Published Mon Mar 31, 2014
Nosimpler
Shared posts
03 Apr 18:30
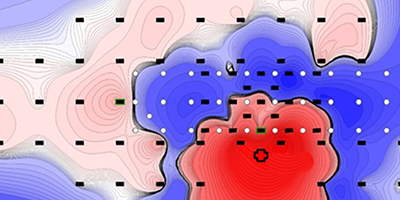
Viewpoint: A Step Towards a Seismic Cloak
A large-scale experiment shows that a periodic array of boreholes embedded in the soil can deflect the energy of an incoming seismic wave.
Published Mon Mar 31, 2014
Published Mon Mar 31, 2014
24 Mar 19:08
This review of Max Tegmark’s book also occurs infinitely often in the decimal expansion of π
by Scott
Two months ago, commenter rrtucci asked me what I thought about Max Tegmark and his “Mathematical Universe Hypothesis”: the idea, which Tegmark defends in his recent book Our Mathematical Universe, that physical and mathematical existence are the same thing, and that what we call “the physical world” is simply one more mathematical structure, alongside the dodecahedron and so forth. I replied as follows:
…I find Max a fascinating person, a wonderful conference organizer, someone who’s always been extremely nice to me personally, and an absolute master at finding common ground with his intellectual opponents—I’m trying to learn from him, and hope someday to become 10-122 as good. I can also say that, like various other commentators (e.g., Peter Woit), I personally find the “Mathematical Universe Hypothesis” to be devoid of content.
After Peter Woit found that comment and highlighted it on his own blog, my comments section was graced by none other than Tegmark himself, who wrote:
Thanks Scott for your all to [sic] kind words! I very much look forward to hearing what you think about what I actually say in the book once you’ve had a chance to read it! I’m happy to give you a hardcopy (which can double as door-stop) – just let me know.
With this reply, Max illustrated perfectly why I’ve been trying to learn from him, and how far I fall short. Where I would’ve said “yo dumbass, why don’t you read my book before spouting off?,” Tegmark gracefully, diplomatically shamed me into reading his book.
So, now that I’ve done so, what do I think? Briefly, I think it’s a superb piece of popular science writing—stuffed to the gills with thought-provoking arguments, entertaining anecdotes, and fascinating facts. I think everyone interested in math, science, or philosophy should buy the book and read it. And I still think the MUH is basically devoid of content, as it stands.
Let me start with what makes the book so good. First and foremost, the personal touch. Tegmark deftly conveys the excitement of being involved in the analysis of the cosmic microwave background fluctuations—of actually getting detailed numerical data about the origin of the universe. (The book came out just a few months before last week’s bombshell announcement of B-modes in the CMB data; presumably the next edition will have an update about that.) And Tegmark doesn’t just give you arguments for the Many-Worlds Interpretation of quantum mechanics; he tells you how he came to believe it. He writes of being a beginning PhD student at Berkeley, living at International House (and dating an Australian exchange student who he met his first day at IHouse), who became obsessed with solving the quantum measurement problem, and who therefore headed to the physics library, where he was awestruck by reading the original Many-Worlds articles of Hugh Everett and Bryce deWitt. As it happens, every single part of the last sentence also describes me (!!!)—except that the Australian exchange student who I met my first day at IHouse lost interest in me when she decided that I was too nerdy. And also, I eventually decided that the MWI left me pretty much as confused about the measurement problem as before, whereas Tegmark remains a wholehearted Many-Worlder.
The other thing I loved about Tegmark’s book was its almost comical concreteness. He doesn’t just metaphorically write about “knobs” for adjusting the constants of physics: he shows you a picture of a box with the knobs on it. He also shows a “letter” that lists not only his street address, zip code, town, state, and country, but also his planet, Hubble volume, post-inflationary bubble, quantum branch, and mathematical structure. Probably my favorite figure was the one labeled “What Dark Matter Looks Like / What Dark Energy Looks Like,” which showed two blank boxes.
Sometimes Tegmark seems to subtly subvert the conventions of popular-science writing. For example, in the first chapter, he includes a table that categorizes each of the book’s remaining chapters as “Mainstream,” “Controversial,” or “Extremely Controversial.” And whenever you’re reading the text and cringing at a crucial factual point that was left out, chances are good you’ll find a footnote at the bottom of the page explaining that point. I hope both of these conventions become de rigueur for all future pop-science books, but I’m not counting on it.
The book has what Tegmark himself describes as a “Dr. Jekyll / Mr. Hyde” structure, with the first (“Dr. Jekyll”) half of the book relaying more-or-less accepted discoveries in physics and cosmology, and the second (“Mr. Hyde”) half focusing on Tegmark’s own Mathematical Universe Hypothesis (MUH). Let’s accept that both halves are enjoyable reads, and that the first half contains lots of wonderful science. Is there anything worth saying about the truth or falsehood of the MUH?
In my view, the MUH gestures toward two points that are both correct and important—neither of them new, but both well worth repeating in a pop-science book. The first is that the laws of physics aren’t “suggestions,” which the particles can obey when they feel like it but ignore when Uri Geller picks up a spoon. In that respect, they’re completely unlike human laws, and the fact that we use the same word for both is unfortunate. Nor are the laws merely observed correlations, as in “scientists find link between yogurt and weight loss.” The links of fundamental physics are ironclad: the world “obeys” them in much the same sense that a computer obeys its code, or the positive integers obey the rules of arithmetic. Of course we don’t yet know the complete program describing the state evolution of the universe, but everything learned since Galileo leads one to expect that such a program exists. (According to quantum mechanics, the program describing our observed reality is a probabilistic one, but for me, that fact by itself does nothing to change its lawlike character. After all, if you know the initial state, Hamiltonian, and measurement basis, then quantum mechanics gives you a perfect algorithm to calculate the probabilities.)
The second true and important nugget in the MUH is that the laws are “mathematical.” By itself, I’d say that’s a vacuous statement, since anything that can be described at all can be described mathematically. (As a degenerate case, a “mathematical description of reality” could simply be a gargantuan string of bits, listing everything that will ever happen at every point in spacetime.) The nontrivial part is that, at least if we ignore boundary conditions and the details of our local environment (which maybe we shouldn’t!), the laws of nature are expressible as simple, elegant math—and moreover, the same structures (complex numbers, group representations, Riemannian manifolds…) that mathematicians find important for internal reasons, again and again turn out to play a crucial role in physics. It didn’t have to be that way, but it is.
Putting the two points together, it seems fair to say that the physical world is “isomorphic to” a mathematical structure—and moreover, a structure whose time evolution obeys simple, elegant laws. All of this I find unobjectionable: if you believe it, it doesn’t make you a Tegmarkian; it makes you ready for freshman science class.
But Tegmark goes further. He doesn’t say that the universe is “isomorphic” to a mathematical structure; he says that it is that structure, that its physical and mathematical existence are the same thing. Furthermore, he says that every mathematical structure “exists” in the same sense that “ours” does; we simply find ourselves in one of the structures capable of intelligent life (which shouldn’t surprise us). Thus, for Tegmark, the answer to Stephen Hawking’s famous question—”What is it that breathes fire into the equations and gives them a universe to describe?”—is that every consistent set of equations has fire breathed into it. Or rather, every mathematical structure of at most countable cardinality whose relations are definable by some computer program. (Tegmark allows that structures that aren’t computably definable, like the set of real numbers, might not have fire breathed into them.)
Anyway, the ensemble of all (computable?) mathematical structures, constituting the totality of existence, is what Tegmark calls the “Level IV multiverse.” In his nomenclature, our universe consists of anything from which we can receive signals; anything that exists but that we can’t receive signals from is part of a “multiverse” rather than our universe. The “Level I multiverse” is just the entirety of our spacetime, including faraway regions from which we can never receive a signal due to the dark energy. The Level II multiverse consists of the infinitely many other “bubbles” (i.e., “local Big Bangs”), with different values of the constants of physics, that would, in eternal inflation cosmologies, have generically formed out of the same inflating substance that gave rise to our Big Bang. The Level III multiverse is Everett’s many worlds. Thus, for Tegmark, the Level IV multiverse is a sort of natural culmination of earlier multiverse theorizing. (Some people might call it a reductio ad absurdum, but Tegmark is nothing if not a bullet-swallower.)
Now, why should you believe in any of these multiverses? Or better: what does it buy you to believe in them?
As Tegmark correctly points out, none of the multiverses are “theories,” but they might be implications of theories that we have other good reasons to accept. In particular, it seems crazy to believe that the Big Bang created space only up to the furthest point from which light can reach the earth, and no further. So, do you believe that space extends further than our cosmological horizon? Then boom! you believe in the Level I multiverse, according to Tegmark’s definition of it.
Likewise, do you believe there was a period of inflation in the first ~10-32 seconds after the Big Bang? Inflation has made several confirmed predictions (e.g., about the “fractal” nature of the CMB perturbations), and if last week’s announcement of B-modes in the CMB is independently verified, that will pretty much clinch the case for inflation. But Alan Guth, Andrei Linde, and others have argued that, if you accept inflation, then it seems hard to prevent patches of the inflating substance from continuing to inflate forever, and thereby giving rise to infinitely many “other” Big Bangs. Furthermore, if you accept string theory, then the six extra dimensions should generically curl up differently in each of those Big Bangs, giving rise to different apparent values of the constants of physics. So then boom! with those assumptions, you’re sold on the Level II multiverse as well. Finally, of course, there are people (like David Deutsch, Eliezer Yudkowsky, and Tegmark himself) who think that quantum mechanics forces you to accept the Level III multiverse of Everett. Better yet, Tegmark claims that these multiverses are “falsifiable.” For example, if inflation turns out to be wrong, then the Level II multiverse is dead, while if quantum mechanics is wrong, then the Level III one is dead.
Admittedly, the Level IV multiverse is a tougher sell, even by the standards of the last two paragraphs. If you believe physical existence to be the same thing as mathematical existence, what puzzles does that help to explain? What novel predictions does it make? Forging fearlessly ahead, Tegmark argues that the MUH helps to “explain” why our universe has so many mathematical regularities in the first place. And it “predicts” that more mathematical regularities will be discovered, and that everything discovered by science will be mathematically describable. But what about the existence of other mathematical universes? If, Tegmark says (on page 354), our qualitative laws of physics turn out to allow a narrow range of numerical constants that permit life, whereas other possible qualitative laws have no range of numerical constants that permit life, then that would be evidence for the existence of a mathematical multiverse. For if our qualitative laws were the only ones into which fire had been breathed, then why would they just so happen to have a narrow but nonempty range of life-permitting constants?
I suppose I’m not alone in finding this totally unpersuasive. When most scientists say they want “predictions,” they have in mind something meatier than “predict the universe will continue to be describable by mathematics.” (How would we know if we found something that wasn’t mathematically describable? Could we even describe such a thing with English words, in order to write papers about it?) They also have in mind something meatier than “predict that the laws of physics will be compatible with the existence of intelligent observers, but if you changed them a little, then they’d stop being compatible.” (The first part of that prediction is solid enough, but the second part might depend entirely on what we mean by a “little change” or even an “intelligent observer.”)
What’s worse is that Tegmark’s rules appear to let him have it both ways. To whatever extent the laws of physics turn out to be “as simple and elegant as anyone could hope for,” Tegmark can say: “you see? that’s evidence for the mathematical character of our universe, and hence for the MUH!” But to whatever extent the laws turn out not to be so elegant, to be weird or arbitrary, he can say: “see? that’s evidence that our laws were selected more-or-less randomly among all possible laws compatible with the existence of intelligent life—just as the MUH predicted!”
Still, maybe the MUH could be sharpened to the point where it did make definite predictions? As Tegmark acknowledges, the central difficulty with doing so is that no one has any idea what measure to use over the space of mathematical objects (or even computably-describable objects). This becomes clear if we ask a simple question like: what fraction of the mathematical multiverse consists of worlds that contain nothing but a single three-dimensional cube?
We could try to answer such a question using the universal prior: that is, we could make a list of all self-delimiting computer programs, then count the total weight of programs that generate a single cube and then halt, where each n-bit program gets assigned 1/2n weight. Sure, the resulting fraction would be uncomputable, but at least we’d have defined it. Except wait … which programming language should we use? (The constant factors could actually matter here!) Worse yet, what exactly counts as a “cube”? Does it have to have faces, or are vertices and edges enough? How should we interpret the string of 1′s and 0′s output by the program, in order to know whether it describes a cube or not? (Also, how do we decide whether two programs describe the “same” cube? And if they do, does that mean they’re describing the same universe, or two different universes that happen to be identical?)
These problems are simply more-dramatic versions of the “standard” measure problem in inflationary cosmology, which asks how to make statistical predictions in a multiverse where everything that can happen will happen, and will happen an infinite number of times. The measure problem is sometimes discussed as if it were a technical issue: something to acknowledge but then set to the side, in the hope that someone will eventually come along with some clever counting rule that solves it. To my mind, however, the problem goes deeper: it’s a sign that, although we might have started out in physics, we’ve now stumbled into metaphysics.
Some cosmologists would strongly protest that view. Most of them would agree with me that Tegmark’s Level IV multiverse is metaphysics, but they’d insist that the Level I, Level II, and perhaps Level III multiverses were perfectly within the scope of scientific inquiry: they either exist or don’t exist, and the fact that we get confused about the measure problem is our issue, not nature’s.
My response can be summed up in a question: why not ride this slippery slope all the way to the bottom? Thinkers like Nick Bostrom and Robin Hanson have pointed out that, in the far future, we might expect that computer-simulated worlds (as in The Matrix) will vastly outnumber the “real” world. So then, why shouldn’t we predict that we’re much more likely to live in a computer simulation than we are in one of the “original” worlds doing the simulating? And as a logical next step, why shouldn’t we do physics by trying to calculate a probability measure over different kinds of simulated worlds: for example, those run by benevolent simulators versus evil ones? (For our world, my own money’s on “evil.”)
But why stop there? As Tegmark points out, what does it matter if a computer simulation is actually run or not? Indeed, why shouldn’t you say something like the following: assuming that π is a normal number, your entire life history must be encoded infinitely many times in π’s decimal expansion. Therefore, you’re infinitely more likely to be one of your infinitely many doppelgängers “living in the digits of π” than you are to be the “real” you, of whom there’s only one! (Of course, you might also be living in the digits of e or √2, possibilities that also merit reflection.)
At this point, of course, you’re all the way at the bottom of the slope, in Mathematical Universe Land, where Tegmark is eagerly waiting for you. But you still have no idea how to calculate a measure over mathematical objects: for example, how to say whether you’re more likely to be living in the first 1010^120 digits of π, or the first 1010^120 digits of e. And as a consequence, you still don’t know how to use the MUH to constrain your expectations for what you’re going to see next.
Now, notice that these different ways down the slippery slope all have a common structure:
- We borrow an idea from science that’s real and important and profound: for example, the possible infinite size and duration of our universe, or inflationary cosmology, or the linearity of quantum mechanics, or the likelihood of π being a normal number, or the possibility of computer-simulated universes.
- We then run with that idea until we smack right into a measure problem, and lose the ability to make useful predictions.
Many people want to frame the multiverse debates as “science versus pseudoscience,” or “science versus science fiction,” or (as I did before) “physics versus metaphysics.” But actually, I don’t think any of those dichotomies get to the nub of the matter. All of the multiverses I’ve mentioned—certainly the inflationary and Everett multiverses, but even the computer-simuverse and the π-verse—have their origins in legitimate scientific questions and in genuinely-great achievements of science. However, they then extrapolate those achievements in a direction that hasn’t yet led to anything impressive. Or at least, not to anything that we couldn’t have gotten without the ontological commitments that led to the multiverse and its measure problem.
What is it, in general, that makes a scientific theory impressive? I’d say that the answer is simple: connecting elegant math to actual facts of experience.
When Einstein said, the perihelion of Mercury precesses at 43 seconds of arc per century because gravity is the curvature of spacetime—that was impressive.
When Dirac said, you should see a positron because this equation in quantum field theory is a quadratic with both positive and negative solutions (and then the positron was found)—that was impressive.
When Darwin said, there must be equal numbers of males and females in all these different animal species because any other ratio would fail to be an equilibrium—that was impressive.
When people say that multiverse theorizing “isn’t science,” I think what they mean is that it’s failed, so far, to be impressive science in the above sense. It hasn’t yet produced any satisfying clicks of understanding, much less dramatically-confirmed predictions. Yes, Steven Weinberg kind-of, sort-of used “multiverse” reasoning to predict—correctly—that the cosmological constant should be nonzero. But as far as I can tell, he could just as well have dispensed with the “multiverse” part, and said: “I see no physical reason why the cosmological constant should be zero, rather than having some small nonzero value still consistent with the formation of stars and galaxies.”
At this, many multiverse proponents would protest: “look, Einstein, Dirac, and Darwin is setting a pretty high bar! Those guys were smart but also lucky, and it’s unrealistic to expect that scientists will always be so lucky. For many aspects of the world, there might not be an elegant theoretical explanation—or any explanation at all better than, ‘well, if it were much different, then we probably wouldn’t be here talking about it.’ So, are you saying we should ignore where the evidence leads us, just because of some a-priori prejudice in favor of mathematical elegance?”
In a sense, yes, I am saying that. Here’s an analogy: suppose an aspiring filmmaker said, “I want my films to capture the reality of human experience, not some Hollywood myth. So, in most of my movies nothing much will happen at all. If something does happen—say, a major character dies—it won’t be after some interesting, character-forming struggle, but meaninglessly, in a way totally unrelated to the rest of the film. Like maybe they get hit by a bus. Then some other random stuff will happen, and then the movie will end.”
Such a filmmaker, I’d say, would have a perfect plan for creating boring, arthouse movies that nobody wants to watch. Dramatic, character-forming struggles against the odds might not be the norm of human experience, but they are the central ingredient of entertaining cinema—so if you want to create an entertaining movie, then you have to postselect on those parts of human experience that do involve dramatic struggles. In the same way, I claim that elegant mathematical explanations for observed facts are the central ingredient of great science. Not everything in the universe might have such an explanation, but if one wants to create great science, one has to postselect on the things that do.
(Note that there’s an irony here: the same unsatisfyingness, the same lack of explanatory oomph, that make something a “lousy movie” to those with a scientific mindset, can easily make it a great movie to those without such a mindset. The hunger for nontrivial mathematical explanations is a hunger one has to acquire!)
Some readers might argue: “but weren’t quantum mechanics, chaos theory, and Gödel’s theorem scientifically important precisely because they said that certain phenomena—the exact timing of a radioactive decay, next month’s weather, the bits of Chaitin’s Ω—were unpredictable and unexplainable in fundamental ways?” To me, these are the exceptions that prove the rule. Quantum mechanics, chaos, and Gödel’s theorem were great science not because they declared certain facts unexplainable, but because they explained why those facts (and not other facts) had no explanations of certain kinds. Even more to the point, they gave definite rules to help figure out what would and wouldn’t be explainable in their respective domains: is this state an eigenstate of the operator you’re measuring? is the Lyapunov exponent positive? is there a proof of independence from PA or ZFC?
So, what would be the analogue of the above for the multiverse? Is there any Level II or IV multiverse hypothesis that says: sure, the mass of electron might be a cosmic accident, with at best an anthropic explanation, but the mass of the Higgs boson is almost certainly not such an accident? Or that the sum or difference of the two masses is not an accident? (And no, it doesn’t count to affirm as “non-accidental” things that we already have non-anthropic explanations for.) If such a hypothesis exists, tell me in the comments! As far as I know, all Level II and IV multiverse hypotheses are still at the stage where basically anything that isn’t already explained might vary across universes and be anthropically selected. And that, to my mind, makes them very different in character from quantum mechanics, chaos, or Gödel’s theorem.
In summary, here’s what I feel is a reasonable position to take right now, regarding all four of Tegmark’s multiverse levels (not to mention the computer-simuverse, which I humbly propose as Level 3.5):
Yes, these multiverses are a perfectly fine thing to speculate about: sure they’re unobservable, but so are plenty of other entities that science has forced us to accept. There are even natural reasons, within physics and cosmology, that could lead a person to speculate about each of these multiverse levels. So if you want to speculate, knock yourself out! If, however, you want me to accept the results as more than speculation—if you want me to put them on the bookshelf next to Darwin and Einstein—then you’ll need to do more than argue that other stuff I already believe logically entails a multiverse (which I’ve never been sure about), or point to facts that are currently unexplained as evidence that we need a multiverse to explain their unexplainability, or claim as triumphs for your hypothesis things that don’t really need the hypothesis at all, or describe implausible hypothetical scenarios that could confirm or falsify the hypothesis. Rather, you’ll need to use your multiverse hypothesis—and your proposed solution to the resulting measure problem—to do something new that impresses me.
20 Mar 16:18
A thread at Reddit addressed the question "If diamonds are made of just carbon, is it possible to get a diamond to catch fire?"
The embedded video answers the question by showing a diamond being burned (heated white-hot, then dropped in liquid oxygen).
Practical significance, for those without liquid oxygen at home and diamonds to burn?
Diamonds are not forever
by Minnesotastan
A thread at Reddit addressed the question "If diamonds are made of just carbon, is it possible to get a diamond to catch fire?"
The embedded video answers the question by showing a diamond being burned (heated white-hot, then dropped in liquid oxygen).
Practical significance, for those without liquid oxygen at home and diamonds to burn?
If your house burns down with the family jewels inside, you can collect the pools of melted gold, but the diamonds will be gone in a puff of CO2. Cheaper, more attractive stones, such as cubic zirconia and synthetic ruby and sapphire, are made of refractory metal oxides that easily withstand the same heat. So it's actually mall trinkets, not diamonds, that are forever.
Luke.stirling likes this
19 Mar 17:12




