ausweichen. Es sind deshalb riesige Netze zum Einsammeln der elektrischen Energie und anschließend noch die berüchtigten „Stromautobahnen“ für den Ferntransport nötig. Alles sehr kapitalintensiv, pflegebedürftig und verwundbar. Oft wird auch noch vergessen, daß diese Anlagen selbstverständlich nur die gleiche geringe Auslastung, wie die Windmühlen und Sonnenkollektoren besitzen können.
Das Speicherdrama
Wind und Sonne können nur die Schildbürger speichern. Elektrische Energie ist die verderblichste Ware überhaupt (Kirchhoffsche Gesetze). Wer also von Speichern faselt, meint in Wirklichkeit Speicher für chemische (Batterien, Power to Gas etc.) oder mechanische Energie (Schwungräder, Pump-Speicher usw.). Es ist also immer eine zweifache Umformung — elektrische Energie in das Speichermedium und anschließend wieder das Speichermedium zurück in elektrische Energie — mit den jeweiligen Verlusten erforderlich. Es geht bei diesen Umformungen mindestens 50% des ohnehin sehr teuren Sonnen- bzw. Windstromes unwiederbringlich verloren. Mit anderen Worten, der Strom der aus dem Speicher kommt, ist dadurch schon mal doppelt so teuer, wie der vor dem Speicher. Das wäre aber nicht einmal der Bruchteil der Kosten: Die „Chemieanlagen“ oder „Speicherseen“ müßten gigantisch groß sein. Sie müssen ja schließlich in der kurzen Zeit, in der sie wetterbedingt überhaupt nur produzieren können (<15%), die elektrische Energie für die gesamte Zeit (100%) herstellen können. Betriebswirtschaftlich eine Katastrophe. Niemand wird eine solch absurde Investition tätigen. Die Schlangenölverkäufer setzen auch hier wieder auf den Staat. Das bekannte „Windhundrennen“ setzt ein: Wer pumpt am schnellsten die „Staatsknete“ ab, bis das System unweigerlich in sich zusammenbricht. Selbstverständlich ist auch hier für einige wenige wieder ein Schlösschen drin.
Auch Wasserkraft ist wetterabhängig. Die Trockenphasen wechseln sich mit Hochwassern ab. Fast alle Staudämme sind deshalb zur Flussregulierung gebaut worden. Selbst das gigantische Drei-Schluchten-Projekt in China. Die Vorstellung, man könnte Wasserkraftwerke wie Gasturbinen nach Bedarf an und abstellen, ist absurd. Abgesehen von technischen Restriktionen sprechen Sicherheitsbelange (Schifffahrt, Wassersportler etc.) und der Umweltschutz dagegen. Ein Fluß ist keine technische Batterie, sondern ein sensibles Ökosystem. Genau aus diesen Gründen werden die Speicherkraftwerke in den Alpen — wie alle konventionellen Kraftwerke — durch die Windenergie aus Deutschland in die roten Zahlen getrieben. Man kann eben nicht immer den Stausee in den Stunden negativer Börsenpreise (Entsorgungsgebühren) schlagartig für die Dunkelflaute befüllen. Im Gegenteil, oft muß man gerade dann den eigenen Strom verkaufen. Und noch einmal für alle Milchmädchen: In den wenigen Stunden, in denen der Wind im Überfluß weht, müßte man die gesamte Energie für die überwiegenden Schwachwindzeiten einspeichern — ein betriebswirtschaftlicher Albtraum.
Die Frage des Brennstoffs
Wenn man ein Kraftwerk benutzen will, muß man Brennstoff am Ort zur Verfügung haben. Alles andere als eine triviale Frage. Alte West-Berliner kennen noch die Tanklager und die sich ständig selbst entzündenden Kohlenhalden gegen eine etwaige „Russenblockade“. Jedenfalls sind Tanklager und Halden noch relativ billig anzulegen.
