A friend who just visited Australia was telling me about "flying foxes" last night. Giant bats! Sounded terribly frightening! What's next, Australia, egg laying mammals with duck bills and a crippling poison? Miniature spiders with deadly venom? Floating sacks of deadly jelly? Poison centipedes of unusual size?
But the "flying foxes" are actually really cute. They're just puppies with wings. They don't have echolocation. They basically have the diet of bees. Well, big bees, anyway (and not the crazy Australian bees).
(ht for general idea to Margafret)
Nosimpler
Shared posts
03 Sep 01:38
Secular chaos [Astronomy]
by Lithwick, Y., Wu, Y.
In the inner solar system, the planets’ orbits evolve chaotically, driven primarily by secular chaos. Mercury has a particularly chaotic orbit and is in danger of being lost within a few billion years. Just as secular chaos is reorganizing the solar system today, so it has likely helped organize it...
02 Sep 19:18



Great Job, Internet!: Cows are also fans of Lorde’s “Royals”
by Kayla Reed
While each cow is her own woman, it’s hard not to stereotype when almost all cattle herd toward the sound of brass instruments. And we know this not because we’re farmers, but because there are a few videos out there already. Still, the newest one from YouTube user Farmer Derek Kingenberg has inevitably gone viral. The trombone player comfortably plops in a lawn chair and begins to play Lorde’s “Royals,” and slowly but surely dozens of cows appear on the horizon and gather closely to listen. That’s not to stereotype and say that all cows listen to Lorde, though, because some of them may have thought it was “Weird Al” Yankovic’s “Foil.”
[via Laughing Squid]
Austin.soplata likes this
01 Sep 20:57
Militarized local SWAT teams can be tricked by hackers into raiding homes of innocent people. The Vice video above illustrates the problem, which is also discussed at Salon:
"Swatting" explained
by Minnesotastan
Militarized local SWAT teams can be tricked by hackers into raiding homes of innocent people. The Vice video above illustrates the problem, which is also discussed at Salon:
“The caller claimed to have shot two co-workers, held others hostage, and threatened to shoot them,” the Littleton Police Department said in a statement. “He stated that if the officers entered he would shoot them as well.”
What the cameras captured is a perilous new prank known as “swatting,” or making a false report to get the SWAT team to invade a rival gamer’s space. As evidenced by the Vice News report below, this can involve disguising the caller identity and making some potentially life-threatening claims.
29 Aug 18:31



Gilian Tett gets it very wrong on racial profiling
by Cathy O'Neil, mathbabe
Last Friday Gillian Tett ran a profoundly disturbing article in the Financial Times entitled Mapping Crime – Or Stirring Hate? (hat tip Marcos Carreira), which makes me sad to say this given how much respect I normally have for her regarding her coverage of the financial crisis.
In the article, Tett describes the predictive policing model used by the Chicago police force, which told the police where to go to find criminals based on where people had been arrested in the past.
Her article reads like an advertisement for racist profiling. First she deftly and indirectly claims the model is super successful at lowering the murder rate without actually coming out and saying so (since she actually has only correlative evidence):
And when Weis launched the programme in early 2010, together with a clever policeman-cum-computer expert called Brett Goldstein, it delivered impressive results. In the first year the murder rate fell 5 per cent and then continued to tumble. Indeed by the summer of 2011 it looked as if Chicago’s annual death toll would soon drop below 400, the lowest since 1965. “The homicide rates for that summer were just crazy low compared to what we had been,” Weis observes.
But then, following his departure from the force, the programme was wound down in late 2011. And, tragically, the murder rate immediately rose again.
Here’s the thing, it’s really hard to actually know why murder rates go up and down. In New York City we’ve been using Stop & Frisk as the violent crime rates have been steadily lowering in this city (and many others), and for a long time Bloomberg took credit for that through the Stop & Frisk practice. But when Stop & Frisk rates went down, murder rates didn’t shoot up. Just saying. And that’s ignoring how reliable the police data is, which is another issue. Let’s take a look at her evidence for a longer time frame:
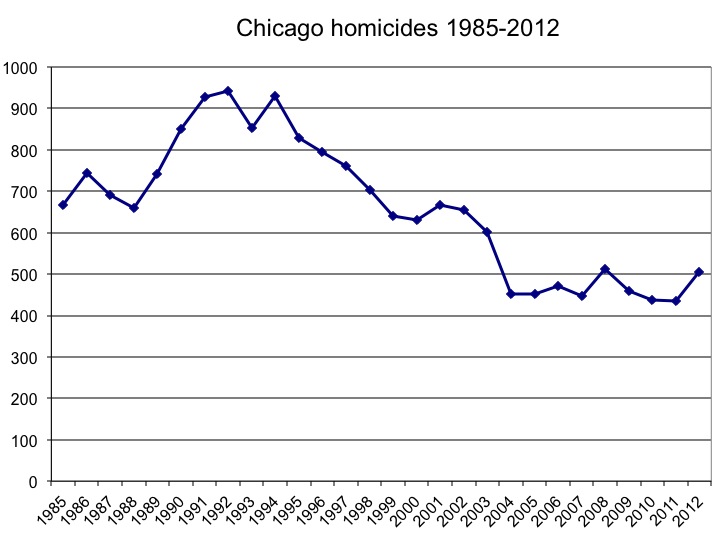
She’s talking about that small uptick at the end, which to the naked eye could well be statistical noise.
The reason I’m pointing out her bad statistics is that she needs them to set up the following, truly disturbing paragraphs (emphasis mine):
But while racism is rightly deemed unacceptable, computer programs pose more subtle questions. If a spreadsheet forecast has a racial imbalance, is this likely to reinforce existing human biases, or racial profiling? Or is a weather map of crime simply a neutral tool? To put it another way, does the benefit of using predictive policing outweigh any worries about political risk?
Personally, I think it does. After all, as the former CPD computer experts point out, the algorithms in themselves are neutral. “This program had absolutely nothing to do with race… but multi-variable equations,” argues Goldstein. Meanwhile, the potential benefits of predictive policing are profound.
No, Gillian Tett, there is no such thing as a neutral tool. No algorithm focused on human behavior is neutral. Anything which is trained on historical human behavior embeds and codifies historical and cultural practices. Specifically, this means that the fact that black Americans are nearly four times as likely as whites to be arrested on charges of marijuana possession even though the two groups use the drug at similar rates would be seen by such a model (or rather, by the people who deploy the model) as a fact of nature that is neutral and true. But it is in fact a direct consequence of systemic racism.
Put it another way: if we allowed a model to be used for college admissions in 1870, we’d still have 0.7% of women going to college. Thank goodness we didn’t have big data back then!
This is very scary to me, when even Gillian Tett, who famously predicted the financial crisis in 2006, can be fooled. We clearly have a lot of work to do.
29 Aug 17:34
Space ethics to test directed panspermia. (arXiv:1407.5618v3 [physics.pop-ph] UPDATED)
by Maxim A. Makukov, Vladimir I. shCherbak
NosimplersssPACE ETHICS
The hypothesis that Earth was intentionally seeded with life by a preceding extraterrestrial civilization is believed to be currently untestable. However, analysis of the situation where humans themselves embark on seeding other planetary systems motivated by survival and propagation of life reveals at least two ethical issues calling for specific solutions. Assuming that generally intelligence evolves ethically as it evolves technologically, the same considerations might be applied to test the hypothesis of directed panspermia: if life on Earth was seeded intentionally, the two ethical requirements are expected to be satisfied, what appears to be the case.
25 Aug 21:34
"Music" heard on the back side of the moon
by Minnesotastan
During a podcast of No Such Thing as a Fish, the elves mentioned in passing a "symphony" heard by astronauts on the far side of the moon. Today I found the following at Above Top Secret:
Most of us Conspiracy Researchers will recall the case of Apollo 10 Astronauts : Tom Stafford, Gene Cernan and John Young discussing the “outer-spacey” music they head while on the far side of the moon. This music happened during the LOS (loss of signal) period that occurred while the communications between themselves and mission control were temporarily unavailable due to their position behind the moon. Gene Cernan is the first to hear the music (in the LM) and the transcripts shows that he radios John Young in the CSM to confirm he is hearing the same thing. John young then replies “Yea, I got it too…….and see who was outside?” Not only does JY confirm he hears it, but look at his following statement, “and see who is outside” ! Now who could be “outside” the space vessels?! More importantly John Young is inferring that there may be a connection between the “music” and “who is outside” of their crafts. After a few minutes of dialogue regarding the mission Gene Cernan brings up the topic again, “boy, that sure is strange music” in which John Young replies “ Were going to have to find out about that. Nobody will Believe us.”More at the link, where you can access Apollo 10 transcripts and experiences by other astronauts. Here is one possible explanation:
During their next orbit of the dark side the “music” RETURNS. Addressing Tom Stafford this time Gene Cernan asks “You hear music Tom? That crazy whistling?” In which Tom Stafford replies “I can hear it.” Gene replies “that’s really weird” and Tom replies “it is.” Further on Gene AGAIN brings up the subject by stating “Listen to eerie music”. They even continue random dialogue regarding the music and how eerie and weird it was, and that nobody is going to believe them.
There hasn't ever really been an "official" explanation of these sounds (described as whistling and buzz-saw sounds). But most scientists offer that it could be attributed to either radio interference in the lander or perhaps an artifact of the Sun's solar wind.
Since the most prominent example of this sound was when the Apollo 15 astronauts were on the far side of the Moon, it could be suggested that the Moon's gravity was gravitationally focusing the Sun's wind (a mix of high energy charged particles) onto the capsule. That interaction would created electromagnetic distortions, which could produce sounds inside the capsule.
Ionut likes this
25 Aug 17:07