How Racist Is Your State's War on Weed? Compare!
by Elizabeth Nolan Brown
 A new interactive website from
the American Civil Liberties Union (ACLU) highlights how many lives
are derailed and billions of dollars wasted fighting a racially
biased war on drugs in America.
A new interactive website from
the American Civil Liberties Union (ACLU) highlights how many lives
are derailed and billions of dollars wasted fighting a racially
biased war on drugs in America.
The site, called The Uncovery, offers state-by-state statistics on U.S. marijuana arrests, emphasizing racial disparities and the cost of enforcing drug laws.
The stats are based on data from the ACLU's "War on Marijuana" report. For the U.S. overall, someone is arrested for marijuana every 0.01 hours and this person is 3.73 times more likely to be black than white. The site notes that the U.S. spent more than $3.6 billion enforcing marijuana laws in 2010 and that 88 percent of marijuana arrests are for possession (in New York and Texas, that figure is 97 percent). The Uncovery also breaks down marijuana arrest and spending stats by state. Let's take a look.
The 10 states spending the most on marijuana law enforcement:
1. New York: $678,450,560
2. California: $490,966,080
3. Texas: $251,648,800
4. Florida: $228,635,840
5. Illinois: $221,431,776
6. New Jersey: $127,342,512
7. Georgia: $121,898,152
8. Ohio: $120,148,064
9. Maryland: $106,702,784
10. Pennsylvania: $100,748,528
Staggering, no? And the disparities in black-to-white arrest ratios are equally horrifying.
The 10 worst states for racially biased marijuana arrests:
In ___, a black person is ___ times more likely to be arrested than a white person for having marijuana.
1. Iowa - 8.33
2. D.C. - 8.05
3. Minnesota - 7.81
4. Illinois - 7.56
5. Wisconsin - 5.98
6. Kentucky - 5.95
7. Pennsylvania - 5.19
8. South Dakota - 4.78
9. Nebraska - 4.65
10. New York - 4.52
States with the smallest racial disparities in marijuana arrests were Hawaii (where blacks were only 0.99 times as likely as whites to be arrested for marijuana), Alaska (1.6 times more likely), New Mexico (1.86), Oregon (2.08), and Maine (2.13). All five of these states have very small African American populations overall.
19 Mar 16:01

