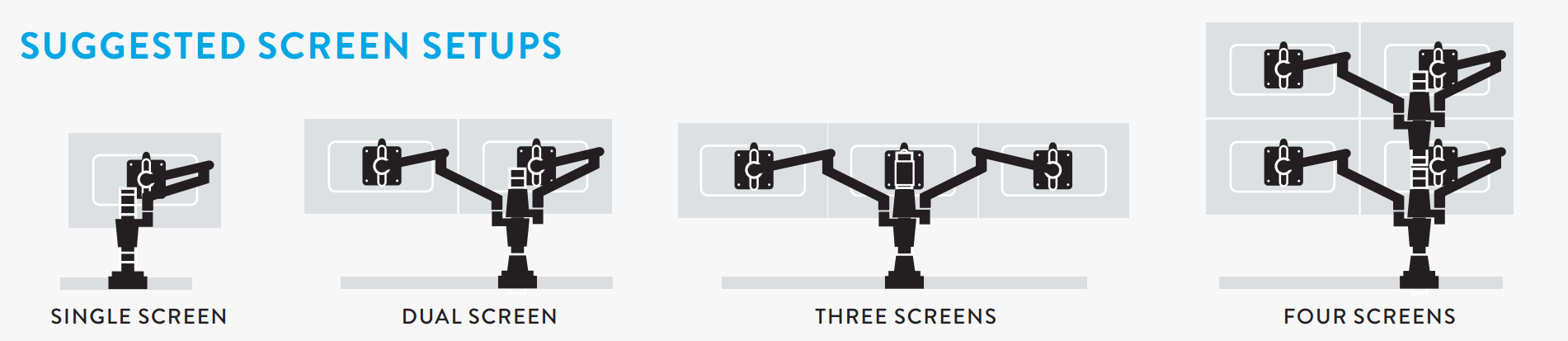
I read Agile is the new Waterfall at first with disgust, then with horror, and then finally with a meager amount of very qualified approval.
The author makes a reasonable point towards the end; but in getting to that point he states a number of falsehoods and eventually discredits a philosophy and discipline that does not deserve it. He is close to throwing everything out with the bathwater.
He begins by claiming that no sane person advocates waterfall. I don’t know what universe the author lives in; but in this universe there are quite a few people who advocate waterfall. Are they sane? By any legal standard they are. Anyone who thinks that the battle against waterfall is over simply hasn’t been fighting in the right trenches.
If you want to get a feel for just how wrong the author is about this, just google “Waterfall Software Teams” and count the number of articles that talk about striking a balance, or mixing the two processes, etc. People are not anxious to give up on the past.
Next he quotes MacBeth’s lament over the futility of life, and equates it with the “the promise of Agile”
“…full of sound and fury, signifying nothing.”
I take rather profound exception to the idea that the events leading up to the Agile Manifesto, and the Manifesto itself are an example of futility and meaningless noise. The author wasn’t there. The author doesn’t know. While I agree that in certain circles there is more heat than light; to claim that the entire movement is insignificant is to ignore a vast swath of software history.
I’m not going to critique the author point by point. Suffice it to say that he knows very little of the history, and what little he does know he’s gotten wrong. In so doing he has cast a pall of disrespect over a large number of people who have made huge contributions to our field. A pall that discredits an ideology that has had a profoundly positive effect.
He rails against the Agile consultancies who try to help organizations make the shift to Agile. Some of his complaints are justified; but most are not. Changing an organization is hard! Those companies that try to change, and hire help to make that change, are courageous.
Are there Agile consultancies that are better than others? Yes. Certainly. Caveat Emptor! But denigrating the entire effort is simply ignorant.
The One Point.
The author is wrong about Agile in virtually every regard. But he does make one good point. Unfortunately the context in which he makes that point is so wrong that the point is almost lost in the cacophony of blather that surrounds it. That point is:
“Bring in the bare minimum amount of process.”
Yes! Of course!
Does every software team need the entire suite of agile practices? Of course not. But let’s look at them:
-
The Planning Game. Over the years it has become very clear that there are many ways to shave this Yak. Some teams need more process around this than others. For some, a simple list of features will do. For others, a Kanban board will be sufficient. Still others will need the full suite of stories, and tasks, and releases, and story points, and… Well, you know. Choose wisely!