Banana Republics and Bad Apples Abroad
by Scott Beauchamp
Photo by Bradley Gordon
Last month, quietly overshadowed by a summer of celebrity deaths and violent instability in the Middle East, the Eleventh Circuit Court of Appeals dismissed a lawsuit against the American produce company Chiquita. Filed on behalf of over 4,000 Colombians, the suit alleged that Chiquita financed and provided logistical support for United Self-Defense Forces of Colombia, a violent right-wing militia known primarily for the murder and kidnapping of leftists during Colombia’s civil war.
Chiquita already admitted to doing as much in 2007 when they pleaded guilty to giving the AUC (the Spanish acronym for United Self-Defense Forces of Colombia), a terrorist organization, almost $2 million to smooth its operations in the country. In other words, Chiquita hired a private army to do whatever it deemed necessary in the name of “protection” so that it could make more money.
After acknowledging they had conducted financial transactions with a terrorist organization, Chiquita agreed to a $25 million settlement as part of a plea agreement. According to the Justice Department, between 1997 and 2004 (the years in which the United States government officially designated AUC as a terrorist organization), Chiquita had made $1.7 million in payments to AUC through its Colombian subsidiary Banadex.
Fernando Aguirre, then CEO of Chiquita, classified the payments as extortion. He claimed that the company was paying for the safety of its employees in a chaotic and war-torn environment. In fact, it was integral to the plea agreement that Chiquita should claim that the company never directly paid for security services.
The “we were the real victims here” attitude was eventually repudiated by Chiquita company internal memos gathered through an FOIA request by the George Washington University Law School and the Digital National Security Archive. According to Michael Evans, the director of the National Security Archive’s Colombia documentation project:
These extraordinary records are the most detailed account to date of the true cost of doing business in Colombia. Chiquita’s apparent quid pro quo with guerrillas and paramilitaries responsible for countless killings belies the company’s 2007 plea deal with the Justice Department. What we still don’t know is why U.S. prosecutors overlooked what appears to be clear evidence that Chiquita benefited from these transactions.
In other words, Chiquita paid militias, who killed or kidnapped the people standing in their way of their profits—mostly union leaders, students, and relatively powerless farmers. By 2003, Banadex in Colombia was Chiquita’s “most profitable operation.” That’s what Chiquita got in return for its investment in AUC.
All this being known, why was the most recent suit thrown out? Well, you can blame our über business-friendly Supreme Court for their narrowest-of-narrow way of implementing something called the Alien Tort Statute.
In theory, the ATS allows citizens living in other countries to sue Americans for committing human rights abuses. But a precedent set by the Supreme Court last year in Kiobel v. Royal Dutch Petroleum makes it inordinately difficult to bring these kinds of suits forward. Using the logic of Kiobel, the Eleventh District Appellate Court threw out the Chiquita case because the crimes that occurred abroad did not “touch and concern” the United States, as the decision states. Still, assuming that that’s true (and we should not be not convinced that it is), of what value would such a narrowly defined ATS be? It hardly seems like a deterrent to corporations subsidizing violence at all.
The Chiquita suit is emblematic of a huge legal loophole, but it isn’t an isolated incident. American companies often use the rest of the Western hemisphere as their lawless playground, while U.S. law provides little to no legal recourse for the people who live there. Coca-Cola, for instance, has become a favored cause for college-age activists in America to rally around in the past decade; “the new Nike,” as some have labeled it. The “Killer Coke” movement has focused on the killing of eight workers—one a prominent union leader—by right-wing mercenaries at a Coke bottling factory in Colombia, allegedly at the behest of the company itself.
The incident led to a 2001 lawsuit filed by the United Steel Workers of America and the International Labor Rights Fund on behalf of the workers against Coca-Cola, alleging that the company “hired, contracted with, or otherwise directed paramilitary forces.” The case was eventually dismissed, but an official New York City fact-finding delegation did corroborate the workers’ story in 2004. The delegation found evidence to support Coca-Cola being at least partially responsible for kidnap, torture, and murder. In all, they found at least 179 instances of human rights violations by Coca-Cola in Colombia.
Even more recent than the cases in Colombia, and maybe scarier to Americans by virtue of proximity, is the case of Wells Fargo Bank working in tandem with Mexican drug cartels. Wachovia, purchased by Wells Fargo in 2008, admitted its guilt in laundering as much as $420 billion for the cartels. At least in this case they were punished, even if it was just a slap on the wrist, with a $160 million fine for violating the Bank Secrecy Act. $420 billion is a lot of money to be kept secret. One can only imagine how much weaponry, ammo, bribes, and assassinations it could pay for.
Although the numbers involved are shocking, the crime isn’t anything new. American capital has been used to finance the violent repression of democratic movements in America for at least as long as there has been a global economy to manipulate. The United Fruit Company, for example, had a record of subsidizing brutal regimes and lobbying for the suppression of populist action. Their stranglehold on Central America is legendary, fictionalized in literature by writers such as Gore Vidal and Gabriel García Márquez, and even earning the moniker “el pulpo,” or “the octopus,” in popular vernacular.
It shouldn’t come as a surprise that United Fruit’s intervention in the inner workings of Central American governments is where the term “Banana Republic” originates. Two of United Fruit Company’s most legendary exploits (a term meant literally in these cases), were its involvement with the 1954 coup in Guatemala and the 1928 “Banana Massacre” in which the United Fruit Company successfully lobbied the Colombian government to violently suppresses a labor strike. United Fruit Company eventually merged with AMK in 1970 to become United Brands Company. United Brands was transformed in 1984 into, you guessed it, Chiquita Brands International. The more things change, etcetera.
So what does this all add up to? We have Chiquita paying off murderers. We have Coca-Cola doing the same. We have Wachovia helping to finance the brutality of drug cartels. And we have a recorded legacy of this kind of thing going back before the Second World War. It adds up to more than just a trend, more than a series of random events, and it should compel us to demand more than piecemeal corrective actions like “fixing” the Alien Tort Statute. Instead, we should be shocked into the recognition of how global capitalism actually operates.
These aren’t “bad apples.” This is the heart of it. As a resident of Gabriel García Márquez’s fictional town of Macondo says after his home is wrecked by the greed of an international fruit corporation, “Look at the mess we’ve got ourselves into just because we invited a gringo to eat some bananas.”
[This post has been updated to correct the spelling of Colombia. Our apologies to both South Carolina and South America.]
24 Aug 17:55
(G)Libertarianism
by noreply@blogger.com (Atrios)
The thing is that liberals see most self-identified libertarians as being completely full of shit. At best, they're in the "I've got mine screw you" and "freedom for me but not for thee" crowds, at worst they're complete sociopaths.
But leaving behind the degree of fullofshitness, there is a liberal view of abuse of state power which self-described libertarians often mention but rarely get that passionate about. Much better to fret about high taxes or occupational licensing. Unwarranted mass incarceration, unaccountable police brutality, authorizing the state to kill its own citizens, absurd civil forfeiture procedures... these are all clear abuses of state power! Much of the rest of it is just a debate over what should be appropriate policies, not whether they're abuses (though glibertarians tend to call anything they don't like an abuse of state power).
There are people such as Radley Balko who take this stuff on! Good for them! Liberals would like libertarians more if they spent more time on the militarization of the police and the approved abuse of (especially) minority populations rather than, say, seatbelt laws and top marginal tax rates. Because top marginal tax rates aren't actually a libertarian issue, just a conservative one.
But leaving behind the degree of fullofshitness, there is a liberal view of abuse of state power which self-described libertarians often mention but rarely get that passionate about. Much better to fret about high taxes or occupational licensing. Unwarranted mass incarceration, unaccountable police brutality, authorizing the state to kill its own citizens, absurd civil forfeiture procedures... these are all clear abuses of state power! Much of the rest of it is just a debate over what should be appropriate policies, not whether they're abuses (though glibertarians tend to call anything they don't like an abuse of state power).
There are people such as Radley Balko who take this stuff on! Good for them! Liberals would like libertarians more if they spent more time on the militarization of the police and the approved abuse of (especially) minority populations rather than, say, seatbelt laws and top marginal tax rates. Because top marginal tax rates aren't actually a libertarian issue, just a conservative one.
22 Aug 19:30

A young man in Florida is accused of murdering his roommate (details at The Telegraph). Evidence at his trial will include information retrieved from his PDA (screencap above).
"Siri, where should I bury my roommate?"
by Minnesotastan
A young man in Florida is accused of murdering his roommate (details at The Telegraph). Evidence at his trial will include information retrieved from his PDA (screencap above).
The Siri device, which had been accessed via Facebook, allegedly responded with the question: "What kind of place are you looking for? Swamps. Reservoirs. Metal foundries. Dumps."..
Detectives who accessed Bravo's phone found that he had used the flashlight facility for 48 minutes on the day of Aguilar's disappearance.
18 Aug 19:15
Best of both worlds: promise of combining brain stimulation and brain connectome.
by Luft CD, Pereda E, Banissy MJ, Bhattacharya J
NosimplerBorg LOL
Best of both worlds: promise of combining brain stimulation and brain connectome.
Front Syst Neurosci. 2014;8:132
Authors: Luft CD, Pereda E, Banissy MJ, Bhattacharya J
Abstract
Transcranial current brain stimulation (tCS) is becoming increasingly popular as a non-pharmacological non-invasive neuromodulatory method that alters cortical excitability by applying weak electrical currents to the scalp via a pair of electrodes. Most applications of this technique have focused on enhancing motor and learning skills, as well as a therapeutic agent in neurological and psychiatric disorders. In these applications, similarly to lesion studies, tCS was used to provide a causal link between a function or behavior and a specific brain region (e.g., primary motor cortex). Nonetheless, complex cognitive functions are known to rely on functionally connected multitude of brain regions with dynamically changing patterns of information flow rather than on isolated areas, which are most commonly targeted in typical tCS experiments. In this review article, we argue in favor of combining tCS method with other neuroimaging techniques (e.g., fMRI, EEG) and by employing state-of-the-art connectivity data analysis techniques (e.g., graph theory) to obtain a deeper understanding of the underlying spatiotemporal dynamics of functional connectivity patterns and cognitive performance. Finally, we discuss the possibilities of using these combined techniques to investigate the neural correlates of human creativity and to enhance creativity.
PMID: 25126060 [PubMed]
18 Aug 19:01

