Jeudi 1er août,le Conseil d'Etat a annulé le moratoire qui frappait depuis 2012 le MON810, un maïs transgénique de la firme américaine Monsanto. Le MON810 est une plante à laquelle un gène a été ajouté pour qu'elle produise une toxine dite "Bt" (du nom de la bactérie Bacillus thuringiensis qui la synthétise naturellement), toxine qui tue les insectes ravageurs de ce maïs, comme la pyrale, en paralysant l'intestin des larves. Dans l'esprit des créateurs de cette plante transgénique, faire fabriquer le pesticide directement par la plante évite aux agriculteurs d'en épandre sur leurs cultures. Cette décision du Conseil d'Etat a une nouvelle fois relancé le débat sur la culture d'organismes génétiquement modifiés (OGM) en France, les opposants aux OGM soulevant plusieurs arguments, comme les risques pour la santé des consommateurs (humains ou animaux d'élevage), la contamination des cultures non-OGM et du miel, le fait que certains insectes utiles seraient victimes de la plante ou bien le développement de résistances à la toxine chez les nuisibles.
Ce débat, qui a depuis longtemps quitté le domaine de la science pour tomber dans celui de la politique – les arguments exploités par les uns et les autres étant plus d'ordre idéologique que biologique –, pourrait bien de toute manière devenir rapidement un combat d'arrière-garde avec la future génération de plantes transgéniques, ainsi que le souligne Sciencedans son numéro spécial du 16 août, consacré à l'épineuse question des pesticides. En effet, les OGM de demain ne seront plus conçus suivant le principe assez basique qui consistait à leur faire produire l'insecticide. Non, ils seront l'insecticide, grâce à une stratégie diabolique, celle de l'interférence ARN.
Ce qu'ont découvert Mello et Fire, c'est que l'on pouvait, à l'aide d'un ARN dit "interférent", intercepter le facteur en cours de route : de tout petits morceaux de cet ARN interférent viennent se coller à l'ARN messager, ce qui entraîne sa destruction. Conclusion : le message ne parvient jamais à l'usine à protéines, la protéine n'est pas synthétisée et son gène est comme éteint. Le phénomène de l'interférence ARN se retrouve dans la nature, soit pour lutter contre l'introduction de génomes étrangers (de virus, par exemple), soit pour moduler l'expression de certains gènes.
L'idée des fabricants de semences OGM consiste à faire fabriquer à leurs plantes un micro-ARN interférent réduisant au silence une protéine-clé pour l'organisme des insectes ravageurs. Une fois que ces derniers auront croqué dans la plante et assimilé l'ARN interférent en question, celui-ci empêchera la production de la protéine vitale et l'animal mourra. On peut dans ce cas considérer que la plante a été transformée en poison pour ces insectes. Une étude canadienne publiée en 2009 a montré que la technique fonctionnait avec plusieurs parasites bien connus, comme le tribolium rouge de la farine, le puceron du pois ou le sphinx du tabac. Autre point important de cette étude : il est possible de cibler une espèce sans porter préjudice à ses cousines proches. Ces chercheurs ont ainsi choisi un gène présent chez quatre drosophiles, mais dont l'écriture varie suivant les espèces. En sélectionnant très précisément un petit morceau du code génétique spécifique à l'une de ces mouches, il a été possible d'éteindre le gène chez elle, alors qu'il demeurait actif chez les trois autres espèces.
Ainsi que l'expliqueScience, les premières plantes OGM à ARN interférent devraient arriver sur le marché d'ici à la fin de la décennie. Les semenciers se sont mis en ordre de bataille, comme le Suisse Syngenta qui, pour plus de 400 millions d'euros, a racheté en 2012 l'entreprise belge DevGen, spécialiste de l'interférence ARN. Monsanto n'est pas en reste qui, toujours en 2012, s'est allié à un autre champion de cette biotechnologie, Alnylam Pharmaceuticals. Par ailleurs, au cours de l'année écoulée, les chercheurs de Monsanto ont publié deux articles (ici et là) dans lesquels ils expliquent avoir mis en sommeil, par interférence ARN, un gène de la chrysomèle des racines du maïs, insecte qui coûte un milliard de dollars par an aux producteurs de maïs américains.
Toute la question est désormais de savoir si ces OGM produisant des micro-ARN interférents seront sans risque pour les mammifères (hommes ou bétail) qui les consommeront. On a longtemps pensé (et certains le pensent toujours) que ces minuscules molécules étaient trop fragiles pour résister au processus de digestion. Mais une étude chinoise publiée en 2011 par la revue Cell Research est venue jeter le doute : ses auteurs affirmaient avoir retrouvé dans le sang d'humains des micro-ARN interférents provenant de plantes diverses et notamment du riz. Et un de ces ARN interférents était même capable de réguler l'élimination du cholestérol !
L'étude ne parlait absolument pas des futurs OGM, mais cela n'a pas empêché le site AlterNet de faire le rapprochement et de lancer l'alerte. De ce long pamphlet contre les OGM, pas toujours très exact, je retiendrai la seule proposition scientifique sensée : avant toute commercialisation d'une plante transgénique fonctionnant sur le principe de l'interférence ARN, il faudra évidemment prendre la précaution élémentaire de vérifier que le micro-ARN sélectionné n'ira pas, par un hasard malheureux, éteindre un gène d'Homo sapiens ou des principaux animaux d'élevage.
Pour le reste, on laissera aux hommes politiques, aux lobbies de tout bord et aux instituts de sondage le soin de décider si les OGM doivent ou pas être cultivés...
Dans une chambre noire, prenez une lampe torche et une boîte à chaussures. Soulevez le couvercle de la boîte, éclairez l'intérieur et éteignez dès que vous avez refermé le couvercle. Attendez une minute. Rouvrez la boîte. Que se passe-t-il ? Rien et c'est normal. Pourtant, des chercheurs allemands viennent de concevoir un système, une espèce de boîte dans laquelle la lumière est stoppée et réémise une minute plus tard, dès que la boîte s'ouvre ! Pour comprendre à la fois la physique et l'enjeu de cette expérience époustouflante, il faut faire un détour par le monde curieux de l'information quantique.
Tout ce que vous voyez sur votre écran, le texte de ce billet, l'image qui l'accompagne, a été codé sous forme de bits. Il en va de même pour les clichés que vous prenez avec votre appareil photo numérique, pour les films de vos DVD, pour la musique de votre lecteur MP3... Toutes ces informations visuelles ou sonores ont été passées à cette moulinette et quand les informations voyagent sur Internet dans les impulsions lumineuses de la fibre optique, elles empruntent aussi cette forme. Dans le monde actuel de l'informatique classique, le bit est ou bien 0 ou bien 1, et rien d'autre. Un jour viendra pourtant où l'on s'affranchira de cette tyrannie du binaire, où tout est noir ou blanc, ouvert ou fermé, haut ou bas. Dans le monde futur, à peine ébauché, de l'informatique quantique, le bit pourra à la fois être 0 et 1. Comme le disent les physiciens, dans le monde quantique les particules peuvent avoir deux états superposés, être ici et là, comme ci et comme ça. Grâce à sa souple gestion des possibles, le bit quantique (aussi connu sous l'abominablement obscène abréviation de qubit) permettra des tâches impossibles au bit classique
Ceci posé, on est encore très loin de l'ère du tout quantique tant sont nombreux les obstacles techniques à surmonter. L'un d'entre eux, et non le moindre, réside dans le domaine des communications : "Il y a un problème majeur quand vous envoyez des photons uniques – des particules de lumière – dans de la fibre optique : ils se font absorber, souligne Hugues de Riedmatten, professeur à l'Institut de sciences photoniques de Barcelone. Pour 100 photons envoyés, il n'en reste plus qu'un au bout de 100 kilomètres." Et, comme me l'a expliqué ce chercheur suisse, au bout de 500kilomètres, il ne reste plus qu'un photon sur 10milliards et plus qu'un sur 100milliards de milliards après 1000kilomètres.
Le problème existe évidemment aussi dans les télécommunications classiques où il est résolu à l'aide de répéteurs installés le long des lignes, à intervalles relativement rapprochés. Ces dispositifs récupèrent le signal et le ré-amplifient, un peu comme des coureurs de relais qui récupèrent le bâton transmis par un équipier en bout de course et lui redonnent du "jus". Malheureusement, cette solution simple et pratique n'est pas applicable au monde de la communication quantique car une telle opération, qui équivaut à une mesure, détruirait tout ce qui fait l'intérêt de l'information quantique portée par les photons. En effet, dans ce monde bizarre, mesurer tel ou tel attribut d'une particule l'oblige à se décider pour le 0 ou pour le 1 : la mesure démolit la superposition d'états. Cette propriété est d'ailleurs exploitée par la cryptographie quantique puisque si quelqu'un espionne une communication sécurisée avec cette méthode, son intervention est aussitôt détectée...
Les physiciens ont donc dû puiser dans leur sac à astuces pour contourner ce problème et concevoir un système de répéteurs quantiques ne faisant que transmettre les états des photons de proche en proche sans jamais les mesurer. Pour cela, ils ont exploité une autre "bizarrerie" quantique, l'intrication. Quand deux systèmes sont intriqués, ils ne forment plus qu'un au sens où leurs états sont les mêmes. Le but du jeu consiste donc à découper la ligne de communication en segments intriqués les uns avec les autres pour pouvoir ainsi transporter l'information d'un bout à l'autre. Toute la difficulté de l'exercice, m'a expliqué Julien Laurat, professeur à l'université Pierre et Marie Curie (Paris) et chercheur au Laboratoire Kastler Brossel, c'est qu'il faut que les extrémités desdits segments soient toutes intriquées en même temps. Or, l'opération ne se décide pas dès qu'on appuie sur un bouton : la durée de construction de l'intrication est aléatoire. "La probabilité pour que tous les événements soient concomitants décroît de manière exponentielle avec le nombre de segments", résume Julien Laurat. Certains segments seront donc préparés avant d'autres et il faudra, le temps que ces derniers soient prêts à leur tour, mettre cette intrication en mémoire. On tombe alors dans un autre casse-tête car allez donc stocker de la lumière dans une boîte...
C'est pourtant l'exploit que viennent de réaliser trois chercheurs de l'Université technologique de Darmstadt (Allemagne) grâce à un magistral tour de passe-passe qu'ils décrivent dans Physical Review Letters. Leur boîte est un cristal dans lequel sont prisonniers des atomes de praséodyme, lesquels vont être les cibles d'un rayon laser. Le hic, c'est qu'en temps normal, ce cristal est en quelque sorte opaque. Qu'à cela ne tienne : à l'aide d'un second laser et d'un phénomène connu sous le nom de transparence induite électromagnétiquement (TIE), une fenêtre de transparence est ouverte dans le cristal, qui permet à la lumière d'y entrer. Celle-ci y est considérablement ralentie et comprimée, au point qu'une brève impulsion lumineuse de quelques microsecondes, qui, dans le vide, mesurerait 2 kilomètres, tient en moins de 3 millimètres !
Puis la TIE est arrêtée, ce qui referme la fenêtre de transparence et la boîte par la même occasion. Les photons sont pris au piège du cristal. De l'extérieur, on a l'impression que la lumière est stoppée mais c'est une illusion – d'où l'expression de tour de passe-passe que j'ai utilisée plus haut. En réalité, l'énergie et les informations des photons sont transférées aux atomes de praséodyme. Toute la difficulté de l'expérience consiste à empêcher ces atomes de les perdre lors d'interactions avec le reste de la matière. L'équipe allemande a, pour préserver cette cohérence, utilisé divers dispositifs et notamment un champ magnétique particulier pour "geler" autant qu'il se pouvait ces interactions destructrices. Cela n'a pas empêché la très grande majorité des informations de disparaître. Toutefois, lorsque les chercheurs ont rouvert la fenêtre de transparence au bout d'une minute, un certain nombre d'atomes de praséodyme ont restitué leur énergie superflue en émettant des photons porteurs de l'information de départ. Celle-ci contenait une image de trois bandes horizontales, qui a été retrouvée, très atténuée, à la sortie, comme on peut le voir ci-dessous.