Black, Latino Firefighters in New York City Settle Long-Running Suit over Racial Discrimination
by mail@democracynow.org (Democracy Now!)
Some 1,500 Black and Latino applicants to the Fire Department of New York have settled a long-running lawsuit with the city and the Justice Department over racially discriminatory hiring practices at the nation’s largest fire department. The agreement grants almost $100 million in back pay to those impacted. When the case was filed in 2007, the Fire Department was 90 percent white, even though African Americans and Latinos totaled half the city’s population. Under the new agreement, the Fire Department will be required to change its recruiting policies in order to increase diversity and make the department more representative of the city’s population. We discuss the settlement with two guests: Paul Washington, past president of the black firefighters’ group, the Vulcan Society of Black Firefighters, and captain of Engine 234 in Crown Heights, Brooklyn; and Richard Levy, the case’s lead attorney.
16 Mar 21:45
Topological implications of negative curvature for biological and social networks. (arXiv:1403.1228v1 [q-bio.MN])
by Reka Albert, Bhaskar DasGupta, Nasim Mobasheri
Network measures that reflect the most salient properties of complex large-scale networks are in high demand in the network research community. In this paper we adapt a combinatorial measure of negative curvature (also called hyperbolicity) to parameterized finite networks, and show that a variety of biological and social networks are hyperbolic. This hyperbolicity property has strong implications on the higher-order connectivity and other topological properties of these networks. Specifically, we derive and prove bounds on the distance among shortest or approximately shortest paths in hyperbolic networks. We describe two implications of these bounds to cross-talk in biological networks, and to the existence of central, influential neighborhoods in both biological and social networks.
16 Mar 20:34



"I want gay people to be able to protect their marijuana plants with guns."
by Nick Gillespie
NosimplerWhat a slogan.

Tim Moen is a Canadian who is apparently the first federal Libertarian Party candidate to run for Parliament from the Fort McMurray-Athabasca area in Alberta.
Here he is talking to the site of Fort McMurray Today:
“To me, that meme [above] is the message of classical liberalism and the philosophy of liberty"...
“People should be allowed to marry whoever they want, put what they want into their bodies as long as no one is hurt, and protect themselves and their property.”...
“I was initially skeptical that political action could make any positive change in the world, but I was convinced by a number of people that I would be best at spreading the message of liberty across the region and Canada.”...
“I do believe if property rights for people and especially First Nations were enforced, there would be a slower, more sustainable and responsible pace of development."...
“The only say I should have, as a government representative, is with helping resolve disputes.”...
“Gun control is not about protection, so much as it is about control. We’ve seen what happens in countries that allow these liberties to be eroded and it’s not pretty.”
The platform of Canada's LP is summarized thusly:
The party believes in a commitment to free trade. It also supports the elimination of income tax and the GST [goods and services tax, a form of sales tax or VAT], opting instead for a system of fees.
It also supports the elimination of all subsidies, social and corporate welfare programs and gun control laws.
Read more at Moen's site and Facebook page.
Hat tip: The Twitter feed of Isidro by way of Victoriano Urbano by way of Frances Martel.
16 Mar 17:35
Optogenetic perturbations reveal the dynamics of an oculomotor integrator.
by Gonçalves PJ, Arrenberg AB, Hablitzel B, Baier H, Machens CK
| Related Articles |
Optogenetic perturbations reveal the dynamics of an oculomotor integrator.
Front Neural Circuits. 2014;8:10
Authors: Gonçalves PJ, Arrenberg AB, Hablitzel B, Baier H, Machens CK
Abstract
Many neural systems can store short-term information in persistently firing neurons. Such persistent activity is believed to be maintained by recurrent feedback among neurons. This hypothesis has been fleshed out in detail for the oculomotor integrator (OI) for which the so-called "line attractor" network model can explain a large set of observations. Here we show that there is a plethora of such models, distinguished by the relative strength of recurrent excitation and inhibition. In each model, the firing rates of the neurons relax toward the persistent activity states. The dynamics of relaxation can be quite different, however, and depend on the levels of recurrent excitation and inhibition. To identify the correct model, we directly measure these relaxation dynamics by performing optogenetic perturbations in the OI of zebrafish expressing halorhodopsin or channelrhodopsin. We show that instantaneous, inhibitory stimulations of the OI lead to persistent, centripetal eye position changes ipsilateral to the stimulation. Excitatory stimulations similarly cause centripetal eye position changes, yet only contralateral to the stimulation. These results show that the dynamics of the OI are organized around a central attractor state-the null position of the eyes-which stabilizes the system against random perturbations. Our results pose new constraints on the circuit connectivity of the system and provide new insights into the mechanisms underlying persistent activity.
PMID: 24616666 [PubMed - in process]
16 Mar 16:45


Train tracks on a torus
by Jesse Johnson
A little over a year ago, I started writing a series of posts on train tracks and normal loops, then got distracted by other things. In the mean time, I wrote a paper with Yoav Moriah involving train tracks and curve complex distances, which gave me a whole new perspective on what train tracks really mean, more in line with much of Masur and Minsky’s work [1]. So, I want to resuscitate the series of posts on train tracks, but in a slightly different direction than where I was headed before. I’ll start by looking at a very simple case: train tracks on a torus. If you need a review of what train tracks are (the mathematical object, not the literal ones), you can reread my earlier post.
We can form a train track on a torus by taking two essential loops in the torus that intersect once, then smoothing the intersection, as in the Figure below. (I’m drawing the torus as a square with opposite sides identified.) There are two possible ways to smooth the intersection, and for now we’ll just arbitrarily pick one. (Later on, we’ll come back to look at the difference between the two smoothings.) The resutling graph isn’t a train track, bit we can turn it into a train track by taking a regular neighborhood of it, then giving the neighborhood a foliation by intervals perpendicular to the original graph. The original graph (shown in the middle of the Figure) is called a train track diagram.

The question I want to explore in this post is: What loops in the torus are carried by this train track? The answer will be in terms of the slopes of the carried loops. Recall that the universal cover of the torus is the plane. In every isotopy class of essential loops, there is a representative that lifts to a straight line in the universal cover. In fact, there’s an infinite family of such loops that lift to different lines in the plane, but all these lines have the same slope. This slope is what we call the slope of the (isotopy class of the) loop in the torus. In the Figure above, the blue loop has slope 0 and the red loop has slope 1/0 or 
In general, we can calculate the absolute value of the slope of a loop by dividing the number of times it intersects the horizontal boundary of the square by the number of times it intersects the vertical boundary. (You can check that this formula holds for the red and blue loops.) For any slope other than 0 and
There are many other loops in the torus, in addition to the red and blue loops above, that are carried by this particular train track. Examples with slopes 



All these loops have positive slopes, and in fact, you can see that no arc from the left side of the square to the bottom of the square can be carried by this train track. So this means that this train track can only carry positive slopes.
On the other hand, we can put in as many copies of either the vertical or the horizontal arc as we want. We can also put in as many arcs as we want from the left side to the top side, and the same number from the bottom to the right side. By choosing the number of such arcs carefully, we can get the intersections between the resulting loops and the sides of the squares to be whatever we want. (If the number of intersections with the top is greater than the number with the bottom, we’ll only use vertical arcs. Otherwise, we’ll only use horizontal arcs.) So, every loop with positive slope will be carried by this train track.
To make it clear, let me summarize what we’ve learned: The train track that we constructed carries all the loops with positive slopes, as well as the loops with slope 0 and
One way that this gets really interesting is when consider what these two classes look like in the curve complex for the surface. This approach is one of the main tools used in Masur and Minsky’s work on the curve complex [1], particularly their proof that curve complexes of surfaces are Gromov 
Recall that the curve complex for a surface S is the simplicial complex whose vertices represent isotopy classes of essential, simple closed curves in S and whose faces span sets of isotopy classes with pairwise-disjoint representatives. The curve complex for a torus is pretty boring: Any two disjoint essential loops in a torus are parallel (and thus isotopic) to each other, so there are no edges in this curve complex- It’s just an infinite collection of discrete vertices.
So instead, one generally works with the Farey graph for the torus. Much like the curve complex, the vertices of the Farey graph represent isotopy classes of essential loops in the torus. In particular, each vertex represents a rational number (a slope) including
 Similarly, we include in the Farey graph all the triangles bounded by loops of three edges. I’ll leave it as an exercise for the reader to check that for every pair of loops in the torus that intersect in exactly one point, there are exactly two other loops such that each of these loops intersects each of the original two loops in a single point. (The two new loops will intersect each other in two points.) So, in other words, each edge in the Farey graph is in the boundary of exactly two triangles. This tells us that the triangles form a surface. In fact, the surface that they form is the disk bounded by the circle along which we placed the vertices in the previous paragraph.
Similarly, we include in the Farey graph all the triangles bounded by loops of three edges. I’ll leave it as an exercise for the reader to check that for every pair of loops in the torus that intersect in exactly one point, there are exactly two other loops such that each of these loops intersects each of the original two loops in a single point. (The two new loops will intersect each other in two points.) So, in other words, each edge in the Farey graph is in the boundary of exactly two triangles. This tells us that the triangles form a surface. In fact, the surface that they form is the disk bounded by the circle along which we placed the vertices in the previous paragraph.
Six of these triangles are shown in the figure on the right, with the slopes corresponding to their vertices indicated as fractions. For each edge in the Farey graph, we can calculate the third vertex representing one of the adjacent triangles as follows: The numerator of the new slope is the sum of the numerators of the original two, and the denominator is the sum of their denominators. Similarly, to get the vertex defining the other triangle, we subtract the numerators and denominators. (To see why this works, you can think about the normal loops and Haken sums that I mentioned in another post from a while back.)
Notice that the triangles in this picture are different sizes, and in fact they get smaller as the numerators and denominators get bigger. But in reality, the edges of the Farey graph should all be the same length. So, you should think about this circle like the boundary of the hyperbolic plane, and the triangles as being ideal triangles. This isn’t exactly right either, since the edges in the Farey graph have finite length, unlike the edges of ideal triangles. But the Farey graph will have the same symmetry group as a tesselation of the hyperbolic plane by ideal triangles.
The Farey graph is closer in structure to a tree. In fact, we can construct a tree by putting a vertex at the center of each triangle and connecting two vertices whenever the corresponding triangles share an edge. The Farey graph will be quasi-isometric to this tree (though if you don’t know what quasi-isometric means, don’t worry about it.) In the same way that each edge in a tree cuts the tree into two separate trees, each edge in the Farey graph cuts the Farey graph (which is really a cell complex) into two disconnected sets of triangles.
Now, lets go back to the train track from the beginning of this post. Recall that the set of loops carried by the train track consisted of all loops with positive slopes, as well as the loops with slopes 0 and
Note that when we constructed this train track, we started with any two loops in the torus that intersect in one point, or equivalently, any edge in the Farey graph. We then had a choice of two different ways to smooth the vertex where they intersect into a pair of switches in the train track. If we had made the other choice with our original two loops, we would have gotten a train track that carried all negative slopes, i.e. the other component defined by the edge between 0 and
The point of all this is that the different train tracks on the torus can be thought of as defining all the different ways of cutting the Farey graph along single edges. Train tracks in higher genus surfaces play a very similar role, though it’s more complicated because the curve complexes of these surfaces are much less tree-like (though they’re still delta hyperbolic, which is close.) In particular, you can’t separate these complexes by removing a single edge, or indeed any finite collection of simplices. But train tracks still define subsets of loops that are very nice with respect to the curve complex structure.
The reason this turns out to be useful is that it is often possible to prove things about the types of loops that are carried by a given train track, which can then be translated into the language of the curve complex. This is one of the main techniques in Masur and Minsky’s papers on the curve complex [1], and on disk sets of handlebodies [2]. It also proved very useful in my work with Yoav Moriah [3] and his earlier work with Martin Lustig [4]. But a discussion along those lines will have to wait for a future post.
16 Mar 16:41
 I love the detail in this painting - the leather strap for adjusting the window, perhaps a small tear on the young lady's cheek. And especially her gaze at the viewer, as though appealing for assistance.
I love the detail in this painting - the leather strap for adjusting the window, perhaps a small tear on the young lady's cheek. And especially her gaze at the viewer, as though appealing for assistance.
Via Eva's Blog and Large Size Paintings.
"The Irritating Gentleman" (1874)
by Minnesotastan
"Berthold Woltze was a German painter who was born in 1829. Several works by the artist have been sold at auction, including 'The Irritating Gentleman' sold at Dorotheum '19th Century Paintings' in 2011 for $43,737. The artist died in 1896."
Via Eva's Blog and Large Size Paintings.
Ionut likes this
16 Mar 16:31

