
Maluco, tudo com lapis ainda, respeito maximo!

Pra mim só tem 2 pessoas no mundo, as que aceitam piadas, e as que são um pé no saco
O nióbio é o elemento químico que ocupa o número 41 da tabela periódica, em cima do tântalo e ao lado do molibdênio. Assim como estes, o nióbio oferece características especiais ao aço e a outras ligas metálicas. Bastam 100 gramas para fazer com que 1 tonelada de aço fique mais resistente, maleável ou condutora. Custa uma fortuna: cada quilo de nióbio vale de 30 a 40 dólares, 400 vezes a cotação do minério de ferro, principal mineral explorado no Brasil.
A CBMM, controlada pela família Moreira Salles, sócia do banco Itaú Unibanco, é pioneira na exploração de nióbio e hoje controla 80% do mercado global, avaliado em 3 bilhões de dólares por ano. Sua mina tem reservas estimadas em 800 milhões de toneladas. Com 60 anos de história, a CBMM é tão discreta que suscitou uma série de teorias conspiratórias sobre seu principal produto. As teorias estão mais populares do que nunca — e o nióbio também.
Recentemente, o metal virou queridinho de Jair Bolsonaro, que visitou a fábrica da CBMM, em Araxá, no interior de Minas Gerais, há dois anos. Bolsonaro cita o nióbio constantemente para ressaltar o potencial mineral do Brasil, inclusive em regiões como a Amazônia. Em viagem ao Japão, em junho, gravou um vídeo mostrando uma correntinha de nióbio.
Instalada nas montanhas a 10 quilômetros do centro de Araxá, a CBMM é uma empresa camarada com os funcionários e clientes. A rua de entrada de seu complexo industrial — formado, além da mina, por 14 fábricas — é decorada com as bandeiras dos países de onde vêm seus sócios e clientes.
Em anos bons — e quase todos o são (em 2018, o lucro foi de 2,8 bilhões de reais) —, os 2.000 funcionários recebem até seis salários de bônus. A CBMM financia 80% dos estudos de empregados e dependentes e mantém uma pré-escola no centro de Araxá. Os impostos pagos respondem por 70% da receita do município de 105.000 habitantes.
Parece um mundo de fantasia, e é esse o grande risco da CBMM. Sobram casos de companhias dominantes em seus mercados que acabaram se acomodando. Para manter o domínio de mercado, a CBMM está concluindo um projeto de expansão de 2 bilhões de reais para elevar a capacidade de produção de 100.000 para 150.000 toneladas por ano. Entre os novos projetos estão turbinas, lentes, baterias — mas não correntinhas.
A versão completa desta reportagem está na edição 1191 da revista EXAME, disponível também na versão digital
Eu trabalhei com desenvolvimento Web boa parte da minha vida, hoje estou transitando entre a Web o mundo mobile através do React Native e estou de olho nas tendências novas para o desenvolvimento móvel e ando explorando bastante um carinha ai chamado Flutter. A ideia aqui é compartilhar um pouco do que é essa ferramenta, quais as diferenças dele para as outras alternativas que temos hoje no mercado.
A ideia desse post é fazer uma visão geral sobre as alternativas que temos hoje no mercado para trabalhar com mobile e entender um pouco mais sobre como o Flutter funciona e a ideia por trás dele, coisas boas, ruins… enfim bora pro post!
Hoje existem diversas formas de criar aplicativos mobile, a padrão é usar Java/Kotlin para codar em Android e Swift/Objetive-C (dependendo do legado que você tem) para programar para o mundo iOS. Embora isso seja o padrão, para desenvolver assim é necessário ter profissionais que demandam conhecimentos das duas plataformas e existem outras dificuldades como sincronizar as features que existem na app de uma plataforma exista na outra e conseguir evoluir a codebase de forma conjunta.
Uma alternativa para isso seria ter uma base de código só que rodasse em ambas as plataformas, as pessoas pensam isso desde muito tempo, sempre que alguém precisa distribuir uma aplicação parecida/igual para mais de uma plataforma surge alguém tentando resolver esse problema e no mundo dos aplicativos surgiu o Apache Cordova e a ideia de usar WebViews

A ideia é maravilhosa, escrevemos com as tecnologias da Web, criamos as interfaces e é possível rodar um código só, cross plataform. Com os adventos das SPAs, frameworks front end que facilitaram trazer páginas mais dinâmicas baseadas em dados vindos de APIs e transições de tela mais próximas dos aplicativos nativos, isso foi ganhando cada vez mais popularidade principalmente para projetar MVPs ou mesmo aplicativos pra valer. Além dessas, outras tecnologias foram surgindo no ecossistema das Webviews dando um suporte melhor para tudo isso como Phonegap, Ionic e outros.
Essa praticidade toda acaba tendo um custo:

Nossa aplicação é carregada por meio de uma WebView dentro da casca de um aplicativo. Ou seja nossa app é basicamente um site e para o usuário final, quando a aplicação inteira é feita dessa forma, em alguns casos, pode acabar gerando uma estranheza em algumas animações ou interações, pois a diferença de performance em vários casos é gritante. Sem contar que não temos o acesso direto a recursos nativos como câmera, sensores, bluetooth… sempre ficamos a mercê de plugins que a comunidade cria que conforme o tempo vai passando, novas atualizações das APIs nativas como a permissão em runtime para acessar a câmera que se não for adaptada simplesmente vai quebrar o App. O maior problema é que do dia pra noite, podemos acabar ficando órfãos de alguns deles, a menos que seu time possa contar com alguém que consiga abrir a lib e adaptar alguma coisa.
Hoje em dia, quanto falamos de aplicativos com uma codebase só (rodar o mesmo código em diferentes plataformas) a primeira coisa que vem na cabeça de muitas pessoas para o mundo mobile é o React Native. Ele possui uma série de vantagens:
Para isso tudo funcionar existe uma estrutura que podemos simplificar em: JavaScript, Bridge, Nativo.

Nossa aplicação é basicamente um arquivo JavaScript gigante que interage com uma ponte que faz a conversão de tudo o que fazemos em JavaScript e as alterações feitas no lado React para o lado Nativo interagindo com Widgets Nativos das plataformas (se você quiser uma visão bem mais hacker desse funcionamento, recomendo assistir essa talk fantástica do @tadeuzagallo). Funciona super bem e atende diversos casos, tanto que existem muitas apps usando como o Nubank, Facebook, Gympass… Mas como nem tudo são flores o bridge pode causar alguns problemas de performance, como no caso de animações onde ele pode chegar a ser acessado 60 vezes em animações, swipes e outras interações do gênero. Se você quiser ver exemplos de algumas limitações, deixo aqui um link para uma futura leitura sobre o tema, mas por hora vamos continuar que o próximo carinha que vamos comentar é o tal do Flutter.
Agora sim, chegamos no objetivo do post, vamos começar sendo justos e falando quais as vantagens de usar o tal do Flutter
De início é isso mesmo, o que o React Native trouxe com os componentes e o conceito de state acaba meio que sendo uma das inspirações do time do Google por trás do Flutter para criar a nova ferramenta, ele começa a ter mais vantagens quando vamos para a forma como ele funciona. Diferente do React Native o Flutter não possui a bridge de JavaScript como um meio de campo para acessar os widgets nativos de cada plataforma, o Flutter cria os widgets diretamente onde as plataformas criam os widgets nativos:

Isso é possível graças ao fato de que para trabalhar com o Flutter usamos uma linguagem chamada Dart. O fato não se deve só a linguagem, o ponto aqui é que ela é compilada inicialmente inicialmente “ahead of time” (AOT) para múltiplas plataformas (como binário e como código no caso do JavaScript) e quando nosso aplicativo é aberto os widgets que criamos e foram compilados interagem diretamente com a API de Canvas das plataformas, essa por sua vez, é a responsável por desenhar o que vemos na tela. Vale ressaltar que o fato do Dart ser compilado para o código nativo diminui o tempo de boot das aplicações (Como o React Native precisa processar o código do JavaScript todo em alguns casos isso pode ter uma diferença e mesmo que pequena vale comentar).
Além do que eu achei legal, acho super importante deixar bem claro o que não gosto do Flutter:
A experiência de desenvolver com uma ferramenta aparentemente estável é bem legal, eu digo isso, pois ele já está em sua versão 1 que foi lançada em 4 de dezembro de 2018. Não cheguei a fazer milhares de integrações mas no que diz respeito a acessar recursos externos, gerenciar navegação, debugging entre outros tópicos consegui fazer tudo sem problemas. A integração com VSCode, Android Studio, IntelliJ e xCode está bem bacana e funcional (tive bem menos crashs por segundo do que quando comecei com React Native).

O suporte para trabalhar com erros roda bem até quando algum problema ocorre com tudo rodando via terminal, o que gera uma independência bem grande de ter um editor como o VSCode ou alguma IDE (embora eu aconselhe você usar sempre um sempre que for trabalhar com Flutter ou outra tecnologia).

Falando em erros, uma feature sensacional que nos ajuda a encontrar algum bug ou erro de forma bem rápida é o suporte ao hot reloading que existe graças a compilação “JIT” (Just in time) que o Flutter usa e abusa da Virtual Machine do Dart em modo de debug, e nos ajuda a identificar alterações na interface de forma mais rápida:

E esse formato de hot reload tem uma integração fantástica com o VsCode (onde eu mais codei até agora), que nos permite fazer breakpoints sem precisar executar nenhum comando adicional:

O Flutter todo é baseado em layouts programáticos/view code, ou seja, aqui não temos JSX ou tags que nos ajudam a escrever o código, tudo são classes e sempre que vamos trabalhar com alguma alteração de valor existe uma outra classe com as configs necessárias para fazermos as operações. Um exemplo legal/triste disso é para fazermos um padding por exemplo, precisamos colocar um componente Padding com a propriedade padding em volta do ícone:

Enquanto em outros lugares como quando estamos utilizando um componente Text, podemos passar um atributo style que recebe um TextStyle com algumas customizações visuais, ao meu ver todos os componentes poderiam ter um atributo style, me incomoda sempre ser um mistério que eu descubro via documentação ou via Ctrl + Espaço no editor o que é customizável em determinado elemento.

Achei bem legal que para trabalhar com imagens existe um componente, até semelhante com a tag img que temos no HTML

Porém quando quis deixar ele redondinho para usar no header do instafake eu precisei usar um componente que nem sabia que existia, o BoxDecoration:

Talvez exista alguma forma mais fácil que eu não descobri ainda, mas achei bem bizarro não poder só dizer que a imagem é circular ou algo assim.
Para quem vem do Front como eu isso tudo pode gerar uma estranheza #saudadesCSS, mas o Flutter tem uma página dedicada a explicar como nós podemos aprender a converter a forma de pensar do front end https://flutter.dev/docs/get-started/flutter-for/web-devs e todos os componentes que ele nos libera são altamente customizáveis e super bem documentados.
Eu também escrevi um post que pode ti ajudar no get started com a ferramenta, vale a pena dar uma olhadinha 
Bom, eu estou fazendo altos experimentos com o Flutter e vários de seus recursos e estou tirando ainda novas conclusões e até mesmo descobrindo, não vou dizer que ele é melhor nem pior que o React Native ou outra solução, ainda existe muito chão pra rolar e muita coisa para ver no projeto que venho trabalhando com ele.
Já tenho bastante material para compartilhar e ao longo das próximas semanas vou compartilhar minhas pesquisas e trazer mais conteúdos, então se você curtiu, não deixe de seguir minhas redes sociais e dar uma olhadinha no meu site que toda semana ta saindo algo novo por lá https://mariosouto.com.br
Até a próxima
Referências:
The post Conhecendo o Flutter, e uma visão do desenvolvimento mobile appeared first on Blog da Caelum: desenvolvimento, web, mobile, UX e Scrum.
 |
| 'Pai da computação' Alan Turing estampará notas de 50 libras. |
Na EnvoyCon, engenheiros de várias empresas apresentaram seus casos de uso para o Envoy. A ideia geral é que o Envoy está se aproximando da sua visão de fornecer uma "API de plano de dados universal".
By Daniel Bryant Translated by Pedro Toth
Uma startup é uma empresa em formação, ela enfrenta limitações, restrições, e mesmo assim sua visão é alcançar disrupções, revoluções, e novos recordes nunca alcançados antes. Nesta palestra vamos explorar alguns conceitos simples que muitos provavelmente estão ignorando, e que pode mudar sua visão de como montar uma startup.
By Fabio Akita
O penúltimo com certeza é veterano de guerra e o último deve ser filho do próprio Satanás HuASUHASuAHSuAHS
Seu smartphone, no primeiro uso inicia normalmente, sem retardos. Com o tempo, a medida que vai instalando seus aplicativos, tende a ficar mais lento. Analogamente, seu sistema Linux pode sofrer retardos na inicialização do sistema, oriundos de diversos processos iniciados em tempo de boot.