Une minute, cela peut sembler bien court comme mémoire, mais dans le monde de l'information quantique, c'est plus de temps qu'il ne faut pour synchroniser les segments d'une ligne de communication. Tout en m'expliquant que l'intérêt de cette expérience tient essentiellement dans ce record de durée (le précédent record, qui date du début de l'année, était de 16 secondes avec un gaz d'atomes ultra-froids), Hugues de Riedmatten et Julien Laurat ont insisté sur le fait que l'équipe allemande a travaillé avec de grosses impulsions laser, c'est-à-dire dans le domaine de l'optique traditionnelle, et qu'elle n'est pas descendue dans ce que les physiciens appellent "le régime quantique", celui où les photons sont envoyés un par un. De plus, l'efficacité du procédé est très faible puisque moins de 1 % des photons sont récupérés. Même s'il commence à être balisé, le chemin vers l'informatique et la communication quantiques est encore long.
The connections between mathematics and music are many. For example, the differential equations of vibrating strings and surfaces help us understand harmonics and tuning systems, rhythm analysis tells us the ways a measure can be divided into beats, and the study of symmetry relates to the translations in time and pitch that occur in a fugue or canon.
This video explores a less well-known connection. It turns out that musical chords naturally inhabit various topological spaces, which show all the possible paths that a composer can use to move between chords. Surprisingly, the space of two-note chords is a Möbius strip, and the space of three-note chords is a kind of twisted triangular torus.
For a thorough presentation of the ideas introduced here, suitable for both mathematicians and musicians, see “A Geometry of Music” by Dmitri Tymoczko.
The “Umbilic Torus” sculpture shown at the end of the video was created by Helaman Ferguson.
Final Term est un projet de terminal pour GNU/Linux, qui va changer sûrement l’idée et l’image qu’ont certains sur les interfaces des terminaux. Son auteur, Philipp Emanuel Weidmann, s’est beaucoup inspiré des IDE et le résultat est bluffant, bien que l’application soit encore qu’à ses débuts .
Parmi les fonctionnalités qui m’ont séduit dès les premières captures d’écran que j’ai vu, il y a la complétion automatique des commandes, via l’historique de ceux déjà exécuté. Très pratique si on veut éviter de ressaisir des longes lignes de commandes.
Quand vous listez les éléments d’un répertoire, si vous cliquez sur fichiers ou dossiers, une boite de dialogue s’ouvre, vous présentant quelques commandes que vous pouvez exécuter (copier/coller, copier le nom du dossier/fichier, déplacer, suppression…).
L’autre fonctionnalité qui m’a vraiment plu, c’est la capacité de Final Term de prendre correctement en charge le texte affiché dans votre terminal que vous redimensioner ce dernier.
Bref, c’est juste un petit aperçu des nombreuses fonctionnalités qu’offre Final Term, je ne les ai pas toutes cité, les curieux peuvent se rendre sur le site du projet et les découvrir, où ils peuvent installer Final Term. Pour Ubuntu, un dépôt PPA a été mis en place par le développeur de l’application :
Plus de pages en français qu'en anglais sur le site web de Debian.
Depuis aujourd'hui, et grâce au travail acharné de l'équipe de traduction française de Debian, il y a d'avantage de pages web en français qu'en anglais sur le site web de Debian.
Comment cela peut-il arriver ?
En fait, les pages web insérées sur le site web de Debian ne sont pas toutes originellement écrites en anglais. Il y a des pages françaises, espagnoles, chinoises, etc. Ces pages ne sont pas traduites en anglais car… il n'y a pas d'équipe de traduction anglaise (la liste de diffusion debian-l10n-english servant surtout à la relecture.)
Et donc, étant donné que les traducteurs français ont traduit presque TOUTES les pages web anglaises et comme il y a pas mal de pages en français seulement, il y a actuellement 5802 pages web en français alors qu'il n'y a que 5801 pages en anglais.
La Cabale Française a finalement atteint son but : nous avons le DPL [NDLT : Responsable du Projet Debian], nous avons le site web. ALL YOUR BASE ARE BELONG TO US.
Je prépare en ce moment une Résolution Générale [NDLT : vote soumis à l'assemblée de tous les Développeurs Debian] afin de faire du français la langue officielle des échanges au sein du projet Debian.
PS: merci à Thomas Vincent qui a largement contribué à ce succès ces derniers jours !
Voici un nouvel épisode de la série d’articles sur les français de la TV connectée que j’ai démarrée en mai 2012 ! C’est le 18ième du genre ! Il concerne cette fois-ci l’une des rares PME du secteur qui fasse plus de 100 salariés, ATEME. C’est un spécialiste renommé dans l’encodage vidéo destiné à la […]
In a world dominated by social media, it’s hard to not come across a client application which you have used to access restricted resources on some other server, for example, you might have used a web-based application (like NY Times) to share an interesting news article on your Facebook wall or tweet about it. Or, you might have used Quora’s iPhone app that accesses your Facebook or Google+ profile and customizes the results based on your profile data, like suggesting to add/invite other users to Quora, based on your friends list. The question is, how do these applications gain access to your Facebook, Twitter or Google+ accounts and how are they able to access your confidential data? Before they can do so, they must present some form of authentication credentials and authorization grants to the resource server.
Now, it would be really uncool to share your Facebook or Google credentials with any third-party client application that only needs to know about your Friends, as it not only gives the app limitless and undesirable access to your account, but it also has the inherent weakness associated with passwords. This is where OAuth comes into play, as it outlines an access-delegation/authorization framework that can be employed without the need of sharing passwords. For this reason, OAuth is often described as a valet key for the web. It can be thought of as a special key that allows access to limited features and for a limited period of time without giving away full control, just as the valet key for a car allows the parking attendant to drive the car for a short distance, blocking access to the trunk and the on-board cell phone.
However, OAuth is not a new concept, but a standardization and combined wisdom of many well established protocols. Also worth noting is that OAuth is not just limited to social-media applications, but provides a standardized way to share information securely between various kinds of applications that expose their APIs to other applications. OAuth 2.0 has a completely new prose and is not backwards compatible with its predecessor spec. Having said that, it would be good to first cover some basic OAuth2.0 vocabulary before diving into further details.
Resource Owner : An entity capable of granting access to a protected resource. Most of the time, it’s an end-user.
Client : An application making protected resource requests on behalf of the resource owner and with its authorization. It can be a server-based, mobile (native) or a desktop application.
Resource Server : The server hosting the protected resources, capable of accepting and responding to protected resource requests.
Authorization Server : The server issuing access grants/tokens to the client after successfully authenticating the resource owner and obtaining authorization.
Access Token : Access tokens are credentials presented by the client to the resource server to access protected resources. It’s normally a string consisting of a specific scope, lifetime and other access attributes and it may self contain the authorization information in a verifiable manner.
Refresh Token : Although not mandated by the spec, access tokens ideally have an expiration time which can last anywhere from a few minutes to several hours. Once an access token is expired, the client can request the authorization server to issue a new access token using the refresh token issued by the authorization server.
What’s Wrong With OAuth 1.0?
OAuth 1.0′s major drawback was the inherent complexity needed to implement the spec.
Nothing really! Twitter still works perfectly fine with OAuth 1.0 and just started supporting a small portion of the 2.0 spec. OAuth 1.0 was a well thought spec and it allowed exchange of secret information securely without the overhead imposed by SSL. The reason why we needed a revamp was mostly based around the complexity faced in implementing the spec. The following are some areas where OAuth 1.0 failed to impress:
Signing Every Request : Having the client generate signatures on every API request and validating them on the server everytime a request is received, proved to be major setback for developers, as they had to parse, encode and sort the parameters before making a request. OAuth 2.0 removed this complexity by simply sending the tokens over SSL, solving the same problem at network level. No signatures are required with OAuth 2.0.
Addressing Native Applications : With the evolution of native applications for mobile devices, the web-based flow of OAuth 1.0 seemed inefficient, mandating the use of user-agents like a Web Browser. OAuth 2.0 have accommodated more flows specifically suitable for native applications.
Clear Separation of Roles : OAuth 2.0 provides the much needed separation of roles for the authorization server authenticating and authorizing the client, and that of the resource server handling API calls to access restricted resources.
OAuth 2.0 in Depth
Before initiating the protocol, the client must register with the authorization server by providing its client type, its redirection URL (where it wants the authorization server to redirect to after the resource owner grants or rejects the access) and any other information required by the server and in turn, is given a client identifier (client_id) and client secret (client_secret). This process is known as Client Registration. After registering, the client may adopt one of the following flows to interact with the server.
Various OAuth Flows
OAuth 2.0 brings about five new flows to the table and gives developers the flexibility to implement any one of them, depending on the type of client involved:
User-Agent Flow : Suitable for clients typically implemented in user-agents (for example, clients running inside a web browser) using a scripting language such as JavaScript. Mostly used by native applications for mobile or desktop, leveraging the embedded or external browser as the user-agent for authorization and it uses the Implicit Grant authorization.
Web Server Flow : This makes use of the Authorization Code grant and is a redirection-based flow which requires interaction with the end-user’s user-agent. Thus, it is most suitable for clients which are a part of web-server based applications, that are typically accessed via a web browser.
Username and Password Flow : Used only when there is a high trust between the client and the resource owner and when other flows are not viable, as it involves the transfer of the resource owner’s credentials. Examples of clients can be a device operating system or a highly privileged application. This can also be used to migrate existing clients using HTTP Basic or Digest Authentication schemes to OAuth by converting the stored credentials to an access token.
Assertion Flow : Your client can present an assertion such as SAML Assertion to the authorization server in exchange for an access token.
Client Credentials Flow : OAuth is mainly used for delegated access, but there are cases when the client owns the resource or already has been granted the delegated access outside of a typical OAuth flow. Here you just exchange client credentials for an access token.
Discussing each flow in detail would be out of the scope of this article and I would rather recommend reading the spec for in-depth flow information. But to get a feel for what’s going on, let’s dig deeper into one of the most used and supported flows: The Web Server Flow.
The Web Server Flow
Since this is a redirection-based flow, the client must be able to interact with the resource owner’s user agent (which in most cases is a web browser) and hence is typically suited for a web application. The below diagram is a bird’s eye view of how the end-user (or the resource owner) uses the client application (web-server based application in this case) to authenticate and authorize with the authorization server, in order to access the resources protected by the resource server.
Authenticate & Authorize the Client
The client, on behalf of the resource owner, initiates the flow by redirecting to the authorization endpoint with a response_type parameter as code, a client identifier, which is obtained during client registration, a redirection URL, a requested scope (optional) and a local state (if any). To get a feel for how it really works, here’s a screenshot of how a typical request/response would look like:
This normally presents the resource owner with a web interface, where the owner can authenticate and check what all permissions the client app can use on the owner’s behalf.
Assuming that the resource owner grants access to the client, the authorization server redirects the user-agent back to the client using the redirection URL provided earlier, along with the authorization code as shown by the response below.
Exchange Authorization Code for Tokens
The client then posts to another authorization endpoint and sends the authorization code received in the earlier step, along with the redirection URL, its client identifier and secret, obtained during client registration and a grant_type parameter must be set as authorization_code.
The server then validates the authorization code and verifies that the redirection URL is the same as it was in the earlier step. If successful, the server responds back with an access token and optionally, a refresh token.