The NSA Can Learn All Your Secrets From Your Phone Metadata |...
The NSA Can Learn All Your Secrets From Your Phone Metadata | Co.Exist | ideas impact
According to the official narrative, monitoring metadata is no big deal. But two Stanford University researchers wanted to see how “sensitive” metadata actually was. So they enlisted hundreds of volunteers to install an app called “MetaPhone” on their Androids to pick up that metadata over several months. What they found shocked them. “The degree of sensitivity among contacts took us aback,” co-authors Jonathan Mayer and Patrick Mutchler wrote on Web Policy, Mayer’s blog. “Participants had calls with Alcoholics Anonymous, gun stores, NARAL Pro-Choice, labor unions, divorce lawyers, sexually transmitted disease clinics, a Canadian import pharmacy, strip clubs, and much more.” The point is, they found, it’s actually really easy to identify names and infer very intimate details about a person’s life just from phone metadata. And things got a lot creepier, and potentially devastating, when researchers posted samples of what these metadata-informed stories could tell. Take, for example, Participant E:Participant E had a long, early morning call with her sister. Two days later, she placed a series of calls to the local Planned Parenthood location. She placed brief additional calls two weeks later, and made a final call a month after.

11 Mar 22:11

Sensory–motor transformations for speech occur bilaterally
by Gregory B. Cogan
Sensory–motor transformations for speech occur bilaterally
Nature 507, 7490 (2014). doi:10.1038/nature12935
Authors: Gregory B. Cogan, Thomas Thesen, Chad Carlson, Werner Doyle, Orrin Devinsky & Bijan Pesaran
Historically, the study of speech processing has emphasized a strong link between auditory perceptual input and motor production output. A kind of ‘parity’ is essential, as both perception- and production-based representations must form a unified interface to facilitate access to higher-order language processes such as syntax and semantics, believed to be computed in the dominant, typically left hemisphere. Although various theories have been proposed to unite perception and production, the underlying neural mechanisms are unclear. Early models of speech and language processing proposed that perceptual processing occurred in the left posterior superior temporal gyrus (Wernicke’s area) and motor production processes occurred in the left inferior frontal gyrus (Broca’s area). Sensory activity was proposed to link to production activity through connecting fibre tracts, forming the left lateralized speech sensory–motor system. Although recent evidence indicates that speech perception occurs bilaterally, prevailing models maintain that the speech sensory–motor system is left lateralized and facilitates the transformation from sensory-based auditory representations to motor-based production representations. However, evidence for the lateralized computation of sensory–motor speech transformations is indirect and primarily comes from stroke patients that have speech repetition deficits (conduction aphasia) and studies using covert speech and haemodynamic functional imaging. Whether the speech sensory–motor system is lateralized, like higher-order language processes, or bilateral, like speech perception, is controversial. Here we use direct neural recordings in subjects performing sensory–motor tasks involving overt speech production to show that sensory–motor transformations occur bilaterally. We demonstrate that electrodes over bilateral inferior frontal, inferior parietal, superior temporal, premotor and somatosensory cortices exhibit robust sensory–motor neural responses during both perception and production in an overt word-repetition task. Using a non-word transformation task, we show that bilateral sensory–motor responses can perform transformations between speech-perception- and speech-production-based representations. These results establish a bilateral sublexical speech sensory–motor system.
06 Mar 22:49
Levy flights do not always optimize random search [Biophysics and Computational Biology]
by Palyulin, V. V., Chechkin, A. V., Metzler, R.
It is generally believed that random search processes based on scale-free, Lévy stable jump length distributions (Lévy flights) optimize the search for sparse targets. Here we show that this popular search advantage is less universal than commonly assumed. We study the efficiency of a minimalist search model based on Lévy...
06 Mar 00:23
Various and Sundry
by woit
NosimplerNow that the geometer-ese is slowly being translated to English, I think I actually study something related to the positive Grassmannian.
- It seems to be too early for April Fool’s day, and yet the arXiv has Dark Matter as a Trigger for Periodic Comet Impacts by Lisa Randall and Matt Reece, a preprint described as “Accepted by Physical Review Letters, 4 figures, no dinosaurs.” The Register has a story: Dark matter killed the dinosaurs, boffins suggest.
Also recently at the arXiv in a similar “too early for April 1″ category is Crossing Stocks and the Positive Grassmannian I: The Geometry behind Stock Market, which deals with the “stockmarkethedron”, also known as the Geometrical Jewel at the Heart of Finance.
- The president’s FY2015 budget request is out, with news for HEP not so good: a 6.6% cut proposed in DOE HEP funding. No details about the NSF budget, but the proposal is basically for flat funding (an overall cut of .03% in the research budget). The NSF is proposing one big increase, 13.5% for management. This is just an initial proposal from the administration, with the possibility of something different ultimately emerging from Congress.
- The particle physics documentary Particle Fever opens here in New York at Film Forum tonight, with appearances tonight and this weekend by the director and “physicists from the film”. There’s a review in today’s New York Times.
I saw the film last fall at the New York Film festival and wrote about it here, with the summary:
most of it I thought was fantastically good and I really hope it finds distribution and gets widely seen. On the other hand, some of it I thought was a really bad idea.
The film is a very inspiring inside look at the LHC experimental search for and discovery of the Higgs. My misgivings were about the theoretical framing of the story, which was the Arkani-Hamed point of view that this is all about two alternatives: SUSY or the multiverse. The NYT review shows that these misgivings were quite justified, with the reviewer’s summary of what they learned about the significance of the Higgs from the film:
While the discovery of the Higgs may not have immediate consequences for the way we live, or applications in the world of technology and industry, its implications, according to “Particle Fever,” could hardly be more profound. Through most of the film, the scientists are awaiting a specific bit of data, a single number that will either vindicate a theory of the universe known as supersymmetry or suggest the possibility of multiple universes.
The differences between these two outcomes seem very stark. In the first case, more particles are likely to be found, contributing to a detailed and orderly picture of the nature of things. In the second, the Standard Model will be thrown into chaos, and the stability of the universe itself may be called into question. It won’t be the end of the world, but for some theorists, it will feel that way.
Mr. Kaplan is hoping for supersymmetry. His friend and sometime table tennis partner, Nima Arkani-Hamed of the Institute for Advanced Study in Princeton, is in the multiverse camp.
Physicists often get outraged when they feel journalists badly misrepresent science to the public. Will they get equally outraged when it is physicists doing the misrepresenting?
- For some insight into the current concerns of particle theorists, you can watch some of the videos at last week’s KITP conference. In particular, there’s Matt Strassler’s talk, where he got all Peter Woit and argued that “one could make the argument” that not seeing SUSY (or anything else stringy) at the LHC “would be significant circumstantial evidence against string theory as a description of nature” and that just seeing the SM at the LHC would be “circumstantial evidence against effective quantum field theory as a complete description of known particle physics”. This got him an argument from Gross about his insufficient enthusiasm for a 100 TeV collider. Gross then also got all Peter Woit, arguing that the failure of the “naturalness” argument for new physics was no big deal since it wasn’t a very good argument to begin with (I get all sorts of grief when I do this..).
The conference ended with a session of people trying to predict the future of the field 30 years hence. This was mostly pretty discouraging, with a lot of people envisioning more of the same: endless generalities about quantum gravity, firewalls etc. Prominent by its absence was any role of mathematics in theoretical physics, with only Greg Moore speaking up for the question of the significance of now popular 6d superconformal theories, and Nati Seiberg mentioning that connections of the field to mathematics were a good thing.Lots of talks mentioned people’s good experiences working with and interacting with Polchinski, who seems to be a very nice guy. I’ve never met him personally, but people have speculated to me that he had something to do with the decision of the arXiv to block links to my blog (he was unhappy about my characterization of his Scientific American article promoting the multiverse). What the truth is about that particular story I suppose I’ll never know.
Update: Another review of Particle Fever leads with this explanation of the main point they got from the film:
Stakes come no higher than in Particle Fever, a dazzling, dizzying documentary about nothing less than whether we exist in a coherent universe of ordered, even beautiful laws — or whether, as Princeton physicist Nima Arkani-Hamed theorizes, our universe is one of an infinite set of other universes defined by a chaotic mash-up of unstable, inexplicable, random conditions.
Update: Reddit has a live Q and A with physicists involved in the film. Savas Dimopoulos (described as “considered the most likely to have a theory confirmed by the LHC”) argues for the multiverse and tells questioners that “We may know about whether Nature prefers the Multiverse or the more traditional (super)symmetry path after the second run of the LHC which will start in a year.” Arkani-Hamed also gives the multiverse argument, also claiming “I envy anyone who is jumping into fundamental physics as a grad student today!”. No theorists in sight who might think there’s more significance to the negative LHC results about SUSY than “must be the multiverse”.
Update: Reddit the next day hosted a live Q and A with Michio Kaku. He there explains to the public that:
The best theory comes from string theory, which states that dark matter is nothing but a higher vibration of the string. We are, in some sense, the lowest octave of a vibrating string. The next octave is dark matter….
The next big accelerator might be the ILC in Japan, a linear collider which might be able to probe the boundaries of string theory…
In the coming decades, I hope we find evidence of dark matter in the lab and in outer space. This would go a long way to proving the correctness of string theory, which is what I do for a living. That is my day job. So string theory is a potentially experimentally verifiable theory.
Seems that well-known theorists going on Reddit to mislead the public is now a daily phenomenon…
04 Mar 18:30


