With the rise of the World Wide Web, relational SQL engines like Oracle, SQL Server and MySQL have seen their market share impacted by the rise of the NewSQL/NoSQL movement. Products such as MongoDb, a free schema document database, and Cassandra, a write optimized wide column store, have found success by implementing relaxed schemas, denormalized data models, and horizontal scalability to meet the demands of fast changing applications. Scalability is achieved by adding commodity hardware nodes instead of continuing to grow on one big server which is also an attractive proposition to eliminate single points of failure and expensive hardware investments.
With the increasing adoption of the public cloud, there is a growing demand to consume database services that shield organizations from having to install, configure and manage these systems on their own. As a response, all of the three major cloud providers (Amazon, Microsoft, and Google) have implemented their own NoSQL/NewSQL offerings as fully managed database services.
These types of database services are characterized by the following traits:
- Fully managed by the cloud provider. This means the user only concerns itself with the provisioning and usage of the service, not with the operating system, patching, backups, etc.
- NoSQL characteristics like multiple consistency models, horizontal scalability, automatic horizontal partitioning, and relaxed schema and data type constraints. Usually it is a combination of these traits that are implemented on each service.
For the scope of this article, the following services will be considered:
- Amazon DynamoDB
- Microsoft Azure Cosmos DB
- Google Cloud Spanner
This is not an exhaustive list of NewSQL/NoSQL cloud offerings; however, they are the flagship products for each of the three major providers and provide the richest set of features.
In order to understand the use cases and business value proposition of each service, each one of them will be evaluated in multiple categories that are of interest to anyone implementing a production system on one of these platforms. The following sections will look at each of these categories and how each one of these systems is placed within it.
Service Level Agreements (SLAs)
An SLA is an objective that the cloud provider agrees to meet for a determined characteristic of a service. The most common one that most IT people are familiar with will be uptime (usually defined as a number of 9s). The reason this category is important is because it lays out the ground rules of when the provider is at fault for not operating under their agreed objective, and usually there is a monetary compensation over the cost of the service.
The quickest one to discuss is DynamoDB simply because it has no public SLA published. Amazon does document that the service replicates across three different facilities over an AWS (Amazon Web Services) region (1) however it doesn’t tie that into a specific uptime SLA with a defined credit.
Google Cloud Spanner does provide an uptime SLA defined as follows (2):
For a Cloud Spanner Multi-Regional Instance:
|
Monthly Uptime Percentage
|
Monthly Service Bill Credit
|
|
99.0% – < 99.999%
|
10%
|
|
95.0% – < 99.0%
|
25%
|
|
< 95.0%
|
50%
|
For a Cloud Spanner Single-Region Instance:
|
Monthly Uptime Percentage
|
Monthly Service Bill Credit
|
|
99.0% – < 99.99%
|
10%
|
|
95.0% – < 99.0%
|
25%
|
|
< 95.0%
|
50%
|
For those keeping track, that is a limit of 52 minutes of downtime per year on a single region and 5 minutes per year on a multi-region instance. For any downtime over that, you can request credits to your bill in accordance to the percentages mentioned.
Turning to Cosmos DB, it offers a 99.99% uptime SLA and a 99.999% read-availability SLA if using multiple-regions. Furthermore, the SLAs offered by Microsoft not only cover uptime but include other service traits such as throughput, latency, and consistency. For these, the percentages and credit are as follows (3):
|
Monthly SLA Trait Attained Percentage
|
Monthly Service Bill Credit
|
|
< 99.99%
|
10%
|
|
< 99.0%
|
25%
|
It is not common for a cloud provider to offer SLAs beyond uptime, so let’s look at what these other Cosmos DB SLAs mean:
- Throughput SLA: the service will deliver the resources you have reserved, or it will be in violation of this SLA.
- Consistency SLA: the service will fulfill requests at the Consistency Level (more on these later) requested by the client, or it will be in violation of this SLA.
- Latency SLA: for a document payload of 1KB or less, the service will deliver sub-10ms reads and sub-15ms writes, or it will be in violation of this SLA.
Clearly in this category Google and Microsoft are the ones that come out ahead. Google is willing to provide a five 9’s uptime SLA when using multi-region instances, and they are willing to go up to a 50% service credit maximum. On the other hand, Microsoft has put SLAs around other service traits besides uptime but is only going up to four 9s except for read-only uptime and up to a 25% credit maximum. This is considered a tie. Amazon lacks any official public SLA, clearly ranking at the bottom in this category.
Regional Availability
The choice of cloud region to deploy your database is important for two reasons:
- It is becoming more common for governing bodies to require that some types of data (medical records for example) stay within a particular geographical region. This is known as ‘data sovereignty’ regulations (4).
- Close geographical proximity between your main application user base and the application stack means less latency and higher application responsiveness.
In the case of data sovereignty, this type of requirement can be a complete show stopper when selecting a cloud database if it simply does not offer a region required by a particular customer.
Comparing the three providers under this category is very straightforward since all three of them publish information about which services are available on which region.
First let’s look at Cloud Spanner (5):
|
Continent
|
Region
|
|
Americas
|
Iowa
|
|
Europe
|
Belgium
|
|
Asia Pacific
|
Taiwan, Tokyo
|
|
Total
|
4
|
Now, let’s look at DynamoDB (6):
|
Continent
|
Region
|
|
Americas
|
Ohio, Virginia, California, Oregon, Montreal, Sao Paulo
|
|
Europe
|
Frankfurt, Ireland, London
|
|
Asia Pacific
|
Mumbai, Ningxia, Seoul, Singapore, Sydney, Tokyo
|
|
Total
|
15
|
And finally, Cosmos DB (7):
|
Continent
|
Region
|
|
Americas
|
Virginia, Iowa, Illinois, Texas, California, US Government Arizona, US Government Texas, Quebec City, Toronto, Sao Paulo
|
|
Europe
|
Ireland, Frankfurt, Magdeburg, London, Cardiff, Netherlands
|
|
Asia Pacific
|
Singapore, Hong Kong, New South Wales, Victoria, Shanghai, Beijing, Pune, Mumbai, Chennai, Tokyo, Osaka, Seoul, Busan
|
|
Total
|
29
|
Clearly there is a large gap in regional availability between what Google has and what AWS and Azure offer, and this has a direct impact on platform choice. For example, laws in Canada regarding medical records would limit a provider developing a solution with this type of data to choosing between AWS and Azure.