-
Customer Tests. Lots of customers don’t want to be bothered with these tests. That’s a shame, since they are demonstrably the best way to specify requirements. For those teams that have customers engaged enough to specify the requirements in terms of Cucumber tests, or FitNesse tests there is no better alternative. Teams that are not so fortunate are not likely to benefit from this practice. My personal rule is: If the customers neither read nor write the tests, then high level unit tests written in code suffice.
-
Small Releases. It’s hard to imagine a team that would not benefit from this practice. Keep the releases small. The more time you wait between exposing the customers to the system, the more can go wrong.
-
Whole Team. Again, it’s hard to imagine a team that would not benefit from a close relationships between the business people, and the developers. Not all teams are so fortunate, of course.
-
Collective Ownership. As far as I’m concerned any team that has individual code ownership is deeply dysfunctional. If the owner of some part of the code decides to leave, the whole team is left in crisis mode. There are many ways to achieve collective ownership, but the bottom line is very simple. No single individual should be able to hold the team hostage. Every part of the code should be known by more than one person – the more the better.
-
Coding Standard. This simply goes along with Collective Ownership. The code should look like the team wrote it, not like one of the individuals wrote it. The members of the team should agree on the way that their code will appear. This isn’t rocket science.
-
Sustainable Pace. This is a real simple idea. Software projects are marathons, not sprints. You dare not run at a rate that you cannot sustain for the long term. Murphy tells us that any team that violates this practice is doomed to flame out at the worst possible moment.
-
Continuous Integration. Certainly there are teams who’s projects are so small that setting up a CI server is redundant. However, for most teams this is such a positive win that neglecting it would be immoral, if not insane.
-
Pair Programming. Some teams benefit greatly by using this practice. Others do not. For the latter, some form of code review is likely necessary. In any case, it is a very good idea for every line of code to have been seen by more than one pair of eyes.
-
Simple Design. If we learned anything in the ’90s it is that over-design is suicide. The level of design is team dependent, of course; but the simpler the better is simply a good rule of thumb.
-
Refactoring. Does anybody really want to argue that programmers should not keep their code as clean as possible? Does anyone want to argue that code should not be improved with time? Teams may choose different degrees of refactoring; but zero is probably not acceptable.
-
Test Driven Development. This is certainly the most controversial of all the Agile practices. But the controversy is not about the word Test. Virtually everyone agrees that writing unit tests is important. Some of us think that the order in which they are written is important too. Different teams will choose different strategies. But teams that ignore testing are not destined for rapid success.
Conclusion
Does every team need every one of these practices? Certainly not. Do most teams need at least some of them? Of course they do! Again, choose wisely!
I believe that the author of the original article was exposed to teams who were doing Flaccid Scrum and made the mistake that that’s all there was to Agile. He is correct that there have been some uninformed consultancies who have taught this poor variant of the Agile practices. In that sense his diatribe is understandable. Still, ignorance is no excuse. If you are going to impugn the character of good people and good ideas, you’d better do your damned homework.
 There's been a lot of enthusiasm lately about the direction that ASP.NET is going lately, and rightfully so.
There's been a lot of enthusiasm lately about the direction that ASP.NET is going lately, and rightfully so. 




























 Aujourd’hui débute à la Villa Savoye de Poissy, dont l’architecte est Le Corbusier, une exposition intitulée Des voitures à habiter : automobile et modernisme XXe-XXIe siècles. Renault en profite pour dévoiler un concept Coupé Corbusier plutôt étonnant. Le nouveau concept Coupé Corbusier de Renault surprend. Il s’affranchit des codes esthétiques que la marque française développe […]
Aujourd’hui débute à la Villa Savoye de Poissy, dont l’architecte est Le Corbusier, une exposition intitulée Des voitures à habiter : automobile et modernisme XXe-XXIe siècles. Renault en profite pour dévoiler un concept Coupé Corbusier plutôt étonnant. Le nouveau concept Coupé Corbusier de Renault surprend. Il s’affranchit des codes esthétiques que la marque française développe […]