Dependendo de quais serviços tenha configurado, esses processos causam pequenos atrasos no tempo de inicialização no Linux. Sendo assim, entenda como isso acontece e descubra quais processos podem estar causando esse “probleminha” imperceptível para maioria dos usuários; principalmente para os iniciantes.
Antes de começarmos, entenda que um processo é a forma que o sistema operacional tem para representar um programa em execução. É o processo que utiliza os recursos do computador – processador, memória, etc – para a realização das tarefas para as quais a máquina é destinada. Inclusive, todo sistema possui um processo inicializador, no caso do Linux o processo init; o primeiro processo do Linux depois que o Kernel é iniciado.
Saber lidar com processos pode ser crucial para manter um computador funcionando e executando suas tarefas normalmente. Isso se torna essencial a administradores de sistemas, mas é importante, até mesmo, ao usuário do cotidiano.
Tendo isso em vista, as distribuições Linux usam um sistema de inicialização carregado, através do processo init, pelo bootloader do sistema. Atualmente, existem alguns, entre eles Systemd, SysVinit ou SysV e o upstart. O Systemd se tornou, há alguns anos, o novo padrão de inicialização no principais sistemas Linux. O Systemd veio em detrimento do uso do SysVinit ou SysV, presente ainda em algumas distribuições Linux. E o upstart foi criado pela Canonical, mantenedora do Ubuntu, e também migrado para o Systemd, na maioria das suas versões.
Sendo assim, vou mostrar na prática como descobrir quais processos podem estar retardando o tempo de inicialização no Linux e como atenuar esse problema.
Primeiramente, é preciso saber qual sistema de inicialização está carregado no seu sistema Linux. Simplesmente, verifique, executando um comando “ls”, em cada diretório abaixo, para obter essa informação:
$ ls /usr/lib/systemd$ ls /usr/share/upstart$ ls /etc/init.dLogo após, é preciso identificar quais processos demandam mais tempo, e se possível, desativá-los. Assim, teremos uma visão de quais recursos são utilizados durante o boot. No caso do Systemd, execute:
$ systemd-analyze
Startup finished in 11.822s (firmware) + 5.590s (loader) + 2.438s (kernel) + 9.614s (userspace) = 29.466s
graphical.target reached after 9.614s in userspaceO comando anterior mostrou um resumo global de tempo de inicialização dos processos no sistema, em torno de 29s. Mas, para obter lista detalhada de quais processos demandam mais tempo, execute:
$ systemd-analyze blame
7.087s NetworkManager-wait-online.service
1.130s docker.service
846ms user-runtime-dir@120.service
809ms systemd-logind.service
769ms lvm2-monitor.service
610ms udisks2.service
590ms man-db.service
463ms logrotate.service
409ms dev-sdb6.device
224ms org.cups.cupsd.service
{...}
Uma longa lista dos processos iniciados durante o boot e o tempo gasto por eles foi apresentado como resposta. O utilitário systemd-analyse também pode mostrar gargalos no desempenho de inicialização. O comando a seguir mostra serviços iniciando com indicadores de quando eles começaram e quanto tempo levaram para iniciar:
$ systemd-analyze critical-chain
└─multi-user.target @9.614s
└─docker.service @8.482s +1.130s
└─network-online.target @8.481s
└─NetworkManager-wait-online.service @1.393s +7.087s
└─NetworkManager.service @1.318s +71ms
└─dbus.service @1.316s
└─basic.target @1.313s
└─sockets.target @1.313s
└─docker.socket @1.312s +764us
└─sysinit.target @1.309s
└─systemd-update-done.service @1.304s +4ms
└─ldconfig.service @1.160s +143ms
└─local-fs.target @1.158s
└─run-user-120.mount @3.295s
{...}
Os números após o símbolo “@” mostram quando o alvo foi atingido e o número após o “+” mostra quanto tempo demorou para iniciar um serviço. No meu caso, podemos ver que o serviço NetworkManager-wait-online está levando um tempo maior (7,087 segundos) para iniciar, o que é mais da metade do tempo total de inicialização. É preciso corrigir sua configuração ou descobrir por que está demorando tanto para concluir suas tarefas.
Alternativamente, sabendo da situação, queremos que o serviço NetworkManager-wait-online gaste menos tempo que o atual para iniciar. Em resumo, esse processo é responsável por garantir que a rede fique ativa antes que certas etapas sejam feitas retardando a inicialização do sistema até que uma conexão de rede seja estabelecida.Ele usa um utilitário chamado nm-online (conjunto de ferramentas do NetworkManager) que verifica, no boot, se alguma rede já foi estabelecida (cabo, wireless e outras).
Por ser um processo essencial para o sistema, desativá-lo não é uma ação recomendada. Contudo, como alternativa, podemos identificar quais conexões WiFi, por exemplo, que já tenha sido realizada, podem ser eliminadas diminuindo as tarefas do NetworkManager.
Ou, mais avançado, podemos ajustar alguns parâmetros de configurações do serviço. Nesse caso, você pode alterar o arquivo /lib/systemd/system/NetworkManager-wait-online.service, como root, e mudar de 30 (padrão) para 10 segundos de espera (–timeout).
Execute as mudanças usando o editor nano e tenha consciência que essa mudança pode causar falhas em outros services que dependam do status da rede. Por sua conta e risco:
$ sudo nano /lib/systemd/system/NetworkManager-wait-online.service
[Unit]
Description=Network Manager Wait Online
Documentation=man:nm-online(1)
Requires=NetworkManager.service
After=NetworkManager.service
Before=network-online.target
[Service]
Type=oneshot
ExecStart=/usr/bin/nm-online -s -q --timeout=10
RemainAfterExit=yes
[Install]
WantedBy=network-online.target
A seguir, “informar” o systemd das mudanças:
$ sudo systemctl daemon-reload
Reinicie o sistema e após o reinício, execute o comando “systemd-analyze critical-chain” novamente e veja o tempo “ganho”. No meu caso, tive uma perda causando um atraso de 4s por conta do serviço docker que foi sensível ao atraso configurado:
$ systemd-analyze critical-chain
└─multi-user.target @12.326s
└─docker.service @8.482s +2.230s
└─network-online.target @8.481s
└─NetworkManager-wait-online.service @1.393s +7.087s
└─NetworkManager.service @1.318s +71ms
{...}
Mas, provavelmente, ao iniciar o sistema, você não irá precisar acessar a internet imediatamente – desde que nenhum outro processo dependa disso. Se for este o caso, podemos desativar o NetworkManager-wait-online.service do boot. A rede só vai entrar alguns segundos depois do login:
$ sudo systemctl disable NetworkManager-wait-online.service
Novamente, reinicie o sistema e após o reinício, execute o comando “systemd-analyze critical-chain” novamente e veja o tempo “ganho”. No meu caso, foi um ganho de 6s nesse cenário:
$ systemd-analyze critical-chain
graphical.target @3.931s
└─multi-user.target @3.930s
└─docker.service @1.330s +2.600s
└─network-online.target @1.329s
└─network.target @1.327s
└─wpa_supplicant.service @2.214s +26ms
└─basic.target @1.255s
└─sockets.target @1.255s
{...}
É importante salientar que não foram apresentados todas as técnicas que melhoram por completo o tempo de inicialização no Linux. O foco foi a nível de processos do sistema. Dentre outras alternativas para obter ganhos significativos, temos: alterar o tempo do GRUB e/ou trocar seu disco HDD por SSD, já que são melhores para ler arquivos pequenos, colocados aleatoriamente, que tendem a melhorar o tempo de inicialização.
Por fim, nesse cenário de processos, cada usuário terá uma resposta diferente e maneiras para atenuar o problema, tendo em vista que cada sistema possui sua pilha de processos. Mas, de qualquer maneira espero que este artigo tenha ajudado!
O post Saiba como melhorar o tempo de inicialização no Linux apareceu primeiro em Linux Descomplicado.
A versão mais recente do GitLab é capaz de usar o Knative e o Kubernetes para criar, implantar e gerenciar implementações serverless, aproveitando o modelo de funções como serviço (FaaS).
By Sergio De Simone Translated by Pedro TothO UserRecon é uma ferramenta desenvolvida em ShellScript que permite realizar a pesquisa de um usuário em mais de 75 redes sociais.
É um ótimo recurso para realizar uma investigação de quem pode estar utilizando um usuário pessoal ou ate mesmo corporativo indevidamente.
Projeto: https://github.com/thelinuxchoice/userrecon
01 Passo
Realize o download e acesso o diretório UserRecon
root@100security:/# git clone https://github.com/thelinuxchoice/userrecon.git
root@100security:/# cd userrecon
root@100security:/userrecon# ls -l

02 Passo
Atribuir a permissão de execução no script userrecon.sh em seguida executá-lo.
root@100security:/userrecon# chmod +x userrecon.sh
root@100security:/userrecon# ./userrecon.sh

03 Passo
Informe o nome do usuário no qual deseja pesquisar, neste exemplo: 100security para que a pesquisa seja iniciada.

04 Passo
Um arquivo com o nome do usuário é gerado contendo a relação de todos os cadastros encontrados com o nome: (ex.) 100security.
root@100security:/userrecon# cat 100security.txt

No QCon SF, Suudhan Rangarajan apresentou a Netflix Play API e o porquê de uma arquitetura evolucionária. Pontos principais: serviços que possuem uma identidade única são mais fáceis de atualizar; gastar tempo identificando decisões-chave que precisam ser feitas ao se construir um serviço; e projetar uma “arquitetura evolucionária” usando ferramentas específicas traz muitos benefícios.
By Daniel Bryant Translated by Camilla Albuquerque
Nesta apresentação mostro as principais formas para desenvolvermos lambda functions usando frameworks como o serverless, apex up e usando apenas a standard lib
By Elton MinettoFala pessoal, hoje vamos entrar em uma série de posts referentes a métricas, para quem está ligado no mundo da tecnologia, vem se falando há bastante tempo sobre SRE [ Ebook do Google ] (https://landing.google.com/sre/) um dos principais temas falado pelo pessoal do Google é em questões de métricas, pois são as métricas que nos fornecem uma visão geral referente a como está o nosso ambiente e nos proporciona a capacidade cada vez maior nossas equipes serem orientadas a dados: Data driven
Prometheus é um Kit de ferramentas de Monitoramento e Alertas Open Source que foi criada pela SoundCloud . Muitas empresas estão adotando o Prometheus para trabalhar com a questão de métricas de seus sistemas e aplicações. Em 2016 o Prometheus foi incorporado dentro da Cloud Native Computing Foundation sendo o segundo projeto hospedado após o Kubernetes.