Bei Erdgas stellt sich die Sache schon ganz anders dar. Ein Gaskraftwerk ist auf eine ziemlich dicke Rohrleitung angewiesen. Das gesamte System vom Bohrloch, über die Aufbereitung, bis zum Endkunden ist nicht viel weniger Komplex als die Stromversorgung. In unseren Breiten wird das meiste Erdgas zur Beheizung unserer Gebäude verwendet. Die Winterspitze ist maßgeblich für die Dimensionierung. Zum Ausgleich setzt man unterirdische Speicher ein. Diese sind aber (bezogen auf den Jahresverbrauch) relativ klein. Jeder eingelagerte Kubikmeter Gas ist totes Kapital. Man steuert deshalb den Absatz über den Preis. Im Sommer ist der Großhandelspreis gering — damit die Gaskraftwerke verstärkt produzieren — und im Winter — wenn es kalt ist und die Nachfrage nach Heizgas ansteigt — hoch. Die Gaskraftwerke ziehen sich dann wieder zurück und überlassen den Kohlekraftwerken die Produktion. Dieses Zusammenspiel hat bis zur Energiewende zu aller Zufriedenheit funktioniert. Man konnte im Sommer sehr gut Revisionen bei den Kohle- und Kernkraftwerken durchführen. Bis die Laiendarsteller kamen und etwas von notwendigen flexiblen Gaskraftwerken für die Energiewende geschwafelt haben. Heute kann man die Investitionsruinen an verschiedenen Standorten besichtigen. Man muß es eigentlich nicht besonders erwähnen, daß die grünen Fachpersonen der Stadtwerke (es haftet ja der Steuerzahler) besonders eifrig auf den Leim gekrochen sind. Um ihre Missetaten zu vertuschen, krähen sie heute besonders laut über die „Klimakatastrophe“ und das „klimafreundliche“ Erdgas.
Das Kraftwerk der großen Transformation
Je länger der Wahnsinn der „Energiewende“ anhält, um so mehr wird der Wettergott das Kommando übernehmen. Prinzipiell nimmt in einem technischen System mit der Häufigkeit der Störungen und der Größe einzelner Störungen die Wahrscheinlichkeit eines Ausfalls zu. Will man ein solchermaßen malträtiertes Stromnetz wieder robust machen, stellen sich in diesem Sinne („Grid Resilience“) zwei Anforderungen an die Kraftwerke:
- Die Kraftwerke müssen von der Konstruktion (z. B. Brennstoffe) her und bezüglich der Fahrweise (z. B. angedrosselt) robust gebaut und betrieben werden. Beides verursacht erhebliche Kosten, die ohne die „Energiewende“ gar nicht entstanden wären. Hinzugerechnet werden muß noch der Umsatzausfall durch den Einspeisevorrang. Werden diese Zusatzkosten nicht vergütet, müssen die Kraftwerke geschlossen werden. Mit jedem konventionellen Kraftwerk das vom Netz geht, wird das gesamte Stromnetz instabiler, was den Aufwand weiter in die Höhe treibt.
- Das Netz muß nach schweren Störungen (Brown oder Black Out) möglichst schnell wieder hochgefahren und in einen neuen stabilen Zustand versetzt werden. Dafür müssen die Kraftwerke technisch (z. B. Schwarzstartfähigkeit) und personell jederzeit in der Lage sein. Die Wiederinbetriebnahme muß nach den Anforderungen der Netzleitzentrale erfolgen. Etwaige Überprüfungen, Wartungen oder gar Reparaturen müssen selbstverständlich vorher erfolgt sein. Dies gilt insbesondere für Schäden, die durch den außergewöhnlichen Netzzustand entstanden sind.
Es ist daher nichts weiter als bösartige und schlechte Propaganda, wenn Scharlatane von dem „Kohlestrom, der die Netze verstopft“ erzählen. Je mehr konventionelle Kraftwerke stillgelegt werden (müssen), desto weniger notwendige Reserven gibt es. Schon jetzt verlassen wir uns auf Kraftwerke im benachbarten Ausland. Man kann nicht erwarten, daß das kostenlos erfolgt. Je mehr wir das System komplizieren und ausweiten, um so mehr koppeln unerwartete Ereignisse auf das Stromnetz zurück: Es gab schon Brände in Erdgasspeichern, die diese für Monate lahmlegten oder Engpässe durch Drosselung in den niederländischen Erdgasfeldern (Mikrobeben) oder Pipelinebrüche. Ganz zu schweigen von der politischen Abhängigkeit gegenüber ausländischen Lieferanten. Kohle und Kernenergie besitzen schon durch ihre einfache Lagerung einen entscheidenden Trumpf.