Request Restricted Resources Using Access Tokens
The client can now consume the APIs provided by the implementation and can query the resource server for a restricted resource by passing along the access token in the Authorization header of the request. A sample CURL request to Google’s Blogger API to get a blog, given its identifier, would look like this:
Note that we have added the Access token as an Authorization header in the request and also escaped the token by including it in single quotes, as the token may contain special characters. Keep in mind that escaping the access token is only required when using curl. It results in sending the following request:
The resource server then verifies the passed credentials (access token) and if successful, responds back with the requested information.
These examples are courtesy of OAuth2.0 Playground and are typical to how Google implements the spec. Differences might be observed when trying the same flow with other providers (like Facebook or Salesforce) and this is where interoperability issues creep in, which we discuss a bit later.
Refreshing Access Token
Although not mandated by the spec, but usually the access tokens are short-lived and come with an expiration time. So when an access token is expired, the client sends the refresh token to the authorization server, along with its client identifier and secret, and a grant_type parameter as refresh_token.
The authorization server then replies back with the new value for the access token.
Although a mechanism does exist to revoke the refresh token issued, but normally the refresh token lives forever and must be protected and treated like a secret value.
What’s Wrong With OAuth 2.0?
The Good Stuff
Going by the adoption rate, OAuth 2.0 is definitely an improvement over its arcane predecessor. Instances of developer community faltering while implementing the signatures of 1.0 are not unknown. OAuth 2.0 also provides several new grant types, which can be used to support many use-cases like native applications, but the USP of this spec is its simplicity over the previous version.
The Bad Parts
There are a few loose ends in the specification, as it fails to properly define a few required components or leaves them up to the implementations to decide, such as:
Loose ends in the OAuth 2.0 spec are likely to produce a wide range of non-interoperable implementations.
Interoperability: Adding too many extension points in the spec resulted in implementations that are not compatible with each other, what that means is that you cannot hope to write a generic piece of code which uses Endpoint Discovery to know about the endpoints provided by the different implementations and interact with them, rather you would have to write separate pieces of code for Facebook, Google, Salesforce and so on. Even the spec admits this failure as a disclaimer.
Short Lived Tokens: The spec does not mandate the lifetime and scope of the issued tokens. The implementation is free to have a token live forever. Although most of the implementations provide us with short-lived access tokens and a refresh token, which can be used to get a fresh access token.
Security: The spec just “recommends” the use of SSL/TLS while sending the tokens in plaintext over the wire. Although, every major implementation has made it a requirement to have secure authorization endpoints as well require that the client must have a secure redirection URL, otherwise it will be way too easy for an attacker to eavesdrop on the communication and decipher the tokens.
The Ugly Spat
It took IETF about 31 draft versions and the resignation of the lead author/developer Eran Hammer from the committee to finally publish the spec. Eran sparked a controversy by calling the spec “a bad protocol and a case of death by a thousand cuts”. According to him, the use of bearer tokens (sending tokens over SSL without signing them or any other verification) over the user of signatures (or MAC-Tokens), used in OAuth 1.0 to sign the request, was a bad move and a result of division of interests between the web and enterprise communities.
Conclusive Remarks
The spec surely leaves many extension points out in open, resulting in implementations that introduce their own parameters, in addition to what the spec already defines, and makes sure that implementations from different providers can’t interoperate with each other. But going with the popularity and adoption rate of this framework, with every big player in town (Google, Twitter, Facebook, Salesforce, Foursquare, Github etc.) implementing and tweaking it the way it suits them, OAuth is far from being a failure. In fact, any web application that plans to expose their APIs to other web applications must support some form of authentication and authorization and OAuth fits the bill here.
On ne se soucie pas assez de la signalétique des liens et de leurs différents états. C’est un défaut d’ergonomie d’autant plus regrettable que l’hyperlien est le fondement de la navigation sur le Web.
Voyons ensemble comment améliorer cela :
Hyperlien, kezako ?
À l’origine du Web tel que nous le connaissons aujourd’hui : l’hypertexte.
Initialement, un document Web est une page de texte. Mais la nouveauté avec l’hypertexte, c’est la possibilité de lier une page à une autre, non par la reliure physique d’un livre, qui ordonne les pages de façon successive — la nouveauté donc, c’est la possibilité de les lier indépendamment de la chronologie de lecture. Au besoin, une page peut en appeler une autre, depuis l’intérieur même du texte. Ce n’est plus du texte simple, mais de l’« hypertexte ». Et ce qui permet de lier, de l’« hyperlien ».
Comment ça marche ? C’est très simple : quelques mots sont « cliquables ». Cliquer dessus a pour conséquence d’afficher la page liée. Ce concept extrêmement simple a été l’un des moteurs principaux de la réussite du Web.
L’hyperlien est la base de la navigation sur Internet. Le Web ne cesse d’évoluer, mais nous cliquons toujours sur des liens.
Ancres et liens
Sur une page Web, des liens ajoutés à des mots, des phrases ou des images, peuvent être cliqués pour vous transporter à un autre endroit. Vous pouvez créer des liens vers n’importe quel point d’une page, auquel vous souhaitez pouvoir accéder d’un simple clic. C’est ce qui s’appelle une ancre.
D’abord les ancres…
L’élément HTML utilisé pour ce faire est a, de l’anglais anchor, qui signifie ancre.
Pour accéder à un emplacement bien précis de la page, il faut placer une ancre juste au-dessus de l’endroit où vous souhaitez atterrir. Une ancre se code ainsi :
Il s’agit donc de deux balises, <a> et </a>, avec le nom de l’ancre indiqué dans l’attribut « id » placé sur la balise ouvrante (et rien entre les deux balises) 1.
Puis les liens : href
Pour accéder à cet emplacement, il faut ajouter, ailleurs dans la page, un lien vers cette ancre. Un lien se code comme suit :
Il s’agit de la même balise <a>, mais l’attribut utilisé cette fois est « href ». La destination est indiquée dans cet attribut. Il s’agit de l’adresse hypertexte de référence à laquelle vous souhaitez vous rendre. L’attribut href est ce qui caractérise l’hyperlien.
Ancres et liens d’une page servent typiquement à constituer des liens d’évitement (« skip links ») ou un sommaire de la page. Mais les liens permettent également de pointer vers d’autres pages et toute autre ressource, interne ou externe au site.
Ancre ou lien, retenons que dans tous les cas il s’agit du couple de balises <a> et </a>. Ce sont les attributs utilisés, id ou href, qui précisent leur rôle.
Pourquoi diable sont-ils bleus soulignés ?
Il fallait trouver un moyen de distinguer les liens du reste du texte, pour rendre visibles ces mots cliquables qui sont comme autant de portes ouvertes dans le texte. Comme vous l’avez remarqué, le texte d’un lien est par défaut coloré en bleu et souligné. Pourquoi ?
Apparence par défaut d’un lien texte
D’où vient ce bleu ?
Saviez-vous que c’est à Sir Tim Berners-Lee, l’inventeur du Web, que nous devons la couleur par défaut des liens ? Il a probablement été le premier à signaler les liens par la couleur bleue, d’après des captures d’écran de son premier navigateur web, en 1993.
À l’époque, on ne disposait pas d’un grand choix de couleurs : seulement 16 (cf.Colors dans la spécification HTML 4.01), car les cartes graphiques les plus courantes n’en affichaient pas davantage.
Mosaic, un des premiers navigateurs web, affichait des pages Web avec du texte noir sur un fond gris. La couleur la plus foncée disponible, lisible sur une telle teinte, hors le noir, était le bleu. Le rouge et le vert ne pouvaient être choisis, en raison de leurs fortes connotations sémantiques respectives (danger/interdit, sécurité/permis, etc.). Le jaune est trop peu contrasté. Par conséquent, pour démarquer les liens du texte brut, de façon à ce qu’ils restent toujours lisibles, c’est la couleur bleue qui a été retenue.
Pourquoi soulignés ?
Les moniteurs en noir et blanc, ou en bichromie (souvent noir et vert), étaient encore fréquents. Pour preuve, le NeXT Cube, l’ordinateur sur lequel a été développé le premier navigateur Web par Tim Berners-Lee, en 1990, ne disposait que d’un affichage en niveaux de gris. Avant la couleur, c’est donc le souligné qui permettait de distinguer les hyperliens.
En typographie, le souligné n’a aucune raison d’être utilisé. Il ne s’emploie que pour pallier l’absence d’italique, lorsque celle-ci n’est techniquement pas disponible, comme c’est le cas dans l’écriture manuscrite ou dactylographique. Il sert alors à accentuer certains passages d’un texte, voire signaler les erreurs, mais aussi parfois à marquer le titre des références bibliographiques. Sur le Web, où l’usage d’italique est possible, le souligné est un enrichissement typographique inutile… disponible pour signaler autre chose, qui n’existe pas sur le papier : les hyperliens.
Pourquoi et que changer ?
Faut-il garder les liens ainsi, bleus soulignés ? Beaucoup répondent « Évidemment non ! C’est la préhistoire du Web ! » et force est de constater qu’énormément de sites aujourd’hui appliquent un style différent à leurs liens hypertextes. Mais ce n’est pas toujours bien fait, avec pour conséquence de faire jouer l’internaute à cache-cache avec les liens de la page…
Avec les CSS, vous pouvez choisir assez librement la présentation de vos liens hypertextes. L’essentiel est qu’ils soient repérables dans la page. Il faut qu’ils ressortent visuellement, au premier coup d’œil. Pour ce faire, plusieurs solutions existent : couleur, soulignement mais aussi cartouche, pictogrammes, etc.
Voici ce qu’il faut savoir, si vous décidez d’en changer l’apparence.
Attention au contraste
Si elle est plus jolie que le bleu d’origine, la couleur utilisée pour vos liens n’a peut-être pas un contraste suffisant pour rester correctement lisible en toutes circonstances : les mots écrits dans cette teinte peuvent être difficiles à déchiffrer en dehors des conditions optimales de luminosité ambiante, par exemple quand vous surfez par temps ensoleillé, dans le train ou dans la rue, ce qui est de plus en plus fréquent. N’oubliez pas non plus que nos chers internautes n’ont pas tous une excellente acuité visuelle.
Voici comment garantir la lisibilité des liens dans le texte : après s’être assuré que le contraste est suffisant entre la couleur du texte et la couleur de son arrière-plan (critère 3.3 Accessiweb 2.2), on choisira une couleur de lien ayant un rapport de contraste supérieur ou égal à 3:1 par rapport au texte environnant (critère 10.6 Accessiweb 2.2). De nombreux outils permettent de mesurer ces contrastes, qui sont présentés dans cet article : Contrastes de texte (OpenWeb, 2012).
D’après les critères d’accessibilité, le contraste suffit à distinguer un lien à partir du moment où « un élément de distinction autre que la couleur est visible lors du focus des liens (graisse, soulignement, icône,etc) » précise le critère RGAA No 7.10. Et c’est ce que l’on voit souvent : des liens de couleur assortie à la charte du site, soulignés au survol… mais pas toujours au focus.
Revisiter le standard
Nos dinosaures de l’Internet que sont Yahoo!, Google, eBay et Amazon, pour ne citer qu’eux, utilisent toujours cette bonne vieille recette du lien bleu, et ce n’est certainement pas le fruit du hasard. Leur besoin d’optimiser la performance et le taux de conversion président ce choix. Le bleu reste préférable, puisqu’il s’agit d’un standard : une majorité d’internautes ont acquis le concept « lien = bleu ». Utiliser cette couleur pour les liens textes, c’est donc leur faciliter la navigation.
Bien que l’accessibilité n’ait peut-être pas été la priorité de Tim Berners-Lee à l’époque, ce choix de couleur est heureux, comme le pointe Joe Clarck, cité dans cette note « Why are Links Blue? » (A List Apart, Zeldman, 2013) :
« Alors que le rouge et le vert sont des couleurs souvent mal distinguées par les daltoniens, presque personne n’a de déficience de perception de la couleur bleue. Par conséquent, presque tout le monde peut voir le bleu, ou, plus exactement, presque tout le monde peut distinguer le bleu comme couleur différente des autres. C’est une vraie chance que les liens soient bleus soulignés par défaut ! »
De même, savez-vous pourquoi le site Facebook a toujours été bleu et blanc ? La raison n’est pas arbitraire, ni esthétique : son créateur, Mark Zuckerberg, souffre de daltonisme et le bleu est la couleur qu’il voit le mieux.