The Impact of Jury Race in Criminal Trials
by Alex Tabarrok
In a great paper, The Impact of Jury Race in Criminal Trials, Shamena Anwar, Patrick Bayer and Randi Hjalmarsson exploit random variation in the jury pool to estimate the effect of race on criminal trials. The authors have data from nearly 800 trials in two Florida counties. On any given day, a jury pool is randomly drawn from a master list based on driver’s licenses. On some days, the pool of about 30 people contains some black members and on other days, purely for random reasons, it does not. The voir dire process– removals, excuses and challenges–whittles down the jury pool to 6 jury members with typically 1 alternate.
removals, excuses and challenges–whittles down the jury pool to 6 jury members with typically 1 alternate.
The authors have data on the race, gender, and age of each member of the jury pool as well as each member of the ultimate jury. The authors also know the race and gender of the defendant and the charges. What the authors discover is that all white juries are 16% more likely to convict black defendants than white defendants but the presence of just a single black person in the jury pool equalizes conviction rates by race. The effect is large and remarkably it occurs even when the black person is not picked for the jury. The latter may not seem possible but the authors develop an elegant model of voir dire that shows how using up a veto on a black member of the pool shifts the characteristics of remaining pool members from which the lawyers must pick; that is, a diverse jury pool can make for a more “ideologically” balanced jury even when the jury is not racially balanced.
The author’s results show not only that blacks and whites are treated differently depending on the composition of the jury pool but also that random variation in the jury pool adds to the variability of sentences holding race constant. Like is not treated as like. The results also suggest that we don’t need racial quotas to increase fairness. We can increase fairness and reduce variability in a racially neutrally way by expanding the size of juries. Six-person juries have become common because they are cheap(er) but a return to twelve person juries would reduce the variability of sentences and greatly equalize conviction rates across race.
15 Aug 20:43


ICM2014 — Bhargava laudatio
by gowers
I ended up writing more than I expected to about Avila. I’ll try not to fall into the same trap with Bhargava, not because there isn’t lots to write about him, but simply because if I keep writing at this length then by the time I get on to some of the talks I’ve been to subsequently I’ll have forgotten about them.
Dick Gross also gave an excellent talk. He began with some of the basic theory of binary quadratic forms over the integers, that is, expressions of the form 




")

")
")
^2+b(2x+y)(5x+3y)+c(5x+3y)^2")
(modulo any mistakes I may have made). Because the matrix is invertible over the integers, the new form can be transformed back to the old one by another change of basis, and hence takes the same set of values. Two such forms are called equivalent.
x^2+(4a+11b+30c)xy+(a+3b+9c)y^2")
For some purposes it is more transparent to write a binary quadratic form as
If we do that, then it is easy to see that replacing a form by an equivalent form does not change its discriminant since it is just -4 times the determinant of the matrix of coefficients, which gets multiplied by a couple of matrices of determinant 1 (the base-change matrix and its transpose).

Given any equivalence relation it is good if one can find nice representatives of each equivalence class. In the case of binary quadratic forms, there is a unique representative such that 


Even more interesting is that the equivalence classes form an Abelian group under a certain composition law that was defined by Gauss. Apparently it occupied about 30 pages of the Disquisitiones, which are possibly the most difficult part of the book.
Going back to the number of forms of discriminant
\sim\frac\pi{18}T^{3/2}")
There was, however, a heuristic justification for the formula. (I can’t remember whether Dick Gross said that Gauss had explicitly stated this justification or whether it was simply a reconstruction of what he must have been thinking.) It turns out that the sum on the left-hand side works out as the number of integer points in a certain region of 
T^{3/2}")
One rather amazing thing that Bhargava did, though it isn’t his main result, was show that if a binary quadratic form represents all the positive integers up to 290 then it represents all positive integers, and that this bound is best possible. (I may have misremembered the numbers. Also, one doesn’t have to know that it represents every single number up to 290 in order to prove the result: there is some proper subset of 
But the first of his Fields-medal-earning results was quite extraordinary. As a PhD student, he decided to do what few people do, and actually read the Disquisitiones. He then did what even fewer people do: he decided that he could improve on Gauss. More precisely, he felt that Gauss’s definition of the composition law was hard to understand and that it should be possible to replace it by something better and more transparent.
I should say that there are more modern ways of understanding the composition law, but they are also more abstract. Bhargava was interested in a definition that would be computational but better than Gauss’s. I suppose it isn’t completely surprising that Gauss might have produced something suboptimal, but what is surprising is that it was suboptimal and nobody had improved it in 200 years.
The key insight came to Bhargava, if we are to believe the story he tells us, when he was playing with a Rubik’s cube. He realized that if he put the letters 

Here’s a fancier way that Dick Gross put it. Bhargava reinvented the composition law by studying the action of SL^3")

")
![R=\mathbb{Z}[(D+\sqrt{D})/2]](https://s0.wp.com/latex.php?latex=R%3D%5Cmathbb%7BZ%7D%5B%28D%2B%5Csqrt%7BD%7D%29%2F2%5D&bg=ffffff&fg=333333&s=0 "R=\mathbb{Z}[(D+\sqrt{D})/2]")

In this way, Bhargava found a symmetric reformulation of Gauss composition. And having found the right way of thinking about it, he was able to do what Gauss couldn’t, namely generalize it. He found 14 more integral representations on objects like 
He was also able to enumerate number fields of small degree, showing that the number of fields of degree 

I spent the academic years 2000-2002 at Princeton and as a result had the privilege of attending Bhargava’s thesis defence, at which he presented these results. It must have been one of the best PhD theses ever written. Are there any reasonable candidates for better ones? Perhaps Simon Donaldson’s would offer decent competition.
It’s not clear whether those results would have warranted a Fields medal on their own, but the matter was put beyond the slightest doubt when Bhargava and Shankar proved a spectacular result about elliptic curves. Famously, an elliptic curve comes with a group law: given two points, you take the line through them, see where it cuts the elliptic curve again, and define that to be the inverse of the product. This gives an Abelian group. (Associativity is not obvious: it can be proved by direct computation, but I don’t know what the most conceptual argument is.) The group law takes rational points to rational points, and a famous theorem of Mordell states that the rational points form a finitely generated subgroup. The structure theorem for Abelian groups tells us that for some 

It is conjectured that the rank can be arbitrarily large, but not everyone agrees with that conjecture. The record so far is held by the curve




discovered by Noam Elkies (who else?) and shown to have rank 19. According to Wikipedia, from which I stole that formula, there are curves of unknown rank that are known to have rank at least 28, so in another sense the record is 28, in that that is the highest known integer for which there is proved to be an elliptic curve of rank at least that integer.
Bhargava and Shankar proved that the average rank is less than 1. Previously this was not even known to be finite. They also showed that at least 80% of elliptic curves have rank 0 or 1.
The Birch–Swinnerton-Dyer conjecture concerns ranks of elliptic curves, and one consequence of their results (or perhaps it is a further result — I’m not quite sure) is that the conjecture is true for at least 66% of elliptic curves. Gross said that there was some hope of improving 66% to 100%, but cautioned that that would not prove the conjecture, since 0% of all elliptic curves doesn’t mean no elliptic curves. But it is still a stunning advance. As far as I know, nobody had even thought of trying to prove average statements like these.
I think I also picked up that there were connections between the delicate methods that Bhargava used to enumerate number fields (which again involved counting lattice points in unbounded sets) and his more recent work with Shankar.
Finally, Gross reminded us that Faltings showed that for hyperelliptic curves (a curve of the form ")

While it is clear from what people have said about the work of the four medallists that they have all proved amazing results and changed their fields, I think that in Bhargava’s case it is easiest for the non-expert to understand just why his work is so amazing. I can’t wait to see what he does next.
Update. Andrew Granville emailed me some corrections to what I had written above, which I reproduce with his permission.
A couple of major things — certainly composition was much better understood by Dirichlet (Gauss’s student) and his version is quite palatable (in fact rather easier to understand, I would say, than that of Bhargava). It also led, fairly easily, to re-interpretation in terms of ideals, and inspired Dedekind’s development of (modern) algebraic number theory. Where Bhargava’s version is interesting is that
1) It is the most extraordinarily surprising re-interpretation.
2) It is a beautiful example of an algebraic phenomenon (involving group actions on representations) that he has been able to develop in many extraordinary and surprising directions.
2/ 66% was proved by Bhargava, Skinner and Wei Zhang and goes some way beyond Bhargava/Shankar, involving some very deep ideas of Skinner (whereas most of Bhargava’s work is accessible to a widish audience).
07 Aug 21:20
WIC'd
by noreply@blogger.com (Atrios)
Was in line behind a Latina woman with not awesome English attempting to use WIC vouchers in a supermarket. The cashier was being a bit of a dick about it. He wasn't too bad, I think he was just frustrated with the whole thing too, but assuming he knew what he was talking about, basically:
The 24 ounce cans of beans weren't eligible. She had to get the
The supermarket branded jumbo eggs weren't eligible. She had to get the large eggs.
Lactaid milk wasn't eligible. Other milk would be.
The corn tortillas weren't eligible. The flour ones would be.
There were a couple of other things that I forget, but you get the idea. When the ordeal started, I thought she was just using SNAP benefits which don't allow everything but do allow "most" things. If I had realized more quickly, I would have (and should have) just offered to pay. She was there with a young boy, too.
Paternalistic nutrition aid programs are ok in theory, but this was just ritual humiliation for what I think was $20 worth of vouchers. Also, too, accounting and other administrative costs.
Just give people some damn money.
The 24 ounce cans of beans weren't eligible. She had to get the
The supermarket branded jumbo eggs weren't eligible. She had to get the large eggs.
Lactaid milk wasn't eligible. Other milk would be.
The corn tortillas weren't eligible. The flour ones would be.
There were a couple of other things that I forget, but you get the idea. When the ordeal started, I thought she was just using SNAP benefits which don't allow everything but do allow "most" things. If I had realized more quickly, I would have (and should have) just offered to pay. She was there with a young boy, too.
Paternalistic nutrition aid programs are ok in theory, but this was just ritual humiliation for what I think was $20 worth of vouchers. Also, too, accounting and other administrative costs.
Just give people some damn money.
07 Aug 18:15
Isaac Newton's sinister heraldry. (arXiv:1310.7494v2 [physics.hist-ph] UPDATED)
by Alejandro Jenkins
After Isaac Newton was knighted by Queen Anne in 1705 he adopted an unusual coat of arms: a pair of human tibiae crossed on a black background, like a pirate flag without the skull. After some general reflections on Newton's monumental scientific achievements and on his enigmatic life, we investigate the story of his coat of arms. We also discuss how its simple design illustrates the concept of chirality, which would later play an important role in the philosophical arguments about Newton's conception of space, as well as in the development of modern chemistry and particle physics.
01 Aug 02:49