In terms of geographic proximity, Microsoft still comes out on top in terms of number of regions where Cosmos DB is available, but AWS has options on all the same continents. Depending on latency requirements, continental availability might be good enough to still deploy Amazon’s DynamoDB.
Resource Provisioning Model
The resource provisioning model is the way in which the clients specify to the service how much resources they will need for their database. This can include storage, CPU, memory and other capabilities like streaming data depending on the service.
Because the services analyzed in this article are all database as a service offerings, the providers usually abstract the actual hardware implementation from the service consumers. Instead of focusing on requiring an exact amount of memory or CPU clock speed, they are provided simpler terms in which to define their performance requirements and to adjust it. Ideally, the resource model should provide three characteristics:
- It allows the client to be as accurate as possible when provisioning the resources they need.
- It allows the client to scale different dimensions of the service independently (more storage does not force more compute or vice versa).
- It allows the client to be flexible on consumption and quickly scale up or down the resources.
Out of the three offerings in scope, both DynamoDB and Cosmos DB define their resource provisioning in terms of service units. These units are used to represent the capacity of the service to perform a certain operation and are designed to allow the customer to estimate their resource requirements based on their practical experience with their workload.
Cosmos DB uses the term ‘request units’ and they are a measurement of blended resources (IO, memory, CPU) required by a particular operation (8). The amount of request units consumed by an operation is deterministic, so you can predict how many RUs you will need based on the information you gather back from the service. Different settings such as indexing policies and consistency levels have an impact on the Request Units consumed by an operation as well.
Cosmos DB has no auto-scaling capability, so you will have to monitor the service and scale up and down as appropriate. If all the Request Units are consumed, then the service will start throttling the requests. Notice that this does not violate the service SLA since it is the client’s responsibility to provision enough Request Units. On the plus side, Microsoft provides a web tool that let’s you upload a sample document and enter your estimated workload volume and get a recommended initial Request Unit setting.
DynamoDB also uses resource units but they are split into separate read and write units. This means you can tweak them independently depending on the characteristics of your workload. Amazon defines the read capacity unit as one strong consistent read per second, or two eventually consistent reads per second, for an item up to 4KB in size. The write capacity unit is defined as one write per second for a 1KB item (9). One big difference from Cosmos DB is that this throughput measurement is not just applied globally to the container but is specified at the table and global index level.
DynamoDB is the only one of the three solutions that also provides auto-scaling capabilities. Using Amazon’s own monitoring and auto-scaling services under the covers, the client can specify the Read/Write unit thresholds that can trigger an event to increase the units or decrease them (10). This is particularly useful for spiky and unpredictable workloads where the user would rather increase the service consumption than experience throttling.
If a client has an eventually consistent read-heavy workload with very low latency requirements, DynamoDB also has a separate in-memory cache called DAX (DynamoDB Accelerator). This cache is implemented as a cluster that can be deployed in between the application and DynamoDB at an additional cost (11). This is another unique capability of DynamoDB compared to Cosmos DB and Spanner.
Unlike DynamoDB and Cosmos DB, Google Cloud Spanner defines their resource provisioning in terms of nodes. You create an instance on these nodes and then databases on the instance share these node resources. According to Google, for an optimally configured database, one node can provide up to 10,000 read queries per second and 2000 write queries per second for single 1KB rows. Each node also comes with 2TiB of storage (12). Keep in mind these are Google’s estimates for an optimal database. For example, if a Cloud Spanner database is developed with skewed partition keys or very large interleaved data (more on this later), then it can have bottlenecks that limit its throughput.
As a general starting point, Google recommends that production databases use at least 3 nodes and to provision enough capacity to run with a CPU level under 75% (12).
Spanner’s resource model is a bit more like running an infrastructure solution than DynamoDB or Cosmos DB’s units’ model. Storage can scale on it’s own but compute is tied to the nodes. Cloud Spanner also does not offer auto-scaling capabilities, adding a node or subsequently removing one is the only way to scale your compute power.
Let’s look at a summary matrix of the different resource models:
|
Service
|
Throughput quantifier
|
Resource Granularity
|
Resource Independence
|
Deterministic consumption
|
Built-in auto-scale capability
|
Built-in cache capability
|
|
DynamoDB
|
Read Compute Unit and Write Compute Unit
|
Table and Global Index
|
Compute and Storage de-coupled
|
Yes
|
Yes
|
Yes
|
|
Cosmos DB
|
Request Units
|
Collection
|
Compute and Storage de-coupled
|
Yes
|
No
|
No
|
|
Cloud Spanner
|
Node
|
Instance
|
Node comes with Compute and Storage
|
No
|
No
|
No
|
Both Amazon and Microsoft come out on top in this category by allowing resource allocation in units and fast scale up and scale down of the database with compute and storage being independent. DynamoDB however, is the overall winner here being the only one with auto-scaling capabilities and the optional in-memory acceleration cache. Spanner couples compute and storage so they can’t be scaled independently and uses the concept of nodes which is a lot more akin to an infrastructure solution.
Security Features
Security breaches and hacks seem to be on the front-page news every other day. Clients are concerned about the safety of their data on-premises and doubly so in the public cloud. The truth is, however, that the security implemented by the major cloud providers in their data center is a big improvement over what the vast majority of companies are doing themselves.
The topic of regulatory compliance is large and complex. It is also very dependent on the client industry and type of solution being built as to which standard they will be measured against. For the medical industry, HIPAA is common in the USA and PCI is as well for credit card processing. A full comparison of how the three major cloud providers compare on all these different standards and different geographies is out of scope for this article. If the reader is interested in a particular standard, then each one of the cloud providers has a landing page for their compliance material: Amazon, Microsoft, and Google.
In terms of built-in security features, Cosmos DB is up first. When a Cosmos DB account is created, it creates a public endpoint. This public endpoint can then be secured through a firewall by specifying the IP addresses that are allowed to establish a connection. Depending on security requirements, having a public endpoint might be a deal breaker for some deployments.
In terms of encryption, Cosmos DB does encryption at rest and in transit. The keys for these are all managed by Microsoft. If a client has a requirement to encrypt data fields, then they need to handle this on the application side. If you have a requirement to audit user operations, the service can log all requests (including failed ones) into Azure Storage or an Event Hub (13).