Vamos monitorar o nosso servidor de Docker com o Prometheus, para isso vamos editar o arquivo daemon.json que já é criado por padrão em:
/etc/docker/daemon.json
C:\ProgramData\docker\config\daemon.json
Dentro desse arquivo vamos adicionar as seguintes linhas:
{
"metrics-addr" : "127.0.0.1:9000"
"experimental" : true
}
Após a criação desse arquivo, ou edição dele, vamos precisar criar o arquivo de configuração do nosso Prometheus, para isso vamos criar o arquivo config.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'docker'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9323']
Com o conf criado vamos criar o serviço para começar a armazenar as métricas, para isso vamos executar:
docker service create --replicas 1 --name my-prometheus \
--mount type=bind,source=/tmp/prometheus.yml,destination=/etc/prometheus/prometheus.yml \
--publish published=9090,target=9090,protocol=tcp \
prom/prometheus
Após isso basta abrir o seu browser e navegar até http://iphost:9090 e você terá acesso ao seu prometheus. Você pode ir até http://iphost:9000/targets/ onde você poderá ver as informações que configramos e verificar se está tudo ok com as coletas de nossas métricas.
Como podemos notar é meio complexo conseguirmos ver as informações referente ao nosso ambiente diretamente pelo Prometheus, então para facilitar esssa visão, vamos utilizar o Grafana como Dashboard, ja falamos dele em um post anterior: Grafana + Influx + Cadvisor
Para criar o container do Grafana vamos executar:
docker run -d --name=grafana -p 3000:3000 grafana/grafana
feito isso vamos acessar http://localhost:3000 após o acesso será solicitado um username e password, por padrão o inicial é admin e admin, em seguida será solicitado um novo password, então basta colocar o seu novo password.
Agora vamos adicionar o nosso prometheus como Data Source, para que sejá possível realizarmos as consultas para preencher os nossos gráficos, para isso vamos clicar no icone conforme a imagem abaixo:
E vamos escolher a opção Data Source
Agora vamos ir até Add Data Source, onde vamos ter alguns campos que são padrões e outros que devem aparecer conforme o tipo de Data Source que será escolhido, nesse caso vamos utilizar o Prometheus.
Dessa vez vamos criar sem autenticação, então pode deixar as questões de AUTH em branco.
Skip TLS Verification (Insecure)
Após isso é só clicar em Save & Test.
Vá até a opção de New Dashboard dentro do Grafana e escolha a opção de “Graph”
Agora vamos editar o nosso Dashboard:
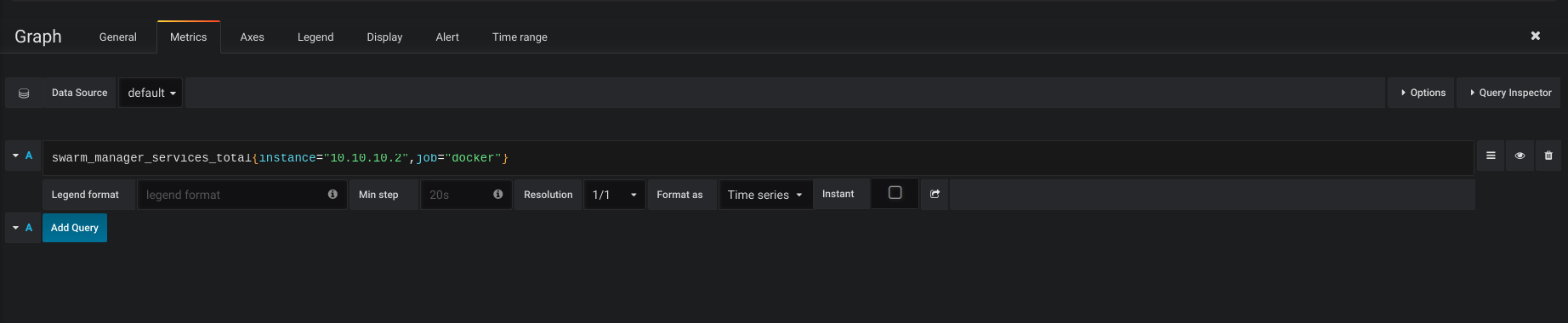
Agora a imaginação é sua, basta verificar no Prometheus quais os dados que você possui para poder fazer seus Dashboards.
Espero que esse post tenha sido útil para vocês e gostaria que deixassem aqui embaixo algum comentário ou dúvidas para que cada vez mais possamos melhorar o nosso conteúdo para que fique simples para todos e também útil, então por hoje era isso pessoal, um grande abraço e muito obrigado!
The post Prometheus + Docker first appeared on Mundo Docker.
Post incialmente públicado em: https://dumpscerebrais.com/2019/01/migrando-do-docker-swarm-para-o-kubernetes
Começamos 2019 e ficou bem claro que o Docker Swarm perdeu para o Kubernetes na guerra de orquestradores de contêineres.
Não vamos discutir aqui motivos, menos ainda se um é melhor que outro. Cada um tem um cenário ótimo para ser empregado como já disse em algumas das minhas palestras sobre o assunto. Mas de uma maneira geral se considerarmos o requisito evolução e compararmos as duas plataformas então digo que se for construir e manter um cluster de contêineres é melhor já começarmos esse cluster usando Kubernetes.
O real objetivo desse artigo é mostrar uma das possíveis abordagens para que nossas aplicações hoje rodando num cluster Docker Swarm, definidas e configuradas usando o arquivo docker-compose.yml possam ser entregues também em um cluster Kubernetes.
Já é meio comum a comparação entre ambos e posso até vir a escrever algo por aqui mas no momento vamos nos ater a um detalhe simples: cada orquestrador de contêineres cria recursos próprios para garantir uma aplicação rodando. E apesar de em alguns orquestradores recursos terem o mesmo nome, como o Services do Docker Swarm e o Services do Kubernetes eles geralmente fazem coisas diferente, vem de conceitos diferentes, são responsáveis por entidades diferentes e tem objetivos diferentes.
O kompose é uma ferramenta que ajuda muito a converter arquivos que descrevem recursos do Docker em arquivos que descrevem recursos do Kubernetes e até dá para utilizar diretamente os arquivos do Docker Compose para gerir recursos no Kubernetes. Também tenho vontade de escrever sobre ele, talvez em breve, já que neste artigo vou focar em como ter recursos do Docker Swarm e do Kubernetes juntos.
Sempre gosto de passar o contexto para as pessoas entenderem como, quando e onde foram feitas as coisas, assim podemos compreender as decisões antes de pré-julgarmos.
Na Dockercon européia de 2017, a primeira sem o fundador Solomon Hykes, foi anunciado e demostrado como usar um arquivo docker-compose.yml para rodar aplicações tanto num cluster Docker Swarm quanto num cluster Kubernetes usando a diretiva Stacks.
A demostração tanto na Dockercon quanto no vídeo acima foram sensacionais. Ver que com o mesmo comando poderíamos criar recursos tanto no Docker Swarm quanto no Kubernetes foi um marco na época. O comando na época:
docker stack deploy --compose-file=docker-compose.yml stackname
Só tinha um problema, isso funcionava apenas em instalações do Docker Enterprise Edition ($$$) ou nas novas versões do Docker for Desktop que eram disponíveis apenas para OSX e Windows.
Aí você pergunta: Como ficaram os usuário de Linux nessa história, Wsilva?
Putos, eu diria.
Assim como outros também tentei fazer uma engenharia reversa e vi que o bootstrap desse Kubernetes rodando dentro do Docker for Mac e Windows era configurado usando o Kubeadm. Fucei, criei os arquivos para subir os recursos Kubernetes necessários e quase consegui fazer rodar mas ainda me faltava descobrir como executar o binário responsável por extender a api do Kubernetes com os parâmetros certos durante a configuração de um novo cluster, todas as vezes que rodei tive problemas diferentes.
Até postei um tweet a respeito marcando a Docker Inc mas a resposta que tive foi a que esperava: a Docker não tem planos para colocar suporte ao Compose no Linux, somente Docker for Desktop e Enterprise Edition.
Ainda bem antes de tentar fazer isso na mão, lá na Dockercon de 2018 (provavelmente também escreverei sobre ela) tive a oportunidade de ver algumas palestras sobre extender a API do Kubernetes, sobre como usaram Custom Resource Definition na época para fazer a mágica de interfacear o comando docker stack antes de mandar a carga para a API do Kubernetes ou para a API do Docker Swarm e também conversei com algumas pessoas no conference a respeito.
A desculpa na época para não termos isso no Docker CE no Linux era uma questão técnica, a implementação dependeria muito de como o Kubernetes foi instalado por isso que no Docker para Desktop e no Docker Enterprise, ambientes controlados, essa bruxaria era possível, mas nas diversas distribuíções combinadas com as diversas maneiras de criar um cluster Kubernetes seria impossível prever e fazer um bootstrap comum a todos.
Na Dockercon européia de 2018, praticamente um ano depois do lançamento do Kubernetes junto com o Swarm finalmente foi liberado como fazer a API do Compose funcionar em qualquer instalação de Kubernetes. Mesmo sem as instruções de uso ainda mas já com os fontes do instalador disponíveis (https://github.com/docker/compose-on-kubernetes) era possível ver que a estrutura tinha mudado de Custom Resource Definition para uma API agregada e relativamente fácil de rodar em qualquer cluster Kubernetes como veremos a seguir.
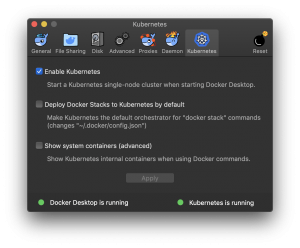
Para rodarmos essa API do Compose no Mac e no Windows, assim como no final de 2017, basta habilitar a opção Kubernetes na configuração conforme a figura e toda a mágica vai acontecer.
No Linux podemos trabalhar com o Docker Enterprise Edition ou com o Docker Community Edition.
Para funcinar com o Docker Community Edition primeiramente precisamos de um cluster pronto rodando kubernetes e podemos fazer teoricamente em qualquer tipo de cluster. Desde clusters criados para produção com Kops – (esse testei na AWS e funcionou), ou Kubespray, ou em clusteres locais como esse que criei para fins educativos: https://github.com/wsilva/kubernetes-vagrant/ (também funcionou), ou Minikube (também funcionou, está no final do post), ou até no saudoso play with kubernetes (também funcionou) criado pelo nosso amigo argentino Marcos Nils.
Para verificar se nosso cluster já não está rodando podemos checar os endpoints disponíveis filtrando pela palavra compose:
$ kubectl api-versions | grep compose
Para instalar a api do Compose em um cluster Kubernetes precisamos do etcd operator rodando e existem maneiras de instalar com e sem suporte a SSL. Mais informações podem ser obtidas nesse repositório.
Neste exemplo vamos utilizar o gerenciador de pacotes Helm para instalar o etcd operator.
Primeiro criamos o namespace compose em nosso Kubernetes:
$ kubectl create namespace compose
Em seguida instalmos ou atualizamos o Helm.
Se estivermos utilizando OSX, podemos instalar de maneira simples com homebrew.
$ brew install kubernetes-helm
Updating Homebrew...
Error: kubernetes-helm 2.11.0 is already installed
To upgrade to 2.12.3, run `brew upgrade kubernetes-helm`
$ brew upgrade kubernetes-helm
Updating Homebrew...
==> Upgrading 1 outdated package:
kubernetes-helm 2.11.0 -> 2.12.3
==> Upgrading kubernetes-helm
==> Downloading https://homebrew.bintray.com/bottles/kubernetes-helm-2.12.3.moja
######################################################################## 100.0%
==> Pouring kubernetes-helm-2.12.3.mojave.bottle.tar.gz
==> Caveats
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completions have been installed to:
/usr/local/share/zsh/site-functions
==> Summary
? /usr/local/Cellar/kubernetes-helm/2.12.3: 51 files, 79.5MB
No Linux podemos optar por gerenciadores de pacotes ou instalar manualmente baixando o pacote e colocando em algum diretório do PATH:
$ curl -sSL https://storage.googleapis.com/kubernetes-helm/helm-v2.12.1-linux-amd64.tar.gz -o helm-v2.12.1-linux-amd64.tar.gz
$ tar -zxvf helm-v2.12.1-linux-amd64.tar.gz
x linux-amd64/
x linux-amd64/tiller
x linux-amd64/helm
x linux-amd64/LICENSE
x linux-amd64/README.md
$ cp linux-amd64/tiller /usr/local/bin/tiller
$ cp linux-amd64/helm /usr/local/bin/helm
Estamos em 2019 então todos os clusters Kubernetes já deveriam estar rodando com RBAC (Role Base Access Control) por questões de segurança. Para isso devemos criar uma Service Account em nosso cluster para o tiller.
$ kubectl --namespace=kube-system create serviceaccount tiller
serviceaccount/tiller created
$ kubectl --namespace=kube-system \
create clusterrolebinding tiller \
--clusterrole=cluster-admin \
--serviceaccount=kube-system:tiller
clusterrolebinding.rbac.authorization.k8s.io/tiller created
Neste exemplo fizemos o bind para o role cluster admin, mas seria interessante criar uma role com permissões mais restritas definindo melhor o que o helm pode ou não fazer em nosso cluster Kubernetes.
Instalamos o etcd operator:
$ helm init --service-account tiller --upgrade
$ helm install --name etcd-operator \
stable/etcd-operator \
--namespace compose
Monitoramos até os pods responsáveis pelo etcd operator estarem de pé:
$ watch kubectl get pod --namespace compose
Com etcd operator de pé podemos matar o watch loop com ctrl+c.
Próximo passo vai ser subir um cluster etcd usando o operator:
$ cat > compose-etcd.yaml <<EOF
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "compose-etcd"
namespace: "compose"
spec:
size: 3
version: "3.2.13"
EOF
$ kubectl apply -f compose-etcd.yaml
Monitoramos novamente até os pods responsáveis pelo nosso etcd cluster estarem de pé:
$ watch kubectl get pod --namespace compose
Com etcd cluster rodando podemos matar o watch loop com ctrl+c.
Em seguida baixamos diretamente do GitHub e executamos o instalador da API do Compose.
Se estivermos utilizando OSX:
$ curl -sSLO https://github.com/docker/compose-on-kubernetes/releases/download/v0.4.18/installer-darwin
chmod +x installer-darwin
./installer-darwin \
-namespace=compose \
-etcd-servers=http://compose-etcd-client:2379 \
-tag=v0.4.18
No Linux:
$ curl -sSLO https://github.com/docker/compose-on-kubernetes/releases/download/v0.4.18/installer-linux
chmod +x installer-linux
./installer-linux \
-namespace=compose \
-etcd-servers=http://compose-etcd-client:2379 \
-tag=v0.4.18
Vamos checar se os pods estão rodando novamente com watch loop:
watch kubectl get pod --namespace compose
Após todos os pods rodando usamos o ctrl+c para parar o watch loop e em seguida podemos verificar se agora temos os endpoints do compose:
$ kubectl api-versions | grep compose
compose.docker.com/v1beta1
compose.docker.com/v1beta2
Sucesso. Agora vamos baixar um arquivo docker compose de exemplo do repositório da própria Docker:
curl -sSLO https://github.com/docker/compose-on-kubernetes/blob/master/samples/docker-compose.yml
Para ver o conteudo do arquivo podemos usar um editor de texto ou o simples cat docker-compose.yml no terminal mesmo.
Agora vamos usar o docker para criar os recursos no kubernetes, como se estivessemos fazendo um deployment em um cluster de Docker Swarm mesmo:
$ docker stack deploy \
--orchestrator=kubernetes \
--compose-file docker-compose.yml \
minha-stack
Podemos usar tando o kubectl como o docker cli para checar os status:
$ kubectl get stacks
NAME SERVICES PORTS STATUS CREATED AT
demo-stack 3 web: 80 Available (Stack is started) 2019-01-28T20:47:38Z
$ docker stack ls \
--orchestrator=kubernetes
NAME SERVICES ORCHESTRATOR NAMESPACE
demo-stack 3 Kubernetes default
Podemos pegar o ip da máquina virtual rodando minikube com o comando minikube ip e a porta do serviço web-published e acessar no nosso navegador.
No próprio repositório temos uma matriz de compatibilidade entre as funcionalidades no Docker Swarm e funcionalidades no Kubernetes: https://github.com/docker/compose-on-kubernetes/blob/master/docs/compatibility.md
Se você está pensando em migrar seus workloads de clusters de Docker Swarm para clusters de Kubernetes você pode optar tanto pelo Kompose quanto pelo Docker Compose no Kubernetes.
Optando pelo Compose no Kubernetes podemos usar o Docker for Mac ou Docker for Windows, basta habilitar nas configurações a opção de cluster Kubernetes.
Se estiver no Linux pode optar por seguir os passos acima ou pagar pelo Docker Enterprise Edition.
Veja como cada uma dessas opções se adequa melhor aos seus processos e divirta-se.
Até a próxima.
The post Migrando do Docker Swarm para o Kubernetes first appeared on Mundo Docker.
Em uma publicação recente em seu blog, o Google anunciou o Cloud DNS Forwarding, permitindo que serviços, tanto na nuvem quanto locais, possam encontrar um ao outro através do DNS. É possível implementar essa funcionalidade tanto pelo DNS do Google como através de um servidor DNS autoritativo privado.
By Eldert Grootenboer Translated by Paulo PinheiroJovem mergulhador faz sucesso no youtube mostrando sua incansável saga em busca de tesouros perdidos no fundo dos rios. Em 2018, Jake encontrou 8 armas, 7 iPhones, 6 GoPros, 5 Apple Watches, 3 Drones e diversos outros objetos.
Confira o vídeo:
O post Este mergulhador encontrou 8 armas, 7 iPhones, 6 GoPros e 5 Apple Watches no rio apareceu primeiro em Blog Insôônia.
O sistema judicial brasileiro é complexo e conta com diversos órgãos que trabalham em conjunto para garantir a justiça. Entre eles, destaca-se o STJ, sigla que representa o Superior Tribunal de Justiça. Você já se perguntou qual o papel desse importante tribunal no nosso sistema jurídico? E qual a diferença entre ele e o Supremo Tribunal Federal?
Neste artigo, vamos desvendar o funcionamento do STJ, explorando a sua estrutura, composição e as áreas em que ele atua. Afinal, entender como o STJ funciona é fundamental para compreender como os nossos direitos são protegidos e como a justiça é aplicada em diferentes esferas da sociedade.
Prepare-se para uma viagem pelo mundo jurídico, onde você conhecerá a importância do STJ e as nuances que o diferenciam de outros tribunais. Continue lendo e descubra como esse órgão essencial contribui para a consolidação do Estado Democrático de Direito no Brasil!
Leia também: O que é o Poder Judiciário?