Des liens bleus, oui, mais pas n’importe lequel. Ces dinosaures, comme d’autres sites plus modernes, révisent le standard. La teinte est mise au goût du jour, pour un bleu avoisinant, souvent moins vibrant et plus foncé, et notons que le souligné n’est pas systématiquement conservé par défaut :
Des liens bleus, oui, mais pas n’importe lequel!
La couleur ne suffit pas
Quand certains mots d’un texte sont en couleur, comment l’internaute peut en deviner la signification sans se tromper ? S’agit-il de la mise en exergue d’une expression importante ? d’un intertitre ? ou d’un hyperlien ? Prenons un exemple :
Où sont les liens ?
Pouvez-vous identifier à coup sûr les liens de l’extrait ci-dessus ? Non. Car si les liens semblent ici signalés par la couleur verte, tous les mots de cette couleur ne sont pas des liens, la bonne blague ! Ici, comme souvent, liens, exergues et titres ont la même couleur : c’est un moyen facile de personnaliser une charte graphique. Mais il faut avouer que ce n’est pas toujours assez explicite.
La différence de couleur n’est pas un élément distinctif suffisant. Cela laisse trop de place aux erreurs d’interprétation, avec le risque que certains utilisateurs passent totalement à côté. C’est ce qu’énonce le critère 3.1 Accessiweb 2.2 : « l’information ne doit pas être donnée uniquement par la couleur ».
Soulignez !
Si ce ne peut pas être par la couleur seule, comment distinguer un lien du texte environnant ? Les écrans monochromes des débuts d’Internet, mais aussi de nos liseuses contemporaines, nous rappellent que le souligné est le moyen à la fois le plus simple et le plus robuste de signaler les hyperliens. Reprenons notre exemple :
Soulignés, on ne s’y trompe plus !
Comme on le voit dans l’exemple ci-dessus, souligner les liens ne laisse plus aucune place au doute et facilite d’autant la navigation. Pourquoi ? Sur le Web, le souligné est une convention forte. C’est le rendu par défaut des navigateurs pour les liens et les utilisateurs s’attendent à ce qu’un texte souligné soit cliquable.
C’est si caractéristique que, pour éviter les clics inutiles sur des contenus soulignés qui seraient perçus comme des hyperliens – comme le montre ce contre-exemple, on réserve le souligné aux seuls hyperliens, comme le recommande la Bonne pratique Opquast n°42.
Le lien dans tous ses états
Un lien n’est pas statique. C’est une porte vers une autre ressource. Comme une porte s’ouvre et se franchit, le lien connaît plusieurs états. Il se survole, se clique et s’active pour aller de page en page. Ces différents états sont par défaut signalés par des couleurs différentes : lorsque vous cliquez sur un lien, il réagit visuellement en passant à la couleur rouge. Quand vous revenez ensuite à ce lien, il a pris une autre couleur encore, violet, pour montrer qu’il a déjà été visité.
Dès lors que l’on modifie l’apparence des liens, il ne faut pas oublier de prendre en compte tous ces états, soit plus de 15 combinaisons stylistiques à prévoir :
Tous les états d’un lien
Ce n’est pas simple car un lien peut avoir plusieurs états à la fois : il peut avoir été visité et être survolé, il est donc violet et souligné… Mais quiconque a déjà utilisé une page Web comprend le principe de ces conventions très rapidement et intuitivement. Tout l’art est donc de faire aussi bien.
Cliquez, tabulez, surfez !
Les liens se cliquent. Mais pas seulement… En activant les liens — par un clic de souris, une entrée au clavier ou une commande vocale — l’utilisateur peut visiter ces ressources.
Signaler le survol (:hover)
Le survol (:hover), c’est passer au-dessus du lien, avec la souris. Il est par défaut signalé par un changement du pointeur, la fameuse petite main qui pointe du doigt (hand).
clic !
Le survol n’est pas pris en charge sur les terminaux tactiles, qui compensent de diverses façons. S’il est important de le signaler, il ne faut pas s’appuyer uniquement sur les déplacements de la souris ou la pseudo-classe CSS :hover, qui peuvent ne pas se comporter comme souhaité sur un appareil à écran tactile comme l’explique l’article : Non hover (en anglais).
Signaler le focus améliore la navigation
Le lien (ou l’élément) qui a le focus (:focus) est celui que l’internaute a atteint. Rappelons qu’il peut être atteint de plusieurs façons : en positionnant le doigt sur l’écran tactile ou le curseur de la souris sur l’élément, ou encore en tabulant au clavier (avec la touche TAB).
Le focus est par défaut signalé par un contour pointillé, ou par un halo bleuté, selon les navigateurs. Cela répond à une exigence d’accessibilité clairement indiquée dans les WCAG et ainsi exprimée dans la méthode d’application française, au Critère 10.7 Accessiweb 2.2 : « Dans chaque page Web, pour chaque élément recevant le focus, la prise de focus est-elle visible ? »
Méfiez-vous donc des reset CSS qui annulent le style natif du focus — d’un coup de :focus { outline: 0; }. Cela prive les internautes naviguant au clavier de tout repère et gêne considérablement leur navigation. À ce propos, vous pouvez consulter ce site dédié : outlinenone.fr.
Au contraire, il est recommandé d’accentuer le focus, car le rendu par défaut est trop discret. Parcourir la page à coup de tabulations fait sauter le focus d’un coin à l’autre de l’écran de façon parfois imprévisible. Pour éviter de le perdre et de trop le chercher du regard, le focus doit attirer l’attention (Signaler le focus améliore la navigation). Vous pouvez accentuer le contraste, le contour, ou lui donner une couleur de fond.
La méthode la plus simple consiste à styler la prise de focus comme le survol. D’une pierre deux coups. Cela évite les défauts majeurs d’accessibilité, par exemple sur les menus dropdown, et c’est aussi une façon de s’assurer d’un rendu homogène à la souris et au tactile.
Et le lien actif (:active) ?
Quand on le clique, le lien est dit « actif » (:active). Cet état est par défaut signalé en rouge. Il est nécessaire de le distinguer pour rendre perceptible que l’action est enclenchée, notamment pour les personnes ayant des difficultés à manipuler la souris. Je vous invite d’ailleurs à lire l’article :hover vs :active écrit par Eric Le Bihan, et publié sur Les Intégristes en 2009.
N’oublions pas les liens visités (:visited)
N’oublions pas l’état visité (:visited) qui, comme son nom l’indique, est l’état d’un lien qui a déjà été suivi. Il est par défaut signalé par la couleur violette. C’était une convention autrefois bien respectée, mais qui est de moins en moins courante. À tort. Changer l’apparence des liens visités facilite l’identification des contenus restant à découvrir, comme le pointe la Bonne pratique Opquast n°124 : c’est une aide pour l’internaute, une incitation à la découverte de nouvelles pages.
Mais, pour des questions de sécurité, la personnalisation de l’état visité des liens est limitée à la couleur de certaines propriétés (color, background-color, border-color, outline-color, fill et stroke). Pour en savoir plus à ce propos, je vous invite à consulter l’article Privacy and the :visited selector sur MDN.
Un exemple ?
On ne se soucie pas assez de signaler les différents états d’un lien. C’est moins simple qu’il y paraît de prime abord, mais il est possible d’allier originalité et ergonomie. Voici un exemple, qui n’est certes pas parfait, mais complet :
Personnalisation de tous les états d’un lien
Difficile de se rendre compte sur une image statique… Pour se donner un bon aperçu de leur nature changeante, il est indispensable de travailler les liens dans leur environnement naturel, c’est-à-dire directement dans le navigateur, pour pouvoir les cliquer, les tabuler et les chatouiller.
Comment styler les liens en CSS ?
Faciliter le repérage du lien pointé ou actif, permettre l’identification des contenus déjà visités… cela se fait en quelques lignes de CSS, avec les « pseudo-classes ». Mais attention à leur ordre de définition !
Les pseudo-classes constituent des classes prédéfinies en CSS. Elles s’appliquent à certains éléments dont l’état peut changer. Les plus connues et plus populaires concernent les liens hypertextes qui possèdent plusieurs états, comme vu précédemment : visité, actif et non visité, sans oublier le survol et le focus. À chacun correspond une pseudo-classe.
Mais attention, il est important de déclarer ces pseudo-classes dans cet ordre :
:link
:visited
:focus
:hover
:active
Par exemple, pour modifier la couleur des liens selon leur état :
La règle a:hover doit être placée après a:link et a:visited, sinon la cascade fera que la propriété color spécifiée sera surchargée.
Pour retenir cet ordre, l’astuce mnémotechnique est l’expression « LoVe Fuck HAte », où les lettres en majuscule signalent ici la première lettre de chaque pseudo-classe, dans le bon ordre. Voir : Ordre des pseudo-classes des liens.
Des liens stylés !
Véritable fondement de la navigation sur le Web, l’hyperlien mérite qu’on s’attarde sur son rendu graphique : c’est le point d’interaction primaire avec l’internaute, il est absolument incontournable. Les conventions sont fortes et établies, certes, mais elles peuvent être revisitées pour personnaliser une charte graphique. Respecter les quelques règles de base que cet article rappelle permet de préserver l’ergonomie.
Amusez-vous bien !
L’attribut name, initialement employé pour les ancres, en HTML 4 (cf. 12.2.1 Syntax of anchor names), est déprécié en XHTML et obsolète en HTML5. L’usage de l’attribut « id » est plus large, puisqu’on peut également l’utiliser pour créer une ancre, dans la balise ouvrante de n’importe quel élément, outre l’élément a. Certains vieux navigateurs ne le supportant pas, les deux attributs étaient parfois employés conjointement, comme suit : <a name="toto" id="toto"></a>.↩
Un cryptographe allemand dit avoir trouvé le moyen de pirater certaines cartes SIM des téléphones portables, pourtant réputées inviolables, et ainsi de détourner des appels ou même d'émettre des paiements frauduleux.
L'année dernière, nous avions relayé la proposition de Tim Bray consistant à créer un nouveau code HTTP. Placé au numéro 451, en hommage au célèbre au roman de Ray Bradbury, Fahrenheit 451, ce code aurait eu pour rôle d'indiquer à l'internaute que la ressource numérique qu'il cherche à atteindre est inaccessible (comprendre : bloquée) pour des raisons judiciaires.
Ce printemps, Tim Bray a indiqué que sa proposition d'un code HTTP 451 n'avait pas encore progressé au sein de l'IETF (Internet Engineering Task Force), qui est le collectif chargé d'élaborer les standards du net. Cependant, il a noté à l'époque un intérêt de la part de la fondation Mozilla pour cette suggestion. L'idée a depuis fait du chemin et conquis en particulier l'ONG britannique Open Rights Group.
Il faut savoir que le Royaume-Uni connaît une phase politique un peu particulière, puisque le premier ministre David Cameron est engagé dans une campagne contre la pornographie. Il est en particulier favorable à la mise en place d'un moyen de blocage par défaut des contenus pour les majeurs, avec le concours des moteurs de recherche et l'usage d'une liste noire pour les situations les plus graves (pédopornographie).
Ce penchant pour le blocage n'est pas limité à la pornographie et à certaines de ses composantes. Il se manifeste aussi dans le cas des plateformes d'échange de fichiers culturels, en P2P, en téléchargement direct ou via streaming. Divers sites ont été bloqués, comme The Pirate Bay, Kat.ph, Fenopy, H33t, Movie2K EZTV, YIFY-Torrents et Download4All, avec une réussite reative du fait des outils de contournement disponibles.