Das robuste Kernkraftwerk für ein „nervöses Netz“
Kernkraftwerke besitzen eine Reihe von Eigenschaften, die besonders wertvoll für „nervöse Stromnetze“ mit einem hohen Anteil von wetterabhängigen Energien sind. Dies mag „Atomkraftgegner“ erschüttern, aber nur Reaktoren können die extremen Lastschwankungen (z. B. 3. Potenz von der Windgeschwindigkeit) sicher verkraften. Nur sie können extremen Wettersituationen sicher widerstehen. Es waren immer die Kernkraftwerke, die als letzte vom Netz mußten (Tsunami und Erdbeben in Japan, Wirbelstürme in den USA, Eiseskälte in Rußland). Es ist allerdings unverständlich, warum man bei den geringen Urankosten die Kernkraftwerke überhaupt drosseln soll, wenn mal die Sonne scheint oder der Wind in der richtigen Stärke weht…
Für Kernkraftwerke, die in einem „nervösen Netz“ zur Stabilisierung betrieben werden, ergeben sich folgende Anforderungen:
ROBUSTE LASTFOLGE
Je schneller und erfolgreicher (noch) kleine Störungen ausgeregelt werden, um so besser für das Netz. Heutige Leichtwasserreaktoren haben große Leistungen. Der im Bau befindliche Turbosatz des Kraftwerks Hinkley Point in GB mit 2 x 1770 MWel hat eine gewaltige Schwungmasse, die zur Frequenzstabilisierung mehrerer Windparks dienen kann und soll. Hinzu kommen die gespeicherten Wärmemengen im Wasser-Dampf-Kreislauf. Automatisch greift bei einem Leichtwasserreaktor die Selbstregulierung über den Zusammenhang von Dichte des Kühlwassers und Moderation der Neutronen. Zusammengenommen ergibt das die steilsten Leistungstransienten aller Kraftwerkstypen. Die alte Greenpeace Propaganda von den „viel zu starren Atomkraftwerken“ beruhte bestenfalls auf der Verwechslung von Technik mit Betriebswirtschaft. Mit anderen Worten: Frankreich kann sich ruhig noch ein paar Windmühlen für das bessere Gewissen erlauben, Deutschland hingegen, geht mit der weiteren Abschaltung immer unruhigeren Zeiten entgegen. Fatal wird es in dem Moment, wenn unsere Nachbarn nicht mehr bereit sind, die Kosten für die Stabilisierung unseres nationalen Stromnetzes zu bezahlen.
ABWEHR ÄUSSERER EINFLÜSSE
Fukushima hat eindrucksvoll gezeigt, wie zerstörerisch Naturgewalten sein können. Eine weltweite Überprüfung aller Kernkraftwerke gegen jegliche Wasserschäden (Starkregen, Überflutungen etc.) war die Folge. Eine Nachrüstung in Richtung „U-Boot“ wurde durchgeführt. Seit dem, haben bereits mehrere Reaktoren einen Betrieb „inmitten von Wasser“ unter Beweis gestellt. Oft waren sie die einzigen noch betriebsbereiten Kraftwerke: Kohlenhalden hatten sich in Schlamm verwandelt, Gaspipelines waren durch die Wassermassen ausgefallen.
Gerade auch Netzstörungen (Sturmschäden, Blitzschlag etc.) wirken oft auf ein Kraftwerk von außen ein. Ein Kraftwerk ohne Netz kann noch so gut funktionieren, aber es kann seine elektrische Energie nicht mehr ausliefern. Oft lösen die Netzstörungen auch Schäden in der Kraftwerksanlage aus. Bei einem Kernkraftwerk sollte keine Schnellabschaltung durch solche Ereignisse ausgelöst werden.
SICHERER INSELBETRIEB
Egal was mit dem Netz passiert, das Kernkraftwerk sollte automatisch in den Inselbetrieb übergehen. Nur so kann bei einer schnellen Reparatur die Produktion unverzüglich wieder aufgenommen werden. Dies erfordert, daß wirklich alle elektrischen Verbraucher des Kraftwerks (verschiedene Spannungsebenen) dauerhaft über den eigenen Generator versorgt werden können.