Criado em 1988 pela Constituição Federal do Brasil, o STJ é um órgão do Poder Judiciário, considerado como a instância máxima da justiça brasileira em matérias de leis federais que estão abaixo da Constituição (legislação infraconstitucional).
O STF (Supremo Tribunal Federal), também é um órgão do Poder Judiciário e assim como o STJ é considerado como a instância máxima da justiça brasileira, porém, no âmbito da Constituição Federal, ou seja, ele somente julga matérias tenham previsão na Constituição Federal.
O STJ é composto por 33 (trinta e três) Ministros que são escolhidos e nomeados pelo Presidente da República com base em uma lista com três nomes que é apresentada pelo próprio Tribunal.
A Constituição Federal estabelece que o STJ tenha uma composição diversificada, sendo que um terço dos Ministros (11 no total) deve ser escolhido entre desembargadores federais, um terço entre desembargadores de justiça e, por fim, um terço entre advogados e membros do Ministério Público, de forma alternada.
Saiba mais sobre o Ministério Público: o que faz?
Internamente, os 33 Ministros do STJ se dividem se organizam em alguns órgãos, sessões e turmas.
O primeiro órgão é o Plenário, que é composto por todos os Ministros, e exerce a função administrativa do STJ, sendo responsável: (1) pela eleição dos membros para os cargos diretivos e de representação; (2) votação de alteração no regimento interno; e (3) elaboração da lista tríplice (com três nomes) de indicados para compor o STJ.
O segundo órgão do organograma do STJ, é denominado de Corte Especial, e é composta pelos 15 (quinze) Ministros mais antigos, sendo responsável por: (1) julgar as ações penais contra governadores e outras autoridades; e (2) decidir recursos quando há interpretação divergente entre os órgãos especializados do próprio STJ.
Além disso, os 33 (trinte e três) Ministros se dividem em Seções e Turmas especializadas, ou seja, são responsáveis por julgar matérias específicas. São três seções e cada seção possui duas Turmas, que possuem 05 (cinco) Ministros.
| 1ª Seção | Direito Público, que são causas que envolvem impostos, previdência social, servidores públicos, indenizações do Estado, improbidade administrativa, dentre outras. | Primeira e Sgunda Turmas |
|---|---|---|
| 2ª Seção | Direito Privado, que são causas que tratam sobre o comércio, consumo, contratos, família, sucessões, por exemplo. | Terceira e Quarta Turmas |
| 3ª Seção | Direito Penal, que são as causas que envolvem os crimes em geral e a federalização de crimes contra direitos humanos, por exemplo. | Quinta e Sexta Turmas |
A principal função do STJ, como órgão do Poder Judiciário, é a de julgamento. No entanto, não é qualquer caso que pode ser julgado por ele. No direito, denominamos o que pode ser julgado por um juiz ou tribunal como a sua competência.
A competência do STJ está definida no artigo 105 da Constituição Federal de 1988, e se divide em: (1) competência originária, que são os casos que se iniciam diretamente no STJ, ou seja, ele funciona como a primeira instância; (2) competência recursal ordinária, que são casos em que o STJ funciona como segunda instância; e (3) competência recursal especial, que são os casos em que o STJ funciona como instância máxima no âmbito da legislação infraconstitucional.
Dentro da sua competência originária, podemos dizer que as principais funções do STJ, são:
(1) julgar os Governadores de Estados e do Distrito Federal quando eles praticam crimes comuns (homicídio, estupro, tráfico de drogas, são exemplos);
(2) julgar os desembargadores dos Tribunais de Justiça dos Estados e do Distrito Federal, os membros dos Tribunais de Contas dos Estados e do Distrito Federal, os dos Tribunais Regionais Federais, dos Tribunais Regionais Eleitorais e do Trabalho, os membros dos Conselhos ou Tribunais de Contas dos Municípios e os do Ministério Público da União que oficiem perante tribunais, quando eles praticam crimes comuns e nos crimes de responsabilidade, que são aqueles praticados contra a existência da União ou contra o livre exercício dos poderes constitucionais, por exemplo;
(3) julgar conflitos de competência entre Tribunais – conflito de competência ocorre quando dois Tribunais distintos (Tribunal de Justiça e Tribunal Regional do Trabalho, por exemplo) reivindicam o julgamento de determinada matéria (conflito positivo de competência) ou quando ambos os Tribunais entendem que não posseum competência para julgar determinada matéria (conflito negativo de competência), cabendo ao STJ decidir qual dos Tribunais será o responsável;
(4) julgar os mandados de segurança e os habeas data contra ato de Ministro de Estado, dos Comandantes da Marinha, do Exército e da Aeronáutica ou do próprio Tribunal.
A lista de competência orginária completa do STJ se encontra prevista no artigo 105, I, da Constituição Federal de 1988.
Além da competência orginária, o STJ tem a função de julgar recursos, ou seja, ele possui a competência recursal, que é quando reexamina os casos já julgados por outro Juiz ou Tribunal. A competência recursal do STJ se dividem em ordinária e especial.
Compete ao STJ julgar, em recurso ordinário, os seguintes casos:
(a) habeas corpus decididos em única ou última instância pelos Tribunais Regionais Federais ou pelos tribunais dos Estados, do Distrito Federal e Territórios, quando a decisão for denegatória (que nega o direito invocado);
(b) mandados de segurança decididos em única instância pelos Tribunais Regionais Federais ou pelos tribunais dos Estados, do Distrito Federal e Territórios, quando denegatória a decisão;
(c) causas em que forem partes Estado estrangeiro ou organismo internacional, de um lado, e, do outro, Município ou pessoa residente ou domiciliada no País.
A competência recursal ordinária do STJ está prevista no artigo 105, II, da Constituição Federal de 1988.
Por fim, compete ao STJ julgar, em recurso especial, as causas decididas, em única ou última instância, pelos Tribunais Regionais Federais ou pelos tribunais dos Estados, do Distrito Federal e Territórios, quando a decisão recorrida:
(1) contrariar tratado ou lei federal, ou negar-lhes vigência;
(2) julgar válido ato de governo local contestado em face de lei federal;
(3) der a lei federal interpretação divergente da que lhe haja atribuído outro tribunal.
A competência recursal especial está prevista no artigo 105, III, da Constituição Federal. É a principal função exercida pelo STJ, e pode ser considerada uma das mais importantes, sendo justamente a função que o define como instância máxima da justiça brasileira em matérias infraconstitucionais.