How much is your data worth?
by Cathy O'Neil, mathbabe
I heard an NPR report yesterday with Emily Steel, reporter from the Financial Times, about what kind of attributes make you worth more to advertisers. She has developed an ingenious online calculator here, which you should go play with.
As you can see it cares about things like whether you’re about to have a kid or are a new parent, as well as if you’ve got some disease where the industry for that disease is well-developed in terms of predatory marketing.
For example, you can bump up your worth to $0.27 from the standard $0.0007 if you’re obese, and another $0.10 if you admit to being the type to buy weight-loss products. And of course data warehouses can only get that much money for your data if they know about your weight, which they may or may not since if you don’t buy weight-loss products.
The calculator doesn’t know everything, and you can experiment with how much it does know, but some of the default assumptions are that it knows my age, gender, education level, and ethnicity. Plenty of assumed information to, say, build an unregulated version of a credit score to bypass the Equal Credit Opportunities Act.
Here’s a price list with more information from the biggest data warehouser of all, Acxiom.
04 Mar 18:26
There are thousands of natural PC problems. Assuming P NE NP how many natural problems are there that are
in NP-P but are NOT NPC? Some candidates are Factoring, Discrete Log, Graph Isom, some in group theory, and any natural sparse set. See
here for some more.
A student asked me WHY there are so few natural intermediary problems. I don't know but here are some
options:
At least in complexity theory there are SOME candidates for intermediary sets.
In computability theory, where we know Sigma_1 \ne \Sigma_0, there are no
candidates for natural problems that are c.e., not decidable, but not complete. There have been some attempts to show that there can't be any
such sets, but its hard to define ``natural'' rigorously. (There ARE sets that are c.e., not dec, not complete, but they are
constructed for the sole purpose of being there. My darling would call them `dumb ass' sets,
a terminology that my class now uses as well.)
A long time ago an AI student was working on classifying various problems in planning. There was one that was c.e. and not decidable
and he was unable to show it was complete. He asked me to help him prove it was not complete. I told him, without looking at it,
that it was COMPLETE!!!!!!!!! My confidence inspired him to prove it was complete.
So, aside from the answers above, is there a MATH reason why there are so few
intermediary problems in Complexity, and NONE in computability theory?
Is there some other kind of reason?
Why are there so few intemediary problems in Complexity? In Computability?
by GASARCH
There are thousands of natural PC problems. Assuming P NE NP how many natural problems are there that are
in NP-P but are NOT NPC? Some candidates are Factoring, Discrete Log, Graph Isom, some in group theory, and any natural sparse set. See
here for some more.
A student asked me WHY there are so few natural intermediary problems. I don't know but here are some
options:
- Bill you moron, there are MANY such problems. You didn't mention THESE problems (Followed by a list of problems
that few people have heard of but seem to be intermediary.)
- This is a question of Philosophy and hence not interesting.
- This is a question of Philosophy and hence very interesting.
- That's just the way it goes.
- By Murphy's law there will be many problems that we can't solve quickly.
At least in complexity theory there are SOME candidates for intermediary sets.
In computability theory, where we know Sigma_1 \ne \Sigma_0, there are no
candidates for natural problems that are c.e., not decidable, but not complete. There have been some attempts to show that there can't be any
such sets, but its hard to define ``natural'' rigorously. (There ARE sets that are c.e., not dec, not complete, but they are
constructed for the sole purpose of being there. My darling would call them `dumb ass' sets,
a terminology that my class now uses as well.)
A long time ago an AI student was working on classifying various problems in planning. There was one that was c.e. and not decidable
and he was unable to show it was complete. He asked me to help him prove it was not complete. I told him, without looking at it,
that it was COMPLETE!!!!!!!!! My confidence inspired him to prove it was complete.
So, aside from the answers above, is there a MATH reason why there are so few
intermediary problems in Complexity, and NONE in computability theory?
Is there some other kind of reason?
27 Feb 04:46
When do microcircuits produce beyond-pairwise correlations?
by Barreiro AK, Gjorgjieva J, Rieke F, Shea-Brown E
When do microcircuits produce beyond-pairwise correlations?
Front Comput Neurosci. 2014;8:10
Authors: Barreiro AK, Gjorgjieva J, Rieke F, Shea-Brown E
Abstract
Describing the collective activity of neural populations is a daunting task. Recent empirical studies in retina, however, suggest a vast simplification in how multi-neuron spiking occurs: the activity patterns of retinal ganglion cell (RGC) populations under some conditions are nearly completely captured by pairwise interactions among neurons. In other circumstances, higher-order statistics are required and appear to be shaped by input statistics and intrinsic circuit mechanisms. Here, we study the emergence of higher-order interactions in a model of the RGC circuit in which correlations are generated by common input. We quantify the impact of higher-order interactions by comparing the responses of mechanistic circuit models vs. "null" descriptions in which all higher-than-pairwise correlations have been accounted for by lower order statistics; these are known as pairwise maximum entropy (PME) models. We find that over a broad range of stimuli, output spiking patterns are surprisingly well captured by the pairwise model. To understand this finding, we study an analytically tractable simplification of the RGC model. We find that in the simplified model, bimodal input signals produce larger deviations from pairwise predictions than unimodal inputs. The characteristic light filtering properties of the upstream RGC circuitry suppress bimodality in light stimuli, thus removing a powerful source of higher-order interactions. This provides a novel explanation for the surprising empirical success of pairwise models.
PMID: 24567715 [PubMed]
26 Feb 03:08
Viruses and Fullerenes - Symmetry as a Common Thread?. (arXiv:1402.4393v1 [math-ph] CROSS LISTED)
by Pierre-Philippe Dechant, Jess Wardman, Tom Keef, Reidun Twarock
We apply here the principle of affine symmetry to the nested fullerene cages (carbon onions) that arise in the context of carbon chemistry. Previous work on affine extensions of the icosahedral group has revealed a new organisational principle in virus structure and assembly. We adapt this group theoretic framework here to the physical requirements dictated by carbon chemistry, and show that we can derive mathematical models for carbon onions within this affine symmetry approach. This suggests the applicability of affine symmetry in a wider context in Nature, as well as offering a novel perspective on the geometric principles underpinning carbon chemistry.
26 Feb 03:01