C'est dans ce contexte que l'ONG britannique Open Rights Group s'est rapproché de l'initiative de Tim Bray et a lancé une campagne baptisée "451 Unavailable" pour aider les FAI à faire savoir les raisons pour lesquelles les sites se retrouvent bloqués et pour encourager les tribunaux à publier des décisions conduisant au blocage de telle ou telle ressource.
"En Angleterre, [le blocage survient] surtout parce que les sites web contiennent des contenus violant le droit d'auteur", écrit Open Rights Group. "Ailleurs dans le monde, les sites web sont ciblés davantage pour leur contenu politique. Les opérateurs ne disent généralement pas pourquoi un site est bloqué et les ordonnances judiciaires sont rarement publiés volontairement".
"Donc lorsque des sites sont bloqués, c'est difficile de savoir pourquoi", ajoute l'ONG, qui souhaite braquer un peu de lumière sur la censure en ligne. Cela ne permettra pas directement de la lever, mais permettra aux militants, aux défenseurs des libertés publiques et aux internautes de mieux comprendre les raisons de la censure, tout en leur donnant des outils pour la combattre, puisque mieux cernée.
I've made a little one-page project about tracking users using ETag headers instead of cookies. It's not new, but many websites employ this while nobody knows about it.
The page pretty much speaks for itself, so here it is:
Gordon Ramsay is a world renowned chef with a surprising amount to say on software development. Well, he says it about cooking and running a restaurant, but it applies to software development too.
You may have seen Gordon Ramsay on one of his many TV shows. Hell's Kitchen is a competition between chefs trying to win a dream job: head chef of their own high-end restaurant. On this show Ramsay is judge, jury, and executioner. And he chops off more than a few heads. Kitchen Nightmares is a show where Ramsay is called in by restaurant owners to help turn around their failing restaurants. On this show Ramsay is there to help.
If you just watch Hell's Kitchen you will likely conclude Ramsay is one of the devil's own helpers ("ram" is the symbol of the devil and "say" means he speaks for the devil: Ramsay). Ramsay screams, yells, cusses, belittles, and throws tantrums even a 7 year old could learn from. Then he does it all over gain just for spite. In Hell's Kitchen there's no evidence at all of why Ramsay is such a respected chef. He is just a nasty man.
Now if you watch the British version of Kitchen Nightmares you will see a slightly different side of Ramsay, he still yells and cusses a lot, but you will also see something else: this guy seriously knows what he is doing. The depth of his knowledge in all phases of the restaurant business is immediately apparent as he methodically works to fix what's broken.
Ramsay knows how to run a profitable restaurant. That's one of his key skills. Anyone can lose money running a restaurant, the secret is knowing how to make money running a restaurant. Apparently if, you run it right, a restaurant can make a lot of money. It can also lose a lot of money.
How does Ramsay teach people how to run a profitable restaurant? It's not what you may be thinking. He isn't about cutting costs, shoddy work, and cheap labor. Ramsay is all about profit through excellence and skill. That's what attracts people to a restaurant and keeps them coming back...and back...and back.
It's great fun to watch Ramsay cuss and cajole his way through the entire restaurant staff putting his finger directly on problems, creating inspired solutions, and then mentoring the staff and owners through the transformations needed to become a good restaurant.
While watching you have to wonder how people who invested their life savings in a restaurant could be so screwed up. But then you realize we are all screwed up at one time or another. From the distance TV provides everyone can look bad. Running a restaurant is hard and it's oh so easy to get in a rut.
And if you were stuck in a rut who would you want to give you a lift out? A super hero? How about Super Chef instead?
Sadly, in the real world when you run into trouble a super hero with curiously sharp knives doesn't come to your rescue. In the real world the same uninspired people apply the same uninspired strategies until losses cause the heart stoppage that blissfully puts an end to the torture. But this isn't the real world, this is TV. And on TV you see Ramsay slap the electroshock paddles on the restaurant and bring it back to life. It's wondrous to see both the restaurant and the people come back to life.
What's fun is when Ramsay revisits the restaurant after six or so weeks to see how the restaurant is doing. Most of the time the restaurant is doing better. There are a lot of happy customers and money is being made. And they don't slavishly follow what Ramsay said to do either. Instead, Ramsay taught them the principles of running a restaurant and then they learned how to apply the principles to their own situation.
Sometimes on Ramsay's reinspection tour he finds the restaurant has closed down or isn't doing as well as you might expect. The reasons for failure vary. Sometimes the initial problems were too great. One guy made a bad deal on a lease so it didn't matter in the end if the restaurant improved or not. Sometimes people are simply stubborn and won't change their ways. An example of this scenario was a fancy French restaurant where the owner gave the chef total control to cook whatever he wanted. It turns out the chef was addicted to complex foods that prevented the restaurant from getting its Michelin star.
While watching Ramsay work his magic in Kitchen Nightmares I began to see how similar a kitchen team was to a software team. Running a successful kitchen is a high stress, high work load, high quality, high variability environment where teamwork and communication are key. Sounds like software development to me.
Here are some of the notes I took on Ramsay's restaurant turn around strategies. I'll leave extending the metaphor into the software world in your capable hands:
Hundreds of thousands of websites and publishers embed Tweets to share the best of Twitter with their readers. From world news, to sports, politics and entertainment, Tweets have changed the way breaking news is covered. And they help people everywhere discover important Tweets, even outside of Twitter.
Hi all! After few weeks of inactivity we are here again and we want to show you some new hints which will try to improve your code in NetBeans 7.4 (at least we hope so ;-). So here they are:
Too Many Lines
So what do you think that it does? Yes, exactly :-) It checks the number of lines of class, interface, trait and method (function) declarations. If the number is exceeded, than IDE warns you. So your elements will be more readable and pretty thin :-)
Do you think that the default value is too strict? Don't worry, you can simply adjust it ;-)
Superglobals
Everyone knows superglobals, but not everyone knows that superglobal arrays shouldn't be accessed directly. Never ever trust to user inputs. Every user input should be somehow filtered/validated. And that's why this hint was created :-)
Braces
As you certainly know, one can use conditional statements and control structures without curly braces (if block doesn't contain more than one statement). But it makes code less readable, so we suggest you to use braces everytime. This hint works for Do-While, While, For and Foreach loops and for If-Else-ElseIf statements.
Empty Statement
Empty statement is just an empty statement so why to pollute your code by stuff which does nothing?
Error Control Operator Misused
Error control operator is pure evil (we talk about an "at" sign). It hides much more errors than you think. So don't use it. But we allow to use it in some special cases like fopen() and such.
Nested Blocks in Functions
Just another hint which tries to make your code more readable. Too many nested blocks make your code ugly and it also tends to violate single responsibility principle. So it tries to check the depth of your blocks and warns you if it seems suspicious.
And you can set your custom depth number of course ;-)
Parent Constructor Call
Constructor of parent class should be called if exists. It ensures the right initialization of instantiated object. So if you override parent constructor we try to check whether you should call parent constructor or not.
Unnecessary Closing Delimiter
Using PHP closing delimiter at the end of file is unnecessary when there is no text after it. It is just a cause of Headers already sent error and such. So if it finds such an unnecessary delimiter, IDE will warn you.
Unreachable Statement
What are unreachable statements? E.g. statements after return statement. Just snippets which will never be executed. They just pollute your code. Hint tries to detect them and warn you.
Please, don't forget, that all hints are just our suggestions. If you don't want, you don't have to use them. You can simply disable every hint which you don't like in: Tools -> Options -> Editor -> Hints -> PHP. Just uncheck it in the list.
And that's all for today and as usual, please test it and if you find something strange, don't hesitate to file a new issue (product php, component Editor). Thanks.
Les lignes téléphoniques en fil de cuivre n'ont pas encore dit leur dernier mot. Si les techniques d'accès à Internet DSL sont concurrencées par d'autres méthodes de connexion filaires comme la fibre optique ou le câble, des avancées notables surviennent dans l'univers des télécommunications. C'est le cas de la norme G.fast, en cours d'élaboration par l'Union internationale des télécommunications (UIT).
L'agence onusienne, qui s'est fendue d'un communiqué pour l'occasion, explique que la norme G.fast "permettra d'atteindre des débits allant jusqu'à 1 Gbit/s sur les lignes téléphoniques en fil de cuivre existantes". Toutefois, impossible de l'utiliser sur l'ensemble du réseau cuivre. La technologie G.fast intervient sur une distance très courte : 250 mètres.
"La norme G.fast devrait être déployée par les fournisseurs désirant proposer des services de type fibre jusqu'au domicile (FTTH), lesquels offriront des débits adaptables en amont et en aval afin de prendre en charge des applications nécessitant une très grande largeur de bande", a commenté l'UIT, qui prévoit de valider la norme G.fast au début de l'année prochaine.
Si son intérêt descend rapidement à mesure que la distance augmente, la norme G.fast peut néanmoins être envisagée en l'articulant avec un déploiement de type FTTB (Fiber To The Building). On pourrait imaginer par exemple un raccordement en fibre optique jusqu'à l'immeuble, tandis que chaque appartement serait ensuite desservi avec la norme G.fast.
Ce serait alors une alternative moins onéreuse que le FTTH (Fiber To The Home, c'est à dire jusqu'à l'abonné) pour les opérateurs puisque ces derniers pourraient mobiliser une partie du réseau déjà existant pour diffuser du très haut débit. Reste à savoir si les FAI s'intéresseront à cette éventualité pour gérer les derniers mètres jusqu'au client, dans la mesure où la norme ne sera pas disponible tout de suite.
Comment créer des coûts inutiles dans la production cinématographique, en protégeant la désuétude de la loi. Dans un arrêt rendu public le 28 juin 2013, le Conseil d'Etat a rejeté une requête déposée par plusieurs associations de producteurs de cinéma, qui demandaient logiquement à ce que la législation sur le dépôt légal des films au CNC soit modernisée pour se conformer aux pratiques d'aujourd'hui. Ils souhaitaient pouvoir déposer une copie uniquement numérique des films destinés aux salles de cinéma, mais devront toujours déposer également une copie sur pellicule, même si le support est fragile, coûteux et se détériore avec le temps.
En effet, le code du patrimoine impose aux producteurs et distributeurs de films de déposer une copie des oeuvres à Conseil National de la Cinématographie et de l'image animée (CNC), en laissant au Gouvernement le soin de définir les modalités du dépôt légal. Or, l'article 13 du décret du 19 décembre 2011 impose que les "documents cinématographiques" soient déposés en deux exemplaire, dont un "sur support photochimique", c'est-à-dire concrètement sur pellicule 35mm.
Les producteurs trouvaient cette obligation désuète et ridicule, puisque la plupart d'entre eux ne produisent plus que des films réalisés de bout en bout en numérique. Ils demandaient donc au Conseil d'Etat d'annuler l'article 13 du décret de 2011, aux motifs qu'il faisait peser sur eux des coûts indus liés au dépôt légal, et qu'il créait une inégalité entre les producteurs qui disposaient d'une copie photochimique, et les autres qui devaient en faire réaliser une spécifiquement pour le CNC.
Mais le Conseil d'Etat a rejeté la requête, avec une argumentation qui restera dans les annales : "il résulte des pièces du dossier que la quasi-totalité des documents cinématographiques sont aujourd'hui produits en version numérique ; qu'ainsi l'obligation de déposer un document sur support photochimique a vocation à peser de manière identique sur l'ensemble des producteurs de cinéma ; qu'ainsi le moyen tiré de la violation du principe d'égalité ne peut qu'être écarté".
Dit autrement, presque tous les producteurs sont soumis à la même loi obsolète, donc il n'y a pas de raison d'en changer.
Juridiquement, le Conseil d'Etat ne pouvait pas dire autre chose. Mais le Gouvernement pourrait tout de même modifier son décret...