Sendo a instância máxima em matérias infraconstitucionais, ao STJ cabe o papel de uniformizar o entendimento jurisprudencial. Jurisprudência é um conjunto de decisões proferidas pelos Tribunais (estaduais e regionais federais) que servem como fundamentamentação, como precedentes, para as decisões proferidas pelos Juízes e pelos Tribunais.
Ocorre, que a ciência jurídica não é uma ciência extata e as leis, muitas vezes, podem ser interpretadas de diferentes formas. Com isso, cada Juiz e cada Tribunal pode aplicar entendimentos divergentes para uma mesma situação, cabendo ao STJ dar a palavra final, uniformizando o entendimento.
A principal ferramenta legal para que o STJ desempenhe esssa função de uniformização do entendimento jurisprudencial é o Recurso Repetitivo, criado em 2008, pela Lei nº. 11.672/08 que alterou o Código de Processo Civil de 1973. Em 2015 foi editado um novo Código de Processo Civil onde se manteve a sistemática do recurso repetitivo.
Recurso Repetivo nada mais é do que uma sistemática de julgamento de recursos que permite ao STJ (e ao STF também) fixar uma tese em um único processo e aplicá-la em milhares de outros processos.
Essa sistemática foi criada com o objetivo de resolver o problema das demandas de massa – que são processos idênticos, com o mesmo pedido e com a mesma fundamentação, ajuizados por milhares de pessoas distintas.
Ao longo do tempo, esses milhares de processos idênticos vão sendo julgados e cada Tribunal aplica um entendimento diferente, e as partes interessadas entram com o Recurso Especial junto ao STJ, para que ele defina qual entendimento deve prevalecer.
Antes de exisitir o Recurso Repetitivo o STJ tinha que julgar cada um desses milhares de processos idênticos, ou seja, tinha que analisar um a um, marcar sessão de julgamento para cada processo, oportunizando às partes a realização de sustentação oral, o que acabou sobrecarregando o Tribunal.
Imaginem: 33 Ministros tendo que julgar milhares e milhares de Recursos Especiais. Isso se tornou um grande problema, pois os Recursos Especiais passaram a demorar muito tempo para serem julgados, além de representarem despesas para os cofres públicos.
Com a implantação do Recurso Repetivo, sempre que houver multiplicidade de recursos especiais idênticos (que tenham a mesma fundamentação jurídica) o STJ pode selecionar apenas um deles, como representativo da controversa, para julgar e fixar uma tese.
Quando isso ocorre, o STJ pode determinar a suspensão do andamento de todos os processos que tratam do mesmo assunto, independentemente de onde se encontram (primeira instância, segunda instância ou no próprio STJ) até que haja um julgamento definitivo daquele recurso especial que foi selecionado como representativo da contraversa.
Uma vez julgado o recurso especial, e fixada a tese (ou tema), esse entendimento deve obrigatoriamente ser aplicado em todos os demais processos, independentemente da instância em que se encontrem.
Portanto, ainda que o processo esteja na primeira instância, caso ele trate de alguma matéria que já foi tema de recurso repetitivo, a decisão do STJ vai ser aplicada no caso. Quando um Juiz ou Tribunal profere decisão que contraria algum tema já pacificado pelo STJ na sistemática dos recursos repetitivos a parte prejudicada pode apresentar uma reclamação diretamente no STJ.
A lei estabelece, ainda, que ao receber um novo processo, se o Juiz verificar que a pretensão do autor é contrária a algum tema que já foi fixado pelo STJ através de recurso repetitivo, deve julgar o processo improcedente antes mesmo de citar a parte contrária.
O STJ já julgou mais de 900 recursos repetitivos, portanto, são mais de 900 teses já fixadas pelo STJ que devem ser obrigatoriamente aplicadas em todos os processos que tratam do mesmo assunto, impactando assim a vida de muitas pessoas.
Para finalizar e demonstrar na prática como as decisões do STJ podem impactar a vida das pessoas, separamos alguns casos que já foram enfrentados pelo Tribubal sob a sistemática dos recursos repetitivos para demonstrar como os temas são fixados.
O Brasil, de tempos em tempos, enfrenta algum tipo de crise econômica. Em momentos de crise, muitos consumidores que financiaram bens (veículos, imóveis, etc) junto às instituições bancárias passam a ter dificuldade para pagar as prestações.
Com o objetivo de revisar o contrato bancário e obter um redução no valor da prestação, os consumidores entram com ação judicial questionando a validade de determindas taxas bancárias que são cobradas no momento da contratação e agregadas ao valor financiado.
Diante da multiplicidade de processos questionando a cobrança das mesmas taxas bancárias, em 2016, o STJ selecionou esse tema para julgar sob a sistemática dos recursos repetitivos, dando origem ao Tema nº. 958.
A questão submetida a julgamento foi:
Validade da cobrança, em contratos bancários, de despesas com serviços prestados por terceiros, registro do contrato e/ou avaliação do bem.
Em 2019 o STJ concluiu o julgamento da questão, e fixou a seguite tese:
2.1. Abusividade da cláusula que prevê a cobrança de ressarcimento de serviços prestados por terceiros, sem a especificação do serviço a ser efetivamente prestado; 2.2. Abusividade da cláusula que prevê o ressarcimento pelo consumidor da comissão do correspondente bancário, em contratos celebrados a partir de 25/02/2011, data de entrada em vigor da Res.-CMN 3.954/2011, sendo válida a cláusula no período anterior a essa resolução, ressalvado o controle da onerosidade excessiva; 2.3. Validade da tarifa de avaliação do bem dado em garantia, bem como da cláusula que prevê o ressarcimento de despesa com o registro do contrato, ressalvadas a: 2.3.1. abusividade da cobrança por serviço não efetivamente prestado; e a 2.3.2. possibilidade de controle da onerosidade excessiva, em cada caso concreto.
O FGTS sempre foi corrigido pela TR – Taxa Refereincial, a qual é manipulada pelo governo federal com o objetivo de conter a inflação e maquiar indicadores econômicos do País. Diante da crises econômicas que, constantemente, assolam o Brasil, em muitos períodos a TR ficou literamente “zerada”, não cumprindo a sua função de corrigir monetariamente os valores do FGTS.
Diante desse cenário, os trabalhadores começaram a entrar com ações judiciais pleiteando a alteração da TR por outro índice que melhor cumprisse a função de corrigir monetariamente os valores do FGTS. Com o tempo, o caso ganhou grande repercussão nacional e os Tribunais passaram a enfrentar avalanches de processos idênticos.
Em 2016, os recursos especiais sobre o assunto começaram a chegar ao STJ, que rapidamente adotou a sistemática dos recursos repetitivos, dando origem ao Tema nº. 731, definindo a seguinte questão a ser julgada:
Discute-se a possibilidade, ou não, de a TR ser substituída como índice de correção monetária dos saldos das contas vinculadas ao FGTS.
No ano de 2018, o STJ concluiu o julgamento da questão fixando a seguinte tese:
A remuneração das contas vinculadas ao FGTS tem disciplina própria, ditada por lei, que estabelece a TR como forma de atualização monetária, sendo vedado, portanto, ao Poder Judiciário substituir o mencionado índice.
Embora o STJ já tenha julgado a questão, decidindo de forma contrária aos trabalhadores, os processos que tratam dessa matéria ainda seguem suspensos, uma vez que a questão também foi submetida ao STF que ainda não concluiu o julgamento.
Ao longo do texto, desvendamos o funcionamento do STJ, desde a sua estrutura e composição até as suas funções e a forma como as suas decisões impactam a vida da população. Conhecemos também a sistemática dos recursos repetitivos, uma ferramenta importante para a uniformização da jurisprudência e para garantir celeridade processual em casos de demandas de massa.
Os exemplos demonstram como o STJ, ao julgar os recursos repetitivos e fixar teses, impacta diretamente a vida de milhares de brasileiros. A uniformização da jurisprudência traz segurança jurídica para as relações sociais e permite que os cidadãos tenham uma previsibilidade sobre as decisões judiciais em determinadas situações.
Compartilhe este conteúdo com seus amigos e familiares nas redes sociais e ajude-nos a disseminar conhecimento sobre o funcionamento do Poder Judiciário. Deixe também seu comentário abaixo com sua opinião sobre o tema ou caso tenha alguma dúvida.
BRASIL, Constituição Federal de 1988
Not so long ago I started exploring server-side rendered single-page applications. Yeah, try saying that three times fast. Building products for startups has taught me SEO is a must if you want an online presence. But, you also want the performance SPAs can provide.
We want the best of both worlds. The SEO boost server-side rendering provides, and the speed of a Single Page Application. Today I'll show you all this while hosting it basically for free in a serverless environment on AWS Lambda.
Let's run through what this tutorial will cover. You can skim through and jump to the section that interest you. Or, be a nerd and keep reading. * whisper * Please be a nerd.
Note: The code we will write is already on GitHub if you need further reference or miss any steps, feel free to check it out. The guys over at Cube.js gave me a quick rundown of React before I started writing this tutorial. They have a serverless analytics framework that plugs nicely into React. Feel free to give it a try.
Well, a blazing-fast React application of course! The cost of every SPA is lousy SEO capabilities though. So we need to build the app in a way to incorporate server-side rendering. Sounds simple enough. We can use Next.js, a lightweight framework for static and server-rendered React.js applications.
To accomplish this we need to spin up a simple Express server and configure the Next app to serve files through Express. It is way simpler than it sounds.
However, from the title you can assume we don't like the word server in my neighborhood. The solution is to deploy this whole application to AWS Lambda! It is a tiny Node.js instance after all.
Ready? Let's get crackin'!
As always, we're starting with the boring part, setting up the project and installing dependencies.
In order for serverless development to not be absolute torture, go ahead and install the Serverless framework.
$ npm i -g serverless
Note: If you’re using Linux or Mac, you may need to run the command as sudo.
Once installed globally on your machine, the commands will be available to you from wherever in the terminal. But for it to communicate with your AWS account you need to configure an IAM User. Jump over here for the explanation, then come back and run the command below, with the provided keys.
$ serverless config credentials \
--provider aws \
--key xxxxxxxxxxxxxx \
--secret xxxxxxxxxxxxxx
Now your Serverless installation knows what account to connect to when you run any terminal command. Let’s jump in and see it in action.
Create a new directory to house your Serverless application services. Fire up a terminal in there. Now you’re ready to create a new service.
What’s a service you ask? View it like a project. But not really. It’s where you define AWS Lambda functions, the events that trigger them and any AWS infrastructure resources they require, all in a file called serverless.yml.
Back in your terminal type:
$ serverless create --template aws-nodejs --path ssr-react-next
The create command will create a new service. Shocker! But here’s the fun part. We need to pick a runtime for the function. This is called the template. Passing in aws-nodejs will set the runtime to Node.js. Just what we want. The path will create a folder for the service.
Change into the ssr-react-next folder in your terminal. There should be three files in there, but for now, let's first initialize npm.
$ npm init -y
After the package.json file is created, you can install a few dependencies.
$ npm i \
axios \
express \
serverless-http \
serverless-apigw-binary \
next \
react \
react-dom \
path-match \
url \
serverless-domain-manager
These are our production dependencies, and I'll go into more detail explaining what they do a bit further down. The last one, called serverless-domain-manager will let us tie a domain to our endpoints. Sweet!
Now, your package.json should look something like this.
// package.json
{
"name": "serverless-side-rendering-react-next",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": { // ADD THESE SCRIPTS
"build": "next build",
"deploy": "next build && sls deploy"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^0.18.0",
"express": "^4.16.4",
"next": "^7.0.2",
"path-match": "^1.2.4",
"react": "^16.6.3",
"react-dom": "^16.6.3",
"serverless-apigw-binary": "^0.4.4",
"serverless-http": "^1.6.0",
"url": "^0.11.0",
"serverless-domain-manager": "^2.6.0"
}
}
We also need to add two scripts, one for building and one for deploying the app. You can see them in the scripts section of the package.json.
Moving on, let's finally open up the project in a code editor. Check out the serverless.yml file, it contains all the configuration settings for this service. Here you specify both general configuration settings and per function settings. Your serverless.yml will be full of boilerplate code and comments. Feel free to delete it all and paste this in.
service: ssr-react-next
provider:
name: aws
runtime: nodejs8.10
stage: ${self:custom.secrets.NODE_ENV}
region: us-east-1
environment:
NODE_ENV: ${self:custom.secrets.NODE_ENV}
functions:
server:
handler: index.server
events:
- http: ANY /
- http: ANY /{proxy+}
plugins:
- serverless-apigw-binary
- serverless-domain-manager
custom:
secrets: ${file(secrets.json)}
apigwBinary:
types:
- '*/*'
customDomain:
domainName: ${self:custom.secrets.DOMAIN}
basePath: ''
stage: ${self:custom.secrets.NODE_ENV}
createRoute53Record: true
# endpointType: 'regional'
# if the ACM certificate is created in a region except for `'us-east-1'` you need `endpointType: 'regional'`
The functions property lists all the functions in the service. We will only need one function because it will run the Next app and render the React pages. It works by spinning up a tiny Express server, running the Next renderer alongside the Express router and passing the server to the serverless-http module.
In turn, this will bundle the whole Express app into a single lambda function and tie it to an API Gateway endpoint. Under the functions property, you can see a server function that will have a handler named server in the index.js file. API Gateway will proxy any and every request to the internal Express router which will then tell Next to render our React.js pages. Woah, that sounds complicated! But it's really not. Once we start writing the code you'll see how simple it really is.
We've also added two plugins, the serverless-apigw-binary for letting more mime types pass through API Gateway and the serverless-domain-manager which lets us hook up domain names to our endpoints effortlessly.
We also have a custom section at the bottom. The secrets property acts as a way to safely load environment variables into our service. They're later referenced by using ${self:custom.secrets.<environment_var>} where the actual values are kept in a simple file called secrets.json.
Apart from that, we're also letting the API Gateway binary plugin know we want to let all types through, and setting a custom domain for our endpoint.
That's it for the configuration, let's add the secrets.json file.
Add a secrets.json file and paste this in. This will keep us from pushing secret keys to GitHub.
{
"NODE_ENV": "production",
"DOMAIN": "react-ssr.your-domain.com"
}
Now, only by changing these values you can deploy different environments to different stages and domains. Pretty cool.
To build a server-side rendered React.js app we'll use the Next.js framework. It lets you focus on writing the app instead of worrying about SEO. It works by rendering the JavaScript before sending it to the client. Once it's loaded on the client side, it'll cache it and serve it from there instead. You have to love the speed of it!
Let's start by writing the Next.js setup on the server.
Create a file named server.js. Really intuitive, I know.
// server.js
const express = require('express')
const path = require('path')
const dev = process.env.NODE_ENV !== 'production'
const next = require('next')
const pathMatch = require('path-match')
const app = next({ dev })
const handle = app.getRequestHandler()
const { parse } = require('url')
const server = express()
const route = pathMatch()
server.use('/_next', express.static(path.join(__dirname, '.next')))
server.get('/', (req, res) => app.render(req, res, '/'))
server.get('/dogs', (req, res) => app.render(req, res, '/dogs'))
server.get('/dogs/:breed', (req, res) => {
const params = route('/dogs/:breed')(parse(req.url).pathname)
return app.render(req, res, '/dogs/_breed', params)
})
server.get('*', (req, res) => handle(req, res))
module.exports = server
It's pretty simple. We're grabbing Express and Next, creating a static route with express.static and passing it the directory of the bundled JavaScript that Next will create. The path is /_next, and it points to the .next folder.
We'll also set up the server-side routes and add a catch-all route for the client-side renderer.
Now, the app needs to be hooked up to serverless-http and exported as a lambda function. Create an index.js file and paste this in.
// index.js
const sls = require('serverless-http')
const binaryMimeTypes = require('./binaryMimeTypes')
const server = require('./server')
module.exports.server = sls(server, {
binary: binaryMimeTypes
}
As you can see we also need to create binaryMimeTypes.js file to hold all the mime types we want to enable. It'll just a simple array which we pass into the serverless-http module.
// binaryMimeTypes.js
module.exports = [
'application/javascript',
'application/json',
'application/octet-stream',
'application/xml',
'font/eot',
'font/opentype',
'font/otf',
'image/jpeg',
'image/png',
'image/svg+xml',
'text/comma-separated-values',
'text/css',
'text/html',
'text/javascript',
'text/plain',
'text/text',
'text/xml'
]
Sweet, that's it regarding the Next.js setup. Let's jump into the client-side code!
In the root of your project create three folders named, components, layouts, pages. Once inside the layouts folder, create a new file with the name default.js, and paste this in.
// layouts/default.js
import React from 'react'
import Meta from '../components/meta'
import Navbar from '../components/navbar'
export default ({ children, meta }) => (
<div>
<Meta props={meta} />
<Navbar />
{ children }
</div>
)
The default view will have a <Meta /> component for setting the metatags dynamically and a <Navbar/> component. The { children } will be rendered from the component that uses this layout.
Now add two more files. A navbar.js and a meta.js file in the components folder.
// components/navbar.js
import React from 'react'
import Link from 'next/link'
export default () => (
<nav className='nav'>
<ul>
<li>
<Link href='/'>Home</Link>
</li>
<li>
<Link href='/dogs'>Dogs</Link>
</li>
<li>
<Link href='/dogs/shepherd'>Only Shepherds</Link>
</li>
</ul>
</nav>
)
This is an incredibly simple navigation that'll be used to navigate between some cute dogs. It'll make sense once we add something to the pages folder.
// components/meta.js
import Head from 'next/head'
export default ({ props = { title, description } }) => (
<div>
<Head>
<title>{ props.title || 'Next.js Test Title' }</title>
<meta name='description' content={props.description || 'Next.js Test Description'} />
<meta name='viewport' content='width=device-width, initial-scale=1' />
<meta charSet='utf-8' />
</Head>
</div>
)
The meta.js will make it easier for us to inject values into our meta tags. Now you can go ahead and create an index.js file in the pages folder. Paste in the code below.
// pages/index.js
import React from 'react'
import Default from '../layouts/default'
import axios from 'axios'
const meta = { title: 'Index title', description: 'Index description' }
class IndexPage extends React.Component {
constructor (props) {
super(props)
this.state = {
loading: true,
dog: {}
}
this.fetchData = this.fetchData.bind(this)
}
async componentDidMount () {
await this.fetchData()
}
async fetchData () {
this.setState({ loading: true })
const { data } = await axios.get(
'https://api.thedogapi.com/v1/images/search?limit=1'
)
this.setState({
dog: data[0],
loading: false
})
}
render () {
return (
<Default meta={meta}>
<div>
<h1>This is the Front Page.</h1>
<h3>Random dog of the day:</h3>
<img src={this.state.dog.url} alt='' />
</div>
</Default>
)
}
}
export default IndexPage
The index.js file will be rendered on the root path of our app. It calls a dog API and will show a picture of a cute dog.
Let's create more routes. Create a sub-folder called dogs and create an index.js file and a _breed.js file in there. The index.js will be rendered at the /dogs route while the _breed.js will be rendered at /dogs/:breed where the :breed represents a route parameter.
Add this to the index.js in the dogs directory.
// pages/dogs/index.js
import React from 'react'
import axios from 'axios'
import Default from '../../layouts/default'
const meta = { title: 'Dogs title', description: 'Dogs description' }
class DogsPage extends React.Component {
constructor (props) {
super(props)
this.state = {
loading: true,
dogs: []
}
this.fetchData = this.fetchData.bind(this)
}
async componentDidMount () {
await this.fetchData()
}
async fetchData () {
this.setState({ loading: true })
const { data } = await axios.get(
'https://api.thedogapi.com/v1/images/search?size=thumb&limit=10'
)
this.setState({
dogs: data,
loading: false
})
}
renderDogList () {
return (
<ul>
{this.state.dogs.map((dog, key) =>
<li key={key}>
<img src={dog.url} alt='' />
</li>
)}
</ul>
)
}
render () {
return (
<Default meta={meta}>
<div>
<h1>Here you have all dogs.</h1>
{this.renderDogList()}
</div>
</Default>
)
}
}
export default DogsPage
And, another snippet in the _breed.js file in the dogs folder.
// pages/dogs/_breed.js
import React from 'react'
import axios from 'axios'
import Default from '../../layouts/default'
class DogBreedPage extends React.Component {
static getInitialProps ({ query: { breed } }) {
return { breed }
}
constructor (props) {
super(props)
this.state = {
loading: true,
meta: {},
dogs: []
}
this.fetchData = this.fetchData.bind(this)
}
async componentDidMount () {
await this.fetchData()
}
async fetchData () {
this.setState({ loading: true })
const reg = new RegExp(this.props.breed, 'g')
const { data } = await axios.get(
'https://api.thedogapi.com/v1/images/search?size=thumb&has_breeds=true&limit=50'
)
const filteredDogs = data.filter(dog =>
dog.breeds[0]
.name
.toLowerCase()
.match(reg)
)
this.setState({
dogs: filteredDogs,
breed: this.props.breed,
meta: { title: `Only ${this.props.breed} here!`, description: 'Cute doggies. :D' },
loading: false
})
}
renderDogList () {
return (
<ul>
{this.state.dogs.map((dog, key) =>
<li key={key}>
<img src={dog.url} alt='' />
</li>
)}
</ul>
)
}
render () {
return (
<Default meta={this.state.meta}>
<div>
<h1>Dog breed: {this.props.breed}</h1>
{this.renderDogList()}
</div>
</Default>
)
}
}
export default DogBreedPage
As you can see in the Default component we're injecting custom meta tags. It will add custom fields in the <head> of your page, giving it proper SEO support!
Note: If you're stuck, here's what the code looks like in the repo.
Let's deploy it and see if it works.
At the very beginning, we added a script to our package.json called deploy. It'll build the Next app and deploy the serverless service as we specified in the serverless.yml.
All you need to do is run:
$ npm run deploy
The terminal will return output with the endpoint for your app. We also need to add the domain for it to work properly. We've already added the configuration in the serverless.yml but there's one more command we need to run.
$ sls create_domain
This will create a CloudFront distribution and hook it up to your domain. Make sure that you've added the certificates to your AWS account. It usually takes around 20 minutes for AWS to provision a new distribution. Rest your eyes for a moment.
Once you're back, go ahead and deploy it all again.
$ npm run deploy
It should now be tied up to your domain. Here's what it should look like.
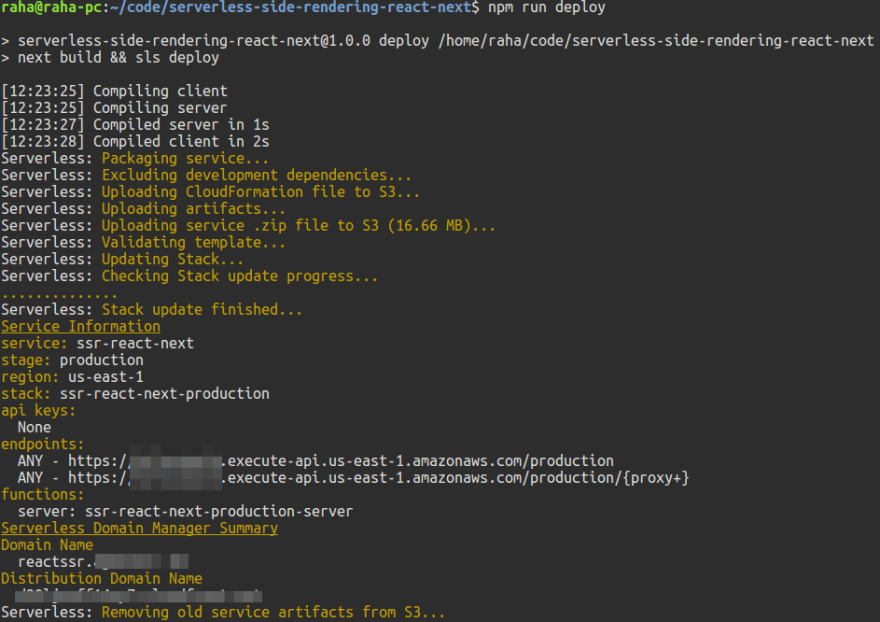
Nice! The app is up-and-running. Go ahead and try it out.
This walkthrough was a rollercoaster of emotions! It gives you a new perspective into creating fast and performant single-page apps while at the same time keeping the SEO capabilities of server-rendered apps. However, with a catch. There are no servers you need to worry about. It's all running in a serverless environment on AWS Lambda. It's easy to deploy and scales automatically. Doesn't get any better.
If you got stuck anywhere take a look at the GitHub repo for further reference, and feel free to give it a star if you want more people to see it on GitHub.
Sample repo for setting up Next and React on AWS Lambda with the Serverless Framework.
If you want to read some of my previous serverless musings head over to my profile or join my newsletter!
Or, take a look at a few of my articles right away:
I also highly recommend checking out this article about Next.js, and this tutorial about the serverless domain manager.
Hope you guys and girls enjoyed reading this as much as I enjoyed writing it. If you liked it, slap that tiny heart so more people here on dev.to will see this tutorial. Until next time, be curious and have fun.