As far as authentication and authorization, Cosmos DB integrates with Azure roles to provide access to specific individuals or groups with Azure identities. It also provides master keys to authorize administrative operations or high level read-write and read-only capabilities. For fine grained access, the service provides resource tokens that expire after a set period of time. In order to avoid storing credentials with the application, developers can also use Azure’s Managed Service Identity to retrieve Cosmos DB credentials, however this must be done through Azure Key Vault, as Cosmos DB does not support Azure Managed Service identities yet.
Amazon’s DynamoDB also provides a public Internet facing endpoint. There is no built-in firewall, however, you can limit access to specific IPs by using IAM (Identity and Access Management) policies (14). Amazon also provides a VPC (Virtual Private Cloud) endpoint if you need to lock down network access further and all the traffic to DynamoDB will not leave Amazon’s internal network (15). This capability is not currently offered by Cosmos DB or Cloud Spanner.
As mentioned above, DynamoDB has full support of Amazon IAM capabilities, including assigning fine grained access to IAM users as well as IAM roles. IAM roles are used to avoid storing credentials, and they are fully integrated into the service model. There is no need to use an intermediate credential manager service for IAM roles as there is currently with Cosmos DB with Managed Identities.
In terms of encryption capability, DynamoDB does not have built-in encryption at rest. You can handle client-side encryption of fields on the application and Amazon provides a library to do this (16). DynamoDB can integrate with AWS’s CloudTrail service for auditing, however this only logs management or DDL style operations; it will not audit actual manipulation or read requests on the data itself (17).
Finally, let’s take a look at Cloud Spanner. Cloud Spanner does not provide built-in firewall or IP filtering support. The ability to connect relies on the authentication of the user, usually done through a service account. This concept of the service account can also be used to provide access to a Cloud Spanner database from a compute resource without having to store credentials like Azure MSIs and AWS IAM roles.
Using Google’s IAM features, permissions can be specified at the instance and database level, however, there are no permissions to the individual table level (18).
Encryption at rest is already done by Google for the storage used by Cloud Spanner. For client-side encryption of specific fields, this must be rolled out by the application developer and Google does not provide a library for it.
Let’s look at a summary matrix of the main security features:
|
Service
|
Encryption at rest
|
Client-side encryption
|
Network filtering
|
Private endpoint
|
Highest Permission Granularity
|
|
DynamoDB
|
No
|
AWS library
|
IP filtering through IAM policy
|
Yes
|
Table
|
|
Cosmos DB
|
Yes
|
Develop your own
|
Built-in service firewall
|
No
|
Document
|
|
Cloud Spanner
|
Yes
|
Develop your own
|
None
|
Yes
|
Database
|
Both AWS and Azure provide similar offerings in terms of security with the lack of encryption at rest being DynamoDB’s biggest weakness, especially for compliance sensitive solutions. On the flip-side, Azure’s lack of a private endpoint offering can also be a show stopper depending on the security requirements. Cloud Spanner is lagging in this area compared to the other two, without having any network level filtering and with high granularity permissions that stop at the database level.
Query Language and Data Model
The concept of a NoSQL Database is a very general term as it has come to represent many different types of databases that are queried and modeled differently. Under this umbrella there are: document databases, key-value stores, wide-column stores, graph databases, and relational stores with NoSQL capabilities (sometimes referenced as NewSQL). These different models are all fit for specific purposes, and, depending on the application use case, one might be more appropriate than the other. Thus, it is important to understand what type of querying and modeling experience comes with each one of the three products evaluated to select the best one for the application that is being built.
Dynamo DB is a wide-column store with flexible schema. It requires a primary key when creating a table, but the rest of the attributes are not fixed. It not only works with scalar types but also allows for complex data types like JSON documents and scalar sets (19). The service does not provide SQL support, instead, queries must be expressed through a JSON definition. This is an example taken from AWS documentation (20):
// Return a single song, by primary key
{
TableName: "Music",
KeyConditionExpression: "Artist = :a and SongTitle = :t",
ExpressionAttributeValues: {
":a": "No One You Know",
":t": "Call Me Today"
}
}
On Cosmos DB with the DocumentDB API and on Cloud Spanner this query would have been expressed with SQL:
SELECT * FROM Music
WHERE Artist=’No One You Know’ and SongTitle=’Call Me Today’
As you can see, the expression definition is not very complex, but it does not have the readability and expressive quality of SQL. DynamoDB does not provide any type of grouping, aggregation, or join support for the queries; these types of operations would need to be implemented by the client application. Another downside to DynamoDB’s implementation is that indexes must be called out explicitly through the code by the developer instead of being selected automatically by the database engine (21). To add to the complexity, if an index must be created across partitions, this ‘Global Secondary Index’ requires its own separate bucket of read and write units (22) provisioned and payed for separately.
Out of the three products, Cloud Spanner is the one that comes closest to the relational paradigm that most developers are used to. It has extensive SQL support extending the ANSI 2011 standard (23) including grouping, aggregates, and joins across tables. It does not provide the referential integrity concept of foreign keys but does something similar with ‘interleaved tables’ where the child data is collocated with the parent record (24). As such, if a client is looking to migrate an existing relational system or wants to keep as much of the relational semantics as possible, Cloud Spanner is a good choice. One current downside is that Google recommends that queries which should use indexes must call them out explicitly on the SQL code using a hint (25) which produces a tight coupling between the query and the physical design on the database.
Cosmos DB was initially released by Microsoft as a purely document database with the name DocumentDB. However, the team continued extending the engine and along with the name change, added support for a Key-Value store API, a Graph API (based on Apache Gremlin), and a Wide-Column API based on Cassandra. Through the document database API, Cosmos DB provides SQL support, including aggregations and self-joins in a document. Cosmos DB also allows fine tuning the indexing policy of the database, but, in the absence of any explicit directions, the system will index all fields. Unlike DynamoDB and Cloud Spanner, the optimizer behind Cosmos DB’s SQL support does not require calling out indexes in any way.