C'est une approche radicalement différente de celle de la France, qui se satisfait manifestement de l'opacité du vote électronique. En Estonie, les autorités ont décidé cette semaine de communiquer le code source, côté serveur, utilisé dans le cadre du vote électronique. Ceux qui souhaitent l'analyser pourront l'obtenir en le téléchargeant depuis GitHub.
L'intérêt de rendre public ce code source saute aux yeux : outre le pas en faveur de transparence, cette démarche permet à ceux ayant des compétences en informatique de vérifier la qualité de la programmation. Dans l'Hexagone, le Parti pirate souhaitait effectuer ce contrôle, via la vérification du code source utilisé pour l'urne virtuelle, conçue par une entreprise du secteur privé. Mais cela lui a été refusé.
Car la tendance est à la généralisation. Sur l'organisation de futures initiatives référendaires, le principe et la généralisation du vote par Internet ont été approuvés par les pouvoirs publics. Dans la vie politique, le principal parti d'opposition s'en est servi alors que la CNIL a déconseillé trois ans auparavant de recourir au vote électronique pour des élections politiques.
Sans parler de la décision regrettable du Conseil constitutionnel, qui a validé l'opacité du dispositif tout en laissant le soin aux détracteurs de prouver le trucage, et des avertissements de certaines entreprises lorsque de la documentation sur la sécurisation de l'hébergement d'une plateforme de vote (consulter, à ce sujet, tous les articles sur le vote électronique publiés sur Numerama).
L'Estonie est-elle plus vertueuse que la France en matière de transparence ? Peut-être. Mais la décision de publier le code source doit se comprendre à la lumière des particularités de ce petit État balte. Il s'agit en effet de l'un des pays les plus connectés du Vieux Continent (rappelons que l'Estonie a instauré des cours de programmation obligatoires à l'école, demandé la transparence de l'ACTA).
C'est également, selon l'OCDE, un pays très en avance sur le déploiement de la fibre optique par rapport aux autres pays européens. La situation est telle que l'accès au réseau est devenu un droit de l'Homme. Aussi, la publication du code source se comprend au mieux au regard de l'importance du net dans la vie quotidienne des individus (accès aux services, procédures administratives, etc...).
Cette décision peut aussi s'analyser à la lumière des évènements survenus en 2007.À l'époque, des infrastructures étatiques ont été ciblées par des agresseurs dont les connexions trouvent leurs origines en Russie. Cet évènement est considéré comme la première "cyberguerre" de l'Histoire, même si l'origine exacte de l'agression et le rôle de l’État russe demeurent obscurs, tandis que la qualification de l'acte est contestée.
This month's "computer security elephant in the room" story is the news of a gaping security hole in Android application security.
Paul Ducklin gives you a visual explanation of what the problem is all about, and offers some simple advice.
Frameworks provide a tool for rapid application development, but often accrue technical debt as rapidly as they allow you to create functionality. Technical debt is created when maintainability isn't a purposeful focus of the developer. Future changes and debugging become costly, due to a lack of unit testing and structure.
Here's how to begin structuring your code to achieve testability and maintainability – and save you time.
We'll Cover (loosely)
DRY
Dependency Injection
Interfaces
Containers
Unit Tests with PHPUnit
Let's begin with some contrived, but typical code. This might be a model class in any given framework.
class User {
public function getCurrentUser()
{
$user_id = $_SESSION['user_id'];
$user = App::db->select('id, username')
->where('id', $user_id)
->limit(1)
->get();
if ( $user->num_results() > 0 )
{
return $user->row();
}
return false;
}
}
This code will work, but needs improvement:
This isn't testable.
We're relying on the $_SESSION global variable. Unit-testing frameworks, such as PHPUnit, rely on the command-line, where $_SESSION and many other global variables aren't available.
We're relying on the database connection. Ideally, actual database connections should be avoided in a unit-test. Testing is about code, not about data.
This code isn't as maintainable as it could be. For instance, if we change the data source, we'll need to change the database code in every instance of App::db used in our application. Also, what about instances where we don't want just the current user's information?
An Attempted Unit Test
Here's an attempt to create a unit test for the above functionality.
class UserModelTest extends PHPUnit_Framework_TestCase {
public function testGetUser()
{
$user = new User();
$currentUser = $user->getCurrentUser();
$this->assertEquals(1, $currentUser->id);
}
}
Let's examine this. First, the test will fail. The $_SESSION variable used in the User object doesn't exist in a unit test, as it runs PHP in the command line.
Second, there's no database connection setup. This means that, in order to make this work, we will need to bootstrap our application in order to get the App object and its db object. We'll also need a working database connection to test against.
To make this unit test work, we would need to:
Setup a config setup for a CLI (PHPUnit) run in our application
Rely on a database connection. Doing this means relying on a data source separate from our unit test. What if our test database doesn't have the data we're expecting? What if our database connection is slow?
Relying on an application being bootstrapped increases the overhead of the tests, slowing the unit tests down dramatically. Ideally, most of our code can be tested independent of the framework being used.
So, let's get down to how we can improve this.
Keep Code DRY
The function retrieving the current user is unnecessary in this simple context. This is a contrived example, but in the spirit of DRY principles, the first optimization I'm choosing to make is to generalize this method.
class User {
public function getUser($user_id)
{
$user = App::db->select('user')
->where('id', $user_id)
->limit(1)
->get();
if ( $user->num_results() > 0 )
{
return $user->row();
}
return false;
}
}
This provides a method we can use across our entire application. We can pass in the current user at the time of the call, rather than passing that functionality off to the model. Code is more modular and maintainable when it doesn't rely on other functionalities (such as the session global variable).
However, this is still not testable and maintainable as it could be. We're still relying on the database connection.
Dependency Injection
Let's help improve the situation by adding some Dependency Injection. Here's what our model might look like, when we pass the database connnection into the class.
class User {
protected $_db;
public function __construct($db_connection)
{
$this->_db = $db_connection;
}
public function getUser($user_id)
{
$user = $this->_db->select('user')
->where('id', $user_id)
->limit(1)
->get();
if ( $user->num_results() > 0 )
{
return $user->row();
}
return false;
}
}
Now, the dependencies of our User model are provided for. Our class no longer assumes a certain database connection, nor relies on any global objects.
At this point, our class is basically testable. We can pass in a data-source of our choice (mostly) and a user id, and test the results of that call. We can also switch out separate database connections (assuming that both implement the same methods for retrieving data). Cool.
Let's look at what a unit test might look like for that.
<?php
use Mockery as m;
use Fideloper\User;
class SecondUserTest extends PHPUnit_Framework_TestCase {
public function testGetCurrentUserMock()
{
$db_connection = $this->_mockDb();
$user = new User( $db_connection );
$result = $user->getUser( 1 );
$expected = new StdClass();
$expected->id = 1;
$expected->username = 'fideloper';
$this->assertEquals( $result->id, $expected->id, 'User ID set correctly' );
$this->assertEquals( $result->username, $expected->username, 'Username set correctly' );
}
protected function _mockDb()
{
// "Mock" (stub) database row result object
$returnResult = new StdClass();
$returnResult->id = 1;
$returnResult->username = 'fideloper';
// Mock database result object
$result = m::mock('DbResult');
$result->shouldReceive('num_results')->once()->andReturn( 1 );
$result->shouldReceive('row')->once()->andReturn( $returnResult );
// Mock database connection object
$db = m::mock('DbConnection');
$db->shouldReceive('select')->once()->andReturn( $db );
$db->shouldReceive('where')->once()->andReturn( $db );
$db->shouldReceive('limit')->once()->andReturn( $db );
$db->shouldReceive('get')->once()->andReturn( $result );
return $db;
}
}
I've added something new to this unit test: Mockery. Mockery lets you "mock" (fake) PHP objects. In this case, we're mocking the database connection. With our mock, we can skip over testing a database connection and simply test our model.
In this case, we're mocking a SQL connection. We're telling the mock object to expect to have the select, where, limit and get methods called on it. I am returning the Mock, itself, to mirror how the SQL connection object returns itself ($this), thus making its method calls "chainable". Note that, for the get method, I return the database call result – a stdClass object with the user data populated.
This solves a few problems:
We're testing only our model class. We're not also testing a database connection.
We're able to control the inputs and outputs of the mock database connection, and, therefore, can reliably test against the result of the database call. I know I'll get a user ID of "1" as a result of the mocked database call.
We don't need to bootstrap our application or have any configuration or database present to test.
We can still do much better. Here's where it gets interesting.
Interfaces
To improve this further, we could define and implement an interface. Consider the following code.
interface UserRepositoryInterface {
public function getUser($user_id);
}
class MysqlUserRepository implements UserRepositoryInterface {
protected $_db;
public function __construct($db_conn)
{
$this->_db = $db_conn;
}
public function getUser($user_id)
{
$user = $this->_db->select('user')
->where('id', $user_id)
->limit(1)
->get();
if ( $user->num_results() > 0 )
{
return $user->row();
}
return false;
}
}
class User {
protected $userStore;
public function __construct(UserRepositoryInterface $user)
{
$this->userStore = $user;
}
public function getUser($user_id)
{
return $this->userStore->getUser($user_id);
}
}
There's a few things happening here.
First, we define an interface for our user data source. This defines the addUser() method.
Next, we implement that interface. In this case, we create a MySQL implementation. We accept a database connection object, and use it to grab a user from the database.
Lastly, we enforce the use of a class implementing the UserInterface in our User model. This guarantees that the data source will always have a getUser() method available, no matter which data source is used to implement UserInterface.
Note that our User object type-hints UserInterface in its constructor. This means that a class implementing UserInterface MUST be passed into the User object. This is a guarantee we are relying on – we need the getUser method to always be available.
What is the result of this?
Our code is now fully testable. For the User class, we can easily mock the data source. (Testing the implementations of the datasource would be the job of a separate unit test).
Our code is much more maintainable. We can switch out different data sources without having to change code throughout our application.
We can create ANY data source. ArrayUser, MongoDbUser, CouchDbUser, MemoryUser, etc.
We can easily pass any data source to our User object if we need to. If you decide to ditch SQL, you can just create a different implementation (for instance, MongoDbUser) and pass that into your User model.
We've simplified our unit test, as well!
<?php
use Mockery as m;
use Fideloper\User;
class ThirdUserTest extends PHPUnit_Framework_TestCase {
public function testGetCurrentUserMock()
{
$userRepo = $this->_mockUserRepo();
$user = new User( $userRepo );
$result = $user->getUser( 1 );
$expected = new StdClass();
$expected->id = 1;
$expected->username = 'fideloper';
$this->assertEquals( $result->id, $expected->id, 'User ID set correctly' );
$this->assertEquals( $result->username, $expected->username, 'Username set correctly' );
}
protected function _mockUserRepo()
{
// Mock expected result
$result = new StdClass();
$result->id = 1;
$result->username = 'fideloper';
// Mock any user repository
$userRepo = m::mock('Fideloper\Third\Repository\UserRepositoryInterface');
$userRepo->shouldReceive('getUser')->once()->andReturn( $result );
return $userRepo;
}
}
We've taken the work of mocking a database connection out completely. Instead, we simply mock the data source, and tell it what to do when getUser is called.
But, we can still do better!
Containers
Consider the usage of our current code:
// In some controller
$user = new User( new MysqlUser( App:db->getConnection("mysql") ) );
$user->id = App::session("user->id");
$currentUser = $user->getUser($user_id);
Our final step will be to introduce containers. In the above code, we need to create and use a bunch of objects just to get our current user. This code might be littered across your application. If you need to switch from MySQL to MongoDB, you'll still need to edit every place where the above code appears. That's hardly DRY. Containers can fix this.
A container simply "contains" an object or functionality. It's similar to a registry in your application. We can use a container to automatically instantiate a new User object with all needed dependencies. Below, I use Pimple, a popular container class.
