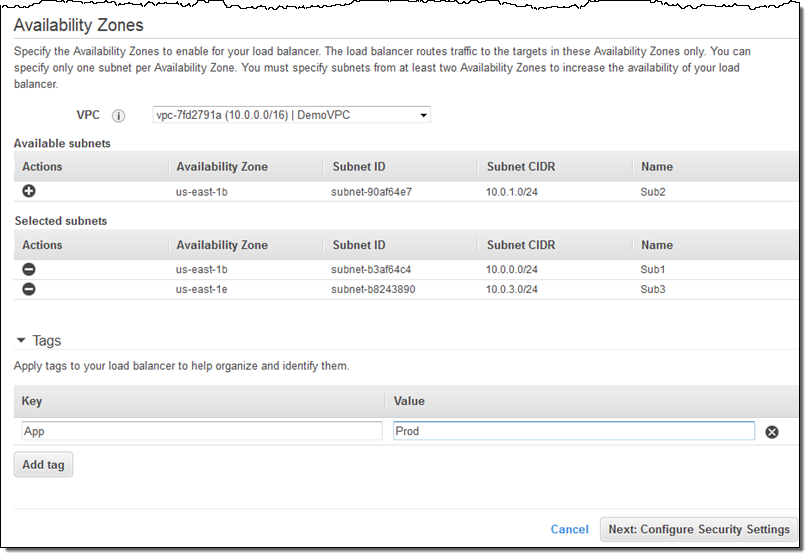
As diversas distribuições Linux existentes não são apenas o kernel Linux, propriamente dito. Todas elas são constituídas por elementos que formam a estrutura dos sistemas Linux. São elementos fundamentais para o funcionamento do sistema operacional, entre eles destaco: o bootloader, o Shell, os softwares GNU, o servidor gráfico, o ambiente desktop e muito mais. Portanto, conheça todos os elementos que compõem a estrutura dos sistemas Linux.
Contextualizando
Muito se fala… “o sistema Linux“. Contudo, o Linux “não é o todo“. Para muitos o Linux, por si, é capaz de oferecer recursos e funcionalidades completas para o computador. Entretanto, o Linux é somente o Kernel (núcleo) do sistema operacional. Todo sistema operacional (Linux, Windows e Mac, por exemplo) possui um kernel. No caso das distribuições Linux, o kernel é o Linux – livre e sendo desenvolvido por colaboradores em todo o mundo.

Conheça a história do Linux
O kernel de um sistema é o componente central que serve “para dá vida” ao hardware. É a camada responsável por garantir que todos os programas e processos tenham acesso aos recursos da máquina de que necessitam (memória RAM, acesso ao disco e controle da CPU, por exemplo) simultaneamente, fazendo com que haja um compartilhamento concorrente desses. A grosso modo é o “cérebro” do sistema operacional; o responsável por coordenar o acesso ao hardware e dados entre os diferentes componentes do sistema.
A outra camada de um sistema operacional é constituída por elementos que oferecem recursos capazes de garantir interação com o usuário; no caso nós  Popularmente referenciada como a camada de software. Esta camada permite que os aplicativos de usuário sejam executados. Entre outras palavras, o kernel do sistema não pode ser acessada diretamente pelo usuário ou administrador do sistema; isso só poderá ser possível através de aplicações utilitárias do sistema, bem como: terminal de linha de comando (CLI), softwares para compilação, software de gestão de disco/memória ou controle de processos do sistema; por exemplo.
Popularmente referenciada como a camada de software. Esta camada permite que os aplicativos de usuário sejam executados. Entre outras palavras, o kernel do sistema não pode ser acessada diretamente pelo usuário ou administrador do sistema; isso só poderá ser possível através de aplicações utilitárias do sistema, bem como: terminal de linha de comando (CLI), softwares para compilação, software de gestão de disco/memória ou controle de processos do sistema; por exemplo.