Here is a summary of the query and modeling capabilities of each service:
|
Service
|
API
|
Index management
|
Querying
|
Join support
|
Optimizer capability
|
|
DynamoDB
|
Wide-Column with JSON support
|
Manual
|
JSON definitions
|
Yes
|
Indexes called out in code
|
|
Cosmos DB
|
Document, Key-Value, Graph, Wide-Column
|
Automatic or Manual
|
SQL
|
Self-document
|
Indexes used automatically
|
|
Cloud Spanner
|
Relational
|
Manual
|
SQL
|
Cross table
|
Indexes called out in code
|
In this category, multiple models and SQL support are considered pluses. Multiple models enable more use cases on the platform, and SQL has more than proven itself over many decades as an established and powerful way to express data querying. On top of that, there is a very large population of developers who are very familiar with one dialect of SQL or the other that will easily adopt a service which uses it. With these criteria in mind, Cosmos DB has the positives of implementing multiple models as well as SQL support. Cloud Spanner also provides SQL support and the fact that it is a relational model will make it a lot easier to adopt and migrate for thousands of relational on-premises systems. It is a tie between these two. In the last spot is Dynamo DB, even though the value of the flexible schema and complex data types is recognized, the lack of any SQL support is a big negative.
Support for Transactions
Transactions are one of the fundamental constructs of database systems. The characteristics of ACID (Atomic – Consistent – Isolated – Durable) have been used to describe database system transactions for decades, and NoSQL engines sometimes make compromises in this area.
It is important to compare transactional capabilities because they might enable or disable use cases depending on the type of data being collected and how rigorous the system must be when handling it. It is also preferable if the database engine itself is the one that implements the transactions instead of leaving the responsibility to library developers and for these libraries to be consumed by the end user developer.
Cosmos DB offers transaction support through JavaScript stored procedures and triggers. These modules exist at the collection level inside the database and are executed on the server side. The model is very simple: if the procedure or trigger completes successfully, then all its operations are committed; if there is an error, then all the operations are rolled back. There is no two-phase commit support, so the transactions must be in the scope of a single logical partition. Cosmos DB implements optimistic concurrency so there are no locks or blocks but instead, if two transactions collide on the same data, one of them will fail and will be asked to retry (26).
Google Cloud Spanner offers read-write transactions as well as read-only transactions. This is an interesting distinction, to specify a transaction even in a read-only scenario. A read-only transaction guarantees consistency between reads and allows reading data based on past timestamps. For writing data, Spanner does pessimistic concurrency, which means that locking, blocking and deadlocking are possible. The transactions themselves are expressed through the different Spanner programming libraries, but the transaction is handled server-side and can even involve two-phase commits between nodes if necessary (27).
Finally, DynamoDB does not provide server-side support for operations that modify multiple items in one ACID operation. To work around this, Amazon has created a transaction library that implements it on the client-side while abstracting away the complexity of managing state, rollback, etc. The transaction library also uses DynamoDB tables to keep track of its operations, and these tables must have their own read and write units provisioned and payed for by the user. In the end, this simply translates to actual monetary cost if the user wants to do transactions in DynamoDB (28).
Let’s look at a summary matrix for transactions:
|
Service
|
Server-side transactions
|
Concurrency
|
Extra cost
|
Language
|
|
DynamoDB
|
No
|
Pessimistic or Optimistic depending on isolation setting
|
Yes
|
Java
|
|
Cosmos DB
|
Yes
|
Optimistic
|
No
|
JavaScript
|
|
Cloud Spanner
|
Yes
|
Pessimistic
|
No
|
C# – Go –Java – Node – PHP – Python – Ruby
|
Cloud Spanner provides the strongest transactional capabilities with support for two-phase commits and multiple language support with the downside of pessimistic locking. Cosmos DB also implements transactions as a core construct on the server side, but the experience is a bit limited with only JavaScript for transactions. Finally, Dynamo DB comes out weakest by implementing transactions purely as a client-side managed construct and, on top of that, requiring the client to pay for the tables used to manage those transactions.
Consistency Models
NoSQL databases popularized the term ‘Eventual Consistency’ as a way to achieve higher system scalability as a trade-off for how up-to-date the data served by the database is. The spectrum of consistency models then goes from ‘Strong’ which guarantees reading the most up-to-date data to ‘Eventual’ which simply means, if no other changes are done, at some point in time all nodes converge on the same value.
In a single data-center or with a small number of nodes, these two consistency models are usually enough to cover most use cases because, even in eventual consistency, data replication between nodes will converge in a very small amount of time (sub-second). However, as a system grows in the number of nodes and replicates data over larger geographic distances, other consistency models that exist in the ’middle areas’ of the spectrum become useful. This usefulness comes from the ability to strike a balance between consistency, latency, availability, and throughput based on tuning the consistency requirements of different application actors.
For this category, Dynamo DB goes first with the option of either a Strongly Consistent Read or an Eventually Consistent Read. Eventual is less expensive in terms of resources consumed (29).
Cloud Spanner also does Strong and Bounded Staleness. With Bounded Staleness, the client application can specify a maximum delay boundary that it is willing to tolerate for the data. Cloud Spanner also allows for Exact Staleness, which means specifying not only a maximum boundary but an exact timestamp in the past to see a past image of a record (30).
Finally, Cosmos DB implements Strong, Eventual, Bounded Staleness, and two more: Session and Consistent Prefix. Session consistency guarantees that any session will always see the latest data that it has manipulated itself. Consistent Prefix guarantees that data is always seen in a consistent order and will not read out of order data modifications (31).
Here is a summary of the consistency models supported per product:
|
Service
|
Strong
|
Bounded Staleness
|
Exact Staleness
|
Session
|
Consistent Prefix
|
Eventual
|
|
DynamoDB
|
Yes
|
No
|
No
|
No
|
No
|
Yes
|
|
Cosmos DB
|
Yes
|
Yes
|
No
|
Yes
|
Yes
|
Yes
|
|
Cloud Spanner
|
Yes
|
Yes
|
Yes
|
No
|
No
|
No
|
In this category, Cosmos DB comes out on top as having implemented five well defined consistency models that all have practical applications. Cloud Spanner comes second as having implemented three of those models to provide a compromise for applications that don’t necessarily need strong consistency but also want some guarantee as to the lag of the data. Finally, Dynamo DB simply implements the two consistency extremes with nothing in between.
Replication Capabilities
Considering the use case of these NewSQL/NoSQL offerings is to create web-scale applications with global reach, replication capabilities are important not only from a disaster recovery point of view but also from a performance standpoint. Having replicated copies of the database across large geographic locations means isolation over natural disasters or regional outages, as well as reducing the latency for users consuming the data.