Mapping the optimal route between two quantum states
by S. J. Weber
Mapping the optimal route between two quantum states
Nature 511, 7511 (2014). doi:10.1038/nature13559
Authors: S. J. Weber, A. Chantasri, J. Dressel, A. N. Jordan, K. W. Murch & I. Siddiqi
A central feature of quantum mechanics is that a measurement result is intrinsically probabilistic. Consequently, continuously monitoring a quantum system will randomly perturb its natural unitary evolution. The ability to control a quantum system in the presence of these fluctuations is of increasing importance in quantum information processing and finds application in fields ranging from nuclear magnetic resonance to chemical synthesis. A detailed understanding of this stochastic evolution is essential for the development of optimized control methods. Here we reconstruct the individual quantum trajectories of a superconducting circuit that evolves under the competing influences of continuous weak measurement and Rabi drive. By tracking individual trajectories that evolve between any chosen initial and final states, we can deduce the most probable path through quantum state space. These pre- and post-selected quantum trajectories also reveal the optimal detector signal in the form of a smooth, time-continuous function that connects the desired boundary conditions. Our investigation reveals the rich interplay between measurement dynamics, typically associated with wavefunction collapse, and unitary evolution of the quantum state as described by the Schrödinger equation. These results and the underlying theory, based on a principle of least action, reveal the optimal route from initial to final states, and may inform new quantum control methods for state steering and information processing.
30 Jul 19:21
Can you touch your nose?
by Sabine Hossenfelder
Yeah, but can you? Believe it or not, it’s a question philosophers have plagued themselves with for thousands of years, and it keeps reappearing in my feeds!
My first reaction was of course: It’s nonsense – a superficial play on the words “you” and “touch”. “You touch” whatever triggers the nerves in your skin. There, look, I’ve solved a thousand year’s old problem in a matter of 3 seconds.
Then it occurred to me that with this notion of “touch” my shoes never touch the ground. Maybe I’m not a genius after all. Let me get back to that cartoon then. Certainly deep thoughts went into it that I must unravel.
To begin with it isn’t just electrostatic repulsion that prevents atoms from getting close, it is more importantly the Pauli exclusion principle which forces the electrons and quarks that make up the atom to arrange in shells rather than to sit on top of each other.
If you could turn off the Pauli exclusion principle, all electrons from the higher shells would drop into the ground state, releasing energy. The same would happen with the quarks in the nucleus which arrange in similar levels. Since nuclear energy scales are higher than atomic scales by several orders of magnitude, the nuclear collapse causes the bulk of the emitted energy. How much is it?
The typical nuclear level splitting is some 100 keV, that is a few 10-14 Joule. Most of the Earth is made up of silicon, iron and oxygen, ie atomic numbers of the order of 15 or so on the average. This gives about 10-12 Joule per atom, that is 1011 Joule per mol, or 1kTon TNT per kg.
This back-of-the envelope gives pretty much exactly the maximal yield of a nuclear weapon. The difference is though that turning off the Pauli exclusion principle would convert every kg of Earthly matter into a nuclear bomb. Since our home planet has a relatively small gravitational pull, I guess it would just blast apart. I saw everybody die, again, see that’s how it happens. But I digress; let me get back to the question of touch.
So it’s not just electrostatics but also the Pauli exclusion principle that prevents you from falling through the cracks. Not only do the electrons in your shoes don’t want to touch the ground, the electrons in your shoes don’t want to touch the other electrons in your shoes either. Electrons, or fermions generally, just don’t like each other.
The 10-8 meter actually seem quite optimistic because surfaces are not perfectly even, they have a roughness to them, which means that the average distance between two solids is typically much larger than the interatomic spacing that one has in crystals. Moreover, the human body is not a solid and the skin normally covered by a thin layer of fluids. So you never touch anything just because you’re separated by a layer of grease from the world.
To be fair, grease isn’t why the Greeks were scratching their heads back then, but a guy called Zeno. Zeno’s most famous paradox divides a distance into halves indefinitely to then conclude then that because it consists of an infinite number of steps, the full distance can never be crossed. You cannot, thus, touch your nose, spoke Zeno, or ram an arrow into it respectively. The paradox resolved once it was established that infinite series can converge to finite values; the nose was in the business again, but Zeno would come back to haunt the thinkers of the day centuries later.
The issue reappeared with the advance of the mathematical field of topology in the 19th century. Back then, math, physics, and philosophy had not yet split apart, and the bright minds of the times, Descarte, Euler, Bolzano and the like, they wanted to know, using their new methods, what does it mean for any two objects to touch? And their objects were as abstract as it gets. Any object was supposed to occupy space and cover a topological set in that space. So far so good, but what kind of set?
In the space of the real numbers, sets can be open or closed or a combination thereof. Roughly speaking, if the boundary of the set is part of the set, the set is closed. If the boundary is missing the set is open. Zeno constructed an infinite series of steps that converges to a finite value and we meet these series again in topology. Iff the limiting value (of any such series) is part of the set, the set is closed. (It’s the same as the open and closed intervals you’ve been dealing with in school, just generalized to more dimensions.) The topologists then went on to reason that objects can either occupy open sets or closed sets, and at any point in space there can be only one object.
Sounds simple enough, but here’s the conundrum. If you have two open sets that do not overlap, they will always be separated by the boundary that isn’t part of either of them. And if you have two closed sets that touch, the boundary is part of both, meaning they also overlap. In neither case can the objects touch without overlapping. Now what? This puzzle was so important to them that Bolzano went on to suggest that objects may occupy sets that are partially open and partially closed. While technically possible, it’s hard to see why they would, in more than 1 spatial dimension, always arrange so as to make sure one’s object closed surface touches the other’s open patches.
More time went by and on the stage of science appeared the notion of fields that mediate interactions between things. Now objects could interact without touching, awesome. But if they don’t repel what happens when they get closer? Do or don’t they touch eventually? Or does interacting via a field means they touch already? Before anybody started worrying about this, science moved on and we learned that the field is quantized and the interaction really just mediated by the particles that make up the field. So how do we even phrase now the question whether two objects touch?
We can approach this by specifying that we mean with an “object” a bound state of many atoms. The short distance interaction of these objects will (at room temperature, normal atmospheric pressure, non-relativistically, etc) take place primarily by exchanging (virtual) photons. The photons do in no sensible way belong to any one of the objects, so it seems fair to say that the objects don’t touch. They don’t touch, in one sentence, because there is no four-fermion interaction in the standard model of particle physics.
Alas, tying touch to photon exchange in general doesn’t make much sense when we think about the way we normally use the word. It does for example not have any qualifier about the distance. A more sensible definition would make use of the probability of an interaction. Two objects touch (in some region) if their probability of interaction (in that region) is large, whether or not it was mediated by a messenger particle. This neatly solves the topologists’ problem because in quantum mechanics two objects can indeed overlap.
What one means with “large probability” of interaction is somewhat arbitrary of course, but quantum mechanics being as awkward as it is there’s always the possibility that your finger tunnels through your brain when you try to hit your nose, so we need a quantifier because nothing is ever absolutely certain. And then, after all, you can touch your nose! You already knew that, right?
But if you think this settles it, let me add...
There is a non-vanishing probability that when you touch (attempt to touch?) something you actually exchange electrons with it. This opens a new can of worms because now we have to ask what is “you”? Are “you” the collection of fermions that you are made up of and do “you” change if I remove one electron and replace it with an identical electron? Or should we in that case better say that you just touched something else? Or are “you” instead the information contained in a certain arrangement of elementary particles, irrespective of the particles themselves? But in this case, “you” can never touch anything just because you are not material to begin with. I will leave that to you to ponder.
And so, after having spent an hour staring at that cartoon in my facebook feed, I came to the conclusion that the question isn’t whether we can touch something, but what we mean with “some thing”. I think I had been looking for some thing else though…
 |
| Best source I could find for this image: IFLS. |
My first reaction was of course: It’s nonsense – a superficial play on the words “you” and “touch”. “You touch” whatever triggers the nerves in your skin. There, look, I’ve solved a thousand year’s old problem in a matter of 3 seconds.
Then it occurred to me that with this notion of “touch” my shoes never touch the ground. Maybe I’m not a genius after all. Let me get back to that cartoon then. Certainly deep thoughts went into it that I must unravel.
The average size of an atom is an Angstrom, 10-10 m. The typical interatomar distance in molecules is a nanometer, 10-9 meter, or let that be a few nanometers if you wish. At room temperature and normal atmospheric pressure, electrostatic repulsion prevents you from pushing atoms any closer together. So the 10-8 meter in the cartoon seem about correct.
But it’s not so simple...To begin with it isn’t just electrostatic repulsion that prevents atoms from getting close, it is more importantly the Pauli exclusion principle which forces the electrons and quarks that make up the atom to arrange in shells rather than to sit on top of each other.
If you could turn off the Pauli exclusion principle, all electrons from the higher shells would drop into the ground state, releasing energy. The same would happen with the quarks in the nucleus which arrange in similar levels. Since nuclear energy scales are higher than atomic scales by several orders of magnitude, the nuclear collapse causes the bulk of the emitted energy. How much is it?
The typical nuclear level splitting is some 100 keV, that is a few 10-14 Joule. Most of the Earth is made up of silicon, iron and oxygen, ie atomic numbers of the order of 15 or so on the average. This gives about 10-12 Joule per atom, that is 1011 Joule per mol, or 1kTon TNT per kg.
This back-of-the envelope gives pretty much exactly the maximal yield of a nuclear weapon. The difference is though that turning off the Pauli exclusion principle would convert every kg of Earthly matter into a nuclear bomb. Since our home planet has a relatively small gravitational pull, I guess it would just blast apart. I saw everybody die, again, see that’s how it happens. But I digress; let me get back to the question of touch.
So it’s not just electrostatics but also the Pauli exclusion principle that prevents you from falling through the cracks. Not only do the electrons in your shoes don’t want to touch the ground, the electrons in your shoes don’t want to touch the other electrons in your shoes either. Electrons, or fermions generally, just don’t like each other.
The 10-8 meter actually seem quite optimistic because surfaces are not perfectly even, they have a roughness to them, which means that the average distance between two solids is typically much larger than the interatomic spacing that one has in crystals. Moreover, the human body is not a solid and the skin normally covered by a thin layer of fluids. So you never touch anything just because you’re separated by a layer of grease from the world.
To be fair, grease isn’t why the Greeks were scratching their heads back then, but a guy called Zeno. Zeno’s most famous paradox divides a distance into halves indefinitely to then conclude then that because it consists of an infinite number of steps, the full distance can never be crossed. You cannot, thus, touch your nose, spoke Zeno, or ram an arrow into it respectively. The paradox resolved once it was established that infinite series can converge to finite values; the nose was in the business again, but Zeno would come back to haunt the thinkers of the day centuries later.
The issue reappeared with the advance of the mathematical field of topology in the 19th century. Back then, math, physics, and philosophy had not yet split apart, and the bright minds of the times, Descarte, Euler, Bolzano and the like, they wanted to know, using their new methods, what does it mean for any two objects to touch? And their objects were as abstract as it gets. Any object was supposed to occupy space and cover a topological set in that space. So far so good, but what kind of set?
In the space of the real numbers, sets can be open or closed or a combination thereof. Roughly speaking, if the boundary of the set is part of the set, the set is closed. If the boundary is missing the set is open. Zeno constructed an infinite series of steps that converges to a finite value and we meet these series again in topology. Iff the limiting value (of any such series) is part of the set, the set is closed. (It’s the same as the open and closed intervals you’ve been dealing with in school, just generalized to more dimensions.) The topologists then went on to reason that objects can either occupy open sets or closed sets, and at any point in space there can be only one object.
Sounds simple enough, but here’s the conundrum. If you have two open sets that do not overlap, they will always be separated by the boundary that isn’t part of either of them. And if you have two closed sets that touch, the boundary is part of both, meaning they also overlap. In neither case can the objects touch without overlapping. Now what? This puzzle was so important to them that Bolzano went on to suggest that objects may occupy sets that are partially open and partially closed. While technically possible, it’s hard to see why they would, in more than 1 spatial dimension, always arrange so as to make sure one’s object closed surface touches the other’s open patches.
More time went by and on the stage of science appeared the notion of fields that mediate interactions between things. Now objects could interact without touching, awesome. But if they don’t repel what happens when they get closer? Do or don’t they touch eventually? Or does interacting via a field means they touch already? Before anybody started worrying about this, science moved on and we learned that the field is quantized and the interaction really just mediated by the particles that make up the field. So how do we even phrase now the question whether two objects touch?
We can approach this by specifying that we mean with an “object” a bound state of many atoms. The short distance interaction of these objects will (at room temperature, normal atmospheric pressure, non-relativistically, etc) take place primarily by exchanging (virtual) photons. The photons do in no sensible way belong to any one of the objects, so it seems fair to say that the objects don’t touch. They don’t touch, in one sentence, because there is no four-fermion interaction in the standard model of particle physics.
Alas, tying touch to photon exchange in general doesn’t make much sense when we think about the way we normally use the word. It does for example not have any qualifier about the distance. A more sensible definition would make use of the probability of an interaction. Two objects touch (in some region) if their probability of interaction (in that region) is large, whether or not it was mediated by a messenger particle. This neatly solves the topologists’ problem because in quantum mechanics two objects can indeed overlap.
What one means with “large probability” of interaction is somewhat arbitrary of course, but quantum mechanics being as awkward as it is there’s always the possibility that your finger tunnels through your brain when you try to hit your nose, so we need a quantifier because nothing is ever absolutely certain. And then, after all, you can touch your nose! You already knew that, right?
But if you think this settles it, let me add...
.JPG) |
| Yes, no, maybe, wtf. |
And so, after having spent an hour staring at that cartoon in my facebook feed, I came to the conclusion that the question isn’t whether we can touch something, but what we mean with “some thing”. I think I had been looking for some thing else though…
29 Jul 15:30
A world without statistics
by Andrew
A reporter asked me for a quote regarding the importance of statistics. But, after thinking about it for a moment, I decided that statistics isn’t so important at all. A world without statistics wouldn’t be much different from the world we have now.
What would be missing, in a world without statistics?