UNENDLICHE NOTKÜHLUNG
Die Besonderheit eines Kernreaktors ist die anfallende Nachzerfallswärme auch nach vollständiger Abschaltung. Die mangelnde Wärmeabfuhr (Ausfall der Kühlmittelpumpen) war die Ursache für den Totalschaden in den Reaktoren von Fukushima. Neuere Reaktoren mit passiven Notkühlsystemen bieten hierfür einen unschätzbaren Vorteil. Alte Kraftwerke müssen mit ausreichender Eigenstromversorgung (mehrfache Notstromaggregate mit ausreichendem Tanklager) nachgerüstet werden. Die eigenen Schaltanlagen für den Notbetrieb müssen — im Gegensatz zu Fukushima — entsprechend geschützt werden.
SCHWARZSTARTFÄHIGKEIT
Ein Kernkraftwerk benötigt für die Inbetriebsetzung eine gewaltige Menge elektrischer Energie. Üblicherweise wird diese dem Netz entnommen. Ist ein Netz im Katastrophenfall schon überlastet, dürfte dies kaum möglich sein. Es müßte also eine Eigenstromversorgung (z. B. Gasturbine) vorhanden sein, wenn ein Schwarzstart für die Robustheit eines Teilnetzes gefordert ist.
Normalerweise ist das Anfahren eines Kernkraftwerkes ein streng reglementierter und langwieriger Vorgang. Unzählige Prüfungen müssen durchgeführt, bestimmte Haltepunkte eingehalten werden. Immer nach dem Grundsatz „Safety First“. Alles andere als ideal für die Wiederherstellung eines Netzes nach einem „Blackout“. Deshalb sollte die Schnellabschaltung unbedingt vermieden werden. Gegebenenfalls ein Schnellverfahren für Notfälle geschaffen werden. Jedenfalls kommt noch eine Menge Arbeit auf die Überwachungs- und Genehmigungsbehörden zu. Aber es ist uns ja nichts zu schwer und zu teuer um wenigstens teilweise wieder ins Mittelalter zurückzukehren.
Der Beitrag erschien zuerst bei NUKEKLAUS hier
Sparkassen bieten ab heute Echtzeit-Überweisungen
BBV: Telekom überbaut "Glasfaser mit Vectoring"
 Bretten bei Karlsruhe ist das erste große Ausbauprojekt eines neuen Glasfaser-Netzbetreibers, hinter dem große Geldgeber stehen. Das will die Telekom offenbar nicht zulassen. (Glasfaser, Open Access)
Bretten bei Karlsruhe ist das erste große Ausbauprojekt eines neuen Glasfaser-Netzbetreibers, hinter dem große Geldgeber stehen. Das will die Telekom offenbar nicht zulassen. (Glasfaser, Open Access) Wie wahrscheinlich sind Flug-Taxis in München? Hersteller nennt sogar ein konkretes Datum

Radfahren: Achtung, Geisterradler!
 Ein Fahrrad mag wenig Platz brauchen. Dürfen Radler deshalb auf dem Fahrradweg entgegen der Fahrtrichtung fahren?
Ein Fahrrad mag wenig Platz brauchen. Dürfen Radler deshalb auf dem Fahrradweg entgegen der Fahrtrichtung fahren?
Equivalence principle of general relativity holds even at gravitational extremes
EU-Leistungsschutzrecht: Verleger erwarten knappen Ausgang der Abstimmung
Am Donnerstag entscheidet das Europäische Parlament über die Zukunft des Leistungsschutzrechts. Kritiker sehen das Internet durch die Reform bedroht. Kurz vor der Abstimmung melden sich jetzt Verleger zu Wort.
Der Streit um das EU-Leistungsschutzrecht eskaliert weiter. Bevor das EU-Parlament am Donnerstag eine Entscheidung über die Reform trifft, haben Verleger und Verwertungsgesellschaften jetzt vor dem Scheitern der Gesetzesinitiative gewarnt. Valdo Lehari jr., Vizepräsident des Verbandes der Europäischen Zeitungsverleger, erwartet ein knappes Ergebnis.
Was umfasst die Reform des Urheberrechts?