DynamoDB has built-in single-region replication capabilities. This means that Amazon replicates the data over three different facilities in one region for high availability. However, in terms of cross-region replication, either for disaster recovery or read performance reasons, the service does not have a managed solution. Instead, Amazon provides a replication library and command line tool that the client can run on a virtual machine to host the replication (32). Being a customer hosted solution, there is no SLA or managed aspect by Amazon. The solution also uses DynamoDB streams which comes with added cost.
Cloud Spanner provides the option of single region or multiple-region instances. It provides high availability by keeping three replicas in different availability zones in a region (12). Multi-region support is also built as a turnkey solution that allows replication over large geographic distances. One downside is that the multi-region configuration is static, meaning that you cannot change it after you create your instance. You also have no control over failover.
Finally, Cosmos DB provides high availability through single-region replication and has turnkey global replication capabilities (33). Global replication is integrated with the consistency models to provide fast access with low latency. It is also possible to trigger failover between regions at will and to provide a policy to geo-fence a database to specific regions. This geo-fencing capability is especially useful when dealing with data sovereignty compliance that requires data to never leave a specific geographical boundary.
Here is the summary chart for replication capabilities:
|
Service
|
Single region HA
|
Cross region replication
|
Policy based Geo-fencing
|
Manual cross-region failover
|
|
DynamoDB
|
Yes
|
Customer hosted
|
No
|
No
|
|
Cosmos DB
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Cloud Spanner
|
Yes
|
Yes
|
No
|
No
|
The clear winner in this category is Cosmos DB as it not only implements cross region managed geo-replication but also allows the configuration to be dynamic and with manual on-demand failovers. The second place goes to Cloud Spanner since they have multi-region instances, but they are lacking capabilities when compared to Cosmos DB. DynamoDB is last as it has simply made this available as a customer hosted solution.
Backup and Recoverability
As it was mentioned before, these databases are all replicated in their regions and some like Cosmos DB and Cloud Spanner, also offer full geo-replication. This redundancy sometimes leads users to believe that they do not need backups as the odds of losing all the redundant copies are low. However, this is a flawed position, as it does not consider, for example, the possibility of data corruption.
Keep in mind that these systems are built to replicate data modifications between nodes as fast as possible. In the event of data being accidentally or maliciously modified incorrectly, the system will propagate the changes to the entire database in a matter of seconds. Thus, in this type of event, a backup would be the only way to recover the data.
For DynamoDB, Amazon does not publish any official backup information and instead encourages users to use some of its other services like Data Pipeline and Elastic MapReduce to export the data and move it to a different region (34). The AWS developer community has also identified this gap and has developed a command line utility that can be used to perform export and import operations called dynamodump (35). Either one of these solutions puts the responsibility of backing up and recovering in the customers hands instead of being a core part of the service management. On top of that, these customer hosted backup operations will also consume resources from the pool of units that the client is paying for.
Cloud Spanner does not mention backup capabilities in the official documentation. Based on information found in online forums (36), the current solution is either in the hands of customers through the use of services like DataFlow, or Google can actually recover a database through a support ticket. Unfortunately, because this is not documented anywhere, there is no way to know the backup schedule or what the retention period is.
Cosmos DB is the only one of the three providers that officially documents the backup policy used and the procedure to request a restore by contacting their tech support (37). According to the rules published by Microsoft, backups are taken every four hours and two are kept at all times. Also, in the event of database deletion, the backups will be kept for thirty days before being discarded. With these rules in place, the client knows that in the event of some unintended data modification, they have an eight-hour window to get support involved and start the restore process. The next step here for Microsoft would be to enable self-service backup and restore capabilities, however that is not available at this moment.
Let’s look at the backup capabilities summary:
|
Service
|
Provider does backups
|
Backup rules officially documented
|
Self-service restore
|
|
DynamoDB
|
No
|
No
|
No
|
|
Cosmos DB
|
Yes
|
Yes
|
No
|
|
Cloud Spanner
|
Yes
|
No
|
No
|
The winner here is Cosmos DB with its documented backup and restore rules and capabilities. Even though there’s no self-service support, at least the ‘ground rules’ for recovering your data are clear on the official documentation. Google makes no mention on the official documentation about how the backup works but, through online resources, it looks like they indeed keep some and could recover through support. Amazon on the other hand seems to leave it 100% in the customer’s hands.
Pricing Model
To finish off the comparative analysis, let’s look at the pricing model used for each service. This category has been put last so that the reader has gotten a solid idea of the value proposition and the strengths and weaknesses of each service before looking at cost. Consider how each one is billed and what the cost can look like for your application in tandem with all that extra information.
Using these pricing models let’s run a price comparison. A sample workload is defined that uses 1KB items (records or documents), 10,000 reads and 2000 writes per second. A 6TB storage target is used as well.
Based on Googles published estimates, the call volume can be served by one node, however, for production purposes, Google recommends three nodes and to keep CPU utilization below 75% (9). Each node also provides 2TB of storage so three are needed to get to 6TB.
All prices were calculated on November 10th, 2017.
Using current pricing in US dollars and the online calculator (38), the monthly cost of this solution on Cloud Spanner is approximately $3,771.