// Somewhere in a configuration file
$container = new Pimple();
$container["user"] = function() {
return new User( new MysqlUser( App:db->getConnection('mysql') ) );
}
// Now, in all of our controllers, we can simply write:
$currentUser = $container['user']->getUser( App::session('user_id') );
I've moved the creation of the User model into one location in the application configuration. As a result:
We've kept our code DRY. The User object and the data store of choice is defined in one location in our application.
We can switch out our User model from using MySQL to any other data source in ONE location. This is vastly more maintainable.
Final Thoughts
Over the course of this tutorial, we accomplished the following:
Kept our code DRY and reusable
Created maintainable code – We can switch out data sources for our objects in one location for the entire application if needed
Made our code testable – We can mock objects easily without relying on bootstrapping our application or creating a test database
Learned about using Dependency Injection and Interfaces, in order to enable creating testable and maintainable code
Saw how containers can aid in making our application more maintainable
I'm sure you've noticed that we've added much more code in the name of maintainability and testability. A strong argument can be made against this implementation: we're increasing complexity. Indeed, this requires a deeper knowledge of code, both for the main author and for collaborators of a project.
However, the cost of explanation and understanding is far out-weighed by the extra overall decrease in technical debt.
The code is vastly more maintainable, making changes possible in one location, rather than several.
Being able to unit test (quickly) will reduce bugs in code by a large margin – especially in long-term or community-driven (open-source) projects.
Doing the extra-work up front will save time and headache later.
Resources
You may include Mockery and PHPUnit into your application easily using Composer. Add these to your "require-dev" section in your composer.json file:
Toy solutions solving Twitter’s “problems” are a favorite scalability trope. Everybody has this idea that Twitter is easy. With a little architectural hand waving we have a scalable Twitter, just that simple. Well, it’s not that simple as Raffi Krikorian, VP of Engineering at Twitter, describes in his superb and very detailed presentation on Timelines at Scale. If you want to know how Twitter works - then start here.
It happened gradually so you may have missed it, but Twitter has grown up. It started as a struggling three-tierish Ruby on Rails website to become a beautifully service driven core that we actually go to now to see if other services are down. Quite a change.
Twitter now has 150M world wide active users, handles 300K QPS to generate timelines, and a firehose that churns out 22 MB/sec. 400 million tweets a day flow through the system and it can take up to 5 minutes for a tweet to flow from Lady Gaga’s fingers to her 31 million followers.
A couple of points stood out:
Twitter no longer wants to be a web app. Twitter wants to be a set of APIs that power mobile clients worldwide, acting as one of the largest real-time event busses on the planet.
Twitter is primarily a consumption mechanism, not a production mechanism. 300K QPS are spent reading timelines and only 6000 requests per second are spent on writes.
Outliers, those with huge follower lists, are becoming a common case. Sending a tweet from a user with a lot of followers, that is with a large fanout, can be slow. Twitter tries to do it under 5 seconds, but it doesn’t always work, especially when celebrities tweet and tweet each other, which is happening more and more. One of the consequences is replies can arrive before the original tweet is received. Twitter is changing from doing all the work on writes to doing more work on reads for high value users.
Your home timeline sits in a Redis cluster and has a maximum of 800 entries.
Users care about tweets, but the text of the tweet is almost irrelevant to most of Twitter's infrastructure.
Twitter knows a lot about you from who you follow and what links you click on. Much can be implied by the implicit social contract when bidirectional follows don’t exist.
It takes a very sophisticated monitoring and debugging system to trace down performance problems in a complicated stack. And the ghost of legacy decisions past always haunt the system.
How does Twitter work? Read this gloss of Raffi’s excellent talk and find out...
Over the past year we’ve added many new features to Google Analytics. Today we are releasing all of this data in the Core Reporting API.
Custom Dimensions and Metrics
We're most excited about the ability to query for custom dimensions and metrics using the API.
Developers can use custom dimensions to send unique IDs into Google Analytics, and then use the core reporting API to retrieve these IDs along with other Google Analytics data.
For example, your content management system can pass a content ID as a custom dimension using the Google Analytics tracking code. Developers can then use the API to get a list of the most popular content by ID and display the list of most popular content on their website.
Mobile Dimensions and Metrics
We've added more mobile dimensions and metrics, including those found in the Mobile App Analytics reports:
ga:appId
ga:appVersion
ga:appName
ga:appInstallerId
ga:landingScreenName
ga:screenDepth
ga:screenName
ga:exitScreenName
ga:timeOnScreen
ga:avgScreenviewDuration
ga:deviceCategory
ga:isTablet
ga:mobileDeviceMarketingName
ga:exceptionDescription
ga:exceptionsPerScreenview
ga:fatalExceptionsPerScreenview
Some examples of questions this new data can answer are:
Qu’est-ce qu’un “langage”? Comment reconnaître le signal du bruit ? L’ADN, les oeuvres littéraires, les connexions neuronales possèdent-ils une structure commune qui peut être soumise à la même analyse et donc être considérée comme du “texte”? On trouve parfois des études sur des sujets marginaux, peu connus, qui pourtant apparaissent comme des avancées vers les réponses à ces questions fondamentales. C’est le cas du travail de Marcelo Montemurro sur le manuscrit Voynich, relaté par le New Scientist.
Marcelo Montemurro n’est pas un spécialiste de la cryptographie et des livres anciens. C’est un neuroscientifique. La plupart de ses publications portent des titres poétiques, comme “Relations des propriétés dynamiques et fonctionnelles des neurones intrinsèquement activés” (ou quelque chose comme ça). C’est pourquoi il est étonnant de voir ce chercheur se pencher sur un tel texte.
Le manuscrit Voynich, ce livre étrange, est l’une des plus grandes énigmes littéraires de tous les temps. Il a fait rêver plus d’un Indiana Jones en herbe. Il s’agit d’un manuscrit rédigé dans un alphabet inconnu qu’il n’a jamais été possible de déchiffrer. A coté de ces écrits mystérieux, on trouve des illustrations assez bizarres de plantes, de constellations et des images qui se rapprochent de celles des écrits alchimiques.
En 1912, un collectionneur bibliophile, Wilfrid Voynich, fait l’acquisition de l’ouvrage. Inclus, une lettre datant de 1666 adressée à Athanasius Kircher, qui contiendrait la première mention historique du manuscrit. Kircher était un jésuite d’une culture étonnante, fasciné par les civilisations antiques. On lui attribue aussi l’invention de la lanterne magique, et donc de la première forme de cinéma, mais cela est contesté. Officiellement, le livre aurait appartenu à Roger Bacon (ne pas confondre avec Francis, le philosophe, et encore moins avec l’autre Francis, le peintre), ce moine et érudit du Moyen Age, était expert dans les sciences du moment, occultes ou non (à l’époque, de toute façon, toutes les sciences étaient plus ou moins occultes). La lettre nous explique que le manuscrit aurait été acquis par l’empereur Rodolphe II, lui-même grand amateur de magie et d’alchimie, pour la “modique” somme de 600 ducats (environ 50 000 euros actuels). On ignore le nom du vendeur. On a soupçonné John Dee, autre grande figure du romantisme occulte de la fin de la Renaissance, mathématicien et cryptographe de première classe, astrologue de la reine Elizabeth, inventeur de l’expression Empire britannique et espion à ses heures. Il signait du sigle 007 ses lettres à la reine – ça ne s’invente pas !
On n’en sait pas beaucoup plus sur l’origine réelle du manuscrit. Les datations au carbone 14 nous apprennent que le papier utilisé aurait été fabriqué vers 1400, mais cela ne signifie pas que le texte et les illustrations n’ont pas été rajoutés bien plus tard.
Depuis 1912, beaucoup se sont attelés à l’étude du manuscrit, nombreux sont ceux qui ont cru en avoir trouvé la clé, mais tous se sont cassé les dents. Outre Roger Bacon, auquel on l’a probablement faussement attribué, on a soupçonné une multitude d’auteurs : Voynich lui-même (qui aurait donc aussi rédigé la pseudo lettre à Kircher), Dee, ou plus exactement son “médium” Edward Kelley alchimiste qui n’aurait pas manqué de compétences de faussaire, d’autres encore, moins connus…
Le mystère Voynich
Mais que signifie le Voynich ? Quel langage cache ce mystérieux alphabet ? Latin ? Langue “exotique” comme le chinois ? Pseudo égyptien ? Idiome artificiel ? A ma connaissance, le klingon et l’elfique comptent parmi les seules solutions à n’avoir pas été envisagées…
Reste l’autre hypothèse : le manuscrit Voynich est un grand n’importe quoi. Il n’a aucune signification. C’est un pur canular, fabriqué de toutes pièces, pour soutirer 600 ducats à ce grand benêt de Rodolphe II.
Il existe bien sûr déjà des analyses statistiques du contenu du Voynich. Elles révèlent une certaine régularité de fréquence dans les lettres et les mots utilisés, ce qui a été considéré pendant longtemps comme la preuve que le document n’était pas un pur galimatias. On pourra objecter que le codex Séraphinianus, autre texte écrit dans un alphabet incompréhensible, rédigé par l’artiste Luigi Serafini, mais sans prétention autre qu’artistique, semble montrer qu’il est possible de créer un fake de ce genre. Mais surtout, cette thèse a été démontée en 2004 par Gordon Rugg, qui a montré qu’en utilisant une technologie déjà bien connue à la Renaissance, la grille de Cardan, il était possible d’écrire un pseudo-texte dénué de sens, mais possédant les apparences et la complexité d’un message réel.
Les travaux de Montemurro relancent le débat. Comme les analyses précédentes du manuscrit, ils reposent sur la théorie de l’entropie : rappelons que ce qui est inattendu possède plus de sens que ce qui ne l’est pas. Un texte purement aléatoire ne possède aucune redondance. L’information est partout. Un texte complètement redondant comme ababababab est aisément prévisible, mais contient un degré d’information très faible. Un “vrai” message possède donc un rapport signal/bruit équilibré, il se trouve, comme le dit le biologiste Henri Atlan, quelque part “entre le cristal et la fumée”.
Vers l’analyse sémantique
Gordon Rugg a donc démontré qu’il était possible de générer de manière aléatoire un pseudo-message possédant les caractéristiques d’un véritable contenu. Montemurro, cependant, prend l’analyse à un autre niveau. Il n’a pas observé les corrélations au plan phonologique ou syntaxique, mais bel et bien au niveau sémantique : comment les mots se situent au sein d’un contexte. Et ce qui est particulièrement intéressant, c’est qu’il a comparé le Voynich à un corpus d’autres textes, comme L’Origine des espèces de Darwin, mais aussi, et c’est peut-être le plus excitant, à des séquences d’ADN, et même, à du code informatique.
Le New Scientist explique ainsi la technique : “La méthode reconnaît que les mots qui sont particulièrement importants apparaîtront plus fréquemment, et fait aussi la distinction entre des mots pauvres en information comme “et”, dont vous vous attendriez aussi à être inondés et des mots au niveau élevé d’information comme “langage”, qui pourraient seulement apparaître dans des sections traitant de ce sujet.”
Les résultats sur d’autres textes permettent ainsi de repérer un ensemble de mots hautement significatifs : pour L’Origine des espèces, ce serait “espèces” “variétés”, “hybrides” et “genres”. Dans Moby Dick, le terme le plus important, serait – qui l’eût cru – “baleine”.
Montemurro aurait ainsi repéré plusieurs “mots” dans le Voynich dont la fréquence semblerait indiquer que texte a véritablement un sens. Lui et son équipe sont allés encore plus loin. Ils ont comparé les différentes sections du livre et les ont examinées en correspondance avec les illustrations qui les accompagnent. Ainsi, celles auxquelles correspondent des illustrations botaniques possèdent entre elles une corrélation plus forte qu’avec celles qui exhibent des images tirées de l’astronomie, ou l’alchimie, par exemple.
