In 2007 I wrote about using PNGout to produce amazingly small PNG images. I still refer to this topic frequently, as seven years later, the average PNG I encounter on the Internet is very unlikely to be optimized.
For example, consider this recent Perry Bible Fellowship cartoon.

Saved directly from the PBF website, this comic is a 800 × 1412, 32-bit color PNG image of 671,012 bytes. Let's save it in a few different formats to get an idea of how much space this image could take up:
| BMP |
24-bit |
3,388,854 |
| BMP |
8-bit |
1,130,678 |
| GIF |
8-bit, no dither |
147,290 |
| GIF |
8-bit, max dither |
283,162 |
| PNG |
32-bit |
671,012 |
PNG is a win because like GIF, it has built-in compression, but unlike GIF, you aren't limited to cruddy 8-bit, 256 color images. Now what happens when we apply PNGout to this image?
| Default PNG |
671,012 |
|
| PNGout |
623,859 |
7% |
Take any random PNG of unknown provenance, apply PNGout, and you're likely to see around a 10% file size savings, possibly a lot more. Remember, this is lossless compression. The output is identical. It's a smaller file to send over the wire, and the smaller the file, the faster the decompression. This is free bandwidth, people! It doesn't get much better than this!
Except when it does.
In 2013 Google introduced a new, fully backwards compatible method of compression they call Zopfli.
The output generated by Zopfli is typically 3–8% smaller compared to zlib at maximum compression, and we believe that Zopfli represents the state of the art in Deflate-compatible compression. Zopfli is written in C for portability. It is a compression-only library; existing software can decompress the data. Zopfli is bit-stream compatible with compression used in gzip, Zip, PNG, HTTP requests, and others.
I apologize for being super late to this party, but let's test this bold claim. What happens to our PBF comic?
| Default PNG |
671,012 |
|
| PNGout |
623,859 |
7% |
| ZopfliPNG |
585,117 |
13% |
Looking good. But that's just one image. We're big fans of Emoji at Discourse, let's try it on the original first release of the Emoji One emoji set – that's a complete set of 842 64×64 PNG files in 32-bit color:
| Default PNG |
2,328,243 |
|
| PNGout |
1,969,973 |
15% |
| ZopfliPNG |
1,698,322 |