Crouching tiger, hidden dimensions
by Terence D Sanger
Nature Neuroscience 17, 338 (2014). doi:10.1038/nn.3663
Authors: Terence D Sanger & John F Kalaska
A study finds that, during movement preparation, when motor cortex is active, but elicits no muscle output, firing of individual neurons in dorsal premotor and primary motor cortex cancels out at the level of population activity.
18 Feb 17:48
.")
Relative Entropy
by john
You may recall how Tom Leinster, Tobias Fritz and I cooked up a neat category-theoretic characterization of entropy in a long conversation here on this blog. Now Tobias and I have a sequel giving a category-theoretic characterization of relative entropy. But since some people might be put off by the phrase ‘category-theoretic characterization’, it’s called:
I’ve written about this paper before, on my other blog:
- Relative Entropy (Part 1): how various structures important in probability theory arise naturally when you do linear algebra using only the nonnegative real numbers.
- Relative Entropy (Part 2): a category related to statistical inference, FinStat,\mathrm{FinStat}, and how relative entropy defines a functor on this category.
- Relative Entropy (Part 3): statement of our main theorem, which characterizes relative entropy up to a constant multiple as the only functor F:FinStat→[0,∞)F : \mathrm{FinStat} \to [0,\infty) with a few nice properties.
But now the paper is actually done! Let me give a compressed version of the whole story here… with sophisticated digressions buried in some parenthetical remarks that you’re free to skip if you want.
Our gives a new characterization of the concept of relative entropy, also known as ‘relative information’, ‘information gain’ or—by people who like to use jargon to make their work seem obscure—‘Kullback-Leibler divergence’.
Here’s the basic idea. Whenever you have two probability distributions pp and qq on the same finite set X,X, you can define the entropy of qq relative to pp:
S(q,p)=∑x∈Xqxln(qxpx) S(q,p) = \sum_{x\in X} q_x \ln\left( \frac{q_x}{p_x} \right)
Here we set
qxln(qxpx)q_x \ln\left( \frac{q_x}{p_x} \right)
equal to ∞\infty when px=0,p_x = 0, unless qxq_x is also zero, in which case we set it equal to 0. Relative entropy thus takes values in [0,∞].[0,\infty].
Intuitively speaking, S(q,p)S(q,p) measures how surprised you’d be if you thought a situation was described by a probability distribution pp… but then someone came along and said no, it’s really qq.
Or if ‘surprise’ sounds too subjective, it’s the expected amount of information gained when you discover the probability distribution is really q,q, when you’d thought it was p.p.
Tobias and I wanted to use category theory to say what’s so great about relative entropy. We did it using a category FinStat\mathrm{FinStat} where:
- an object (X,q)(X,q) consists of a finite set XX and a probability distribution x↦qxx \mapsto q_x on that set;
- a morphism (f,s):(X,q)→(Y,r)(f,s) : (X,q) \to (Y,r) consists of a measure-preserving function ff from XX to Y,Y, together with a probability distribution x↦sxyx \mapsto s_{x y} on XX for each element y∈Yy \in Y, with the property that sxy=0s_{x y} = 0 unless f(x)=yf(x) = y.
If the raw math seems hard to swallow, perhaps some honey-coated words will help it go down. I think of an object of FinStat\mathrm{FinStat} as a system with some finite set of states together with a probability distribution on its states. This lets me think of a morphism
(f,s):(X,q)→(Y,r) (f,s) : (X,q) \to (Y,r)
in a nice way. First, there’s a measurement process f:X→Yf : X \to Y, a function from the set XX of states of some system being measured to the set YY of states of some measurement apparatus. The condition that ff be measure-preserving says the probability that the apparatus winds up in any state y∈Yy \in Y is the sum of the probabilities of all states of XX leading to that outcome:
ry=∑x∈f−1(y)qx \displaystyle{ r_y = \sum_{x \in f^{-1}(y)} q_x }
Second, there’s a hypothesis ss. This is a guess about the probability that the system being measured is in the state x∈Xx \in X given any measurement outcome y∈Y.y \in Y. The guess is the number sxys_{x y}.
Now, suppose we have any morphism
(f,s):(X,q)→(Y,r) (f,s) : (X,q) \to (Y,r)
in FinStat.\mathrm{FinStat}. From this we get two probability distributions on XX. First, we have the probability distribution pp given by
px=∑y∈Ysxyry♡♡♡ \displaystyle{ p_x = \sum_{y \in Y} s_{x y} r_y } \qquad \qquad \heartsuit\heartsuit\heartsuit
This is our best guess about the the probability that the system is in any given state, given our hypothesis and the probability distribution of measurement results. Second, we have the ‘true’ probability distribution qq.
In fact, this way of assigning relative entropies to morphisms defines a functor
RE:FinStat→[0,∞] RE : \mathrm{FinStat} \to [0,\infty]
where we use [0,∞][0,\infty] to denote the category with one object, the numbers 0≤x≤∞0 \le x \le \infty as morphisms, and addition as composition. More precisely, if
(f,s):(X,q)→(Y,r) (f,s) : (X,q) \to (Y,r)
is any morphism in FinStat,\mathrm{FinStat}, we define
RE(f,s)=S(q,p) RE(f,s) = S(q,p)
where pp is defined as in equation ♡♡♡\heartsuit\heartsuit\heartsuit. This tells us how surprised we are when we learn the true probability distribution qq, if our measurement results were distributed according to rr and our hypothesis was ss.
The fact that RERE is a functor is nontrivial and rather interesting! It says that given any composable pair of measurement processes:
(X,q)⟶(f,s)(Y,r)⟶(g,t)(Z,u) (X,q) \stackrel{(f,s)}{\longrightarrow} (Y,r) \stackrel{(g,t)}{\longrightarrow} (Z,u)
the relative entropy of their composite is the sum of the relative entropies of the two parts:
RE((g,t)∘(f,s))=RE(g,t)+RE(f,s). RE((g,t) \circ (f,s)) = RE(g,t) + RE(f,s) .
We prove that RERE is a functor. However, we go further: we characterize relative entropy by saying that up to a constant multiple, RERE is the unique functor from FinStat\mathrm{FinStat} to [0,∞][0,\infty] obeying three reasonable conditions.
Lower semicontinuity
The first condition is that RERE is lower semicontinuous. The set P(X)P(X) of probability distibutions on a finite set XX naturally has the topology of an (n−1)(n-1)-simplex when XX has nn elements. The set [0,∞][0,\infty] has an obvious topology where it’s homeomorphic to a closed interval. However, with these topologies, the relative entropy does not define a continuous function
S:P(X)×P(X)→[0,∞](q,p)↦S(q,p). \begin{array}{rcl} S : P(X) \times P(X) &\to& [0,\infty] \\ (q,p) &\mapsto & S(q,p) . \end{array}
The problem is that
S(q,p)=∑x∈Xqxln(qxpx)\displaystyle{ S(q,p) = \sum_{x\in X} q_x \ln\left( \frac{q_x}{p_x} \right) }
and qxln(qx/px)q_x \ln(q_x/p_x) is ∞\infty when px=0p_x = 0 and qx>0q_x > 0 — but it’s 00 when px=qx=0.p_x = q_x = 0.
So, it turns out that SS is only lower semicontinuous, meaning that if pi,qip^i , q^i are sequences of probability distributions on XX with pi→pp^i \to p and qi→qq^i \to q then
S(q,p)≤liminfi→∞S(qi,pi) S(q,p) \le \liminf_{i \to \infty} S(q^i, p^i)
We give the set of morphisms in FinStat\mathrm{FinStat} its most obvious topology, and show that with this topology, RERE maps morphisms to morphisms in a lower semicontinuous way.
(Lower semicontinuity may seem like an annoying property. But there’s a way to redeem it. There’s a sneaky topology on [0,∞][0,\infty] such that a function taking values in [0,∞][0,\infty] is lower semicontinuous (in the lim inf sense above) if and only if it’s continuous with respect to this sneaky topology!
Using this idea, we can make FinStatFinStat and [0,∞][0,\infty] into topological categories — that is, categories internal to Top — in such a way that lower semicontinuity simply says
RE:FinStat→[0,∞] RE : FinStat \to [0,\infty]
is a continuous functor.
A bit confusingly, this sneaky topology on [0,∞][0,\infty] is called the upper topology. I’ve fallen in love with the upper topology on [0,∞][0,\infty]. Why?
Well, [0,∞][0,\infty] is a very nice rig, or ‘ring without negatives’. Addition is defined in the obvious way, and multiplication is defined in the almost-obvious way, except that
0⋅∞=∞⋅0=0 0 \cdot \infty = \infty \cdot 0 = 0
Even this is actually obvious if you remember that it’s required by the definition of a rig. But if you try to put the ordinary closed interval topology on [0,∞][0,\infty], you’ll see multiplication is not continuous, because a⋅∞a \cdot \infty is infinite when a>0a \gt 0 but then it suddenly jumps down to zero when aa hits zero. However, multiplication is continuous if we give [0,∞][0,\infty] the upper topology! Then [0,∞][0,\infty] becomes a topological rig.)
Convex linearity
The second condition is that RERE is convex linear. We describe how to take convex linear combinations of morphisms in FinStat,\mathrm{FinStat}, and then the functor RERE maps any convex linear combination of morphisms in FinStat\mathrm{FinStat} to the corresponding convex linear combination of numbers in [0,∞].[0,\infty].
Intuitively, this means that if we take a coin with probability PP of landing heads up, and flip it to decide whether to perform one measurement process or another, the expected information gained is PP times the expected information gain of the first process plus 1−P1-P times the expected information gain of the second process.
(Operadically, the point is that both FinStatFinStat and [0,∞][0,\infty] are algebras of an operad P whose operations are convex linear combinations. The nn-ary operations in P are just probability distributions on an nn-element set. In other words, they’re points in the (n−1)(n-1)-simplex.
So, saying that RERE is convex linear means that
RE:FinStat→[0,∞] RE: FinStat \to [0,\infty]
is a map of P-algebras. But we avoid discussing this in our paper because FinStatFinStat, being a category, is just a ‘weak’ P-algebra, and we decided this would be too much for our poor little readers.
For those who like fine nuances: P is a topological operad, and FinStatFinStat and [0,∞][0,\infty] are algebras of this in the topological category TopCat. As I mentioned, FinStatFinStat is a ‘weak’ P-algebra, meaning the laws for convex linear combinations hold only up to coherent natural isomorphism. [0,∞][0,\infty] is strict… but to get convex linear combinations like λ⋅0+(1−λ)∞\lambda \cdot 0 + (1 - \lambda) \infty to behave continuously, we have to give [0,∞][0,\infty] the upper topology!)
Vanishing on a subcategory
The third condition is that RERE vanishes on morphisms (f,s):(X,q)→(Y,r)(f,s) : (X,q) \to (Y,r) where the hypothesis ss is optimal. By this, we mean that equation ♡♡♡\heartsuit\heartsuit\heartsuit gives a probability distribution pp equal to the ‘true’ one, qq.
That makes a lot of sense conceptually: we don’t gain any information upon learning the truth about a situation if we already knew the truth!
(But the subcategory of FinStatFinStat where we keep all the objects but only these ‘optimal’ morphisms also has a nice category-theoretic significance. Tom Leinster called it FP in this post:
That’s because it’s the ‘free P-algebra on an internal P-algebra’, where P is the operad I mentioned. I won’t explain what this means here, because Tom did it! Suffice it to say that it’s a shockingly abstract piece of operad theory that nonetheless manages to capture the concept of entropy very neatly. But that’s plain old entropy, not relative entropy.)
The result
Here, then, is our main result:
Theorem. Any lower semicontinuous, convex-linear functor
F:FinStat→[0,∞] F : \mathrm{FinStat} \to [0,\infty]
that vanishes on every morphism with an optimal hypothesis must equal some constant times the relative entropy. In other words, there exists some constant c∈[0,∞]c \in [0,\infty] such that
F(f,s)=cRE(f,s) F(f,s) = c RE(f,s)
for any any morphism (f,s):(X,p)→(Y,q)(f,s) : (X,p) \to (Y,q) in FinStat.\mathrm{FinStat}.
The proof
The proof is surprisingly hard. Or maybe we’re just surprisingly bad at proving things. But the interesting thing is this: the proof is swift and effective in the ‘generic’ case — the case where the support of the probability measures involved is the whole set they’re living on, and the constant cc is finite.
It takes some more work to handle the case where the probability measures have smaller support.
But the really hard work starts when we handle the case that, in the end, has c=∞c = \infty. Then the proof becomes more like analysis than what you normally expect in category theory. We slowly corner the result, blocking off all avenues of escape. Then we close in, grab its neck, and strangle it, crushing its larynx ever tighter, as it loses the will to fight back and finally expires… still twitching.
You’ve got to read the proof to understand what I mean.
jnaciona likes this
18 Feb 17:34



Big Banks, Food Stamps, and the Trouble With Vouchers
by Jesse Walker
The American Prospect has posted a story headlined "How Big Banks Are Cashing In On Food Stamps." Here's an excerpt:
Banks reap hefty profits helping governments make payments to individuals, business that only got better when agencies switch from making payments on paper—checks and vouchers—to electronic benefits transfer (EBT) cards. EBT cards look and work like debit cards, and by 2002, had entirely replaced the stamp booklets that gave the food stamp program its name. SNAP is the most well-known program delivered via EBT, but they also carry payments for Temporary Aid to Needy Families (TANF); Women, Infants and Children (WIC); childcare subsidies; state general assistance; and many other programs....
Distributing government benefits is a lucrative industry. According to the Government Accountability Institute, J.P. Morgan Chase, which currently controls EBT contracts in 21 states, Guam, and the Virgin Islands, made more than half a billion dollars between 2004 and 2012 providing government benefits to U.S. citizens. In New York alone, J.P. Morgan Electronic Financial Services (EFS) holds a nine-year, $177 million EBT services contract with the State Office of Temporary and Disability Services (OTDA). New York currently pays $0.95 per month for each its 1.7 million SNAP cases. In addition, J.P. Morgan EFS collects penalties and fees from benefit recipients: $5 to replace a lost EBT card, $0.40 for each balance inquiry, $0.50 each time their cards are declined for insufficient funds, and $1.50 per withdrawal if they use ATMs to get cash more than once a month. While information about profit margins on EBT contracts is neither collected at the national level nor released by banks, EBT is a significant growth area for big banks. Last year, the Federal Reserve Payments Study reported that the number of EBT transactions more than doubled since 2006.
You can read the rest here. J.P. Morgan Chase's role in these programs has been covered before, but the Prospect piece moves the story forward with details about the new farm bill, which may have lowered benefits to the low-income Americans spending those subsidies but could end up actually sending more money to the banks, since the law's provisions for anti-fraud enforcement will mean there's more government contracts to be won.
 Food stamps, of course, are a voucher program,
and free-market types have a history of proposing vouchers as an
alternative to the direct state or federal provision of services.
There are obviously good reasons to expect the market to do a
better job of providing food (or education, or housing, or
whatever) than the government, and in some contexts vouchers may be
a step in the right direction. But voucher markets are tightly
regulated, with special administration required and with strings
attached for both buyers and sellers, and they thus open up new
opportunities for rent-seeking.
(The Government Accountability Institute has
noted a steady increase in J.P. Morgan Chase's donations to
members of the House and Senate agriculture committees.) Those
rent-seekers then become new constituents for the program, a fact
that should aggravate conservatives; and those constituents' chief
interest is not the reduction of poverty, a fact that should
aggravate liberals.
Food stamps, of course, are a voucher program,
and free-market types have a history of proposing vouchers as an
alternative to the direct state or federal provision of services.
There are obviously good reasons to expect the market to do a
better job of providing food (or education, or housing, or
whatever) than the government, and in some contexts vouchers may be
a step in the right direction. But voucher markets are tightly
regulated, with special administration required and with strings
attached for both buyers and sellers, and they thus open up new
opportunities for rent-seeking.
(The Government Accountability Institute has
noted a steady increase in J.P. Morgan Chase's donations to
members of the House and Senate agriculture committees.) Those
rent-seekers then become new constituents for the program, a fact
that should aggravate conservatives; and those constituents' chief
interest is not the reduction of poverty, a fact that should
aggravate liberals.
If you want to propose a more market-oriented system that stops short of withdrawing the government's fingers altogether, it would be better just to send poor people money: That takes away a lot of these opportunities for companies to game the market, and it makes it easier to start collapsing all these different programs into a lump payment like Milton Friedman's negative income tax. (Indeed, it offers a gradualist route toward the negative income tax: You can cashify and combine transfer payments one by one.) I have seen the best voucher, and it is called cash.
Bonus fun fact: The recent cut in SNAP benefits reduced payments to poor people by nearly $5 billion. The program's combined federal and state administrative costs, meanwhile, are nearly $7 billion.
17 Feb 17:44