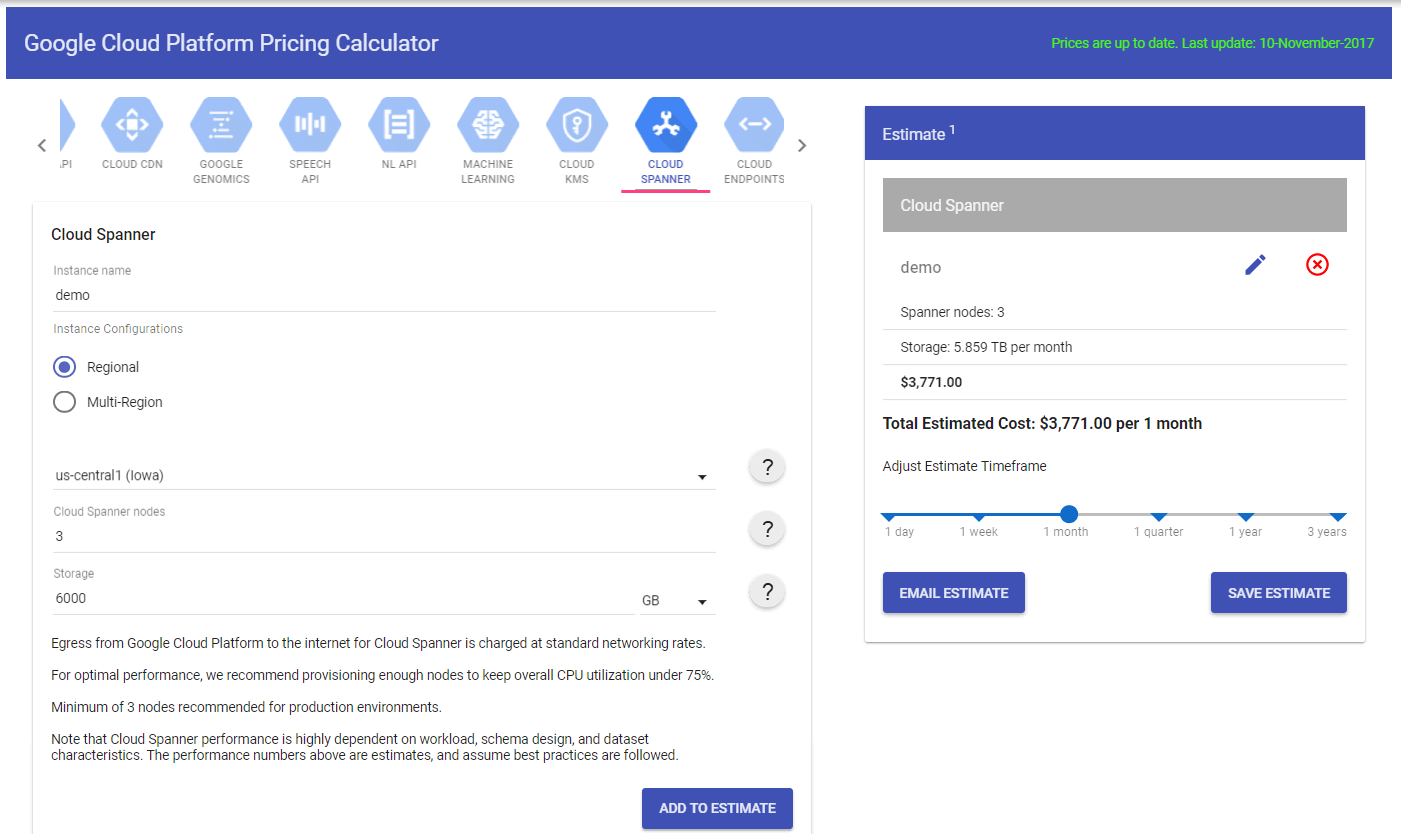
For DynamoDB on AWS, the calculator returns a total estimate of $3529.17 US dollars. The same parameters of 1KB item, 6TB storage, 10,000 reads and 2000 writes were used. Optionally, the client could decrease the consistency requirement to decrease this cost but, to keep things equal, Strong consistency was kept as the default on the calculator (39).
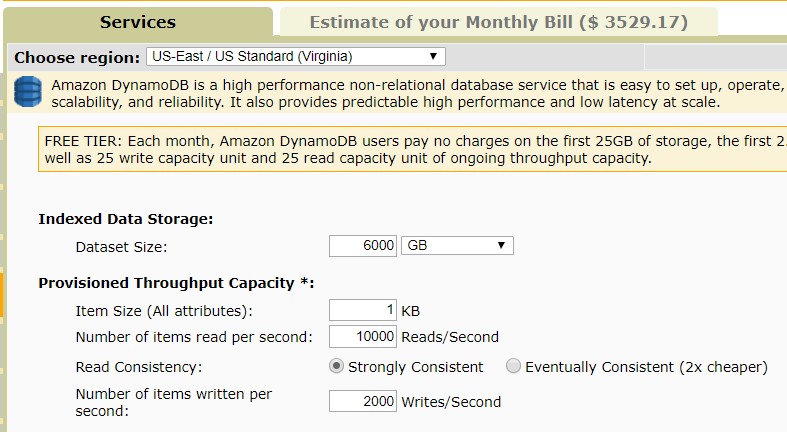
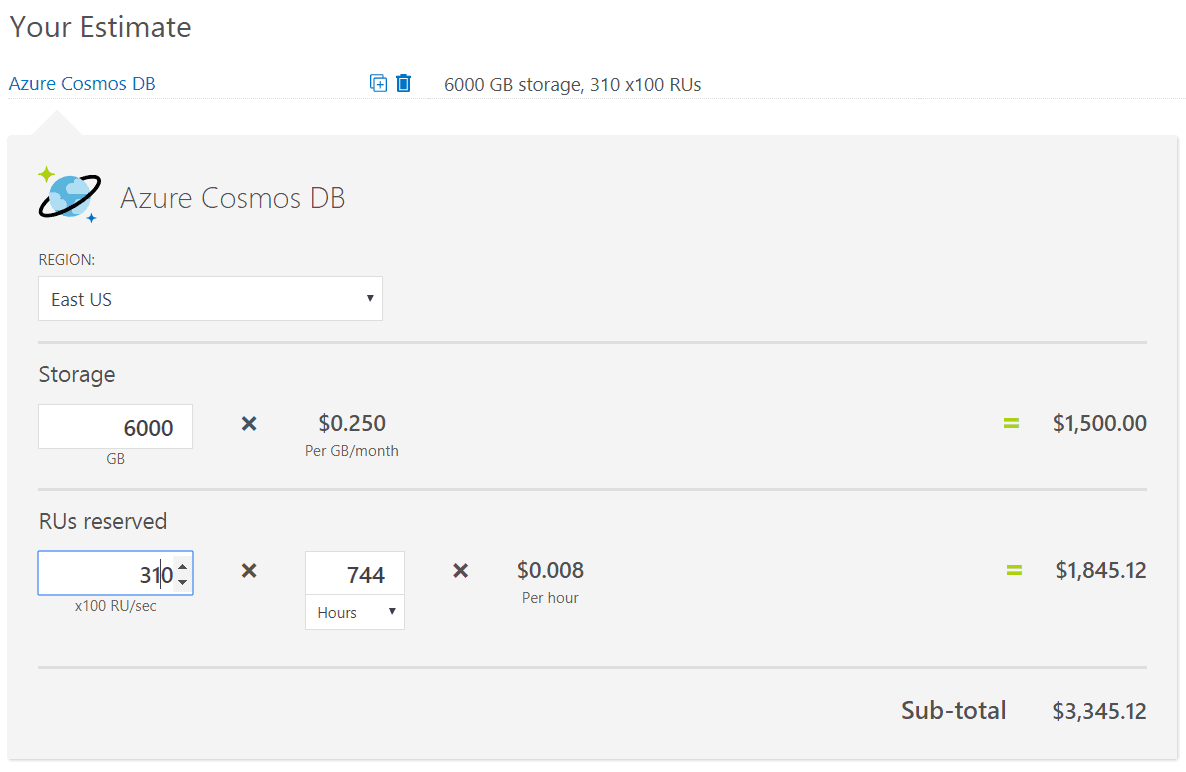
For Cosmos DB, first the online capacity planner (40) was used to estimate the necessary amount of Request Units necessary for the 1KB, 10,000 reads, 2000 writes workload.