27% |
Wow. Sign me up for some of that.
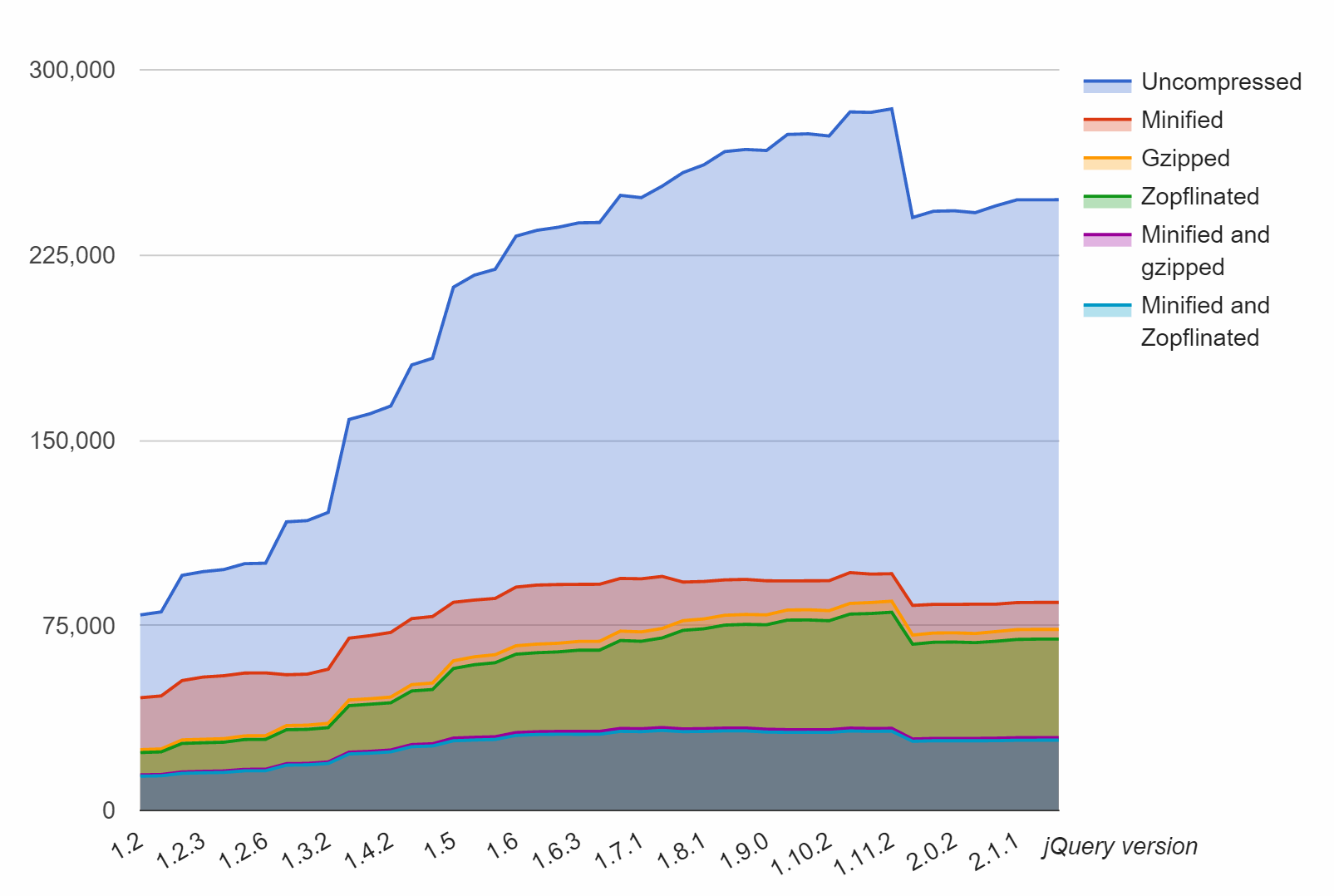
In my testing, Zopfli reliably produces 3 to 8 percent smaller PNG images than even the mighty PNGout, which is an incredible feat. Furthermore, any standard gzip compressed resource can benefit from Zopfli's improved deflate, such as jQuery:
Or the standard compression corpus tests:
|
gzip -9 |
kzip |
Zopfli |
| Alexa 10k |
128mb |
125mb |
124mb |
| Calgary |
1017kb |
979kb |
975kb |
| Canterbury |
731kb |
674kb |
670kb |
| enwik8 |
36mb |
35mb |
35mb |
(Oddly enough, I had not heard of kzip – turns out that's our old friend Ken Silverman popping up again, probably using the same compression bag of tricks from his PNGout utility.)
But there is a catch, because there's always a catch – it's also 80 times slower. No, that's not a typo. Yes, you read that right.
gzip -9 |
5.6s |
7zip mm=Deflate mx=9 |
128s |
| kzip |
336s |
| Zopfli |
454s |
Gzip compression is faster than it looks in the above comparsion, because level 9 is a bit slow for what it does:
|
Time |
Size |
gzip -1 |
11.5s |
40.6% |
gzip -2 |
12.0s |
39.9% |
gzip -3 |
13.7s |
39.3% |
gzip -4 |
15.1s |
38.2% |
gzip -5 |
18.4s |
37.5% |
gzip -6 |
24.5s |
37.2% |
gzip -7 |
29.4s |
37.1% |
gzip -8 |
45.5s |
37.1% |
gzip -9 |
66.9s |
37.0% |
You decide if that whopping 0.1% compression ratio difference between gzip -7and gzip -9 is worth the doubling in CPU time. In related news, this is why pretty much every compression tool's so-called "Ultra" compression level or mode is generally a bad idea. You fall off an algorithmic cliff pretty fast, so stick with the middle or the optimal part of the curve, which tends to be the default compression level. They do pick those defaults for a reason.
PNGout was not exactly fast to begin with, so imagining something that's 80 times slower (at best!) to compress an image or a file is definite cause for concern. You may not notice on small images, but try running either on a larger PNG and it's basically time to go get a sandwich. Or if you have a multi-core CPU, 4 to 16 sandwiches. This is why applying Zopfli to user-uploaded images might not be the greatest idea, because the first server to try Zopfli-ing a 10k × 10k PNG image is in for a hell of a surprise.