Science would be pretty much ok. Newton didn’t need statistics for his theories of gravity, motion, and light, nor did Einstein need statistics for the theory of relativity. Thermodynamics and quantum mechanics are fundamentally statistical, but lots of progress could’ve been made in these areas without statistics. The second law of thermodynamics is an observable fact, ditto the two-slit experiment and various experimental results revealing the nature of the atom. The A-bomb and, almost certainly, the H-bomb, maybe these would never have been invented without statistics, but on balance I think most people would feel that the world would be a better place without these particular scientific developments. Without statistics, we could forget about discovering the Hibbs boson etc, but that doesn’t seem like such a loss for humanity.
At a more applied level, statistics helped to win World War 2, most notably in cracking the Enigma code but also in various operations-research efforts. And it’s my impression that “our” statistics were better than “their” statistics. So that’s something.
Where would civilian technology be without statistics? I’m not sure. I don’t have a sense of how necessary statistics was for quantum theory. In a world without statistics, would the study of quantum physics have progressed far enough so that transistors were invented? This one, I don’t know. And without statistics we wouldn’t have modern quality control, so maybe we’d still be driving around in AMC Gremlins and the like. Scary thought, but not a huge deal, I’d think. No transistors, though, that would make a difference in my life. No transistors, no blogging! And I guess we could also forget about various unequivocally beneficial technological innovations such as modern pacemakers, hearing aids, cochlear implants, and Clippy.
Modern biomedicine uses lots and lots of statistics, but would medicine be so much worse without it? I don’t think so, at least not yet. You don’t need statistics to see that penicillin works, nor to see that mosquitos transmit disease and that nets keep the mosquitos out. Without statistics, I assume that various mistakes would get into the system, various ineffective treatments that people think are effective, etc. But on balance I doubt these would be huge mistakes, and the big ones would eventually get caught, with careful record-keeping even without statistical inference and adjustments. Without statistics, biologists would not be able to sequence the gene, and I assume they’d be much slower at developing tools such as tests that allow you to check for chromosomal abnormalities in amnio. I doubt all these things add up to much yet, but I guess there’s promise for the future. Statistics is also necessary for a lot of drug development—right now my colleagues and I are working on a pharmacodynamic model of dosing—but, again, without any of this, it’s not clear the world would be so much different.
The Poverty Lab team use statistics and randomized experiments to see what works to help the lives of poor people around the world. That’s cool but I’m not ultimately convinced this all makes a difference in the big picture. Or, to put it another way, I suspect that the statistical validation serves mostly as a way to build political consensus for economic policies that will be effective in sharing the wealth. By demonstrating in a scientific way that Treatment X is effective, this supports the idea that there is a way to help the sort of people who live in what Nicholas Wade would describe as “tribal” societies. So, sure, fine, but in this case the benefits of the statistical methods are somewhat indirect.
Without statistics, we wouldn’t have most of the papers in “Psychological Science,” but I could handle that. Piaget didn’t need any statistics, and I think the modern successors of Piaget could’ve done pretty much what they’ve done without statistics, just by careful observation of major transitions.
Careful observation and precise measurement can be done, with or without statistical methods. Indeed, researchers often use statistics as a substitute for careful observation and precise measurement. That is a horrible thing to do, and if you have a clear understanding of statistical theory, you can see why. But statistics is hard, and lots of researchers (and journal editors, news reporters, etc.) don’t have that understanding. When statistics is used as a substitute for, rather than an adjunct to, scientific measurement, we get problems.
OK, here’s another one: no statistics, no psychometrics. That’s too bad but one could make the argument that, on the whole, psychometrics has done more harm than good (value-added assessment, anyone?). Don’t get me wrong—I like psychometrics, and a strong argument could be made that it’s done more good than harm—but my point here is that the net benefit is not clear; a case would have to be made.
Polling. Can’t do it well without statistics. But, would a world without polling be so horrible? Much as I hate to admit it, I don’t think so. Don’t get me wrong, I think polling is on balance a good thing—I agree with George Gallup that measurement of public opinion is an important part of the modern democratic process—but I wouldn’t want to hang too much of the benefits of statistics on this one use, given that I expect lots of people would argue that opinion polls do more harm than good in politics.
The alternative to good statistics is . . .
Perhaps the most important benefits of statistics come not from the direct use of statistical methods in science and technology, but rather in helping us learn about the world. Statisticians from Francis Galton and Ronald Fisher onward have used statistics to give us a much deeper understanding of human and biological variation. I can’t see how any non-statistical, mechanistic model of the world could reproduce that level of understanding. Forget about p-values, Bayesian inference, and the rest: here I’m simply talking about the nature of correlation and variation.
For a more humble example, consider Bill James. Baseball is a silly example, sure, but the point is to see how much understanding has been gained in this area through statistical measurement and comparison. As James so memorably wrote, the alternative to good statistics is not “no statistics,” it’s “bad statistics.” James wrote about baseball commentators who would make asinine arguments which they would back up by picking out numbers without context. In politics, the equivalent might be a proudly humanistic pundit such as New York Times columnist David Brooks supporting his views by just making up numbers or featuring various “too good to be true” statistics and not checking them.
So here’s one benefit to the formal study of statistics: Without any statistics, there still would be numbers, along with people trying to interpret them.
Could governments and large businesses be managed well without statistics? I’m not sure. Given that half the U.S. Congress seems willing to shut down the government from time to time, it’s not clear than any agreement on the numbers will have much to do with political action. Similarly, all the statistics in the world don’t seem to be stopping the euro-zone from drifting. But maybe things would be much worse without a common core of statistical agreement. I don’t know; unfortunately this seems like the sort of causal question that is too difficult for statistics to answer.
Finally, one way that statistics is potentially having a huge impact in our lives is through the measurement of global warming and all the rest. But I’m guessing that a lot of this could be done with a pre-statistical understanding. The basic physics is already there, as would be the careful measurements. Statistical modeling is certainly relevant to the study of climate change—if you’re trying to reconstruct historical climate conditions from tree-ring data, it’s tough enough to do it with statistical modeling, I can’t imagine how it could be done otherwise—but the basic patterns of carbon dioxide, temperature, melting ice, etc., are apparent in any case. And, even with statistics, much uncertainty remains.
Summary
When I started writing this post, I was thinking that statistics doesn’t really matter, but I think that’s because I was focusing on some of the more highly-publicized but less beneficial applications of statistics: the use of statistical experimentation and inference to get p-values for tabloid-bait scientific papers, or for Google, Amazon, etc., to perfect their techniques for squeezing money out of their customers or, even at best, to test a medical treatment that increases survival rate for some rare disease by 2 percentage points. But statistics is central to how we think about the world. I still think that statistics is much less central to our lives than, say, chemistry. But it ain’t nothing.
The post A world without statistics appeared first on Statistical Modeling, Causal Inference, and Social Science.
19 Jul 18:57
Weaponized Moods, or ‘Twitter as a Nightmare We Will Never Wake From’When I was fourteen...
Weaponized Moods, or ‘Twitter as a Nightmare We Will Never Wake From’
When I was fourteen I bought 'Philosophical Investigations.’ It’s a book that’s famous for three things apart from its ideas about mind and language: 1) Nobody that reads it can deny that Wittgenstein was probably the smartest person that has ever lived. 2) Nobody that reads it can deny that Wittgenstein was probably the purest person that has ever lived. 3) The book says that if you disagree with anything in the book it’s because you are confused or lying to yourself. I spent most of the year between fourteen and fifteen reading it and crying and throwing it at the wall and hiding it around the house hoping I can’t remember where I put the book. The internet is harder to hide underneath the sink, and though there may not be a Wittgenstein on it it’s full of people that perpetually make me go 'this person isn’t stupid or corrupt, I can tell, and they’re saying you got to be stupid or corrupt to disagree with them, and only someone stupid or corrupt would say a thing like that if it’s not true, and even if I’ll tell myself that I agree with them I’ll know I don’t really agree with them, and even if I tell myself they’re stupid or corrupt I’ll know they aren’t really stupid or corrupt, so really the best thing is not to be born and the second best thing is to die soon.’
When I was fourteen I bought 'Philosophical Investigations.’ It’s a book that’s famous for three things apart from its ideas about mind and language: 1) Nobody that reads it can deny that Wittgenstein was probably the smartest person that has ever lived. 2) Nobody that reads it can deny that Wittgenstein was probably the purest person that has ever lived. 3) The book says that if you disagree with anything in the book it’s because you are confused or lying to yourself. I spent most of the year between fourteen and fifteen reading it and crying and throwing it at the wall and hiding it around the house hoping I can’t remember where I put the book. The internet is harder to hide underneath the sink, and though there may not be a Wittgenstein on it it’s full of people that perpetually make me go 'this person isn’t stupid or corrupt, I can tell, and they’re saying you got to be stupid or corrupt to disagree with them, and only someone stupid or corrupt would say a thing like that if it’s not true, and even if I’ll tell myself that I agree with them I’ll know I don’t really agree with them, and even if I tell myself they’re stupid or corrupt I’ll know they aren’t really stupid or corrupt, so really the best thing is not to be born and the second best thing is to die soon.’
I get it the worst when I find some online-famous school of thought or art or politics or style ridiculous for its myopia but then learn that friends I love respect it, and I spend some time with it and I discover it articulates things no one else articulates, and these things are so real once they’re articulated, and the people who see these things best, whom I’m dependent on to give me the articulations of these things, are adamant that you can’t bring considerations from outside the world that they’re articulating to the conversation (or the conversation in your head). It feels at a real fundamental level like I can’t, not even in my mind, access the insights without taking up their terms, and I start crumbling into nothingness. And I’m not only talking about cultural-critique or avant-garde or Marxian or Wittgensteinian or social-justice types – try telling a Utilitarian that donates 90% of her income to economic development charities that 'autonomy’ or 'liberation’ or 'community’ or 'creativity’ or 'justice’ or 'respect’ are irreducibly important, you will feel so dumb. Dumb in the old sense, even. Like your words are trained defensive barks that don’t refer to anything. Before the twitter era this would happen to me maybe once a year but now it happens two three times a week. Twitter’s a damn sky full of black holes.
I think it has something to do with moods in the Heidegger sense – like, phenomenologically basic prisms that disclose some aspects of the world (or of experiences or of ideas or whatever) and foreclose some other aspects that are salient in other moods. When faced with extreme arguments from somebody that powerfully channels a mood, counter-arguments that aren’t immanent to that mood turn to ashes in your mouth. You still believe the things that you believe but you can’t find a reason for believing them, because their roots are all in parts of your experience that aren’t in the world this mood discloses, so your beliefs become this grotesque alienating fact about yourself. And twitter’s lousy with powerful oracles of new moods talking at you all at the same time, from every direction, and a lot of them of have something real and new to show you – it can be consciousness-raising on a bad dynamic, or revealing a new type of humor, or discovering the beauty of top 40 pop, or a new way to be self-critical – and most of them work the most cutting, narrow possible mood that will show it. A feral mood that unshows everything else, cuts off your access to anything else. So if I ever get a flash of 'oh that’s actually really cool’ when I’m hate-reading some recently trending radical, whether political or not, I’m ready to text [reducted] asking if she has Xanax to spare.
(Trying communication in these contexts has gone mostly just exactly like the conversations in my head – I think that twitter conversation’s actually a good representation of what conversations that aren’t wholly positive are even possible within the literary/intellectual/activist world right now. Tho obviously there is a two-way feedback process between the centrality of twitter and the transformation of the literary/intellectual/activist scene into something for which twitter’s necessary and sufficient: Mood’s the only intellectual content that you can communicate on twitter, so you’ve got to make a mood that’s cutting enough to take over the jobs arguments used to be for, and, mutatis mutandis, twitter’s everything you need once you move on from arguments to weaponized moods.)
But then again I don’t know that there’s any other way, and I don’t know that it’s not worth it.
18 Jul 14:48
.")
The Categorical Origins of Lebesgue Integration
by leinster
NosimplerPart of my long quest to understand just wtf integration is.
I’ve just come back from the big annual-ish category theory meeting, Category Theory 2014 in Cambridge, also attended by Café hosts Emily and Simon. The talk I gave there was called The categorical origins of Lebesgue integration — click for slides — and I’ll briefly describe it now.
There are two theorems.
Theorem A The Banach space L 1[0,1]L^1[0, 1] has a simple universal property. This leads to a unique characterization of integration on [0,1][0, 1].
Theorem B The functor L 1:L^1: (finite measure spaces) →\to (Banach spaces) has a simple universal property. This leads to a unique characterization of integration on finite measure spaces.
The talk’s pretty simple, and I don’t think I can summarize it much better than by repeating the abstract, which went like this:
Lebesgue integration is a basic, essential component of analysis. Yet most definitions of Lebesgue integrability and integration are rather complicated, typically depending on a series of preliminary definitions. For instance, one of the most popular approaches involves the class of functions that can be expressed as an almost everywhere pointwise limit of an increasing sequence of step functions. Another approach constructs the space of Lebesgue-integrable functions as the completion of the normed vector space of continuous functions; but this depends on already having the definition of integration for continuous functions.
So we might wish for a short, direct description of Lebesgue integrability that reflects its fundamental nature. I will present two theorems achieving this.
The first characterizes the space L 1[0,1]L^1[0, 1] by a simple universal property, entirely bypassing all the usual preliminary definitions. It tells us that once we accept two concepts — Banach space and the mean of two numbers — then the concept of Lebesgue integrability is inevitable. Moreover, this theorem not only characterizes the Lebesgue integrable functions on [0,1][0, 1]; it also characterizes Lebesgue integration of such functions.
The second theorem characterizes the functor L 1L^1 from measure spaces to Banach spaces, again by a simple universal property. Again, the theorem characterizes integration, as well as integrability, of functions on an arbitrary measure space.
17 Jul 15:20
Public Service in the 21st Century
by noreply@blogger.com (Jay Ackroyd (@jayackroyd))
One of the central tenets of our centrist technocratic leaders is that the real public policy experts are those who have risen through merit and diligence to become highly comped executives in key private sector firms. It's asking a lot, though, to ask them to give up their well-paid (and well-earned!) positions among the one percent to accept a government position. But today, there's no need for sacrifice.
Many large corporations with a strong incentive to influence public policy award bonuses and other incentive pay to executives if they take jobs within the government. CitiGroup, for instance, provides an executive contract that awards additional retirement pay upon leaving to take a “full time high level position with the U.S. government or regulatory body.” Goldman Sachs, Morgan Stanley, JPMorgan Chase, the Blackstone Group, Fannie Mae, Northern Trust, and Northrop Grumman are among the other firms that offer financial rewards upon retirement for government service.(h/t Gaius Publius)
15 Jul 17:25
Synopsis: Carbon-12 Caught in a Triangle
The discovery of a new excited state in carbon-12 hints at this nucleus’s triangular symmetry.