Assim, deve ficar claro o porquê do Linux se popularizar tanto no meio técnico. Entre outros aspectos, ele, através destes aplicativos, pode ser “facilmente” acessado e controlado pelo usuário que tiver domínio e condições para isso. Além disso, pode ser estudado e distribuído livremente \o/
Por fim, feito a analogia de que o Kernel é o “cérebro” do sistema, deixo claro que o kernel por si só, assim como cérebro humano, não pode realizar todas as tarefas desempenhadas pelo sistema operacional sozinho. A união desses outros elementos com o kernel formam a estrutura do sistema Linux.
Estrutura do Linux
Ciente de que o Linux é apenas o kernel do sistema, você pode se perguntar: “Então, o que faz o sistema Linux funcionar completamente desde da inicialização ao carregamento do ambiente gráfico disponibilizado para o usuário?!”
Mesmo com todos os subsistemas do kernel (Gerenciamento de Processos, Gerenciamento de Memória, Gerenciamento de Redes, Sistema de Arquivos e outros), existem elementos que precisam compor essa base mantida no núcleo do sistema operacional para que ele funcione completamente. Entre eles destaco: o bootloader, o Shell, os softwares GNU, o servidor gráfico, o ambiente desktop e muito mais.
Todos esses elementos são desenvolvidos e mantidos por diferentes grupos de desenvolvedores. Todos independentes do desenvolvimento do kernel Linux, que é coordenado pelo Linus Torvalds (criador) e mantido pela comunidade mundial. Assim, “unindo” todos esses elementos com o Kernel Linux, um sistema operacional completo é criado – assim surgem as distribuições Linux.
A expressão “distribuição Linux” significa que diversos sistemas são criados a partir do kernel Linux. Ou seja, quem usa o Ubuntu usa Linux; contudo, o kernel Linux e os elementos adotados/criados pela comunidade Ubuntu.Daí, também surge a expressão “baseado de/da/do…”. A distribuição Debian é “mãe” de muitas outras porque “deu base” para outras distribuições Linux; como o Ubuntu, por exemplo.
Linus Torvalds – A mente por trás do Linux
Histórico de desenvolvimento do kernel Linux exposto em gráficos
Bootloader
Um Bootloader (“carregador de inicialização”), também chamado de gerenciador de inicialização (boot), é um pequeno programa que carrega o sistema operacional de um computador na memória.
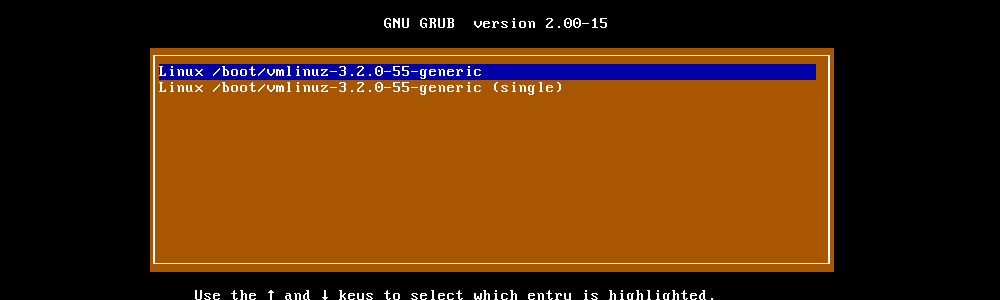
Quando um computador é ligado, a BIOS ou a UEFI realiza alguns testes iniciais das atividades básicas para o correto funcionamento de todos os recursos da máquina; e então transfere o controle para o Registro Mestre de Inicialização (MBR – Master Boot Record), onde o Bootloader se encontra.
No sistemas Linux, geralmente, o gerenciador de inicialização usado é o Grub. Com ele instalado, além de gerenciar o processo de inicialização do sistema, é possível ter vários sistemas operacionais instalados e escolher qual deve ser iniciado. O Grub fornece um menu que permite que você escolha entre as opções de sistemas disponíveis. Recurso comumente chamado de “dual-boot“.
Caso não possua diversos sistemas instalados na máquina (somente uma distribuição Linux), o Grub pode inicializar o sistema Linux quase que instantaneamente. Mesmo que você não o veja, ele ainda está lá.
Em resumo, o Grub, pelo fato de ser um Bootloader, é responsável pelo processo de inicialização do Linux. Sem ele, uma distribuição Linux não iria iniciar
Shell
Primeiramente, o shell (ou interpretador de linha de comando) é um módulo que atua como camada externa (“concha“) entre o usuário e o sistema operacional. Existem diversos tipos de shell. O primeiro deles foi o Bourne shell (sh) que oferecia diversos comandos internos que permitiam ao usuário solicitar chamadas ao sistema operacional. A partir daí houveram evoluções significativas do shell.

Atualmente, a maioria dos sistemas Linux usam, por padrão, uma evolução do Bourne shell, chamada Bash (Bourne Again Shell). O Bash, além das funcionalidades das versões anteriores, também implementa um linguagem simples de programação que permite o desenvolvimento de pequenos programas (os famosos shell scripts).
Em resumo, o shell é um programa independente do usuário, executado fora do kernel, que fornece uma interface para interpretação de comandos. Ele permite a interação com o sistema executando comandos em uma interface de texto (CLI). Mesmo que você esteja apenas usando o ambiente gráfico e nunca tenha precisado usar ou executar nenhum comando Linux, o shell está em constante execução. Quando você abrir o terminal de linha de comando, você verá o shell em pleno funcionamento
Saiba como aprender 20 comandos Linux em apenas alguns minutos
20 comandos Linux que você talvez não conheça
Softwares GNU
O shell fornece alguns comandos básicos embutidos, mas a maioria dos comandos que podem ser executados no shell Linux não são oferecidos por ele. Por exemplo, o comando cp (para copiar um arquivo), o comando ls (para listar os arquivos em um diretório) e comando rm (para apagar arquivos) são parte do pacote utilitários básicos GNU (“coreutils“). Nem todos os utilitários e programas de linha de comando são desenvolvidos pelo projeto GNU. Alguns comandos e programas de terminais possuem o seu próprio projeto independente.