BitTorrent Sync: The NSA-Resistant File Sharing Service You Might Have Missed
by Alyssa Hertig
NosimplerIs there a word for ideas that you had but didn't actually do anything about? vole.cc and syncnet are those.

BitTorrent Inc. is shifting the emphasis of its business to BitTorrent Sync, a transformative file-sharing service that boasts NSA resistance.
Last year, Belarussian Konstantin Lissounov threw together a crude version of Sync at a BitTorrent hackathon. It allowed him to “quickly and easily send encrypted photos of his three children across dodgy Eastern European network lines to the rest of his family.” Now, the peer-to-peer file synchronization tool boasts two million users a month and is developing into BitTorrent's primary product. Wired shines some light on the motivation for the move around:
A big part of the commercial opportunity for the tool, BitTorrent executives believe, lies in the reality that large corporations are aggressively reining in data following Snowden’s revelations.
Like Dropbox, BitTorrent Sync enables easy transfer of music, documents, and other files. But Sync's decentralized structure distinguishes it. Sync replaces data-storage centers, which the NSA can easily tap, with a peer-to-peer network. Like the BitTorrent protocol, users can share files directly, from one device to another. This leaves absolutely no opportunity for an agency like the NSA to harvest bulk data, because it cannot penetrate a central server. This method of file-sharing is somewhat less convenient because, Wired explains, “in order to synchronize files across multiple systems, all must be online at the same time.” But CEO Eric Klinker believes that the pros outweigh the cons for many consumers.
Sync has also been used as a platform for other exciting projects. Wired reports:
Two open source programmers, one in Texas and one in South Africa, have launched vole.cc, a distributed social network built on Sync. Last month, an engineer who works for Harvard University unveiled SyncNet, a parallel version of the world wide web that runs on Sync.
Decentralized technologies are stirring a productive excitement. Bitcoin, the cryptocurrency, similarly relies on a peer-to-peer protocol. Projects like BitCloud, which aims to “decentralize the internet,” are popping up. The sharing economy is nurturing disruptive technologies that grant increased privacy, cheaper access, and a decentralized protocol. The “Dropbox killer” is embedded in that trend.
05 Feb 13:44
Compressed multiresolution basis for the Laplacian [Applied Mathematics]
by Ozolins, V., Lai, R., Caflisch, R., Osher, S.
This paper describes an regularized variational framework for developing a spatially localized basis, compressed plane waves, that spans the eigenspace of a differential operator, for instance, the Laplace operator. Our approach generalizes the concept of plane waves to an orthogonal real-space basis with multiresolution capabilities.
Meichen_Yu likes this
05 Feb 13:42
Self-replicating colloidal clusters [Physics]
by Zeravcic, Z., Brenner, M. P.
We construct schemes for self-replicating clusters of spherical particles, validated with computer simulations in a finite-temperature heat bath. Each particle has stickers uniformly distributed over its surface, and the rules for self-replication are encoded into the specificity and strength of interactions. Geometrical constraints imply that a compact cluster can copy...
Meichen_Yu likes this
03 Feb 19:14



Did Woody Allen Molest His Daughter, Dylan Farrow? And If So, Should You Disavow His Films?
by Nick Gillespie
 The New York Times'
Nicholas Kristof has posted
a letter from Dylan Farrow, the daughter of Woody Allen and Mia
Farrow, in which Dylan says her father repeatedly sexually abused
her:
The New York Times'
Nicholas Kristof has posted
a letter from Dylan Farrow, the daughter of Woody Allen and Mia
Farrow, in which Dylan says her father repeatedly sexually abused
her:
What’s your favorite Woody Allen movie? Before you answer, you should know: when I was seven years old, Woody Allen took me by the hand and led me into a dim, closet-like attic on the second floor of our house. He told me to lay on my stomach and play with my brother’s electric train set. Then he sexually assaulted me. He talked to me while he did it, whispering that I was a good girl, that this was our secret, promising that we’d go to Paris and I’d be a star in his movies. I remember staring at that toy train, focusing on it as it traveled in its circle around the attic. To this day, I find it difficult to look at toy trains....
Dylan Farrow (also known as Malone Farrow) has circulated the letter because Allen is the recipient of a Golden Globe Lifetime Achievement Award and is nominated for an Oscar.
In an introductory note, Kristof writes that Allen "was never prosecuted in this case and has consistently denied wrongdoing; he deserves the presumption of innocence" but also that "because countless people on all sides have written passionately about these events, but we haven’t fully heard from the young woman who was at the heart of them."
 Farrow's letter concludes:
Farrow's letter concludes:
Imagine your seven-year-old daughter being led into an attic by Woody Allen. Imagine she spends a lifetime stricken with nausea at the mention of his name. Imagine a world that celebrates her tormenter.
Are you imagining that? Now, what’s your favorite Woody Allen movie?
The issue has many similarities with the controversy surrounding Roman Polanski, who in 1978 pled guilty to a charge of unlawful sex with a minor and then fled the United States before the sentencing phase. In 2009, when Polanski was arrested in Switzerland and put under house arrest, many critical admirers and Hollywood associates of the director came to his defense, saying that he should not be imprisoned despite his admission of guilt.
Allen, of course, has never been prosecuted, let alone convicted, of any sex crime. As Farrow writes in her open letter:
After a custody hearing denied my father visitation rights, my mother declined to pursue criminal charges, despite findings of probable cause by the State of Connecticut – due to, in the words of the prosecutor, the fragility of the “child victim.”
In a recent story at The Daily Beast, Robert B. Weide, who directed a documentary about Allen, throws significant shadows on the claims made by the Farrows (Dylan, brother Ronan, and mother Mia) over the years while hardly exonerating Allen. "Did this event actually occur?," asks Weide, "If we’re inclined to give it a second thought, we can each believe what we want, but none of us know. Why does the adult Malone (Dylan) say it happened? Because she obviously believes it did, so good for her for speaking out about it." By his own admission, Weide doesn't say he can definitively say what did or didn't happen, but he makes a strong case that the accusations, while doubtless believed by Dylan Farrow, are not true.
With the understanding that clarity doesn't abound in the case, I'm curious as to how readers feel about evaluating creative work in light of not simply scandalous but criminal biography. In the case of Polanski, I've generally stopped seeing his films, a decision made easy by the fact that most of his movies are simply terrible. With some few notable exceptions, his output is tilted decidedly more toward execrable junk like Pirates, Frantic, Fearless Vampire Killers, and The Ninth Gate than it is toward Chinatown. Similarly for Allen, who ceased to produce consistently interesting movies decades ago (IMO at least).
But is there a general principle that should be applied? If artists are not simply awful human beings but criminals, should we turn away from their work? Arthur Koestler was a rapist, according to one of his biographers. Does that mean his great anti-totalitarian novel, Darkness at Noon, should go unread? Edmund Wilson was a wife-beater, Picasso well beyond a sociopath, and on and on. When it comes to figures such as Martin Heidegger (an actual Nazi) and Paul de Man (a Nazi collaborator) and others in the past, the question is simpler: We can add new disclosures or information to a study of their influence and an estimation of whether their reputations are deserved. When faced with living, breathing creators such as Allen and Polanski, that sort of dodge isn't really available. Add to that the notion that even the most devoted critic of either would have to really be nuts to claim that The Curse of the Jade Scorpion or another version of Oliver Twist would justify a parking ticket much less sexual abuse of children.
What do you think readers? When - if ever - does the biography of a creator mean that you cannot or should not in good conscience patronize an artist?
03 Feb 18:51