Published Mon Jun 30, 2014
Published Mon Jun 30, 2014
07 Jul 21:58

Laboratory-grown vaginas
by Minnesotastan
Four teenage girls have received vaginas grown from their own cells in a lab. And they work.Further details at the Washington Post. Image from a video at the Wall Street Journal (safe for work, unless someone at work is offended by tissue culture).
These girls were born with underdeveloped or missing vaginas because of a rare condition called Mayer-Rokitansky-Küster-Hauser Syndrome that affects about 1 in 5,000 women. While their labia looked like those of other girls, their vaginas, cervixes and wombs, which are necessary for menstruation and childbirth, never fully formed.
Medical researchers took a vaginal tissue sample from each patient, who were between 13 and 18 at the time, and used them to grow cells in the lab. After four weeks, the researchers had enough cells to layer them on to degradable scaffolding...
Six months later, the patients were able to menstruate and have sexual intercourse for the first time. “After the operation they were able to function normally,” Atala told reporters. “They had normal levels of desire, arousal, satisfaction and orgasm.” Some may also be able to have children.
Luke.stirling likes this
06 Jul 01:40


Happy Birthday Richard Stanley!
by Gil Kalai

This week we are celebrating in Cambridge MA , and elsewhere in the world, Richard Stanley’s birthday. For the last forty years, Richard has been one of the very few leading mathematicians in the area of combinatorics, and he found deep, profound, and fruitful links between combinatorics and other areas of mathematics. His works enriched and
influenced combinatorics as well as other areas of mathematics, and, in my opinion,
combinatorics matured greatly as a mathematical discipline thanks to his work.
Trivia Quiz
Correct or incorrect?
(1) Richard drove cross-country at least 8 times
(2) In his youth, at a wild party, Richard Stanley found a proof of FLT consisting of a few mathematical symbols.
(3) Richard jumped at least once from an airplane
(4) Richard is actively interested in the study of consciousness
(5) Richard found a mathematical way to divide by zero
Seven Early Papers by Richard Stanley That You Must Read.