Encore plus loin dans l’analyse statistique, l’équipe de Montemurro a examiné des ensembles de mots importants, et comment ces différents ensembles se retrouvent dans les “textes” étudiés. Ils ont donc pris, pour l’anglais, L’Origine des espèces, pour le chinois, Les Archives du grand historien, pour le latin, Les Confessions de Saint Augustin, pour la biologie, de l’ADN de levure, et enfin, pour l’informatique, un extrait de code fortran (Montemurro aurait peut être besoin d’une mise à jour sur les langages de programmation modernes).
Dans un vrai livre, nous explique le New Scientist, ces ensembles comptent généralement un nombre de mots assez élevé. Au contraire, les écrits composés de citations révèlent des ensembles bien moins volumineux.
Après analyse, il s’avère que le texte anglais comportait des ensembles de 800 mots environ. Le chinois et le latin, autour de 500. Le code Fortran révélait des ensembles d’environ 300 mots, tandis que la levure tournerait autour d’une dizaine.
Quant au Voynich il contiendrait des ensembles d’environ… 800 mots. Ce qui, pour Montemurro, est une preuve supplémentaire du caractère linguistique du code Voynich.
Les différences entre le chinois, l’anglais et le latin seraient dues essentiellement à des syntaxes différentes impliquant un vocabulaire plus ou moins conséquent. L’important est de savoir que les langages humains se situent au-delà de 500 mots précise Montemurro dans son papier.
Évidemment, ces recherches ne font pas l’unanimité. Gordon Rugg, nous explique le New Scientist, pense que bien des résultats de Montemurro peuvent être recréés spontanément de manière aléatoire à l’aide la grille de Cardan.
A noter que Rugg a pris la peine de répondre dans les commentaires de l’article du New Scientist. Pour lui, s’il est bien entendu inimaginable que les créateurs du “canular” aient pris la peine de créer volontairement de telles corrélations, il est tout à fait possible que les structures ainsi découvertes soient un effet secondaire des techniques de cryptage utilisées à la Renaissance, et produites de manière totalement involontaire.
Cela dit, sans être expert sur le sujet, le fait que les pages correspondant à des images issues de la botanique possèdent le même type de fréquences, par opposition à celles illustrant un autre domaine, me paraît quand même constituer une sacrée coïncidence. Le débat illustre en tout cas la difficulté que nous avons à faire la distinction entre le repérage de patterns déjà existantes et l’invention de celles-ci par un lecteur ou un observateur.
Au delà du texte
Les recherches sur le Voynich entrent donc complètement dans le nouveau champ de l’analyse statistique de corpus textuels dont nous avons déjà parlé. Mais il ne s’arrête pas à un travail d’ordre littéraire. Le New Scientist conclut que “Montemurro espère maintenant analyser d’autres séquences porteuses d’informations qui ne sont pas nécessairement des langues, comme l’ADN, voire des signaux neuraux. Ceci pourrait aider des généticiens à se focaliser sur les portions d’ADN ayant le plus de valeur et révéler si les différentes parties du cerveau “communiquent” l’une avec l’autre via un code.” Vu le métier de Montemurro, on se doute que c’est vers ce type de recherche qu’il va s’orienter.
C’est peut-être le plus intéressant. Le mystère du manuscrit Voynich est encore loin d’être levé. Mais des recherches sur un livre mystérieux du Moyen Age ou de la Renaissance pourraient nous aider à comprendre le vivant et le cerveau. Qui sait !
En avril, une étude (.pdf) sur l'interopérabilité des formats du livre numérique et conduite par l'université allemande Johannes Gutenberg de Mayence était publiée. Dans celle-ci, les auteurs ont conclu "qu'aucune raison technologique ou fonctionnelle [ne] justifie la poursuite de l'utilisation de formats propriétaires pour les livres numériques".
Dit autrement, il n'y a aucun obstacle pour faire de l'EPUB 3 la "norme unique de format interopérable (ouvert) du livre numérique" ou, à défaut, "l'une des normes". Cependant, l'étude note que les deux principaux acteurs du marché, "Amazon et Apple utilisent, propagent et développent leurs formats propriétaires principalement pour des raisons de stratégie commerciale (et peut-être de compatibilité avec les versions antérieures)".
Face à ces deux géants, les libraires européens ne pèsent pas lourd. Même réunis au sein de l'European & International Booksellers Federation (EIBF), les professionnels sont conscients de la nécessité de mobiliser la Commission européenne sur ce sujet, même si Bruxelles ne dispose pas d'une marge de manœuvre suffisante pour réglementer ce secteur.
Il n'en demeure pas moins que l'EIBF compte sur la Commission européenne. Comme le pointe ActuaLitté, la fédération considère que Bruxelles doit faire de ce dossier une "priorité absolue", estimant que l'interopérabilité sera profitable à l'ensemble des clients européens. Ainsi, un courrier a été adressé aux services de Roberto Viola, directeur général adjoint de la DG réseaux de communication, contenu et technologies.
Un courrier a aussi été envoyé à Neelie Kroes, en charge de la politique numérique de l'Union. L'été dernier, la commissaire avait écrit une tribune dans laquelle elle appelait à la constitution d'un marché unique pour les livres numériques en Europe. Parmi les obstacles identifiés figuraient, en plus de la TVA et des droits d'auteurs, l'interopérabilité.
In the 1930s, Michael Goldberg designed a family of highly symmetric spherical forms consisting of hexagons and pentagons. Because of their aesthetic appeal, organic feel and easily understood structure, they have since found a surprising number of applications ranging from golf-ball dimple patterns to nuclear-particle detector arrays.
For more information, see George Hart, “Goldberg Polyhedra,” in Shaping Space, 2nd ed., edited by Marjorie Senechal, 125–138, Springer, 2012.
 Jeudi 1er août, le Conseil d'Etat a annulé le moratoire qui frappait depuis 2012 le MON810, un maïs transgénique de la firme américaine Monsanto. Le MON810 est une plante à laquelle un gène a été ajouté pour qu'elle produise une toxine dite "Bt" (du nom de la bactérie Bacillus thuringiensis qui la synthétise naturellement), toxine qui tue les insectes ravageurs de ce maïs, comme la pyrale, en paralysant l'intestin des larves. Dans l'esprit des créateurs de cette plante transgénique, faire fabriquer le pesticide directement par la plante évite aux agriculteurs d'en épandre sur leurs cultures. Cette décision du Conseil d'Etat a une nouvelle fois relancé le débat sur la culture d'organismes génétiquement modifiés (OGM) en France, les opposants aux OGM soulevant plusieurs arguments, comme les risques pour la santé des consommateurs (humains ou animaux d'élevage), la contamination des cultures non-OGM et du miel, le fait que certains insectes utiles seraient victimes de la plante ou bien le développement de résistances à la toxine chez les nuisibles.
Jeudi 1er août, le Conseil d'Etat a annulé le moratoire qui frappait depuis 2012 le MON810, un maïs transgénique de la firme américaine Monsanto. Le MON810 est une plante à laquelle un gène a été ajouté pour qu'elle produise une toxine dite "Bt" (du nom de la bactérie Bacillus thuringiensis qui la synthétise naturellement), toxine qui tue les insectes ravageurs de ce maïs, comme la pyrale, en paralysant l'intestin des larves. Dans l'esprit des créateurs de cette plante transgénique, faire fabriquer le pesticide directement par la plante évite aux agriculteurs d'en épandre sur leurs cultures. Cette décision du Conseil d'Etat a une nouvelle fois relancé le débat sur la culture d'organismes génétiquement modifiés (OGM) en France, les opposants aux OGM soulevant plusieurs arguments, comme les risques pour la santé des consommateurs (humains ou animaux d'élevage), la contamination des cultures non-OGM et du miel, le fait que certains insectes utiles seraient victimes de la plante ou bien le développement de résistances à la toxine chez les nuisibles.









































 Les lignes téléphoniques en fil de cuivre n'ont pas encore dit leur dernier mot. Si les techniques d'accès à Internet DSL sont concurrencées par d'autres méthodes de connexion filaires comme la fibre optique ou le câble, des avancées notables surviennent dans l'univers des télécommunications. C'est le cas de la norme G.fast, en cours d'élaboration par l'Union internationale des télécommunications (UIT).
Les lignes téléphoniques en fil de cuivre n'ont pas encore dit leur dernier mot. Si les techniques d'accès à Internet DSL sont concurrencées par d'autres méthodes de connexion filaires comme la fibre optique ou le câble, des avancées notables surviennent dans l'univers des télécommunications. C'est le cas de la norme G.fast, en cours d'élaboration par l'Union internationale des télécommunications (UIT).

 C'est une approche radicalement différente de celle de la France, qui se satisfait manifestement de
C'est une approche radicalement différente de celle de la France, qui se satisfait manifestement de 



 En avril,
En avril, 
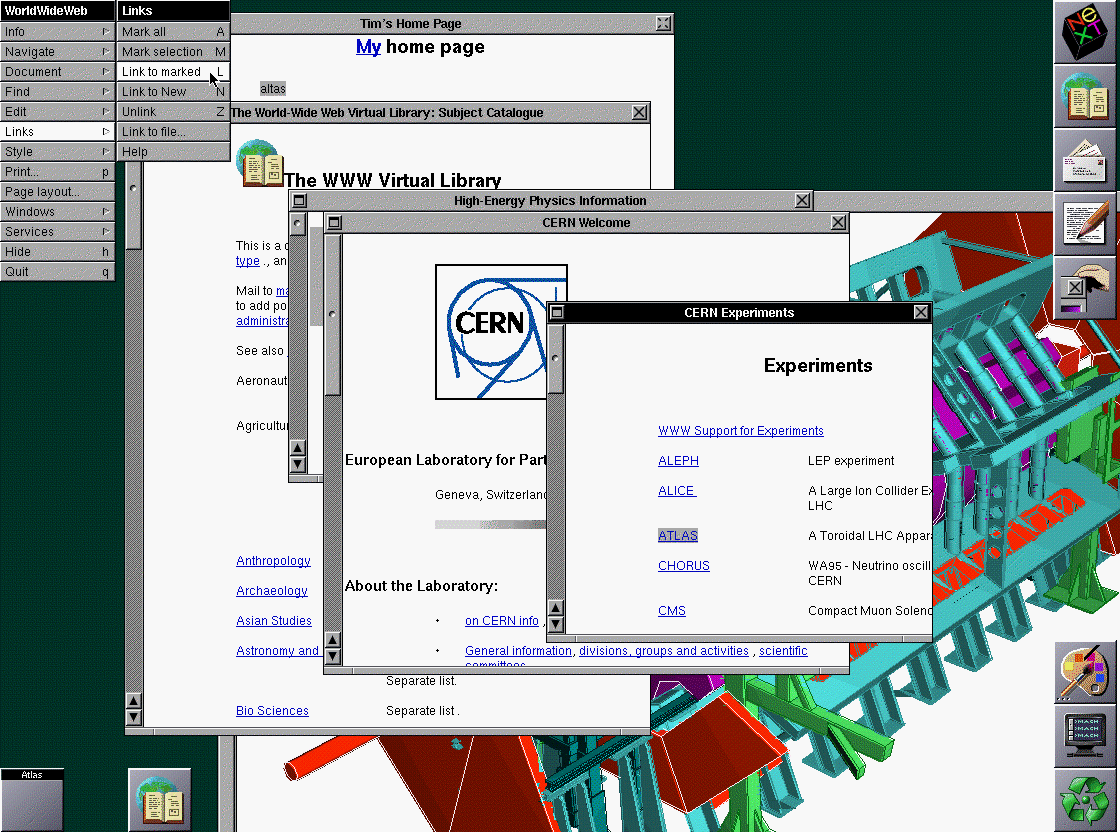{kind=link}