How to work out proofs in Analysis I
by gowers
Now that we’ve had several results about sequences and series, it seems like a good time to step back a little and discuss how you should go about memorizing their proofs. And the very first thing to say about that is that you should attempt to do this while making as little use of your memory as you possibly can.
Suppose I were to ask you to memorize the sequence 5432187654321. Would you have to learn a string of 13 symbols? No, because after studying the sequence you would see that it is just counting down from 5 and then counting down from 8. What you want is for your memory of a proof to be like that too: you just keep doing the obvious thing except that from time to time the next step isn’t obvious, so you need to remember it. Even then, the better you can understand why the non-obvious step was in fact sensible, the easier it will be to memorize it, and as you get more experienced you may find that steps that previously seemed clever and nonobvious start to seem like the natural thing to do.
For some reason, Analysis I contains a number of proofs that experienced mathematicians find easy but many beginners find very hard. I want to try in this post to explain why the experienced mathematicians are right: in a rather precise sense many of these proofs really are easy, in the sense that if you just repeatedly do the obvious thing you will solve them. Others are mostly like that, with perhaps one smallish idea needed when the obvious steps run out. And even the hardest ones have easy parts to them.
I feel so strongly about this that a few years ago I teamed up with a colleague of mine, Mohan Ganesalingam, to write a computer program to solve easy problems. And after a lot of effort, we produced one that can solve several (but not yet all — there are still difficulties to sort out) problems of the kind I am talking about: easy for the experienced mathematician, but hard for the novice. Now you have some huge advantages over a computer. For example, you understand the English language. Also, you can be presented with a vague instruction such as “Do any obvious simplifications to the expression and then see whether it reminds you of anything,” and you will be able to follow it. (In principle, so could the program, but only if we spent a long time agonizing about what exactly constitutes an “obvious” simplification, what kind of similarity should be sufficient for one mathematical expression to trigger the program to call up another, and so on.) So if a mere computer can solve these problems, you should definitely be able to solve them.
What I plan to do in this post is basically explain how the program would go about proving some of the theorems we’ve proved in the course. To explain exactly how it works would be complicated. However, because you are humans, there are lots of technical details that I don’t need to worry about, and what remains of the algorithm when you ignore those details is really pretty simple.
The rough idea is that you should equip yourself with a small set of “moves” and simply apply these moves when the opportunity arises. That is an oversimplification, since sometimes one can do the moves in “silly” ways, but merely being consciously aware of the moves is very useful. (Incidentally, the notion of “silliness” is hard to define formally but is something that humans find easy to recognise when they see examples of it. So that’s another example of the kind of advantage you have over the computer.)
Subsequences of Cauchy sequences
I’m going to describe a way of keeping track of where you have got to in your discovery of a proof. It’s not something I suggest you do for the rest of your mathematical lives. Rather, it is something that you might like to consider doing if you find it hard to come up with typical Analysis I proofs. If you use this technique a few times, then it should get easier, and after a while you will find that you don’t need to use the technique any more.
The technique is simply to record what statements you are likely to want to use, and what statement you are trying to prove. Both of these can change during the course of your proof discovery, as we shall see.
I think the easiest way to explain this and the moves is to begin by giving an example of the whole process in action. Then I’ll talk about the moves in a more abstract way. Let’s take as an example the proof that if a Cauchy sequence has a convergent subsequence then the sequence itself is convergent.
To begin with, we have nothing we obviously need to use, and a statement that we want to prove. That statement is the following.
—————————————————-
Every Cauchy sequence with a convergent subsequence converges
Let us begin by writing that very slightly more formally, to bring out the fact that it starts with 
—————————————————-
\ (a_n)")
")
")
The next step is to apply the “let” move, which I’ve talked about several times in lectures. If you ever have a statement to prove of the form “For every 
")
")
In our case, we write, “Let
——————————————-
Maybe the purpose of those strange horizontal lines is becoming clearer at this point. I am listing statements that we can assume above the line and ones that we are trying to prove below the line.
At this point it seems natural to give a name to the convergent subsequence that we are given. Let us call it ")
——————————————-
Having done that, I think I’ll remove the second hypothesis, since the fact that
——————————————-
The second hypothesis here is again telling us we’ve got something: a limit of the subsequence. So let’s apply the naming move again, calling this limit 
——————————————-
\to a")
That’s enough reformulation of our assumptions. It’s time to think about what we are trying to prove. To do that, we use a process called expansion. That means taking a definition and writing it out in more detail. It tends to be good to avoid expanding definitions unless you are genuinely stuck: that way you won’t miss opportunities to use results from the course rather than proving everything from first principles. However, here a proof from first principles is what is required. I’m going to do a partial expansion to start with: a sequence converges if there exists a real number that it converges to.
——————————————-
")
Now our target has changed to an existential statement. How are we going to find an
Sometimes proving existential statements is very hard, but here it is easy, since we have a candidate for the limit staring us in the face, and better still it is the only candidate around. So let us make a very reasonable guess that the sequence is going to converge to
——————————————-
That’s nice because we’ve got rid of that existential quantifier. But what do we do next? We must continue to expand: this time the definition of 
——————————————-

Now we have a target that begins with a universal quantifier, so it’s time for the “let” move again.
——————————————-


Now things become slightly harder, because this time we do not have a candidate staring us in the face for the thing we are trying to find. (The thing we are trying to find is 
Eventually all terms of
Eventually all terms of
————————————————
Eventually all terms of
The rough idea of the proof should now be clear: if all terms in the subsequence are close to
Since we are going to need to take two steps from a term in 
——————————————-


Now we are once again in a position where we have been “given” something — in this case 

——————————————-


How do we propose to “force” 







So our plan is going to be to choose 



We are now in a position to choose 

——————————————-

Now we can apply the “let” move again, to get rid of the universal quantifier in the target statement.
——————————————-

We know we’re going to take 
——————————————-

Just to make clear what I did there, it was a move called substitution. If you have a hypothesis of the form \implies Q(u)")


Since I’ve used the hypothesis
Now we have to decide how to choose 

——————————————-


Now we can substitute 
——————————————-

We can also substitute
——————————————-

And now we are done by the triangle inequality.
What were the moves we used?
Now that we have gone through a proof, let me list the main proof-generating moves we used.
The “let” move
If you are trying to prove a statement of the form “For every
The “naming” move
If you are told that something exists, then give it a name. For example, if you are given the hypothesis 
Expansion
If you are trying to prove something and you can’t find a high-level argument (by which I mean one that uses results from the course that are relevant to the statement you are trying to prove), and if what you are trying to prove involves concepts such as convergence or continuity that can be written out in low-level language (often, but not always, involving quantifiers), then rephrase what you are trying to prove in this lower-level way. That is, expand out the definition.
Substitution into a hypothesis
If you are given a hypothesis of the form ")
For example, in the proof above, we had the hypothesis “

We decided to substitute in 

(We then applied the “naming” move to get rid of the 
Modus ponens
Often a hypothesis takes a slightly more general form, where conditions are assumed. That is, it takes the form
or still more generally
\wedge\dots\wedge P_k(u)\implies Q(u)")
There the symbol 
,\dots,P_k(x)")
Substitution into a target
Suppose that you are trying to prove a statement of the form ")

We did this when we moved from trying to prove that
This is not a complete set of useful moves. However, it is a start, and I hope it will help to back up my assertion that a large fraction of the proof steps that I take when writing out proofs in lectures are fairly automatic, and steps that you too will find straightforward if you put in the practice. I’ll try to discuss more moves in future posts.
03 Feb 18:35
Debunking the value of "creativity"
by Minnesotastan
From an interesting essay by Thomas Frank in the June 2013 issue of Harper's:
What was really sick-making, though, was [the] easy assumption that creativity was a thing our society valued. Our correspondent had been hearing this all his life, since his childhood in the creativity-worshipping 1970s. He had even believed it once, in the way other generations had believed in the beneficence of government or the blessings of Providence. And yet his creative friends, when considered as a group, were obviously on their way down, not up. The institutions that made their lives possible — chiefly newspapers, magazines, universities, and record labels — were then entering a period of disastrous decline. The creative world as he knew it was not flowering, but dying.
When he considered his creative friends as individuals, the literature of creativity began to seem even worse — more like a straight-up insult. Our writer-to-be was old enough to know that, for all its reverential talk about the rebel and the box breaker, society had no interest in new ideas at all unless they reinforced favorite theories or could be monetized in some obvious way. The method of every triumphant intellectual movement had been to quash dissent and cordon off truly inventive voices. This was simply how debate was conducted. Authors rejoiced at the discrediting of their rivals (as poor Jonah Lehrer would find in 2012). Academic professions excluded those who didn’t toe the party line. Leftist cliques excommunicated one another. Liberals ignored any suggestion that didn’t encourage or vindicate their move to the center. Conservatives seemed to be at war with the very idea of human intelligence. And business thinkers were the worst of all, with their perennial conviction that criticism of any kind would lead straight to slumps and stockmarket crashes...
And what was the true object of this superstitious stuff? A final clue came from Creativity: Flow and the Psychology of Discovery and Invention (1996), in which Mihaly Csikszentmihalyi acknowledges that, far from being an act of individual inspiration, what we call creativity is simply an expression of professional consensus. Using Vincent van Gogh as an example, the author declares that the artist’s “creativity came into being when a sufficient number of art experts felt that his paintings had something important to contribute to the domain of art.” Innovation, that is, exists only when the correctly credentialed hivemind agrees that it does. And “without such a response,” the author continues, “van Gogh would have remained what he was, a disturbed man who painted strange canvases.” What determines “creativity,” in other words, is the very faction it’s supposedly rebelling against: established expertise.
Consider, then, the narrative daisy chain that makes up the literature of creativity. It is the story of brilliant people, often in the arts or humanities, who are studied by other brilliant people, often in the sciences, finance, or marketing. The readership is made up of us — members of the professional-managerial class — each of whom harbors a powerful suspicion that he or she is pretty brilliant as well. What your correspondent realized, relaxing there in his tub one day, was that the real subject of this literature was the professional-managerial audience itself, whose members hear clear, sweet reason when they listen to NPR and think they’re in the presence of something profound when they watch some billionaire give a TED talk. And what this complacent literature purrs into their ears is that creativity is their property, their competitive advantage, their class virtue. Creativity is what they bring to the national economic effort, these books reassure them — and it’s also the benevolent doctrine under which they rightly rule the world.
Ionut likes this
03 Feb 18:33
How taxpayers support the National Football League
by Minnesotastan
In the wake of all the Superbowl hoopla, it seems appropriate to offer some excerpts from a trenchant article in The Atlantic:
Last year was a busy one for public giveaways to the National Football League. In Virginia, Republican Governor Bob McDonnell, who styles himself as a budget-slashing conservative crusader, took $4 million from taxpayers’ pockets and handed the money to the Washington Redskins, for the team to upgrade a workout facility. Hoping to avoid scrutiny, McDonnell approved the gift while the state legislature was out of session. The Redskins’ owner, Dan Snyder, has a net worth estimated by Forbes at $1 billion. But even billionaires like to receive expensive gifts...
In Minnesota, the Vikings wanted a new stadium, and were vaguely threatening to decamp to another state if they didn’t get it. The Minnesota legislature, facing a $1.1 billion budget deficit, extracted $506 million from taxpayers as a gift to the team...
A year after Hurricane Katrina hit New Orleans, the Saints resumed hosting NFL games: justifiably, a national feel-good story. The finances were another matter. Taxpayers have, in stages, provided about $1 billion to build and later renovate what is now known as the Mercedes-Benz Superdome... Taxpayers even footed the bill for the addition of leather stadium seats.. Though Louisiana Governor Bobby Jindal claims to be an anti-spending conservative, each year the state of Louisiana forcibly extracts up to $6 million from its residents’ pockets and gives the cash to Benson as an “inducement payment”—the actual term used—to keep Benson from developing a wandering eye...
That’s right—extremely profitable and one of the most subsidized organizations in American history, the NFL also enjoys tax-exempt status. On paper, it is the Nonprofit Football League... The insertion of professional football leagues into the definition of not-for-profit organizations was a transparent sellout of public interest. This decision has saved the NFL uncounted millions in tax obligations..
Baseball, basketball, ice hockey, and other sports also benefit from this same process. But the fact that others take advantage of the public too is no justification.
30 Jan 21:55

Not an electric telephone obviously, but a true "phone" designed to transmit sounds over distances, created in South America before the era of European contact. Smithsonian has the story:
This telephone is 1,200 years old
by Minnesotastan
Not an electric telephone obviously, but a true "phone" designed to transmit sounds over distances, created in South America before the era of European contact. Smithsonian has the story:
The marvel of acoustic engineering—cunningly constructed of two resin-coated gourd receivers, each three-and-one-half inches long; stretched-hide membranes stitched around the bases of the receivers; and cotton-twine cord extending 75 feet when pulled taut—arose out of the Chimu empire at its height. The dazzlingly innovative culture was centered in the Río Moche Valley in northern Peru, wedged between the Pacific Ocean and the western Andes. “The Chimu were a skillful, inventive people,” Matos tells me as we don sterile gloves and peer into the hollowed interiors of the gourds. The Chimu, Matos explains, were the first true engineering society in the New World, known as much for their artisanry and metalwork as for the hydraulic canal-irrigation system they introduced, transforming desert into agricultural lands...More at the link. I've been unable to locate a better photograph than the embed, but it's clear that this was the equivalent of a modern tin-can telephone.
dh.oregonwild, Ionut and one other like this