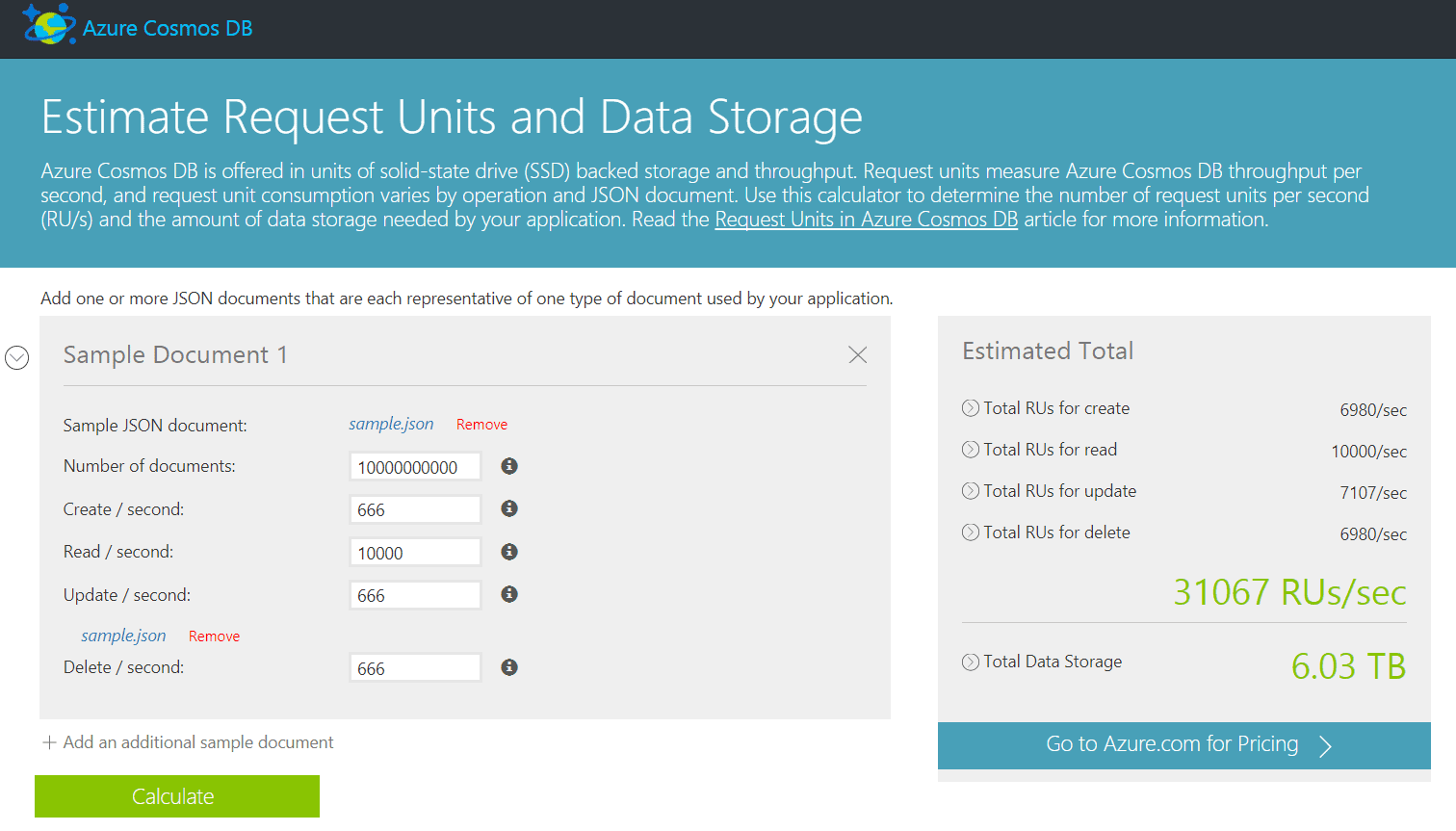
With the estimation produced by the capacity planner, the Azure pricing calculator (41) was then used to come up with the estimated monthly price using the RUs and target 6TB storage as inputs.
The total in this case came to $3345.12 US dollars per month.
Once again, it’s worth reiterating that the pure dollar monthly value cannot be used in isolation to consider which service is more expensive than the other. For all of them, there are extra considerations to make since they might offer capabilities that the other does not. This is the case for geo-replication, in-memory caching, etc. On top of that, depending on the size of your organization, different discounts and agreements can get you a significant discount over this publicly posted price.
Furthermore, the change in price is not drastically different from one platform to the other where this can even be considered a driving factor to select a solution. The other categories mentioned in the article should have a higher weight for this decision.
For this reason, the price model category will not be ranked based on the dollar cost but instead based on the flexibility of the pricing model. With this criteria in mind, DynamoDB comes out on top by allowing independent cost of compute and storage. DynamoDB also splits the cost of compute between read and write to fine tune the resource usage of your workload. Cosmos DB comes in second by having the cost also specified in units that can be quickly scaled and decoupling compute from storage. Finally, Cloud Spanner is last due to having the cost tied to a very ‘infrastructure-like’ concept of nodes that come coupled with compute and storage.
Summary
The following chart summarizes how each offering performs on each one of the categories. Each category scores each service as First, Second, Tie, or Third. A total score or absolute ranking is not provided intentionally as that would be misleading. The advice is that each client look at the score of the areas that are of particular interest to them. With this comparative information, a more informed technical choice of database platform can be made.