A arte desse cara (Osamu Obi) é tão pica, mas tão pica...que vai ser exibida durante 3 anos em um dos maiores museus do mundo, no Japão.
Reza a lenda que ele levou em torno de 2 a 3 anos para finalizar essa obra, apesar do artista não ter revelado essa informação.

O Kubernetes é um projeto em pleno crescimento, e consolidado como o orquestrador de Containers do mundo de TI. Pouco se sabe porém sobre as iniciativas para estender o Kubernetes, tornando-o algo mais que somente um orquestrador de Containers. Essa palestra irá desmistificar essa limitação, demonstrando a extensão da API com Service Catalog e muito mais!
By Ricardo Katz |
| Ex-catador de latinhas vai cursar Ciência da Computação em Harvard. |
Decades ago, I wrote page after page of code in 6502 assembly language. After assembling and linking the code, I would load it into memory, set breakpoints at strategic locations, and step through to make sure that everything worked as intended. These days, I no longer have the opportunity to write or debug any non-trivial code, so I was a bit apprehensive when it came time to write this blog post (truth be told, I have been procrastinating for several weeks).
SAM CLI
I want to tell you about the new Serverless Application Model (SAM) Command Line Interface, and to gain some confidence in my ability to build something using AWS Lambda as I do so! Let’s review some terms to get started:
 AWS SAM, short for Serverless Application Model, is an open source framework you can use to build serverless applications on AWS. It provides a shorthand syntax you can use to describe your application (Lambda functions, API endpoints, DynamoDB tables, and other resources) using a simple YAML template. During deployment, SAM transforms and expands the shorthand SAM syntax into an AWS CloudFormation template. Then, CloudFormation provisions your resources in a reliable and repeatable fashion.
AWS SAM, short for Serverless Application Model, is an open source framework you can use to build serverless applications on AWS. It provides a shorthand syntax you can use to describe your application (Lambda functions, API endpoints, DynamoDB tables, and other resources) using a simple YAML template. During deployment, SAM transforms and expands the shorthand SAM syntax into an AWS CloudFormation template. Then, CloudFormation provisions your resources in a reliable and repeatable fashion.
The AWS SAM CLI, formerly known as SAM Local, is a command-line interface that supports building SAM-based applications. It supports local development and testing, and is also an active open source project. The CLI lets you choose between Python, Node, Java, Go, .NET, and includes a healthy collection of templates to help get you started.
The sam local command in the SAM CLI, delivers support for local invocation and testing of Lambda functions and SAM-based serverless applications, while running your function code locally in a Lambda-like execution environment. You can also use the sam local command to generate sample payloads locally, start a local endpoint to test your APIs, or automate testing of your Lambda functions.
Installation and Setup
Before I can show you how to use the SAM CLI, I need to install a couple of packages. The functions provided by sam local make use of Docker, so I need to work in a non-virtualized environment for a change! Here’s an overview of the setup process:
Docker – I install the Community Edition of Docker for Windows (a 512 MB download), and run docker ps to verify that it is working:
 Python – I install Python 3.6 and make sure that it is on my Windows PATH:
Python – I install Python 3.6 and make sure that it is on my Windows PATH:
Visual Studio Code – I install VS Code and the accompanying Python Extension.
AWS CLI – I install the AWS CLI:
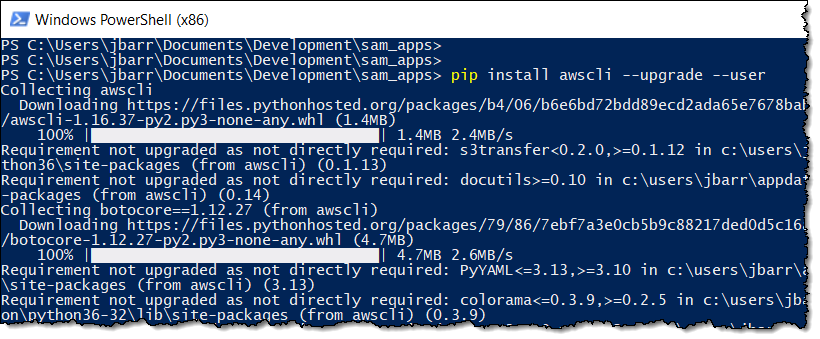
And configure my credentials:
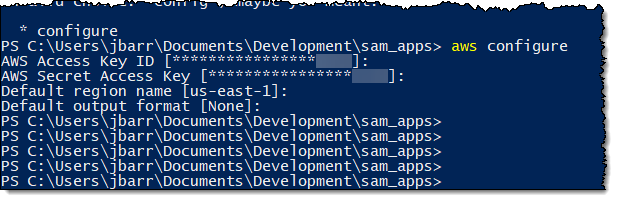
SAM – I install the AWS SAM CLI using pip:
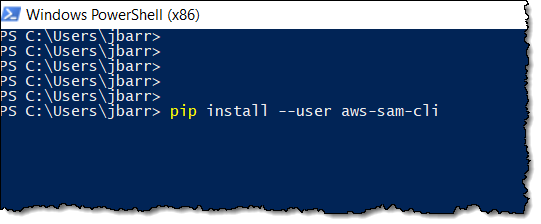
Now that I have all of the moving parts installed, I can start to explore SAM.
Using SAM CLI
I create a directory (sam_apps) for my projects, and then I run sam init to create my first project:
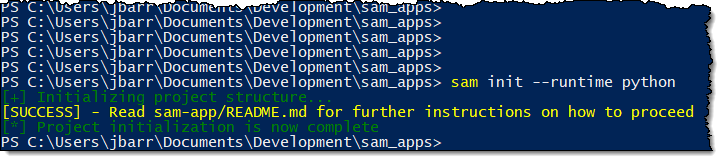
This creates a sub-directory (sam-app) with all of the necessary source and configuration files inside:
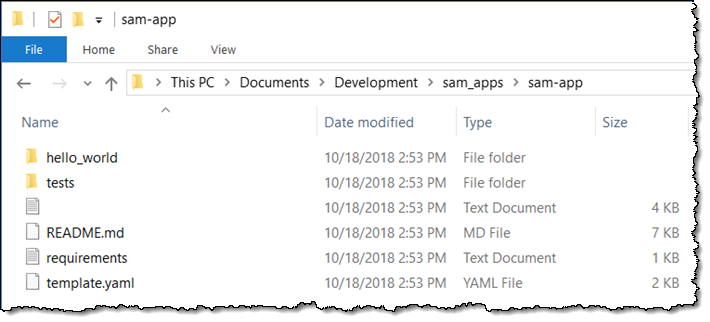
I create a build directory inside of hello_world, and then I install the packages defined in requirements. The build directory contains the source code and the Python packages that are loaded by SAM Local:
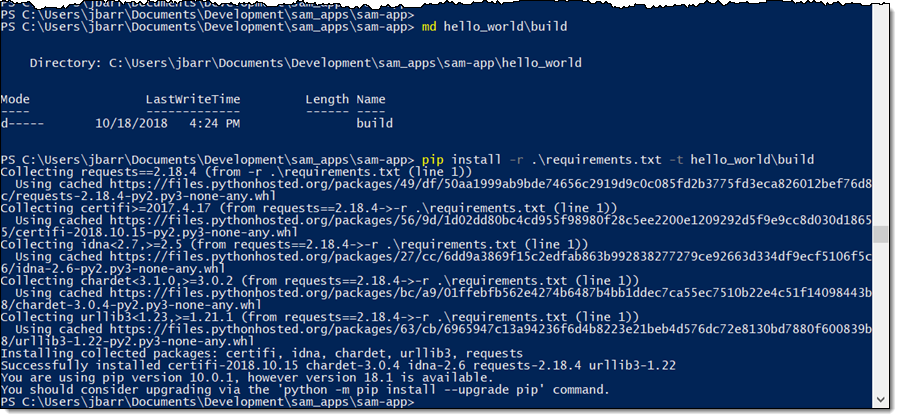
And one final step! I need to copy the source files to the build directory in order to deploy them:
My app (app.py and an empty __init__.py) is ready to go, so I start up a local endpoint:
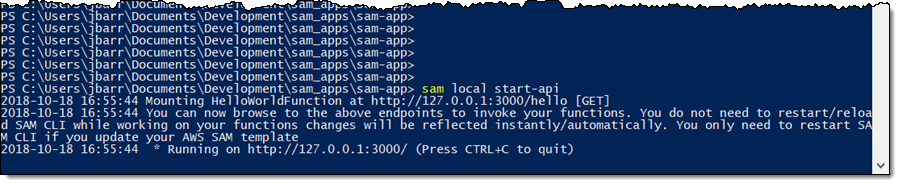
At this point, the endpoint is listening on port 3000 for an HTTP connection, and a Docker container will launch when the connection is made. The build directory is made available to the container so that the Python packages can be loaded and the code in app.py run.
When I open http://127.0.0.1:3000/hello in my browser, the container image is downloaded if necessary, the code is run, and the output appears in my browser:
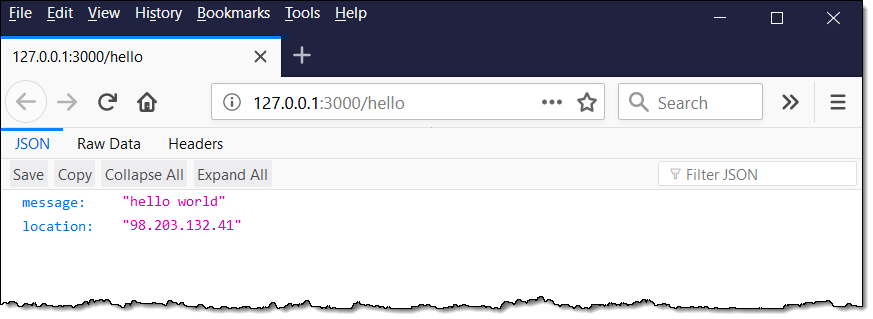
Here’s what happens on the other side. You can see all of the important steps here, including the invocation of the code, download of the image, mounting the build directory in the container, and the request logging:
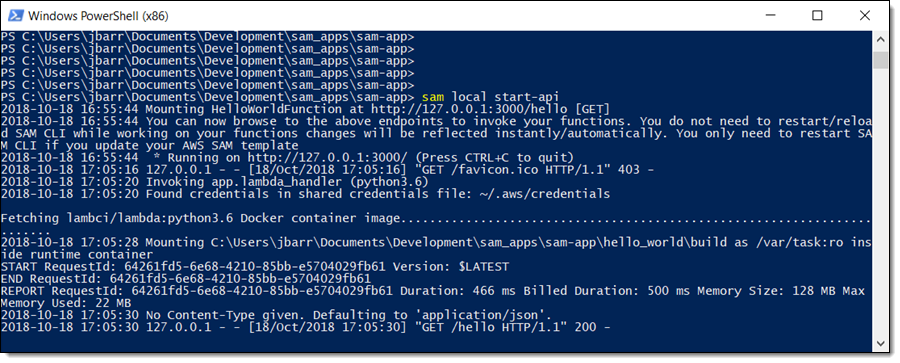
I can modify the code, refresh the browser tab, and the new version is run:
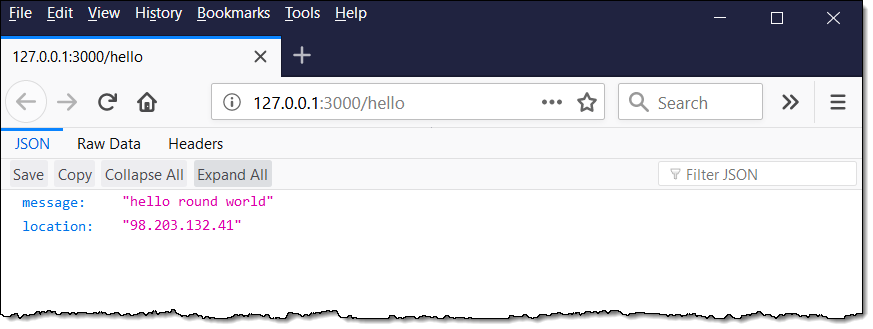
The edit/deploy/test cycle is incredibly fast, and you will be more productive than ever!
There is one really important thing to remember here. The initial app.py file was created in the hello_world directory, and I copied it to the build directory a few steps ago. I can do this deployment step each time, or I can simply decide that the code in the build directory is the real deal and edit it directly. This will affect my source code control plan once I start to build and version my code.
What’s Going On
Now that the sample code is running, let’s take a look at the SAM template (imaginatively called template.yaml). In the interest of space, I’ll skip ahead to the Resources section:
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Properties:
CodeUri: hello_world/build/
Handler: app.lambda_handler
Runtime: python3.6
Environment: # More info about Env Vars: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#environment-object
Variables:
PARAM1: VALUE
Events:
HelloWorld:
Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api
Properties:
Path: /hello
Method: get
This section defines the HelloWorldFunction, indicates where it can be found (hello_world/build/), how to run it (python3.6), and allows environment variables to be defined and set. Then it indicates that the function can process the HelloWorld event, which is generated by a GET on the indicated path (/hello).
This template is not reloaded automatically; if I change it I will need to restart SAM Local. I recommend that you spend some time altering the names and paths here and watching the errors that arise. This will give you a good understanding of what is happening behind the scenes, and will improve your productivity later.
The remainder of the template describes the outputs from the template (the API Gateway endpoint, the function’s ARN, and the function’s IAM Role). These values do not affect local execution, but are crucial to a successful cloud deployment.
Outputs:
HelloWorldApi:
Description: "API Gateway endpoint URL for Prod stage for Hello World function"
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/"
HelloWorldFunction:
Description: "Hello World Lambda Function ARN"
Value: !GetAtt HelloWorldFunction.Arn
HelloWorldFunctionIamRole:
Description: "Implicit IAM Role created for Hello World function"
Value: !GetAtt HelloWorldFunctionRole.ArnYou can leave all of these as-is until you have a good understanding of what’s going on.
Debugging with SAM CLI and VS Code
Ok, now let’s get set up to do some interactive debugging! This took me a while to figure out and I hope that you can benefit from my experience. The first step is to install the ptvsd package:
Then I edit requirements.txt to indicate that my app requires ptvsd (I copied the version number from the package name above):
requests==2.18.4
ptvsd==4.1.4Next, I rerun pip to install this new requirement in my build directory:

Now I need to modify my code so that it can be debugged. I add this code after the existing imports:
import ptvsd
ptvsd.enable_attach(address=('0.0.0.0', 5858), redirect_output=True)
ptvsd.wait_for_attach()The first statement tells the app that the debugger will attach to it on port 5858; the second pauses the code until the debugger is attached (you could make this conditional).
Next, I launch VS Code and select the root folder of my application:
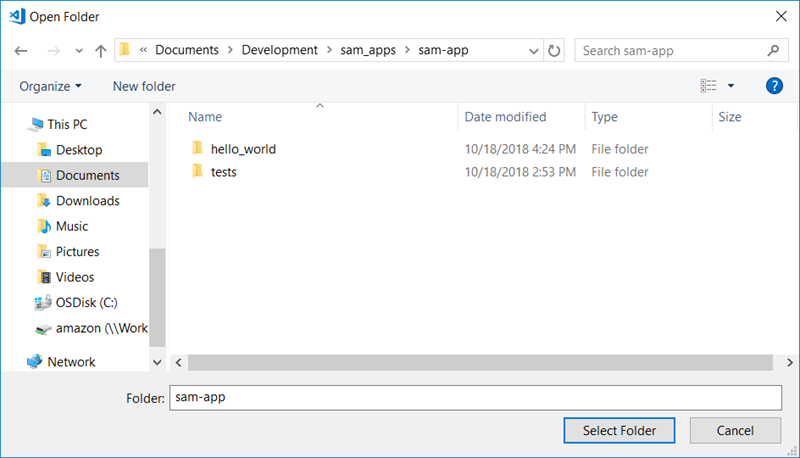
Now I need to configure VS Code for debugging. I select the debug icon, click the white triangle next to DEBUG, and select Add Configuration:
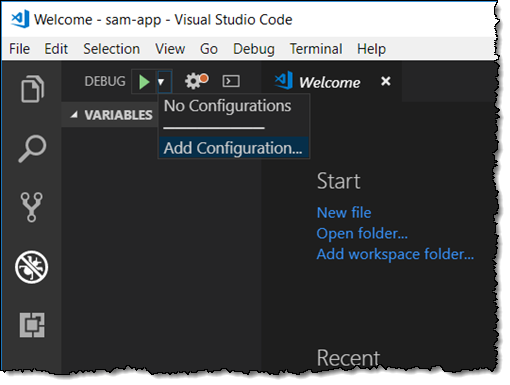
I select the Python configuration, replace the entire contents of the file (launch.json) with the following text, and save the file (File:Save).
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Debug with SAM CLI (Remote Debug)",
"type": "python",
"request": "attach",
"port": 5858,
"host": "localhost",
"pathMappings": [
{
"localRoot": "${workspaceFolder}/hello_world/build",
"remoteRoot" : "/var/task"
}
]
}
]
}Now I choose this debug configuration from the DEBUG menu:
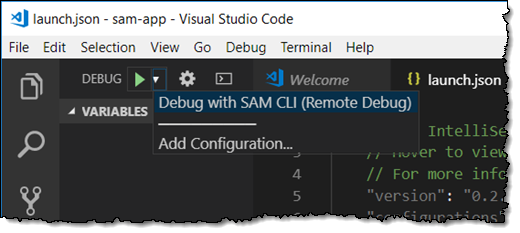
Still with me? We’re almost there!
I start SAM Local again, and tell it to listen on the debug port:

I return to VS Code and set a breakpoint (good old F9) in my code:
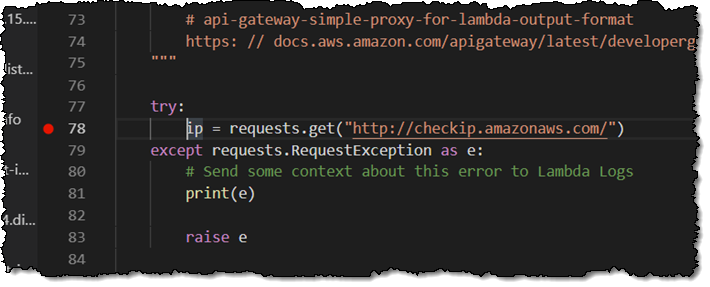
One thing to remember — be sure to open app.py in the build directory and set the breakpoint there.
Now I return to my web browser and visit the local address (http://127.0.0.1:3000/hello) again. The container starts up to handle the request and it runs app.py. The code runs until it hits the call to wait_for_attach, and now I hit F5 in VS Code to start debugging.
The breakpoint is hit, I single-step across the requests.get call, and inspect the ip variable:
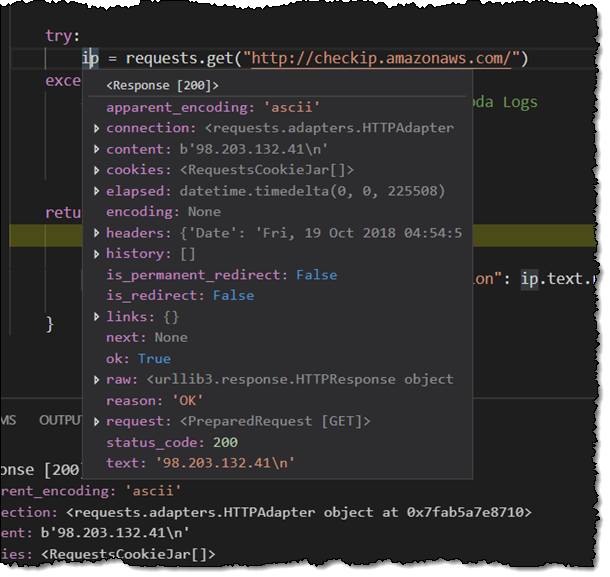
Then I hit F5 to continue, and the web request completes. As you can see, I can use the full power of the VS Code debugger to build and debug my Lambda functions. I’ve barely scratched the surface here, and encourage you to follow along and pick up where I left off. To learn more, read Test Your Serverless Applications Locally Using SAM CLI.
Cloud Deployment
The SAM CLI also helps me to package my finished code, upload it to S3, and run it. I start with an S3 bucket (jbarr-sam) and run sam package. This creates a deployment package and uploads it to S3:

This takes a few seconds. Then I run sam deploy to create a CloudFormation stack:

If the stack already exists, SAM CLI will create a Change Set and use it to update the stack. My stack is ready in a minute or two, and includes the Lambda function, an API Gateway, and all of the supporting resources:
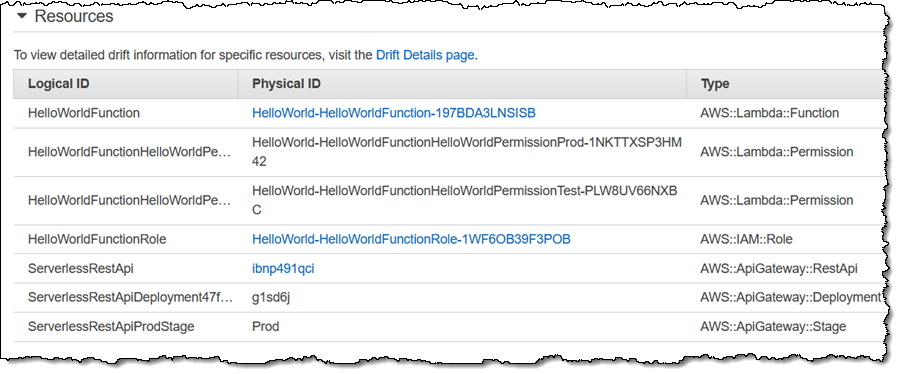
I can locate the API Gateway endpoint in the stack outputs:
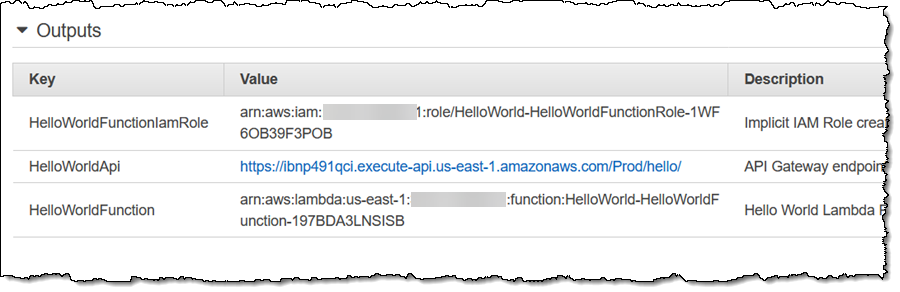
And access it with my browser, just like I did when the code was running locally:
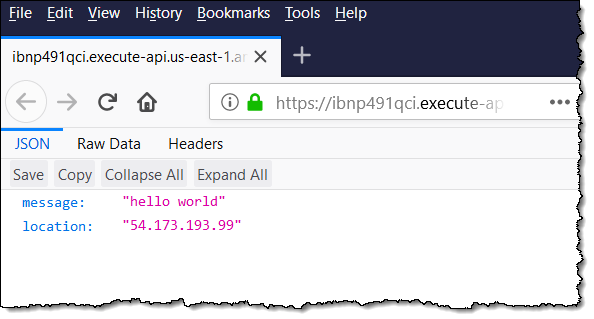
I can also access the CloudWatch logs for my stack and function using sam logs:
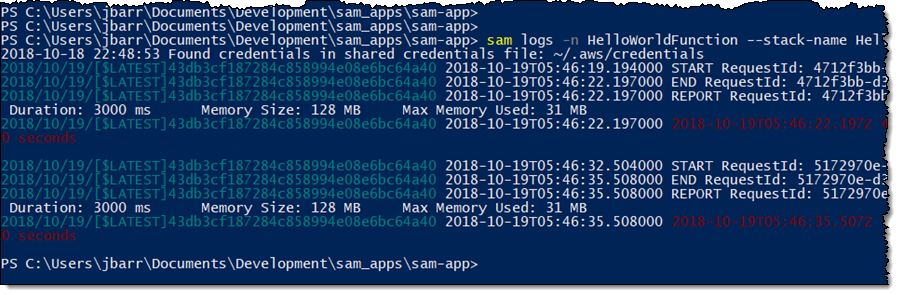
My SAM apps are now visible in the Lambda Console (this is a relatively new feature):
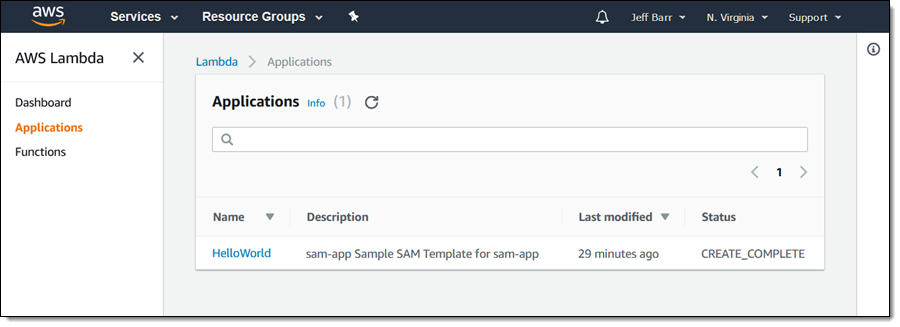
I can see the template and the app’s resources at a glance:
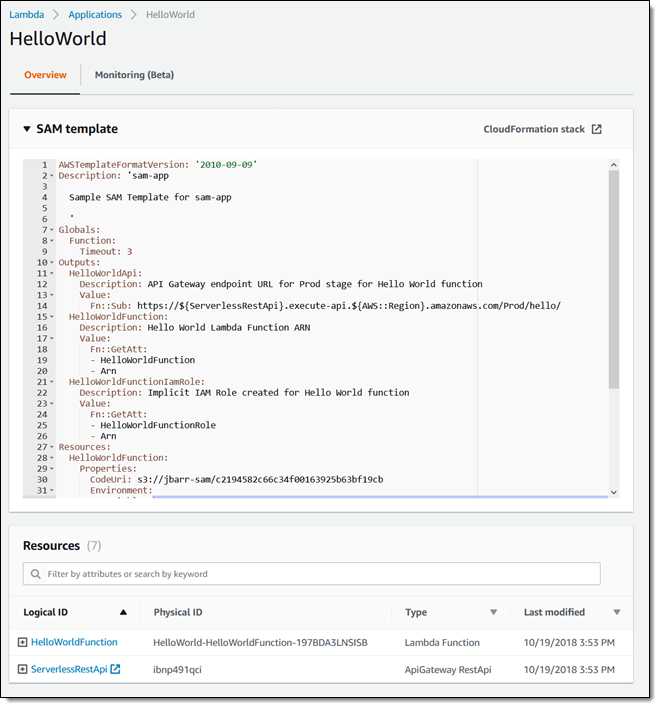
And I can see the relationship between resources:
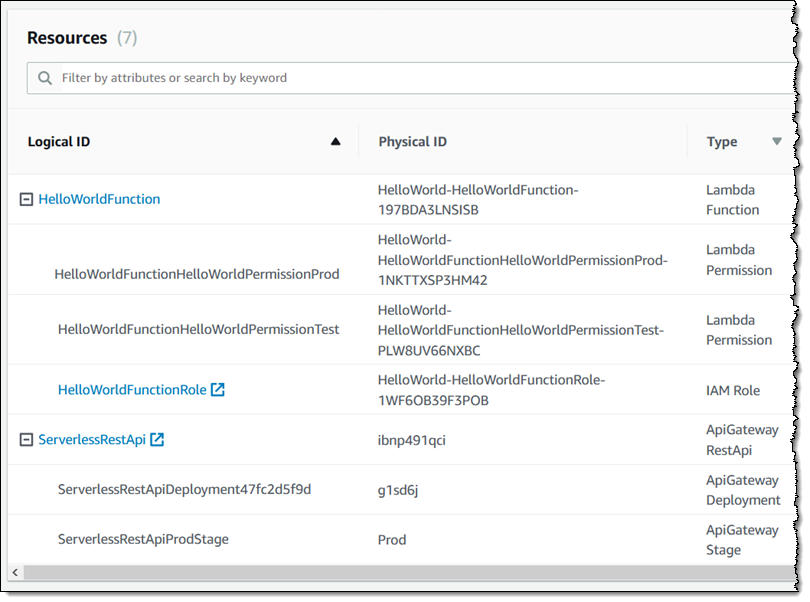
There’s also a monitoring dashboard:
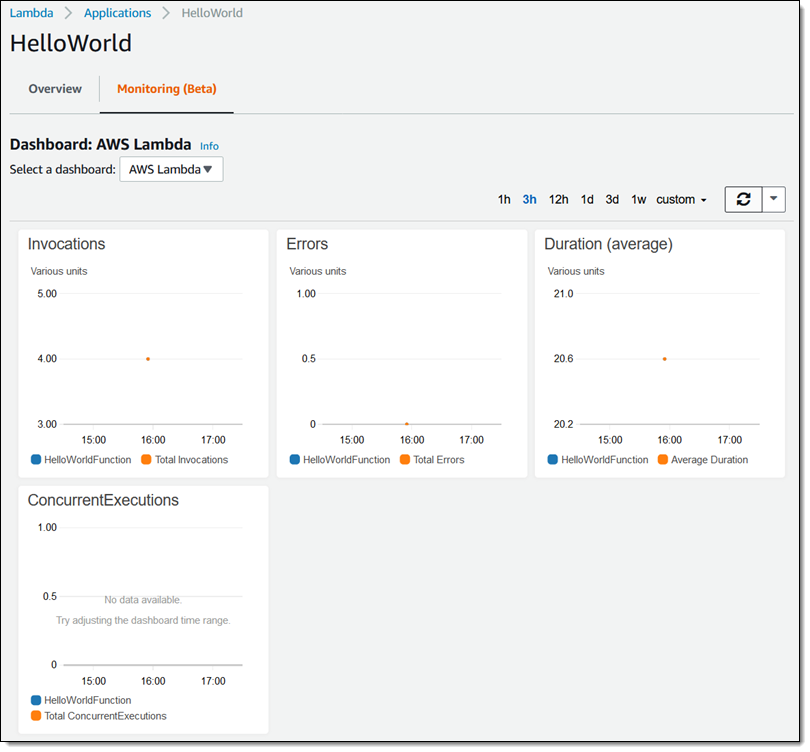
I can customize the dashboard by adding an Amazon CloudWatch dashboard to my template (read Managing Applications in the AWS Lambda Console to learn more).
That’s Not All
Believe it or not, I have given you just a taste of what you can do with SAM, SAM CLI, and the sam local command. Here are a couple of other cool things that you should know about:
Local Function Invocation – I can directly invoke Lambda functions:

Sample Event Source Generation – If I am writing Lambda functions that respond to triggers from other AWS services (S3 PUTs and so forth), I can generate sample events and use them to invoke my functions:
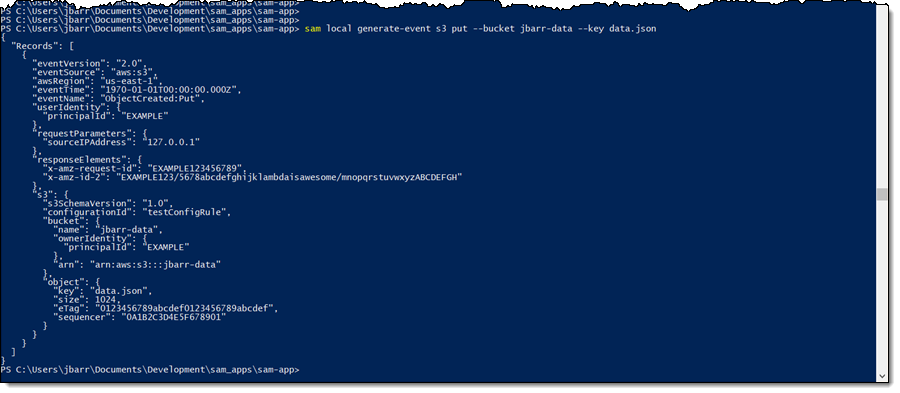
In a real-world situation I would redirect the output to a file, make some additional customization if necessary, and then use it to invoke my function.
Cookiecutter Templates – The SAM CLI can use Cookiecutter templates to create projects and we have created several examples to get you started. Take a look at Cookiecutter AWS Sam S3 Rekognition Dynamodb Python and Cookiecutter for AWS SAM and .NET to learn more.
 CloudFormation Extensions – AWS SAM extends CloudFormation and lets you benefit from the power of infrastructure as code. You get reliable and repeatable deployments and the power to use the full suite of CloudFormation resource types, intrinsic functions, and other template features.
CloudFormation Extensions – AWS SAM extends CloudFormation and lets you benefit from the power of infrastructure as code. You get reliable and repeatable deployments and the power to use the full suite of CloudFormation resource types, intrinsic functions, and other template features.
Built-In Best Practices – In addition to the benefits that come with an infrastructure as code model, you can easily take advantage of other best practices including code reviews, safe deployments through AWS CodePipeline, and tracing using AWS X-Ray.
Deep Integration with Development Tools – You can use AWS SAM with a suite of AWS tools for building serverless applications. You can discover new applications in the AWS Serverless Application Repository. For authoring, testing, and debugging SAM-based serverless applications, you can use the AWS Cloud9 IDE. To build a deployment pipeline for your serverless applications, you can use AWS CodeBuild, AWS CodeDeploy, and AWS CodePipeline. You can also use AWS CodeStar to get started with a project structure, code repository, and a CI/CD pipeline that’s automatically configured for you. To deploy your serverless application you can use the AWS SAM Jenkins plugin, and you can use Stackery.io’s toolkit to build production-ready applications.
Check it Out
I hope that you have enjoyed this tour, and that you can make good use of SAM in your next serverless project!
— Jeff;



A Cloud Native Community Foundation anunciou o Kubernetes 1.12. Essa versão traz snapshot e restauração de volumes, melhorias no TLS, Horizontal Pod Autoscaler (HPA), topologia com provisionamento dinâmico, auditoria avançada, suporte de topologia para o plugin Container Storage Interface (CSI), e mais.
By Diogo Carleto Translated by Diogo CarletoA Hashicorp lançará o Terraform 0.12. Esta versão inclui uma série de novas melhorias muito solicitadas para o Terraform com base no feedback e ideias da comunidade. As mais notáveis são: expressões first-class, a expressão for e condicionais. A atualização para a nova versão pode causar quebras de compatibilidade para alguns usuários.
By Matt Campbell Translated by Delermando Santos
O Kubernetes (k8s) percorreu um longo caminho em muito pouco tempo. Apenas dois anos atrás, ele teve que competir e provar ser melhor do que as soluções Fleet, Docker Swarm, Cloud Foundry Diego, Nomad, Kontena, Rancher's Cattle, Apache Mesos, Amazon ECS, etc.
By Bilgin Ibryam Translated by Marcelo Costa
Async e Await chegaram no ES8 (ES2017), e já funcionam em todos os navegadores modernos e no Node.js. Entenda nessa talk porque você precisa conhecê-los. Acredite, eles vão mudar completamente o código JavaScript que você escreve. Veremos como utilizá-los hoje, como funcionam, boas e más práticas, e um pouco da história de como chegamos aqui.
By Giovanni BassiA Amazon anunciou uma atualização para a Simple Queue Service (SQS) - os desenvolvedores agora podem usar o SQS para acionar funções do AWS Lambda. Além disso, os desenvolvedores não precisam mais executar um serviço de pesquisa ou criar um mapeamento SQS para SNS.
By Steef-Jan Wiggers Translated by Mayra Michels