Mit einer Änderung und Ausweitung des seit 2013 existierenden Leistungsschutzrechtes (LSR), das es so bislang nur in Deutschland und Spanien gibt, steht das Internet in Europa vor einer tiefgreifenden Zäsur. Die Reform umfasst in Artikel 13 die Einführung von verpflichtenden Uploadfiltern. Diese arbeiten im Hintergrund mit riesigen Datenbanken und Algorithmen, die über die Verwertung von Inhalten im Internet entscheiden. Bei einem Verdacht auf Urheberrechtsverstoß würden Inhalte blockiert werden. Artikel 11 verankert das neue Verlegerrecht, das Presseverlage befähigt, Lizenzgebühren zu erheben, wenn Internetplattformen mit einer kleinen Vorschau auf den den Inhalt verlinken, so wie es aktuell beispielsweise Google News tut.
In Deutschland hatte das LSR aus dem Jahr 2013 nicht zu nennenswerten Geldzahlungen von Konzernen wie Google an die Verlage geführt, weil die von der Verwertungsgesellschaft VG Media aufgerufenen Tarife nicht akzeptiert wurden. Google ließ die Verlage eine Verzichtserklärung unterschreiben – andernfalls wären die Links ohne die kurzen Anreißer, auch Snippets, bei Google News angezeigt worden. In Spanien stellte der Internet-Gigant sogar sein Angebot Google News komplett ein, um nicht zahlen zu müssen. Lehari betonte, ein europäisches Leistungsschutzrecht werde auch die Position der Verlage in Deutschland stärken. „Markt-Monopolisten wie Google können in Europa dann nicht auf Länder ausweichen, in denen es kein Leistungsrecht gibt.“
Der Verleger des Reutlinger General-Anzeigers betonte, dies sei nicht nur die Auffassung großer Medienunternehmen wie Axel Springer. In Europa machten sich 5.300 Zeitungstitel und über 15.000 Zeitschriftenverlage mit 50.000 Titeln für diese Reform stark. Verlage könnten mit einem „nennenswerten Betrag“ zur Stärkung der journalistischen Arbeit rechnen. „Aber es geht letztendlich auch um eine Prinzip-Frage, dass das, was kreativ geschaffen wurde, im Grunde immer geschützt werden muss.“
Kritiker warnen vor „Linksteuer“
Eine Bilanz des seit 2013 existierenden Gesetzes liegt dem EU-Parlament trotz mehrfacher Aufforderung der Grünen nicht vor, wie Spiegel Online Anfang Juni zusammenfasste. Weder der bei Inkrafttreten des Gesetztes verantwortliche Justizminister Heiko Maas noch seine Nachfolgerin Katarina Barley wollten sich einer Evaluierung des Gesetzes annehmen. Für die Verleger bedeutete die deutsche Version des LSR bisher vor allem Kosten – und Google, die das Gesetz eigentlich treffen sollte, ließ alle relevanten Verlage in Deutschland Verzichtserklärungen unterschreiben. Das neue LSR, sollte es eine Mehrheit im EU-Parlament finden, soll nun die Gesetzeslage noch einmal verschärfen.
Kritiker warnen vor einem tiefgreifenden Eingriff in die Informationsfreiheit durch Uploadfilter. Andere automatisierte Systeme zu Erkennung von Urheberrechtsverletzungen zeigen regelmäßig, wie fehleranfällig sie sind: So blockte der von Google eingerichtete Filter bei Youtube immer wieder auch völlig legale Inhalte – wie beispielsweise Kurse der US-Universität MIT. Die nochmals verschärfen Regeln zur Lizenzzahlungen selbst bei kleinsten Text-Snippets bezeichnen Kritiker wie die Europa-Abgeordnete Julia Reda als „Linksteuer“.
Auch eine von der EU-Kommission 2016 in Auftrag gegebene Studie zur Wirksamkeit des deutschen und des vergleichbaren spanischen Gesetzes stuft das Gesetz als kontraproduktiv ein – das Ergebnis wurde aber nie offiziell veröffentlicht.