The age of the products must be considered as well since DynamoDB was released in 2012, Cosmos DB’s first iteration as DocumentDB was released in 2014, and Cloud Spanner was just released in 2017.
|
Service
|
SLAs
|
Regional Availability
|
Performance Model
|
Security Features
|
Query language
|
Transaction support
|
Consistency Models
|
Geo-Replication
|
Backup
|
Price Model Flexibility
|
|
DynamoDB
|
Third
|
Second
|
First
|
Tie
|
Third
|
Third
|
Third
|
Third
|
Third
|
First
|
|
Cloud Spanner
|
Tie
|
Third
|
Third
|
Third
|
Tie
|
First
|
Second
|
Second
|
Second
|
Third
|
|
Cosmos DB
|
Tie
|
First
|
Second
|
Tie
|
Tie
|
Second
|
First
|
First
|
First
|
Second
|
In Conclusion
The three main cloud providers, Amazon, Google, and Microsoft, all offer very robust and feature-packed NewSQL/NoSQL offerings. The attractiveness of the flexibility, scalability and efficiency of these Database as a Service products makes them each a series contender when picking the database platform for a new solution. Relational is no longer the only mature platform around, and clients are advised to truly pick a database product that tightly fits their priorities and use case.
Works Cited
- http://aws.amazon.com/dynamodb/faqs/#scale_anchor
- https://cloud.google.com/spanner/sla
- https://azure.microsoft.com/en-us/support/legal/sla/cosmos-db/v1_0/
- https://en.wikipedia.org/wiki/Data_localization
- https://cloud.google.com/about/locations/
- http://docs.aws.amazon.com/general/latest/gr/rande.html#ddb_region
- https://azure.microsoft.com/en-ca/regions/services/
- https://docs.microsoft.com/en-us/azure/cosmos-db/request-units
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.ProvisionedThroughput.html#HowItWorks.ProvisionedThroughput.AutoScaling
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/AutoScaling.html
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DAX.html
- https://cloud.google.com/spanner/docs/instances
- https://docs.microsoft.com/en-us/azure/cosmos-db/logging
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/specifying-conditions.html
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/vpc-endpoints-dynamodb.html
- https://aws.amazon.com/blogs/developer/client-side-encryption-for-amazon-dynamodb/
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/logging-using-cloudtrail.html
- https://cloud.google.com/spanner/docs/iam
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.NamingRulesDataTypes.html
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SQLtoNoSQL.ReadData.Query.html
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SQLtoNoSQL.Indexes.QueryAndScan.html
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GSI.html
- https://cloud.google.com/spanner/docs/overview
- https://cloud.google.com/spanner/docs/schema-and-data-model
- https://cloud.google.com/spanner/docs/sql-best-practices#use_secondary_indexes_to_speed_up_common_queries
- https://docs.microsoft.com/en-us/azure/cosmos-db/programming#database-program-transactions
- https://cloud.google.com/spanner/docs/transactions
- https://aws.amazon.com/blogs/aws/dynamodb-transaction-library/
- http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.ReadConsistency.html
- https://cloud.google.com/spanner/docs/reference/rest/v1/TransactionOptions
- https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
- https://github.com/awslabs/DynamoDB-cross-region-library
- https://docs.microsoft.com/en-us/azure/cosmos-db/introduction
- https://aws.amazon.com/blogs/aws/cross-region-import-and-export-of-dynamodb-tables/
- https://github.com/bchew/dynamodump
- https://stackoverflow.com/questions/42519288/external-backups-snapshots-for-google-cloud-spanner
- https://docs.microsoft.com/en-us/azure/cosmos-db/online-backup-and-restore
- https://cloud.google.com/products/calculator/
- http://calculator.s3.amazonaws.com/index.html#s=DYNAMODB
- https://www.documentdb.com/capacityplanner
- https://azure.microsoft.com/en-us/pricing/calculator/
The post Current State of the NewSQL/NoSQL Cloud Arena appeared first on Simple Talk.





 The governor of Japan's Fukui Prefecture has today approved the restart of units 3 and 4 of Kansai Electric Power Company's Ohi nuclear power plant. The utility reportedly plans to restart both units by mid-March.
The governor of Japan's Fukui Prefecture has today approved the restart of units 3 and 4 of Kansai Electric Power Company's Ohi nuclear power plant. The utility reportedly plans to restart both units by mid-March.

 Den passenden Tarif zu finden ist bei der Vielzahl an Angeboten nicht einfach. Wir zeigen Ihnen, welches Datenvolumen zu unterschiedlichen Nutzertypen passt.
Den passenden Tarif zu finden ist bei der Vielzahl an Angeboten nicht einfach. Wir zeigen Ihnen, welches Datenvolumen zu unterschiedlichen Nutzertypen passt.
 In den USA soll Pokémon Go in den ersten 148 Tagen nach Erscheinen zu mehreren Todesfällen geführt und bis zu 7,3 Milliarden US-Dollar an Schäden verursacht haben. Besonders gefährlich sei der Bereich rund um Pokéstops, sagen Wissenschaftler der Purdue University. (
In den USA soll Pokémon Go in den ersten 148 Tagen nach Erscheinen zu mehreren Todesfällen geführt und bis zu 7,3 Milliarden US-Dollar an Schäden verursacht haben. Besonders gefährlich sei der Bereich rund um Pokéstops, sagen Wissenschaftler der Purdue University. (


 Honda will bis 2022 Elektroautos entwickeln, die sich in 15 Minuten aufladen lassen. Außerdem sollen die Karosserien leichter werden, um die Reichweite zu erhöhen. (
Honda will bis 2022 Elektroautos entwickeln, die sich in 15 Minuten aufladen lassen. Außerdem sollen die Karosserien leichter werden, um die Reichweite zu erhöhen. ( Die R+V Versicherung und Fraport haben auf dem Gelände des Flughafens Frankfurt einen kleinen autonomen Elektrobus getestet. Dieser darf nun auch auf einem anderen Betriebsgelände in Hessen fahren. Unfälle hat es bisher nicht gegeben. (
Die R+V Versicherung und Fraport haben auf dem Gelände des Flughafens Frankfurt einen kleinen autonomen Elektrobus getestet. Dieser darf nun auch auf einem anderen Betriebsgelände in Hessen fahren. Unfälle hat es bisher nicht gegeben. (