However, remember that decompression is still the same speed, and totally safe. This means you probably only want to use Zopfli on pre-compiled resources, which are designed to be compressed once and downloaded millions of times – rather than a bunch of PNG images your users uploaded which may only be viewed a few hundred or thousand times at best, regardless of how optimized the images happen to be.
For example, at Discourse we have a default avatar renderer which produces nice looking PNG avatars for users based on the first letter of their username, plus a color scheme selected via the hash of their username. Oh yes, and the very nice Roboto open source font from Google.
We spent a lot of time optimizing the output avatar images, because these avatars can be served millions of times, and pre-rendering the whole lot of them, given the constraints of …
- 10 numbers
- 26 letters
- ~250 color schemes
- ~5 sizes
… isn't unreasonable at around 45,000 unique files. We also have a centralized https CDN we set up to to serve avatars (if desired) across all Discourse instances, to further reduce load and increase cache hits.
Because these images stick to shades of one color, I reduced the color palette to 8-bit (actually 128 colors) to save space, and of course we run PNGout on the resulting files. They're about as tiny as you can get. When I ran Zopfli on the above avatars, I was super excited to see my expected 3 to 8 percent free file size reduction and after the console commands ran, I saw that saved … 1 byte, 5 bytes, and 2 bytes respectively. Cue sad trombone.
(Yes, it is technically possible to produce strange "lossy" PNG images, but I think that's counter to the spirit of PNG which is designed for lossless images. If you want lossy images, go with JPG or another lossy format.)
The great thing about Zopfli is that, assuming you are OK with the extreme up front CPU demands, it is a "set it and forget it" optimization step that can apply anywhere and will never hurt you. Well, other than possibly burning a lot of spare CPU cycles.
If you work on a project that serves compressed assets, take a close look at Zopfli. It's not a silver bullet – as with all advice, run the tests on your files and see – but it's about as close as it gets to literally free bandwidth in our line of work.















 Audi vient d’annoncer en début de semaine avoir renforcé son partenariat dans les biocarburants avec la société Global Bioenergies. Un nouvel accord a été signé autour de la technologie de production d’essence bio-sourcée développée par la jeune start-up. Les deux sociétés travaillent conjointement depuis 2014 pour le développement d’un carburant, l’isooctane, produit par Global Bioenergies à […]
Audi vient d’annoncer en début de semaine avoir renforcé son partenariat dans les biocarburants avec la société Global Bioenergies. Un nouvel accord a été signé autour de la technologie de production d’essence bio-sourcée développée par la jeune start-up. Les deux sociétés travaillent conjointement depuis 2014 pour le développement d’un carburant, l’isooctane, produit par Global Bioenergies à […]
 Avec les kilomètres qui s’accumulent pour les prototypes de véhicules autonomes, s’accumule aussi l’expérience et une tendance inattendue apparaît au grand dam des ingénieurs qui créent le logiciel qui anime ces automobiles sans conducteur : le nombre d’accidents dans lesquels elles sont impliquées est plus important que pour le reste des véhicules, mais elles ne sont jamais […]
Avec les kilomètres qui s’accumulent pour les prototypes de véhicules autonomes, s’accumule aussi l’expérience et une tendance inattendue apparaît au grand dam des ingénieurs qui créent le logiciel qui anime ces automobiles sans conducteur : le nombre d’accidents dans lesquels elles sont impliquées est plus important que pour le reste des véhicules, mais elles ne sont jamais […]














 Steve Wozniak est l’un des cofondateurs d’Apple. Lors du Gartner Symposium/ITxpo de Gold Coast en Australie, le scientifique a livré sa vision du paysage automobile dans les 20 prochaines années. Les constructeurs automobiles devront bientôt faire avec un petit nouveau. La marque à la pomme prépare en effet son arrivée sur quatre roues. Pour Apple, […]
Steve Wozniak est l’un des cofondateurs d’Apple. Lors du Gartner Symposium/ITxpo de Gold Coast en Australie, le scientifique a livré sa vision du paysage automobile dans les 20 prochaines années. Les constructeurs automobiles devront bientôt faire avec un petit nouveau. La marque à la pomme prépare en effet son arrivée sur quatre roues. Pour Apple, […]

{kind=link}