Mit Material von dpa
Mehr zum Thema EU-Leistungsschutzrecht:
- Vergesst die DSGVO: Das Netz verliert gerade seine Informationsfreiheit
- Leistungsschutzrecht: Kaum Einnahmen, aber 7,6 Millionen Euro Kosten
- Links verbieten und Innovation ausschalten: Lobbyisten plauderten wahre Intention des EU-Leistungschutzrechts aus
Zukunft autonomes Fahren: 4 Vorteile für Familien
Einsteigen und dem Autopiloten die Kontrolle überlassen – in Zukunft werden selbstfahrende Autos das Reisen revolutionieren. Aber auch für Familien? Im Auftrag der Deutschen Bahn hat das Meinungsforschungsinstitut forsa Mütter und Väter befragt, wie sie aktuell über die neue Technologie denken.* Diese Vorteile erhoffen sich Eltern und Verkehrsexperten künftig vom autonomen Fahren:
1. Entspannter Ankommen
Ein Auto, das seine Passagiere selbstständig ans Ziel bringt: Hätten Sie gedacht, dass schon Leonardo da Vinci davon träumte? Vor rund 500 Jahren skizzierte er das wohl erste Roboterauto. Heute ermöglichen es Sensoren und Algorithmen, dass Hightech-Fahrzeuge führerlos ihren Weg finden. Schaffen diese in Zukunft den Durchbruch, wird das autonome Fahren für Entspannung sorgen – weil man nicht mehr auf den Verkehr achten muss. Davon sind nach Angaben von forsa aktuell 56 Prozent der Eltern überzeugt.
2. Mehr Zeit für die ganze Familie
Am Autofenster flitzt die Landschaft vorbei, im Wagen jagt ein Spiel das nächste. 69 Prozent der von forsa Befragten sind davon überzeugt: Im autonom fahrenden Wagen bleibt in Zukunft mehr Zeit für die Kinderbetreuung. Aber auch Eltern verschafft die neue Technologie künftig neue Freiräume: Knapp jede dritte Mutter (29 Prozent) und gut jeder dritte Vater (35 Prozent) denkt, dass sie oder er sich im selbstfahrenden Auto in Zukunft mehr Zeit für sich selbst nehmen kann.
3. Bessere Luft und weniger Staus
Mehr Mobilität für Familien und Ältere – und noch dazu weniger Staus. Sie ahnen es: Es gibt viele gute Gründe für selbstfahrende Fahrzeuge. Aber wussten Sie schon, dass die neue Technik sich auch für die Umwelt lohnt? Nach Angaben des Verbands der Automobilindustrie (VDA) trägt sie künftig dazu bei, den Ausstoß von klimaschädlichem Kohlendioxid zu reduzieren. Denn dann wird der Verkehr dank selbstfahrender, miteinander vernetzter Autos besser fließen.
4. Noch mehr Sicherheit
Ein weiterer Pluspunkt: Autonomes Fahren soll in Zukunft für weniger Unfälle und damit mehr Sicherheit auf den Straßen sorgen, prognostizieren die Experten. Bis Sie in einer vollautomatisch fahrenden Familienkutsche in den Urlaub reisen können, müssen Sie sich allerdings noch gedulden. Viele Fragen zu Sicherheit und Datenschutz sind derzeit ungeklärt, an den neuen Technologien wird gefeilt. Kein Wunder, dass es für 62 Prozent der Eltern laut forsa aktuell nicht in Frage kommt, im autonomen Auto in den Urlaub zu starten.
Verreisen mit der Deutschen Bahn – ohne Gurt, aber mit allen Vorzügen des autonomen Fahrens
Das Tolle am Bahnfahren: Die Vorteile, die künftig selbstfahrende Autos bieten, genießen Sie und Ihre Familie heute schon in der Bahn – nur ohne Anschnallen! Das schafft viel Freiraum für Entdeckungstouren oder Snack-Pausen im Bordbistro, die keine Reisezeit kosten. Und wer während der Fahrt auf die Toilette muss, kann einfach gehen. Unser Tipp: Kinder unter fünf Jahren finden jede Menge Platz zum Spielen und Kuscheln im Kleinkindabteil – und mit Glück neue Reisefreunde.
Gegen Langeweile helfen zudem spannende Familienfilme und -serien bei maxdome onboard oder in der Kinderwelt im ICE Portal. Auch die Kinderbetreuer der Deutschen Bahn springen an Wochenenden auf ausgewählten Strecken in vielen ICE ein, wenn Eltern eine Verschnaufpause brauchen – zum Beispiel mit tollen Spielideen, Kinderschminken, Malstiften und Play Mais. Damit Ihr Urlaub so entspannt wie möglich beginnt.


* Repräsentative Umfrage „Autonomes Fahren bei Autoreisen mit der Familie“ des Meinungsforschungsinstituts forsa im Auftrag der Deutschen Bahn. Im April 2018 wurden in Deutschland 1.005 Eltern mit Kindern bis zu bis 14 Jahren befragt.