Richard’s Green book: Combinatorics and Commutative Algebra
Combinatorics and Commutative Algebra
(1) R. P. Stanley, The upper bound conjecture and Cohen-Macaulay rings.
Studies in Appl. Math. 54 (1975), no. 2, 135–142.
The two seminal papers (1) and (3) (below) showed remarkable and unexpected applications of commutative algebra to combinatorics. In each of these papers a central
conjecture in combinatorics was solved in a completely unexpected way which was the basis for a later remarkable theory. Paper (1) is the starting point for the interrelation between commutative algebra and combinatorics of simplicial complexes and their
topology. In this work Richard Stanley proved the Motzkin-Klee upper bound conjecture for triangulations of spheres. This conjecture asserts that the maximum number
of k-faces for a triangulation of a (d-1)-dimensional sphere with n vertices is attained by the boundary complex of the cyclic d-dimensional polytope with
n vertices. Peter McMullen proved this conjecture for simplicial polytopes and Richard Stanley proved it for arbitrary triangulations of spheres. The key point was that a certain ring (the Stanley-Reisner ring) associated with a simplicial polytope has the Cohen-Macaulay property.
The connection between combinatorics and commutative algebra is
far reaching, and in subsequent works combinatorial problems led to
developments in commutative algebra and techniques from the two areas were
combined. A more recent important paper by Richard on applications of commutative algebra for the study of face numbers is: R. P. Stanley, Subdivisions and local h-vectors. J. Amer. Math. Soc. 5 (1992), no. 4, 805–851.
And here is, a few weeks old important development in this theory: Relative Stanley-Reisner theory and Upper Bound Theorems for Minkowski sums, by Karim A. Adiprasito and Raman Sanyal.
The Cohen-Macaulay property, magic squares and lattice points in polytopes
(2) R. P. Stanley, Magic labelings of graphs, symmetric magic squares,
systems of parameters, and Cohen-Macaulay rings. Duke Math. J. 43 (1976),
no. 3, 511–531.
This paper starts with a theorem about enumeration of certain magic squares. Solving a long-standing open problem, Stanley proved that the generating function for the
number of k by k integer matrices (k- fixed) with nonnegative entries and row sums and column sums equal to nis rational. This is the starting
point of a deep algebraic theory of integral points in polyhedra.
Enters the Hard-Lefshetz Theorem: McMullen’s g-conjecture
(3) R. P. Stanley, The number of faces of a simplicial convex polytope. Adv. in Math. 35 (1980), no. 3, 236–238.
The g-conjecture proposes a complete characterization of face numbers of d-dimensional polytopes. One linear equality that holds among face numbers is, of course, the Euler-Poincaré relation. This relation implies additional [d/2] equalities called the Dehn-Sommerville relations. Peter McMullen proposed an additional system of linear and nonlinear inequalities as a complete characterization of face numbers of polytopes. The sufficiency part of this conjecture was proved by Billera and Lee. Richard Stanley’s brilliant proof for McMullen’s inequalities that established the g-conjecture was based on the Hard Lefschetz Theorem from algebraic topology. Starting from a simplicial polytope P (with rational vertices) we associate to it a toric variety T(P). It turned out that the cohomology ring of this variety is closely related to the Stanley-Reisner ring mentioned above. The Hard Lefschetz Theorem implies an algebraic property of the Stanley-Reisner ring from which McMullen inequalities can be deduced by direct combinatorial reasoning. Richard found a number of other combinatorial applications of the Hard Lefschetz theorem (including the solution of the Erdos-Moser conjecture).
Here is the abstract of Lou Billera’s lecture
LOUIS BILLERA (CORNELL)
Even more intriguing, if rather less plausible…
The title is how Peter McMullen described his own conjectured characterization of the f-vectors of simplicial polytopes in his 1971 lecture notes on the upper bound conjecture written with Geoffrey Shephard. Yet by the end of that decade, the so-called g-conjecture would become the g-theorem, and algebraic combinatorics (as practiced at MIT) would have attracted the attention of mainstream mathematics, almost entirely due to the startling proof given by Richard Stanley.
I will briefly describe some of the events leading to this proof and some of its still developing consequences.
Enumeration
Enumeration is Richard’s true mathematical love.

Richard’s monumental books EC1 and EC2 (The picture is of EC1 and a young fan)
(4) A baker’s dozen of conjectures concerning plane partitions, in Combinatoire Énumérative (G. Labelle and P. Leroux, eds.), Lecture Notes in Math., no. 1234, Springer-Verlag, Berlin/Heidelberg/New York, 1986, pp. 285-293.
13 beautiful conjectures on counting plane partitions with various forms of symmetry.
(5) Generating functions, in Studies in Combinatorics (G.-C. Rota, ed.), Mathematical Association of America, 1978, pp 100-141.
For me this was the best introduction to generating functions, clear and inspiring. The entire MAA 1978 Rota’s blue little volume on combinatorics is great. Buy it!
Posets everywhere
(5) Supersolvable lattices, Algebra Universalis 2 (1972), 197-217.
This paper provides a profound link between group theory and the study of
partially ordered sets. It can be seen as a starting point of Stanley’s own work on the Cohen-Macaulay property and it had much influence on later works on combinatorial properties of lattices of subgroups by Quillen and many others, and also on the study of POSETS (=partially ordered sets) arising from arrangements of hyperplanes. The algebraic notion of supersolvable groups is translated to an important combinatorial notion for partially ordered sets. (There is a more detailed paper which I could not find online: R. P. Stanley, Supersolvable semimodular lattices. Mobius algebras (Proc. Conf., Univ. Waterloo, Waterloo, Ont., 1971), pp. 80–142. Univ. Waterloo, Waterloo, Ont., 1971.)
Combinatorics and representation theory
(6) On the number of reduced decompositions of elements of Coxeter groups, European J. Combinatorics 5 (1984), 359-372.
This paper gives an important result proved using representation theory. It is one of
many results by Stanley on connections between enumerative combinatorics,
representation theory, and invariant theory. Again, this paper represents an exciting area of research about the connection of enumerative combinatorics and representation theory that I am less familiar with. A very inspiring survey paper is: Invariants of finite groups and their applications to combinatorics, Bull. Amer. Math. Soc. (new series) 1 (1979), 475-511.
Here are abstracts of two lectures from the meeting on some recent developments in combinatorial representation theory and symmetric functions.
GRETA PANOVA (UCLA)
The Kronecker coefficients: an unexpected journey
Kronecker coefficients live at the intersection of representation theory, algebraic combinatorics and, most recently, complexity theory. They count the multiplicities of irreducible representations in the tensor product of two other irreducible representations of the symmetric group. While their journey started 75 years ago, they still haven’t found their explicit positive combinatorial formula, and present a major open problem in algebraic combinatorics. Recently, they were given a new role in the field of Geometric Complexity Theory, initiated by Mulmuley and Sohoni, where certain conjectures on the complexity of computing and deciding positivity of Kronecker coefficients are part of a program to prove the “”P vs NP”” problem.
We will take the Kronecker coefficients to asymptotics land and bound them. As an unexpected consequence of this trip, we find bounds for the difference of consecutive coefficients in the q-binomial coefficients (as polynomial in q), generalizing Sylvester’s unimodality theorem and connecting with results of Richard Stanley.
Joint work with Igor Pak.
THOMAS LAM (U MICHIGAN)
Truncations of Stanley symmetric functions and amplituhedron cells
Stanley symmetric functions were invented (by Stanley) with applications to the enumeration of reduced words in the symmetric group in mind. Recently, the “amplituhedron” was introduced in the study of scattering amplitudes in N=4 super Yang Mills. I will talk about a formula for the cohomology class of a (tree) amplituhedron variety as the truncation of an affine Stanley symmetric function.
Two combinatorial applications of the Aleksandrov-Fenchel inequalities;
(7) Two combinatorial applications of the Aleksandrov-Fenchel inequalities, J. Combinatorial Theory (A) 31 (1981), 56-65.
In this amazing paper Stanley used inequalities of classical convexity
to settle an important conjecture on probability of events in partially
ordered sets. A special case of the conjecture was settled earlier by Ron
Graham using the FKG inequality. The profound relation between classical
convexity inequalities, combinatorial structures, polytopes, and
probability theory was further studied by many authors including Stanley
himself and there is much more to be done.
I see that I ran out of my seven designated slots. Certainly you should read Richard’s combinatorial constructions of polytopes, like Two poset polytopes, Discrete Comput. Geom. 1 (1986), 9-23, and his papers on arrangements. Let me mention a more recent paper of Stanley in this general area: A polytope related to empirical distributions, plane trees, parking functions, and the associahedron (with J. Pitman), Discrete Comput. Geom., 27 (2002), 603-634.
More
(Mostly from RS’s homepage.)
Chess and Mathematics
(12 page PDF file) An excerpt (version of 1 November 1999) from a book Richard is writing with Noam Elkies.
An unusual method for proving the Riemann hypothesis.
Richard Stanley’s Mathoverflow question on MAGIC
Magic trick based on deep mathematics
Richard the Catalan
(From RS’s homepage)
Excerpt (27 page PDF file) from EC2 on problems related to Catalan numbers (including 66 combinatorial interpretations of these numbers).
Solutions to Catalan number problems from the previous link (23 page PDF file).
Catalan addendum (Postscript or PDF) (version of 25 May 2013; 96 pages). An addendum of new problems (and solutions) related to Catalan numbers. Current number of combinatorial interpretations of Cn: 207.
The material on Catalan numbers is being collected into a monograph, to be published by Cambridge University Press in late 2014 or early 2015.