Dá pra ver que os comandos listados são fundamentais para o funcionamento do sistema Linux. Além deles, existem softwares utilitários essenciais para o funcionamento do sistema, como os utilitários de compilação e bootloader GRUB; também desenvolvidos e mantidos pelo projeto GNU. Assim, os sistemas Linux não iriam funcionar sem esses utilitários tão importantes. Tão importantes, que, na verdade, o shell Bash, propriamente dito, faz parte do projeto GNU.
O Projeto GNU, criado por Richard Stallman, foi concebido em 1983 como uma maneira de trazer de volta o espírito cooperativo que prevalecia na comunidade de computação nos seus primórdios — para tornar a cooperação possível novamente ao remover os obstáculos à cooperação impostos pelos donos de software proprietário. Leia mais aqui.
Assim, diante dessa situação, você deve ter visto muitas discussões à respeito sobre a controvérsia do uso da nomenclatura “Linux” com a “GNU/Linux”. O uso, apenas, do nome “Linux” indica que somente o Linux é capaz de oferecer sozinho as funcionalidades que ele tão bem oferece. Contudo, o uso do nome “GNU/Linux” representa mais fielmente que o sistema também inclui outros softwares utilitários fundamentais para o funcionamento do sistema.
Saiba como compilar e instalar programas Linux distribuídos diretamente pelo código-fonte [tar.gz]
Lista completa de GNU Softwares
Linux e o Sistema GNU
Servidor gráfico
O modo gráfico no Linux é gerado pelo servidor gráfico X (X Window System), que não é parte do kernel Linux. Entre outras funções, ele é responsável pela ativação da placa de vídeo, mouse e teclado; permitindo ao usuário o uso de interfaces gráficas que são chamadas de Gerenciadores de Janelas e Ambientes Desktops. Os Ambientes Desktops dispõem de interface completa para o usuário (GUI), bem como: barra de ferramentas, botões, ícones, wallpapers e bibliotecas gráficas. Já os Gerenciadores de Janelas dão base para os Ambientes Desktops.

Existem diversos Ambientes Desktops diferentes. E essa é uma das características mais fascinantes do mundo Linux. A possibilidade em poder personalizar seu sistema. Por exemplo, se não gostar de um Ambiente Desktop, você pode facilmente trocar por outro que se adeque as suas necessidades
Atualmente, o servidor gráfico mais popular é o X.org. Entretanto, já existem em funcionamento outros servidores gráficos em destaque, que no caso são: o Wayland e o Mir (desenvolvido pela Canonical – Ubuntu). Ambos com o propósito de serem substituto ao X Window System.
Em resumo, o servidor gráfico interage com sua placa de vídeo, monitor, mouse e outros dispositivos que preparam o ambiente para os Gerenciadores de Janelas e Ambientes Gráficos. Um servidor gráfico não fornece um Ambiente Desktop completo, apenas um sistema gráfico que Ambientes Desktop e ferramentas podem funcionar sobre ele.
Saiba como executar aplicações gráficas remotamente através de uma conexão SSH
Ambientes Desktops
Se você está usando uma distribuição Linux agora, o que você está realmente vendo e interagindo é um Ambiente Desktop Linux. Por exemplo, o Ubuntu oferece o Ambiente Desktop Unity, o Fedora oferece o GNOME e Linux Mint, geralmente, inclui Cinnamon ou MATE. Estes Ambientes Desktop fornecem tudo que você vê e interage – o fundo da tela, painéis, barras de título das janelas e muito mais.

Manjaro 16.06 – GNOME
Além de diversas características, os Ambientes Desktops incluem seus próprios utilitários. Por exemplo, GNOME e o Unity incluem o gerenciador de arquivos chamado Nautilus desenvolvido como parte do GNOME. Já o KDE inclui o gerenciador de arquivos chamado Dolphin, desenvolvido como parte do projeto KDE.
Em resumo, todos esses Ambientes Desktops citados são desenvolvidos independentemente do desenvolvimento do kernel Linux. Assim, diversos projetos acabam surgindo para aumentar o leque de opções disponíveis para o usuário escolher qual usar. E são nesses Ambientes Desktops que a maioria dos usuários resolvem mudar tema, cor dos ícones e outras mudanças na aparência; deixando, literalmente, “a sua cara”
Top 10 extensões do GNOME Shell que melhoram sua interface e usabilidade
5 super temas do KDE e Gnome Shell para você instalar no seu sistema
Saiba como personalizar o Ubuntu/Elementary OS em alguns cliques
Os 7 ambientes gráficos mais populares do mundo Linux
Via | HowToGeek
O post Muito além do kernel – conheça todos os elementos que formam a estrutura do sistema Linux apareceu primeiro em Linux Descomplicado.