02 Jul 18:11
Discrete activity states en route to consciousness [Neuroscience]
by Hudson, A. E., Calderon, D. P., Pfaff, D. W., Proekt, A.
It is not clear how, after a large perturbation, the brain explores the vast space of potential neuronal activity states to recover those compatible with consciousness. Here, we analyze recovery from pharmacologically induced coma to show that neuronal activity en route to consciousness is confined to a low-dimensional subspace. In...
Nosimpler likes this
30 Jun 06:32




Lawmaker Slams Ex-NSA Chief: ‘Nothing to Offer’ but State Secrets
by Zenon Evans
 Keith Alexander, since stepping
down from his position as National Security Agency (NSA) and U.S.
Cyber Command chief following last year's mass surveillance
revelations, has gotten himself in the business of cybersecurity
consulting.
Keith Alexander, since stepping
down from his position as National Security Agency (NSA) and U.S.
Cyber Command chief following last year's mass surveillance
revelations, has gotten himself in the business of cybersecurity
consulting.
And not everyone's comfortable with that. Rep. Alan Grayson (D-Fl.) yesterday published letters he sent to the "Securities Industry and Financial Markets Association, the Consumer Bankers Association, the Financial Services Roundtable and the Clearing House—all of which Alexander reportedly has approached about his services," according to Wired. The congressman, who sits on both the Committee on Foreign Affairs and the Committee on Science, Space, and Technology, gave a roundabout warning to former spy chief:
Disclosing or misusing classified information for profit is, as Mr. Alexander well knows, a felony. I question how Mr. Alexander can provide any of the services he is offering unless he discloses or misuses classified information, including extremely sensitive sources and methods. Without the classified information he acquired in his former position, he literally would have nothing to offer to you.
He concluded by turning up the heat and asks the organizations to be transparent:
Please send me all information related to your negotiations with Mr. Alexander, so that Congress can verify whether or not he is selling military and cybersecurity secrets to the financial industry for personal gain.

Grayson isn't the only skeptic. In his letter, he cites top computer security expert Bruce Schneier, who has similar concerns. Regarding Alexander's eye-popping rates, $600,000 to $1 million a month, earlier this week Schneier asked his readers to "think of how much actual security they could buy with that $600K a month. Unless he's giving them classified information."
There's a pinch of irony that Alexander, who does a lot of handwringing over Edward Snowden for exposing government secrets, is now on the receiving end suspicion for similar actions.
28 Jun 08:32

Why Brink Lindsey opposes a guaranteed annual income
by Tyler Cowen
NosimplerNow it's on everybody's radar, and the detractors are looking like idiots.
…my reading of the available evidence convinces me that a social policy that channels benefits through work and thereby encourages paid employment has important advantages over a UBI [universal basic income] in helping the disadvantaged to live full, happy, productive, and rewarding lives.
What evidence? Let’s start with the well-established finding that unemployment has major negative effects on well-being, including both mental and physical health. And the effects are remarkably persistent. A study using German panel data examined changes in reported life satisfaction after marriage, divorce, birth of a child, death of a spouse, layoff, and unemployment. All had predictable effects in the short term, but for five of the six the effect generally wore off with time: the joy of having a new baby subsided, while the pain of a loved one’s death gradually faded. The exception was unemployment: even after five years, the researchers found little evidence of adaptation.
Evidence even more directly on point comes from the experience of welfare reform – specifically, the imposition of work requirements on recipients of public assistance. Interestingly, studies of the economic consequences of reform showed little or no change in recipients’ material well-being. But a pair of studies found a positive impact on single mothers’ happiness as a result of moving off welfare and finding work.
There is more here. And Ross Douthat offers related remarks on whether it really is possible to encourage work — how well have previous welfare reforms succeeded in this end?
28 Jun 08:29


We are not ready for health data mining
by Cathy O'Neil, mathbabe
There have been two articles very recently about how great health data mining could be if we could only link up all the data sets. Larry Page from Google thinks so, which doesn’t surprise anyone, and separately we are seeing that the consequence of the new medical payment system through the ACA is giving medical systems incentives to keep tabs on you through data providers and find out if you’re smoking or if you need to fill up on asthma medication.
And although many would consider this creepy stalking, that’s not actually my problem with it. I think Larry Page is right – we might be able to save lots of lives if we could mine this data which is currently siloed through various privacy laws. On the other hand, there are reasons those privacy laws exist. Let’s think about that for a second.
Now that we have the ACA, insurers are not allowed to deny Americans medical insurance coverage because of a pre-existing condition, nor are they allowed to charge more, as of 2014. That’s good news on the health insurance front. But what about other aspects of our lives?
For example, it does not generalize to employers. In other words, a large employer like Walmart might take into account your current health and your current behaviors and possibly even your DNA to predict future behaviors, and they might decide not to give jobs to anyone at risk of diabetes, say. Even if medical insurance casts were taken out of the picture, which they haven’t been, they’d have incentives not to hire unhealthy people.
Mind you, there are laws that prevent employers from looking into HIPAA-protected health data, but not Acxiom data, which is entirely unregulated. And if we “opened up all the data” then the laws would be entirely moot. It would be a world where, to get a job, the employer got to see everything about you, including your future health profile. To some extent this is already happening.
Perhaps not everyone thinks of this as bad. After all, many people think smokers should pay more for insurance, why not also work harder to get a job? However, lots of the information gleaned from this data – even behaviors – have much more to do with poverty levels than circumstance than with conscious choice. In other words, it’s another stratification of society along the lucky/unlucky birth lottery spectrum. And if we aren’t careful, we will make it even harder for poor people to eke out a living.
I’m all for saving lives but let’s wait for the laws to catch up with the good intentions. Although to be honest, it’s not even clear how the law should be written, since it’s not clear what “medical” data is nowadays nor how we could gather evidence that a private employer is using it against someone improperly.
27 Jun 18:23



Excruciating Pain from Above: Drones Get Pepper Spray
by Scott Shackford
 It was inevitable. Now it's
happening. Desert Wolf, a company in South Africa, has created a
drone capable of shooting pepper spray and "blinding lasers" at
unruly crowds. The company has sold 25 of the drones to a mining
company after showing them off at a trade show, the BBC reports.
They offer more details of
the drones' weaponry:
It was inevitable. Now it's
happening. Desert Wolf, a company in South Africa, has created a
drone capable of shooting pepper spray and "blinding lasers" at
unruly crowds. The company has sold 25 of the drones to a mining
company after showing them off at a trade show, the BBC reports.
They offer more details of
the drones' weaponry:
Desert Wolf's website states that its Skunk octacopter drone is fitted with four high-capacity paintball barrels, each capable of firing up to 20 bullets per second.
In addition to pepper-spray ammunition, the firm says it can also be armed with dye-marker balls and solid plastic balls.
The machine can carry up to 4,000 bullets at a time as well as "blinding lasers" and on-board speakers that can communicate warnings to a crowd.
CNet notes that these "blinding lasers" are forbidden for use in war by the Geneva Convention and adds that weapons that are classified as "non-lethal" often do kill anyway:
"These weapons cannot be sufficiently well controlled to avoid causing serious injury, especially to eyes," warns Mark Gubrud of campaign group the International Committee for Robot Arms Control. "Many existing "non-lethal" crowd-control weapons can and often do kill."
Right now it appears that mining companies in countries that have seen violent clashes between striking workers and authorities are most interested. But is it only a matter of time before the infamous "pepper spray cop" is replaced by a "pepper spray drone"? Well, at least the drone won't apply for workers' compensation payments afterward.
27 Jun 00:13



Can Someone Just Invent an 'I Consent to Sex' iPhone App Already?
by Robby Soave
NosimplerHahaha "I'm counting on the free market to work its magic and provide a sensible and convenient method of demonstrating mutual consent."
 Over at Slate, Amanda Hess came to the
defense of legislation—currently under consideration by the
California State Assembly—that would pressure colleges to police
their students' sexual activities.
Over at Slate, Amanda Hess came to the
defense of legislation—currently under consideration by the
California State Assembly—that would pressure colleges to police
their students' sexual activities.
California Senate Bill 967 would force state universities to strictly define consensual sex between students as an "affirmative, unambiguous, and conscious decision." It would also clarify that "lack of protest or resistance does not mean consent, nor does silence mean consent," and that the person "initiating the sexual activity" is responsible for obtaining consent.
This legislatively-enforced definition of consent is much needed, wrote Hess:
This standard improves on the old "no means no" model in a number of ways. A partner who is asleep or passed out can’t say "no." Neither can a partner who’s frozen in shock or fear when an encounter escalates into an assault. Victims who are threatened with sexual assault aren’t always equipped to respond in rape prevention talking points. Just like with any other violent physical assault, many victims respond by shutting down, going silent, or laying motionless, hoping not to anger their attackers further, or disassociating from the attacks as an attempt at self-preservation. Also, consenting to sex one time doesn’t mean consenting to sex any other time. And consenting to one act (like vaginal intercourse) doesn’t imply consent for all other acts (like anal sex). Having sex with a person who is lying limply on a bed is not consensual, unless that person happens to be really, really into that—but that’s a situation that requires a conversation, not an assumption.
So are affirmative consent laws a good idea? If they are broad enough to include nonverbal cues, I think so. If we can admit that enthusiastic consent is often communicated in body language or knowing looks, then we must also accept that the lack of consent doesn’t always manifest itself in a shouted "no" or "stop," either. It shouldn’t be the sole responsibility of the uninterested party to speak up during a sexual encounter. If you think it’s easy for a person to just say no, then why would it be so hard for his or her partner to just ask?
My only substantial quibble with this definition is the "person initiating" clause. Is it always so clear that one person is initiating sex with another? Isn't the decision to have sex sometimes mutually arrived at by both parties?
Setting that aside, maybe it's a good idea for the California legislature to broaden the parameters of sexual assault. Maybe "only yes means yes" is a better standard than "no means no," and it is desirable for cultural attitudes about consensual sex to shift in that direction.
But why on earth should that involve universities? Rape is a crime, not an academic offense. I'm open to the argument that the criminal justice system should navigate sexual assault cases differently, but I don't accept that there should be some extralegal method of punishing accused rapists where the burden of proof is lower, due process is nonexistent, and he said/she said is often an automatic loss for the accused. The punishments are not as severe as they are under the normal justice system, sure, but expulsion is still a harsh sentence (synonymous with the loss of thousands of dollars toward a now unobtainable degree), given the conviction process is handled by people totally unequipped to fairly judge such matters.
The legislature is telling state universities to more aggressively involve themselves in their students' sex lives. Given administrators' track records, there is little reason to think that either victims or the accused will be well served by such mandate.
Ultimately, I'm counting on the free market to work its magic and provide a sensible and convenient method of demonstrating mutual consent. Several writers have suggested an iPhone app that allows users to clearly consent to sex—maybe they would have to input a password and then touch phones, or something?—would do the trick.
Consensual sex? There's an app for that. One day soon. Hopefully.